![]()


RDMA Underprinning
InfiniBand Transport Protocol
RoCE v1/v2 Transport Protocol
iWARP Transport Protocol
Software-RoCE(rxe) Transport Protocol
RDMA Practice
RDMA Hardware NIC(RNIC)/Switch
RDMA Software Protocol Stack(Verbs)
PD(Protection Domain)
RDMA Performance Analysis and Diagnosis
In-Depth Research on RDMA Mechanisms
OpenShmem 💡
GPUDirect Storage(NVMe-oF) 💡
NVShmem 💡
None-pin RDMA
On-Demand Paging For RDMA
Fast Memory Registration/FRWR
SRQ/XRC
Memory Window(MW)
NCCL 💡
RDMA + CXL
RDMA Specification


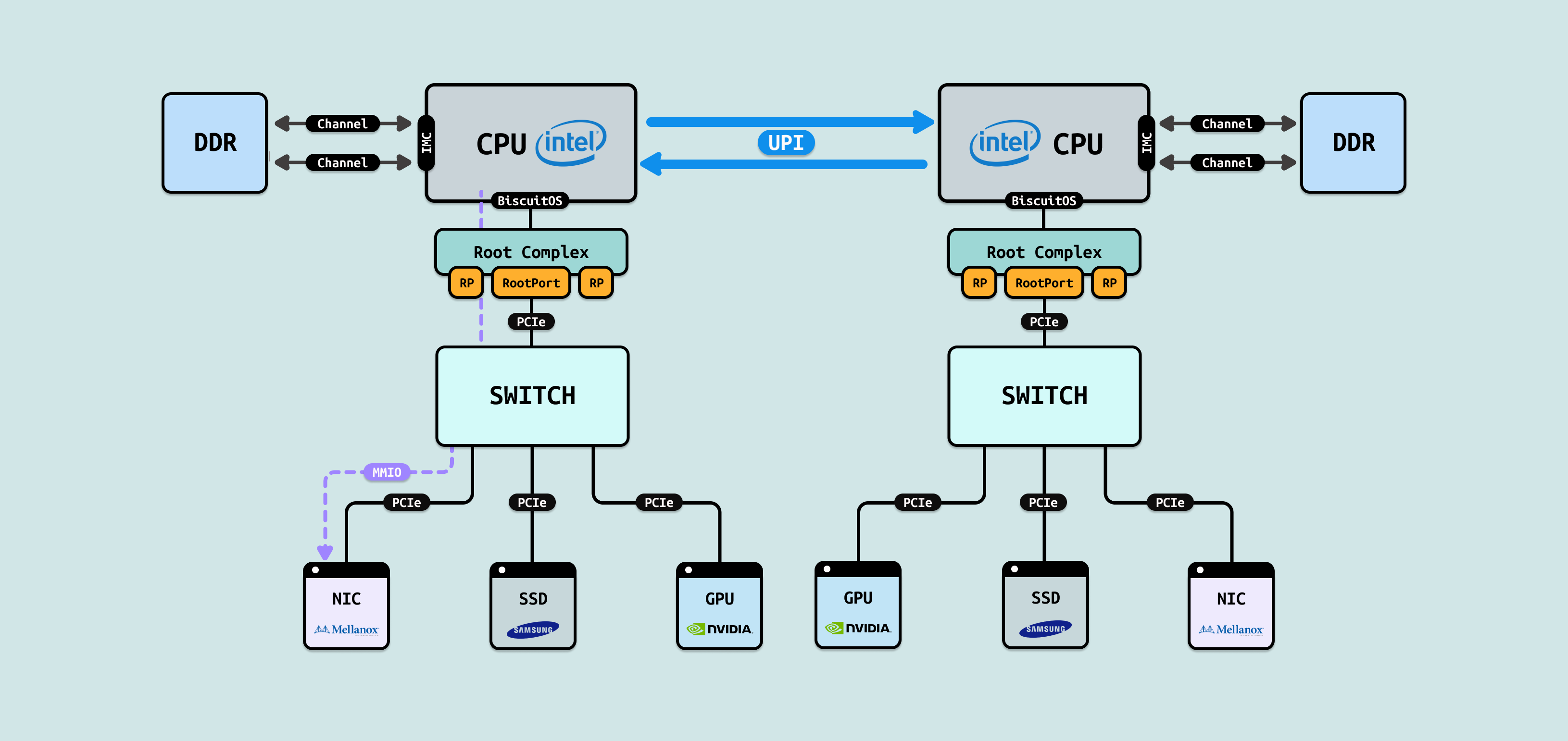
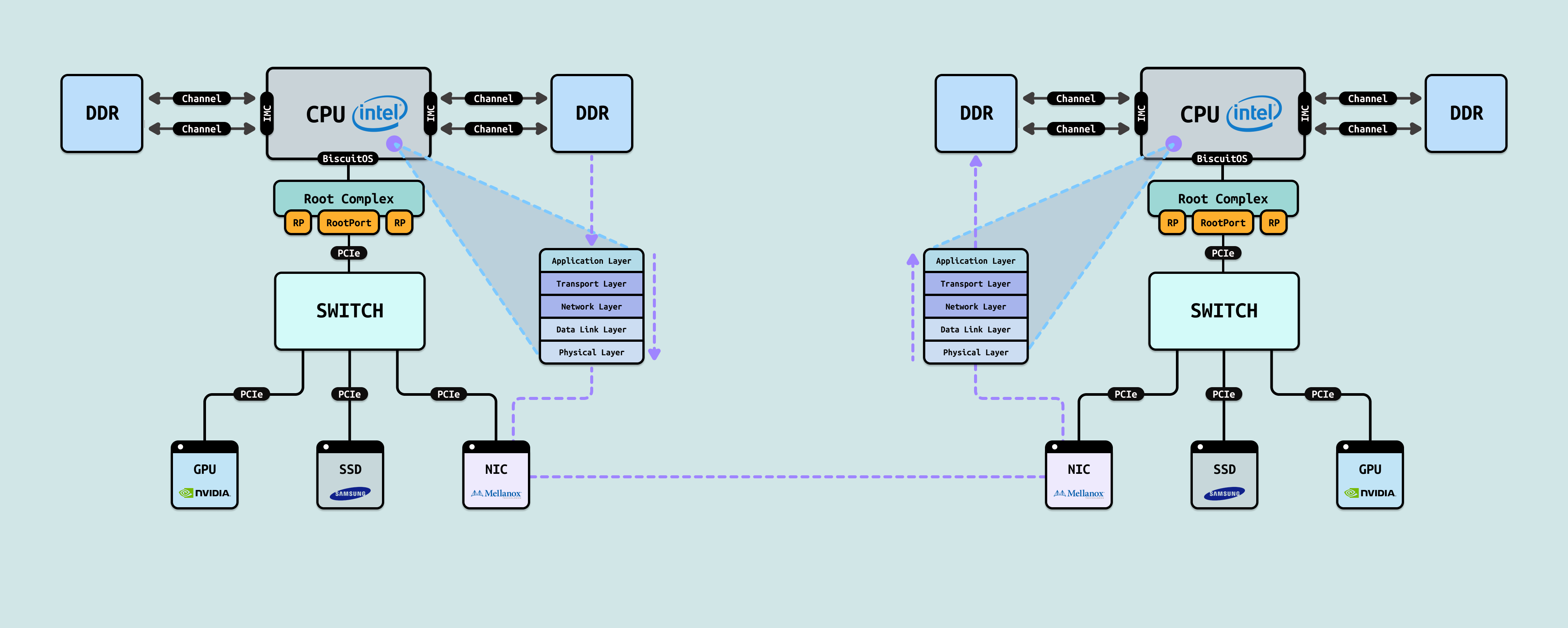
当计算机上有一个 PCIe 外设,CPU 需要访问其内部内存,那么 PCIe 可以将其内部内存映射到系统物理地址空间,形成一段独立的物理区域 MMIO. 于是 CPU 可以将虚拟内存映射到 MMIO,接着使用各种 MOV 指令从 MMIO 上拷贝数据到指定寄存器,这些数据并不会被缓存到 CACHE,因为 MMIO 采用 UC 方式映射. CPU 会花很长时间从 PCIe 上拷贝数据,不仅占用了大量的 CPU 资源,并且 CPU 只是纯粹的拷贝操作,这有点浪费昂贵的 CPU 资源. 另外 CPU 每次访问 MMIO 的延迟也是极大,比访问内存慢 3-1000 倍.
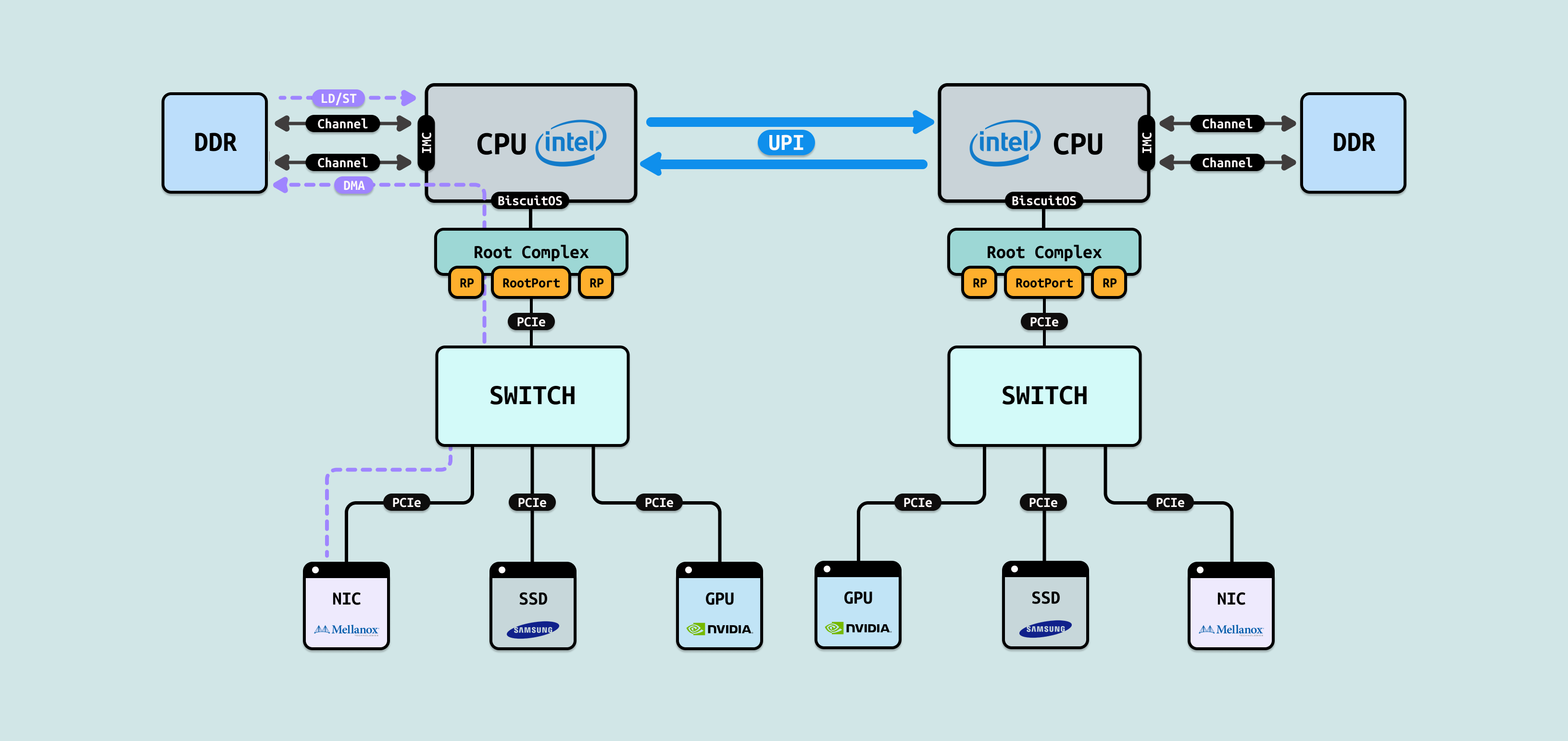
基于上面的场景,可以使用 DMA(Direct Memory Access), CPU 可以在物理内存上申请一块连续的物理内存(这块物理内存称为 “DMA 内存”), 然后告诉 PCIe 设备将其内存拷贝到 “DMA 内存” 的位置/长度/方向等信息,那么 Kick 一下之后,PCIe 就独立进行 DMA 将数据在 “DMA 内存”和 PCIe 内存之间进行搬运,搬运完毕之后再通知 CPU,CPU 在搬运过程中无需介入,只有在收到通知之后在通过 LD/ST 方式访问 “DMA 内存”,这样最大程度释放 CPU 资源. 另外 DMA 搬运的性能是 MMIO 的 50-300 倍.
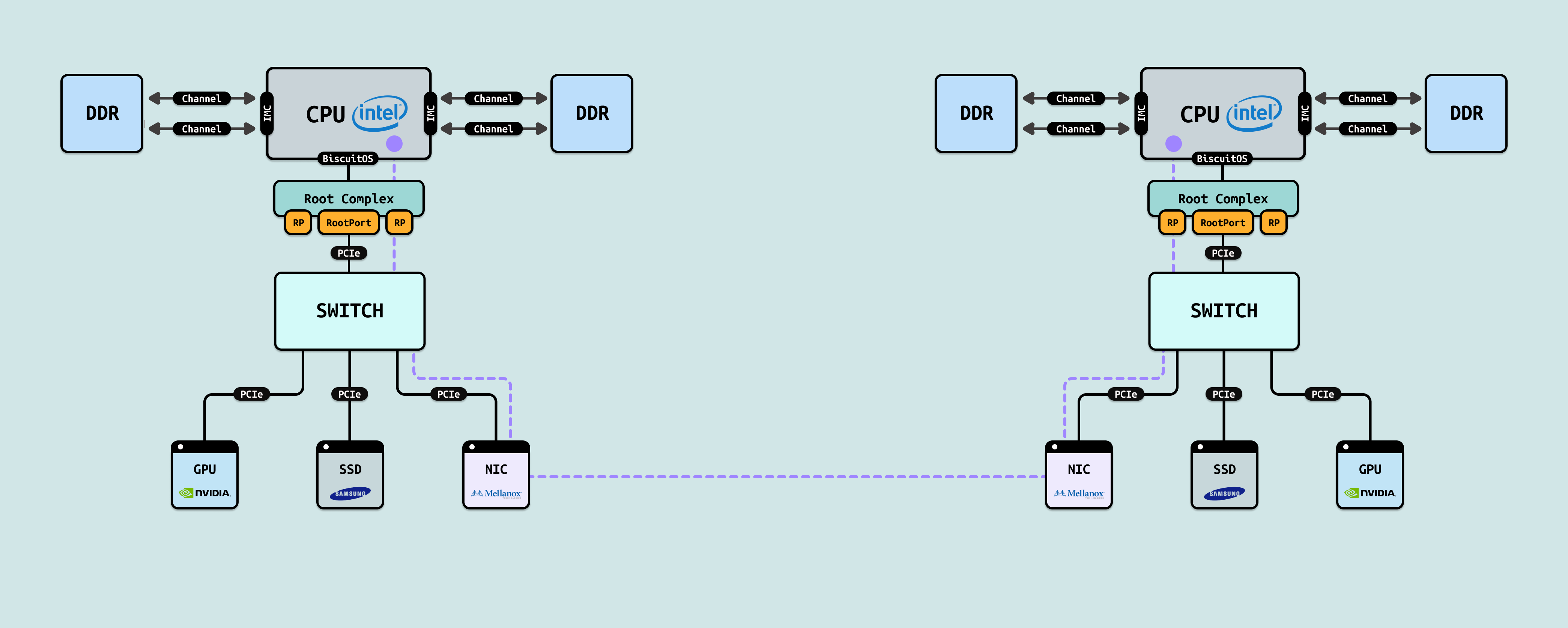
在大规模 AI 集训集群场景,多个计算节点之间需要进行数据交互,通常是使用网络方案,计算节点之间通过 NIC 卡进行网络数据交换. 当节点 A 向节点 B 发送数据时,节点 A 会将数据从内存搬运到自己的 NIC 卡发送到网络,然后经过网络转发到节点 B 的 NIC 网卡,节点 B 在将数据从自己 NIC 卡搬运到内存, 这样实现了两个节点之间的数据交换.
网络数据交互核心使用 TCP/IP 网络协议,随着 AI 火热, 数据中心承载的网络数据量越来越大,但困难重重,一个 1G 网卡的服务器,处理流量能达到 800M 就相当不错了,TCP/IP 网络协议分为五层,其中灰色标记的代表硬件部分,紫色标记的代表是系统软件部分,绿色标记的代表是应用软件部分. 当一个数据包从网卡进入系统后,它需要依次经过网络层(IP)和传输层(TCP/UDP)的处理,最终才能到达用户态的应用缓冲区. 整个过程高度依赖 CPU 资源,CPU 必须完成一系列复杂的工作: 进行 CRC 校验、解析 IP 头部、查找路由表、驱动 TCP 状态机、处理序列号和 ACK、维护滑动窗口、管理重传机制等. 此外,还涉及多次内存拷贝(从网卡 DMA 到内核 skb 缓冲区,再从内核拷贝到用户态缓冲区),以及伴随而来的上下文切换、软中断调度、CPU 缓存污染等问题. 当网络报文速率上升时,CPU 的消耗会呈现线性甚至超线性增长. 与此同时,CPU 利用率开始剧烈波动,缓存 miss 率显著增加,调度抖动加剧. 这些因素相互叠加,最终导致系统整体网络性能变得不稳定,表现为丢包率上升、延迟出现明显抖动、实际吞吐量下降等问题. 传统 TCP/IP 协议栈的这种”CPU 密集型”处理方式,正是高性能网络场景下的主要瓶颈之一
正是传统 TCP/IP 协议栈这种 “CPU 密集型”的处理方式,成为了高性能网络场景下的主要瓶颈: 报文速率越高,CPU 消耗越大,性能波动越明显,延迟抖动和吞吐下降几乎不可避免. 面对这样的困境,RDMA(Remote Direct Memory Access) 作为一种革命性的网络传输技术应运而生,它通过将数据传输的核心工作从 CPU 彻底卸载到网卡硬件,实现了真正的“内核旁路(Kernel Bypass)”和“零拷贝(Zero Copy)”. 图中灰色标记的代表硬件部分,绿色标记的代表是应用软件部分. RDMA 技术的最大突破在于,它将传统网络协议栈中的网络层和传输层处理彻底从 CPU 移到了网卡硬件中. 当数据报文到达服务器网卡时,网卡硬件便直接完成四层协议的解析、校验、重组等所有工作,并将数据零拷贝地送达应用层软件,整个过程几乎无需 CPU 干预. 这正是 RDMA 能够同时实现极低延迟、极高带宽和极低 CPU 占用率的根本原因,也是它最具吸引力的核心价值. 一个拥有 1G 网卡的服务器,使用 RDMA 技术,应用软件处理的数据速度就可以接近 1G.
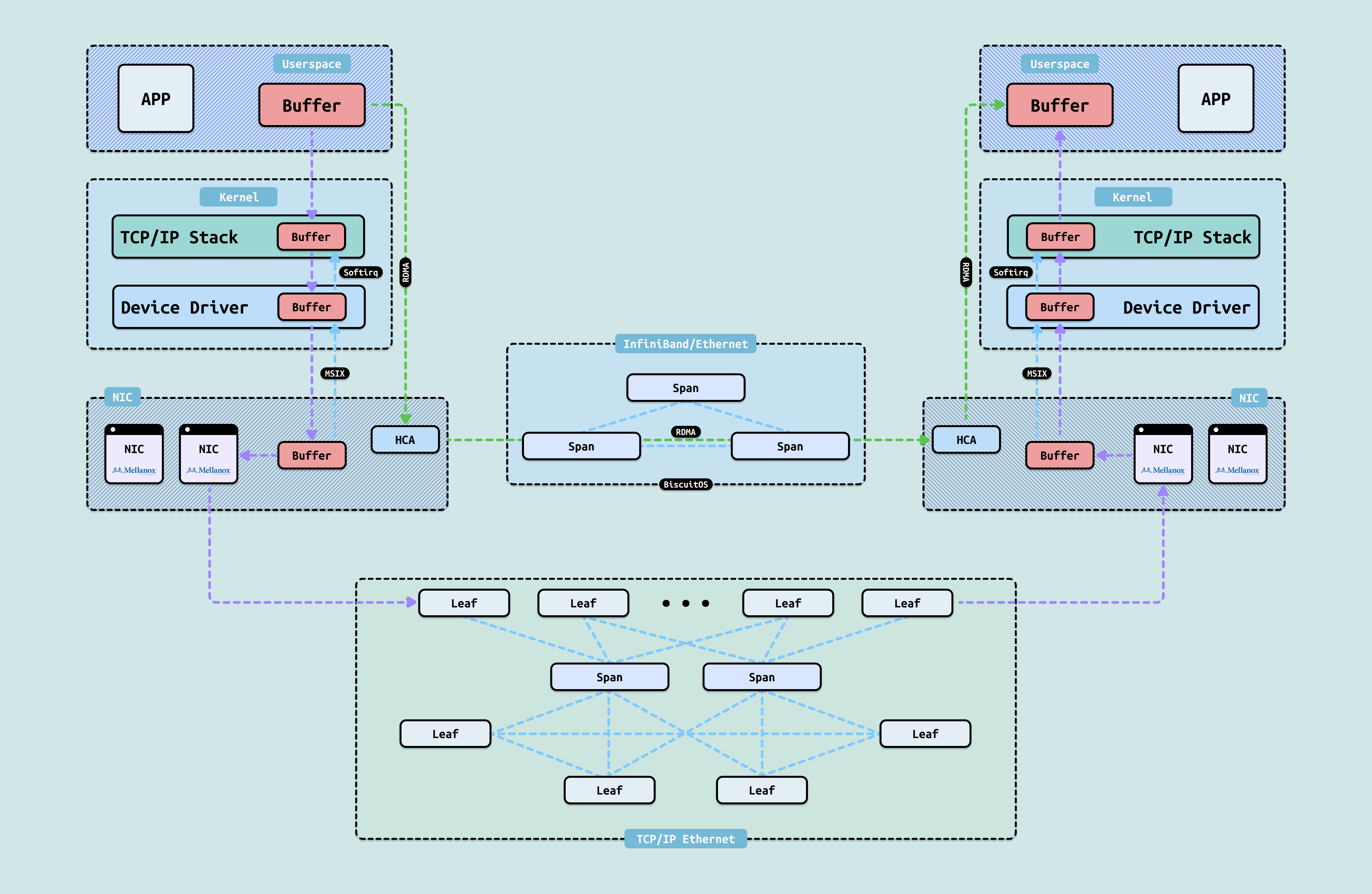
RDMA(Remote Direct Memory Access,远程直接内存访问)技术的出现,正是为了解决传统网络传输中服务器端数据处理的高延迟和高 CPU 消耗问题而诞生的核心创新. 它的核心思想是通过网卡硬件直接完成数据的高效搬运,将数据从发送方的内存直接写入或读取到接收方的内存缓冲区,整个过程几乎完全绕过操作系统内核和 CPU 的干预,从而彻底消除了传统 TCP/IP 协议栈中那些耗时的外部内存拷贝、上下文切换、协议解析、校验计算和软中断开销. 当应用发起一次 RDMA 读或写请求时,数据无需经过内核协议栈的层层处理,也不需要执行任何用户态到内核态的内存复制. 请求直接从用户空间的应用提交到本地网卡,网卡硬件接管后续所有工作: 数据封装、可靠传输、CRC 校验、报文发送等全部在硬件层面完成,然后通过网络直达远程服务器的网卡,由远程网卡直接将数据写入预先注册的内存区域,最后通过完成队列(Completion Queue)异步通知应用,整个路径真正实现了“零拷贝”和“内核旁路”. 正是这种设计,让 RDMA 带来了传统网络难以企及的三大优势:
- 极低的延迟, 微秒级甚至亚微秒级
- 极高的带宽利用率, 接近线速
- 极低的 CPU 占用, CPU 几乎只负责提交请求和收完成通知
在高负载场景下,CPU 不再被网络协议处理拖累,可以将几乎全部计算资源投入到实际业务逻辑中,显著提升系统整体吞吐量和稳定性. 这也是 RDMA 成为现代高性能计算、AI 分布式训练、NVMe-oF 存储、金融低延迟交易等领域的基石技术的根本原因.
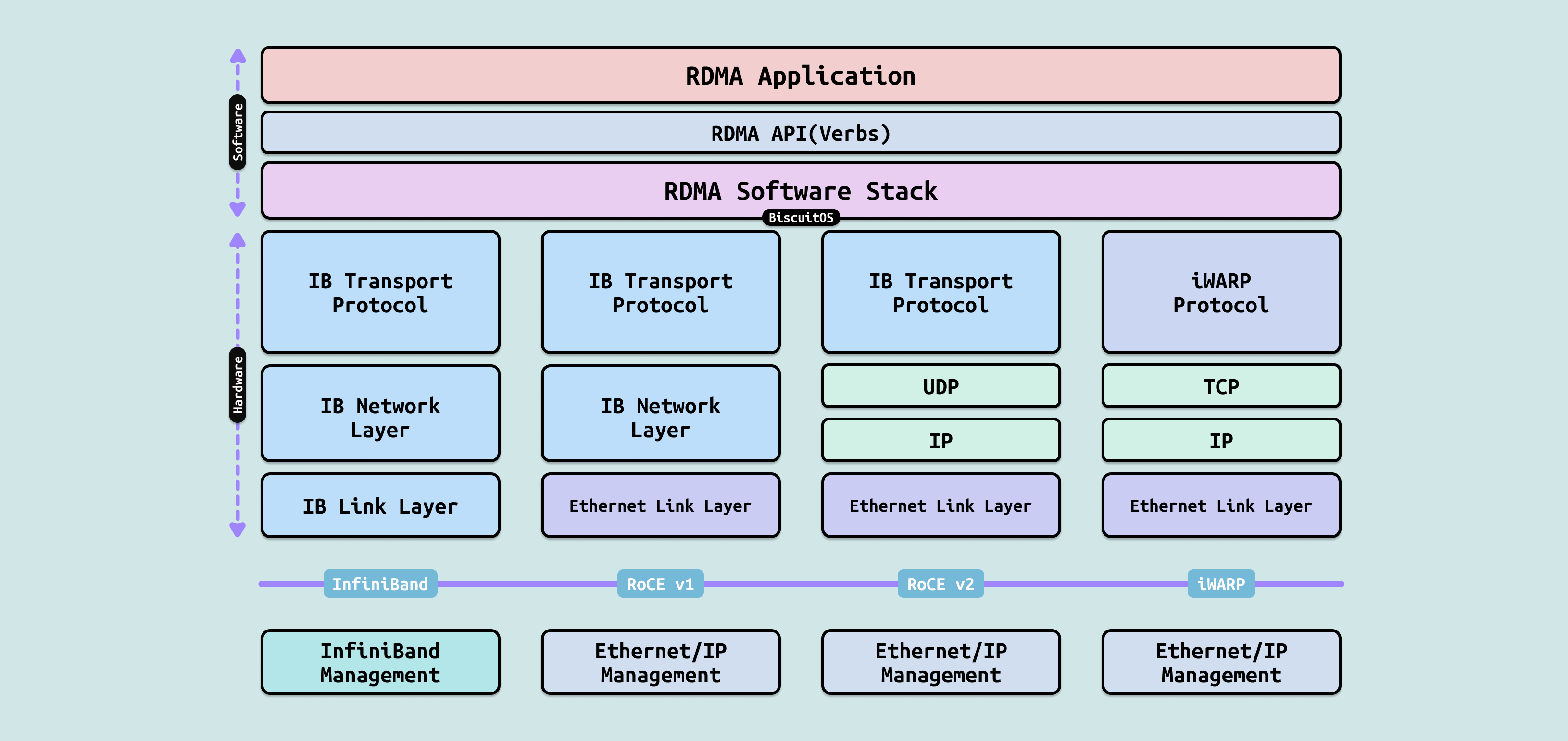
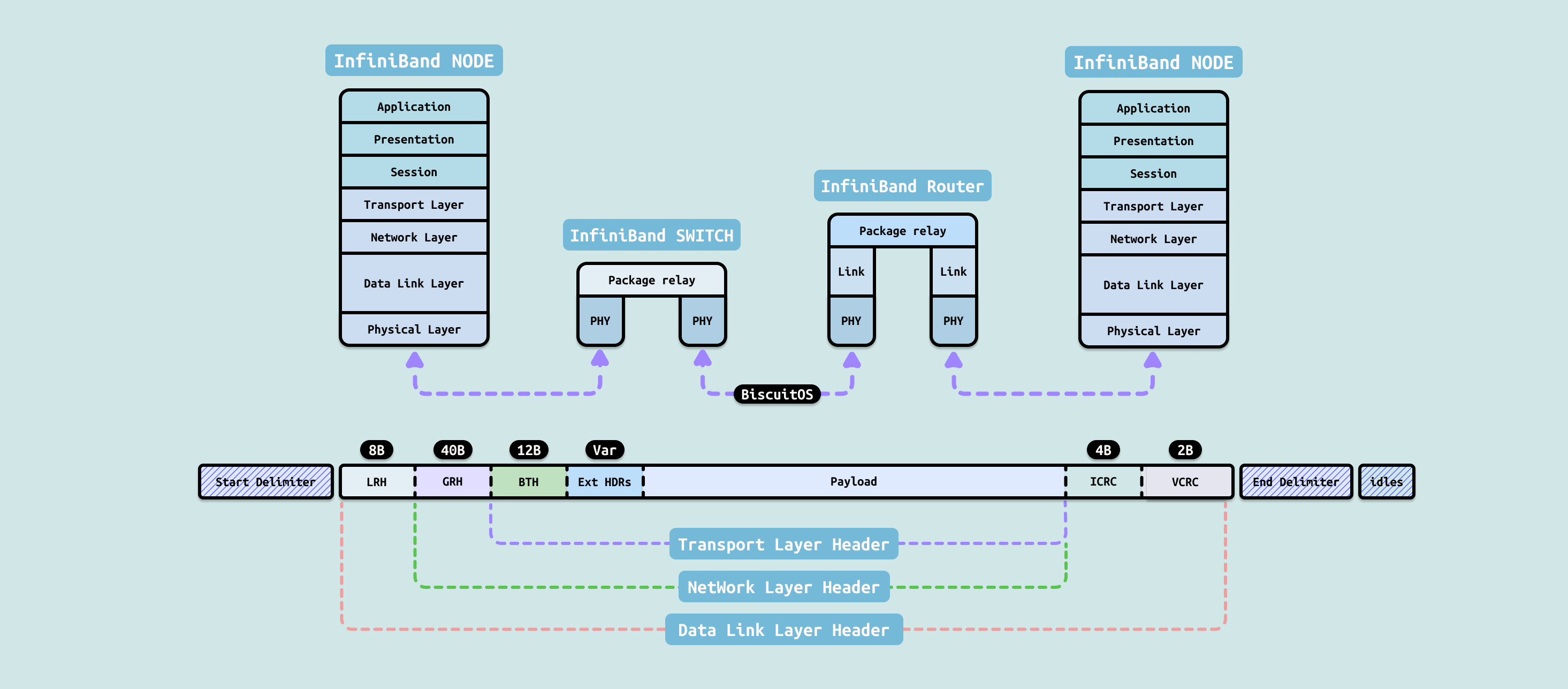
RDMA 作为一种高性能网络传输技术,其协议类型主要分为四种主流实现方式,它们在底层传输协议和链路层上有所不同,但核心目标都是提供低延迟、高带宽、内核旁路和零拷贝的远程内存访问能力. 包括 InfiniBand、RoCE V1、RoCE V2 以及 iWARP. RDMA 的核心价值在于传输层(Transport Protocol)始终是 InfiniBand 定义的那一套可靠传输机制,而差异主要体现在链路层和网络层的实现方式上. 这四种协议共同构成了 RDMA 的”家族”,其中 RoCE v2 已成为当前数据中心和 AI 时代的主流选择的. 四种实现方式具体实现如下:
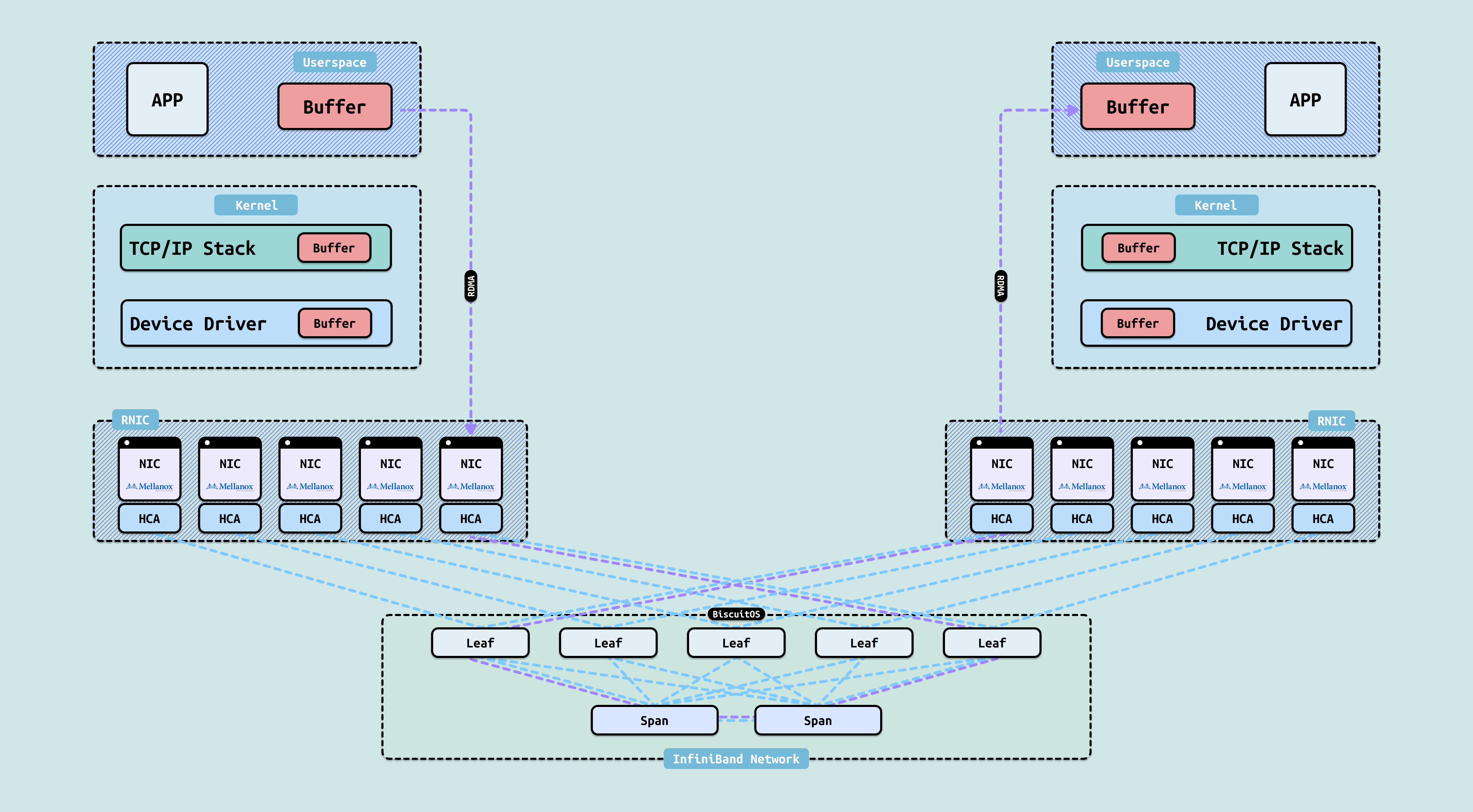
InfiniBand: InfiniBand 是 RDMA 技术的原始和最纯粹的实现,由 InfiniBand Trade Association(IBTA)制定并主导. 它拥有完全独立的专属协议栈,从物理层到传输层一应俱全,包括 IB Link Layer(链路层)、IB Network Layer(网络层)和 IB Transport Protocol(传输层). InfiniBand 原生支持 RDMA 操作,提供可靠连接(RC)、不可靠连接(UC)和不可靠数据报(UD)等多种传输模式,具备极低的延迟(通常达到亚微秒级)和极高的带宽,是传统高性能计算(HPC)和超级计算机集群的首选互连技术. 然而,由于需要专用的 InfiniBand 硬件、电缆和交换机,其生态相对封闭,部署成本较高,这也限制了其在更广泛商业场景中的普及