
![]()



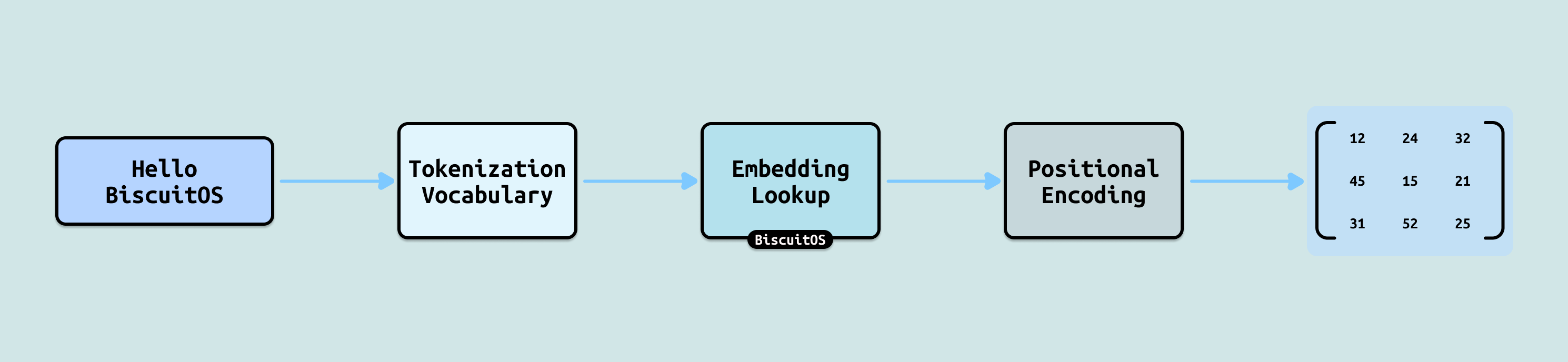
推理的第一步是 “读懂问题”, 这里的读懂并不是理解问题本身,而是将人类的语言转换成 LLM 可以看懂的语言. LLM 完全不会直接“看”文字,它只能处理数字. 因此, 推理第一步就是把人类的文字输入转换成纯数字矩阵(Matrix). 这个过程会把每个词(字)变成固定长度的向量(Embedding),向量可以理解为 Token 的特征,通过这些特征 LLM 可以知道 Token 的含义.
另外会在每个 Token 向量上加入位置信息,因为自然语言的顺序非常重要,因为 “我爱他” 和 “他爱我” 意思完全不同. 最后将输入的 Token 统一成一个矩阵形式,方便后面的矩阵运算,就像我之前说的 “LLM 就是一个矩阵的计算过程”.
没有这一步,模型就根本不知道输入的是什么,后面的注意力、推理等所有计算都无法开始. 这相当于把”文字语言”翻译成”模型能懂的数学语言”. 下面我们用例子 “我爱 Linux,学内核就是 BiscuitOS” 完整走一遍计算过程.

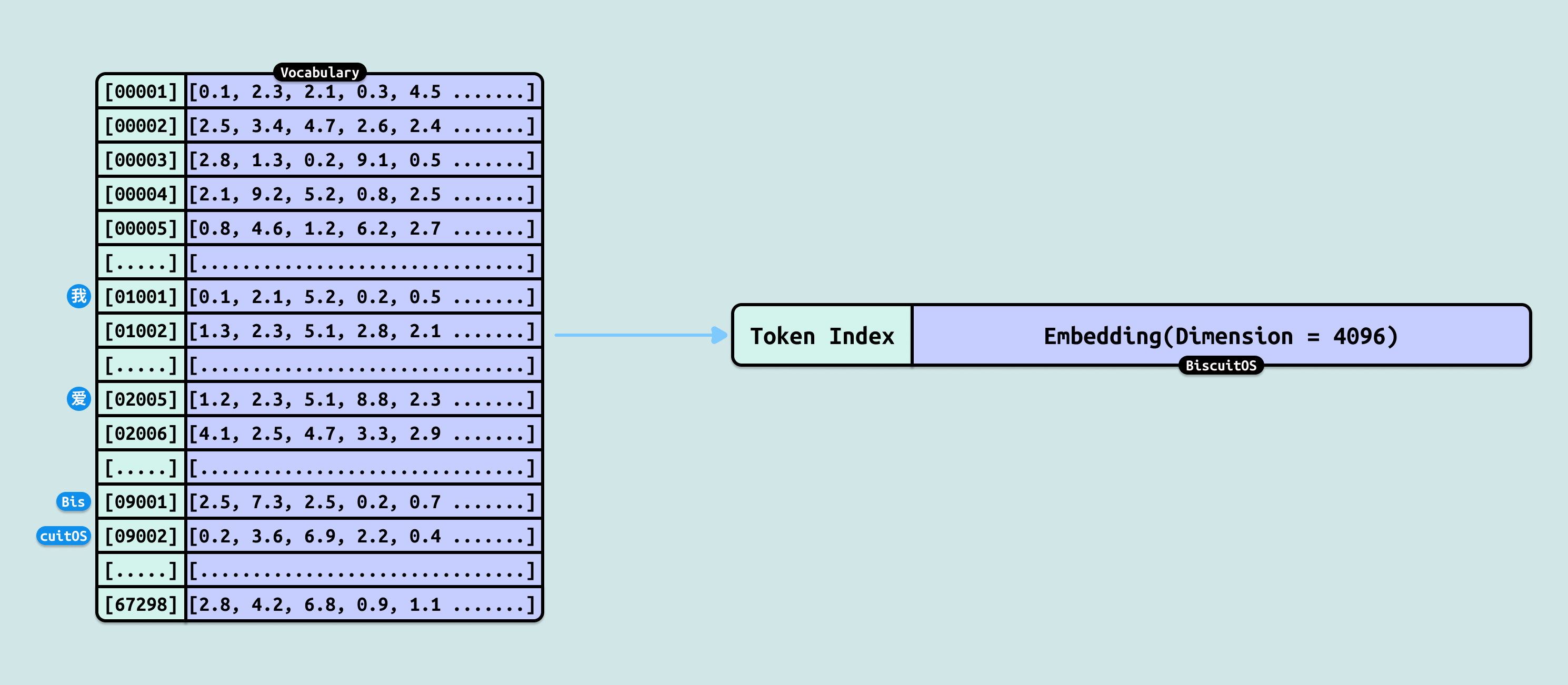
模型不是随意把字变成数字的, 而是依赖一个事先训练好的词表(Vocabulary). 词表是一个固定大小的字典(常见 32k~128k 条目),里面存放了模型在海量文本预训练时见过的最常见”词块”(可以是整词、子词、单字甚至单个字母). 每一条目对应一个唯一的整数 ID(Token ID),从 0 开始编号. 例如,一个典型的中文+英文混合词表可能包含:
- 常见汉字: 如”我” → ID 1001
- 常见中文词: 如”爱” → ID 2005
- 英文子词: 如 “Lin” → ID 3001, “ux” → ID 3002
- 特殊符号: 如”,” → ID 5001
- 项目专有名词: 如 “BiscuitOS” 可能被拆成 “Bis”, “cuit”, “OS”,但为演示我们假设它完整在词表中 → ID 9001
