


目录
匿名内存(Anonymous) With PageFault
匿名映射可读可写内存缺页场景
匿名映射只读(Read-Only)内存缺页场景
匿名映射写保护(Write-Protection)内存缺页场景
匿名映射 COW(Copy-On-Write) 内存缺页场景
匿名映射内存交换(SWAP) 缺页场景
匿名映射内存压缩(ZSWAP) 缺页场景
匿名映射内存 KSM 缺页场景
匿名映射内存 NUMA Balancing 缺页场景
匿名映射内存 MCE 缺页场景
匿名映射之堆(Heap) 缺页场景
匿名映射之栈(Stack) 缺页场景
匿名映射内存 Protection Key 缺页场景
匿名映射之 PmdMapped THP 内存缺页场景


匿名内存(Anonymous) With PageFault
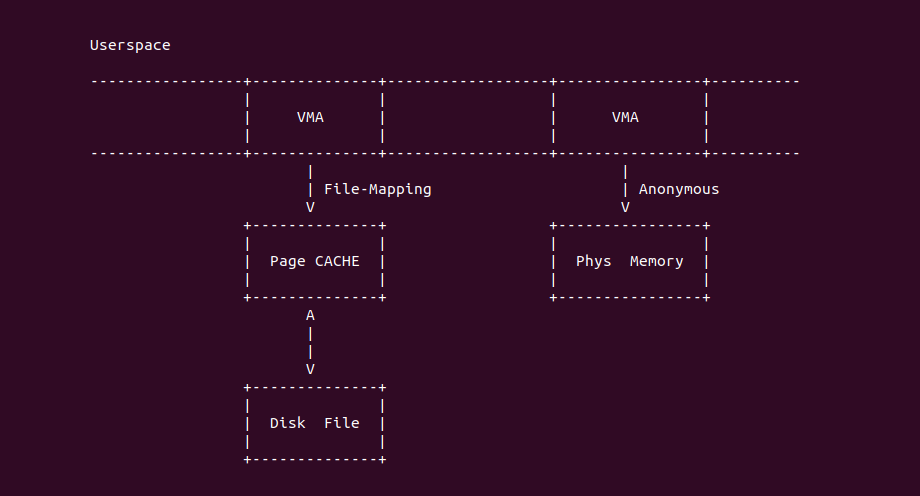
在 Linux 用户空间,虚拟内存可以通过两种映射方式与物理内存建立映射关系,第一种是 File-Mapping 文件映射,其可以将文件内容映射到用户空间,虚拟内存和磁盘文件中间通过 Page CACHE 进行数据中转,因此可以像普通虚拟内存一样访问文件; 另外一种是 Anonymous-Mapping 匿名映射, 用于将用户空间虚拟内存映射到物理内存上,以满足进程对内存的需求,例如堆(Heap)内存、堆栈(Stack)内存、以及 MMAP 内存等。两种映射方式的不同点在于是否有后端文件,匿名内存 可以通过 malloc/brk/mmap 进行分配
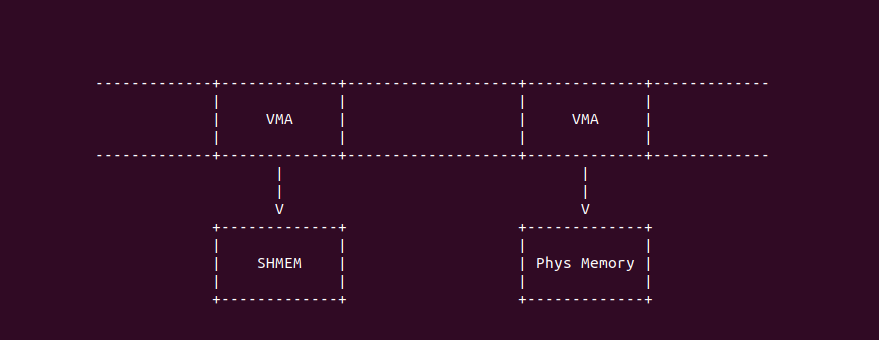
另外 Linux 还支持共享内存,其可以通过 mmap 函数进行分配,分配时采用分配标志: MAP_SHARED 与 MAP_ANONYMOUS. 而匿名内存同样可以使用 mmap 进行分配,其分配标志是: MAP_PRIVATE 与 MAP_ANONYMOUS。虽然两者都采用了 MAP_ANONYMOUS, 但是两者的处理逻辑是不同的,虽然共享内存没有明确指明后端文件,当内核会为每个共享文件关联一个 tmpfs 文件系统的文件,而匿名内存 Linux 是不会关联任何文件的,因此从这个角度来看,采用 MAP_PRIVATE 与 MAP_ANONYMOUS 的内存才能称为匿名内存.
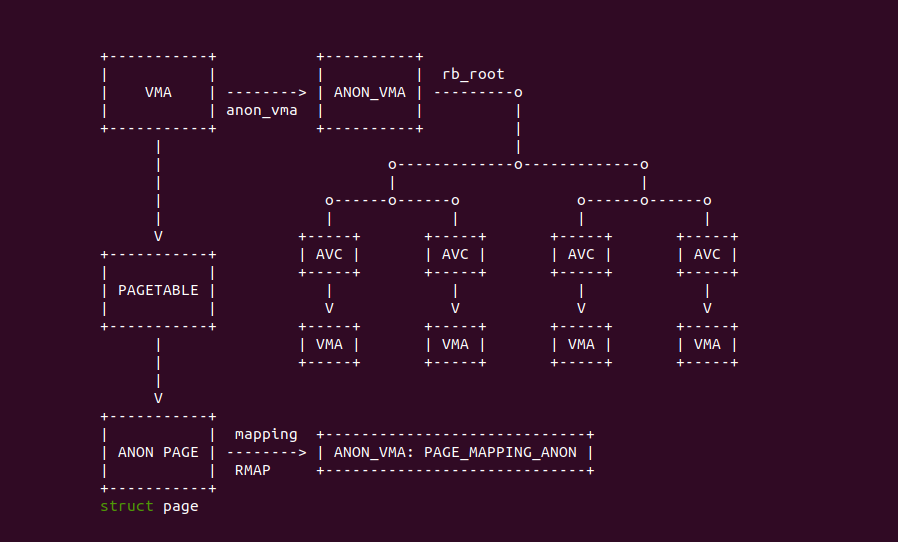
在匿名内存架构里,VMA 通过页表正向映射到匿名页上,并且每个 VMA 维护一个 STRUCT anon_vma 的数据结构(简称为 AV),该数据结构里存在一颗红黑树,该红黑树的节点为 STRUCT anon_vma_chain(简称为 AVC), 每个 AVC 都指向另外一个 VMA,那么每个 AVC 可以表示映射到该匿名页的 VMA,最后将匿名页的 mapping 指向 AV。有了上面的关系之后,如果获得一个匿名页之后,想通过逆向映射知道哪些 VMA 映射了该匿名页,那么可以通过匿名页的 mapping 获得 AV,然后遍历 AV 对应的红黑树获得每一个 AVC,在通过 AVC 获得 VMA 即可.
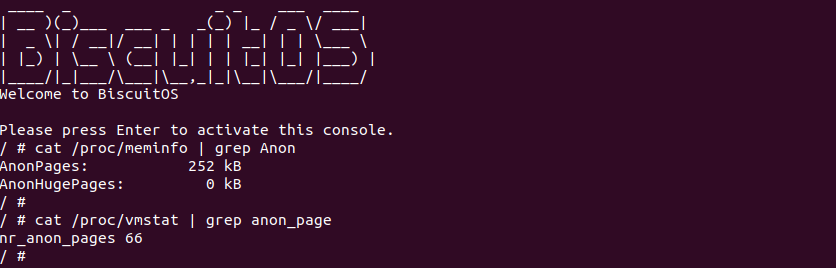
在 Linux 系统里,匿名内存的数量可以通过 ‘/proc/meminfo’ 文件提供的信息获得,其中 AnonPages 字段表示匿名内存的大小; 同理 ‘/proc/vmstat’ 文件也提供了信息,其中 nr_anon_pages 字段表示匿名页的数量.
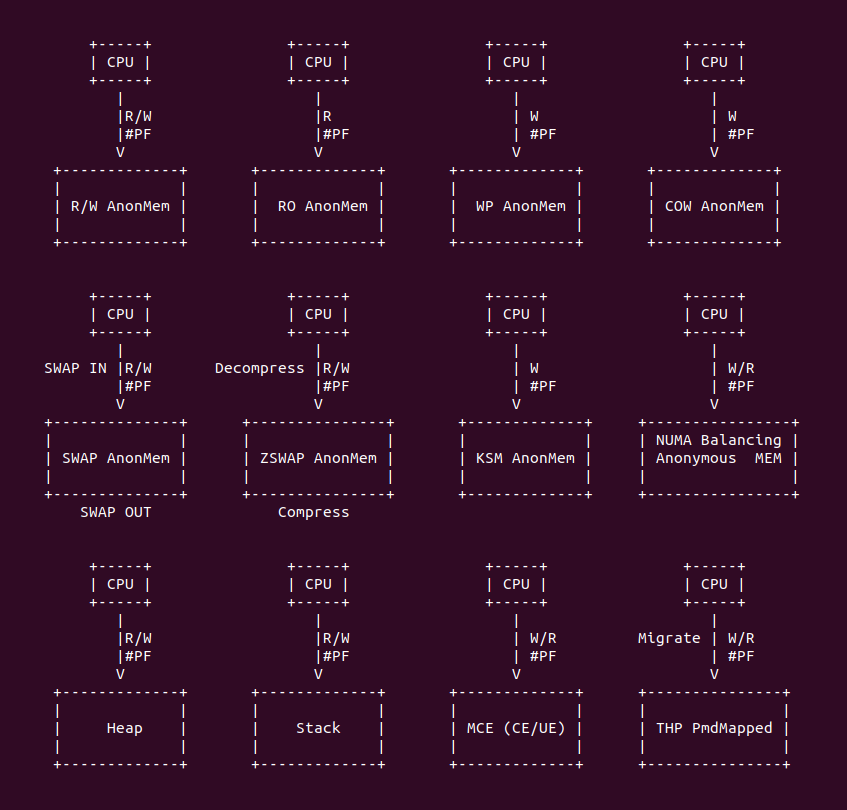
匿名映射内存发生缺页最常见的场景就是: 当 CPU 访问了未建立页表的匿名内存,MMU 触发缺页异常. 但在 Linux 里还有很多场景也会导致匿名内存发生缺页,总结包括如下场景:
- 可读可写匿名内存场景: 进程访问了一块未与物理内存建立映射的匿名内存,MMU 检查到该场景并触发缺页异常,经过缺页异常处理函数分配物理内存建立页表之后,进程可以正常访问匿名内存.
- 只读匿名内存场景: 进程对一块未与物理内存建立映射的匿名内存执行读操作,MMU 检查到该场景并触发缺页异常,经过缺页异常处理函数将虚拟内存映射到 ZERO Page 之后,进程可以对虚拟内存进行读操作. 但继续对只读虚拟内存执行写操作,MMU 检查该该场景再次触发异常,并因权限检查异常发送 SIG_BUS 导致进程 SegmentFault.
- 写保护匿名内存场景: 匿名内存已经与物理内存建立页表,但匿名内存被设置为写保护(Write-Protection), 当进程对该匿名内存进行写操作,MMU 检查到该场景再次触发缺页异常,缺页异常处理函数会按 WP 处理逻辑给页表添加 _PAGE_RW 写权限,接下来进行可以对该匿名内存进行写操作.
- 写时拷贝场景: 匿名内存已经与物理内存建立页表,父进程可以对匿名内存进行读写操作,父进程调用 fork() 函数创建子进程,fork() 将匿名内存设置为写保护,那么子进程可以对匿名内存读操作,但子/父进程对匿名内存进行写操作,MMU 会检查到没有写权限触发缺页异常,缺页异常处理函数可能会将匿名内存的内容拷贝到一个新的物理页上,然后将页表映射到新的物理页上,并添加 _PAGE_RW 写权限,那么进程可以对匿名内存进行读写操作.
- SWAP 场景: 匿名内存已经与物理内存建立页表,进程可以正常访问匿名内存,但是由于系统内存紧缺,于是系统将部分匿名内存交换到 SWAP Space,那么当进程再次访问匿名内存时,MMU 检查到对应的物理内存不存在,那么触发缺页异常,缺页异常处理函数发现物理内存被交换到 SWAP Space,于是 SWAP In 到新的物理页上,并将页表更新到新的物理页上,那么进程可以正常访问匿名内存.
- 内存压缩场景: 匿名内存已经与物理内存建立页表,进程可以正常访问匿名内存,但是由于系统内存紧缺,于是系统将部分匿名内存进行压缩,那么进程再次访问匿名内存时,MMU 检查到对应的物理内存不存在,那么触发缺页异常。缺页异常处理函数发现物理内存被压缩,于是解压缩到新的物理页上,并将页表更新到新的物理页上,那么进程可以正常访问匿名内存.
- KSM 场景: 匿名内存已经与物理内存建立页表,进程可以正常访问匿名内存,但是由于 KSM 机制,KSM 将匿名内存与另外一块匿名内存进行合并,然后将匿名内存标记为写保护,那么进程可以正常对匿名内存进行写操作,但当进程对匿名内存进行写操作时,MMU 检查到写保护的存在,于是触发缺页异常,缺页异常处理函数将 KSM 页内容拷贝到一个新的物理页上,并将更新页表到新的物理页上,那么进程可以对匿名内存执行写操作.
- NUMA Balancing 场景: 进程分配了跨 NUMA NODE 的匿名内存,进程可以对匿名内存进行读写操作,但 NUMA Balancing 机制会定期轮询进程的内存,将跨 NUMA NODE 的内存重新迁移到本地 NUMA NODE 之后,并将虚拟内存的页表修改为 PROTNONE, 即匿名内存即不可读也不可写。当进程再次访问匿名内存时,MMU 检查到权限异常,那么触发缺页异常。缺页异常发现物理内存发生了 NUMA Balancing,那么将物理页迁移到本地 NUMA NODE,并更新页表,那么进程可以正常对匿名内存进行读写操作.
- 堆场景(Heap): 进程可以从堆上分配内存,堆的特点是紧贴进程的数据段(BSS 段),并向进程地址空间高地址生长,堆内存也是一种匿名内存。当进程从堆上分配的内存并没有与物理内存建立映射,那么进程访问该段堆内存时,MMU 检查到物理内存不存在,那么触发缺页异常,缺页异常处理函数分配新的物理页,并建立页表映射到该物理页上,那么进程可以可以正常访问堆内存.
- 栈场景(Stack): 进程可以使用栈上的内存,该内存是进程创建时分配的,但在特除情况下,堆栈发生了溢出,并且进程访问了溢出的内存,那么 MMU 发现对应的物理内存不存在,并触发缺页异常,异常处理函数检查到栈异常,直接发送 SIG_BUS 导致程序 SegmentFault 退出.
- MCE 场景: 匿名内存已经与物理内存建立页表映射,进程也可以对匿名内存进行读写操作,但由于硬件故障导致物理内存发送了 UE,那么当进程再次访问匿名内存时,硬件检测到 UE 异常直接触发缺页异常,缺页异常处理函数检测到是 UE 故障,那么直接发送 SIG_BUS 导致进程 SegmentFault 退出.
- Protection Key 场景: 匿名内存已经与物理聂村建立页表映射,进程也可以对匿名内存进行读写操作,但进程使用 Protection Key 机制修改匿名内存的权限,使进程没有权限访问匿名内存,那么此时进程访问匿名内存,Protection Key 机制会检查权限异常之后,直接触发缺页异常,缺页异常处理函数检查 Protection Key 权限不足时,直接发送 SIG_BUS 导致进程 SegmentFault 退出.
- THP Migration 场景: 进程分配了大块的匿名内存,进程可以对匿名内存进行访问,此时系统开启了 THP 功能,并且 THP 任务该匿名内存可以合成 THP 大页,那么将匿名内存对应的页表修改,并将对应的零散物理内存迁移到 THP 物理内存中,在迁移过程中,进程再次对匿名内存进行访问,那么系统会终止内存迁移动作,然后做回退动作,重新更新页表,这样进行可以访问匿名内存。
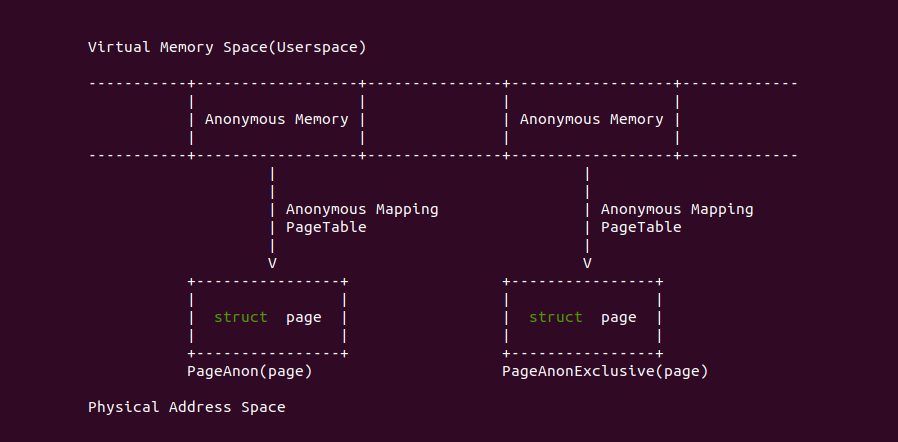
开发者可能在其他地方看到这些术语: 匿名内存、匿名映射、匿名页等,那么它们具体指的是什么。匿名映射: 指的是进程分配一段虚拟内存直接映射到系统物理内存的方式,匿名映射是相对与文件映射而言; 匿名页: 进程通过匿名映射的物理页,每个物理页都用对应的 struct page 数据结构体,那么可以通过 PageAnon(page) 判断物理页是否为匿名页, 另外如果该物理页只被一个 VMA 映射,那么该物理页也称为独占匿名页(Exclusive Anonymous Page), 同理可以使用 PageAnonExclusive(page) 进行区分; 最后一般将进程通过匿名映射的内存称为匿名内存,其既包括虚拟内存部分,也包括物理内存部分, 其对应的 VMA 通过 vma_is_anonymous() 函数进行判断. 匿名内存可以通过 mmap(MAP_PRIVATE | MAP_ANONYMOUS) 方式获得,也可以通过 malloc/brk 从堆上分配,亦或者从堆栈(Stack) 上获得.
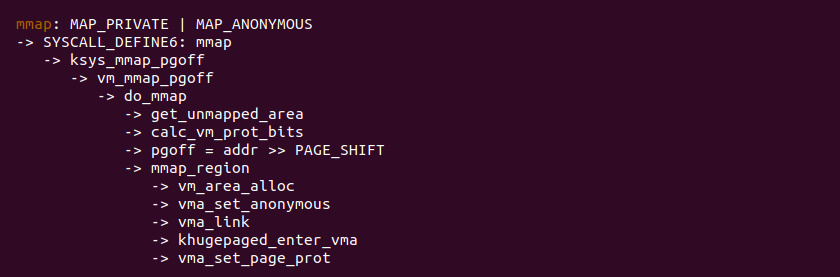
当调用 mmap 函数分配匿名内存时,其在 mmap 系统调用处理了逻辑如上图,与文件映射不同的地方是 pgoff 设置为虚拟地址的页号,并且调用 vma_set_anonymous 将 VMA 标记为匿名映射,那么 VMA 对应的 vm_ops 为空,因此可以用该条件判断 VMA 是否采用了匿名映射. 其余操作与文件映射差异不大,经过 mmap 系统调用之后,进程分配到一段虚拟内存,但这段虚拟内存是没有映射物理内存的,那么接下来进程一旦访问这段虚拟内存,那么就会触发缺页异常:
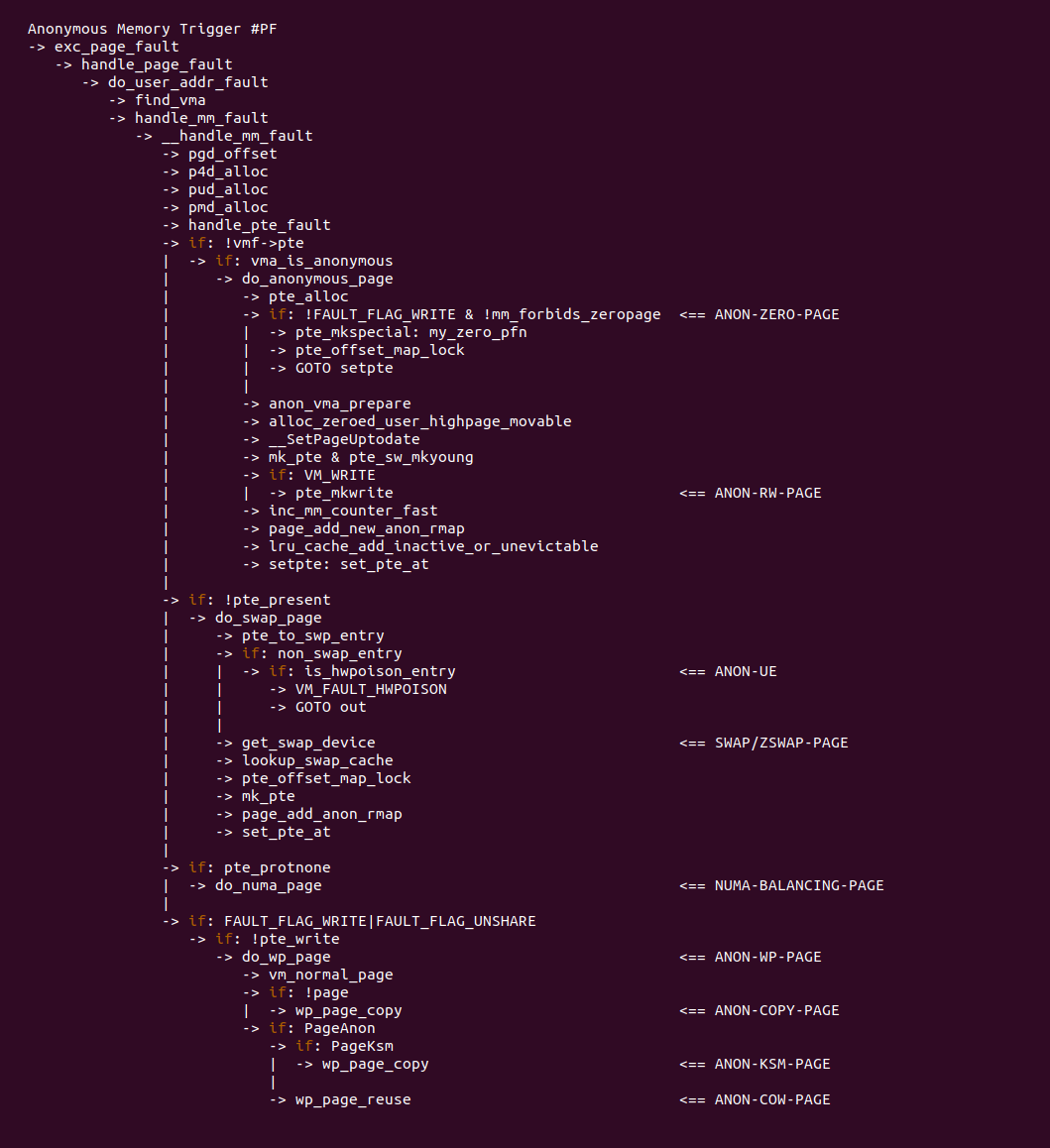
当匿名内存发生缺页时,根据触发场景不同,缺页异常处理函数的流程也会不同,匿名内存能够触发的场景如上图,例如对可读可写匿名读写操作会触发缺页,缺页异常处理函数会走到 ANON-RW-PAGE 分支; 对发生 fork 系统调用的匿名内存进行写操作,会触发缺页,并在缺页流程里完成 COW; 又如对 SWAP OUT 的匿名内存执行读写操作,会触发缺页,缺页流程会走到 SWAP/ZSWAP-PAGE 分支等等. 为了详细分析匿名内存不同场景的缺页,加下来会对每一种场景进行详细分析:
匿名映射可读可写内存缺页场景
匿名映射只读(Read-Only)内存缺页场景
匿名映射写保护(Write-Protection)内存缺页场景
匿名映射 COW(Copy-On-Write) 内存缺页场景
匿名映射内存交换(SWAP) 缺页场景
匿名映射内存压缩(ZSWAP) 缺页场景
匿名映射内存 KSM 缺页场景
匿名映射内存 NUMA Balancing 缺页场景
匿名映射内存 MCE 缺页场景
匿名映射之堆(Heap) 缺页场景
匿名映射之栈(Stack) 缺页场景
匿名映射内存 Protection Key 缺页场景
匿名映射之 PmdMapped THP 内存缺页场景

匿名映射内存 NUMA Balancing 缺页场景
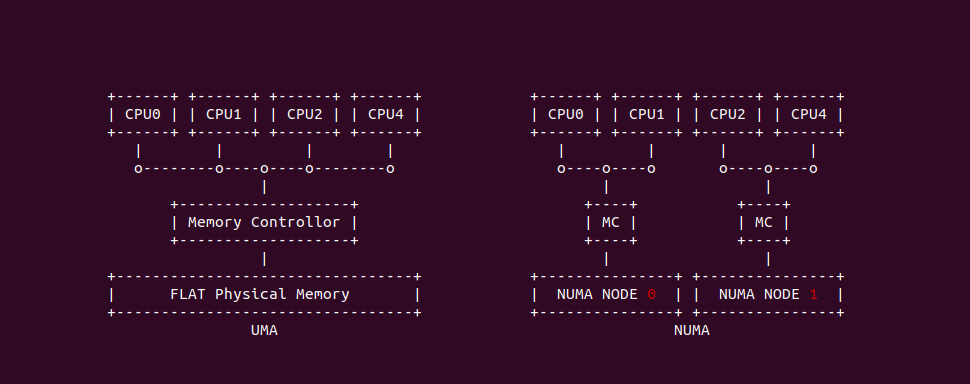
在 Linux 和其他操作系统中,UMA(Uniform Memory Access) 和 NUMA(Non-Uniform Memory Access) 都是与内存访问模型和多处理器系统设计相关的术语。这两个术语描述的是处理器如何访问系统中的内存区域以及相关的性能特性, 上图大致描述了 UMA 和 NUMA 之间的差异,总结如下:
- UMA(Uniform Memory Access): UMA 是一种内存架构,其中所有处理器访问内存所需的时间是均匀的,无论内存是哪一部分. 处理器共享同一内存资源,并且每次访问的延迟都是相同的. 缺点是当多个处理器尝试同时访问内存时,可能会导致内容竞争,从而限制系统的可扩展性.
- NUMA(Non-Uniform Memory Access): NUMA 是一种内存架构,针对多处理器系统设计,其中处理器访问内存的时间取决于内存所在的位置. 在 NUMA 架构中,系统内存被划分为多个节点,每个节点与一个或多个处理器相关联. 当处理器访问其本地节点的内存时,访问速度最快。但是访问其他节点(非本地或远程节点)的内存时,访问速度会变慢. 这种架构的主要优势在于,它能更好地扩展到具有大量处理器的系统,并尽量减少内存访问的竞争状况.
在 NUMA 架构里,正常情况下 CPU 优先分配本地(LOCAL)节点上的内存,但在内存紧缺或者特殊需求场景下,CPU 也可以分配远端(REMOTE)节点的内存,这样做的好处是解决内存压力,但降低内存访问的性能.
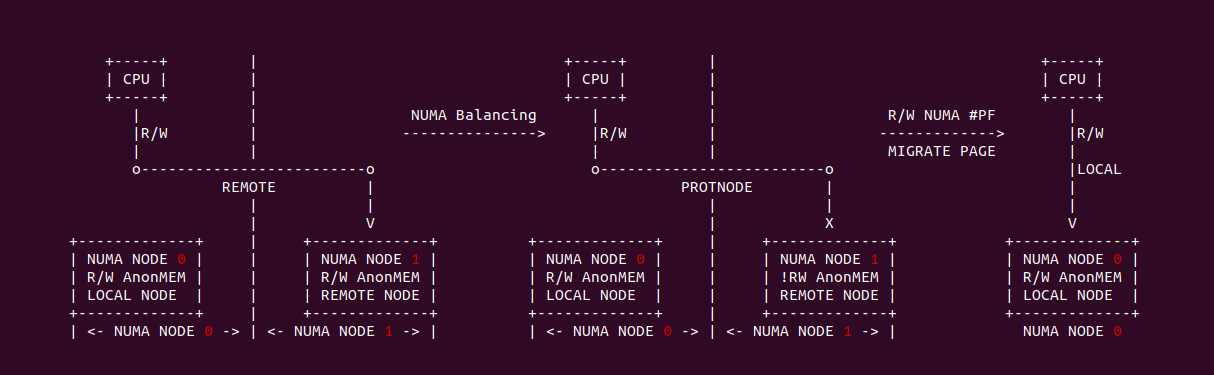
在 Linux 中,NUMA Balancing 是一个内核特性,用于自动改善多处理器系统上的应用程序性能,特别是在 NUMA 架构上。这一特性旨在确保内存分配和进程调度与 NUMA 架构保持一致,以便获得最佳的性能. NUMA Balancing 机制一般会做以下几个操作:
- 巡检: 在进程创建的时候,NUMA Balancing 机制会为每个进程启动一个定时任务, 该任务会扫描进程里跨 NUMA 的物理页
- 标记: 巡检过程中,NUMA Balancing 机制会对跨 NUMA 物理页进行标记,将其标记为 PROTNONE,这里不是 PROT_NONE, 被标记的内存没有读写权限.
- 替换: 当进程访问被标记的内存会触发缺页,缺页异常处理函数识别出被标记的页之后,将其迁移(Migrate)到本地(LOCAL)节点上,并恢复正常的页表属性.
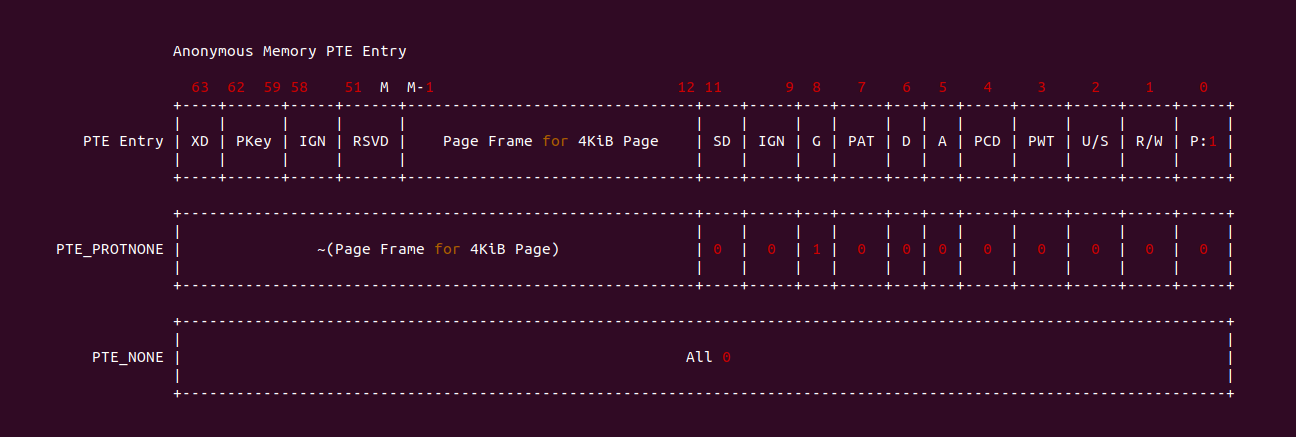
NUMA Balancing 机制一个重要任务就是将跨 NUMA Page 对应的页表修改为 PROTNONE,这里的 PROTNONE 是一种特殊的页表,对应的匿名内存即不可读也不可写,与 PROT_NONE 不同的是,PROTNONE 是将原先的 PTE Entry 分作两部分,高于 BIT12 的字段存储物理页帧的反码,低于 BIT12 的字段则将 BIT8 置位,其余全部清零,因此缺页异常处理函数首先判断 _PAGE_PRESENT 清零,然后判断 BIT8(_PAGE_PROTNONE) 置位,那么知道该 Entry 对应着 NUMA Balancing 的页表,因此接下来的逻辑就按 NUMA Balancing Page Fault 进行处理.
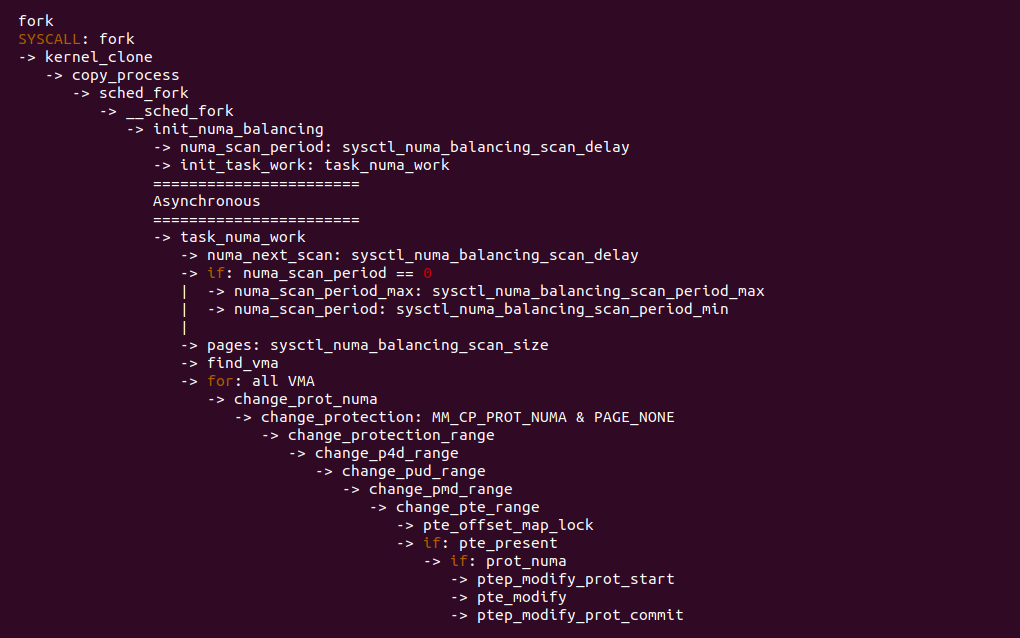
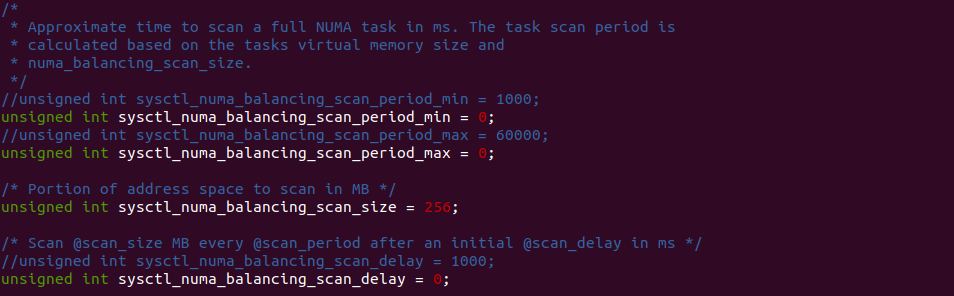
上图为 NUMA Balancing 机制的运作逻辑,其为每个进程维护一个 NUMA Balancing 的内核线程,该内核线程通过多个 sysctl 变量进行控制,当 NUMA Balancing 内核线程被唤醒,其将执行 task_numa_work 函数,该函数会检查进程地址空间中那些跨 NUMA 的区域,然后获得对应的 PTE Entry,并调用 pte_modify 函数将页表修改为 PROTNONE. 在不同版本 Linux 里,四个 sysctl 有的导到 sysctl 系统工具里,但有的内核没有导出,开发者可以修改下面几个变量控制任务的执行:
- numa_balancing_scan_period_min_ms: 以毫秒为单位扫描任务虚拟内存的最小时间, 它有效地控制了每个任务的最大扫描速率.
- numa_balancing_scan_delay_ms: 任务初始分叉时使用的起始“扫描延迟
- numa_balancing_scan_period_max_ms: 以毫秒为单位扫描任务虚拟内存的最大时间, 它有效地控制了每个任务的最小扫描速率.
- numa_balancing_scan_size_mb: 为给定的扫描扫描的页面价值多少兆字节.
结合起来,扫描延迟和扫描大小确定了扫描速率。当扫描延迟减小时,扫描速率增加。扫描延迟和因此每个任务的扫描速率都是自适应的,并取决于历史行为。如果页面被正确放置,那么扫描延迟增加,否则扫描延迟减小。 扫描大小不是自适应的,但是扫描大小越大,扫描速率就越高。更高的扫描速率会导致更高的系统开销,因为必须捕获页面错误,并且可能需要迁移数据。但是扫描速率越高,如果工作负载模式发生变化,任务内存就会更快地迁移到本地节点,从而减小由于远程内存访问而引起的性能影响。这些 sysctl 参数控制了扫描延迟和扫描页面数量的阈值。经过对 NUMA Balancing 机制的研究,理论上已经知道其如何工作了,接下来通过一个实践案例进一步了解该场景,实践案例在 BiscuitOS 上的部署逻辑如下(实践之前需要打开内核 CONFIG_NUM-A_BALANCING 宏):
cd BiscuitOS
# 部署实践案例
make
# 源码目录
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-PAGING-PF-ANON-NUMA-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build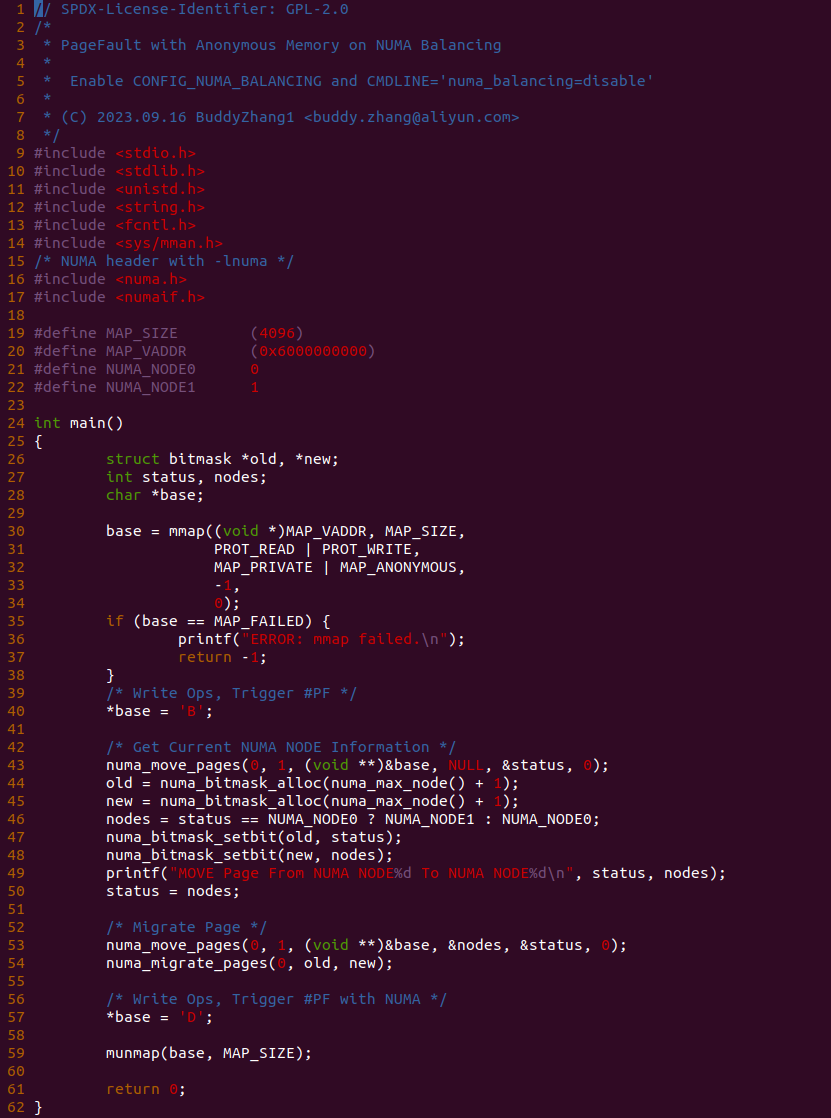
实践案例由一个应用程序构成,其分作三部分,首先是 30 行调用 mmap 函数结合 MAP_PRIVATE 和 MAP_ANONYMOUS 分配一段可读可写的匿名内存,并在 40 行对匿名内存执行写操作. 第二部分是利用 libnuma 提供的库函数,从 43-54 行构造一个跨 NUMA 的匿名页. 最后是第三部分,程序在 57 行再次对匿名内存执行写操作,此时会再次触发缺页并被识别为 NUMA Balancing Page Fault. 以上便是一个最基础的实践案例,可以知道 40 行读操作和 57 行写操作都会触发缺页,为了可以看到内存在缺页异常里的流动,本次在 57 行前后加上 BS_DEBUG 开关:
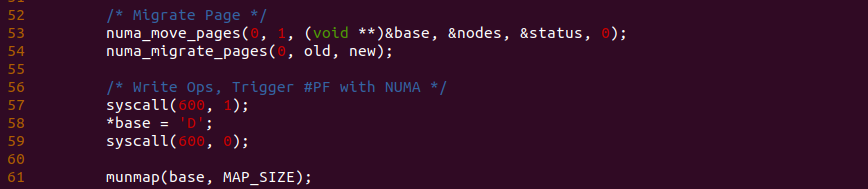
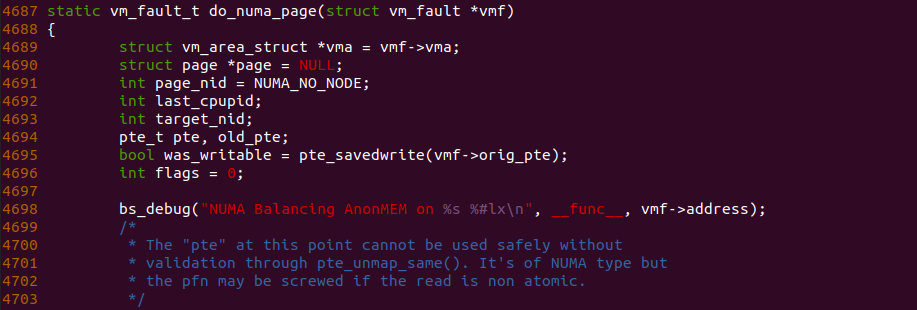
接着在匿名内存缺页流程必经之路上任意位置加上 BS_DEBUG 函数,以此观察内存在某个函数里的流动,例如上图在 do_numa_page 函数的 4698 行加上 bs_debug 打印,以此确认内存是向哪个函数流动,另外为了加速调试进度,需要修改 “kernel/sched/fair.c” 文件中 sysctl 变量的值,这里全部设置为 0,接下来执行如下命令进行实践:
# 编译应用程序
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-PAGING-PF-ANON-NUMA-default/
# 编译内核
make kernel
# 安装 libnuma
make prepare
# 编程程序
make build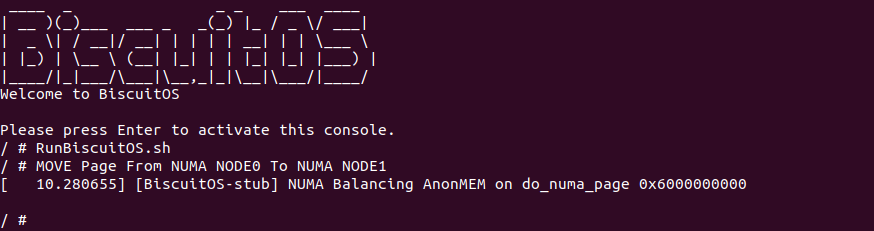
当 BiscuitOS 启动之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包括实践所需的命令,可以看到进程执行之后对虚拟内存的访问引起了缺页异常,并且该案例的缺页异常处理流程打印了字符串 “NUMA Balancing AnonMEM on do_numa_page 0x6000000000”, 说明缺页异常处理函数执行过 NUMA Balancing PROTNONE 缺页. 通过实践可以看到实践案例按着之前分析的代码路径流动。最后开发者可以在该路径上的任何地方使用 bs_debug 查看匿名内存在缺页异常处理流程里的流动.
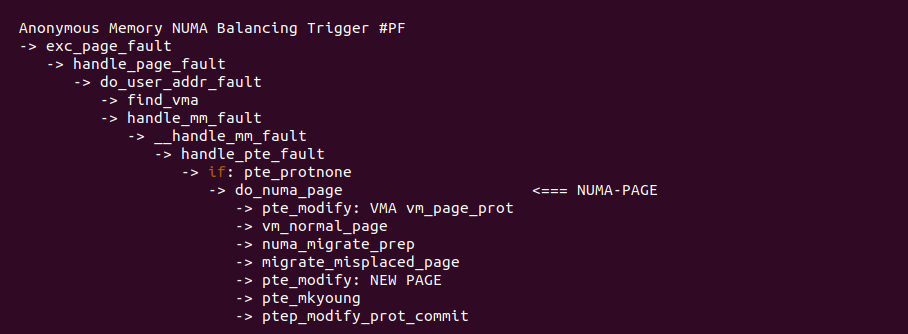
对于 NUMA Balancing 引起的缺页,缺页异常处理函数根据 PROTNONE 进行区分,一旦确认是 NUMA Balancing Page Fault, 那么进入 “NUMA-PAGE” 分支进行处理.
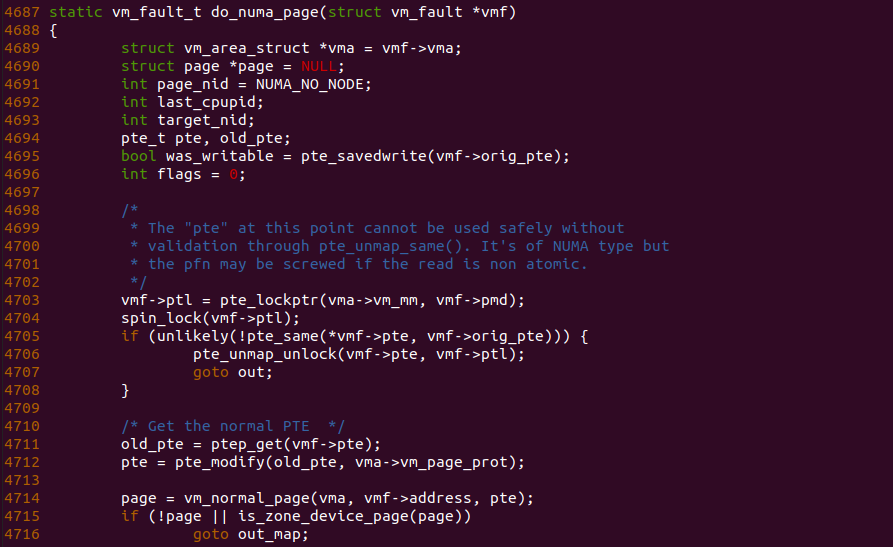
对于 “NUMA-PAGE” 分支核心处理函数是 do_numa_page 函数,由于该函数长度太长,这里只做部分解析,函数首先获得 PTE Entry 的内容,由于此时还是 PROTNONE 格式,因此函数在 4712 行调用 pte_modify() 函数将 PROTNONE 内容转换成一个正常的 PTE Entry,该 PTE Entry 页表属性字段来自 VMA 提供的 vm_page_prot, 页帧字段则来自 PROTNONE 高 BIT12 字段的反码. 有了 PFN 信息之后,函数在 4714 行调用 vm_normal_page 函数获得对应的匿名页.
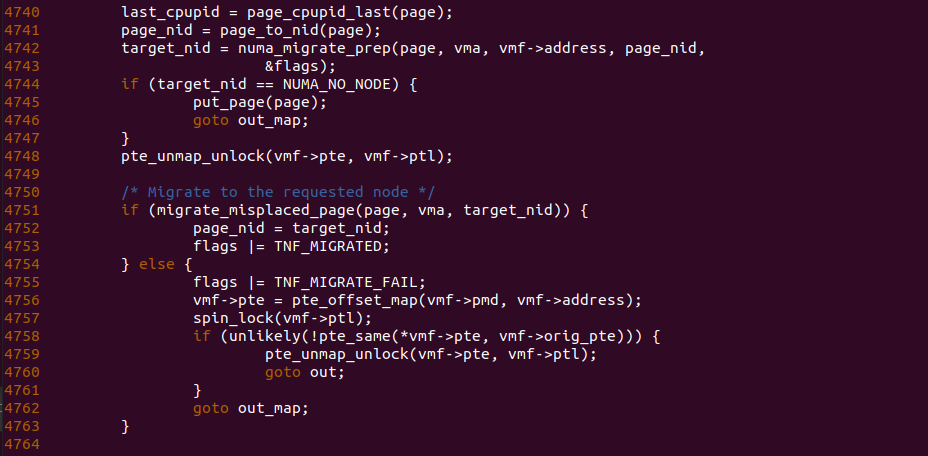
do_numa_page 函数在获得匿名页之后,此时在 4741 行调用 page_to_nid 函数获得匿名页所在 NUMA NODE 信息,然后调用 numa_migrate_prep 函数获得进程 LOCAL NUMA NODE 信息,此时 page_nid 和 target_nid 不相等,那么接下来 4751 行调用 migrate_misplaced_page 函数将匿名页迁移到 LOCAL NUMA NODE 上,迁移过程就是在目标 NUMA NODE 上分配一个新的物理页,然后将内容拷贝到新物理页上.
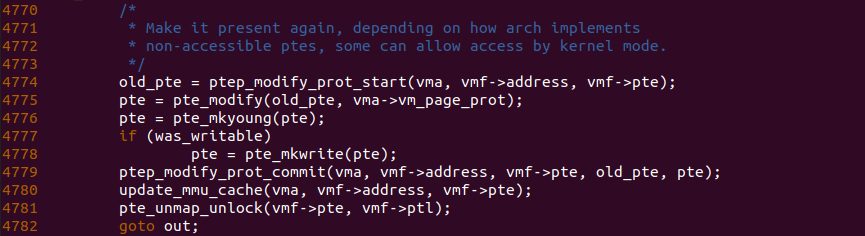
do_numa_page 函数迁移完毕之后,在 4774-4779 行调用相关的函数更新页表,使页表映射到新的物理页上,此时新的物理页变成匿名页. 至此 NUMA Balancing Page Fault 主要处理逻辑已经完成,待缺页异常处理函数返回之后,进程可以继续访问 LOCAL NUMA NODE 的匿名页,且不会再触发缺页.
