

Inter-Thread Communication
Inter-KThread Communication
ZEROCOPY Underprinning
内存优化主要围绕“空间和时间”两个维度进行,有的场景最求极致的内存访问延迟,而有的场景又追求使用最小内存量, 两者就像量子纠缠一样,当内存使用量变小,内存访问延迟就增加,反之内存延迟减低,内存消耗又增加. 作为性能优化,只能在两者中取一个最合适的比例,才能让系统性能发挥最佳效果. 内存拷贝(Memory Copy) 是计算机里最常见的行为,其可以在不同进程之间拷贝数据,也可以在用户态和内核态之间拷贝数据,内存拷贝的本质是将内容从一块物理内存拷贝到另外一块物理内存上,该过程需要消耗 CPU、内存带宽、IO 等资源,因此内存拷贝会带来系统性能上的消耗.
ZEROCOPY 机制皆在减少数据间的拷贝,让生产者和消费者在同一块物理内存上消费数据,这样将大大节省 CPU、内存带宽和 IO 资源,从整体来看将提升系统性能. 狭义的 ZEROCOPY 限定在节省内存之间的拷贝,广义的 ZEROCOPY 则是节省拷贝的行为,最终的目的是节省时间提升性能. 本文将从不同角度来讲解 Linux 存在的 ZEROCOPY 场景,也为各位开发者提供性能优化的方向.
Inter-Process Communication
在 Linux 里,用户进程具有独立的线性地址空间,在该线性地址空间里,用户进程使用里低端部分,而内核则使用高端部分,两者不能直接越界访问. 虽然 Linux 系统可以同时运行多个用户进程,但用户进程之间无法直接看到对方,他们可以同时看到同一个内核空间.
在有的场景下,用户进程之间需要一定的通信,Linux 提供了很多通信手段,包括: SYSV、SHMEM、FILE、MSGQ、PIPE、FIFO 等,内核将用户进程间通信称为 IPC(Inter-Process Communication). 用户进程之间通信难免需要拷贝数据,拷贝数据的手段以及耗时将影响通信效率,本节针对每种通信手段进行分析,以此确认 ZEROCPOY 机制是否能为其性能带来提升.

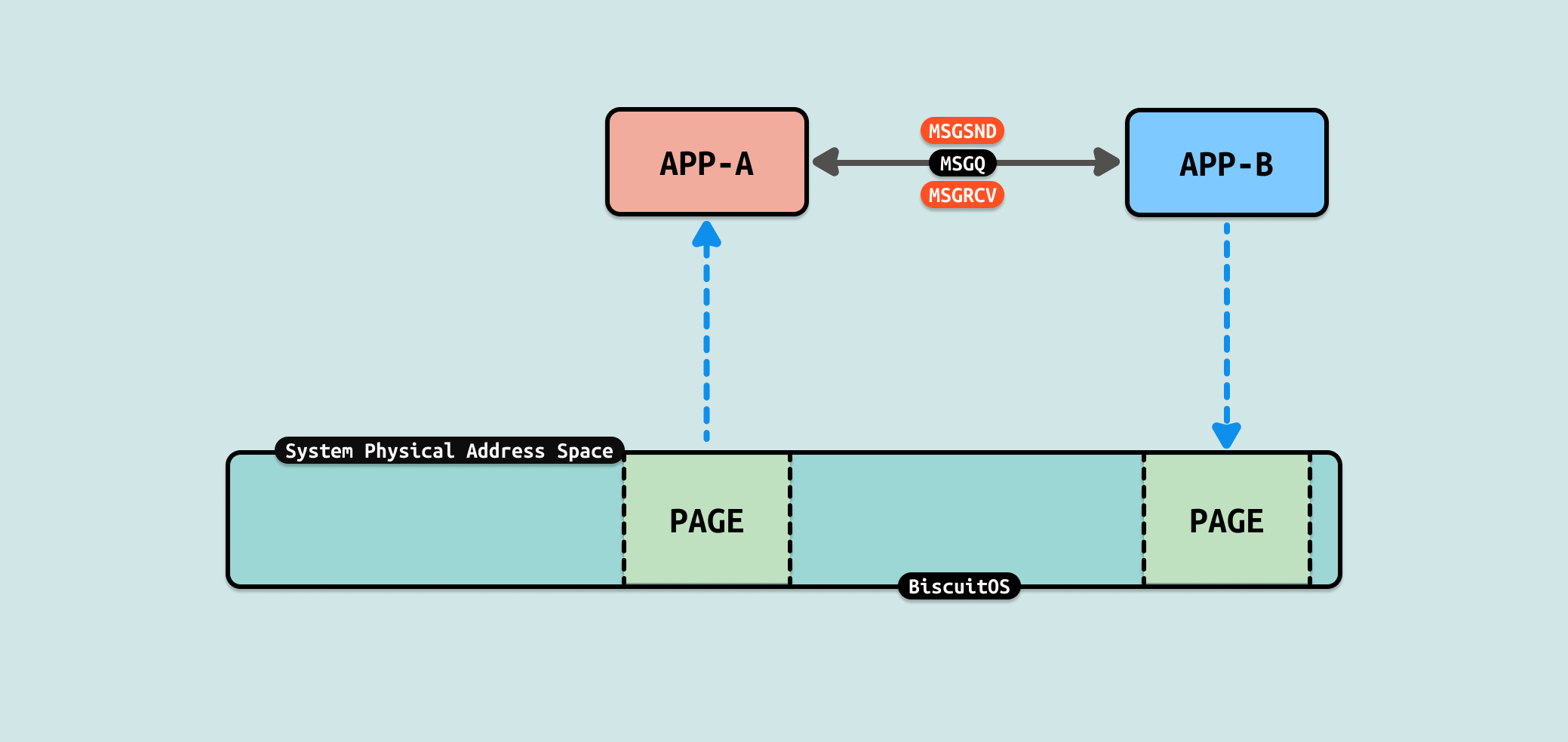
Message Queue(消息队列) 是一种用于进程间通信(IPC)的机制,允许不同进程通过发送和接收消息来进行信息交换. 在 Unix 和 Linux 系统中,SystemV 消息队列是一种常见的实现, 消息队列提供了一种异步的、基于消息的通信方式. 消息队列的特点:
- 异步通信: 发送方和接收方不需要同时存在或同步执行, 消息可以在队列中等待,直到接收方准备好处理它们
- 消息有类型: 每个消息都有一个类型标识符,接收方可以根据类型选择性地接收消息
- 持久性: 消息队列存在于内存中,直到系统重启或明确删除它们
Message Queue(消息队列) 的好处就是进程之间在通信的时候,不需要使用额外的同步技术就可以实现通信,并且通信是异步的,这让进程间通信变得更简单. Linux 提供了多个系统调用和库函数实现 Message Queue,包括如下:
- msgget: 创建或访问一个消息队列
- msgsnd: 向消息队列发送消息
- msgrcv: 从消息队列接收消息
- msgctl: 控制消息队列的各种操作,如获取状态、设置属性、删除队列等
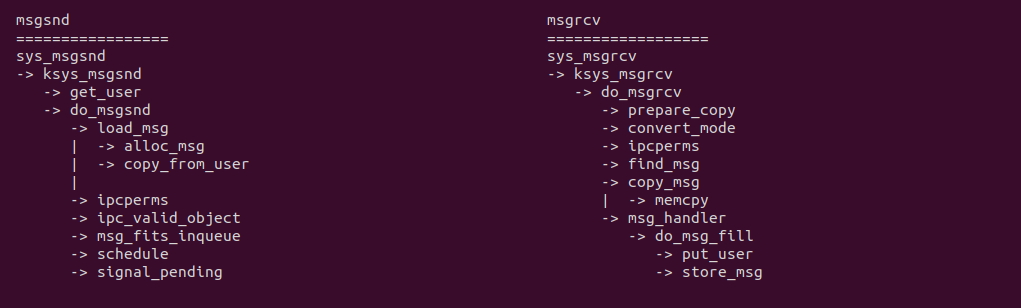
从 msgsnd 系统调用可以看出,当生产者进程需要发送数据时, 用户进程用户态准备好数据,切换到用户进程内核态之后,其调用 load_msg 函数从 SLAB 分配器分配一段内存,然后使用 copy_from_user 函数将数据从用户空间拷贝到内核空间,然后将数据放入队列并返回用户态. 消费者使用 msgrcv 系统调用接收数据,其先在用户态分配一段内存,然后通过 sys_msgrcv 系统调用进入用户进程内核态,接着从队列里获得可用消息之后,调用 do_msg_fill 函数,其使用 store_msg 将数据拷贝到用户态,其核心是 copy_to_user 函数.
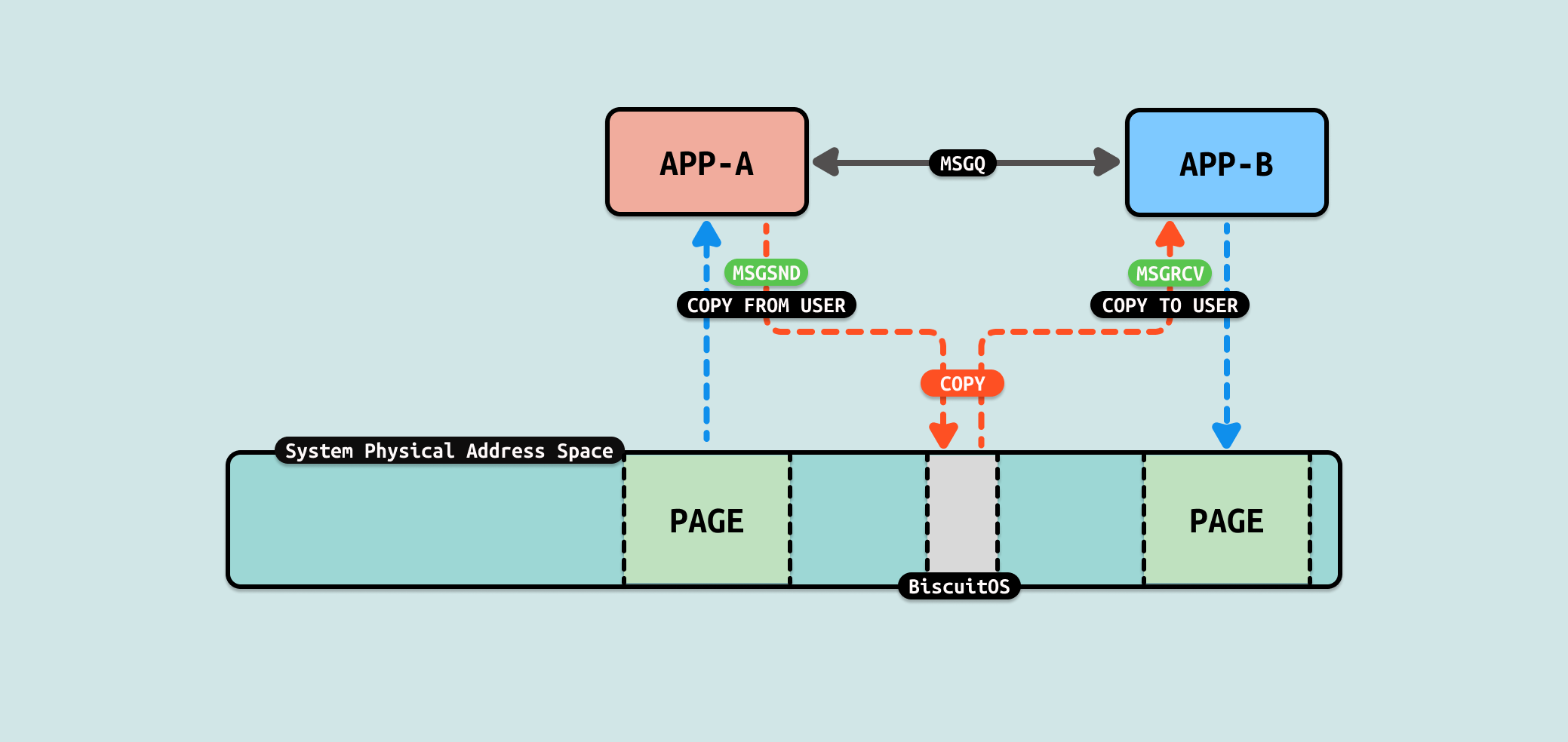
从 Message Queue(消息队列) 机制实现来看,数据流动时从生产者的用户空间拷贝到内核空间,然后消费者从内核空间将数据拷贝到用户态. 从这个流程看出 COPY USER 将是性能瓶颈,另外内核空间分配的内存大小也是瓶颈. 接下来通过一个实践案例实际测试其性能,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] Package --->
[*] ZERO COPY MECHANISM
[*] FORBID ZEROCOPY(IPC): Exchange Between MESSAGE QUEUE --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-ZEROCOPY-IPC-MSGQ-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build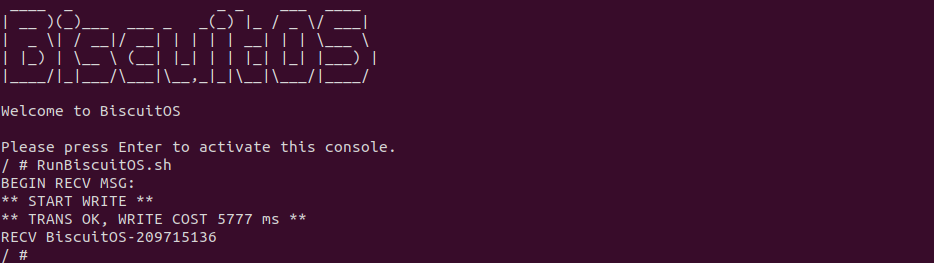
BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了实践案例运行的所有命令,案例包含一个生产者用户进程,其向 MSGQ 写入 200MiB 数据,案例还包含一个消费者用户进程 ,其从 MSGQ 里读出数据,并对生产者用户进程发送数据过程进行计时. 可以看到 200MiB 数据花费了 5777 ms. 接下来分析源码:
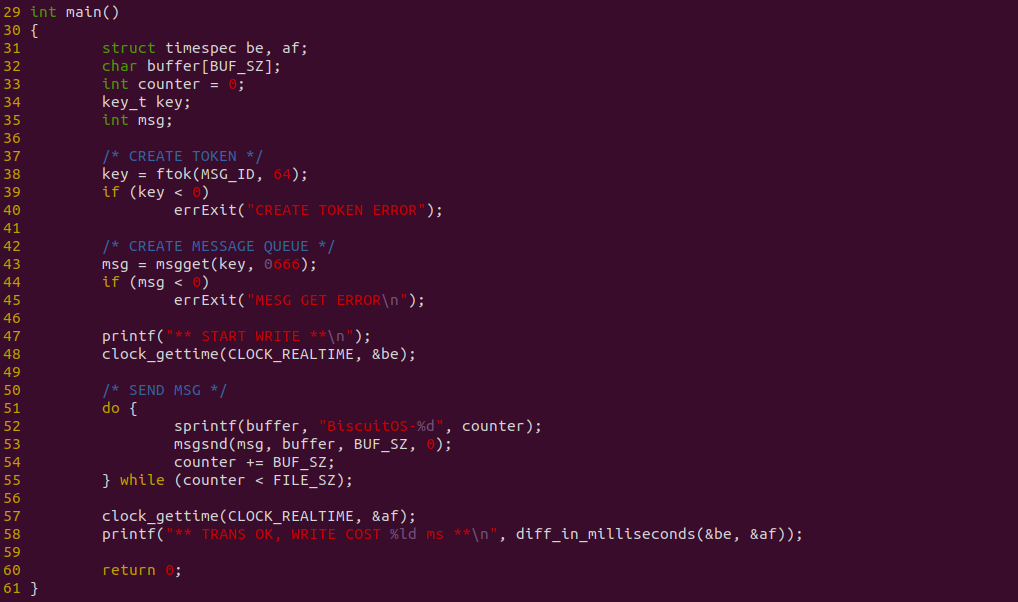
上图是生产者代码,函数在 38 行调用 ftok 创建独立的 TOKEN,然后在 43 行创建 MESSAGE QUEUE,并在 51-55 行向 MSGQ 发送数据,其中 52 行在用户空间准备数据,在 53 行使用 msgsnd 函数发送准备好的数据,最终发送长度为 FILE_SZ 的数据,并使用 clock_gettime 对发送过程进行计时.
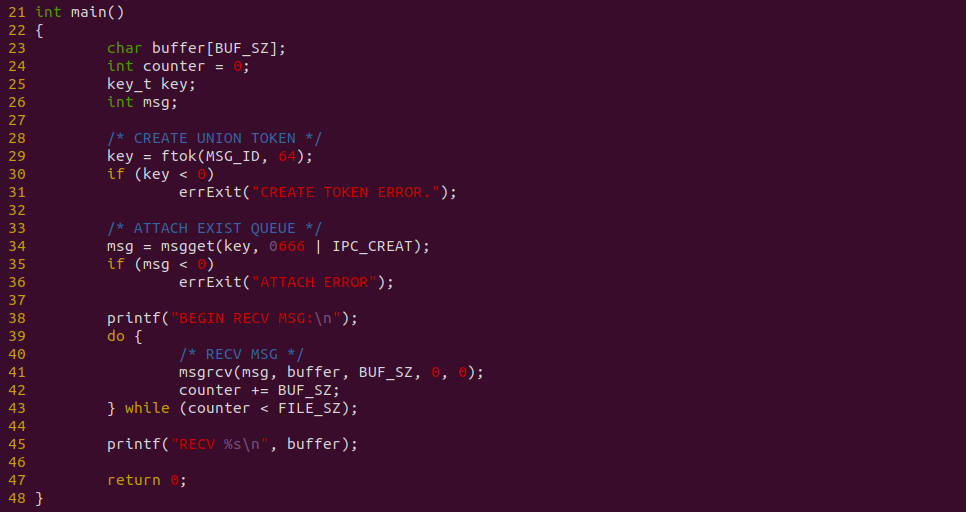
上图是消费者代码,函数在 29 行调用 ftok 和 34 行调用 msgget 获得生产者创建的消息队列,接着在 39-44 行使用循环,并调用 msgrcv 从消息队列拷贝数据到用户空间,总共拷贝 FILE_SZ 长度的数据. 以上便是源码,接下来对不同数据量进行耗时测试:
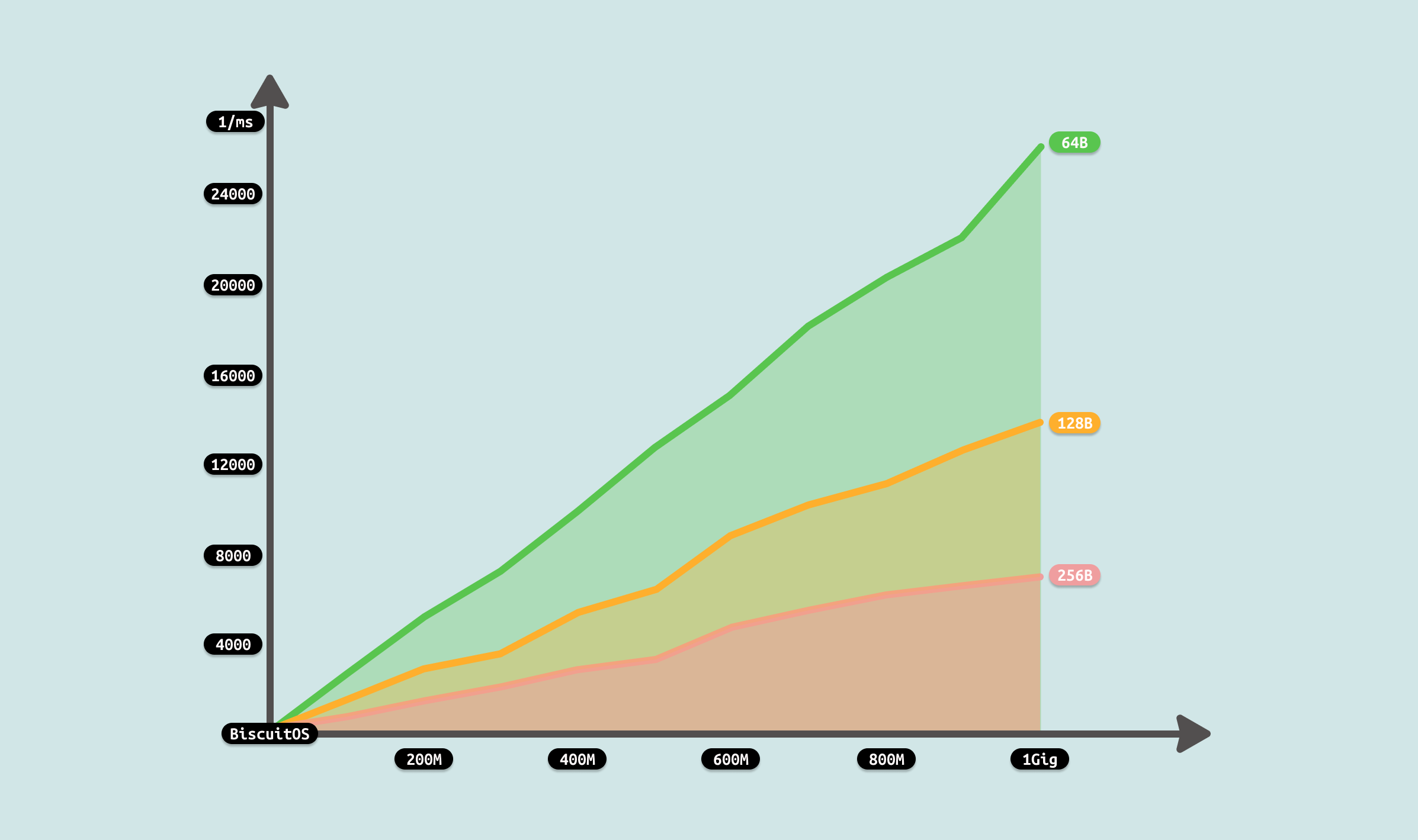
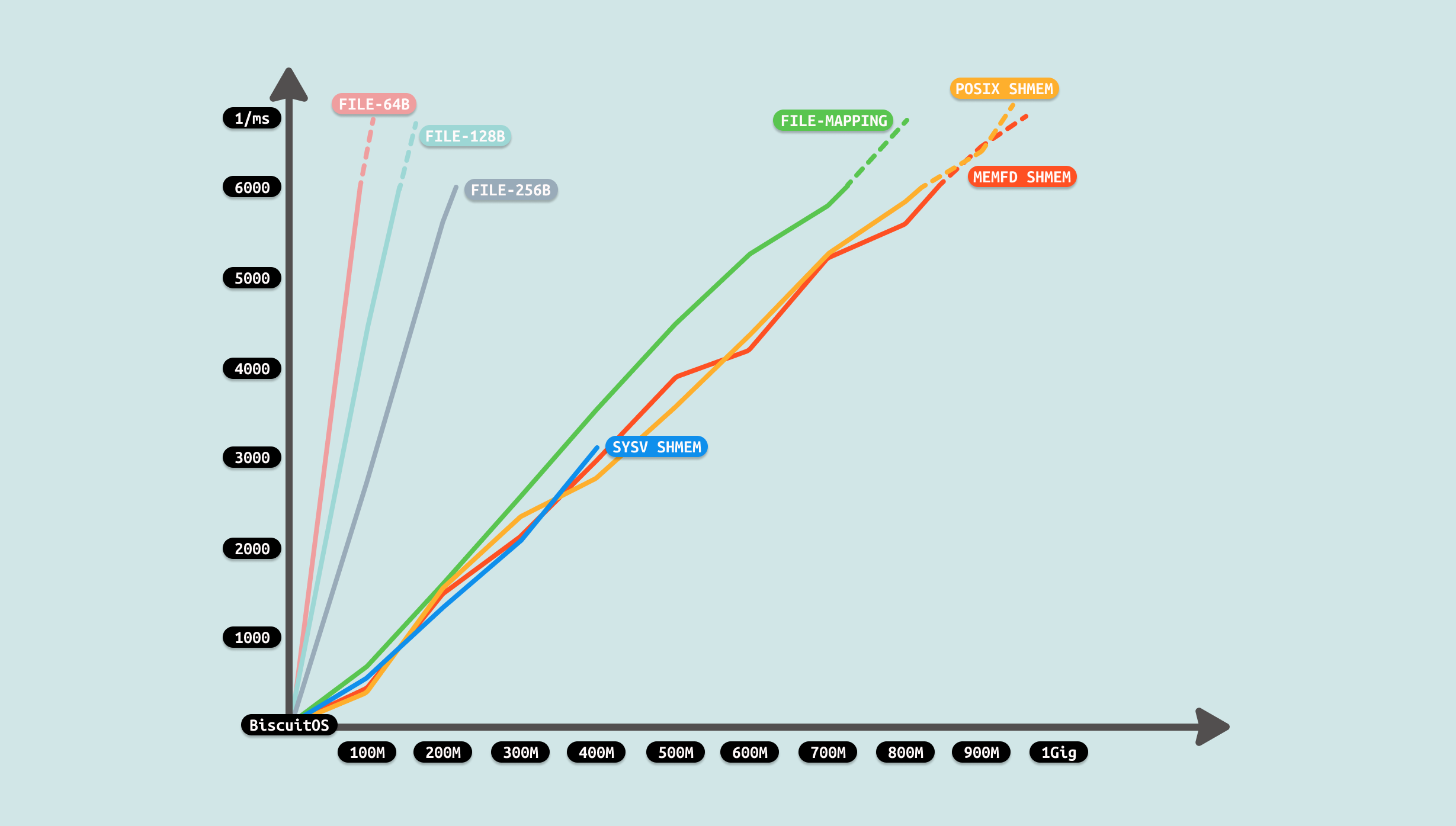
测试从两个维度进行,首先是传输数据总量,其次是每次传输的数据量. 从传输数据总量来看,传输数据越多,耗时越多,数据总量成倍数增长,耗时基本接近倍数增长. 另外从每次传输数据量来看,每次传输数据量越大,耗时越小,每次传输数成倍增长,耗时基本接近成倍减少. 通过上面的数据分析,可以看到性能优化的方向有两个,首先就是超过延迟底线的数据就不要使用消息队列进行传输,另外一个方向是增大每次消息传输的数据量. 接下来使用如下命令分析哪个函数比较消耗 CPU:
# PREPARE
touch /mnt/BiscuitOS-MSG
# Running
CONSUMER &
sleep 1
PRODUCT &
sleep 0.1
PID=$(pidof PRODUCT)
perf top -p ${PID} -g --call-graph dwarf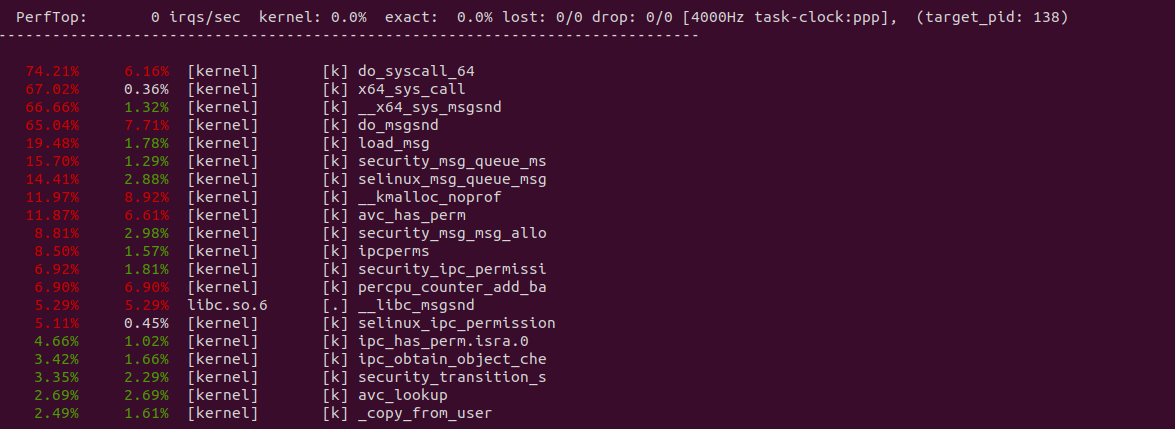
从 perf 获得实时观察系统中正在运行的程序的性能热点,可以看出占大头的操作是系统调用,接着是 do_msgsnd 函数和 load_msg, 其中 load_msg 就是负责从用户空间拷贝数据到内核空间的逻辑.
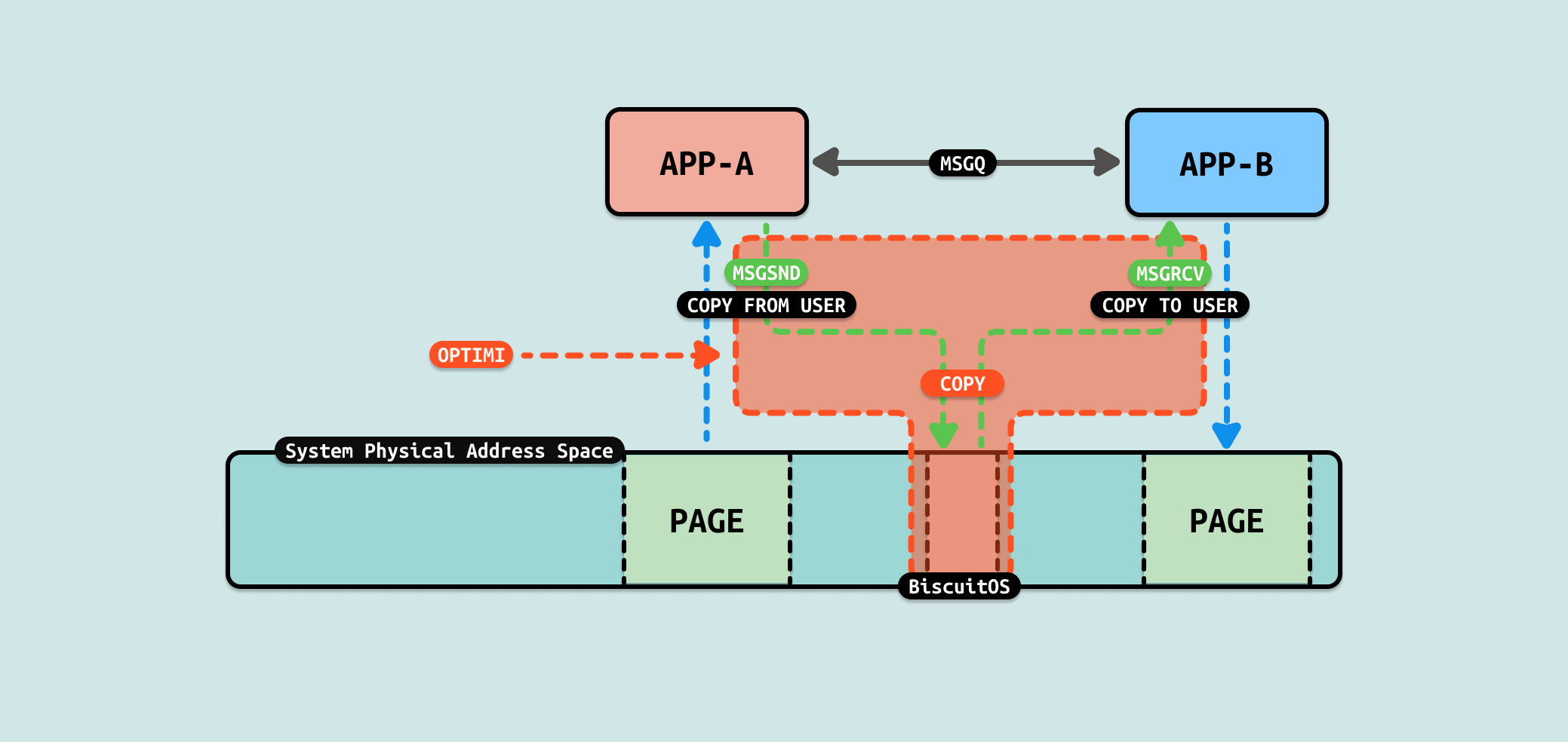
结合上图和前面的数据分析,性能优化的方向有两点,要么减少系统调用的数量, 要么减少数据拷贝. 减少系统调用很难做到,但可以采用减少数据拷贝,从上图可以看到,数据从用户态缓冲区拷贝到 MSGQ 在内核的内存,又从内核的内存拷贝到用户态缓冲区,拷贝过程中没有其他任何操作,因此可以从这里入手进行优化,具体优化方案参考如下:



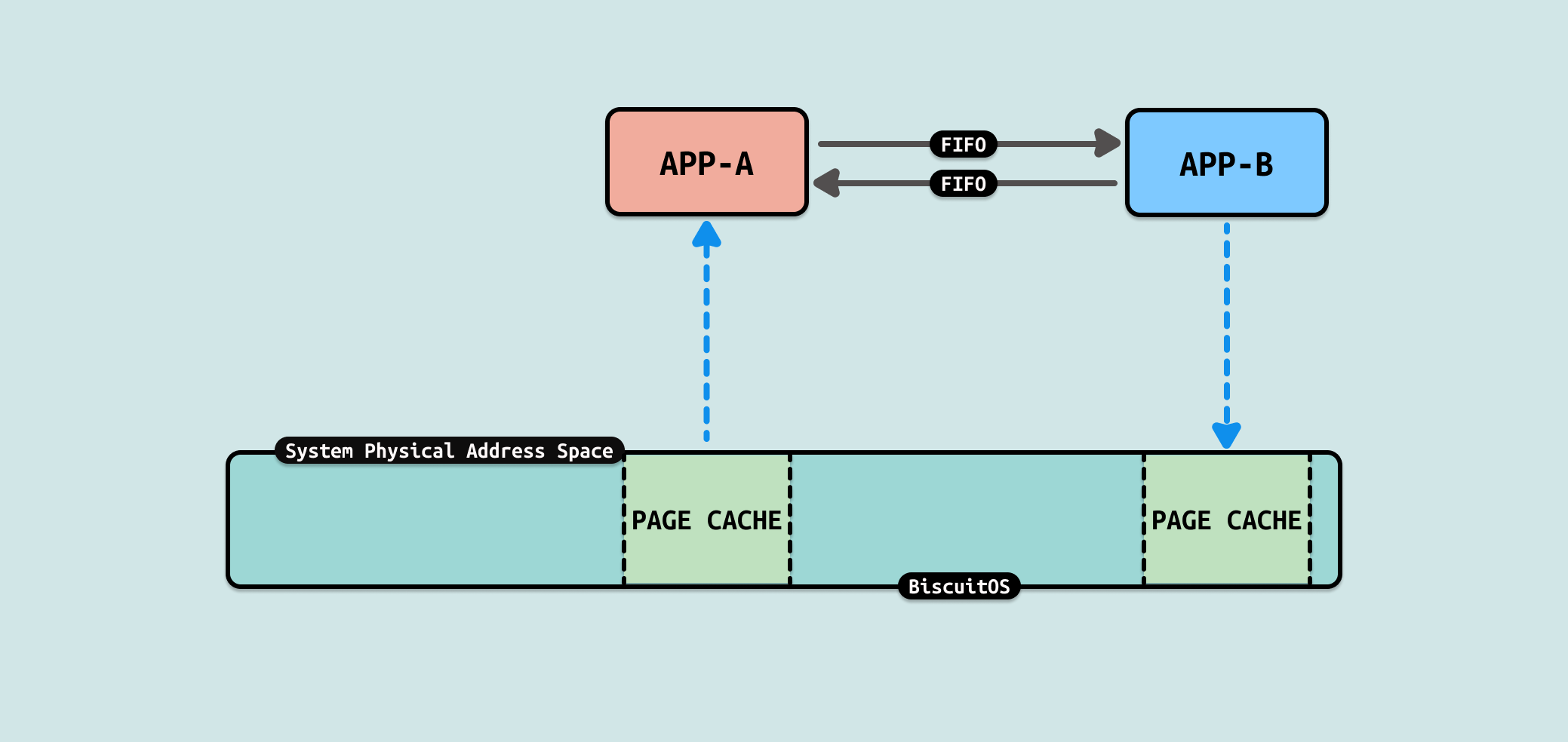
FIFO(First In First Out),也称为命名管道,是一种进程间通信(IPC)的手段. 与匿名管道不同,FIFO 有一个名称(路径)与之关联,通常存在于文件系统中, 这使得即使通信的两个进程不存在父子关系(即并不需要共享祖先进程),它们仍然可以通过共享的 FIFO 文件进行数据传递. FIFO 的基本特性是一端写入,另一端读取,并且数据的传递遵循先进先出的顺序. FIFO 具有以下特点:
- 文件系统中的实体: FIFO 是文件系统中的一种特殊文件,通常可以通过 “ls -l” 查看其类型为 p(pipe). 它会出现在文件系统中,但不存储数据,仅用于进程间通信
- 全双工通信: FIFO 默认是单向的, 一个进程写入,另一个进程读取. 如果需要双向通信,通常需要创建两个 FIFO 文件(一个用于写,一个用于读)
- 阻塞特性: 默认情况下,读操作会阻塞,直到有数据可读. 写操作会阻塞,直到有进程读取数据. 可以通过设置文件的非阻塞模式(O_NONBLOCK)改变这一行为
- 无亲缘关系限制: 匿名管道只能用于父子进程之间,而 FIFO 不要求通信的进程有任何亲缘关系
- 数据流特性: 数据是按字节流的方式传递的,遵循先进先出的顺序. 如果没有进程读取数据,写入的数据会存储在内核缓冲区中,直到被读取
FIFO 的好处是可以在两个没有血缘关系的用户进程之间使用,并且其与文件形式存在,那么就可以直接向文件一样操作 FIFO,例如一下操作:
- 创建 FIFO: 使用 mkfifo 命令或者 mkfifo 函数进行有名管道创建
- 打开 FIFO: 使用 open/fopen 函数打开有名管道
- 从 FIFO 读数据: 使用 read/fread 命令进行读取
- 向 FIFO 写数据: 使用 write/fwrite 命令写入数据
- 关闭 FIFO: 使用 close/fclose 关闭打开的 FIFO
- 销毁 FIFO: 使用 unlink 函数销毁管道,或者使用 rm 命令删除
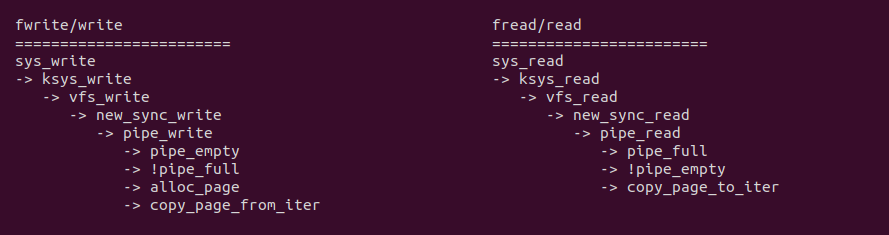
从 write 系统调用向 FIFO 写入数据可以看到,sys_write 最终调用 FIFO 专有线路 pipe_write, 该函数会在调用 alloc_page 在内核动态扩容一片缓冲区,然后调用 copy_page_from_iter 函数从用户态将数据拷贝到内核态的缓冲区里. 同理从 read 系统调用从 FIFO 读出数据可以看到,sys_read 最终调用 FIFO 专用线路 pipe_write, 其更直接,当发现缓冲区不空,直接使用 copy_page_to_iter 函数将数据从内核空间拷贝到用户空间.
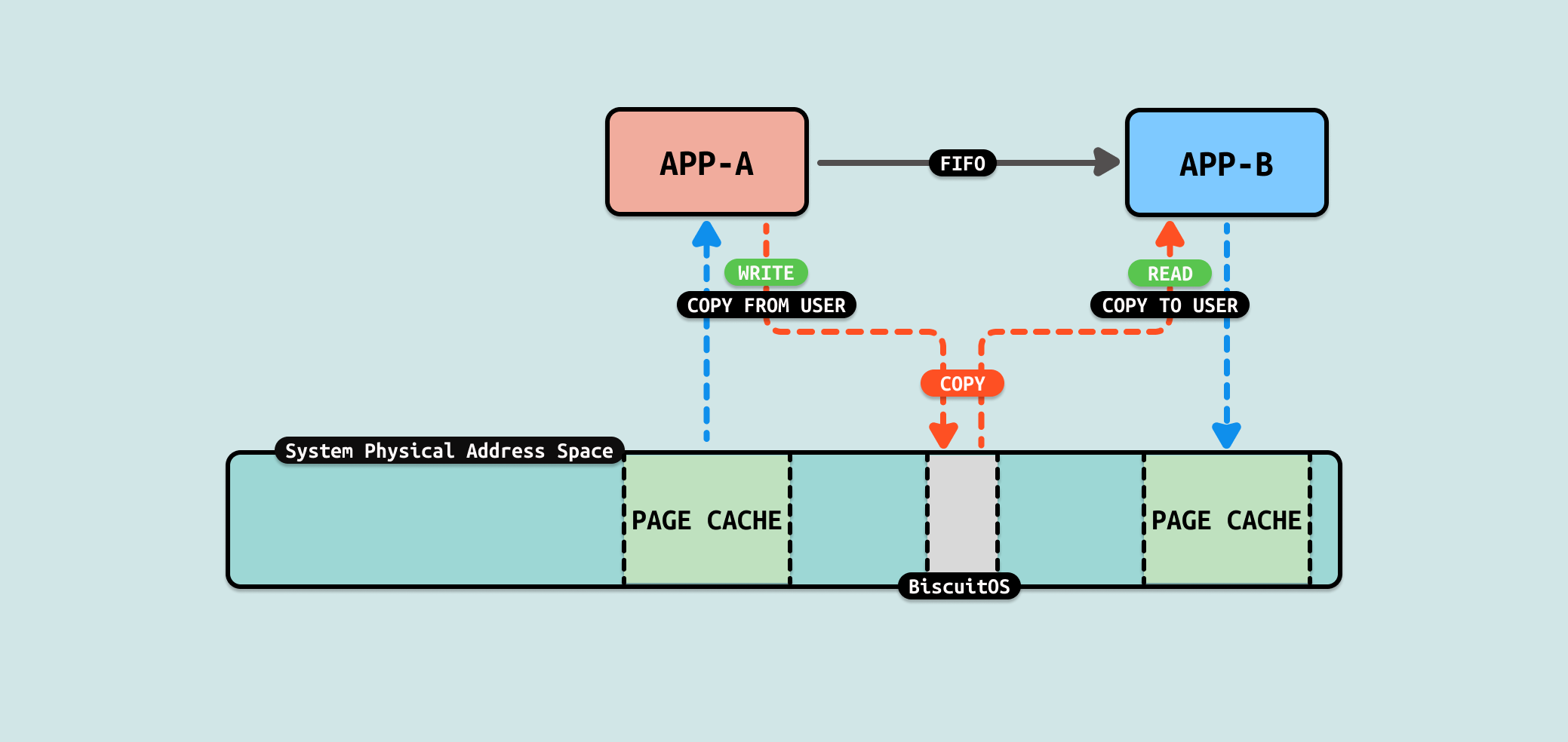
从 FIFO 机制实现来看,数据流动时从生产者的用户空间拷贝到内核空间,然后消费者从内核空间将数据拷贝到用户态. 从这个流程看出 COPY USER 将是性能瓶颈,另外内核空间分配的内存大小也是瓶颈. 接下来通过一个实践案例实际测试其性能,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] Package --->
[*] ZERO COPY MECHANISM
[*] FORBID ZEROCOPY(IPC): Exchange Between FIFO --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-ZEROCOPY-IPC-FIFO-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build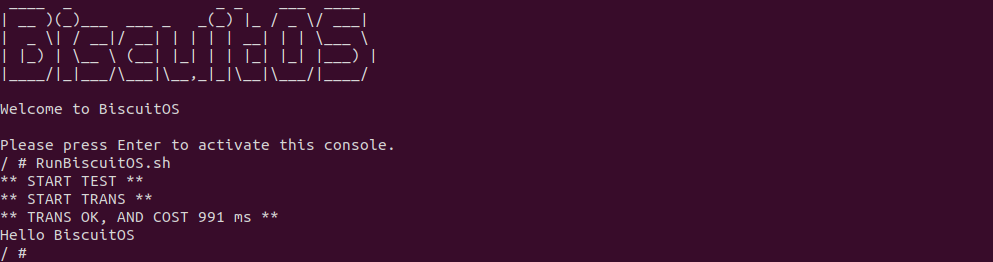
BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了实践案例运行的所有命令,案例包含一个生产者用户进程,其从 “BiscuitOS-Share.txt” 文件读取 200M 数据写入 FIFO,案例还包含一个消费者用户进程 ,其从 FIFO 里读出数据,并对生产者用户进程发送数据过程进行计时. 可以看到 200MiB 数据花费了 991 ms. 接下来分析源码:
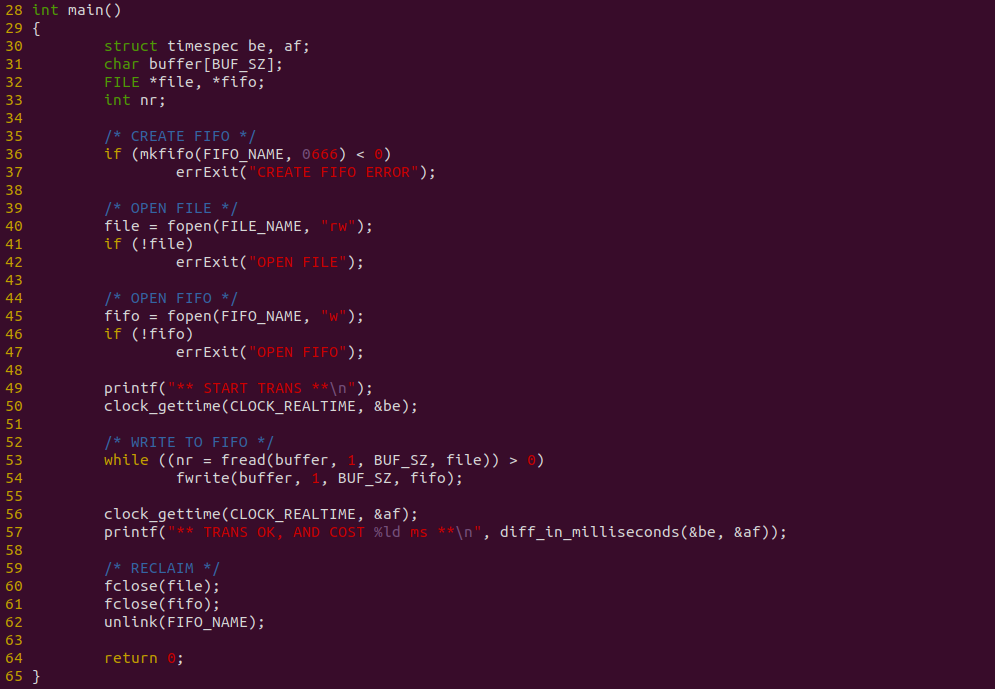
上图是生产者代码,程序在 36 行调用 mkfifo 创建一个有名管道,然后在 40 行调用 fopen 打开 “BiscuitOS-Share.txt” 文件,以及在 45 行使用 fopen 打开 FIFO,接着在 53-54 行从文件读出的数据直接写入到 FIFO 里,并使用 clock_gettime 在数据发送先后进行计时.
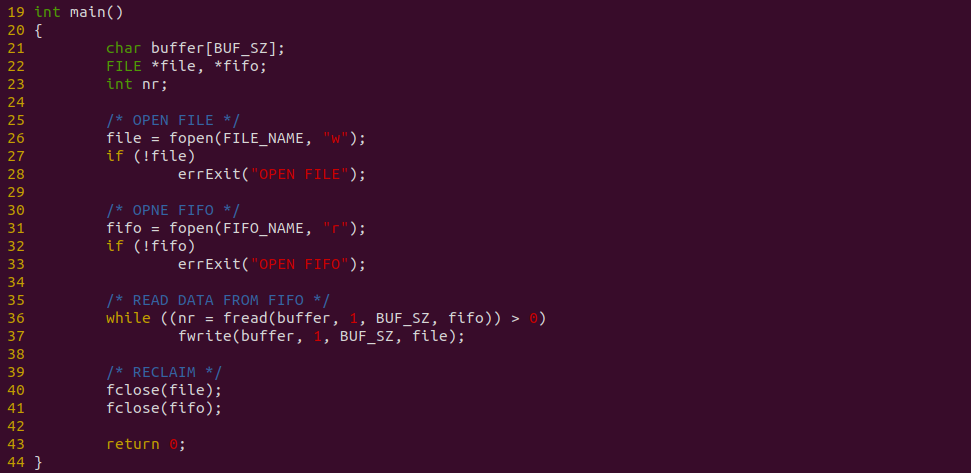
上图是消费者代码,程序在 26 行打开存储数据用的文件,接着在 31 行使用 fopen 函数打开 FIFO,并在 36-37 行从 FIFO 读出的数据直接写入到文件里. 以上便是源码,接下来对不同数据量进行耗时测试:
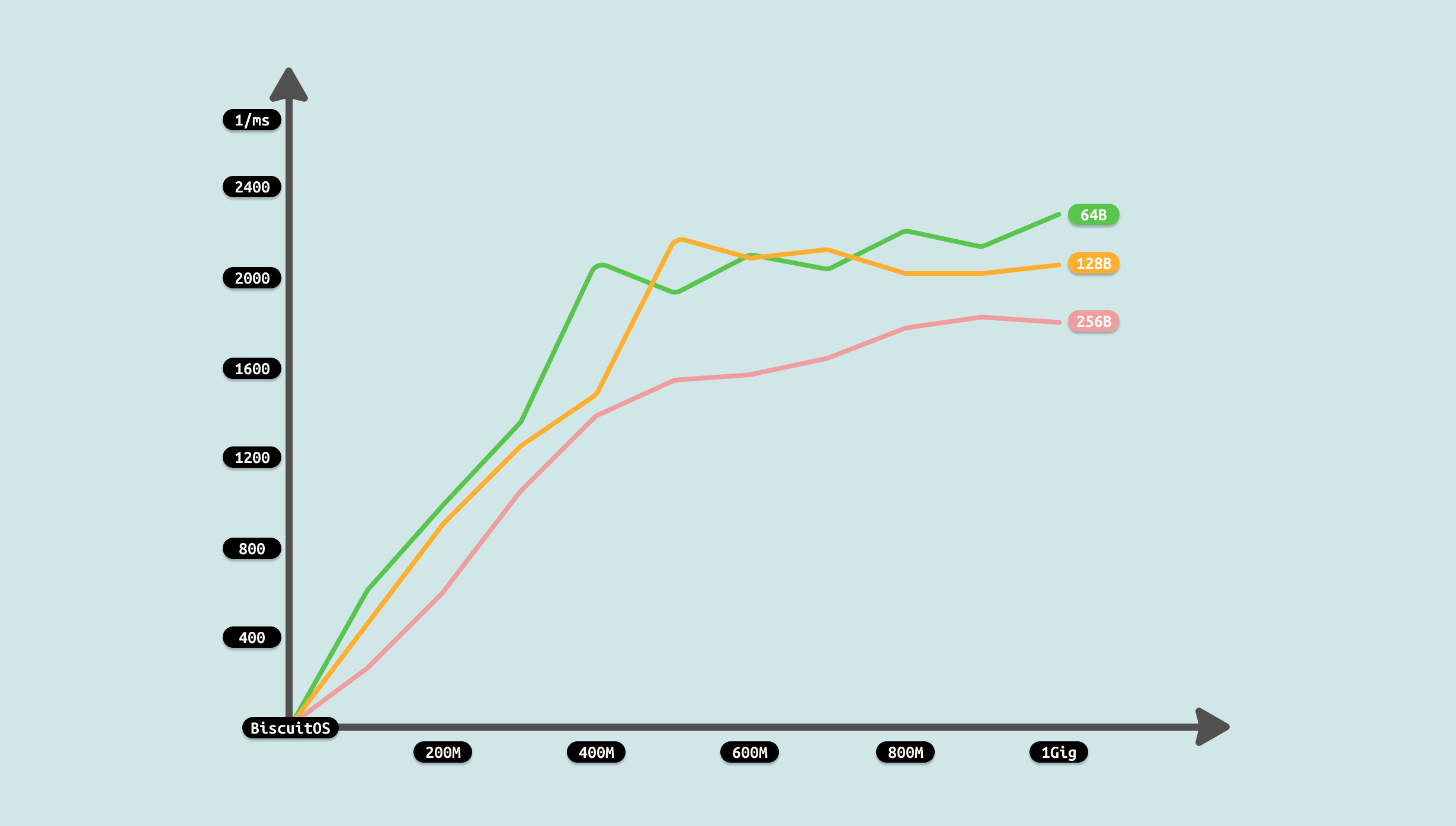
由于计时包括从文件里读取数据到缓存,然后将缓存内容写入到 FIFO 里,因此测试从两个维度进行,首先是传输数据总量,其次是每次传输的数据量. 从传输数据总量来看,传输数据越多,耗时越多,但并不是线性增长,表现为某个区间趋于稳定,这个可能与 FIFO 拥塞有关. 另外从每次传输数据量来看,每次传输数据量增大,虽然耗时减少,但并不是成倍数的减少,只是平稳在某个区间. 通过上面的数据分析,可以看到性能优化的方向有两个: 比较合适的传输数据量可以最大最优性能,每次传输的数据量随着增加收益降低,因此一个合适的数据量最优. 接下来使用如下命令分析哪个函数比较消耗 CPU:
# PREPARE
dd if=/dev/urandom of=/mnt/Freeze/BiscuitOS-Share.txt bs=1M count=1024 > /dev/null 2>&1
echo -n "Hello BiscuitOS" > temp.txt
dd if=temp.txt of=/mnt/Freeze/BiscuitOS-Share.txt bs=1 seek=0 conv=notrunc > /dev/null 2>&1
dd if=temp.txt of=/mnt/Freeze/BiscuitOS-Share.txt bs=1 seek=$((1024 * 1024 * 1024 - 15)) conv=notrunc > /dev/null 2>&1
rm temp.txt
[ -f /mnt/Freeze/BiscuitOS-Ex.txt ] && rm /mnt/Freeze/BiscuitOS-Ex.txt
echo "** START TEST **"
# Running
FIFO-PRODUCT &
sleep 0.1
PID=$(pidof FIFO-PRODUCT)
FIFO-CONSUMER &
perf top -p ${PID} -g --call-graph dwarf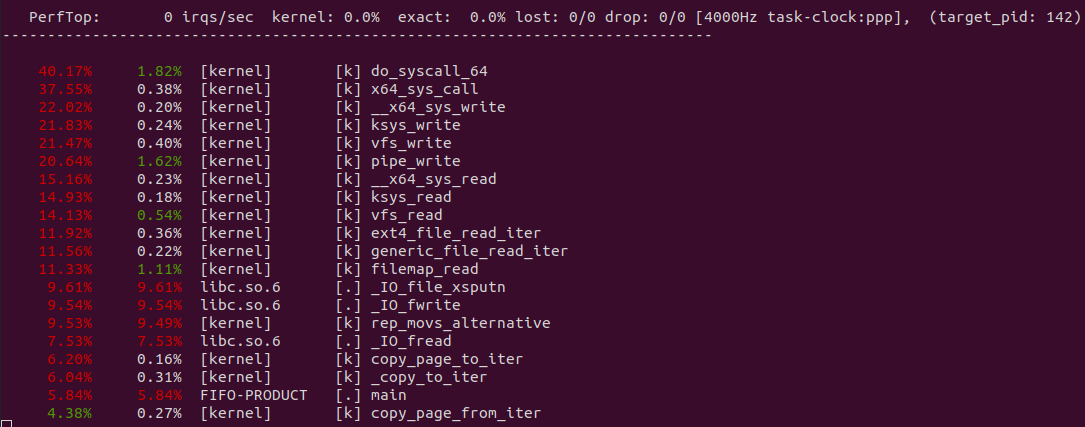
从 perf 获得实时观察系统中正在运行的程序的性能热点,可以看出文件的读写系统调用占了大头,其中包括将数据从文件的 PAGECACHE 里读取到缓存区,然后调用 _copy_from_iter 将数据从缓存区拷贝到内核态的 FIFO 缓冲区.
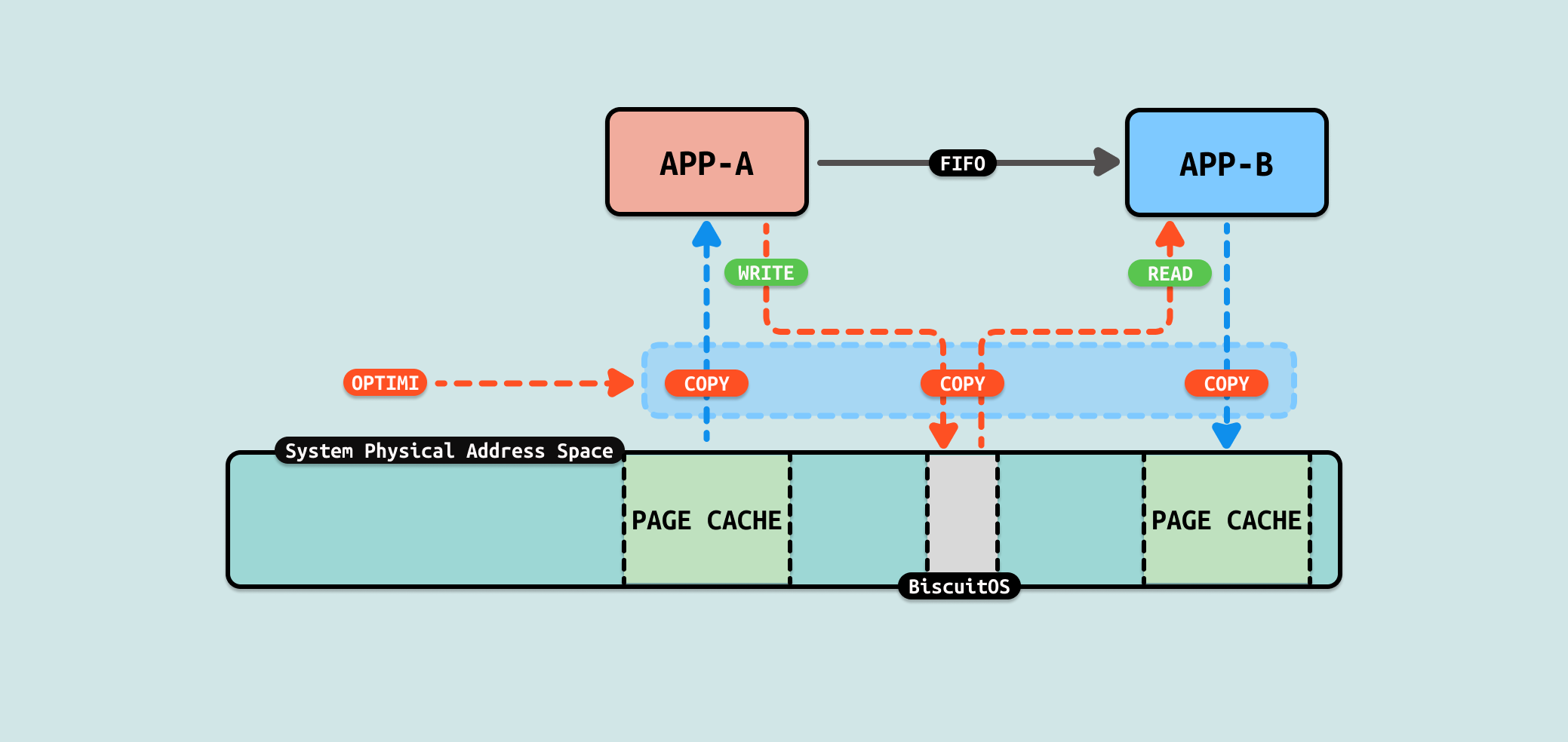
文件数据从内核空间拷贝到用户空间,又从用户空间拷贝到内核空间,只是纯粹的数据拷贝,没有做其他额外的操作,那么这里可以进行优化. 如果将生产者的 PAGECACHE 作为 FIFO 在内核态的缓冲区,那么就可以省去一次拷贝. 因此可以从这个方向进行 ZEROCOPY 优化, 具体优化方案如下:


当使用 FIFO 在两个用户进程之间通信交换数据时,存在一个场景是用户进程 A 需要将文件的内容发送给用户进程 B,那么常用的做法是用户进程 A 将文件数据拷贝到缓冲区,然后将缓冲区的数据写入到 FIFO 里,接着用户进程 B 从 FIFO 中读出数据到缓冲区,然后将缓冲区的数据写入到自己的文件里.
来分析一下数据的流动,首先用户进程 A 从文件的 PAGECACHE 里将数据从内核态拷贝到用户态的缓冲区,然后将缓冲区的数据写入到 FIFO,此时将用户态缓冲区数据拷贝 FIFO 内核态缓冲区里. 用户进程 B 从 FIFO 内核态缓冲区读取数据到用户态缓冲区,接着将用户态缓冲区数据写入到文件内核态的 PAGECACHE 里.
从这个流程里看到了数据在用户态和内核态被多次拷贝,并且是纯粹的拷贝. 那么是否可以减少数据的拷贝,例如将用户进程 A 文件 PAGECACHE 的数据直接拷贝到 FIFO 内核态的缓冲区里,这样可以减少 1 次拷贝. 同理可以将 FIFO 缓存区的数据直接拷贝到用户进程 B 文件的 PAGECACHE,这样可以减少 1 次拷贝. 总的来说这样的优化可以减少 2 次拷贝.
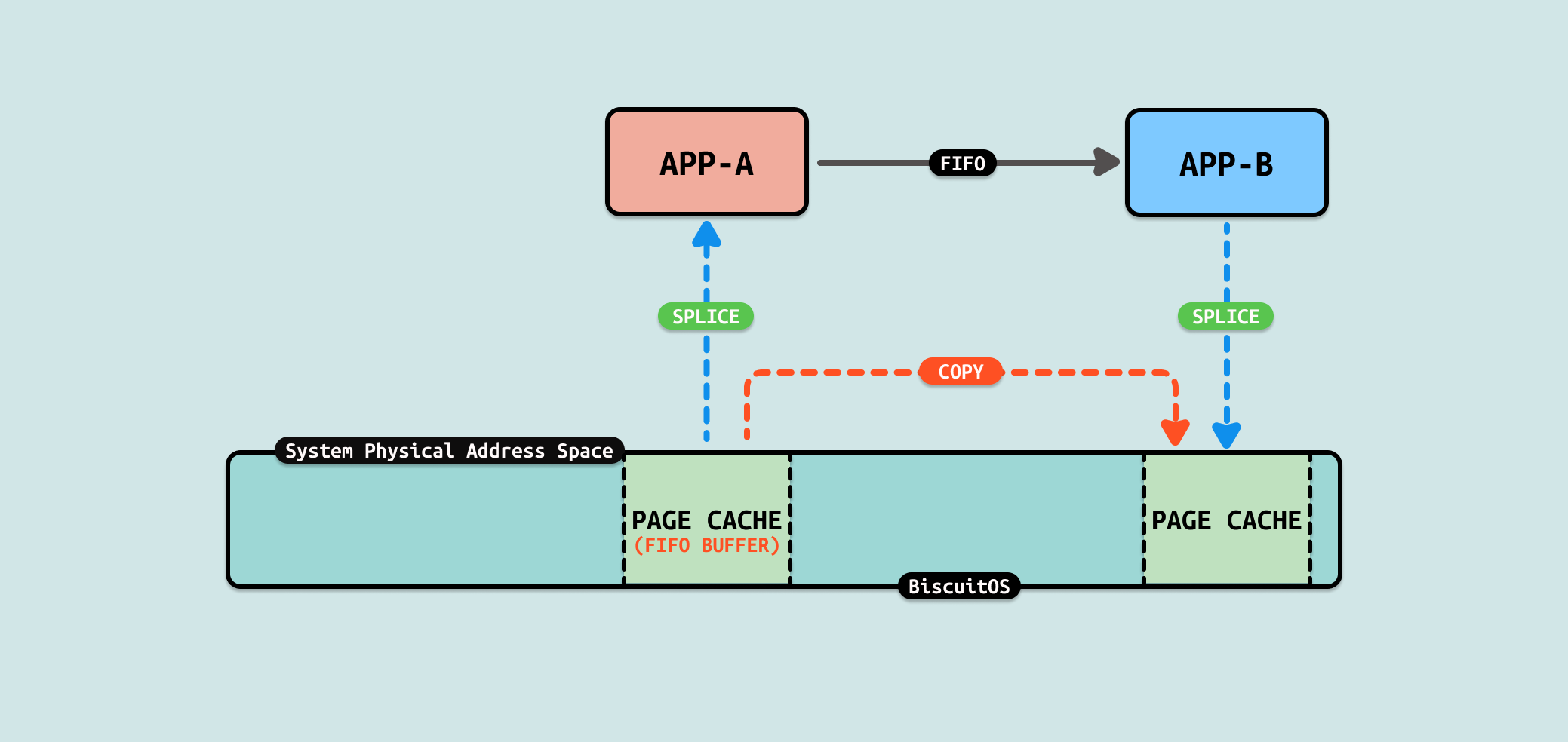
splice 是 Linux 内核中的一个系统调用,它用于在两个文件描述符之间移动数据,而不需要在用户空间中复制数据, 这种方式可以显著提高 I/O 操作的效率,特别是在处理大量数据的时候,因为它减少了内核与用户空间之间的数据复制开销. 对于这个场景,FIFO 正好也是一个文件,因此可以利用这个系统调用减少文件的冗余拷贝.
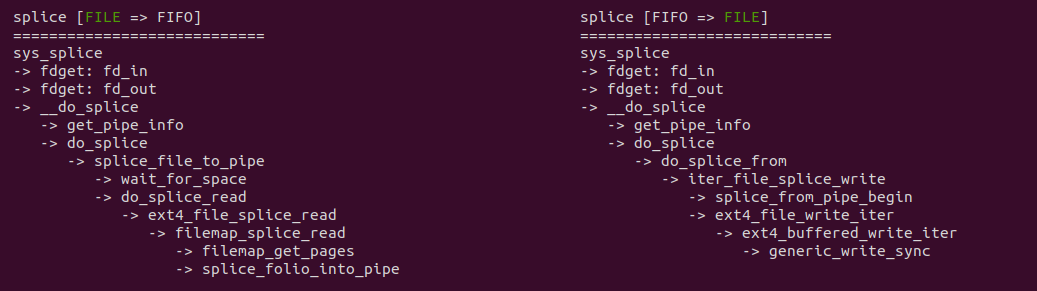
当调用 splice 系统调用将数据从文件拷贝到 FIFO 的代码路径可以看到,其核心依赖于文件系统的具体实现,例如在 EXT4 文件系统,其提供了 ext4_file_splice_read,其核心逻辑是直接将文件的 PAGECACHE 作为 FIFO 的缓冲区,因此直接不需要任何拷贝. 当调用 splice 系统调用将数据从 FIFO 拷贝到文件时,其核心逻辑也依赖于具体的文件系统,例如在 EXT4 文件系统,当获得 FIFO 的缓冲区之后,调用 ext4_file_write_iter 函数将数据拷贝到文件的 PAGECACHE 里,因此只涉及一次拷贝. 通过源码的分析,可以看到相比原始的 FIFO 方式,拷贝次数有 4 次减少到 1次. 接下来通过一个实践案例实际测试其性能,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] Package --->
[*] ZERO COPY MECHANISM
[*] OPTIMI ZEROCOPY(IPC): Exchange Between FIFO SPLICE --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-ZEROCOPY-IPC-FIFO-SPLICE-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build
BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了实践案例运行的所有命令,案例包含一个生产者用户进程,其使用 splice 系统调用将 “BiscuitOS-Share.txt” 文件 200M 数据写入 FIFO,案例还包含一个消费者用户进程 ,其从 FIFO 里读出数据,并使用 splice 将数据写入到新文件,并对生产者用户进程发送数据过程进行计时. 可以看到 200MiB 数据花费了 438 ms. 接下来分析源码:
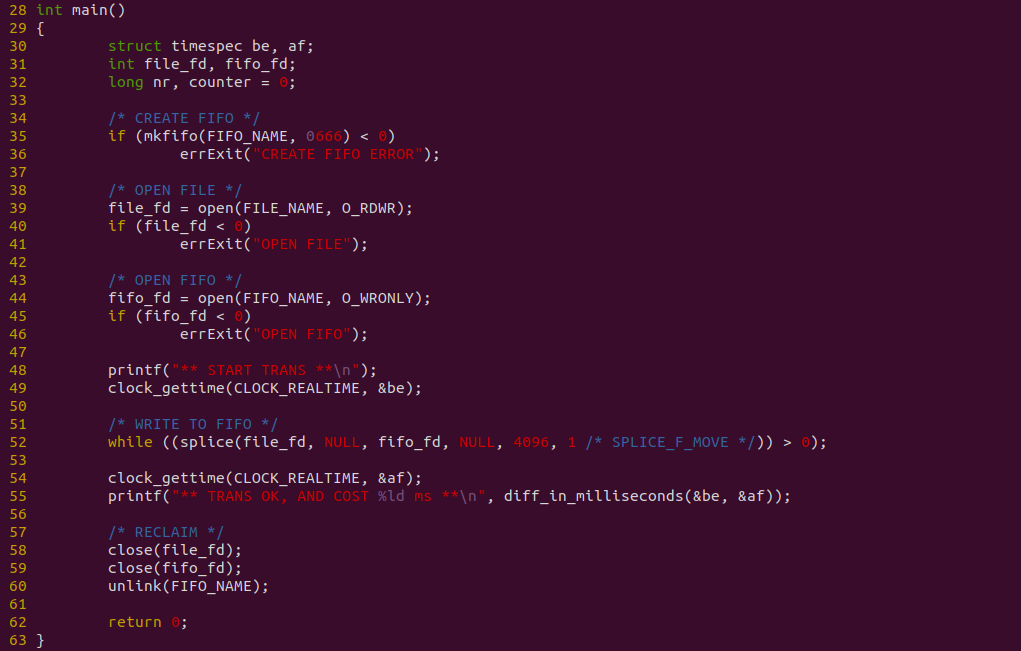
上图是生产者代码,程序在 35 行调用 mkfifo 创建一个有名管道,然后在 39 行调用 open 打开 “BiscuitOS-Share.txt” 文件,以及在 44 行使用 open 打开 FIFO,接着在 52- 行使用 splice 系统调用将文件数据写入到 FIFO 里,并使用 clock_gettime 在数据发送先后进行计时.
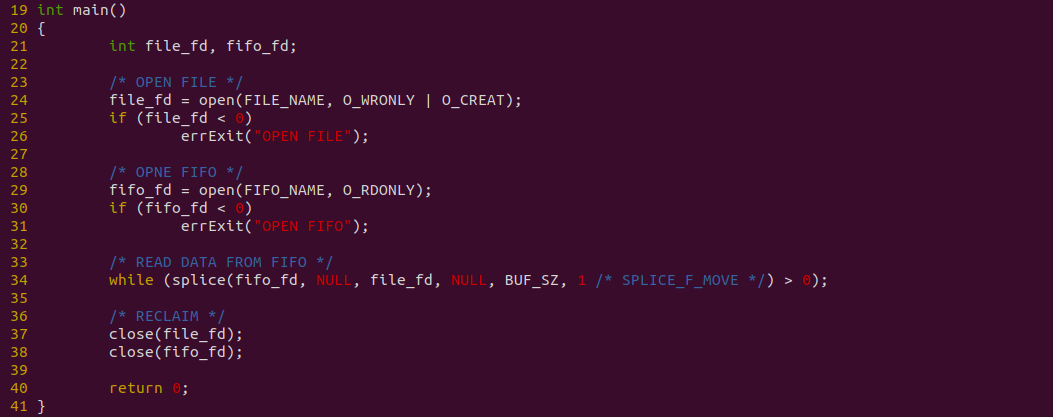
上图是消费者代码,程序在 24 行打开存储数据用的文件,接着在 29 行使用 open 函数打开 FIFO,并在 34 行调用 splice从 FIFO 读出的数据直接写入到文件里. 以上便是源码,接下来对不同数据量进行耗时测试:
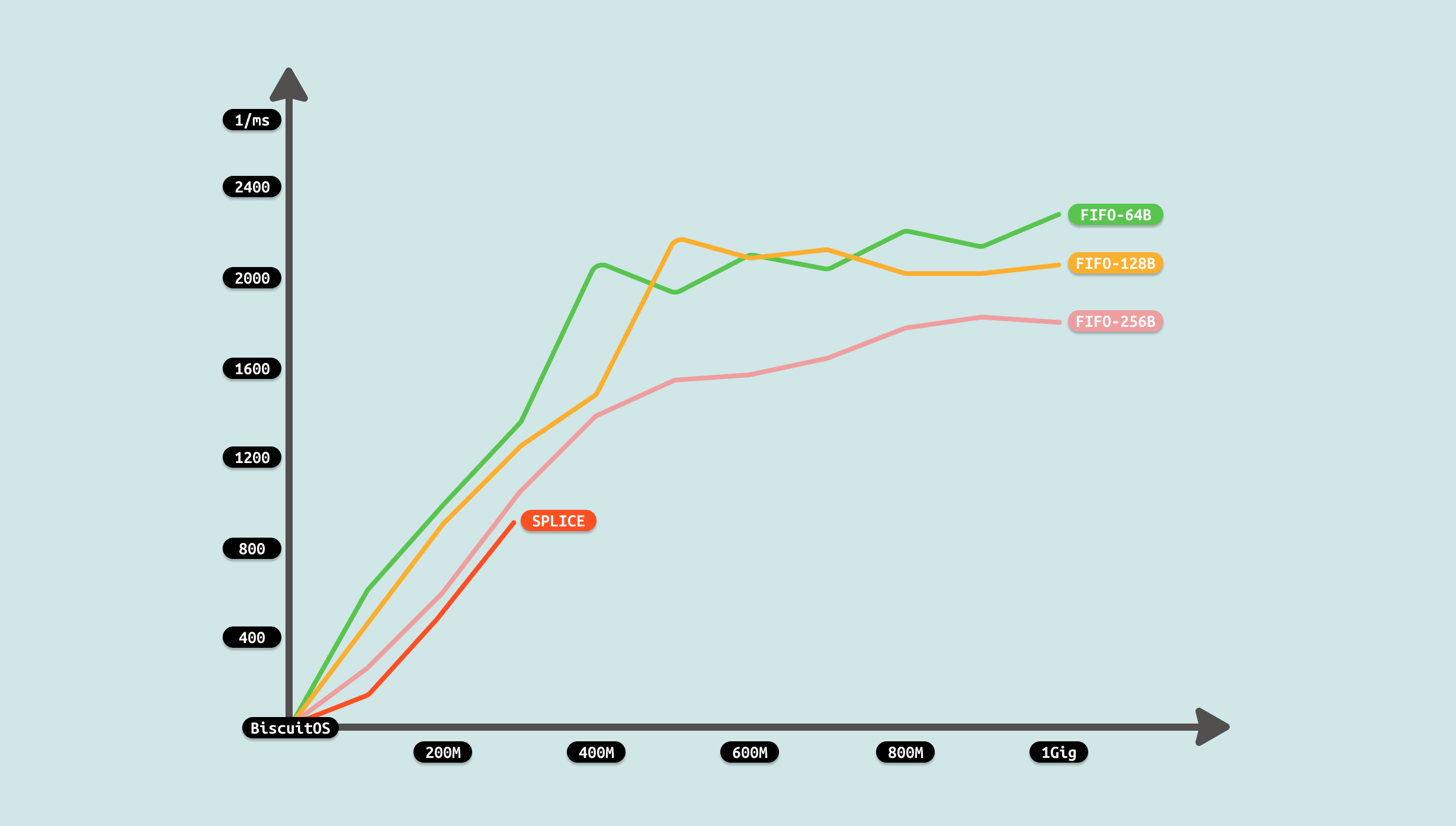
测试过程中发现,splice 支持文件大小不能超过 400M,可能受限于 FIFO 缓存区大小,也受限于系统可用物理内存大小,毕竟使用 PAGECACHE 充当 FIFO 缓冲区. 但从前几组数据可以看到相比原始 FIFO 案例,性能已经有了提升,因此优化有效. 在这次优化中,就利用了 ZEROCOPY 机制,找到原始 FIFO 方案中存在冗余拷贝的过程,可以看到使用 SPLICE 之后,拷贝由 4 次减少到 1次,性能提升是明显. 因此开发者在遇到相似 IPC FIFO 场景,可以利用该 ZEROCOPY 优化方案进行优化.

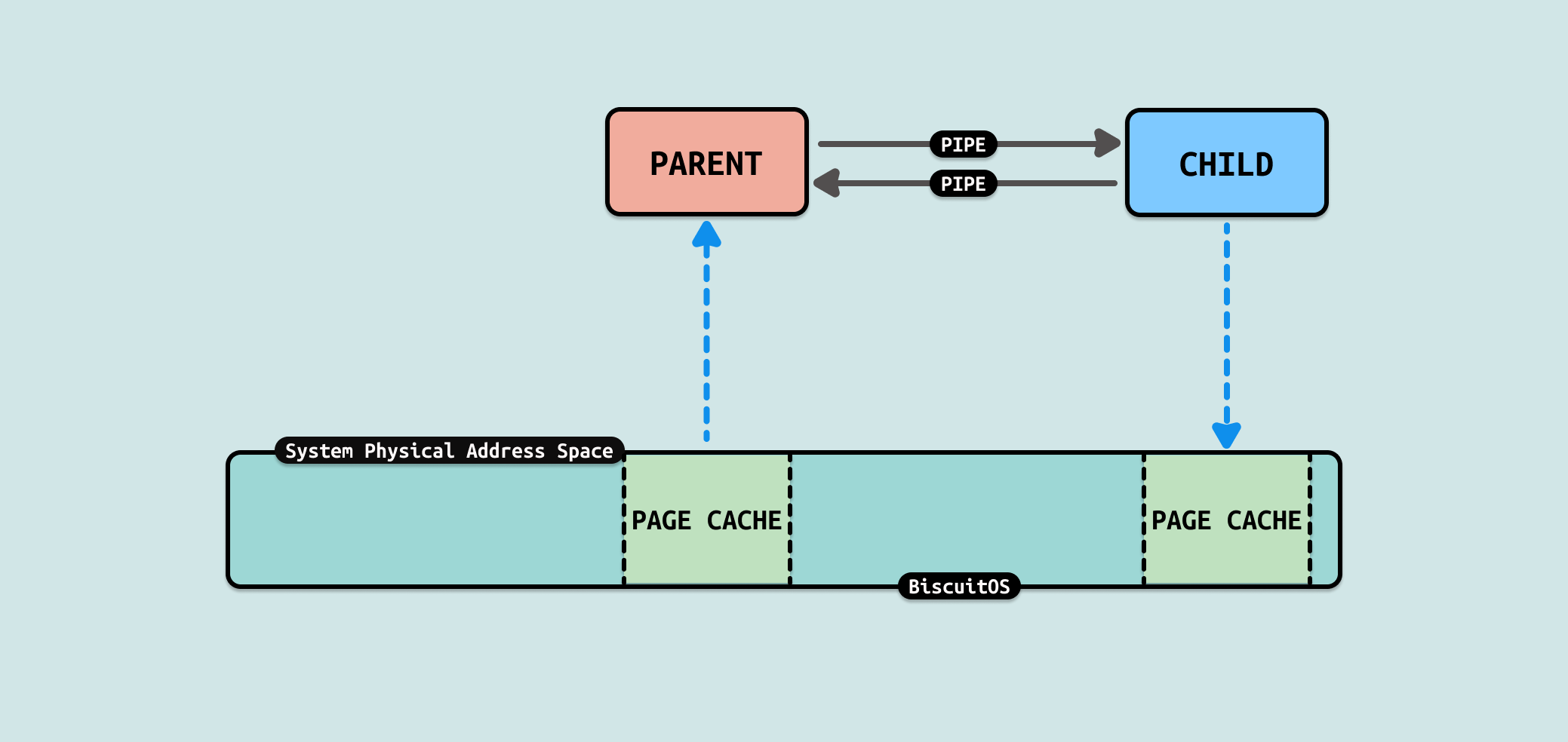
匿名管道(PIPE) 是一种用于在同一台主机上的两个用户进程之间进行通信的机制,与 FIFO 有名通道类似,匿名管道是单向的,只能从一个进程的写端流向另一个进程的读端. 匿名管道通常用于父进程与子进程之间的通信,PIPE 在创建时由父进程建立,然后通过进程复制机制(如 fork)传递给子进程. 匿名管道没有名字,只存在于创建它们的进程及其子进程之间,无法被其他无关进程访问. 与 FIFO 类似,数据以先进先出的顺序传输,保证写入数据的顺序和读取数据的顺序一致. Linux 提供 “pipe()” 系统调用用于创建匿名管道. 如果管道的缓冲区满了,写操作会阻塞;如果缓冲区空了,读操作会阻塞,直到数据可用. PIPE 需要在两个有血缘关系的用户进程之间使用,并且其与文件形式存在,那么就可以直接向文件一样操作 PIPE,例如一下操作:
- 创建 PIPE: 使用 pipe 函数创建匿名管道, 其中描述符 0 为读方向,1 为写方向
- 打开 PIPE: 使用 open/fopen 函数打开有名管道,
- 从 PIPE 读数据: 使用 read/fread 命令进行读取
- 向 PIPE 写数据: 使用 write/fwrite 命令写入数据
- 关闭 PIPE: 使用 close/fclose 关闭打开的 FIFO
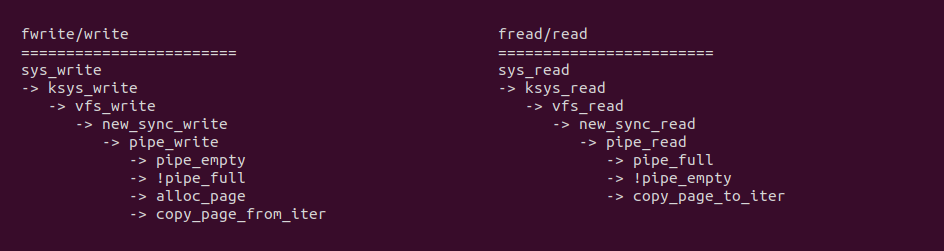
从 write 系统调用向 PIPE 写入数据可以看到,sys_write 最终调用 PIPE 专有线路 pipe_write, 该函数会在调用 alloc_page 在内核动态扩容一片缓冲区,然后调用 copy_page_from_iter 函数从用户态将数据拷贝到内核态的缓冲区里. 同理从 read 系统调用从 PIPE 读出数据可以看到,sys_read 最终调用 PIPE 专用线路 pipe_write, 其更直接,当发现缓冲区不空,直接使用 copy_page_to_iter 函数将数据从内核空间拷贝到用户空间.
从 PIPE 机制实现来看,数据流动时从生产者的用户空间拷贝到内核空间,然后消费者从内核空间将数据拷贝到用户态. 从这个流程看出 COPY USER 将是性能瓶颈,另外内核空间分配的内存大小也是瓶颈. 接下来通过一个实践案例实际测试其性能,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] Package --->
[*] ZERO COPY MECHANISM
[*] *** Inter-Process Communication(IPC) ***
[*] FORBID ZEROCOPY(IPC): Exchange Between PIPE --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-ZEROCOPY-IPC-PIPE-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build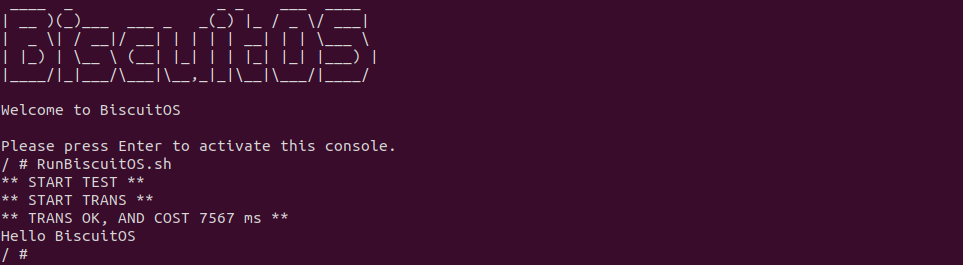
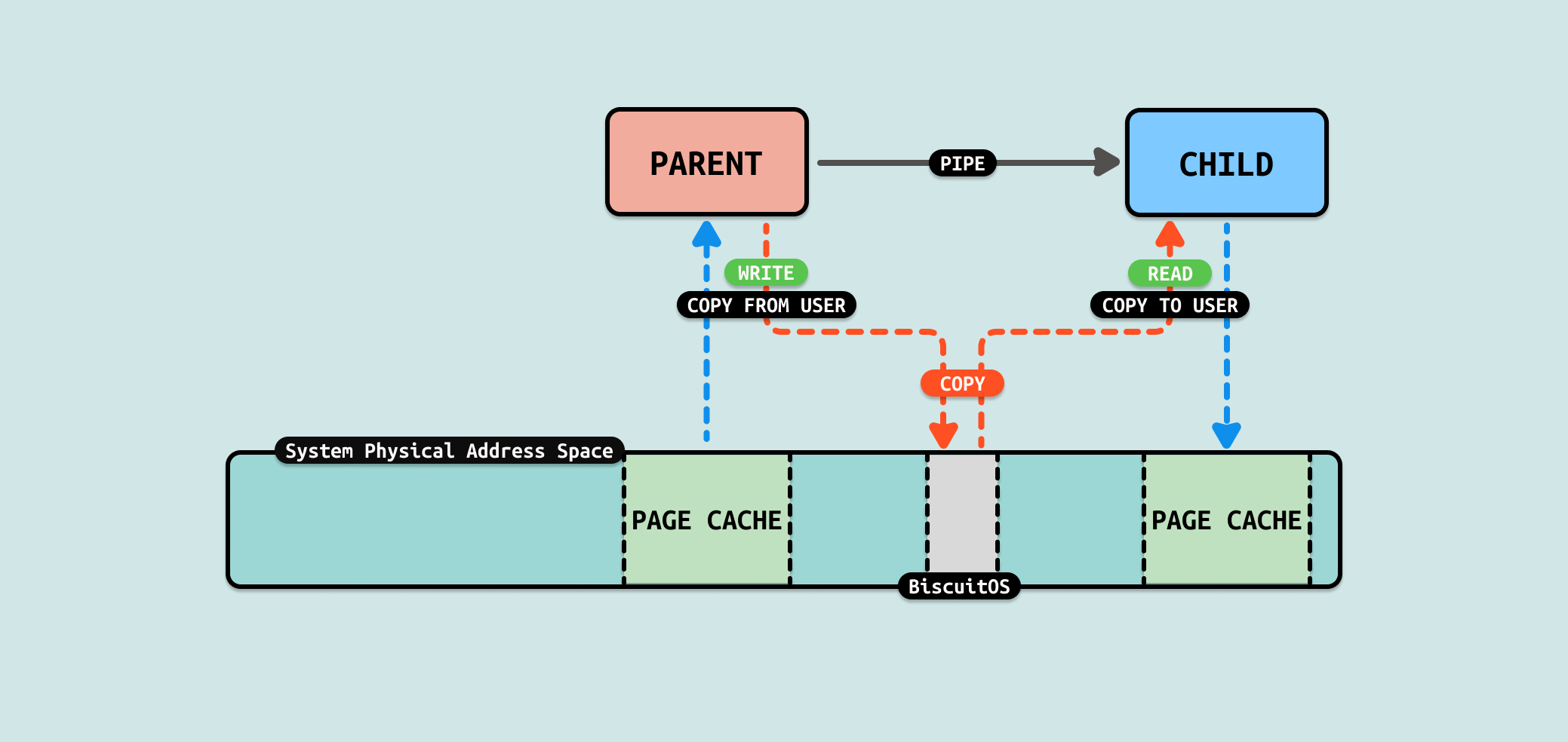
BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了实践案例运行的所有命令,案例包含一个父进程和一个子进程,在创建子进程之间创建了匿名管道,接着父进程从文件里读取 200M 数据到 PIPE 匿名管道里,子进程则从 PIPE 匿名管道读取数据写入到对应的文件里,可以看到父进程写入 200M 数据到 PIPE 匿名管道花费的时间为 7567 ms,接下来分析源码:
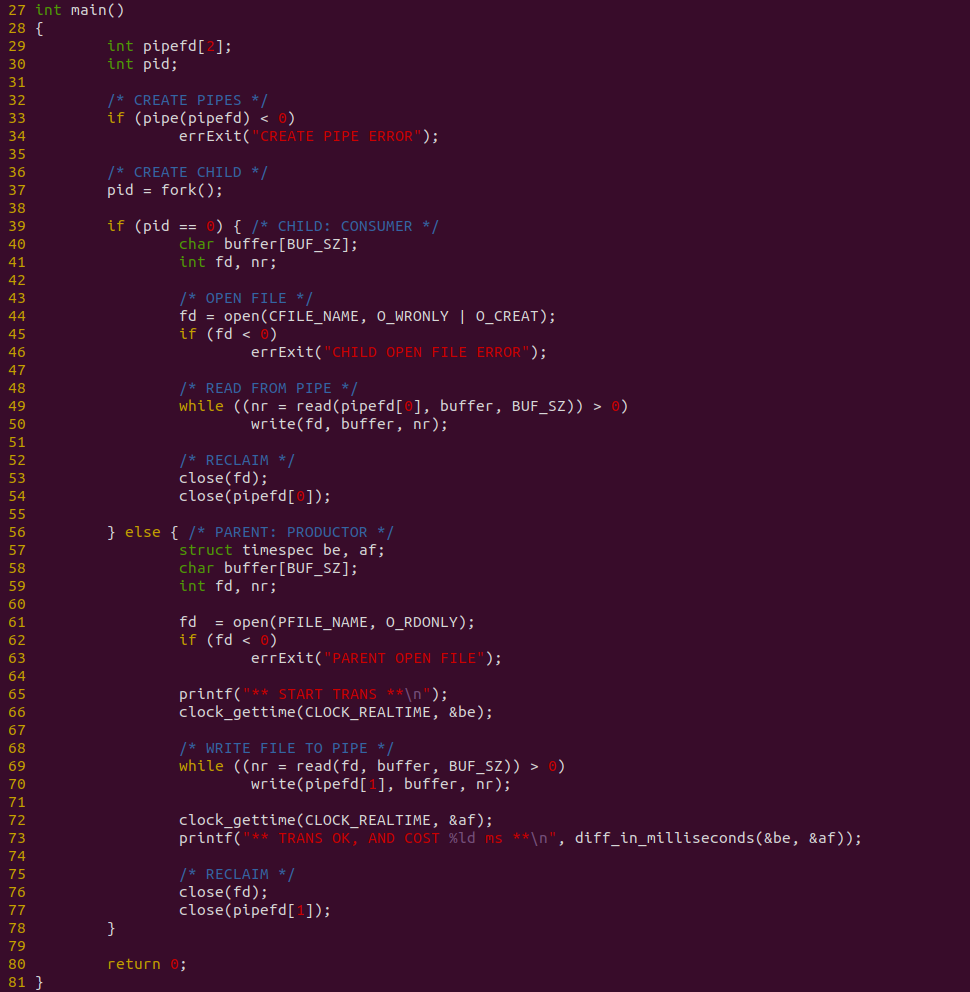
源码在 33 行调用 pipe 创建一个匿名管道,然后在 37 行调用 fork 创建一个子进程,56-78 行为父进程逻辑,其在 61 行调用 open 函数打开一个文件,然后在 69 行使用 while 循环从文件里读取数据到缓冲区,然后调用 write 函数将缓冲区数据写入到 PIPE 匿名管道中,写完毕之后调用 close 关闭打开的文件和匿名管道. 39-55 行为子进程逻辑,其在 44 行调用 open 函数打开存储文件,接着在 49 行使用 while 循环从 PIPE 匿名管道里读取数据到缓冲区,然后 50 行将缓冲区的数据写入到存储文件里,写入完成之后调用 close 函数关闭打开的文件和匿名管道. 在这个过程中,使用 clock_gettime 函数对父进程从文件读数据写入到 PIPE 管道进行全计时. 接下来对不同数据量进行耗时测试:
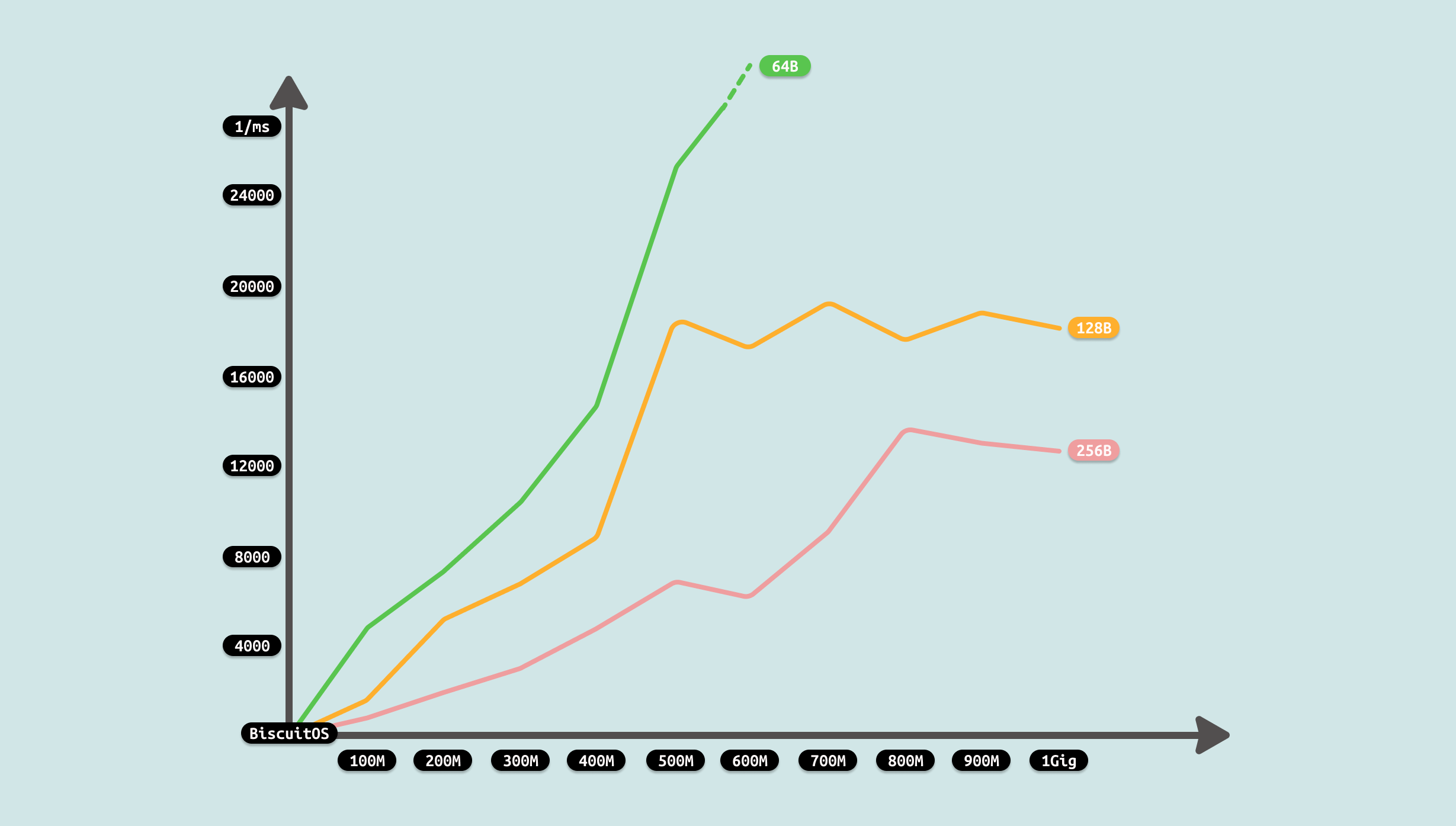
由于计时包括从文件里读取数据到缓存,然后将缓存内容写入到 PIPE 里,因此测试从两个维度进行,首先是传输数据总量,其次是每次传输的数据量. 从传输数据总量来看,传输数据越多,耗时越多,但并不是线性增长,表现为某个区间趋于稳定,这个可能与 PIPE 拥塞有关. 另外从每次传输数据量来看,每次传输数据量增大,虽然耗时减少,但并不是成倍数的减少,只是平稳在某个区间. 通过上面的数据分析,可以看到性能优化的方向有两个: 比较合适的传输数据量可以最大最优性能,每次传输的数据量随着增加收益降低,因此一个合适的数据量最优. 接下来使用如下命令分析哪个函数比较消耗 CPU:
# PREPARE
dd if=/dev/urandom of=/mnt/Freeze/BiscuitOS-Share.txt bs=1M count=1024 > /dev/null 2>&1
echo -n "Hello BiscuitOS" > temp.txt
dd if=temp.txt of=/mnt/Freeze/BiscuitOS-Share.txt bs=1 seek=0 conv=notrunc > /dev/null 2>&1
dd if=temp.txt of=/mnt/Freeze/BiscuitOS-Share.txt bs=1 seek=$((1024 * 1024 * 1024 - 15)) conv=notrunc > /dev/null 2>&1
rm temp.txt
[ -f /mnt/Freeze/BiscuitOS-Ex.txt ] && rm /mnt/Freeze/BiscuitOS-Ex.txt
echo "** START TEST **"
# Running
BiscuitOS-ZEROCOPY-IPC-PIPE-default &
sleep 1
PID=$(pidof BiscuitOS-ZEROCOPY-IPC-PIPE-default | awk '{print $1}')
perf top -p ${PID} -g --call-graph dwarf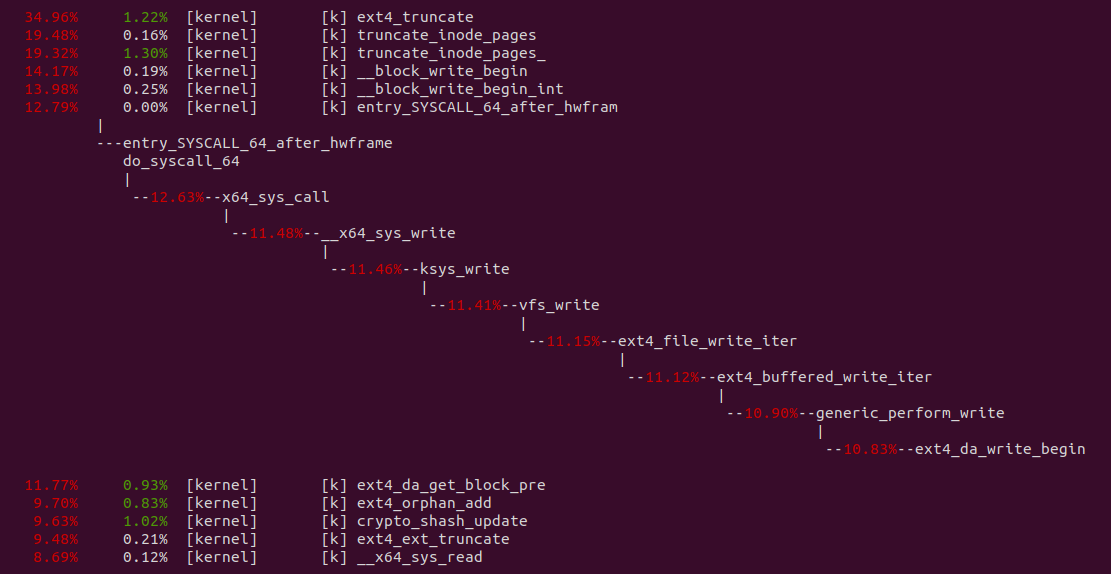
从 perf 获得实时观察系统中正在运行的程序的性能热点,可以看出文件的读写系统调用占了大头,其中包括将数据从文件的 PAGECACHE 里读取到缓存区,然后调用 _copy_from_iter 将数据从缓存区拷贝到内核态的 PIPE 缓冲区
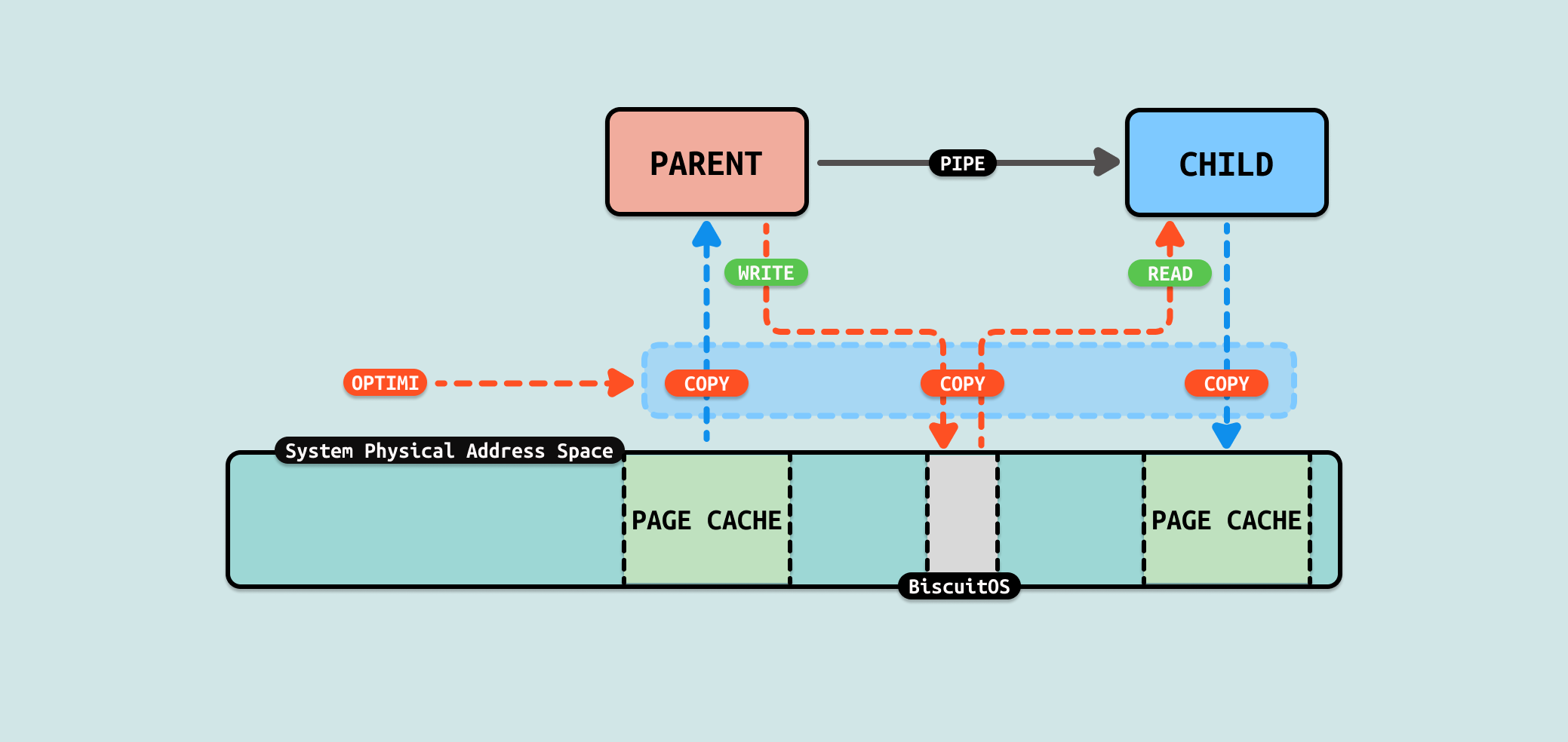
文件数据从内核空间拷贝到用户空间,又从用户空间拷贝到内核空间,只是纯粹的数据拷贝,没有做其他额外的操作,那么这里可以进行优化. 接下来文章讲解如何优化这个过程.


当使用 PIPE 在父子进程之间通信交换数据时,存在一个场景是父进程需要将文件的内容发送给子进程,那么常用的做法是父进程将文件数据拷贝到缓冲区,然后将缓冲区的数据写入到 PIPE 里,接着子进程从 PIPE 中读出数据到缓冲区,然后将缓冲区的数据写入到自己的文件里.
来分析一下数据的流动,首先父进程从文件的 PAGECACHE 里将数据从内核态拷贝到用户态的缓冲区,然后将缓冲区的数据写入到 PIPE,此时将用户态缓冲区数据拷贝 PIPE 内核态缓冲区里. 子进程从 FIFO 内核态缓冲区读取数据到用户态缓冲区,接着将用户态缓冲区数据写入到文件内核态的 PAGECACHE 里.
从这个流程里看到了数据在用户态和内核态被多次拷贝,并且是纯粹的拷贝. 那么是否可以减少数据的拷贝,例如将父进程将文件 PAGECACHE 的数据直接拷贝到 PIPE 内核态的缓冲区里,这样可以减少 1 次拷贝. 同理可以将 PIPE 缓存区的数据直接拷贝到子进程文件的 PAGECACHE,这样可以减少 1 次拷贝. 总的来说这样的优化可以减少 2 次拷贝.
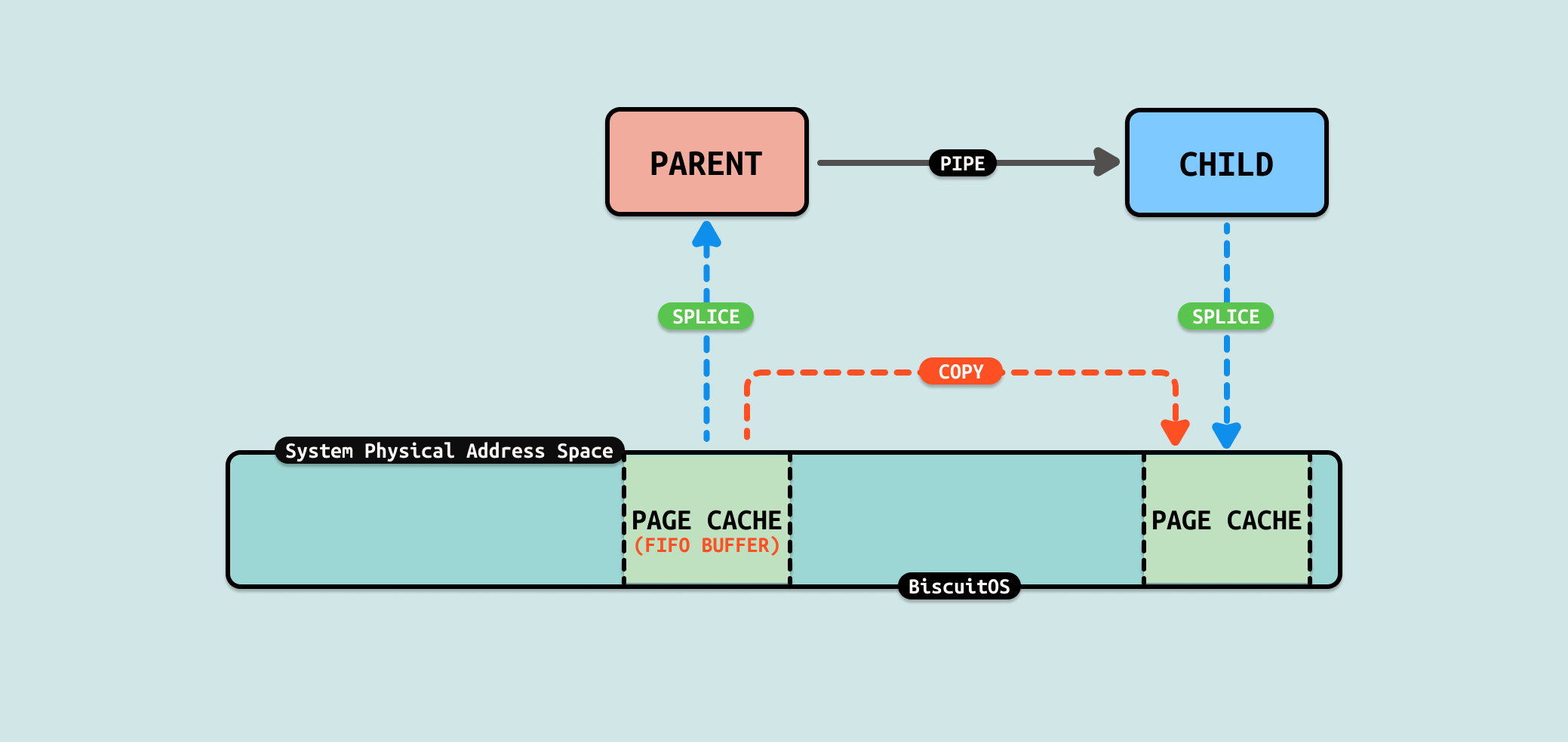
splice 是 Linux 内核中的一个系统调用,它用于在两个文件描述符之间移动数据,而不需要在用户空间中复制数据, 这种方式可以显著提高 I/O 操作的效率,特别是在处理大量数据的时候,因为它减少了内核与用户空间之间的数据复制开销. 对于这个场景,PIPE 正好也是一个文件,因此可以利用这个系统调用减少文件的冗余拷贝.
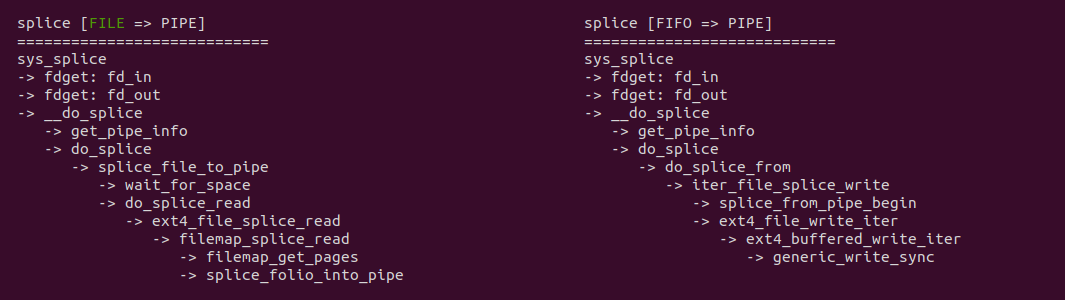
当调用 splice 系统调用将数据从文件拷贝到 FIFO 的代码路径可以看到,其核心依赖于文件系统的具体实现,例如在 EXT4 文件系统,其提供了 ext4_file_splice_read,其核心逻辑是直接将文件的 PAGECACHE 作为 FIFO 的缓冲区,因此直接不需要任何拷贝. 当调用 splice 系统调用将数据从 FIFO 拷贝到文件时,其核心逻辑也依赖于具体的文件系统,例如在 EXT4 文件系统,当获得 FIFO 的缓冲区之后,调用 ext4_file_write_iter 函数将数据拷贝到文件的 PAGECACHE 里,因此只涉及一次拷贝. 通过源码的分析,可以看到相比原始的 PIPE 方式,拷贝次数有 4 次减少到 1次. 接下来通过一个实践案例实际测试其性能,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] Package --->
[*] ZERO COPY MECHANISM
[*] *** Inter-Process Communication(IPC) ***
[*] OPTIMI ZEROCOPY(IPC): Exchange Between PIPE SPLICE --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-ZEROCOPY-IPC-PIPE-SPLICE-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build
BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了实践案例运行的所有命令,案例包含一个父进程和一个子进程,在创建子进程之间创建了匿名管道,接着父进程使用 SPLICE 将文件数据写入到 PIPE 匿名管道里,子进程则通过 SPLICE 从 PIPE 匿名管道读取数据写入到对应的文件里,可以看到父进程写入 200M 数据到 PIPE 匿名管道花费的时间为 586ms,接下来分析源码:
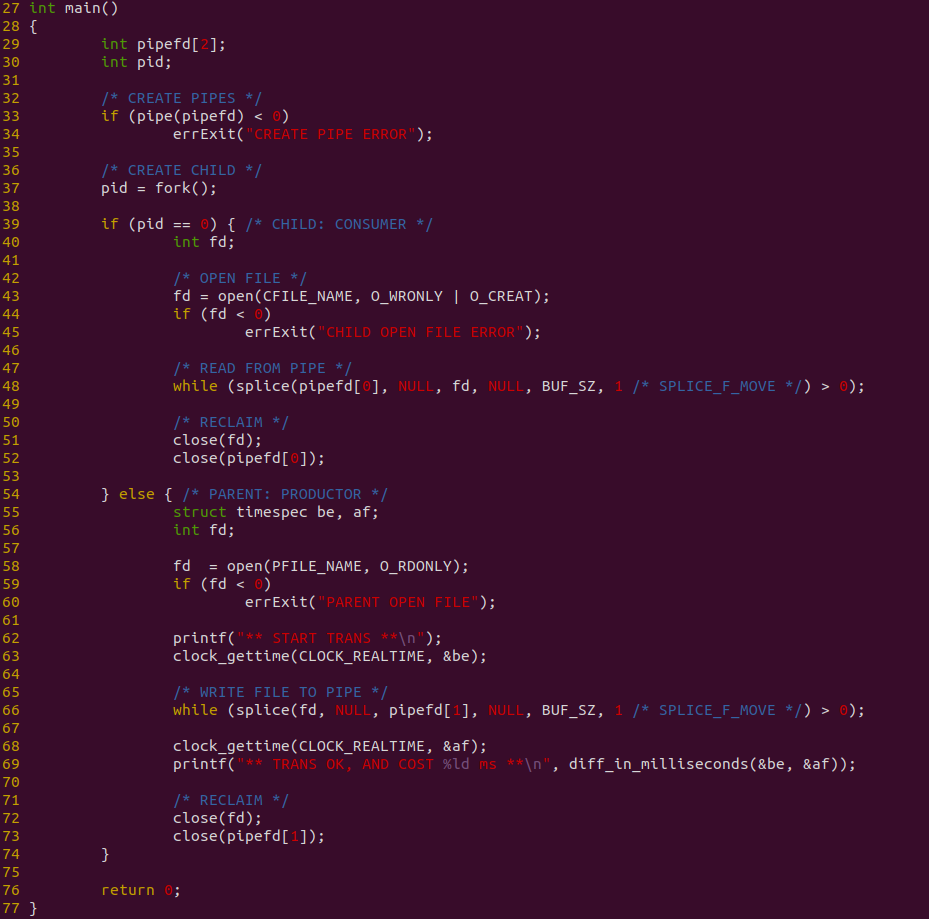
源码在 33 行调用 pipe 创建一个匿名管道,然后在 37 行调用 fork 创建一个子进程,55-73 行为父进程逻辑,其在 58 行调用 open 函数打开一个文件,然后在 66 行使用 while 循环并调用 splice 函数将文件内容写入到 PIPE 匿名管道,写完毕之后调用 close 关闭打开的文件和匿名管道. 39-54 行为子进程逻辑,其在 43 行调用 open 函数打开存储文件,接着在 49 行使用 while 循环并调用 splice 函数从 PIPE 管道读取数据到存储文件里,写入完成之后调用 close 函数关闭打开的文件和匿名管道. 在这个过程中,使用 clock_gettime 函数对父进程从文件读数据写入到 PIPE 管道进行全计时. 接下来对不同数据量进行耗时测试:
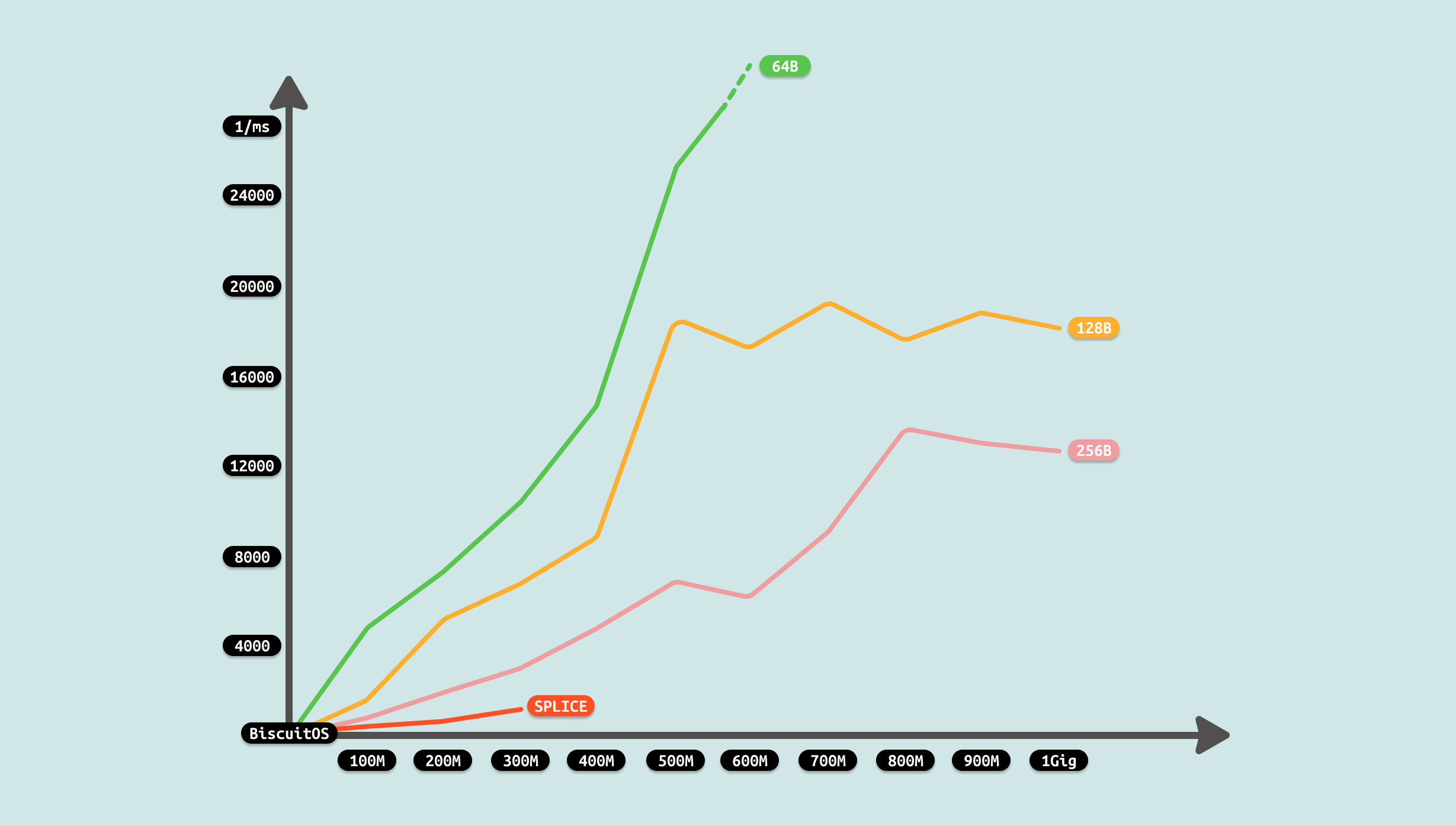
测试过程中发现,splice 支持文件大小不能超过 400M,可能受限于 PIPE 缓存区大小,也受限于系统可用物理内存大小,毕竟使用 PAGECACHE 充当 PIPE 缓冲区. 但从前几组数据可以看到相比原始 PIPE 案例,性能已经提升很大,因此优化有效.
在这次优化中,就利用了 ZEROCOPY 机制,找到原始 PIPE 方案中存在冗余拷贝的过程,可以看到使用 SPLICE 之后,拷贝由 4 次减少到 1次,性能提升是明显. 因此开发者在遇到相似 IPC PIPE 场景,可以利用该 ZEROCOPY 优化方案进行优化.

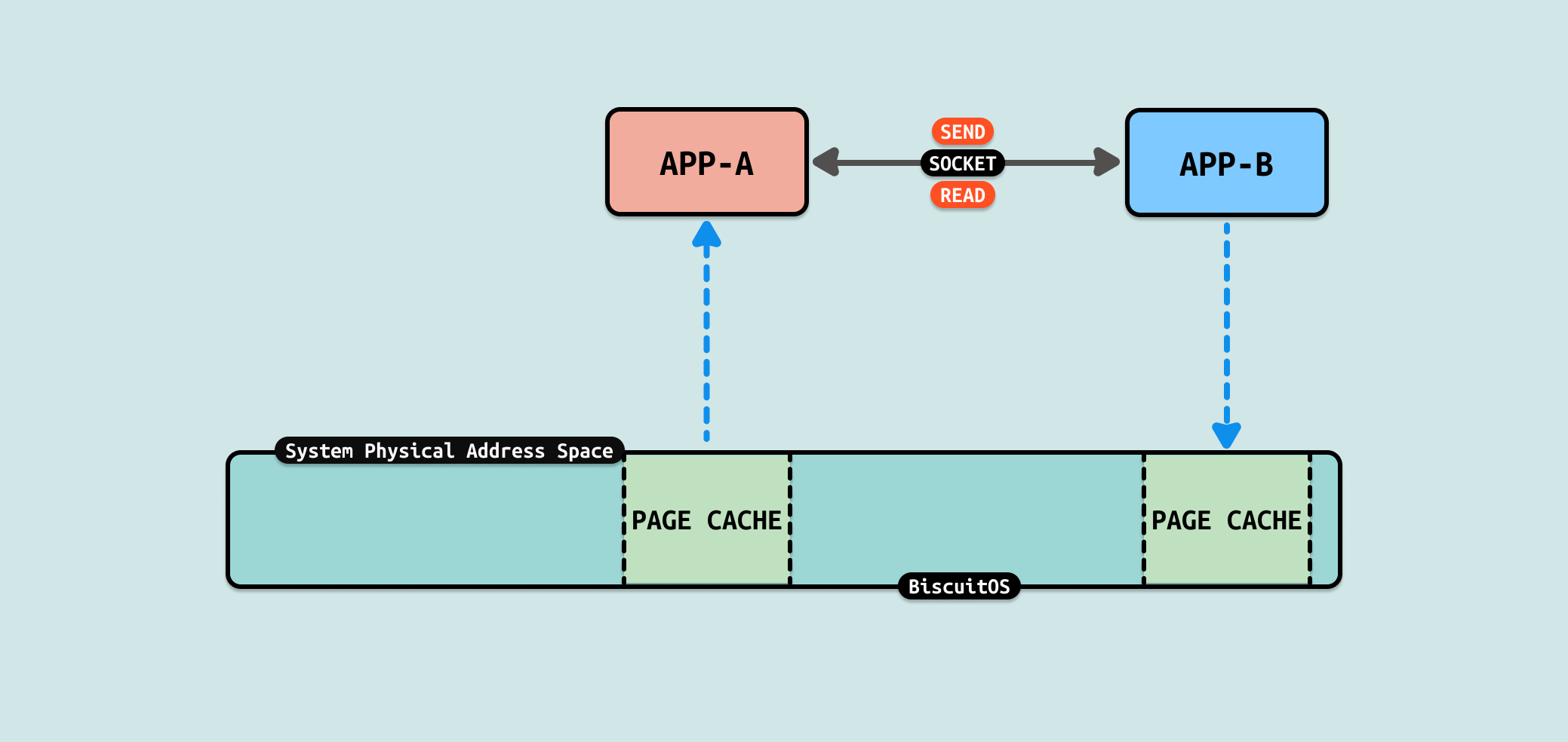
套接字(Socket) 是一种广泛用于进程间通信(IPC)的机制,尤其是在网络通信中, 它允许在同一台计算机上或不同计算机之间的进程进行数据交换. 套接字最初设计用于网络通信,可以在不同主机之间传输数据。它支持多种网络协议,最常用的是 TCP 和 UDP. 套接字支持双向通信,允许进程之间发送和接收数据, 可以在本地进行进程间通信(通过 Unix 域套接字)或在网络上进行通信(通过 TCP/IP 套接字). Socket 使用基本步骤:
- 创建套接字: 使用 socket 函数创建一个套接字
- 绑定地址(服务器端): 使用 bind 函数将套接字绑定到一个特定的地址和端口
- 监听连接(服务器端): 使用 listen 函数等待客户端连接
- 接受连接(服务器端): 使用 accept 函数接受客户端的连接请求
- 连接到服务器(客户端): 使用 connect 函数连接到服务器的套接字
- 数据传输: 使用 send 和 recv 函数进行数据发送和接收
- 关闭套接字: 使用 close 函数关闭套接字,释放相关资源
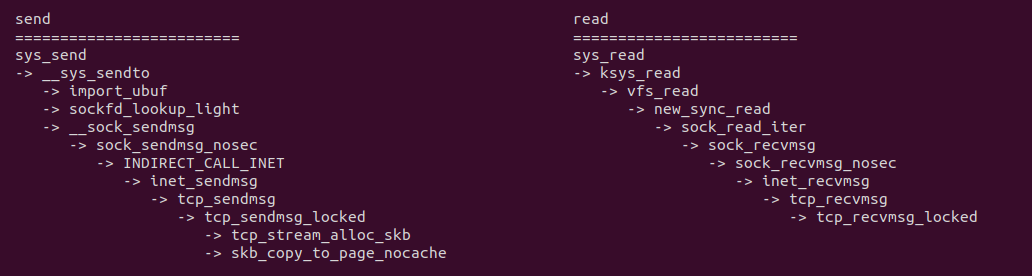
在使用 TCP 的 SOCKET 发送数据时,使用 send 系统调用,该系统调用会在 tcp_sendmsg_locked 函数创建 SKB,并在内核创建一块发送缓冲区,此时使用 skb_copy_to_page_nocache 函数将数据从用户态缓冲区拷贝到内核发送缓冲区,接下来在通过 TCP 协议发送到目的端. 对于接收端来说,其使用 read 系统调用直接从 SOCKET 里读取输出,其通过 sys_read 系统调用最终调用到 tcp_recvmsg_locked,找到对应的 SKB,然后将数据拷贝到用户空间缓冲区.
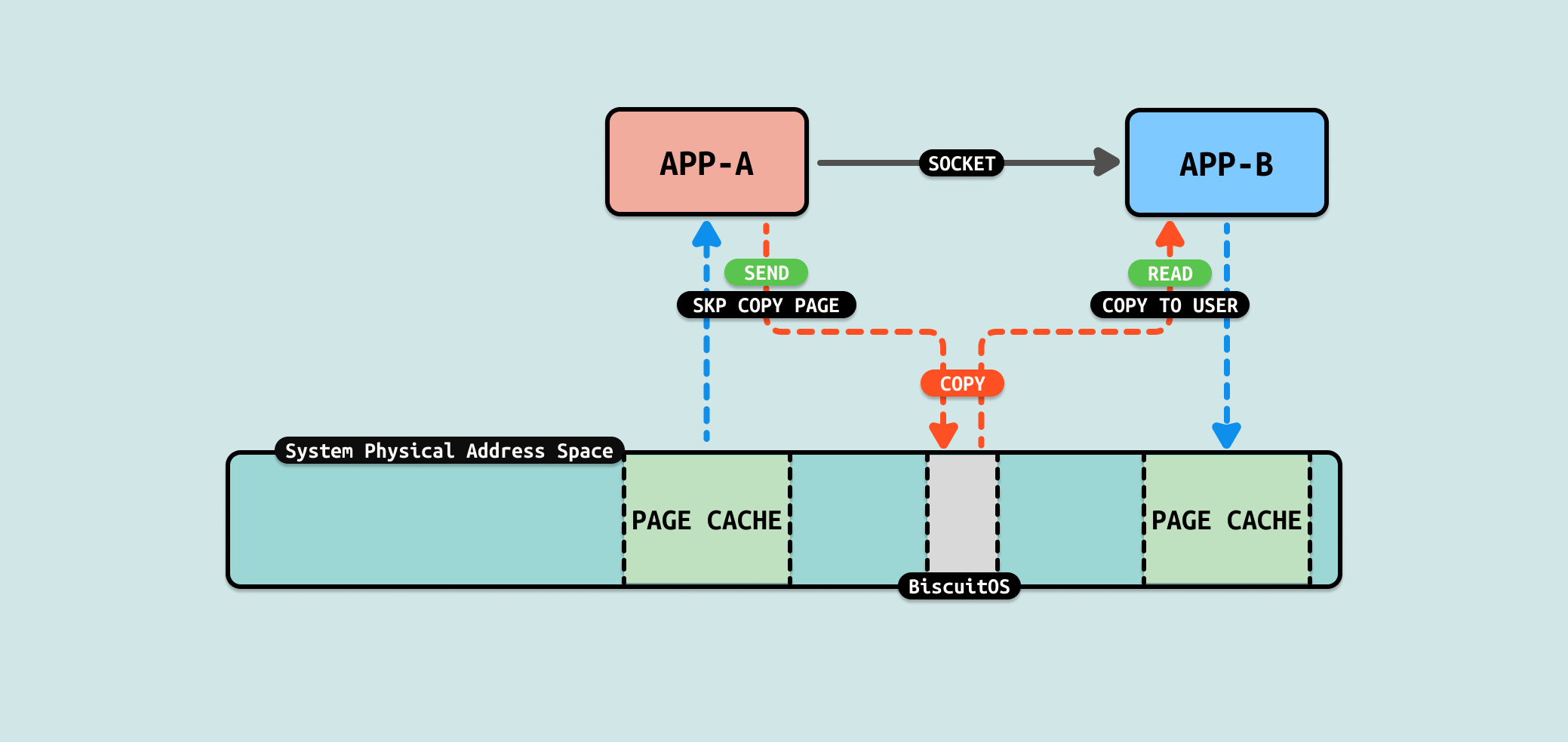
从 TCP SOCKET 机制实现来看,数据流动时从生产者的用户空间拷贝到内核空间,然后消费者从内核空间将数据拷贝到用户态. 从这个流程看出数据拷贝将是性能瓶颈,另外内核空间分配的内存大小也是瓶颈. 接下来通过一个实践案例实际测试其性能,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] Package --->
[*] ZERO COPY MECHANISM
[*] *** Inter-Process Communication(IPC) ***
[*] FORBID ZEROCOPY(IPC): Exchange Between SOCKET --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-ZEROCOPY-IPC-SOCKET-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build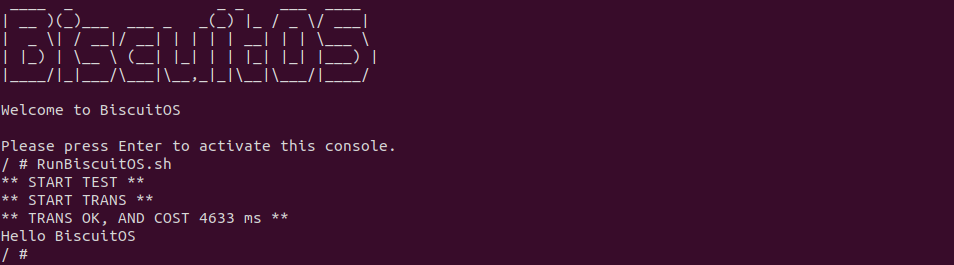
BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了实践案例运行的所有命令,案例包含包含两个用户进程,一个作为客户端,另外一个作为服务器端,当客户端连接到服务器端之后,服务器端用户进程向客户端发送 200M 文件数据,可以看到花费时间 4633ms, 接下来分析源码:
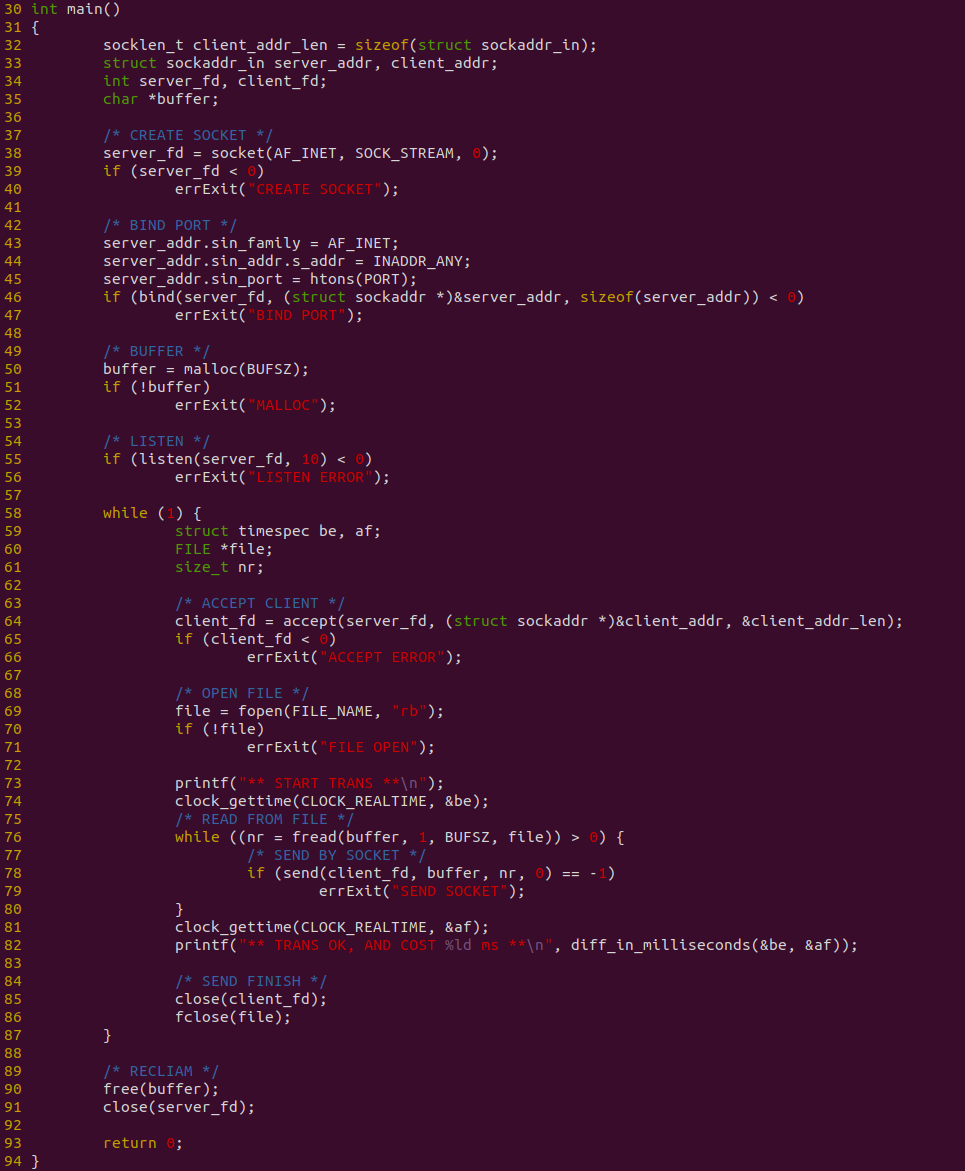
服务器端程序如上图,程序在 38 行调用 socket 函数创建一个 SOCKET,然后在 46 行调用 bind 函数将端口 PORT 绑定到该 SOCKET 上,接着在 50 行创建一个用户态缓冲区,55 行调用 listen 开始监听端口,当有服务请求连接时,在 64 行调用 accept 处理连接请求. 连接成功之后,在 69 行调用 fopen 函数打开一个文件,并在 76 行使用 WHILE 循环从文件里读出数据到缓冲区,然后调用 send 函数将缓冲区的数据写入到 SOCKET 里,写完之后调用 close 关闭请求. 该过程中,使用 clock_gettime 对文件读取和 SOCKET 发送整个过程进行计时.
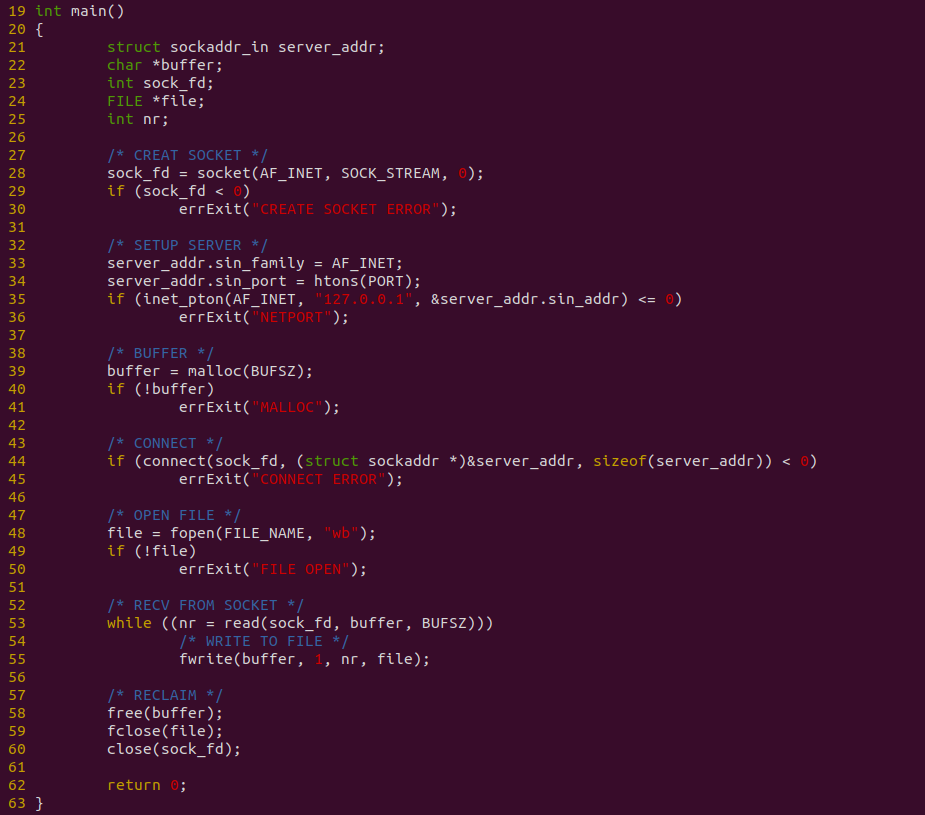
客户端程序如上图,程序在 28 行调用 socket 创建 SOCKET,并在 35 行调用 inet_pton 绑定一个本地 TCP 端口,接着在 39 行创建一个用户态缓冲区,并在 44 行调用 connect 函数连接到服务器端,连接成功之后,在 48 行调用 fopen 打开存储用的文件,然后在 53-54 行使用 WHILE 循环方式从 SOCKET 里读取数据并写入存储文件. 写完之后关闭文件和断开连接等. 接下来对不同数据量进行耗时测试:
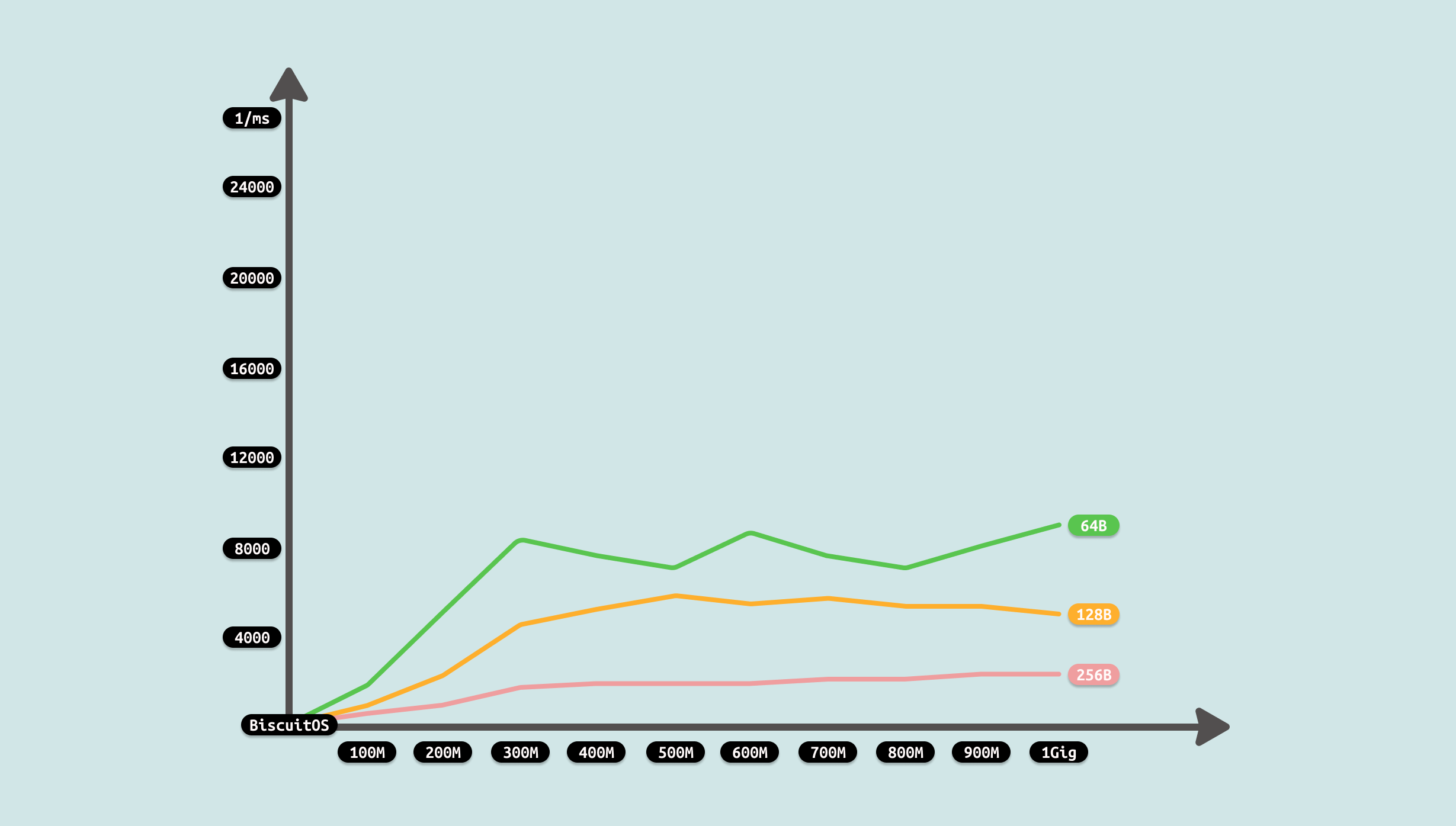
由于计时包括从文件里读取数据到缓存,然后将缓存内容写入到 SOCKET 里, 并通过 TCP 发送出去,因此测试从两个维度进行,首先是传输数据总量,其次是每次传输的数据量. 从传输数据总量来看,传输数据越多,耗时越多,但并不是线性增长,表现为某个区间趋于稳定,这个可能与 SOCKET 拥塞有关. 另外从每次传输数据量来看,每次传输数据量增大,虽然耗时减少,但并不是成倍数的减少,只是平稳在某个区间, 这可能是首先与从文件拷贝数据到用户态缓冲区的瓶颈. 通过上面的数据分析,可以看到性能优化的方向有两个: 比较合适的传输数据量可以最大最优性能,每次传输的数据量随着增加收益降低,因此一个合适的数据量最优. 接下来使用如下命令分析哪个函数比较消耗 CPU:
# PREPARE
dd if=/dev/urandom of=/mnt/Freeze/BiscuitOS-Share.txt bs=1M count=1024 > /dev/null 2>&1
echo -n "Hello BiscuitOS" > temp.txt
dd if=temp.txt of=/mnt/Freeze/BiscuitOS-Share.txt bs=1 seek=0 conv=notrunc > /dev/null 2>&1
dd if=temp.txt of=/mnt/Freeze/BiscuitOS-Share.txt bs=1 seek=$((100 * 1024 * 1024 - 15)) conv=notrunc > /dev/null 2>&1
rm temp.txt
[ -f /mnt/Freeze/BiscuitOS-Ex.txt ] && rm /mnt/Freeze/BiscuitOS-Ex.txt
echo "** START TEST **"
# Running
SERVER &
sleep 1
PID=$(pidof SERVER)
CLIENT &
perf top -p ${PID} -g --call-graph dwarf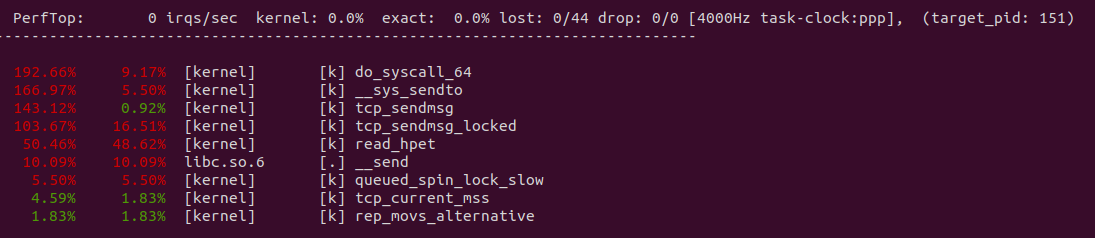
从 perf 获得实时观察系统中正在运行的程序的性能热点,可以看出文件的读写系统调用占了大头,其中包括将数据从文件的 PAGECACHE 里读取到缓存区,然后调用 _copy_from_iter 将数据从缓存区拷贝到内核态的 SOCKET 缓冲区.
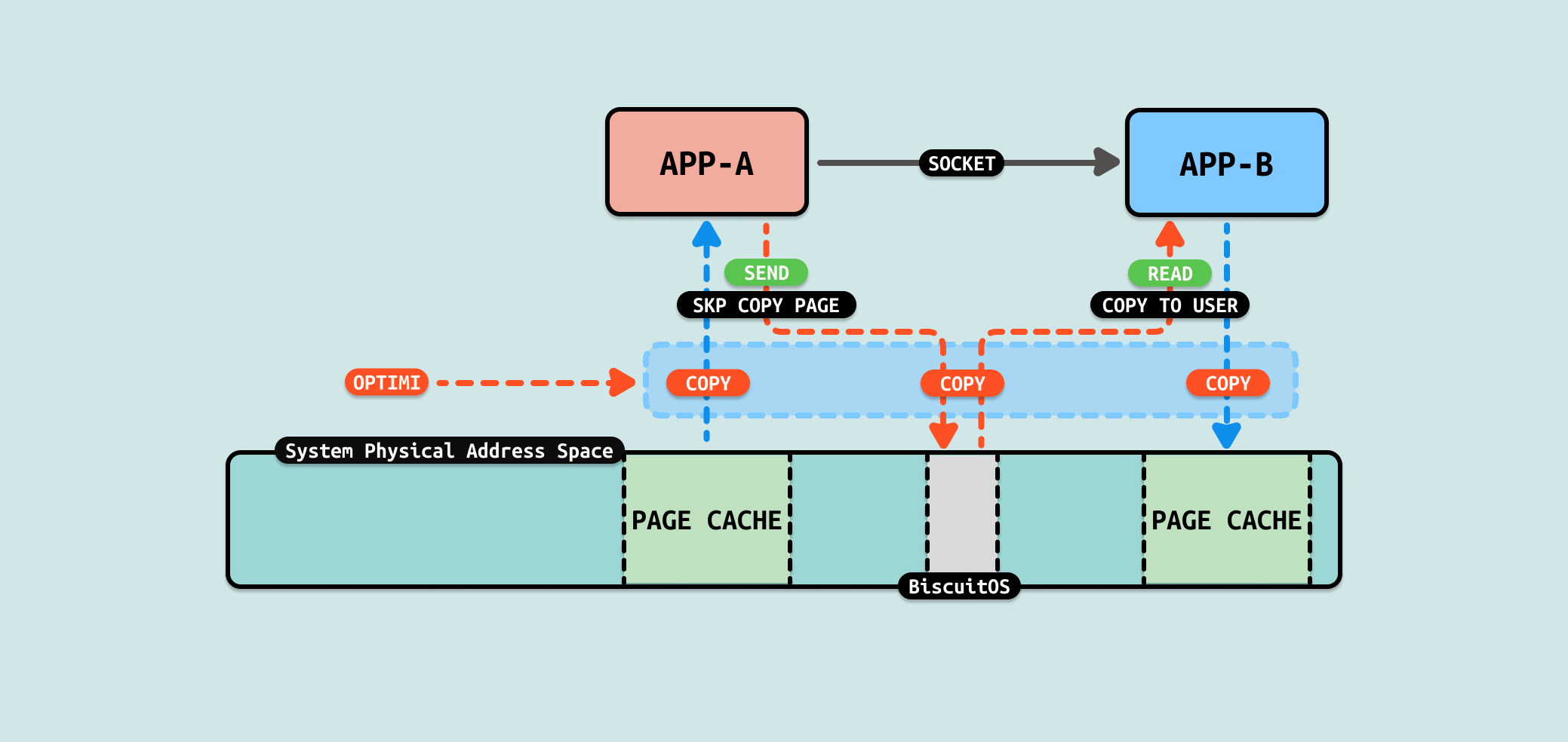
文件数据从内核空间拷贝到用户空间,又从用户空间拷贝到内核空间,只是纯粹的数据拷贝,没有做其他额外的操作,那么这里可以进行优化. 接下来文章讲解如何优化这个过程.


当使用 SOCKET 在两个用户进程之间传递文件数据时,服务器端进程需要从文件中读取数据到用户态缓冲区,然后再将数据从用户态缓冲区写入到 SOCKET 在内核态创建的发送缓冲区. 从发送端分析一下数据流动,首先发送端进程从文件的 PAGECACHE 里将数据从内核态拷贝到用户态缓冲区里,然后将用户态缓冲区的数据拷贝到 SOCKET 内核态的发送缓冲区,在该过程中,并未在用户态缓冲区做任何操作,纯粹拷贝, 因此这里是优化的方向.
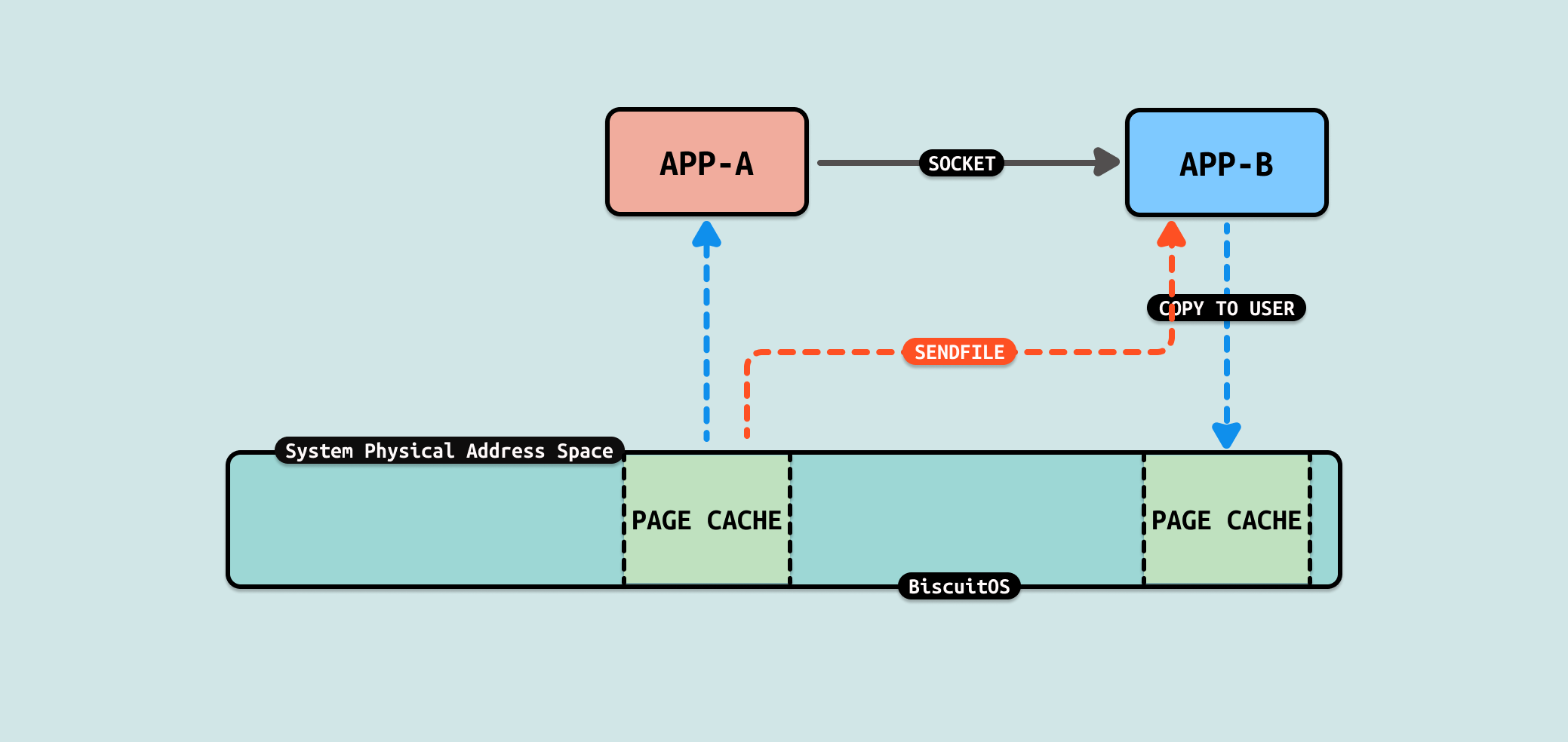
sendfile 是一种用于在两个文件描述符之间直接传输数据的系统调用, 它最常用于将文件数据直接发送到网络套接字(socket)中,而不需要在用户空间缓冲区中经过拷贝. sendfile 的这种直接数据传输方式可以显著提高性能,尤其是在需要传输大量数据时. 由于减少了内核空间与用户空间之间的数据拷贝,sendfile 提高了数据传输的效率,降低了 CPU 的使用率
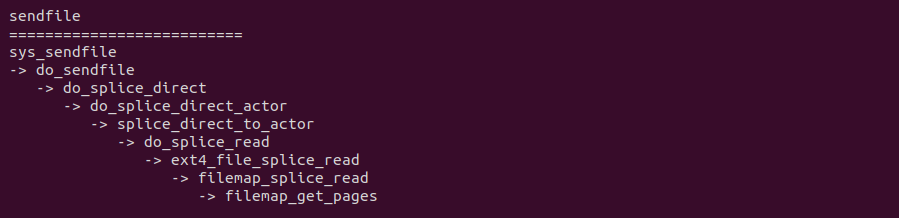
当调用 sendfile 系统调用将数据从文件拷贝到 SOCKET 的代码路径可以看到,其核心依赖于文件系统的具体实现,例如在 EXT4 文件系统,其提供了 ext4_file_splice_read,其核心逻辑是直接将文件的 PAGECACHE 作为 FIFO 的缓冲区,因此直接不需要任何拷贝, 这里创建了一个 FIFO 传递给 SOCKET, SOCKET 直接将这个作为发送缓冲区,因此节省了 2 次拷贝. 接下来通过一个实践案例实际测试其性能,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] Package --->
[*] ZERO COPY MECHANISM
[*] *** Inter-Process Communication(IPC) ***
[*] OPTIMI ZEROCOPY(IPC): Exchange Between SOCKET SENDFILE --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-ZEROCOPY-IPC-SOCKET-SENDFILE-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build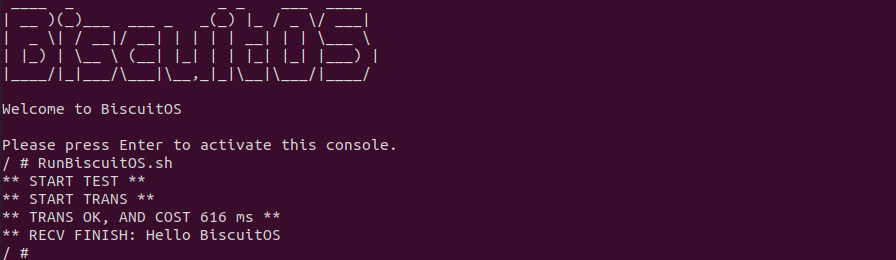
BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了实践案例运行的所有命令,案例包含包含两个用户进程,一个作为客户端,另外一个作为服务器端,当客户端连接到服务器端之后,服务器端用户进程向客户端发送 200M 文件数据,可以看到花费时间 616ms, 接下来分析源码:
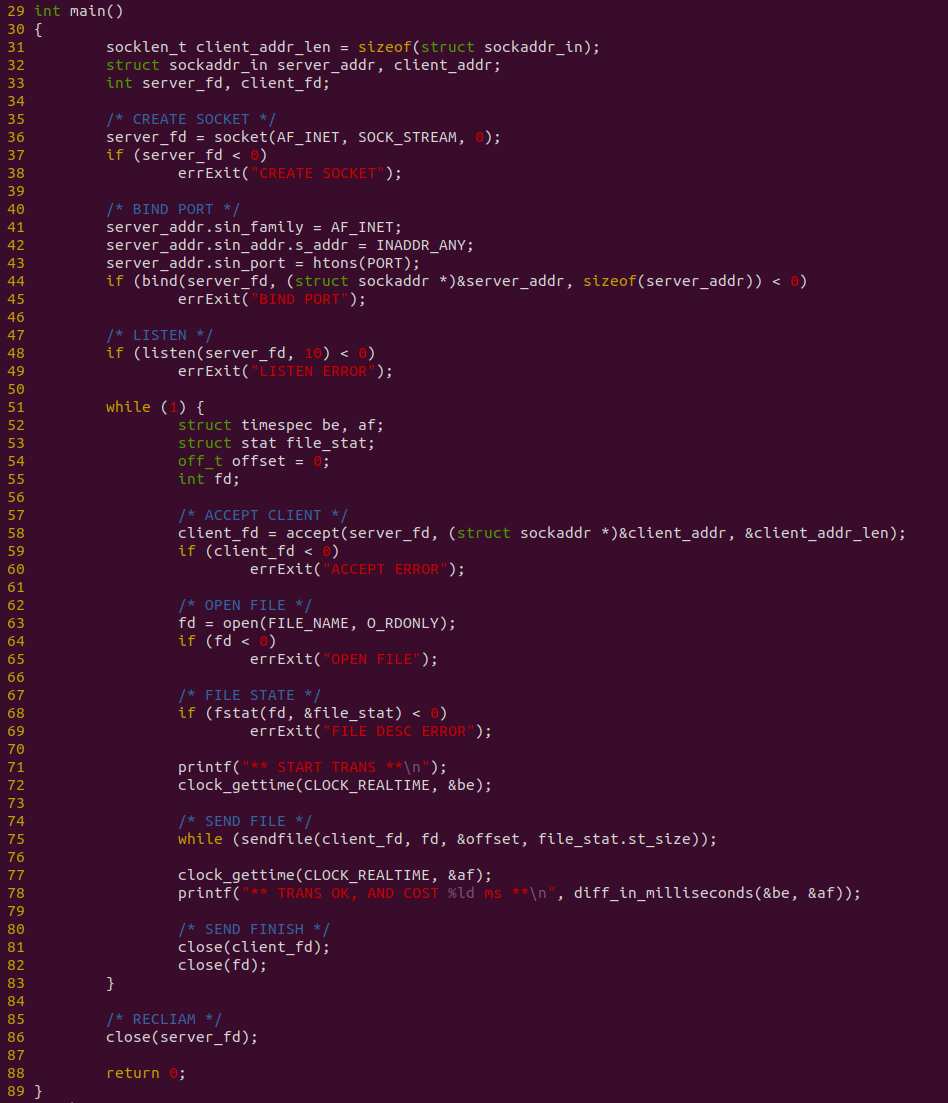
服务器端程序如上图,程序在 36 行调用 socket 函数创建一个 SOCKET,然后在 44 行调用 bind 函数将端口 PORT 绑定到该 SOCKET 上,接着在 48 行调用 listen 开始监听端口,当有服务请求连接时,在 58 行调用 accept 处理连接请求. 连接成功之后,在 63 行调用 open 函数打开一个文件,并在 75 行使用 WHILE 循环使用 sendfile 将文件内容写入到 SOCKET 里,写完之后调用 close 关闭请求. 该过程中,使用 clock_gettime 对文件读取和 SOCKET 发送整个过程进行计时.
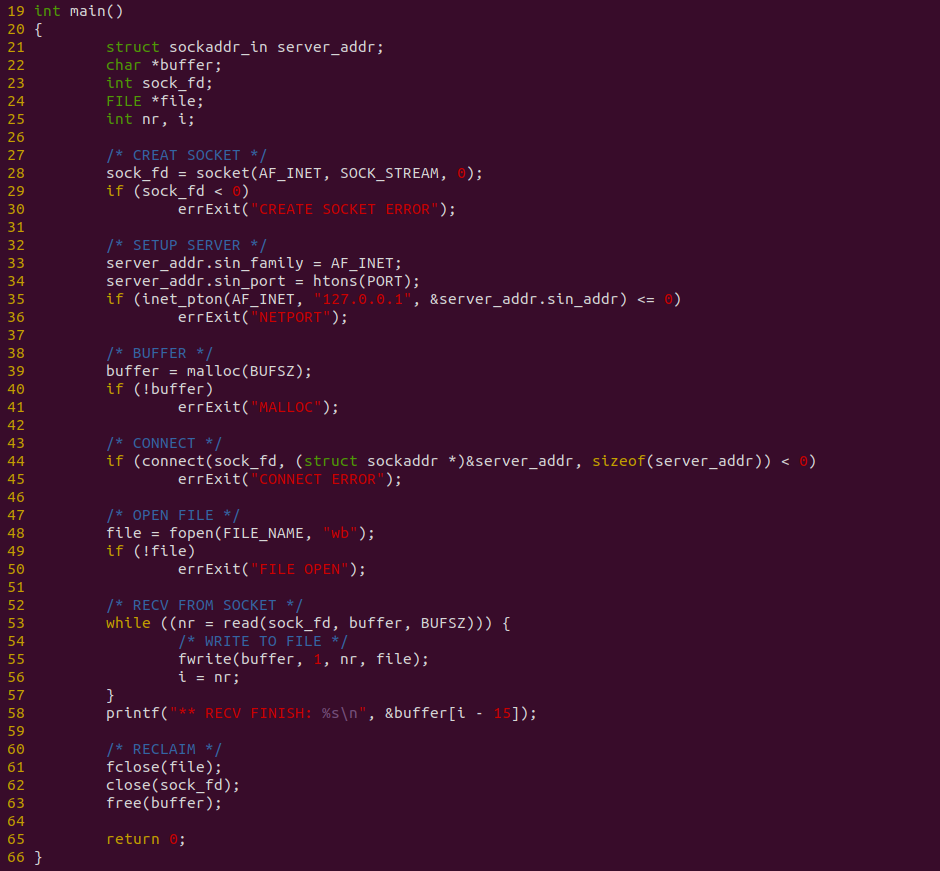
客户端程序如上图,程序在 28 行调用 socket 创建 SOCKET,并在 35 行调用 inet_pton 绑定一个本地 TCP 端口,接着在 39 行创建一个用户态缓冲区,并在 44 行调用 connect 函数连接到服务器端,连接成功之后,在 48 行调用 fopen 打开存储用的文件,然后在 53-54 行使用 WHILE 循环方式从 SOCKET 里读取数据并写入存储文件. 写完之后关闭文件和断开连接等. 接下来对不同数据量进行耗时测试:
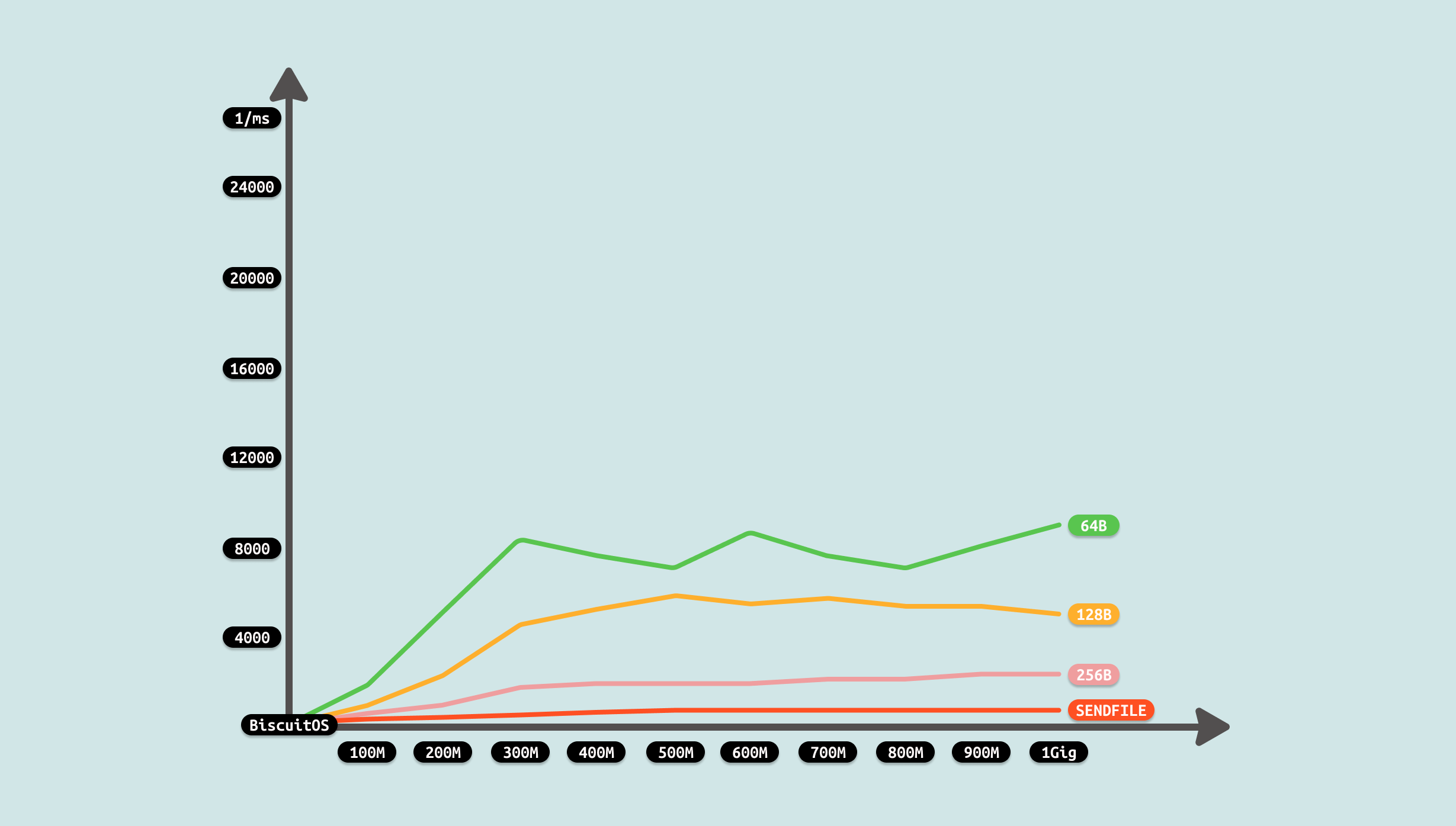
测试过程发现,总耗时大体上随着文件的大小而增加,但不是线性增加,而是稳定在某个区间,此时性能瓶颈可能是网络的拥塞,但整体来看耗时远低于非 SENDFILE SOCKET 方案, 因此优化有效,性能得到很大提升. 因此开发者在遇到相似的 IPC SOCKET 场景时,可以利用该 ZEROCOPY 优化方案进行优化.

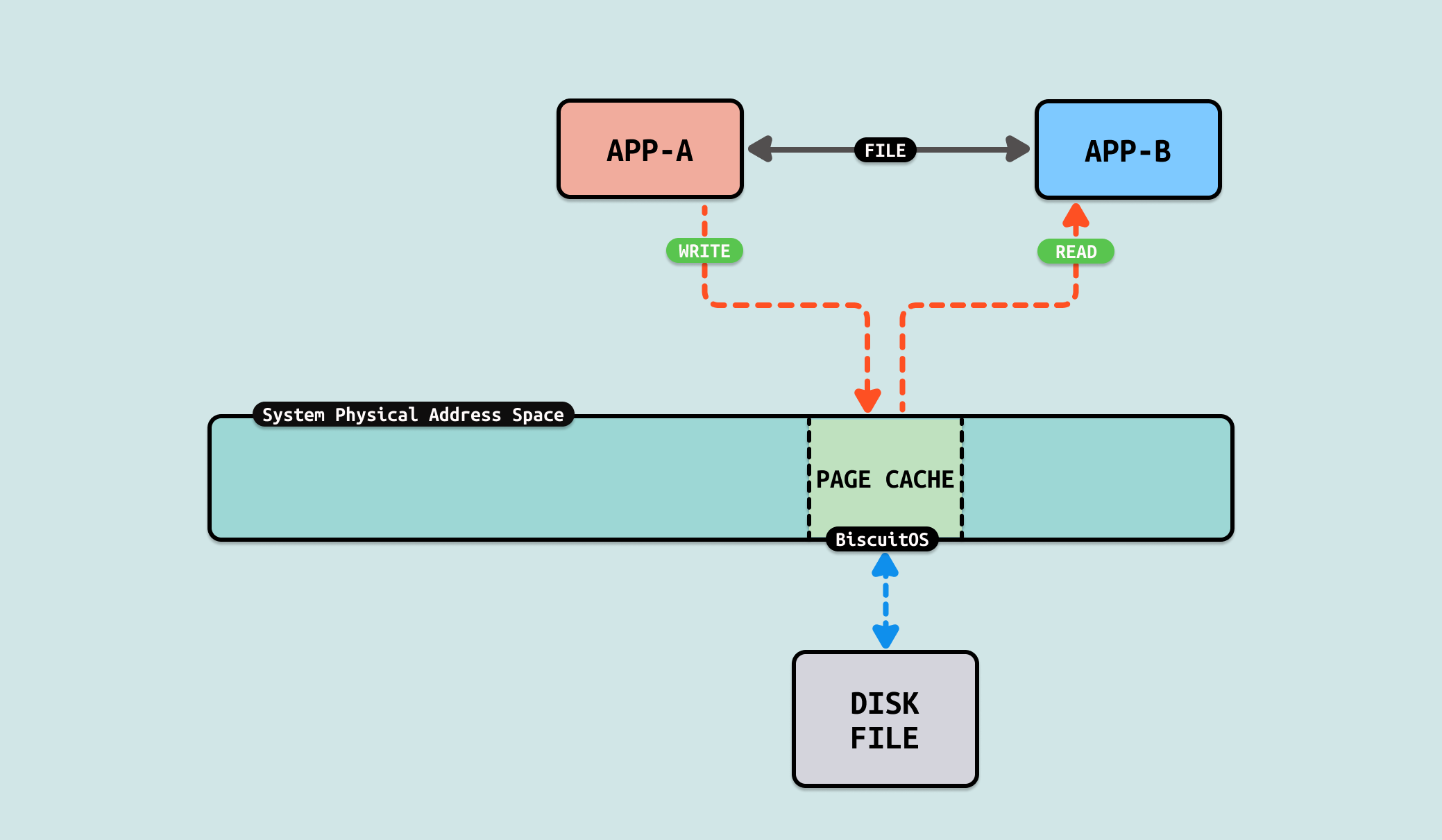
在 UNIX 和类 UNIX 系统中,通过文件实现两个用户进程之间的通信是一种简单而有效的进程间通信(IPC)方式. 两个进程通过共同访问一个或多个文件来实现数据交换. 一个进程可以将数据写入文件,另一个进程随后读取文件以获得数据. 因为文件是持久存储的,所以这种方法不仅适用于并发进程,也适用于时间上不重叠的进程. FILE 使用基本步骤:
- 文件创建: 通常由一个进程负责创建用于通信的文件, 可以使用标准的文件创建和打开系统调用,如 open()、fopen() 等
- 写入数据: 发送方进程将数据写入文件, 写入时要注意文件的同步问题,以避免多个进程同时写入导致的数据混乱
- 文件同步: 如果文件需要在多个进程间共享访问,通常需要某种形式的文件锁或其他同步机制(如 flock())来避免竞争条件
- 读取数据: 接收方进程读取文件中的数据, 读取后接收方可以选择删除文件中的数据或整个文件,以防止重复读取
- 文件清理: 通信结束后,通常需要清理文件,以释放存储空间并防止冗余数据的影响
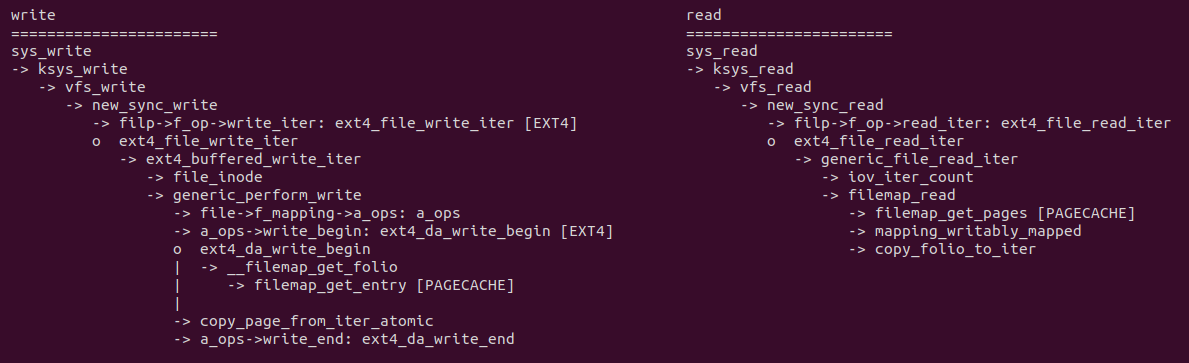
在使用 WRITE 系统调用写文件时,其通过 sys_write 系统调用和 VFS,以及 EXT4 文件找到对应的 PAGECACHE,如上图 ext4_da_write_begin 函数可以获得文件对应的 PAGECACHE,PAGECACHE 也是一个物理页,接着使用 copy_page_from_iter_atomic 函数从用户态缓冲区将数据拷贝到 PAGECACHE 里. 消费者使用 READ 系统调用从文件里读取数据,其通过 sys_read、VFS 和 EXT4 文件系统最终调用 filemap_get_pages 找到对应的 PAGECACHE, 此时该 PAGECACHE 就是之前的被写入数据的物理页,此时使用 copy_folio_to_iter 函数将 PAGECACHE 上的内容拷贝到用户态的缓冲区.
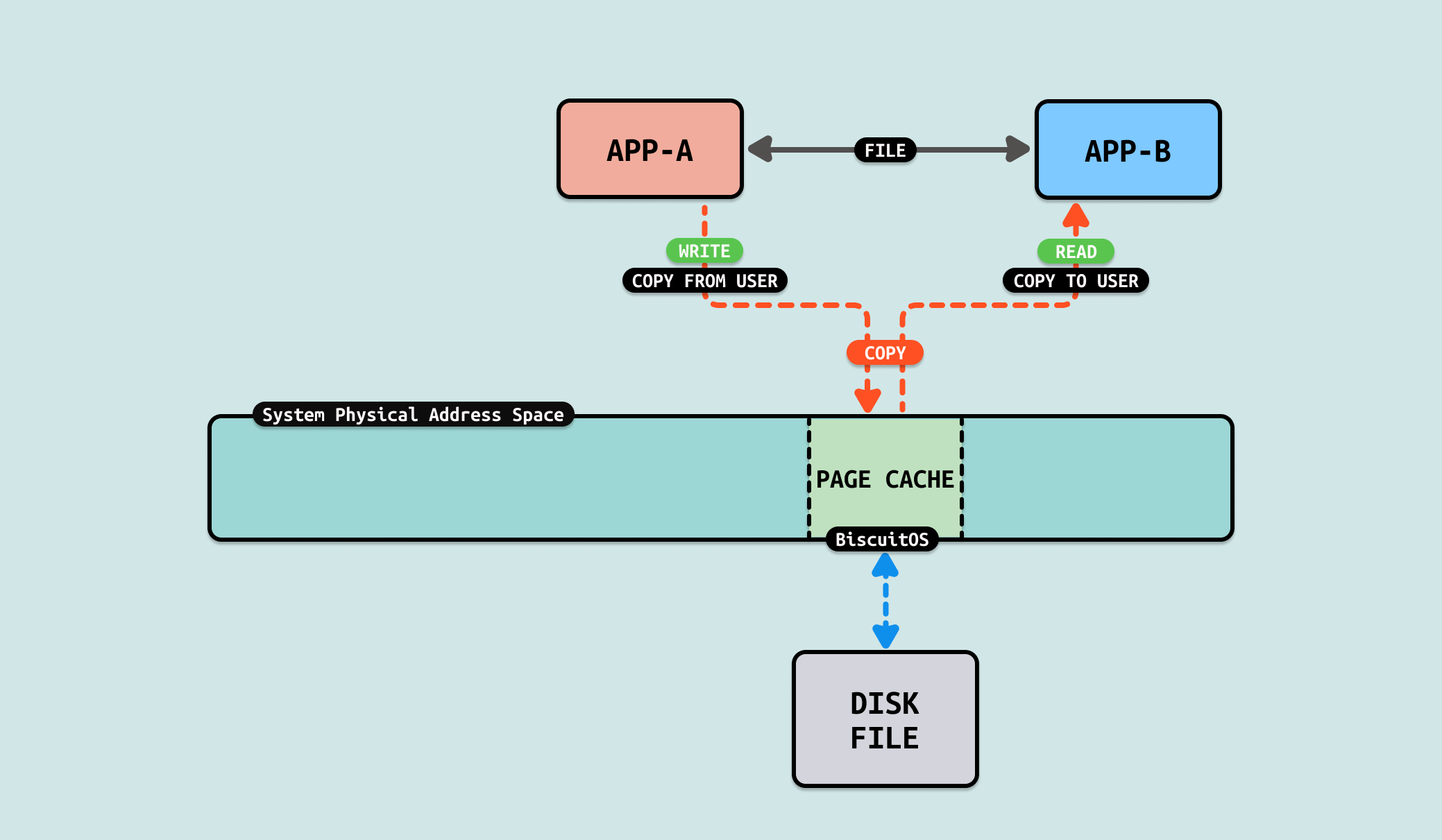
READ/WRITE 操作文件的方法称为 “BUFFER-IO”,可以看到数据从生产者用户空间缓冲区拷贝到文件的 PAGECACHE 里,然后消费者再将 PAGECACHE 的数据拷贝到用户空间的缓冲区里. 从这个流程看出拷贝数据的次数以及每次拷贝大小会是性能瓶颈. 接下来通过一个实践案例实际测试其性能,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] Package --->
[*] ZERO COPY MECHANISM
[*] *** Inter-Process Communication(IPC) ***
[*] FORBID ZEROCOPY(IPC): Exchange Between FILE --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-ZEROCOPY-IPC-FILE-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build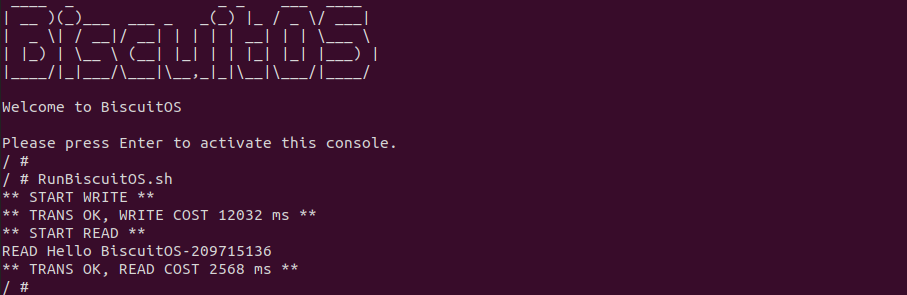
BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了实践案例运行的所有命令,案例包含两个用户进程,其中生产者进程向文件写入 200MB 数据,而消费者在获得文件锁之后,从文件里读取 200MiB 的数据到缓冲区, 可以看到花费时间 12032ms, 接下来分析源码:
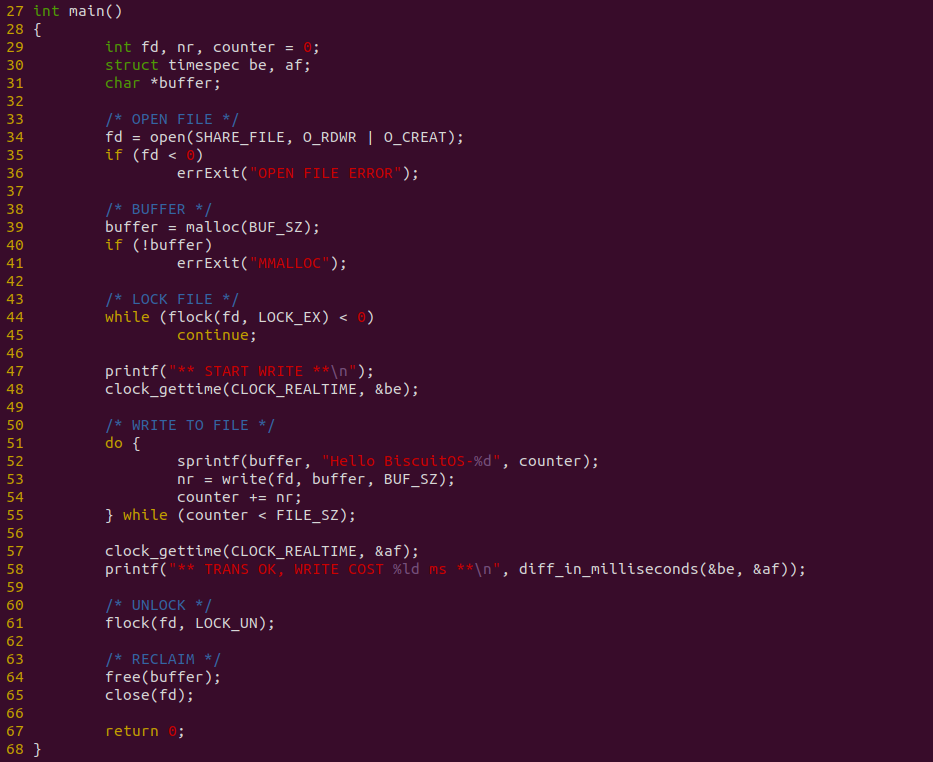
生产者源码如上图,其在 34 行调用 open 系统调用创建一个文件,然后在 39 行调用 malloc 函数创建缓冲区. 44 行调用 flock 获得文件锁,放着消费者读到空数据. 生产者接着在 51-55 行使用循环,先在缓冲区写入数据,然后调用 write 函数将缓冲区数据写入到文件里. 操作完毕之后在 61 行释放文件锁,并对写文件进行计时.
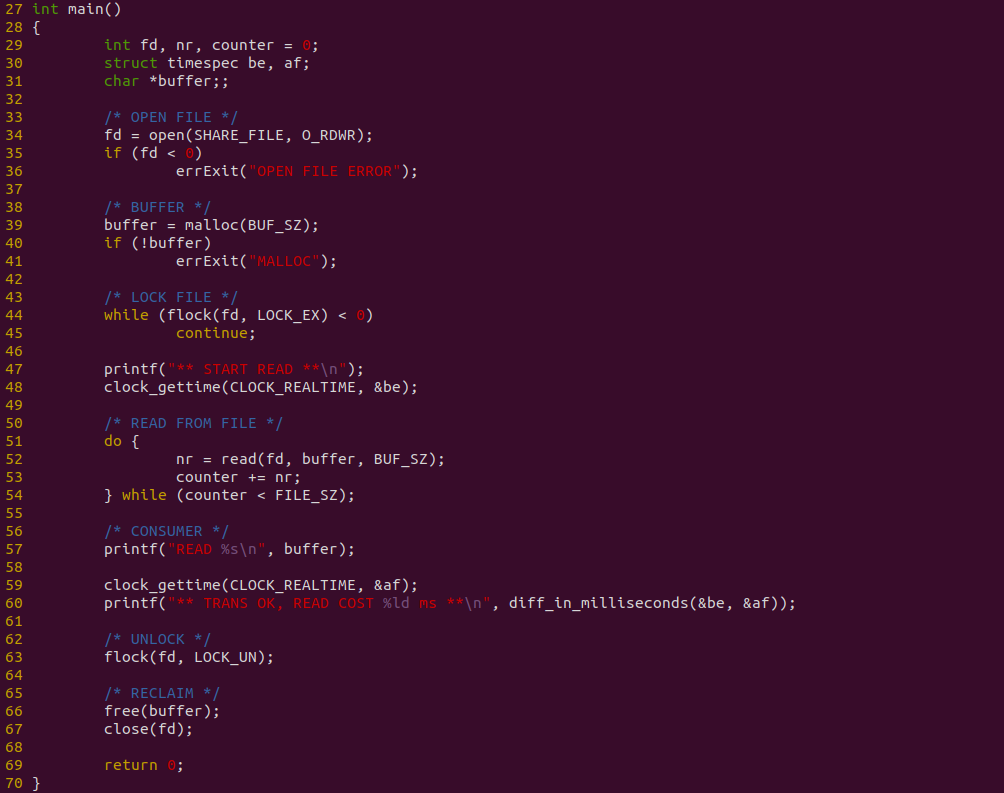
消费者源码如上图,其在 34 行调用 open 系统调用打开文件,然后在 39 行调用 malloc 函数创建缓冲区,接着在 44 行调用 flock 获得文件锁,以防止读到空数据. 接着在 51-54 行使用 DO-WHILE 循环,调用 read 函数从文件读取数据到缓冲区 buffeer,最后在 57 行打印缓冲区的数据. 对整个读文件进行计时. 接下来对不同的数据量进行耗时测试:
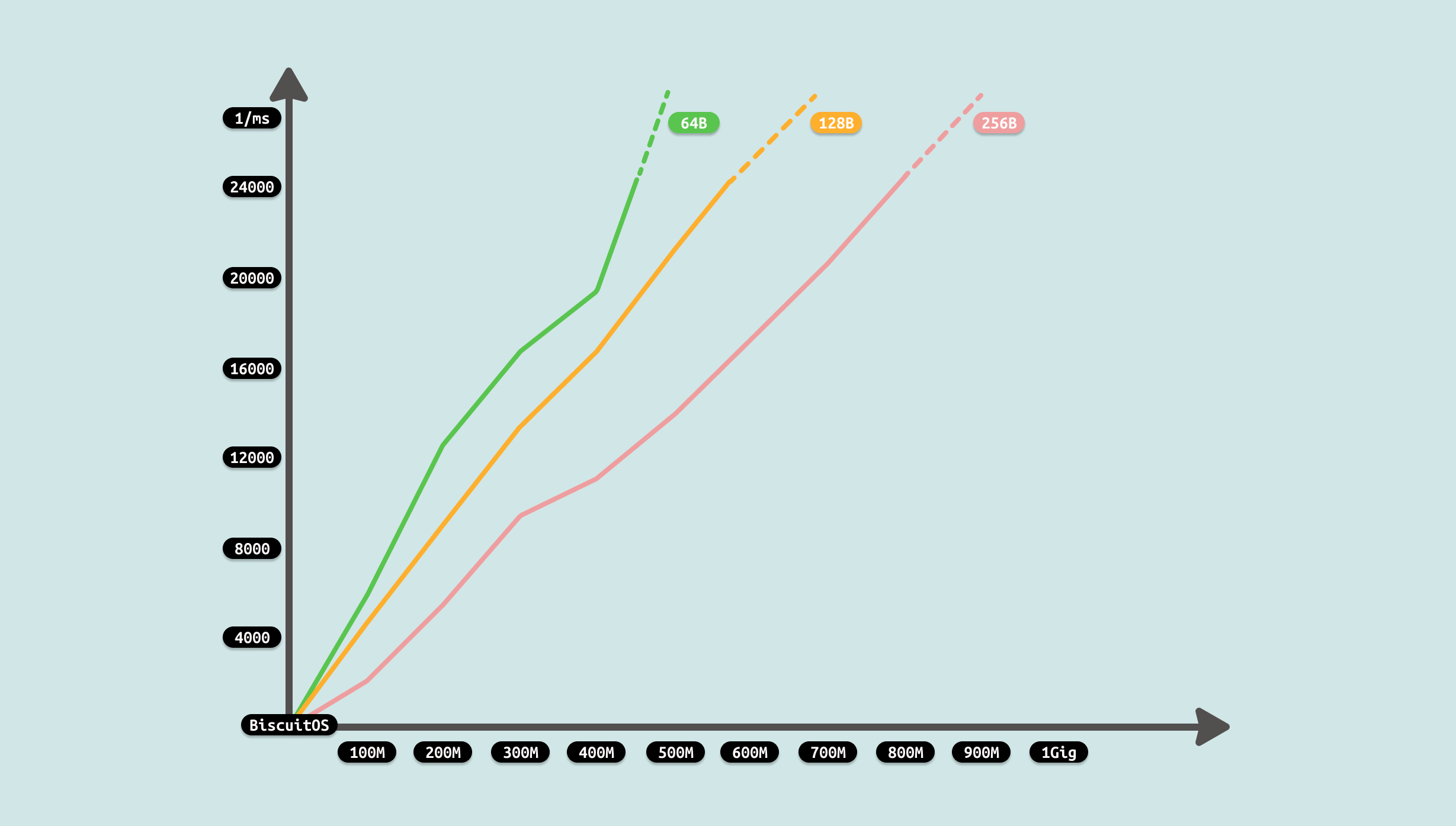
由于计时包括生产者写文件和消费者读文件,因此测试从两个维度进行,首先是传输数据总量,其次是每次读写的数据量. 从传输数据总量来看,数据总量越大,耗时越多,并且趋向线性增长. 另外从每次读写数据量来看,每次读写数据量越大,耗时越少,并且趋向线性关系. 因此可以看到数据拷贝已经成为了性能的瓶颈,在数据总量不变的情况下,减少拷贝次数可以减少耗时. 接下来使用如下命令分析哪个函数比较消耗 CPU:
# Running
PRODUCT &
PID=$(pidof PRODUCT)
sleep 1
#CONSUMER &
perf top -p ${PID} -g --call-graph dwarf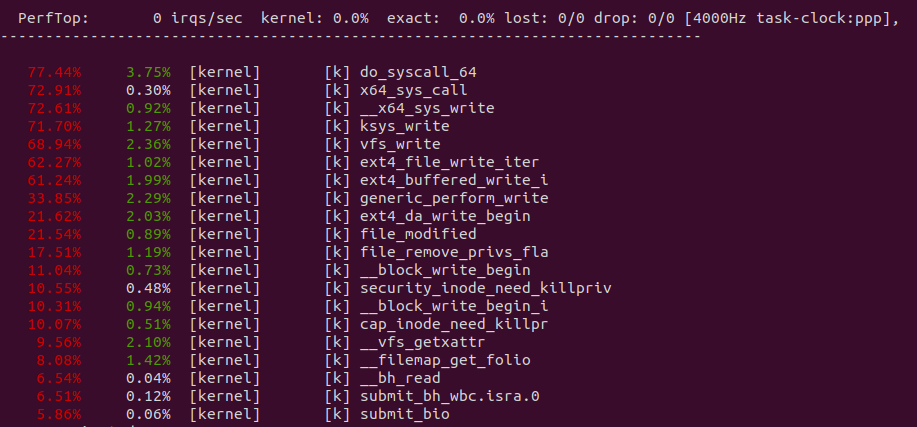
从 perf 获得实时耗时数据,可以看到写文件系统调用最耗时,其中 copy_page_from_iter_atomic 是耗时点,同理消费者读系统调用也是耗时点.
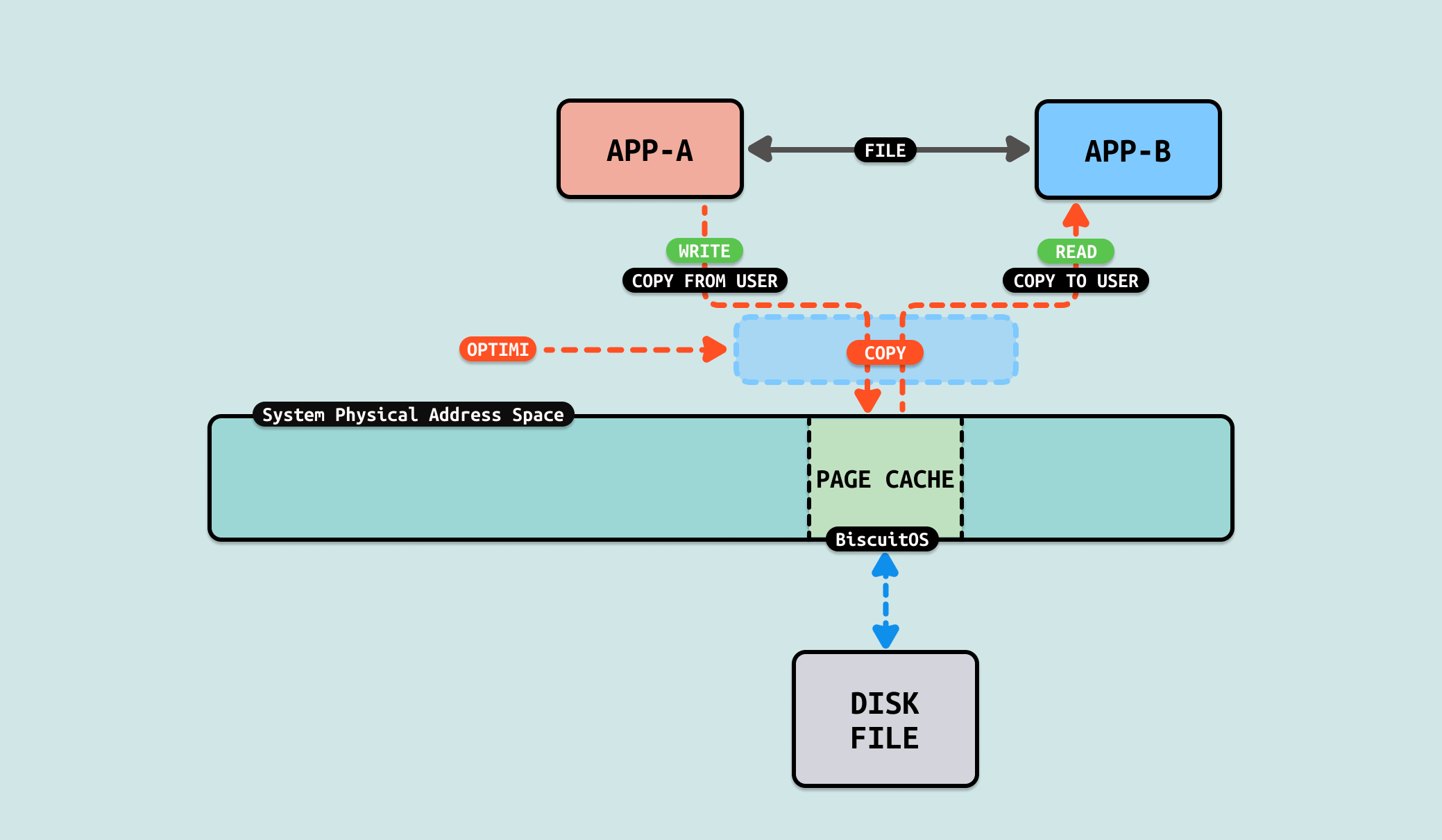
数据从生产者缓冲区拷贝到文件的 PAGECACHE,然后从文件的 PAGECACHE 拷贝到消费者的缓冲区,这里包括 2 次拷贝并且这两次拷贝并没有对数据进行额外处理,仅仅是拷贝,因此可以从这两次拷贝作为切入点进行优化,具体优化方案如下:





当使用文件在两个进程或者多个进程之间共享数据,以此实现进程间的通信. 在该方案中,生产者会将需要共享的数据从用户态的缓冲区写入文件,写入过程中,内核会将写入的数据由生产者缓冲区拷贝到文件对应的 PAGECACHE 里. 接着消费者从文件里读取共享的数据,此时内核从文件对应的 PAGECACHE 将数据拷贝到消费者缓冲区里. 通过这样的方法,用户进程间可以实现通信.
该方案里,生产者和消费者为了传递数据,需要在两者的缓冲区和文件 PAGECACHE 之间完成两次拷贝,才能完成信息交换,交换过程中只是对数据拷贝,并没有对数据其他处理.
另外随着交换数据量变大,整体耗时也在不断增大. 另外在交换数据量不变的情况下,读写次数越多,也就是每次读写量变小,耗时也会增加. 因此要让进程间通信更快速,可以从优化拷贝策略入手.
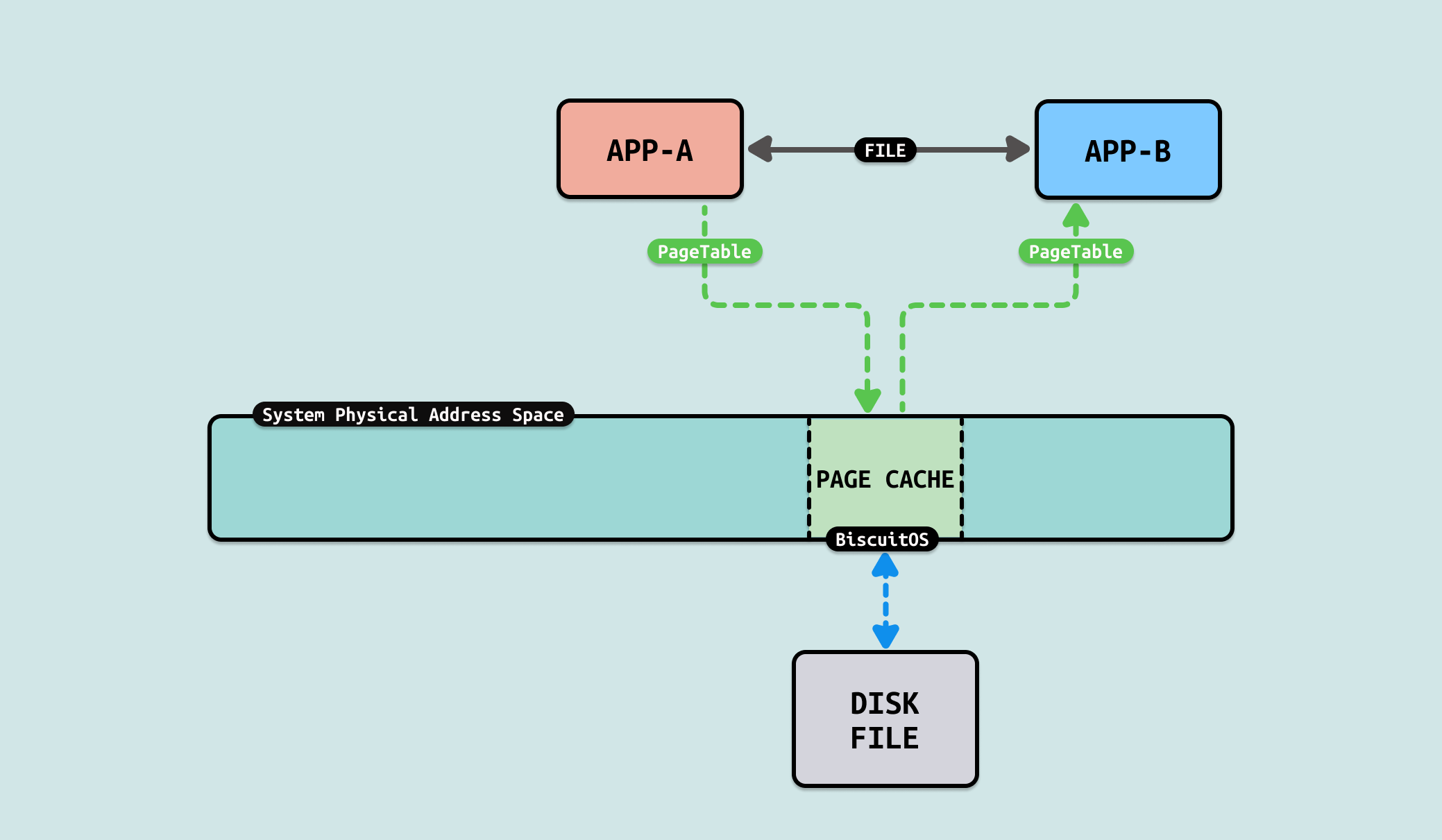
File-Mapping(文件映射)是一种常用的内存机制,其从用户空间分配一段内存,并将虚拟内存映射到文件的 PAGECACHE 上,然后可以向操作内存一样操纵文件. 与 BUFFER-IO(read/write) 方案相比,用户进程无需在缓冲区和 PAGECACHE 之间拷贝数据来读取文件,而是直接读取虚拟内存就可以访问文件. 因此在进程通信里,可以使用 File-MApping 方案加速数据交互.
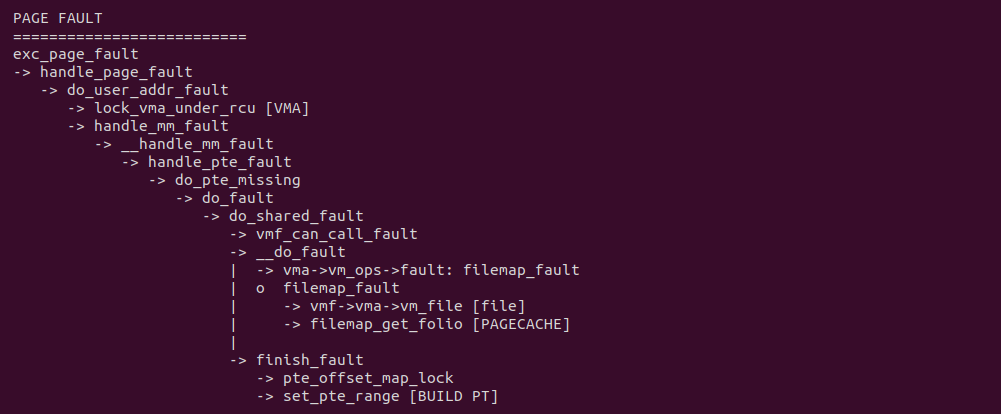
当生产者或者消费者将文件映射到各自的虚拟地址空间之后,对其访问会触发缺页异常,在缺页异常处理函数里,do_shared_fault 逻辑会被调用,其首先找到虚拟内存映射的文件,然后从文件里找到对应的 PAGECACHE,最后在 finish_fault 逻辑里建立好页表. 当缺页异常处理函数返回之后,生产者和消费者可以直接访问虚拟内存,并通过一些同步机制实现数据交互. 对比原先的 FILE 方式,生产者和消费者之间没有任何的拷贝操作,因此节省 2 次拷贝. 接下来通过一个实践案例实际测试其性能,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] Package --->
[*] ZERO COPY MECHANISM
[*] *** Inter-Process Communication(IPC) ***
[*] OPTIMI ZEROCOPY(IPC): Exchange Between FILE MAPPING --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-ZEROCOPY-IPC-FILE-MMAP-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build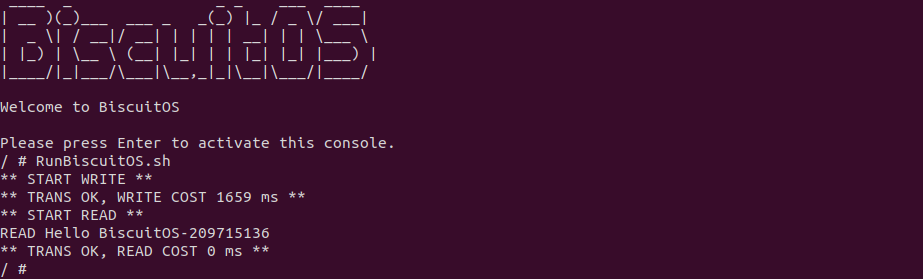
BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了实践案例运行的所有命令,案例包含包含两个用户进程,一个作为生产者,另外一个作为消费者,生产者用户进程向消费者进程发送 200M 文件数据,可以看到花费时间 1659ms, 接下来分析源码:
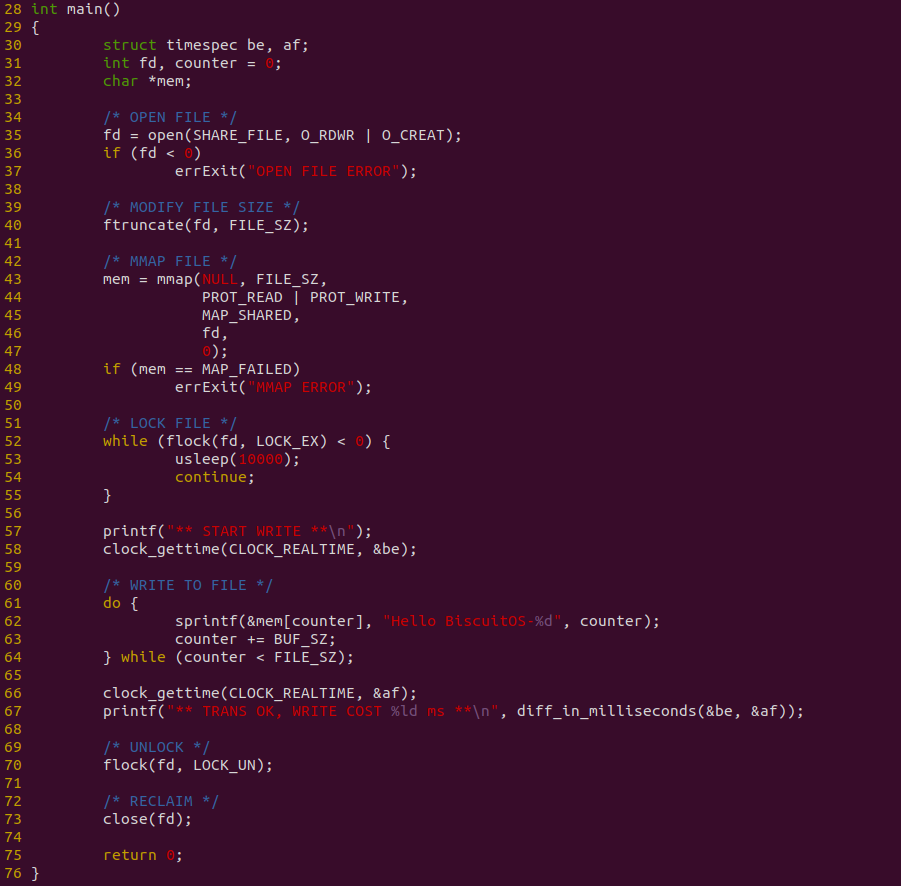
生产者程序如上图,程序在 35 行调用 open 函数打开共享文件,然后在 40 行将共享文件长度设置为共享区的大小,接着在 43 行调用 mmap 函数将文件映射到生产者用户空间,然后在 52 行调用 flock 函数获得文件锁,以此避免消费者读到空内容. 接下来在 61-64 行使用 DO-WHILE 循环向共享区域写入数据,此时的写入是 62 行内存一样的写入. 程序对整个写入过程进行计时.
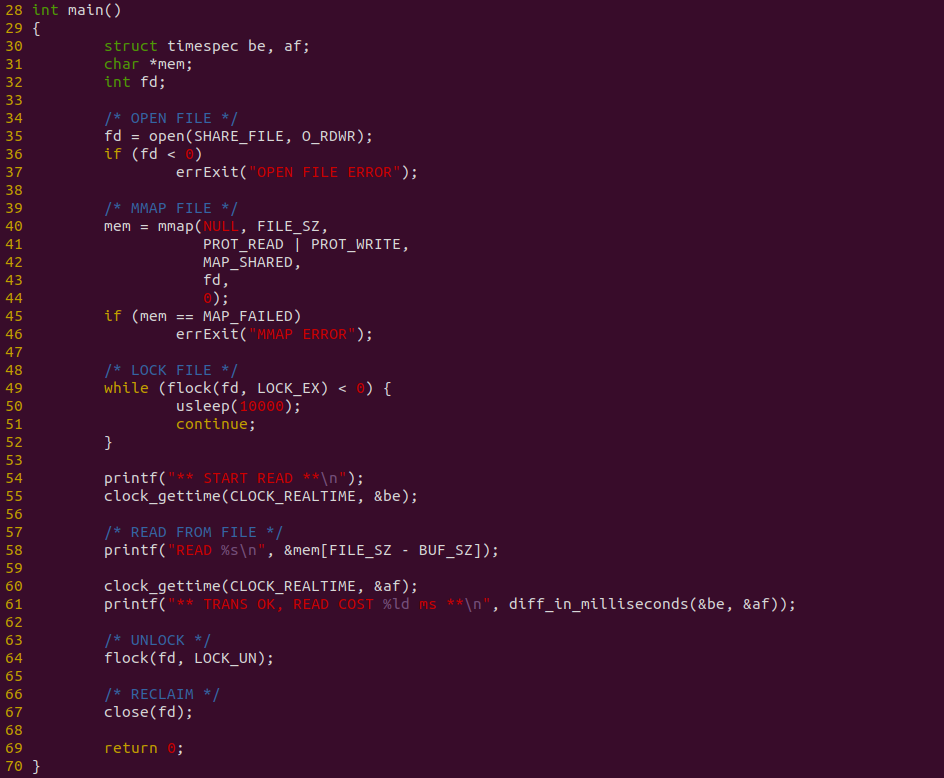
消费者程序如上图,程序在 35 行调用 open 函数打开共享文件,然后在 40 行调用 mmap 将文件映射到消费者虚拟空间,并在 49 行调用 flock 函数获得文件锁,以此按正确的顺序获得数据. 程序直接在 58 行使用访问内存方式直接读取数据. 程序对整个读取数据进行计时. 接下来对不同的数据量进行耗时测试:
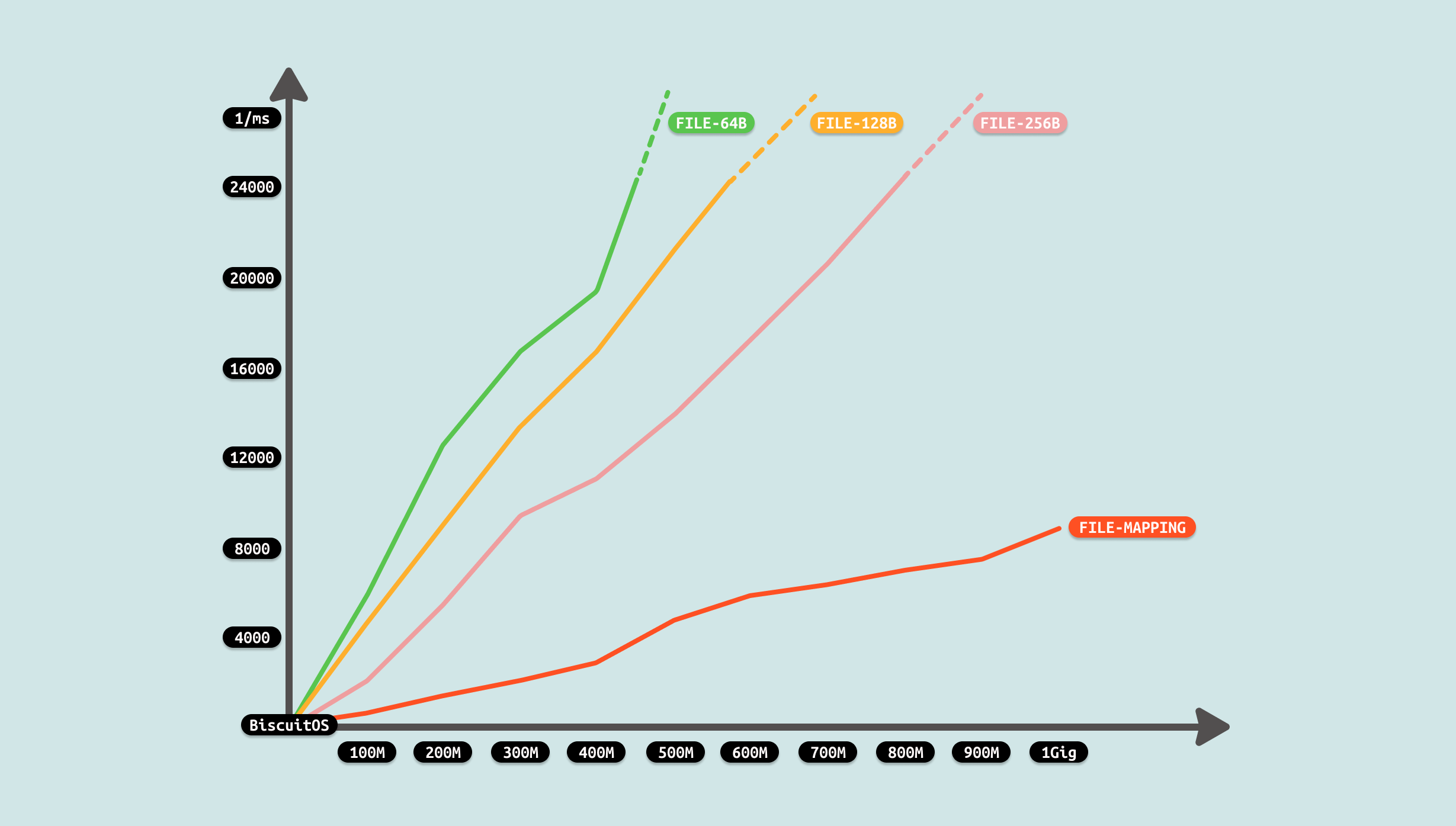
测试过程发现,生产者制造数据需要花费一些时间,并且这个时间随着数据量变大而变大,且是线性增加. 对于消费者来说,其已经不需额外的拷贝,直接读数据,因此耗时为 0. 整体耗时降低很多,因此优化成功. 因此开发者在遇到相似的 IPC FILE 场景时,可以利用该 ZEROCOPY 优化方案进行优化.

当使用文件在两个进程或者多个进程之间共享数据,以此实现进程间的通信. 在该方案中,生产者会将需要共享的数据从用户态的缓冲区写入文件,写入过程中,内核会将写入的数据由生产者缓冲区拷贝到文件对应的 PAGECACHE 里. 接着消费者从文件里读取共享的数据,此时内核从文件对应的 PAGECACHE 将数据拷贝到消费者缓冲区里. 通过这样的方法,用户进程间可以实现通信.
该方案里,生产者和消费者为了传递数据,需要在两者的缓冲区和文件 PAGECACHE 之间完成两次拷贝,才能完成信息交换,交换过程中只是对数据拷贝,并没有对数据其他处理.
另外随着交换数据量变大,整体耗时也在不断增大. 另外在交换数据量不变的情况下,读写次数越多,也就是每次读写量变小,耗时也会增加. 因此要让进程间通信更快速,可以从优化拷贝策略入手.
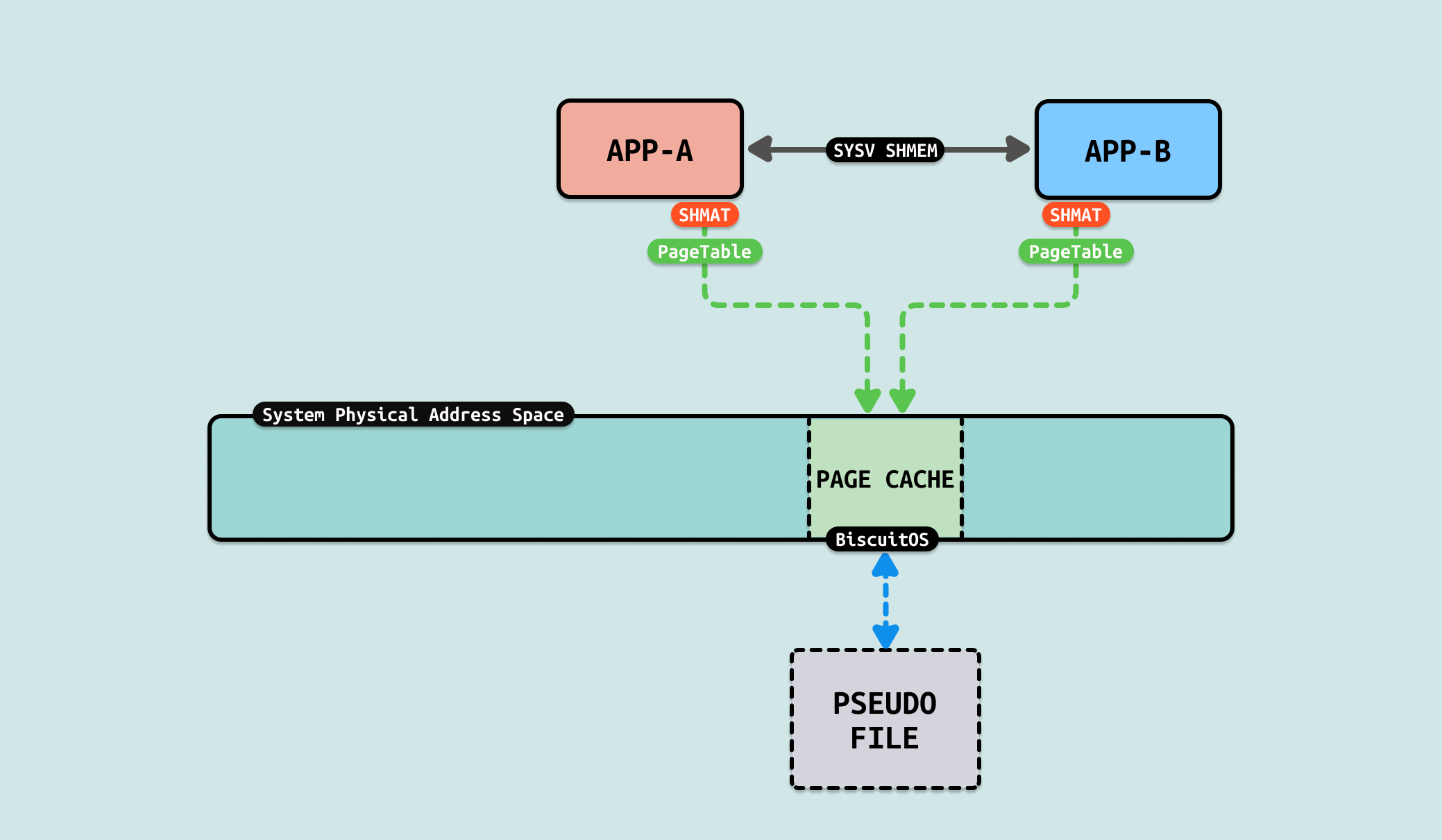
SystemV Shared Memory 是 Linux 和类 Unix 系统中一种基于 System V IPC(进程间通信)机制的共享内存实现方式. 它允许多个进程通过共享的内存区域进行通信和数据交换,提供了一种高效的进程间通信方法. 共享内存是所有 IPC 中速度最快的方式,因为它直接利用内存进行数据交换,而不需要通过内核进行额外的数据拷贝. 共享内存本质上是多个进程能够同时访问的资源,因此需要使用信号量或其他同步机制来保证数据的正确性. 使用 SystemV 共享内存需要通过一系列系统调用来操作:
- shmget: 用于创建一个新的共享内存段或获取一个现有的共享内存段
- shmat: 用于将共享内存段映射到当前进程的地址空间,返回共享内存段的起始地址
- shmdt: 用于将共享内存段从进程地址空间中分离
- shmctl: 用于执行共享内存段的各种控制操作,例如修改权限、销毁共享内存段等
相比使用 FILE 作为媒介进行进程间通信,SystemV 共享内存不需要依赖文件,这样可以节省存储文件数据的空间,因此在进程通信里,可以使用 “SystemV 共享内存” 方案加速数据交付.
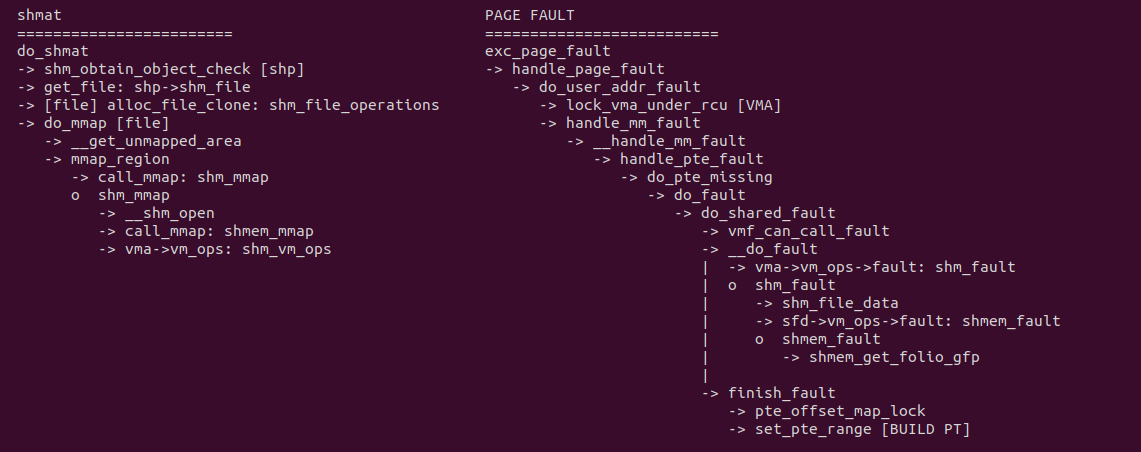
生产者/消费者使用 shmat 分配共享内存,内核会为共享内存先创建一个文件,并将文件的操作函数设置为 shm_file_operations, 接着使用 do_mmap 函数从用户进程的地址空间分配一段内存映射该文件. 与 FILE MAPING 方案相比其并不需要一个真实的持久文件,内核最后将 VMA 的操作函数设置为: shm_vm_ops. 当生产者或消费者访问这段共享内存时,由于没有页表触发缺页,缺页处理函数采用 do_shared_fault 逻辑,并最终使用 shmem_fault 函数分配共享内存使用的物理内存,最后使用 finish_fault 函数建立共享内存到物理内存的页表映射. 对比原先的 FILE 方式,生产者和消费者之间没有任何的拷贝操作,因此节省 2 次拷贝. 接下来通过一个实践案例实际测试其性能,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] Package --->
[*] ZERO COPY MECHANISM
[*] *** Inter-Process Communication(IPC) ***
[*] OPTIMI ZEROCOPY(IPC): Exchange Between SYSV SHMEM --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-ZEROCOPY-IPC-SYSV-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build
BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了实践案例运行的所有命令,案例包含包含两个用户进程,一个作为生产者,另外一个作为消费者,生产者用户进程向消费者进程发送 200M 文件数据,可以看到花费时间 1387ms, 接下来分析源码:
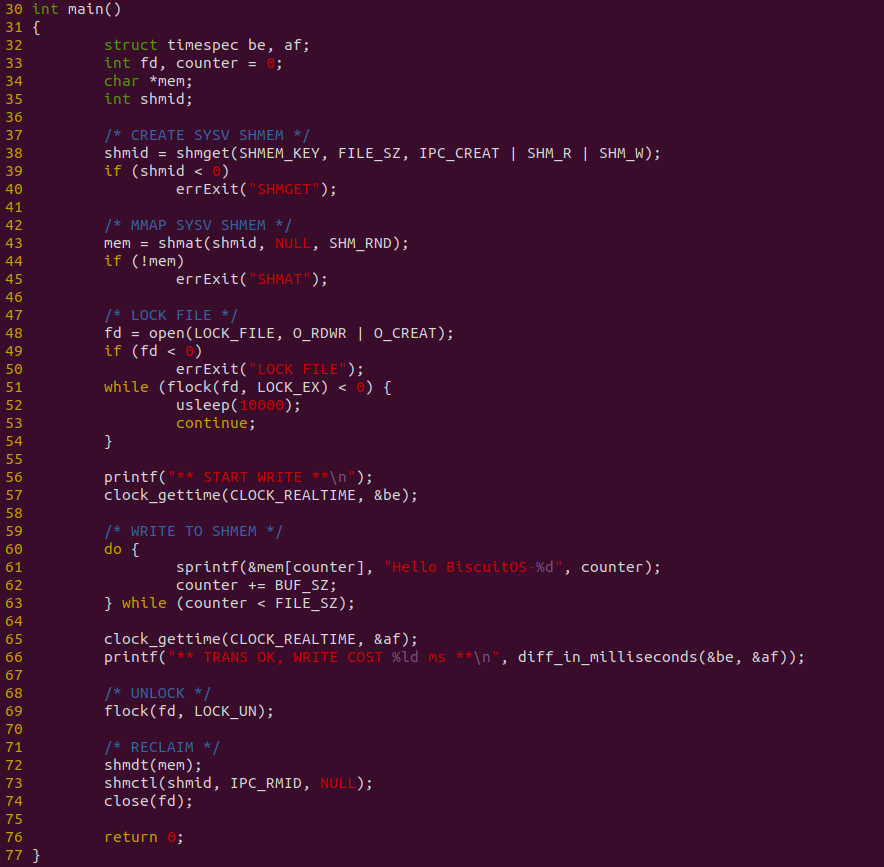
生产者程序如上图,程序在 38 行调用 shmget 创建一段共享内存,然后在 43 行调用 shmat 将共享内存映射到进程的地址空间,并子啊 48 行调用 flock 获得文件锁,以此保证消费者读到正确的数据. 程序接着在 60-63 行使用 DO-WHILE 循环向共享区域直接写入数据, 并且对整个写入过程进行计时.
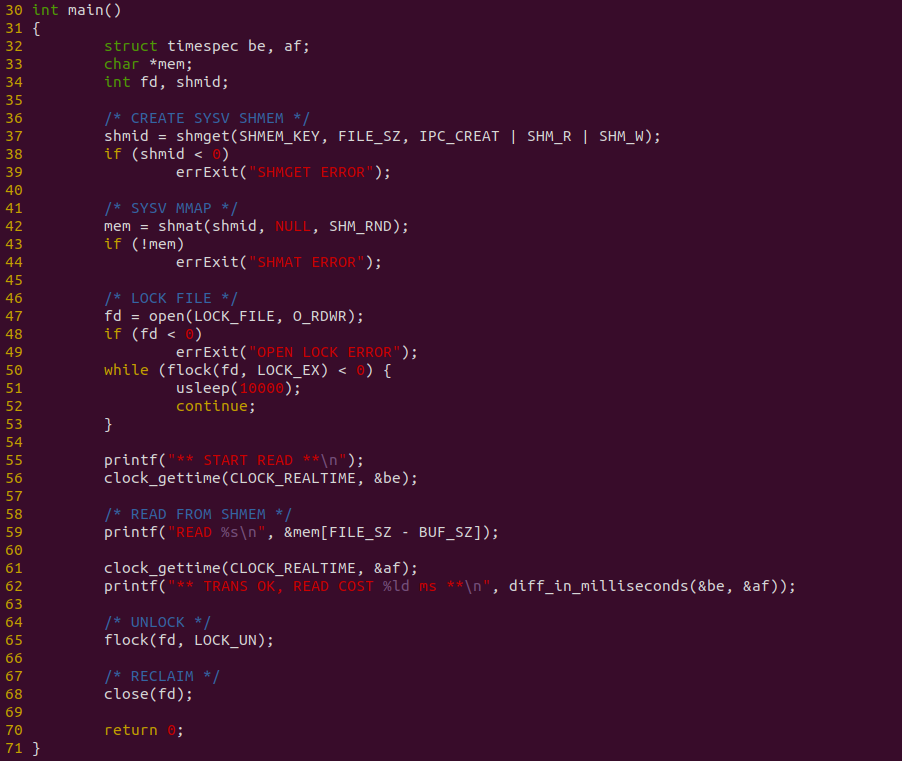
消费者程序如上图,程序在 37 行调用 shmget 获得共享内存信息,然后在 42 行调用 shmat 函数将共享内存映射到进程地址空间,并在 50 行 flock 函数获得文件锁,以此通过正确的顺序读到正确的数据. 程序在 59 行直接从共享内存里读取数据, 并对整个读取过程计时. 接下来对不同的数据量进行耗时测试:
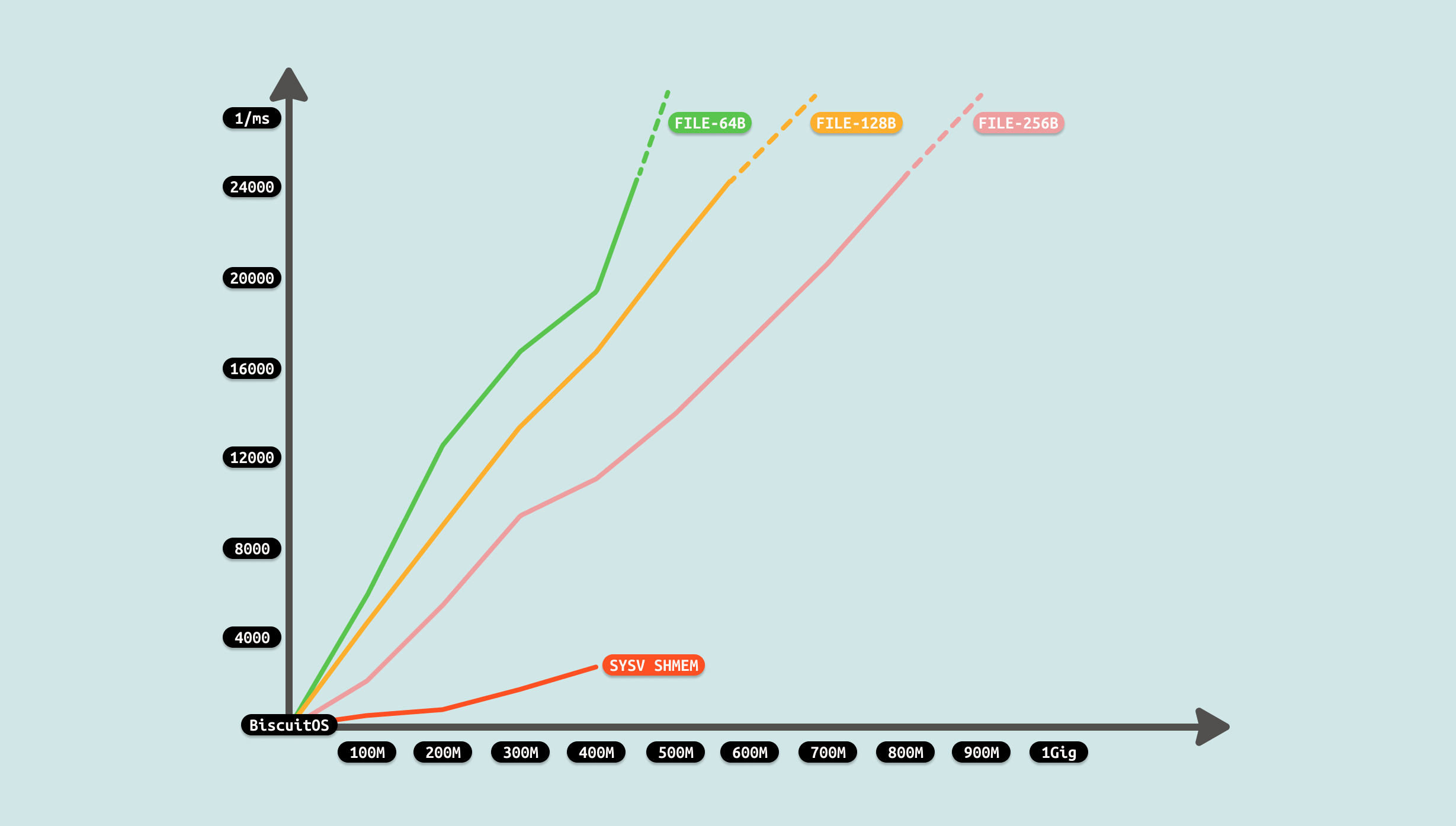
测试过程发现,生产者制造数据需要花费一些时间,并且这个时间随着数据量变大而变大,且是线性增加. 对于消费者来说,其已经不需额外的拷贝,直接读数据,因此耗时为 0. 整体耗时降低很多,对比 FILE 方案优化成功. 从测试可以看出,共享区域最大只能是 524288000B, 因此开发者在遇到相似的 IPC FILE 场景时,可以利用该 ZEROCOPY 优化方案进行优化.

当使用文件在两个进程或者多个进程之间共享数据,以此实现进程间的通信. 在该方案中,生产者会将需要共享的数据从用户态的缓冲区写入文件,写入过程中,内核会将写入的数据由生产者缓冲区拷贝到文件对应的 PAGECACHE 里. 接着消费者从文件里读取共享的数据,此时内核从文件对应的 PAGECACHE 将数据拷贝到消费者缓冲区里. 通过这样的方法,用户进程间可以实现通信.
该方案里,生产者和消费者为了传递数据,需要在两者的缓冲区和文件 PAGECACHE 之间完成两次拷贝,才能完成信息交换,交换过程中只是对数据拷贝,并没有对数据其他处理.
另外随着交换数据量变大,整体耗时也在不断增大. 另外在交换数据量不变的情况下,读写次数越多,也就是每次读写量变小,耗时也会增加. 因此要让进程间通信更快速,可以从优化拷贝策略入手.
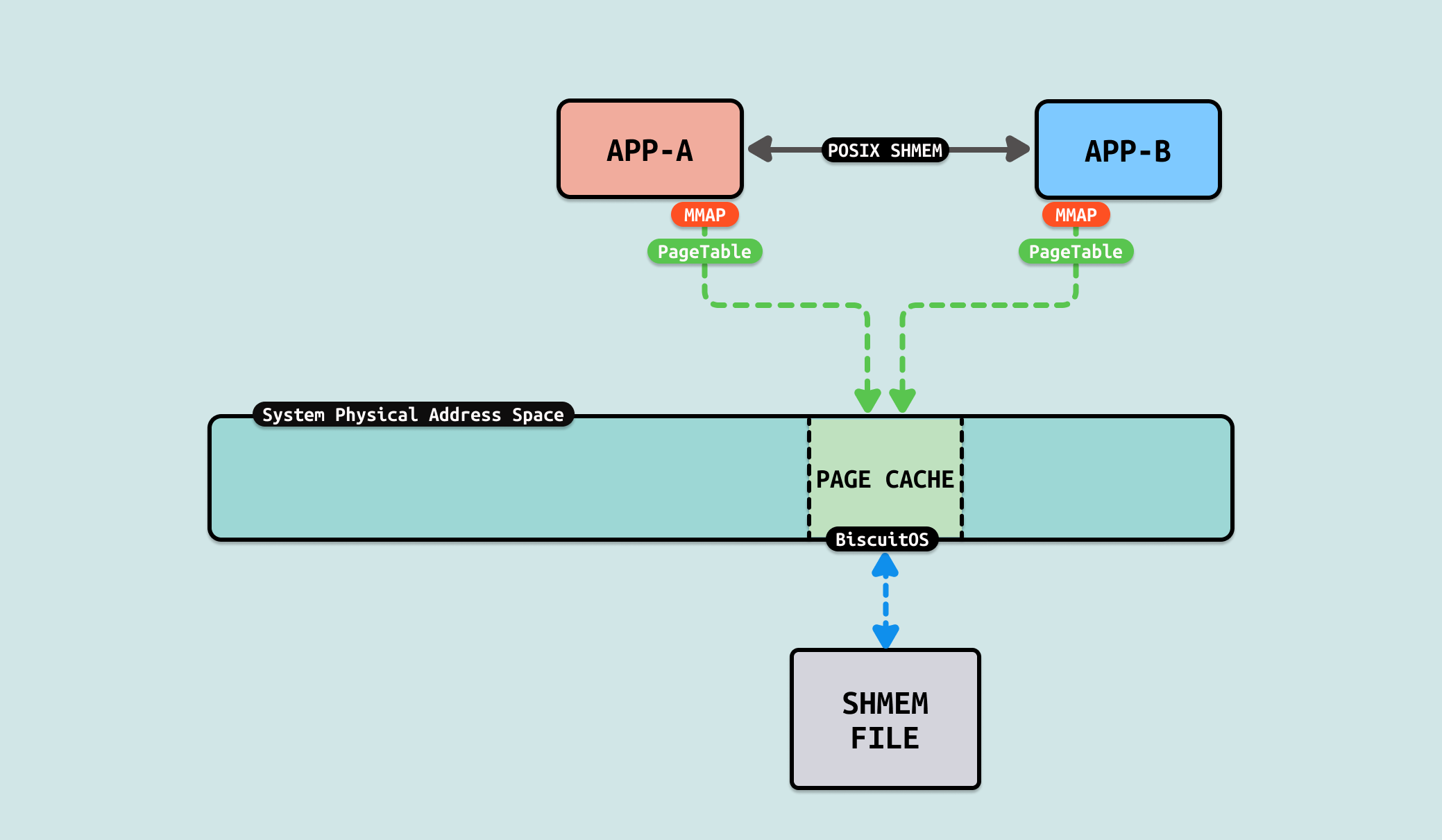
POSIX Shared Memory 是基于 POSIX 标准的共享内存机制,专用于支持进程间通信, 该机制允许多个进程共享同一块内存区域以便实现数据交换,是 Linux 中的一个重要特性. POSIX 共享内存使用 “/dev/shm” 的文件系统命名空间. 共享内存对象可以通过名称进行创建和访问,这个名称类似于文件路径. 共享内存对象通过文件描述符进行管理,可以使用标准文件操作(如 mmap、ftruncate 等)进行内存映射和大小调整. 共享内存对象具有权限控制机制,支持设置读写权限. 与 SYSV SHMEM 相比,POSIX SHMEM 的接口更简单和直接,使用起来更为便利, 其提供如下接口:
- shm_open: 用于创建或打开一个共享内存对象
- mmap: 用于将共享内存对象映射到进程的地址空间
- ftruncate: 用于设置共享内存对象的大小
- shm_unlink: 用于销毁共享内存对象
相比使用 FILE 作为媒介进行进程间通信,POSIX 共享内存不需要依赖特定文件,这样可以节省存储文件数据的空间,因此在进程通信里,可以使用 “POSIX 共享内存” 方案加速数据交付.
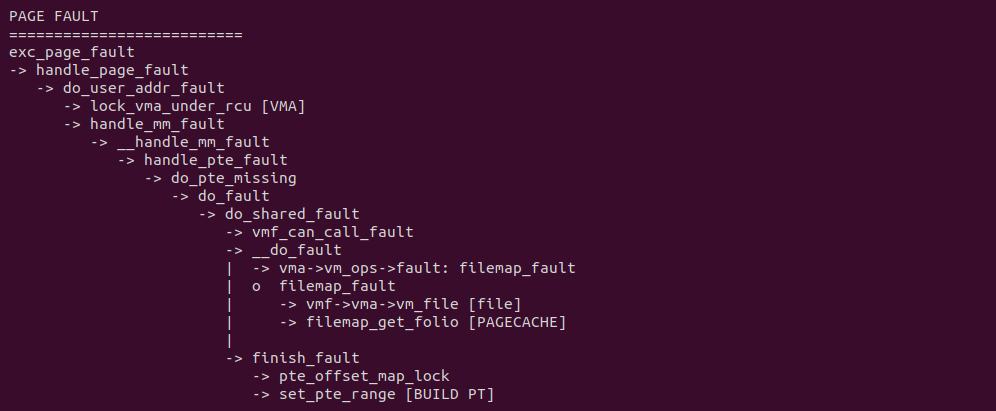
生产者使用 shm_open 在共享内存打开共享文件,本质还是调用 open 函数在 “/dev/shm” 目录下创建一个文件. 生产者或者消费者将共享文件映射到各自的虚拟地址空间之后,对其访问会触发缺页异常,在缺页异常处理函数里,do_shared_fault 逻辑会被调用,其首先找到虚拟内存映射的文件,然后从文件里找到对应的 PAGECACHE,最后在 finish_fault 逻辑里建立好页表. 当缺页异常处理函数返回之后,生产者和消费者可以直接访问虚拟内存,并通过一些同步机制实现数据交互. 对比原先的 FILE 方式,生产者和消费者之间没有任何的拷贝操作,因此节省 2 次拷贝. 接下来通过一个实践案例实际测试其性能,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] Package --->
[*] ZERO COPY MECHANISM
[*] *** Inter-Process Communication(IPC) ***
[*] OPTIMI ZEROCOPY(IPC): Exchange Between POSIX SHMEM --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-ZEROCOPY-IPC-POSIX-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build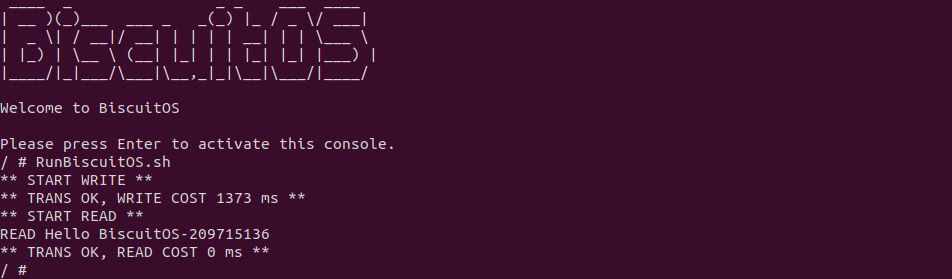
BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了实践案例运行的所有命令,案例包含包含两个用户进程,一个作为生产者,另外一个作为消费者,生产者用户进程向消费者进程发送 200M 文件数据,可以看到花费时间 1373ms, 接下来分析源码:
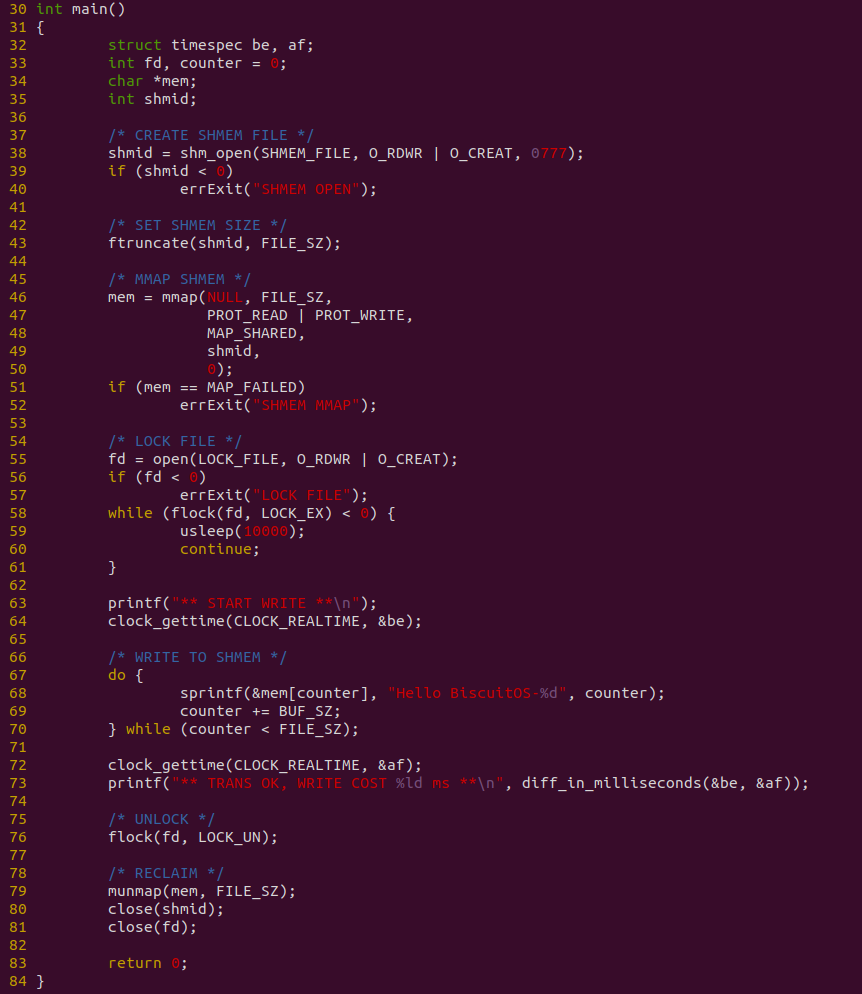
生产者程序如上图,程序在 38 行调用 shm_open 创建共享文件,然后在 43 行调用 ftruncate 调整文件的大小,接着在 46 行调用 mmap 函数将共享文件映射到进程的地址空间,并在 58 行调用 flock 获得文件锁,以此保证消费者读到正确的数据. 程序接着在 67-70 行使用 DO-WHILE 循环向共享区域直接写入数据, 并且对整个写入过程进行计时.
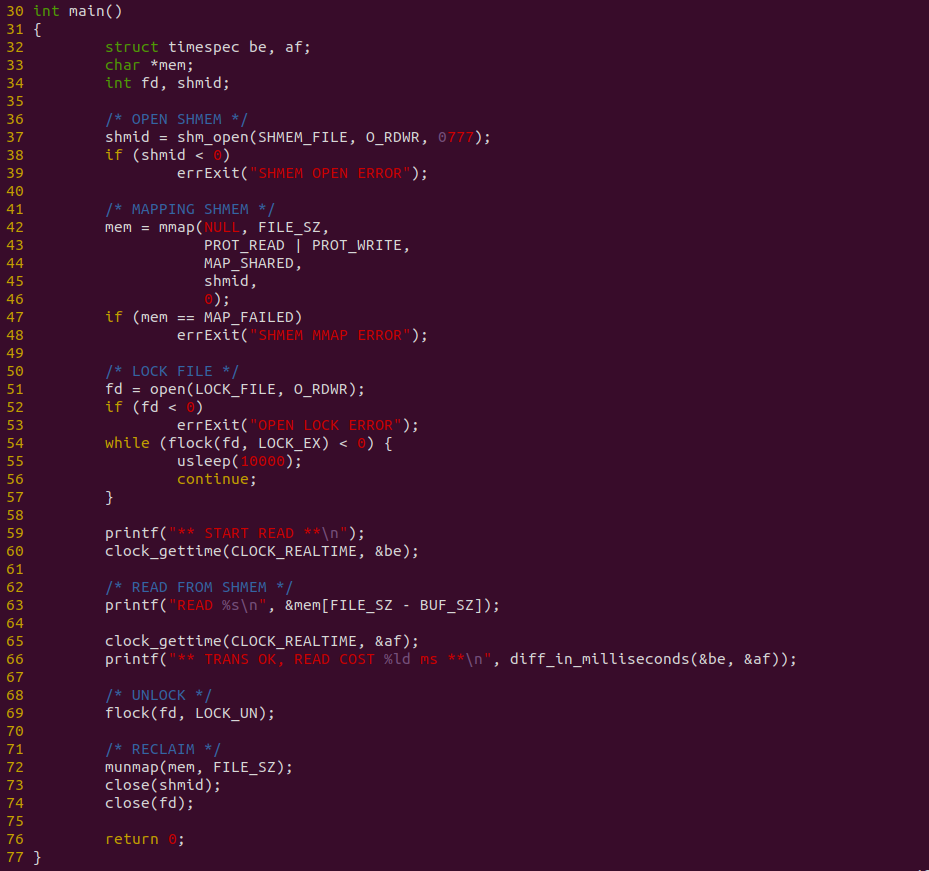
消费者程序如上图,程序在 37 行调用 shm_open 打开 POSIX 共享文件,然后在 42 行调用 mmap 函数将共享文件映射到进程地址空间,并在 54 行 flock 函数获得文件锁,以此通过正确的顺序读到正确的数据. 程序在 63 行直接从共享内存里读取数据, 并对整个读取过程计时. 接下来对不同的数据量进行耗时测试:
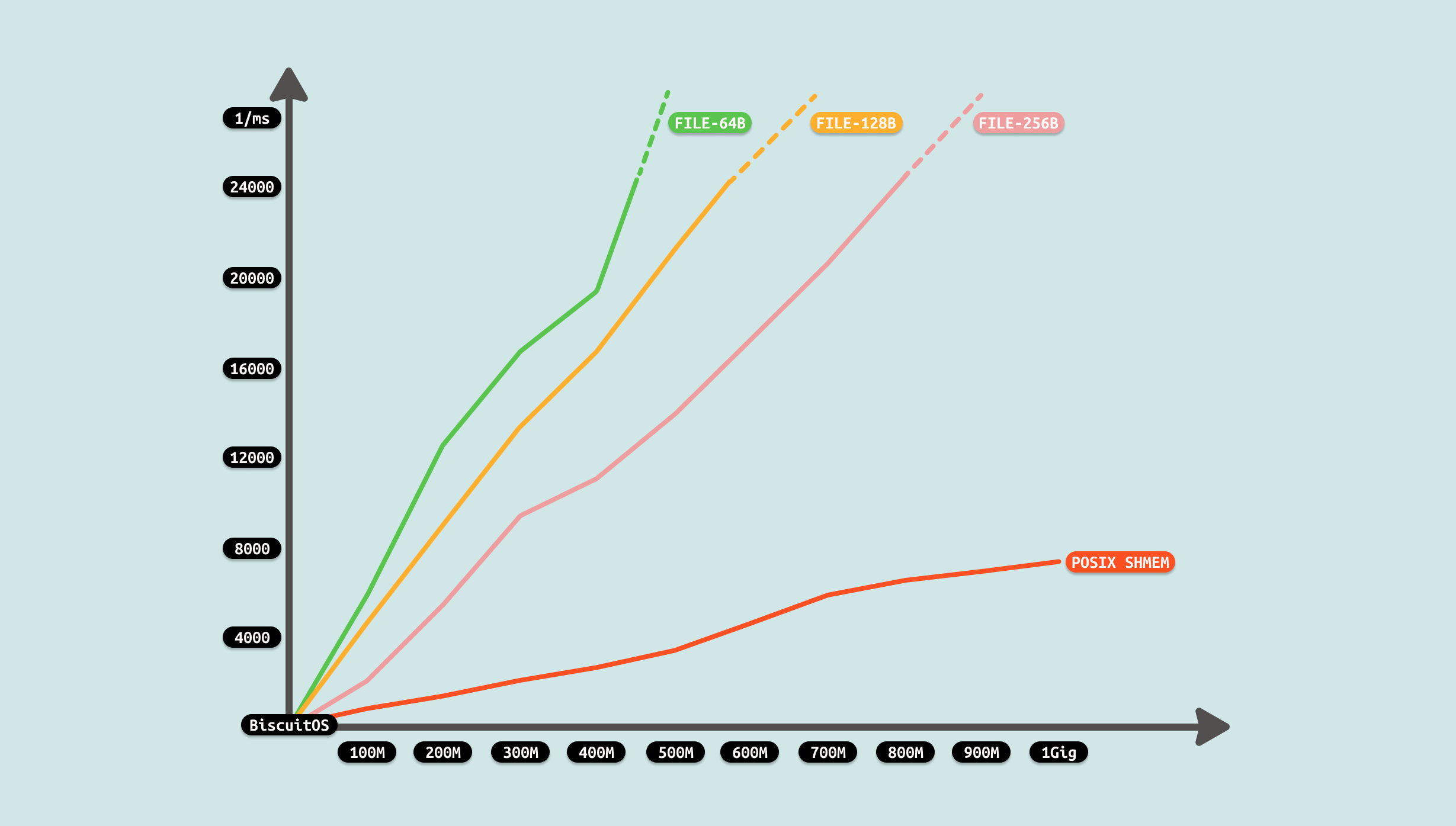
测试过程发现,生产者制造数据需要花费一些时间,并且这个时间随着数据量变大而变大,且是线性增加. 对于消费者来说,其已经不需额外的拷贝,直接读数据,因此耗时为 0. 整体耗时降低很多,对比 FILE 方案优化成功. 从测试可以看出,共享区域并没有像 SYSV 一样被限制在 500M,其只受系统可用内存影响, 因此开发者在遇到相似的 IPC FILE 场景时,可以利用该 ZEROCOPY 优化方案进行优化.

当使用文件在两个进程或者多个进程之间共享数据,以此实现进程间的通信. 在该方案中,生产者会将需要共享的数据从用户态的缓冲区写入文件,写入过程中,内核会将写入的数据由生产者缓冲区拷贝到文件对应的 PAGECACHE 里. 接着消费者从文件里读取共享的数据,此时内核从文件对应的 PAGECACHE 将数据拷贝到消费者缓冲区里. 通过这样的方法,用户进程间可以实现通信.
该方案里,生产者和消费者为了传递数据,需要在两者的缓冲区和文件 PAGECACHE 之间完成两次拷贝,才能完成信息交换,交换过程中只是对数据拷贝,并没有对数据其他处理.
另外随着交换数据量变大,整体耗时也在不断增大. 另外在交换数据量不变的情况下,读写次数越多,也就是每次读写量变小,耗时也会增加. 因此要让进程间通信更快速,可以从优化拷贝策略入手.
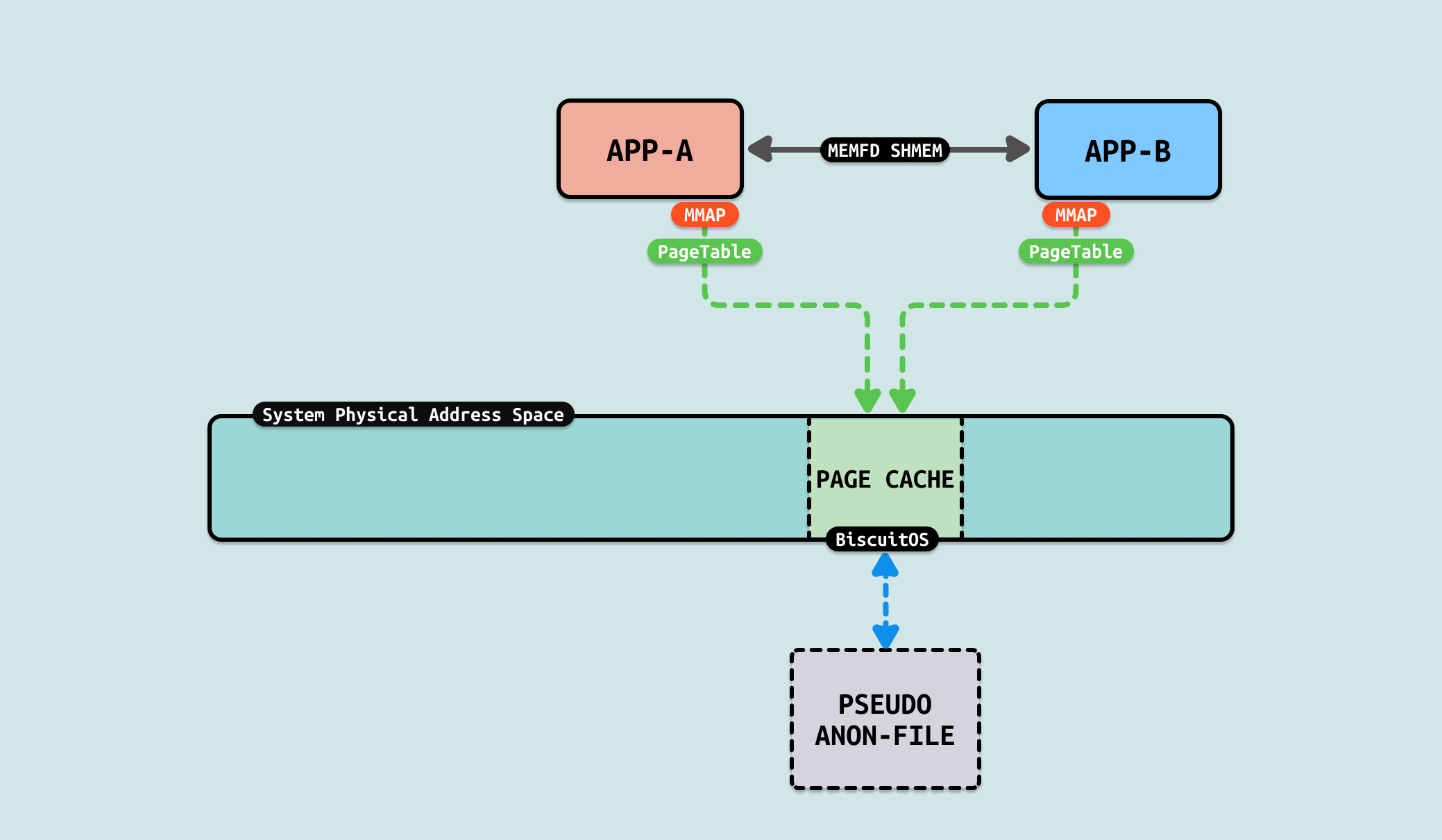
MEMFD SHMEM 是 Linux 内核中提供的一种共享内存机制,利用 memfd_create 系统调用创建匿名的内存文件对象, 不在文件系统中持久化,因此不会有路径名与之关联. 它融合了匿名文件和共享内存的特性,是一种灵活且高效的进程间通信方式. memfd_create 创建的对象可以使用标准文件操作进行管理,比如 mmap、read、write 等. 通过 Unix 域套接字,文件描述符可以在进程间传递,从而实现共享内存的传递. 其提供了一下接口:
- memfd_create: 是创建 MEMFD SHMEM 的核心调用,允许创建匿名内存文件
- ftruncate: 设置内存文件的大小
- mmap: 将内存文件映射到进程的地址空间
- munmap: 解除映射,关闭文件描述符,并进行资源清理
相比使用 FILE 作为媒介进行进程间通信,MEMFD 共享内存创建匿名文件,不会出现在文件系统中,这减少了数据泄露的风险, 在安全性需求较高的场景中更为适合. MEMFD SHMEM 匿名文件在关联的文件描述符关闭时会自动释放资源,这简化了内存管理,避免了资源泄露的问题, 可以使用 “MEMFD 共享内存” 方案加速数据交付.
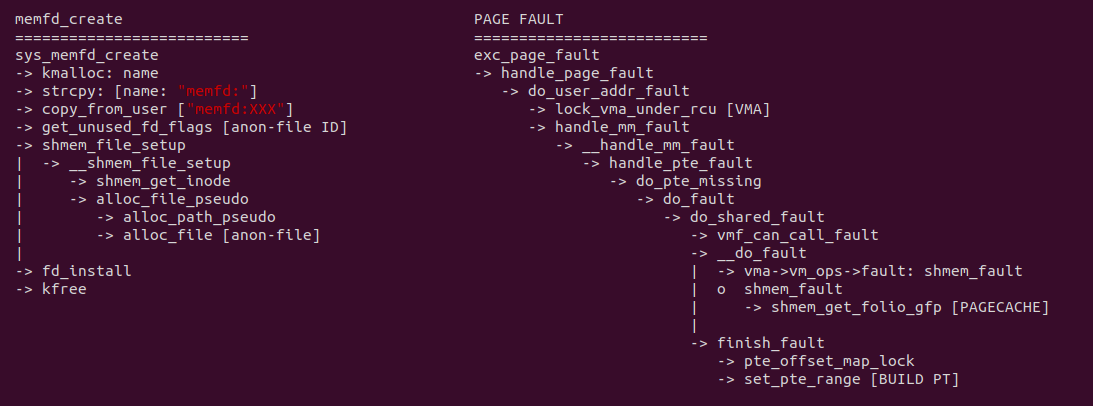
生产者使用 memfd_create 创建共享匿名文件,生产者或者消费者将匿名共享文件映射到各自的虚拟地址空间之后,对其访问会触发缺页异常,在缺页异常处理函数里,do_shared_fault 逻辑会被调用,其首先找到虚拟内存映射的文件,然后从文件里找到对应的 PAGECACHE,最后在 finish_fault 逻辑里建立好页表. 当缺页异常处理函数返回之后,生产者和消费者可以直接访问虚拟内存,并通过一些同步机制实现数据交互. 对比原先的 FILE 方式,生产者和消费者之间没有任何的拷贝操作,因此节省 2 次拷贝. 接下来通过一个实践案例实际测试其性能,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] Package --->
[*] ZERO COPY MECHANISM
[*] *** Inter-Process Communication(IPC) ***
[*] OPTIMI ZEROCOPY(IPC): Exchange Between MEMFD SHMEM --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-ZEROCOPY-IPC-MEMFD-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build
BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了实践案例运行的所有命令,案例包含包含两个用户进程,一个作为生产者,另外一个作为消费者,生产者用户进程向消费者进程发送 200M 文件数据,可以看到花费时间 1435ms, 接下来分析源码:
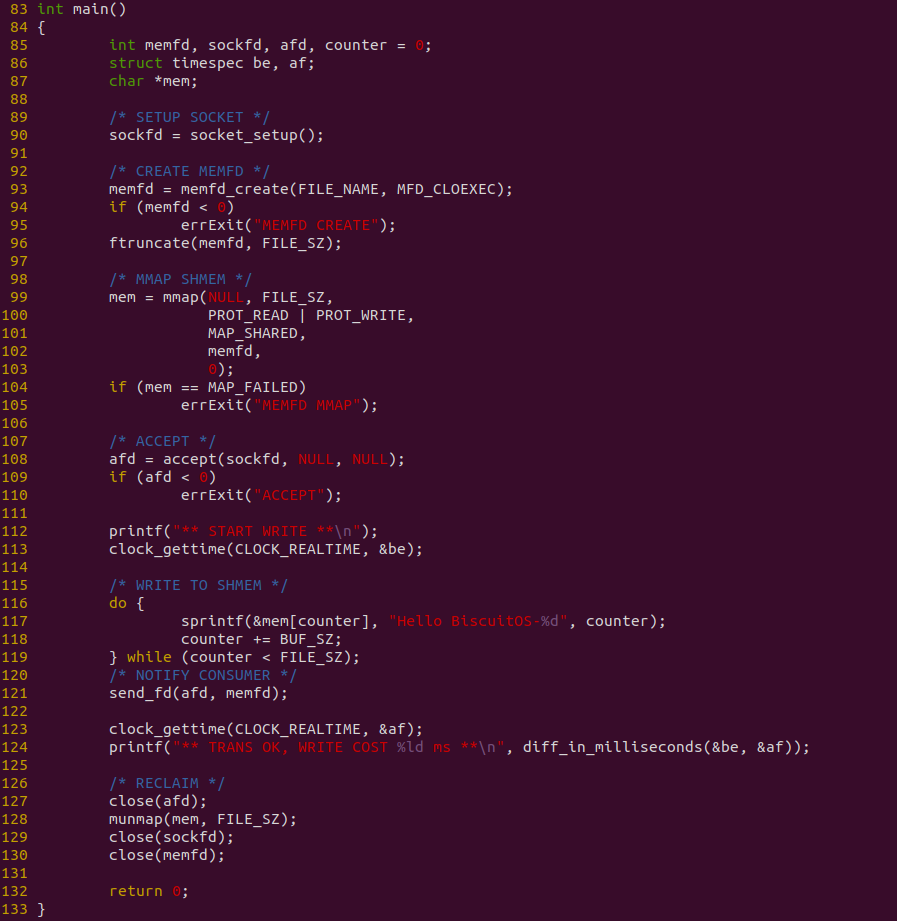
生产者程序如上图,程序首先在 90 行调用 socket_setup 函数构建好 SOCKET 通道,然后在 93 行调用 memfd_create 创建匿名共享文件,并在 96 行调用 ftruncate 将文件大小调整为 FILE_SZ 大小. 另外函数在 99 行调用 mmap 函数将匿名共享文件映射到进程地址空间,接下来调用 accept 监听消费者请求,当接收到消费者请求之后,程序在 116-119 行使用 DO-WHILE 循环向共享区域写入内容,写入完毕之后调用 send_fd 将共享匿名文件发送给消费者. 程序对整个写入过程进行计时.
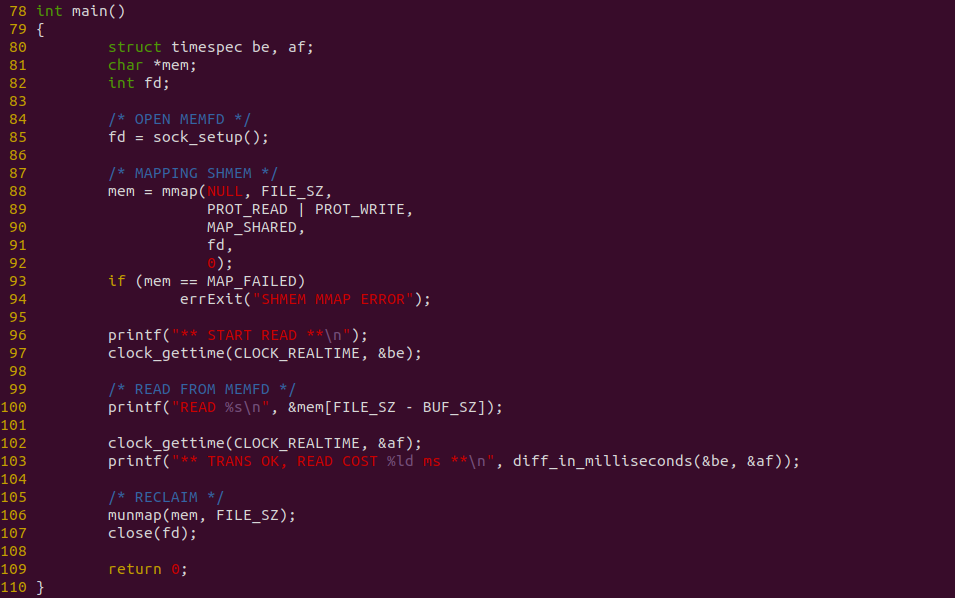
消费者程序如上图,程序在 85 行调用 sock_setup 构建 SOCKET 通道,并向生产者发送请求,生产者处理完请求之后,将共享匿名文件发送给消费者,消费者收到匿名共享文件之后,在 88 行调用 mmap 函数将共享匿名文件映射到进程地址空间,接着在 100 行直接对共享内存进行读操作. 程序对读操作进行计时. 接下来对不同的数据量进行耗时测试:
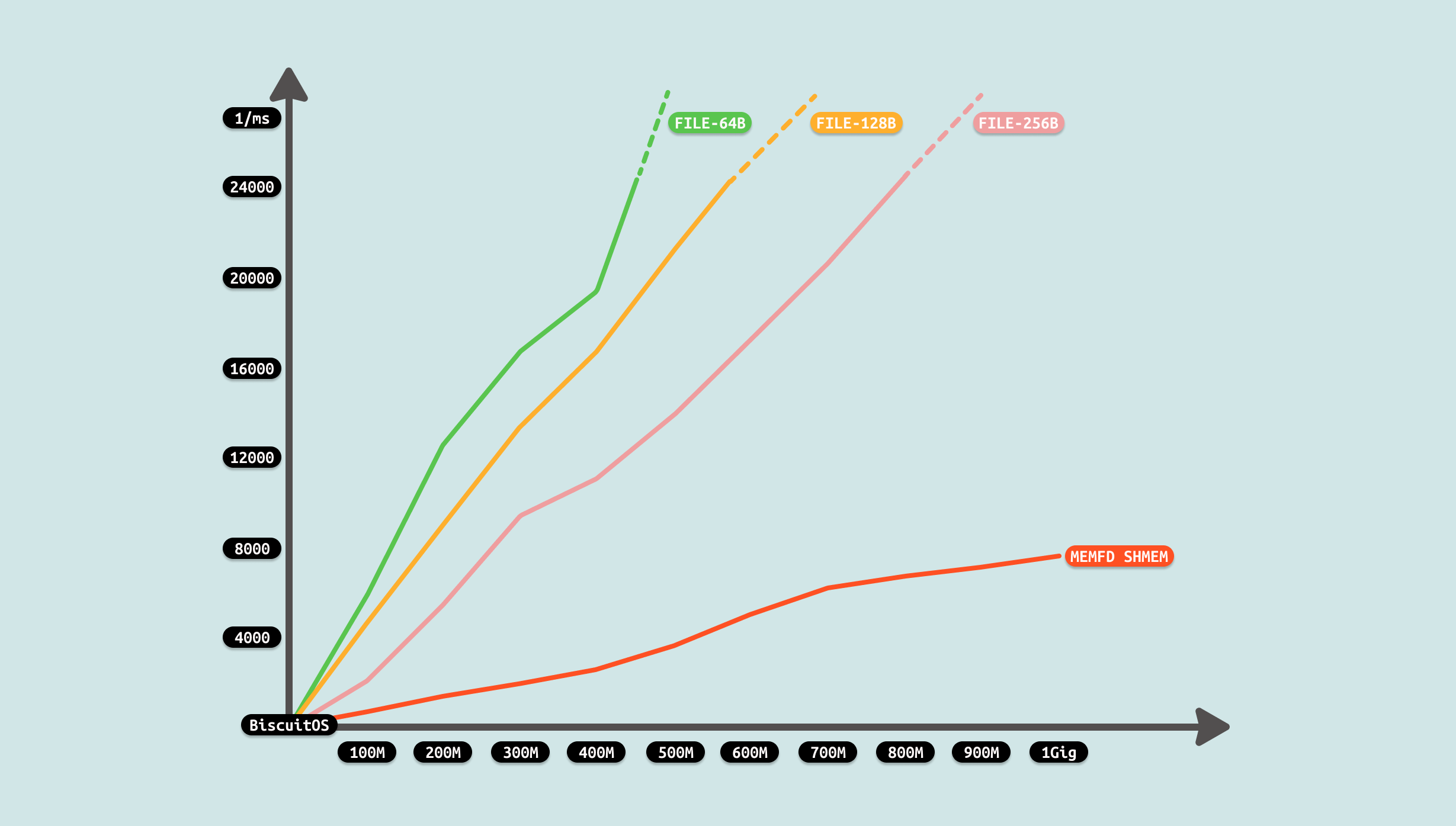
测试过程发现,生产者制造数据需要花费一些时间,并且这个时间随着数据量变大而变大,且是线性增加. 对于消费者来说,其已经不需额外的拷贝,直接读数据,因此耗时为 0. 整体耗时降低很多,对比 FILE 方案优化成功. 从测试可以看出,MEMFD SHMEM 方案和 POSIX SHMEM 相差很小, 因此可以结合不同的场景进行选型. 开发者在遇到相似的 IPC FILE 场景时,可以利用该 ZEROCOPY 优化方案进行优化.
User-Kernel Communication
在 Linux 里,用户进程具有独立的线性地址空间,在该线性地址空间里,用户进程使用里低端部分,而内核则使用高端部分,两者不能直接越界访问. 但在某些场景下,用户进程和内核线程,以及用户进程用户态和用户进程内核态之间需要交互数据,此时需要用户空间和内核空间交互数据.
Linux 提供了很多通信手段实现用户空间和内核空间交互数据,包括 BUFFER-IO、FILE SHMEM、以及 NETLINK 等. 内核将用户空间和内核空间的间通信称为 UKC(User-Kernel Communication). 用户空间和内核空间之间的通信难免需要拷贝数据,拷贝数据的手段以及耗时将影响通信效率,本节针对每种通信手段进行分析,以此确认 ZEROCPOY 机制是否能为其性能带来提升.
UKC Exchange Data via COPYUSER Scenario
在 Linux 及其他类 Unix 操作系统中,内核空间和用户空间是两个不同的内存区域,各自承担着不同的职责并具备不同的访问权限。内核空间是操作系统核心运行的地方,具有对硬件的完全访问权限. 用户空间则是用户应用程序运行的地方,访问权限受到限制,以确保系统的稳定性和安全性.
COPY USER 机制是 Linux 内核中用于在内核空间和用户空间之间安全传输数据的重要接口,这些函数对于维护系统的安全性和稳定性至关重要,因为它们防止用户应用程序直接访问内核内存,从而避免潜在的安全漏洞和系统崩溃. 这些函数执行必要的检查以确保内存地址是有效且可访问的,防止段错误和潜在的崩溃. 因此可以使用 COPY USER 提供的接口安全的在用户空间和内核空间进行数据拷贝. 结合使用场景,用户进程用户态和用户进程内核态之间如果有数据拷贝需求,可以使用该机制实现数据交互. 该机制需要使用如下函数实现数据交付:
- open: 用户态打开交互文件
- read: 用户态实现从内核空间拷贝数据到用户空间
- write: 用户态实现从用户空间拷贝数据到内核空间
- copy_to_user: 内核态实现从内核空间拷贝数据到用户空间
- copy_from_user: 内核态实现从用户空间拷贝数据到内核空间
从 msgsnd 系统调用可以看出,当生产者进程需要发送数据时, 用户进程用户态准备好数据,切换到用户进程内核态之后,其调用 load_msg 函数从 SLAB 分配器分配一段内存,然后使用 copy_from_user 函数将数据从用户空间拷贝到内核空间,然后将数据放入队列并返回用户态. 消费者使用 msgrcv 系统调用接收数据,其先在用户态分配一段内存,然后通过 sys_msgrcv 系统调用进入用户进程内核态,接着从队列里获得可用消息之后,调用 do_msg_fill 函数,其使用 store_msg 将数据拷贝到用户态,其核心是 copy_to_user 函数.
从 Message Queue(消息队列) 机制实现来看,数据流动时从生产者的用户空间拷贝到内核空间,然后消费者从内核空间将数据拷贝到用户态. 从这个流程看出 COPY USER 将是性能瓶颈,另外内核空间分配的内存大小也是瓶颈. 接下来通过一个实践案例实际测试其性能,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] Package --->
[*] ZERO COPY MECHANISM
[*] FORBID ZEROCOPY(IPC): Exchange Between MESSAGE QUEUE --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-ZEROCOPY-IPC-MSGQ-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build
BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了实践案例运行的所有命令,案例包含一个生产者用户进程,其向 MSGQ 写入 200MiB 数据,案例还包含一个消费者用户进程 ,其从 MSGQ 里读出数据,并对生产者用户进程发送数据过程进行计时. 可以看到 200MiB 数据花费了 5777 ms. 接下来分析源码:
上图是生产者代码,函数在 38 行调用 ftok 创建独立的 TOKEN,然后在 43 行创建 MESSAGE QUEUE,并在 51-55 行向 MSGQ 发送数据,其中 52 行在用户空间准备数据,在 53 行使用 msgsnd 函数发送准备好的数据,最终发送长度为 FILE_SZ 的数据,并使用 clock_gettime 对发送过程进行计时.
上图是消费者代码,函数在 29 行调用 ftok 和 34 行调用 msgget 获得生产者创建的消息队列,接着在 39-44 行使用循环,并调用 msgrcv 从消息队列拷贝数据到用户空间,总共拷贝 FILE_SZ 长度的数据. 以上便是源码,接下来对不同数据量进行耗时测试:
测试从两个维度进行,首先是传输数据总量,其次是每次传输的数据量. 从传输数据总量来看,传输数据越多,耗时越多,数据总量成倍数增长,耗时基本接近倍数增长. 另外从每次传输数据量来看,每次传输数据量越大,耗时越小,每次传输数成倍增长,耗时基本接近成倍减少. 通过上面的数据分析,可以看到性能优化的方向有两个,首先就是超过延迟底线的数据就不要使用消息队列进行传输,另外一个方向是增大每次消息传输的数据量. 接下来使用如下命令分析哪个函数比较消耗 CPU:
# PREPARE
touch /mnt/BiscuitOS-MSG
# Running
CONSUMER &
sleep 1
PRODUCT &
sleep 0.1
PID=$(pidof PRODUCT)
perf top -p ${PID} -g --call-graph dwarf
从 perf 获得实时观察系统中正在运行的程序的性能热点,可以看出占大头的操作是系统调用,接着是 do_msgsnd 函数和 load_msg, 其中 load_msg 就是负责从用户空间拷贝数据到内核空间的逻辑.
结合上图和前面的数据分析,性能优化的方向有两点,要么减少系统调用的数量, 要么减少数据拷贝. 减少系统调用很难做到,但可以采用减少数据拷贝,从上图可以看到,数据从用户态缓冲区拷贝到 MSGQ 在内核的内存,又从内核的内存拷贝到用户态缓冲区,拷贝过程中没有其他任何操作,因此可以从这里入手进行优化,具体优化方案参考如下: