
![]()

自 2010 年代以来,GPU 从单纯的图形渲染加速器逐步演变为通用并行计算的核心引擎, 特别是在深度学习和大模型时代,GPU 的高吞吐浮点运算能力(TFLOPS 级别)和海量内存带宽(HBM3/HBM3e 可达数 TB/s)使其成为 AI 训练和推理的首选硬件. 大规模分布式训练进一步放大了这一趋势: 从早期的单节点多卡,到如今的数千甚至上万张 GPU 集群,模型参数和数据集的爆炸式增长要求高效的节点间通信.
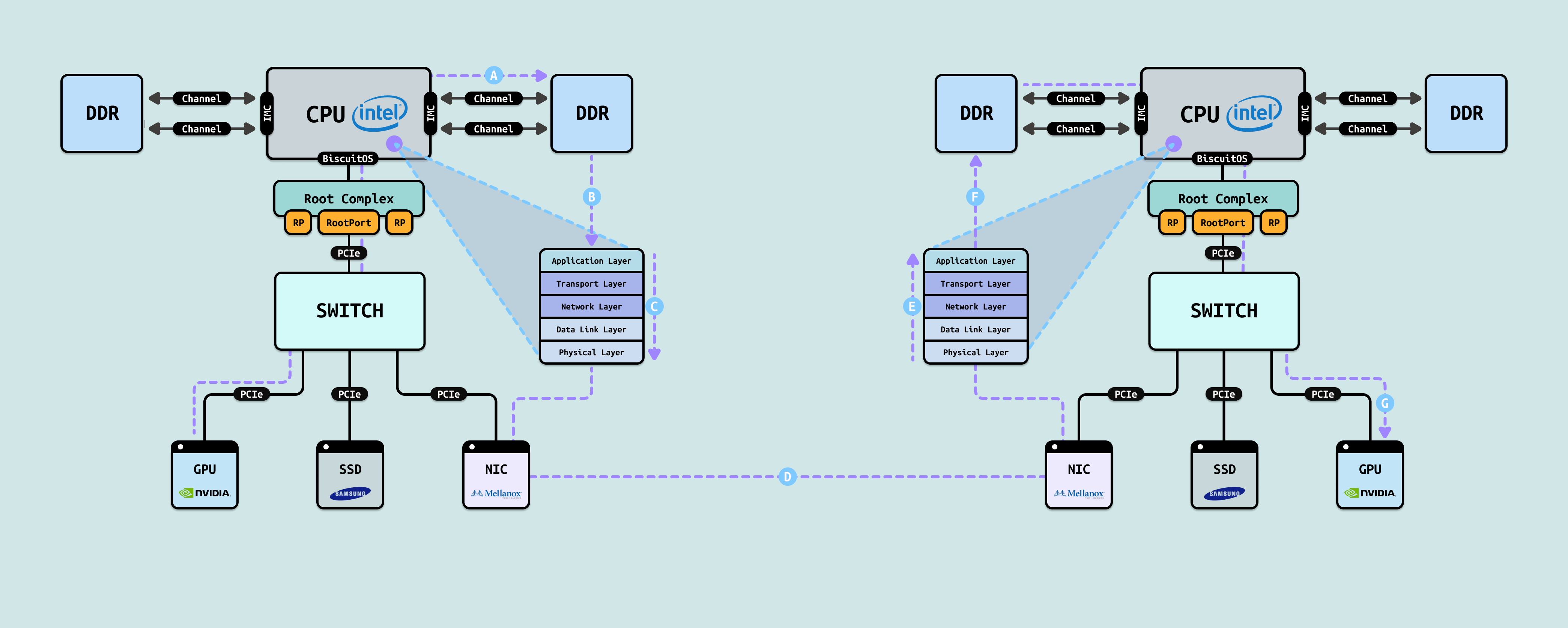
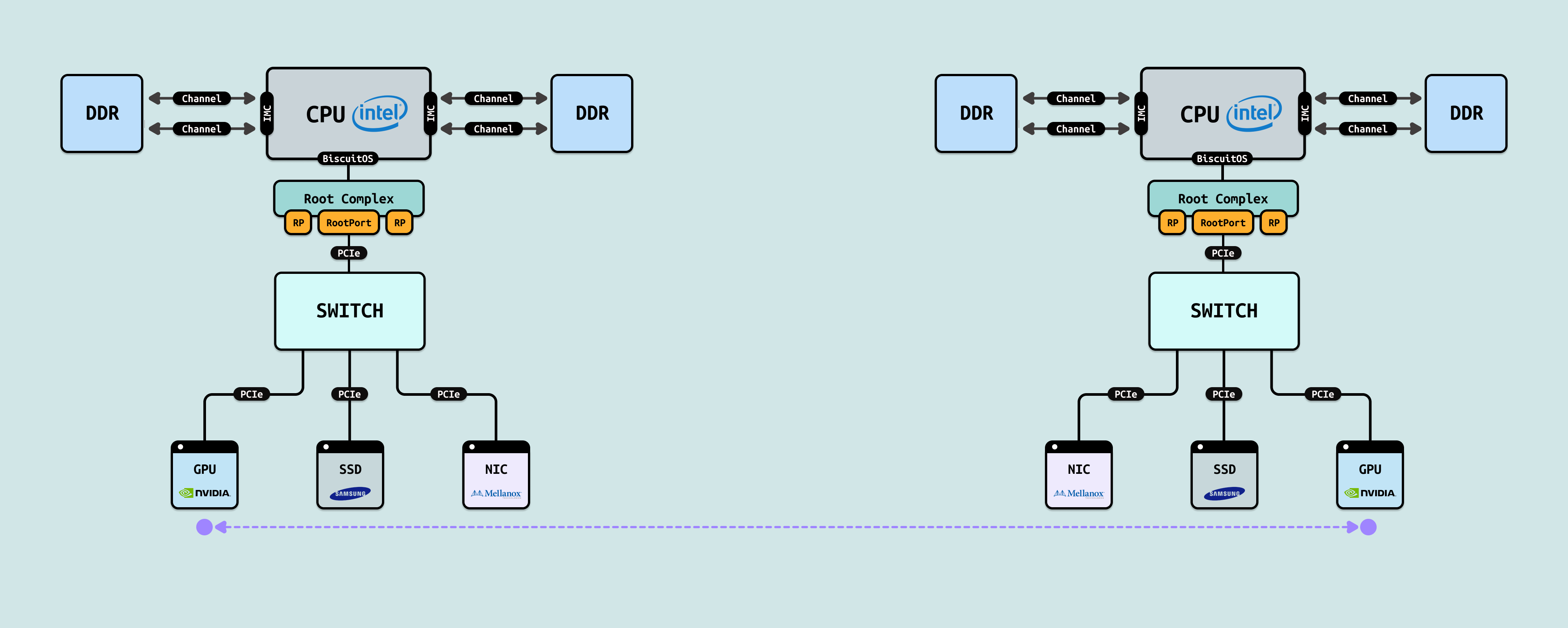
上图描绘了一个典型的传统 GPU 集群(无 GPUDirect RDMA 启用或不支持时)的跨节点数据交换路径. 图中展示了两个对称的计算节点(左节点和右节点),每个节点包含 Intel CPU、DDR 内存、PCIe Root Complex、PCIe Switch,以及挂载的 GPU(NVIDIA)、SSD 和 NIC(Mellanox). 当左节点 GPU → 右节点 GPU 的数据传输(即从左边 GPU 发送数据到右边 GPU),传统路径(不使用 GPUDirect RDMA)会强制数据经过主机内存(系统 DRAM)和 CPU 介入,具体数据流动如下:
- A. 源 GPU → 系统内存(左节点 DDR): 这步通常由 cudaMemcpy(…, cudaMemcpyDeviceToHost) 或类似操作完成,数据进入用户态缓冲区或内核缓冲区. 应用程序(或 CUDA 驱动)通过 PCIe DMA 将数据从 NVIDIA GPU 显存拷贝到主机 DDR. 路径: GPU → PCIe → PCIe Switch → Root Complex → CPU → IMC → DDR
- B. 系统内存 → TCP/IP 协议栈处理(CPU 深度介入): CPU 需要处理 checksum 计算、分段、ACK 管理等,消耗大量周期. CPU 接管数据: 从用户缓冲区拷贝到内核 socket 缓冲区(或直接使用 sendfile/zero-copy 优化,但仍需 CPU 参与). 路径: DDR → IMC → CPU(协议栈处理). 执行 TCP/IP 协议栈全流程:
- Application Layer → Transport Layer(TCP:序列号、窗口、拥塞控制、重传等)
- Network Layer(IP:路由、封装)
- Data Link Layer(Ethernet/InfiniBand over IP 的链路层)
- Physical Layer
- C. TCP/IP 协议栈 → 本地 NIC(左节点 Mellanox): NIC 此时接收的是已完成封装的网络包,而不是原始的 GPU 数据块(图中从 CPU 到 NIC 的 PCIe 下行). 内核通过 PCIe 将已打包好的 TCP/IP 数据包(包含头部 + 负载)DMA 到 NIC 的发送队列. 路径: CPU → Root Complex → PCIe Switch → NIC
- D. 本地 NIC → 网络 → 远程 NIC: 这里是真正的网络传输,但由于是 TCP/IP,会有三次握手、拥塞控制、可能的重传等开销. NIC 通过物理网络(InfiniBand 或 Ethernet/RoCE,但走 TCP/IP over it)发送 TCP 数据包. 路径: 左 NIC → 网络链路 → 右 NIC
- E/F. 远程 NIC → 系统内存(右节点 DDR): 远程 NIC 接收 TCP 数据包,通过 DMA 写入右节点系统内存的内核 socket 缓冲区. CPU 介入处理: TCP 重组、乱序处理、checksum 验证、交付到用户态 socket. 路径: 右 NIC → PCIe Switch → Root Complex → CPU → IMC → DDR
- G. 系统内存 → 目标 GPU(右节点 NVIDIA GPU): 又一次显式拷贝, 应用程序从 socket 读取数据(recv),CPU 将数据从内核缓冲区拷贝到用户缓冲区,再通过 cudaMemcpy(…, cudaMemcpyHostToDevice) 拷贝到目标 GPU 显存. 路径: DDR → IMC → CPU → Root Complex → PCIe Switch → GPU
传统路径要求所有数据在发送端和接收端都必须两次落入系统内存(DDR),并由 CPU 全权负责 TCP/IP 协议栈的处理,包括数据拷贝、协议封装、状态管理以及网络开销. 这种设计导致了高延迟、高 CPU 负载、多次内存拷贝以及网络带宽利用率低下. 即使底层物理网络是高速的 InfiniBand 或 Ethernet,走 TCP/IP 也会引入额外的性能损失. 整个路径至少涉及 4 次显式内存拷贝:
- GPU 显存 → 系统 DDR: 发送端 cudaMemcpy DeviceToHost
- 系统 DDR → 内核 socket 缓冲区: 发送端用户态到内核态拷贝
- 内核 socket 缓冲区 → 系统 DDR: 接收端内核态到用户态
- 系统 DDR → GPU 显存: 接收端 cudaMemcpy HostToDevice
这些拷贝不仅占用 CPU 周期,还消耗 PCIe 带宽和系统内存带宽,进一步放大延迟和功耗. A、B、F 路径(CPU 与 DDR、Root Complex 的频繁交互),以及 C、E 路径(协议栈各层处理), 当数据量较大或连接数较多时,CPU 很容易成为系统瓶颈,导致整体吞吐量受限,甚至影响其他计算任务.
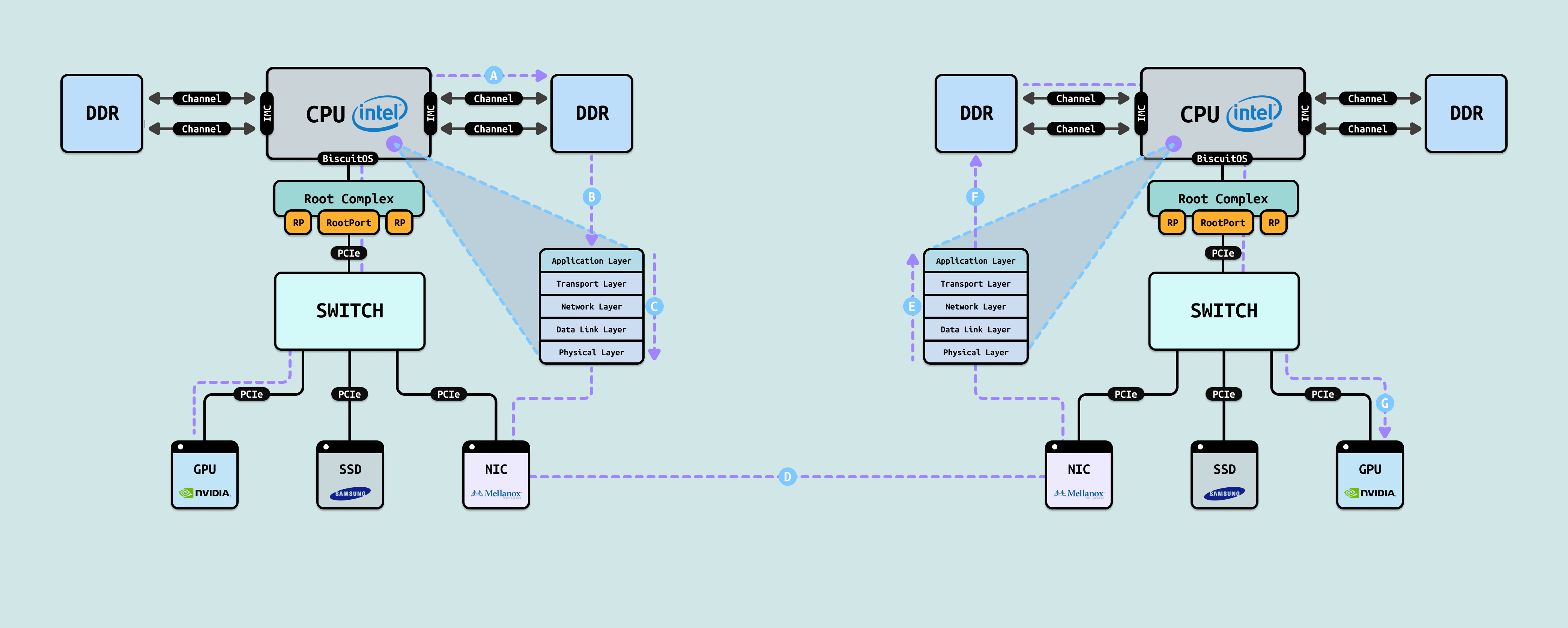
当采用普通 RDMA(即标准 RDMA over InfiniBand 或 RoCE,使用 ibv_reg_mr 注册主机内存缓冲区)进行跨节点数据传输时,数据路径会实现网络部分的零拷贝和 CPU bypass,但仍需强制经过主机系统内存(DDR)作为中转站,无法直接访问 GPU 显存.普通 RDMA 的核心优势在于: NIC 硬件 offload 了网络协议栈(无 CPU 处理 TCP/IP),但在 GPU 场景下,数据仍必须先从 GPU 拷贝到主机 DDR(发送端),然后远程 NIC 写入远程主机 DDR,最后再拷贝到目标 GPU. 这种路径比传统 TCP/IP 高效得多(网络零拷贝、低延迟). 下面是左节点 GPU → 右节点 GPU 的普通 RDMA 数据传输路径:
- A. 源 GPU(左节点) → 系统内存(左节点 DDR): 应用程序先通过 CUDA API(如 cudaMemcpy)将数据从 NVIDIA GPU 显存拷贝到主机 DDR 的注册缓冲区. 这步是显式拷贝(cudaMemcpy DeviceToHost),CPU 调度,但开销相对小(单次拷贝). 路径: GPU → PCIe → PCIe Switch → Root Complex → CPU → IMC → DDR
- B/C. 系统内存(左节点 DDR) → 本地 NIC(左节点 Mellanox): 应用程序使用 ibv_reg_mr 注册主机 DDR 缓冲区(标准 RDMA 内存区域),然后 post RDMA 操作(ibv_post_send). CPU 几乎 bypass 数据路径(RDMA Verbs 硬件 offload),但注册和完成轮询仍需少量 CPU. 路径: DDR → IMC → CPU(轻度介入,主要是完成事件) → Root Complex → PCIe Switch → NIC.
- D. 本地 NIC → 网络链路 → 远程 NIC: 本地 NIC 使用标准 RDMA 协议(InfiniBand 或 RoCE) 将数据发送到远程节点. NIC 硬件处理整个 RDMA 协议(QP、rkey、序列号、重传等),无 CPU 介入网络栈. 路径: 左 NIC → 网络链路 → 右 NIC
- E/F. 远程 NIC(右节点) → 系统内存(右节点 DDR): 远程 NIC 根据 RDMA 操作,直接 DMA 将数据写入远程注册的主机 DDR 缓冲区. 零拷贝 到主机内存,无需 CPU 拷贝数据. 路径: 右 NIC → PCIe Switch → Root Complex → IMC → DDR
- G: 系统内存(右节点 DDR) → 目标 GPU(右节点 NVIDIA GPU): 应用程序从 DDR 缓冲区拷贝数据到目标 GPU 显存. 步又是显式拷贝(cudaMemcpy HostToDevice),CPU 调度. 路径: DDR → IMC → CPU → Root Complex → PCIe Switch → GPU
有了 RDMA 相比传统 TCP/IP 的最大优势在于,它通过硬件 offload 网络协议栈、实现网络零拷贝和 CPU bypass,大幅降低了延迟(通常从 10–20 μs 降至 2–5 μs)、提升了带宽利用率、显著减少了 CPU 开销,从而在高性能计算和分布式 AI 训练中带来 2–5 倍的通信效率提升. 但在 GPU 场景下,普通 RDMA 仍存在强制经过主机内存(DDR)中转的问题,导致两次额外的 cudaMemcpy 拷贝(GPU ↔ DDR),无法实现真正的端到端零拷贝和完全绕过 CPU 的数据路径.
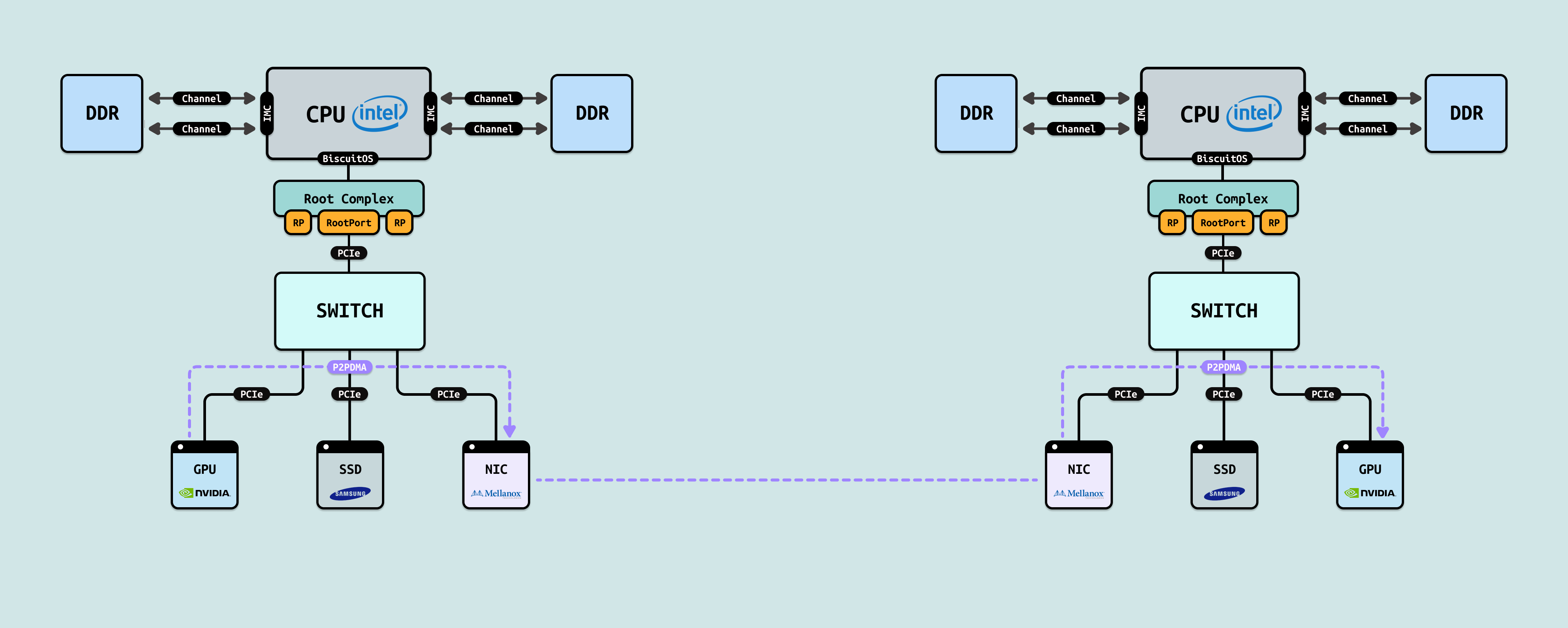
问题讨论到这里,其实也就多绕了一次主机内存. 聪明的我突然灵光一闪: 在不支持 RDMA 的情况下,左节点的 GPU 和 NIC 明明挂在同一个 PCIe Switch 下,为什么不直接让它们之间进行 P2PDMA 呢? 这样就能完全绕过系统内存,直接在 GPU 和 NIC 间交换数据,岂不是美滋滋? 理想很丰满,现实很骨感 – 虽然硬件层面确实支持 P2PDMA,但 GPU 的原始数据传到 NIC 后,NIC 只认得已经打包好的 TCP/IP 报文,对裸数据完全无能为力,所以这条路还是走不通.
