

目录
CXL 基础原理
CXL 实践
MORE
CCIX
GEN-Z
OpenCAPI

CXL Underprinning
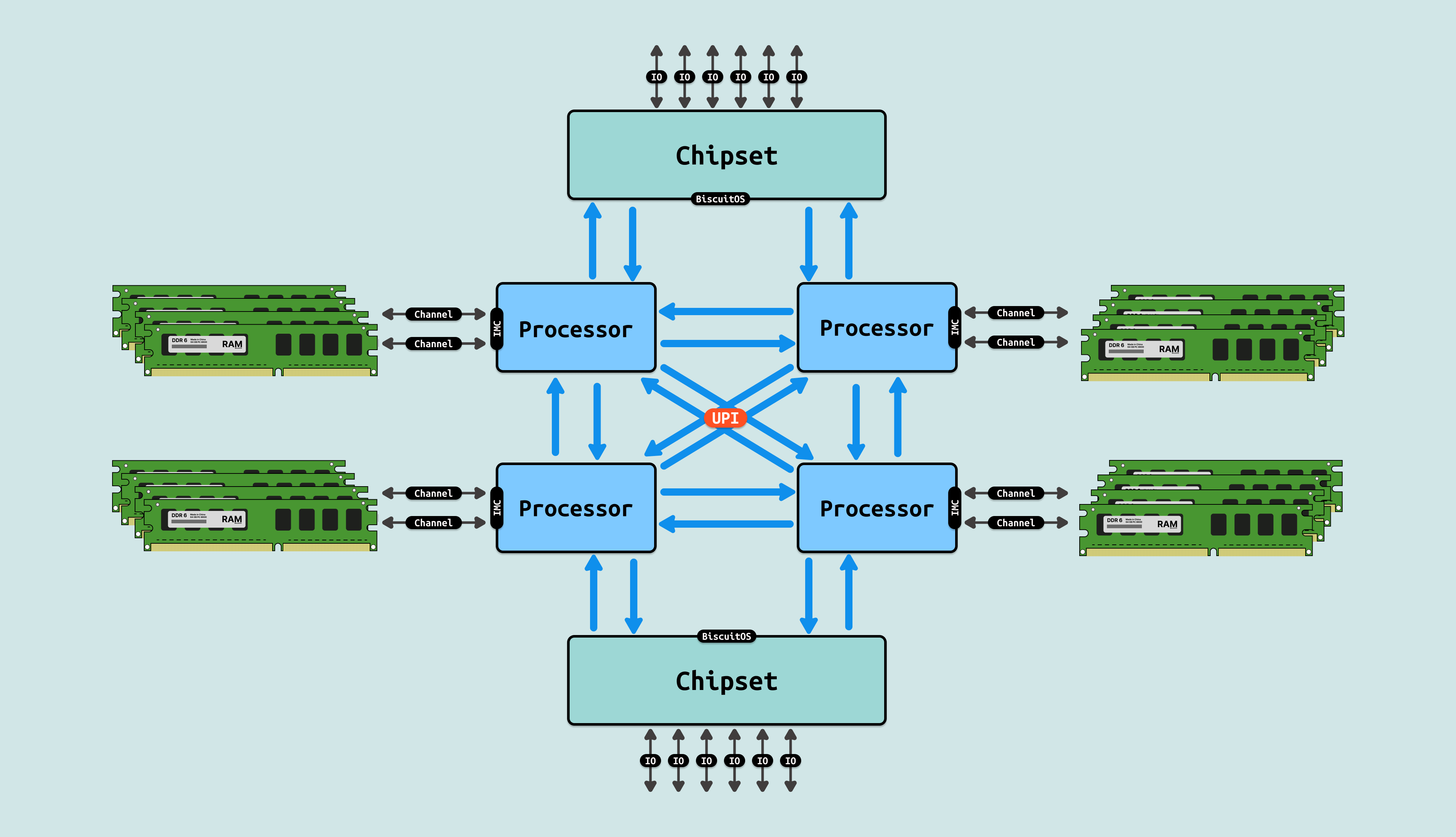
在现代 CPU 架构里,内存控制器(IMC) 已经集成到芯片内部,DIMM 内存条通过内存通道(Channel)与内存控制器相连,处理器在内部通过访问内存控制器,就可以直接访问到 DIMM 内存, 因此 DIMM 内存构成了系统物理地址空间里的物理内存. 在这种模式中,内存条插入到 DIMM 插槽并通过内存通道(Channel) 连接到内存控制器,处理器可以利用多通道技术,以及距离 CPU 近的缘故,可以提供高带宽低延迟的内存访问.

随着技术不断进步,以及 AI 推理和机器学习不断普及,业务场景对内存需求不断增强,随即 Intel 引入了 PMEM(NIVDIMM) 新型内存,其同样插入到 DIMM 插槽内进行访问,PMEM 的出现不仅可以提供大容量的内存,其也在不断降低内存成本. 另外在服务器端,内存池化的概念不断被提出,不同的厂家有提出了多种解决方案,其中类似通过 PCIe 外设提供内存加速卡或者大容量低速内存的方案. 这些新科技的出现为系统物理内存的来源提供了更多的选择,但新的技术无法很好的解决以下几个痛点:
- 内存瓶颈: 传统的 DDR 内存只能直接与 CPU 连接,并且受限于内存通道数量和速度,难以进一步扩展. 此外,多处理器系统中的内存共享和通信效率较低.
- 处理器和加速器的协同工作效率低下: 处理器和加速器之间的数据传输通常依赖 PCIe 接口,但 PCIe 协议最初是为 I/O 设计的,其本身并不专为低延迟、高带宽的内存访问而设计, 这使得加速器的性能在处理复杂任务时受限于与主内存或其他处理器通信的延迟
- 内存池化和共享: 现代应用需要高效的内存资源分配和池化,但当前的内存管理方式(包括 PCIe 加速卡和 PMEM 等技术)在跨多个设备和处理器时存在限制
- PMEM 特性受限: PMEM(Persistent Memory) 是持久性存储器,主要用于提供低延迟、高容量的存储,它的速度介于 DRAM 和传统 SSD 之间, PMEM 可用于扩展内存容量,但其本质上仍是存储器,尽管支持内存模式,但其访问延迟较高
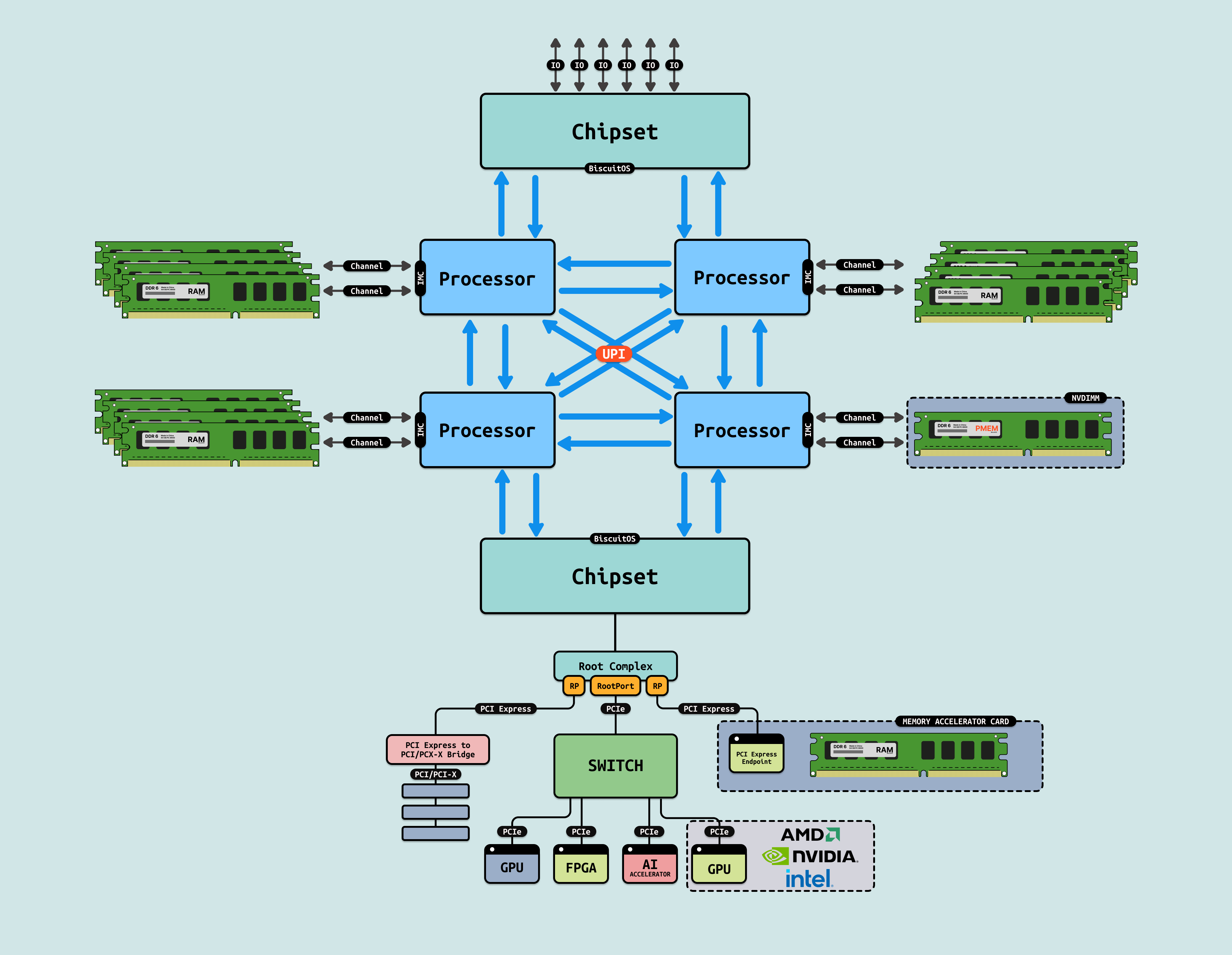
随着 AI 和机器学习等领域的兴起,异构计算体系结构变得越来越普遍, 处理器与加速器(如 GPU、FPGA、AI 专用加速芯片)之间需要紧密协作, 然而传统的 PCIe 通信接口不适合处理频繁的、低延迟的数据传输需求, 需要更高效的连接方式来加速数据处理. 现有的 CPU 与 GPU、FPGA 等加速器之间的数据传输主要依赖于 PCIe,而 PCIe 是为 I/O 设备设计的协议,虽然提供高带宽,但在低延迟、内存一致性等方面并未做出优化,导致在处理复杂计算任务时,数据传输成为瓶颈, 并且随着数据量的爆炸性增长,尤其是在大规模云计算和数据密集型应用中,系统对内存的需求显著增加.

2019 年由 Intel 发起 CXL 项目,随后得到了业内广泛的支持,包括 AMD、NVIDIA、Arm、Google、Microsoft、Facebook 等科技巨头. CXL 的初衷是为了扩展和优化基于 PCIe 的通信标准,特别是针对 CPU 和加速器、内存等设备之间的高效互连需求, 并应对现代计算和数据中心基础架构中出现的挑战,尤其是在高性能计算(HPC)、人工智能、大数据和云计算等领域. 随着这些领域的飞速发展,传统的内存和处理器通信方式已经不能有效支持日益增长的数据处理需求,为了打破这些瓶颈,CXL 应运而生.
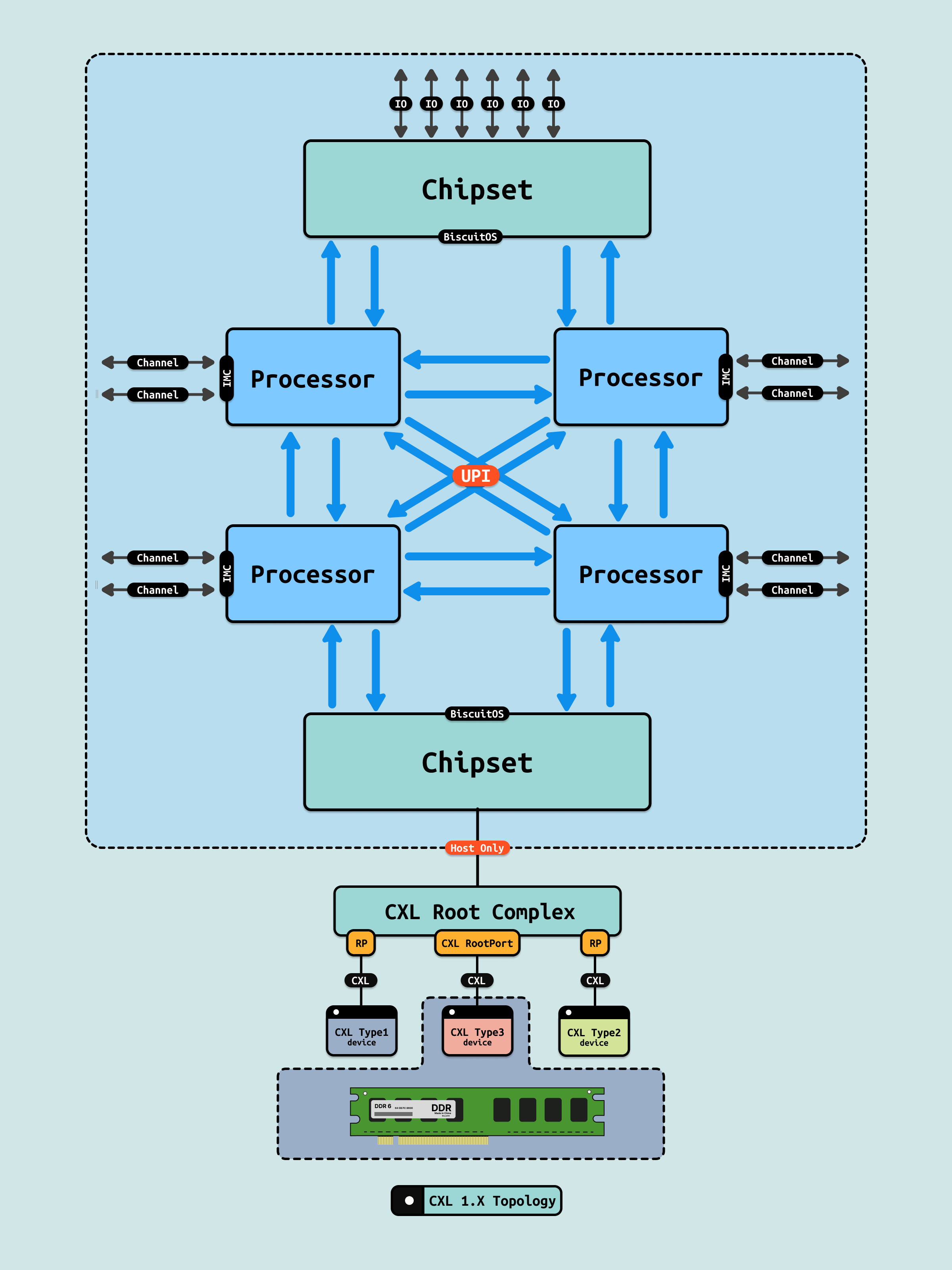
CXL 1.0/1.1 是 CXL 的首个广泛采用的版本,它基于 PCIe 5.0 物理层,并在其上构建了三个协议来支持不同的设备类型和内存访问需求. 其目标是解决处理器与加速器、内存扩展之间的低延迟通信问题. CXL 1.0/1.1 标准主要集中在 CPU 和加速器、内存设备之间的高效连接和内存一致性. CXL 1.0/1.0 版本里,CXL 只能在一个主机上使用,并没有实现多个主机之间资源池化, 其具有以下几个特点:
- 内存一致性支持: 加速器可以通过 CXL 直接访问主内存,同时保持与处理器之间的一致性
- 低延迟通信: CXL 通过改进的协议层降低了加速器和 CPU 之间的数据传输延迟,适用于高性能计算和加速器的应用
- PCIe 兼容性: CXL 1.0/1.1 基于 PCIe 5.0 物理层,因此在硬件层面上兼容 PCIe 通信设备
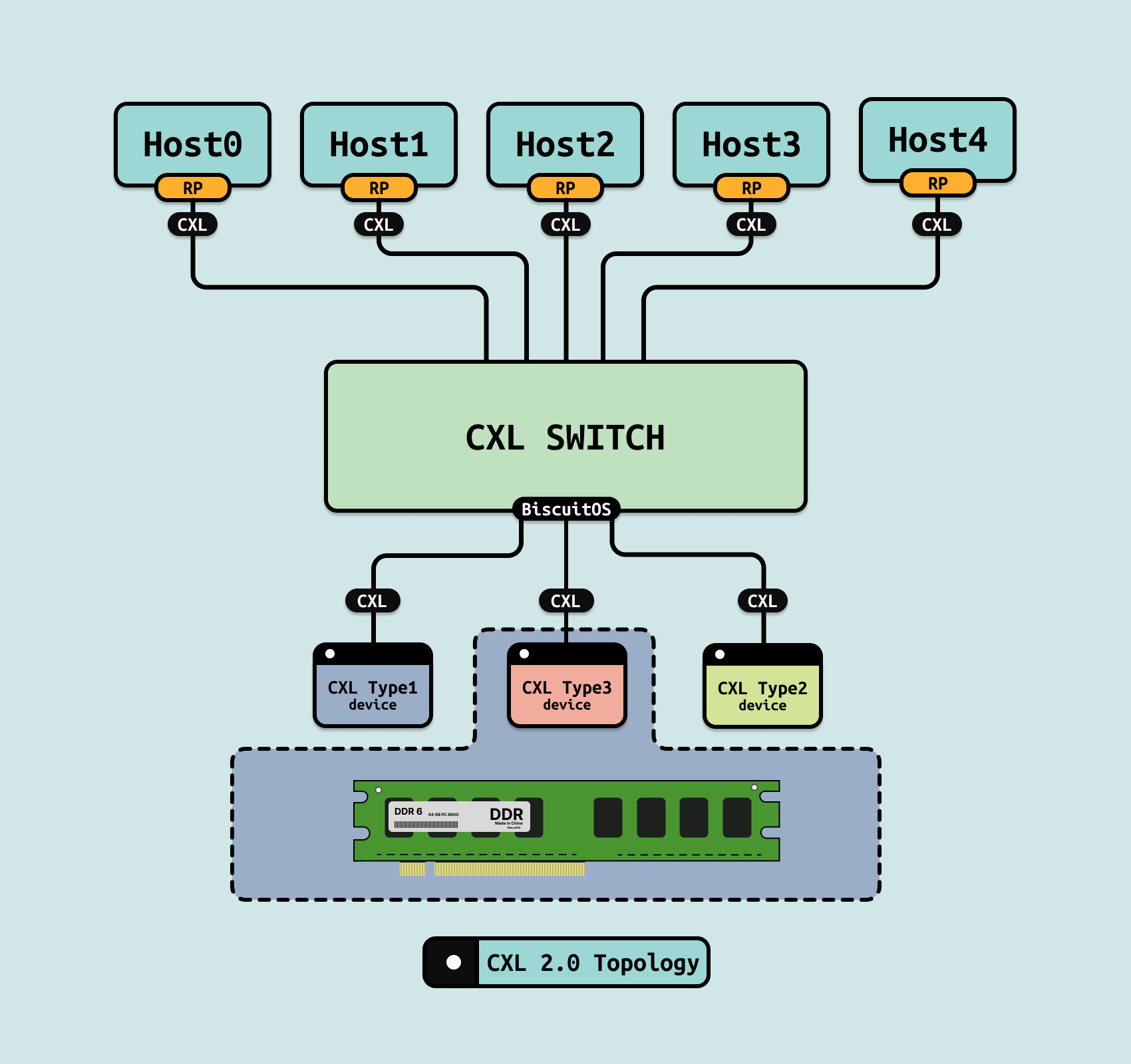
2020 年发布 CXL2.0,其对 CXL 1.1 的重要升级,增加了对内存池化、多设备支持和更复杂系统拓扑的功能. CXL 2.0 引入的新功能显著增强了系统的灵活性和扩展能力,特别是针对大规模云计算和数据中心的需求. CXL 2.0 保留了 CXL 1.1 的三层协议结构(CXL.io、CXL.cache 和 CXL.mem),但在内存池化和多设备共享上引入了更多优化,能够支持更多的内存拓扑和灵活配置, 具体新增功能如下:
- 内存池化(Memory Pooling): 支持多个主机共享同一片内存资源,允许不同的处理器动态地使用和分配共享内存池,提高内存资源的利用率,特别适合云计算和虚拟化场景
- 热插拔支持: 设备可以在不关闭系统的情况下动态添加或移除(如内存扩展卡或加速器),增强了数据中心的灵活性
- 安全增强: CXL2.0 在通信协议中加入了更强的安全性功能,以应对在数据中心环境中可能存在的安全威胁
- 持久性内存(Persistent Memory)支持: 支持与持久性内存设备的直接通信,扩展了内存的应用场景
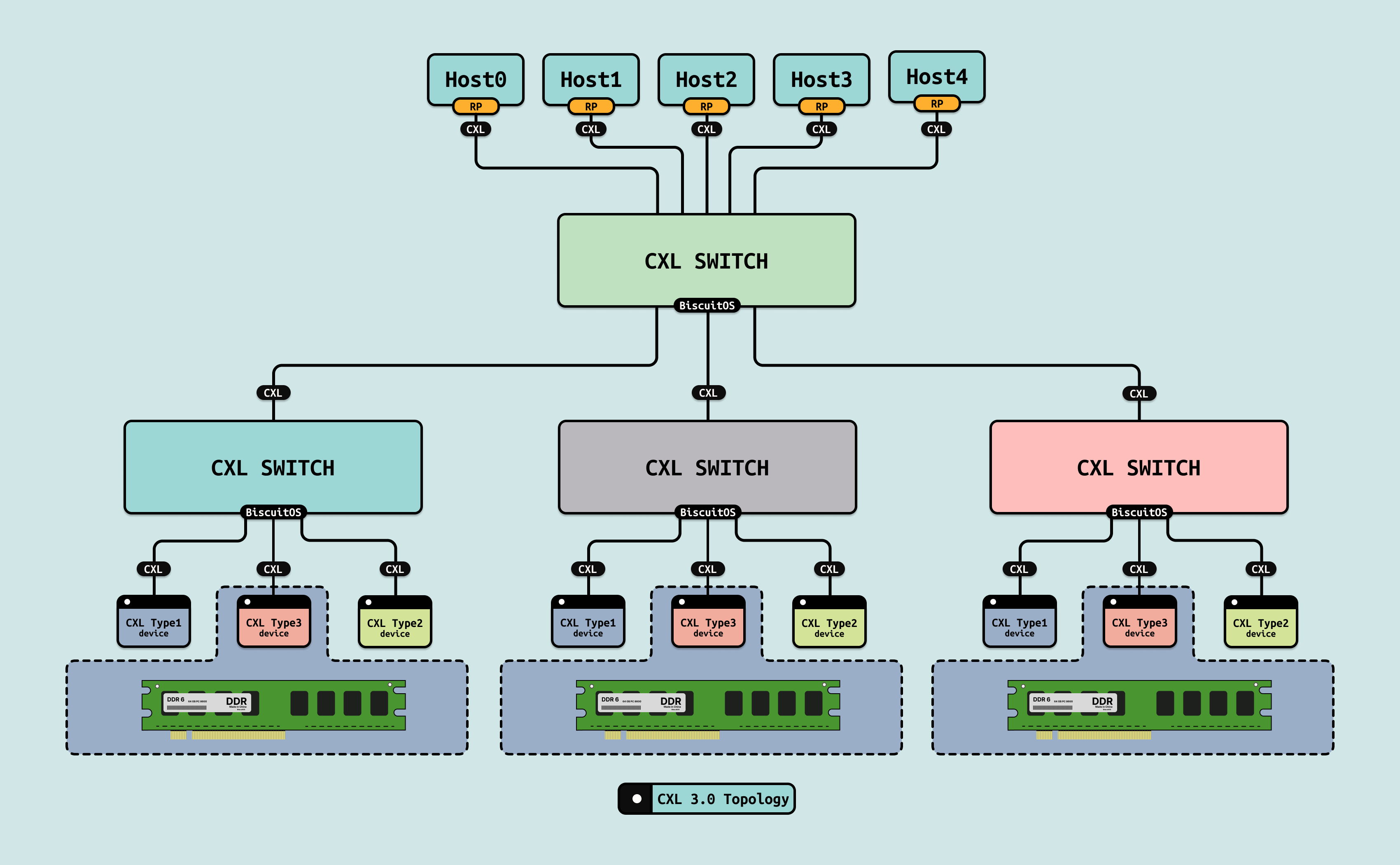
2022 年发布 CXL3.0,进一步扩展了 CXL 协议的功能,支持更加复杂的内存拓扑、设备间通信,并大幅提高了系统的扩展能力. CXL 3.0 的目标是彻底优化高性能计算和云数据中心的架构,允许多主机、多设备和更大规模的系统集成.
- 多层次内存拓扑(Multi-Level Memory Topology): 支持更复杂的内存拓扑结构,不仅限于 CPU 和单个内存扩展设备之间的通信,还允许不同设备之间直接进行内存访问和数据共享
- 增强的内存池化: CXL3.0 在 CXL2.0 的基础上进一步增强了内存池化功能,支持更多主机和设备同时访问共享的内存池,显著提高了系统的灵活性和扩展性
- 设备间通信(Direct Peer-to-Peer Communication): CXL3.0 支持设备之间的直接通信,而无需通过 CPU 进行中介, 这大大提高了设备之间的数据传输效率,尤其是在复杂计算任务中,如 GPU 间的协同工作
- 更高带宽和更低延迟: 通过优化协议,CXL3.0 提供了更高的带宽和更低的延迟,进一步提升了高性能计算和数据中心的吞吐量和响应速度
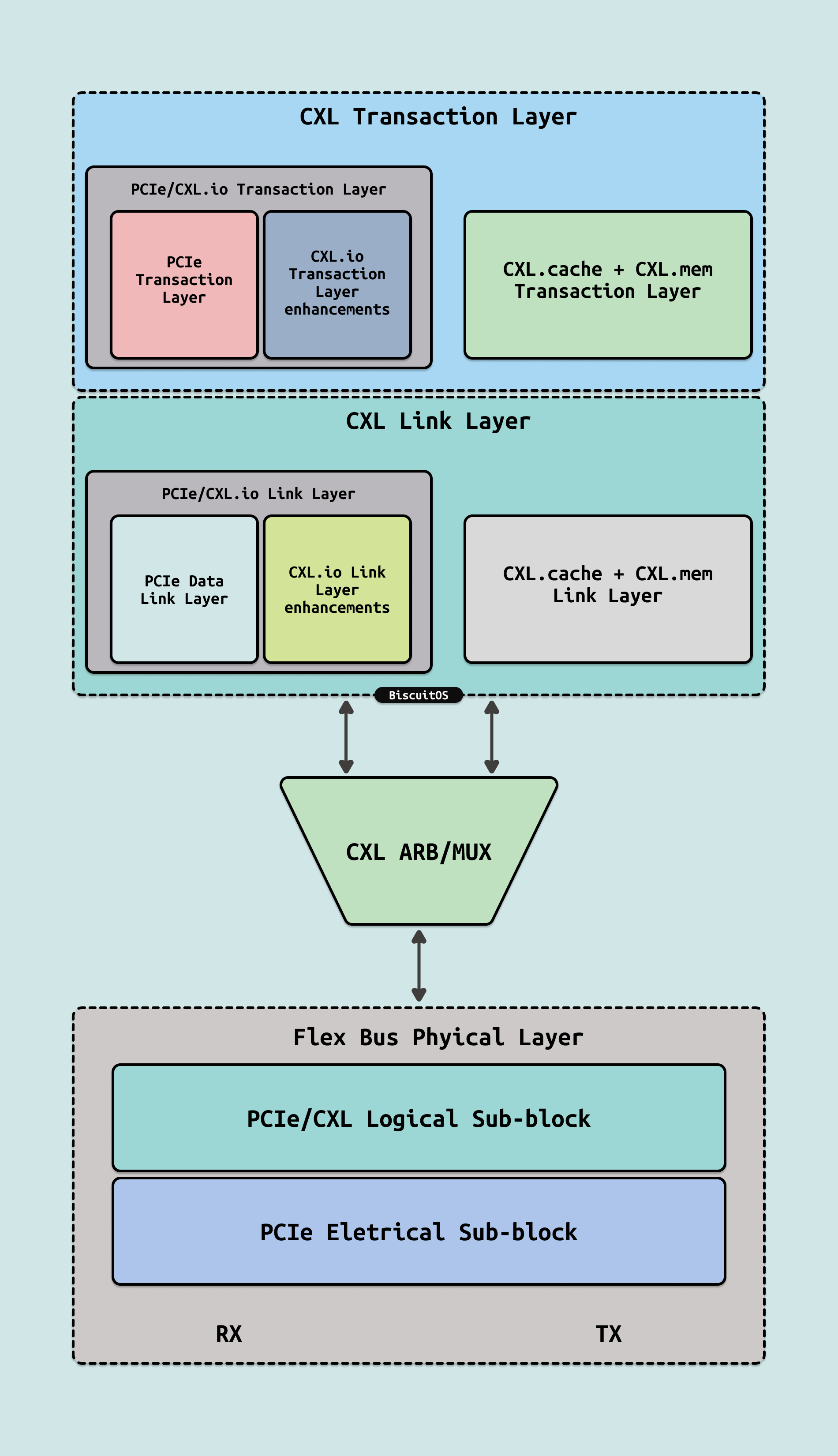
CXL协议是在 PCIe 技术的基础上开发的,特别是在物理层和链路层上与 PCIe 共享许多相同的技术特性. CXL Flex Bus 是 CXL 和 PCIe 共用同一物理总线的机制,它允许一个设备通过同一个硬件接口同时支持 PCIe 和 CXL 协议. 这意味着硬件只需一个物理连接(例如 PCIe 插槽), 设备就可以根据需要选择运行 PCIe 或 CXL 协议. CXL 的协议栈由 Transaction Layer、Link Layer 和 Physical Layer 三个主要层次构成,每一层负责不同的功能,协同工作以确保 CXL 在设备之间的高效数据传输、内存一致性和低延迟通信. CXL 主要支持三种协议: CXL.io、CXL.cache 和 CXL.mem, 三种协议的特点和主要功能:
- CXL.io: CXL.io 协议用于管理传统的 I/O 操作,并且在功能上与 PCIe 的标准 I/O 操作兼容, 它主要负责设备的配置、内存映射和标准读写操作. 特点包括:
- 兼容 PCIe: CXL.io 与 PCIe I/O 操作完全兼容,负责设备的发现、配置、读写和中断管理, 它确保 CXL 设备可以执行与 PCIe 设备类似的 I/O 操作
- 设备管理: CXL.io 支持对设备进行配置和管理,包括枚举设备、初始化以及处理标准的设备操作,如读写命令、设备状态监控等
- I/O 传输: CXL.io 支持标准的 I/O 事务,包括对内存映射 I/O(MMIO)的支持,允许设备和主机通过内存地址空间交换数据
- CXL.cache: CXL.cache 协议的作用是支持异构设备(如 CPU 和加速器)之间的缓存一致性管理. 它允许设备(如加速器或内存扩展卡)通过缓存访问共享的主内存,而无需反复复制数据,这极大提高了处理速度并降低了延迟, 特点包括:
- 缓存一致性: CXL.cache 使得加速器、内存扩展卡等设备可以直接缓存主内存的数据,并且确保缓存的一致性. 这样多个设备可以同时访问相同的内存数据,而不需要频繁的数据复制操作
- 加速器协作: CXL.cache 允许 CPU 和加速器设备(如 GPU、FPGA)协同工作, 加速器可以缓存 CPU 的内存数据,实现低延迟的数据访问,适合高性能计算(HPC)、机器学习和其他数据密集型任务
- 减少数据复制: 通过缓存一致性机制,CXL.cache 避免了处理器和设备之间频繁的数据复制,从而降低了数据传输延迟和开销
- CXL.mem: CXL.mem 协议负责设备与主内存之间的直接内存访问(Direct Memory Access, DMA),允许设备直接读取和写入主机的内存, 这是 CXL 协议最重要的特性之一,它实现了低延迟、高带宽的内存访问,并支持扩展内存容量, 其特点如下:
- 直接内存访问: CXL.mem 允许加速器、内存扩展卡或其他设备直接访问主内存(DDR),并且以与 CPU 访问内存相同的方式进行操作, 这种机制避免了传统架构中的内存拷贝或数据传输操作,从而减少了延迟
- 内存扩展: CXL.mem 使得系统可以通过附加设备(如内存扩展卡)来扩展物理内存容量,而不受传统 DDR 通道数量的限制, 这对于需要大规模内存的应用(如大数据处理)尤为重要
- 共享内存模型: CXL.mem 提供共享内存模型,允许多个设备同时访问同一内存地址空间,提升了资源利用率和计算性能
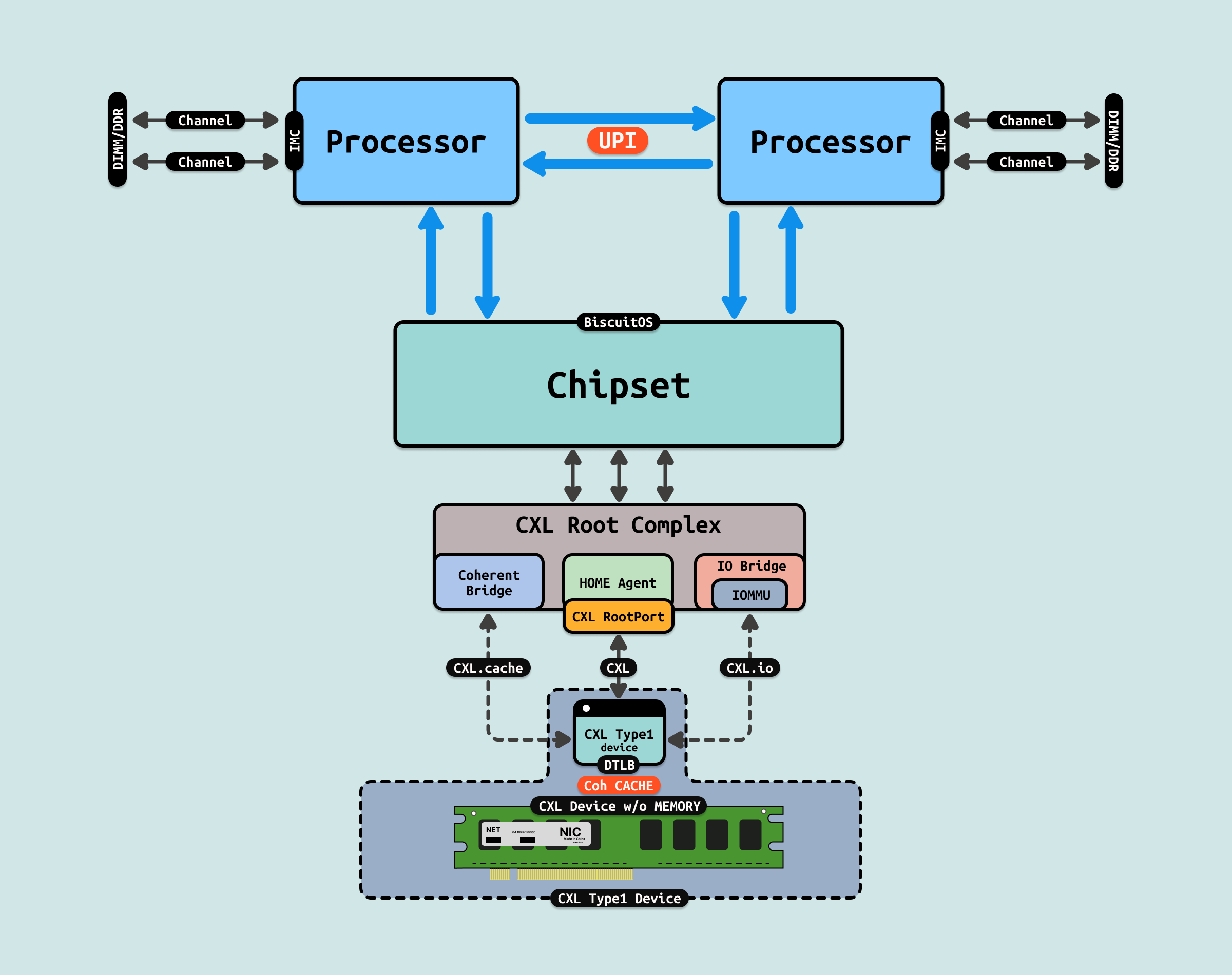
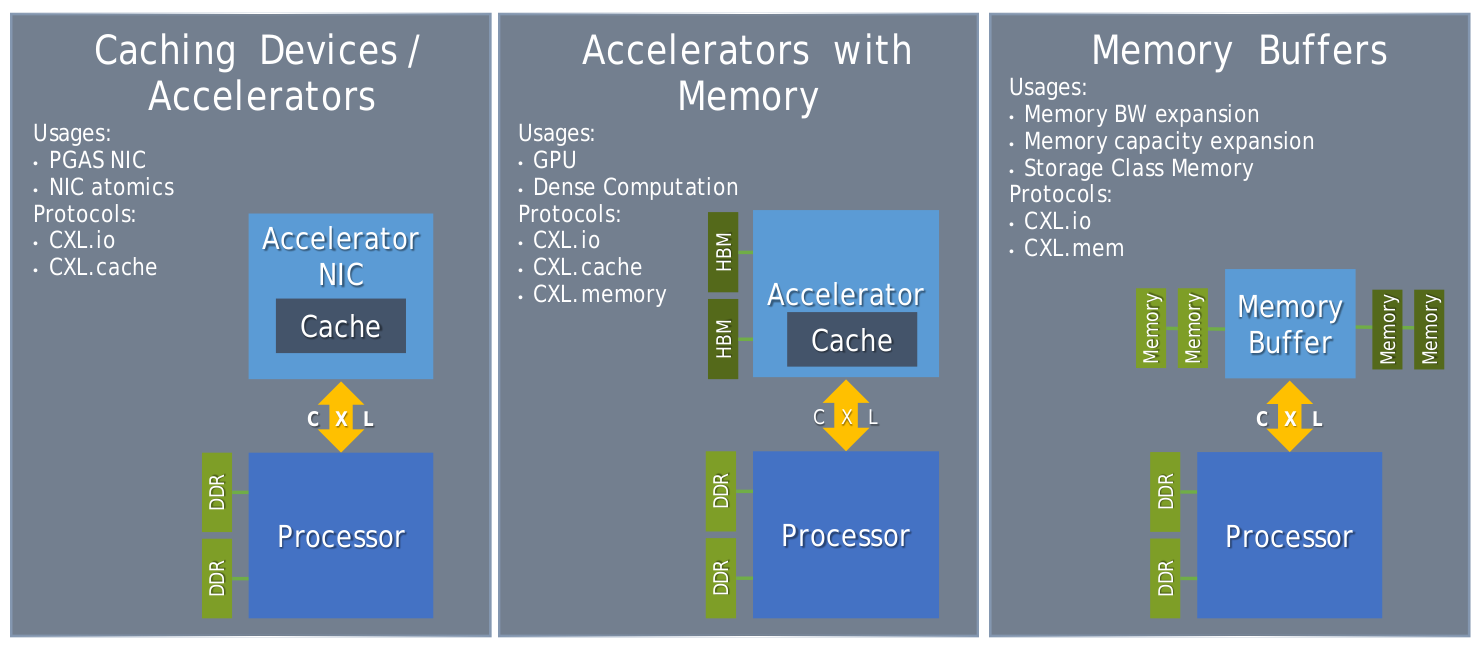
CXL 设备分为三种类型:Type1、Type2 和 Type3,每种类型的设备有不同的特性,适用于不同的应用场景. Type1 设备主要是那些具有计算能力,但没有自己的专用内存的设备, 它们依赖于主机 CPU 的内存,而不需要独立的内存空间. 通常这类设备是 I/O 加速器,如网络接口卡(NIC)或一些特定领域的加速器. Type1 设备的特点:
- 无专用内存: Type1 设备没有独立的内存,它们依赖于主机的内存空间进行所有的内存操作
- 低延迟访问主内存: 通过 CXL.mem 和 CXL.cache 协议,Type1 设备能够低延迟地访问主机内存,并保持与主机 CPU 一致的内存视图
- 缓存一致性: Type1 设备可以利用 CXL.cache 协议,允许设备缓存主机内存的数据,同时保持数据一致性. 这对于那些频繁与主机通信的加速器非常重要
- I/O 操作: 设备可以执行标准的 I/O 操作,利用 CXL.io 协议进行数据传输和设备管理
Type1 涉笔应用场景可以是网络加速器,如智能网卡(SmartNIC)等,处理网络流量时需要与主机 CPU 高效协同工作,但不需要专用内存. 又如特定任务加速器,一些用于加速特定任务的硬件加速器,它们通过 CXL 与主机协同工作,但不需要大量的本地内存.
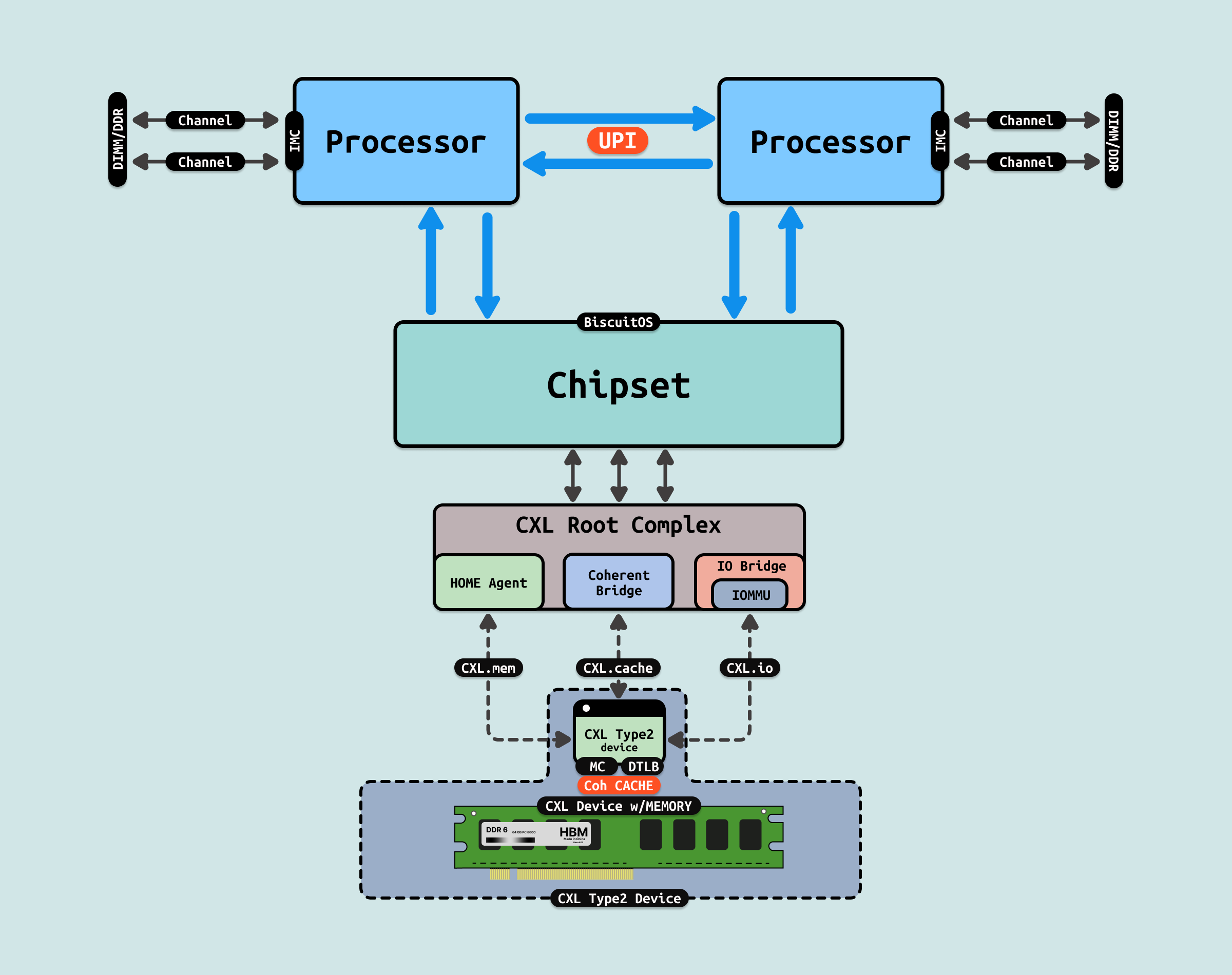
Type2 设备是具有计算能力并且拥有自己的本地内存的设备, 它们不仅可以进行数据处理,还能使用独立的内存存储数据, Type2 设备通常是加速器设备,如 GPU、FPGA 或 AI 加速器, 其具有如下特点:
- 拥有独立的内存: Type2 设备具有自己的本地内存,这使它们可以在独立的内存空间中执行计算任务,而不依赖主机内存来存储所有数据
- 低延迟访问主内存: 虽然 Type2 设备有自己的内存,但它们仍然可以通过 CXL.mem 访问主机的内存,并保持较低的延迟. 这种能力允许设备在需要时使用主机内存来处理更大的数据集
- 缓存一致性: 通过 CXL.cache,Type2 设备可以与主机保持内存的一致性, 这对需要频繁共享数据的任务(如 AI 推理、机器学习等)非常有用
- 计算与存储分离: Type2 设备能够独立进行计算并使用自己的内存空间,这种计算与存储的分离使其非常适合用于高性能计算、机器学习等场景
type2 典型设备如 GPU/FPGA 加速器,在 AI、机器学习、图形渲染等领域,GPU 和 FPGA 设备通常需要高性能计算和大规模内存支持,Type2 设备能够同时利用自己的内存和主机内存,提升计算效率. 又如 AI 加速器,专用的 AI 处理设备,如 AI 推理加速器和训练设备,需要高性能计算和内存共享以处理复杂的神经网络运算.
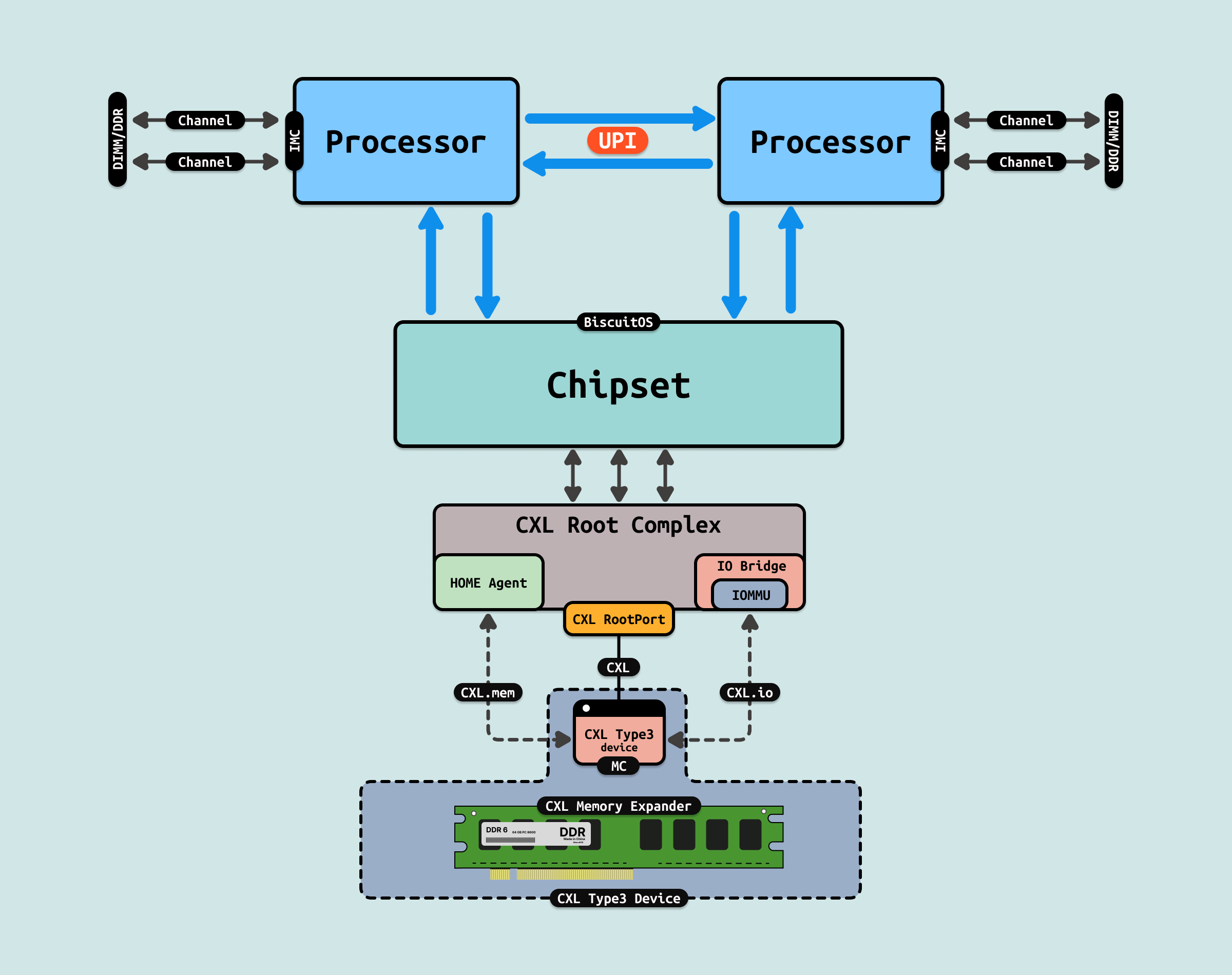
Type3 设备是没有计算能力,但拥有大量内存的设备, 它们的主要功能是内存扩展,用于为主机提供额外的内存空间, Type3 设备并不执行计算任务,而是通过 CXL.mem 提供对其内存的低延迟访问. 其特点如下:
- 无计算能力: Type3 设备不进行计算操作,它们只是为系统提供额外的内存资源
- 大容量内存扩展: Type3 设备的主要作用是提供大规模的内存扩展,允许系统通过连接这种设备来扩展物理内存容量, 这对于需要大量内存但不需要额外计算资源的应用场景非常适用
- 低延迟内存访问: 尽管 Type3 设备没有计算能力,但它们可以通过 CXL.mem 提供低延迟的内存访问能力,这使得它们非常适合内存密集型的任务
- 持久性内存支持: Type3 设备还可以使用持久性内存(PMEM),这意味着即使系统掉电,数据仍然可以保存在设备的内存中,从而提高数据可靠性和安全性
type3 可以做内存扩展模块,用于大规模云计算或数据中心的内存扩展场景,Type3 设备可以为需要大量内存的任务(如大数据处理、虚拟化等)提供所需的内存资源. 另外 type3 还可以做持久性内存设备,在需要高数据持久性和快速恢复的应用中,如数据库系统、文件系统等,Type3 设备可以提供持久性内存支持,确保数据的可靠存储.
CXL 基础概念

2001 年,英特尔公布了第三代 I/O 技术: 3GIO 技术(后更名为 PCI Express,即PCIe),以高性能、高扩展性、高可靠性及出色的兼容性取代了包括 AGP 和 PCI 在内所有的内部总线并且不断升格.
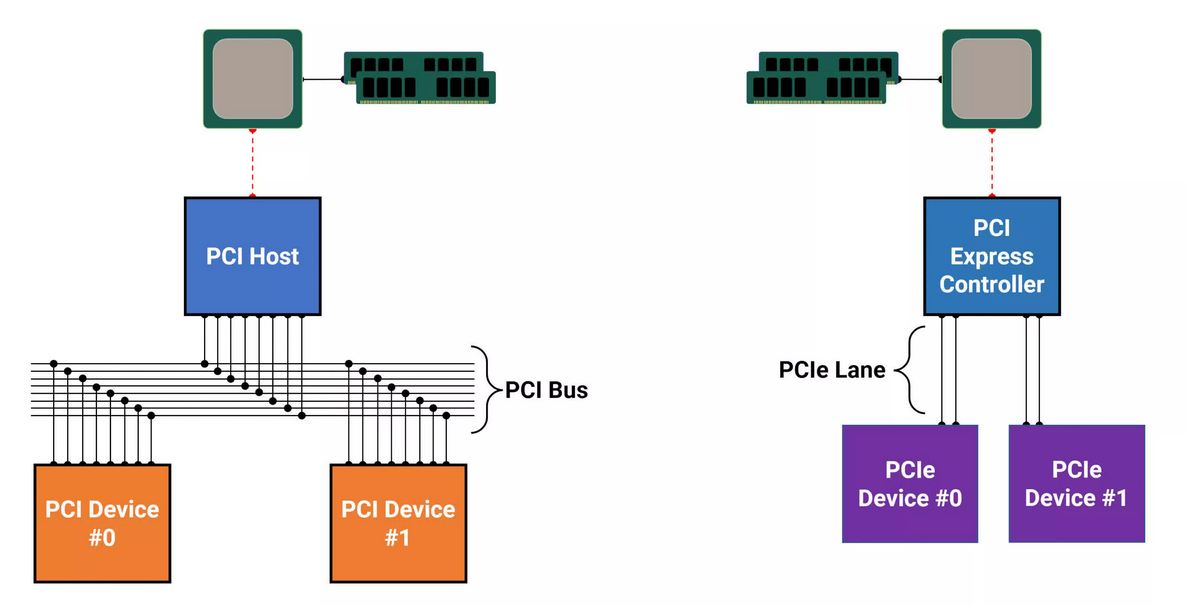
例如,2019 年 5 月底公布的 PCIe 5.0,其以 32Gb/s 的单通道带宽与 32GT/s(Giga Trans-mission per second) 每通道数据传输速率,满足了现今绝大多数的需求。但应对数据 TB 级增长、异构计算大行其道的当下,PCIe 在内存使用效率、延迟和数据吞吐量等方面,已经面临压力.

曾经的未来之星 PCIe 已经开始出现后继无人的现象,无法成为 CPU、GPU、FPGA 以及其他 AI 计算设备之间沟通的桥梁。为了达到最佳的计算效果,越来越期待一种以内存为中心的、富有变革性的新技术出现,基于 PCIe 协议的 CXL 技术便在此环境下出世. 2019 年,英特尔推出的 CXL 技术似乎杀出了重围。
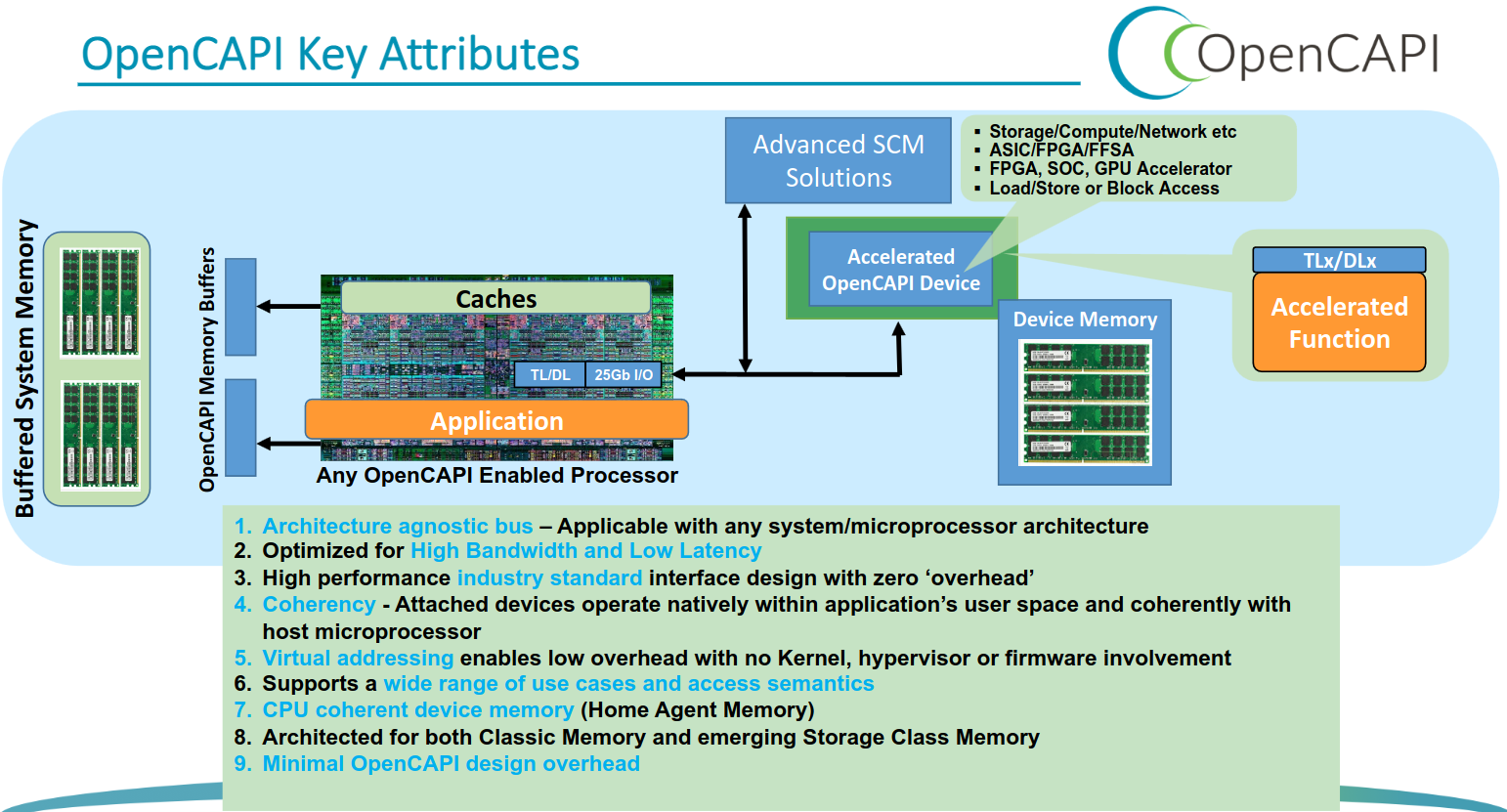
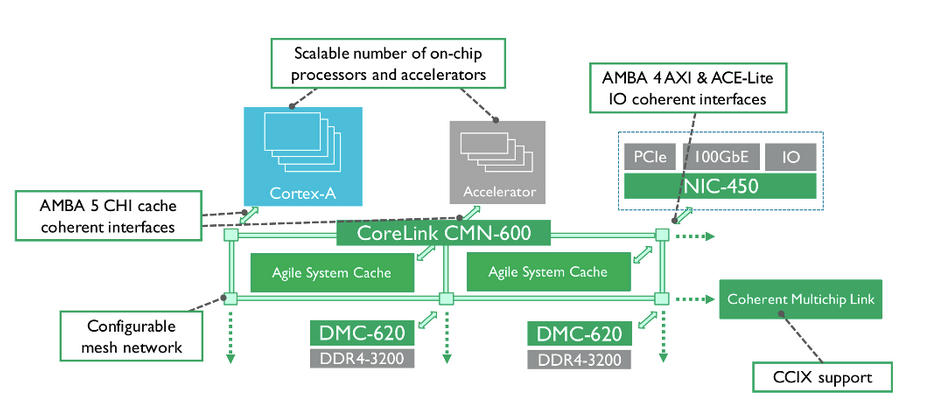
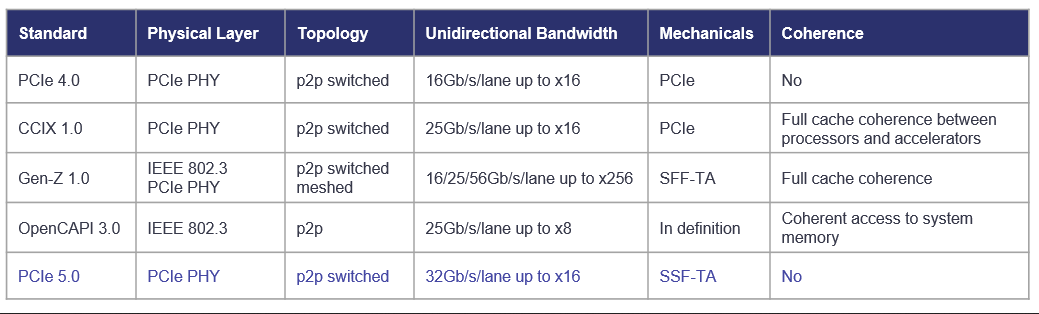
短短几年时间,CXL 便成为业界公认的先进设备互联标准,其最为强劲的竞争对手 Gen-Z、OpenCAPI 都纷纷退出了竞争,并将 Gen-Z 协议、OpenCAPI 协议转让给 CXL.
CXL
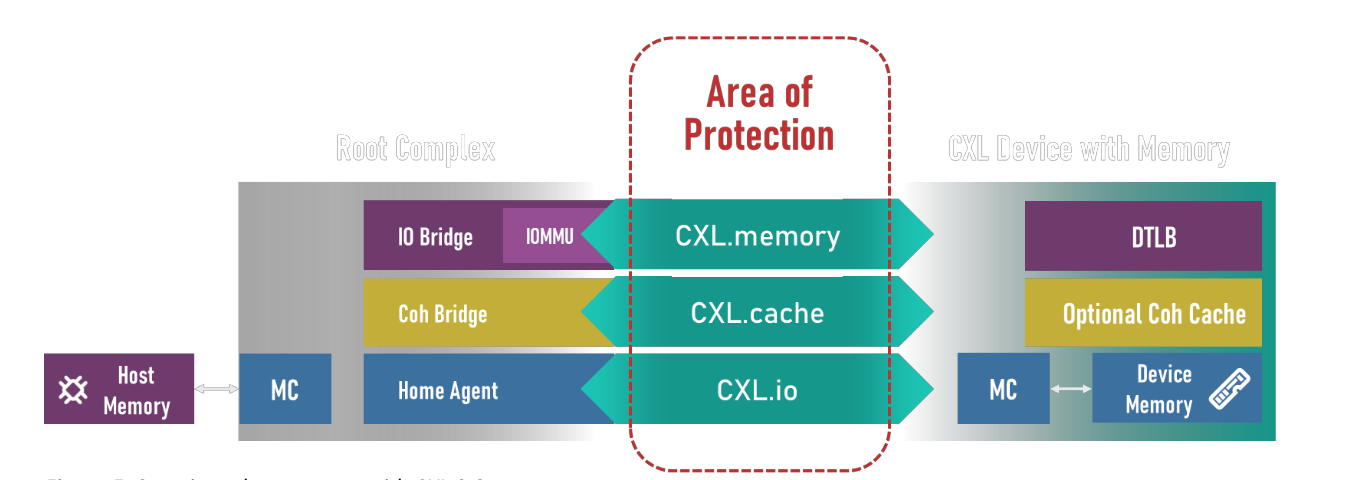
CXL(全称为 Compute Express Link),作为一种全新的开放式互联技术标准,其能够让 CPU 与 GPU、FPGA 或其他加速器之间实现高速高效的互联,从而满足高性能异构计算的要求,并且其维护 CPU 内存空间和连接设备内存之间的一致性。总体而言,其优势高度概括在极高兼容性和内存一致性两方面上
CXL 协议
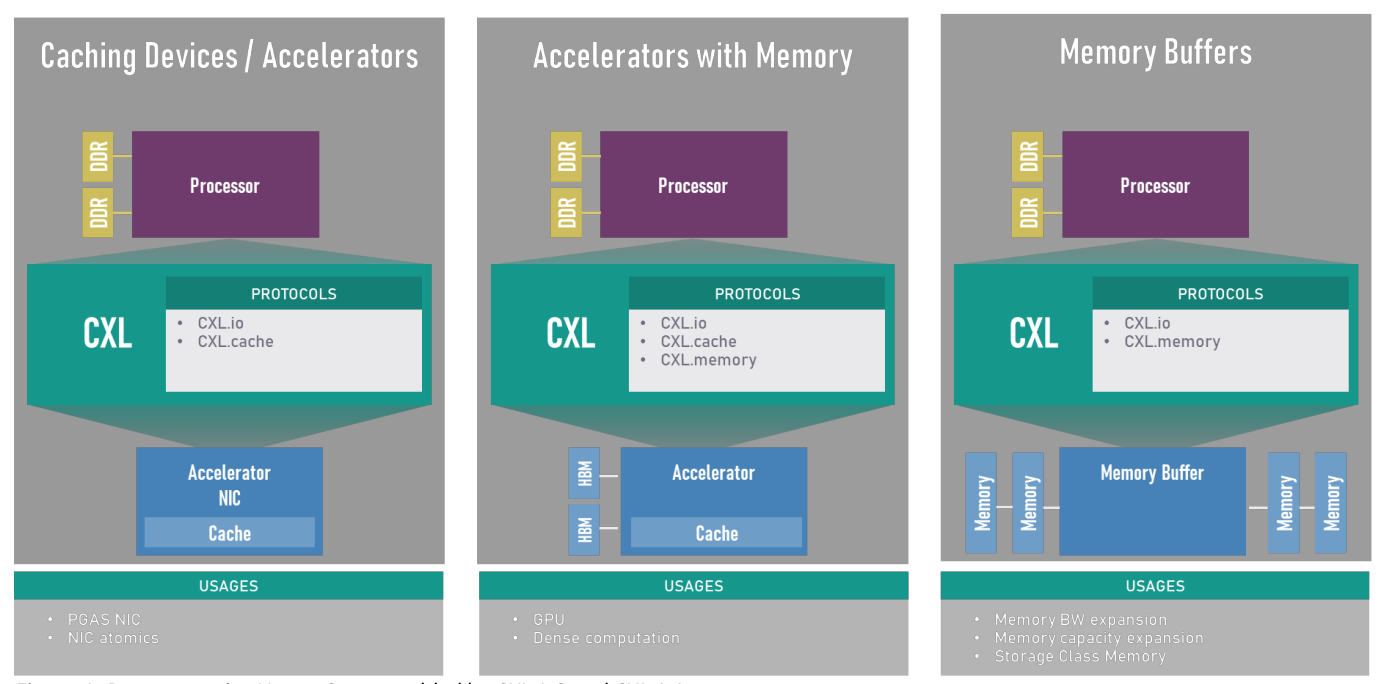
CXL 标准定义了 3 个协议,这些协议在通过标准 PCIe 5.0 PHY 以 32 GT/s 传输之前一起动态复用:
- CXL.io 协议: 本质上是经过一定改进的 PCIe 5.0 协议,用于初始化、链接、设备发现和列举以及寄存器访问. 它为 I/O 设备提供了非一致的加载/存储接口
- CXL.cache 协议: 定义了主机和设备之间的交互,允许连接的 CXL 设备使用请求和响应方法以极低的延迟高效地缓存主机内存
- CXL.mem 协议: 提供了主机处理器,可以使用加载和存储命令访问设备连接的内存,此时主机 CPU 充当主设备,CXL 设备充当从属设备,并且可以支持易失性和持久性存储器架构
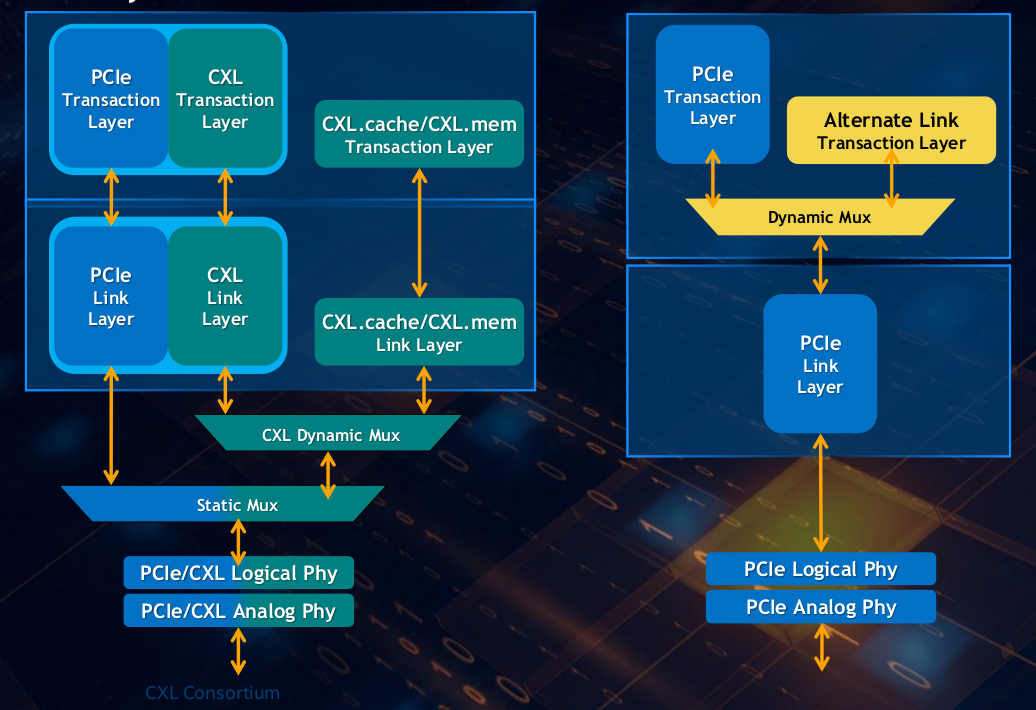
如图所示,CXL.cache 和 CXL.mem 合并且共享一个公共链路和事务层,而 CXL.io 有自己的链路和事务层. 三个协议产生的数据都通过仲裁和多路复用(ARB/MUX) 模块一起动态复用,然后被移交到 PCIe 5.0 PHY,进而以 32GT/s 的速度进行传输。ARB/MUX 在 CXL 链路层(CXL.io 和 CXL.cache/mem) 发出的请求之间进行仲裁,并根据仲裁结果复用数据,仲裁结果使用加权循环仲裁,权重由主机设置。ARB/MUX 还处理链路层发出的功耗状态转换请求,向物理层创建实现有序降耗操作的单个请求.
CXL 设备类型
CXL.io 协议用于初始化和链接,所以必须获得所有 CXL 设备的支持,如果 CXL.io 协议发生故障,链接就无法运行。其他两个协议的不同组合产生了总共三种被定义并受 CXL 标准支持的独特 CXL 设备类型。
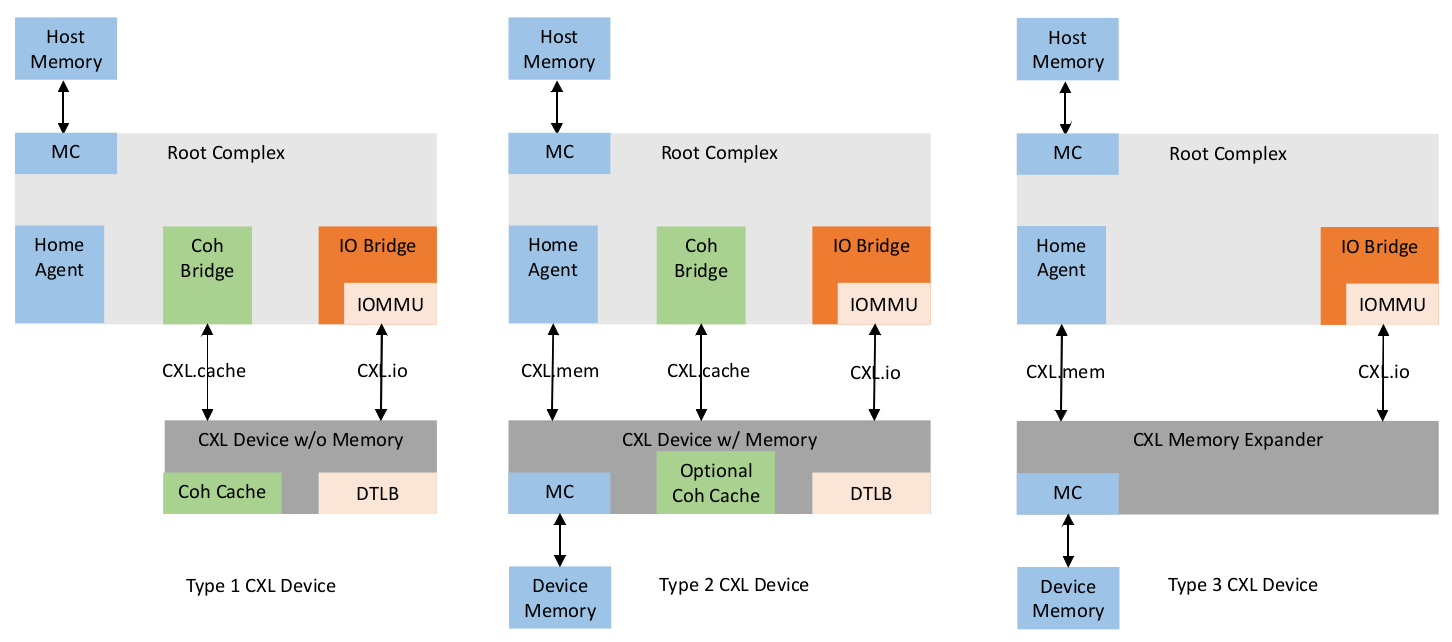
上图显示了三种已定义的 CXL 设备类型及其相应的协议、典型应用以及支持的存储器访问类型。对于 Type2 型设备,CXL 定义了两个一致性“偏置”,用于控制 CXL 对主机和设备连接存储器之间的一致性数据的处理方式。偏置模式指主机偏置和设备偏置,并且操作模式可以根据需要发生改变,从而在链路操作期间优化给定任务的性能。

TYPE2 型设备(例如,加速器)处理提交给主机的工作时间及其后续完成之间的数据时,设备偏置模式用于确保设备可以直接访问其设备连接的存储器,而无需与主机的一致性引擎通信。因此,设备可保证主机没有缓存线路。这为设备提供了最优的延迟性能,使得设备偏置成为加速器执行工作的主要操作模式。主机处于设备偏置模式时,主机仍然可以访问设备连接的存储器,但性能却不是最优。
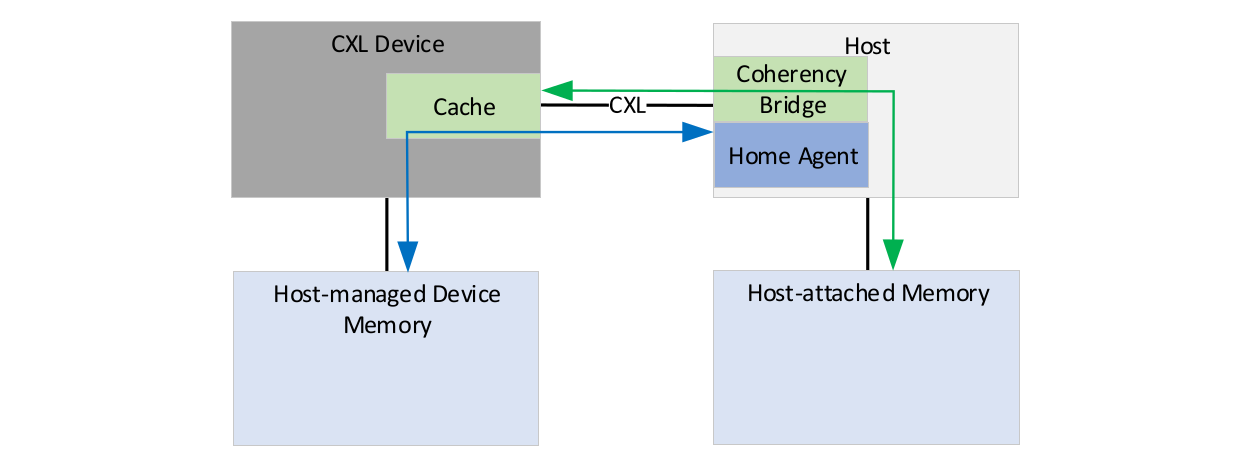
主机偏置模式优先考虑从主机到设备连接存储器的一致性访问。该模式通常在工作提交期间使用,此时数据会从主机写入设备连接的存储器,而且在主机将数据从设备连接的存储器中导出后,可使用该模式完成工作。在主机偏置模式下,设备连接的存储器对于设备而言就像主机连接的存储器一样,如果设备需要访问,就通过一条发送到主机的请求进行处理。
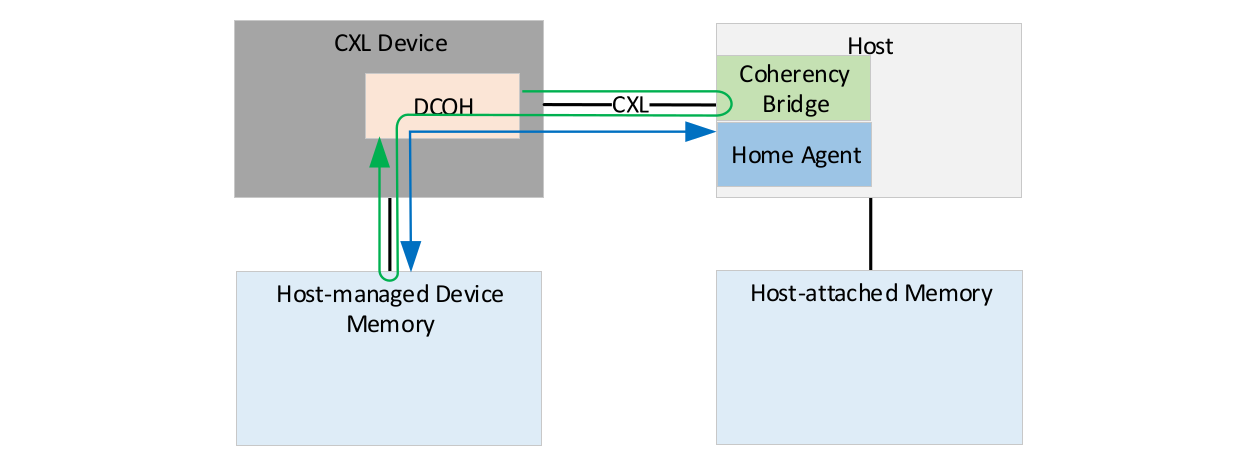
可以使用软件或硬件,通过软件辅助和硬件自治这两种受支持的模式管理机制来控制偏置模式。加速器或其他 2 型设备可以选择偏置模式,如果两种模式均未选择,则系统默认为主机偏置模式,这样就必须通过主机路由对设备连接存储器进行所有访问。偏置模式可以使用 4KB 页面的颗粒度进行更改,并通过 2 型设备中执行的偏置表进行跟踪。
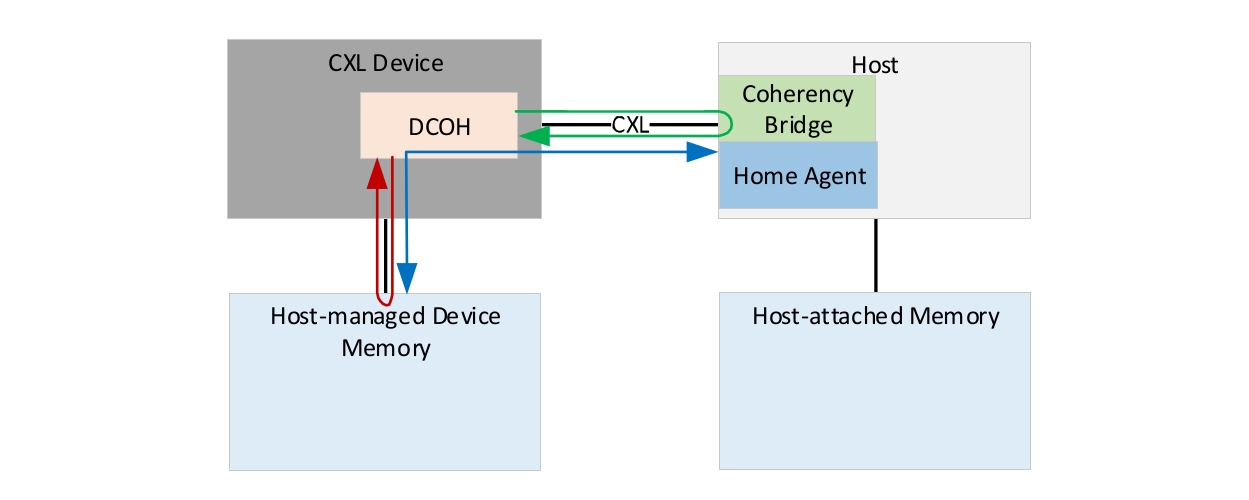
CXL 标准的一个重要特征是一致性协议是不对称的。Home 缓存代理仅停留在主机中。因此,主机控制存储器的缓存,从而解决连接的 CXL 设备请求的给定地址的整个系统的一致性问题。这完全不同于正在使用的现有专有和公开的一致性协议,特别是那些用于 CPU 到 CPU 连接的协议,因为它们通常是对称的,会使得所有互连设备都变得对等。 虽然这样有一些优点,但是对称的高速缓存一致性协议更加复杂,并且所有设备都必须处理由此产生的复杂性。具有不同架构的设备可以采用不同的方法来实现在微架构级别优化的一致性,而这一情况可能会为实现广泛的行业采用增加难度。通过使用主机控制的非对称方法,可以将不同的 CPU 和加速器轻松纳入新兴 CXL 生态系统。