
![]()


PCIe Practice
PCIe Hardware Compoument
PCIe Root Complex(RC)
PCIe Domain/Segment
PCIe Host Bridge
PCIe RootPort(RP)
Root Complex Integrated Endpoint(RCiEP)
PCIe Lane
PCIe Link
PCIe SWITCH
PCIe Endpoint(EP)
PCIe Slot
PCIe Protocl
PCIe Transaction Layer
Non-Posted TLP
Posted TLP
Completion TLP(Cpl/Cpld)
Memory Read TLP
Memory Write TLP
I/O Read/Write TLP
Configuration Read/Write TLP
Message TLP
PCIe Physical Layer
PCIe Data Link Layer
PCIe Address Space
System Physical Address Space
PCIe Memory Space
PCIe Device Memory
PCIe Device BAR-Mapping Memory
PCIe Device Internal Memory
GPU Physical Address Space
PCIe IO Space
PCIe Configuration Space
PCIe Address Assignment 编址
PCIe BDF(Bus/Device/Function)
DFS 算法
PCIe BAR Mapping
DFS/BAR-MApping On SeaBIOS 编址实践
PCIe Addressing 寻址
Address-Based Addressing
ID-Based Addressing
PCIe Software Architecture
PCIe Compoument
PCIe HOST Bridge
PCIe Device
PCIe Bridge: RootPort/Switch
PCIe Endpoint
PCIe BUS
Linux PCIe Core
SeaBIOS Initiazlie PCIe
ACPI Pass PCIe Information
Build PCIe Core Subsystem
Linux PCIe Device Driver
PCIe Sysfs Interface
Access PCIe BAR
Access PCIe Configuration Space
PCIe MSI/MSIX Interrupt
PCIe 软件编程指南
PCIe Configuration Space Bitmap
Type0 Space
Type1 Space
PCIe Performance Analysis and Diagnosis
In-Depth Research on PCIe Mechanisms
PCIe DMA
PCIe SGDMA
PCIe P2PDMA
VFIO
PCIe IOMMU
PCIe ATS/PASID
PCIe Hotplug
PCIe DOE
RDMA
NTB
NTRDMA
RoPCIe
AER/Inject
PCIe Specification
- PCIe Specification v6.0


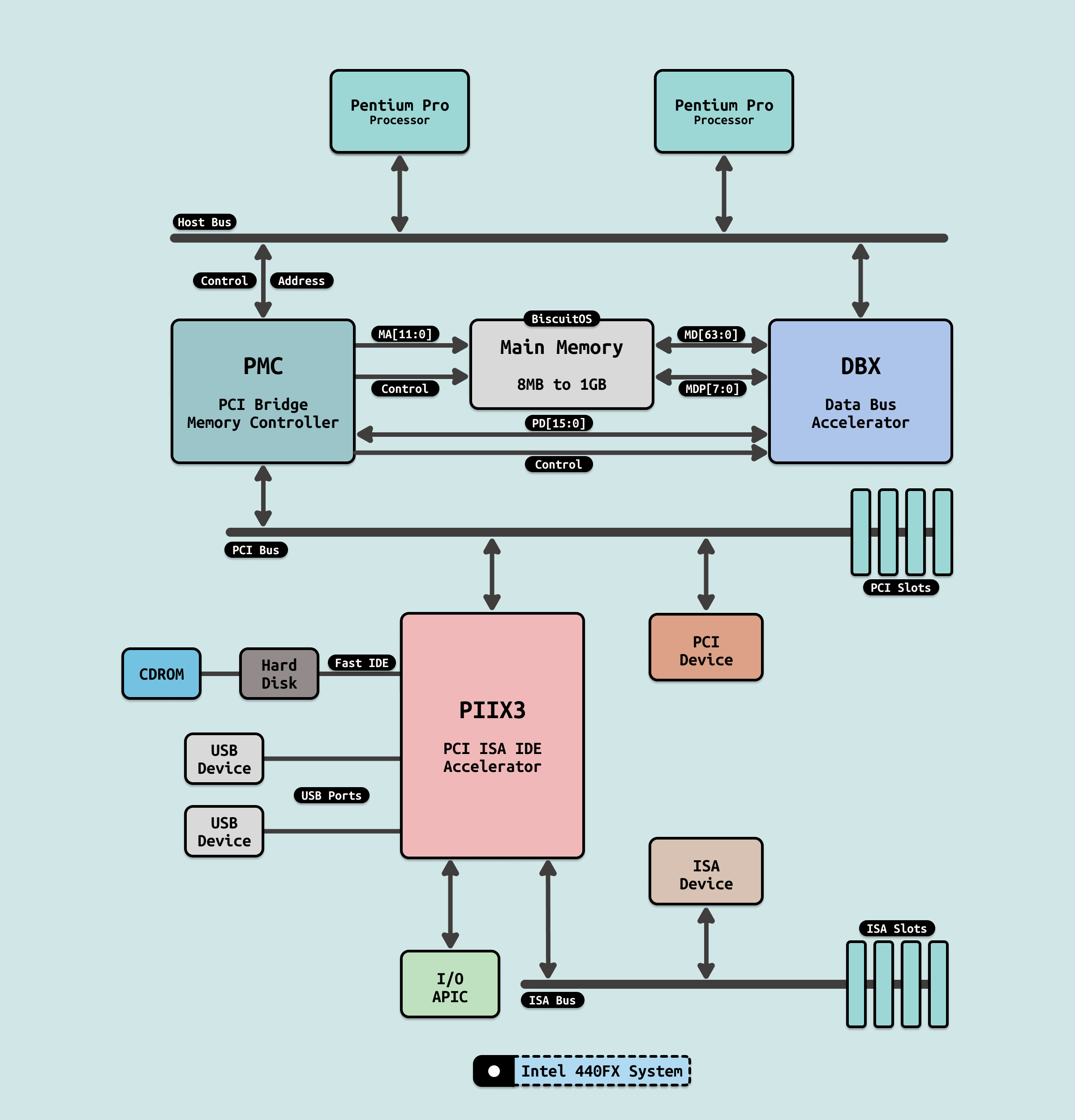
在计算机硬件领域,PCI(Peripheral Component Interconnect)总线标准曾经是连接主板与扩展卡(如显卡、网卡、声卡等)的核心技术. 它于 1992 年由 Intel 主导推出,并迅速成为行业标准. 作为一个共享并行总线,PCI 为早期个人电脑的扩展提供了高效的解决方案. 然而,随着计算需求的爆炸式增长,PCI 的设计局限性逐渐暴露出来,这促使行业在 2003 年引入 PCI Express(PCIe) 作为其继任者. PCIe 并非从零开始,而是基于 PCI 的软件兼容性进行了革命性的硬件升级,旨在解决 PCI 在性能、可扩展性和可靠性方面的瓶颈. PCI 的设计源于 20 世纪 90 年代的计算环境,那时的数据传输需求相对较低, 但随着多媒体、高性能图形处理和网络应用的兴起,PCI 的问题日益突出:
- 并行传输的物理限制: PCI 采用并行总线架构,即多个数据线同时传输比特. 这在低速时(如 PCI 1.0 的 33MHz 时钟,带宽约133MB/s)工作良好,但当试图提高速度时,会出现时钟偏移(clock skew) 和信号干扰的问题. 数据线之间的同步变得困难,导致错误率上升和传输距离受限. 举例来说,PCI-X(PCI 的扩展版本)试图将频率提升到 133MHz,但这进一步放大了这些物理挑战,使得总线长度难以超过几厘米,无法适应现代大型服务器或多槽位系统.
- 共享总线的带宽瓶颈: PCI 是一个共享总线,所有连接的设备(如多个扩展卡)竞争同一带宽资源. 这意味着当一个设备(如高带宽的显卡)占用总线时,其他设备必须等待,导致延迟增加和整体性能下降. 在多设备环境中,这类似于一条单车道公路上多辆车争抢通行权. 随着设备数量增多,带宽利用率低下,无法满足如 3D 图形渲染或高速存储(如早期 RAID 系统)的高吞吐需求. PCI 2.0 的最大带宽仅为533MB/s(64位、66MHz),远低于现代应用的需要.
- 可扩展性和未来兼容性不足: PCI 的架构难以进一步升级, 增加总线宽度或频率会引入更多复杂性和成本,同时兼容性问题也阻碍了创新. 例如,PCI 不支持热插拔(hot-plugging),这在服务器维护中很不方便. 此外,随着处理器速度的飞速提升(如从 MHz 到 GHz 级),PCI 成为系统瓶颈,无法跟上 Moore 定律的步伐.
- 功耗和噪声问题: 并行总线需要大量引脚(例如,PCI 插槽有124个引脚),这增加了主板设计的复杂性和功耗. 同时,电磁干扰(EMI)在高频下更严重,影响系统稳定性.
这些问题在 2000 年代初变得尤为紧迫, 当时图形处理器(GPU)的快速发展(如NVIDIA/AMD 的 3D 加速卡)要求更高的数据吞吐率,而网络接口(如千兆以太网)也需要低延迟传输, 行业需要一种新标准来打破这些壁垒.
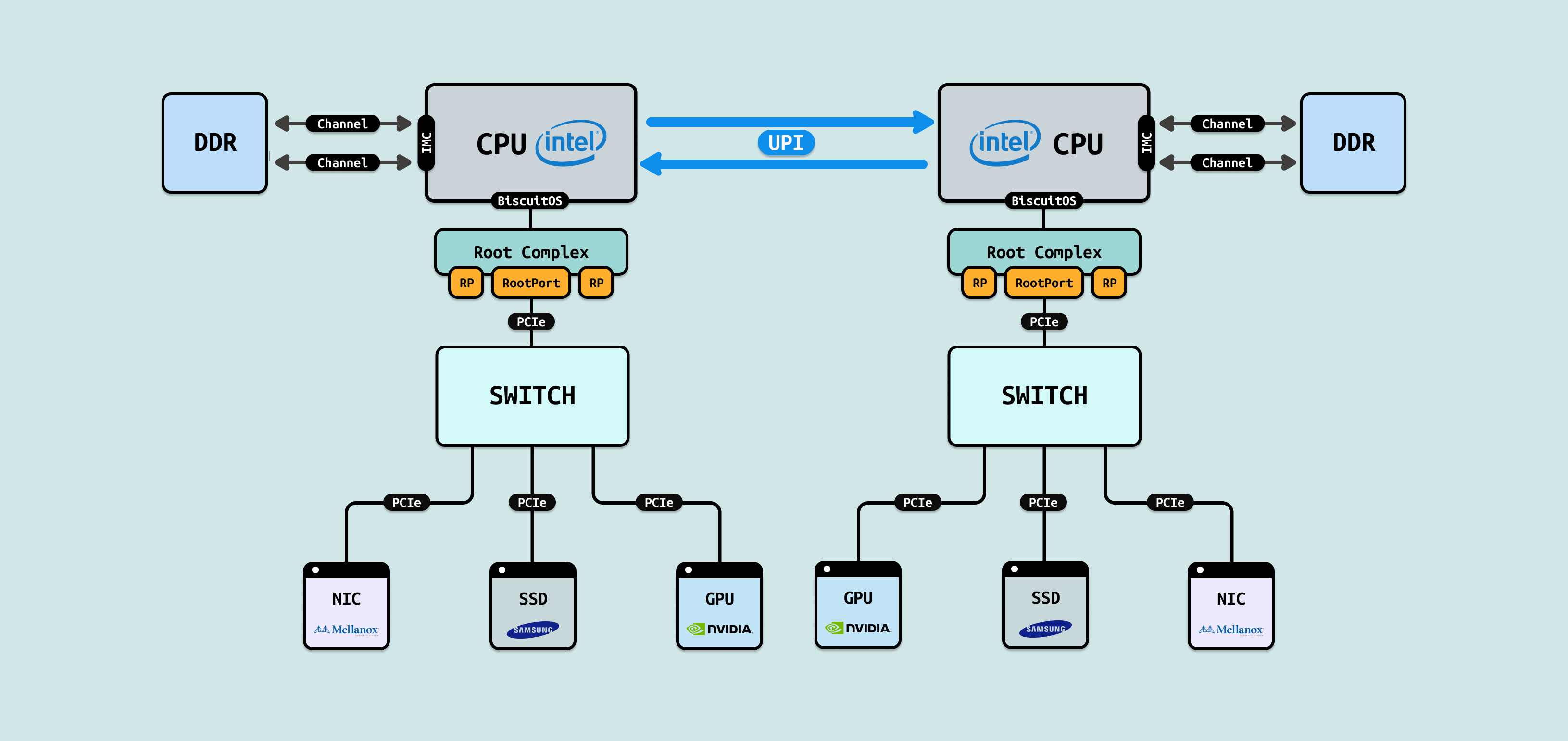
PCIe 由 PCI-SIG(PCI Special Interest Group) 组织开发,于 2003 年正式发布第一版规范(PCIe 1.0). 它的核心创新在于从并行转向串行传输,并采用点对点拓扑结构,这直接解决了 PCI 的痛点,同时保持了软件层面的向后兼容(即现有 PCI 驱动程序无需大改即可在 PCIe 上运行). 以下是 PCIe 如何针对上述问题提供解决方案:
- 串行传输与差分信号: 克服物理限制. PCIe 使用串行链路(serial lanes),每个 lane 由一对差分信号线组成(发送和接收独立). 这大大减少了引脚数量(一个 x1 槽只需少量引脚),降低了噪声和干扰. 差分信号还能在更高频率下稳定工作,例如 PCIe 1.0 的单 lane 传输速率为 2.5 GT/s(gigatransfers per second),提供 250MB/s 单向带宽(双向 500MB/s). 后续版本如 PCIe 4.0(16 GT/s) 和 PCIe 5.0(32 GT/s)进一步提升速度,而无需担心并行总线的同步问题. 这使得 PCIe 能支持更长的传输距离和更高的可靠性,适用于从笔记本到数据中心的各种场景.
- 点对点连接: 消除共享瓶颈. 与 PCI 的共享总线不同,PCIe 为每个设备分配专用通道(lanes). 例如,一个 x16 槽(16 lanes)可以为高性能显卡提供专用带宽,而不影响其他设备. 这类似于高速公路的多车道系统,每个设备有自己的”车道”. 结果是更高的并发性和更低的延迟 – 多个设备可以同时传输数据,而不会相互干扰. 带宽也可通过聚合 lanes 来扩展: 一个 x4 设备(如 SSD)可达数 GB/s,远超 PCI 的极限.
- 可扩展性和未来导向设计: PCIe 的规范设计为模块化,支持版本迭代而不破坏兼容性. 新版本(如从 PCIe 3.0 到 6.0)只需更新物理层编码(如从 8b/10b 到 128b/130b),即可成倍提升带宽. 同时,它引入了热插拔、电源管理和错误校正(如 CRC 和重传机制),提高了系统的灵活性和可靠性. PCIe 还支持分层协议栈(transaction、data link 和 physical layers),便于未来扩展到新应用,如 NVMe 存储或 AI 加速器.
- 功耗优化和生态兼容: PCIe 降低了整体功耗,通过动态链路管理(如链路宽度协商)适应不同负载. 此外它与现有 PCI 软件生态无缝集成,允许旧设备通过桥接器在 PCIe 系统上运行. 这加速了其采用率 – 如今,几乎所有现代计算机都使用 PCIe 作为主要扩展接口.
PCIe 的引入是为了应对 PCI 在高速计算时代下的根本性缺陷,它通过串行、点对点和可扩展设计,奠定了现代硬件基础. 引入 PCIe 不仅解决了带宽和可靠性的即时问题,还为未来的技术创新(如 PCIe 7.0 的 64 GT/s)铺平了道路.
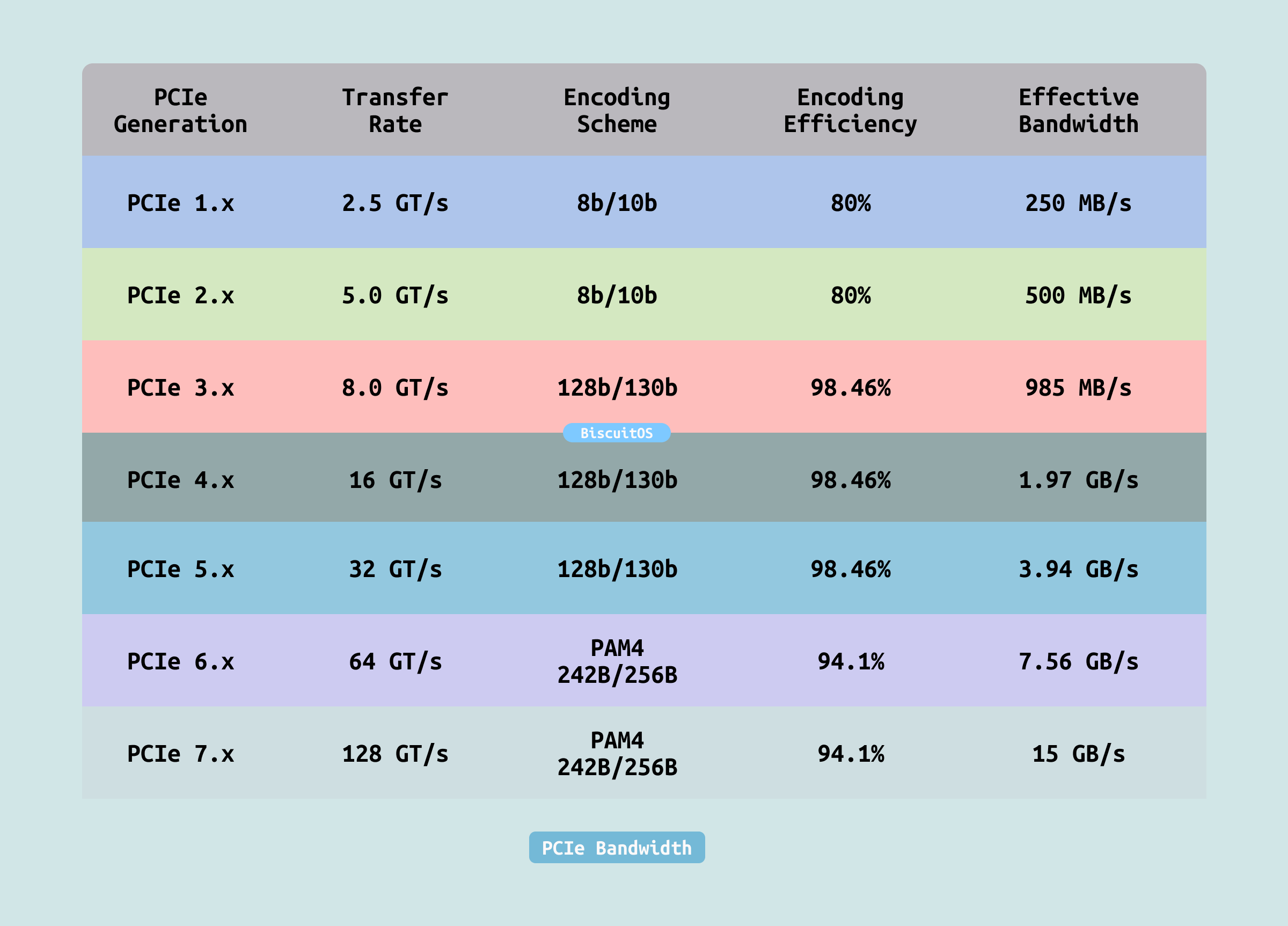

PCIe 采用串行高速差分信号传输,每条 Lane(通道)都是全双工(同时可收发). 其理论带宽由传输速率(GT/s)和编码效率共同决定. GT/s(Giga Transfers per second) 表示每秒传输次数, 每次传输一个 bit. 那么”有效带宽 = 理论带宽 × 编码效率(已扣除编码开销)”. 最终可用带宽通常比理论值低 3%~8%(协议开销、TLP/DLLP 包头、CRC 等), PCIe 是全双工,x16 配置下上行和下行带宽各自独立. 当前主流服务器/显卡多采用 PCIe 4.0/5.0 x16,分别提供约 32GB/s 和 64GB/s 的单向带宽.
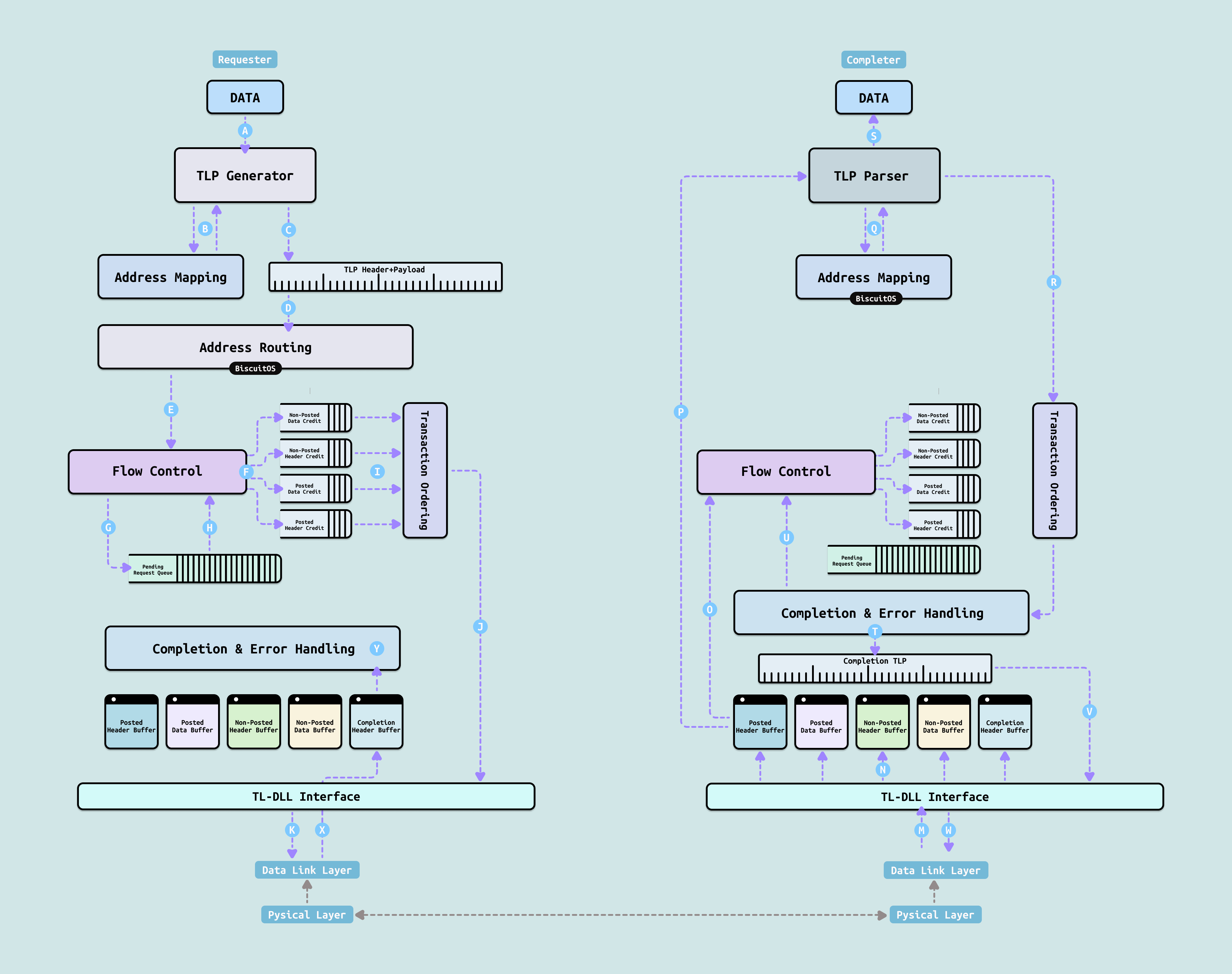
PCIe 事务层(Transaction Layer, 简称 TL) 是 PCIe 协议栈中最上层,也是最接近软件的一层. 它主要负责生成和解析 TLP(Transaction Layer Packet,事务层数据包),实现 PCIe 设备与主机之间的所有数据交换操作,包括:
- Memory Read/Memory Write
- I/O Read / I/O Write
- Configuration Read/Write 配置空间访问
- Message 中断、电源管理、错误报告等
事务层引入了流量控制(Flow Control)机制,通过 Credit-Based 方式防止接收端缓冲区溢出. 同时支持QoS(Quality of Service),通过 TC(Traffic Class)和 VC(Virtual Channel)实现不同事务的优先级管理. 此外它还负责TLP 的可靠传输、序列号管理、错误检测与重传等核心功能. 简单来说,事务层是 PCIe “大脑”,它把上层软件的读写请求转化为标准 TLP 数据包,并负责端到端的传输可靠性与服务质量,是 PCIe 实现高性能、高可靠通信的核心逻辑层.
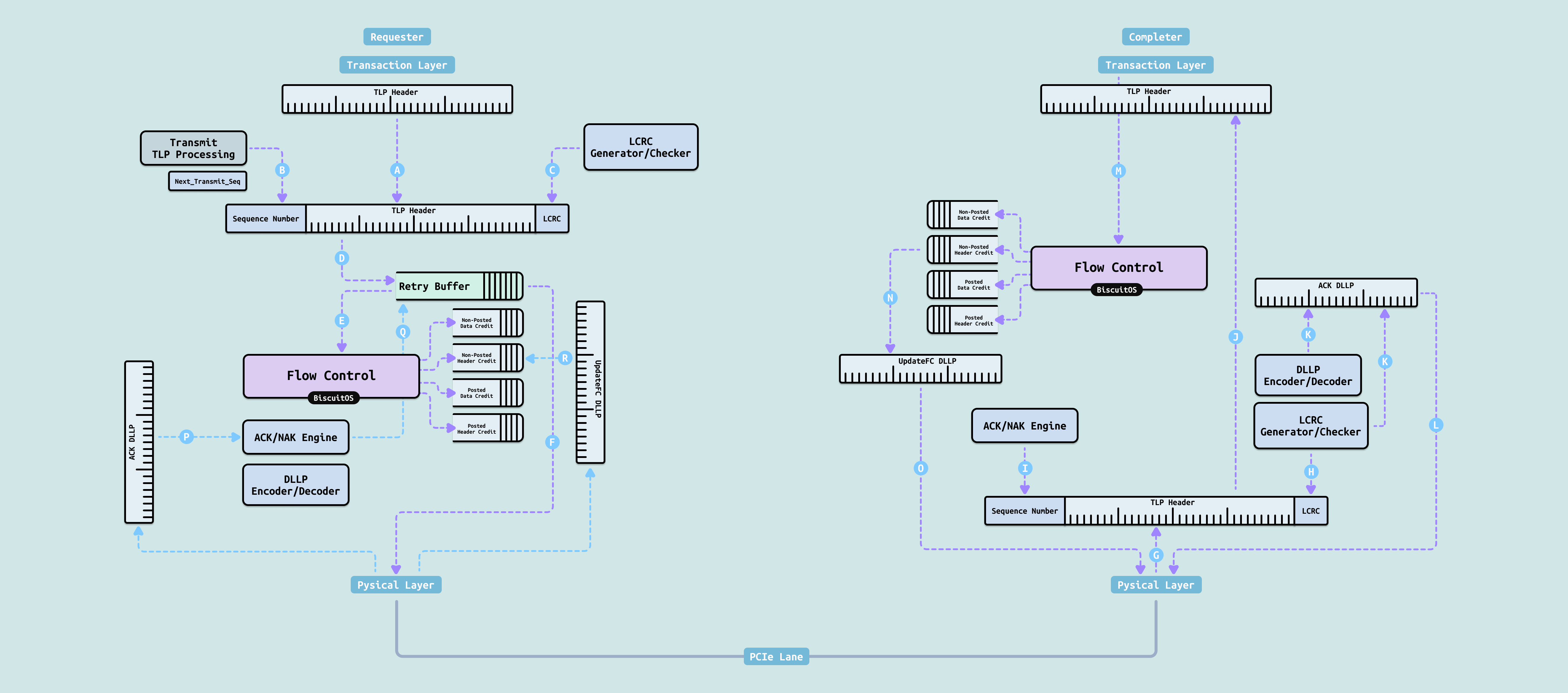
PCIe 数据链路层(Data Link Layer, 简称 DLL) 位于事务层(Transaction Layer)和物理层(Physical Layer)之间,是 PCIe 协议栈中负责可靠传输的核心层. 它的主要功能包括:
- 对事务层下发的 TLP 附加序列号(Sequence Number) 和 LCRC(Link CRC)校验码,形成可可靠传输的数据链路层帧
- 实现 ACK/NACK 确认机制和重传缓冲区(Replay Buffer),当 TLP 传输出错或丢失时自动重传
- 生成并处理 DLLP(Data Link Layer Packet),包括 Ack/Nak DLLP、流量控制(Flow Control)更新 DLLP、电源管理 DLLP 等,用于链路管理和对端通信
- 支持 Credit-Based Flow Control,防止接收端缓冲区溢出
简单来说,数据链路层是 PCIe 的可靠传输引擎, 它把事务层不具备可靠性的 TLP 转化为可靠、有序、可流控的数据流,同时通过轻量级的 DLLP 完成链路管理和控制,是 PCIe 实现”高可靠、低延迟”传输的重要保障层.
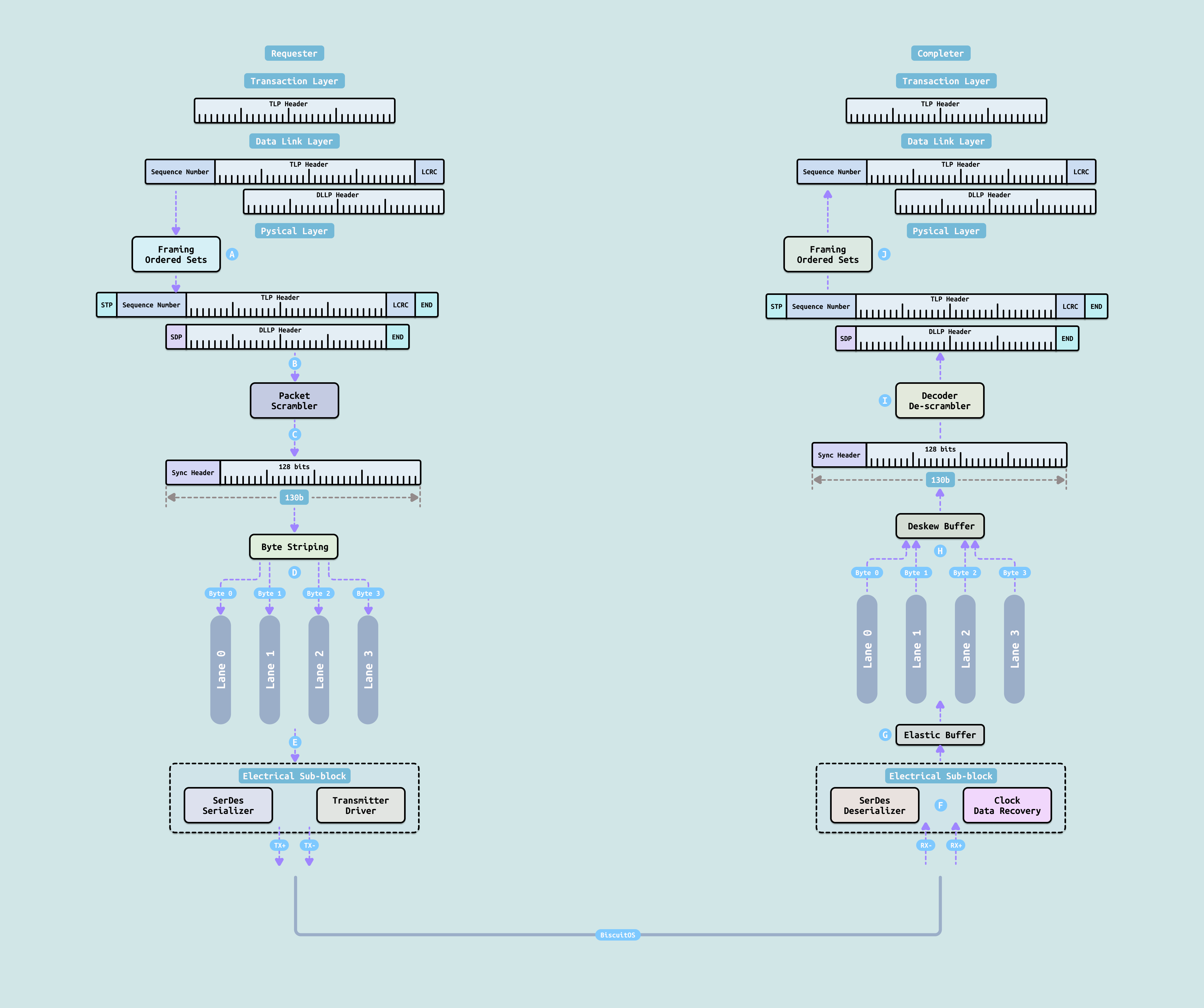
PCIe 物理层(Physical Layer, 简称 PHY) 是 PCIe 协议栈的最底层,直接与物理信号打交道. 它主要负责:
- 串行化与解串行化(SerDes): 将数据链路层送来的并行数据转换成高速串行差分信号发送出去,并把接收到的串行信号还原成并行数据
- 编码/解码: 根据不同代 PCIe 采用 8b/10b(Gen1/2)、128b/130b(Gen3/4/5)或 PAM4 + FEC(Gen6/7)等编码方式
- 链路训练与状态机(LTSSM): 负责链路初始化、速率协商(Gen1~Gen7)、链路宽度协商(x1~x16)、极性翻转、均衡(Equalization)等复杂过程
- 时钟恢复(CDR)、信号完整性处理以及电源管理
简单来说,物理层是 PCIe 的”电气与信号层”,它把上层逻辑数据包转换成真实的高速串行电信号在铜缆或走线中可靠传输,是决定 PCIe 最终速度、稳定性和兼容性的最关键一层.
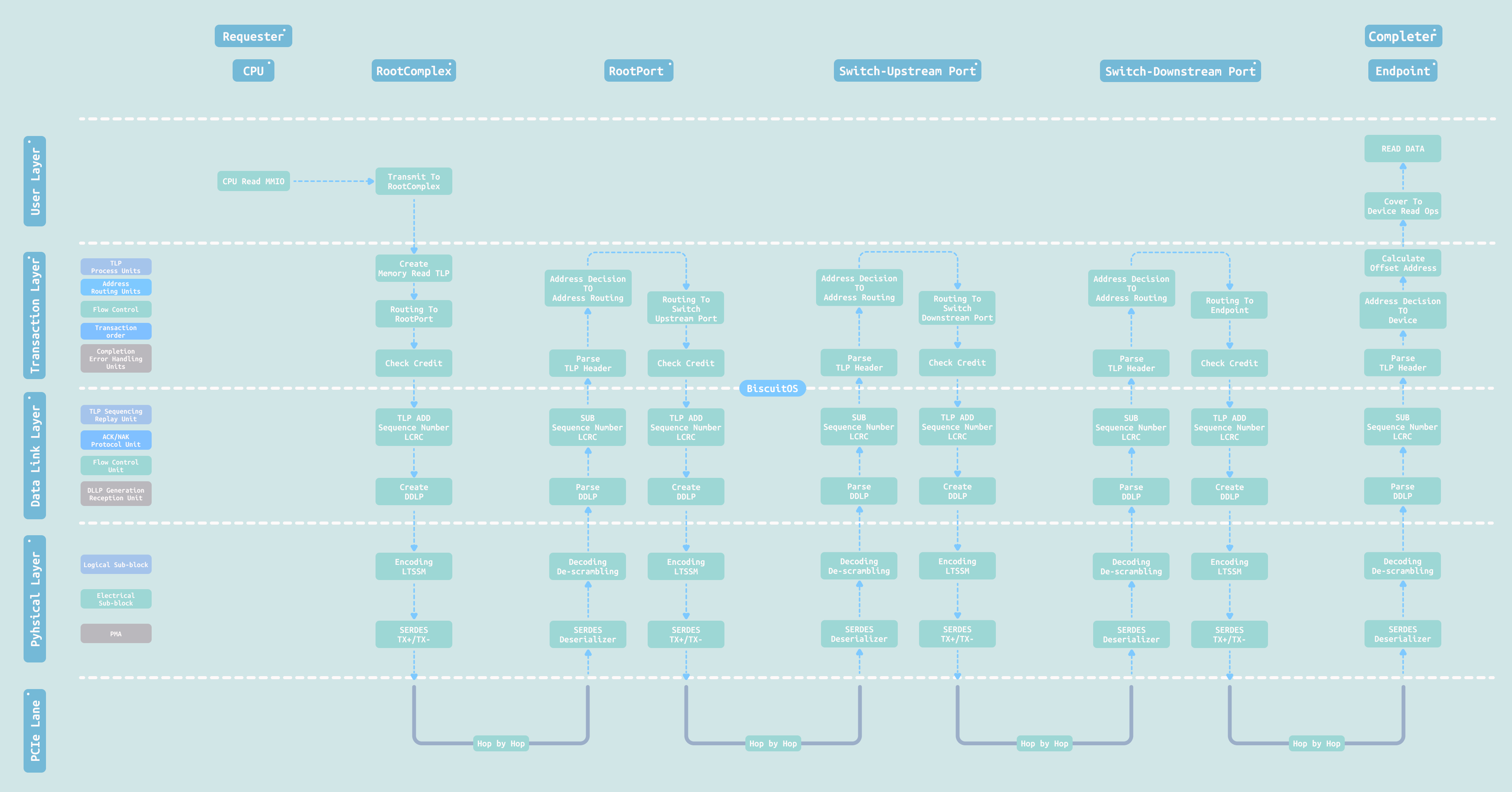
当 CPU 需要访问 PCIe Endpoint(EP) 的 BAR 空间时,整个访问流程为: CPU → Root Complex(RC) → Root Port(RP) → PCIe Switch → EP. CPU 对 BAR 映射的内存地址发起普通的 Memory Read 或 Memory Write 操作,该请求被 Root Complex(RC)封装成 TLP(Transaction Layer Packet). TLP 通过 Root Port(RP)发送到下游,中间的 PCIe Switch 根据 TLP 中的目标地址进行路由决策,将其转发到连接目标 EP 的下游端口. 最终 TLP 到达 EP,EP 根据地址匹配自身配置的 BAR 窗口,完成对本地设备内存或寄存器的访问,并返回 Completion TLP(对于读操作). 整个过程对软件完全透明,CPU 就像访问本地内存一样完成对远端 PCIe EP 的读写.
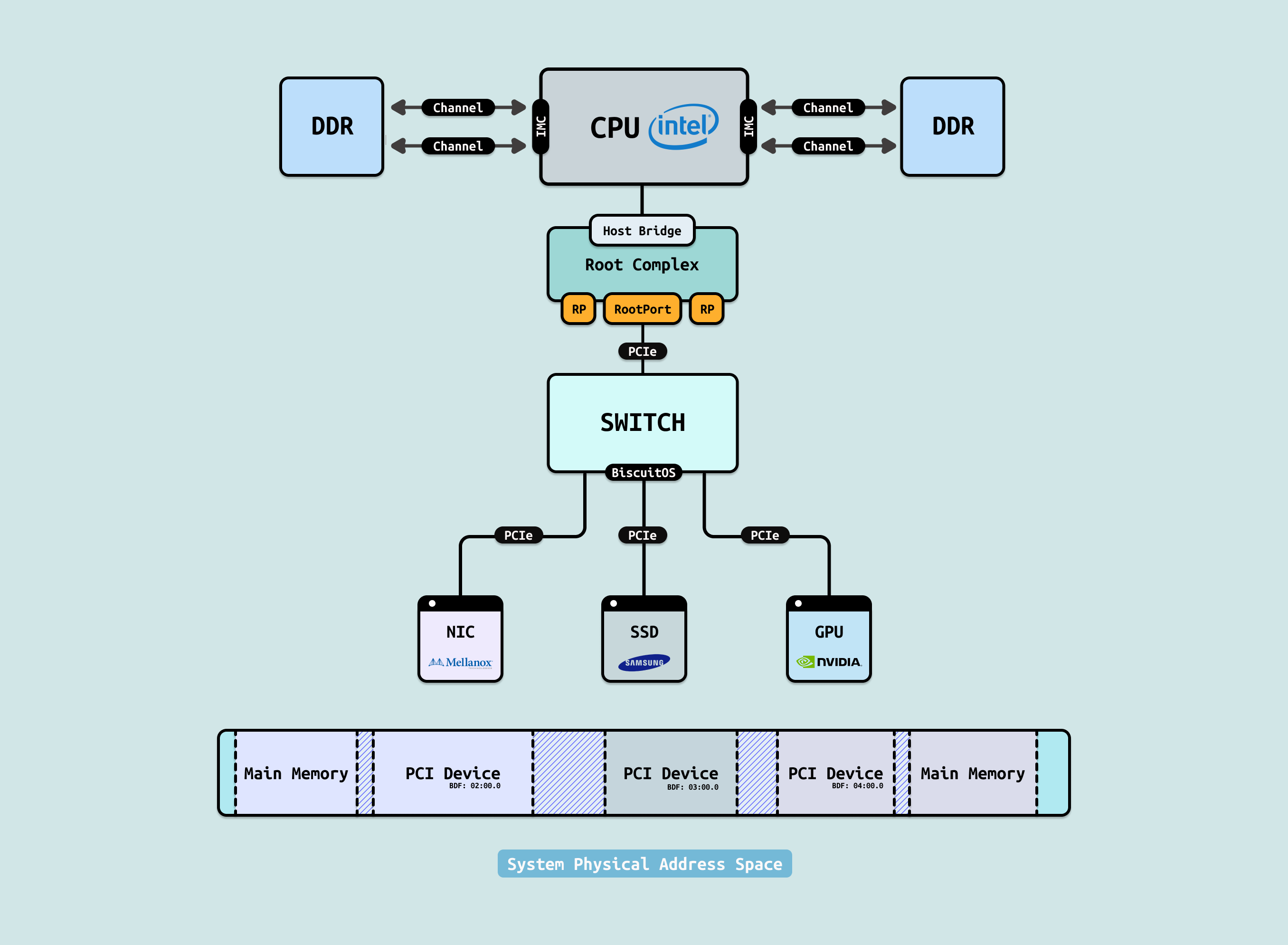
在 x86_64 架构中,PCIe Memory Space 与系统物理地址空间进行 1:1 映射 是一个非常精妙的设计, 这一设计避免了复杂的地址转换开销,将 PCIe 设备暴露的存储空间(MMIO)和 DDR 物理内存统一抽象到同一个系统物理地址空间中. 对软件而言,我们只需记住以下对应关系即可:
- 物理内存 = DDR 映射的区域
- MMIO = PCIe 设备通过 BAR 暴露出来的存储空间(包括设备寄存器和内存)
得益于系统物理地址空间的统一抽象,软件可以在虚拟内存层面直接映射到对应的物理地址,从而实现对 DDR 和 PCIe 设备存储空间的访问, 具体来说:
- 用户态程序: 可通过 “/dev/mem” 设备文件直接访问 MMIO 区域(需 root 权限)
- 内核态代码: 则通常使用 ioremap()(或 ioremap_wc()、ioremap_cache() 等变体)将 MMIO 物理地址映射到内核虚拟地址空间后进行访问
