

目录
内存屏障预备知识
指令乱序
编译乱序 Compiler Reorderubg
CACHE Coherent
Store Buffer
内存一致性模型
Sequential Consistency: SC 模型
Total Store Order: TSO 模型
Relaxed Memory Order: RMO 模型
Memory Barrier
Memory Barrier 实践
Memory Barrier 使用
SMP RMB/WMB 使用
内存屏障实现无锁同步
smp_wmb 实现无锁并发资源访问
内存屏障实现计数和行为的统一
Memory Barrier 使用场景
VMALLOC vmallocinfo 场景
TTU: Isoloation Dirty Page 场景
页表安装并发访问场景
无锁 Tail Page 剥离场景
MemoryPool 场景
Memory Barrier 进阶研究
X86 架构内存屏障指令
Paper/Doc
Video for Memory Barrier


指令乱序
乱序执行: 程序里代码执行顺序可能被编译器、CPU 根据某种策略调整(俗称乱序), 但乱序执行不影响执行的结果. 程序为什么需要乱序呢? 只要原因>是 CPU 内部采用流水线技术,抽象且简化看, 一个 CPU 指令的执行过程可以分成 4 个阶段: 取指、译码、执行、写回.
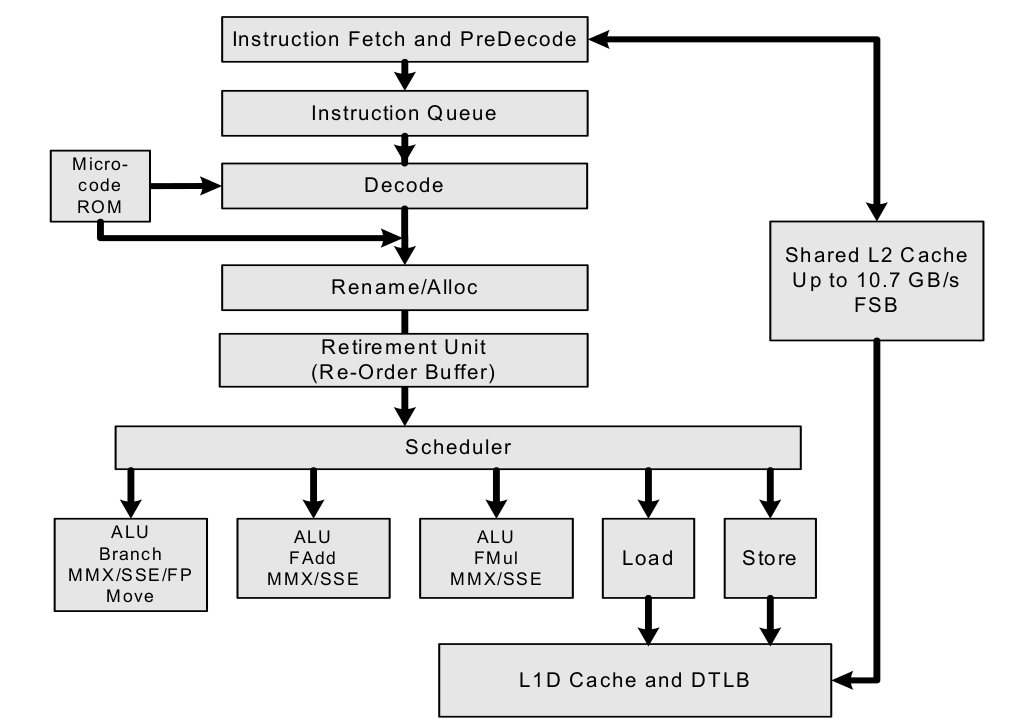
这四个阶段分别由 4 个独立物理执行单元来完成,在这种情况下,如果指令之间没有依赖关系,后一条指令并不需要等到前一条指令完成执行再开始执行,而是 前一条指令完成取指之后,后一条指令边可以开始执行取指操作.
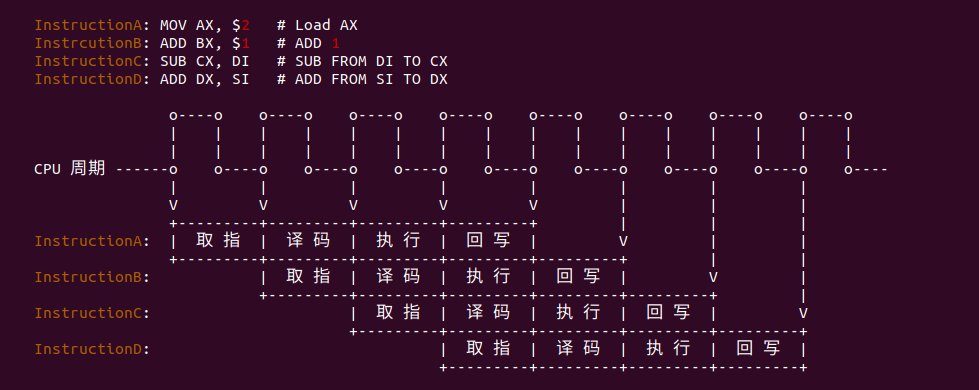
理想状态下,Instruct A-D 四条指令之间没有依赖,那么可以使流水线的并行度最大化。第一条指令完成取指,第二条指令就可以开始取指; 第一条指 令完成译码之后,第二条指令可以开始执行译码, 那么第三条指令可以开始取指, 依次类推.
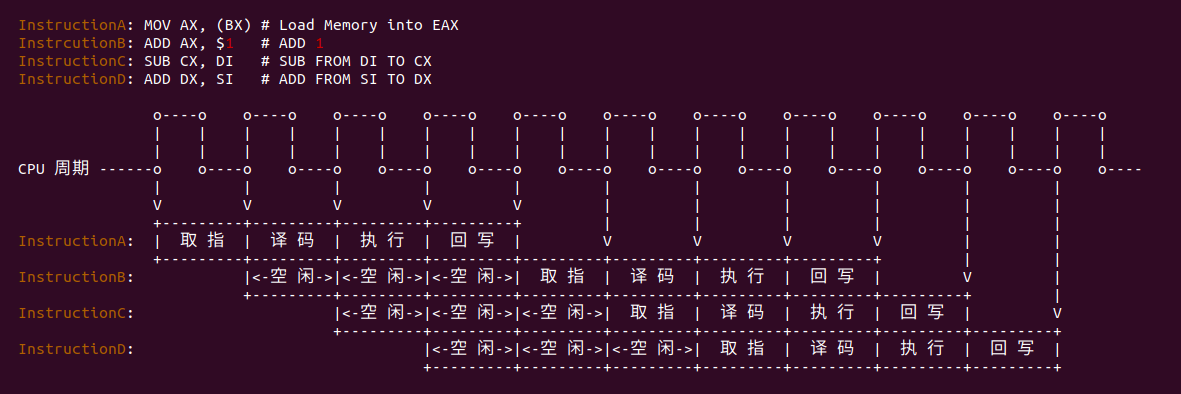
在按顺序执行的情况下,一旦遇到指令依赖的情况,流水线就会停滞,例如 InstructionB 依赖 InstructionA 的结果,那么在 InstructionA 执行完之前 InstructionB 无法执行,这会让流水线的执行效率大大降低. 例如上图由于 InstructionB 依赖 InstructionA 的结果,导致剩余三条流水线多出现多个空闲周期.
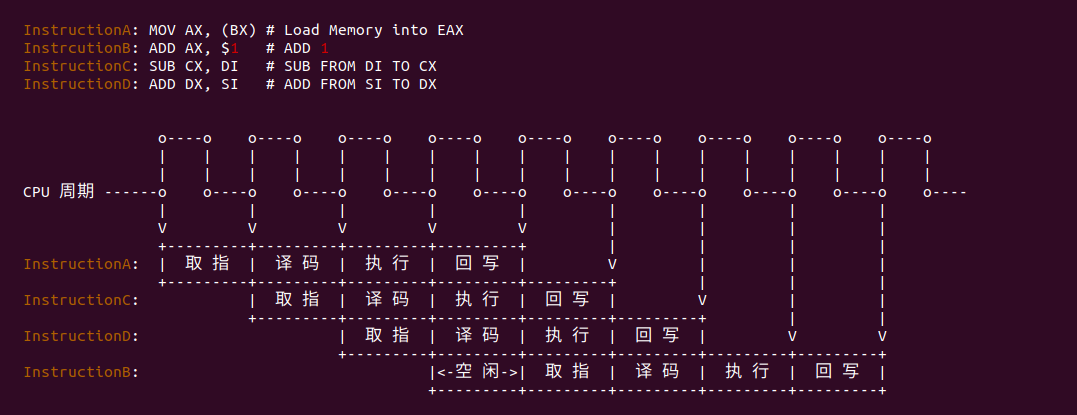
InstructionC 和 InstructionD 指令对其他指令并没有依赖,可以考虑将 InstructionC 和 InstructionD 乱序 到指令 InstructionB 之前,那么流水线>执行单元就可以尽可能处于工作状态。通过上面的案例大概了解了系统为什么需要乱序执行,通过乱序执行合理调整指令执行顺序,可以提高流水线的>运行效率,让指令的执行能尽可能地并行起来.
订阅内存屏障专题

内存屏障专题订阅中,需要的同学请扫码进行订阅,订阅内容如下:
- 订阅价格: 40 元 (BiscuitOS 社区成员可领优惠卷)
- 订阅服务: 文档主体、2 节视频课(视频课位于学浪,支持苹果、Android、PC 端永久观看)
- 订阅特色: 配合图片和实践案例,对内存屏障原理通透讲解; 针对 Linux 中经典使用内存屏障场景进行讲解; 提供多个实践案例用于介绍内存屏障如何使用. 视频做到手把手实践教学, 并提供多个内存屏障相关的 Paper 和 Youtube 视频(非 2 节视频课).