
![]()

IOTLB
Page Table Walker
Root Table
Context Table
Context CACHE
IO PageTable
IOMMU Practice
IOMMU Software Architecture
IOMMU Domain
IO PageTable(Generic Radix Page Table)
IOMMU Group
IOMMU 编程指南
In-Depth Research on PCIe Mechanisms
ACS(Access Control Services)
ATS(Address Translation Services)
ATC(Address Translation Cache)/Device TLB
RPI(Page Request Interface)
IO PageFault Handler
VFIO
IOMMU-FD


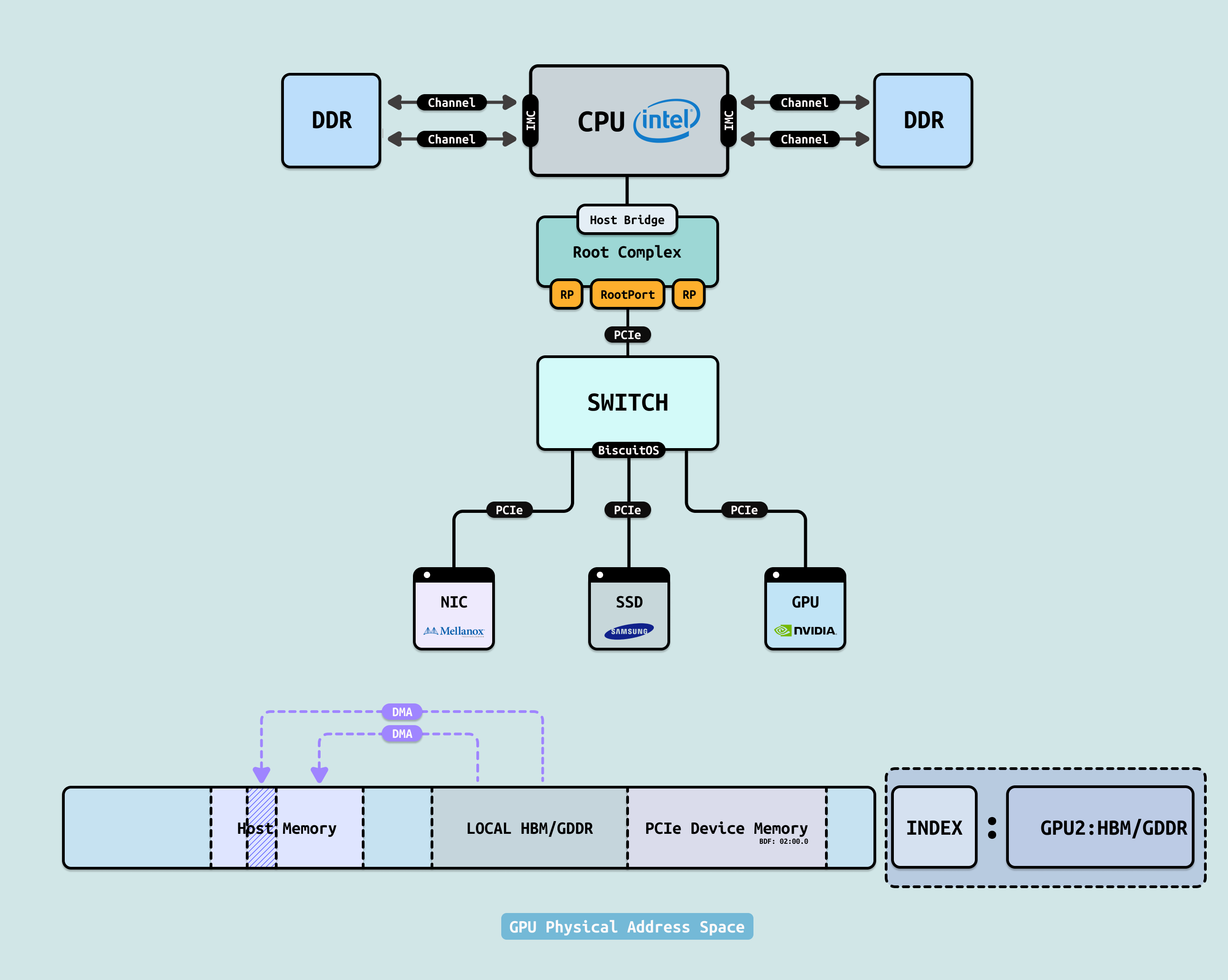
在学习 PCIe 专题时可以知道,对于一个 PCIe 设备,其 PCIe Memory Space 是其可以看到(访问)的地址空间,该空间上包括各 PCIe 设备暴露出来的 BAR-Mapping 存储空间,也包括系统物理内存. PCIe 设备可以使用 DMA 技术访问 PCIe Memory Space 上的存储介质,并且没有任何硬件的限制. 那么这就回出现一个严重的安全,PCIe 设备可以与物理内存任意位置进行 DMA 操作,那么对于不安全的 DMA 操作,其可能会严重影响物理内存的安全. 问题暴露后,社区和厂商没坐以待毙,搞出了一系列”中间态”技术,像给狂暴机器人戴上手铐、蒙上眼睛的临时方案:
- Bounce Buffers/SWIOTLB: 最经典的”软件模拟 IOMMU”.
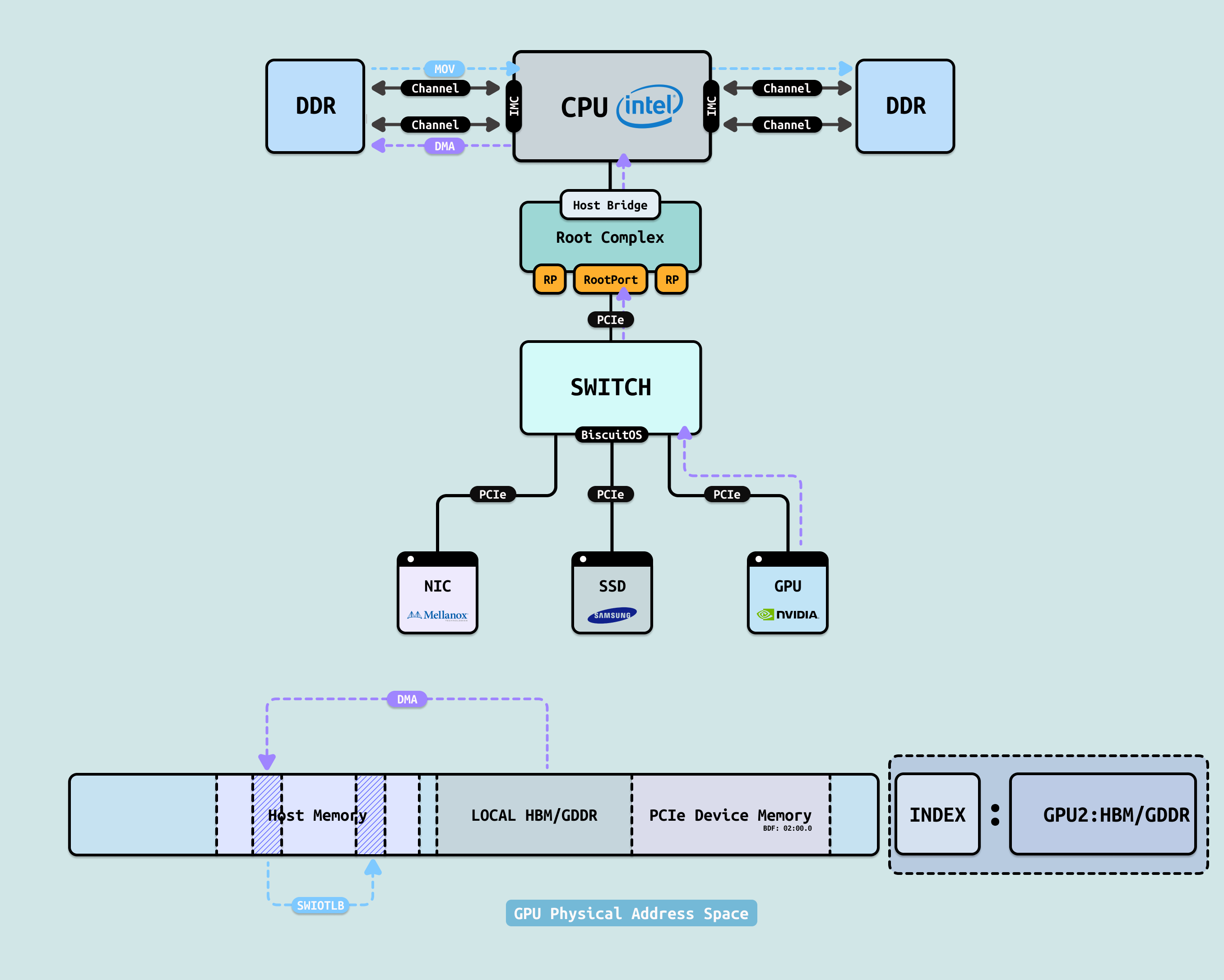 系统预留一小块低地址内存(通常 64MB)当”中转站”. 设备 DMA 时,先把数据拷贝到这个缓冲区,再由 CPU 搬运到目标内存. 像快递机器人只能把包裹扔到门卫室,再由保安手动分发. 优点是兼容性强(32位设备访问 64GB+ 内存时必备),缺点是 CPU 拷贝开销巨大,尤其在高带宽网卡(40G/100G)上, 性能像从高铁降到自行车. 很多老系统或无硬件 IOMMU 的嵌入式设备还在靠它活着.
系统预留一小块低地址内存(通常 64MB)当”中转站”. 设备 DMA 时,先把数据拷贝到这个缓冲区,再由 CPU 搬运到目标内存. 像快递机器人只能把包裹扔到门卫室,再由保安手动分发. 优点是兼容性强(32位设备访问 64GB+ 内存时必备),缺点是 CPU 拷贝开销巨大,尤其在高带宽网卡(40G/100G)上, 性能像从高铁降到自行车. 很多老系统或无硬件 IOMMU 的嵌入式设备还在靠它活着. - GART(Graphics Address Remapping Table): 早期 AGP/PCIe 显卡专用的地址重映射,算是 IOMMU 的”爷爷辈”, 它给显卡一个有限的窗口,但颗粒度粗、功能单一,只管图形,不解决通用设备问题
- 其他权宜手段: 像 Intel 的早期芯片组限制、软件驱动里的地址检查、甚至物理隔离(把设备塞到单独的 PCIe 根端口), 这些方案要么牺牲性能,要么覆盖面窄,要么管理复杂, 就像给每个房间单独装报警器,但总有漏网之鱼
这些中间态让系统”能跑”,但始终像戴着镣铐跳舞: 安全是打了补丁的,性能是打折的,运维是头疼的.
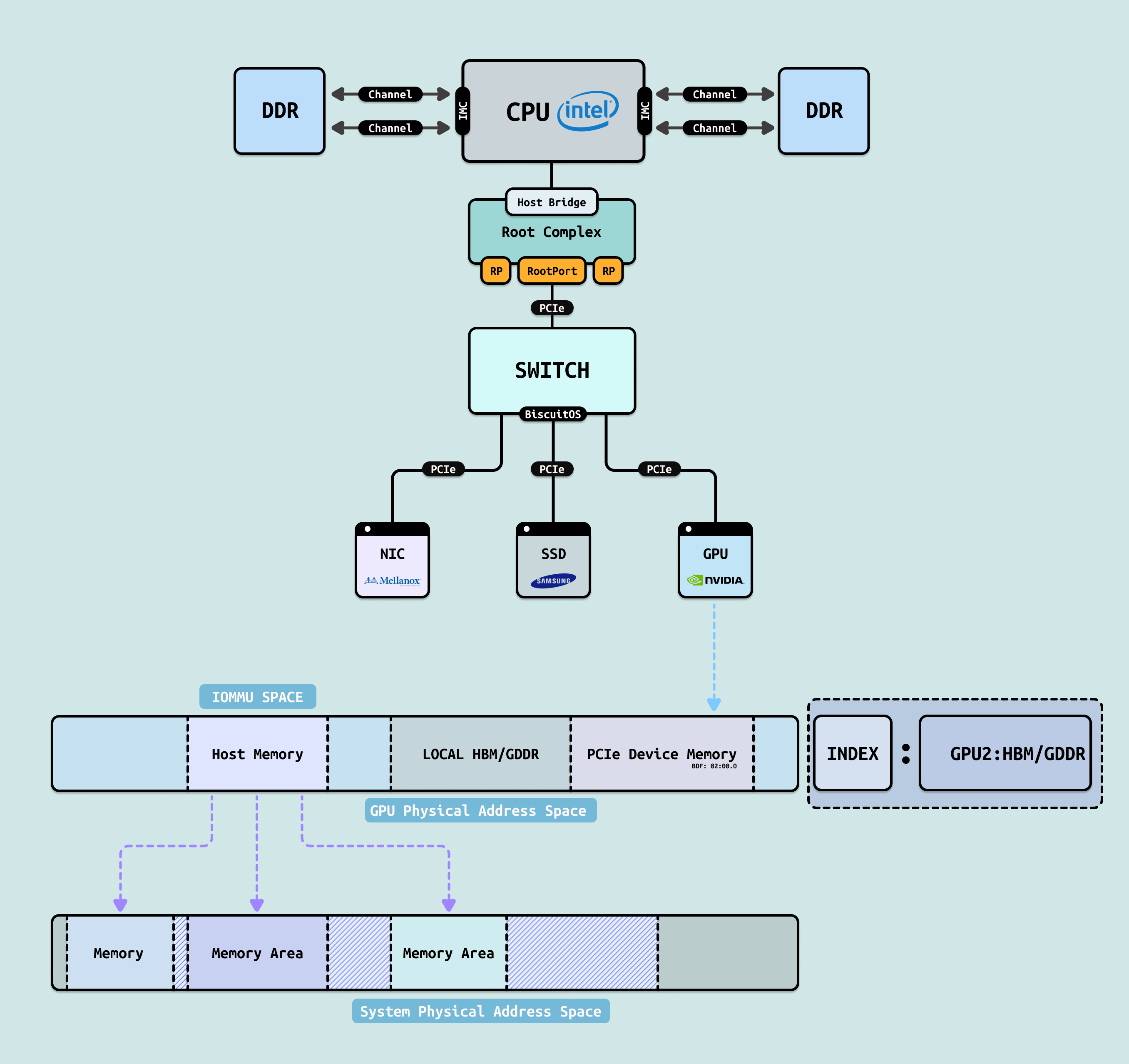
IOMMU(Input-Output Memory Management Unit) 终于像一位严谨的智能门禁系统,彻底改变了游戏规则. Intel 叫 VT-d,AMD 叫 AMD-Vi(或 IOMMU),ARM 有 SMMU——本质都是硬件 MMU 的 I/O 版. 它为每个设备(或设备组) PCIe Memory Space 里的 Host Memory 区域维护独立的地址转换表(类似 CPU 的页表):
- 设备看到的只是 IOVA(I/O Virtual Address),IOMMU 在硬件层面翻译成真实的物理地址
- 可以精确划定每个设备只能访问哪块内存区域,甚至精确到页面级别,还能做权限控制(读/写/执行)
- 额外 bonus: 中断重映射(防止恶意设备伪造中断)、设备隔离(IOMMU Groups)、支持 SR-IOV 多虚拟功能安全共享
对于 PCIe Memory Space,IOMMU 基本不介入 BAR-Mapping 区域和内部存储(GDDR/HBM), IOMMU 只针对 Host Memory 部分. 只有设备主动发起的 DMA 事务(Memory Read/Write Request TLP)才会经过 IOMMU.
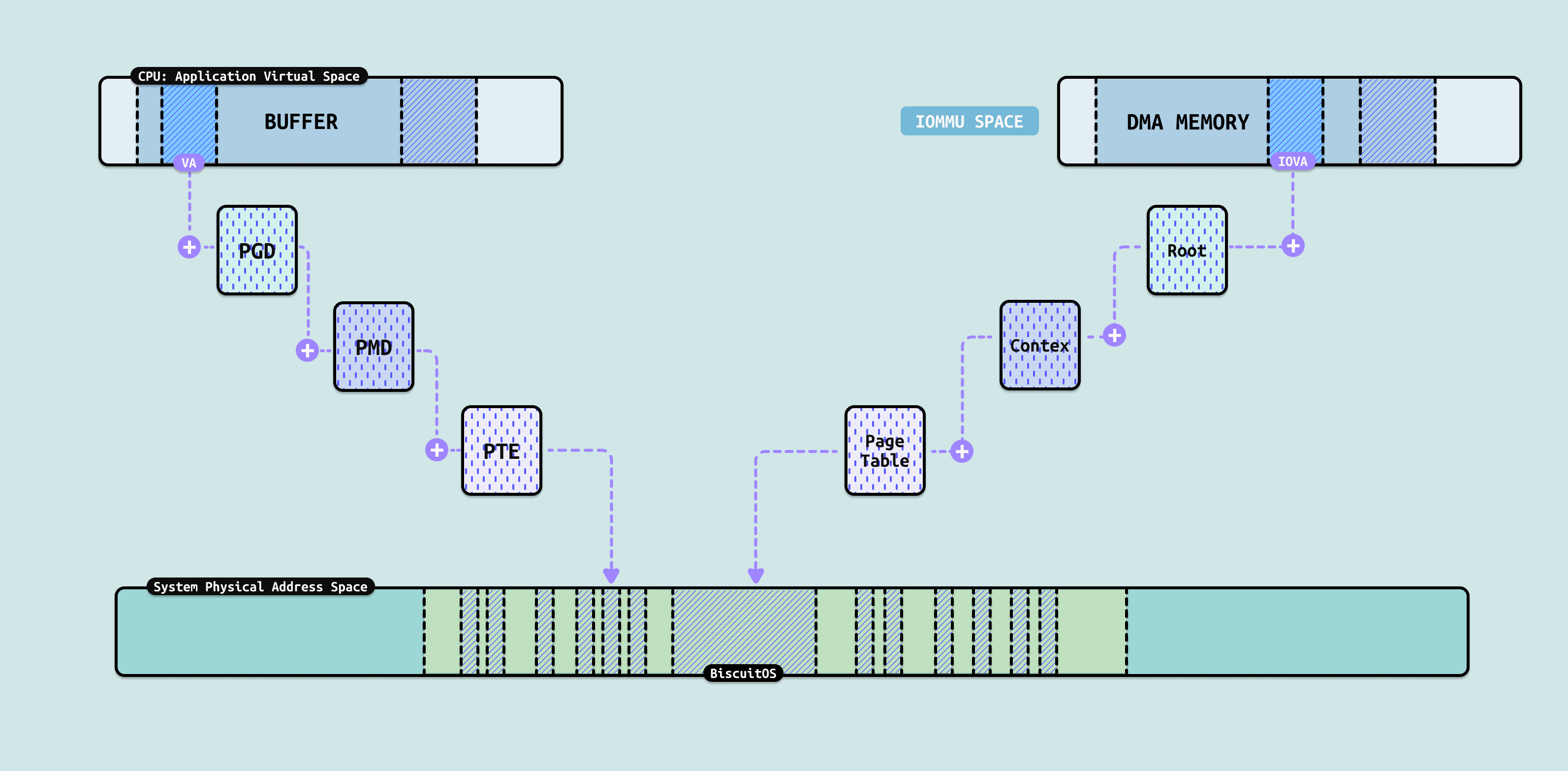
IOMMU 的实现原理,本质上就是给 PCIe 设备装一个独立的小 MMU,让设备发出的每一次 DMA 都像 CPU 访问内存一样,经过硬件地址翻译和权限检查,而不是裸奔直达物理内存. 例如系统为每个用户进程抽象出一块独立连续的地址空间,这块空间就是虚拟地址空间,只有该用户进程可以访问,其他用户进程不可以访问, 系统通过 MMU 提供的页表将进程的虚拟地址空间映射到物理内存上,这样用户进程对虚拟地址的访问最终落到物理内存上. 另外虽然映射的物理页离散分布,但虚拟地址空间时连续的. 对于 IOMMU,其为每个 PCIe 设备或者一组 PCIe 设备抽象了一块连续的地址空间,这块地址空间的地址称为 IOVA,IOMMU 也提供了一套特殊的页表机制将这块连续的地址空间映射到离散的物理页上.
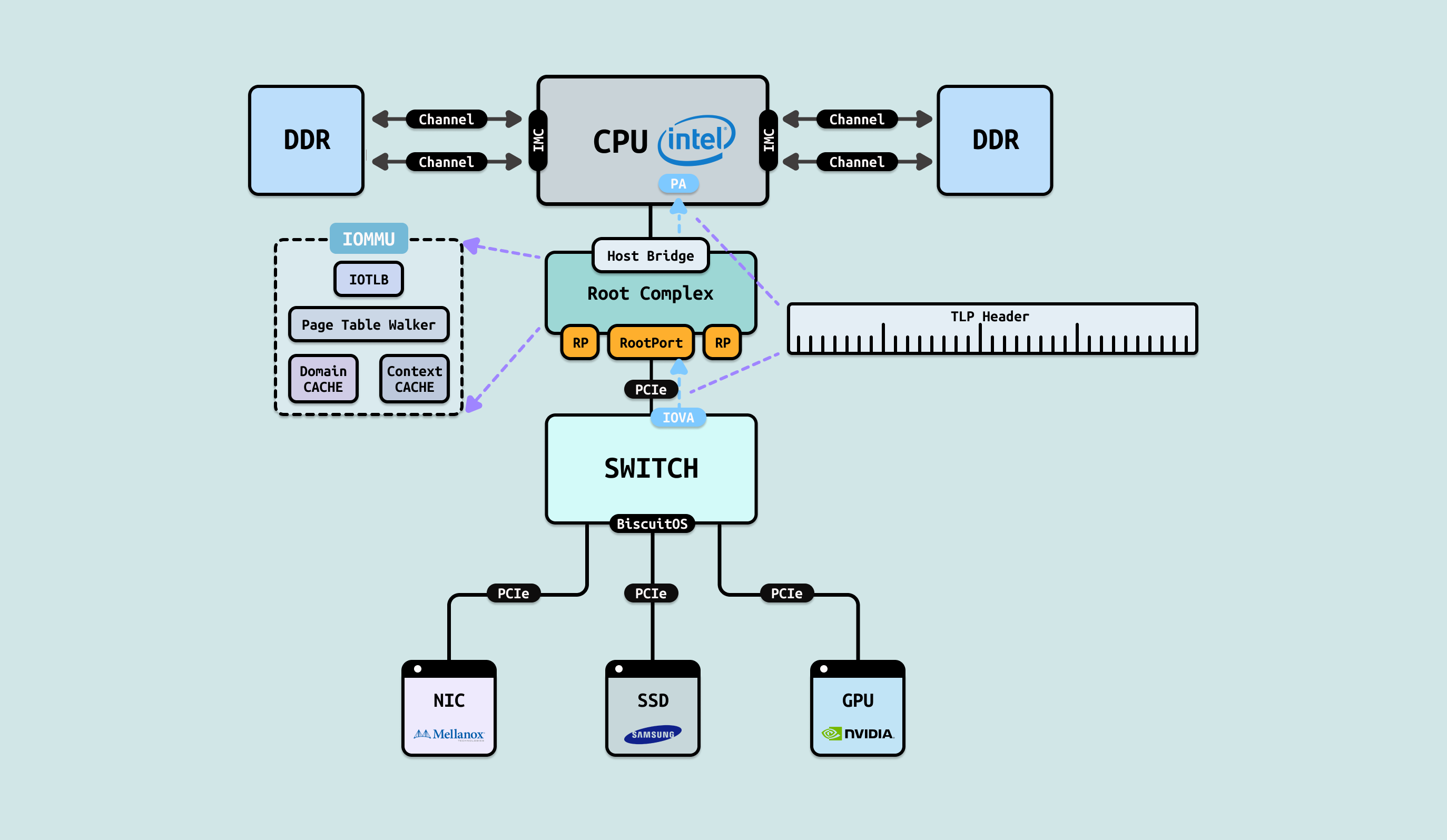
IOMMU 通常集成在 Root Complex(北桥/ CPU 集成)里,位于 PCIe 控制器和系统内存控制器之间. 首先 PCIe 设备发出的 Memory Read/Write Request(TLP 包,里面带地址 = IOVA), 然后 IOMMU 引擎拦截这些事务,查表翻译, 最后将翻译后的真实物理地址(HPA)发给 DRAM 控制器. 关键组件包括:
- IOTLB(I/O TLB): 缓存最近的地址翻译,像 CPU TLB,命中超快
- Page Table Walker: IOTLB miss 时,硬件自动遍历页表(类似 CPU 页表行走)
- Context/Domain Cache: 加速查找哪个设备对应哪个页表
- Command Queue/Fault Log: 软件(内核)通过 MMIO 给 IOMMU 下命令,IOMMU 报告错误
IOMMU 在不同的硬件架构叫法不同,Intel 叫 VT-d(Virtualization Technology for Directed I/O),AMD 叫 IOMMU/AMD-Vi,ARM 叫 SMMU,原理高度相似,但数据结构略有不同.
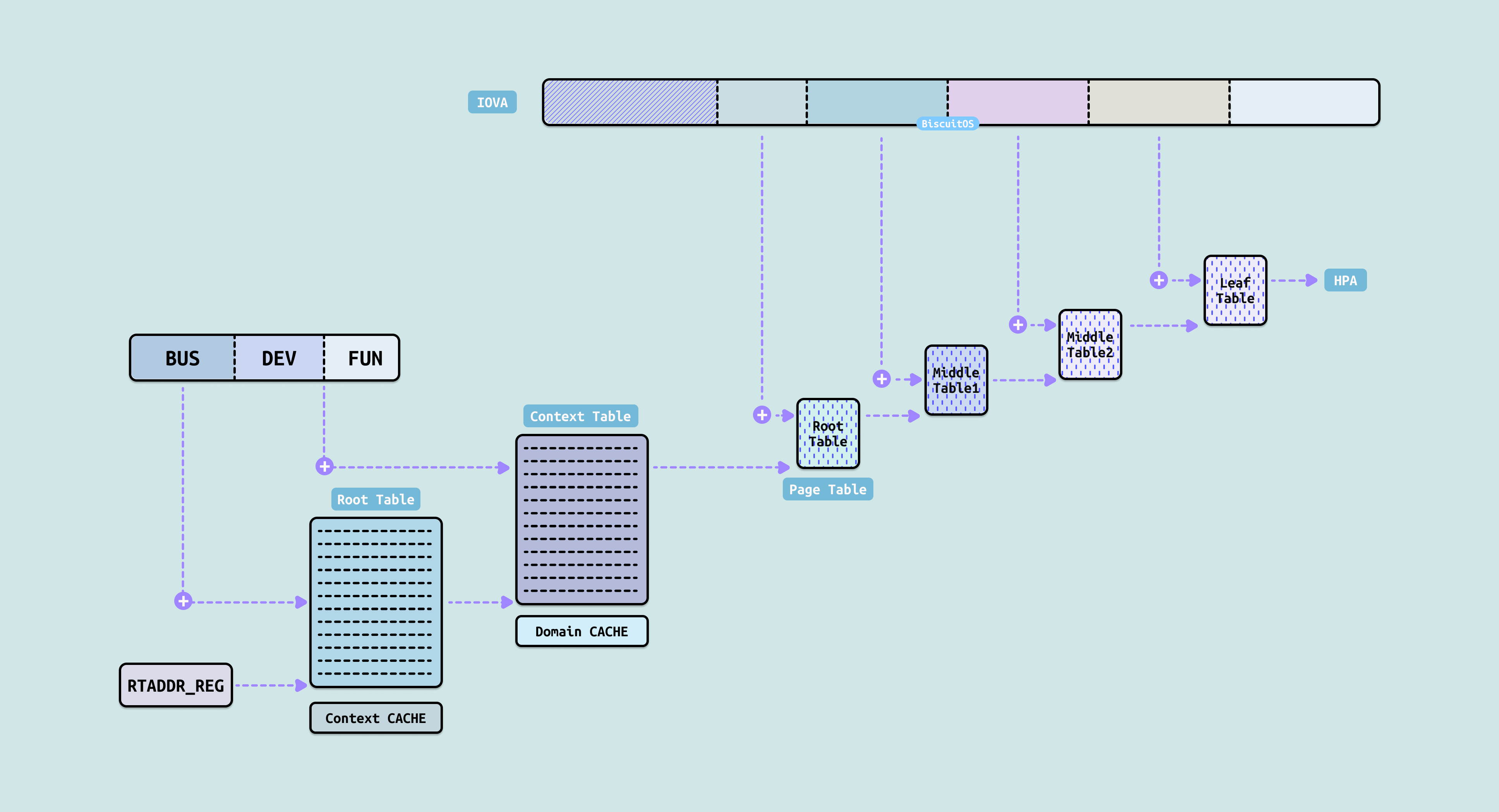
IOMMU 不直接给每个设备一个页表,而是用 Domain + Context 的方式实现高效共享与隔离. Domain 表示一个”地址空间容器”,一个虚拟机、一个驱动、或一组设备可以共享同一个 Domain(即同一个页表根). 每个 PCIe 设备(或 Bus:Device:Function)对应一个 Context Entry, 里面记录:
- 这个设备属于哪个 Domain
- 页表根指针(Root Pointer,指向顶级页表)
- 地址宽度(4-level/5-level 等)
- 权限控制
IOMMU 页表类似 CPU 的 4 级页表,但专为 I/O. 顶级是 Root Table(Root Entry Table),根据设备 Bus 号索引, 然后是 Context Table, 根据设备的 Device:Function 进行索引,其可以获得 Domain 的页表树. 页表树的叶子是 4KB/2MB/1GB 等页面映射(支持 Huge Page). 页表里每条映射包含 IOVA → HPA + Read/Write/Execute 权限 + 其他标志(No Execute、Snoop 等).
