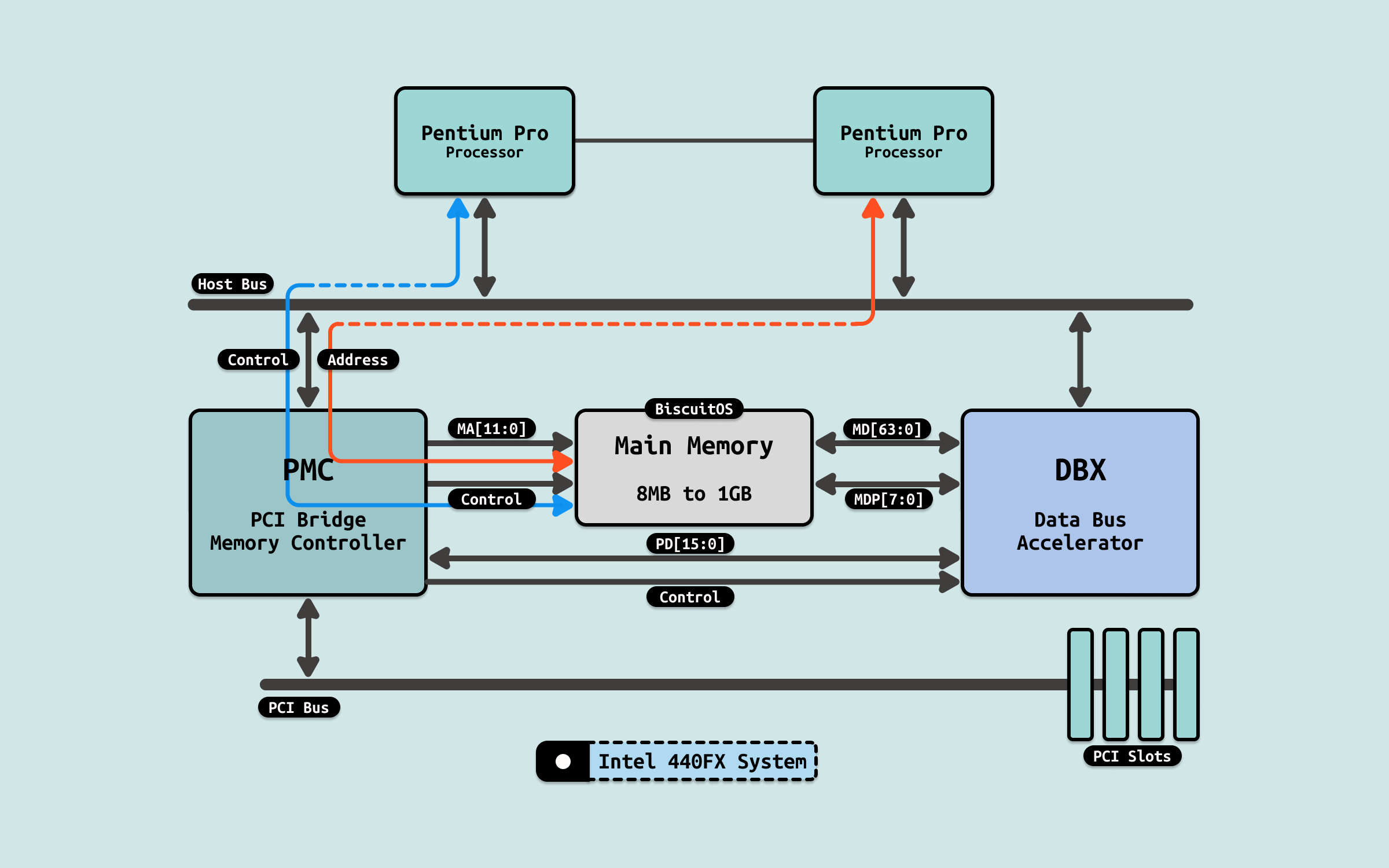
在早期系统了,所有的 CPU 通过共享总线 FSB 与北桥相连,北桥芯片上连接内存控制器和南桥,CPU 要访问内存就必须要通过北桥,再经过内存控制器,才能访问到 DIMM 内存. 此时 CPU 在访问完一次内存之后,需要一定的时间间隔才能执行下一次内存访问,这里的时间间隔包括: L(CAS 延时)、tRCD(RAS 到 CAS 延时)、tRP(预充电有效周期) 等. 因此在早期系统里,内存带宽受限与 FSB 总线和北桥.
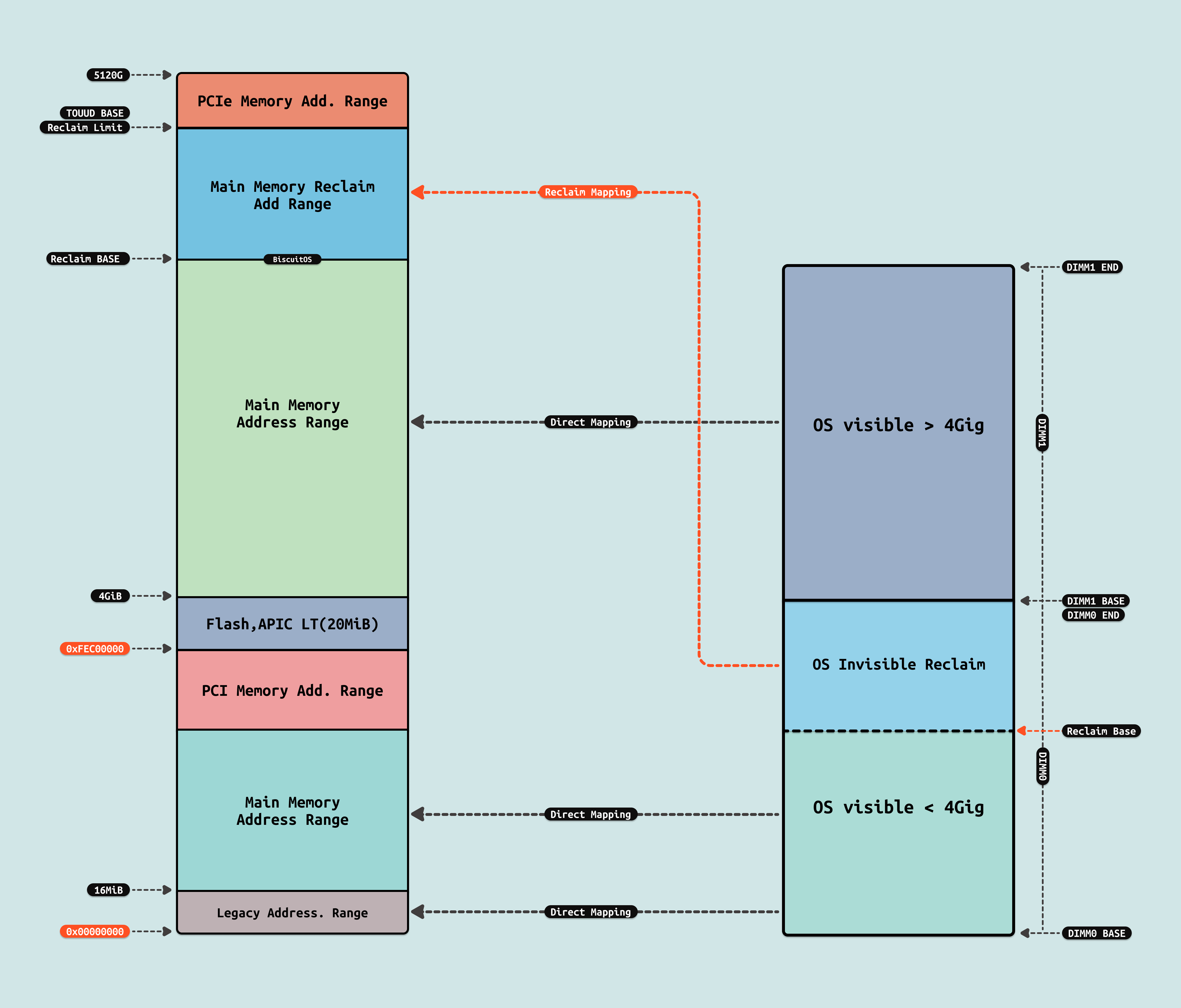
在这种架构下,早期的硬件将 DIMM 内存直接映射到连续的系统物理地址空间里,因此 CPU 看到连续的物理内存来自同一块 DIMM. 结合程序的局部性原理,程序会把代码和数据都放在连续的物理内存上,并且 CACHE 也会根据局部性原理将连续的物理内存预加载到 CACHE 里,因此程序都会放到同一个 DIMM 上,因此系统只能串行的访问内存. 此时内存带宽为:
- 总带宽 = 单条内存带宽
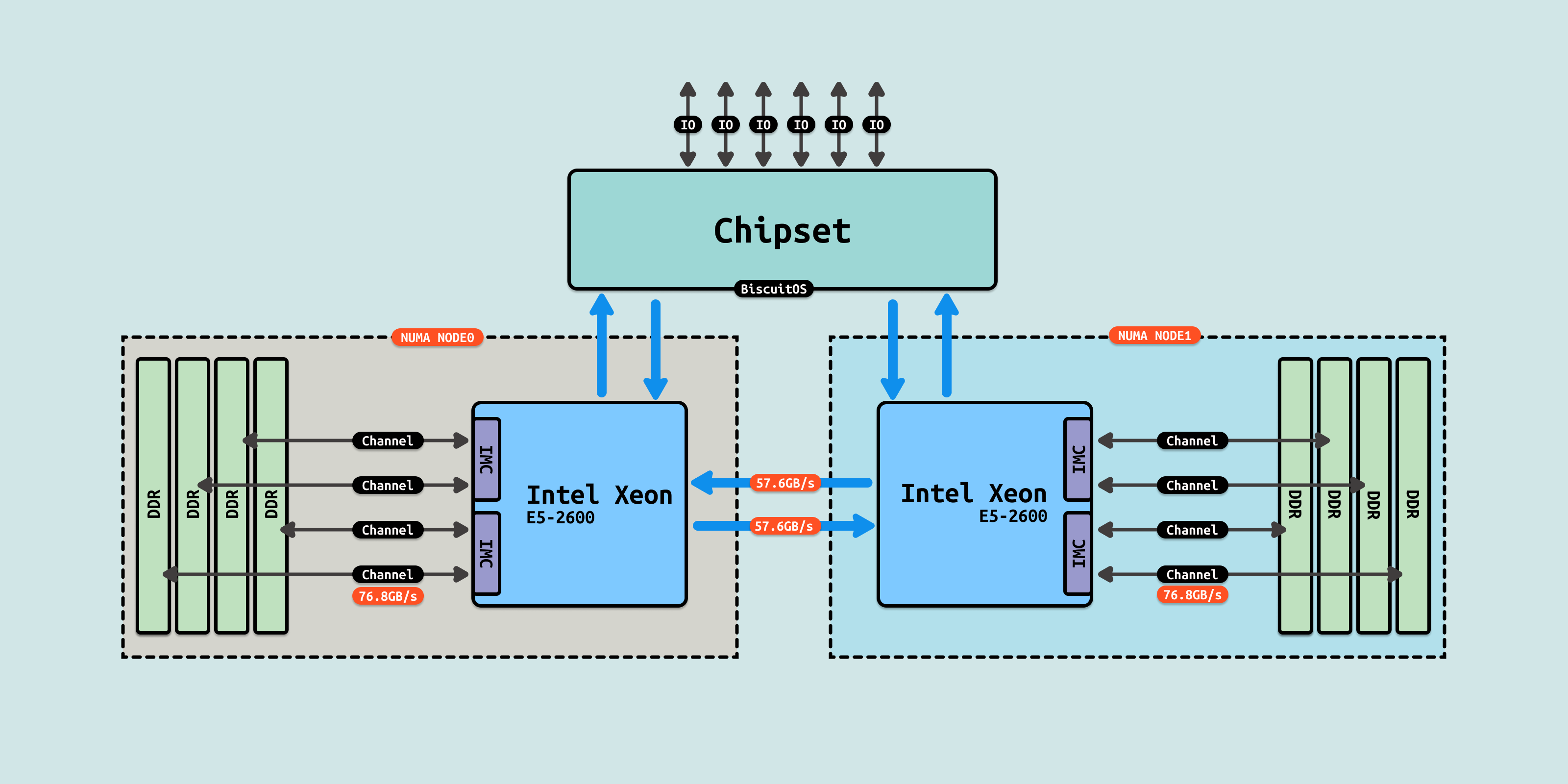
随机技术不断的发展,多核 CPU 不断出现,传统的 FSB 总线已经无法满足多核场景,Intel 针对该场景提出了 QPI 和 UPI 多 Socket 互联技术. 此时内存控制器已经集成到 CPU Die 内部,CPU 可以直接访问内存控制器,进而访问到 DIMM 内存. 由于 CPU Die 内核心数不断的增加,CPU Die 内部出现了两个内存控制器(IMC), 每个内存控制器通过多个通道(Channel)连接到多个 DIMM 插槽. 此时如果数据存储在不同的 DIMM 上,那么内存控制器可以并行读取这些数据,因此此时内存带宽计算如下:
- 总带宽 = 单条内存条带宽 * 通道数