
![]()



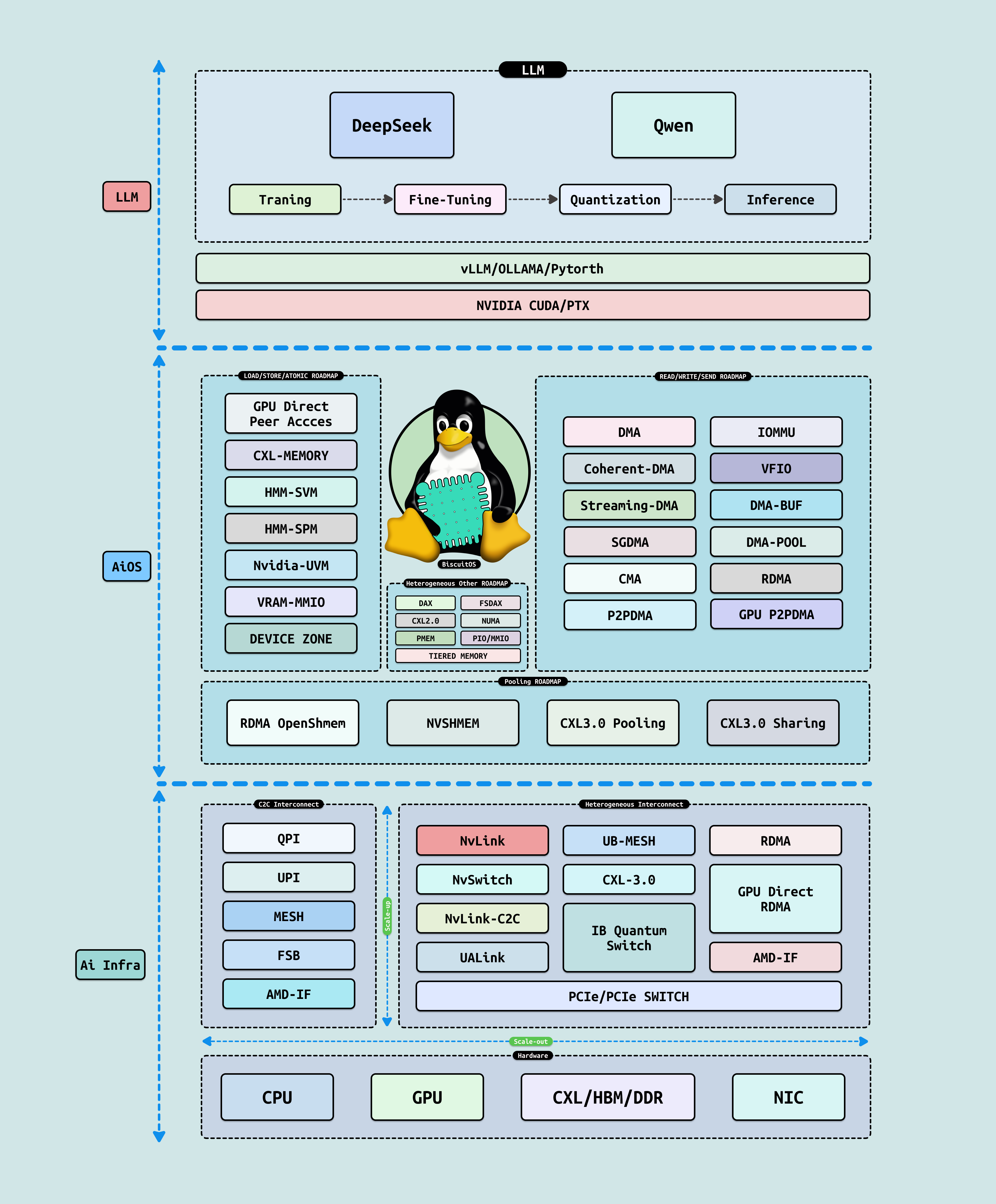
在高性能计算(HPC) 时代,AI 已成为 PB 级模拟与预测的核心驱动力,从量子化学到气候建模,TB 级数据集的处理需求正挑战 Linux 内核的极限. 作为 BiscuitOS 社区的内核开发者,我们需从系统级视角审视 AI: 它不仅是用户空间的“黑箱”,更是可工程化的栈层,需要内核优化以实现 ‘TB/s’ 带宽和 ‘PFLOPS’ 吞吐. 本文基于从上到下的架构剖析,揭示 AI 在 HPC 中的脉络与落地路径,帮助你构建高效的 AI 加速模块. BiscuitOS AI 架构分为三层,层层递进,确保 AI 从抽象到硬件的无缝桥接:
- LLM 层: 聚焦主流大语言模型如 DeepSeek 和 Qwen,该层核心围绕 LLM 的生命周期展开: 训练(海量预训练与分布式并行)、微调(领域适应如 PEFT 量化)和推理(高效 KV 缓存与批处理). 这一层定义 AI 的 “智能内核”, 但依赖下层服务以突破计算瓶颈
- AiOS 层: 作为操作系统中介,AiOS 向上为 LLM 提供资源抽象服务(如动态调度与内存池),向下适配新兴硬件(NvLink/UaLink/UB-Mesh). 它桥接用户空间框架(如 PyTorch/CUDA) 与内核,实现跨节点负载均衡,减少调度开销和数据拷贝
- Ai Infra 层: 底层基础设施,涵盖主流异构互联硬件,如 NVIDIA NVLink(高带宽 GPU 互连)、UALink(开放式 AI 加速器联盟标准)和多 GPU 集群技术. 这些硬件通过内核 RDMA/InfiniBand/HMM 驱动,确保 NUMA 亲和与 AER 错误恢复,支持 HPC 级扩展
作为 BiscuitOS 社区的创始人,我写这个专题的初衷很简单,就是想拉着社区里的各位童鞋,一起撸起袖子搞明白 AI 这玩意儿到底是怎么一回事儿. 咱们内核开发者天天泡在代码堆里,PCIe 驱动写得飞起,NUMA 优化闭眼来,但一遇到 AI,总觉得像进了个雾里看花的迷宫: LLM 听起来高大上,可训练微调推理的细节咋落地? AiOS 说它是操作系统,怎么就给 LLM 当”保姆”了,还得向下啃硬件适配的硬骨头? Ai Infra 那些 NVLink、UALink 的异构互联,又该怎么在内核里驯服成自家后院?
这些问题搁谁身上都挠头,我也不例外. 但正因为这样,我才想用最接地气的语言,从上到下捋一捋这个技术栈: 不整那些云里雾里的理论堆砌,而是直奔实践, 每个层级都配上可运行的代码片段、调试技巧和 HPC 场景下的坑点解析,让你边看边试,搞懂为什么 AiOS 的内存池能让跨节点训练不卡壳,为什么 Infra 层的 RDMA 驱动一调优,就能把 GPU 集群的吞吐拉到 TB/s 级别. 最终,我还独家贡献了多张张手绘图片: 不是冷冰冰的 UML 图,而是像漫画一样把抽象概念具象化: 想象 LLM 训练像一场”分布式接力赛”,AiOS 是赛道上的”智能裁判”,Ai Infra 则是那些”闪电高铁”般的硬件轨道. 一张张看下来,你会发现那些高难度技术,原来就藏在日常调试的逻辑里. 希望通过这篇文章,BiscuitOS 的童鞋们不光能读懂 AI,还能上手搞出自己的 AI 项目,一起把社区的内核 AI 生态推向新高度. 接下来,我们将逐层展开,从 LLM 的训练微调入手,一步步拆解工程细节,直至 Infra 硬件的内核驯服之道.

Large Language Models(LLM),即大型语言模型,是 AI 生态的顶层支柱,通过 Transformer 等架构处理海量文本数据,实现自然语言理解、生成和推理,如 OpenAI 的 GPT-4、Meta 的 Llama3、DeepSeek AI 的 DeepSeek-V2(开源高效中文-英文双语模型,支持长上下文推理)和阿里云的 Qwen2(通义千问系列,多模态大模型,优化企业级部署)等已成为 AGI 开发的基石. LLM 不仅代表计算规模的巅峰(万亿参数级),更体现了 AI 从数据到智能的完整闭环: 从预训练捕捉知识,到微调适配任务,再到量化压缩和高效推理,支持实时应用部署. 在本白皮书的层递进结构中,LLM 作为最上层,承接 AiOS 的统一资源抽象(如 UVM/UPM 内存池化和 Load/Store 语义) 和 AI Infra 的池化硬件(如 CXL/NVLink 互联),向下逐步展开为框架层(vLLM/Ollama/PyTorch 的抽象屏蔽)和运行时层(CUDA Runtime/PTX 的执行基础). 这一结构从应用需求驱动到硬件执行,确保大模型无缝调用异构资源,屏蔽底层复杂性,实现”模型即服务”的高效统一,推动 AI 从基础设施向智能应用的终极跃迁
- LLM 训练:
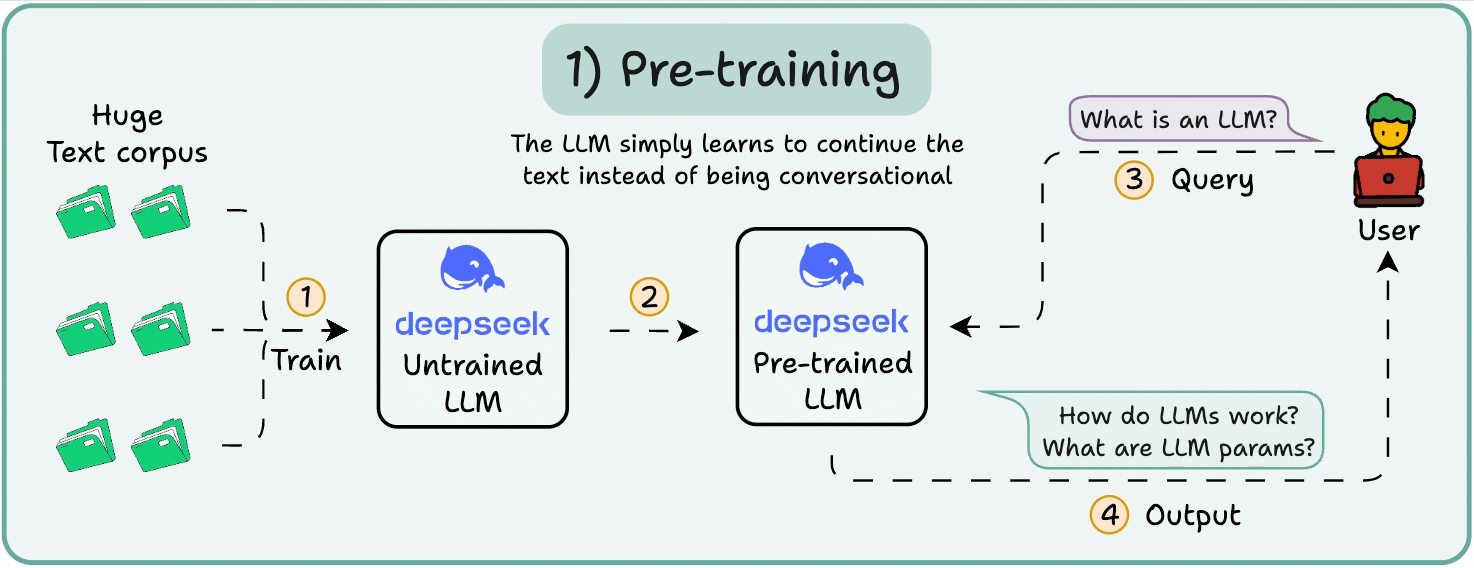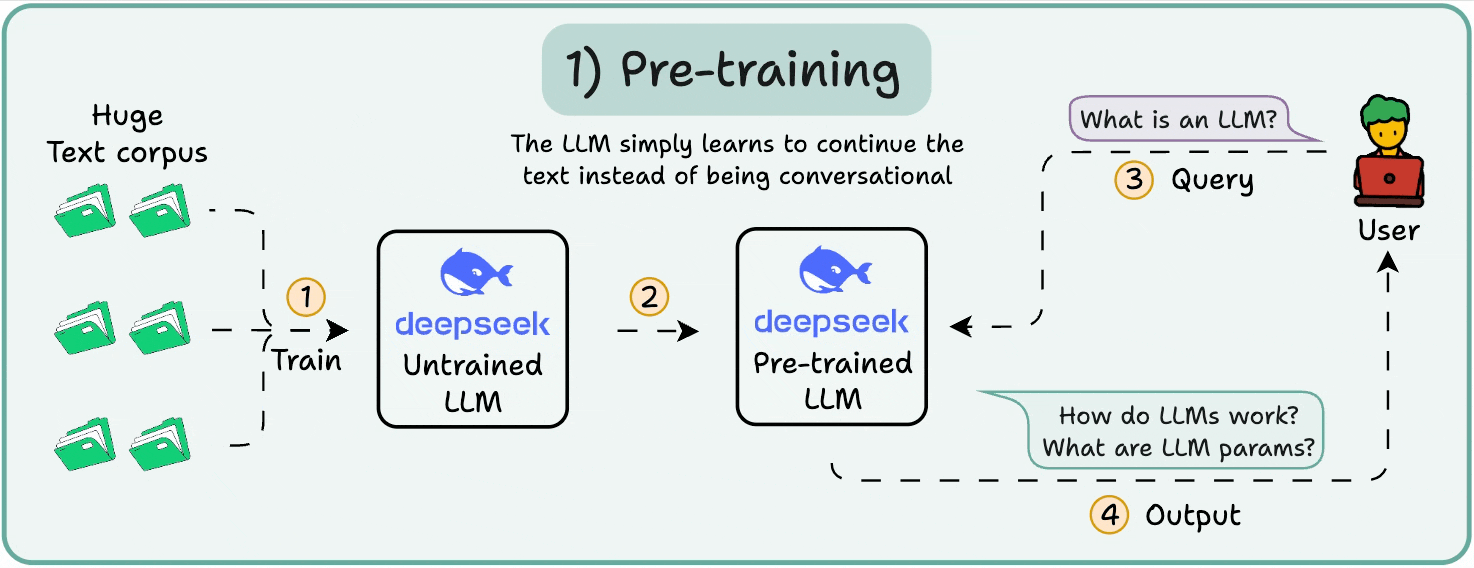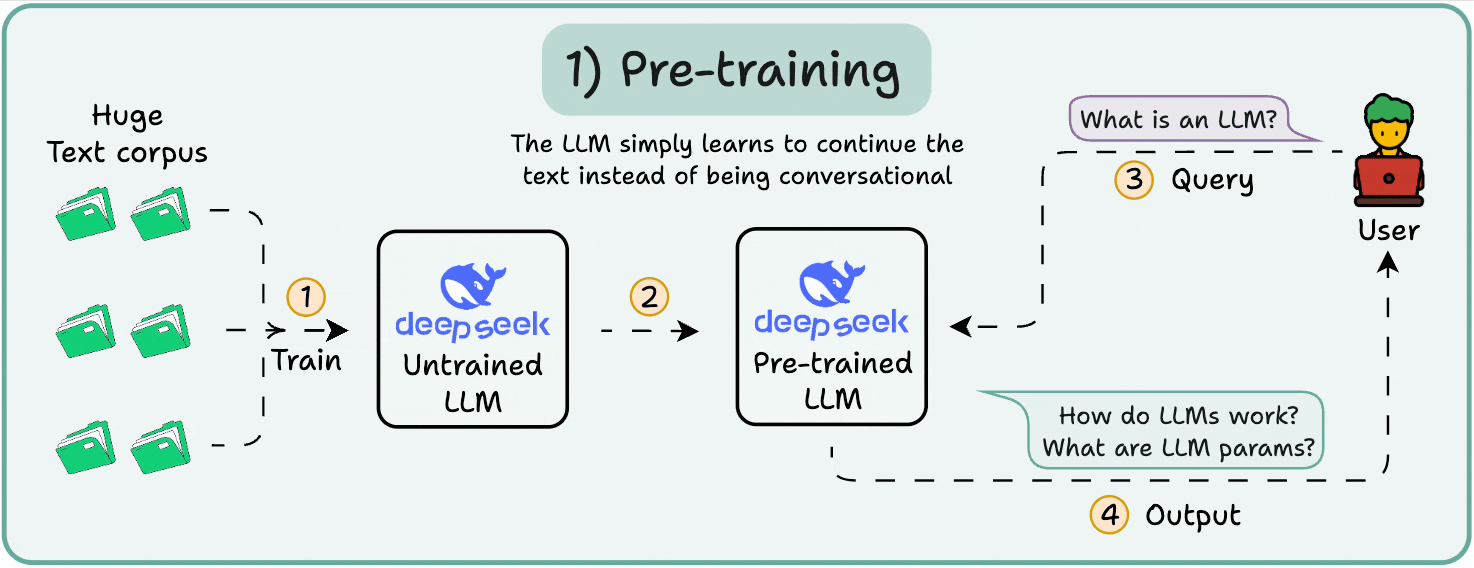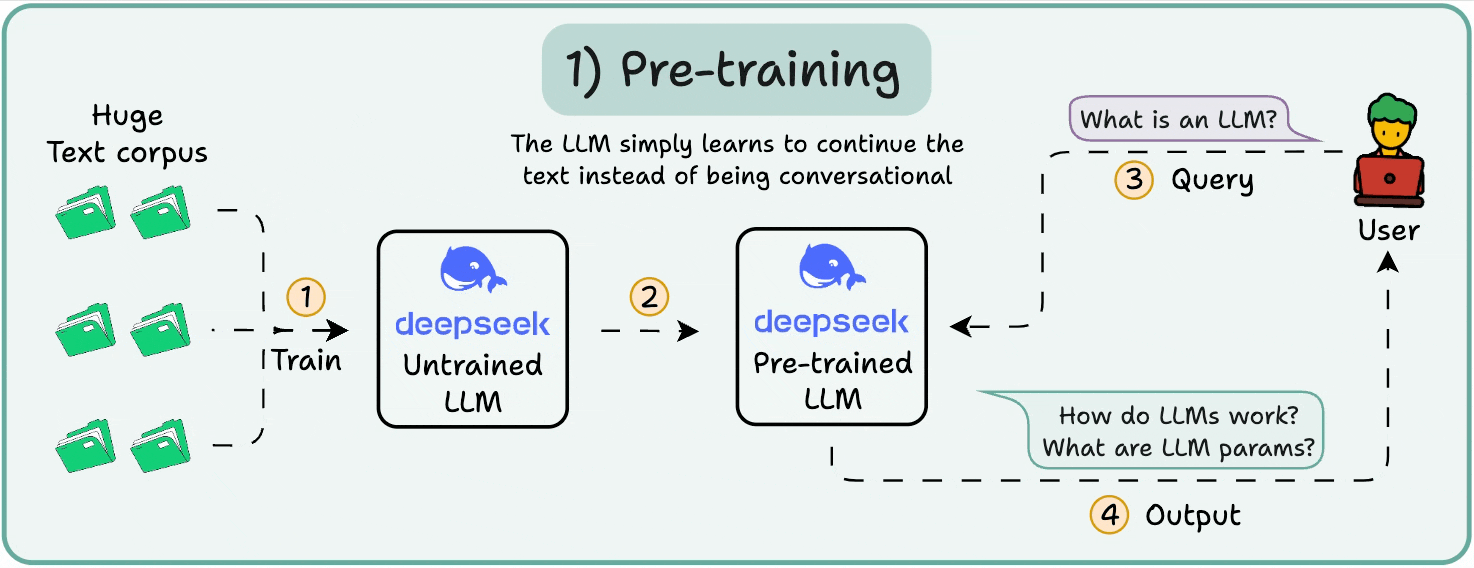 从数据到知识的规模化构建. LLM 训练(Pre-training)是生命周期的起点,通过海量无标签数据(如万亿 Token)预训练 Transformer 架构,学习语言模式和世界知识. 典型流程包括数据预处理(清洗/分词,利用 AI Infra 的存储池化如 NVMe 加速 ETL)、模型初始化(从零或迁移学习)和分布式训练(Data Parallelism 或 Pipeline Parallelism). 框架如 PyTorch 的 DistributedDataParallel(DDP) 或 DeepSpeed ZeRO 优化,抽象 AiOS 的 UVM/UPM 统一内存,支持跨节点张量分发. AiOS 的 Load/Store 语义确保高效 coalesced 访问,屏蔽 CXL 池化延迟(~50ns),而 Read/Write 间接 DMA 处理远程 HBM 迁移. 在规模上,2025 年标准为万亿参数级(如 GPT-5),依赖 AI Infra 的 NVLink Scale-out 实现 AllReduce 同步,迭代时间缩短至小时级. 优势在于泛化能力强,但挑战是计算饥饿,AiOS 通过动态核心池化(如 NVLink C2C)提升利用率 15x,支持 AGI 知识蒸馏
从数据到知识的规模化构建. LLM 训练(Pre-training)是生命周期的起点,通过海量无标签数据(如万亿 Token)预训练 Transformer 架构,学习语言模式和世界知识. 典型流程包括数据预处理(清洗/分词,利用 AI Infra 的存储池化如 NVMe 加速 ETL)、模型初始化(从零或迁移学习)和分布式训练(Data Parallelism 或 Pipeline Parallelism). 框架如 PyTorch 的 DistributedDataParallel(DDP) 或 DeepSpeed ZeRO 优化,抽象 AiOS 的 UVM/UPM 统一内存,支持跨节点张量分发. AiOS 的 Load/Store 语义确保高效 coalesced 访问,屏蔽 CXL 池化延迟(~50ns),而 Read/Write 间接 DMA 处理远程 HBM 迁移. 在规模上,2025 年标准为万亿参数级(如 GPT-5),依赖 AI Infra 的 NVLink Scale-out 实现 AllReduce 同步,迭代时间缩短至小时级. 优势在于泛化能力强,但挑战是计算饥饿,AiOS 通过动态核心池化(如 NVLink C2C)提升利用率 15x,支持 AGI 知识蒸馏 - LLM 微调:
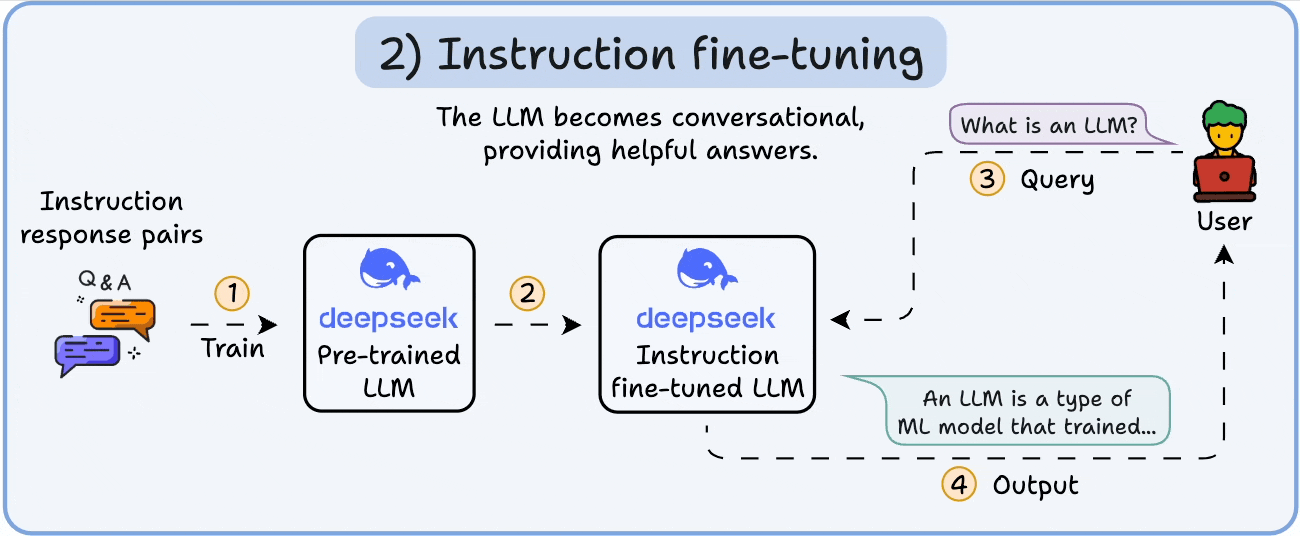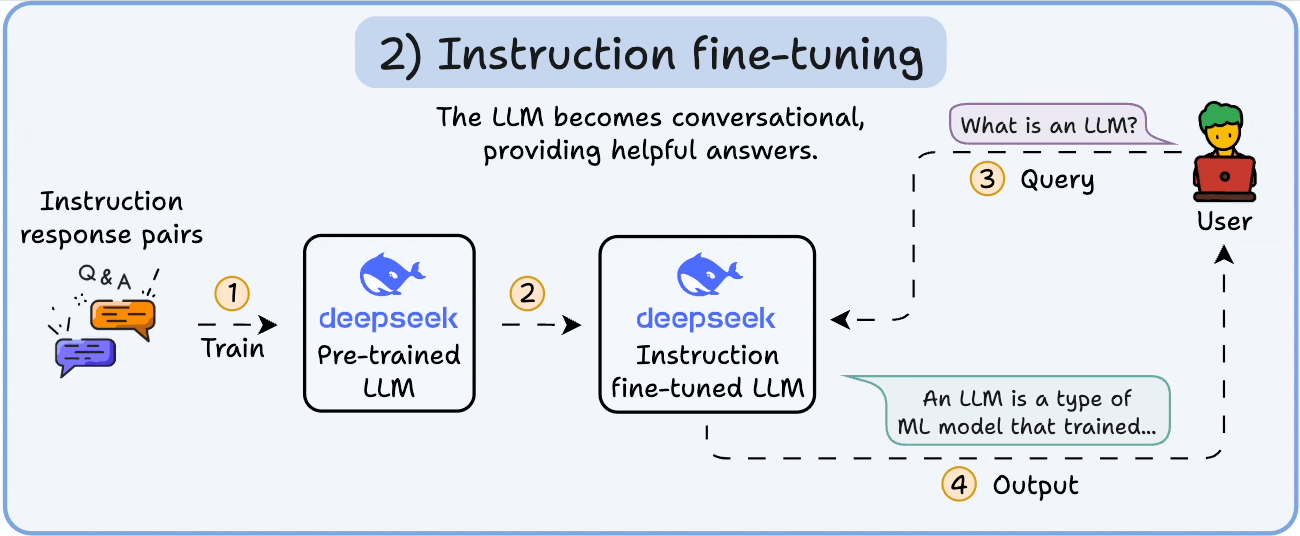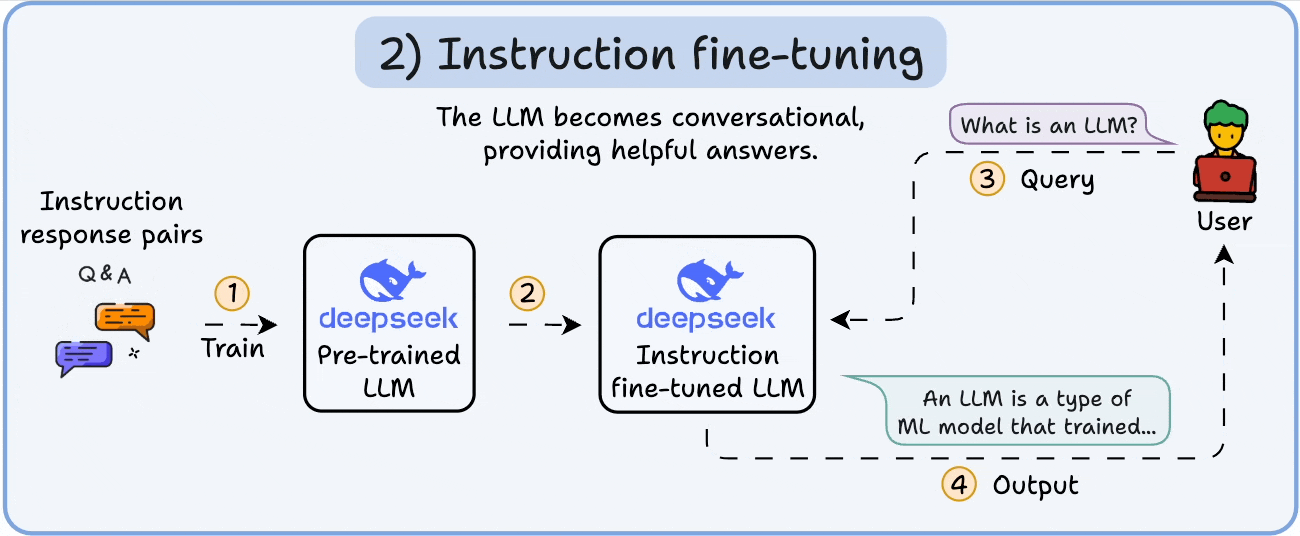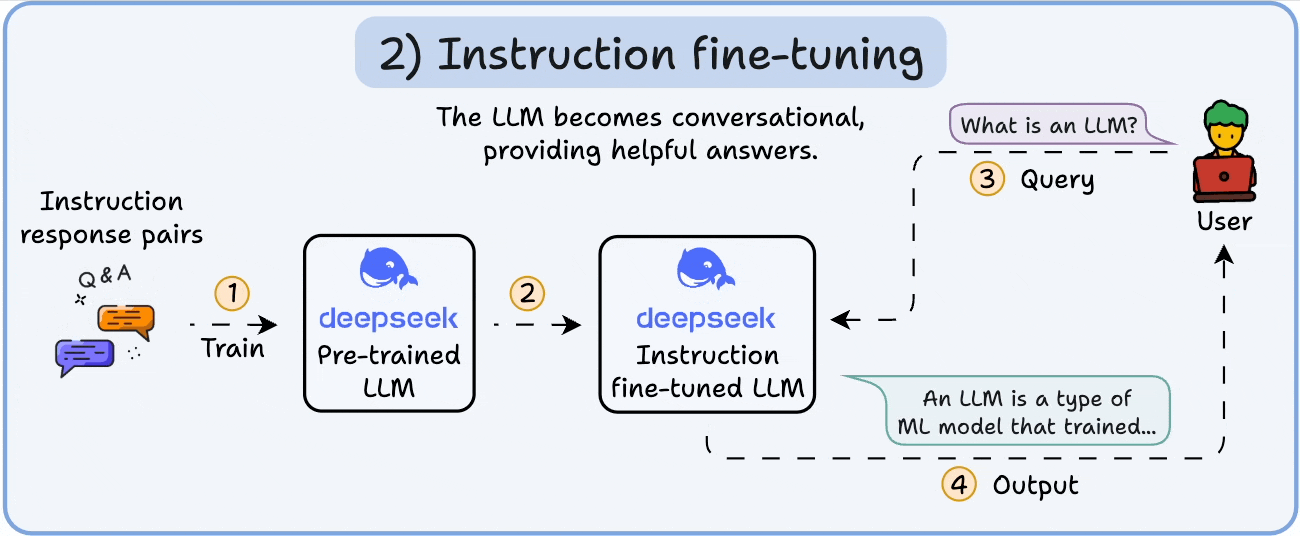 从通用到专精的适配优化. LLM 微调(Fine-tuning) 是训练后的精炼阶段,使用少量标签数据(如 10B Token)适配特定任务,如对话或代码生成. 核心方法包括参数高效微调(PEFT)和检索增强生成(RAG)的结合,前者直接调整模型参数,后者通过外部知识增强推理. 框架如 Hugging Face PEFT 或 DeepSpeed 集成,调用 AiOS 的统一 API 管理资源借用(如从”只有 GPU 的服务器”拉取 SM 核心). AiOS 的 Read/Write 范式支持间接 MMIO 配置适配器权重,Load/Store 直接优化本地激活计算,结合 AI Infra 的 UB-Mesh Scale-out 实现跨域同步. 2025 年趋势是 LoRA(Low-Rank Adaptation)主导 PEFT,仅更新 1% 参数(如 DeepSeek-V2 的 LoRA 适配器),而 RAG(Retrieval-Augmented Generation)作为辅助,通过动态检索外部知识库(如向量数据库)注入上下文,避免全参数微调的开销. 优势在于任务适配性强(准确率升 20%),但易过拟合. AiOS 通过缓存一致性屏蔽异构差异,确保稳定梯度更新,支持企业级定制如 Qwen 2 的多模态微调
从通用到专精的适配优化. LLM 微调(Fine-tuning) 是训练后的精炼阶段,使用少量标签数据(如 10B Token)适配特定任务,如对话或代码生成. 核心方法包括参数高效微调(PEFT)和检索增强生成(RAG)的结合,前者直接调整模型参数,后者通过外部知识增强推理. 框架如 Hugging Face PEFT 或 DeepSpeed 集成,调用 AiOS 的统一 API 管理资源借用(如从”只有 GPU 的服务器”拉取 SM 核心). AiOS 的 Read/Write 范式支持间接 MMIO 配置适配器权重,Load/Store 直接优化本地激活计算,结合 AI Infra 的 UB-Mesh Scale-out 实现跨域同步. 2025 年趋势是 LoRA(Low-Rank Adaptation)主导 PEFT,仅更新 1% 参数(如 DeepSeek-V2 的 LoRA 适配器),而 RAG(Retrieval-Augmented Generation)作为辅助,通过动态检索外部知识库(如向量数据库)注入上下文,避免全参数微调的开销. 优势在于任务适配性强(准确率升 20%),但易过拟合. AiOS 通过缓存一致性屏蔽异构差异,确保稳定梯度更新,支持企业级定制如 Qwen 2 的多模态微调 - LLM 量化:
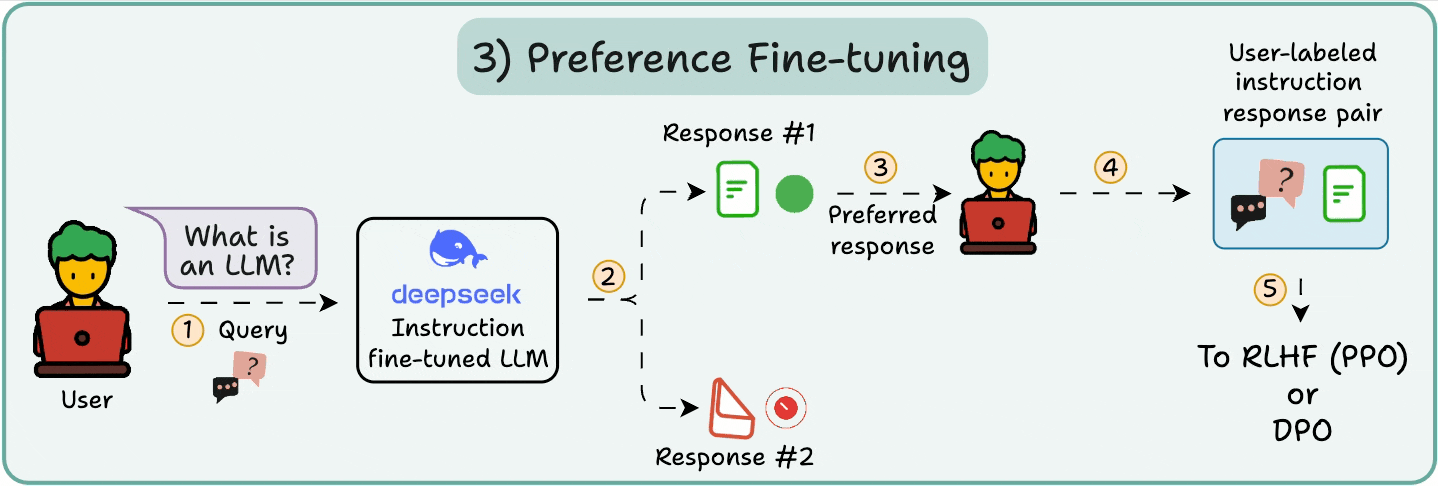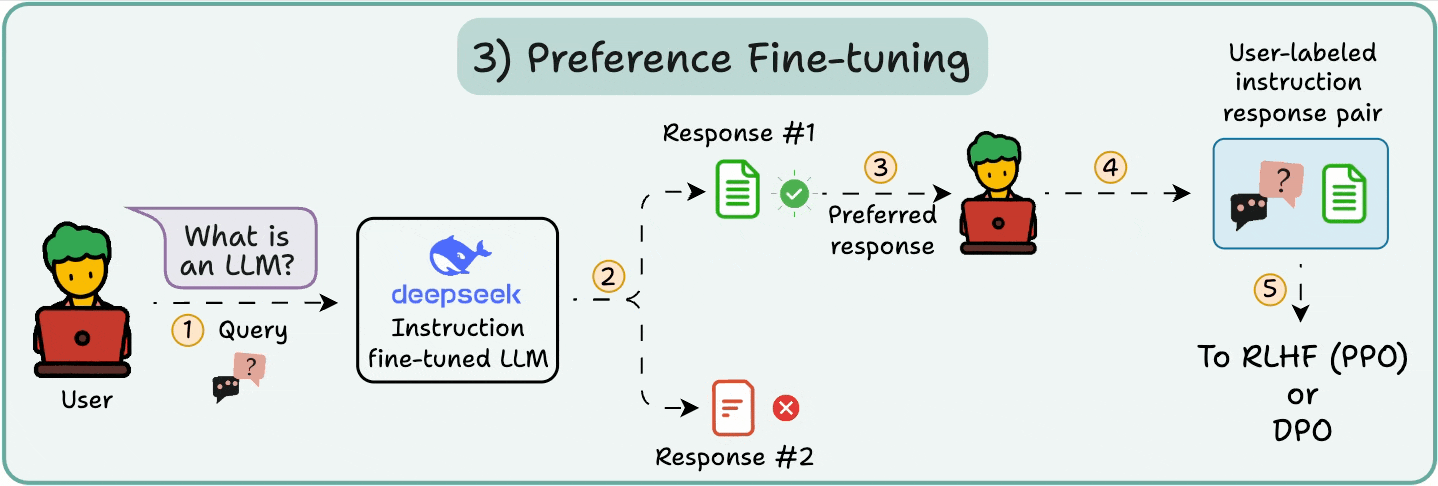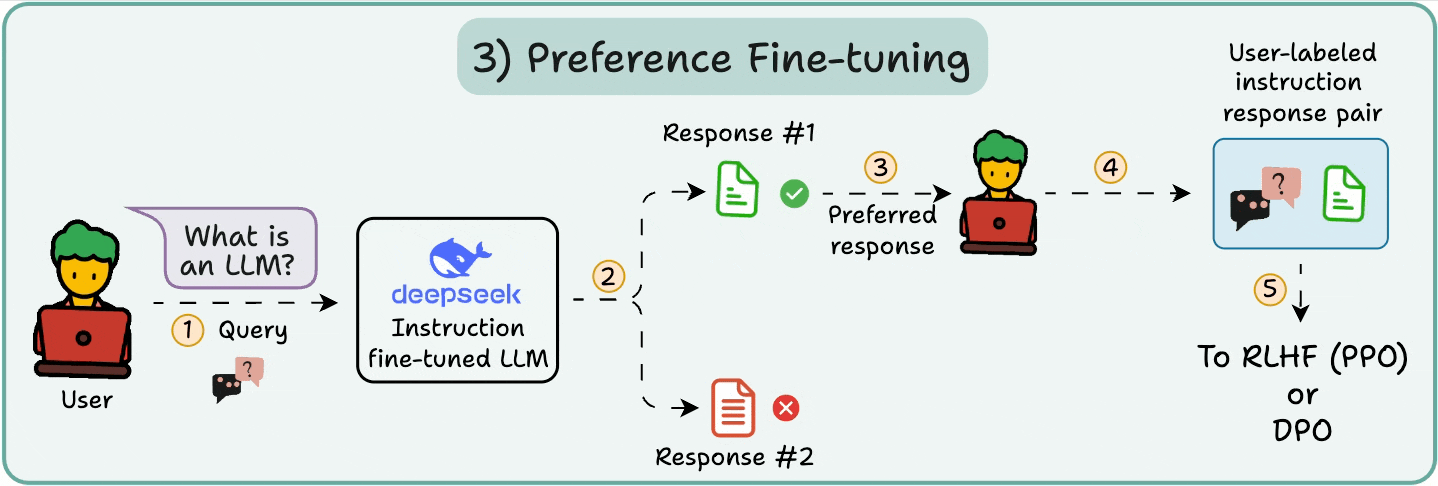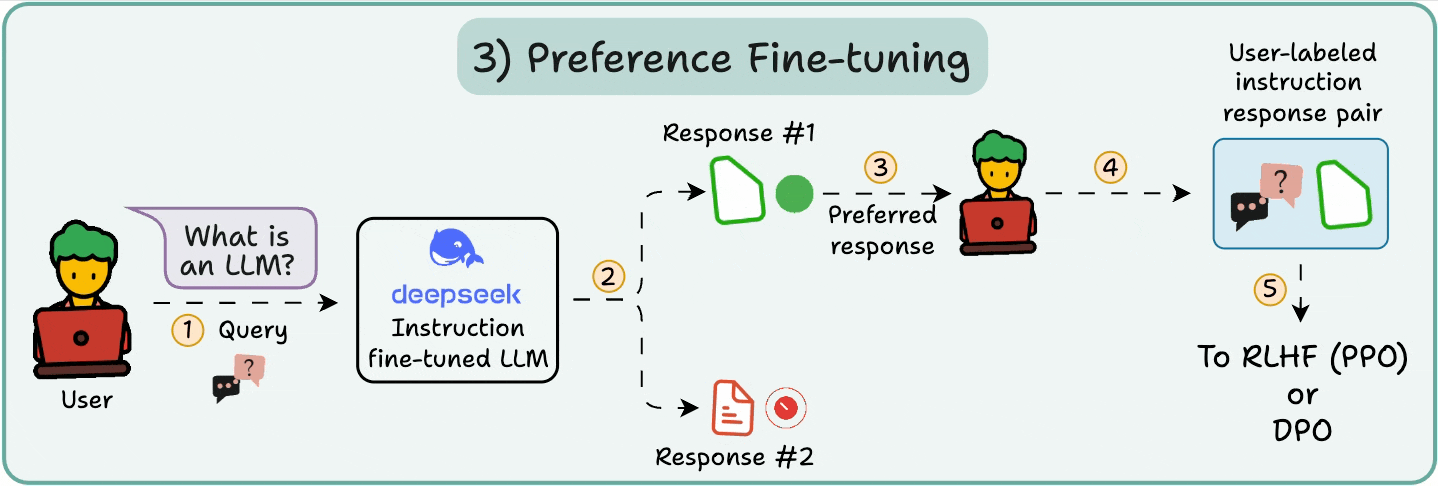 从高精度到高效的模型压缩. LLM 量化(Quantization) 是优化阶段,通过降低权重/激活精度(如 FP16 → INT4/FP4)压缩模型大小和计算需求,减少内存占用 75%+,加速推理. 技术包括 Post-Training Quantization(PTQ,如 BitsAndBytes 库) 和 Quantization-Aware Training),框架如 vLLM 或 Optimum 集成 PTX 优化,支持动态范围校准. AiOS 的 GMMU/MMU 映射确保量化权重在池化内存中一致访问,Load/Store 范式直接处理低精度寄存器运算,Read/Write 间接 DMA 迁移压缩数据. AiOS 通过统一语义屏蔽硬件(如 HBM vs. DDR 的精度支持),实现跨设备量化无缝,支持边缘 AGI 推理
从高精度到高效的模型压缩. LLM 量化(Quantization) 是优化阶段,通过降低权重/激活精度(如 FP16 → INT4/FP4)压缩模型大小和计算需求,减少内存占用 75%+,加速推理. 技术包括 Post-Training Quantization(PTQ,如 BitsAndBytes 库) 和 Quantization-Aware Training),框架如 vLLM 或 Optimum 集成 PTX 优化,支持动态范围校准. AiOS 的 GMMU/MMU 映射确保量化权重在池化内存中一致访问,Load/Store 范式直接处理低精度寄存器运算,Read/Write 间接 DMA 迁移压缩数据. AiOS 通过统一语义屏蔽硬件(如 HBM vs. DDR 的精度支持),实现跨设备量化无缝,支持边缘 AGI 推理 - LLM 推理:
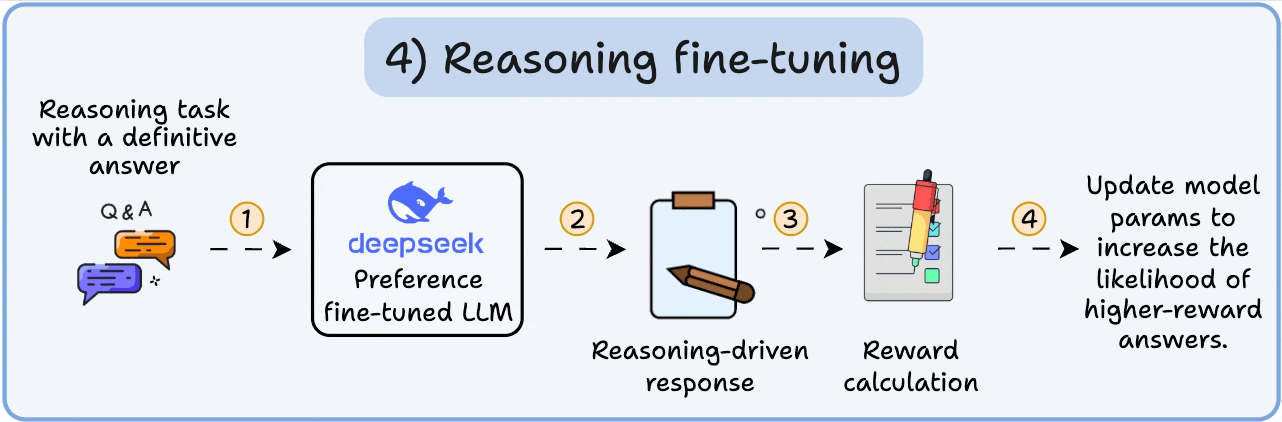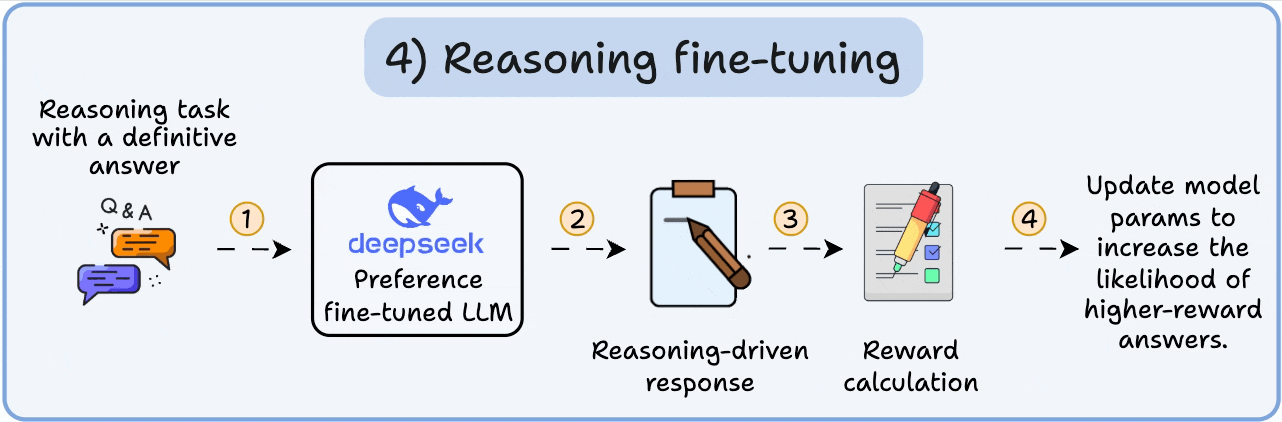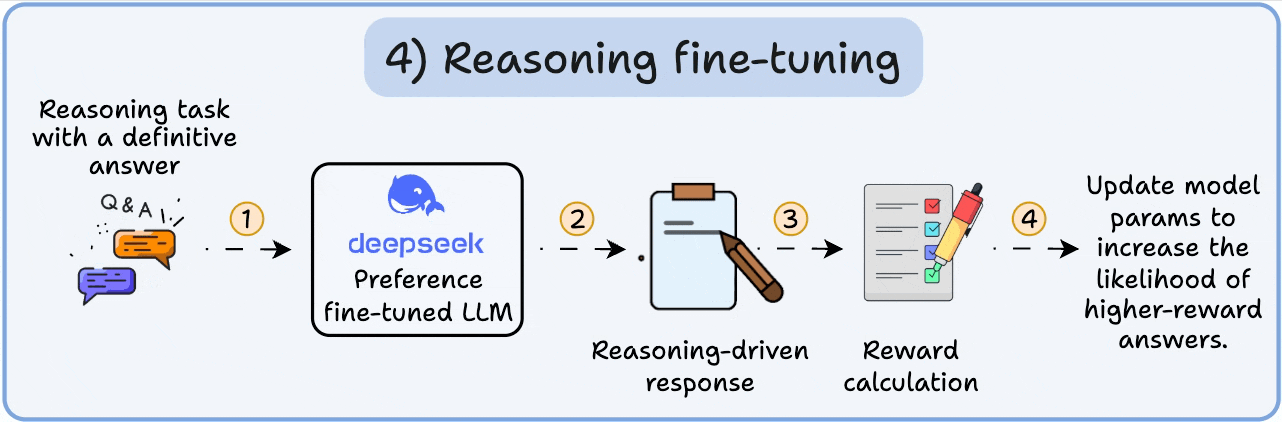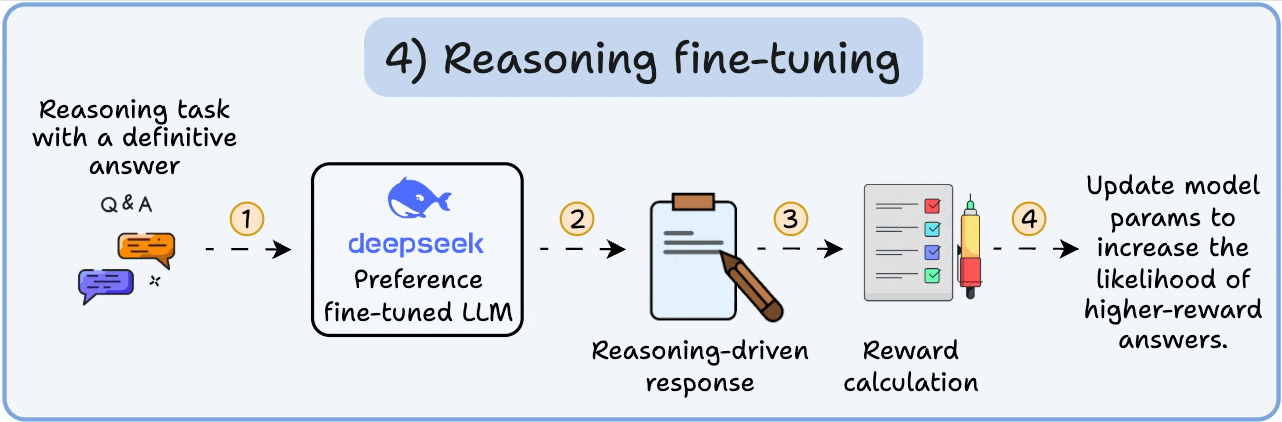 从静态到动态的实时部署. LLM 推理(Inference) 是生命周期的终端,通过输入 Prompt 生成输出,支持聊天/翻译等应用. 核心是 KV Cache 管理(PagedAttention)和批处理优化,框架如 vLLM(连续批处理,吞吐 10x)或 Ollama(本地部署,轻量 API). AI OS 的 UVM 统一虚拟内存自动迁移 Prompt 数据,Load/Store 优化 SM 级 Token 生成,Read/Write 间接 RDMA 处理远程池化 Cache. AiOS 通过协议栈抽象(如 CUDA Runtime 到 PTX)屏蔽差异,确保大模型在异构集群中稳定服务,支持 AGI 的交互式部署
从静态到动态的实时部署. LLM 推理(Inference) 是生命周期的终端,通过输入 Prompt 生成输出,支持聊天/翻译等应用. 核心是 KV Cache 管理(PagedAttention)和批处理优化,框架如 vLLM(连续批处理,吞吐 10x)或 Ollama(本地部署,轻量 API). AI OS 的 UVM 统一虚拟内存自动迁移 Prompt 数据,Load/Store 优化 SM 级 Token 生成,Read/Write 间接 RDMA 处理远程池化 Cache. AiOS 通过协议栈抽象(如 CUDA Runtime 到 PTX)屏蔽差异,确保大模型在异构集群中稳定服务,支持 AGI 的交互式部署
LLM 框架层作为生命周期管理的”中间枢纽”,通过 VLLM、Ollama 和 PyTorch 等工具抽象 AiOS 的统一语义(如 Read/Write 间接 DMA 和 Load/Store 直接访问)和 AI Infra 的池化资源(如 CXL HBM),屏蔽底层硬件差异,提供高效、模块化的接口,支持大模型从训练到推理的无缝开发. 这一层向上为应用开发者简化 API 调用(如 torch.tensor 统一操作),向下通过 CUDA Runtime/PTX 桥接执行,确保资源动态借用和一致性维护,提升整体效率
- PyTorch: 作为核心深度学习框架,主导训练和微调阶段,支持 DistributedDataParallel(DDP)和 TorchServe 部署,利用 AI OS 的 UVM/UPM 实现跨节点张量共享,抽象 Load/Store 为自动 coalescing 操作,优化 LoRA/RAG 适配(如 DeepSeek-V2 的参数高效微调),减少 60% 代码复杂度
- vLLM: 专注于推理优化的引擎,通过 PagedAttention 和连续批处理管理 KV Cache,支持 INT4/FP8 量化部署,屏蔽 PTX 差异,提供高吞吐服务,在 AI Infra 的 NVLink Scale-out 下加速 Qwen 2 的实时响应
- Ollama: 轻量本地部署工具,简化 Ollama run 等命令,支持多模态模型运行,利用 Unified Memory 自动迁移数据,抽象框架差异为”一键部署”接口,适合边缘 AGI 推理,减少 70% 配置开销

LLM Runtime 层通过 CUDA Runtime 库和 PTX提供底层执行引擎,确保大模型的生命周期从抽象到硬件的平滑落地. CUDA Runtime 是 NVIDIA 的核心 API 库,管理 GPU 上下文创建、内核启动(如 cudaLaunchKernel)和统一内存分配(如 cudaMallocManaged),支持 UVM 自动迁移和 GPUDirect RDMA 集成,为 LLM 训练/推理屏蔽异构细节: 如 PyTorch DDP 调用 Runtime 实现跨 NVLink 节点同步,减少 50% 启动开销. vLLM 通过 Runtime 的异步流管理 KV Cache,提升推理吞吐. PTX 作为中间表示语言(IR),由 JIT 编译器从 CUDA 源生成,优化低级指令,支持混合精度执行(如 FP8/INT4 GEMM)和动态代码生成,确保 LLM 量化后的效率, 在 LoRA 微调中,PTX 加速 Warp 级张量操作,降低 40% 寄存器压力,支持 AGI 的自适应部署. 这一层向上为框架提供稳定接口,向下桥接 AiOS 的池化资源,实现从 Prompt 到 Token 生成的无缝执行,推动大模型生态的规模化与可持续.


在人工智能(AI)生态中,“AI Infra”(AI 基础设施) 扮演着”隐形引擎”的角色, 它不仅仅是硬件资源的堆砌,更是支撑从模型训练到推理部署的全生命周期的坚实底盘. 随着 AI 模型规模从亿级参数跃升至万亿级(如 GPT-4o 和 Llama 3),计算需求呈指数爆炸,AI Infra 已成为决定系统性能、成本和可扩展性的核心瓶颈. 根据 Gartner 2025 报告,全球 AI 基础设施投资预计将达 5000 亿美元,占 AI 总支出的 40% 以上. 它桥接了算法创新与实际部署的鸿沟,确保数据流动顺畅、资源利用高效,并为边缘到云端的无缝迁移提供保障. 在 AI Infra 的架构中,互联技术是关键支柱,它从基础的同构连接演进到复杂的异构协作,逐步构建出弹性、智敏的计算织构.

AI Infra 的互联演进路径犹如一条从微观协作到宏观共享的”计算脊梁”,以 GPU 为主导的异构架构为核心,逐级突破瓶颈,实现 AI 负载的规模化与弹性化. 这一路径分为五个关键阶段,每一阶段针对特定粒度优化带宽、延迟与拓扑,逐步打破“资源墙”(利用率低)和“通信墙”(传输开销高),从 IDC 2025 预测的万亿参数模型训练中,可将整体 TCO(总拥有成本) 降低 30% 以上. 以下概述其逻辑递进,为后续详述奠基.
- 第一阶段: CPU 间的互联奠定同构基础, 通过 UPI 或 Infinity Fabric 等链路,多 CPU socket 实现 NUMA 一致性与数百 GB/s 共享,支撑 AI 数据预处理和调度,确保通用计算的低延迟协作(如 50ns 级),为异构引入预留 I/O 桥接
- 第二阶段: CPU 与 GPU 的异构互联开启加速时代, 借助 NVLink 或 CXL,CPU 卸载并行任务至 GPU,提供 900GB/s 点对点带宽,延迟降至 ‘<10ns’,解决PCIe共享瓶颈. 在 NVIDIA H100 系统中,此融合将 AI 推理吞吐提升 5 倍,桥接控制流与数据流
- 第三阶段: GPU 与 GPU 在单节点内的互联构建局部高密度织构, NVSwitch 或类似交换织构实现 8-16 GPU 的全互连,TB/s 级总带宽支持节点内 All Reduce 操作,适用于边缘训练,如 DGX B200 服务器中 1.8TB/s GPU 间同步,最大化 HBM 内存局部性
- 第四阶段: GPU 与 GPU 基于 NIC 的多节点异构互联扩展集群规模, InfiniBand NDR 或 RoCEv2 via SmartNIC(如 BlueField-3) 启用 RDMA 零拷贝传输, 400-800Gb/s 东-西流量优化 Fat-Tree 拓扑. 在多节点 AI 集群中,此层将跨机同步延迟从 ms 级压至 μs,支撑 Llama 3 的分布式微调
- 第五阶段: 作为未来愿景的统一池化模式,CPU、GPU、NIC 与 DDR 内存通过 CXL/UaLink/NVLink 等开放/专有标准深度融合,形成 Tb/s 级全局统一总线织构. 这一想象中的 “资源大陆” 将数千节点抽象为无缝计算池,支持硅光子扩展与 AI 驱动动态重构,彻底打破“资源墙”(利用率飙升至 98%,碎片化归零)和“通信墙”(零拷贝、语义级共享,延迟趋近原生). 在这一范式下,AI Infra 的统一编排平台将负载如量子增强的 GPT-6+ 可在云-边-端瞬时迁移,赋能 EFLOPS 级多模态 AI 生态,预示计算从 “孤岛” 向 “海洋” 的跃越.
上述五级演进路径是 AI Infra 从硬件原子到生态巨网的实证蓝图,每一跃迁如齿轮咬合,驱动计算从刚性向流体转型: CPU 同构筑基、CPU-GPU 桥接点火、单节点 GPU 织核爆、多节点 NIC 铺高速、统一池化融无界. 针对 AI 痛点如同步瓶颈与碎片利用,此链条将训练周期缩短 50% 以上(IDC 2025). 后续章节逐级深剖核心协议(UPI 至 CXL/UaLink/Nvlink)、拓扑(Mesh 至F at-Tree)、案例(DGX 至 Aurora 超算),直面功耗与抽象挑战,辅以量化指标与趋势. 层层剥笋,从 CPU 同构入手,探异构互联的无限潜能,推动AI从 “饥荒” 向 “丰裕” 跨越.


在 AI Infra 的五级演进路径中,第一阶段聚焦 CPU 间的同构互联,作为整个异构生态的“地基”. 这一层级强调多核、多 socket CPU 间的无缝协作,确保通用计算任务如数据管道构建和任务调度的高效执行,而非引入加速器异质性. 它为后续 GPU 融合预留 I/O 通道,IDC 2025 报告显示,在 AI 训练前置阶段,此互联可将 CPU 利用率提升 40%,奠定系统稳定性. 为直观理解,以 Intel Xeon Granite Rapids(第六代 Xeon Scalable)为例,该处理器代表现代服务器 CPU 的典型架构,其内部硬件基础构成了同构互联的微观织构:
- Register: 寄存器,CPU 核心内临时存储,<1 ns 访问,用于即时计算.
- CACHE: L1/L2/L3 Cache 多级缓存,Granite Rapids 单核 L1 112KB、L2 2MB、共享 L3 最高 504MB,1-100 ns 延迟,提供数据预取
- DDR: DRAM 内存控制器集成,支持 DDR5-6400,~100 ns 访问,Granite Rapids 支持 12 通道,总带宽 ~900 GB/s
- 南北桥: Northbridge 已集成至 CPU Die 处理内存/图形,Southbridge 演变为 PCH 芯片组,管理 I/O 如 USB/PCIe
- 磁盘存储: 经 PCH 连接 NVMe SSD 或 SATA HDD,~10 μs-ms 延迟,用于持久化数据
- UPI: Ultra Path Interconnect,Granite Rapids 支持 Gen 2,每链路 24 GT/s,双向 ~48 GB/s,用于多 socket 互联

这些组件协同形成“性能漏斗”,Granite Rapids 双 socket 配置可实现 ~150 GB/s 聚合 UPI 带宽,适用于 AI 数据预处理基准测试. 以下按逻辑顺序分点详述其演进机制,从存储访问基础到架构转型,逐步揭示同构协作的内在脉络
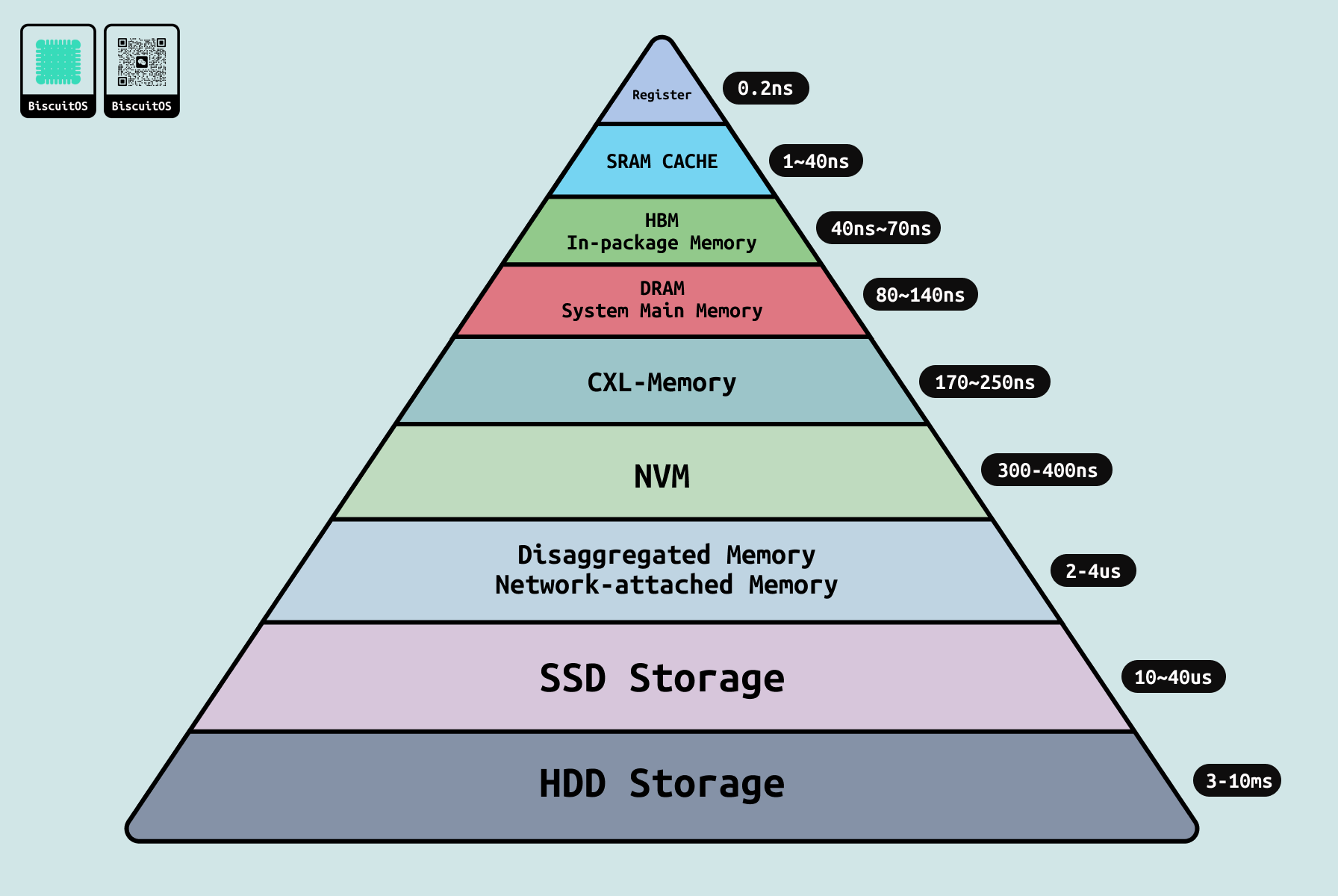
不同存储介质的访问延迟: 性能漏斗的起点, CPU 间互联的效能深受内存层次影响,这一路径从最快到最慢构成了经典的“性能漏斗”,直接制约 AI 数据流动效率. 在多 CPU 环境中,访问延迟梯度如下:
- Register: <1 ns,瞬时访问
- L1/L2 Cache: 1-10 ns,本地高速缓存
- L3 Cache: 20-100 ns,共享一致性维护
- HBM: 40~70ns, 高带宽内存
- LOCAL DDR DRAM: ~80 ns,本地访问
- REMOTE DDR DRAM: NUMA 远程可达 140 ns
- CXL 1.0 扩展设备: ~200 ns I/O 一致性
- NVM: PMEM 300ns~400ns 持久内存
- Disaggregated Memory: 2~4 μs 基于网络的内存
- SSD: NVMe,~10-100 μs,闪存级持久化
- Disk/HDD: ~5-10 ms,机械级批量存储
这一层次确保 AI 工作流中 80% 访问局限于 Cache/DDR 层,减少 I/O 瓶颈,但远程访问延迟翻倍易击穿”内存墙”. UPI 或 Infinity Fabric 链路优化跨介质迁移,将整体延迟均值压低 30%,为数据预处理注入活力. 以 Ice Lake 为例,其集成 DDR 控制器与 UPI 链路协同,将远程 DDR 访问延迟控制在 150 ns 内,支持 ETL 操作的流畅执行.

从单核到 SMP 的转变: 多核协作的奠基, 早期单核 CPU 受限于串行执行,无法匹配 AI 的并行需求,SMP(Symmetric Multi-Processing,对称多处理)架构的引入标志着同构互联的首次跃迁. 通过共享总线(如 FSB)连接多核(4-16 核),SMP 实现统一地址空间和缓存相干,支持 OpenMP 线程化调度. 在 AI Infra 中,此转变加速 ETL 操作,例如单 CPU 加载数据集需 20 s,而 SMP 配置下降至 5 s,提升 pipeline 吞吐 4 倍. 但共享总线易拥塞(带宽瓶颈 ~25 GB/s),促使向专用链路演进,为后续 Socket 扩展铺路. Granite Rapids 的 128 核 SMP 配置(单 socket)即体现此跃迁,其 L3 Cache 共享机制将多线程张量处理效率提升 3 倍.

UMA 到 NUMA 的转变: 可扩展性的权衡, UMA(Uniform Memory Access,统一内存访问)虽简单(全共享内存,延迟均匀 ~100 ns),但规模受限(socket ≤4),难以支撑 AI 的内存饥饿. NUMA(Non-Uniform Memory Access,非均匀内存访问)的转型引入分布式内存模型,每 Socket 绑定本地 DDR(~100 ns),远程访问经 UPI/Infinity Fabric 链路(延迟 50-200 ns,带宽 100+ GB/s). 这一转变支持 8-12 Socket 配置,通过目录协议(如 MESIF)维护一致性,MESH/环状拓扑最小化路径直径. 在 AI 场景中,NUMA 优化张量分片,减少跨节点流量 50%,但 NUMA 效应仍存“通信墙”,需 BIOS 亲和性工具(如 numactl)缓解. 进一步地,多 NUMA 配置(如通过 SNC3 模式在单 Socket 内划分多个 NUMA 域)与 SNC(Sub-NUMA Clustering)相结合,提供显著 AI 优势, SNC 将 Granite Rapids socket 分成 3 个独立 NUMA 域,优化内存地址分区,降低本地访问延迟约 8-10%(从 ~80 ns 至 ~74 ns),提升线程亲和性和数据局部性,尤其在 AI 训练中加速张量操作和模型加载,整体吞吐量可提高 15-20%,减少跨域通信开销. Granite Rapids 通过 UPI Gen 2 实现 NUMA 域间 ~40 GB/s 传输,适用于多 socket 数据分发
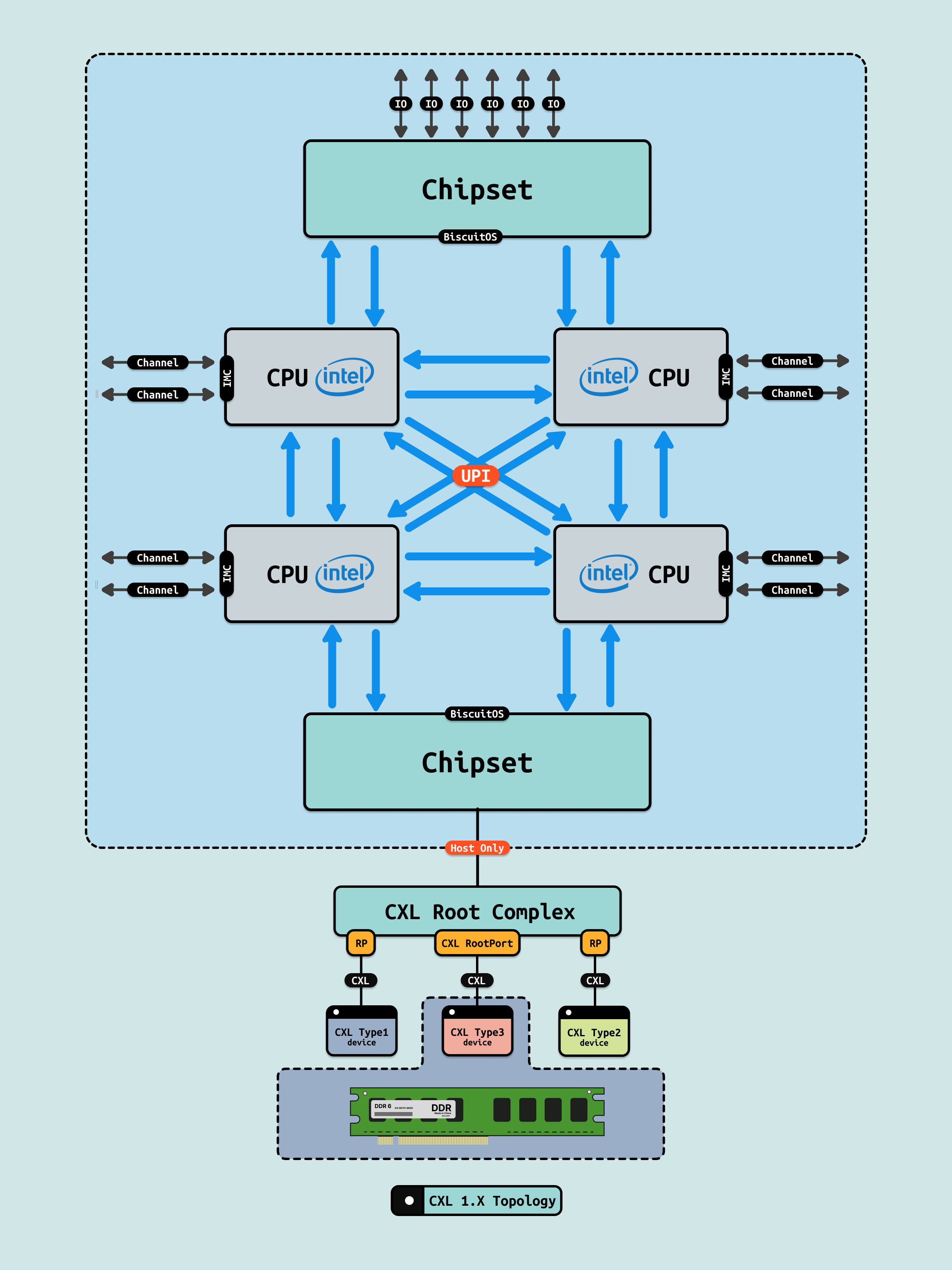
CXL 1.0 的引入: I/O 一致性的桥梁, 作为 2025 年 PCIe 5.0 基础的开放标准,CXL 1.0 注入 I/O 协议层,主要功能聚焦于缓存一致性(CXL.cache) 和基本内存访问语义(CXL.mem),支持设备级低延迟一致性访问(~100 ns),从而模糊 CPU 与外围设备(如加速卡)的边界. 它为后续版本的内存扩展奠定基础,实现点对点 NUMA 路径扩展和初步跨 Socket DDR 共享,带宽达 32 GB/s,低功耗 <15W. 在 AI Infra 中,CXL 1.0 通过引入一致性协议初步缓解“内存墙”瓶颈,允许主机高效访问设备内存(如添加 DRAM 扩展),加速模型加载和数据分发 1-2 倍,提升 AI 训练的资源利用率(从 ~30% 至 ~60%),并为 GPU 等加速器提供低延迟数据路径,同时降低初步 TCO ~20%/GB,为第二阶段 GPU 卸载注入兼容性. Granite Rapids 的 PCH 已集成 CXL 2.0 兼容路径(向后兼容 1.0),支持 ~100 ns I/O 访问扩展,并通过切换机制初步启用设备级内存池化,进一步优化 AI 工作负载的内存分配.


在 AI Infra 的五级演进路径中,第二阶段聚焦 “CPU-to-GPU 异构互联”,作为整个异构生态的”加速层”. 这一层级引入 GPU 的并行计算能力,与 CPU 的通用任务调度无缝融合,实现张量运算和模型训练的卸载,提升整体系统吞吐量,而非局限于同构 CPU 协作. 它构建于第一阶段的 I/O 通道(PCI Express),IDC 2025 报告显示,在 AI 推理和训练阶段,此互联可将计算效率提升 5-10 倍,降低能耗 30%,为后续多 GPU/异构融合奠定高带宽数据桥接. 为直观理解,以 NVIDIA Hopper H100 GPU 为例,该架构代表现代 GPGPU 的典型设计,其硬件基础构成了异构互联的计算织构:
- GPC(Graphics Processing Cluster): 图形处理集群, 顶级集群单元,负责整体渲染管道和负载均衡. H100 配置 7 个 GPC,每个 GPC 集成多个 TPC 和 ROP(Render Output Units,像素输出单元), 管理光栅化和混合操作,支持 AI 中的批量矩阵处理
- TPC(Texture Processing Cluster): 纹理处理集群, 中层处理集群,每 GPC 包含 8 个 TPC,专注于纹理采样和过滤(通过 16 个纹理单元),并桥接 SM 执行. TPC 优化空间数据访问,如卷积神经网络(CNN)的特征提取
- SM(Streaming Multiprocessor): 流式多处理器,底层执行单元,H100 总 132 个 SM,每个 SM 支持 2048 个活跃线程(32 Warp × 64 线程/Warp),集成 128 个 CUDA 核心(通用计算)、4 个 Tensor Core(AI 矩阵加速)和 Warp Scheduler(线程调度). SM 通过 Crossbar 互连共享 L2 缓存,实现 intra-GPU 一致性

SM 作为 GPU 并行计算的核心”原子”,其内部执行管道高度模块化,分为四个象限布局(每个象限包含调度器、寄存器文件和专用运算单元),以平衡负载和最小化延迟. 这种设计确保 Warp 级指令高效分发,支持 AI 工作负载的混合精度运算. 以下基于 H100 SM 的硬件逻辑拓扑图(展示象限模块化结构、计算路径和内存交互),详述关键硬件单元的作用,这些单元协同优化从整数逻辑到浮点加速的多样化任务: !
- INT32 单元: 每个象限 16 个,SM 总共 128 个. 32 位整数运算单元,专责整数加减乘除、位移和逻辑操作(如 AND/OR),在 AI 中优化地址计算、循环索引和稀疏张量处理(如索引查找),减少分支预测开销,支持 INT8 混合精度加速,吞吐率达 1024 OPS/clk,提升模型压缩效率 2-3 倍
- FP32 单元: 每个象限 32 个,SM 总共 256 个. 32 位单精度浮点运算单元,处理浮点 FMA(融合乘加)等核心计算,支持通用神经网络激活和梯度更新. 在拓扑中,这些单元与 INT32 交织,形成混合精度管道,适用于 Transformer 的前向/反向传播,峰值 60 TFLOPS,优化 AI 训练的数值稳定性
- FP64 单元: 每个象限 8 个,SM 总共 64 个. 64 位双精度浮点运算单元,扩展 FP32 的高精度计算路径,专用于科学模拟和精确 AI 基准(如物理建模),在 SM 象限中并行于 FP32 路径,提供 1:1 与 FP32 的时钟匹配,支持 HPC-AI 融合场景,吞吐率 30 TFLOPS
- Tensor Core: 每个 SM 4 个,总 528 个. 张量核心,专为矩阵乘法-累加(MMA)设计的 AI 加速单元,支持 FP8/FP16/INT8 等低精度运算(如 4x4x4 矩阵内核),在拓扑中独立管道与 FP32 交汇,提供 Warp 级并行执行. 在 AI Infra 中,Tensor Core 加速深度学习的核心运算(如 GEMM),H100 实现 4 PFLOPS FP8 峰值,将 Llama 3 训练迭代时间缩短 8-10 倍,同时支持 Sparsity 稀疏性优化,减少计算量 50%
- LD/ST 单元: 每个象限 8 个,SM 总共 64 个. 加载/存储单元(Load/Store),管理数据从寄存器/共享内存到 L1 缓存的读写路径,支持原子操作和 Coalesced 访问. 在拓扑中位于象限底部,与 SFU 邻接,优化 AI 数据流水线(如从 HBM 加载张量到 Tensor Core),减少内存墙影响,带宽达 2 (TB/s)/SM
- SFU(Special Function Unit): 每个象限 4 个,SM 总共 16 个. 特殊函数单元,加速非标准数学函数如 sin/cos、exp/log2 和 rsqrt(倒数平方根),无需多周期软件模拟. 在 SM 布局中紧邻 LD/ST,提供 Warp 级广播,支持 AI 激活函数(如 GELU/Swish) 的硬件级实现,精度 FP32/FP64,降低计算开销 5-10 倍
- Tex(Texture Units): 每个 TPC 16 个,桥接 SM,总 896 个. 纹理单元,位于 SM 外围,执行高级内存采样(如双线性过滤、mipmap LOD 计算),支持 2D/3D 纹理缓存(~16 KB/SM). 在拓扑中连接 L1 指令/数据缓存,优化 AI 图像/视频处理(如 GAN 生成或 CNN 特征提取), 缓存命中率 85-95%,带宽 1 TB/s
这些组件协同形成”并行漏斗”,H100 通过 PCIe 5.0 x16 接口与 CPU(如 Granite Rapids)连接,实现 ~64 GB/s 双向带宽,适用于 AI 模型卸载基准测试. 以下按逻辑顺序分点详述其关键机制,从 GPU 基础架构到数据交换路径,逐步揭示异构协作的内在脉络.
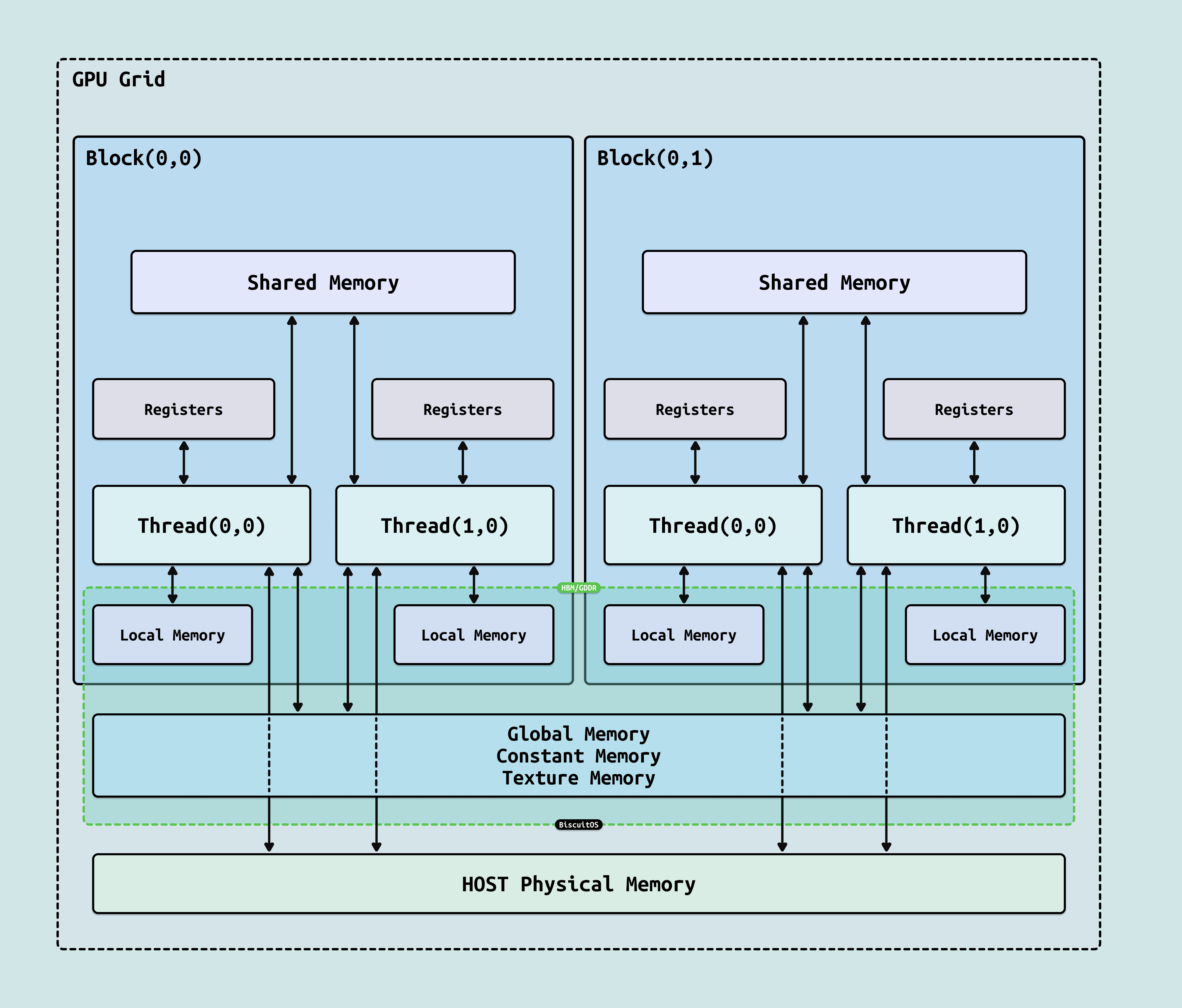
GPU 的并行计算依赖于软件定义的线程层次组织与硬件执行单元的映射,这种设计将抽象任务分解为高效硬件利用: Grid(网格) 是最高层,由软件(如 CUDA 内核启动)定义,包含多个 Block,代表整个任务范围(如一个 AI 批次矩阵乘法),跨多个 SM 执行,确保全局并行覆盖. Block(块) 是中层,包含 1-1024 个 Thread,支持 1D/2D/3D 索引映射,由软件分区数据(如张量分片),动态分配到单个 SM 执行,提供 Block 级同步(如 “__syncthreads()”). Thread(线程) 是最低层,执行标量代码路径,由软件编写核心逻辑(如激活函数),但实际以 Warp(32 线程组) 为单位调度. Warp 是硬件基本执行单元,固定 32 个 Thread 组成 SIMD 组,由 SM 的 Warp Scheduler 管理,支持上下文切换(隐藏延迟). 这种 Grid-Block-Thread-Warp 关系桥接软件与硬件: 软件任务通过 Grid/Block 维度声明并行性,硬件(SM)将 Block 映射到 Warp 执行(每个 SM 支持 32-64 个并发 Warp),确保 100% 利用率. 在 AI 中,此映射将 Llama 3 批次并行化 1000x+,Warp 级 coalescing 优化内存访问,减少 40% 无效周期. 在此基础上,GPU 存储结构采用”漏斗式”多级设计,从线程私有高速访问到全局高容量存储,确保 80% 操作局限于低延迟层,缓解并行线程的内存饥饿. 存储访问范围与 “Grid-Block-Thread-Warp” 紧密耦合, Warp 级合并访问提升效率,Block 共享资源优化局部性(H100 示例如下):
- 寄存器(Registers): 线程私有临时存储,”<1ns” 访问,每 SM 64 KB(65536 × 32-bit),用于即时标量运算,支持 Warp 级广播. 在 Grid-Block-Thread 中,仅 Thread/Warp 访问,优化激活函数计算
- 局部内存(Local Memory): 线程私有变量溢出到全局内存,”~100ns” 延迟,高容量但易击穿缓存,用于动态数组. Thread 独占,适用于 Block 内不共享的临时张量
- 共享内存(Shared Memory): 块内线程共享,”~几 ns” 延迟,每 SM 128 KB(可配置与 L1 缓存),支持 Bank 交错访问,优化数据局部性(如矩阵分块,减少全局流量 50%). Block 级共享,加速 Thread/Warp 间协作,如 CNN 卷积窗口
- 全局内存(Global Memory): 所有线程访问,高容量 GDDR6X/HBM3(H100 用 HBM3,80 GB 容量,3 TB/s 带宽,~100-200 ns 延迟),经内存控制器(64-512 通道)管理 ECC 和 Coalescing(合并访问,提升效率 4x). Grid 级持久存储,适合大规模模型权重
- L1/L2 缓存: L1(每 SM 128 KB,与共享内存动态分配)提供读写一致性. L2(50 MB 芯片级共享)缓冲全局访问,~20 ns 延迟. 跨 Block/SM 缓存,优化 Warp 合并访问
- 常量/纹理内存: 只读优化,常量内存(64 KB 广播)用于标量常量, 纹理内存(专用缓存)支持 2D/3D 过滤,适用于 AI 图像增强. Grid 级广播,Thread/Warp 高效采样
- Host Memory: CPU 侧系统 DRAM,通过 PCIe 互联访问,”~200ns” 延迟,高容量(TB 级),用于 CPU-GPU 数据交换.
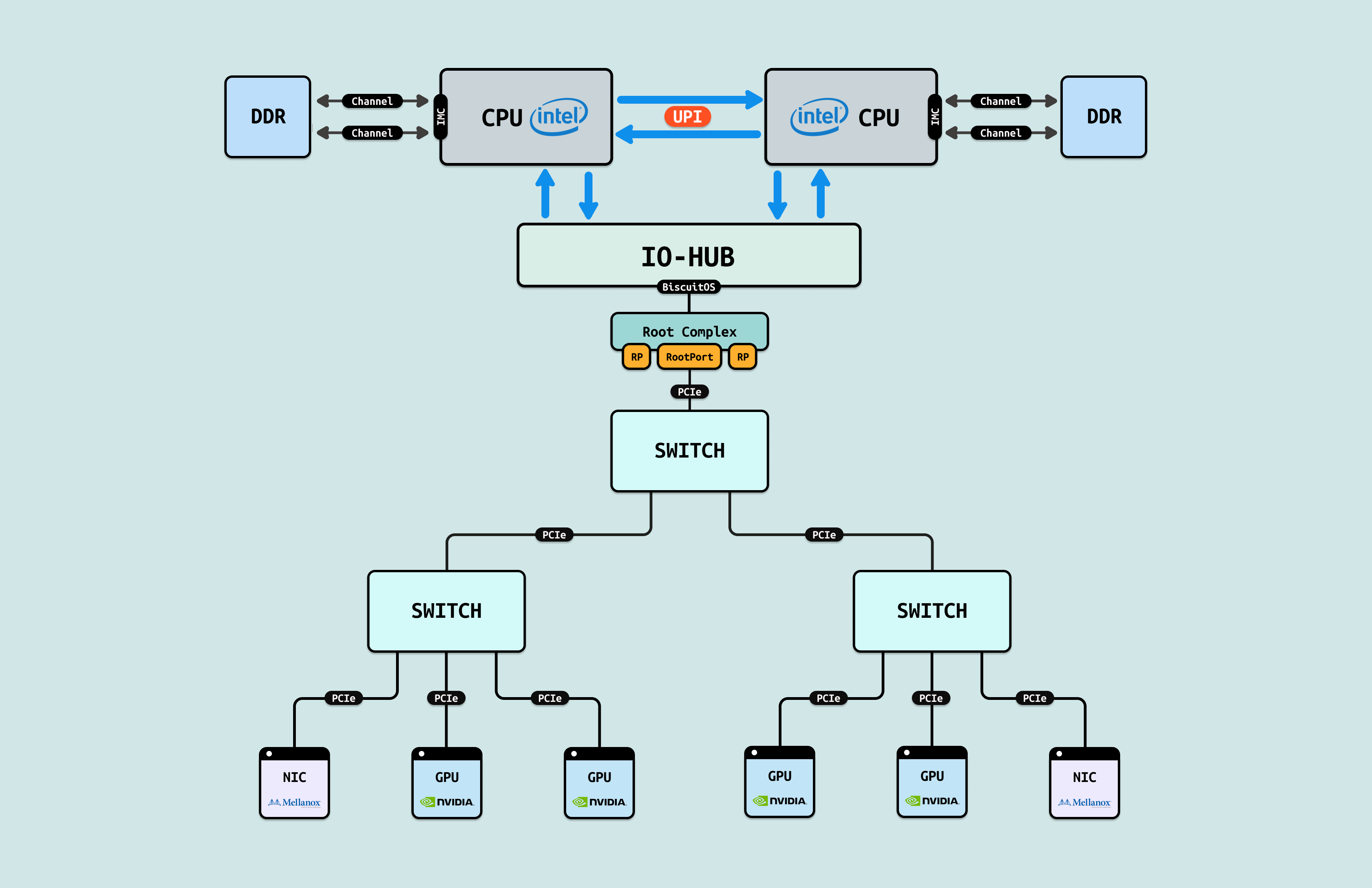
在介绍完 GPU 内部结构之后,接下来探讨 CPU 如何与 GPU 互联, 传统方式下,CPU 通过 PCIe 连接到 GPU. 在现代 Intel Xeon 处理器(如 Granite Rapids)上,北桥已集成到 CPU 内部,CPU 直接向外提供 Root Port 接口. 我们将 CPU 内部处理 PCIe 的部件统一抽象为 Root Complex. CPU 的 IO-HUB 上集成了 Root Complex,Root Complex 作为 PCIe 树的根节点,向下扩展出多个 Root Port,Root Port 上可以直接接入 PCIe EP,也可以连接 PCIe Switch 的上游端口,支持树状扩展. 如图所示,双 Granite Rapids CPU 通过 UPI 实现 NUMA 一致性,并连接 DDR 通道. IO-HUB 集成 Root Complex,作为 PCIe 树的根节点,从 Root Port 向下扩展至 PCIe Switch 的上游端口. Switch 分支出下游链路, 一个主 Switch 连接两个子 Switch,每个子 Switch 有三个下游端口,分别接入 NIC 和 2 个 H100 GPU. 这种星状拓扑最小化路径直径,支持多 GPU 扩展,确保 AI 数据从 CPU NUMA 域高效流向 GPU SM 集群,而无需 CPU 干预中转.
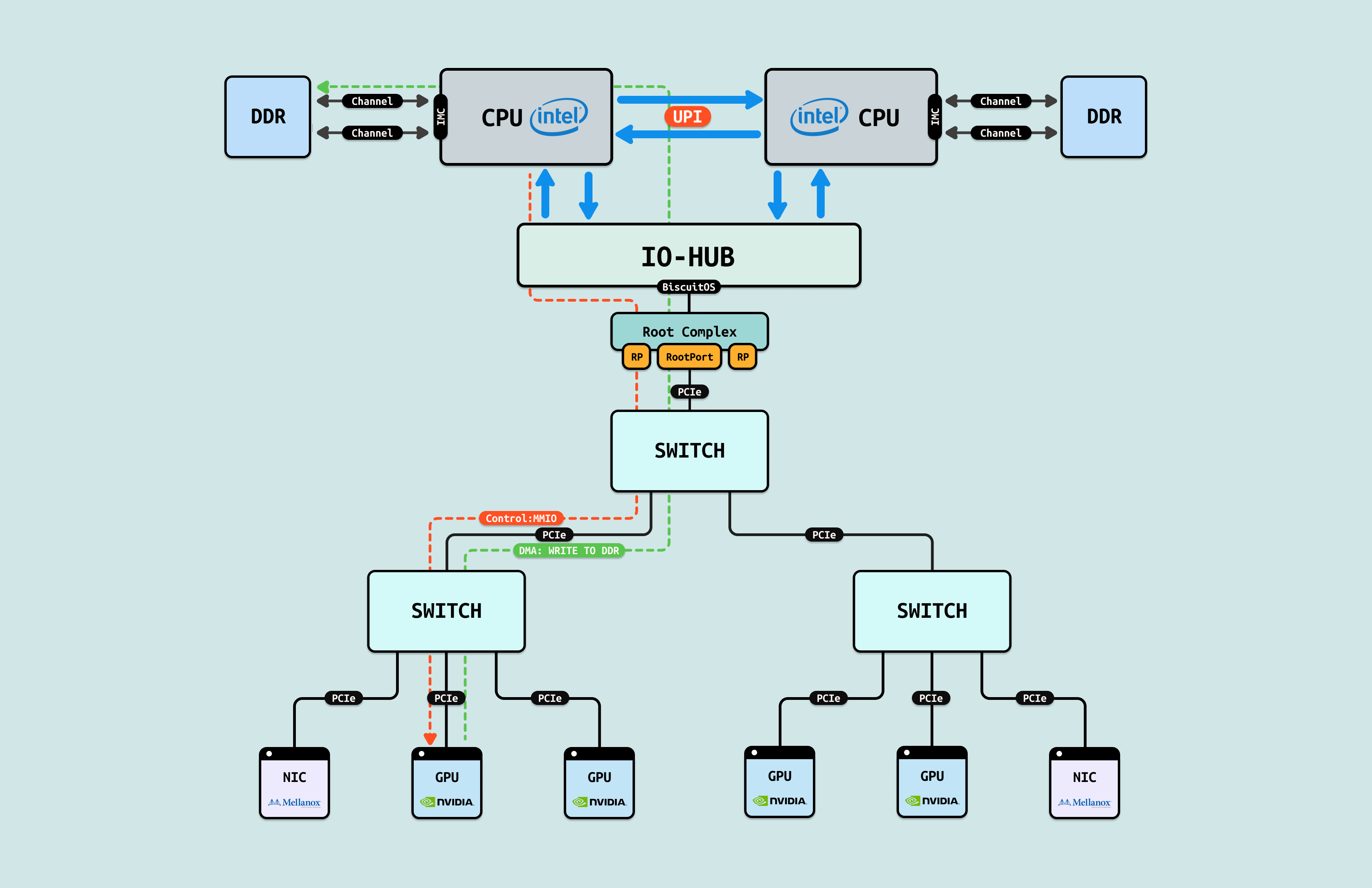
如果 GPU 没有把显存通过 MMIO 映射到系统物理地址空间,CPU 无法看到且直接访问 GPU 内部的显存(GDDR/HBM) 等存储空间,然而 GPU 是可以看到 HOST 侧的系统物理内存,但同时也无法直接访问(Load/Store). 于是 GPU 会将一部分寄存器通过 MMIO 方式映射到系统物理地址空间,CPU 可以通过这些寄存器让 GPU 发起对 HOST 内存的访问操作,该过程称为 DMA 操作. CPU 发起 DMA 首先需要控制面配置 GPU DMA 操作的基础信息,接着在无需 CPU 介入的情况下,GPU 独自发起对 HOST 内存的读写操作,GPU 的 DMA 完毕之后,CPU 在访问 DMA 操作的物理内存,因此可以通过 DMA 间接访问 GPU 的显存, 这里将 DMA 操作使用的物理内存称为 DMA 内存.
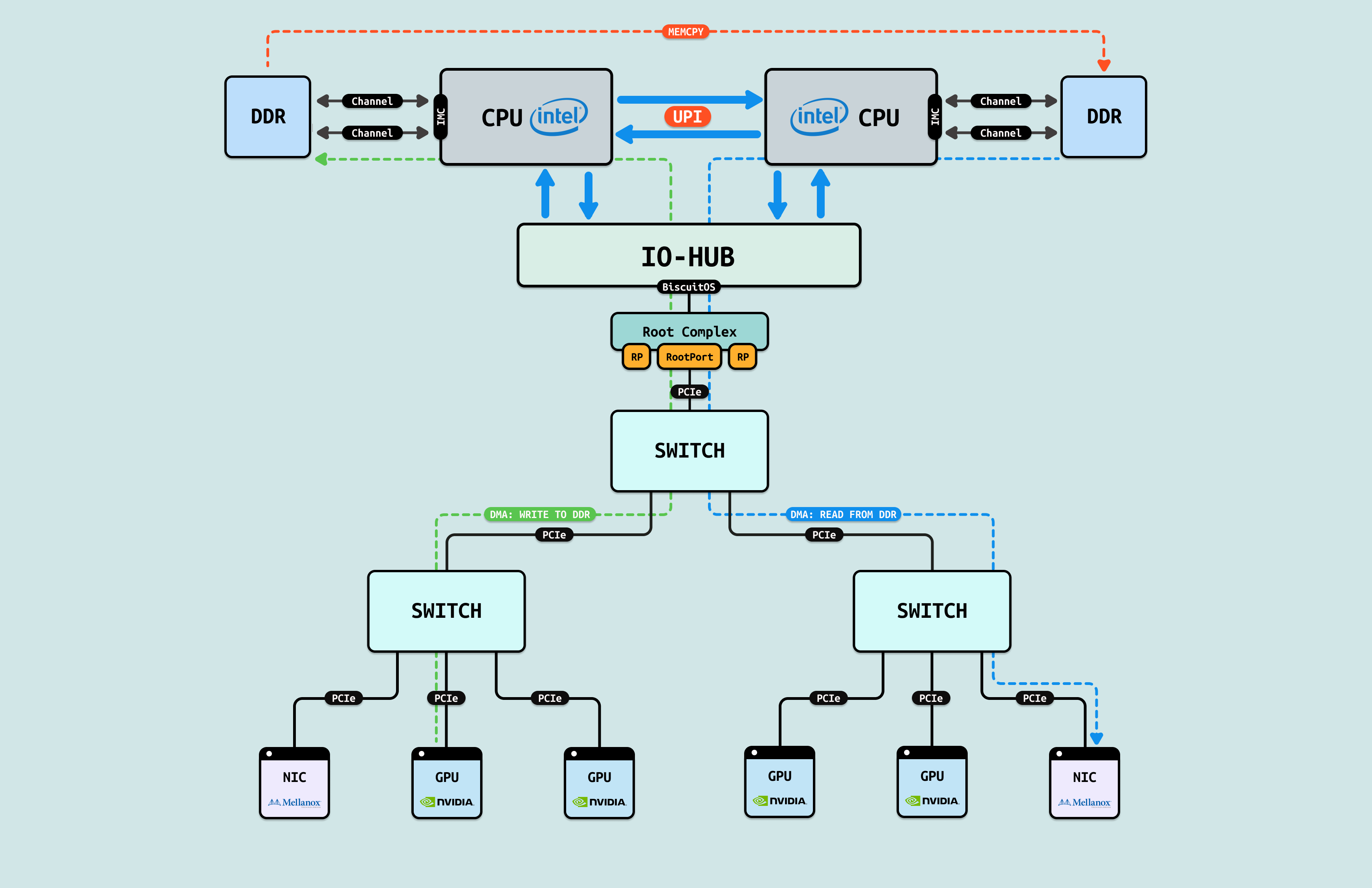
CPU 通过控制面(MMIO)和数据面(DMA) 与 GPU 进行数据交互,从而打破了数据墙,但在有的情况下,GPU 与 NIC 或者 GPU 与 GPU 之间需要进行数据交互,如果按传统的 DMA 方式,那么 GPU1 先要将数据通过 DMA 拷贝到一块 DMA 内存上,然后 CPU 通过内存拷贝(MEMCPY)将数据搬运到另外一块 DMA 内存上,接着 NIC 或者另外 GPU 再通过 DMA 将数据搬运到各自内部. 这就像在这些 GPU/NIC 和 GPU/GPU 间存在一道内存墙.
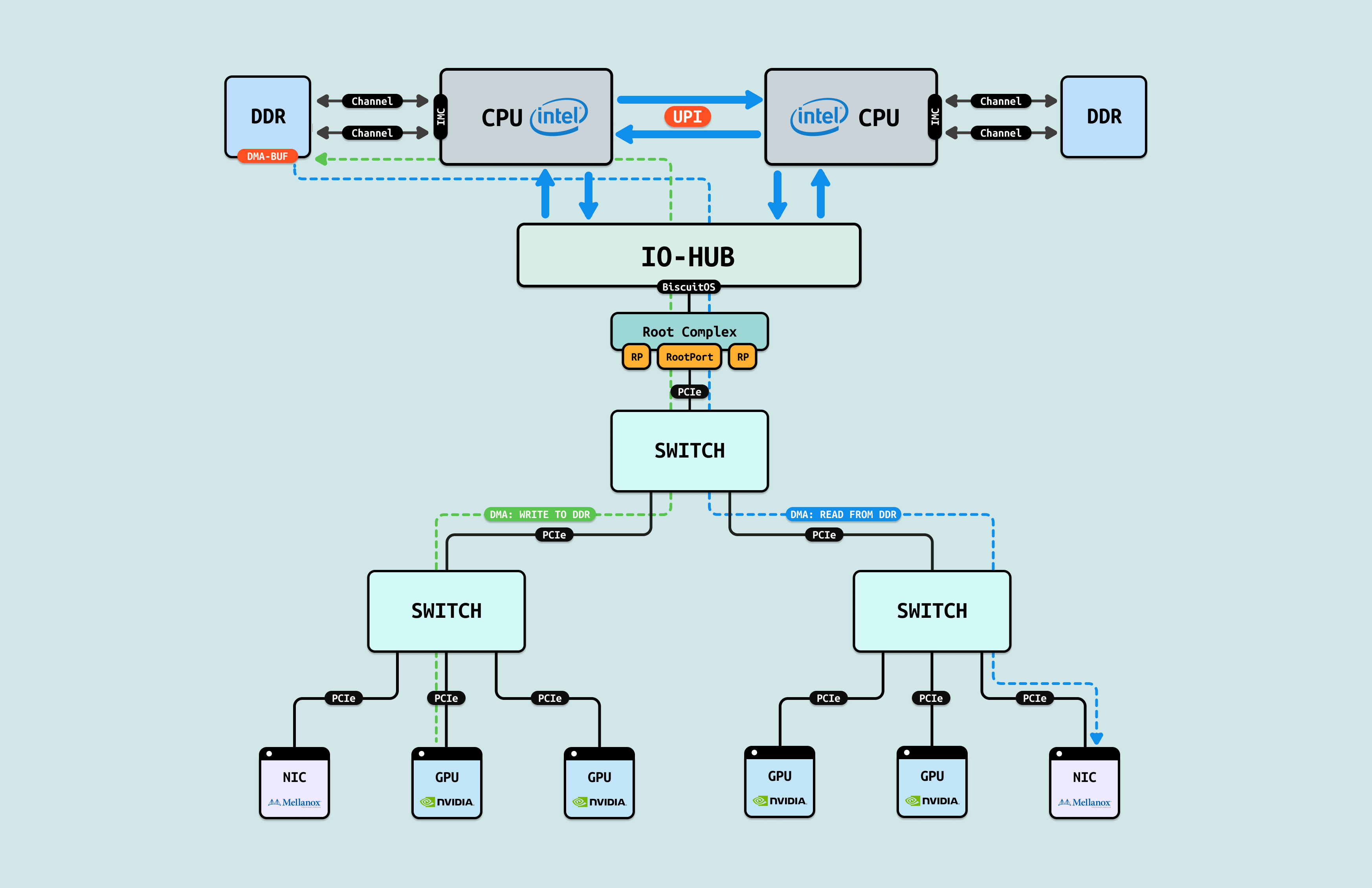
对于 GPU/GPU 和 GPU/NIC 之间存在的内存墙,第一种解决方案是 “DMA-BUF”, 其可以将多个进程使用的 DMA 内存合并成同一个 DMA 内存,那么 GPU 将数据 DMA 到 DMA 内存之后,NIC/GPU 直接发起 DMA 将数据搬运到其内部即可, 这样省去了无脑的内存拷贝,以及避免了 CPU 介入导致缓存污染.
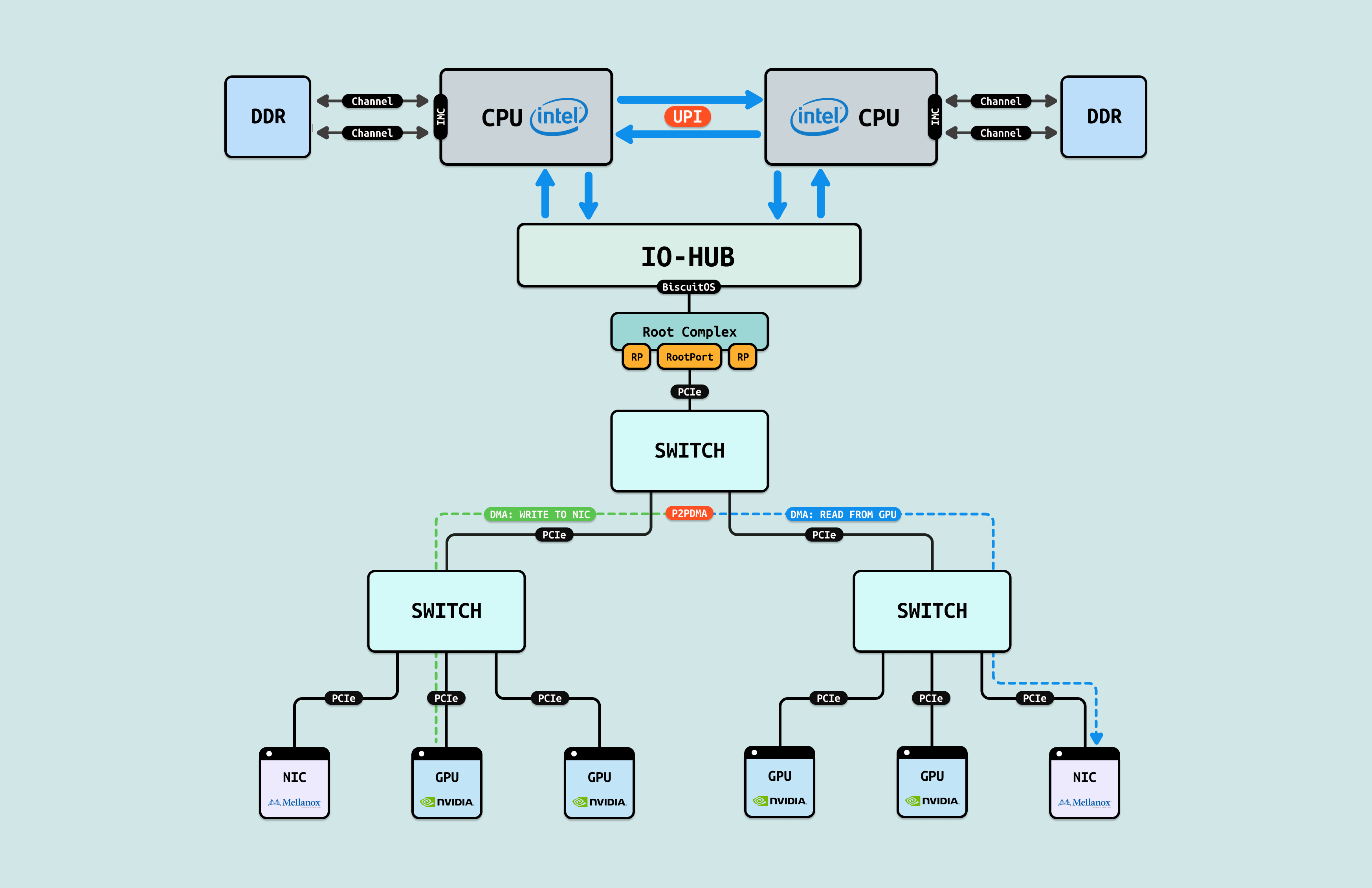
对于 GPU/GPU 和 GPU/NIC 之间存在的内存墙,第一种解决方案是 “P2PDMA”, 其先将各自的一部分内部存储空间映射到 PCIe 地址空间(系统物理地址空间),让对方都能看到. 其次是 CPU 从控制面配置好 P2PDMA 之后,GPU/GPU 或 GPU/NIC 之间直接进行 DMA 操作,数据流在临近的 PCIe Switch 直接流动,不会绕到 RC 去,这样即缩短了数据链路的距离,也缓解了其他 PCIe 链路的拥塞.
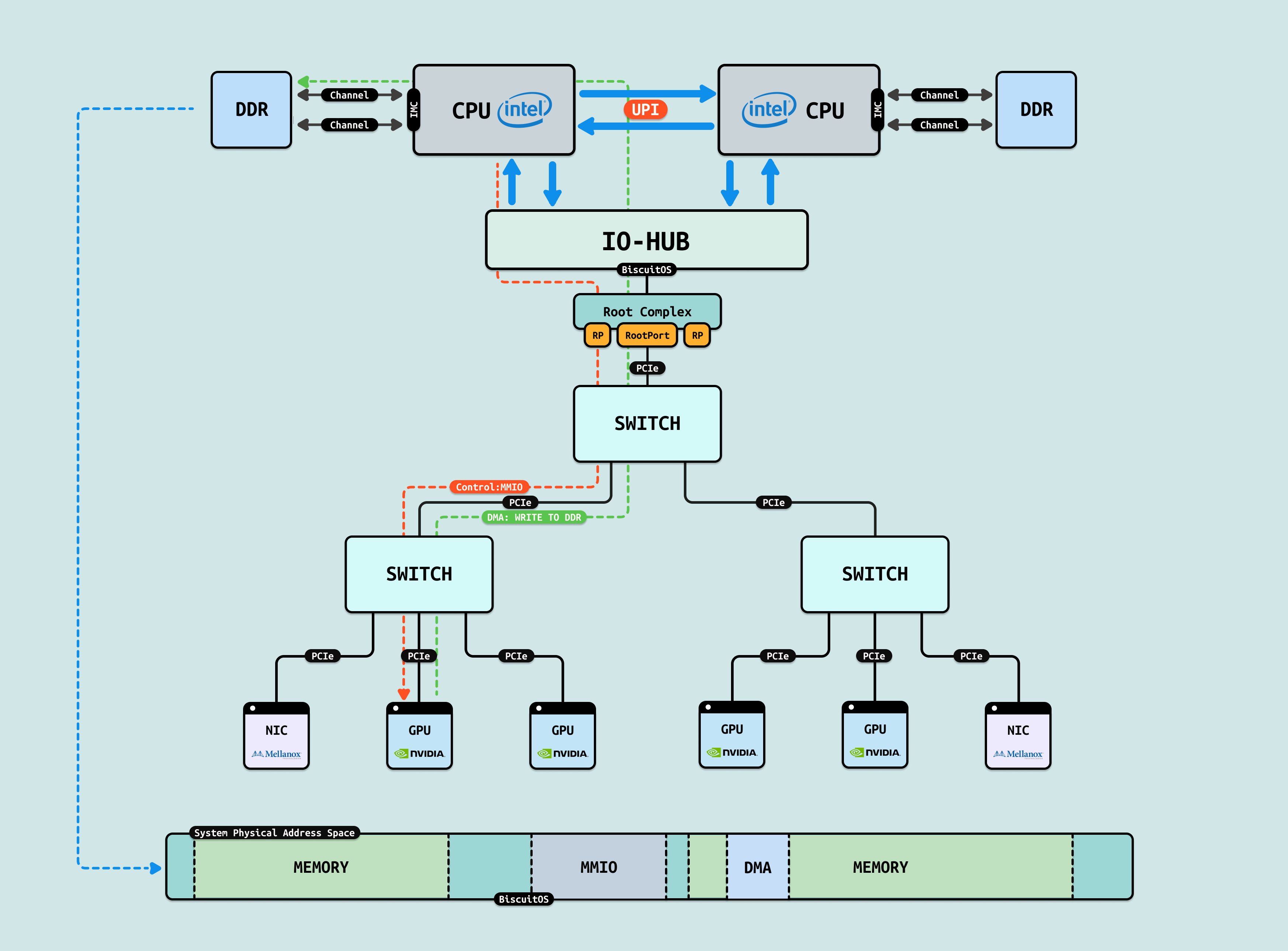
GPU 在做 DMA 之前,CPU 需要准备一块连续的物理内存作为 DMA 内存,Linux 内核使用 BUDDY 分配器默认能分配出最大连续物理内存为 8MiB. 首先 Ai 训练数据由 CPU 侧应用程序准备,其用于存储数据的内存默认为离散 4KB 物理页组成的,那么 DMA 只能按离散 4KB 大小多次搬运. 另外由于最大连续 DMA 内存的限制,大块数据也会被拆分成多次 DMA 操作,这样大大增加了 PCIe 总线的压力,同时也降低了突发性数据传递的优势. 这些都降低了 CPU 和 GPU 之间数据交互的效率,为此提供了多种解决方案.
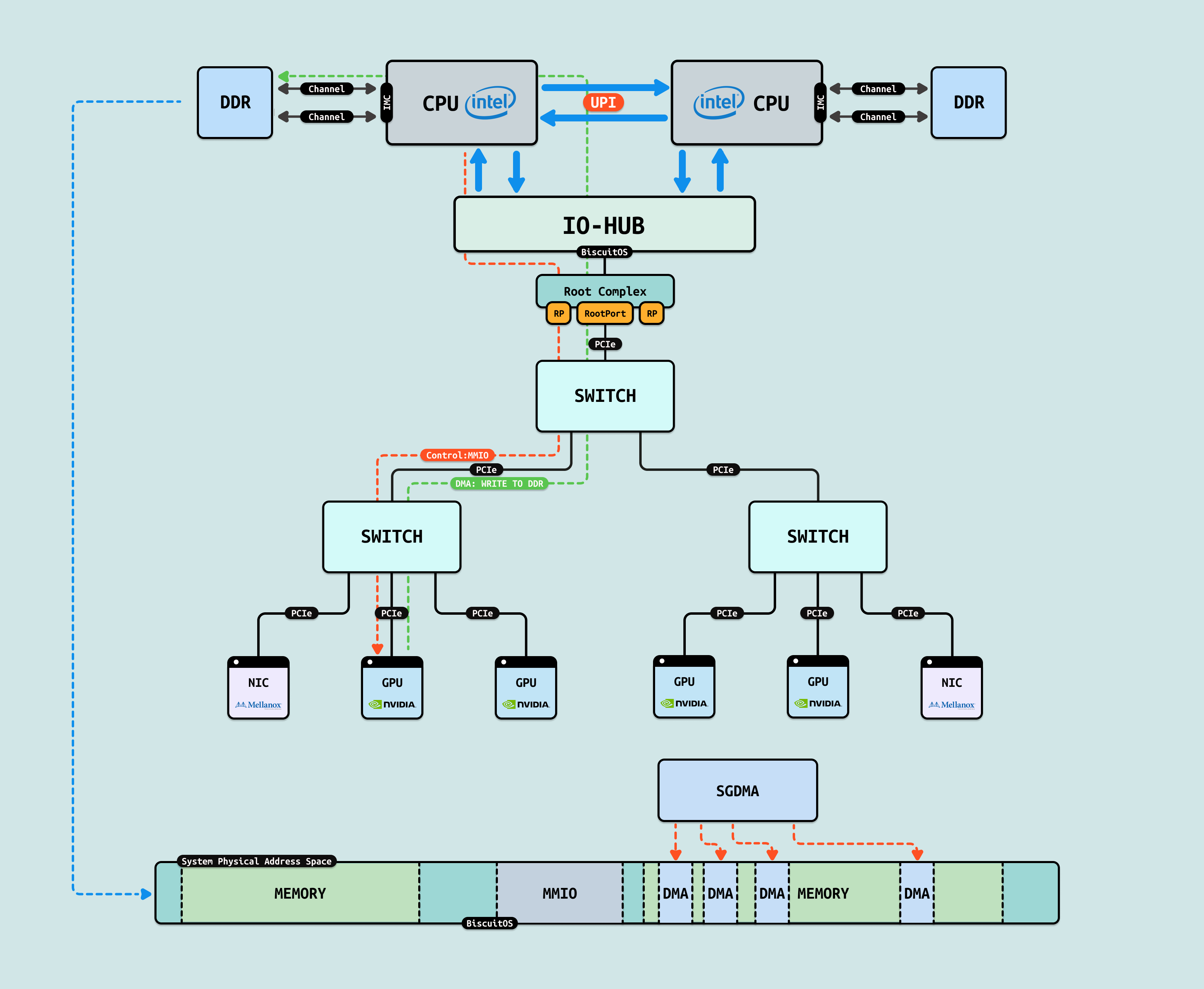
方案 A: SGDMA(Scatter-Gather) 通过 Scatter list(分散列表)将离散的物理页抽象为连续的 DMA 内存,GPU 可以高效的批量数据移动. 应用程序将大量的训练数据存储在虚拟内存里,其对应的物理内存就是离散的物理页,因此 SGDMA 可以将 AI 训练数据高效的搬运到 GPU 内.
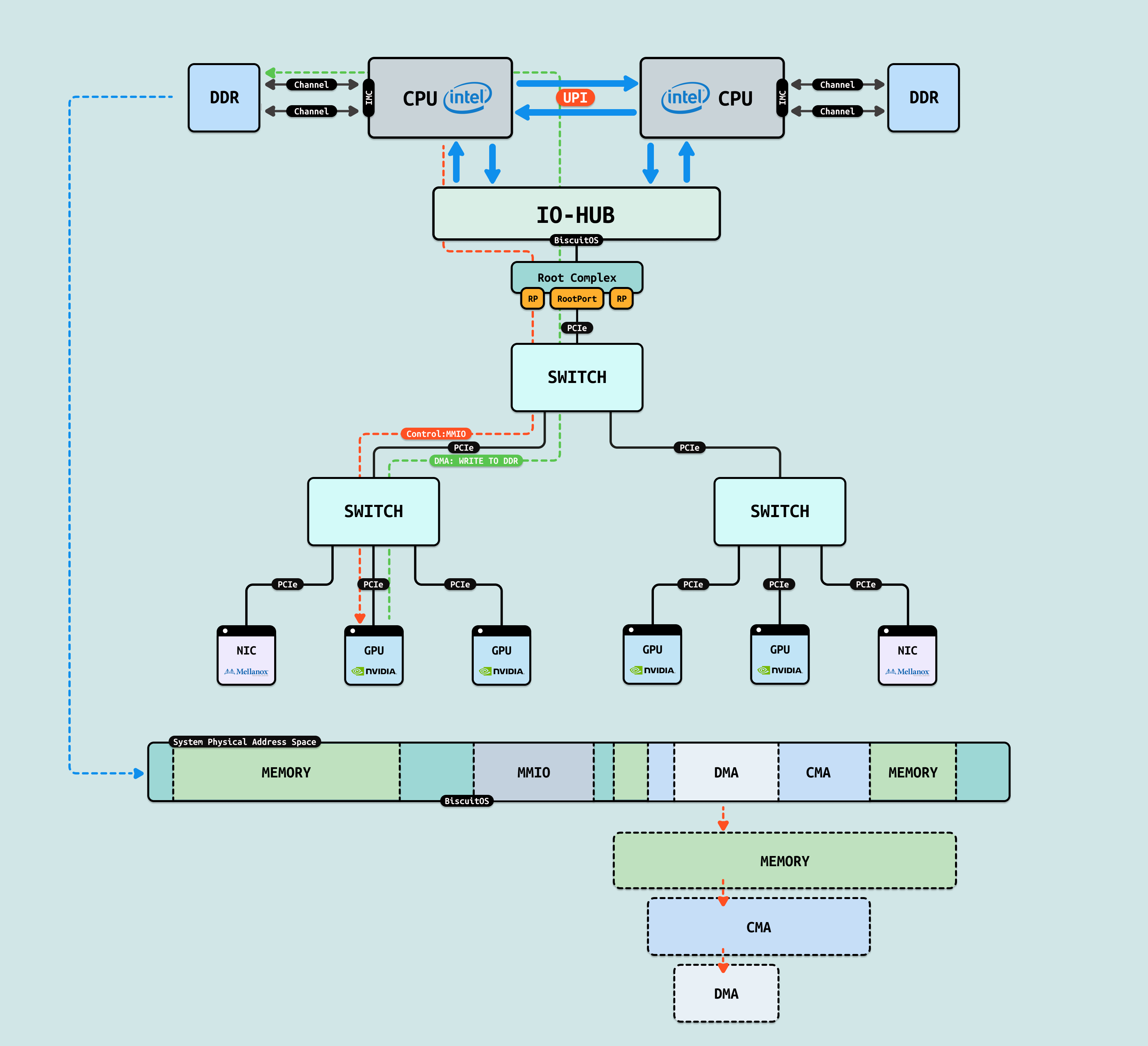
方案 B: 既然 Linux 内核默认只能提供 8MiB 连续的物理内存,那么可以使用 CMA(Contiguous Memory Allocator) 机制,其可以提供超大块连续的物理内存. CMA 基于 Buddy 分配器构建,可以动态伸缩,在提供大块连续物理内存和内存压力之间找到一个平衡. 当 Ai 需要向 GPU 搬运大量训练数据,可以从 CMA 里分配大块连续物理内存作为 DMA 内存,当使用完毕之后,CMA 将大块连续物理内存释放会 Buddy.
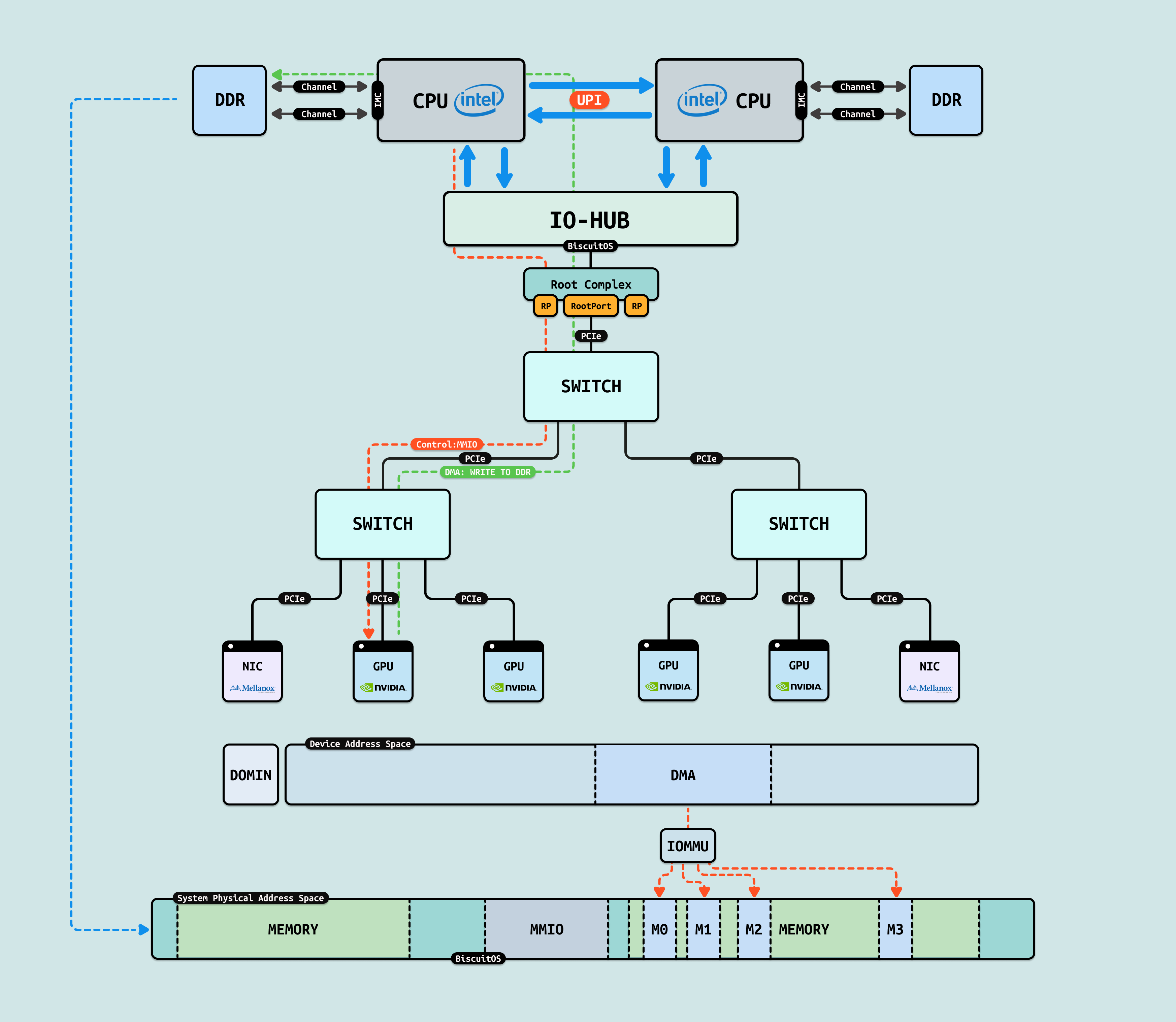
方案 C: SGDMA 和 CMA 都能够缓解连续物理内存不足的问题,但无法缓解 DMA 安全问题,由于 PCIe 地址空间会映射系统物理内存,因此所有的外设(GPU/NIC/SSD) 都可以看到同一块物理内存,并且 DMA 无需 CPU 干预,因此 GPU 可以向任意物理内存搬运数据,这会造成严重的内存踩踏. 于是 IOMMU 机制孕育而生, IOMMU 机制为每个外设抽象一个独立的 PCIe 地址空间,在这个独立的 PCIe 地址空间,系统可以控制外设可见的物理区域. 另外 IOMMU 还存在类似与 CPU MMU 的地址转换单元(PageTable/TLB), 因此外设独立的 PCIe 地址空间看到的连续的物理内存可以映射到离散的物理页上. 有了 IOMMU 的加持,GPU 等外设可以安全高效的与 CPU 交换数据.

在 AI Infra 的五级演进路径中,第三阶段聚焦 “单节点多 GPU 互联”,作为整个异构生态的”扩展层”. 这一层级扩展第二阶段的 CPU-GPU 桥接,实现 GPU 间的高带宽 P2P(Peer-to-Peer) 通信,支持 AllReduce 和数据分发操作,提升单机训练规模,而非依赖跨节点网络. 它构建于 PCIe/NVLink 等通道,IDC 2025 报告显示,在大规模模型训练阶段,此互联可将 GPU 利用率提升 4-6 倍,减少通信开销 60%,为后续分布式集群奠定节点内协同.

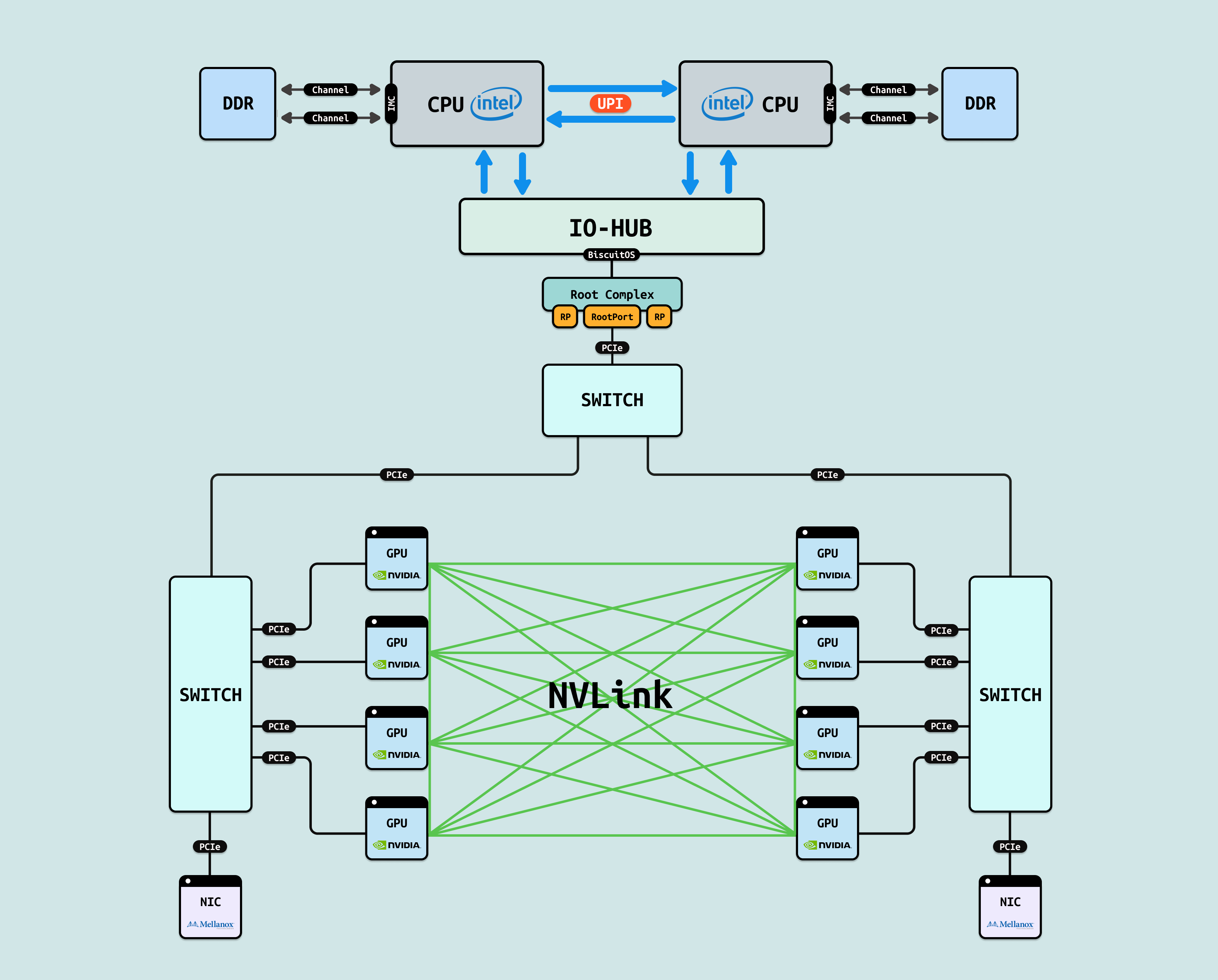
为直观理解,以 NVIDIA Hopper H100 多卡配置为例,该架构代表现代单节点 GPGPU 的典型扩展,其互联基础构成了 GPU 协同的织构.
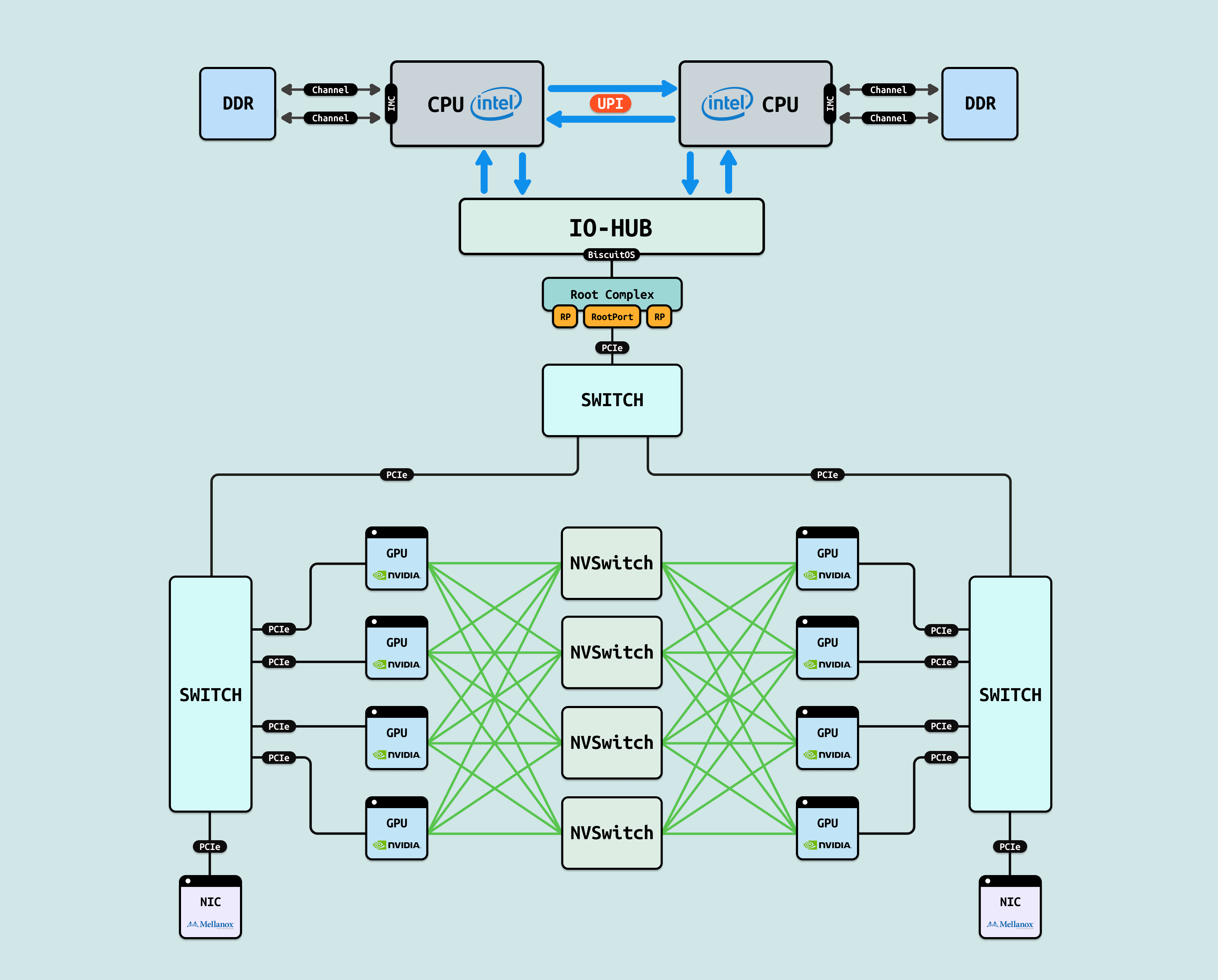
NVLink 是 NVIDIA 开发的专有高带宽 GPU 互连技术,基于高速 SerDes 链路实现 GPU 间直接 P2P 通信,支持全对全(all-to-all)拓扑,如环状或网格布局. 在 H100 GPU 中,每个 GPU 配置 18 个 NVLink 4.0 端口,每端口提供 900 GB/s 双向带宽,聚合可达 16 TB/s,用于单节点多 GPU 扩展,避免 PCIe 瓶颈. NVSwitch 是 NVLink 的配套交换芯片,充当”织构”核心,支持动态路由和负载均衡. 通过 4-6 个 NVSwitch,可连接 8-256 个 GPU,形成低延迟路径(~10 ns),确保全连接通信. 使用 NVLink 和 NVSwitch 的优势在于其超高带宽(PCIe 的 100 倍)和低延迟,支持 GPUDirect P2P 零拷贝传输,在 AI 训练中加速 NCCL AllReduce 操作 5x,提升 Llama 3 等模型的分布式同步效率 4 倍,同时优化能耗和扩展性,适用于 DGX 等单节点集群.
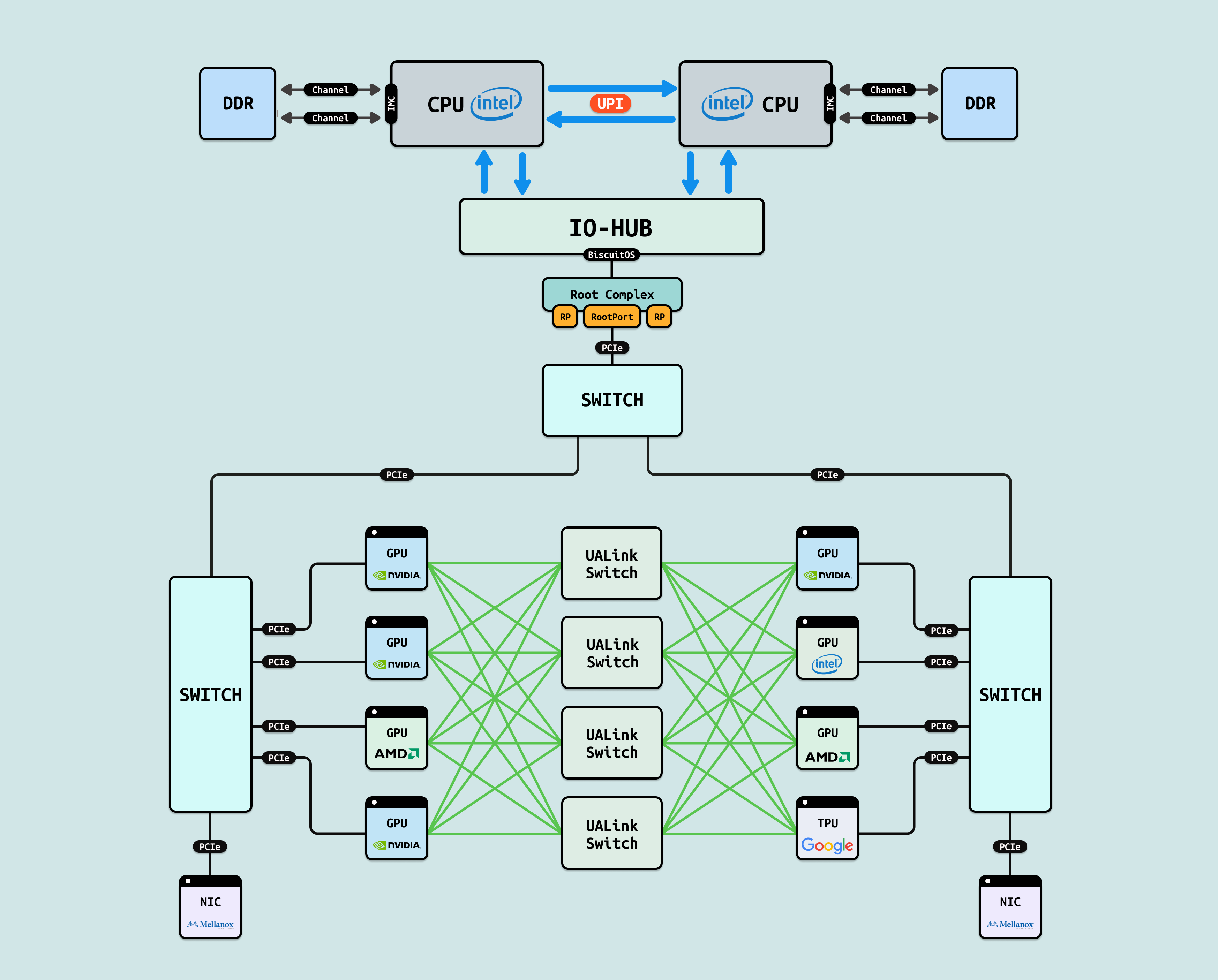
UAlink(开放 GPU 互连标准) 是 2025 年发布的开放规范(UALink Consortium 推动,成员包括 AMD、Intel、Broadcom 和 Google),旨在提供跨厂商 GPU 互连,支持 200G/400G 端口(x1-x4 配置),带宽 ~200-800GB/s,实现树状或网格拓扑,用于单节点多 GPU 扩展,避免 PCIe 瓶颈. 使用 UAlink 的原因是专有标准(如 NVLink)导致厂商锁定和生态碎片化,UAlink 通过开放协议促进异构计算统一,支持 NVIDIA/AMD/Intel GPU 混用,降低部署门槛,推动 AI 基础设施的标准化演进. 其优势在于兼容性强(跨厂商 P2P DMA),带宽高效(PCIe 的 10-20 倍),低功耗. 在 AI 中加速 NCCL 兼容 AllReduce 3x,提升 Llama 3 异构训练利用率 85%,并减少 TCO 30%. 8x 混合 GPU 配置下,UAlink 将层间通信延迟从 500 μs 降至 50 μs,支持开放集群扩展
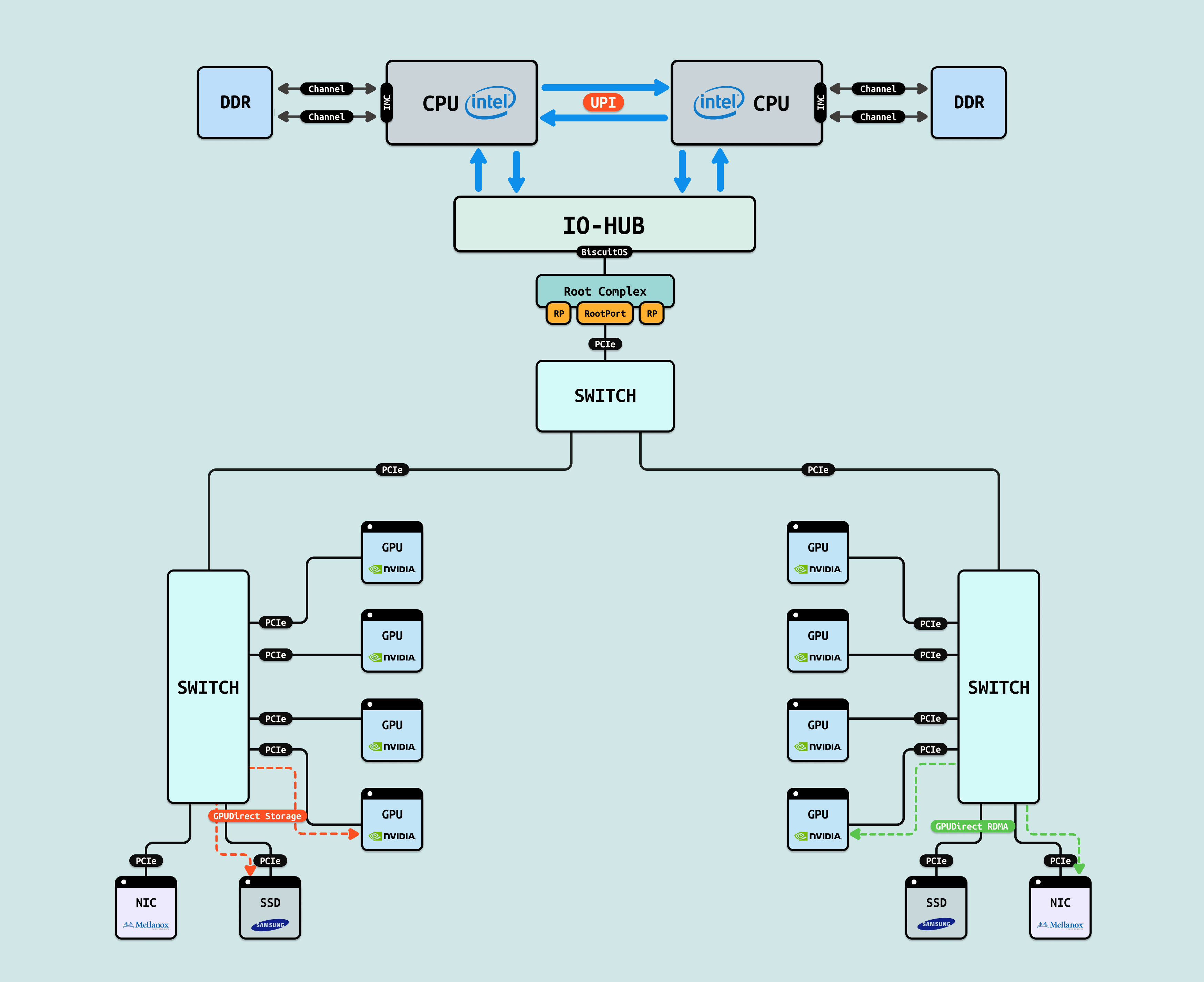
DirectGPU: GPUDirect RDMA 是 NVIDIA 的软件框架(GPUDirect 扩展),允许 GPU 直接访问远程内存(如 InfiniBand/RoCE NIC),而 GPUDirect Storage 进一步扩展到存储设备(如 NVMe SSD),通过异步 RDMA 绕过 CPU 缓存,实现 GPU 直达 I/O,支持 NCCL/MPI 库的 P2P 传输. H100 配置下,RDMA 带宽 ~400GB/s(RoCE v2),Storage 吞吐 ~10GB/s/通道,支持零拷贝 DMA 列表. 使用 GPUDirect 的原因是传统 CPU 代理导致高延迟和瓶颈,RDMA/Storage 通过 GPU 驱动映射内存页,直接注入 HBM/GDDR,提升单节点/分布式 AI 的数据流动效率. 其优势在于低开销(CPU 利用率升 90%),兼容 PCIe/NVLink,RDMA 加速 AllReduce 6x,Storage 减少 ETL 加载时间 4 倍. 在 8x H100 配置下,将 Llama 3 数据预取延迟从 5 ms 降至 500 μs,支持端到端 AI 管道优化,利用率达 92%.


在 AI Infra 的五级演进路径中,第四阶段聚焦 “多节点异构互联”,作为整个异构生态的”分布式层”. 这一层级扩展第三阶段的单节点扩展,实现跨主机 GPU 的高带宽一致性通信,支持 Scale-up(垂直扩展,节点内资源强化)和 Scale-out(水平扩展,集群级并行),加速万卡级模型训练,而非局限于单机瓶颈. 它构建于 NVLink/PCIe 等通道,IDC 2025 报告显示,在超大规模 AI 训练阶段,此互联可将分布式效率提升 10x,降低通信能耗 40%,为第五阶段的全局池化奠定跨域协同. 为直观理解,以 NVIDIA Hopper H100 多节点集群为例,该架构代表现代分布式 GPGPU 的典型设计,其互联基础构成了 GPU 协同的分布式织构. 这些机制协同形成”分布式漏斗”,1024x H100 配置可实现 ~100TB/s 聚合带宽,适用于 GPT-4 级预训练基准测试. 以下按逻辑顺序详述三种关键技术,从传统网络到开放标准,逐步揭示 Scale-up/out 的内在脉络
NVIDIA InfiniBand Switch: Scale-out 网络的低延迟织构 InfiniBand(IB) Switch 是 NVIDIA(Mellanox) 主导的专用网络交换机,支持 NDR 800G 端口(x1-x4 配置),带宽 ~800GB/s/链接,延迟 <100 ns,形成 fat-tree,用于多节点 GPU 集群扩展. 使用 InfiniBand Switch 的原因是其支持 Scale-up 通过节点内 IB Adapter 强化 GPU 访问(~400 GB/s/节点)和 Scale-out 跨 1000+ 节点形成全局路由,加速集体操作如 SHARP(Scalable Hierarchical Aggregation and Reduction Protocol). 其机制在于 GPU 通过 GPUDirect RDMA 映射 HBM 到 Switch 路径,Switch 动态负载均衡 FLITs(固定长度包),兼容 NCCL 库. 其优势在于带宽高(PCIe 的 10x),子微秒延迟,支持 RoCE over IB 混合. 在 AI 中加速 AllReduce 8x,优化万卡训练通信,但局限在于高成本和需专用硬件. H100 1024x 集群下,IB Switch 将梯度同步时间从 10 ms 降至 1 ms,提升 Scale-out 吞吐 6 倍
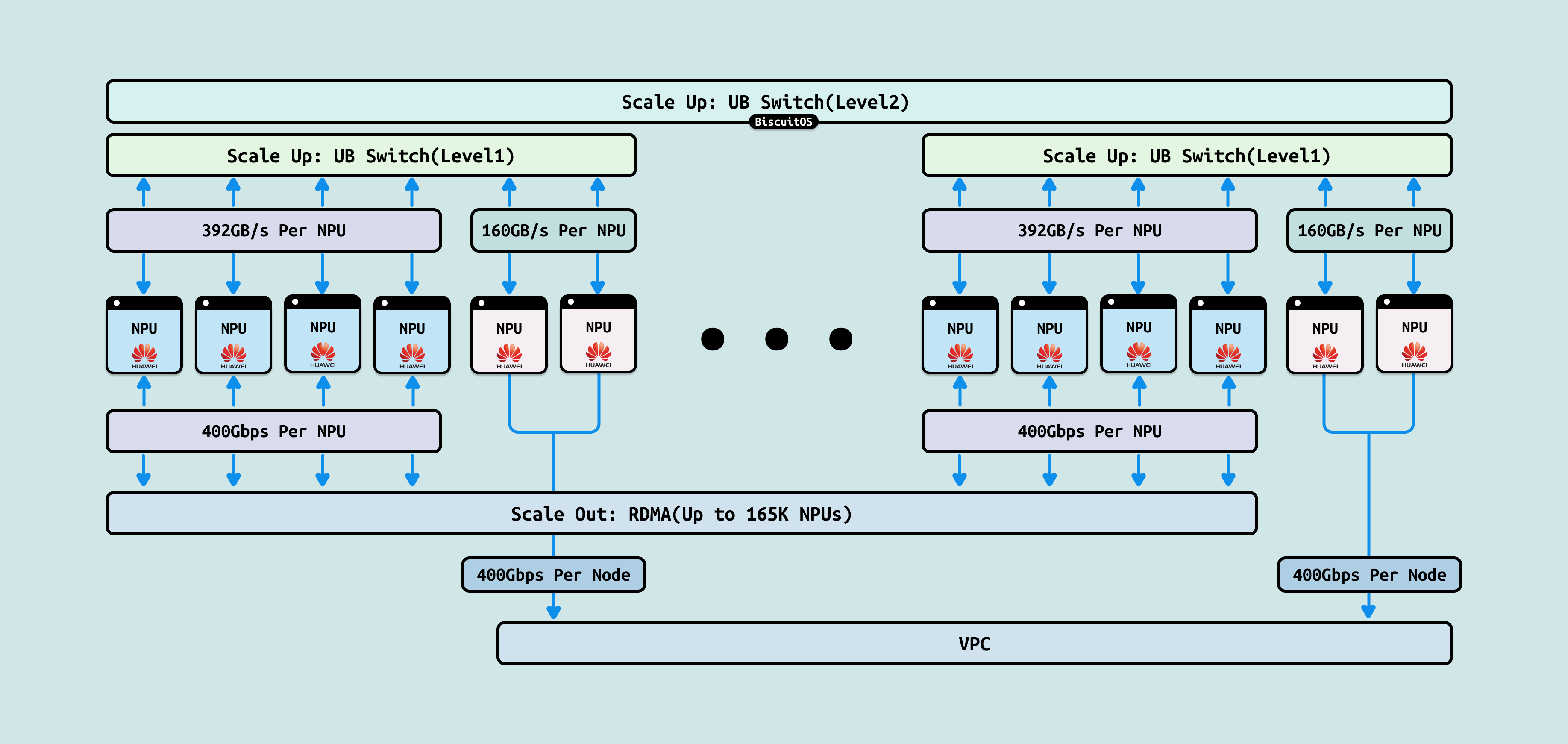
UB-Mesh 是华为 Ascend 910B/910C GPU 的专有多节点互联技术,基于 400G Ethernet 变体,支持 mesh 拓扑,带宽 ~400-800GB/s/链接,延迟 ~200 ns,形成全对全或分层网格,用于异构集群扩展. 使用 UB-Mesh 的原因是其支持 Scale-up 通过节点内 UB-Link 强化 GPU 聚合(~2 TB/s/节点) 和 Scale-out 跨 512+ 节点形成动态 mesh,加速集体操作如 HCCL 原生优化. 其机制在于 GPU 通过 UB-Adapter 桥接 Switch,形成自适应路由,集成 RDMA 和 FEC(前向纠错),兼容 CXL 内存语义. 其优势在于成本低(Ethernet 基底),易集成云环境. 在 AI 中加速 MindSpore 框架的 Scale-out 5x,优化 Ascend 集群的张量分发,但局限在于华为生态依赖,兼容性需适配。Ascend 910C 512x 集群下,支持混合 Scale-up/out 训练

CXL 3.0: Scale-out 内存池化的跨域织构 CXL 3.0(Compute Express Link 3.0) 是开放标准(2025 年 PCIe 6.0 基础),支持多主机内存池化,带宽 ~128GB/s/链接,延迟 ~100 ns,形成 mesh 或树状拓扑,用于 GPU 间/跨节点一致性共享. 使用 CXL 3.0 的原因是其支持 Scale-out 通过跨主机共享内存池(TB 级 GFAM,Global Fabric Attached Memory) 动态分配资源,消除传统网络的通信墙,实现万节点级扩展,而 Scale-up 则通过节点内 CXL Switch 强化 GPU HBM 池(~1 TB/节点). 其机制在于 GPU 通过 CXL.mem/cache 协议访问远程池,Switch 启用 P2P DMA 和目录一致性,兼容 PCIe ATS,支持多级切换(multi-level switching). 其优势在于内存级共享(TB 级池化),低开销一致性. 在 AI Scale-out 中加速跨节点张量分片 7x,优化 AllReduce 操作,消除“内存墙”.

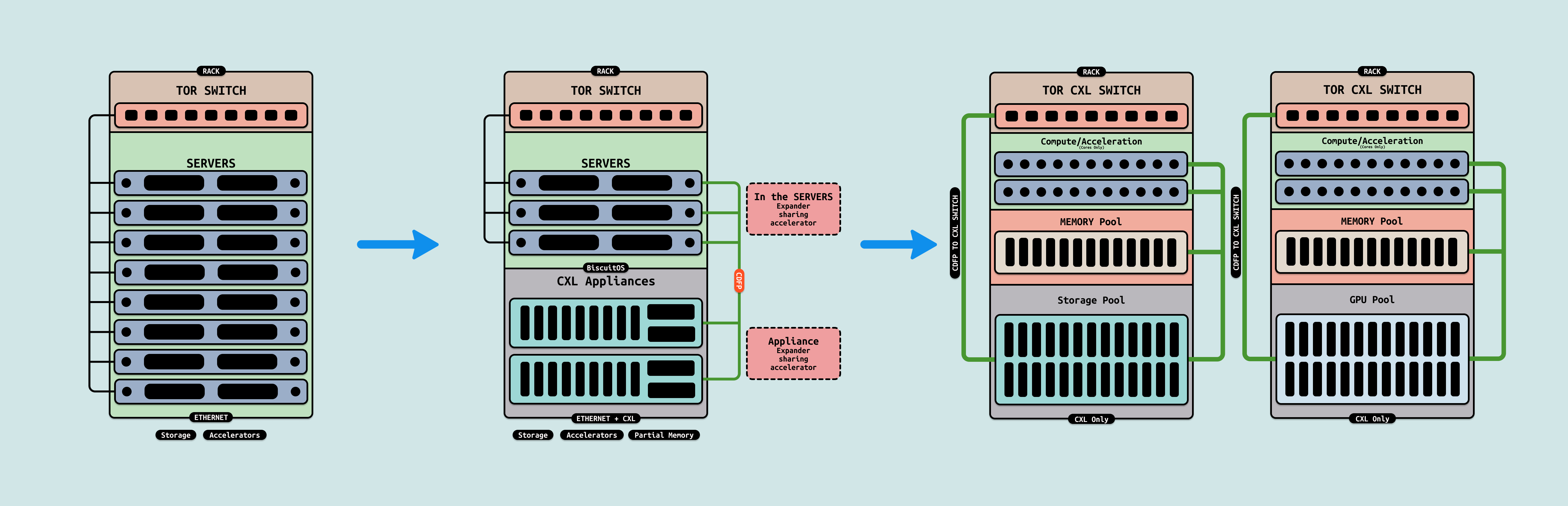
在 AI Infra 的五级演进路径中,第五阶段聚焦 “超节点异构融合”,作为整个异构生态的“全局池化层”. 这一层级打破传统内存墙和通信墙,实现 CPU Core、内存、存储和 GPU 的全面池化,支持动态资源分配和万亿参数级训练,而非受限于节点边界. 此时我门会看到只有内存的服务器,以及只有 CPU 或者 GPU 的服务器,服务器数据中心的整个形态将被彻底改变.
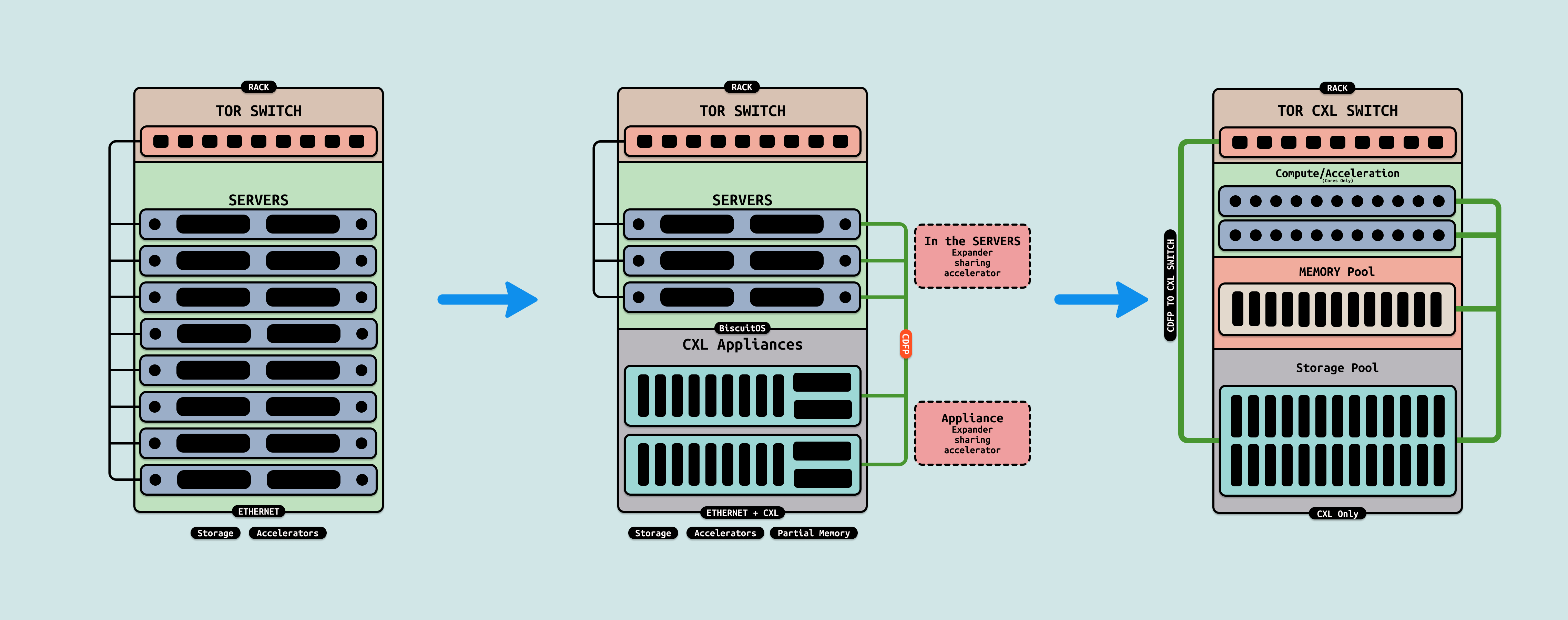
CXL3.0 Pooling/Sharing: 打破单节点内存墙的全局动态池化, CXL3.0 在设想中演变为跨域内存/存储池化协议,支持 GFAM(Global Fabric Attached Memory)机制,带宽 ~256GB/s/链接,延迟 ~50 ns,形成多主机共享池,用于 CPU/GPU/存储的无界访问. Pooling 指动态分配 TB 级 HBM/DDR/NVMe 池,Sharing 指一致性缓存(CXL.cache)实现跨节点读写.
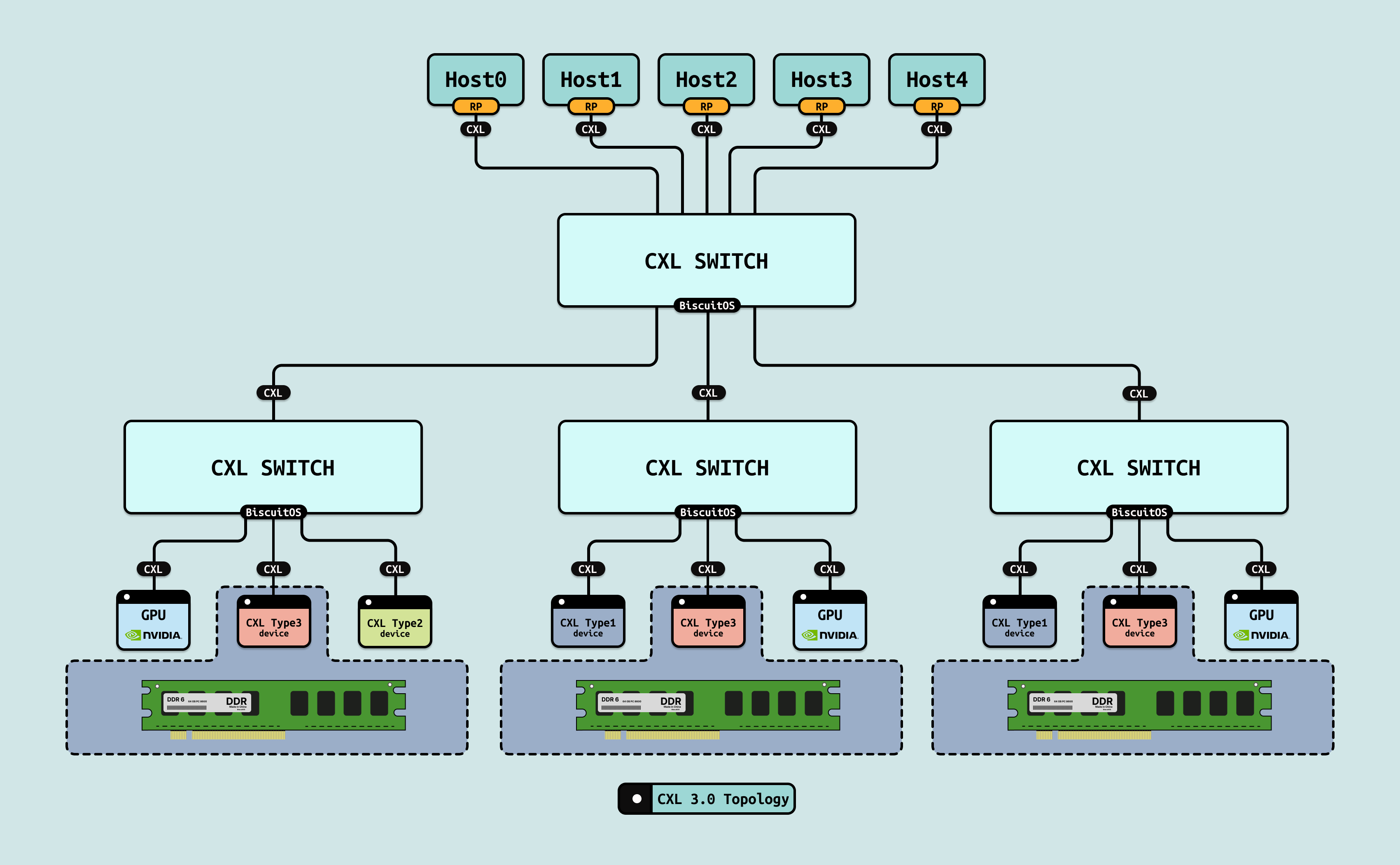
通过多级 CXL Switch 和目录协议(如 MESIF 扩展),所有资源(如 GPU HBM 和 NVMe SSD)形成统一地址空间,支持细粒度分区(e.g., 4KB 页级共享),打破 NUMA 边界,实现”内存即服务”. 这一构想直接打破数据中心单节点服务器的内存墙, 传统服务器受限于本地 DDR/HBM 容量(~1 TB/节点),导致 AI 训练中频繁的跨节点迁移开销. CXL3.0 Pooling 将内存池化到 EB 级,允许动态借用远程资源,消除 80% I/O 瓶颈,提升 AGI 数据流动 15x. 其优势在于低开销迁移(<100 ns),但需全栈兼容硬件,安全挑战(如加密开销)仍存
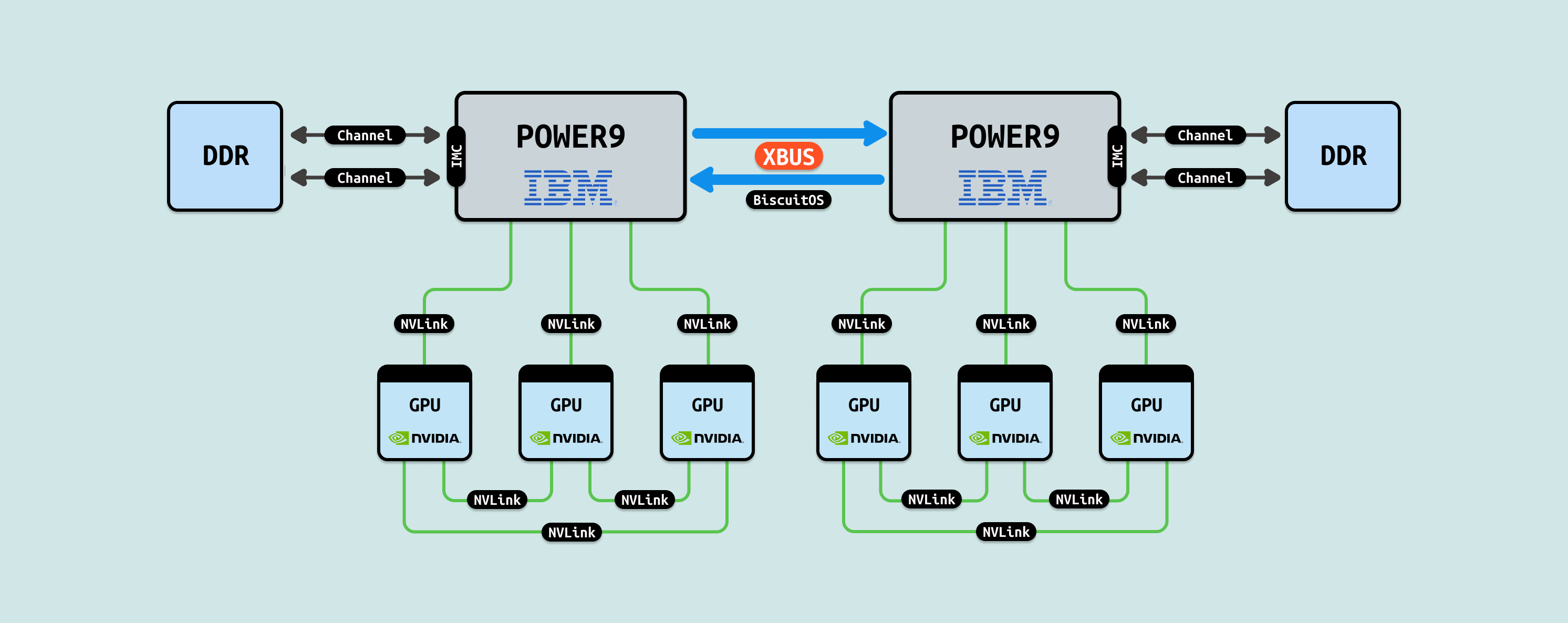
IBM POWER9 NVLink C2C: 混合实现的跨域核心池化, IBM POWER9 NVLink C2C 是现有实现的混合池化方案,支持 Power10 架构的 NVLink 3.0/4.0 扩展,带宽 ~300GB/s/链接,延迟 ~20 ns,形成 CPU/GPU 核心的跨域共享,用于企业级异构融合. 基于 OpenCAPI + NVLink,POWER9 Core 与 GPU SM 通过 C2C 桥接实现线程池化,支持 OpenMP 扩展的动态迁移,池化 1000+ 核级资源,已在 IBM Watsonx 部署. 这一构想进一步打破服务器集群样式: 传统数据中心以通用服务器为主(含 CPU+内存+GPU),导致资源闲置和迁移复杂. POWER9 NVLink C2C 推动专用化演进,可能出现”只有内存的服务器”(纯存储池节点)、”只有 CPU 的服务器”(调度池节点)和”只有 GPU 的服务器”(计算池节点),通过 C2C 织构动态组装,提升企业模型训练 8x.

Huawei UB-Mesh Pooling 是华为 Ascend 生态的超融合池化方案,基于 UBoE协议统一总线和网络,支持 Load/Store + RDMA + URPC(Unified Remote Procedure Call) 机制,带宽 ~400GB/s/链接,延迟 ~100ns,形成 Ethernet 原生网格拓扑,用于 CPU/NPU/GPU/MEM/SSU/DPU/Switch 的全局池化. 使用 UB-Mesh Pooling 的原因是传统协议转换开销导致高延迟和碎片化,UBoE 通过统一 SerDes 端口实现任意设备互联,简化架构,支持动态资源借用,推动数据中心从专用服务器向池化演进. 其机制在于高速度 SerDes 复用任意目的(如 CPU 调度 GPU Warp 或 MEM 共享 HBM),兼容 Ethernet 网络,无需协议转换开销,实现”总线即网络”的原生运行. 其优势在于降低延迟(任意端口转发无开销)、更高带宽(SerDes 全速利用)和简化方案(Load/Store + RDMA + URPC 覆盖所有访问). 在 AI Scale-out 中加速跨域张量池化 6x,提升 AGI 资源利用率 90%,并兼容现有 Ethernet 基础设施,但局限在于华为生态依赖,标准化需时.

在 AI Infra 的演进中,AiOS 作为关键中间层,扮演承上启下的角色. 它向下组织和调度新型异构硬件(如 CPU、GPU、NPU 的池化资源),确保高效利用 NVLink/CXL 等互联. 向上屏蔽硬件差异,提供稳定、统一的资源和服务层,为大模型抽象出无缝计算环境. IDC 2025 报告指出,AiOS 可将异构系统利用率从 60% 提升至 95%,减少 70% 开发复杂性,支持 AGI 级应用的动态扩展. AiOS 的设计理念是“统一即服务”: 通过协议抽象和资源虚拟化,实现从 Read/Write 到 Load/Store,再到 SVM/SPM 的全栈归一化. AiOS 致力于打破“资源墙”和“通信墙”,让大模型运行在一个统一资源统一通信域的环境中,提升硬件资源的使用效率.
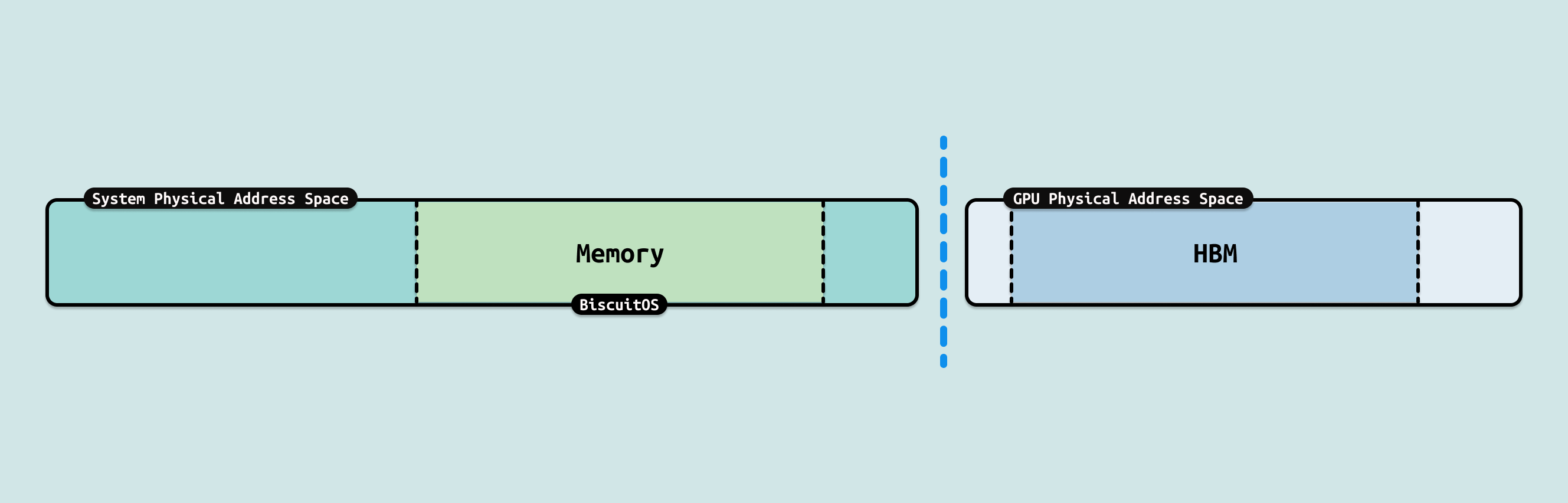
在 AiOS 的内存语义设计中,Read/Write 和 Load/Store 是两种核心访问范式,用于定义处理器与共享资源(如池化内存)的交互. 这些范式确保跨异构硬件(CPU/GPU/NPU)的通信有序、一致,并最终实现资源统一: 即将分散的 CPU Core、HBM/DDR 内存和存储池抽象为单一视图,支持大模型的无缝访问. 通信的本质目的是打破隔离,通过这些语义屏蔽硬件差异,让资源“统一在一起”,如 CXL 池化下的动态借用或 NVLink C2C 的核心迁移,提升 AGI 级应用的效率.
- Load/Store(LD/ST):
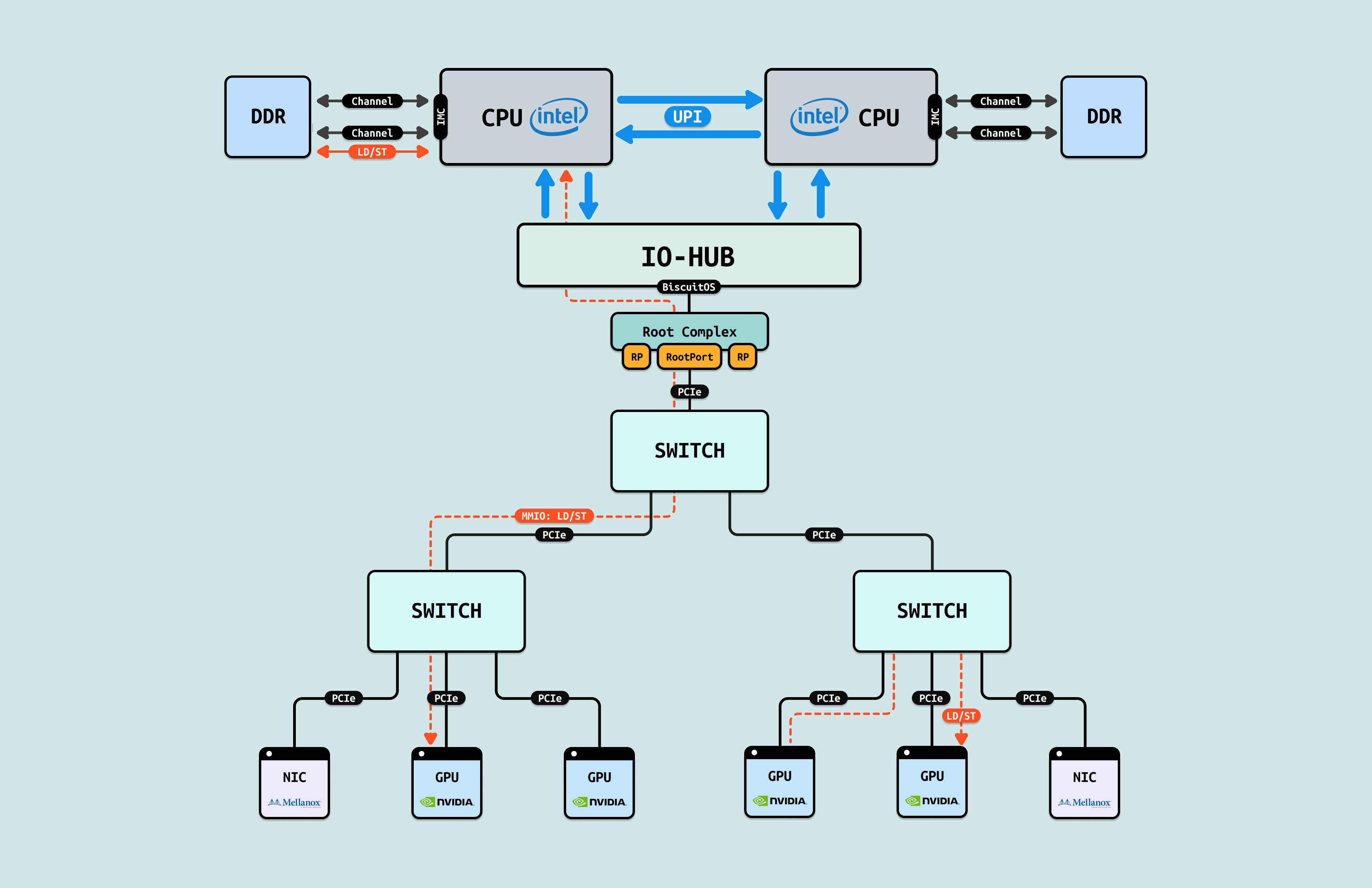 LD/ST 有两层含义,第一层是 CPU 可以直接访问(寻址)的物理地址区域,例如 CPU 可以通过 Load/Store 指令访问物理内存, 物理空间能被 LD/ST 的前提是其必须映射到系统物理地址空间,例如 DDR 映射到系统物理地址空间形成物理内存,又如 GPU 将其内部寄存器通过 BAR 映射到系统物理地址空间形成 MMIO. LD/ST 的第二层含义是 CACHE 一致性,支持 LD/ST 的物理区域一定能够支持 CACHE 一致性,例如物理内存支持 WB,MMIO 支持 UC, 这可以保证 CPU 和 GPU 看到的数据保持一致. LD/ST 不仅仅适用于 CPU,GPU 可以通过 LD/ST 访问其自己的显存,也可以借助 Nvlink/NvSwitch 访问其他 GPU 的显存.
LD/ST 有两层含义,第一层是 CPU 可以直接访问(寻址)的物理地址区域,例如 CPU 可以通过 Load/Store 指令访问物理内存, 物理空间能被 LD/ST 的前提是其必须映射到系统物理地址空间,例如 DDR 映射到系统物理地址空间形成物理内存,又如 GPU 将其内部寄存器通过 BAR 映射到系统物理地址空间形成 MMIO. LD/ST 的第二层含义是 CACHE 一致性,支持 LD/ST 的物理区域一定能够支持 CACHE 一致性,例如物理内存支持 WB,MMIO 支持 UC, 这可以保证 CPU 和 GPU 看到的数据保持一致. LD/ST 不仅仅适用于 CPU,GPU 可以通过 LD/ST 访问其自己的显存,也可以借助 Nvlink/NvSwitch 访问其他 GPU 的显存. - Read/Write:
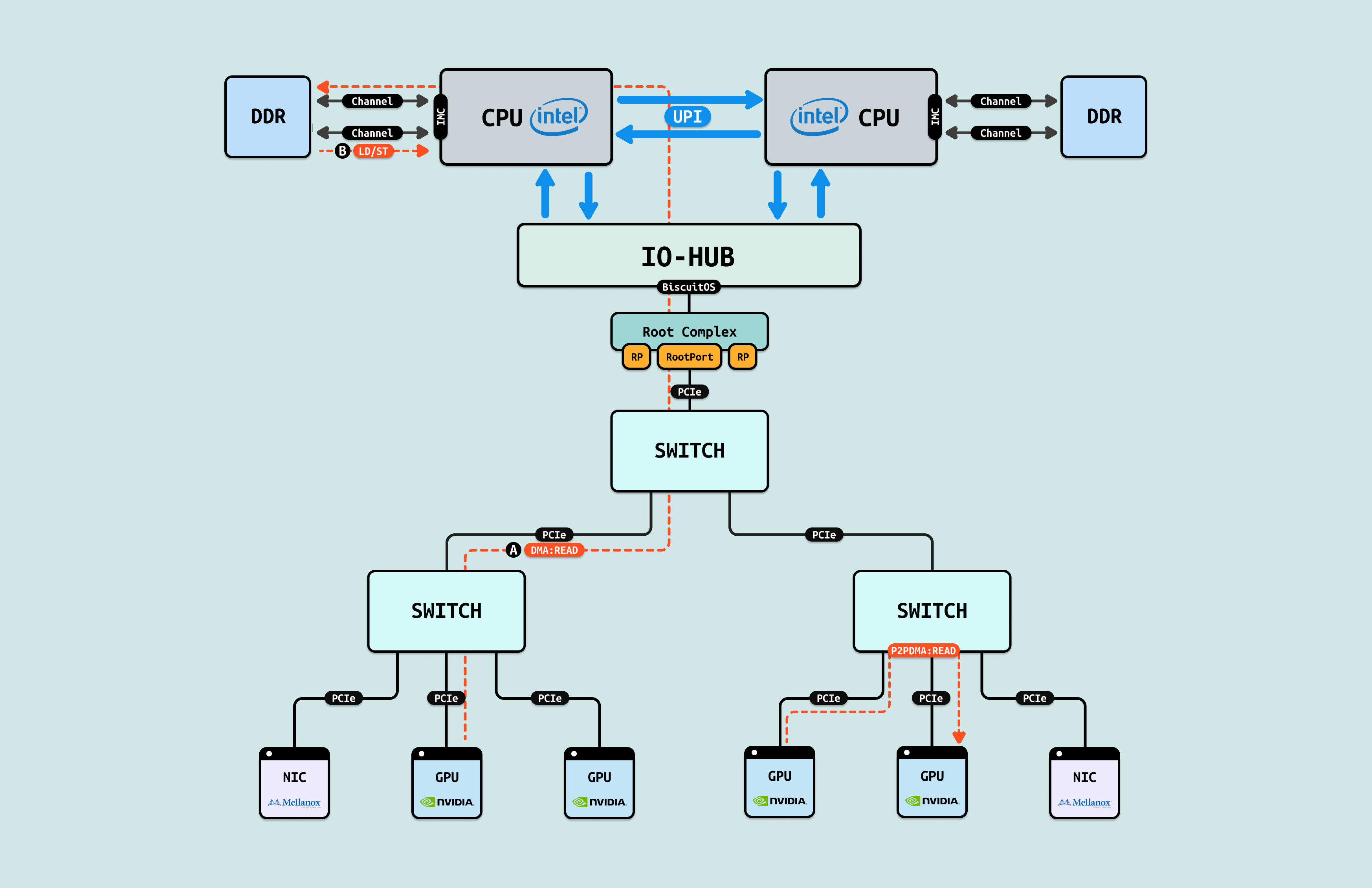 Read/Write 有两层含义,第一层是 CPU 只能通过间接访问 GPU 内部资源,例如 CPU 要访问 GPU 的 HBM 显存,那么需要 GPU 先将 HBM 资源 DMA 到物理内存,搬运完毕之后,CPU 再访问物理内存,这样才能够访问到 GPU 显存的内容, Read/Write 导致物理地址空间割裂,CPU 可访问系统物理地址空间,但看不到 GPU 内部物理地址空间. Read/Write 第二层含义是不支持 CACHE 一致性,因此在间接访问之前需要手动保持 CACHE 一致性. GPU 也存在 Read/Write 场景,其访问其他 GPU 显存也需要 Read/Write 间接访问, 并且自己确保 CACHE 一致性,那么 GPU 之间的地址空间就是撕裂独立的.
Read/Write 有两层含义,第一层是 CPU 只能通过间接访问 GPU 内部资源,例如 CPU 要访问 GPU 的 HBM 显存,那么需要 GPU 先将 HBM 资源 DMA 到物理内存,搬运完毕之后,CPU 再访问物理内存,这样才能够访问到 GPU 显存的内容, Read/Write 导致物理地址空间割裂,CPU 可访问系统物理地址空间,但看不到 GPU 内部物理地址空间. Read/Write 第二层含义是不支持 CACHE 一致性,因此在间接访问之前需要手动保持 CACHE 一致性. GPU 也存在 Read/Write 场景,其访问其他 GPU 显存也需要 Read/Write 间接访问, 并且自己确保 CACHE 一致性,那么 GPU 之间的地址空间就是撕裂独立的.
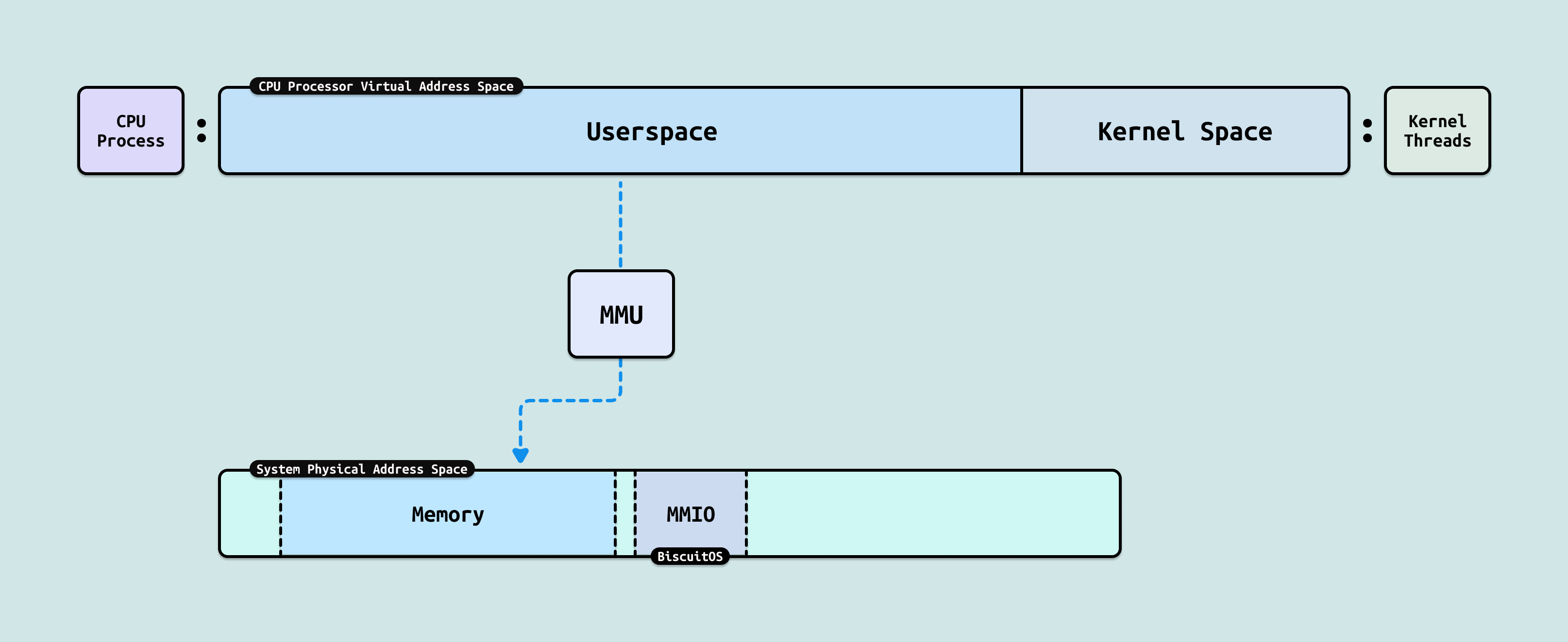
在 CPU 侧,进程是一个独立任务主体,其独占一份虚拟地址空间,虚拟地址空间包括两个部分,用户空间(Userspace) 由用户进程独占使用,内核空间(Kernel Space) 有内核线程或者用户进程内核态使用. 每个用户进程并不直接感知到其他进程的存在,需要通过 IPC 等手段才能与其他进程进行通信,因此 CPU 可以让多个任务并行运行,并作为调度实体进行资源调度. 进程的虚拟内存通过 MMU(内存管理单元) 映射到系统物理地址空间. 对于 CPU,系统物理空间可以映射 DDR 成物理内存,也可以映射 GPU 内部寄存器为 MMIO.
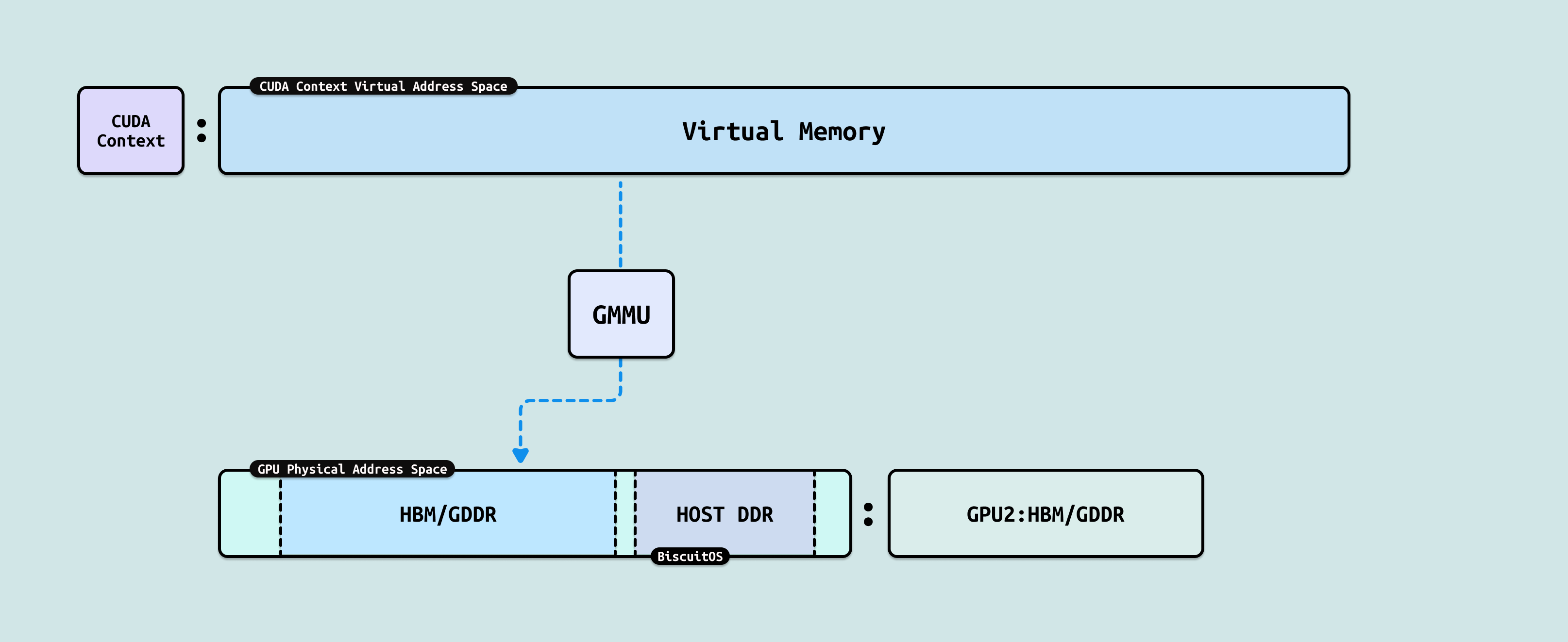
GPU 侧也有类似 CPU 进程的概念,其称为 GPU 上下文(或 CUDA 上下文),每个 GPU 上下文代表一个 “GPU 进程”,其也独占一份虚拟地址空间(Virtual Address Space). 由于 GPU 进程的存在,可以在 GPU 硬件上并发多个 GPU 应用而不冲突. 对于 GPU 其物理地址空间可以映射 HBM/GDDR 显存,也可以映射 Host 侧 DDR,形成一个统一连续的物理地址空间, 另外由于 NVlink/NVSwitch 的作用,GPU 可以通过 Read/Write 或者 Load/Store 的方式访问其他 GPU 的 HBM/GDDR, 因此其他 GPU 的 HBM 对于本 GPU 来说是一块块分离的地址空间. GPU 同样也存在 GMMU 组件,其可以将 GPU 进程虚拟内存映射到 GPU 物理地址空间.
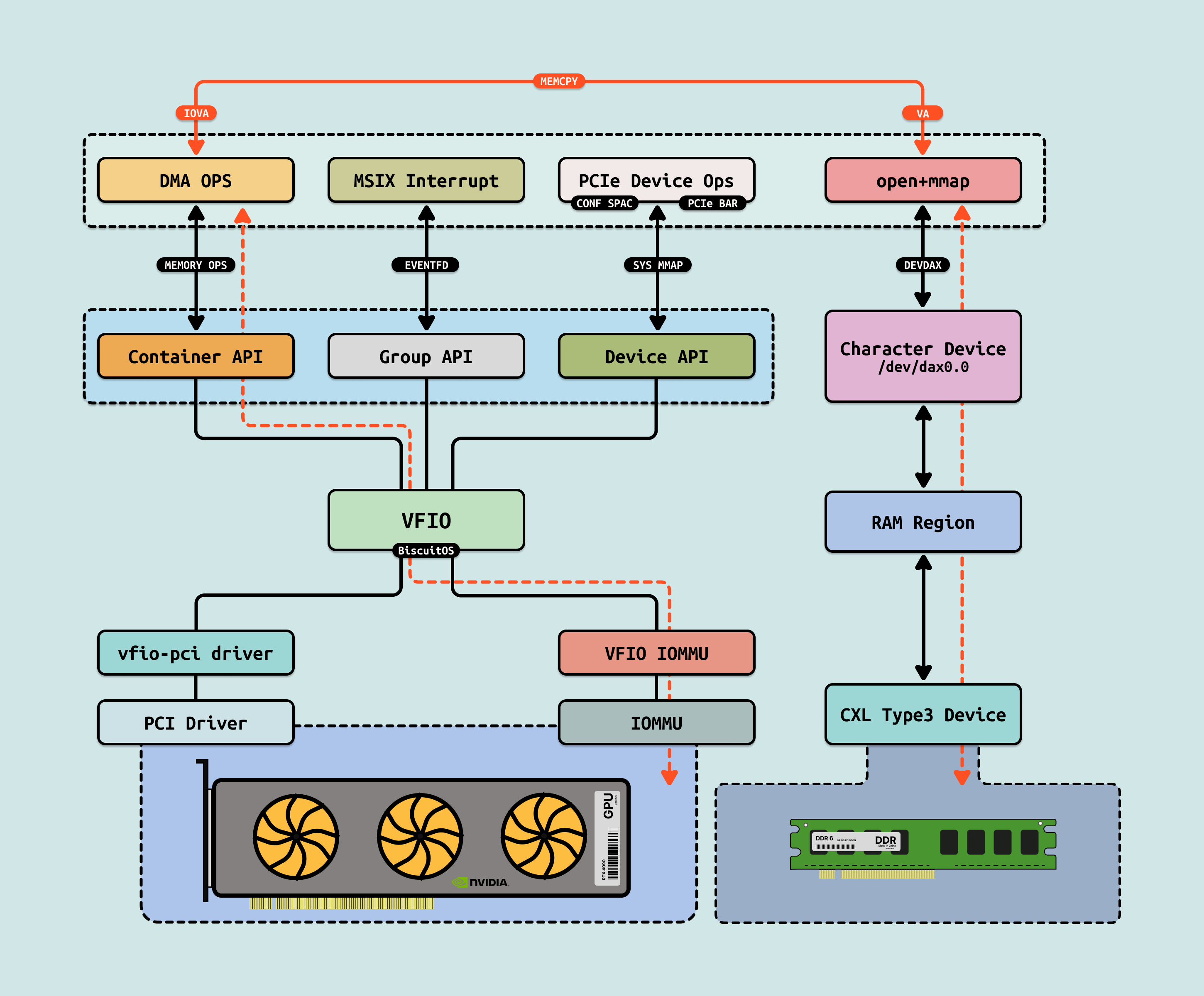
AiOS 里存在大量的技术栈,其初衷都是为打破 CPU 和 GPU 之间的通信墙和内存墙,较少无效数据搬运和降低资源占用,让有限的资源运行更多的大模型任务. CPU 与 GPU 通信需要基于 PCIe 驱动进行,大模型业务通过 IOCTL 方式与 PCIe Driver 进行交互,进而控制 GPU 执行指定的操作. 也可以借助 VFIO 机制将 GPU 驱动迁移到用户态,这样便于虚拟化和 CUDA Runtime 直接访问 GPU. 接下来从三个阶段讲解 AiOS 在大模型场景下的技术演进

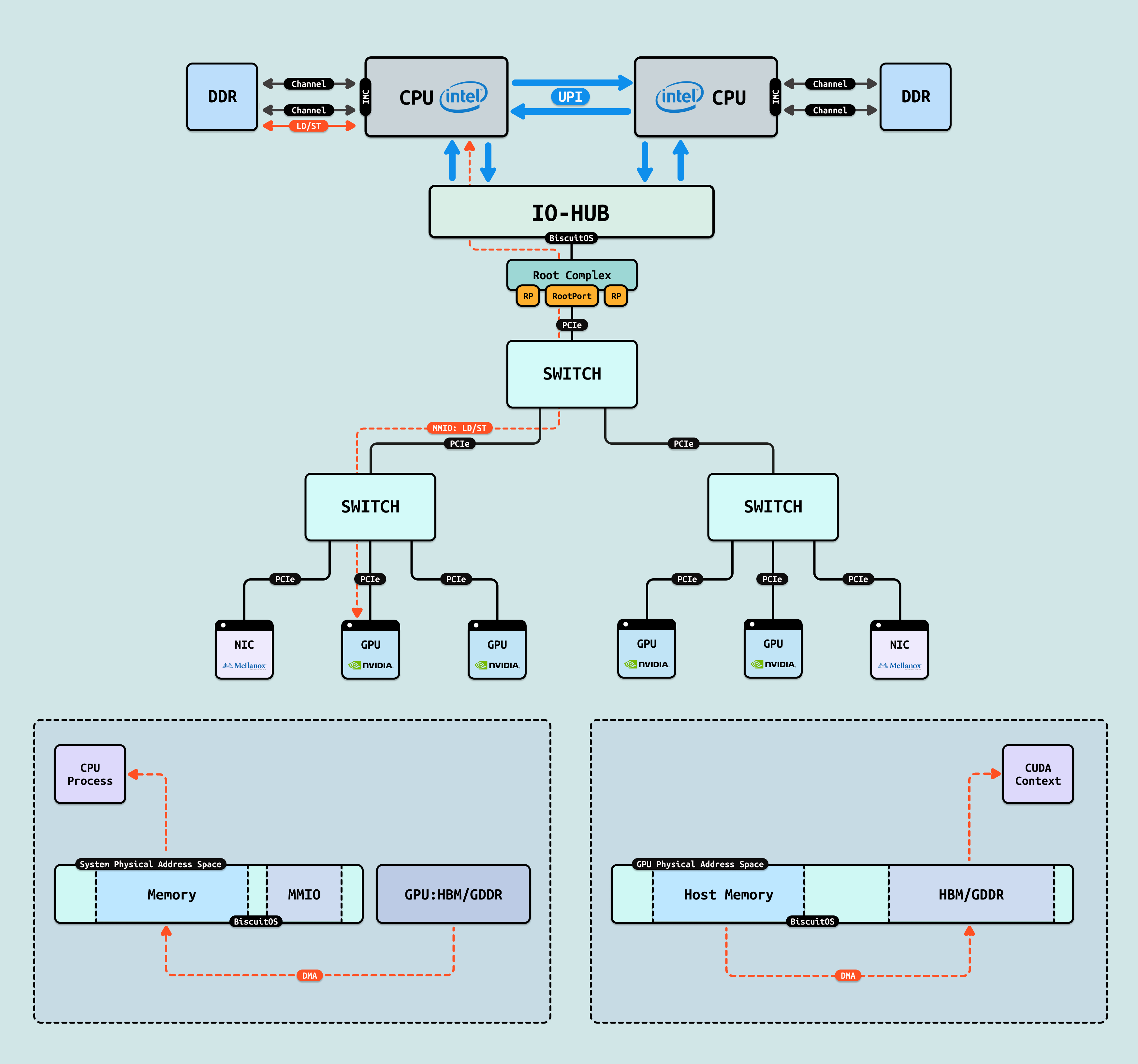
DMA: DMA 作为整个 CPU-GPU 交换数据的基础,其也是一种典型的 Read/Write 场景. 从 CPU 进程角度,CPU 并不能看到 GPU 内部的显存,只能通过驱动告诉 GPU,然后 GPU 发起的 DMA 将内部显存的数据搬运到 Host 侧物理内存,DMA 完毕之后再通知 CPU 从物理内存读取数据. 从 GPU 进程角度来看,其可以看到自己的显存(HBM/GDDR)和 Host 侧物理内存,但 GPU 无法做到 Host 侧物理内存 CACHE 一致性,因此其还是只能先发起 DMA 操作,将数据从 Host 物理内存搬运到自己显存,然后再访问显存的方式间接访问 CPU 侧数据.
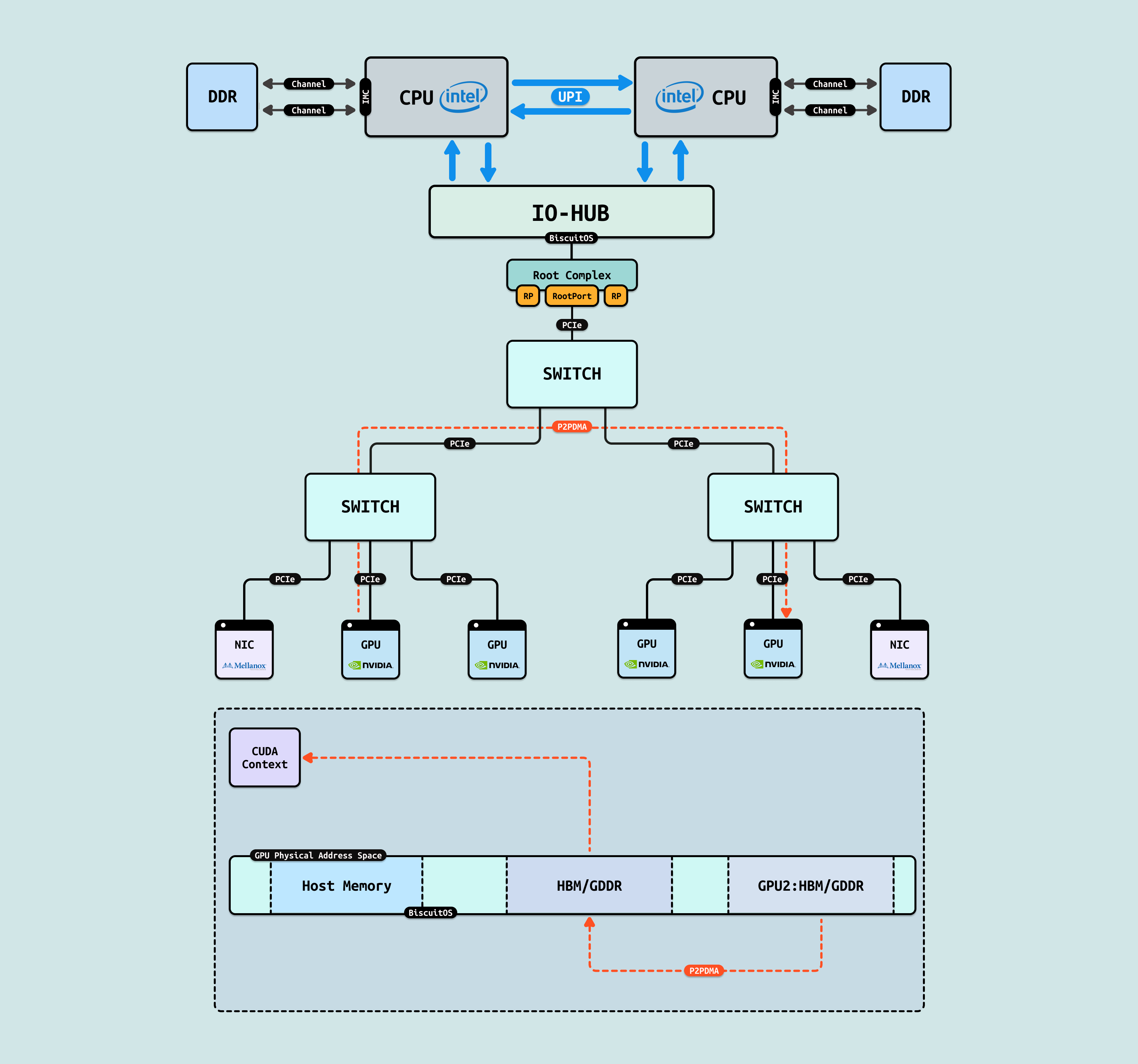
P2PDMA: DMA 的特点是每次需要将数据搬运到系统物理内存,但对于两个 GPU 之间数据交互可以进行直接搬运,无需绕道 RC 在本地 SWITCH 即可完成. P2PDMA 可以实现两个 GPU 之间直接搬运数据,但前提是需要将两个 GPU 要搬运的显存映射到 PCIe 地址空间上. 对于 GPU,其物理地址空间既可以看到自己的 HBM/GDDR 显存和 Host 侧内存,又可以看到 GPU2 暴露出来的 HBM/GDDR 显存, 同理 GPU 也将一部分显存暴露到 PCIe 地址空间上. 虽然 GPU 可以看到另外一个 GPU 的显存,但由于其无法另一个 GPU 显存 CACHE 一致性,因此其只能先通过 P2PDMA 将数据搬运到自己的显存,然后在访问显存里的数据.

RDMA: 将 DMA 搬运的范围拓展到其他主机的物理内存,这就是 RDMA 核心作用,基于网络在多主机之间实现 DMA 搬运. 从 CPU 进程角度来看,其物理地址空间并不能看到其他主机的物理内存,其他主机物理内存就是一些分离的地址空间,这就是所谓的内存墙,那么可以通过 RDMA 从远端主机将其物理内存数据搬运到本地,然后 CPU 再通过访问本地内存的方式访问到远端主机内存. 由于 RDMA 同时也不能保证远端物理内存的 CACHE 一致性,因此在搬运前需要手动保持 CACHE 一致性.
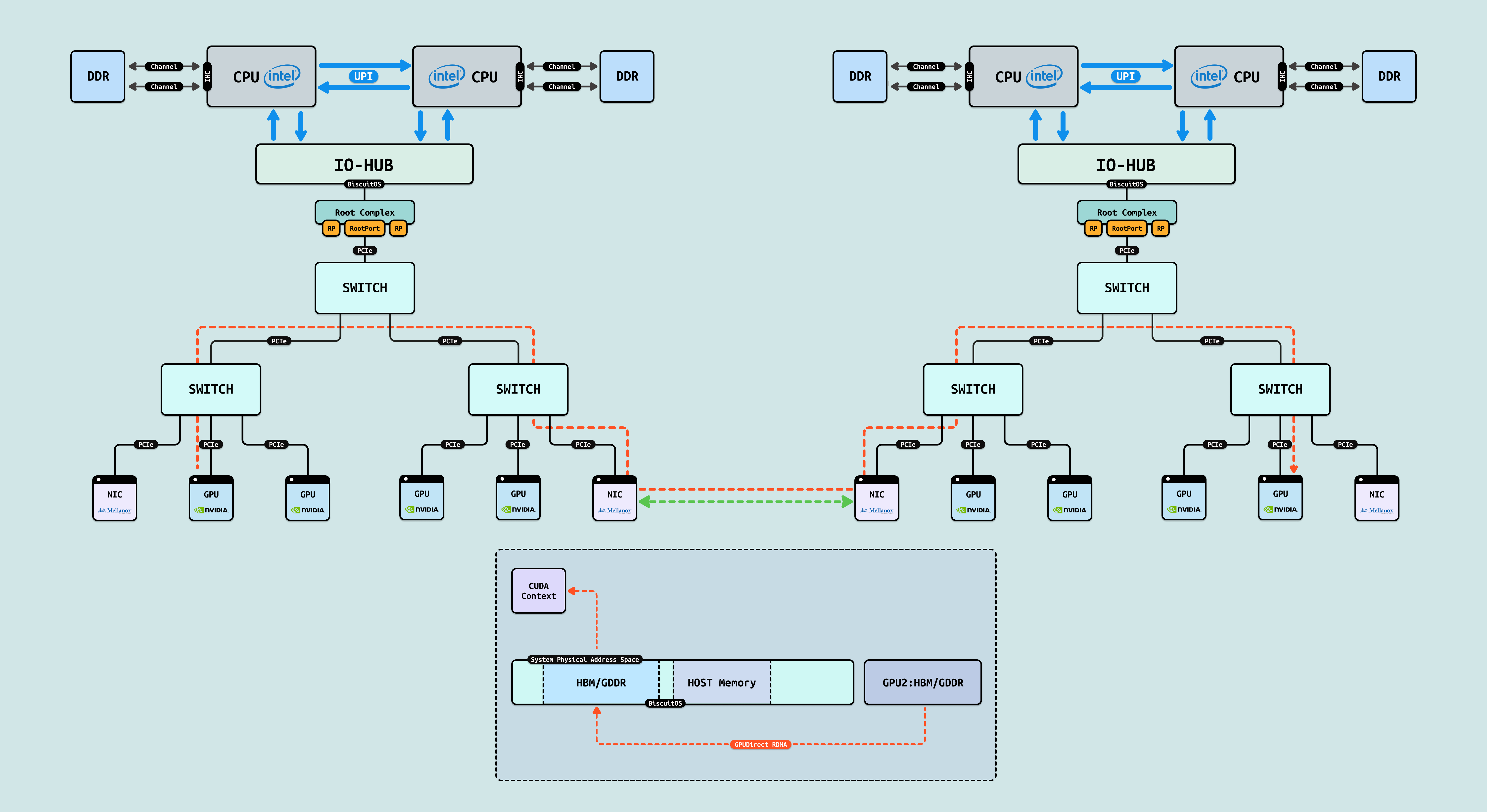
GPUDirect RDMA: RDMA 可以实现主机直接内存搬运,结合单节点内的 P2PDMA 和 GPU P2PDMA,GPUDirect RDMA 可以让两个节点 GPU 之间通过 RDMA 直接进行数据搬运,也就是单节点内 GPU 的数据直接搬运到 NIC 网卡,再通过网络到达目的端节点,目的端网卡将收到的数据直接搬运到 GPU. 这样大大减少了多节点 GPU 间的数据搬运,提升了 GPU 间共享数据的效率. GPU 进程并不能直接在其物理地址空间看到远端的 GPU 显存,因此只能通过 Read/Write 方式进行数据交互.
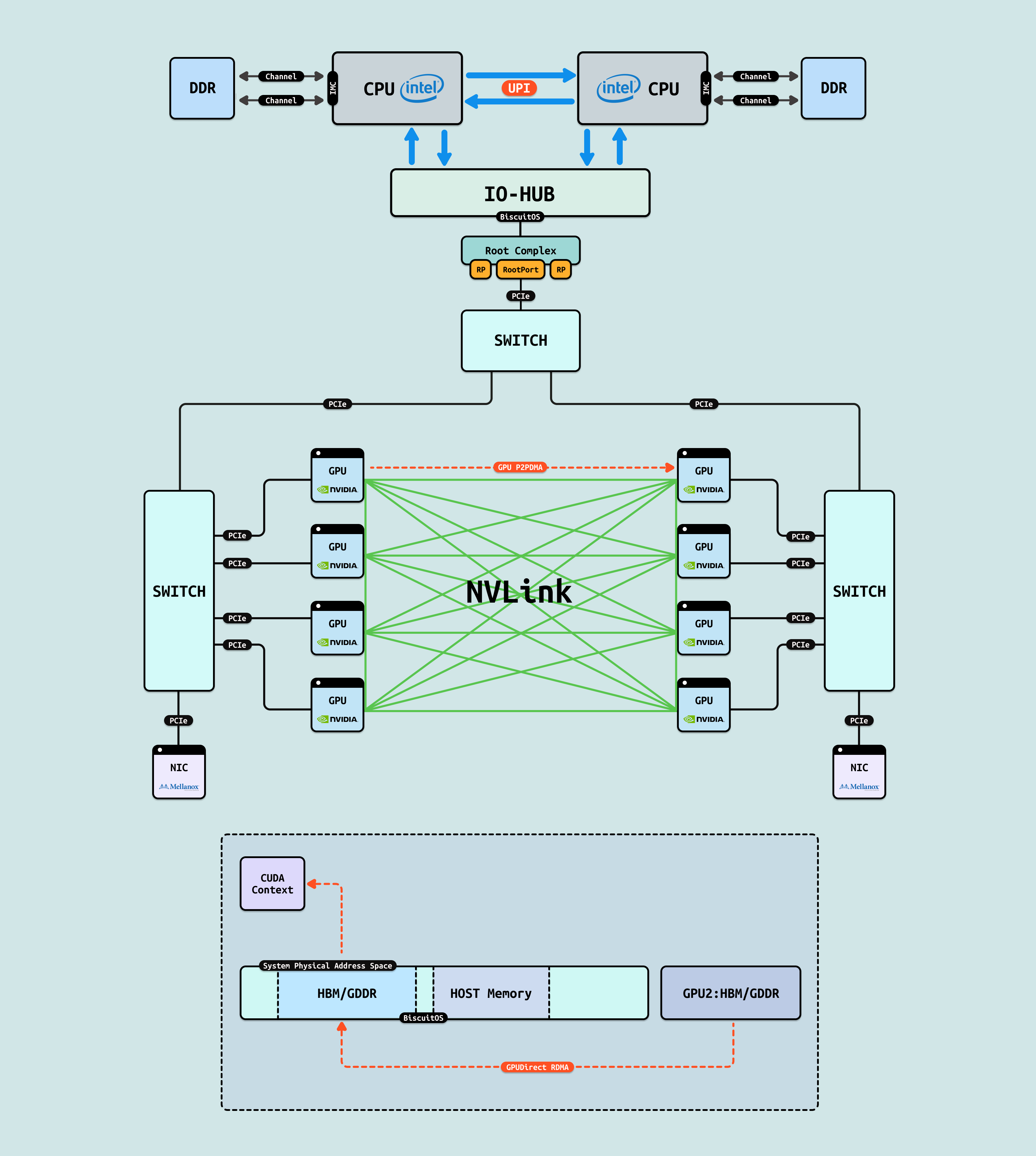
GPU P2PDMA: 在单节点内,GPU 进程的物理地址空间并不能看到其他 GPU 的显存,因此 GPU 进程要访问其他 GPU 的显存就只能通过 Read/Write 方式进程,GPU P2PDMA 就是其中一种技术,可以先将目标 GPU 显存搬运到本地显存,然后再访问本地显存,以此间接访问其他 GPU 显存. 与 P2PDMA 不同的是,其并不需要将各自的显存暴露出来.

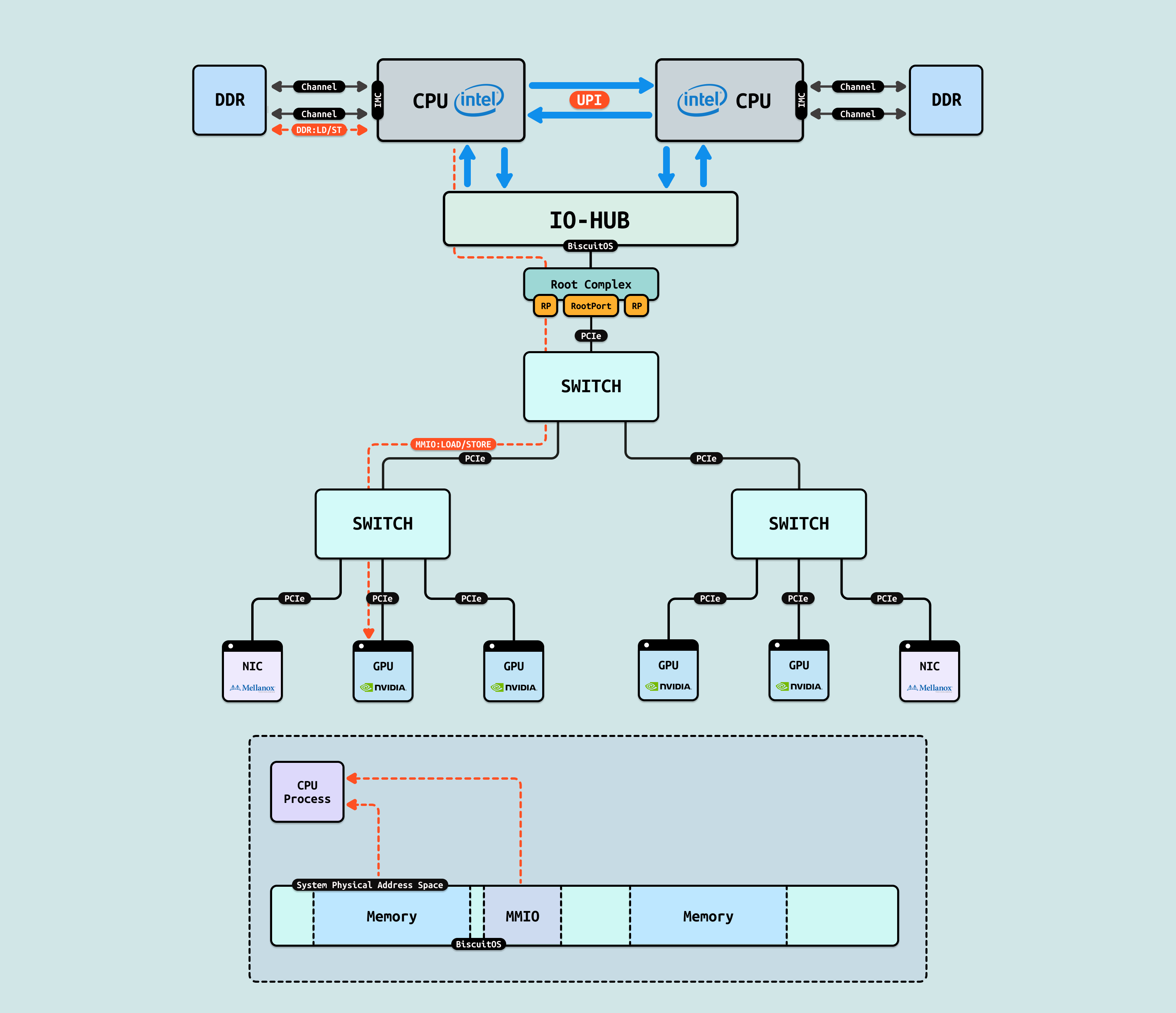
DDR/MMIO: 系统物理地址空间可以直接映射 DDR 为物理内存,同时也可以将 GPU 的寄存器映射为 MMIO. 由于 DDR 映射为 WB 并在总线上保证了 CACHE 一致性,而外设的 MMIO 映射为 UC,因此也可以保证 CACHE 一致性,因此 CPU 进程对物理内存和 MMIO 的访问可以是 LD/ST, 直接将数据送往 CPU 寄存器.
HBM/GDDR: 在 GPU 内部,其物理地址空间可以看到自己的 HBM/GDDR, 以及 Host 侧的物理内存,但只有 HBM/GDDR 可以映射为 WB,因此可以确保 CACHE 一致性. GPU 进程可以直接访问本地显存,这包括本地内存(Local Memory)、全局内存(Global Memory)、常量内存和纹理内存, 这些内存的数据可以直接送到 GPU 的 CACHE 和 Register 里. 然后 Host Memory 为 WB,GPU 无法保证其 CACHE 一致性,因此无法进行 LD/ST 访问.
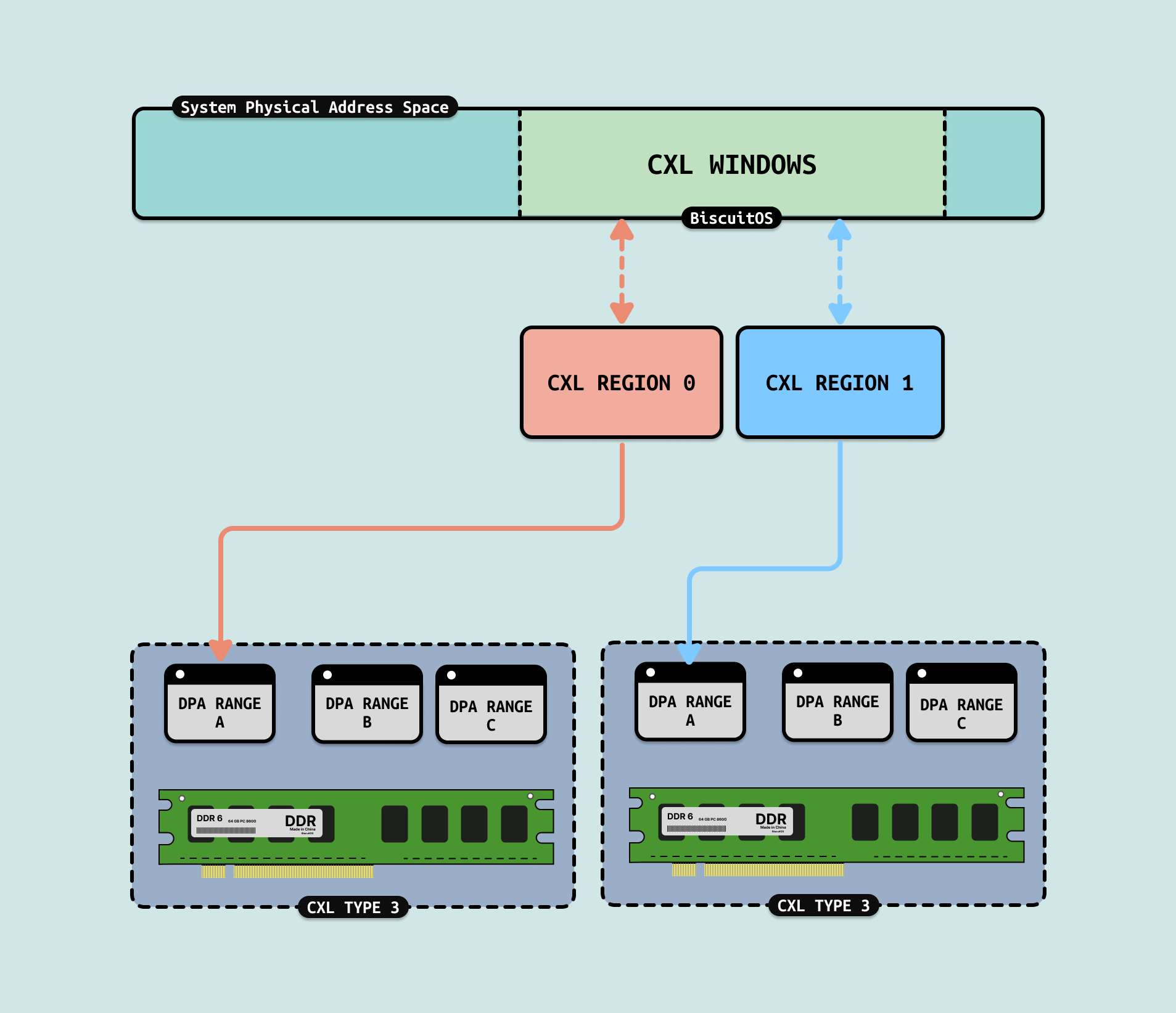
CXL: CXL 可以将 CXL Type3 内存映射到系统物理地址空间,形成慢速内存. 对应 CPU 进程,其并不能识别到这段内存与普通 DDR 有何区别,内核使用分层内存(Tiered Memory) 实现对 CXL 内存的访问. 在 CXL1.0/2.0 里,在单主机上可以支持 CACHE 一致性,在 CXL3.0 多主机节点支持 CACHE 一致性,因此 CPU 进程可以通过 LD/ST 方式直接访问 CXL 内存.
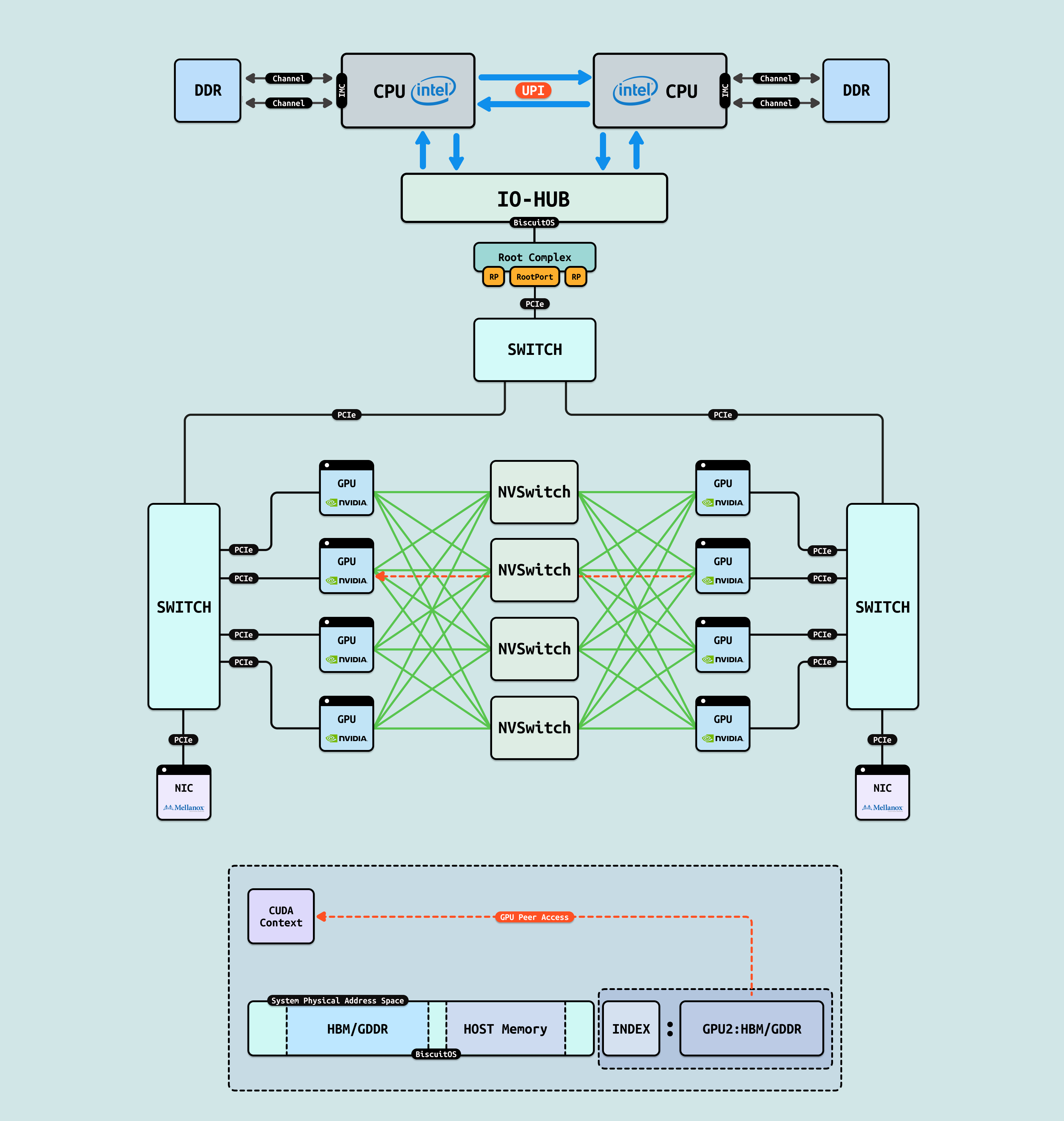
GPU Peer Access: 在 Nvlink/NvSwitch 的基础上,GPU 可以通过 “Index+Offset” 的方式直接访问其他 GPU 的 HBM/GDDR 显存, 并且 Nvlink/NvSwitch 会保证 CACHE 的一致性,因此 CUDA 进程可以直接将虚拟内存映射到其他 GPU 的显存,并通过 LD/ST 方式直接访问其他 GPU 的显存,大大提到了 GPU 间数据共享的能力.

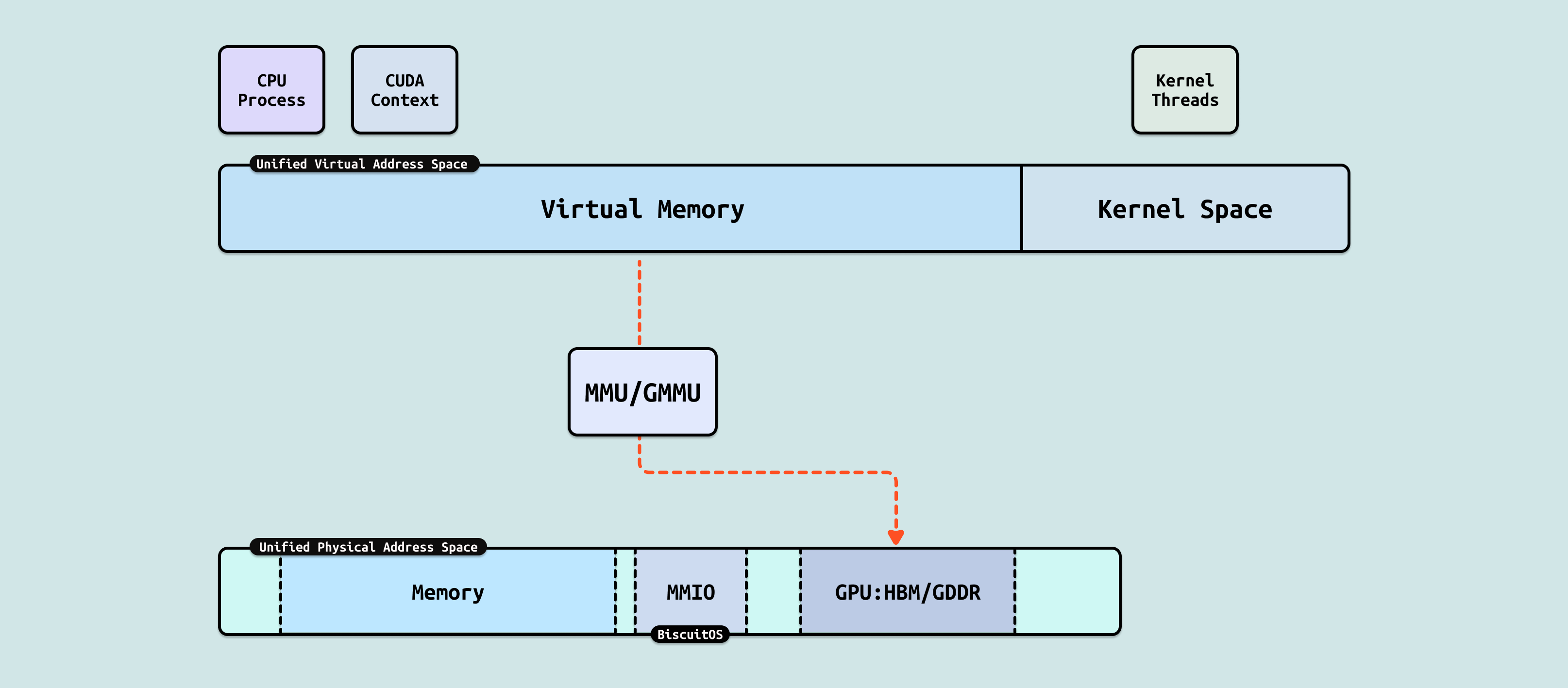
从 “Read/Write” 到 “Load/Store”, 异构融合的一个目标是创建统一虚拟地址空间(UVM: Unified Virtual Memory)和统一物理地址空间(UPM: Unified Virtual Memory), 当实现 UVM 的时候,可以将 CPU 进程和 GPU 进程加入到同一个虚拟地址空间,那么这将打破异构互联的通信墙. 当实现 UPM 的时候,CPU 进程或者 GPU 进程可以通过 LD/ST 直接访问所有的存储(DDR,GDDR,HBM…), 并保证 CACHE 一致性,届时 CPU 进程和 GPU 进程处于相同的地位,最终形成资源的池化.
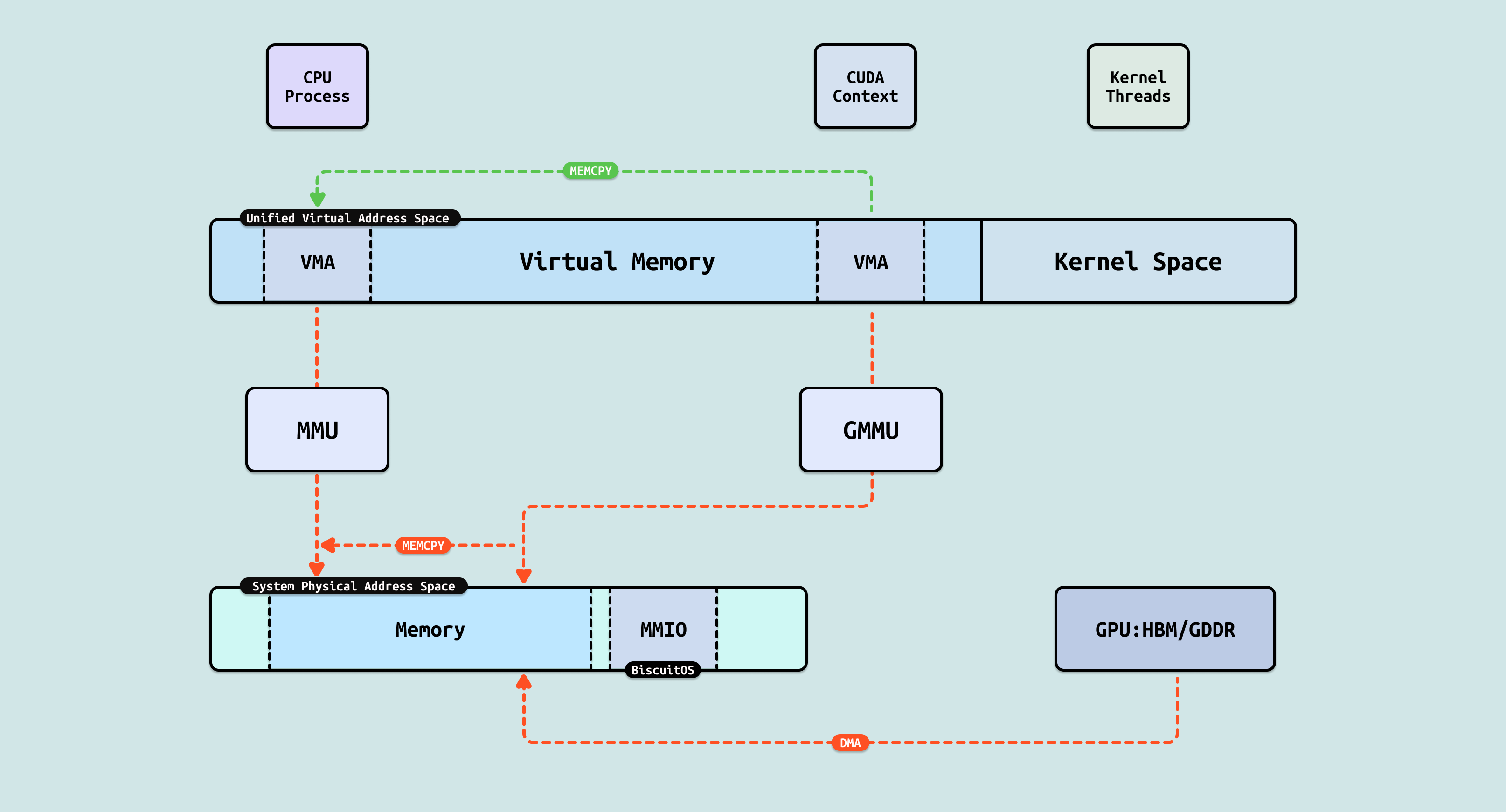
HMM: Linux 提供的一种实现 UVM 方案,其可以提供统一的虚拟地址空间,CPU 进程和 CUDA 进程都在同一个虚拟地址空间内,之间可是实现指针级互相访问,减少了通信成本. 虽然 CPU 进程和 GPU 进程都在统一虚拟空间,但底层还是依赖驱动程序,当 CPU 进程访问 GPU 进程的虚拟内存时,GPU 发起 DMA 操作将 HBM/GDDR 显存数据 DMA 到物理内存,然后 CPU 再访问这块物理内存. HMM 的好处打破了 CPU 进程和 GPU 进程间的通信墙.
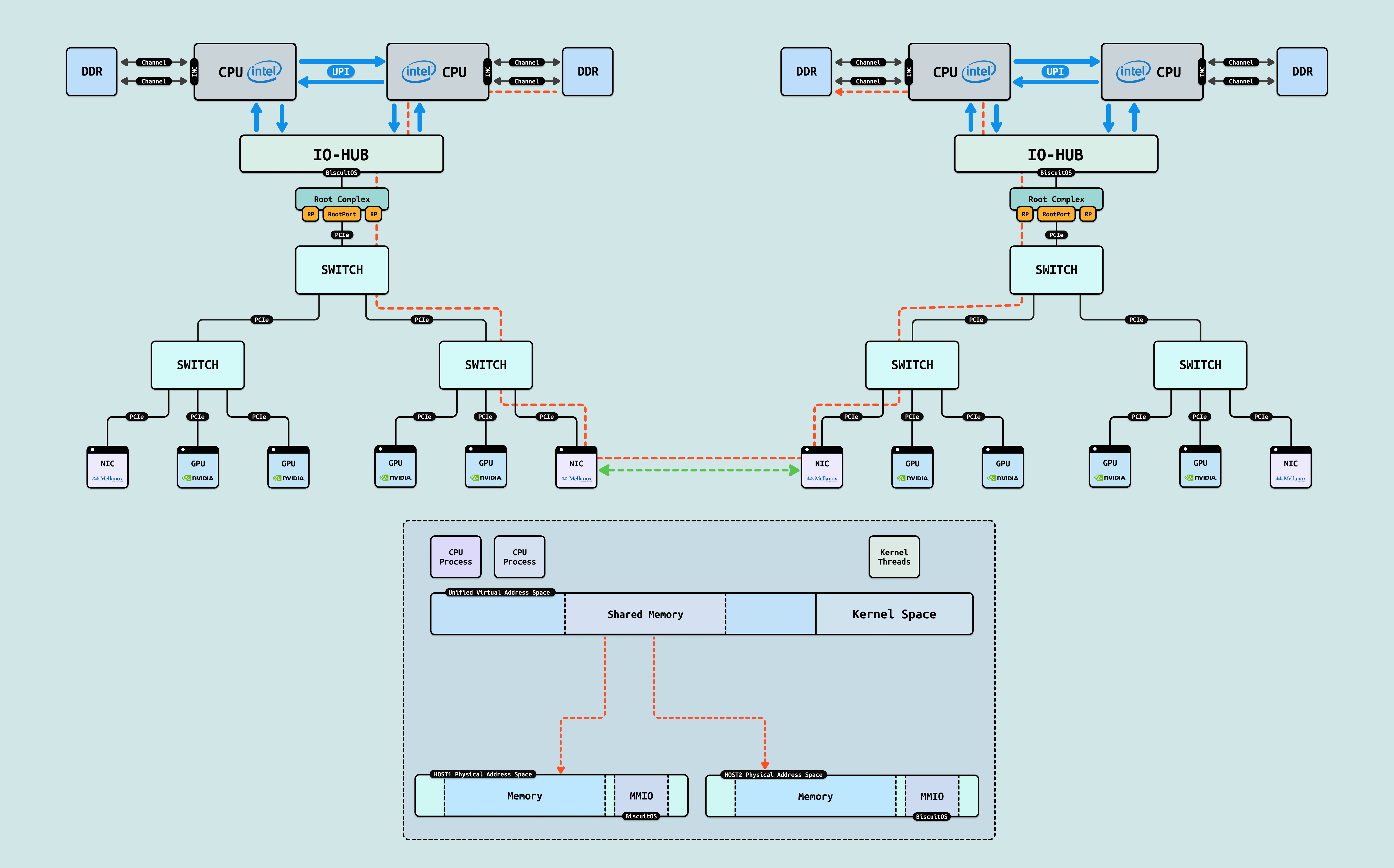
OpenShmem: Linux 提供的另外一种实现 UVM 方案,其基于 RDMA 实现多台主机间内存共享,其是在本机 CPU 进程和其他主机 CPU 进程虚拟地址空间内存划分一段共享区域,这段虚拟内存被划分成多个区域,例如区域 A 来自 Host1 内存,区域 B 来自 Host2 内存. OpenShmem 提供了一套进程间通信库,并提供 GET/PUT 方式在共享区域上访问数据. 同理,CPU 进程使用 GET/PUT 访问内存时,底层则通过 RDMA 在主机的物理内存上搬运数据.
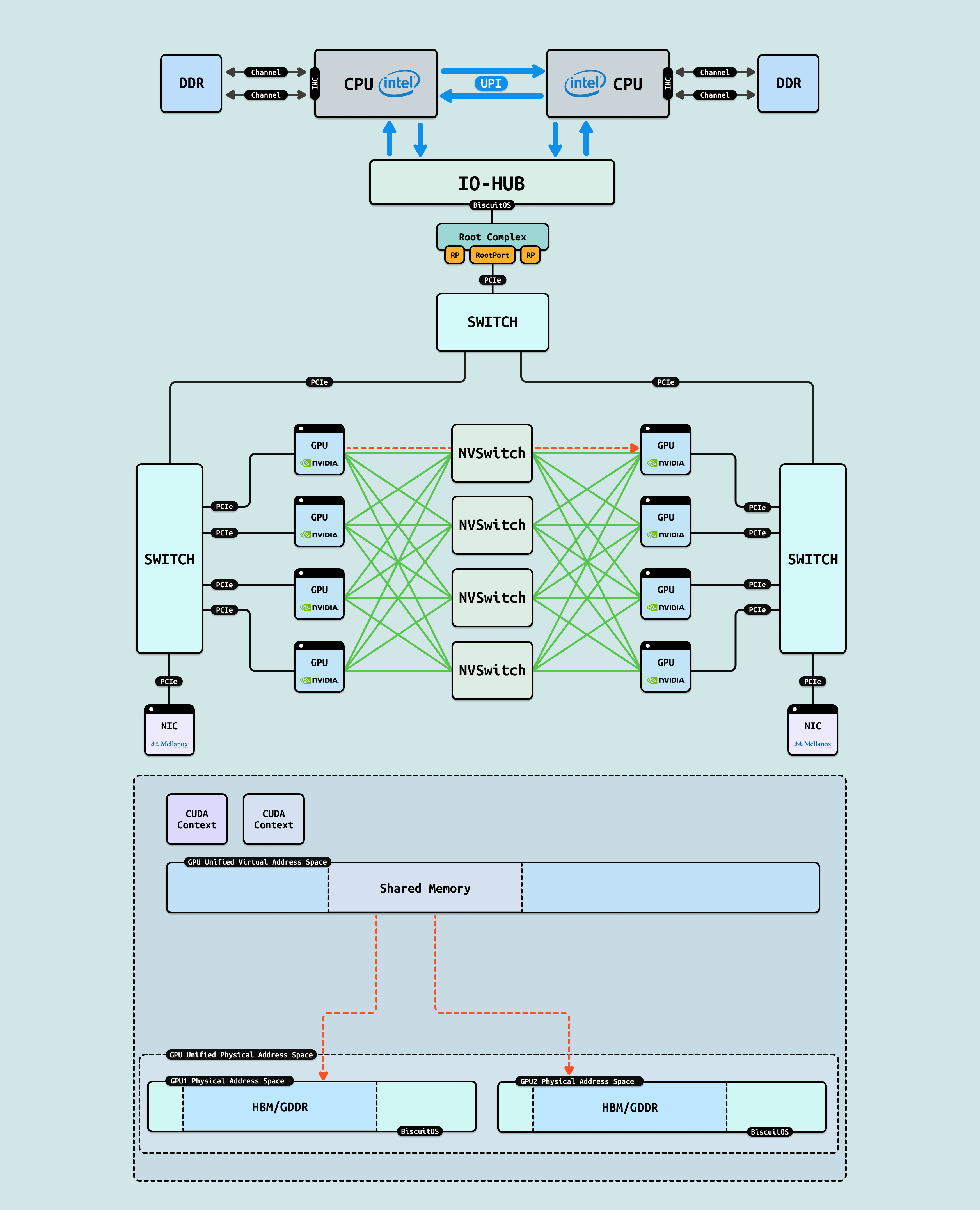
NVShmem: 借助 NVLink/NVSwitch, GPU 之间可以通过 “Index:Offset” 方式 LD/ST 访问其他 GPU 显存,因此可以将离散的 “Index:offset” 物理区域抽象成连续的 GPU UPM 空间. 同时多个 GPU 进程可以将虚拟地址空间进行统一,那么多个 GPU 进程可以实现指针级共享,并且在访问其他 GPU 的指针时,硬件不再是 DMA 搬运,而是直接 LD/ST 数据到各自的 CUDA Core, 这样大大提升了 GPU 进程间共享数据的效率.
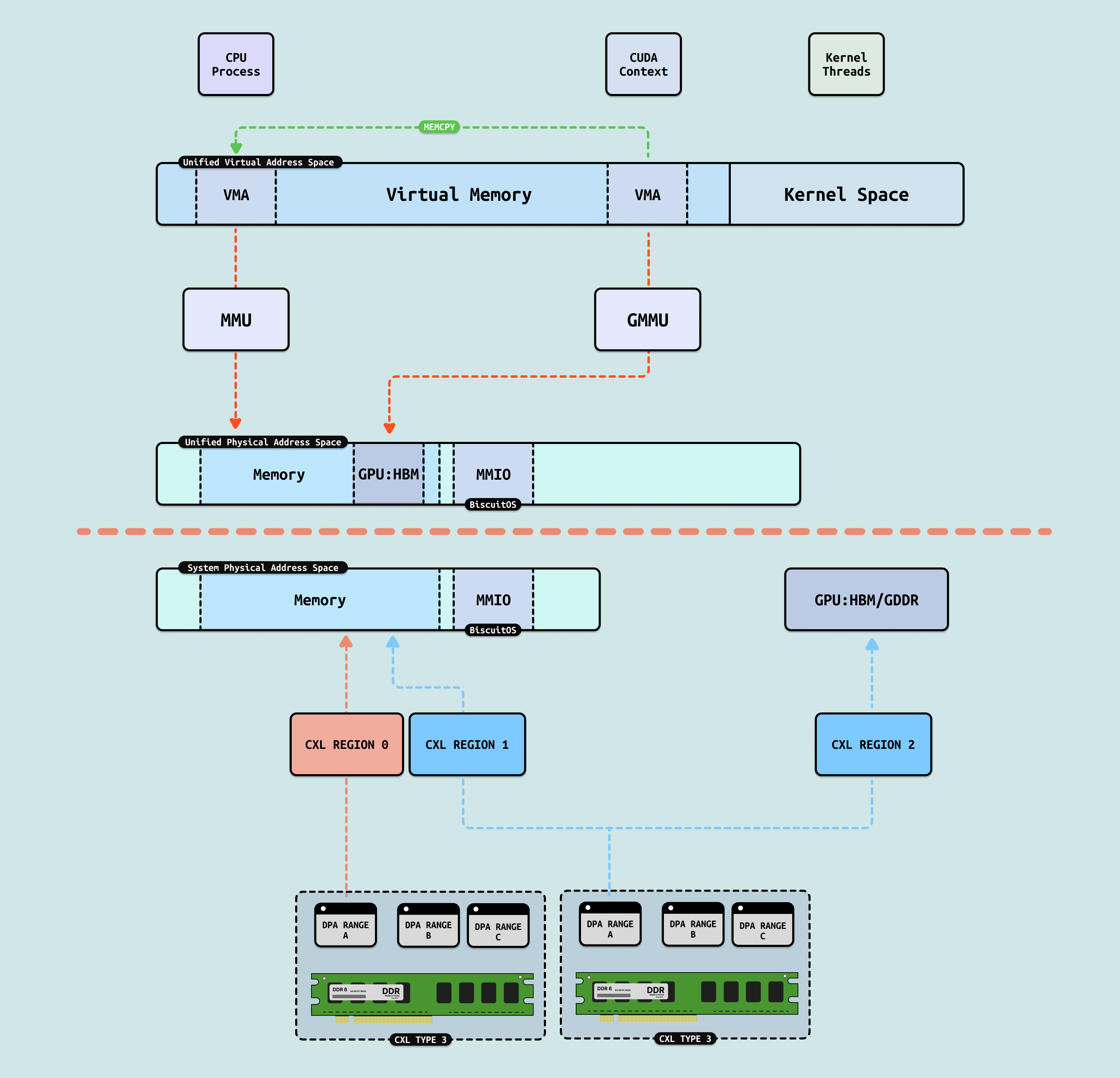
CXL Sharing/Pooling: CXL3.0 提供的 Sharing 能力可以将同一份 CXL Type3 Memory 映射到 Host 物理地址空间作为物理内存,同时映射到 GPU 的物理地址空间形成显存,CXL3.0 保证了其 CACHE 一致性,因此 CPU 进程对 CXL 内存进行读写操作时,GPU 显存就可以看到修改的结果,这就是 UPM 的基础. 同时 GPU 进程和用户进程都访问同一份虚拟地址,并且物理地址空间也是同一份.

LLM
Deepseek/Qwen
LLM Traning
LLM Fine-Tuning
LLM Quantization
LLM Inference
vLLM/Ollama/Pytorch
NVIDIA CUDA/PTX
AiOS
Load/Store/Atomic Roadmap
GPU Direct Peer ACCESS
CXL-MEMORY
HMM(Heterogeneous Memory Management): SVM/SPM
Nvidia-UVM
VRAM-MMIO/DEVICE-ZONE
MEMORY READ/WRITE Roadmap
DMA/SGDMA/Coherent-DMA/Streaming-DMA/CMA
P2PDMA
GPU P2PDMA
IOMMU/VFIO
DMA-BUF
DMA-POOL
Pooling Roadmap
RDMA-OpenShmem
NvSHMEM
CXL Pooling/CXL-Sharing
Heterogeneous Other Roadmap
DAX/FSDAX/PMEM
CXL 1.0/2.0
MMIO/PIO
TIERED-MEMORY
NUMA
AI Infra
C2C Interconnect
Intel QPI/UPI/MESH
AMD Infinity Fabric
Heterogeneous Interconnect
UALink
NvLink/NvSwitch/NvLink-C2C
UB-Mesh
CXL-3.0
IB Quantum Switch
RDMA
GPU Direct RDMA
PCIe/PCIe-Switch
Hardware
CPU(Intel/AMD/ARM)
GPU(Nvidia/AMD)
CXL/HBM/DDR
NIC