

目录
Intel® X86 ™Processors 架构 CACHE 机制
ARM 架构 CACHE 机制(弃用)
Linux CACHE 机制
CACHE 实践教程
CACHE 调试工具合集
OProfile: Performance System profiler
CACHE BUG/Fault
Spectre: CVE-2017-5753/CVE-2017-5715
Meltdown: CVE-2017-5754
CACHE 进阶研究
CACHE 与 TLB 研究(Updating)
CACHE 与 Combine Write Buffer(Updating)
CACHE 与 Store Buffer(Updating)
CACHE 与 Memory Barrier(Updating)


初识 CACHE
什么是 CACHE? CACHE 应该怎么用? SMP 多核架构下 CACHE 起到什么作用? 学会了 CACHE 是否改变对软件的认知? …. BiscuitOS 社区推出的 CACHE 实践专题通过图形化、实践化的方法带大家了解、学习、并使用 CACHE,首先通过一个实践案例认识 CACHE,其在 BiscuitOS 的部署逻辑如下:(第一次使用 BiscuitOS 实践的童鞋请先戳 CACHE 实践)
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
(4096) Memory Size(MiB)
(hugepagesz=1G hugepages=1) CMDLINE on Kernel
[*] Package --->
[*] CACHE --->
[*] CACHE on BiscuitOS --->
# 源码目录
# Module
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
实践案例是一个用户空间的程序,逻辑很简单,定义了两个数组 Colour_base0[] 和 Colour_base1[], 并申请了一个匿名大页,Colour_base0[] 按 LLC_CACHE_BIN_SIZE 为粒度从匿名大页起始处连续采集 ARRAY_SIZE 个虚拟地址,将这些虚拟地址存储到数组里; Colour_base1[] 则按 CACHE_LINE_SIZE 粒度从大页起始虚拟地址之后 PAGE_SIZE 处连续采集 ARRAY_SIZE 个虚拟地址; 接下来将两个数组传入 performance_testing() 函数里进行性能测试,测试的逻辑是循环 LOOP 次,每次程序都会遍历访问数组的每个成员,最后统计循环耗时. 两个数组的数据量是相同的,按理来说性能差异应该很小。那么接下来在 BiscuitOS 上实践该案例:
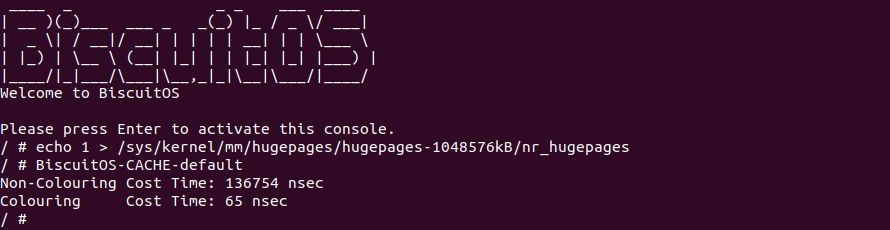
BiscuitOS 运行之后,向内核申请一个 1G 的 Hugetlb 大页,然后运行测试程序,可以看到两侧测试性能差异巨大。回看程序,都是访问相同的数据量,为什么会存在这么大的性能差异,这就是 CACHE 的魅力,是不是很魔法,明明软件上没有任何差异的操作,结果天差地别, 在从另外一个层面认识 CACHE:
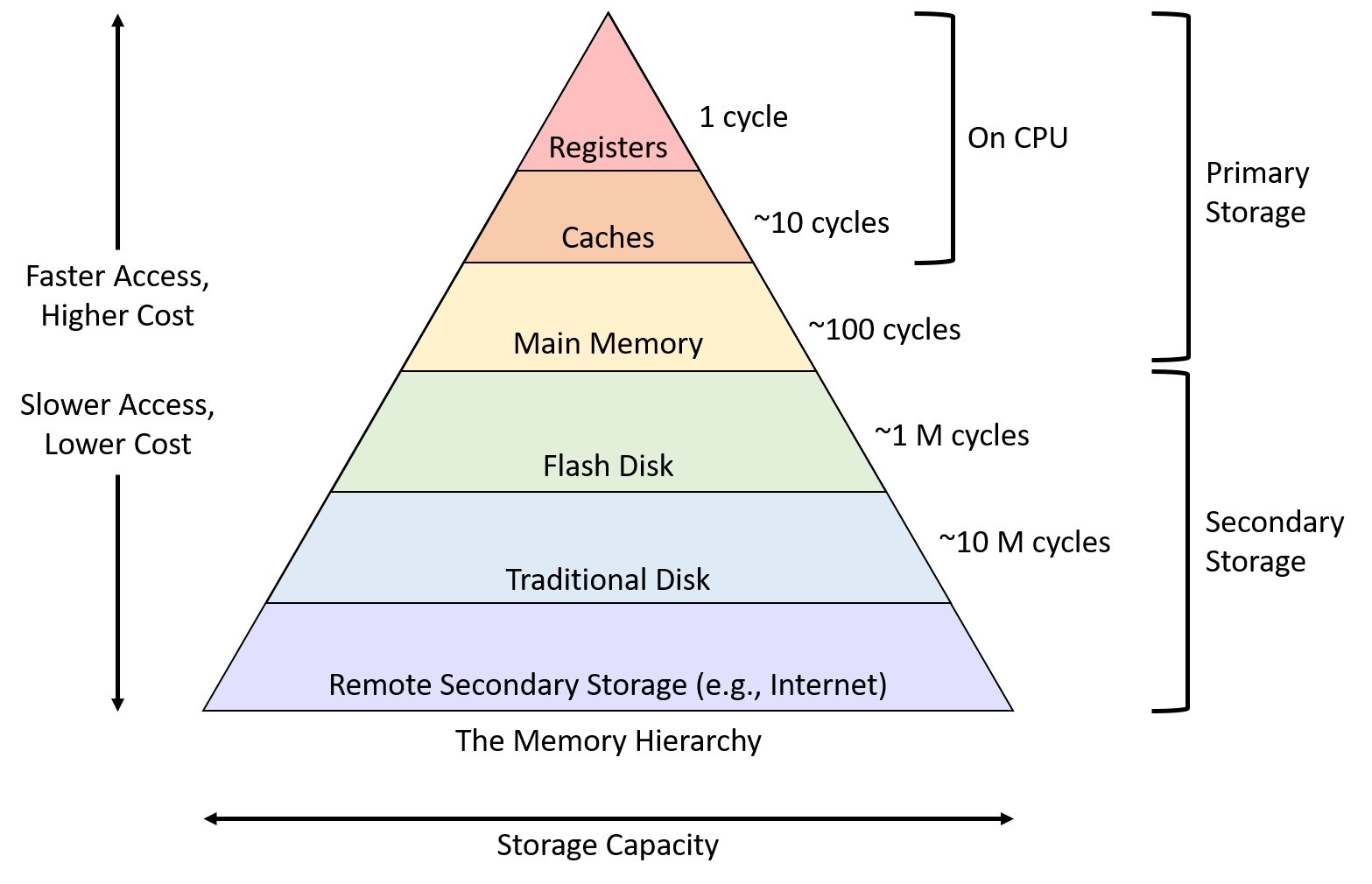
上图是典型的存储系统性能金字塔,可以看到 CACHE 位于 Register 和 Main Memory 之间,为什么 CACHE 的使用可带来性能的极致提升,这还得从一个故事讲起: 假设将 CPU 访问数据比作开发者在图书馆找资料,那么:
- CPU 访问 L1 CACHE 相当于开发者在书桌上的书本里查找资料
- CPU 访问 L2 CACHE 相当于开发者发现桌上的书本没有找到,那么从身后的书包里的书进行查找
- CPU 访问 L3 CACHE 相当于开发者发现书包的书本没有找到,那么从远处的书架上的书进行查找
- CPU 访问内存相当于书架上的书没有找到,那么去问管理员,管理员告诉你书在五楼某个书架,然后你从一楼跑去五楼的书架上去找书
- CPU 访问磁盘相当于你跑到 5 楼的书架却发现书已经没了,从管理员那里知道这本书正在捕获,需要等半年之后才能到,于是你等了半年之后等到了书.
从上面的实践案例和故事是不是对 CACHE 有了初步认识,在单核年代 CACHE 是比较容易理解的,就是加速内存的访问,但到了多核年代,事情变得越来越复杂,虽然硬件自动完成很多工作了,但对于折腾性能不休的我们,学习 CACHE 从中对多核架构下的编程将带来颠覆性的认知,从而利用 CACHE 优化程序的性能,使收益最大化。BiscuitOS 社区提供的 CACHE 专题将从以下几个方面对 CACHE 进行讲解,开发者可以按照以下顺序进行学习:
- CACHE 实践教程: 实践是认知的源泉,千里之行始于实践
- CACHE 通用基础: 基础不牢地动山摇,夯实基础,厚积薄发
- Linux CACHE 机制: 学以致用,Coding on Linux
- Intel® X86 ™Processors 架构 CACHE 机制: 洞悉前沿科技
- CACHE 调试工具合集: 工欲善其事,必先利其器
- CACHE 应用场景: 丢掉幻想,直接实战
- CACHE BUG/Fault: 思其过,行长远
- CACHE 进阶研究: 得其意,忘其形

CACHE 基础概念
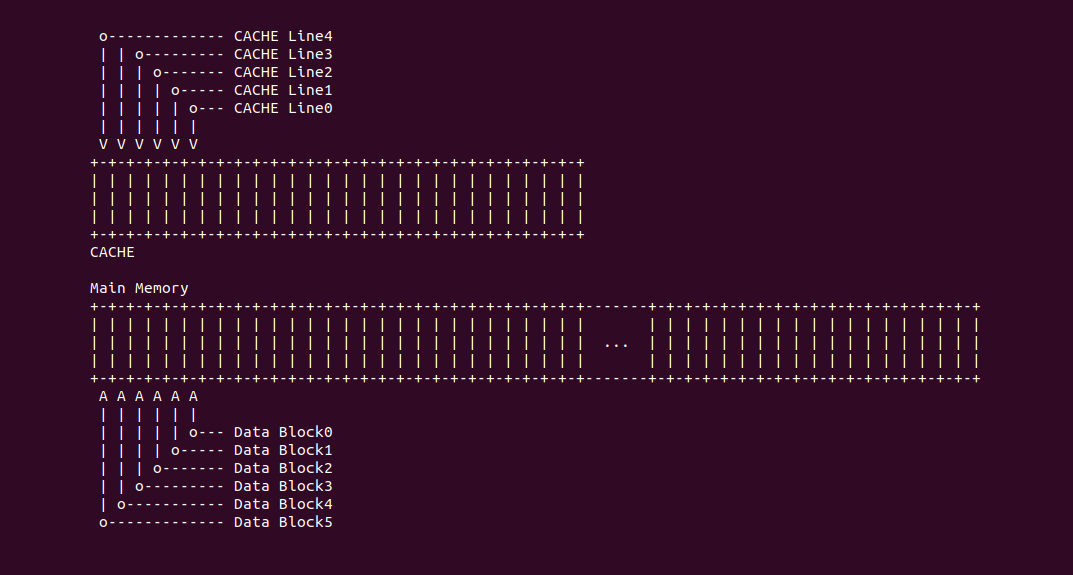
CACHE 是由一组称为缓存行(CACHE Line)固定大小的数据块组成,其长度称为 CACHE Line Size, 在有的架构中 CACHE Line Size 为 64 个字节。每个 CACHE Line 完全是在一个突发读操作周期中进行填充或更新, 即使处理器只访问存储器上的一个字节,CACHE 控制器也会将 CACHE Line Size 的数据块加载到 CACHE 里. 同理将内存中 CACHE Line Size 大小的数据块称为 Data Block.
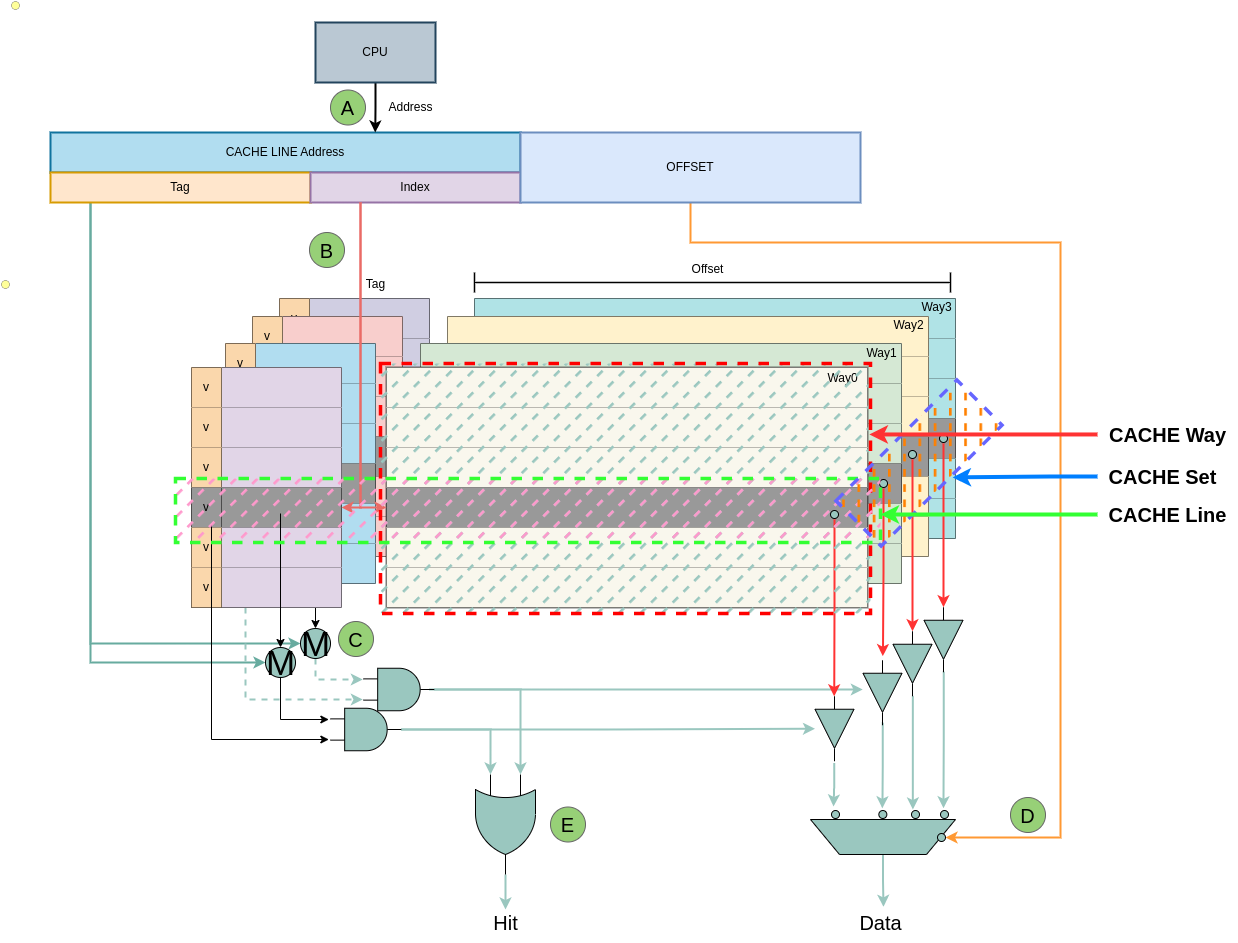
CACHE Line 是 CACHE 最基础的组成单位,将 N 个 CACHE Line 组成的集合称为 CACHE Set, 那么称 CACHE 是 N 路组相联(N-Way Set-associative Cache), 所以从硬件结构来看 CACHE 被划分成 N 个垂直面,每个垂直面上有多个 CACHE Line,对所有的 CACHE 垂直面进行一次横切的 CACHE Line 合集就是 CACHE Set. CACHE Line 由两部分组成: Tag 和 Offset 部分,其中 Tag 字段由于匹配具体的 Data Block,Tag 字段中还包含了 valid 标志位,该位置位说明 CACHE Line 的内容有效,反之 CACHE Line 的内容无效。CACHE Line 的 Offset 部分存储 Data Block 的内容.
- CACHE Hit(命中): 指的是 CPU 要访问的地址正好缓存在 CACHE Line 中
- CACHE Miss(缺失): 指 CPU 要访问的地址没有缓存在 CACHE Line 中.
- CACHE 颠簸: 指的是 CPU 访问多个地址导致某个 CACHE Line 来回更新和填充.
直接映射
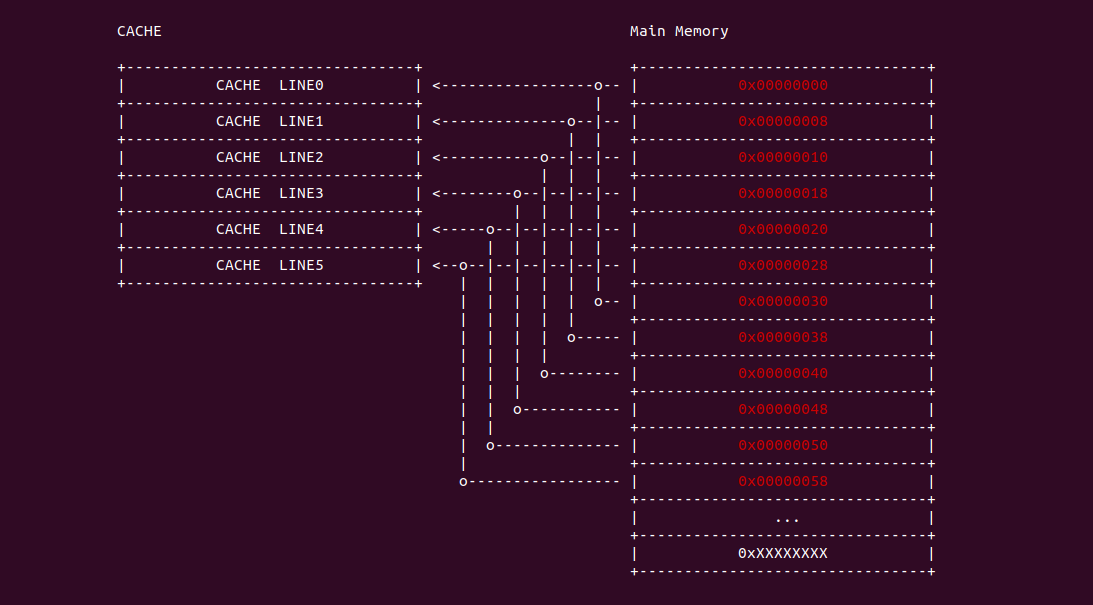
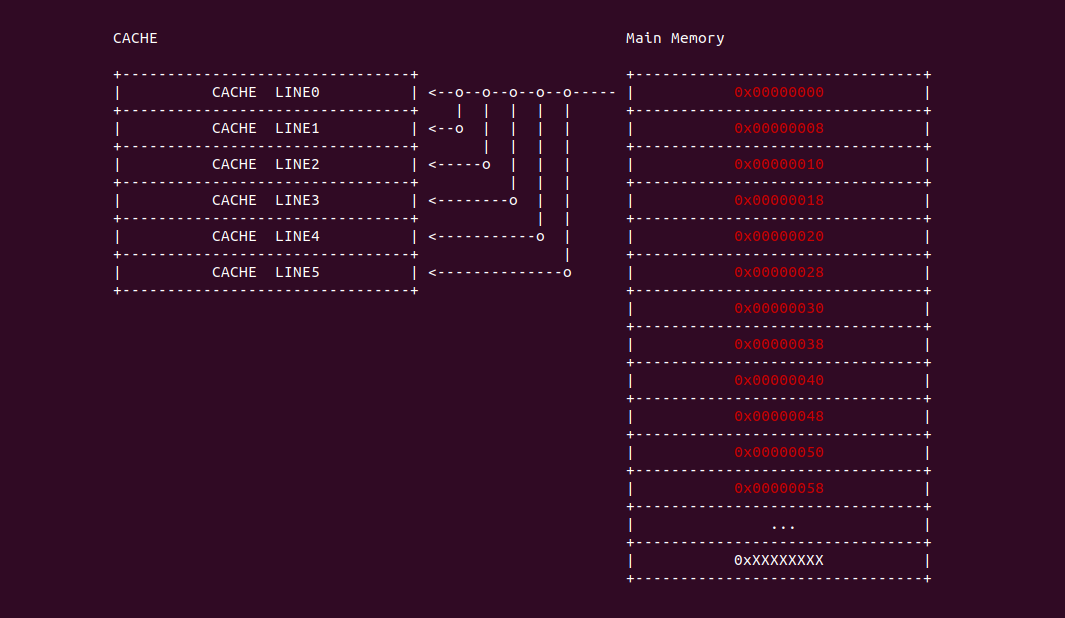
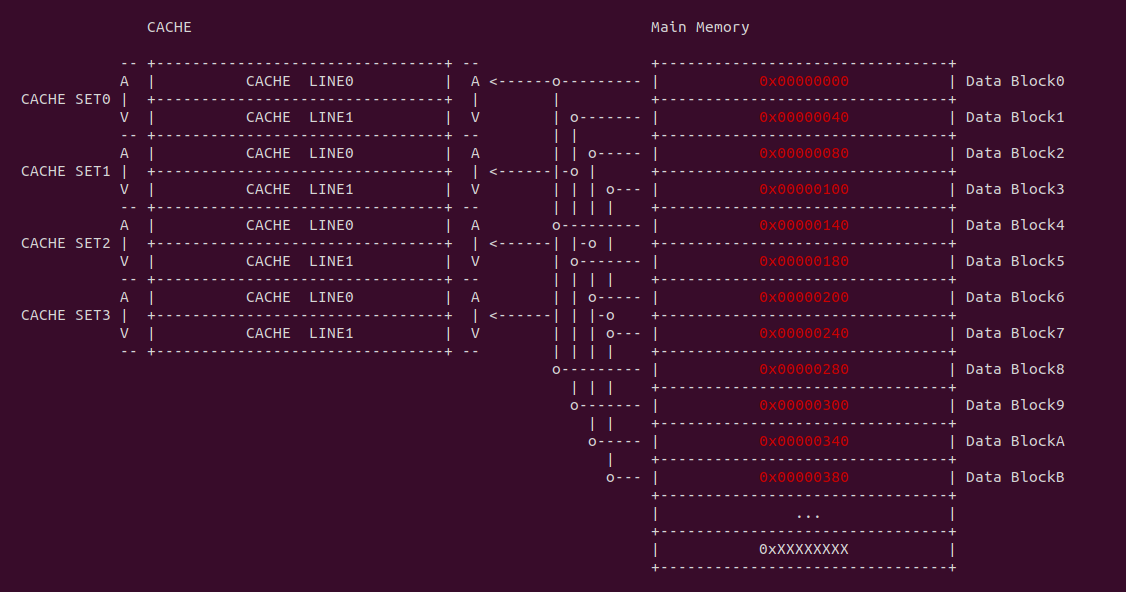
直接映射(Direct-mapped) 指的是内存中的 data block 按顺序映射到指定的 CACHE Line, 且每个 data block 只能映射到一个 CACHE Line 里,那么内存 data block 与 CACHE Line 一一对应,那么可以使用一个线性公式表示两者之间的关系,这个线性公式是求模公式,模数即为 CACHE Line 的数量,内存地址求模之后就可以知道其映射的 CACHE Line,那么模相同的内存 data block 会映射到同一个 CACHE Line 里. 例如上图的案例中,内存 data block 的长度和 CACHE LINE 的长度都是 64Bytes,内存 data block 0x0000000 只能被加载到 CACHE Line0, 0x00000008 只能加载到 CACHE Line1,以此类推,由于 0x00000030 的模数与 0x00000000 相同,那么其也映射到 CACHE Line0 上。相比其他的 CACHE 设计方案,直接映射有自己的简单的优点,但缺点也很明显:
- 优点: 硬件设计简单、成本低
- 缺点: 灵活性差,内存 data block 只能映射到固定的 CACHE Line 上,很容易与同一 CACHE Line 的 data block 冲突,从而引起Cache 颠簸. CACHE 的容量比较大才能显示直接映射的优势.
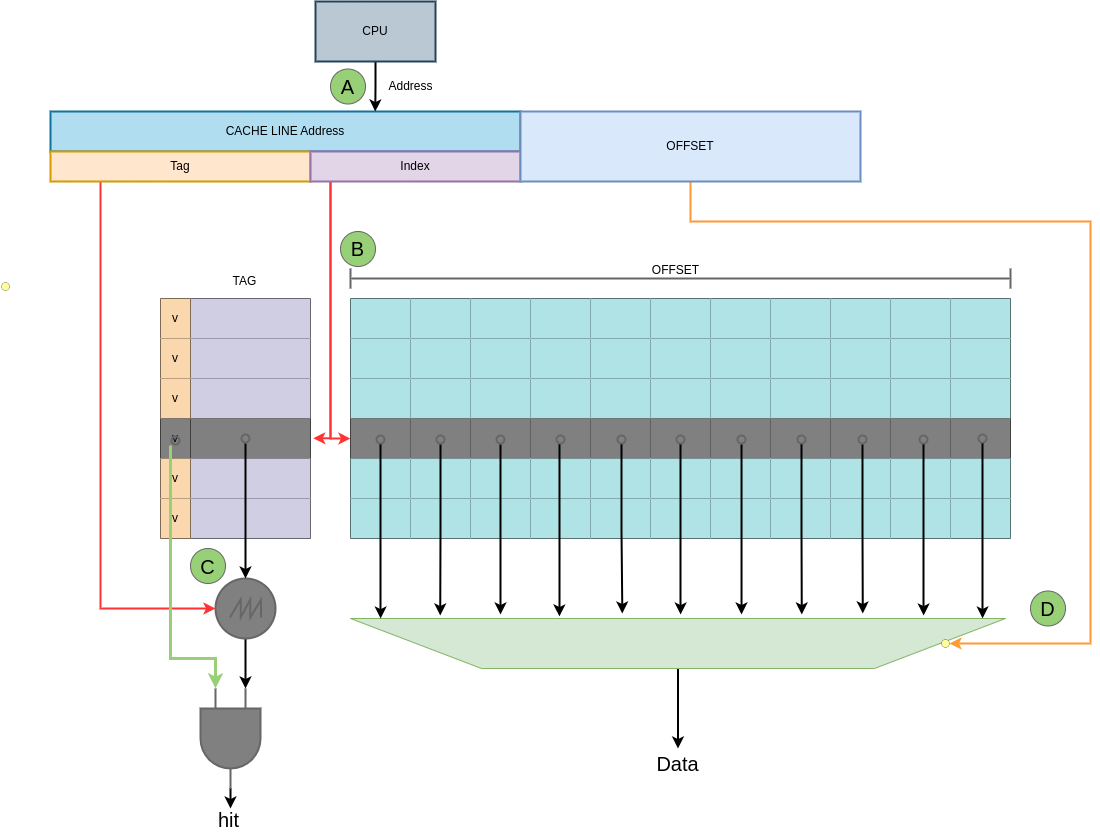
直接映射硬件设计简单, CACHE 内部在一个平面内将所有的 CACHE LINE 按顺序依次排列组成,每一行就是一个 CACHE Line,每个 CACHE Line 包含了两部分,TAG 和 OFFSET,其中 TAG 部分还包含了一个 valid 位,Valid 位置位时表示 CACHE Line 维护的数据有效, 反之该位清零时表示 CACHE Line 维护的数据无效. 硬件处理过程如上图:
- A: CPU 生成需要访问地址,地址被划分成 3 个部分: Tag、Index 和 Offset
- B: CACHE 从访问地址的 Index 部分在 CACHE 中找到对应的 CACHE Line
- C: 将 CACHE Line 的 Tag 部分与访问地址的 Tag 部分进行比较,当匹配上且 CACHE Line Tag 的 valid 位置位,那么命中(Cache hit); 反之如果 valid 位清零或者 Tag 字段不匹配,那么缺失(Cache miss).
- D: 当命中之后,CACHE 根据访问地址的 Offset 字段从 CACHE Line 中获得最终的值.
全相联映射
全相联映射(Full-associative) 指的是内存中的 data block 可以映射到任意 CACHE Line. 例如上图的案例中内存 0x00000000 可以映射到任一 CACHE Line 上,0x00000008 也可以映射到任一个 CACHE Line. 由于内存 data block 可以映射到任一 CACHE Line,因此 CACHE 需要花费更多的时间或者更多的资源去查找对应的 CACHE Line 中是否包含所需的数据.
- 优点: 灵活性好,CACHE 只要有空闲的 CACHE Line 就可以加载内存 data block.
- 缺点: 利用率不高,因为存在一个 m 位的标记,使 CACHE Line 中包含一些对存储无用的信息. 速度慢、硬件成本高,每次访问 CACHE 需要依次遍历,直到命中才能确认 data block 是否在 CACHE 中.
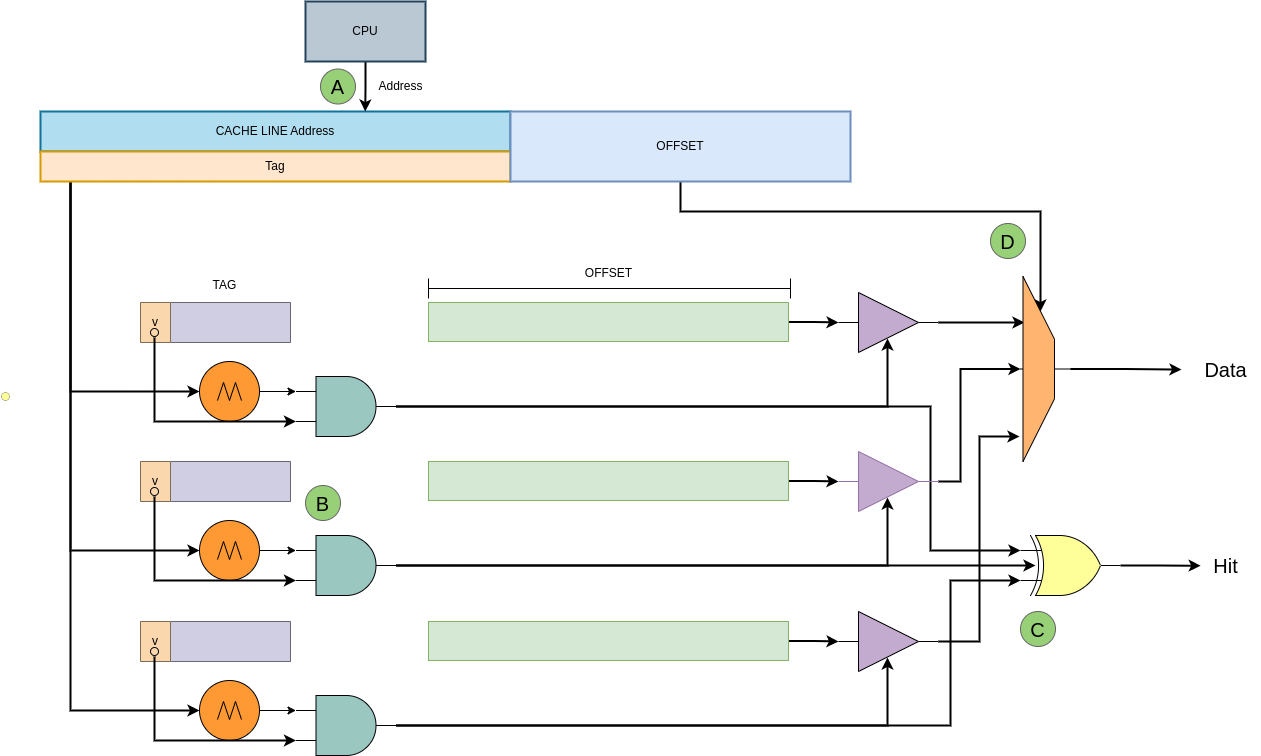
全相联映射的硬件相对复杂,CACHE 内部在一个平面内将所有的 CACHE LINE 按顺序依次排列,每个 CACHE Line 都存在一个比较模块,用于比较 CACHE Line 的 Tag 部分,其中 TAG 部分还包含了一个 valid 位,Valid 位置位时表示 CACHE Line 维护的数据有效, 反之该位清零时表示 CACHE Line 维护的数据无效. 全相联结构的 CACHE 有着最大的灵活性,因此缺失(Cache miss)率是最低的,但从硬件结构来看,由于有着大量的内容需要进行比较,它的延迟也是最大的,因此一般这种结构的 CACHE 都不会有很大的容量. 硬件处理过程如上图:
- A: CPU 生成需要访问地址,地址被划分成 2 个部分: Tag 和 Offset
- B: CACHE 从访问地址的 Tag 部分依次与 CACHE Line 的 Tag 部分进行比较
- C: 当匹配上且 CACHE Line Tag 的 valid 位置位,那么命中(Cache hit); 反之如果 valid 位清零或者 Tag 字段不匹配,那么缺失(Cache miss).
- D: 当命中之后,CACHE 根据访问地址的 Offset 字段从 CACHE Line 中获得最终的值.
组相联映射
组相联映射(Set-associative) 是直接映射和全映射的折中方案,将多个 CACHE Line 组成一个组称为 CACHE Set,同样将多个 Data block 组成一个组称为 Data Set,每个 Data Set 按直接映射的方式映射到指定的 CACHE Set. Data Set 内的任意 Data block 可以映射到 CACHE Set 中任意 CACHE Line. 对于组相联映射的 CACHE 来说,一个 Data block 可以被加载到 CACHE Set 的 N 个 CACHE Line,那么称这个 CACHE 是 N 路组相联的 CACHE(n-way set-associative Cache). 相比其他两种映射方式,组相联映射组内具有一定的灵活性,而且组内行数较少,比较的硬件电路比全相联方式简单,并且空间利用率比直接映射方式高.
组相联映射的硬件是一个立体的结构,每个 CACHE Way 就是一个垂直平面,多个 CACHE Way 组成了一个立体的存储结构,那么一个 CACHE Set 就是在多个 CACHE Way 组成的立体结构上进行一次横切,那么同一个 Data Set 里面的 Data block 可以存储在横切之后 CACHE Set 里任意一个 CACHE Line 里. 硬件处理过程如上图:
- A: CPU 生成需要访问地址,地址被划分成 3 个部分: Tag、Index 和 Offset
- B: CACHE 从访问地址的 index 部分在 CACHE 中找到对应的 CACHE Set.
- C: 依次将 CACHE Set 里的 CACHE Line 的 Tag 部分与访问地址的 Tag 部分进行比较,如果匹配上且 Tag 的 valid 位置位,那么命中(Cache hit); 反之如果 valid 位清零或者 Tag 字段没有匹配,那么缺失(Cache miss).
- D: 当命中之后,CACHE 根据访问地址的 Offset 字段从 CACHE Line 中获得最终的值.
CACHE Tag and Index
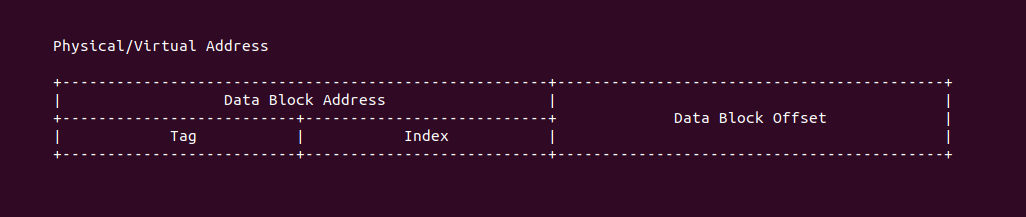
对于一段索引 CACHE 的内存地址(可以是虚拟机地址或者物理地址),其分为以上三部分: Tag、Index 和 Offset. 三者组合可以在 CACHE 中定位唯一的 CACHE Line,其中 Index 字段用于定位 CACHE Set,Tag 用于在 CACHE Set 中定位到指定的 CACHE Line,Offset 用于在 CACHE Line 的数据域定位指定的数据.

CACHE Line 内部结构如上图,其由 Tag、Flags 和数据域组成。Tag 部分用于在内存地址 Index 找到 CACHE Set 的情况下,与内存地址 Tag 相比较以此找到指定的 CACHE Line; Flags 字段包括 Valid 位,在数据 CACHE 中还包括 Dirty 位,Valid 位用于指明 CACHE Line 是否有效,Dirty 位则表明 CACHE Line 是否包含脏数据; Data 数据域包含了从 Data Block 取来的 CACHE Line Size 字节的数据.
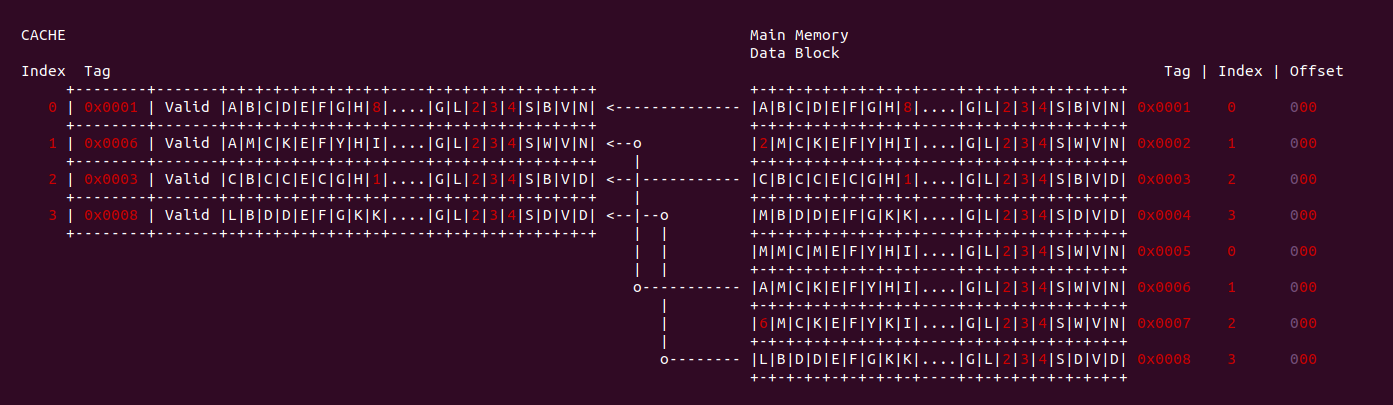
内存 Data Block 首次加载到 CACHE 时,先根据内存地址的 Index 字段在 CACHE 中找到对应的 CACHE Set,然后将 CACHE Set 中找到一个合适的 CACHE Line 将内存地址 Tag 字段存入 CACHE Line 的 Tag 字段,然后将内存 Data Block 的数据存储到 CACHE Line 的 Data 区域. 例如 Data Block 的地址为 0x00061000, 其 Index 为 1, 那么其被加载到 CACHE 时其会选择 CACHE Set 为 1,由于案例中 CACHE Set 只包含一个 CACHE Line,那么 Data Block 加载到 CACHE Line1 里,此时 CACHE 将 Data Block 的 Tag 字段 0x0006 存储到 CACHE Line1 的 Tag 字段,并将 Data Block 的数据加载到 CACHE Line1 的 Data 域. 以上便是一个最简单的 CACHE Load 内存的过程.
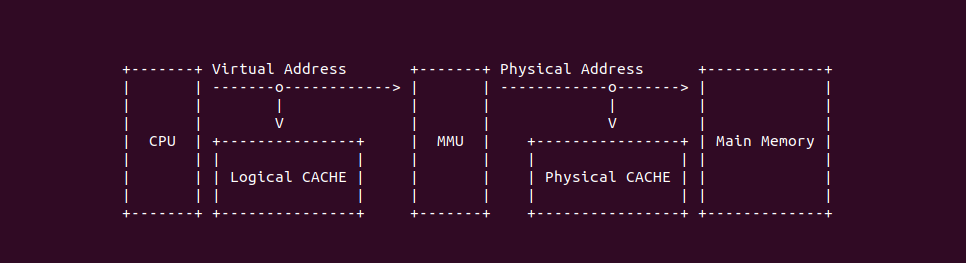
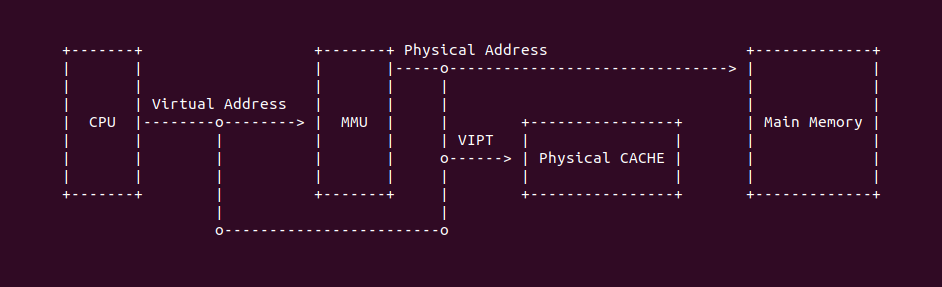
在开启分页之后,CPU 直接使用的是虚拟地址,但索引 CACHE 的内存地址可以是物理地址,也可以是虚拟地址,存在这样的逻辑是因为 CACHE 的位置决定的。当 CACHE 位于 CPU 和 MMU 之间,那么称为逻辑 CACHE,可以使用虚拟地址的 Index 索引 CACHE Set,并称虚拟地址的 Index 为 VI(Virtual Index); 当 CACHE 位于 MMU 和主存之间,那么称为 物理 CACHE, 可以使用物理地址的 Index 索引 CACHE Set,并称物理地址的 Index 为 PI(Physical Index). 另外需要使用物理地址 Tag 确认 CACHE Line 的 Tag,那么物理地址 Tag 为 PT(Physical Tag), 同理需要使用虚拟地址 Tag 确认 CACHE Line 的 Tag,那么虚拟地址 Tag 称为 VT(Virtual Tag).
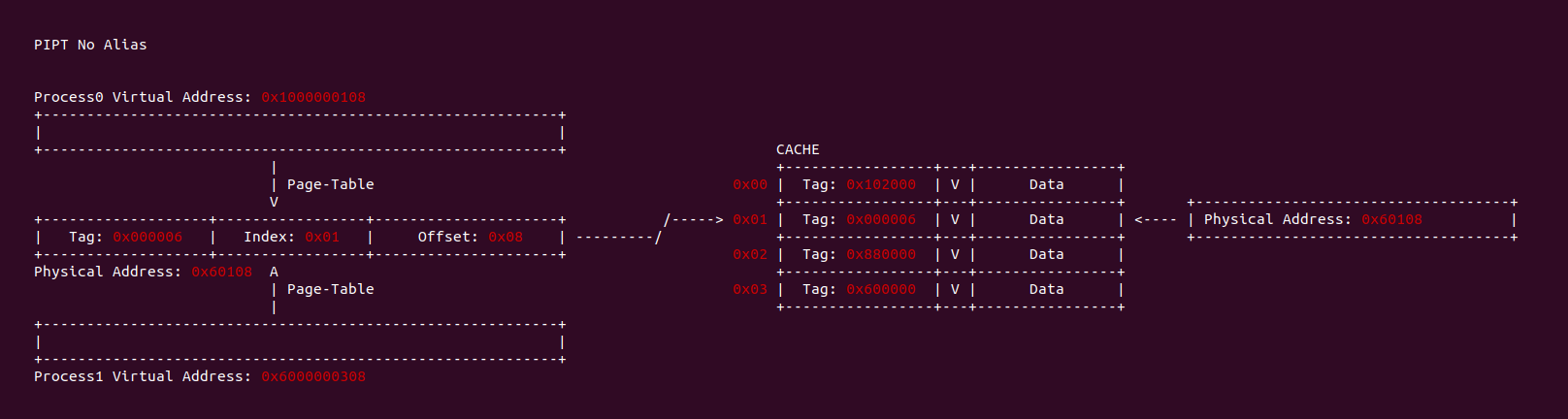
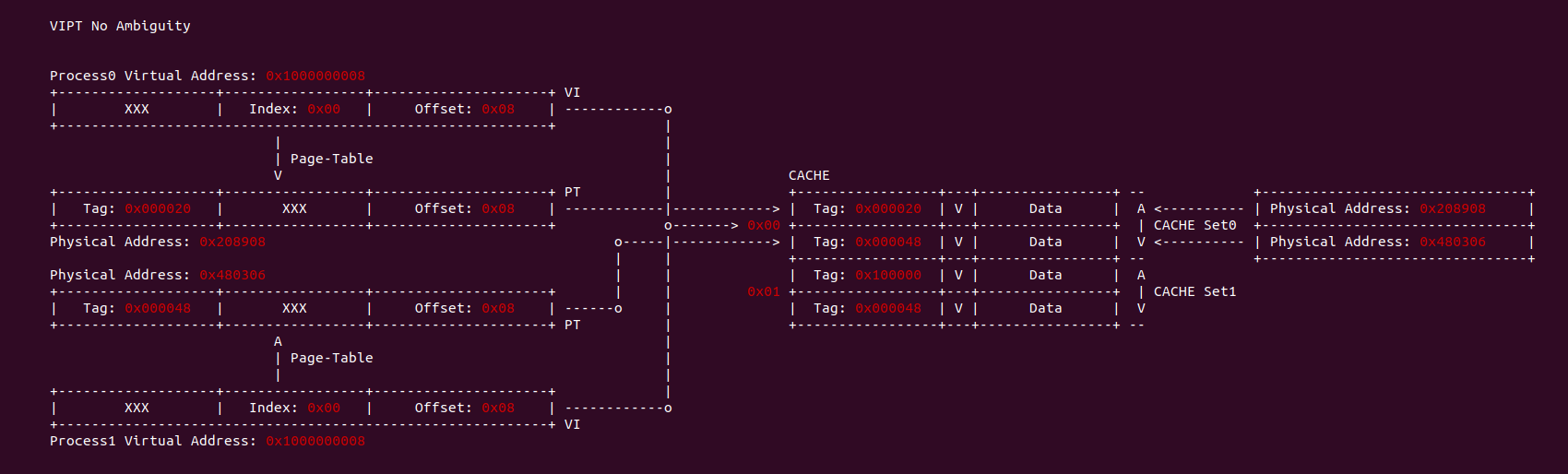
CACHE 歧义(Ambiguity)
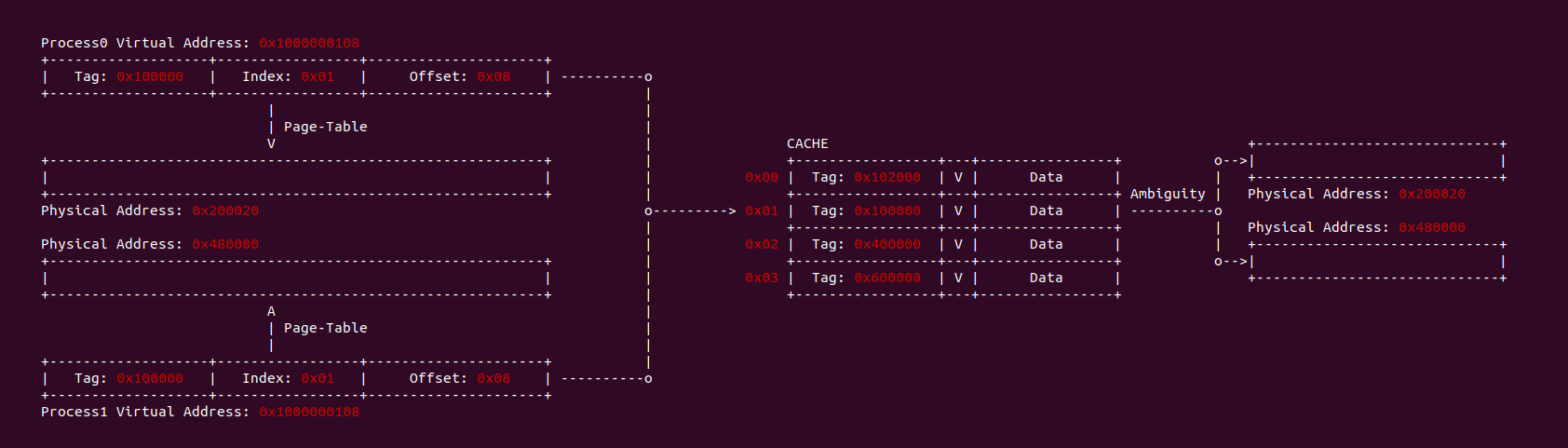
当 CACHE 控制器使用虚拟地址索引 CACHE Line,即使用 VIVT(Virtual Index Virtual Tag),当两个进程相同的虚拟地址映射到不同的物理地址,例如上图中进程 0 的虚拟地址 0x1000000108 映射了物理地址 0x200020, 而进程 1 同样的虚拟地址 0x1000000108 映射了物理地址 0x300020. 由于 CACHE 控制器使用了虚拟地址 Index 所有 CACHE Set,那么两个虚拟地址的 Index 都是 0x01, 并且使用虚拟地址的 Tag 确认 CACHE Line 的 Tag,此时两个虚拟地址都有相同的 Tag,因此两个进程的虚拟地址在 CACHE 中找到了同一个 CACHE Line,换个角度就是同一个 CACHE Line 映射不同的物理地址, 称这种现象为 CACHE 歧义(Ambiguity). 内核通过如下方法避免歧义:
- 进程切换时 flush cache,并使主存 Data Block 有效。针对 WriteBack 高速缓存,首先应使主存数据有效,保证已经修改数据 CACHE Line 已经写入主存,避免修改的数据丢失.
- 进程切换时 flush cache,并使 CACHE Line 无效,保证切换之后的进程不会错误命中切换之前进程的 CACHE Line.
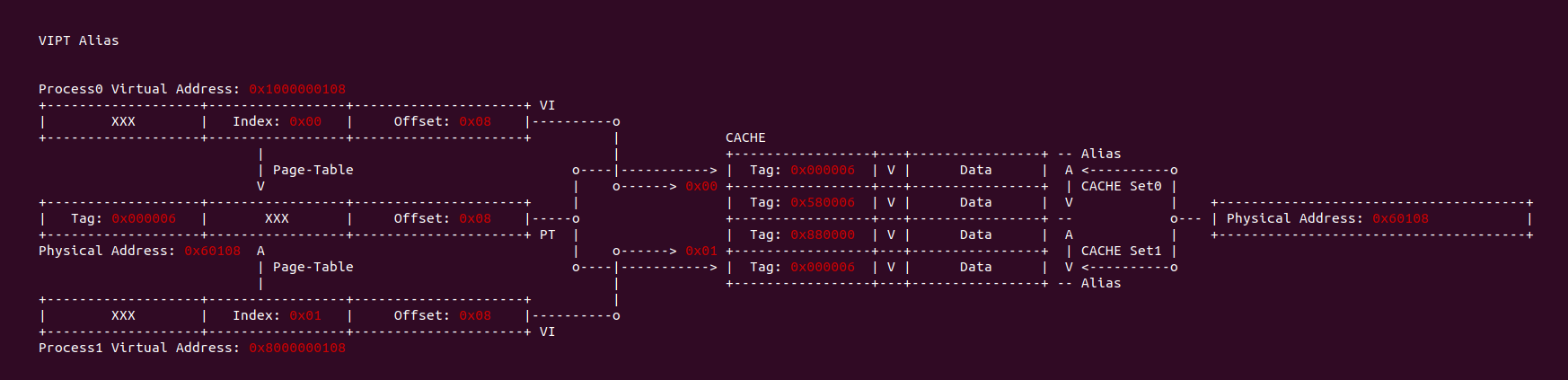
CACHE 别名(Alias)
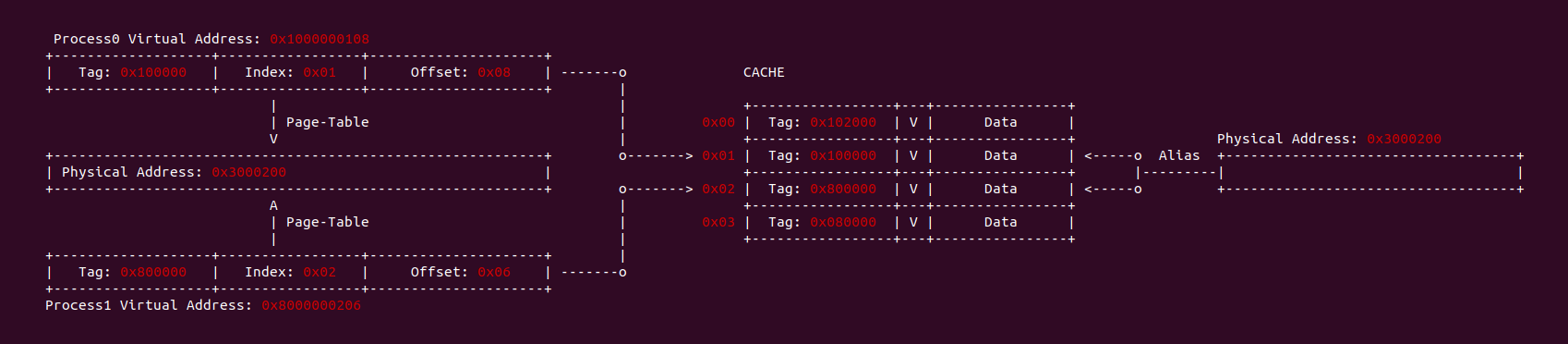
当 CACHE 控制器使用虚拟地址索引 CACHE Line,即使用 VIVT(Virtual Index Virtual Tag). 当两个进程不同的虚拟地址映射到同一个物理地址上,例如上图进程 0 的虚拟地址 0x1000000108 和进程 1 的虚拟地址 0x8000000206 都映射到了物理地址 0x3000200,由于 CACHE 控制器使用 VIVT,那么此时就会出现两个虚拟地址会索引到不同 CACHE Set 的 CACHE Line 上,换个角度就是一个物理地址被缓存到不同的 CACHE Line 里,称这种现象为 CACHE 别名(Alias). 别名问题会导致 CACHE 一致性问题(后面会讨论).
VIVT
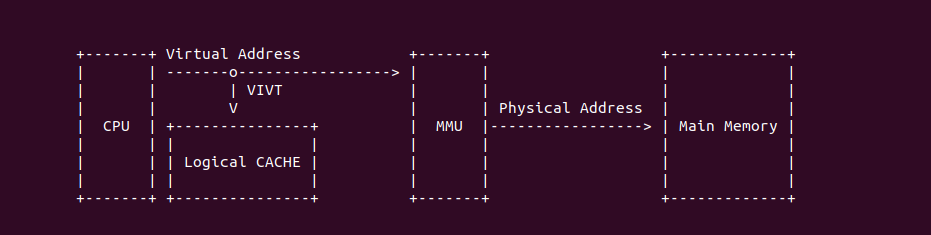
VIVT(Virtual Index Virtual Tag) 指的是虚拟 CACHE 控制器通过虚拟地址提供的 Tag 和 Index 索引 CACHE Line. VIVT 不需要经过 MMU 翻译,具有很小的延时,但会引起别名和歧义问题.
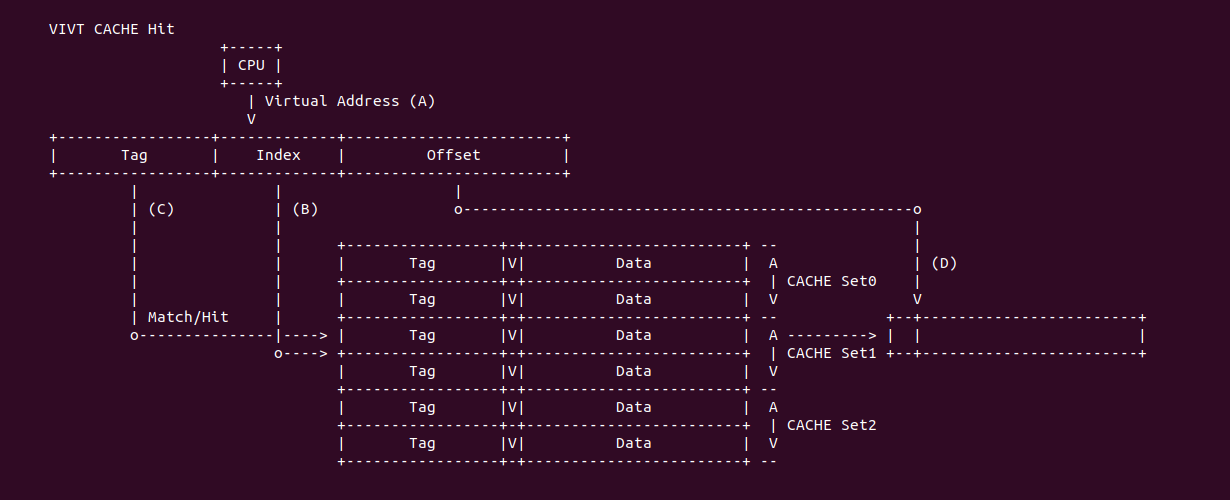
VIVT CACHE Hit: 当 CACHE 控制器使用 VIVT 索引 CACHE Line:
- (A) CPU 产生的虚拟地址可以直接传递给 CACHE 控制器进行索引
- (B) CACHE 控制器从虚拟地址中提取 Index 字段,Index 可以选择指定的 CACHE Set,此时选中 CACHE Set1,其组内包含了两个 CACHE Line
- (C) CACHE 控制器从虚拟地址中提取 Tag 字段,与 CACHE Set1 的所有 CACHE Line 的 Tag 字段进行比较,一旦 Tag 匹配,并且 Valid 字段有效,那么找到指定的 CACHE Line.
- (D) CACHE 控制器从 CACHE Line 中区域 Data 区域,并从虚拟地址提取 Offset 字段,最终在 CACHE Line 的 Data 区域中读取指定的数据.
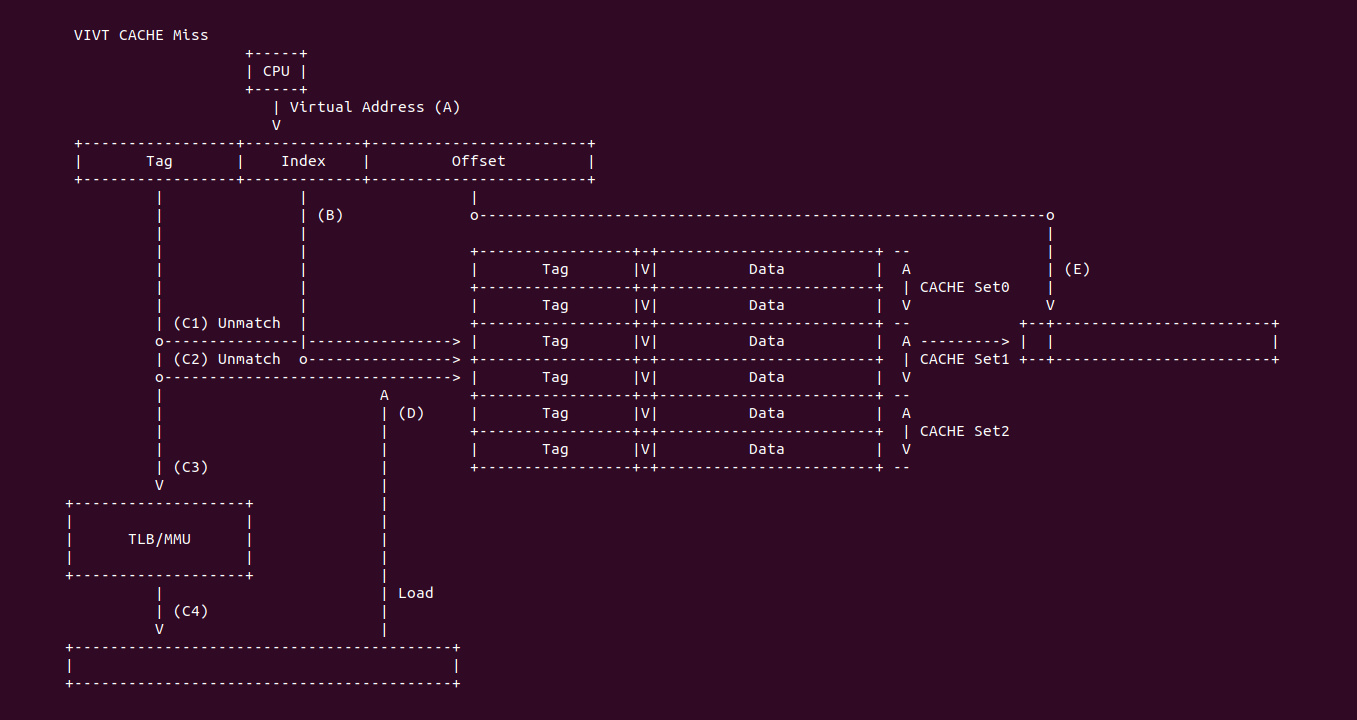
VIVT CACHE Miss: 当 CACHE 控制器使用 VIVT 索引 CACHE Line:
- (A) CPU 产生的虚拟地址可以直接传递给 CACHE 控制器进行索引
- (B) CACHE 控制器从虚拟地址中提取 Index 字段,Index 可以选择指定的 CACHE Set,此时选中的 CACHE Set1,其组内包含了两个 CACHE Line.
- (C1) CACHE 控制器从虚拟地址中提取 Tag 字段,与 CACHE Set1 的第一个 CACHE Line 的 Tag 字段进行比较,发现不匹配
- (C2) CACHE 控制器继续与 CACHE Set1 剩下的 CACHE Line Tag 字段进行比较,发现还是不匹配,那么 CACHE 控制器认为发送 CACHE Miss
- (C3) CACHE Miss 之后 CACHE 控制器将虚拟地址传递给 TLB 或者 MMU 查询虚拟地址对应的物理内存
- (C4) 系统从 TLB 或者 MMU 中找到了虚拟地址对应的物理内存(可能也找不到)
- (D) CACHE 控制器根据替换算法将 CACHE Set1 中指定的 CACHE Line 刷出,然后将找到的物理内存 Data Block 加载到该 CACHE Line,并更新 Tag 和 Valid 字段
- (E) CACHE 控制器继续将 CACHE Line 的 Data 域取出,然后配合虚拟地址的 Offset 域找到最终的数据.
VIVT 优缺点: 通过上面对 VIVT Hit 和 Miss 场景的分析,VIVI 模式下 CPU 不需要将虚拟地址转换成物理地址就可以在 CACHE 中找到 CACHE Line,在一定程度上提升了 CACHE 的速度,因为访问虚拟地址转换成物理地址可能需要几十到几百个周期,只有在 CACHE Miss 的时候才会发送虚拟地址到物理地址的转换,硬件设计上更加简单. 但 VIVT 模式容易引入歧义和别名问题, 具体如下:
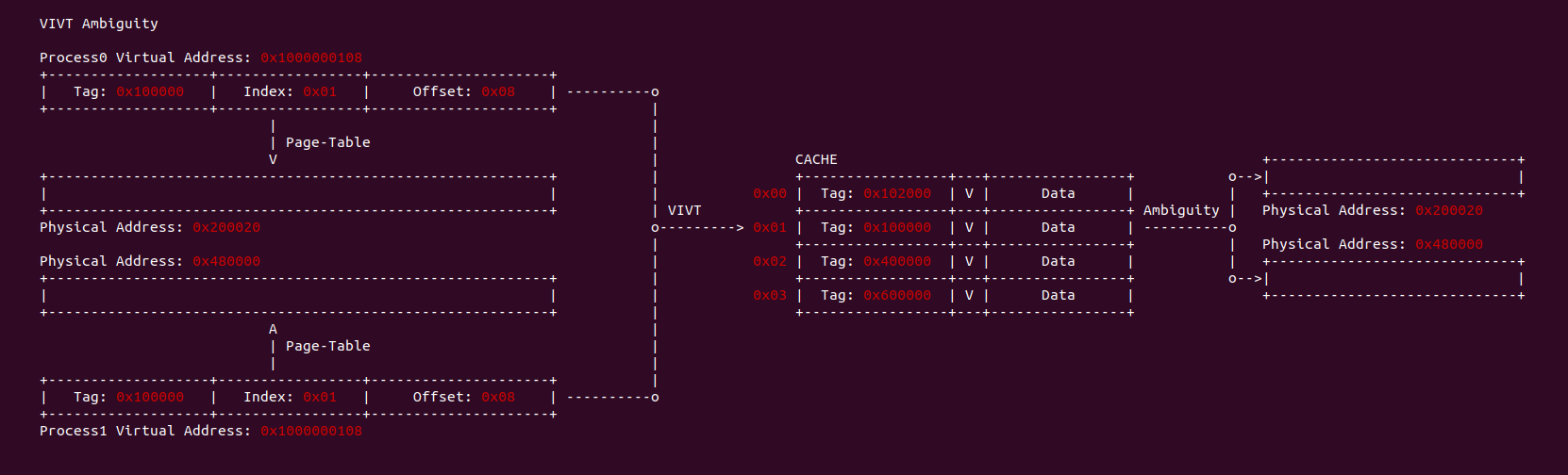
在不同的进程地址空间里,虚拟地址虽然相同,但映射到不同的物理内存上,如果 CACHE 控制器使用虚拟地址的 Index 和 Tag 查找 CACHE Line,那么会出现同一个 CACHE Line 会映射不同的物理地址,这就是 VIVT 的歧义问题. 为了保证系统的正确工作,操作系统需要负责避免歧义出现,可以通过按需清除 CACHE Line,或者为每一个进程的地址空间添加标记(PCID/ASID),当进程切换时刷掉指定的 CACHE Line, 不过这样做会导致进程调度回来时出现大量的 CACHE Miss,影响程序的性能.
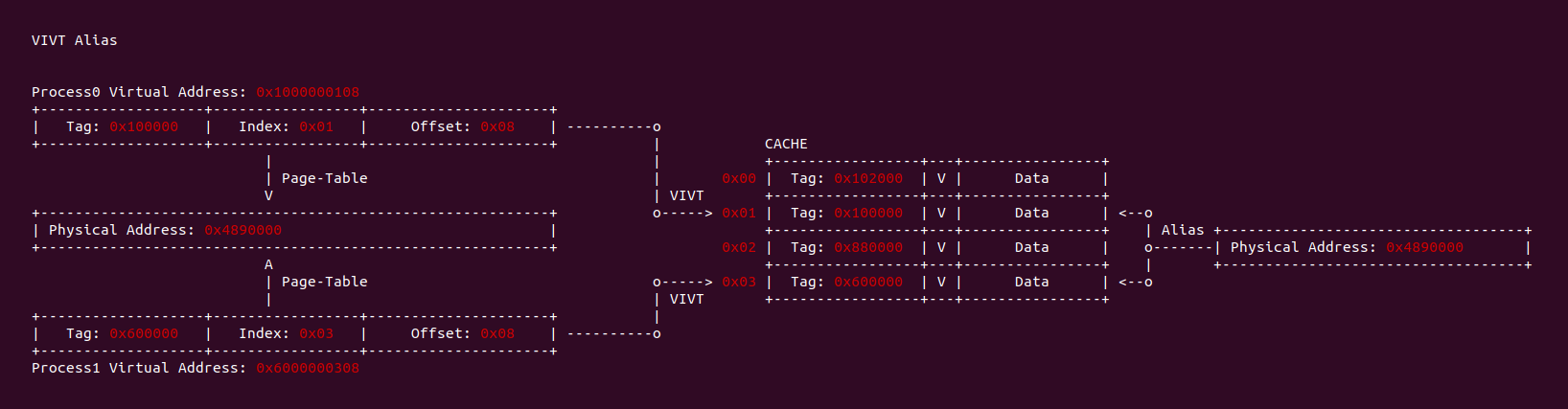
同样是不同进程不同的虚拟地址同时映射到同一个物理地址上,如果 CACHE 控制器使用虚拟地址的 Index 和 Tag 查找 CACHE Line,那么不同的虚拟地址可以找到不同的 CACHE Line,但找到的 CACHE Line 却缓存了同一个物理地址的 Data Block,也就同一个物理地址会被映射到不同的 CACHE Line,这就是 VIVT 的别名问题. 该问题会引起 CACHE 的一致性问题,例如更新了存在别名 CACHE Line 的数据,那么同别名的 CACHE Line 的数据没有被更新,导致 CACHE 数据一致性问题. 同歧义问题一样,可以通过 Flush CACHE 的方式避免别名问题,也可以针对共享的数据映射相同物理地址时采用 NOCACHE 的方式,但这样会损失 CACHE 带来的性能提升.
PIPT
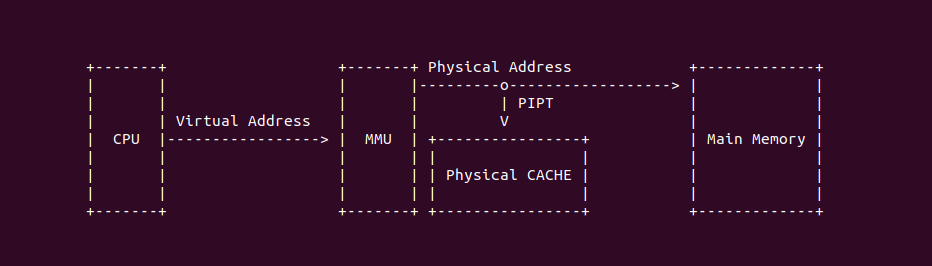
PIPT(Physical Index Physical Tag) 指的是物理 CACHE 控制器通过物理地址提供的 Tag 和 Index 索引 CACHE Line. PIPT 需要将 CPU 产生的虚拟地址经过 TLB/MMU 翻译,获得物理地址之后才能在 CACHE 中查找 CACHE Line,因此 CACHE 的速度受限于 TLB/MMU 转换的效率. 由于物理地址的唯一性,那么 Physical Index 和 Physical Tag 也具有唯一性,那么不会引入 CACHE 别名问题和 CACHE 歧义问题.
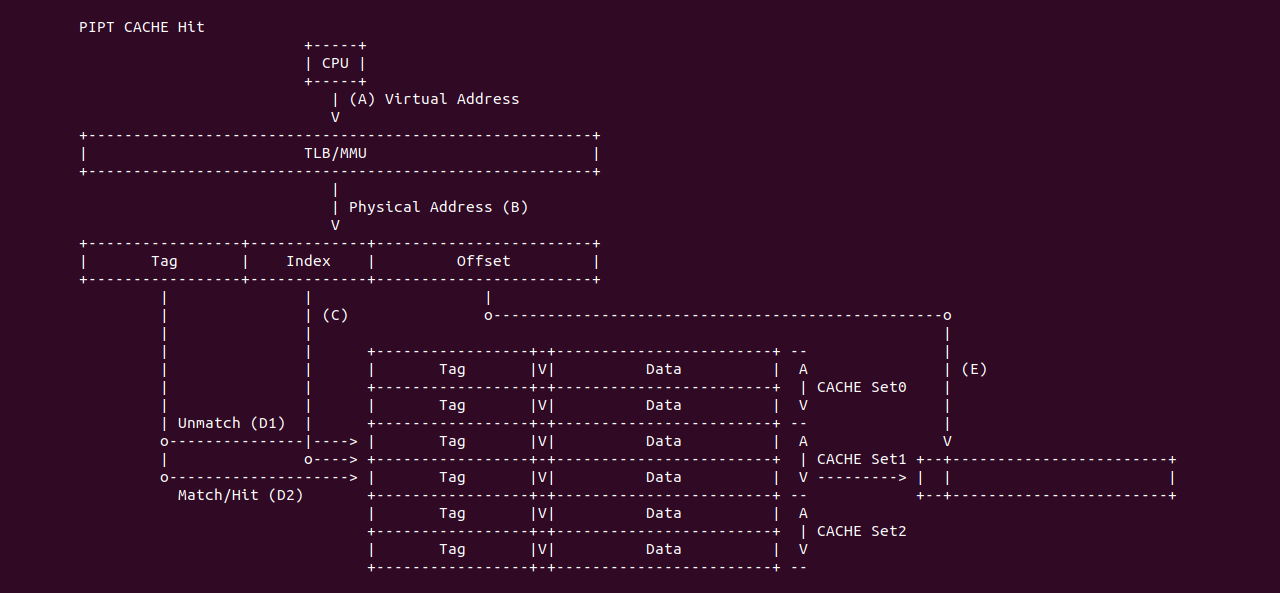
PIPT CACHE Hit: 当 CACHE 控制器使用 PIPT 索引 CACHE Line 发生 CACHE Hit:
- (A) CPU 产生的虚拟地址首先传递给 TLB/MMU 进行地址转换
- (B) TLB/MMU 将虚拟地址转换成物理地址, 并传递给 CACHE 控制器
- (C) CACHE 控制器从物理地址中提取 Index 字段,然后找到对应的 CACHE Set1,组内包含了两个 CACHE Line
- (D1) CACHE 控制器从物理地址中提取 Tag 字段,然后与 CACHE Set1 组内第一个 CACHE Line 的 Tag 字段进行比较,此时两个 Tag 字段并不匹配.
- (D2) CACHE 控制器继续与 CACHE Set1 组内最后一个 CACHE Line 的 Tag 字段进行比较,此时两个 Tag 匹配,并检查到 Valid 字段有效,那么 CACHE Hit
- (E) CACHE 控制器从匹配 CACHE Line 中提取其 Data 域,并从物理地址中提取 Offset 字段,最后从 Data 域中获得所需的数据.
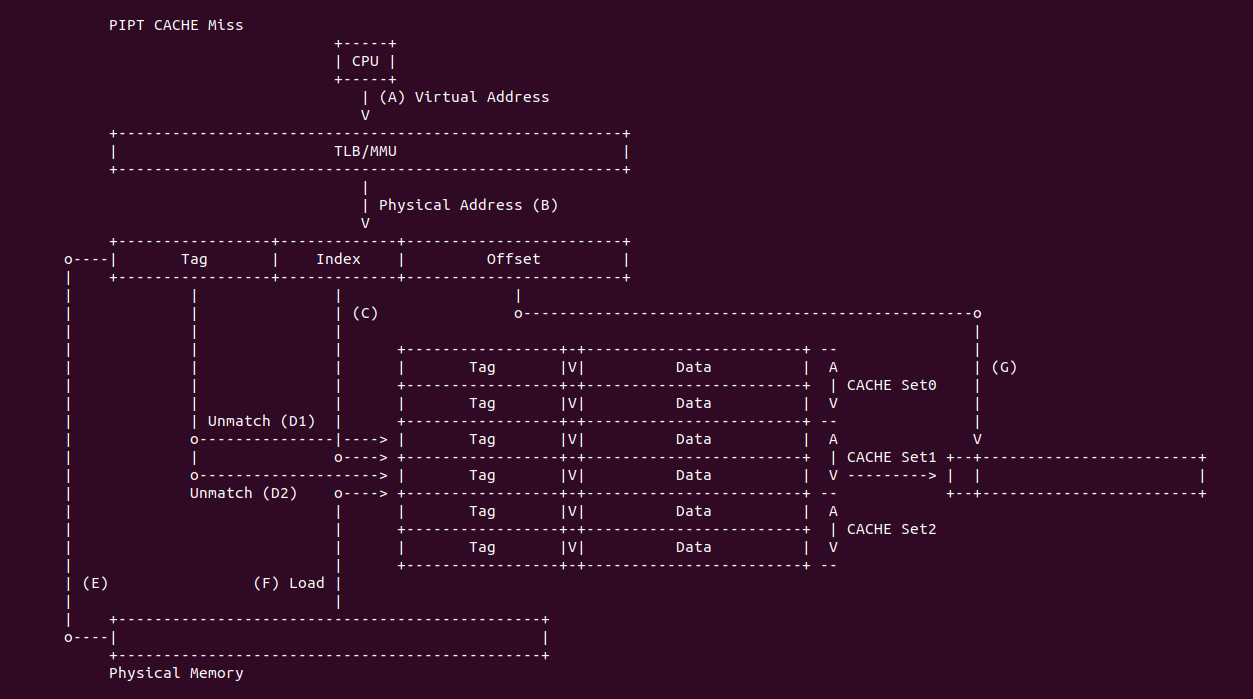
PIPT CACHE Miss: 当 CACHE 控制器使用 PIPT 索引 CACHE Line 发生 CACHE Miss:
- (A) CPU 产生的虚拟地址首先传递给 TLB/MMU 进行地址转换
- (B) TLB/MMU 将虚拟地址转换成物理地址,并传递给 CACHE 控制器
- (C) CACHE 控制器从物理地址中提取 Index 字段,然后找到对应的 CACHE Set1,组内包含了两个 CACHE Line
- (D1) CACHE 控制器从物理地址中提取 Tag 字段,然后与 CACHE Set1 组内第一个 CACHE Line 的 Tag 字段进行比较,此时两个 Tag 字段并不匹配.
- (D2) CACHE 控制器继续与 CACHE Set1 组内最后一个 CACHE Line 的 Tag 字段进行比较,此时两个 Tag 还是不匹配(或者就算 Tag 匹配但 Valid 域无效),那么 CACHE Miss
- (E) CACHE 根据物理地址在主内存中找打对应的 Data Block
- (F) CACHE 根据一定的替换算法在 CACHE Set1 中指定的 CACHE Line 刷出,然后将主内存 Data Block 加载到 CACHE Line,并更新 Tag 和 Valid 字段
- (G) CACHE 控制器从新更新的 CACHE Line 中提取其 Data 域,并从物理地址中提取 Offset 字段,最后从 Data 域中获得所需的数据.
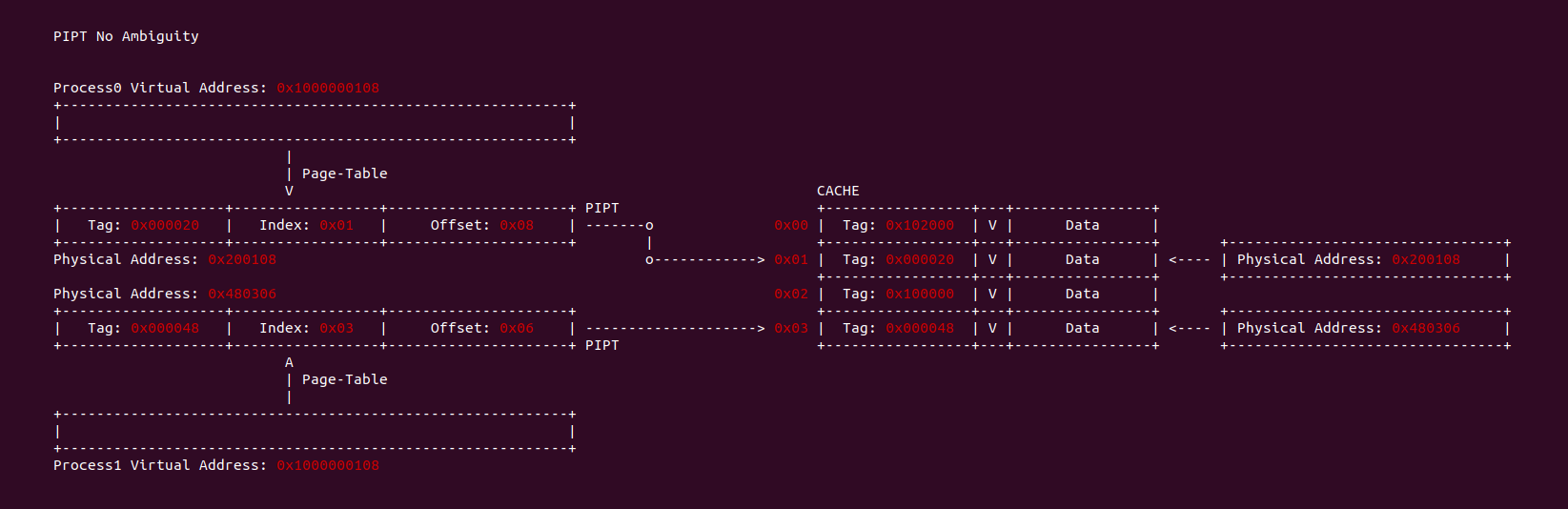
在不同的进程地址空间里,虚拟地址相同,但映射到不同的物理内存上,如果 CACHE 控制器使用物理地址的 Index 和 Tag 查找 CACHE Line,那么不会出现歧义问题. 由于物理地址的唯一性,就算虚拟地址相同,但物理地址是不同的,因此可以保证 Index 和 Tag 索引到的 CACHE Line 只映射一个的物理地址, 从而避免了 CACHE 歧义问题.
同样是不同进程不同的进程的空间虚拟地址映射到同一个物理地址,如果 CACHE 控制器使用物理地址的 Index 和 Tag 查找 CACHE Line,那么不会出现别名问题. 由于物理地址的唯一性,就算不同的虚拟地址映射到同一个物理地址,因此可以保证物理地址只被加载到一个 CACHE Line 中,从而避免了 CACHE 别名问题.
PIPT 优缺点: PIPT 带来的好处是很明显的,软件层面基本不需要任何维护就可以避免歧义和别名问题,但硬件设计上比 VIVT 复杂很多,因此硬件成本更高。最后对一个架构来说,CPU、TLB/MMU 和 CACHE 是三个不同的硬件模块,如果采用 PIPT 的话,CPU 发出虚拟地址经过 TLB/MMU 地址转译获得物理地址之后,CACHE 才能进行查询,这个串行操作直接损害性能, 因此没有 VIVT 高效.
VIPT
VIPT(Virtual Index Physical Tag) 指的是物理 CACHE 控制器通过虚拟地址提供的 Index 和物理地址提供的 Tag 索引 CACHE Line. CPU 产生虚拟地址之后,可以同时将虚拟地址传递给 CACHE 控制器和 TLB/MMU 并发处理,这样索引 CACHE Set 和地址转译在时间上并发。歧义问题和别名问题在 VIPT 中是不存在的。
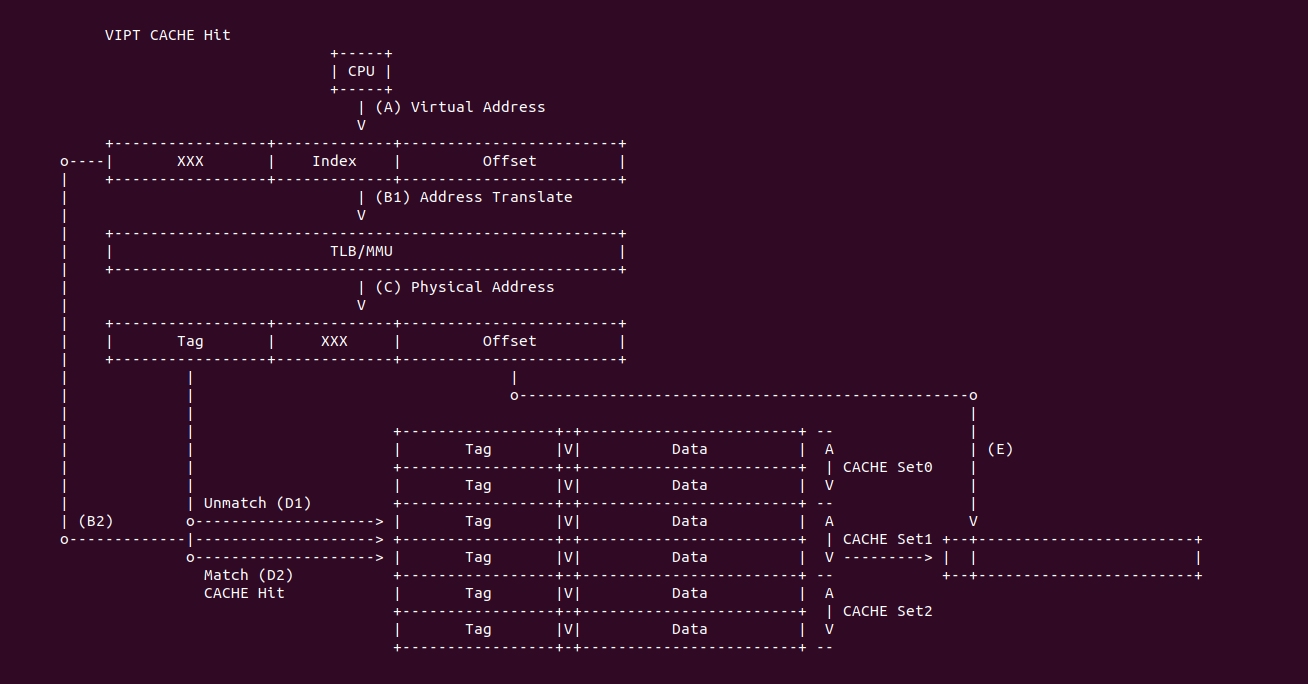
VIPT CACHE Hit: 当 CACHE 控制器使用 VIPT 索引 CACHE Line 发生 CACHE Hit:
- (A) CPU 产生的虚拟地址同时传递给 CACHE 控制器和 TLB/MMU 组件
- (B1) 虚拟地址传送给 TLB/MMU 进行地址转译,以此获得物理地址
- (B2) 虚拟地址传送给 CACHE 控制器之后,提取虚拟地址的 Index 字段在 CACHE 中找到 CACHE Set1,组内包含两个 CACHE Line
- (C) TLB/MMU 地址转译完毕获得物理地址
- (D1) CACHE 控制器从物理地址中提取 Tag 字段与 CACHE Set1 第一个 CACHE Line 的 Tag 字段进行比对,结果不匹配
- (D2) CACHE 继续将物理地址提取的 Tag 字段与 CACHE Set1 的最后一个 CACHE Line 的 Tag 字段进行比对,匹配成功,并且此时 CACHE Line 的 Valid 字段有效,CACHE Hit.
- (E) CACHE 将匹配到的 CACHE Line Data 域取出,然后从物理地址或虚拟地址中获得 Offset 字段,最终从 Data 域中获得所需的数据.
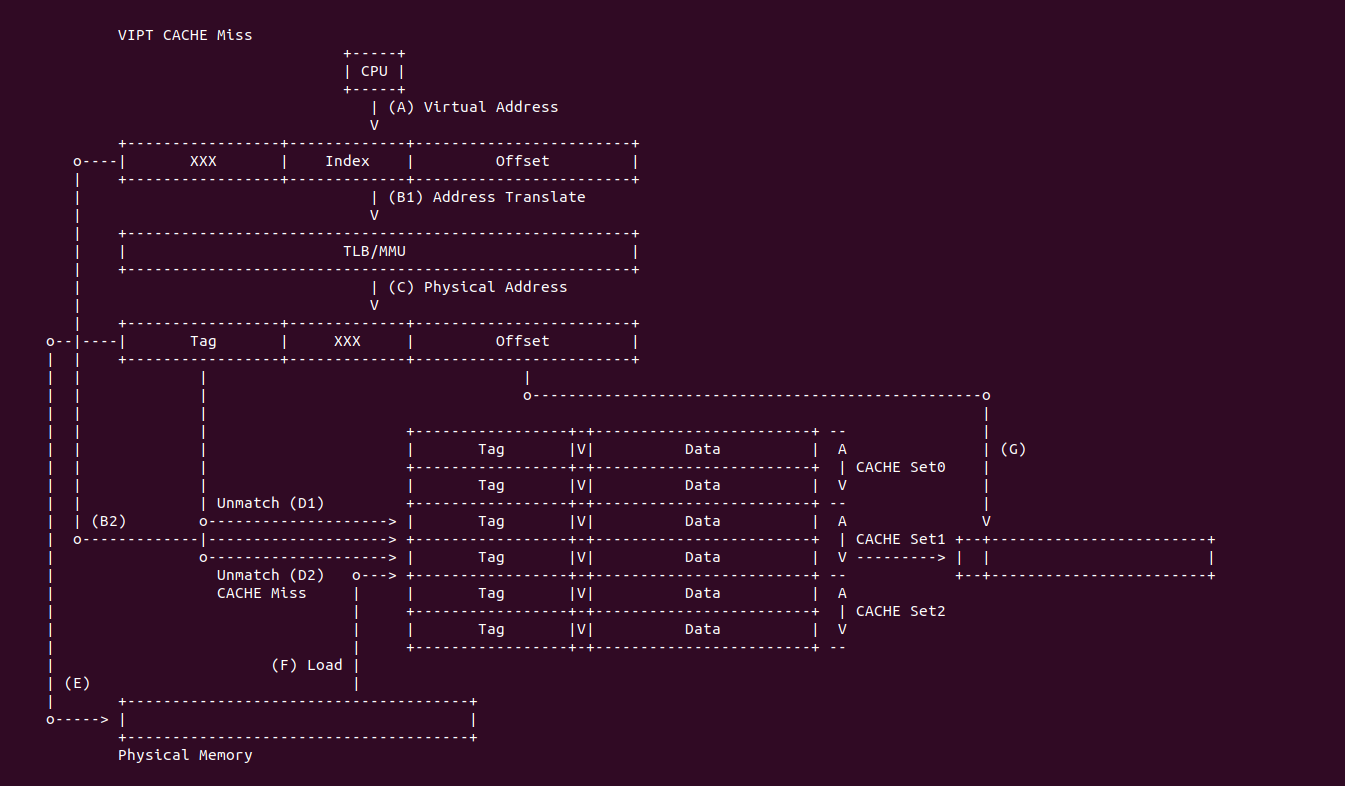
VIPT CACHE Miss: 当 CACHE 控制器使用 VIPT 索引 CACHE Line 发生 CACHE Miss:
- (A) CPU 产生的虚拟地址同时传递给 CACHE 控制器和 TLB/MMU 组件
- (B1) 虚拟地址传送给 TLB/MMU 进行地址转译,以此获得物理地址
- (B2) 虚拟地址传送给 CACHE 控制器之后,提取虚拟地址的 Index 字段在 CACHE 中找到 CACHE Set1,组内包含两个 CACHE Line
- (C) TLB/MMU 地址转译完毕获得物理地址
- (D1) CACHE 控制器从物理地址中提取 Tag 字段与 CACHE Set1 第一个 CACHE Line 的 Tag 字段进行比对,结果不匹配
- (D2) CACHE 继续将物理地址提取的 Tag 字段与 CACHE Set1 的最后一个 CACHE Line 的 Tag 字段进行比对,结果不匹配(或者匹配当 Valid 无效),那么 CACHE Miss.
- (E) CACHE 控制器根据物理地址在主存中找到对应的 Data Block
- (F) CACHE 控制器在 CACHE Set1 根据替换算法将指定的 CACHE Line 刷出,然后将 Data Block 加载到 CACHE Line,并更新 Tag 和 valid 字段
- (G) CACHE 将新更新的 CACHE Line Data 域取出,然后从物理地址或虚拟地址中获得 Offset 字段,最终从 Data 域中获得所需的数据.
在 VIPT 场景下,当两个进程的地址空间相同的虚拟地址映射到不同的物理地址,那么两个虚拟地址的 Index 是相同的,因此 CACHE 会定位到相同的 CACHE Set,但由于 CACHE Set 内包含多个 CACHE Line,由于物理地址的唯一性,不同的物理地址的 Tag 是不相同的,因此该场景下会对应两个不同的 CACHE Line,因此 VIPT 不存在歧义问题.
在 VIPT 场景下,当不同进程的地址空间不相同的虚拟地址映射到同一个物理地址,那么两个虚拟地址的 Index 不相同,因此物理内存 Data block 可以加载到任意多个 CACHE Set。该场景下假设 CACHE 控制器通过虚拟地址 Index 找到 CACHE Set 之后,根据物理 Tag 发现该 CACHE Set 的所有 CACHE Line Tag 都不匹配,但物理内存的 Data block 已经加载到另外的 CACHE Set,CACHE 控制器现在无法获得其他 CACHE Set 的信息,因此引起了别名问题.
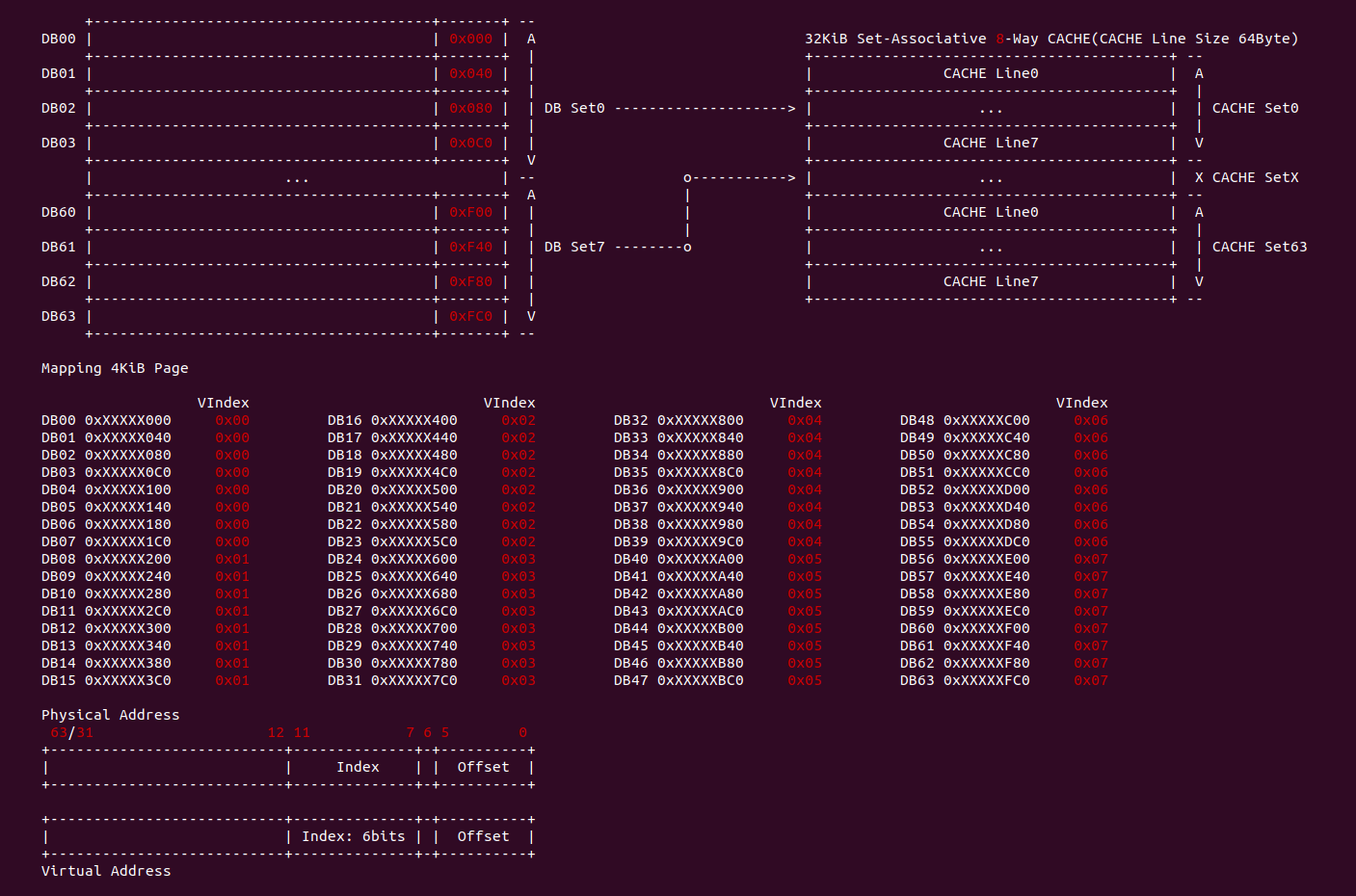
4KiB 别名问题: 对于 VIPT 的别名问题,在 Linux 上是有解法的,例如在 8-Way 32KiB 组相联映射 CACHE 中 CACHE Line Size 为 64Bytes,一共包含 64 个 CACHE Set,因此需要虚拟地址提供 6bits 作为 Index。当映射 4KiB 物理页时,其包含 64 个 Data Block,将 8 个 Data Block 作为一组,其中物理地址 [0:5] 作为 Offset 字段,物理地址 [6:11] 寻址所有的 CACHE Set,实际只需要 3bit 就可以寻址所有 Data Block 组。由于映射 4KiB 页的低 12 位虚拟地址的内容和物理地址一致,那么虚拟地址 Index 6bit 与物理地址 [6:11] 字段内容是一致的,此时虚拟地址 Index 等效于物理地址 Index, 因此可以解决 VIPT 别名问题.
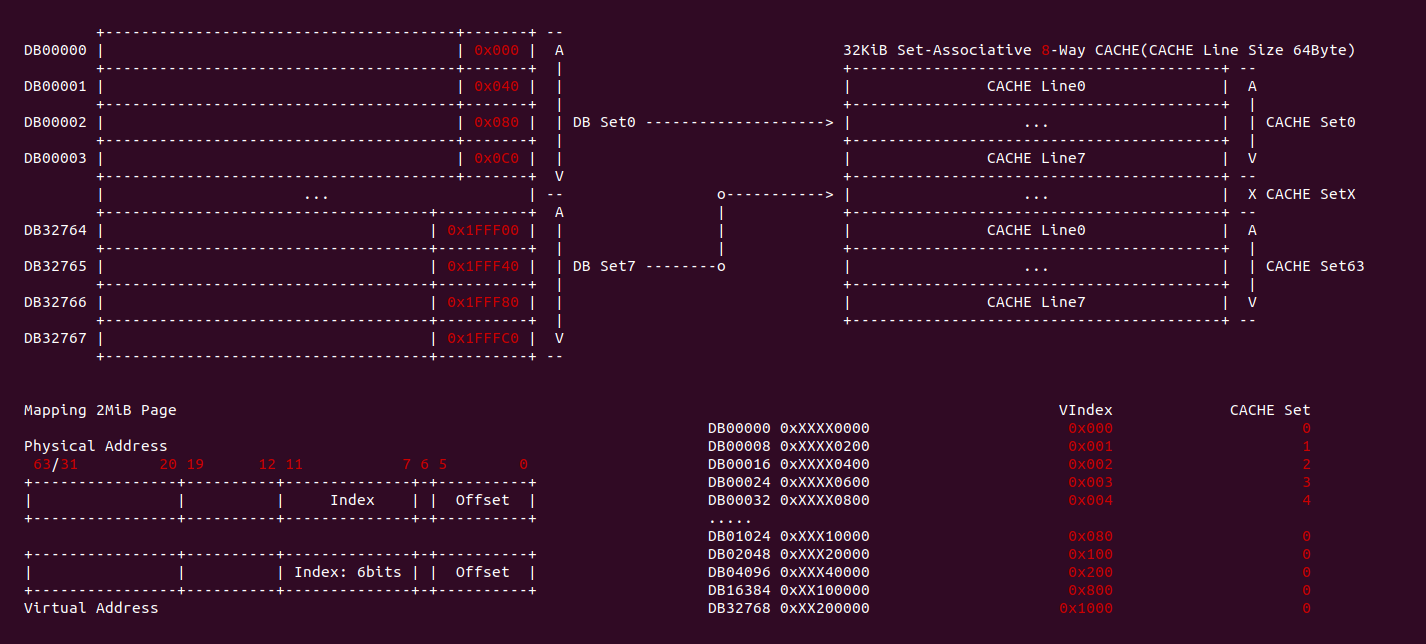
2MiB 别名问题: 在 8-Way 32KiB 组相联映射 CACHE 中 CACHE Line Size 为 64Bytes,一共包含 64 个 CACHE Set,因此需要虚拟地址提供 6bits 作为 Index。当映射 2MiB 物理页时,其包含 32768 个 Data Block,将 8 个 Data Block 作为一组,一共 4096 Data block 组。其中物理地址 [0:5] 作为 Offset 字段,物理地址 [7: 11] 可以寻址所有的 CACHE Set, 实际需要 12bit 才能寻址所有的 Data Block 组,由于映射 2MiB 页的低 20 位虚拟地址的内容和物理地址一致,因此只要虚拟地址 6Bit 位于低 20 bit,那么虚拟地址 Index 就和物理 Index 一致,可以做到 2MiB 页内的物理地址只会加载到唯一的 CACHE Set 中,也可以解决 VIPT 的别名问题.
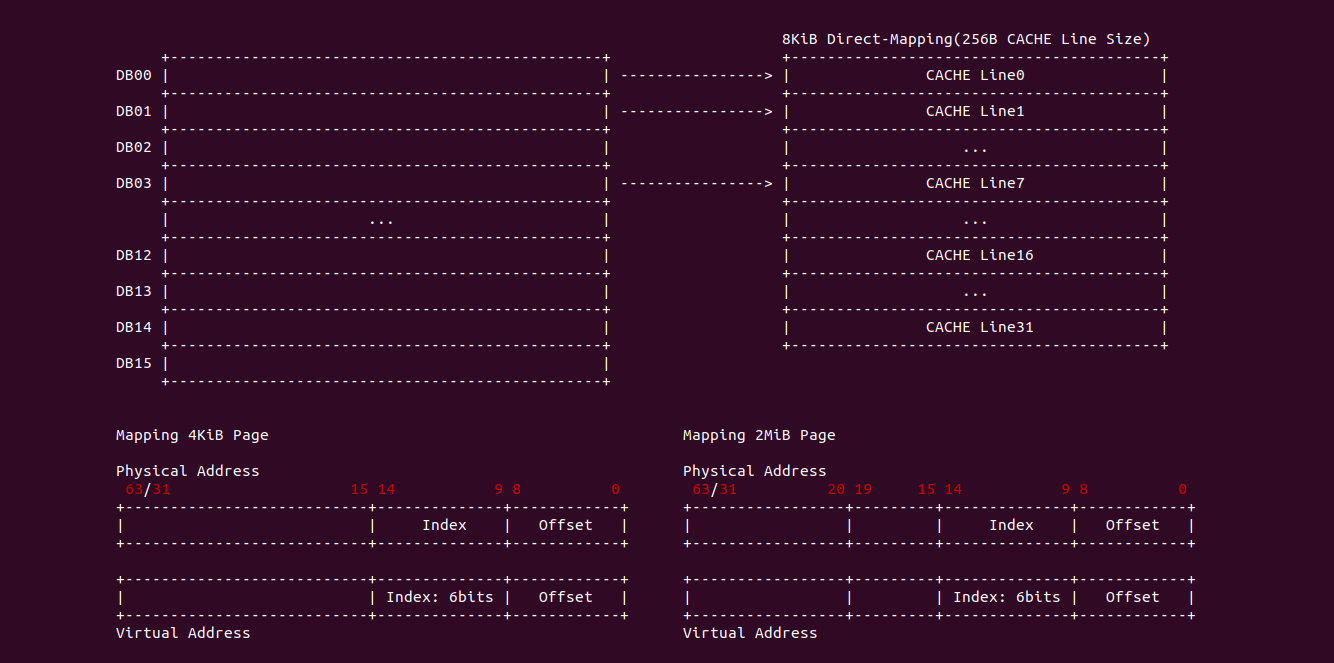
直接映射别名问题: 在 8KiB 采用直接映射的 CACHE 中,CACHE Line Size 为 256 字节,其一共包含 32 个 CACHE Line,因此虚拟地址需要提供 5bit 寻址 CACHE Line,9 bit 用于 Offset 字段。在映射 4KiB 物理页的场景中,由于虚拟地址 [0:8] 区域用于 Offset 字段,虚拟地址 [9:14] 区域用于 Index 字段,由于 4KiB 映射物理页只有低 12 位虚拟地址和物理地址内容相同,因此此时虚拟地址 Index 不等效于物理地址 Index,因此会出现别名问题; 但同样的环境映射 2MiB 的物理页,由于低 20 位虚拟地址和物理地址内容一致,因此此时虚拟地址 Index 等效物理地址 Index, 此时不存在别名问题.
VIPT 别名问题总结: 通过上面的案例分析,VIPT 要避免别名问题与 CACHE 的映射方式有关: 当使用组相联映射时,CACHE Set 的数量会影响别名问题,具体来说 CACHE Set 越大越容易引发别名问题; 当使用直接映射时,CACHE Line Size 会影响别名问题,当 CACHE Line Size 越大,Index 字段就会超过 4KiB/2MiB 低一致位,那么更容易引发一致性问题. 目前主流解决 VIPT 问题就是是 CACHE 采用组相联映射方式,CACHE 规模为 32KiB 8-Way(CACHE Line Size: 64B). 对于目前处理器 L1 CACHE 都是 VIPT,可以和 TLB/MMU 并发 CACHE 查询过程,但 VIPT 不是所有级 CACHE 的最佳选择,CACHE 越大需要的 Index 字段越大,那么越容易引发别名问题,因此 L2/L3 采用物理地址 Index 是最佳选择.
PIVT
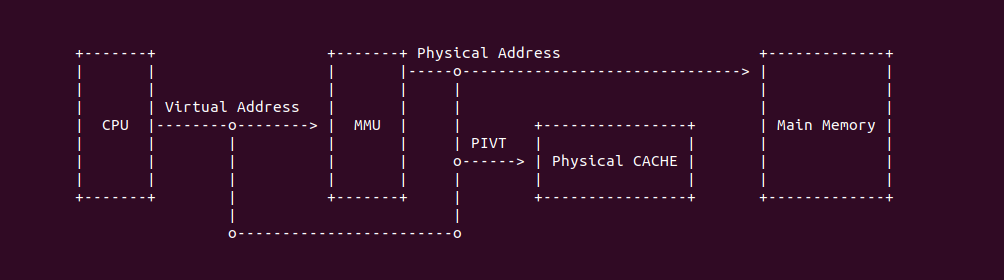
PIVT(Physical Index Virtual Tag) 指的是物理 CACHE 控制器通过物理地址提供的 Index 和虚拟地址提供的 Tag 索引 CACHE Line. CPU 产生虚拟地址之后,PIVT 并不能像 VIPT 那样并发的在 CACHE 和 TLB/MMU 中工作,因为 CACHE 在查找 CACHE Line 时需要先定位 CACHE Set,再结合 Tag 字段才能定位 CACHE Line,但 PIVT 首先需要将虚拟地址传递给 TLB/MMU 进行地址转译,获得物理地址 Index 字段之后传递给 CACHE 才能定位 CACHE Set,最后根据虚拟地址的 Tag 定位 CACHE Line. PIVT 既包含了别名和歧义问题,而且性能也比 VIVT 或者 VIPT 方式慢很多.
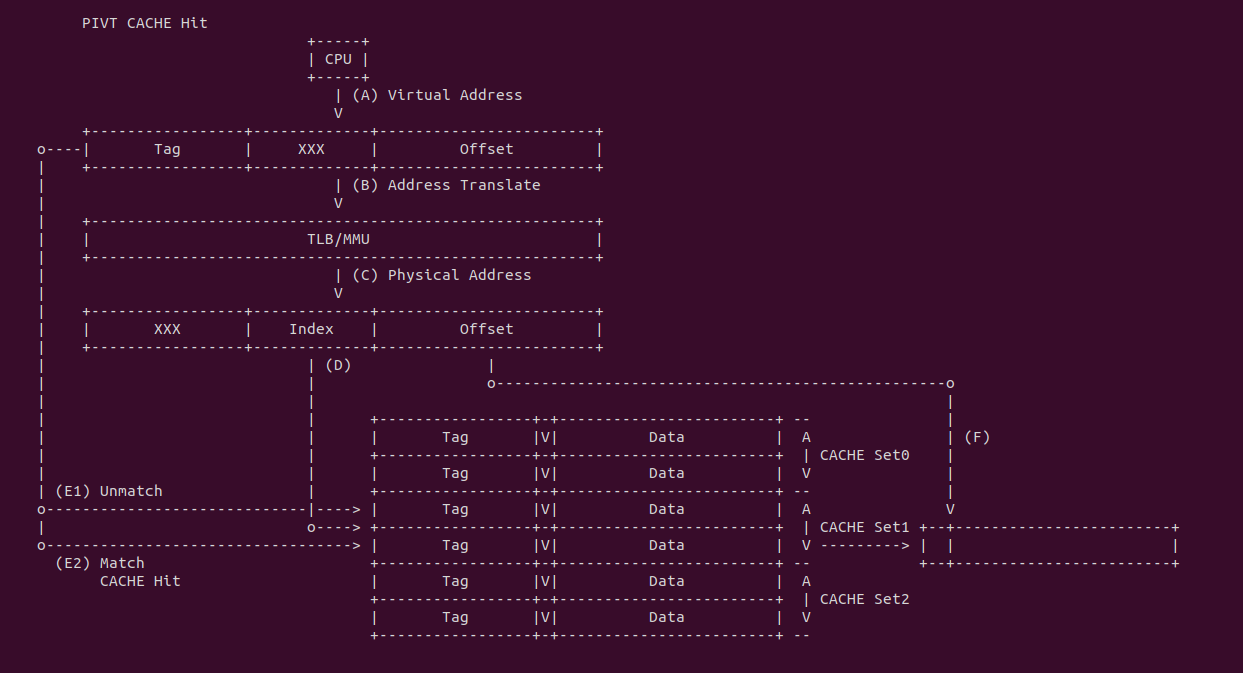
PIVT CACHE Hit: 当 CACHE 控制器使用 PIVT 索引 CACHE Line 发生 CACHE Hit:
- (A) CPU 产生虚拟地址
- (B) CPU 将虚拟地址传递给 TLB/MMU 进行地址转译
- (C) TLB/MMU 地址转译完毕,获得物理地址
- (D) 将物理地址的 Index 传递给 CACHE 控制器,匹配到 CACHE Set1,组内包含了两个 CACHE Line
- (E1) CACHE 控制器从虚拟地址提取 Tag 字段与 CACHE Set1 第一个 CACHE Line 的 Tag 字段进行比对,结果发现不匹配
- (E2) CACHE 控制器继续与 CACHE Set1 的最后一个 CACHE Line 的 Tag 字段进行比对,发现匹配且 CACHE Line 的 Valid 位有效,那么 CACHE Hit.
- (F) CACHE 将匹配到的 CACHE Line Data 域取出,然后从物理地址或虚拟地址中获得 Offset 字段,最终从 Data 域中获得所需的数 据.
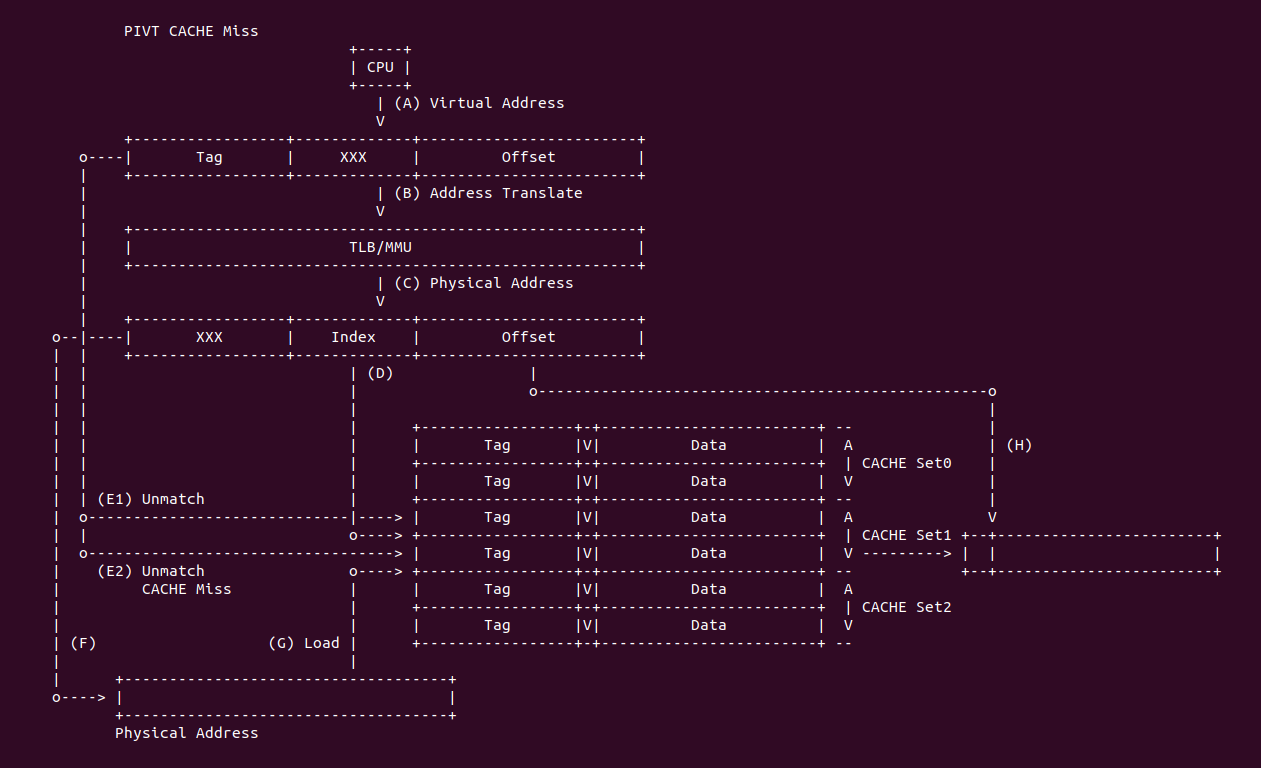
PIVT CACHE Miss: 当 CACHE 控制器使用 PIVT 索引 CACHE Line 发生 CACHE Miss:
- (A) CPU 产生虚拟地址
- (B) CPU 将虚拟地址传递给 TLB/MMU 进行地址转译
- (C) TLB/MMU 地址转译完毕,获得物理地址
- (D) 将物理地址的 Index 传递给 CACHE 控制器,匹配到 CACHE Set1,组内包含了两个 CACHE Line
- (E1) CACHE 控制器从虚拟地址提取 Tag 字段与 CACHE Set1 第一个 CACHE Line 的 Tag 字段进行比对,结果发现不匹配
- (E2) CACHE 控制器继续与 CACHE Set1 的最后一个 CACHE Line 的 Tag 字段进行比对,结果发现不匹配或者就算匹配,当 CACHE Line 的 Valid 标志位无效,因此 CACHE Miss.
- (F) CACHE 控制器利用物理地址在主存中找到对应的 Data Block
- (G) CACHE 控制器根据一定的替换算法将 CACHE Set1 中的某个 CACHE Line 刷出去,然后将找到的 Data Block 加载到该 CACHE Line 里
- (H) CACHE 将匹配到的 CACHE Line Data 域取出,然后从物理地址或虚拟地址中获得 Offset 字段,最终从 Data 域中获得所需的数 据.
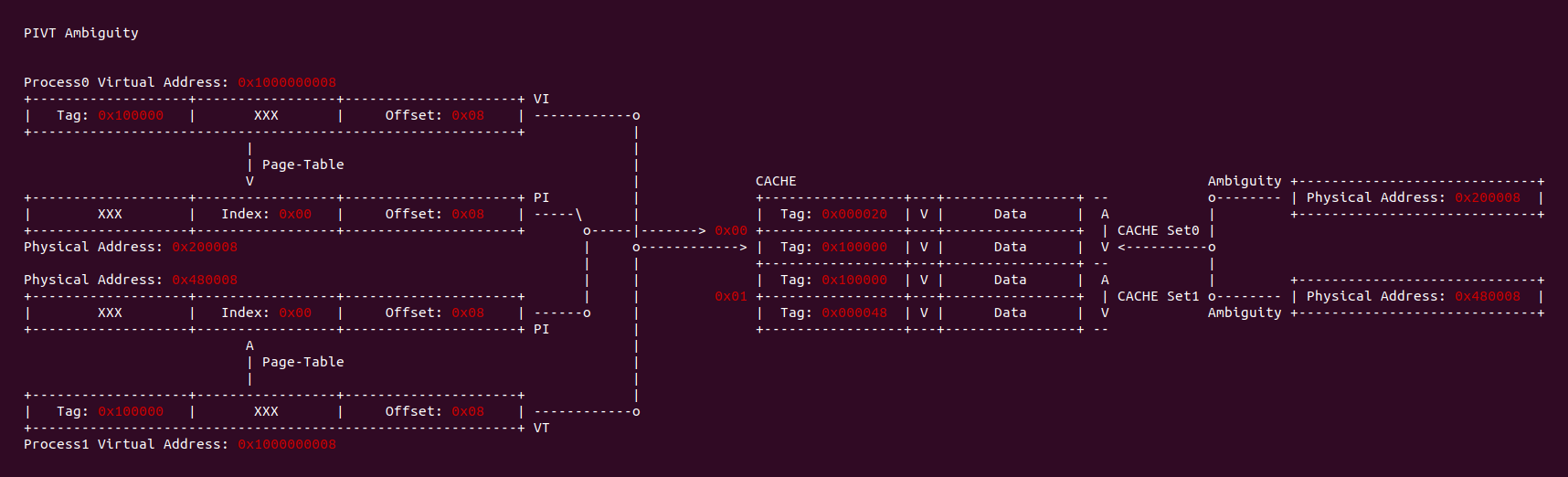
在不同的进程地址空间,虚拟地址虽然相同,但映射到不同的物理内存,如果 CACHE 控制器使用物理地址 Index 和虚拟地址 Tag 查找 CACHE Line,那么会出现同一个 CACHE Line 映射不同的物理地址,这就是 PIVT 的歧义问题. 为了保证系统的正确工作,操作系统需要负责避免歧义出现,可以通过按需清除 CACHE Line,或者为每一个进程的地址空间添加标记(PCID/ASID),当进程切换时刷掉指定的 CACHE Line, 不过这样做会导致进程调度回来时出现大量的 CACHE Miss,影响程序的性能.
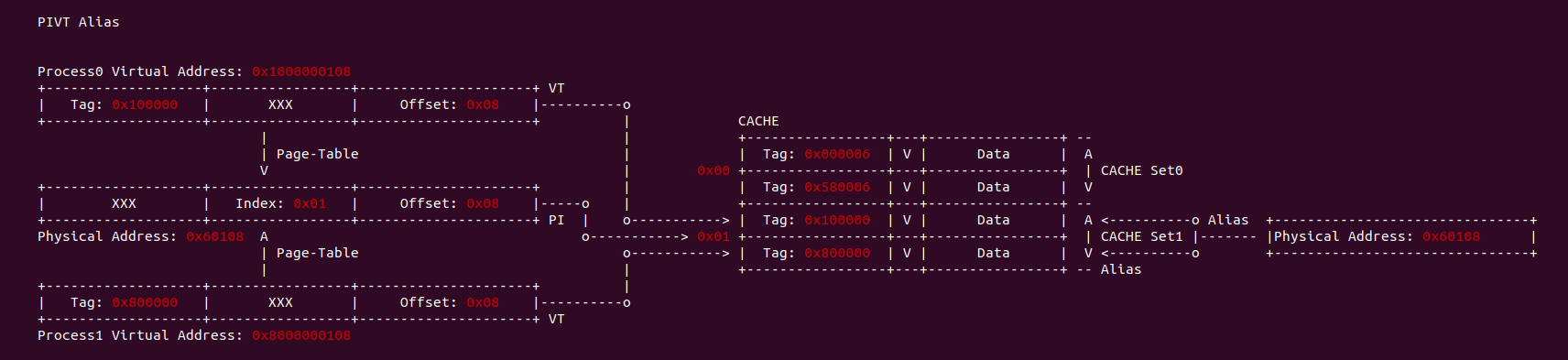
同样是不同进程的地址空间不同的虚拟地址映射到同一个物理地址上,如果 CACHE 控制器使用物理地址的 Index 和虚拟地址 Tag 查找 CACHE Line,那么由于同一个物理地址,因此会定位到同一个 CACHE Set,但由于 Tag 不同,那么不同的虚拟地址 Tag 会定位到不同的 CACHE Line,此时出现了同一个物理地址被映射到不同 CACHE Line, 这就是 PIVT 的别名问题. 该问题会引起 CACHE 的一致性问题,例如更新了存在别名 CACHE Line 的数据,那么同别名的 CACHE Line 的数据没有被更新,导致 CACHE 数据一致性问题. 同歧义问题一样,可以通过 Flush CACHE 的方式避免别名问题,也可以针对共享的数据映射相同物理地址时采用 NOCACHE 的方式,但这样会损失 CACHE 带来的性能提升.
PIVT 优缺点: 通过上面对 PIVT 进行分析,发现 PIVT 具有 VIVT 的别名和歧义缺点,另外还没有 VIPT 并行特点,因此 PIVT 并没有任何优势可言.
VIVT/VIPT/PIPT/PIVT 总结
CACHE 对 CPU 的性能至关重要,目前主流处理器 L1 CACHE 采用 VIPT,CACHE 控制器通过虚拟地址 Index 取出一组 CACHE Line,同时并行进行 TLB/MMU 地址转译获得物理地址 Tag,最后从 CACHE Line 组中找到目标 CACHE Line,另外 Index 字段所需的位数在页表页偏移之内,那么虚拟地址 Index 是等效于物理地址 Index,那么这个时候不存在歧义和别名问题。但 VIPT 并不是所有级 CACHE 的首选,随着 CACHE 体积变大,Index 字段的长度会不断变大,当超过虚拟内存映射物理内存页内偏移区域之后,虚拟地址 Index 不再等效于物理地址 Index,便会增加歧义和别名问题的概率,因此 L2/L3 CACHE 选择 PIPT 的索引方式,这样可以避免歧义和别名问题. VIVT 软件维护成本太高,并会引入歧义和别名问题,需要在进程切换时 Flush 指定的 CACHE Line,软件管理难度大。现在主流使用 VIPT 和 PIPT。在多路组相联的 CACHE 中,CACHE Way 的大小等于 4KiB,一般硬件采用 VIPT 方式可以有效避免歧义和别名问题,等效于 PIPT; 当 CACHE Way 的大小大于 4KiB,一般采用 PIPT 方式,可以减轻操作系统的压力.
CACHE 回写/通写
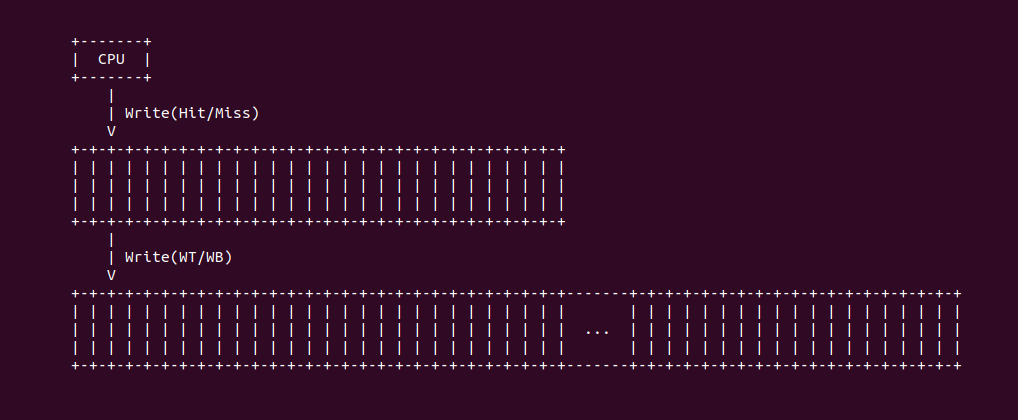
CACHE 写数据分为两种情况: 1. 将被改写的数据在 CACHE 中. 2. 被改写的数据不在 CACHE 中. 针对情况 1,CACHE 有两种策略来写数据:
- 回写(Write Back): 只改写 CACHE 中的 CACHE Line,不更新主存 Data Block. 优点是速度快,因为不用访问速度较慢的主存,缺点是只改写了 CACHE Line,CACHE Line 和主存 Data Block 数据不再一致,如果有别的核来访问主存中的 Data Block,那么它将读到错误的数据。另外在 CACHE Line 被替换出去的时候,数据应该被写入主存 Data Block,这就需要系统判断哪些 CACHE Line 被更新过,反应在电路上就需要增加一个 Dirty 位,当一个被标记为 Dirty 的 CACHE Line 被替换出去,其内容要被更新到主存.
- 通写(Write Through): 改写 CACHE 中的 CACHE Line 和主存 Data Block. 优点是时刻保持存储器数据一致,缺点是每次 store 指令都需要更新主存中的 Data Block,这个延时代价特别高.
针对第二种情况, 被改写的数据不在 CACHE 中,也有两种策略,一般情况下,回写和写分配组合,通写和写不分配组合:
- 写不分配: 直接把数据写入主存 Data Block.
- 写分配: 先把 Data block 放到 CACHE Line,然后回写或通写.
通写和写不分配
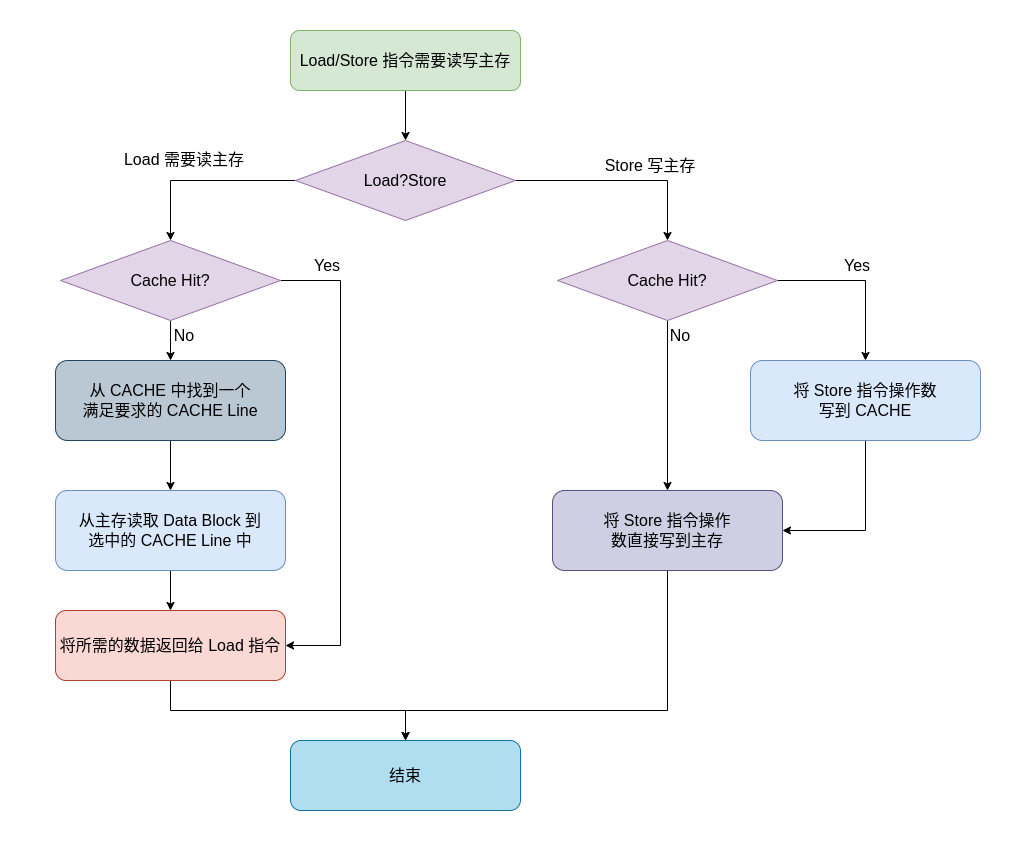
上图是通写和写不分配的处理逻辑,当 CPU 执行了 Load/Store 指令需要读写数据(Load 读请求、Store 写请求),可能出现一下几种情况:
- Load CACHE Hit: 此时 Load 需要读取的数据在 CACHE 中,那么直接从 CACHE Line 中读取 Load 所需的数据.
- Load CACHE Miss: 此时 Load 需要读取的数据不在 CACHE 中,那么首先从 CACHE 中找到一块 CACHE Line,然后从主存中将 Data Block 加载到 CACHE Line 中,最后从 CACHE Line 中读取 Load 所需的数据.
- Store CACHE Hit: 此时 Store 需要写入的数据在 CACHE 中,那么先将 Store 指令写入的数据写入到 CACHE Line 中,然后写入到主存的 Data Block.
- Store CACHE Miss: 此时 Store 需要写入的数据不在 CACHE 中,那么直接将 Store 指令写入的数据写入到主存的 Data Block 里.
回写与写分配
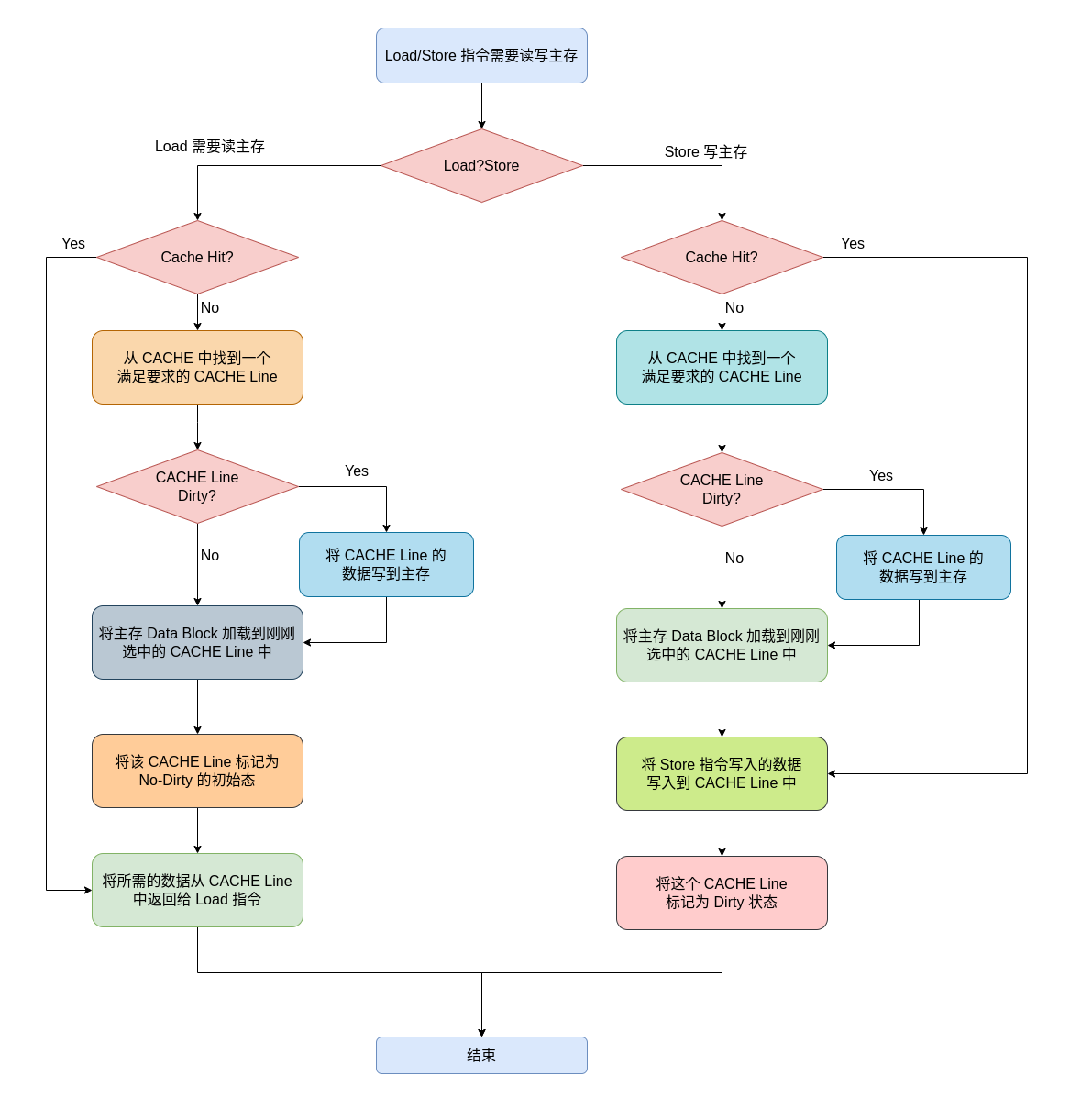
上图是回写和写分配的处理逻辑,当 CPU 执行 Load 指令需要读数据,可能出现以下几种情况:
- Load CACHE Hit: 此时 Load 需要读取的数据在 CACHE 中,那么直接将对应 CACHE Line 的数据返回给 Load 指令.
- Load CACHE Miss 且 CACHE Line No Dirty: 此时 Load 需要读取的数据不在 CACHE 中,CACHE 找了一块 No-Dirty 的 CACHE Line 加载主存中的 Data Block,并将 CACHE Line 标记为 No-Dirty, 最后将 CACHE Line 的数据返回给 Load 指令.
- Load CACHE Miss 且 CACHE Line Dirty: 此时 Load 需要读取的数据不在 CACHE 中,CACHE 找到一块 Dirty 的 CACHE Line,先将 CACHE Line 更新到主存,然后将主存中的 Data Block 加载到 CACHE Line 中,并标记 CACHE Line 为 No-Dirty,最后将 CACHE Line 的数据返回给 Load 指令.
当 CPU 执行 Store 指令需要写数据时,可能会出现一下几种情况:
- Store CACHE Hit: 此时 Store 需要写入的 Data Block 已经在 CACHE 中,那么直接将 Store 指令写如的数据更新到 CACHE Line 中,然后将 CACHE Line 标记为 Dirty.
- Store CACHE Miss 且 CACHE Line No Dirty: 此时 Store 需要写入的 Data Block 不在 CACHE 中,那么 CACHE 首先找到了一块 No-Dirty 的 CACHE Line,然后将主存中的 Data Block 加载到 CACHE Line,接着将 Store 指令需要的数据写入到 CACHE Line,最后将 CACHE Line 标记为 Dirty.
- Store CACHE Miss 且 CACHE Line Dirty: 此时 Store 需要写入的 Data Block 不在 CACHE 中,那么 CACHE 首先找到了一块 Dirty 的 CACHE Line,然后将 CACHE Line 的内容刷新到主存中,接着将主存中的 Data Block 加载到 CACHE Line 中,并将 Store 指令的数据写入到 CACHE Line 中,最后将 CACHE Line 标记为 Dirty.
CACHE 替换策略
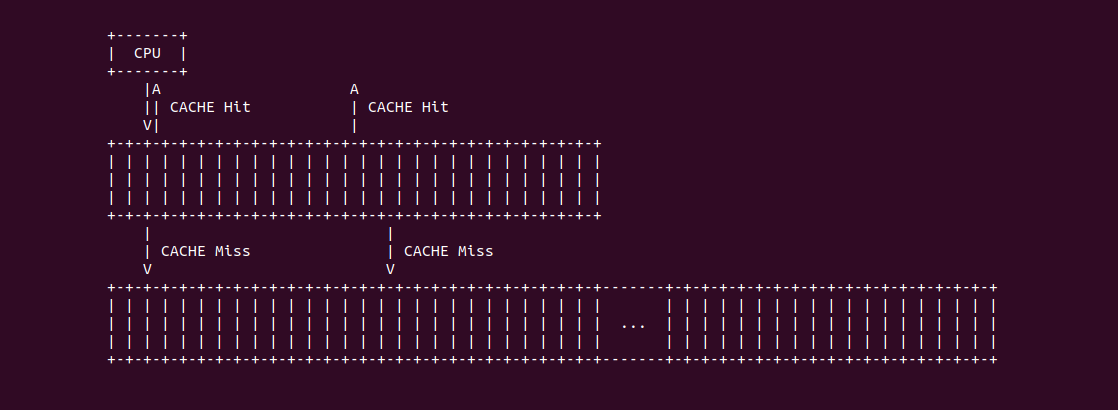
无论 CPU 执行 Store/Load 读或写数据时,一旦 CACHE 发生 CACHE Miss,那么需要替换某个 CACHE Line,然后将所需的 Data Block 加载到 CACHE Line。Load 读数据 CACHE Miss 时需要从主存中将 Data Block 加载到 CACHE 中,这个 Data Block 需要替换某个 CACHE Line,这时需要替换算法决定顶替谁; Store 写数据 CACHE Miss 时如果是写分配,那么需要将主存中的 Data Block 加载到 CACHE 中,因此 CACHE 也需要决定 Data Block 替换哪个 CACHE Line. CACHE 支持多种替换算法,包括 FIFO(先进先出)、LRU(最近最少使用) 和随机替换策略等.
LRU(最近最少使用) 策略
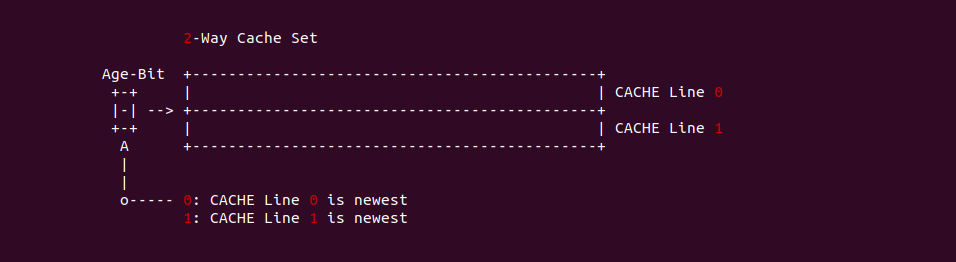
LRU 策略的基本思想就是选择最近一段实践使用次数最少的 CACHE Line 进行替换. CACHE 控制器需要对一个 CACHE Set 中的每个 CACHE Line 的使用情况进行跟踪,可以通过每一个 CACHE Line 都设置年龄位, 但起始状态所有 CACHE Line 都没有使用过,因此只需记录已经被使用的 CACHE Line 的年龄,例如 2-Way 的 CACHE,其每个 CACHE Set 有两个 CACHE Line,但只需一个年龄位,其通过如下逻辑进行判断:
- 当两个 CACHE Line 一直没有使用,那么年龄位一直为 0,那么替换时直接选择 CACHE Line0 替换出去
- 当 CACHE Line1 被使用,年龄位依旧保持 0,那么替换时选择 CACHE Line0 替换出去
- 当 CACHE Line0 被使用,年龄位设置为 1,那么替换的时候选择 CACHE Line1 替换出去
通过案例可以知道,在 2-Way 的 CACHE Set 一个年龄位置位或者清零已经表示有一个 CACHE Line 年龄已经变大. 如果 CACHE Set 里包含的 CACHE Line 越来越多,那么N-Way CACHE Set 需要 Log2(N)
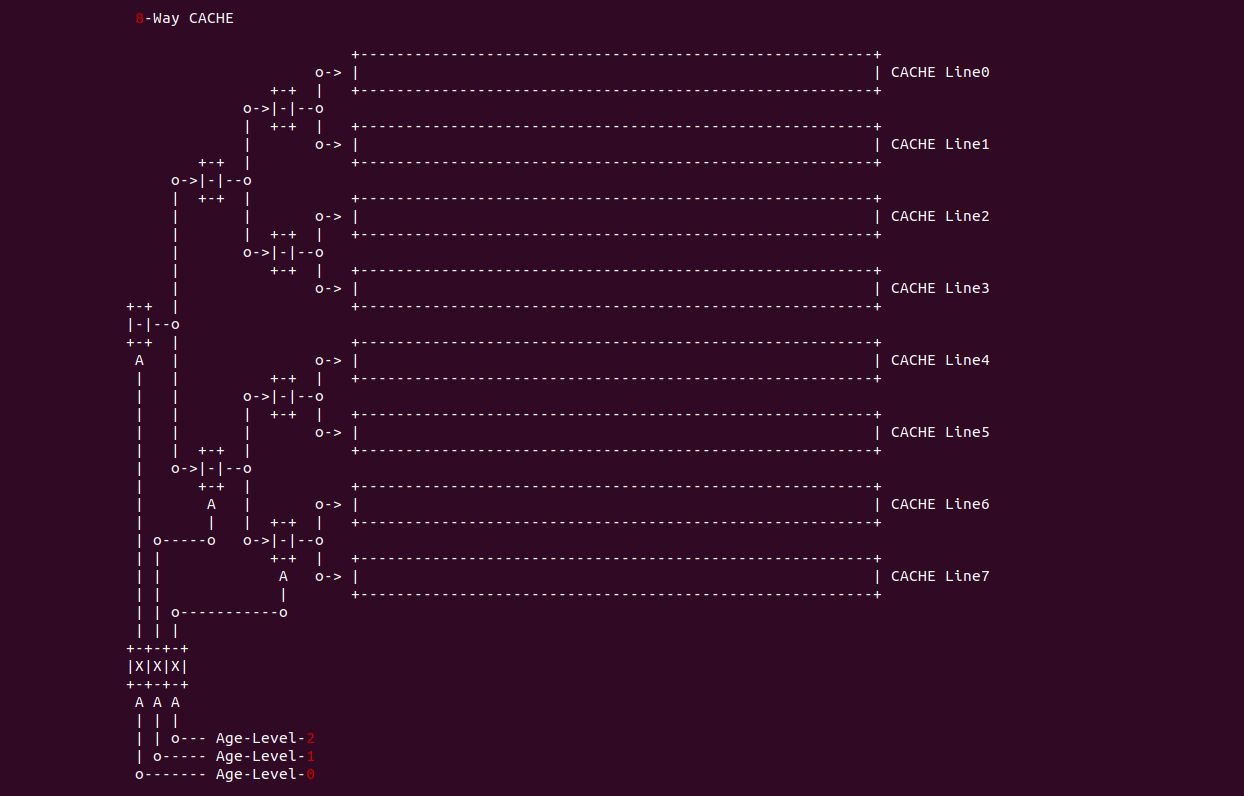
在 8-Way CACHE 中,CACHE Set 采用了 3 个年龄位,每个年龄位被分成不同的年龄级层,Age-level-0 用于将 CACHE Set 中的 CACHE Line 分作两半,当 Age-level-0 置位,那么表示 CACHE Line0 到 CACHE Line3 没有被访问过,反之 Age-level-0 清零,那么 CACHE Line4 到 CACHE Line7 没有被访问过; Age-level-1 则描述 Age-level-0 识别出没有被访问过的 CACHE Line,当 Age-level-1 位清零,那么表示前半部分 CACHE Line 没有被访问过,反之 Age-level-1 位置位,那么表示后半部分的 CACHE Line 被访问过,Age-level-2 依次类推,最终会定位到最近最少被访问的 CACHE Line, 接下来以 CACHE Line4 为例子进行讲解:
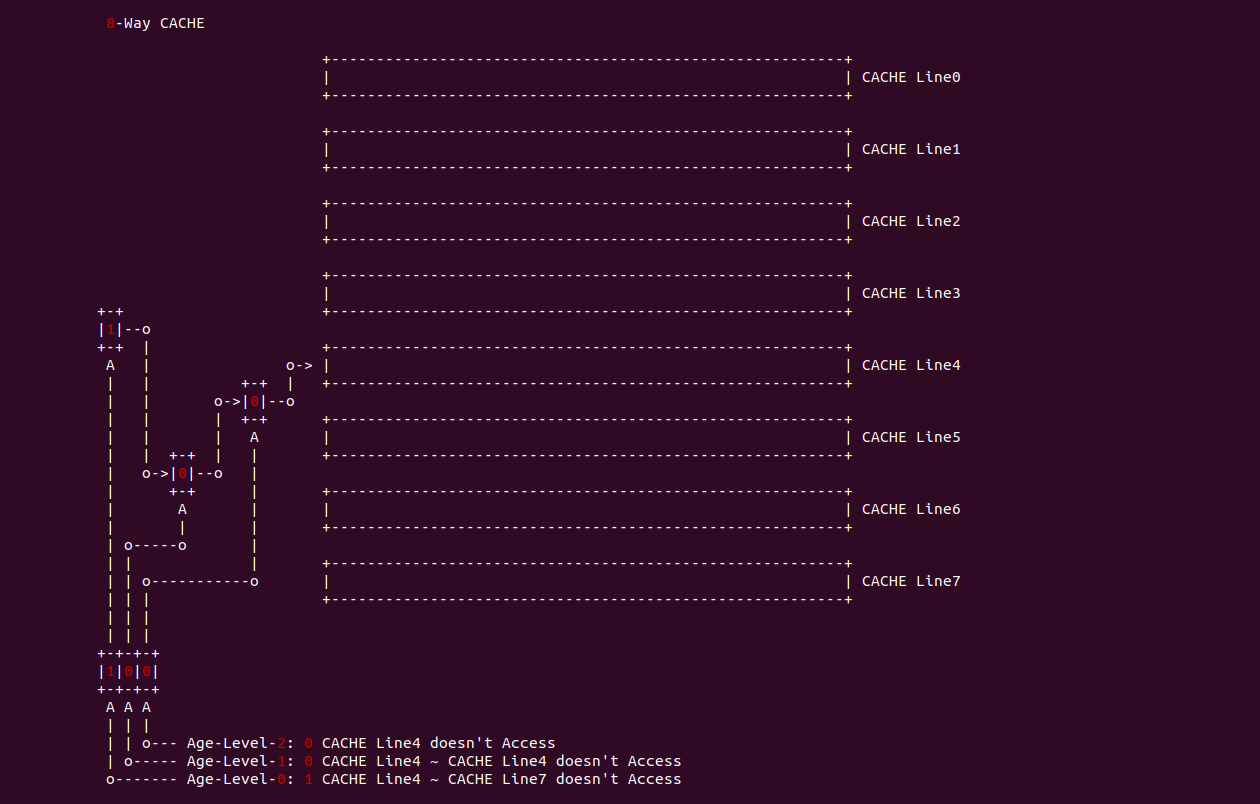
当 Age-level-0 置位,那么表示 CACHE Line4 到 CACHE Line7 没有被访问过,那么 Age-level-1 清零表示 CACHE Line4 到 CACHE Line 5 没有被访问过,最后 Age-level-2 清零表示 CACHE Line4 没有被访问过. 再如 CACHE Line0 为例进行讲解:
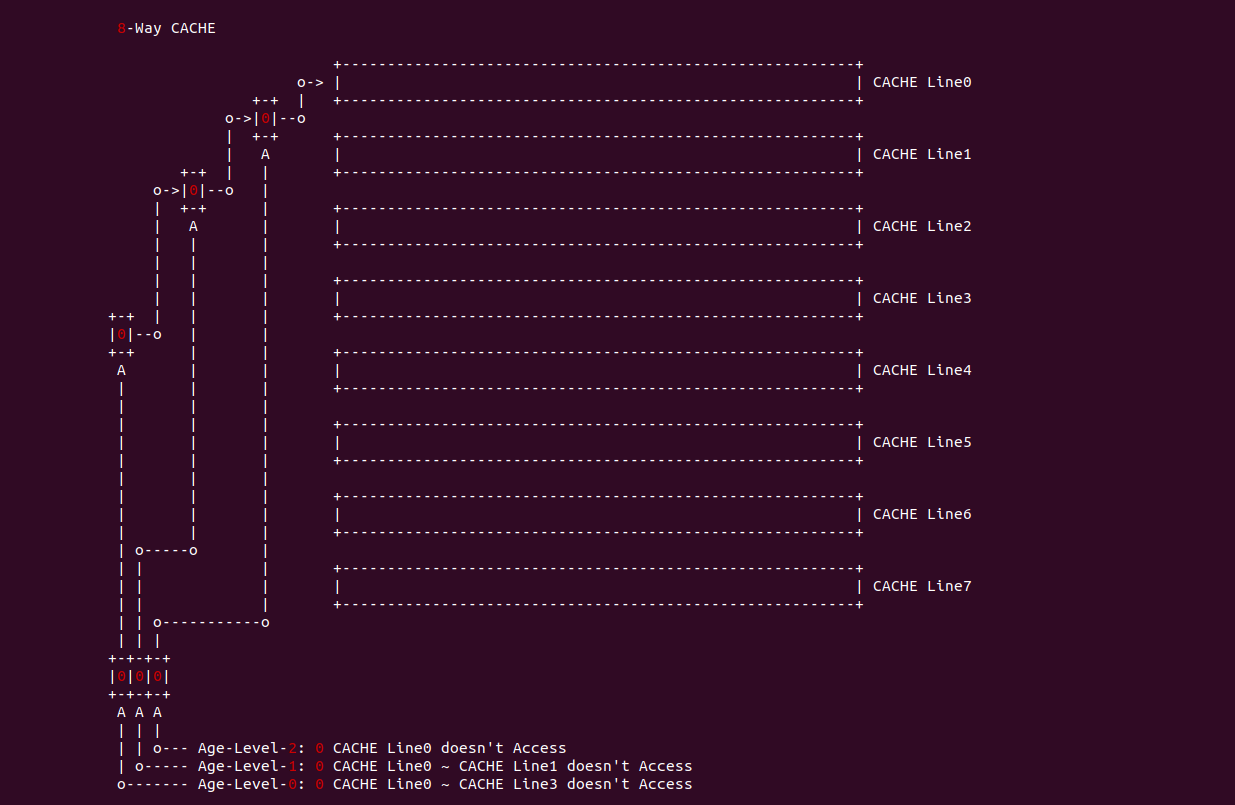
当 Age-level-0 清零,那么表示 CACHE Line0 到 CACHE Line3 没有被访问过,那么 Age-level-1 清零表示 CACHE Line0 到 CACHE Line1 没有被访问过,最后 Age-level-0 清零,那么表示 CACHE Line0 没有被访问过.
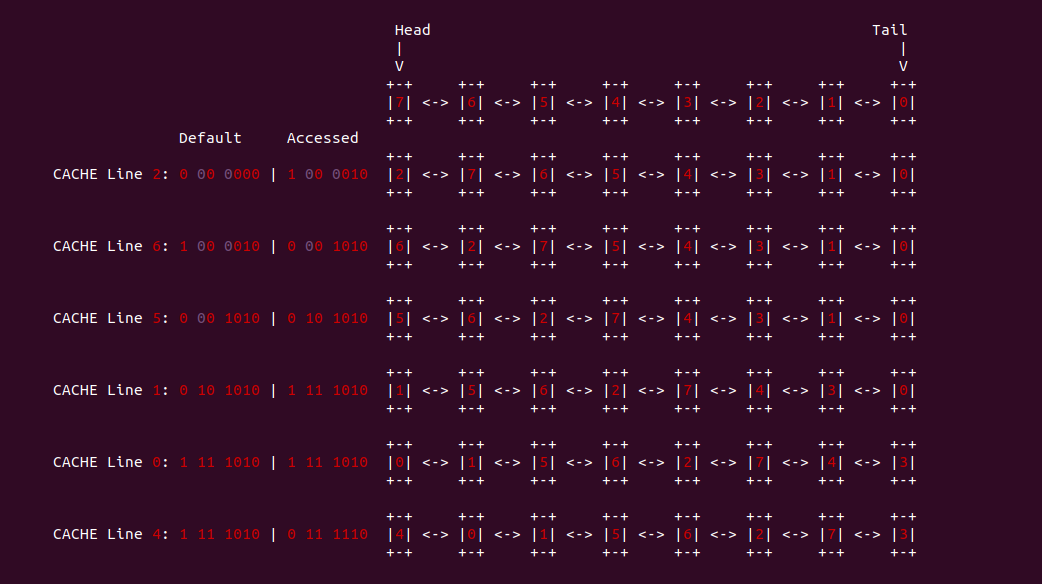
在多路 CACHE 中,需要多个年龄位进行维护,当一个 CACHE Line 被使用,那么它对应的年龄应该被设置为最大,其他 CACHE Line 的年龄按照之前的顺序排在它之后,这个过程类似于把单链表中的某个节点放到了链表表头,其余节点按之前的顺序连接在节点头之后。替换的时候总是替换年龄最小的那个 CACHE Line,也就是单链表表尾替换掉.
LFU(最不经常使用) 策略
LFU(Least Frequently Used) 策略将一段时间内被访问次数最少的 CACHE Line 替换出去,其原理是为每个 CACHE Line 设置一个计数器,从 0 开始计数,每访问以此对应的 CACHE Line 计数器加一。当需要替换时,将计数值最小的 CACHE Line 替换出去,同时将所有的计数器清零. 这种策略将计数周期限定在两次替换之间的时间间隔内,不能严格反应近期访问情况,新调入的块很容易被替换出去.
随机替换策略
随机替换算法完全不管 CACHE 的情况,简单地根据一个随机数选择一块替换出去,随机替换算法在硬件上容易实现,且速度也比前面两种策略块。缺点就是降低了 CACHE 的命中率和 CACHE 工作效率.
CACHE 一致性
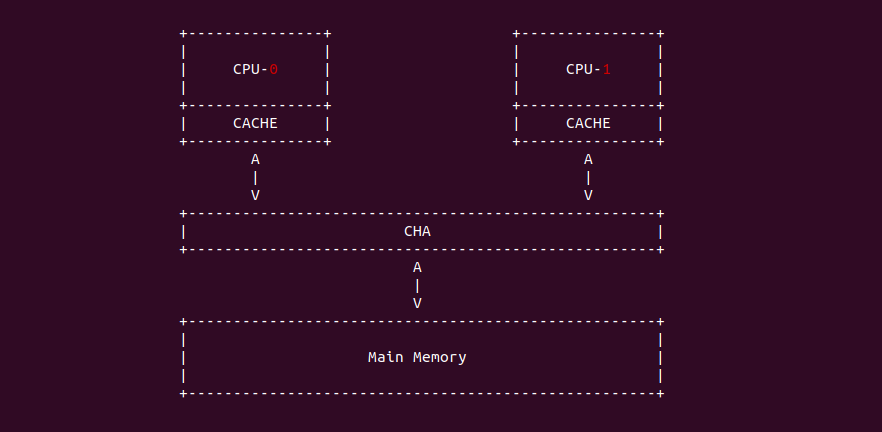
什么是 CACHE 一致性? 先看一个案例,之前的学习中可以知道 CPU-0 访问 Main Memory Data Block X 之后,其会被加载到 CPU-0 CACHE 的某个 CACHE Line,然后 CPU-0 就可以在 CACHE 中访问而不用去主存中访问数据. 在单核年代,CPU 对该数据的修改可以直接在 CACHE Line 中进行,然后配合适合的硬件同步机制再将 CACHE Line 中的数据同步到主存中; 但到了多核年代,CPU-0 CACHE 中缓存了主存 Data Block X, 然而 CPU-0 CACHE 同样也缓存 Data Block X, 那么 CPU-0 修改了 CACHE 中 Data Block X 的数据,同时 CPU-1 读取了 CACHE 中 Data Block X, 此时 Data Block X 在两个 CPU CACHE 的缓存的数据不一致,这种情况称为 CACHE 一致性问题.
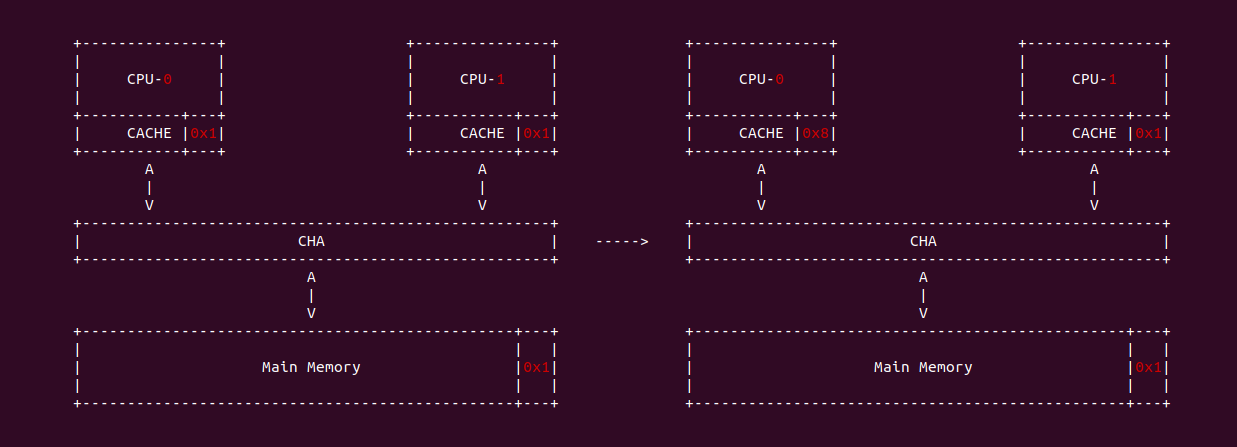
那么如何解决 CACHE 一致性问题呢? 这里通过一个例子进行讲解,当 CPU0 和 CPU1 的 CACHE Line 都缓存了主内存的 Data Block 的数据,且都为 0x1. 当 CPU0 对 Data block 执行写操作并写入 0x8, CPU0 更新了私有 CACHE Line 中的值,同时 CPU1 读取 Data Block 的值,此时 CPU1 发现 CACHE Line 命中,然后直接从私有的 CACHE Line 中读取 0x1. 从这里例子看到造成了 CPU0 和 CPU1 CACHE Line 数据不一致现象, 这样就会导致数据的观察者 (CPU/CPU/DMA) 看到数据不一致,因此维护 CACHE 一致性非常必要。维护 CACHE 一致性的关键就是需要跟踪每个 CACHE Line 的状态,并且根据读写操作和总线上相应的传输内容来更新 CACHE Line 在不同 CPU 上的 CACHE Hit 状态.

维护 CACHE 一致性有软件和硬件两种方式,现在主流架构采用硬件维护. 在处理器中通过 CACHE 一致性协议实现,这些协议维护一个有限状态机, 根据存储器读写指令或总线上的传输内容,进行状态迁移或相应 CACHE Line 操作来维护 CACHE 一致性。CACHE 一致性协议主要分为两大类:
- 监听协议: 每个 CACHE Line 被监听或者监听其他 CACHE Line 的总线活动
- 目录协议: 全局统一管理 CACHE Line 状态
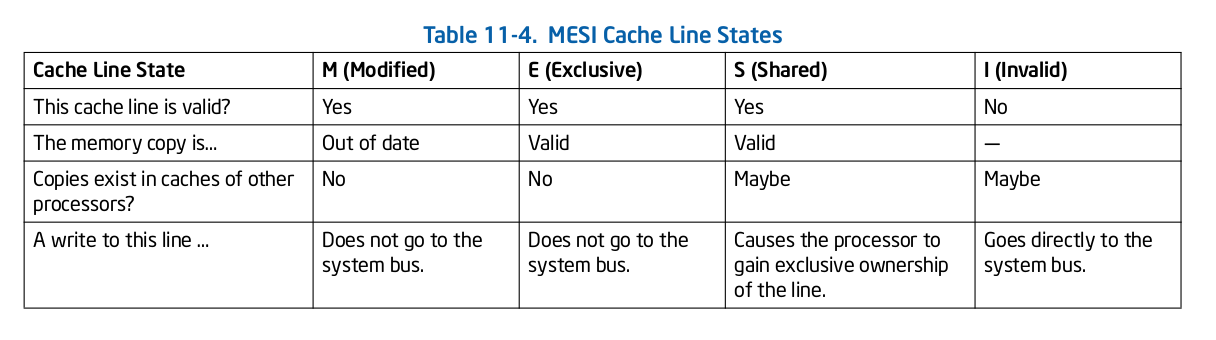
这里介绍主流的 MESI 协议(Write-Once 总线监听协议), MESI 分别代表 Modify、Exclusive、Shared 和 Invalid. CACHE Line 的状态必须是其中的一种。前三种状态均是数据有效下的状态, CACHE Line 的 Flags 域包含了两个标志: Dirty 和 Valid,Dirty 置位代表该 CACHE Line 与主存 Data Block 内容不一致,Valid 置位则代表 CACHE Line 是有效的.
MESI
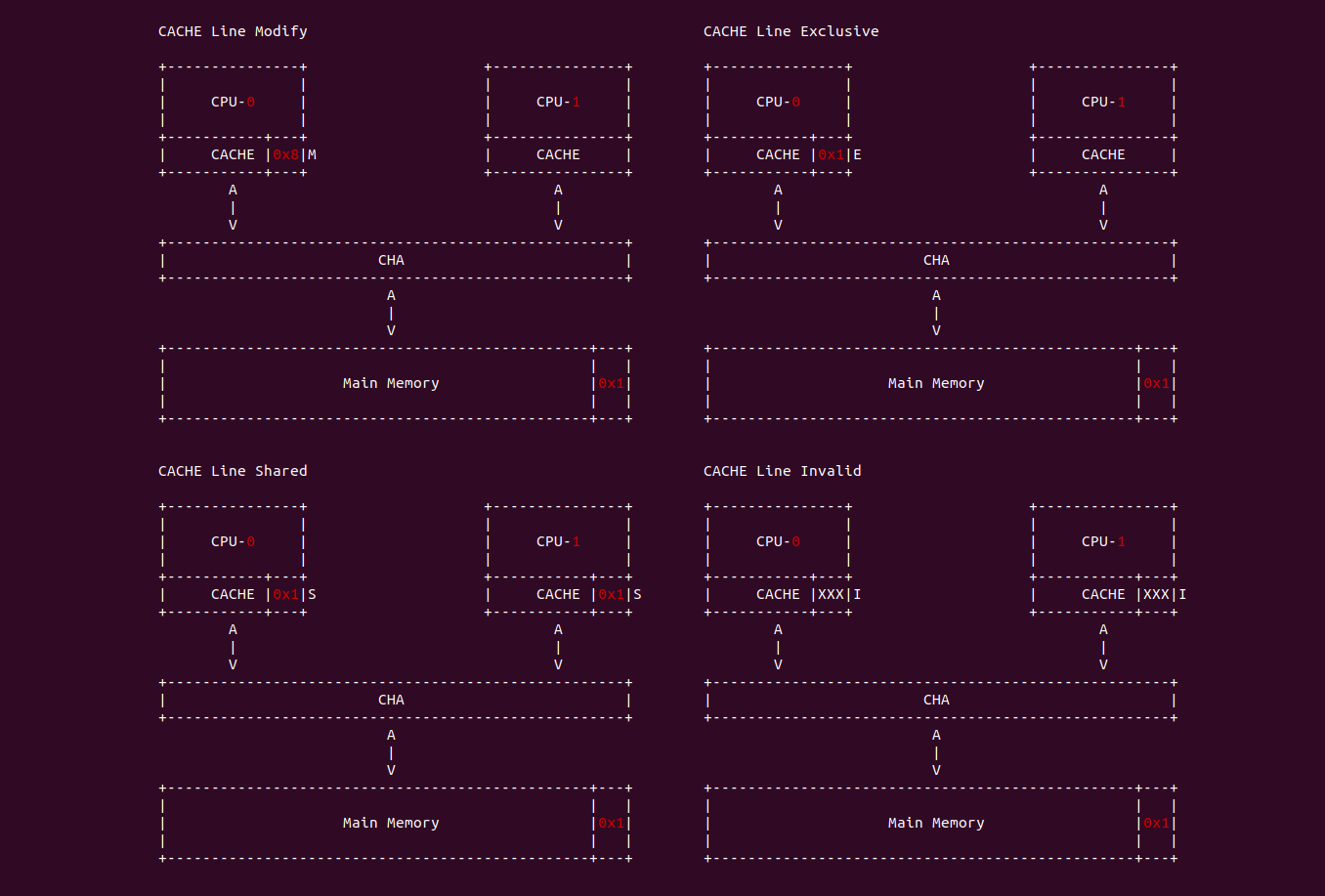
- M(Modify): CACHE Line 数据已经被修改,与主存中数据不一致,该数据只缓存在本地 CACHE Line 中,其他 CPU 没有缓存该副本.
- E(Exclusive): CACHE Line 中的数据与主存一致,且该数据只在本地 CACHE Line 中,其他 CPU 没有缓存该副本.
- S(Shared): CACHE Line 中的数据与主存一致,且多个 CACHE Line 都缓存该数据.
- I(Invalid): 该 CACHE Line 没有缓存该数据.
MESI 在总线上的操作分为本地读写和总线操作. 当操作类型为本地读写时, CACHE Line 的状态指的是本地 CPU(Local CPU); 而当操作类型为总线读写时,CACHE Line 的状态指的是远端 CPU(Remote CPU):
- 本地读: 本地 CPU 读取 CACHE Line.
- 本地写: 本地 CPU 更新 CACHE Line.
- 总线读/远端读: 总线监听一个来自远端 CPU 的读 CACHE 信号. 收到信号的 CPU 先检查 CACHE 是否存在该数据,然后广播应答
- 总线写/远端写: 总线监听一个来自远端 CPU 的写 CACHE 信号. 收到信号的 CPU 先检查 CACHE 是否存在该数据,然后广播应答
- 总线更新: 总线收到更新请求,请求其他 CPU 干活. 其他 CPU 收到请求后,若 CPU 有 CACHE 副本,则使其 CACHE Line 无效.
- 刷新: 总线监听到刷新请求,收到请求的 CPU 将本地 CACHE Line 内容写入主内存
- 刷新到总线: 收到该请求的 CPU 将本地 CACHE Line 发送到总线上,发起请求的 CPU 会获取该 CACHE Line 的内容.
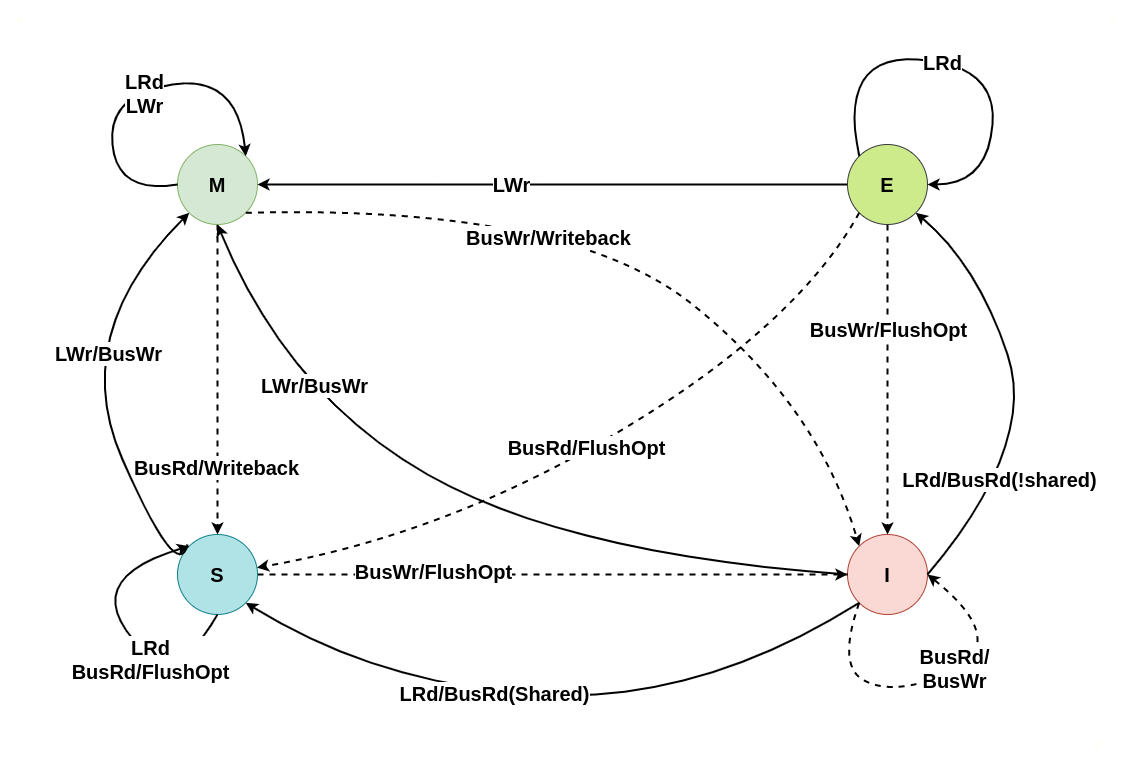
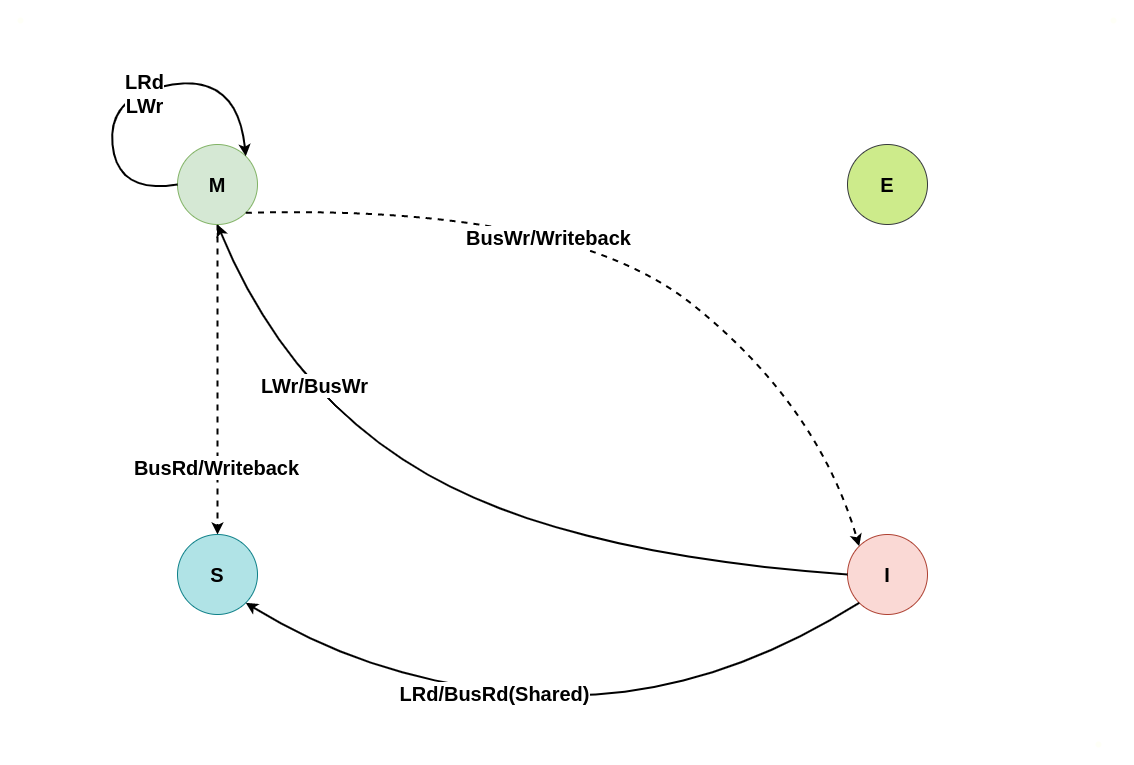
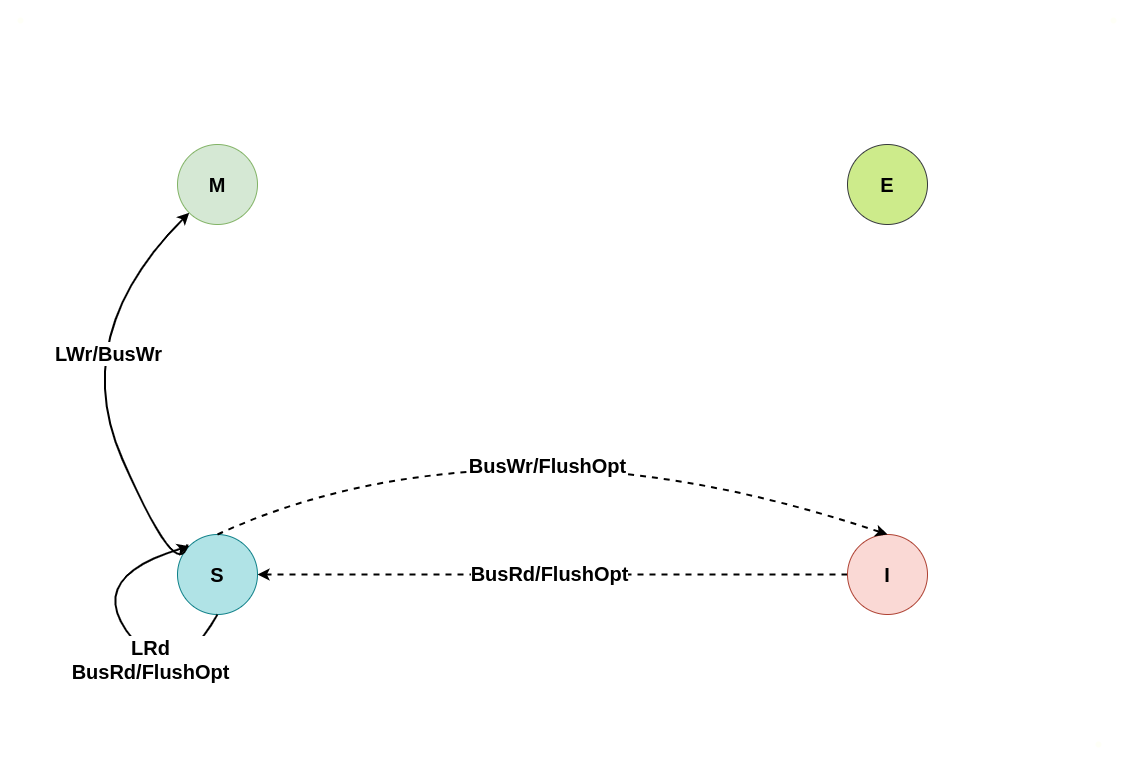
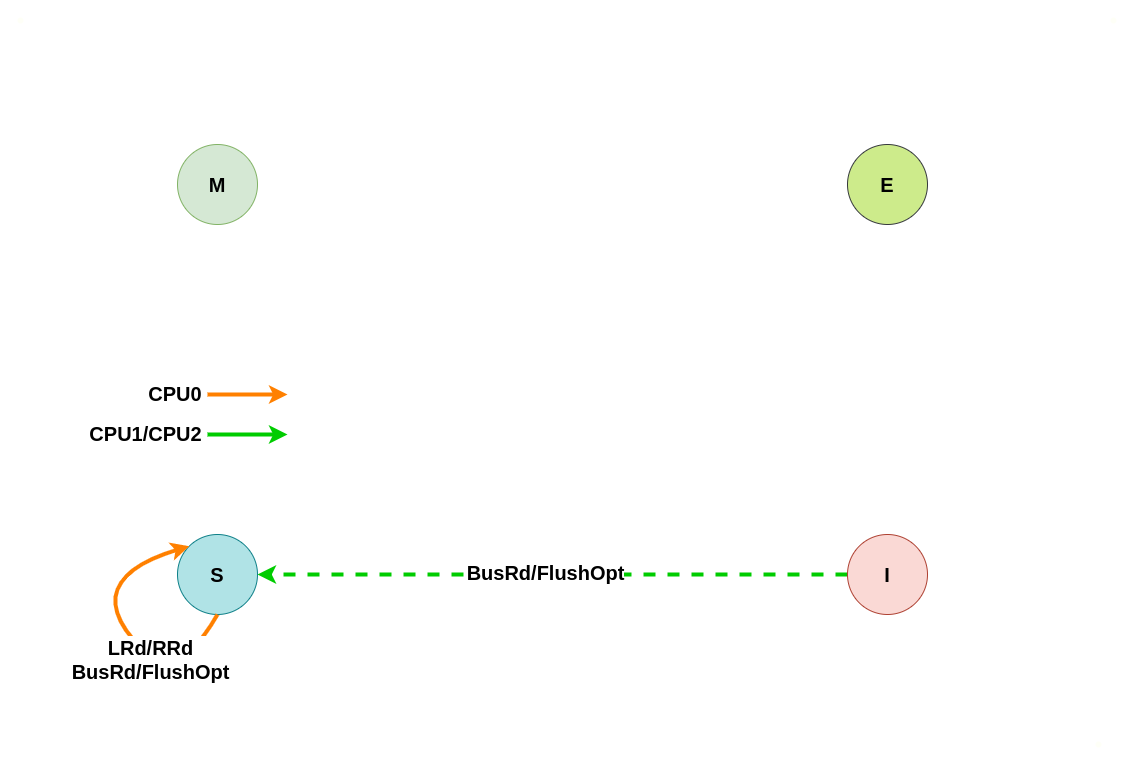
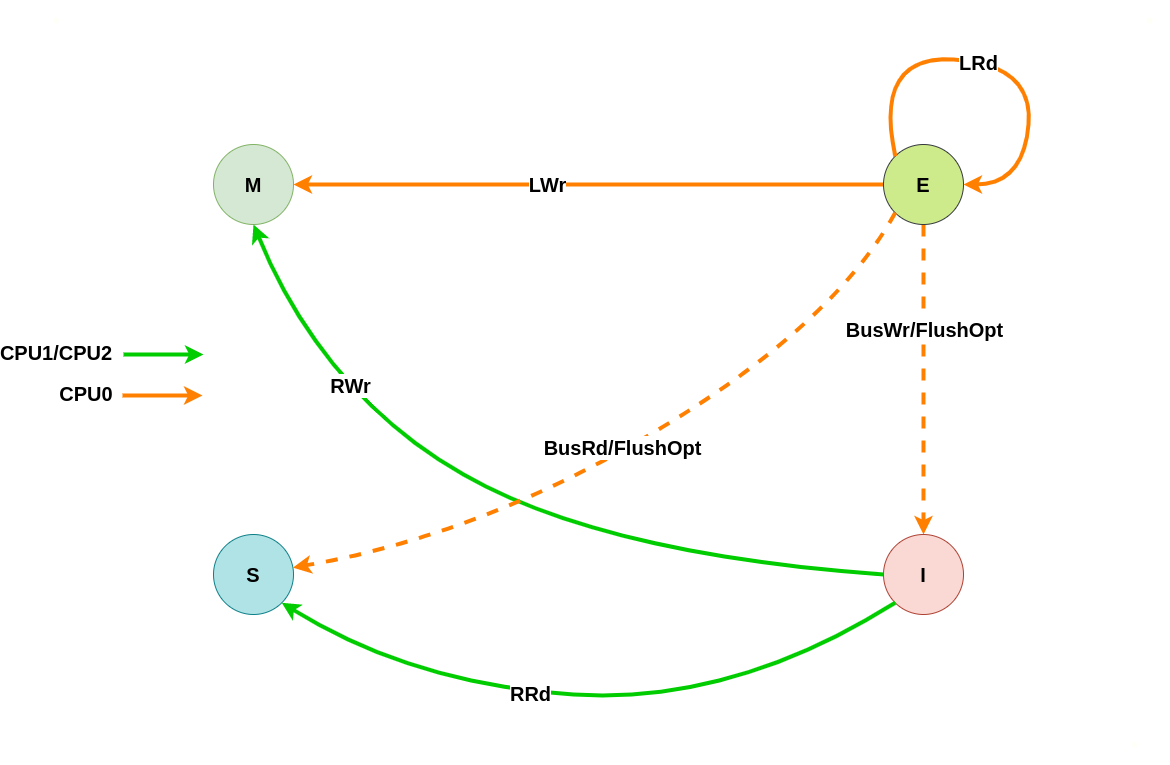
上图为 MESI 之间变换的状态图,LRd 表示本地读、LWr 表示本地写、BusRd 表示远端读或者监听到总线读请求、BusWr 表示远端写或监听到总线写请求、FlushOpt 表示把当前 CACHE Line 内容发到总线上、Writeback 表示将 CACHE Line 内容更新到内存. 接下来通过具体理解讲解每种状态之间变化过程:
初始状态为 Invalid
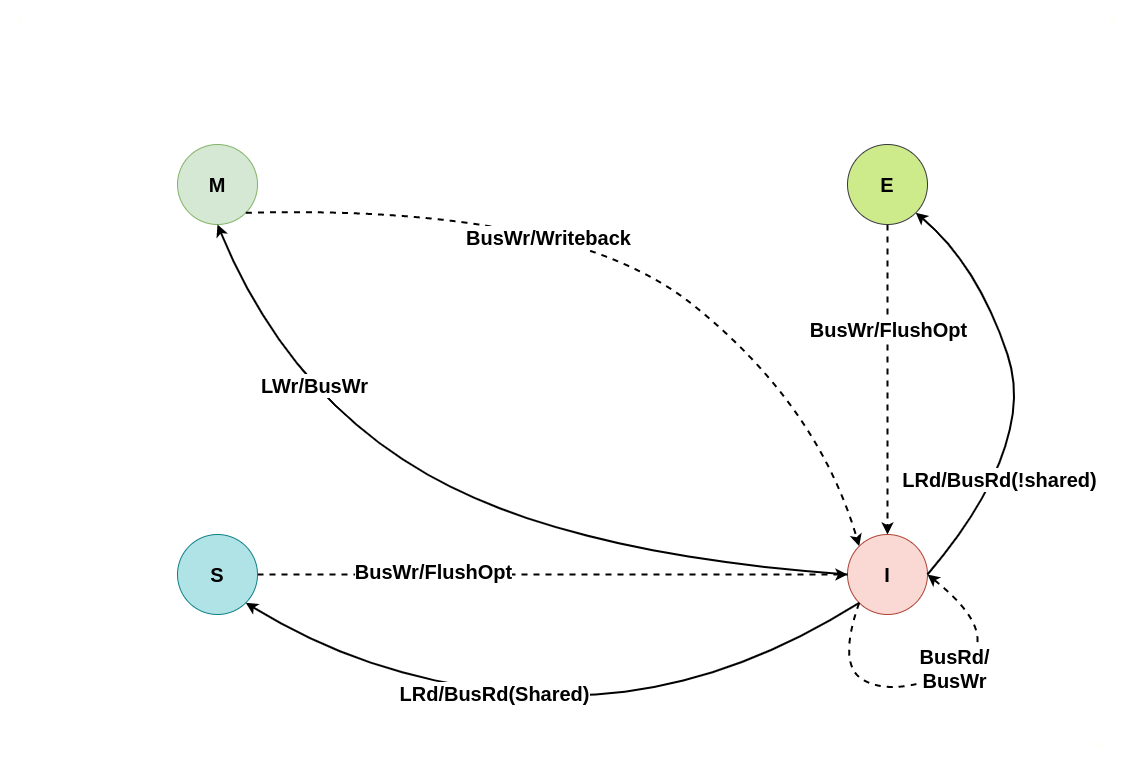
当本地 CACHE Line 的状态为 Invalid 时,其会触发本地 CPU 访问时 CACHE Miss,此时无论是本地读还是本地写,都会转换成总线读或者总线写信号,远端 CPU 的 CACHE 监听到总线信号之后会将其缓存的 CACHE Line 状态进行改变,具体改变可以从读请求和写请求进行分析:
本地/远端读请求
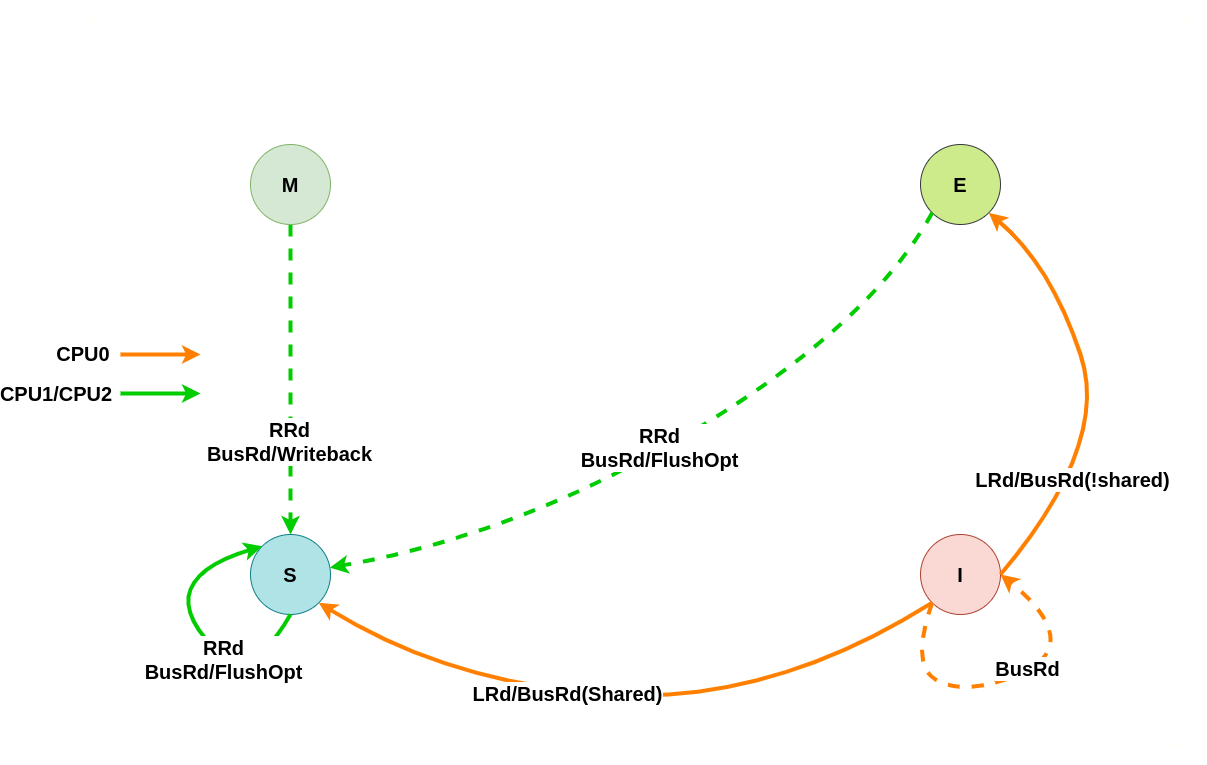
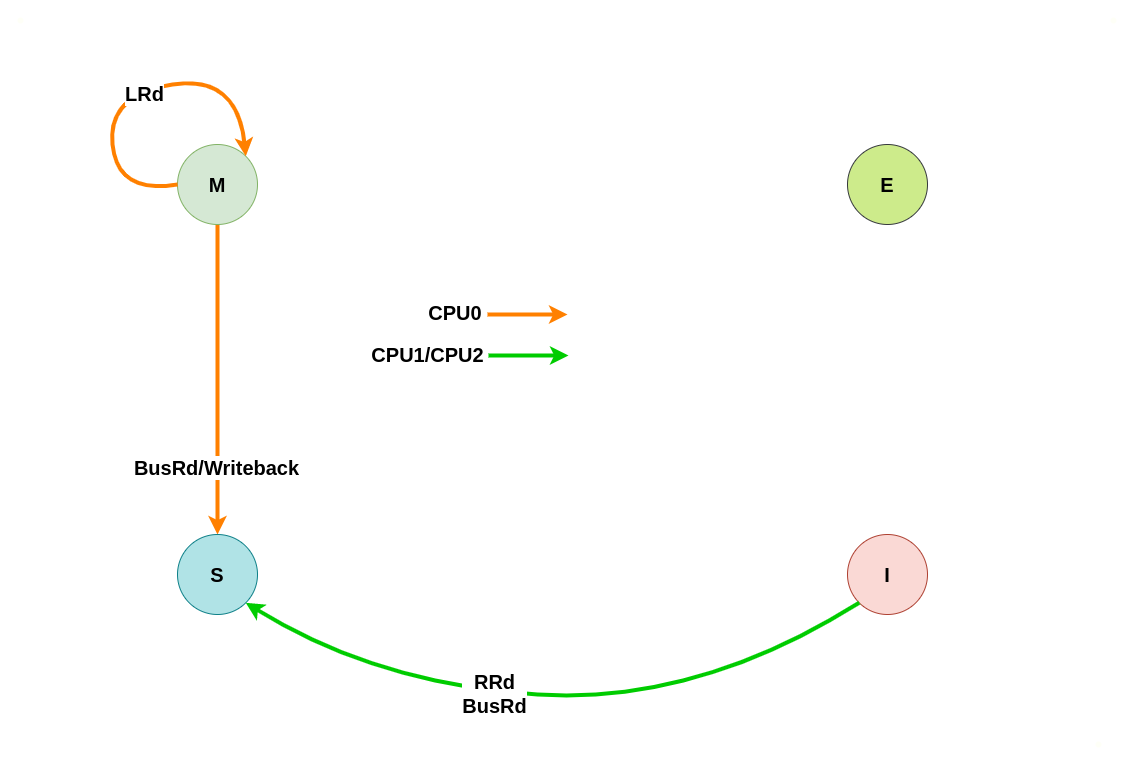
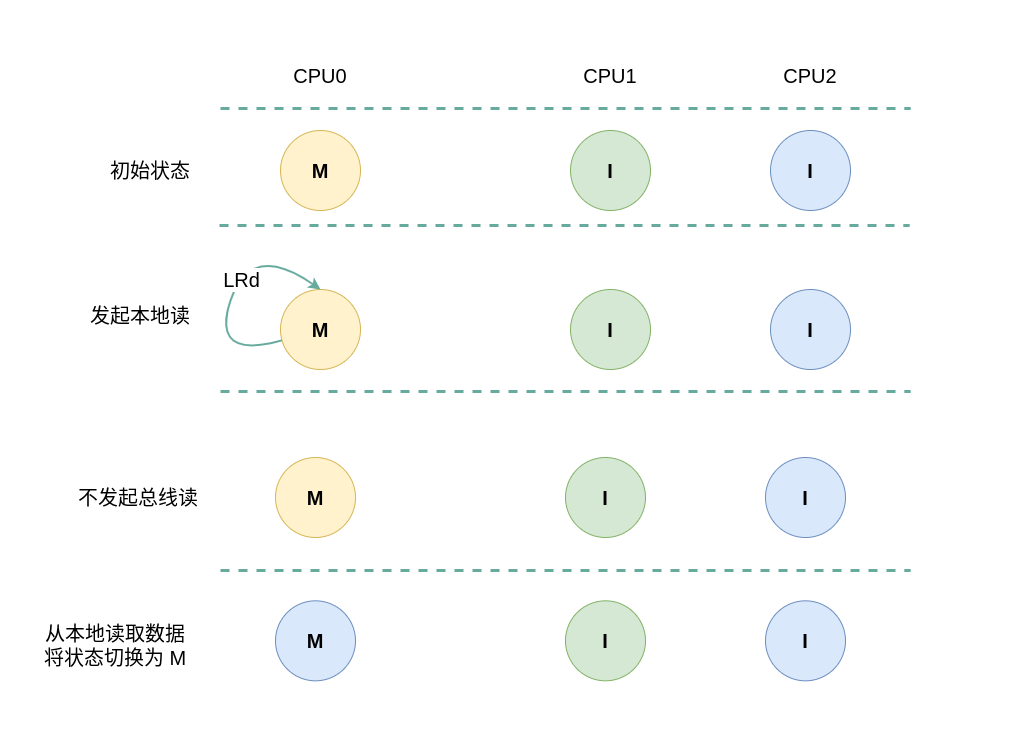
假设系统有 3 个 CPU,分别是 CPU0、CPU1 和 CPU2,并且 CPU0 为本地视角,CPU1 和 CPU2 为远端视角. 当 CPU0 发起本地读请求 LRd 或者 CPU1/CPU2 发起远端读请求 RRd 时,此时 CPU0 对应的 CACHE Line 为 Invalid,CPU1、CPU2 对应的 CACHE Line 的状态可能是 Invalid、Shared 或者 Exclusive, 那么所有 CACHE Line 的变化包含如下几种情况:
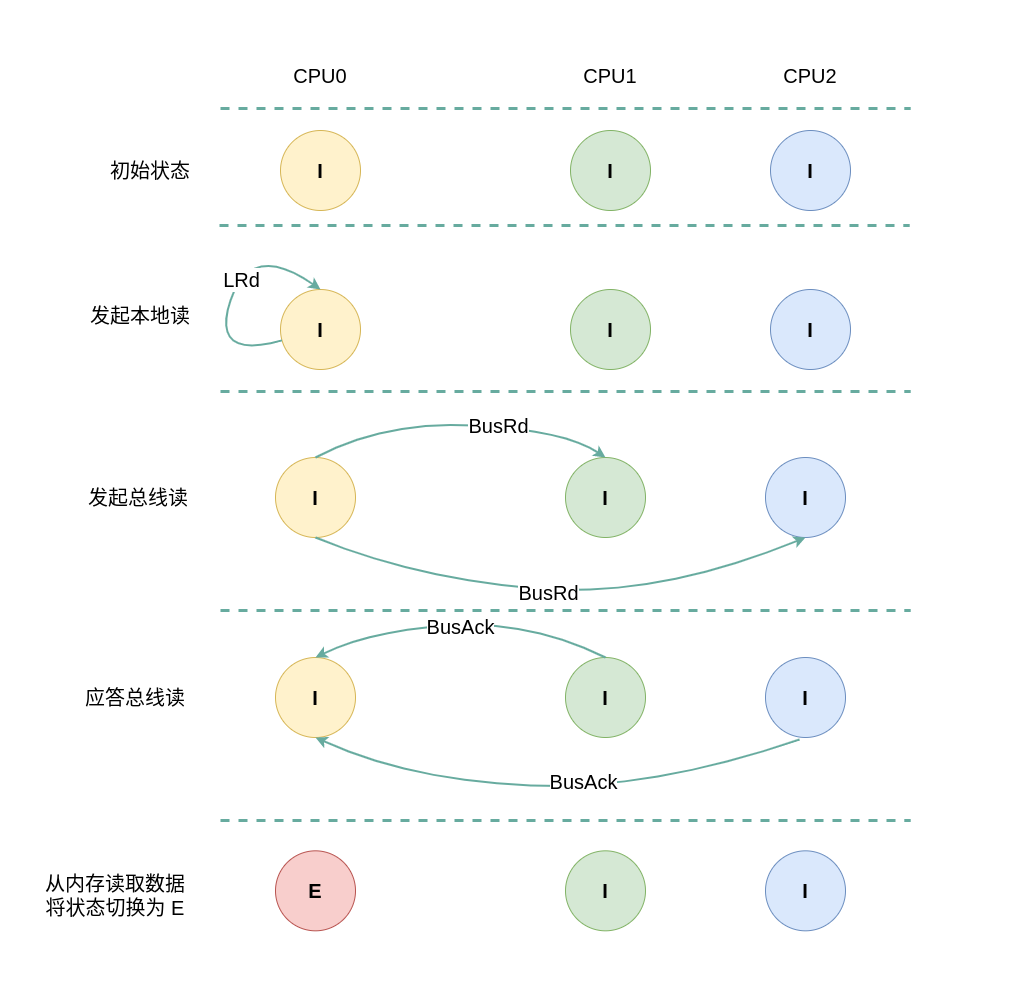
(1) 本地读全 Invalid: 当 CPU0 发起本地读请求 LRd 时,发现本地 CACHE Line 的状态为 Invalid,即 CACHE 中没有缓存对应的内容 CACHE Miss,那么在总线上产生一个 总线读 BusRd,CPU1 和 CPU2 监听到 BusRd 之后检查 CACHE 中是否包含副本,此时 CPU1 和 CPU2 的 CACHE Line 都为 Invalid,没有包含副本, 接着 CPU1 和 CPU2 向总线发送应答信号. CPU0 广播完所有的 CPU 之后发现总线上并没有数据,那么其从内存中读取数据到本地 CACHE Line,并将 CACHE Line 的状态切换到 Exclusive.
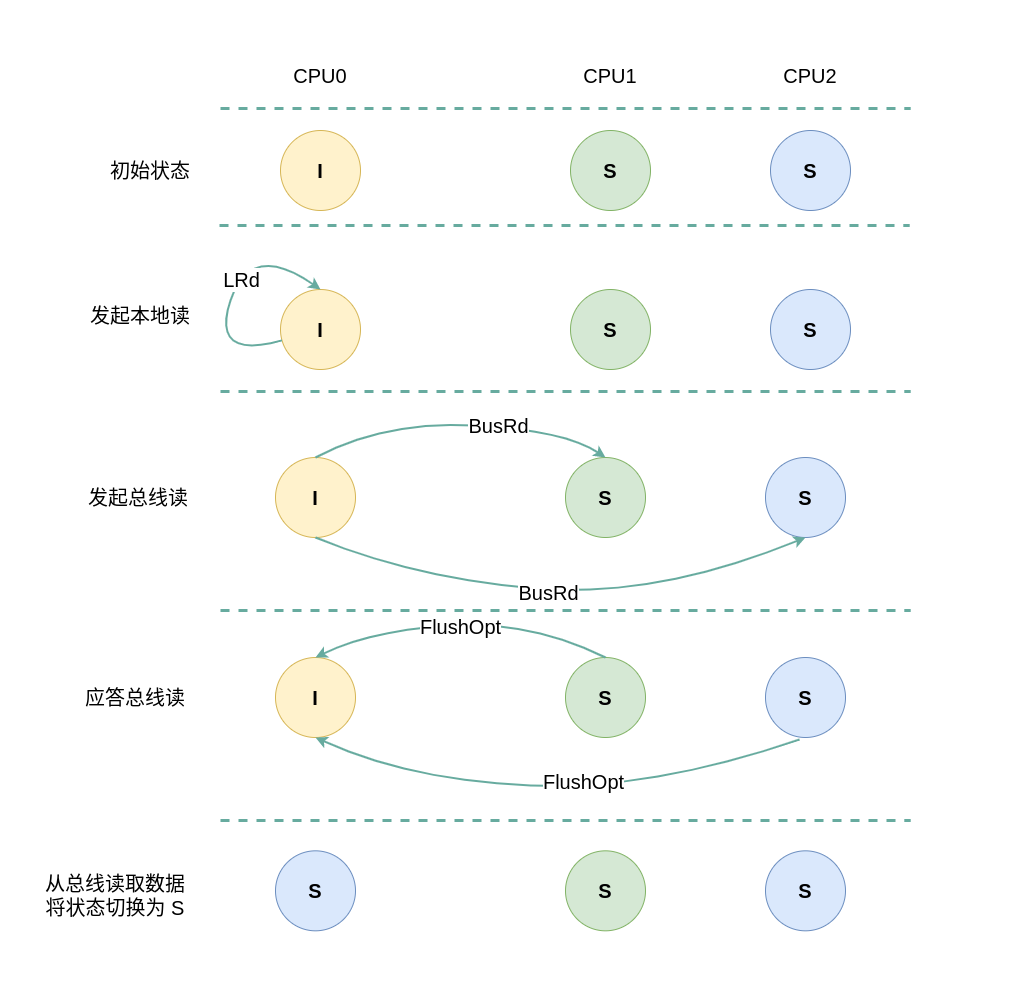
(2) 本地读远端 Shared: 当 CPU0 发起本地读请求 LRd 时,发现本地 CACHE Line 的状态为 Invalid,即 CACHE 中没有缓存对应的内容 CACHE Miss,那么在总线上产生一个 总线读 BusRd,CPU1 和 CPU2 监听到 BusRd 之后检查 CACHE 中是否包含副本,此时 CPU1 和 CPU2 检查到其缓存了副本,且 CACHE Line 的状态为 Shared,那么 CPU1/CPU2 向总线回复一个 FlushOpt 信号,并将 CACHE Line 的内容发送到总线上. CPU0 收到 FlushOpt 信号之后从总线上读取了数据并缓存到本地的 CACHE Line,并将 CACHE Line 的状态标记为 Shared.
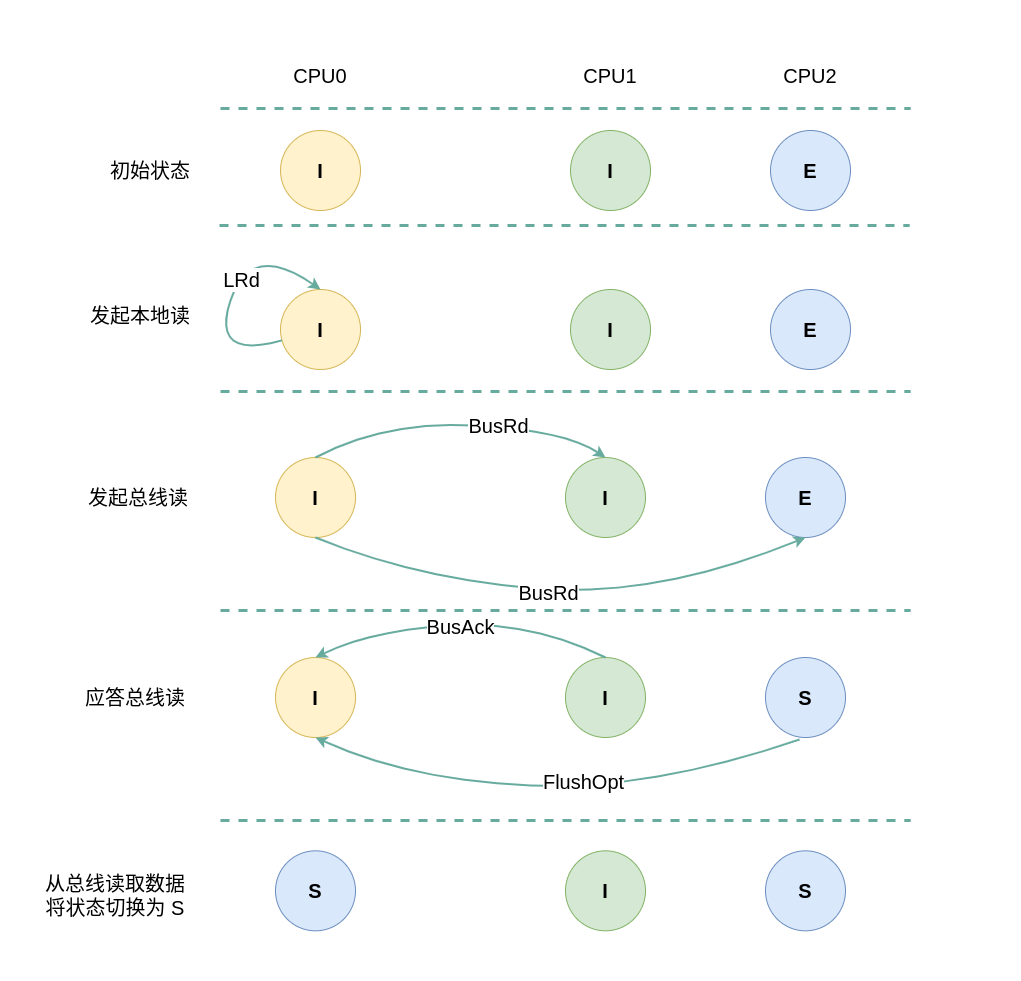
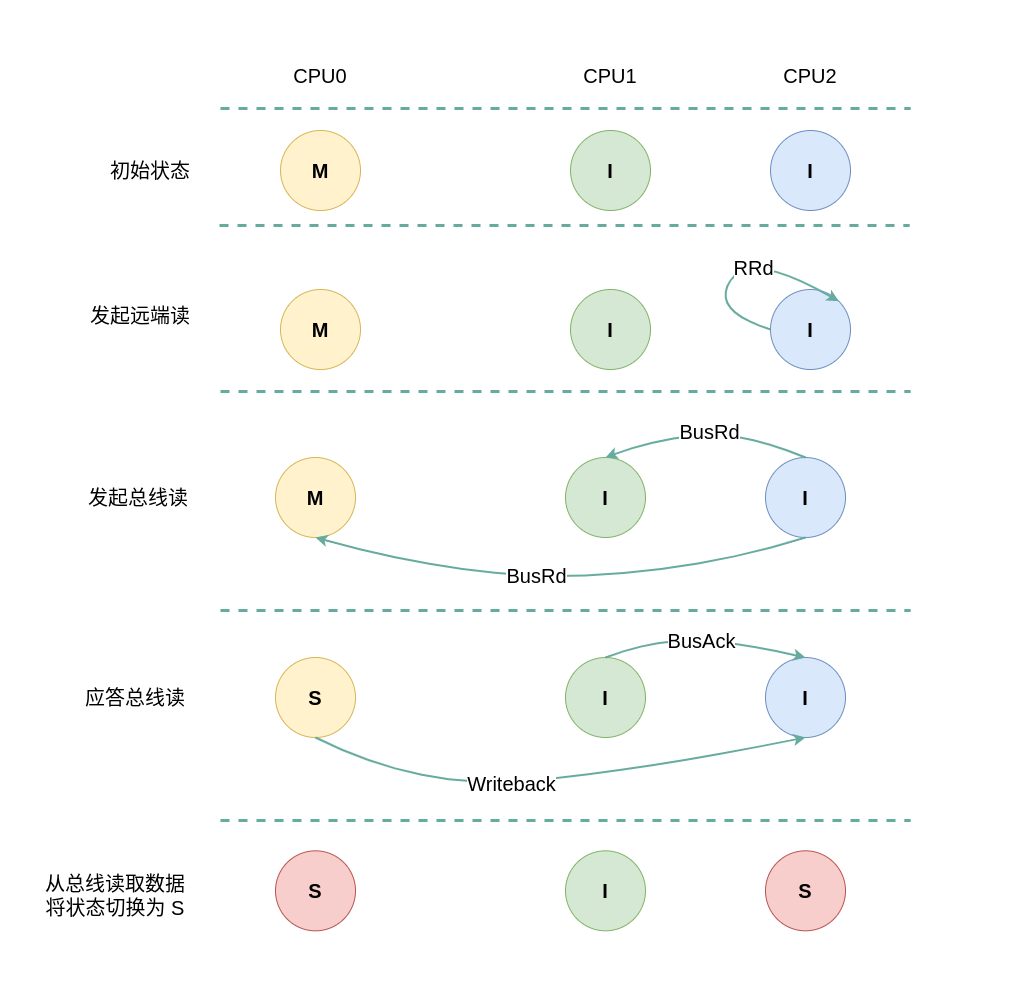
(3) 本地读远端 Exclusive: 当 CPU0 发起本地读请求 LRd 时,发现本地 CACHE Line 的状态为 Invalid,即 CACHE 中没有缓存对应的内容 CACHE Miss,那么在总线上产生一个 总线读 BusRd,CPU1 和 CPU2 监听到 BusRd 之后检查 CACHE 中是否包含副本,此时 CPU1 的 CACHE Line 都为 Invalid,那么没有包含副本,那么 CPU1 直接向总线发送应答信号; CPU2 检查到其缓存了副本,且该 CACHE Line 的状态为 Exclusive,那么 CPU2 向总线回复一个 FlushOpt 信号,并将 CACHE Line 的内容发送到总线上, 并将 CACHE Line 的状态切换成 Shared. CPU0 收到 FlushOpt 信号之后从总线上读取了数据并缓存到本地的 CACHE Line,并将 CACHE Line 的状态标记为 Shared.
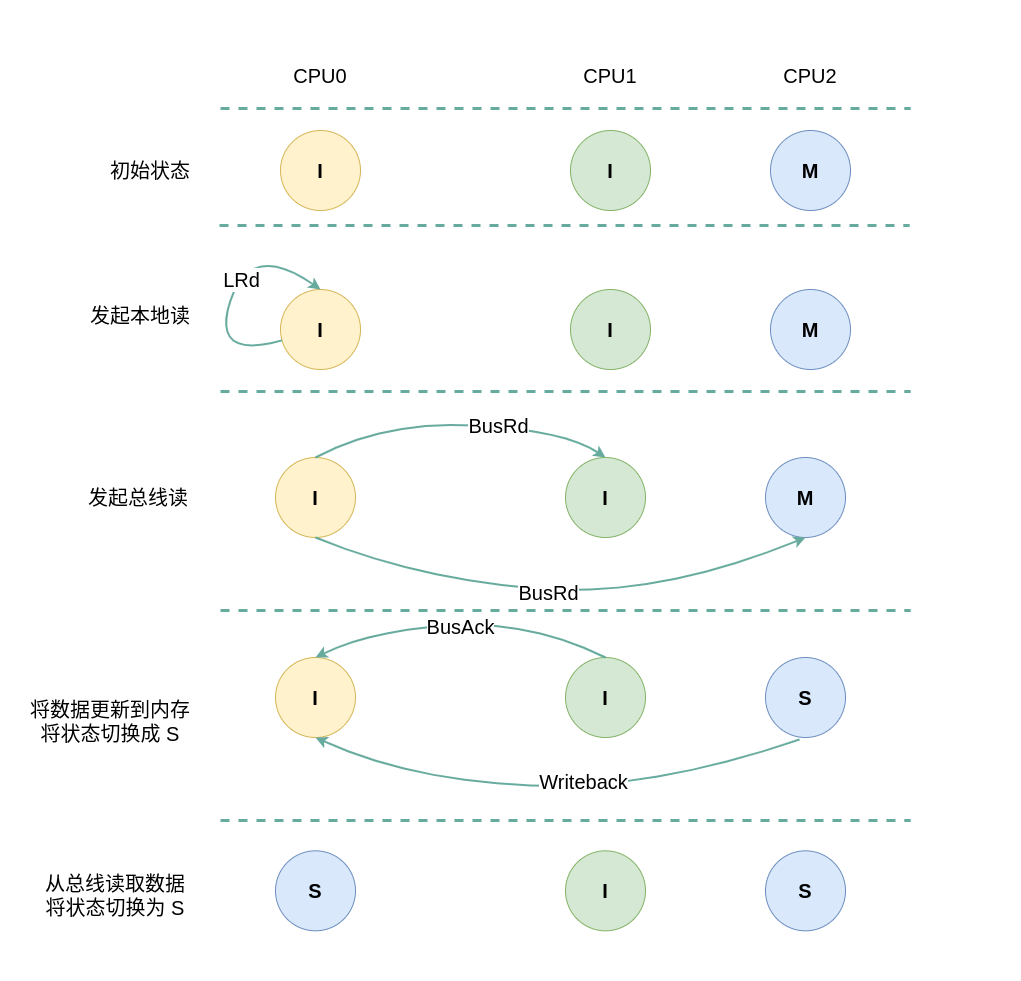
(4) 本地读远端 Modify: 当 CPU0 发起本地读请求 LRd 时,发现本地 CACHE Line 的状态为 Invalid,即 CACHE 中没有缓存对应的内容 CACHE Miss,那么在总线上产生一个 总线读 BusRd,CPU1 和 CPU2 监听到 BusRd 之后检查 CACHE 中是否包含副本,此时 CPU1 的 CACHE Line 都为 Invalid 没有包含副本,那么 CPU1 直接向总线发送应答信号; CPU2 检查到其缓存了副本,且该 CACHE Line 的状态为 Modify,那么 CPU2 向总线回复一个 Writeback 信号,并先将 CACHE Line 的内容更新到内存,然后发送到总线上, 并将 CACHE Line 的状态切换成 Shared. CPU0 收到 Writeback 信号之后从总线上读取了数据并缓存到本地的 CACHE Line,并将 CACHE Line 的状态标记为 Shared.
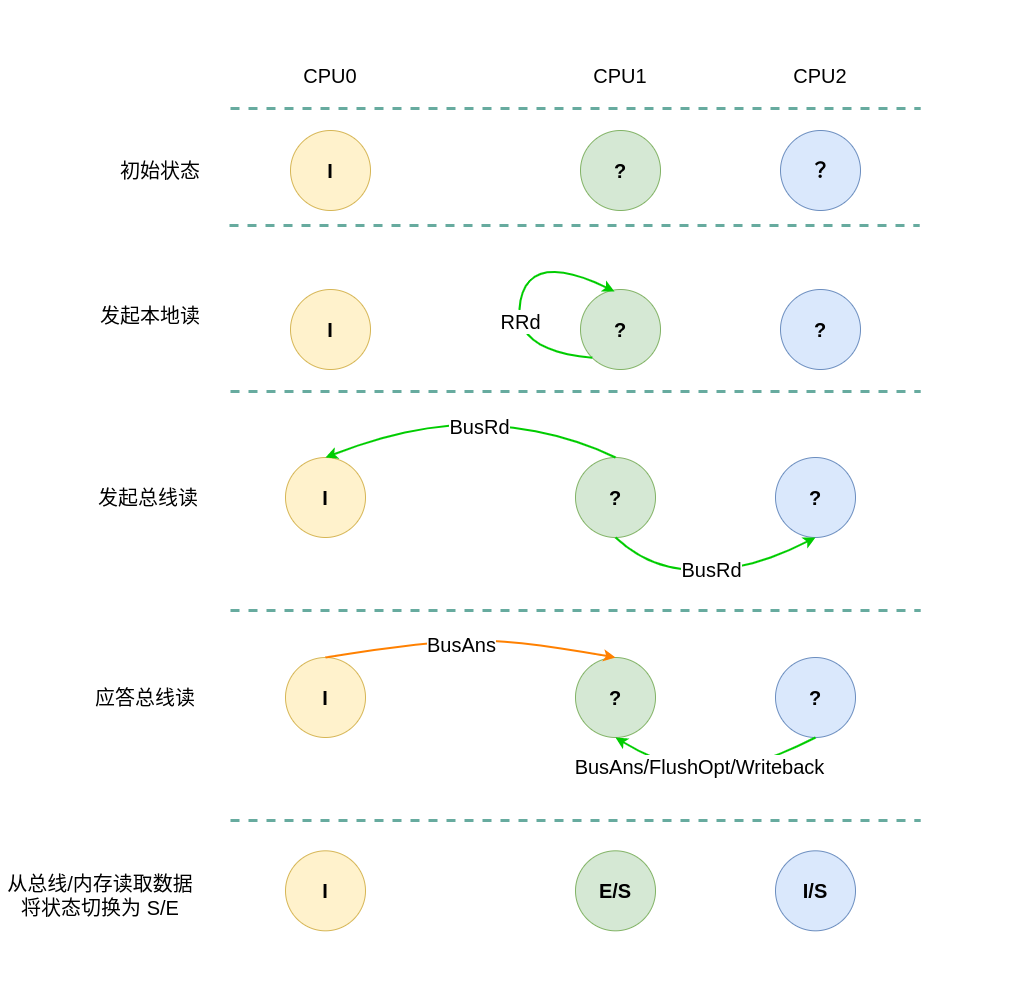
(5) 远端读本地 Invalid: 当 CPU1 发起远端读请求 RRd 时,无论远端 CACHE Line 的状态如何,也无论是否产生总线读请求 BusRd,CPU0 监听到 BusRd 信号之后,检查其 CACHE 中并没有副本,然后直接应答总线,然后继续保持 Invalid.
本地/远端写请求
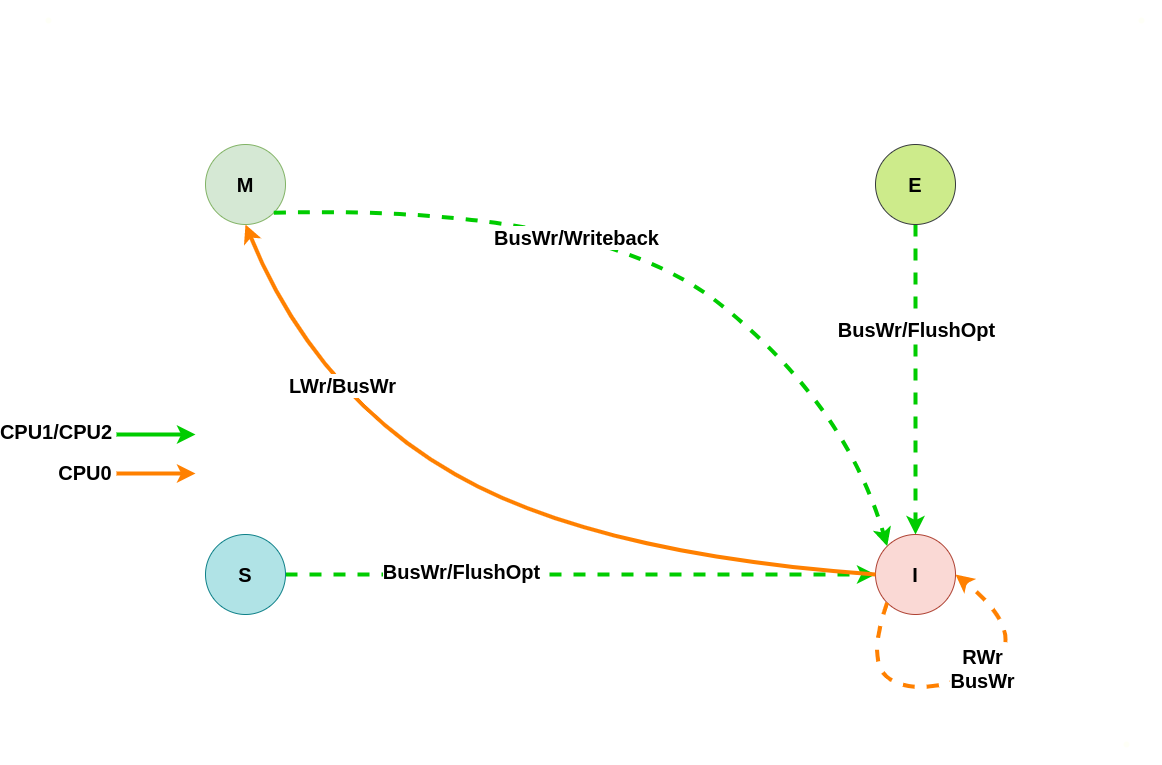
假设系统有 3 个 CPU,分别是 CPU0、CPU1 和 CPU2,并且 CPU0 为本地视角,CPU1 和 CPU2 为远端视角, 当 CPU0 发起本地写请求 LRd 或者 CPU1/CPU2 发起远端写请求 RWr,当本地 CACHE Line 为 Invalid 状态,远端 CACHE Line 可能是 Invalid、Modify、Exclusive 和 Shared,那么 CACHE Line 的变化包含以下几种情况:
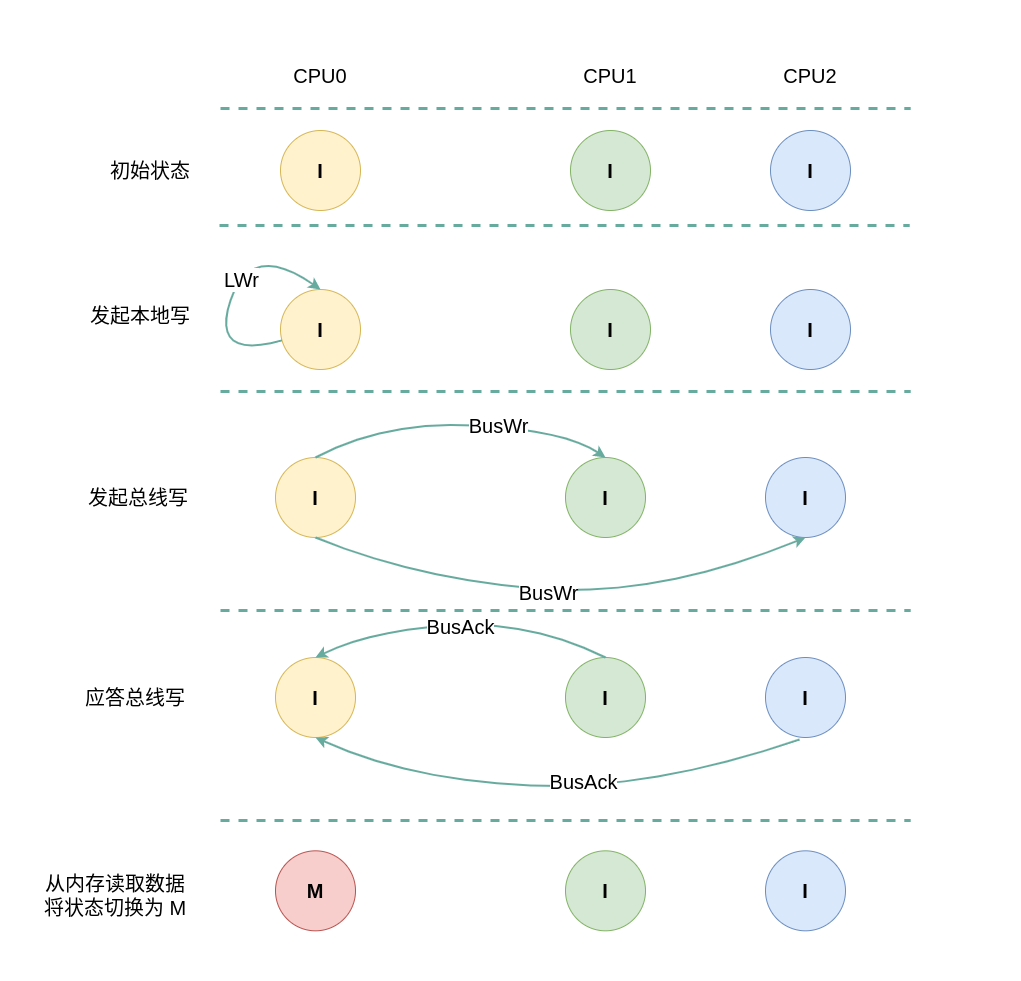
(1) 本地写全 Invalid: 当 CPU0 发起本地写请求 LWr 时,发现本地 CACHE Line 的状态为 Invalid,即 CACHE 中没有缓存对应的内容 CACHE Miss,那么在总线上产生一个 总线写 BusWr,CPU1 和 CPU2 监听到 BusWr 之后检查 CACHE 中是否包含副本,此时 CPU1 和 CPU2 的 CACHE Line 都为 Invalid,那么没有包含副本. 接着 CPU1 和 CPU2 向总线发送应答信号,并继续广播剩余的 CPU. CPU0 广播完所有的 CPU 之后发现总线上并没有数据,那么其从内存中读取数据到本地 CACHE Line,然后再修改 CACHE Line 中的数据,并将 CACHE Line 的状态切换到 Modify.
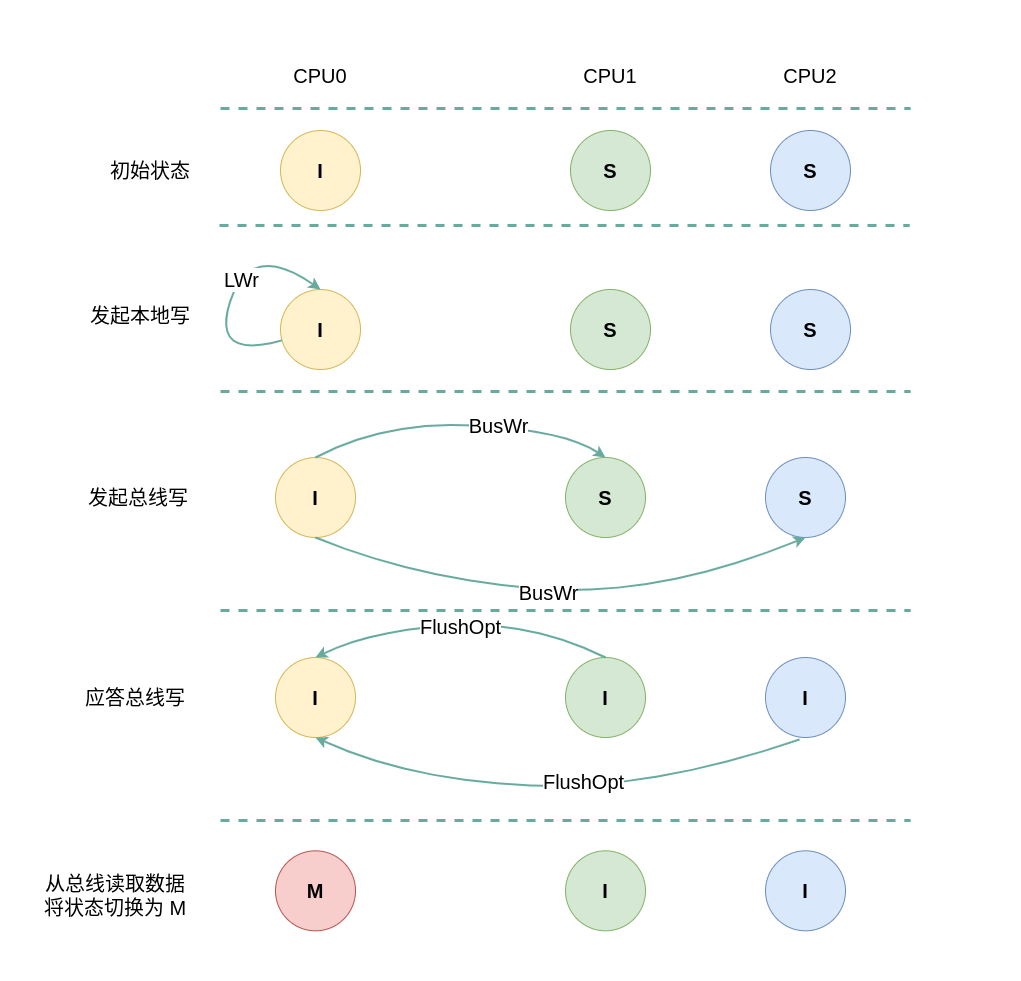
(2) 本地写远端 Shared: 当 CPU0 发起本地写请求 LWr 时,发现本地 CACHE Line 的状态为无效,即 CACHE 中没有缓存对应的内容 CACHE Miss,那么在总线上产生一个 总线写 BusWr,CPU1 和 CPU2 监听到 BusWr 之后检查 CACHE 中是否包含副本,此时 CPU1 和 CPU2 的 CACHE Line 都为 Shared,那么都有副本. 接着 CPU1 和 CPU2 向总线发送 FlushOpt 应答信号,并将副本的内容发送到总线,此时将 CACHE Line 状态都设置为 Invalid. CPU0 广播完所有的 CPU 之后发现总线上存在数据,那么其从总线上读取数据到本地 CACHE Line,然后修改 CACHE Line 中的数据,并将 CACHE Line 的状态切换到 Modify.
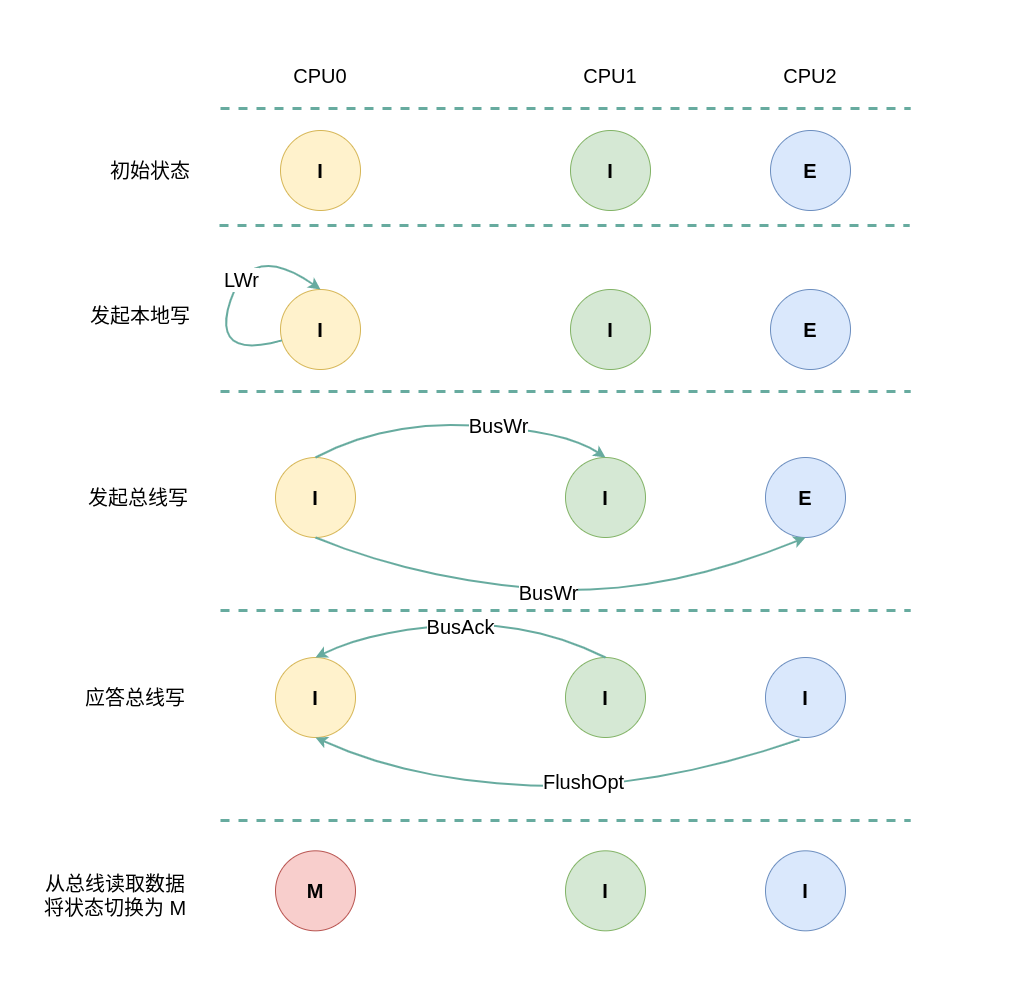
(3) 本地写远端 Exclusive: 当 CPU0 发起本地写请求 LWr 时,发现本地 CACHE Line 的状态为无效,即 CACHE 中没有缓存对应的内容 CACHE Miss,那么在总线上产生一个 总线写 BusWr,CPU1 和 CPU2 监听到 BusWr 之后检查 CACHE 中是否包含副本,此时 CPU1 没有包含对应的副本,那么直接应答总线. CPU2 中包含副本,且 CACHE Line 的状态为 Exclusive,接着 CPU2 向总线发送 FlushOpt 应答信号,并将副本的内容发送到总线,然后将 CACHE Line 状态都设置为 Invalid. CPU0 广播完所有的 CPU 之后发现总线上存在数据,那么其从总线上读取数据到本地 CACHE Line,然后修改 CACHE Line 中的数据,并将 CACHE Line 的状态切换到 Modify.
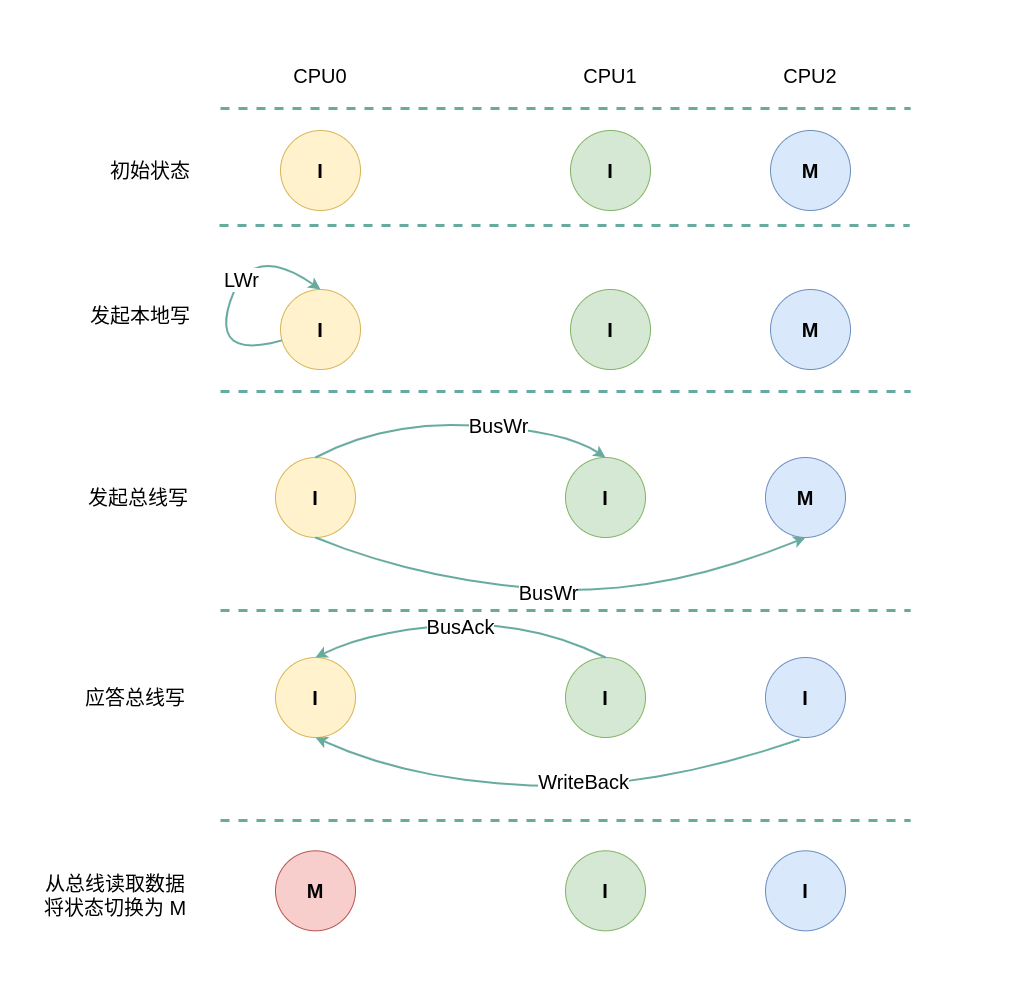
(4) 本地写远端 Modify: 当 CPU0 发起本地写请求 LWr 时,发现本地 CACHE Line 的状态为无效,即 CACHE 中没有缓存对应的内容 CACHE Miss,那么在总线上产生一个 总线写 BusWr,CPU1 和 CPU2 监听到 BusWr 之后检查 CACHE 中是否包含副本,此时 CPU1 没有包含对应的副本,那么直接应答总线. CPU2 中包含副本,且 CACHE Line 的状态为 Modify,接着 CPU2 向总线发送 WriteBack 信号,并将副本的内容写入内存,再将副本发送到总线,然后将 CACHE Line 状态都设置为 Invalid. CPU0 广播完所有的 CPU 之后发现总线上存在数据,那么其从总线上读取数据到本地 CACHE Line,然后修改 CACHE Line 中的数据,并将 CACHE Line 的状态切换到 Modify.
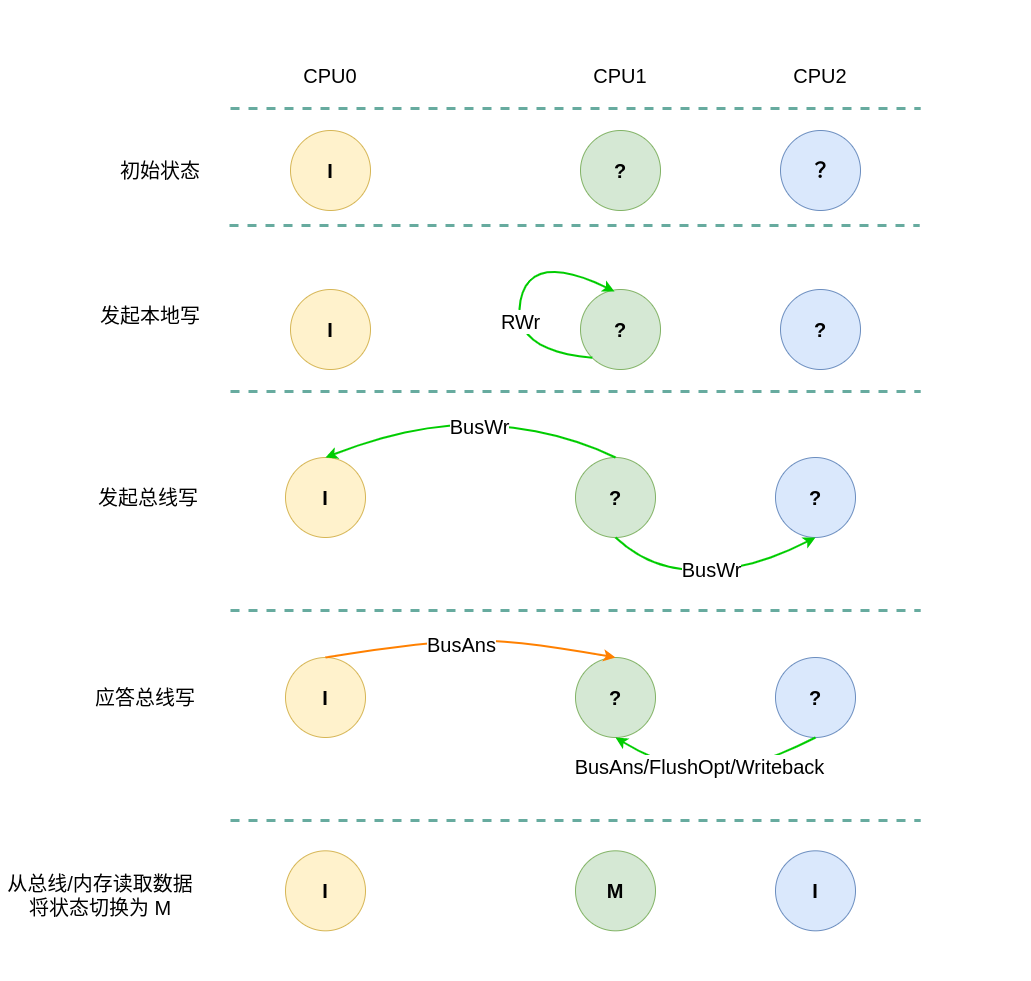
(5) 远端写本地 Invalid: 当 CPU1 发起远端写请求 RWr 时,无论远端 CACHE Line 的状态如何,也无论是否产生总线读请求 BusWr,CPU0 监听到 BusWr 信号之后,检查其 CACHE 中并没有副本,然后直接应答总线,然后继续保持 Invalid.
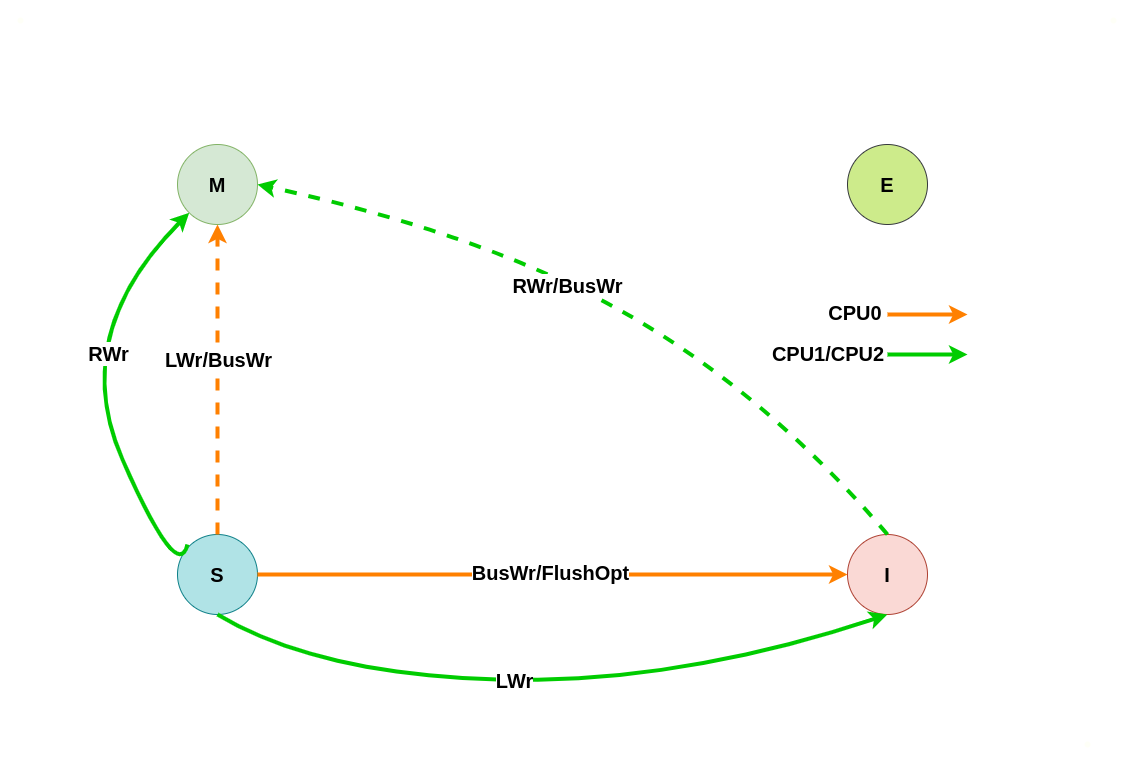
初始状态为 Modify
当本地 CACHE Line 的状态是 Modify,那么说明本地 CPU 修改了 CACHE Line 的值,但没有刷新到内存里,是一份脏数据, 并且其他 CPU 没有缓存副本。. 本地或远端发起的读写请求都会概念 CACHE Line 的状态,具体变化如下场景:
本地/远端读请求
假设系统有 3 个 CPU,分别是 CPU0、CPU1 和 CPU2,并且 CPU0 为本地视角,CPU1 和 CPU2 为远端视角,由于 CPU0 的 CACHE Line 状态为 Modify,那么其他 CPU 没有副本。读请求会引起 CACHE Line 状态在 Modify 和 Shared 之间转换, 具体如下:
(1) 本地读请求: 当 CPU0 发起本地读请求 LRd 时,发现本地 CACHE Line 的状态为 Modify,即 CACHE 中缓存对应内容 CACHE Hit, 并且 CACHE Line 中的数据是最新的,与内存中的数据不一致,那么 CPU0 直接从本地 CACHE Line 中读取数据,并保持 CACHE Line 状态为 Modify.
(2) 远端读本地 Modify: 当 CPU2 发起本地读请求 RRd 时,发现本地 CACHE Line 的状态为 Invalid,即 CACHE 中没有缓存对应内容 CACHE Miss, 那么在总线上产生一个总线读 BusRd, CPU1 监听到 BusRd 之后由于没有对应的副本,那么直接应答总线; CPU0 监听到 BusRd 之后发现具有对应的 CACHE Line 副本,且此时 CPU0 CACHE Line 的状态为 Modify,那么其向总线发送一个 Writeback 信号,同时将 CACHE Line 的数据发送到总线,并且将数据也写入到内存,最后将 CPU0 CACHE Line 状态设置为 Shared; CPU2 收到总线 Writeback 信号之后从总线上获得数据,并存储在 CPU2 的 CACHE Line,最后将 CACHE Line 状态设置为 Shared.
本地/总线写请求
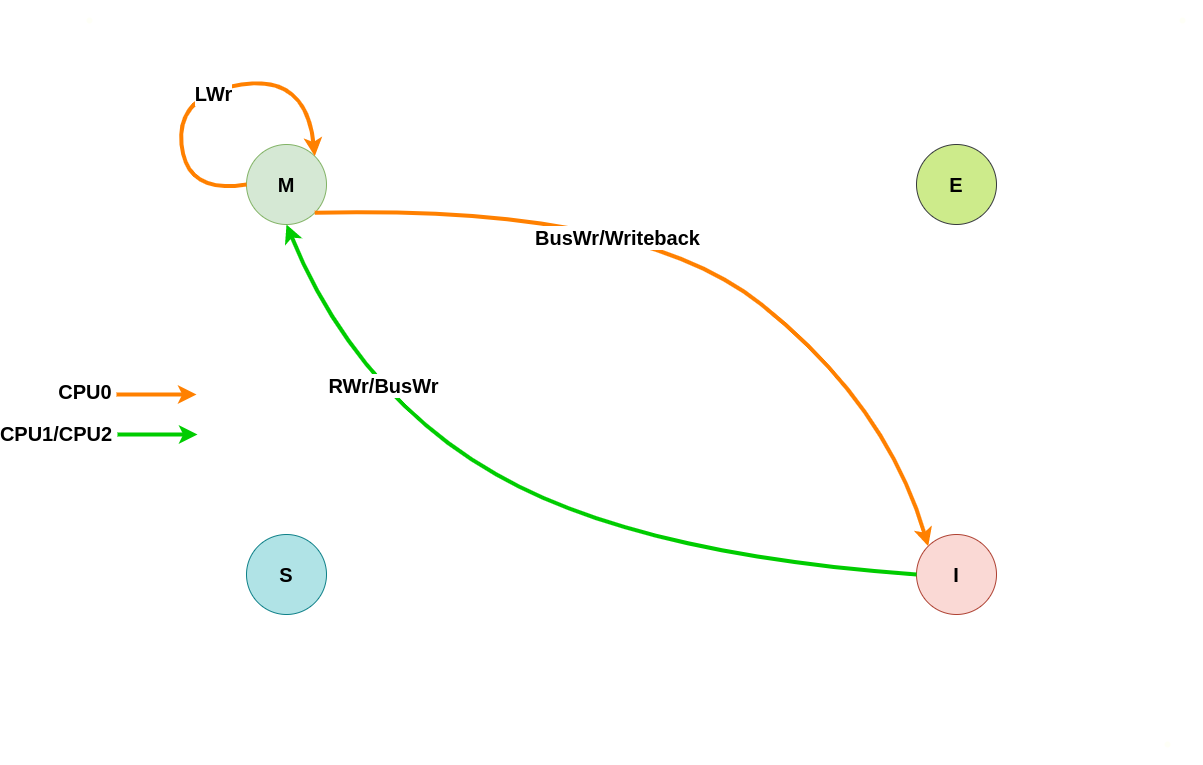
假设系统有 3 个 CPU,分别是 CPU0、CPU1 和 CPU2,并且 CPU0 为本地视角,CPU1 和 CPU2 为远端视角,由于 CPU0 的 CACHE Line 状态为 Modify,那么其他 CPU 没有副本。写请求会引起 CACHE Line 状态在 Invalid 和 Modify 之间转换, 具体场景如下:
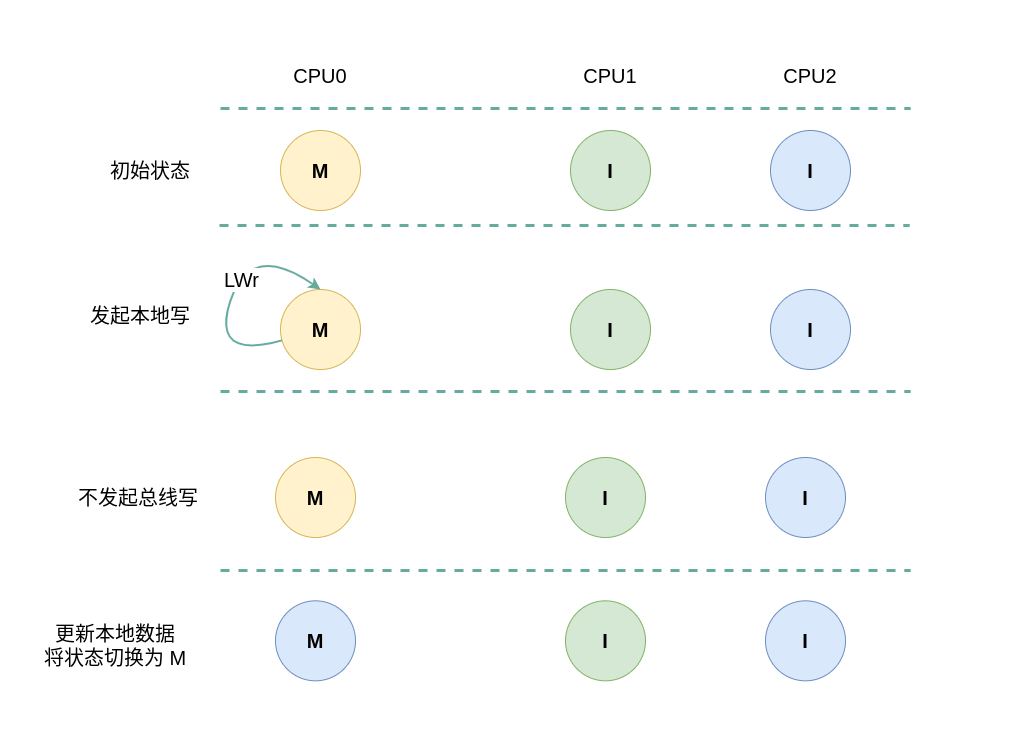
(1) 本地写请求: 当 CPU0 发起本地写请求 LWr 时,发现本地 CACHE Line 的状态为 Modify,即 CACHE 中缓存对应内容 CACHE Hit, 并且 CACHE Line 中的数据是最新的,与内存中的数据不一致,那么 CPU0 直接更新本地 CACHE Line 中数据,并保持 CACHE Line 状态为 Modify.
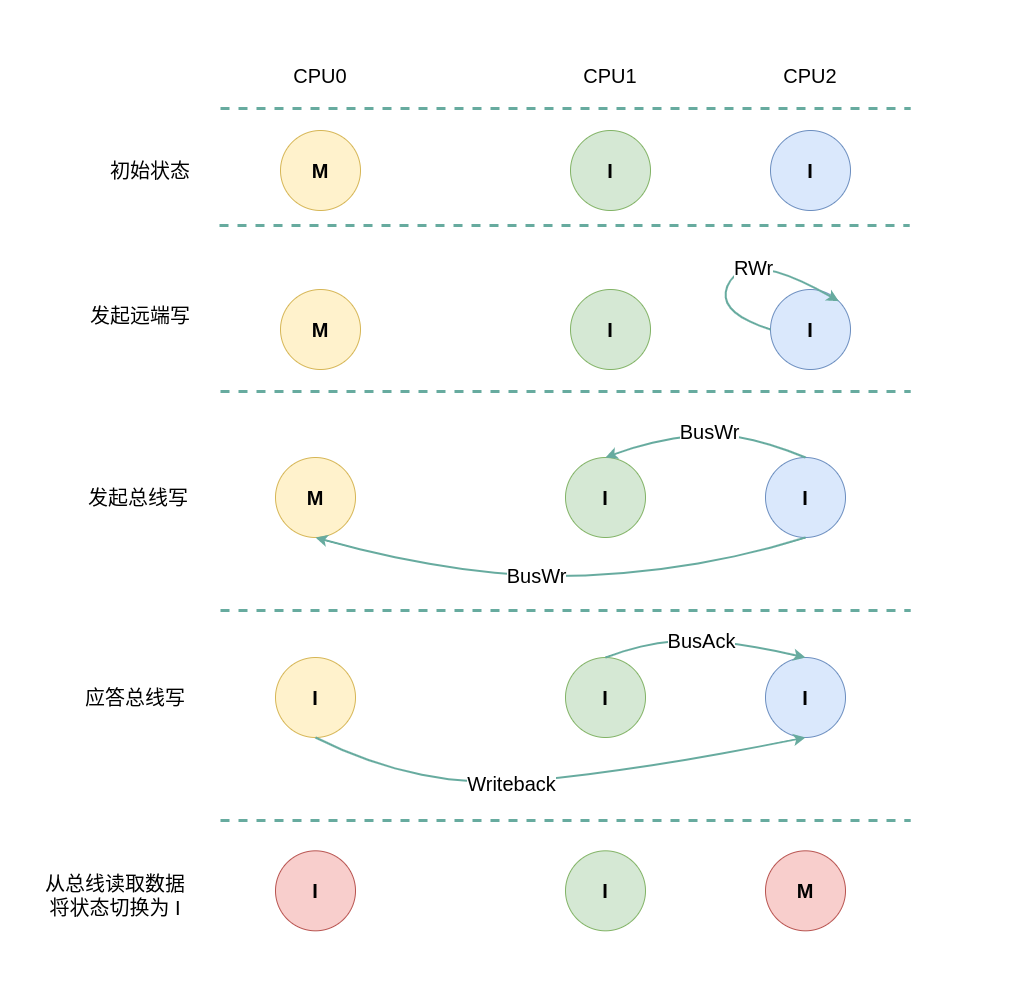
(2) 远端写本地 Modify: 当 CPU2 发起本地写请求 RRd 时,发现本地 CACHE Line 的状态为 Invalid,即 CACHE 中没有缓存对应内容 CACHE Miss, 那么在总线上产生一个总线写 BusWr, CPU1 监听到 BusWr 之后由于没有对应的副本,那么直接应答总线; CPU0 监听到 BusWr 之后发现具有对应的 CACHE Line 副本,且此时 CPU0 CACHE Line 的状态为 Modify,那么其向总线发送一个 Writeback 信号,同时将 CACHE Line 的数据发送到总线,并且将数据也写入到内存,最后将 CPU0 CACHE Line 状态设置为 Invalid; CPU2 收到总线 Writeback 信号之后从总线上获得数据,并存储在 CPU2 的 CACHE Line,接着更新 CACHE Line 中的内容,最后将 CACHE Line 状态设置为 Modify.
初始状态为 Shared
当本地 CACHE Line 的初始状态为 Shared,那么说明其他 CPU 也缓存了该副本,且 CACHE Line 的状态可能是 Invalid 或者 Shared. 此时无论是本地读写还是远端读写,都会改变 CACHE Line 的状态,具体改变可以从读请求和写请求场景进行分析:
本地/远端读请求
假设系统有 3 个 CPU,分别是 CPU0、CPU1 和 CPU2,并且 CPU0 为本地视角,CPU1 和 CPU2 远端视角. 当 CPU0 发起本地读请求 LRd或者 CPU1/CPU2 发起远端读请求 RRd,当本地 CACHE Line 的状态为 Shared 状态,远端 CACHE Line 的状态可能是 Shared 或 Invalid,那么 CACHE Line 的变化包括如下几种场景:
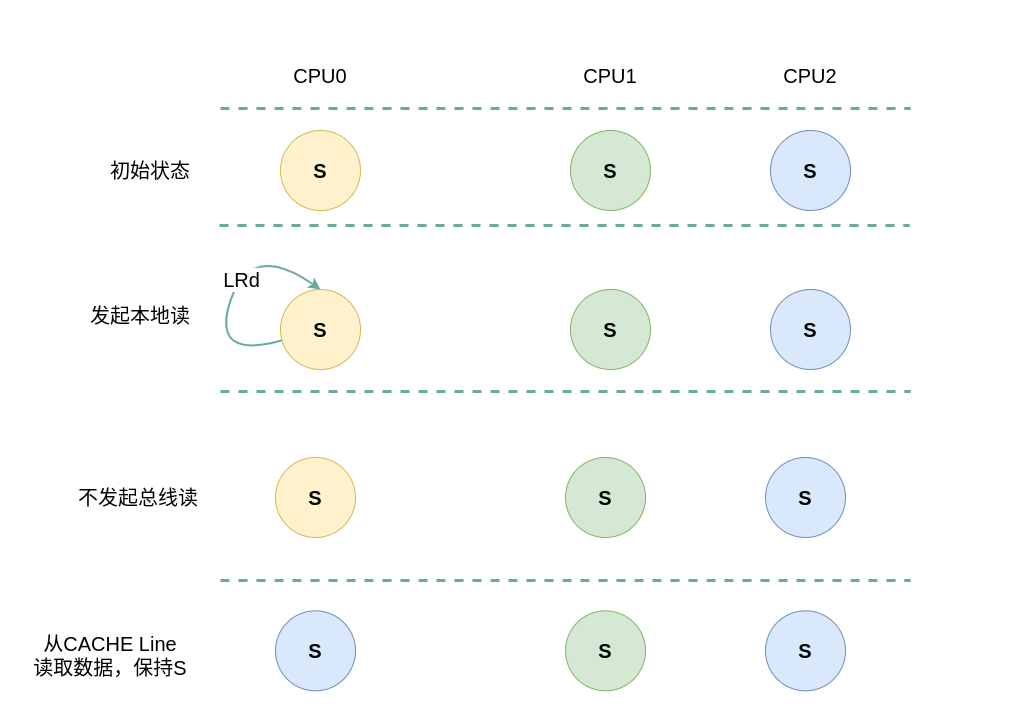
(1) 本地读请求: 当 CPU0 发起本地读请求 LRd 时,发现本地 CACHE Line 的状态为 Shared,即 CACHE 中有缓存对应内容 CACHE Hit, 其他 CPU 也有相应的副本,且所有的副本与内存上的数据是一致的,因此本地 CACHE Line 的状态保持 Shared,不会向总线发起 BusRd 信号,而是直接从 CACHE Line 中读取数据.
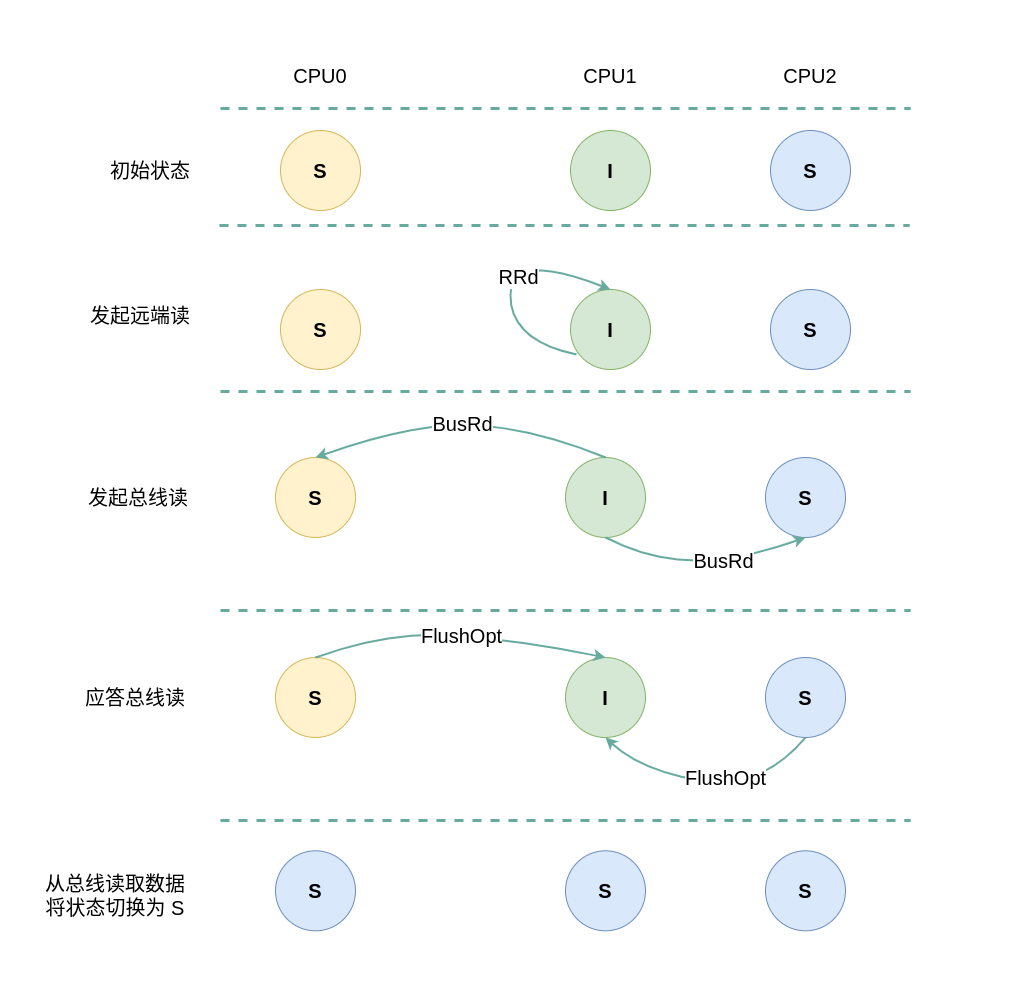
(2) 远端写请求: 当 CPU1 发起远端读请求 RRd 时,发现其 CACHE Line 的状态为 Invalid,即 CACHE 中有没有缓存对应内容 CACHE Miss, 那么在总线上产生一个总线读请求 BusRd,CPU0 监听到 BusRd 信号之后,发现其具有副本且 CACHE Line 状态为 Shared,那么直接应答一个 FlushOpt 信号,并将 CACHE Line 的内存发送到总线上,其他 CACHE Line 为 Shared 的也会做同样操作; CPU1 收到 FlushOpt 信号之后,从总线上读取数据到自己的 CACHE Line,并将 CACHE Line 信号更改为 Shared.
本地/远端写请求
假设系统有 3 个 CPU,分别是 CPU0、CPU1 和 CPU2,并且 CPU0 为本地视角,CPU1 和 CPU2 远端视角. 当 CPU0 发起本地写请求 LWr或者 CPU1/CPU2 发起远端写请求 RWr,当本地 CACHE Line 的状态为 Shared 状态,远端 CACHE Line 的状态可能是 Shared 或 Invalid,那么 CACHE Line 的变化包括如下几种场景:
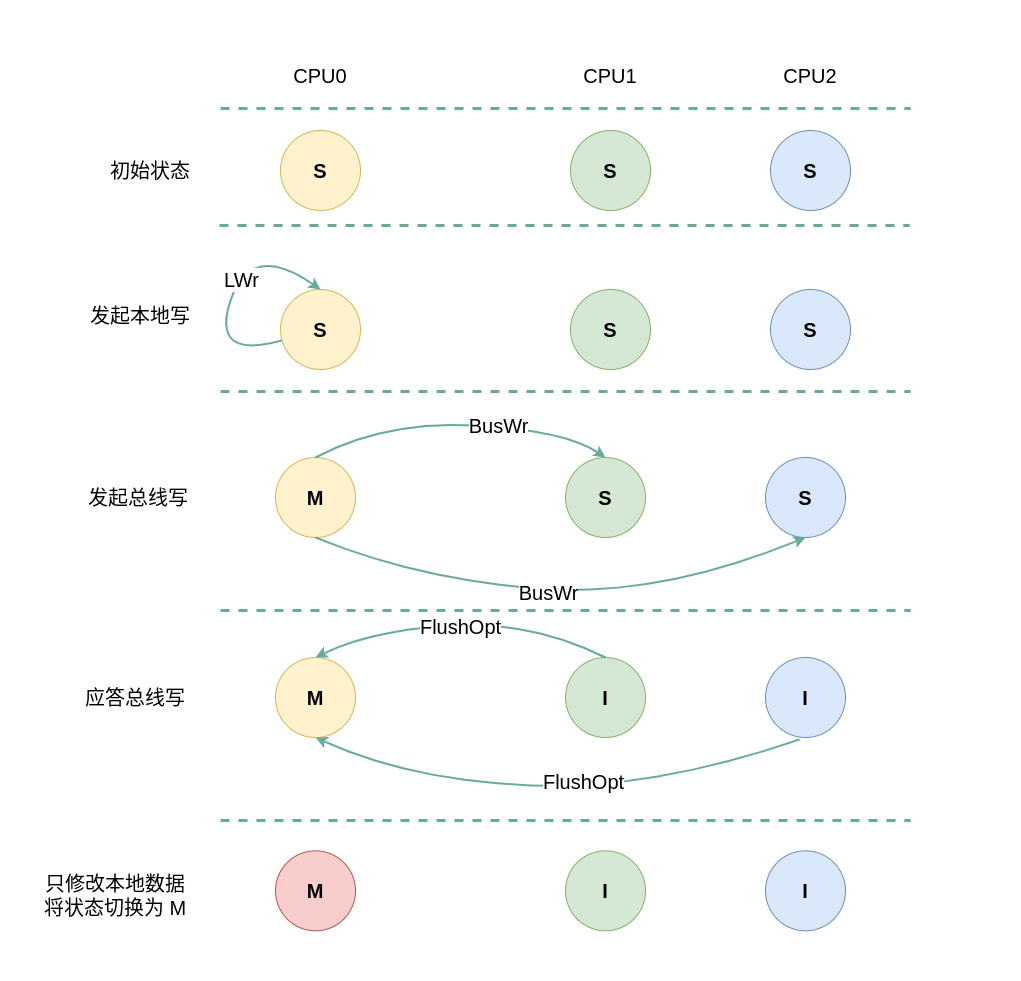
(1) 本地写请求: 当 CPU0 发起本地写请求 LWr 时,发现本地 CACHE Line 的状态为 Shared,即 CACHE 中有缓存对应内容 CACHE Hit, 其他 CPU 也有相应的副本,且所有的副本与内存上的数据是一致的,CPU0 向总线产生一个总线写 BusWr, 其他 CPU 监听到 BusWr 之后检查是否包含对应的副本,如果有则将对应的 CACHE Line 状态设置为 Invalid,并回应一个 FlushOpt 信号. CPU0 收到 FlushOpt 应答之后直接修改本地 CACHE Line 的内容,并将 CACHE Line 的状态修改为 Modify.
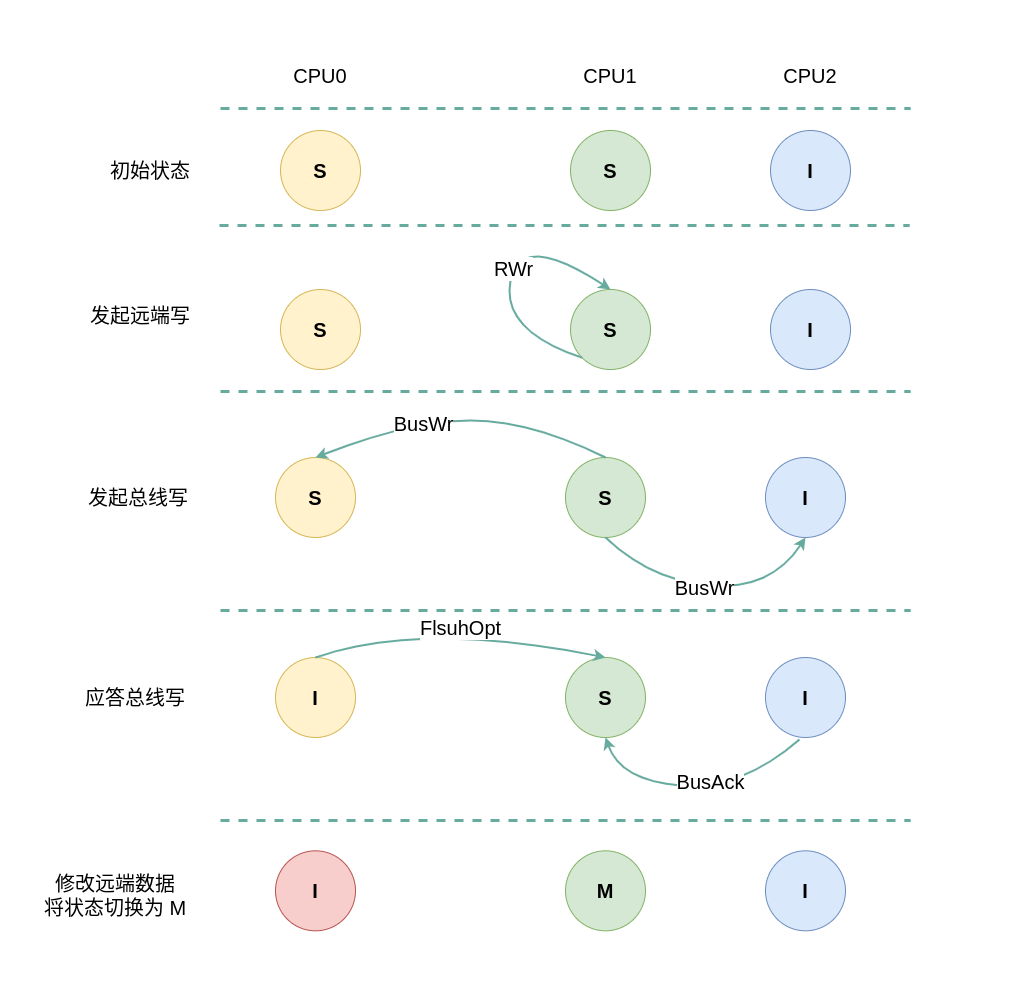
(2) 远端写请求: 当 CPU1 发起远端写请求 RWr 时,发现其 CACHE Line 的状态为 Shared,即 CACHE 中有缓存对应内容 CACHE Hit, 其他 CPU 也有相应的副本,且所有的副本与内存上的数据是一致的,CPU1 向总线产生一个总线写 BusWr, CPU0 监听到 BusWr 之后检查包含对应的副本,CPU0 则将对应的 CACHE Line 状态设置为 Invalid,并回应一个 FlushOpt 信号. CPU2 监听到 BusWr 之后检查不包含对应的副本,直接应答总线. CPU1 收到 FlushOpt 应答之后直接修改其 CACHE Line 的内容,并将 CACHE Line 的状态修改为 Modify.
初始状态为 Exclusive
当本地 CACHE Line 的状态为 Exclusive,那么说明其他 CPU 并没有该 CACHE Line 的副本,并且本地 CACHE Line 的内容和内存中的内存是一致的. 此时无论是本地读写还是远端读写,都会改变 CACHE Line 的状态,具体改变可以从读请求和写请求场景进行分析:
本地/远端读请求
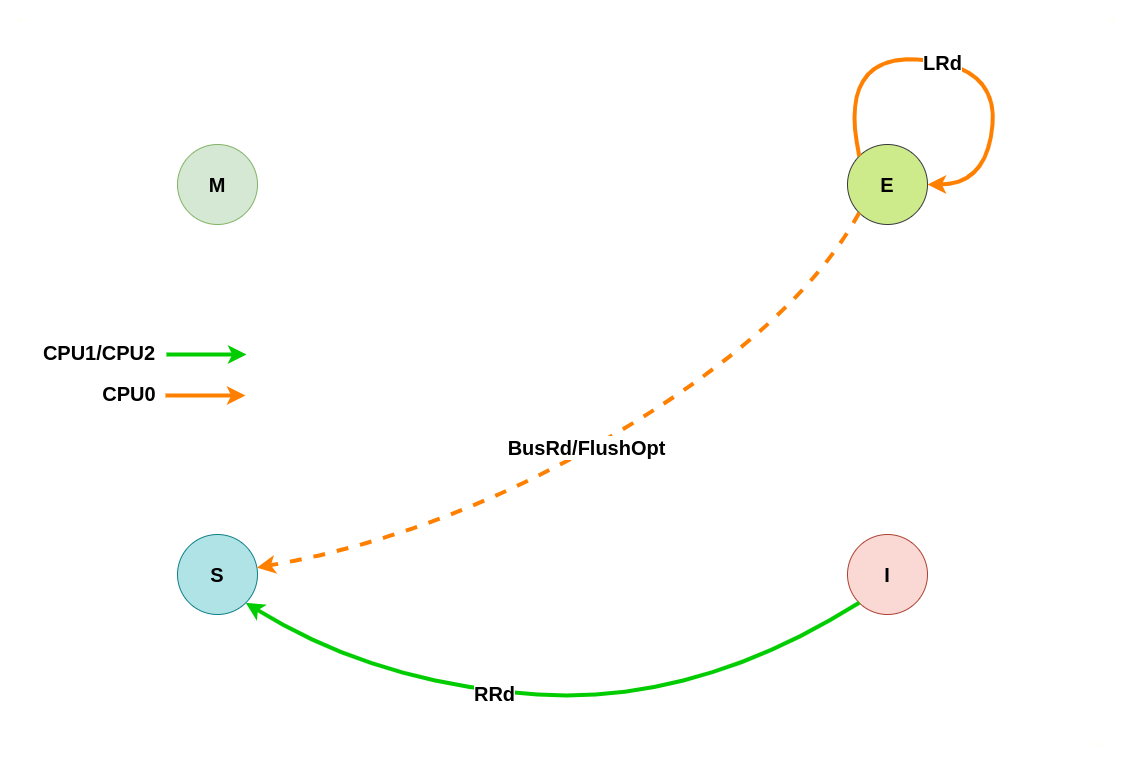
假设系统有 3 个 CPU,分别是 CPU0、CPU1 和 CPU2,并且 CPU0 为本地视角,CPU1 和 CPU2 远端视角. 当 CPU0 发起本地读请求 LRd或者 CPU1/CPU2 发起远端读请求 RRd,当本地 CACHE Line 的状态为 Exclusive 状态,远端 CACHE Line 的状态是 Invalid,那么 CACHE Line 的变化包括如下几种场景:
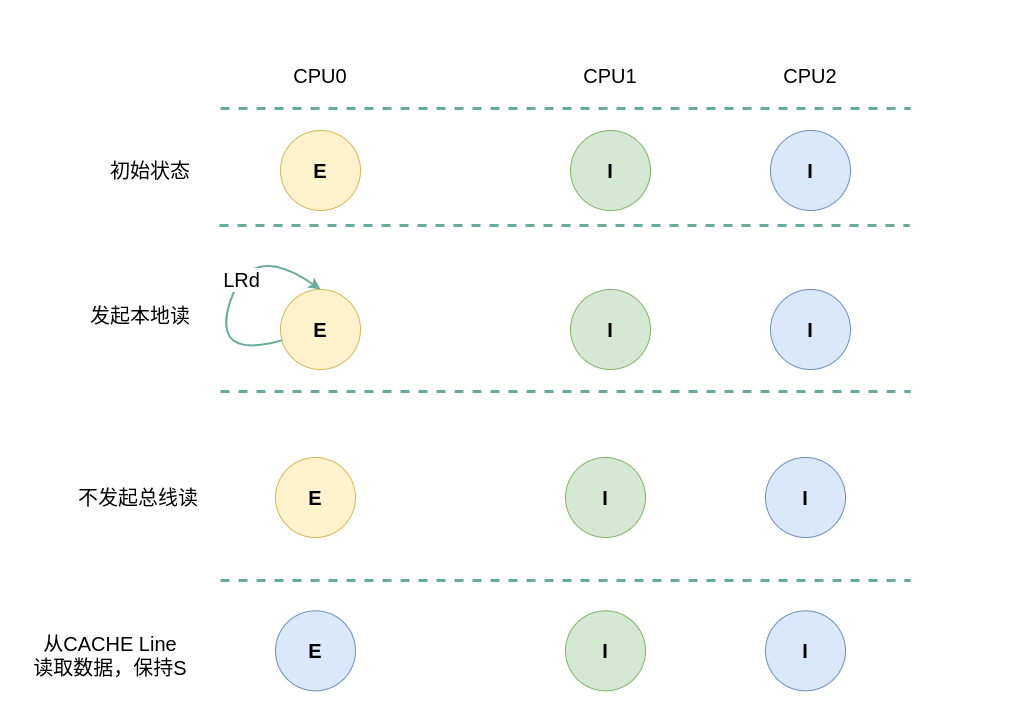
(1) 本地读请求: 当 CPU0 发起本地读请求 LRd 时,发现本地 CACHE Line 的状态为 Exclusive,即 CACHE 中有缓存对应内容 CACHE Hit, 其他 CPU 没有有相应的副本,且 CACHE Line 与内存上的数据是一致的,因此本地 CACHE Line 的状态保持 Exclusive,不会向总线发起 BusRd 信号,而是直接从 CACHE Line 中读取数据.
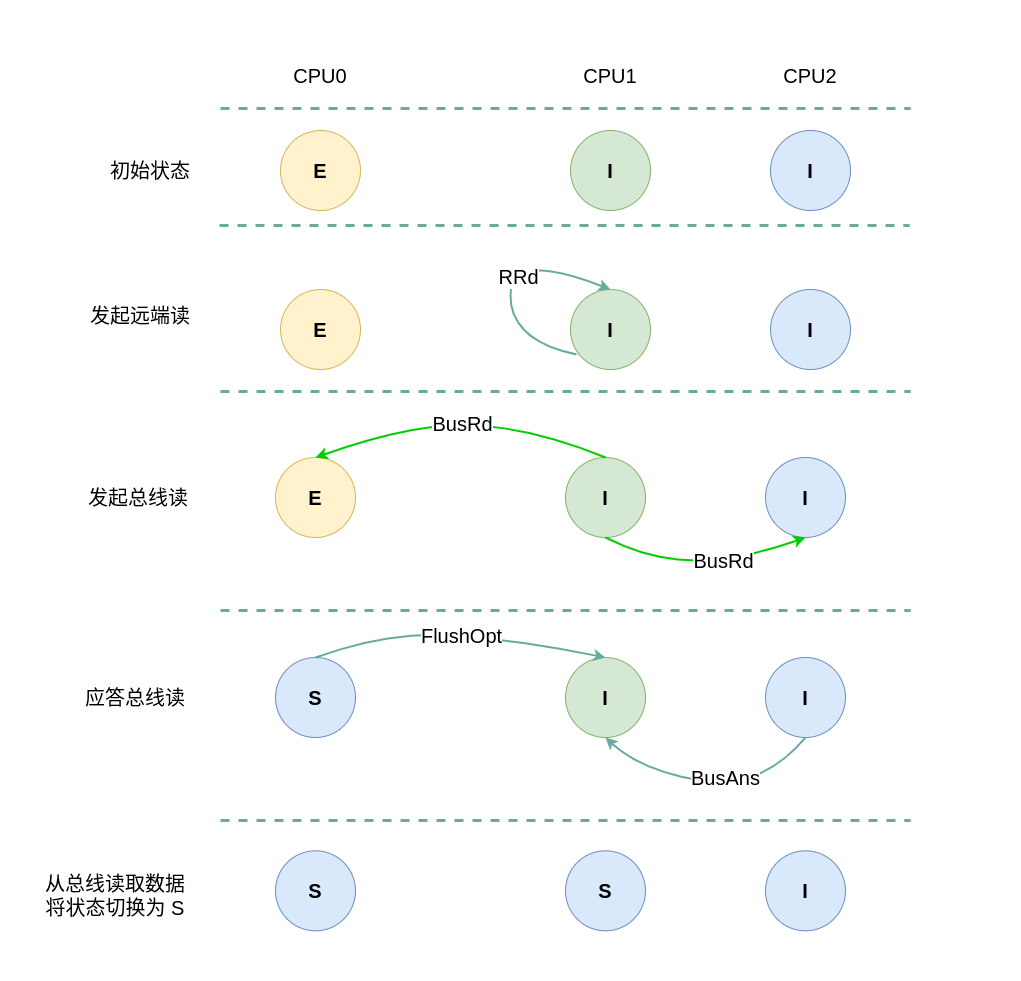
(2) 远端读请求: 当 CPU1 发起本地读请求 LRd 时,发现本地 CACHE Line 的状态为 Invalid,即 CACHE 中没有缓存对应内容 CACHE Miss, 那么产生一个总线读请求 BusRd. CPU0 监听到 BusRd 信号之后,检查其 CACHE 中存在副本,那么向总线发送 FlushOpt 信号并将 CACHE Line 内容发送到总线上,然后将其 CACHE Line 的状态切换成 Shared; CPU2 收到 BusRd 信号之后,检查其没有对应的副本,那么直接应答总线; CPU1 收到 FlushOpt 信号之后从总线上读取内容到本地的 CACHE Line,然后将 CACHE Line 状态设置为 Shared.
本地/远端写请求
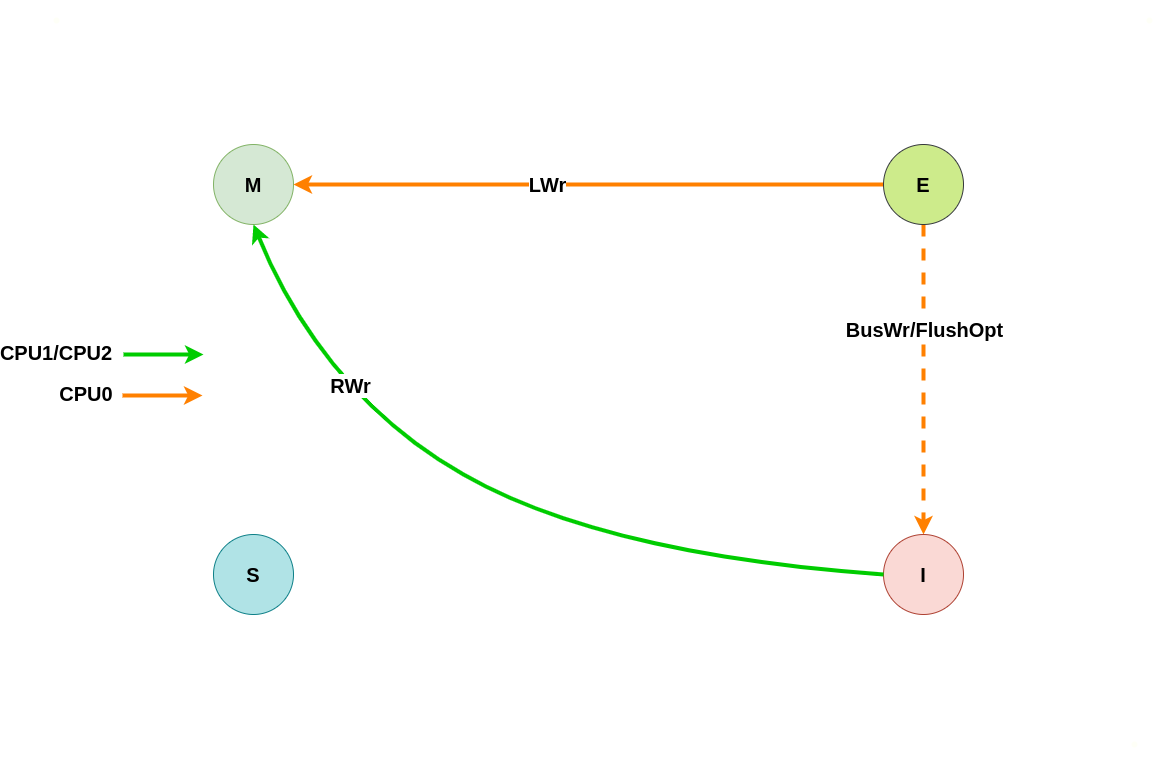
假设系统有 3 个 CPU,分别是 CPU0、CPU1 和 CPU2,并且 CPU0 为本地视角,CPU1 和 CPU2 远端视角. 当 CPU0 发起本地写请求 LWr或者 CPU1/CPU2 发起远端写请求 RWr,当本地 CACHE Line 的状态为 Exclusive 状态,远端 CACHE Line 的状态是 Invalid,那么 CACHE Line 的变化包括如下几种场景:
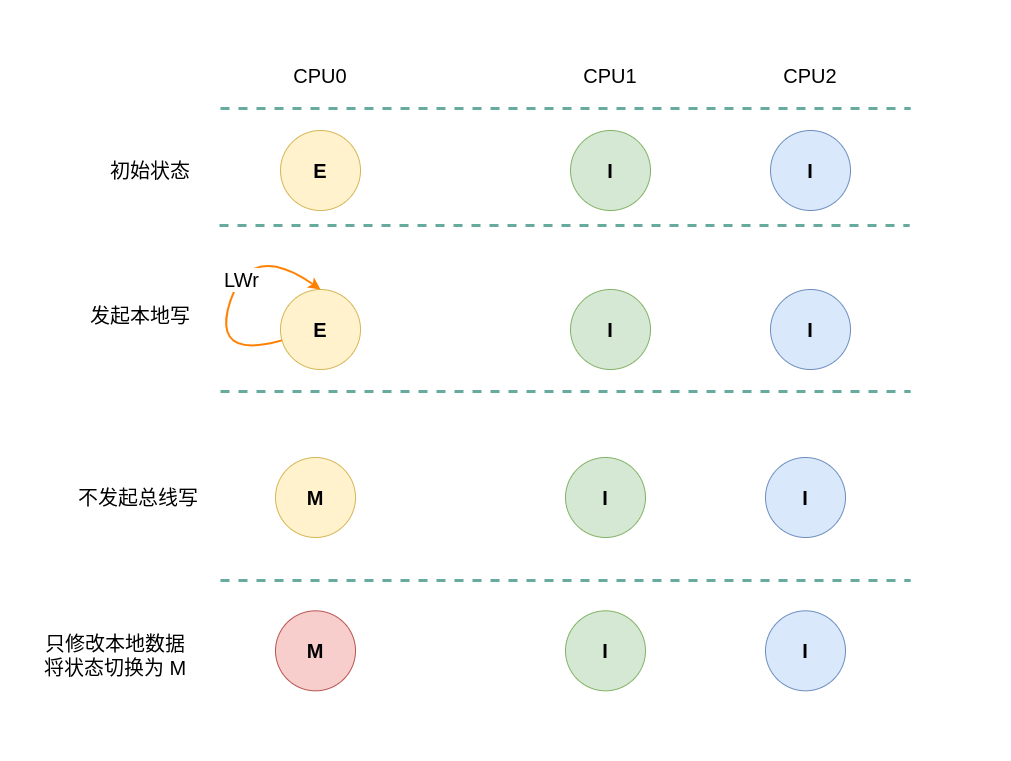
(1) 本地写请求: 当 CPU0 发起本地写请求 LRd 时,发现本地 CACHE Line 的状态为 Exclusive,即 CACHE 中有缓存对应内容 CACHE Hit, 其他 CPU 没有有相应的副本,且 CACHE Line 与内存上的数据是一致的,因此直接修改 CACHE Line 的内容,并将 CACHE Line 的状态切换为 Modify.
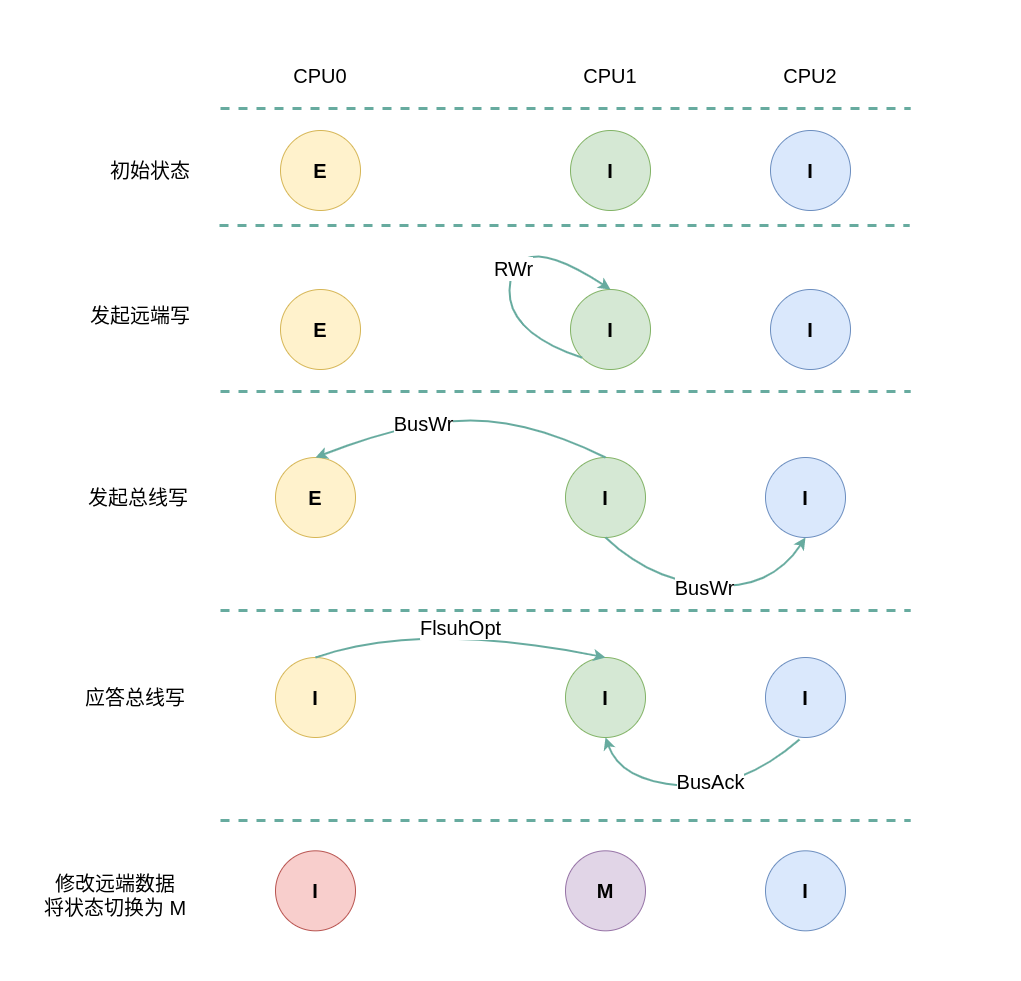
(2) 远端写请求: 当 CPU1 发起本地写请求 LRd 时,发现本地 CACHE Line 的状态为 Invalid,即 CACHE 中没有缓存对应内容 CACHE Miss, 那么产生一个总线写请求 BusWr. CPU0 监听到 BusWr 信号之后,检查其 CACHE 中存在副本,那么向总线发送 FlushOpt 信号并将 CACHE Line 内容发送到总线上,然后将其 CACHE Line 的状态切换成 Invalid; CPU2 收到 BusWr 信号之后,检查其没有对应的副本,那么直接应答总线; CPU1 收到 FlushOpt 信号之后从总线上读取内容到本地的 CACHE Line,然后修改 CACHE Line 内容,并将 CACHE Line 状态设置为 Modify.
多级 CACHE 架构
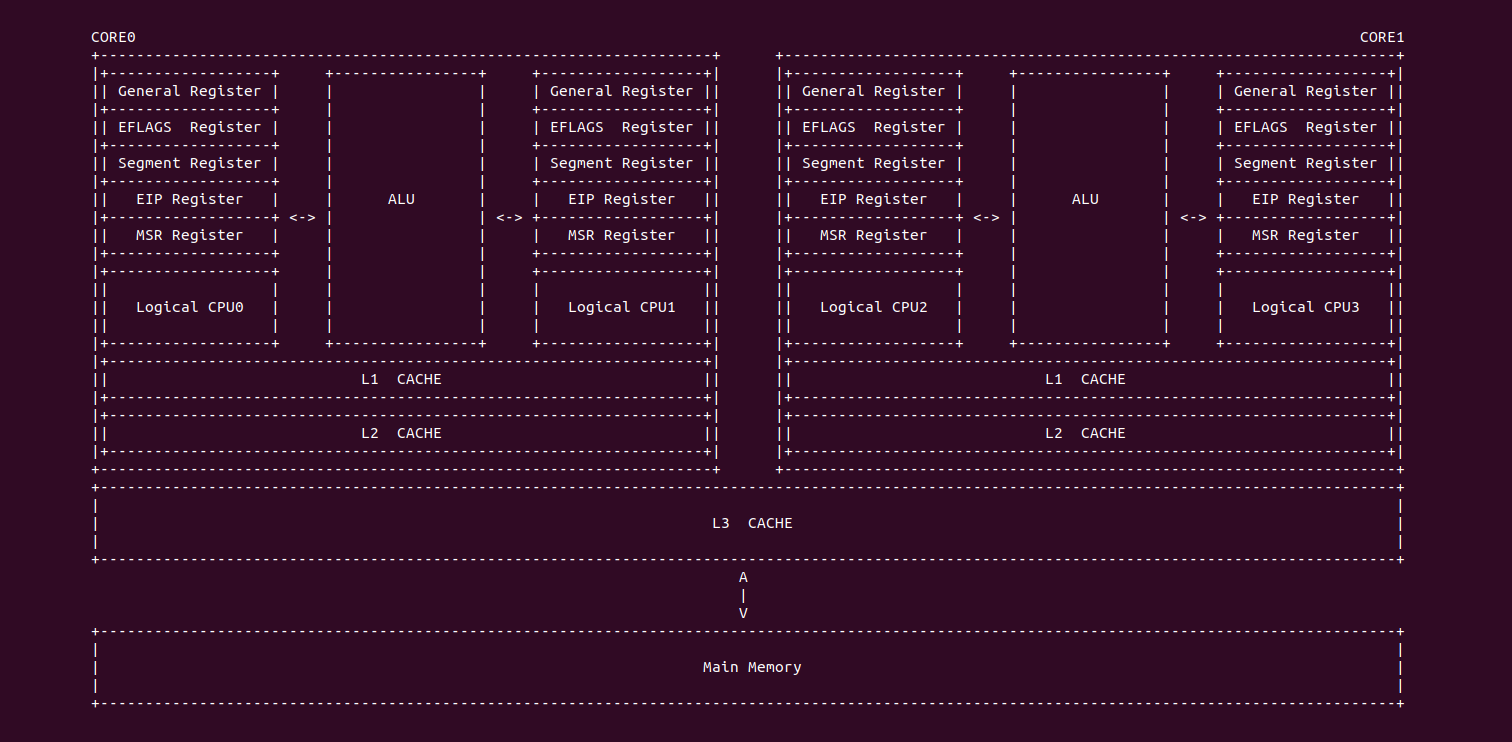
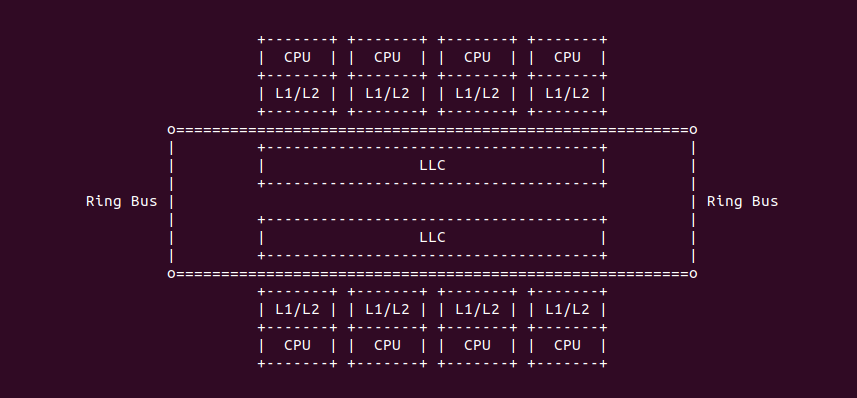
随着多核技术的不断普及以及摩尔定律的失效,CPU 的频率已经不是限制性能的主要因素,内存访问延时成为了系统性能的瓶颈,各大厂商在多核架构下通过增加 CACHE 的级数和 CACHE 容量,以此来加速对内存的访问。例如在 Intel 架构下,一个物理 Core 包含了两个逻辑核,两个逻辑核共用 L1 和 L2 CACHE,也就是一个物理核只有一个 L1 和 L2 CACHE。一个 CPU Socket 上面可能有一个或多个物理核,这些物理核共用 L3 CACHE,L3 CACHE 也被称为 LLC(Last Level CACHE),L2 CACHE 则被称为 MLC(Middle LeveL CACHE). L1 CACHE 又分为 Data CACHE 和 Instruct CACHE. 在有的架构中可能存在 4 级 CACHE,本文重点描述 3 级 CACHE 的架构.
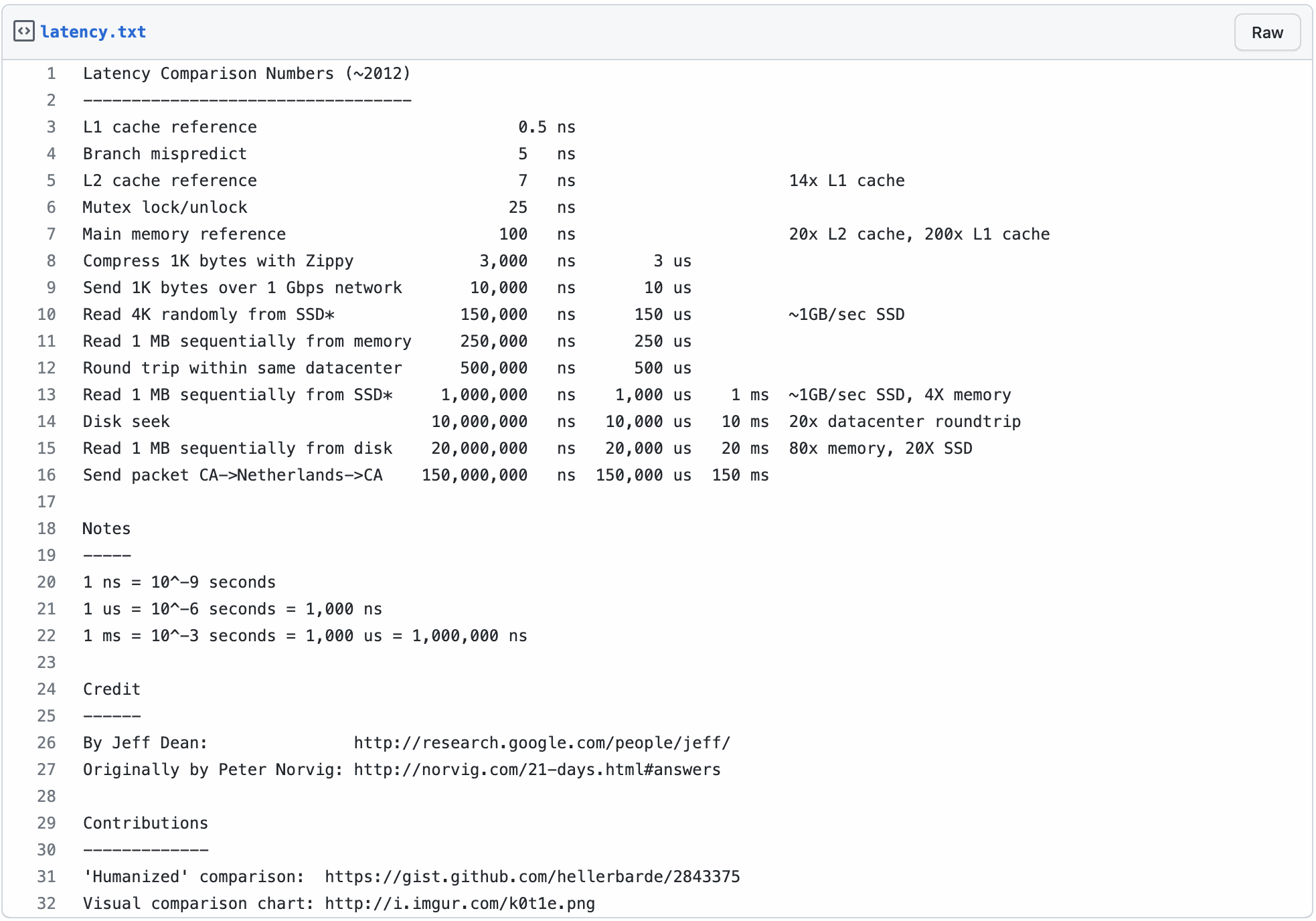
上表是 X86 架构下各级 CACHE 的 latency,CPU 访问每一级 CACHE 的延时不相同,L1 CACHE 的延时基本和指令执行的周期一致,MLC 的延时为 7ns,访问主存的时延是 100ns. 为什么采用多级 CACHE 架构就能显著提升系统性能呢? 这里通过一个例子进行讲解:
- 假设把 CPU 的一个时钟周期看做 1s,系统访问数据比作在图书管理里面查资料
- 从 L1 CACHE 读取信息就好比拿起桌上一张草稿纸(3s), 草稿纸上没有则从书包里找.
- 从 L2 CACHE 读取信息就好比是从书包里找书(14s). 书包里如果没有则去书架上找.
- 从 L3 Cache 读取信息好比从身边的书架上取出一本书(60s). 3 楼书架没有则去 1 楼书架找.
- 从主存中读取数据好比从 3 楼去 1 楼书架上查找(6 分钟). 1 楼没有则联系开发商补书.
- 从磁盘中读取数据好比联系开发商重新补印书本(长达一年零三个月).
通过上面的例子就知道多级 CACHE 对系统性能提升的重要性了吧,可以看到在性能极佳的场景下,CPU 访问的数据都在 L1 CACHE 中,系统基本没有延时的访问数据。而性能最差的场景则是所有访问的数据都在磁盘上, 系统大部分时间浪费在等待磁盘访问上,这简直是系统的噩耗.
多级 CACHE 架构发展
最早出现缓存的时候其实是单级缓存(L1 CACHE), 但随着技术的不断演进,多级缓存提供了更好的低平均请求延迟 Latency(平均所有命中和未命中). 另外目前处理器采用多核架构,所有核心都共享连接相对高延迟的 DRAM,因此多级是必不可少的。另外一个原因是多级缓存设计可以分开设计功率,而功率/热量是现代 CPU 设计中最重要的限制因素之一. 目前的 CPU 处理器都有 3 级 CACHE,但是三者存在明显差异。L1 CACHE 注重速度,L2 CACHE 要在 L1 CACHE Miss 之后才发挥作用,更注重节能和容量,L3 CACHE 则更追求容量和共享。但查询一个地址时,L1、L2 和 L3 的行为是不同的:
- L1 CACHE 会把多个 CACHE Line 的 Tag 和数据全部取出,然后再比较 Tag 看哪个命中或者都没命中,如果命中直接使用数据.
- L2 CACHE 虽然也是 N 路组相联,但比较时先只取 Tag,当找到命中的 CACHE Line 之后再去把对应的数据取出来.
- L3 CACHE 位于核外,多个物理核共享,因此还需要额外考虑一致性等.
L1 CACHE
L1 CACHE 与 CPU Core 紧密耦合,CPU 每次访问内存时都会访问 L1 CACHE,需要非常快速地返回数据,通常延时在 0.5ns,基本和时钟周期一致,因此 L1 需要非常快(低延时和高吞吐), 也意味着其命中率有限. 为了提高带宽,需要大量的读写端口来支持 L1 CACHE 的高速访问,端口数量是一个非常重要的设计点,会消耗芯片面积,这是因为端口会向 CACHE 添加线路(铜线). 同时高吞吐量也意味着能够在每个周期处理多个读取和写入(多个端口),使得功率暴增.
L1 CACHE 又分配 L1 Data CACHE(L1D) 和 L1 Instruction CACHE(L1I), 其在 CPU 内部的布局如上图。L1I 可以放置在物理上接近代码获取逻辑,而 L1D 可以放置在物理上靠近加载/存储单元. 这样的设计当时钟周期仅持续 1/3 纳秒时(2.5GHz, 为 0.4ns),光速传输线延迟也称为大问题,所以布线也很重要(例如 Intel 最新处理器硅片上有 13+ 层铜,类似 PCB 13 层板).
L1 CACHE 容量: L1 CACHE 的特点就是快,如果 L1 变得更大,它将增加 L1 访问延迟从而降低性能, 因此 L1 CACHE 的大小几乎没有争议。目前主流处理器的 L1 CACHE 大小为 64KiB。即使决定增加 L1 CACHE,L2 CACHE 也会同步跟进增加,以此加速 L1 CACHE Miss,但这样带来了成本和功耗的暴增.
L2 CACHE: MLC
系统中如果不存在 L2 CACHE,那么 L1 CACHE Miss 之后直接从主存中存取数据, 这样直接导致很多访问进入内存,不但意味着需要更多的内存带宽,也意味着性能严重降级. 所以 L2 CACHE 是为了缓解内存带宽压力,保持 L2 CACHE 一定大小,使其具备一定的带宽能力是非常必须的。如果架构中没有 L3 CACHE,那么 L2 CACHE 通常作为带宽过滤器,减少内存带宽使用. 如果架构中包含 L3 CACHE,那么 L2 CACHE 可以有效减少对片上互联和对 L3 的访问.
L2 CACHE 没有像 L1 CACHE 分为 L1 Data CACHE 和 L1 Instruction CACHE,而是无差别对待指令和数据,因此称 L2 CACHE 为 L2 Unitied CACHE. L2 CACHE 的位置如上图,其位于 CPU CORE 内部,被多个逻辑核共享,且每个物理核只有一个 L2 CACHE. 虽然 L1 区分指令和数据对速度有很多的帮助,当统一的 L2 CACHE 还是最佳的选择,因为有些任务的代码量比较小,但其数据量远大于代码量,L2 CACHE的统一以适应不同的任务负载是有意义,而不是静态地划分为代码和数据.
L3 CACHE: LLC
主流的架构中都包含了 L3 CACHE,并且 L3 CACHE 作为最后一级 CACHE,简称为 LLC. L3 CACHE 不在物理核内部,其位于一个 CPU Socket 内部,被多个物理核共享. L3 CACHE 通常使用 ECC,可以完成 ECC 在较大的块上以降低开销. 相对 L2 CACHE,L3 CACHE 速度更慢,慢速可以以较低的电压/时钟速度运行,减少热量. 甚至可以为每个存储单元使用不同的晶体管布置,以使存储器更优化功率而不是高速存储器.
Inclusive 与 Exclusive
在 《CACHE 一致性章节》描述了 MESI 如何维护 CACHE 一致性的,其中 CACHE Line 具有 Exclusive 状态,其表示只有该 CPU 缓存了 CACHE Line,并且 CACHE Line 中的内存与主存中的一致.

Intel® X86 架构 CACHE 机制

Intel® Core-i7 and Xeon CACHE
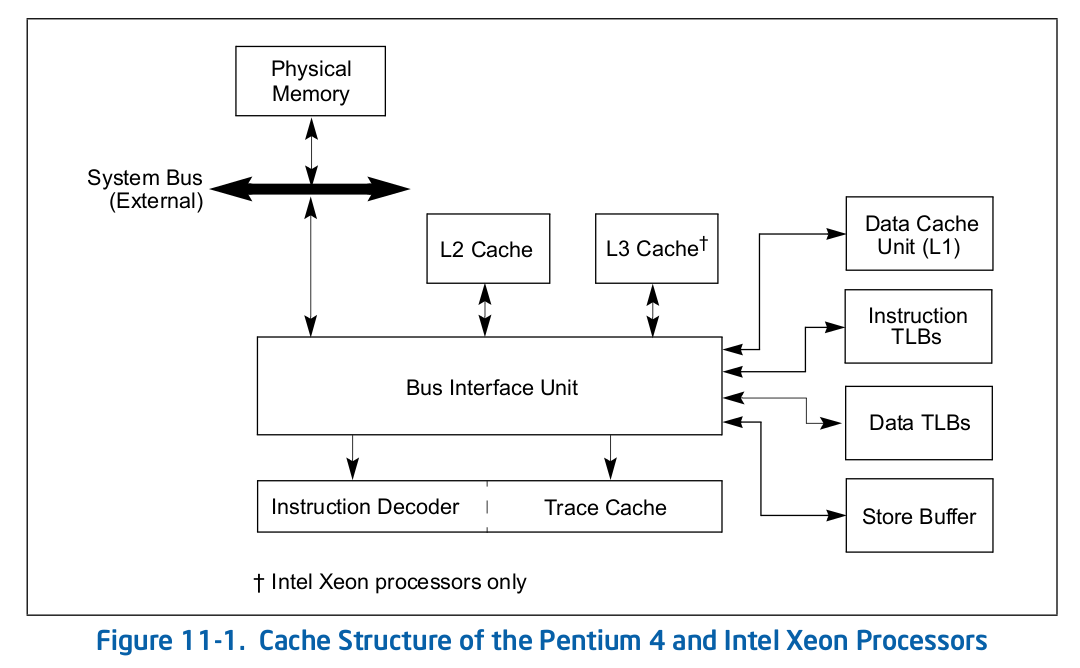
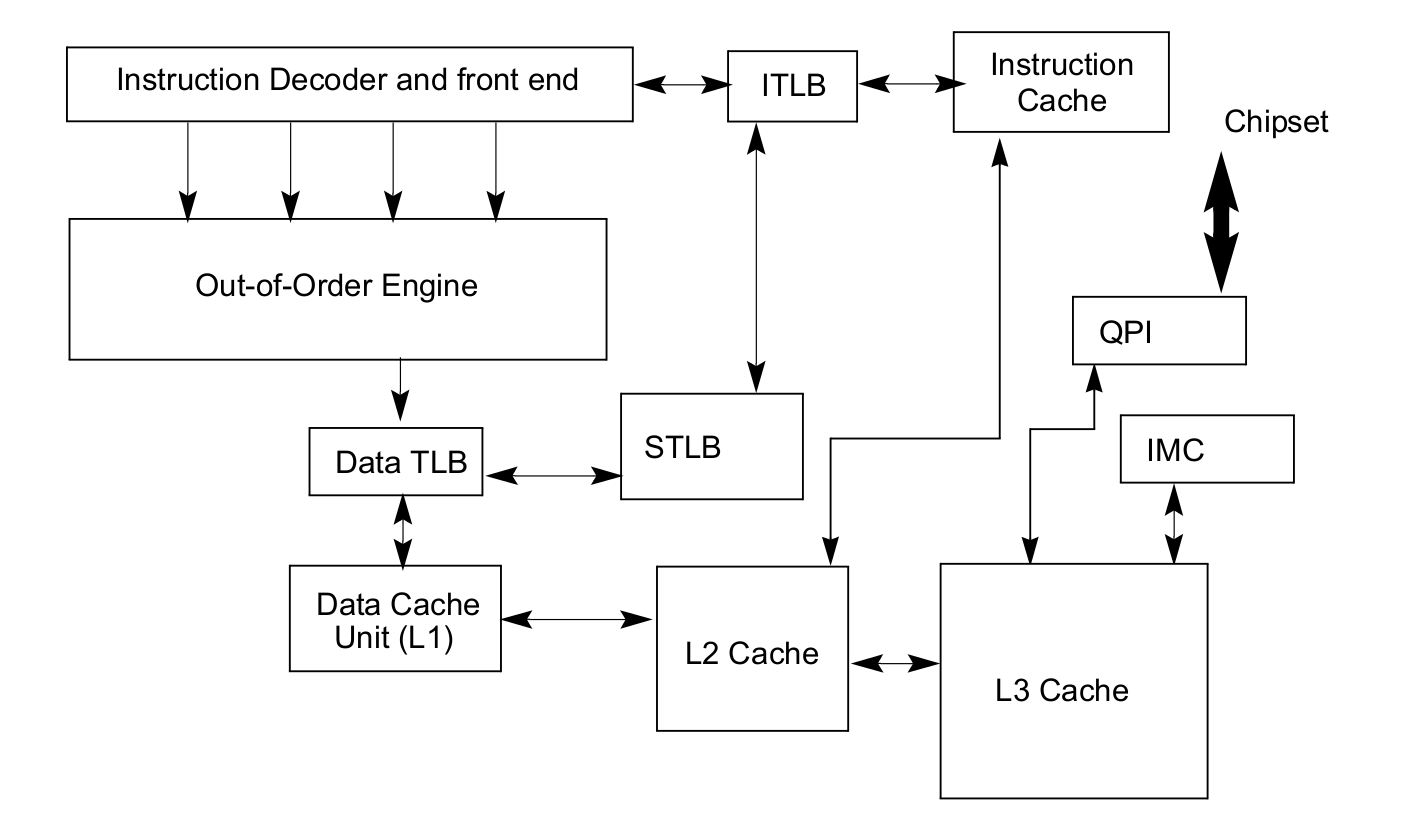
Intel 64 架构和 IA-32 架构的 CACHE 系统由Data CACHE Unit(L1)、Instruction CACHE、Data TLB、Instruction TLB、L2 CACHE、L3 CACHE、Store Buffer 以及 Trace CACHE 等硬件组成,不同系列的处理器 CACHE 架构可能有所差异,大体上可以分为 Xeon 系列和 Core 系列,Figure 11-1 展示 Xeon 系列处理器 CACHE 基本组成架构,Figure 11-2 则展示了 Core i7 处理器的 CACHE 基本架构。两种图的差异不仅体现在硬件组织方式,还体现在同种硬件的大小,其与具体的系列有关系,那么接下来对每种硬件进行介绍:
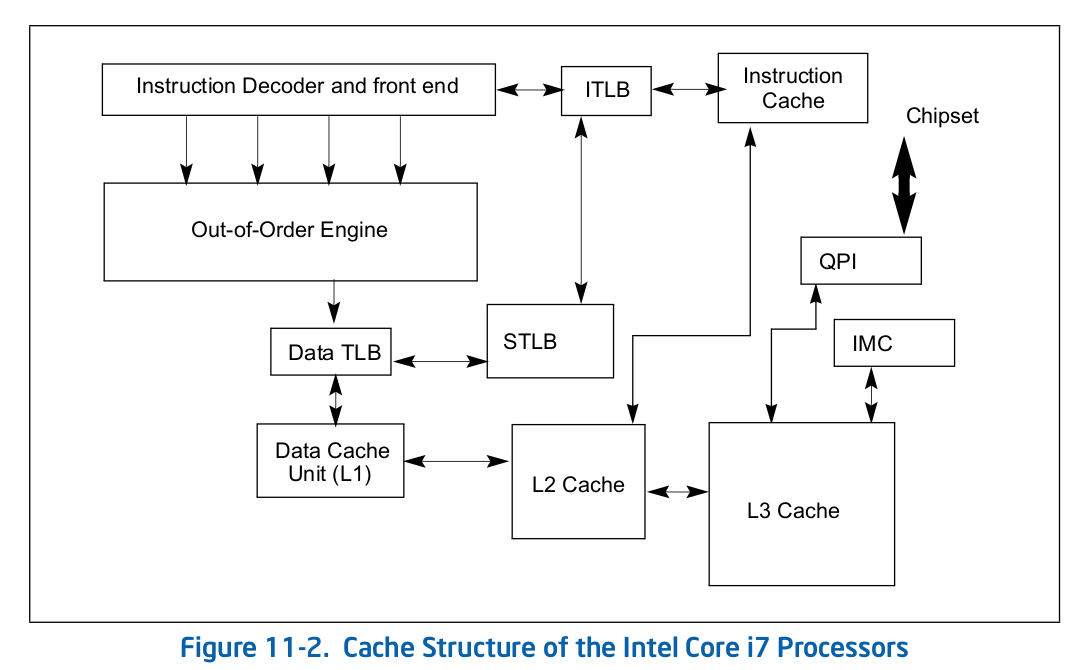
Trace CACHE Trace CACHE 是一种加快指令提取的技术,使用处理器能以更短时间读取更多的指令,能有效的提高处理器性能. L1 Instruct CACHE 片上 L1 指令 CACHE,靠近代码获取逻辑,专门用于缓存指令,加速指令的读取. L1 Data CACHE 片上 L1 数据 CACHE,靠近加载/存储单元,专门用于缓存数据,加速数据的读取. L2 Unitied CACHE 片上的 L2 CACHE,不区分指令和数据,缓解内存带宽压力,通常作为带宽过滤器. L3 Unified CACHE 被同一个 Socket 上的物理核共享,不缺分指令和数据,缓解内存带宽压力. Instruction TLB(4-KByte Pages) 用于缓存 L1 Instruction CACHE 中虚拟地址到 4KiB 物理页的映射关系, 加速地址翻译.
Data TLB(4-KByte Pages) 用于缓存 L1 Data CACHE 中虚拟地址到 4KiB 物理页的映射关系, 加速地址翻译. Instruction TLB(Large Pages) 用于缓存 L1 Instruction CACHE 中虚拟地址到巨型物理页(2M/1G/512G HugePage)的映射关系,加速地址翻译. Data TLB(Large Pages) 用于缓存 L1 Data CACHE 中虚拟地址到巨型物理页(2M/1G/512G HugePage)的映射关系, 加速地址翻译. Second-level Unified TLB(4-KByte Pages) 用于缓存 L2 Unified CACHE 中虚拟地址到物理页的映射关系,加速地址翻译. Store Buffer 可先将 CPU 写数据缓存到 Store Buffer,然后给其他 CPU 发送消息,然后处理其他事,待其他 CPU 发送应答消息之后,再将数据从 Store Buffer 写入到 CACHE Line. Write Combining(WC) Buffer 当 L1 CACHE Write Miss,WC Buffer 为了减少 Write Miss 带来的性能开销,可以把多个对同一 CACHE Line Store 操作的数据放到 WC Buffer,等到需要读取时再一次性写入,以此减少写入的次数和总线的压力.
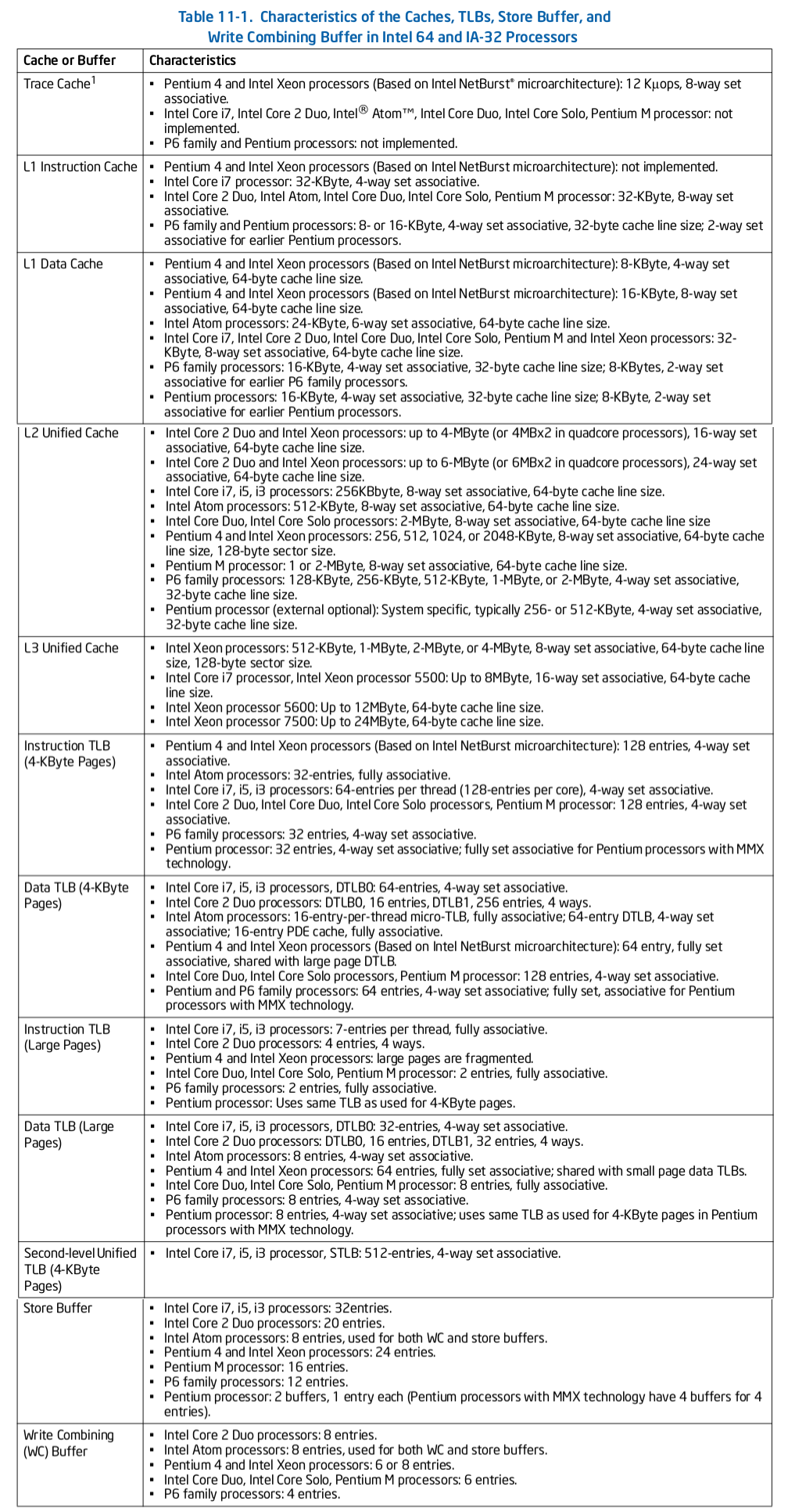
Table 11-1 描述了各硬件在不同系列的 Intel 处理器的大小信息.
Intel® Smart CACHE Technology
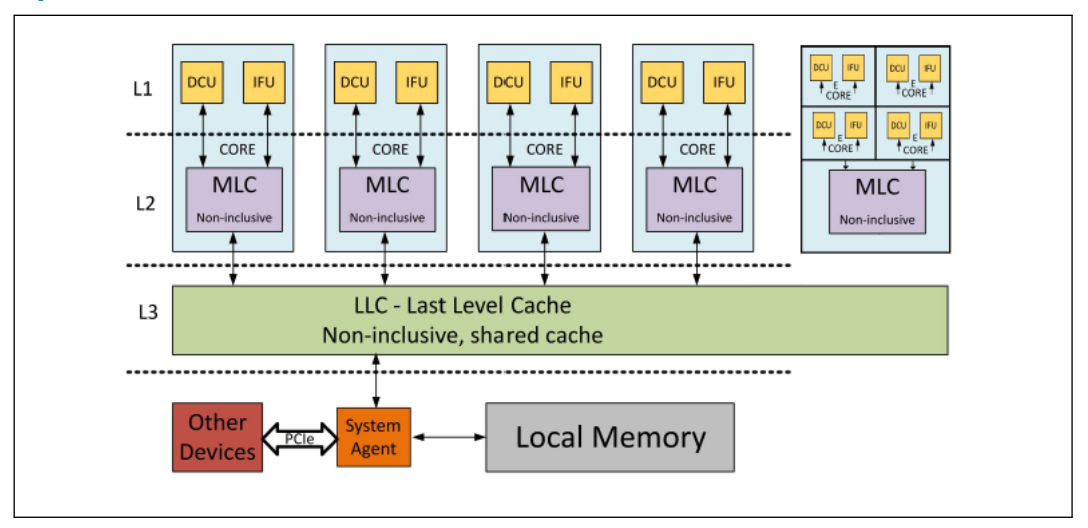
在 Intel 12 代 Core CPU 上使用了 Smart CACHE 技术,其共享了最后一级缓存 LLC. 由于共享了最后一级 CACHE,那么 LLC 具有了 non-inclusive 特点,LLC 被所有的物理核共享(因为只有一个 Socket). 上图为 12 代 CPU 的 Hybrid CACHE 架构, CPU 被换分为 P-Core 和 E-Core,P-Core 用于处理较重的任务,而 E-Core 则是低功耗且处理相对轻松的后台任务.
L1 CACHE: P-Core 的 L1 CACHE 被分为数据 CACHE (DFU) 和指令 CACHE (IFU), L1 CACHE 包含了 48KiB 的 DFU 和 32KiB 的 IFU, L1 CACHE 是一个 12-Way 的组相联 CACHE 架构, P-Core L1 CACHE 不被其他物理核共享. E-Core 的 L1 CACHE 同样被分为数据 CACHE(DFU) 和指令 CACHE(IFU), L1 CACHE 包含了 64KiB DFU 和 32KiB IFU,E-Core 的 L1 CACHE 是一个 8-Way 的组相联 CACHE 架构, E-Core L1 CACHE 不被其他物理核共享.
L2 CACHE: L2 CACHE 不区分数据和指令,其也被称为 MLC. P-Core L2 CACHE 大小为 1.25MiB, 10-Way non-inclusive 组相联 CACHE 结构,P-Core 不与其他物理核共享 L2 CACHE. E-Core 由 4 个物理核共享一个 L2 CACHE,其 16-Way non-inclusive 组相联的 2MiB CACHE.
L3 CACHE: L2 CACHE 不区分数据和指令,其被称为 LLC. LLC 被所有 P-Core 共享,且每个 P-Core 物理核最大包含 3MiB 的 12-Way 组相联 CACHE. LLC 也被所有 E-Core 共享,但 4 个 E-Core 包含 3MiB 的 12-Way 组相联 CACHE.
From《2.4.2 12 IA Cores L1 and L2 Caches - 12th Generation Intel® Core ™Processors》
Intel® Memory Type
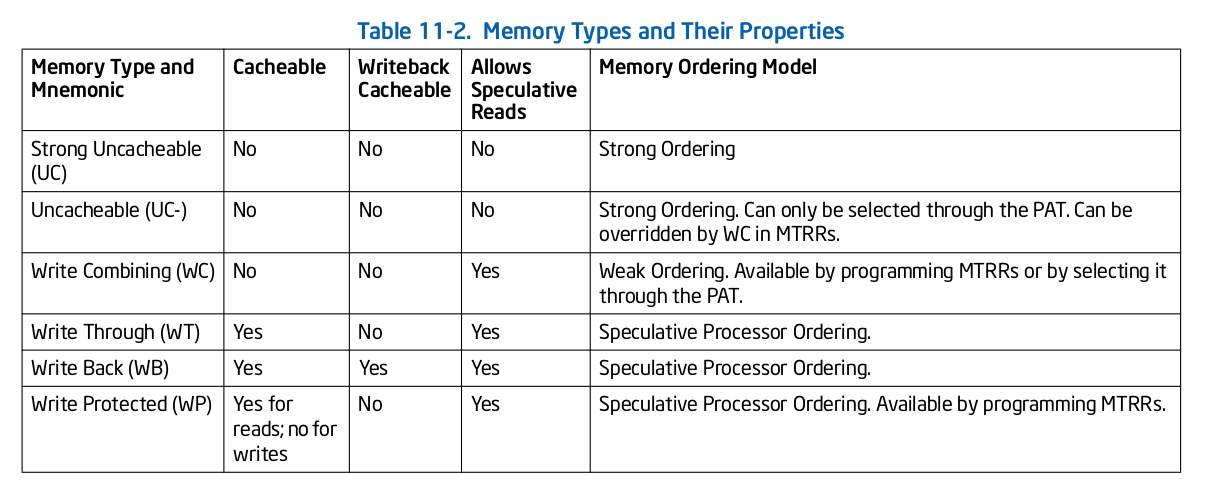
Intel X86 架构可以将所有的物理内存缓存到 L1/L2/L3 CACHE, 并且架构支持按独立页或者独立区域的粒度设置物理内存的缓存方式,在 Intel 架构下将物理内存缓存方式称为 memory type. Table 11-2 定义了 Intel 64 和 Intel IA-32 架构都支持的 memory type, 包括了 UC/UC-/WC/WT/WB/WP, 那么接下来对每种缓存类型进行详细的分析.
Strong Uncacheable (UC)
Strong Uncacheable (UC): 强非缓存类型,该类型的物理内存不使用任何缓存机制. 系统对该类型的物理内存的读写请求会直接发送到总线上,另外硬件上不会对该类型物理内存的访问和对应页表遍历预测功能,同样也不会对分支进行预测. UC 缓存类型通常用于映射外设的 MMIO,因为外设不具有监听(snoop)总线的能力,为了保持设备看物理区域与 CPU 看到的一致,因此将该物理区域设置为 UC 之后,CPU 对该区域的读写请求直接访问到物理地址上,不会缓存在 CACHE 里,因此可以保持设备和 CPU 看到数据的一致性. 不建议将普通的物理内存的缓存类型设置为 UC,这样会 CPU 每次都对物理内存进行访问,这会大大影响系统性能. 接下来通过一个实践案例介绍内核如何将一段 MMIO 区域的缓存类型设置为 UC, 其在 BiscuitOS 上的部署逻辑如下:
内核空间虚拟地址映射 UC MMIO
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] UNCACHE(UC): Mapping UC MMIO on Kernel --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-UNCACHE-MMIO-KERNEL-default
# 部署源码
make download
# 在 BiscuitOS/Broiler 中实践
make broilerBiscuitOS-CACHE-UNCACHE-MMIO-KERNEL-default Source Code on Gitee
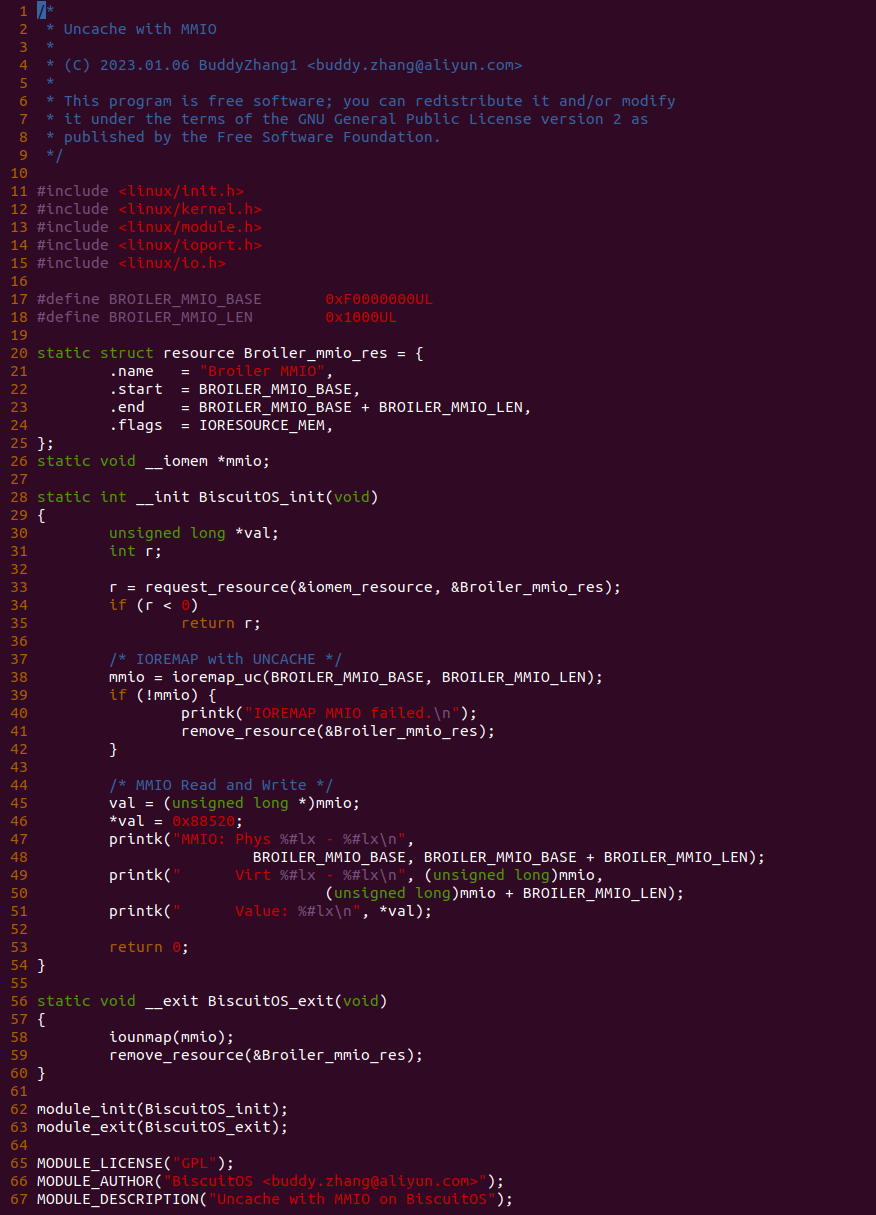
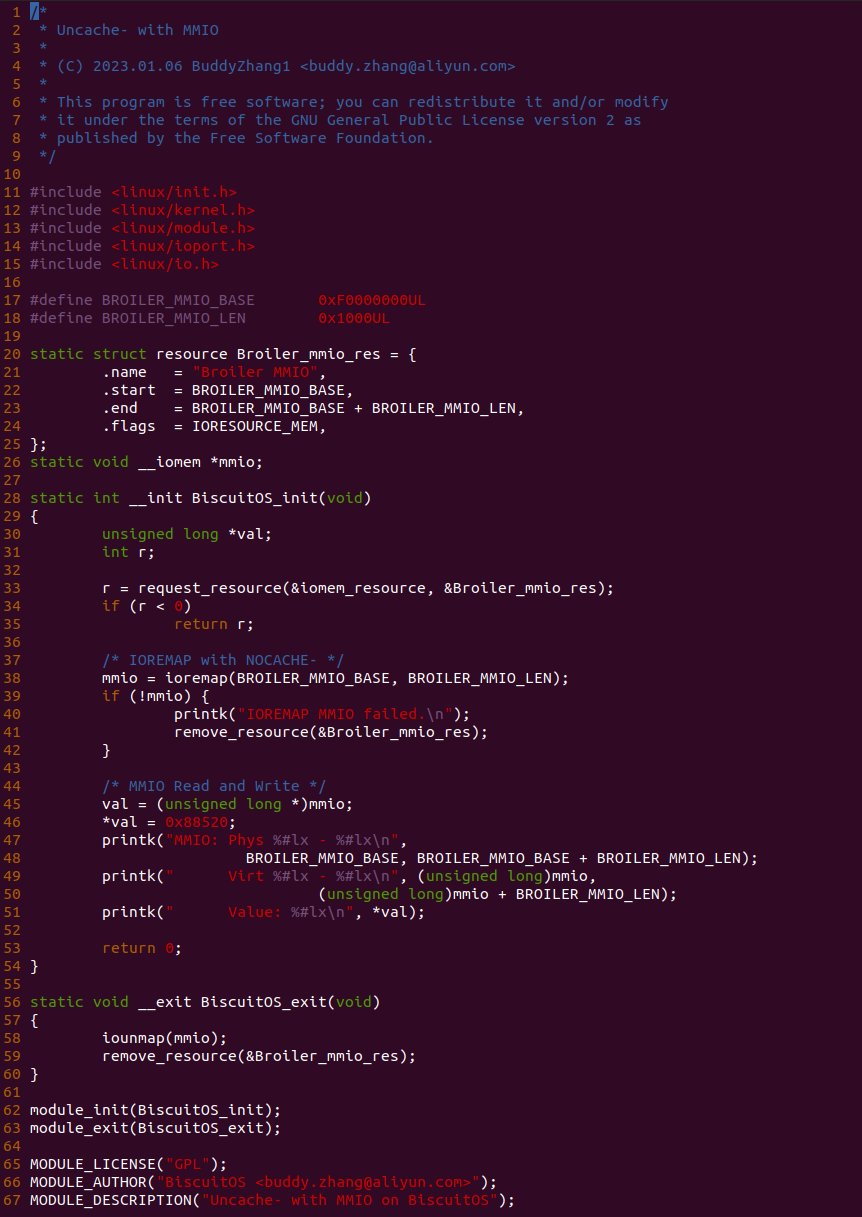
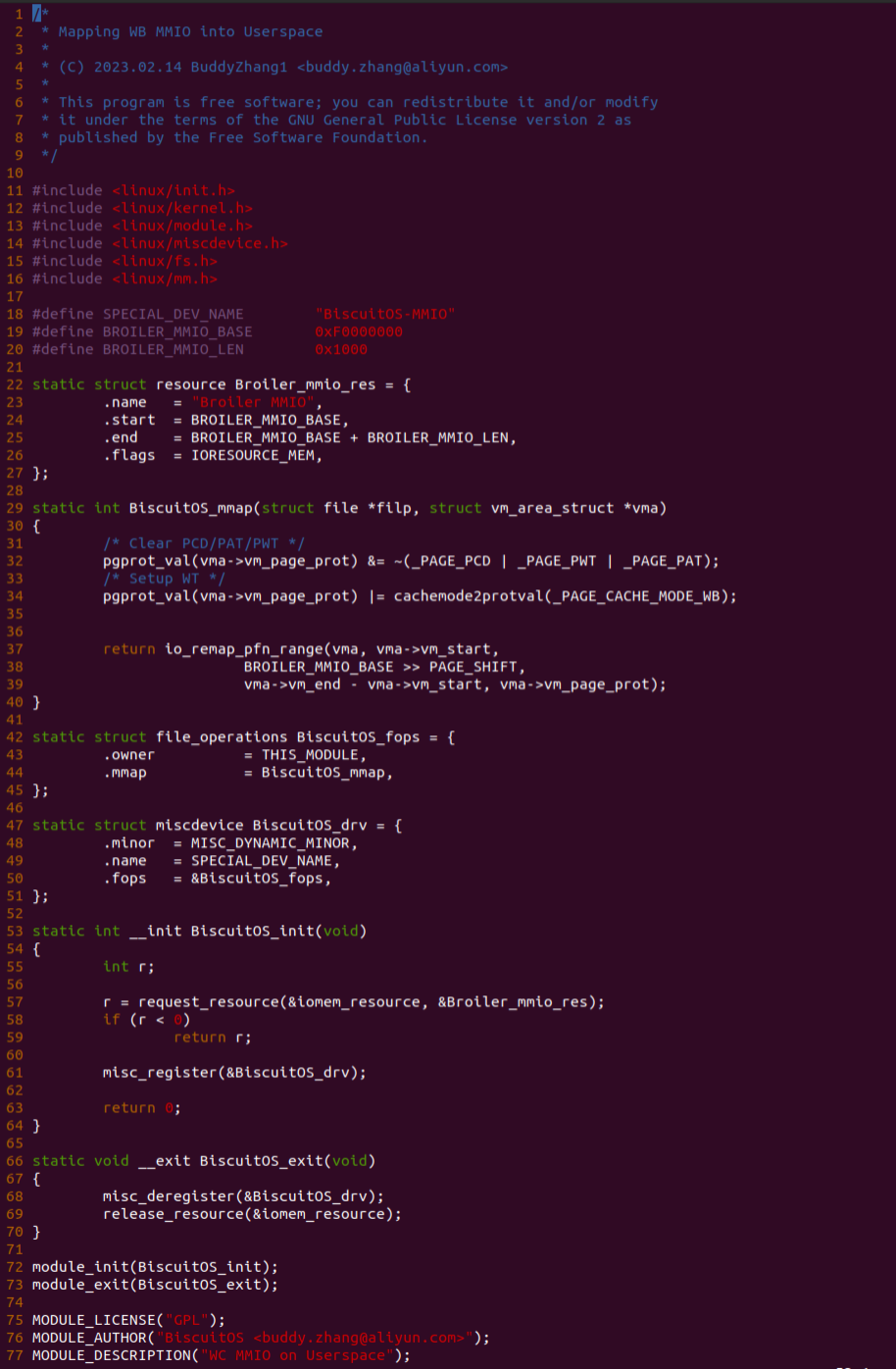
源码通过一个内核模块进行展示,模块有两部分组成,第一部分是 20-35 行,模块向系统资源总线注册了一段 MMIO,这段 MMIO 起始物理地址是 BROILER_MMIO_BASE, 长度为 BROILER_MMIO_LEN, 注册完毕之后可以在系统启动之后,通过 ‘/proc/iomem’ 接口查看到该段信息; 第二部分是 38-46 行,模块在 38 行调用 ioremap_uc() 函数将 BROILER_MMIO_BASE 开始且长度为 BROILER_MMIO_LEN 的 MMIO 区域,映射为 Uncached 的 memory type, 映射完毕之后函数在 46 行对 MMIO 进行访问,此时并不会触发缺页,因为 ioremap_uc() 函数已为 MMIO 分配了对应的虚拟地址并建立了页表,因此模块可以直接访问 MMIO. 最后在 BiscuitOS 上实践模块,由于需要一段真实的 MMIO 才能运行模块,因此可使用 Broiler 模拟一段 MMIO,其起始物理地址为 0xF0000000(Broiler 已经模拟好硬件),开发者直接在源码目录执行 make broiler 即可:
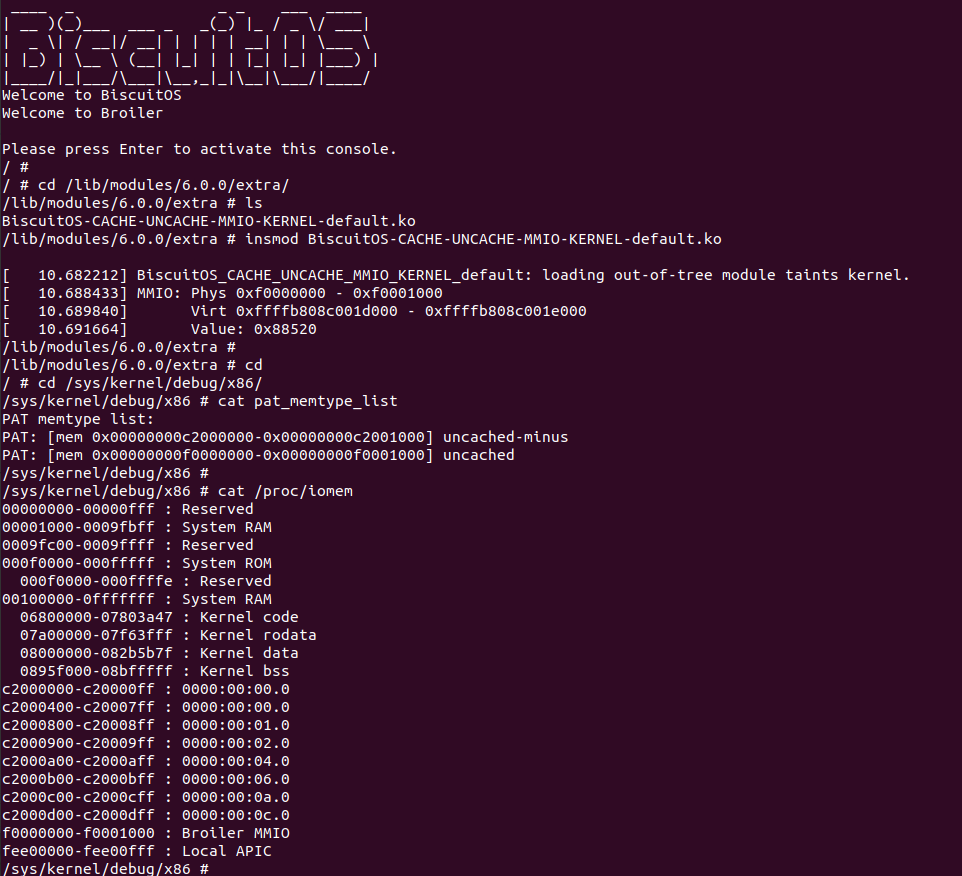
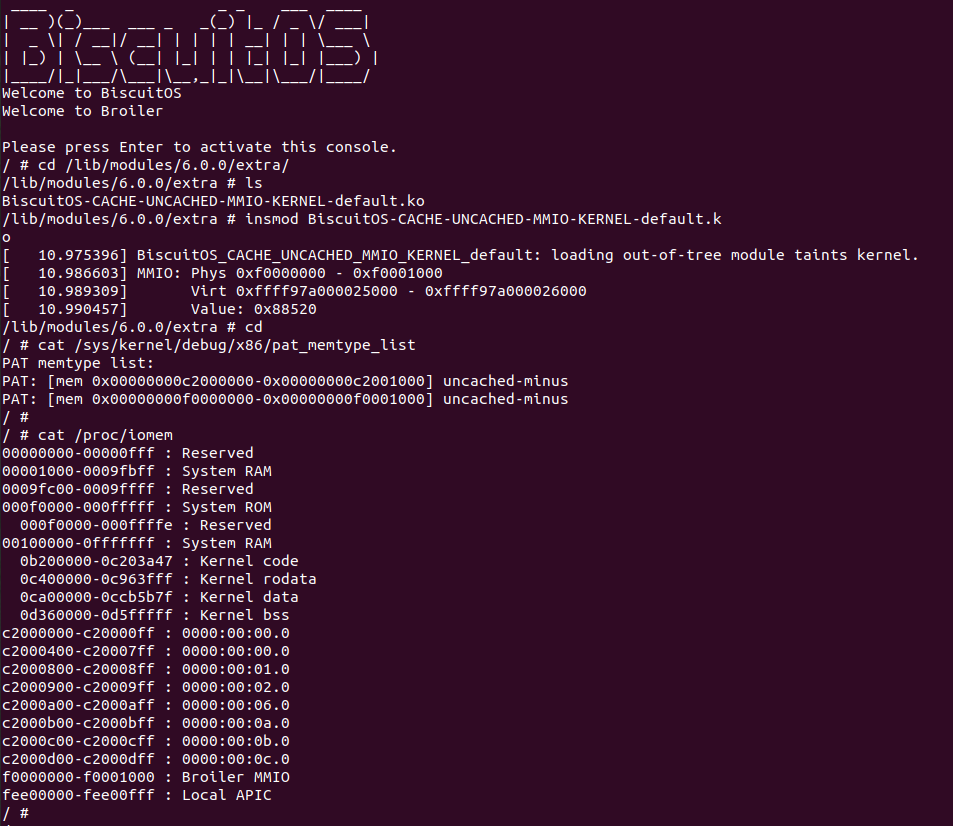
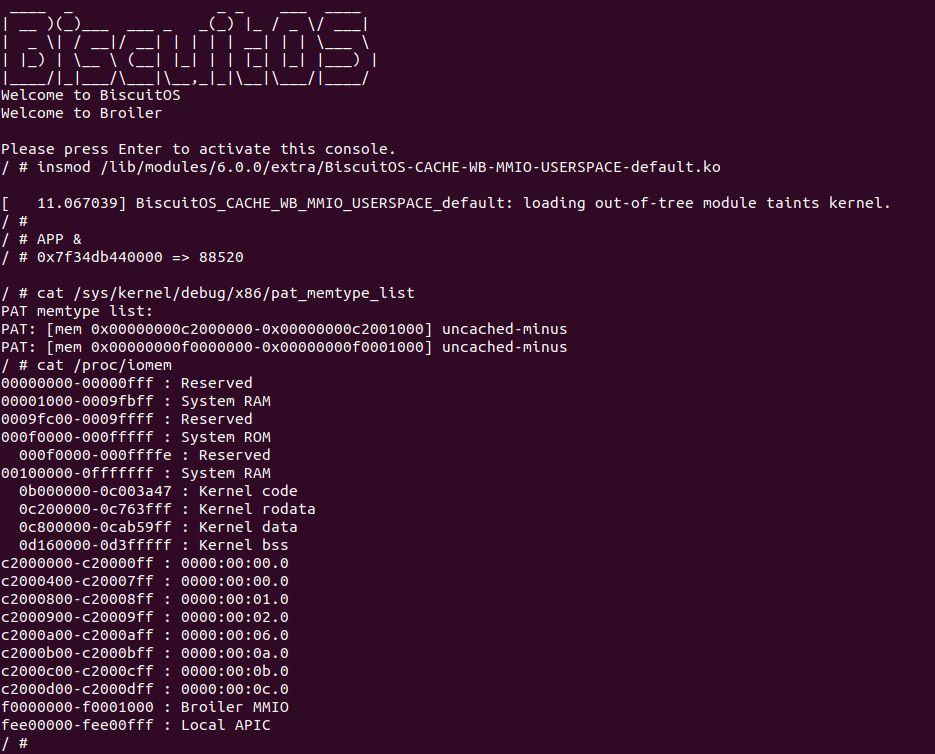
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-UNCACHE-MMIO-KERNEL-default.ko 模块之后,从打印的内核信息可以看出模块已经映射了 MMIO,并且向 MMIO 写入 0x88520 之后可以读出正确的数据,最后查看 ‘/sys/kernel/debug/x86/pat_memtype_list’ 节点查看系统 MMIO memory_type 信息,可以看到模块映射的 MMIO [0xF0000000, 0xF0001000] 为 uncached, 另外查看 ‘/proc/iomem’ 节点查看物理地址空间信息,可以看到 [0xF0000000, 0xF0001000) 为 Broiler MMIO 区域, 实践符合预期. 接下来一个实践案例用于介绍如何将用户空间虚拟地址映射成 UC 的 MMIO,BiscuitOS 部署逻辑如下:
用户空间虚拟地址映射 UC MMIO
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] UNCACHE(UC): Mapping UC MMIO on Userspace --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-UNCACHE-MMIO-USERSPACE-default
# 部署源码
make download
# 在 BiscuitOS/Broiler 中实践
make broilerBiscuitOS-CACHE-UNCACHE-MMIO-USERSPACE-default Source Code on Gitee

实践案例由两个部分组成,main.c 为内核模块部分,负责映射 MMIO 的底层逻辑。模块首先在 22-26 行定义了 MMIO 区域的信息,然后在 56-57 行通过调用 request_resource() 函数将 MMIO 区域添加到系统物理地址空间树里。模块通过注册一个 MISC 驱动,向用户空间提供 “/dev/BiscuitOS-MMIO” 接口,用户空间程序打开该接口,并调用 mmap() 映射 MMIO 时会调用到模块的 BiscuitOS_mmap() 函数,该函数首先在 32 行将虚拟地址对应的页表属性里的 _PAGE_PAT、_PAGE_PCD 和 _PAGE_PWT 标志清除,然后在 34 行调用 cachemode2protval() 函数,结合 _PAGE_CACHE_MODE_UC 将相关的 PAT 页表属性赋值到 vm_page_prot 成员里,接下来调用 io_remap_pfn_range() 函数进行虚拟地址到 MMIO 的映射工作。映射完毕之后用户空间虚拟地址就可以以 UC 方式访问 MMIO.
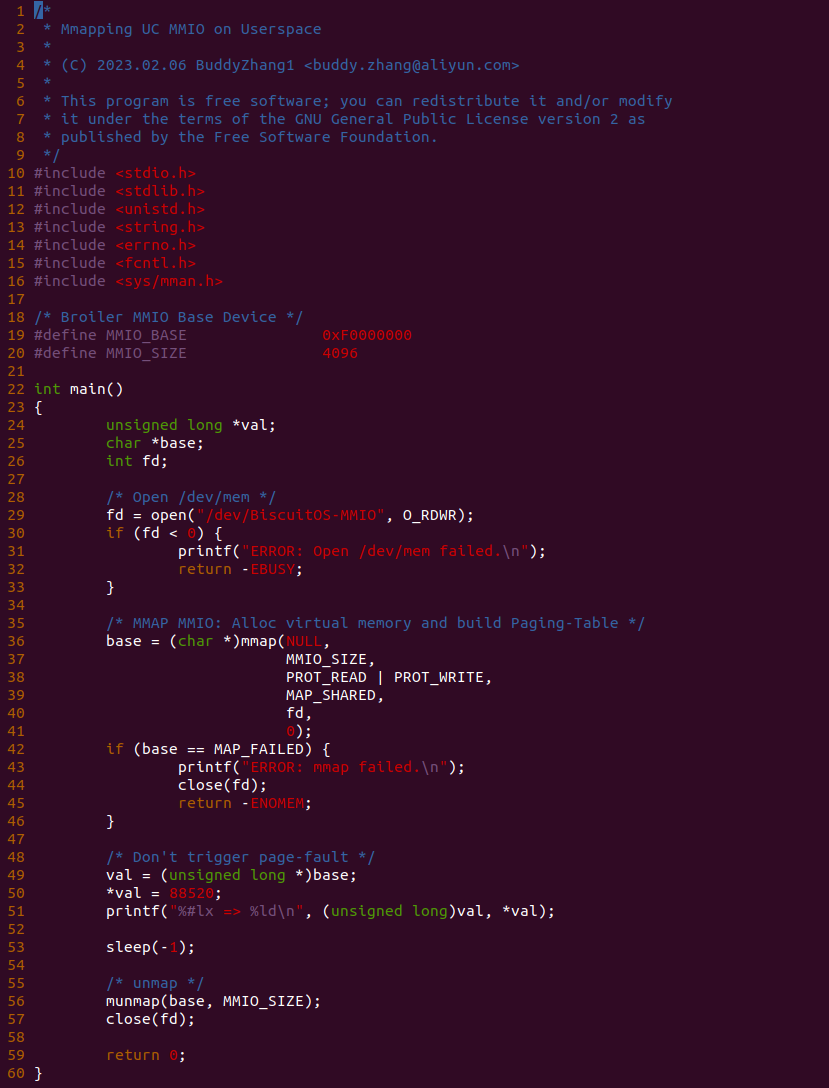
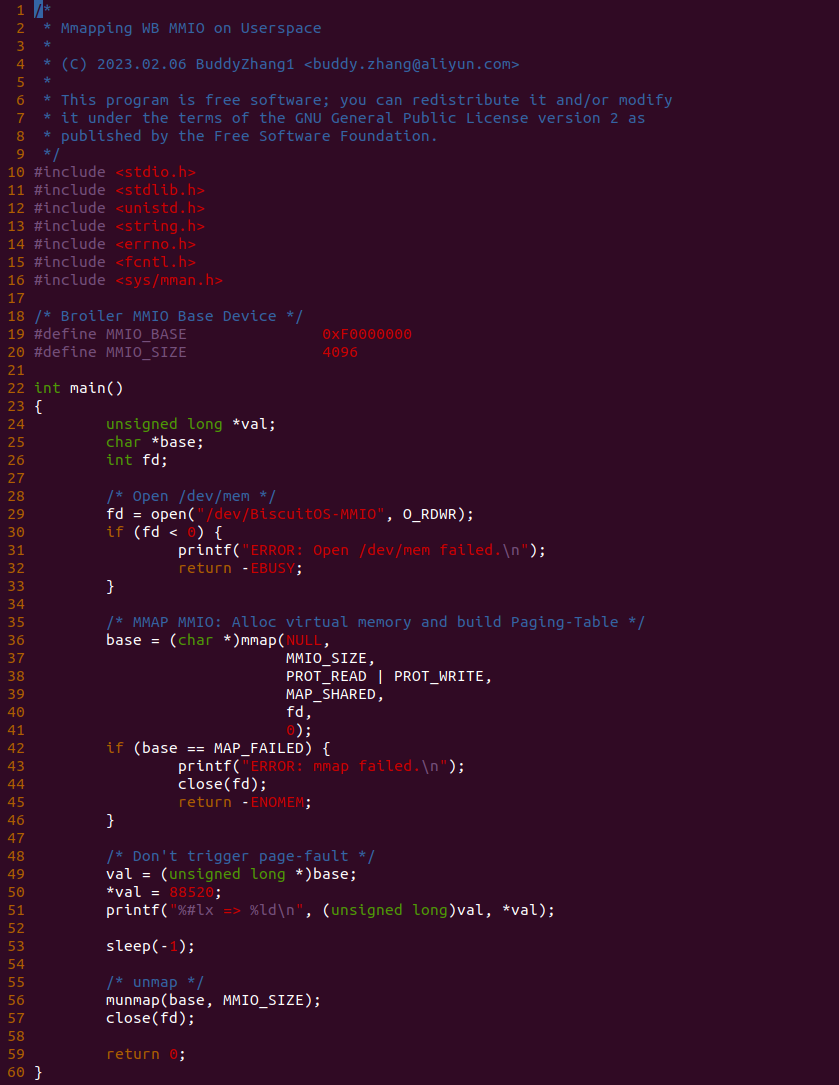
实践案例的另外一部分位于 app.c 内,其为用户空间程序,用于映射虚拟地址到 MMIO 并进行访问. 程序首先在 29 行通过 open() 函数打开 “/dev/BiscuitOS-MMIO” 节点,然后在 36-46 通过 mmap() 函数将进程地址空间的虚拟地址映射到 MMIO,接下来在 49-51 行对映射之后对 MMIO 进行访问,最后在 56-57 行释放相应的资源. 源码分析完毕之后在 BiscuitOS 进行实践,由于 MMIO 绑定在具体的硬件上,此时可以使用 Broiler 进行模块,直接使用 “make broiler” 命令进行实践:
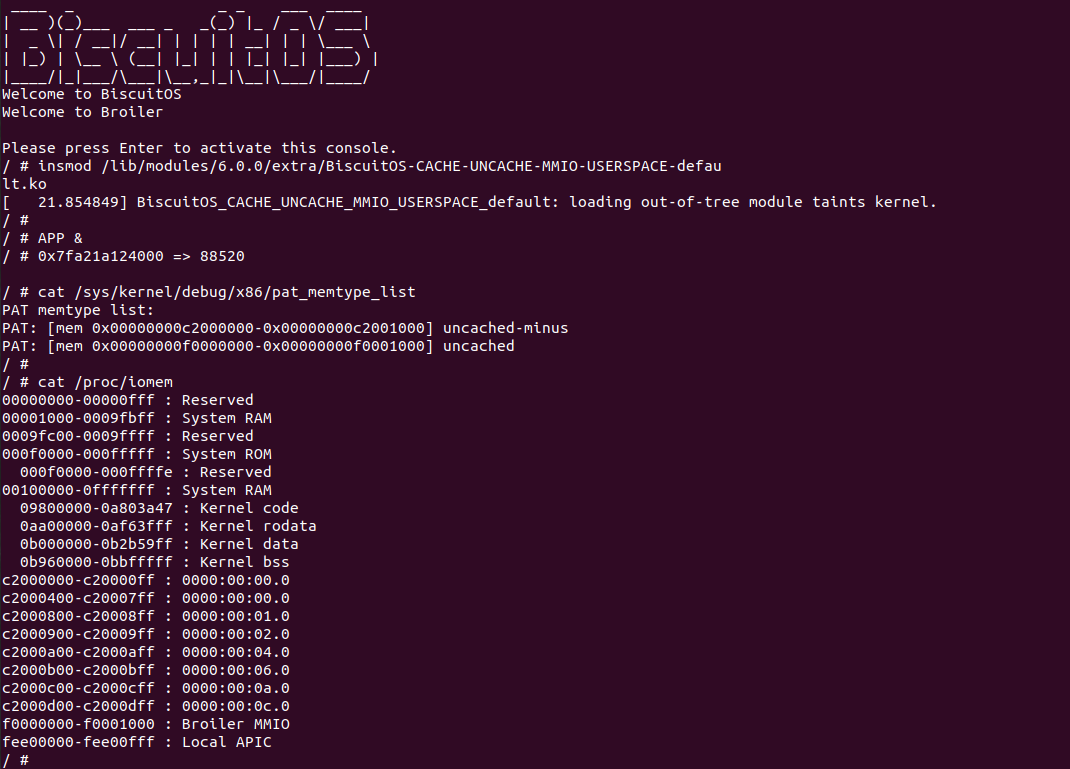
BiscuitOS Broiler 运行之后加载 BiscuitOS-CACHE-UNCACHE-MMIO-USERSPACE-default.ko, 接着运行用户态程序 APP,这里以后台方式运行,因此查看其他有用信息,运行之后可以看到正常访问 MMIO。接下来查看 /sys/kernel/debug/x86/pat_memtype_list 节点,可以看到 [0xF0000000, 0xF0001000) 区域映射为 uncached,最后查看 /proc/iomem 系统物理地址空间,可以看到 Broiler MMIO 对应的区域正好是 [0xF0000000, 0xF0001000)。实践结果符合预期,那么接下来对普通物理内存映射为 UC 场景进行实践:
用户空间虚拟内存映射 UC 物理内存
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] UNCACHE(UC): Mapping UC Memory on Userspace --->
-*- CACHE User-Page for Kernel Stub (Basic) --->
# 进入源码目录
# Userspace: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-UNCACHE-MEM-USERSPACE-default/
# Kernel: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default/
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-UNCACHE-MEM-USERSPACE-default/
# 部署源码
make prepare
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-UNCACHE-MEM-USERSPACE-default Source Code on Gitee
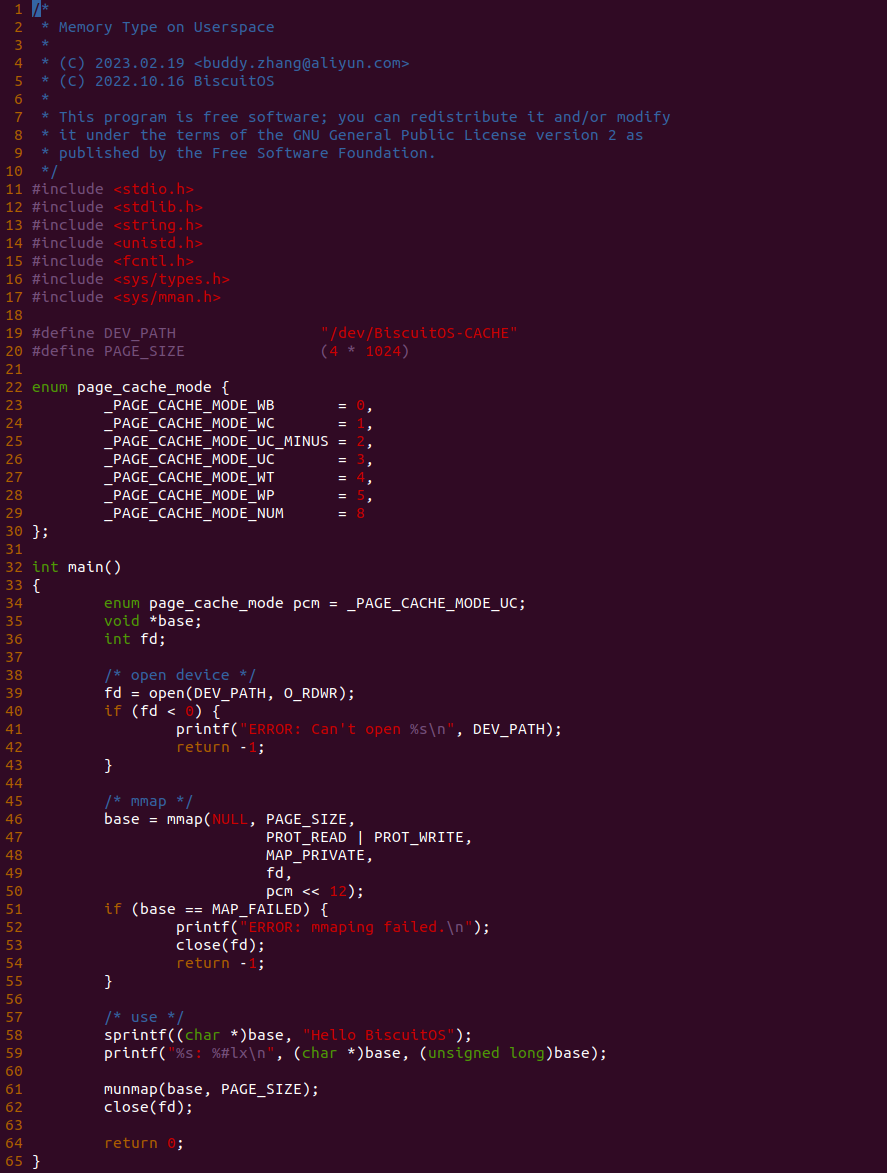
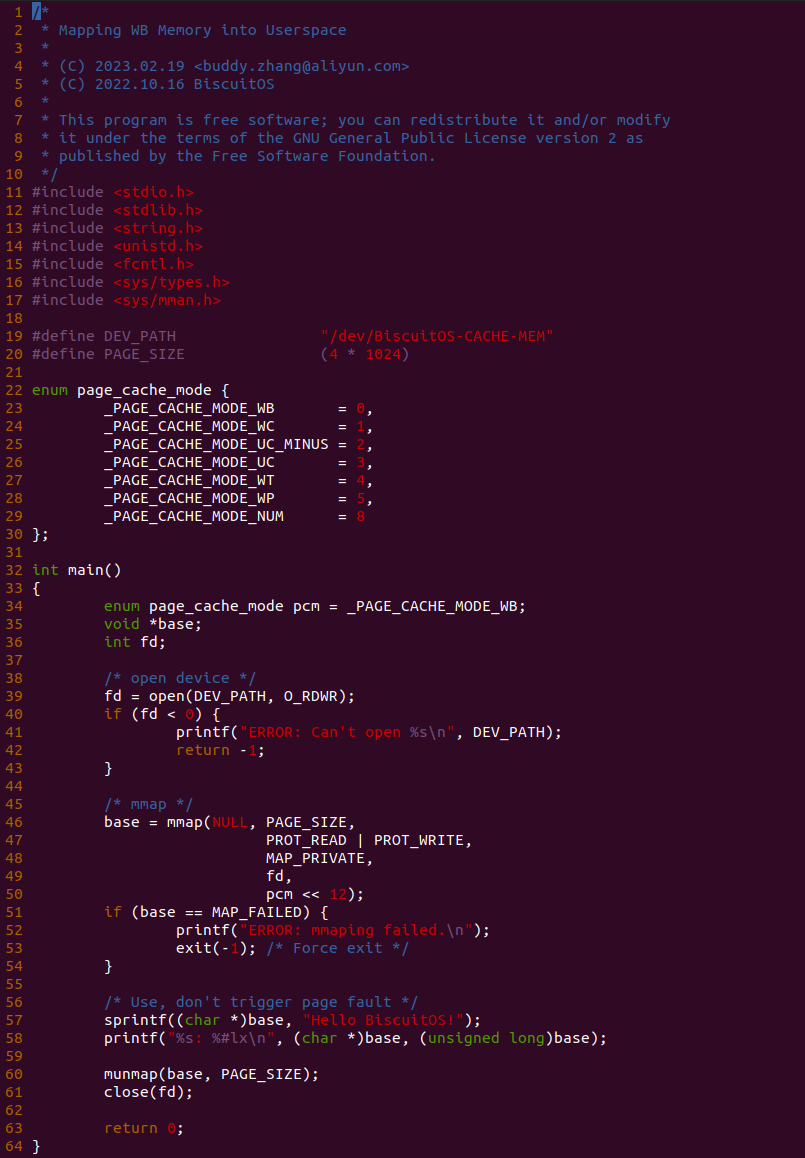
源码分成两部分,其中一部分为用户空间程序(上图所示), 用户空间代码的主要功能是映射一段虚拟内存,并将其缓存类型设置为 UC. 函数首先在 34 行将 pcm 变量设置为 _PAGE_CACHE_MODE_UC, 然后在 39 行打开 “/dev/BiscuitOS-CACHE” 节点,并基于该节点映射长度为 PAGE_SIZE 的虚拟内存,此时在函数 50 行将 pcm 传入到 mmap() 函数,映射完毕后函数在 58-59 行使用 UC 的内存,使用完毕在 61-62 行解除映射并关闭文件。
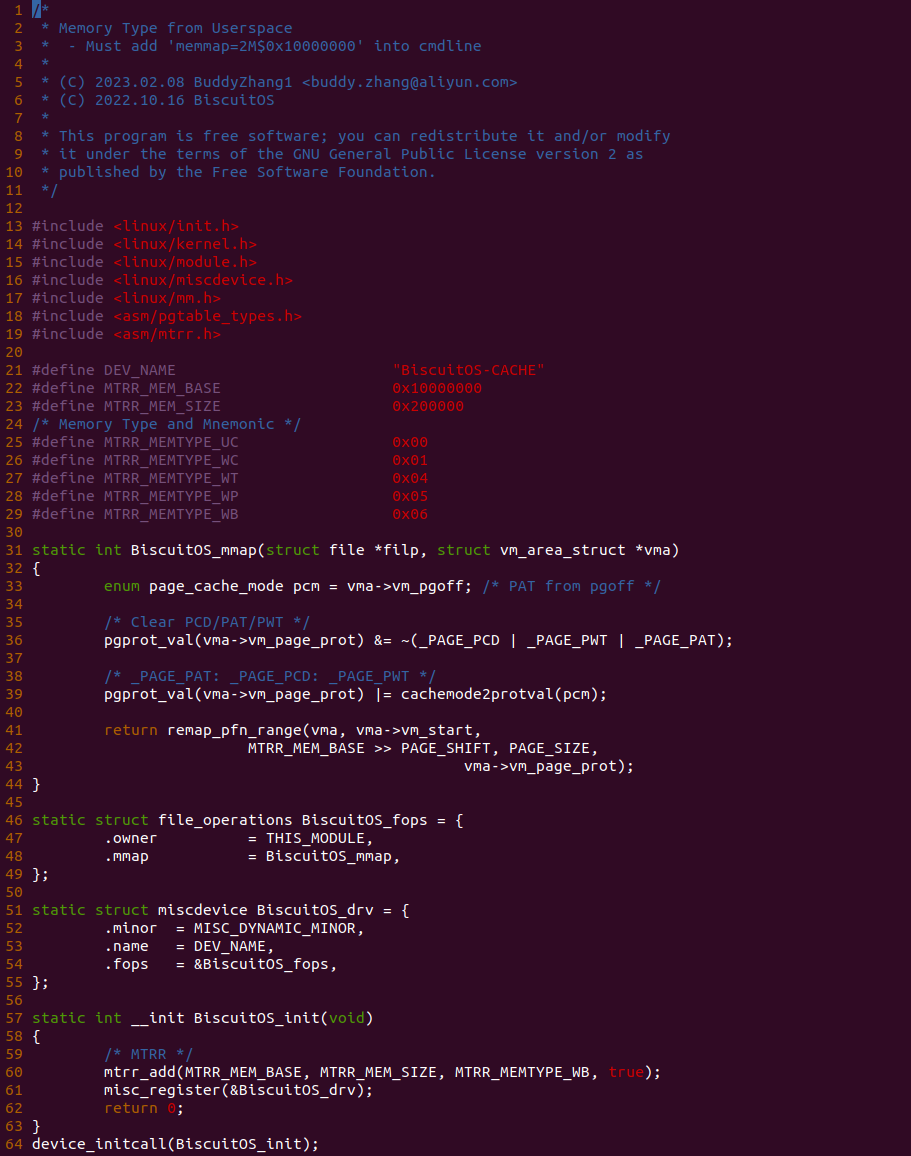
BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default Source Code on Gitee
源码的另外一部分位于内核空间,其主要功能是进行实际的映射任务。模块通过一个 MISC 驱动进行实现,其提供了 mmap 接口 BiscuitOS_mmap(), 当用户空间基于 “/dev/BiscuitOS-CACHE” 节点调用 mmap() 函数时,BiscuitOS_mmap() 函数就会别调用。模块首先在 60 行调用 mtrr_add() 函数将 [MTRR_MEM_BASE, MTRR_MEM_SIZE + MTRR_MEM_BASE) 区域的 MTRR 设置为 WB. 模块接着在 33 行在用户空间调用 mmap() 函数时从 vma 的 vm_pgoff 成员中获得 PAGE CACHE MODE 信息,接着在 36 行将 vma_page_prot 成员中移除 _PAGE_PCD、_PAGE_PWT 和 _PAGE_PAT 属性,并在 39 行调用 cachemode2protval() 函数将 PAGE CACHE MODE 转换成对应的页表属性,并重新存储到 vma 的 vm_page_prot, 以此作为用于空间设置的 memory type 页表属性,最后模块在 41 行调用 remap_pfn_range() 函数为虚拟内存建立页表并映射到 MTRR_MEM_BASE 对应的物理内存上. 接下来在 BiscuitOS 上实践该案例:
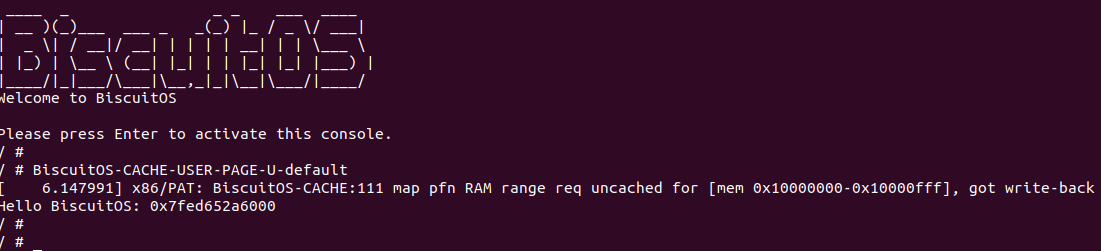
BiscuitOS 运行之后, 执行应用程序 BiscuitOS-CACHE-USER-PAGE-U-default,此时系统提示了程序预期将 [0x10000000-0x10000fff] 为 uncached,但是系统还是将对应的 memory type 设置为 write-back, 这个与预期不符合. 查看内核模块源码的 3 行提示需要将 [0x10000000, 0x10200000) 进行预留,那么在 CMDLINE(CMDLINE 位于 RunBiscuitOS.sh 文件中) 中添加预留字段后再次实践:
BiscuitOS 在次运行之后,运行应用程序,可以看到系统没有再提示修改信息了,那么用户进程已经成功将一段物理内存的 memory type 设置为 UC. 实践符合预期,那么接下来实践内核空间虚拟地址映射 UC 物理内存:
内核空间虚拟内存映射 UC 物理内存
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] UNCACHE(UC): Mapping UC Memory on Kernel --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-UNCACHE-MEM-KERNEL-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-UNCACHE-MEM-KERNEL-default Source Code on Gitee
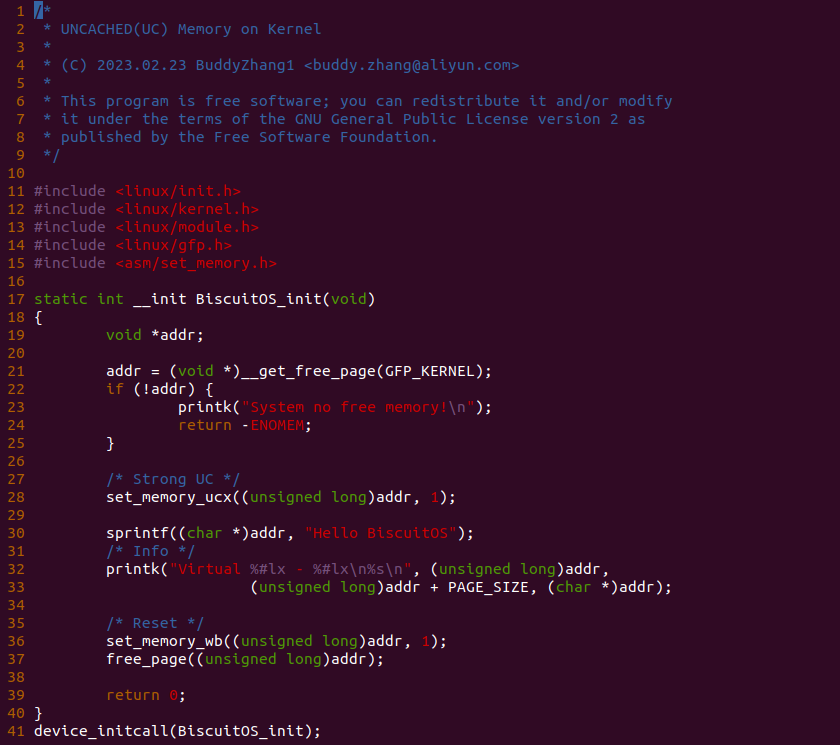
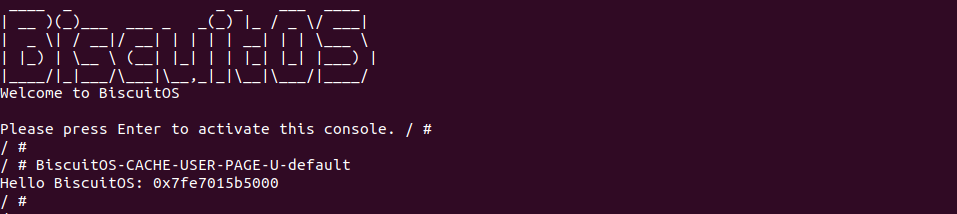
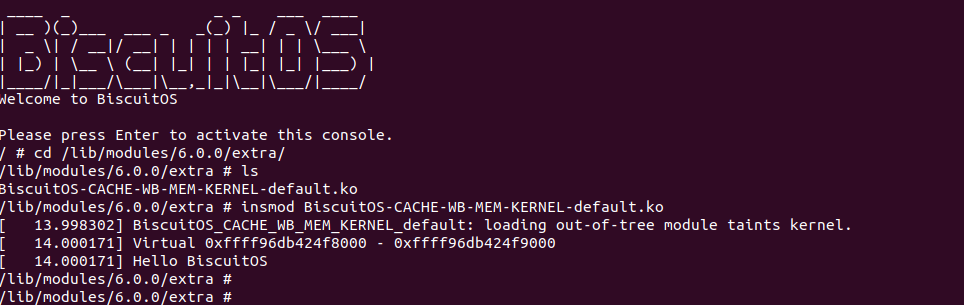
实践案例主要目的是在内核空间申请一段内存之后,将对应的虚拟地址以 UC 的方式映射到物理内存,并进行访问。案例在 21-25 行通过 __get_free_page() 函数分配一个物理页并获得对应的虚拟地址,然后在 28 行调用 set_memory_ucx() 函数进行 UC 方式的映射,案例接着在 30-33 行对映射之后的虚拟地址进行访问。最后在 36-37 行回收设置,值得注意的是当将内核空间虚拟地址设置为非 WB 之后,在回收时要主动设置为 WB。另外由于内核不支持 UC 映射物理内存方式,因此需要对内核进行修改,参考如下补丁:
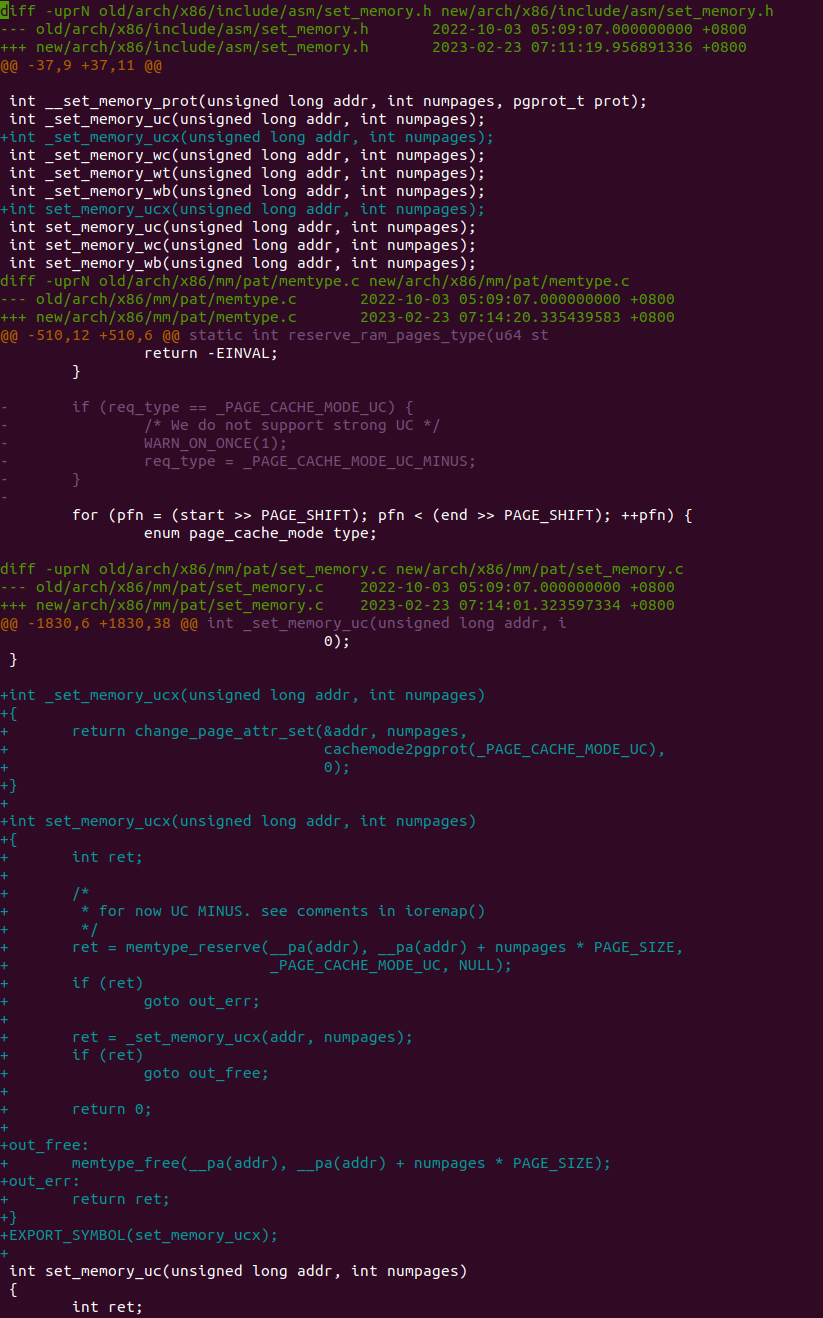
PATCH 主要做了两个事情,首先对 set_memory_ucx() 函数进行实现,然后在头文件中导出相应的函数定义,最后在 reserve_ram_page_type() 函数解除内核对 _PAGE_CACHE_MODE_UC 不支持的逻辑。接下来在 BiscuitOS 上进行实践:
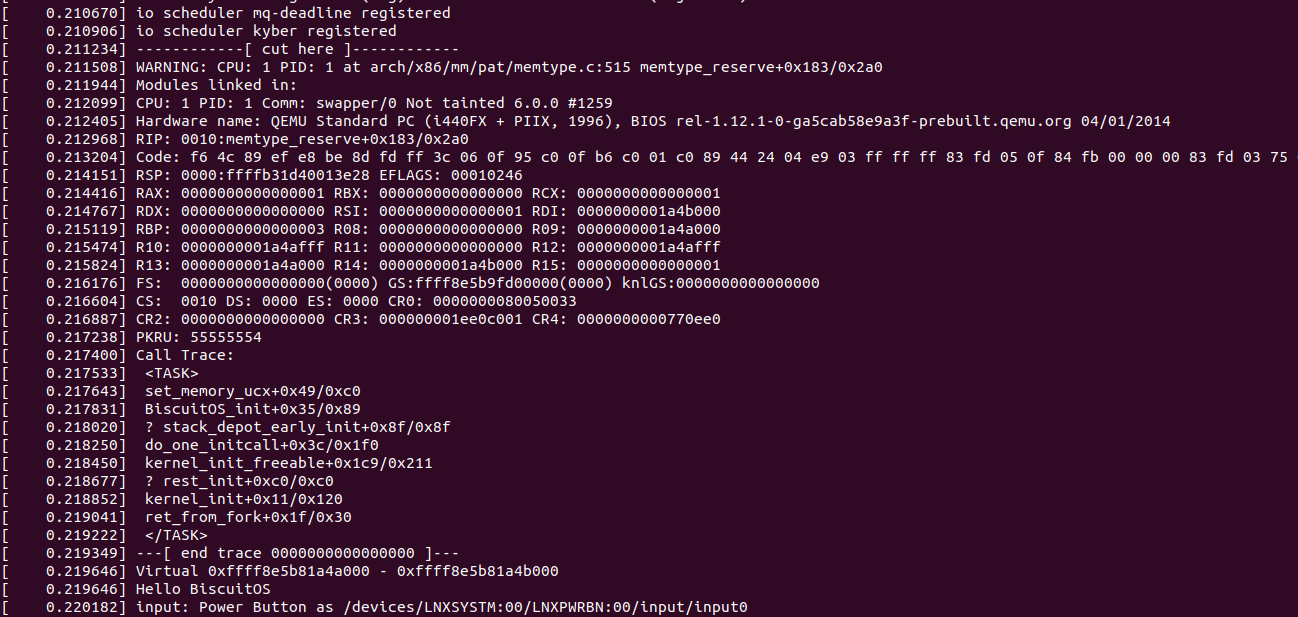
BiscuitOS 运行之后查看 dmesg 可以看到映射过程,由于没有合入 reserve_ram_page_type() 的 patch,内核会提示异常,那么开发者可以自行合入补丁之后,该异常会消失,系统就可以将内核虚拟地址以 UC 方式映射到物理内存上. 另外通过前面的分析,如果将物理内存设置为 UC 之后,其性能将会受到极大影响,那么接下来通过一个实践案例对比 UC 和 WB(默认为 WB) 物理内存之间性能差异,案例在 BiscuitOS 的部署逻辑为:
UC Vs. WB 物理内存性能比对
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] CACHE Performance: WB Vs. UC on Normal Memory --->
-*- CACHE User-Page for Kernel Stub (Basic) --->
# 进入源码目录
# Userspace: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-PERFORMANCE-WB-UC-default/
# Kernel: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default/
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-PERFORMANCE-WB-VS-UC-default/
# 部署源码
make prepare
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-PERFORMANCE-WB-VS-UC-default Source Code on Gitee
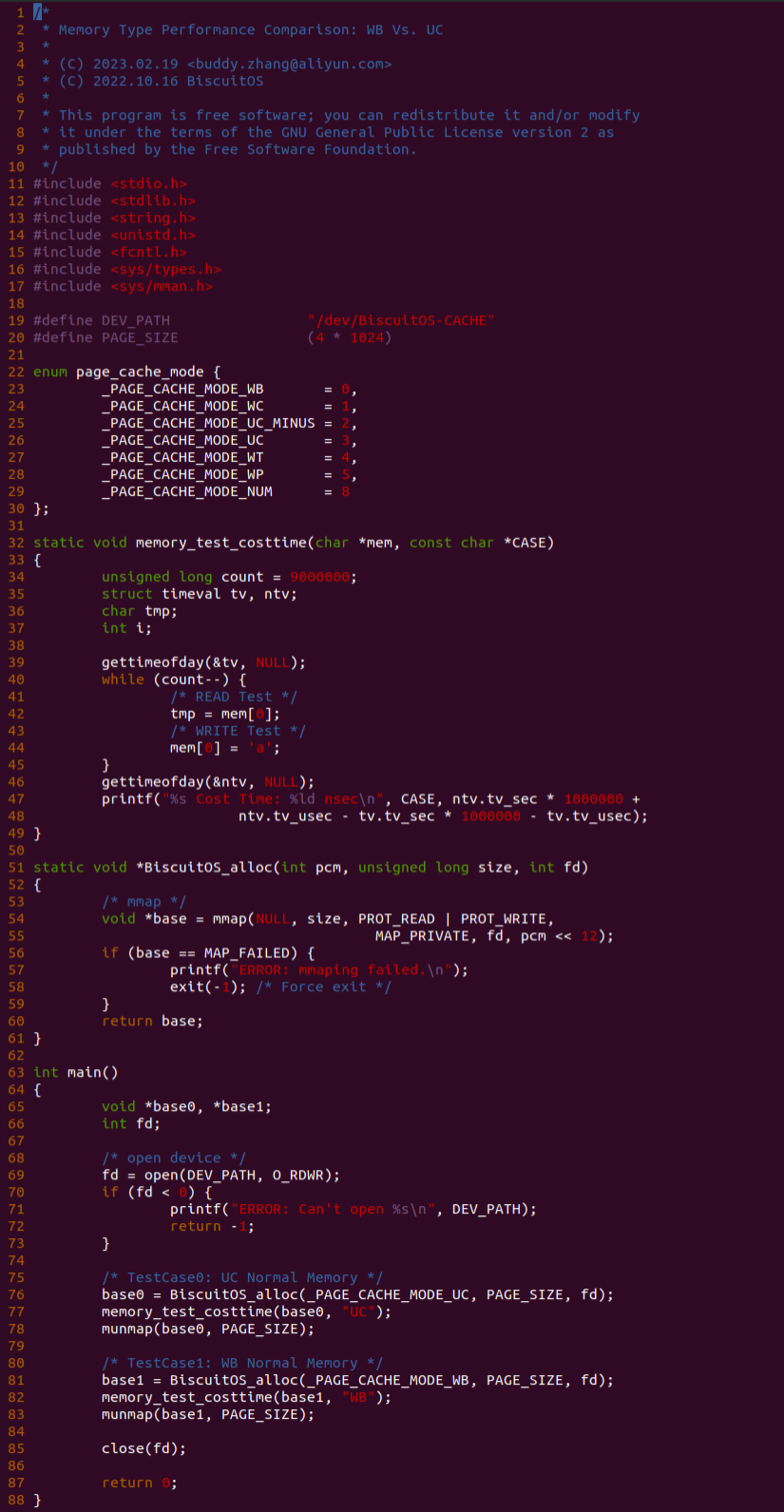
基于上一个实践案例进行改进,实践案例提供了 memory_test_costtime() 函数,其逻辑是对同一个地址循环读写 9000000 次,并计算所消耗的时间,并将时间按 ns 进行打印。其他的代码逻辑和上一个分析一致,并且其也对应一个内核模块。那么接下来直接在 BiscuitOS 上运行程序查看结果(运行前在 CMDLINE 中添加预留内存字段):
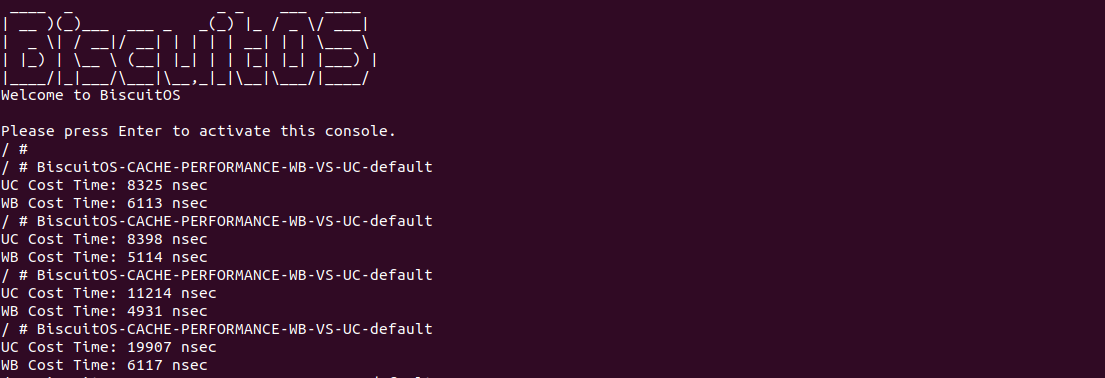
BiscuitOS 运行之后,分别运行 BiscuitOS-CACHE-PERFORMANCE-WB-VS-UC-default 5 次,查看每次 WB 和 UC 之间的差异,可以看到差异最大的一组 WB 仅仅消耗 6117ns, 而 UC 消耗达到 19907ns. 通过实践可以初步得出结论不同的 memory type 之间会存在性能差异,并且 WB 在读写测试中明显优于 UC 内存, 因此建议不要把普通物理内存映射为 UC!
Uncacheable (UC-)
Uncacheable (UC-): 非缓存类型,该类型的物理内存不使用任何缓存机制. 系统对该类型的物理内存的读写请求会直接发送到总线上,另外硬件上不会对该类型物理内存的访问和对应页表遍历预测功能,同样也不会对分支进行预测, 与 UC 不同的是 UC- 会被 WC 给覆盖. UC- 缓存类型通常用于映射外设的 MMIO,因为外设不具有监听(snoop)总线的能力,为了保持设备看物理区域与 CPU 看到的一致,因此将该物理区域设置为 UC- 之后,CPU 对该区域的读写请求直接访问到物理地址上,不会缓存在 CACHE 里,因此可以保持设备和 CPU 看到数据的一致性. 不建议将普通的物理内存的缓存类型设置为 UC-,这样会 CPU 每次都对物理内存进行访问,这会大大影响系统性能. 接下来通过一个实践案例介绍内核如何将一段 MMIO 区域的缓存类型设置为 UC-, 其在 BiscuitOS 上的部署逻辑如下:
内核空间虚拟地址映射 UC- MMIO
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] UNCACHED(UC-): Mapping UC- MMIO on Kernel --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-UNCACHED-MMIO-KERNEL-default
# 部署源码
make download
# 在 BiscuitOS/Broiler 中实践
make broilerBiscuitOS-CACHE-UNCACHED-MMIO-KERNEL-default Source Code on Gitee
源码通过一个内核模块进行展示,模块有两部分组成,第一部分是 20-35 行,模块向系统资源总线注册了一段 MMIO,这段 MMIO 起始物理地址是 BROILER_MMIO_BASE, 长度为 BROILER_MMIO_LEN, 注册完毕之后可以在系统启动之后,通过 ‘/proc/iomem’ 接口查看到该段信息; 第二部分是 38-46 行,模块在 38 行调用 ioremap() 函数将 BROILER_MMIO_BASE 开始且长度为 BROILER_MMIO_LEN 的 MMIO 区域,映射为 UC- 的 memory type, 映射完毕之后函数在 46 行对 MMIO 进行访问,此时并不会触发缺页,因为 ioremap() 函数已为 MMIO 分配了对应的虚拟地址并建立了页表,因此模块可以直接访问 MMIO. 最后在 BiscuitOS 上实践模块,由于需要一段真实的 MMIO 才能运行模块,因此可使用 Broiler 模拟一段 MMIO,其起始物理地址为 0xF0000000(Broiler 已经模拟好硬件),开发者直接在源码目录执行 make broiler 即可:
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-UNCACHED-MMIO-KERNEL-default.ko 模块之后,从打印的内核信息可以看出模块已经映射了 MMIO,并且向 MMIO 写入 0x88520 之后可以读出正确的数据,最后查看 ‘/sys/kernel/debug/x86/pat_memtype_list’ 节点查看系统 MMIO memory_type 信息,可以看到模块映射的 MMIO [0xF0000000, 0xF0001000] 为 uncached-minus, 另外查看 ‘/proc/iomem’ 节点查看物理地址空间信息,可以看到 [0xF0000000, 0xF0001000) 为 Broiler MMIO 区域, 实践符合预期. 接下来一个实践案例用于介绍如何将用户空间虚拟地址映射成 UC- 的 MMIO,BiscuitOS 部署逻辑如下:
用户空间虚拟地址映射 UC- MMIO
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] UNCACHED(UC-): Mapping UC- MMIO on Userspace --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-UNCACHED-MMIO-USERSPACE-default
# 部署源码
make download
# 在 BiscuitOS/Broiler 中实践
make broilerBiscuitOS-CACHE-UNCACHED-MMIO-USERSPACE-default Source Code on Gitee
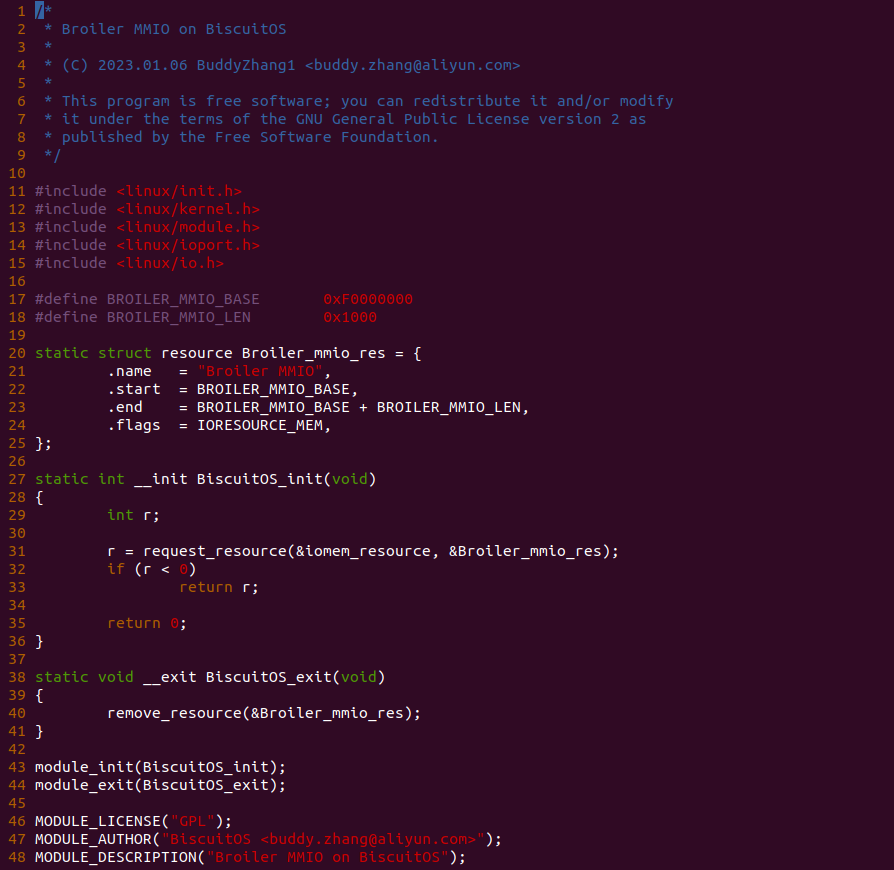
实践案例由两个部分组成,main.c 为内核模块部分,负责映射 MMIO 的底层逻辑。模块首先在 22-26 行定义了 MMIO 区域的信息,然后在 56-57 行通过调用 request_resource() 函数将 MMIO 区域添加到系统物理地址空间树里。接下来基于 Linux 提供的 “/dev/mem” 接口进行映射 MMIO.
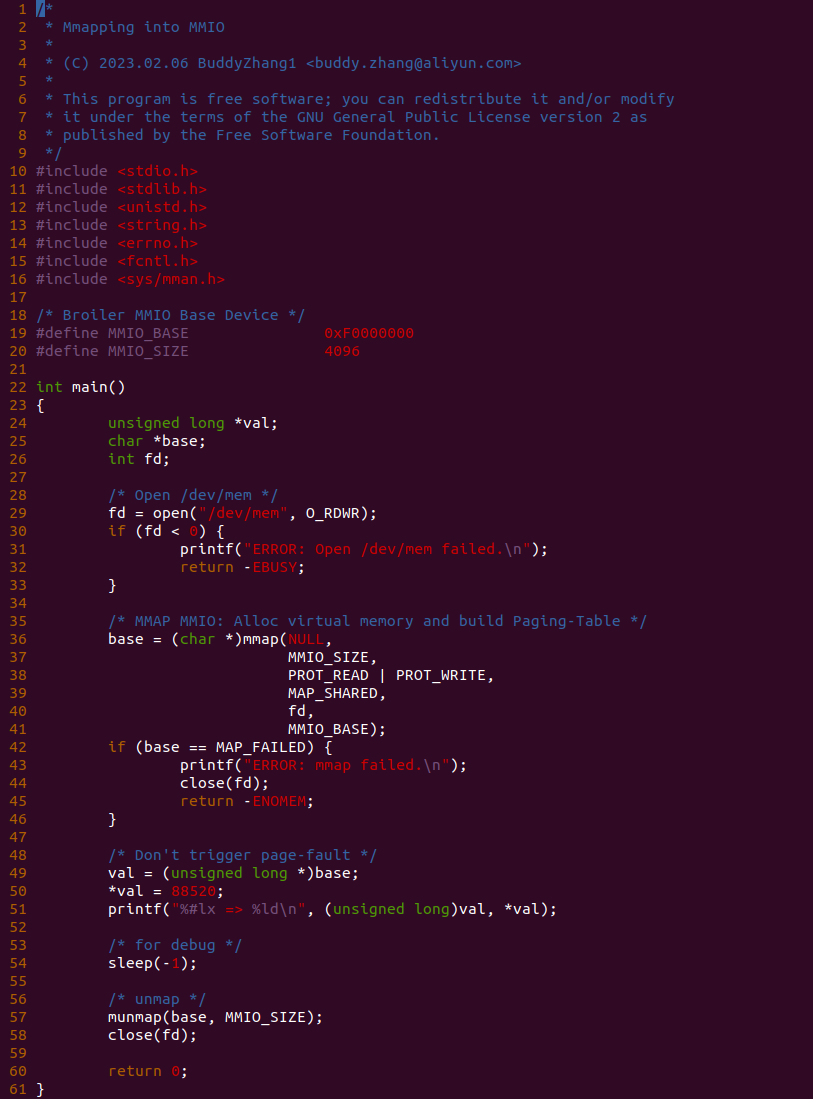
实践案例的另外一部分位于 app.c 内,其为用户空间程序,用于映射虚拟地址到 MMIO 并进行访问. 程序首先在 29 行通过 open() 函数打开 “/dev/mem” 节点,然后在 36-46 通过 mmap() 函数将进程地址空间的虚拟地址映射到 MMIO,接下来在 49-51 行对映射之后对 MMIO 进行访问,最后在 56-57 行释放相应的资源. 源码分析完毕之后在 BiscuitOS 进行实践,由于 MMIO 绑定在具体的硬件上,此时可以使用 Broiler 进行模块,直接使用 “make broiler” 命令进行实践:
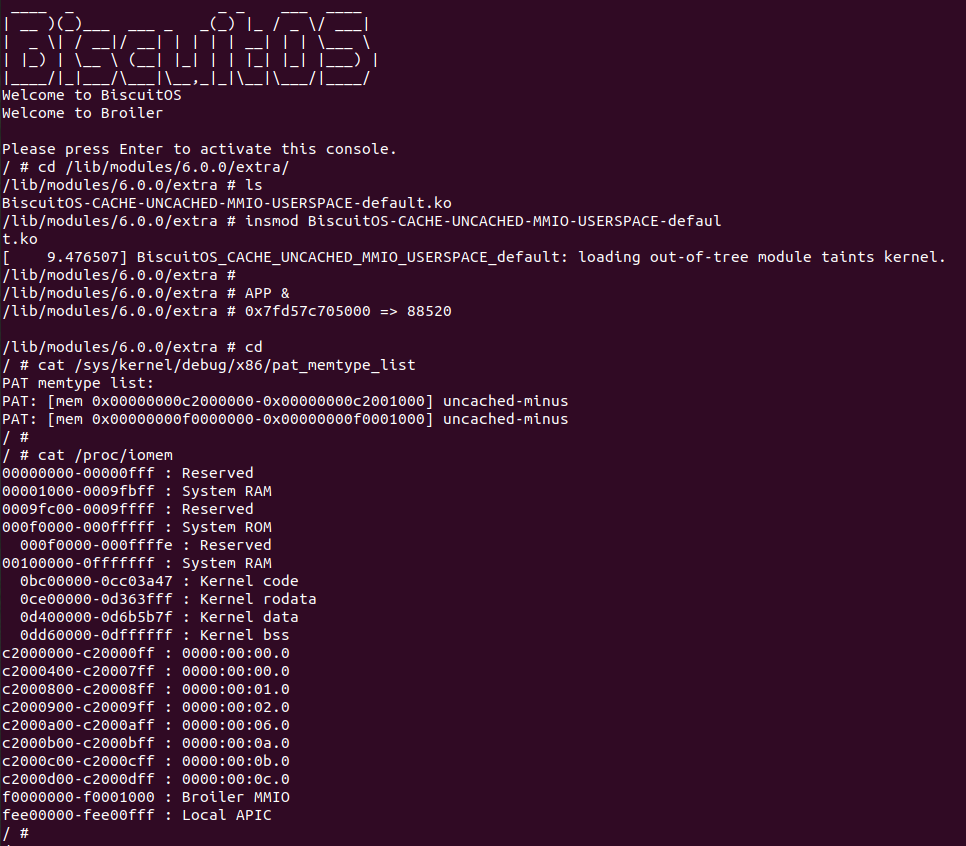
BiscuitOS Broiler 运行之后加载 BiscuitOS-CACHE-UNCACHED-MMIO-USERSPACE-default.ko, 接着运行用户态程序 APP,这里以后台方式运行,因此查看其他有用信息,运行之后可以看到正常访问 MMIO。接下来查看 /sys/kernel/debug/x86/pat_memtype_list 节点,可以看到 [0xF0000000, 0xF0001000) 区域映射为 uncached-minus,最后查看 /proc/iomem 系统物理地址空间,可以看到 Broiler MMIO 对应的区域正好是 [0xF0000000, 0xF0001000)。实践结果符合预期,那么接下来对普通物理内存映射为 UC- 场景进行实践:
用户空间虚拟内存映射 UC- 物理内存
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] UNCACHED(UC-): Mapping UC- Memory on Userspace --->
-*- CACHE User-Page for Kernel Stub (Basic) --->
# 进入源码目录
# Userspace: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-UNCACHED-MEM-USERSPACE-default/
# Kernel: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default/
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-UNCACHED-MEM-USERSPACE-default/
# 部署源码
make prepare
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-UNCACHED-MEM-USERSPACE-default Source Code on Gitee
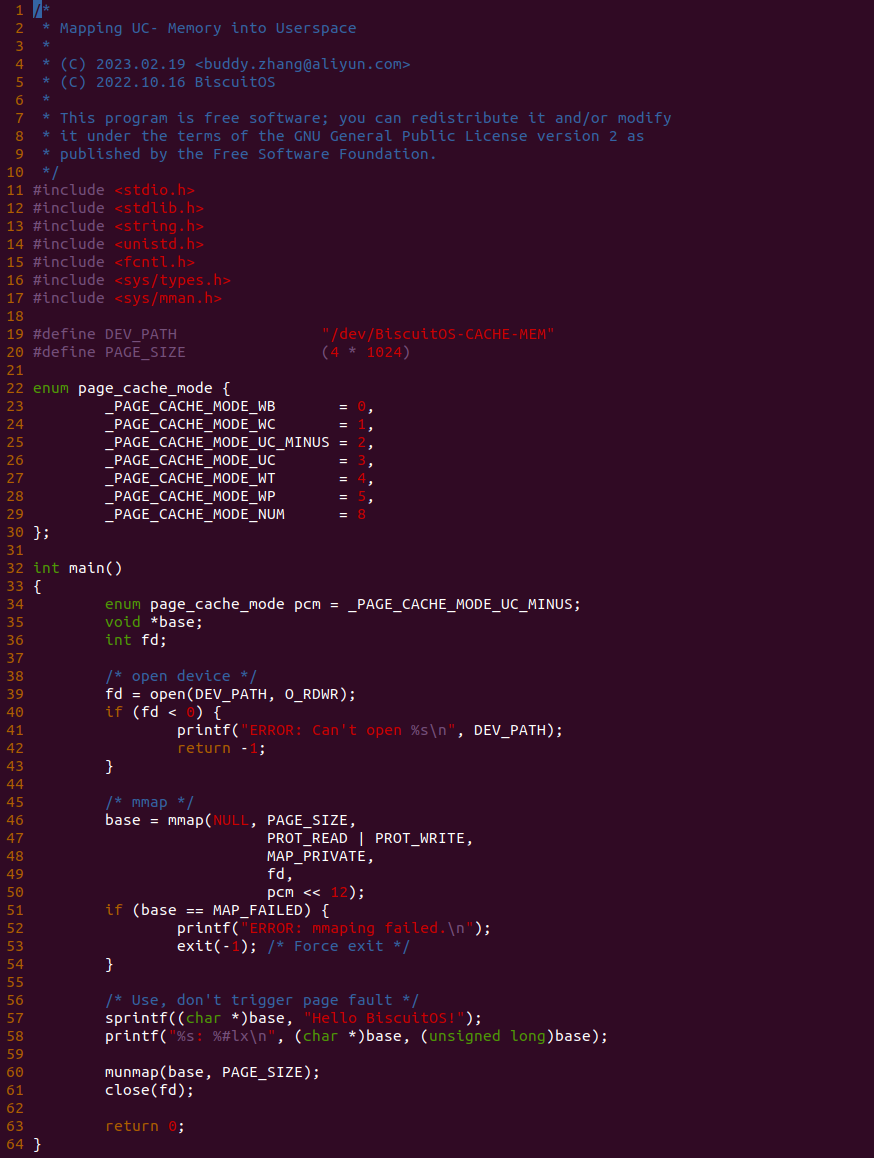
源码分成两部分,其中一部分为用户空间程序(上图所示), 用户空间代码的主要功能是映射一段虚拟内存,并将其缓存类型设置为 UC-. 函数首先在 34 行将 pcm 变量设置为 _PAGE_CACHE_MODE_UC_MINUS, 然后在 39 行打开 “/dev/BiscuitOS-CACHE” 节点,并基于该节点映射长度为 PAGE_SIZE 的虚拟内存,此时在函数 50 行将 pcm 传入到 mmap() 函数,映射完毕后函数在 58-59 行使用 UC 的内存,使用完毕在 61-62 行解除映射并关闭文件。
BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default Source Code on Gitee
源码的另外一部分位于内核空间,其主要功能是进行实际的映射任务。模块通过一个 MISC 驱动进行实现,其提供了 mmap 接口 BiscuitOS_mmap(), 当用户空间基于 “/dev/BiscuitOS-CACHE” 节点调用 mmap() 函数时,BiscuitOS_mmap() 函数就会别调用。模块首先在 60 行调用 mtrr_add() 函数将 [MTRR_MEM_BASE, MTRR_MEM_SIZE + MTRR_MEM_BASE) 区域的 MTRR 设置为 WB. 模块接着在 33 行在用户空间调用 mmap() 函数时从 vma 的 vm_pgoff 成员中获得 PAGE CACHE MODE 信息,接着在 36 行将 vma_page_prot 成员中移除 _PAGE_PCD、_PAGE_PWT 和 _PAGE_PAT 属性,并在 39 行调用 cachemode2protval() 函数将 PAGE CACHE MODE 转换成对应的页表属性,并重新存储到 vma 的 vm_page_prot, 以此作为用于空间设置的 memory type 页表属性,最后模块在 41 行调用 remap_pfn_range() 函数为虚拟内存建立页表并映射到 MTRR_MEM_BASE 对应的物理内存上. 接下来在 BiscuitOS 上实践该案例:
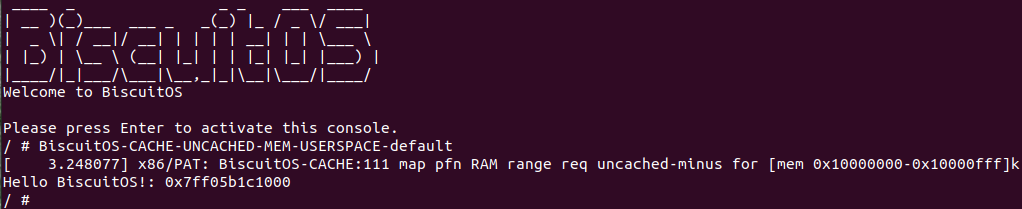
BiscuitOS 运行之后, 执行应用程序 BiscuitOS-CACHE-USER-PAGE-U-default,此时系统提示了程序预期将 [0x10000000-0x10000fff] 为 uncached-minus,但是系统还是将对应的 memory type 设置为 write-back, 这个与预期不符合. 查看内核模块源码的 3 行提示需要将 [0x10000000, 0x10200000) 进行预留,那么在 CMDLINE(CMDLINE 位于 RunBiscuitOS.sh 文件中) 中添加预留字段后再次实践:
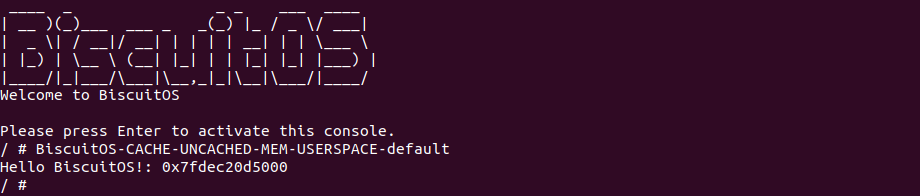
BiscuitOS 在次运行之后,运行应用程序,可以看到系统没有再提示修改信息了,那么用户进程已经成功将一段物理内存的 memory type 设置为 UC-. 实践符合预期,那么接下来实践内核空间虚拟地址映射 UC- 物理内存:
内核空间虚拟内存映射 UC- 物理内存
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] UNCACHED(UC-): Mapping UC- Memory on Kernel --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-UNCACHED-MEM-KERNEL-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-UNCACHED-MEM-KERNEL-default Source Code on Gitee
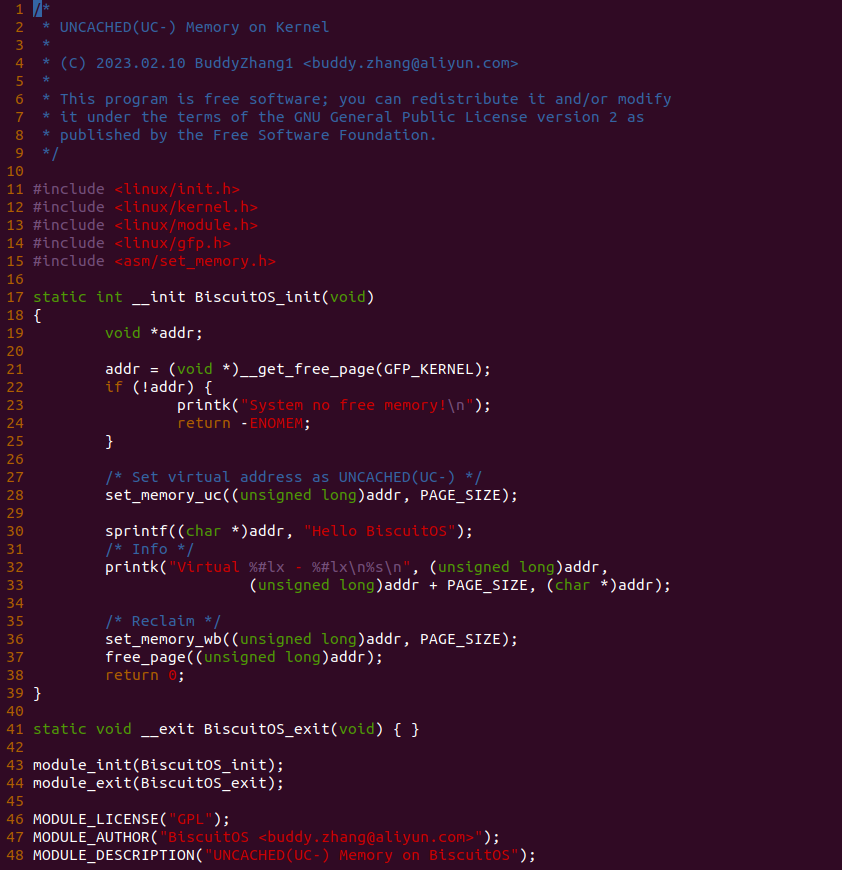
实践案例主要目的是在内核空间申请一段内存之后,将对应的虚拟地址以 UC- 的方式映射到物理内存,并进行访问。案例在 21-25 行通过 __get_free_page() 函数分配一个物理页并获得对应的虚拟地址,然后在 28 行调用 set_memory_uc() 函数进行 UC- 方式的映射,案例接着在 30-33 行对映射之后的虚拟地址进行访问。最后在 36-37 行回收设置,值得注意的是当将内核空间虚拟地址设置为非 WB 之后,在回收时要主动设置为 WB. 接下来在 BiscuitOS 上进行实践:
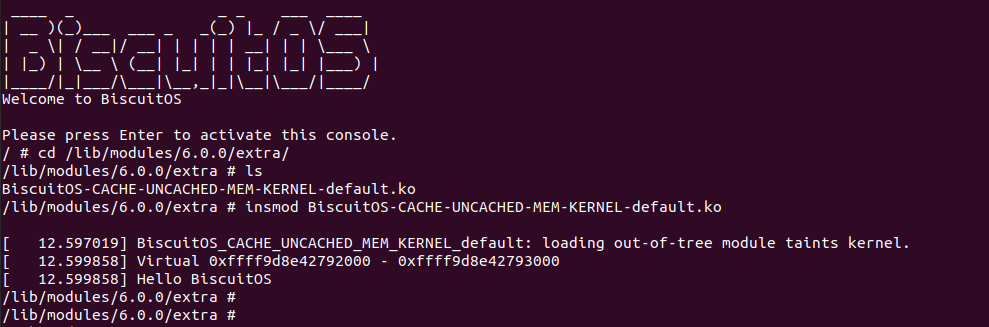
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-UNCACHED-MEM-KERNEL-default.ko 模块,可以看到系统可以使用 UC- 的虚拟内存,并打印字符串 “Hello BiscuitOS”, 符合预期.
Write Combining (WC)
Write Combining (WC): 写合并类型,该类型与 UC 类似不使用任何缓存机制,并且不保证 CACHE 一致性协议。WC 允许读预测,但写请求可能会被延后并合并缓存到 Write Combining Buffer(WC) 里,以此减少对总线拥堵。如果 WC Buffer 没有满,那么写请求很可能被延时并合并到 WC buffer,直到下一个串行事件发生之后,写请求才会被真正写入内存. 这类型应用的场景包括 Video Frame Buffer,其特点就是对写的顺序不是很重要,只要最后更新数据的时候都能在图形设备上显示. 具体可以参考如下章节对 WriteCombining Buffer 进一步了解, 那么接下来通过一组实践案例介绍内核和用户空间如何使用 WC 类型的内存.
内核空间虚拟地址映射 WC MMIO
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] WriteCombining(WC): Mapping WC MMIO on Kernel --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WC-MMIO-KERNEL-default
# 部署源码
make download
# 在 BiscuitOS/Broiler 中实践
make broilerBiscuitOS-CACHE-UNCACHE-WC-KERNEL-default Source Code on Gitee
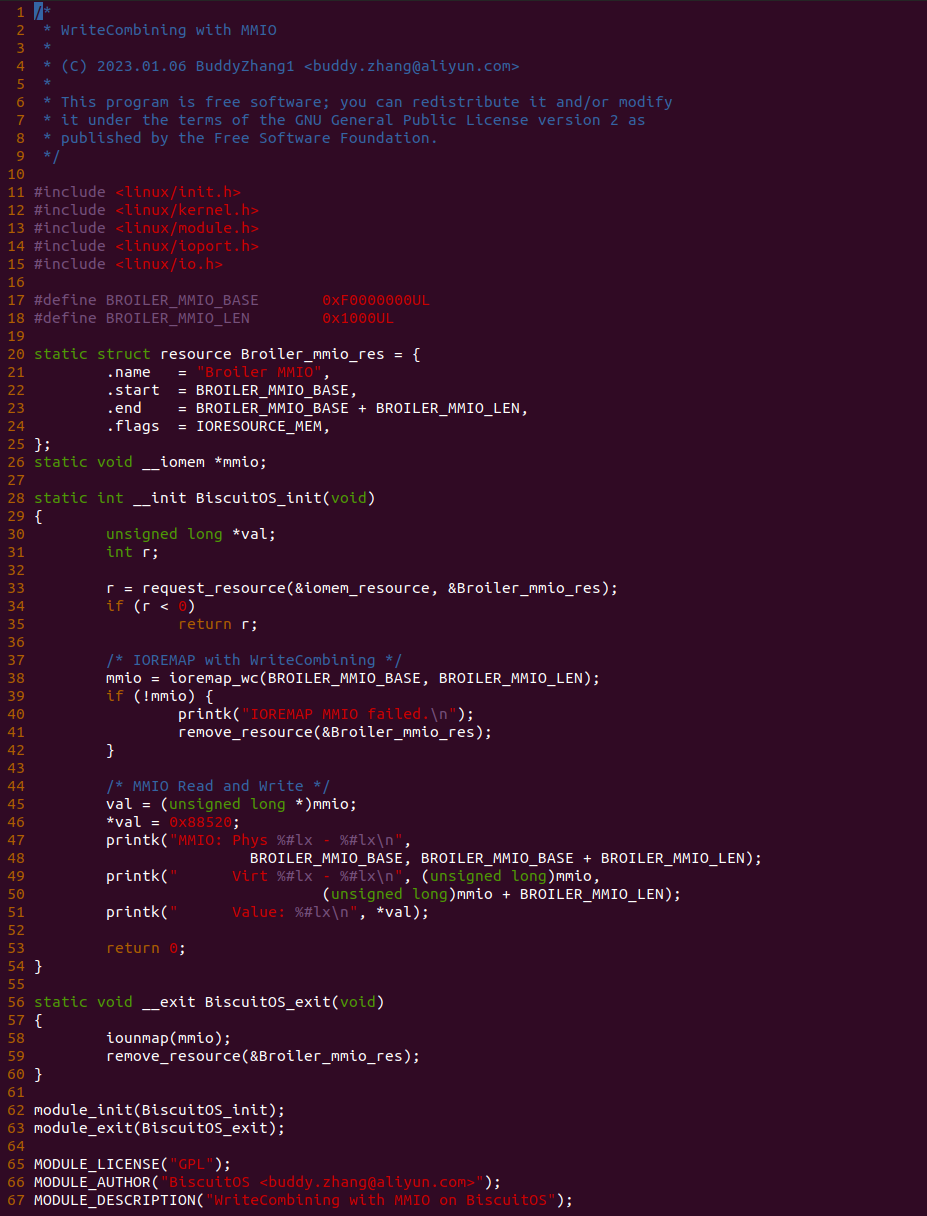
源码通过一个内核模块进行展示,模块有两部分组成,第一部分是 20-35 行,模块向系统资源总线注册了一段 MMIO,这段 MMIO 起始物理地址是 BROILER_MMIO_BASE, 长度为 BROILER_MMIO_LEN, 注册完毕之后可以在系统启动之后,通过 ‘/proc/iomem’ 接口查看到该段信息; 第二部分是 38-46 行,模块在 38 行调用 ioremap_wc() 函数将 BROILER_MMIO_BASE 开始且长度为 BROILER_MMIO_LEN 的 MMIO 区域,映射为 WriteCombining 的 memory type, 映射完毕之后函数在 46 行对 MMIO 进行访问,此时并不会触发缺页,因为 ioremap_wc() 函数已为 MMIO 分配了对应的虚拟地址并建立了页表,因此模块可以直接访问 MMIO. 最后在 BiscuitOS 上实践模块,由于需要一段真实的 MMIO 才能运行模块,因此可使用 Broiler 模拟一段 MMIO,其起始物理地址为 0xF0000000(Broiler 已经模拟好硬件),开发者直接在源码目录执行 make broiler 即可:
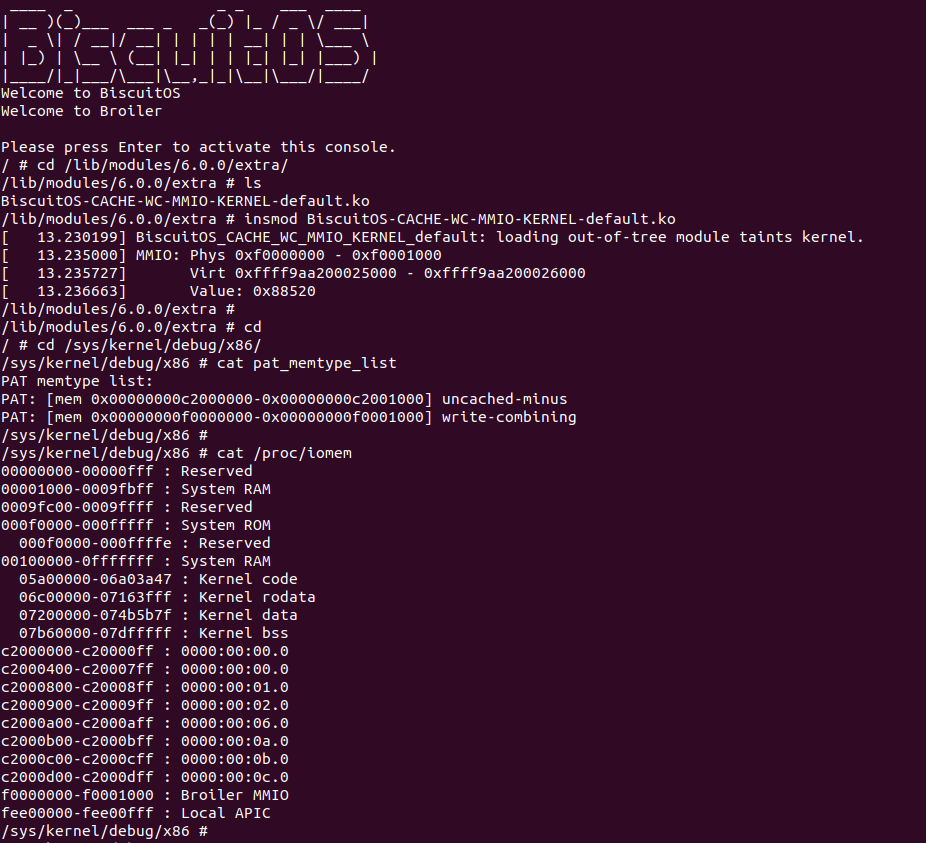
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-WC-MMIO-KERNEL-default.ko 模块之后,从打印的内核信息可以看出模块已经映射了 MMIO,并且向 MMIO 写入 0x88520 之后可以读出正确的数据,最后查看 ‘/sys/kernel/debug/x86/pat_memtype_list’ 节点查看系统 MMIO memory_type 信息,可以看到模块映射的 MMIO [0xF0000000, 0xF0001000] 为 write-combining, 另外查看 ‘/proc/iomem’ 节点查看物理地址空间信息,可以看到 [0xF0000000, 0xF0001000) 为 Broiler MMIO 区域, 实践符合预期. 接下来一个实践案例用于介绍如何将用户空间虚拟地址映射成 WC 的 MMIO,BiscuitOS 部署逻辑如下:
用户空间虚拟地址映射 WC MMIO
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] WriteCombining(WC): Mapping WC MMIO on Userspace --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WC-MMIO-USERSPACE-default
# 部署源码
make download
# 在 BiscuitOS/Broiler 中实践
make broilerBiscuitOS-CACHE-WC-MMIO-USERSPACE-default Source Code on Gitee
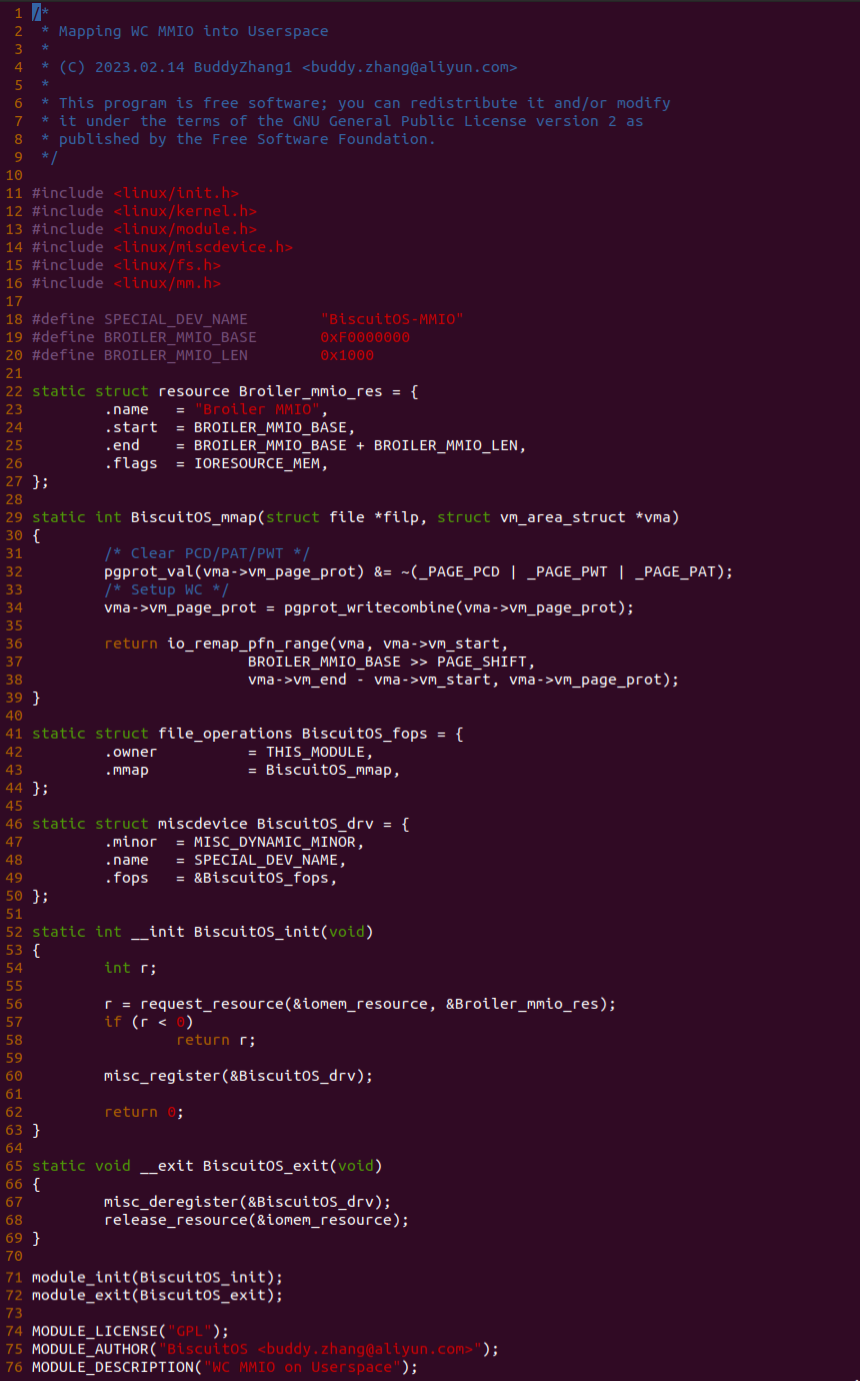
实践案例由两个部分组成,main.c 为内核模块部分,负责映射 MMIO 的底层逻辑。模块首先在 22-26 行定义了 MMIO 区域的信息,然后在 56-57 行通过调用 request_resource() 函数将 MMIO 区域添加到系统物理地址空间树里。模块通过注册一个 MISC 驱动,向用户空间提供 “/dev/BiscuitOS-MMIO” 接口,用户空间程序打开该接口,并调用 mmap() 映射 MMIO 时会调用到模块的 BiscuitOS_mmap() 函数,该函数首先在 32 行将虚拟地址对应的页表属性里的 _PAGE_PAT、_PAGE_PCD 和 _PAGE_PWT 标志清除,然后在 34 行调用 pgport_writecombine() 函数,将 WC 属性赋值到 vm_page_prot 成员,接下来调用 io_remap_pfn_range() 函数进行虚拟地址到 MMIO 的映射工作。映射完毕之后用户空间虚拟地址就可以以 WC 方式访问 MMIO.
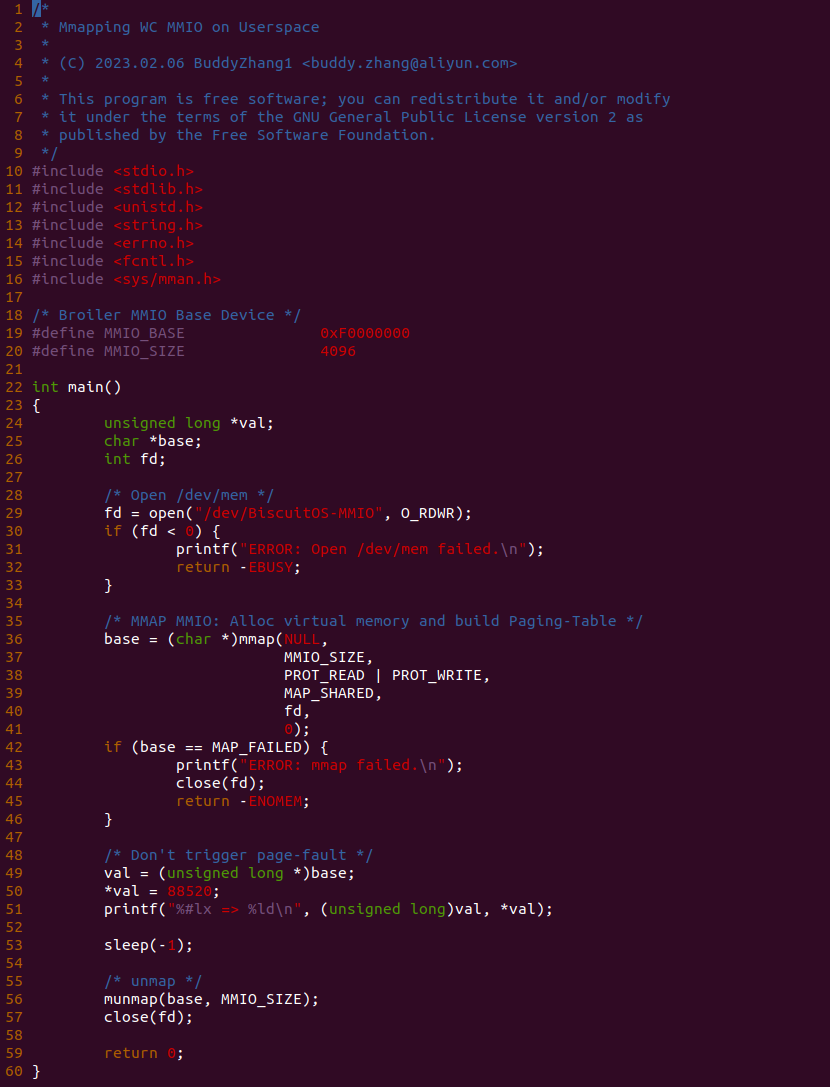
实践案例的另外一部分位于 app.c 内,其为用户空间程序,用于映射虚拟地址到 MMIO 并进行访问. 程序首先在 29 行通过 open() 函数打开 “/dev/BiscuitOS-MMIO” 节点,然后在 36-46 通过 mmap() 函数将进程地址空间的虚拟地址映射到 MMIO,接下来在 49-51 行对映射之后对 MMIO 进行访问,最后在 56-57 行释放相应的资源. 源码分析完毕之后在 BiscuitOS 进行实践,由于 MMIO 绑定在具体的硬件上,此时可以使用 Broiler 进行模块,直接使用 “make broiler” 命令进行实践:
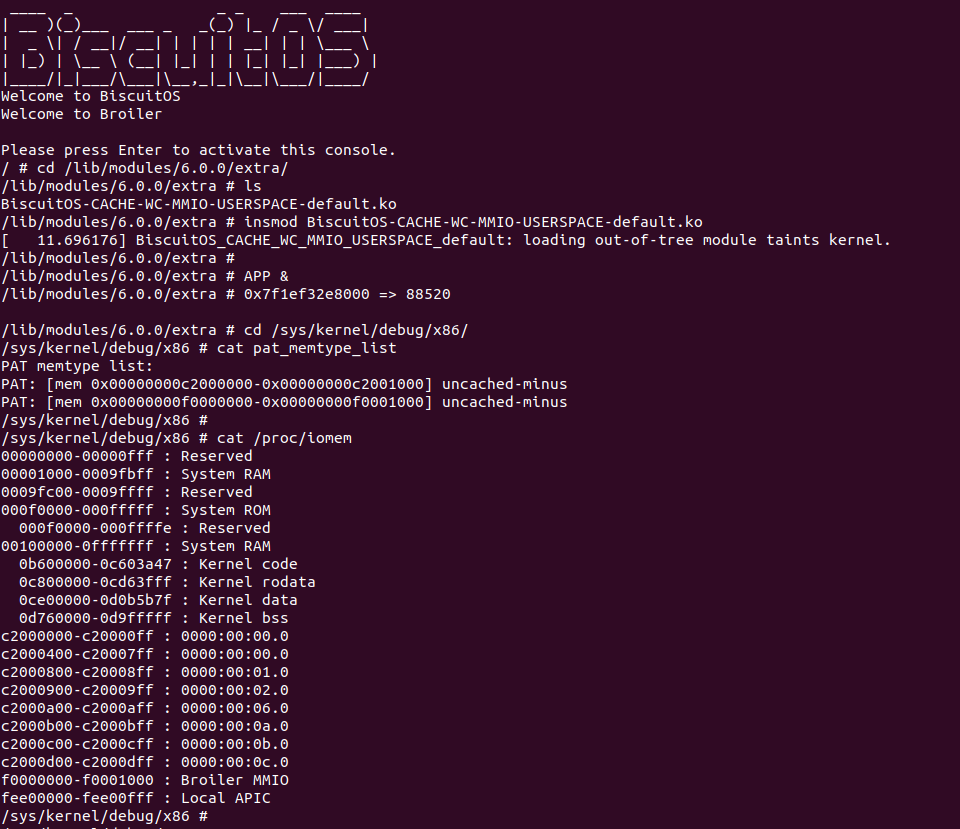
BiscuitOS Broiler 运行之后加载 BiscuitOS-CACHE-WC-MMIO-USERSPACE-default.ko, 接着运行用户态程序 APP,这里以后台方式运行,因此查看其他有用信息,运行之后可以看到正常访问 MMIO。接下来查看 /sys/kernel/debug/x86/pat_memtype_list 节点,可以看到 [0xF0000000, 0xF0001000) 区域映射为 uncached-minus,最后查看 /proc/iomem 系统物理地址空间,可以看到 Broiler MMIO 对应的区域正好是 [0xF0000000, 0xF0001000)。实践结果不符合预期,为什么用户空间无法映射 WC MMIO 呢? 具体分析请看. 那么接下来对普通物理内存映射为 WC 场景进行实践:
用户空间虚拟内存映射 WC 物理内存
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] WriteCombining(WC): Mapping WC Memory on Userspace --->
-*- CACHE User-Page for Kernel Stub (Basic) --->
# 进入源码目录
# Userspace: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WC-MEM-USERSPACE-default/
# Kernel: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default/
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WC-MEM-USERSPACE-default/
# 部署源码
make prepare
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-WC-MEM-USERSPACE-default Source Code on Gitee
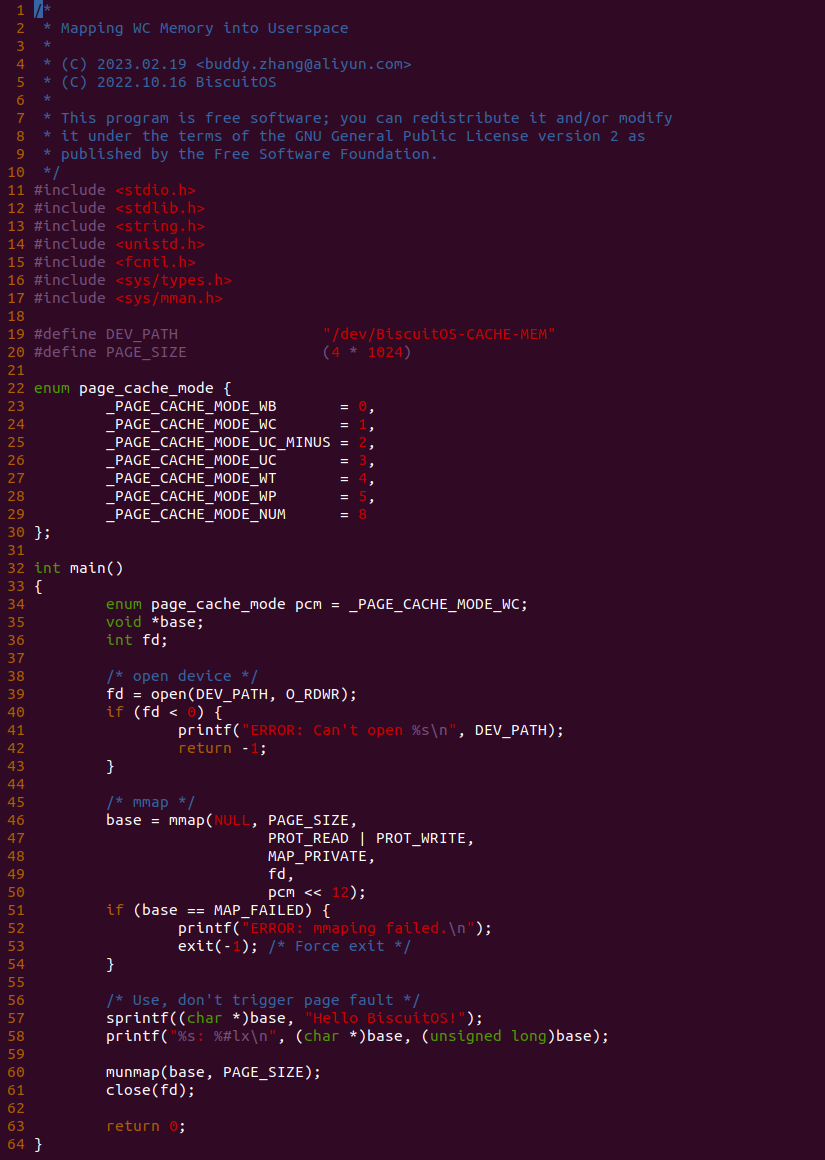
源码分成两部分,其中一部分为用户空间程序(上图所示), 用户空间代码的主要功能是映射一段虚拟内存,并将其缓存类型设置为 WC. 函数首先在 34 行将 pcm 变量设置为 _PAGE_CACHE_MODE_WC, 然后在 39 行打开 “/dev/BiscuitOS-CACHE” 节点,并基于该节点映射长度为 PAGE_SIZE 的虚拟内存,此时在函数 50 行将 pcm 传入到 mmap() 函数,映射完毕后函数在 58-59 行使用 WC 的内存,使用完毕在 61-62 行解除映射并关闭文件。
BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default Source Code on Gitee
源码的另外一部分位于内核空间,其主要功能是进行实际的映射任务。模块通过一个 MISC 驱动进行实现,其提供了 mmap 接口 BiscuitOS_mmap(), 当用户空间基于 “/dev/BiscuitOS-CACHE” 节点调用 mmap() 函数时,BiscuitOS_mmap() 函数就会别调用。模块首先在 60 行调用 mtrr_add() 函数将 [MTRR_MEM_BASE, MTRR_MEM_SIZE + MTRR_MEM_BASE) 区域的 MTRR 设置为 WB. 模块接着在 33 行在用户空间调用 mmap() 函数时从 vma 的 vm_pgoff 成员中获得 PAGE CACHE MODE 信息,接着在 36 行将 vma_page_prot 成员中移除 _PAGE_PCD、_PAGE_PWT 和 _PAGE_PAT 属性,并在 39 行调用 cachemode2protval() 函数将 PAGE CACHE MODE 转换成对应的页表属性,并重新存储到 vma 的 vm_page_prot, 以此作为用于空间设置的 memory type 页表属性,最后模块在 41 行调用 remap_pfn_range() 函数为虚拟内存建立页表并映射到 MTRR_MEM_BASE 对应的物理内存上. 接下来在 BiscuitOS 上实践该案例:
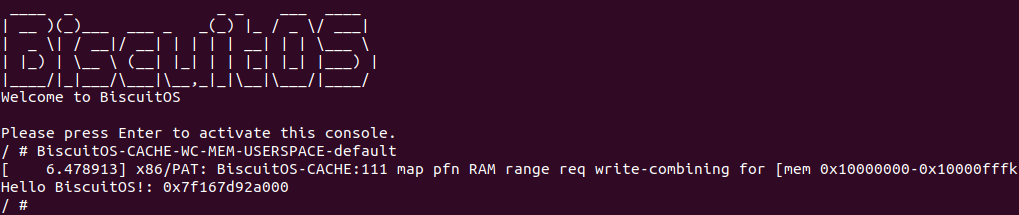
BiscuitOS 运行之后, 执行应用程序 BiscuitOS-CACHE-WC-MEM-USERSPACE-default,此时系统提示了程序预期将 [0x10000000-0x10000fff] 为 write-combining,但是系统还是将对应的 memory type 设置为 write-back, 这个与预期不符合. 查看内核模块源码的 3 行提示需要将 [0x10000000, 0x10200000) 进行预留,那么在 CMDLINE(CMDLINE 位于 RunBiscuitOS.sh 文件中) 中添加预留字段后再次实践:
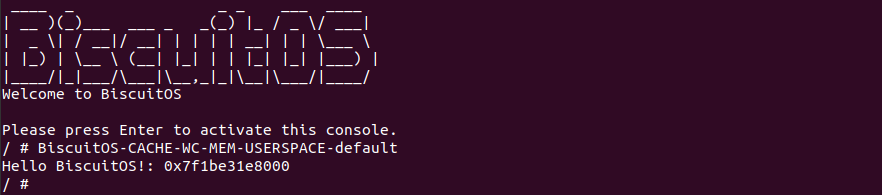
BiscuitOS 在次运行之后,运行应用程序,可以看到系统没有再提示修改信息了,那么用户进程已经成功将一段物理内存的 memory type 设置为 WC. 实践符合预期,那么接下来实践内核空间虚拟地址映射 WC 物理内存:
内核空间虚拟内存映射 WC 物理内存
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] WriteCombining(WC): Mapping WC Memory on Kernel --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WC-MEM-KERNEL-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build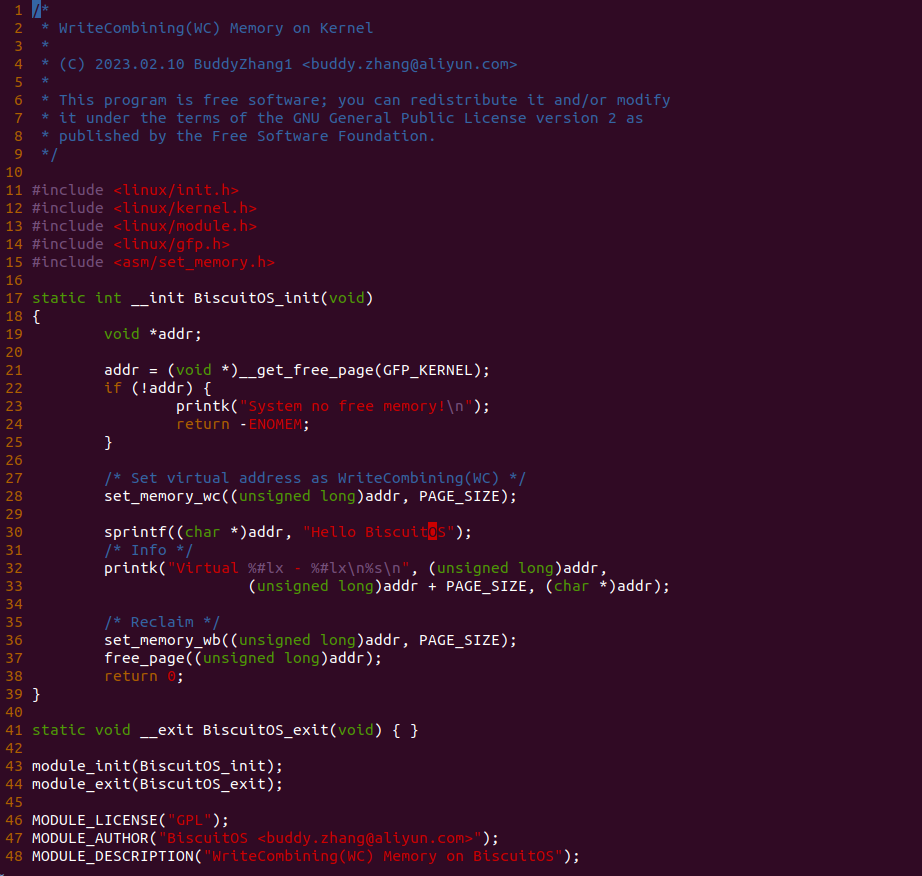
实践案例主要目的是在内核空间申请一段内存之后,将对应的虚拟地址以 WC 的方式映射到物理内存,并进行访问。案例在 21-25 行通过 __get_free_page() 函数分配一个物理页并获得对应的虚拟地址,然后在 28 行调用 set_memory_wc() 函数进行 WC 方式的映射,案例接着在 30-33 行对映射之后的虚拟地址进行访问。最后在 36-37 行回收设置,值得注意的是当将内核空间虚拟地址设置为非 WB 之后,在回收时要主动设置为 WB, 接下来在 BiscuitOS 上实践该案例:
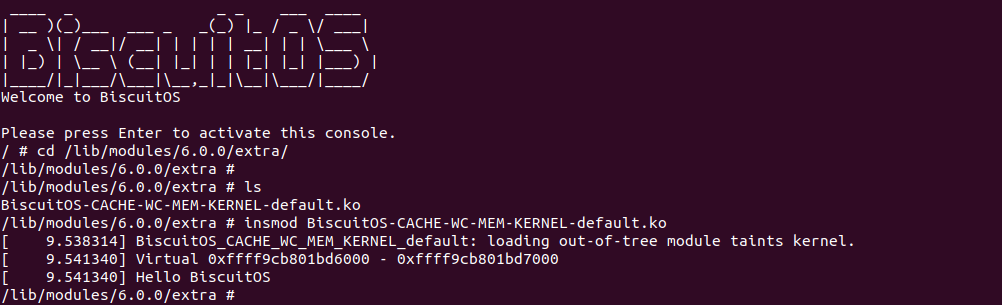
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-WC-MEM-KERNEL-default.ko 模块,可以看到系统可以使用 WC 的虚拟内存,并打印字符串 “Hello BiscuitOS”, 符合预期.
Write-Through (WT)
Write Through (WT): 通写类型,该类型会缓存读写请求。当 Read CACHE Hit 时直接从 CACHE Line 中读取数据,当 Read CACHE Miss 时先进行 CACHE Fill,然后再从 CACHE Line 中读取数据; 当 Write CACHE Hit 时,即更新 CACHE Line 的数据,也更新 Memory 中的数据, 当 Write CACHE Miss 时不会 CACHE Fills,而是直接更新 Memory 中的数据. 当 WT 类型时预测读是允许的,并且 Write Combining 也是允许的。WT 类型通常应用于 Frame Buffer 或者会访问内存的设备,这类设备会访问总线,但没有监听总线的能力. WT 强制遵循 CACHE 一致性原理. 那么接下来通过一组实践案例介绍内核和用户空间如何使用 WT 类型的内存:
内核空间虚拟地址映射 WT MMIO
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] WriteThrough(WT): Mapping WT MMIO on Kernel --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WT-MMIO-KERNEL-default
# 部署源码
make download
# 在 BiscuitOS/Broiler 中实践
make broilerBiscuitOS-CACHE-UNCACHE-WT-KERNEL-default Source Code on Gitee
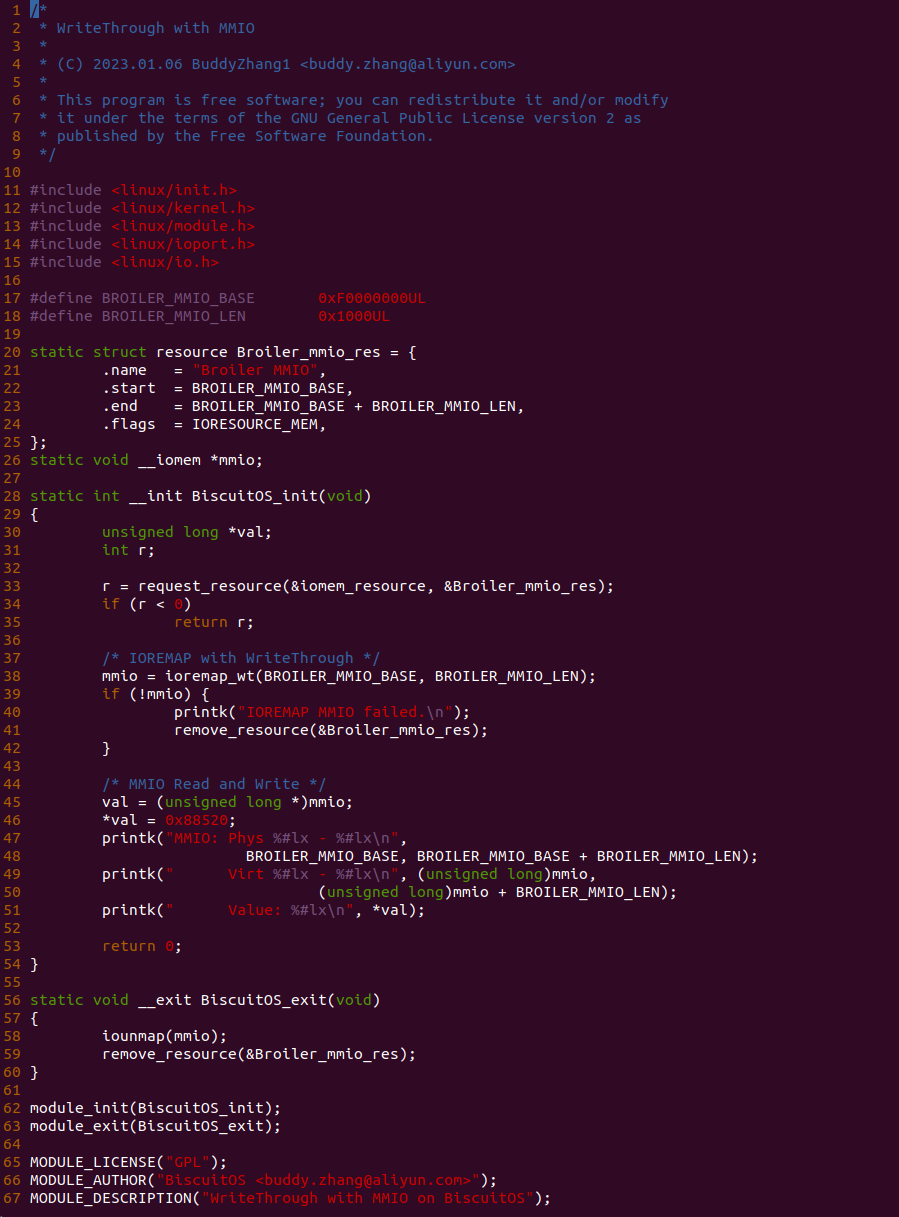
源码通过一个内核模块进行展示,模块有两部分组成,第一部分是 20-35 行,模块向系统资源总线注册了一段 MMIO,这段 MMIO 起始物理地址是 BROILER_MMIO_BASE, 长度为 BROILER_MMIO_LEN, 注册完毕之后可以在系统启动之后,通过 ‘/proc/iomem’ 接口查看到该段信息; 第二部分是 38-46 行,模块在 38 行调用 ioremap_wt() 函数将 BROILER_MMIO_BASE 开始且长度为 BROILER_MMIO_LEN 的 MMIO 区域,映射为 Write-Through 的 memory type, 映射完毕之后函数在 46 行对 MMIO 进行访问,此时并不会触发缺页,因为 ioremap_wt() 函数已为 MMIO 分配了对应的虚拟地址并建立了页表,因此模块可以直接访问 MMIO. 最后在 BiscuitOS 上实践模块,由于需要一段真实的 MMIO 才能运行模块,因此可使用 Broiler 模拟一段 MMIO,其起始物理地址为 0xF0000000(Broiler 已经模拟好硬件),开发者直接在源码目录执行 make broiler 即可:
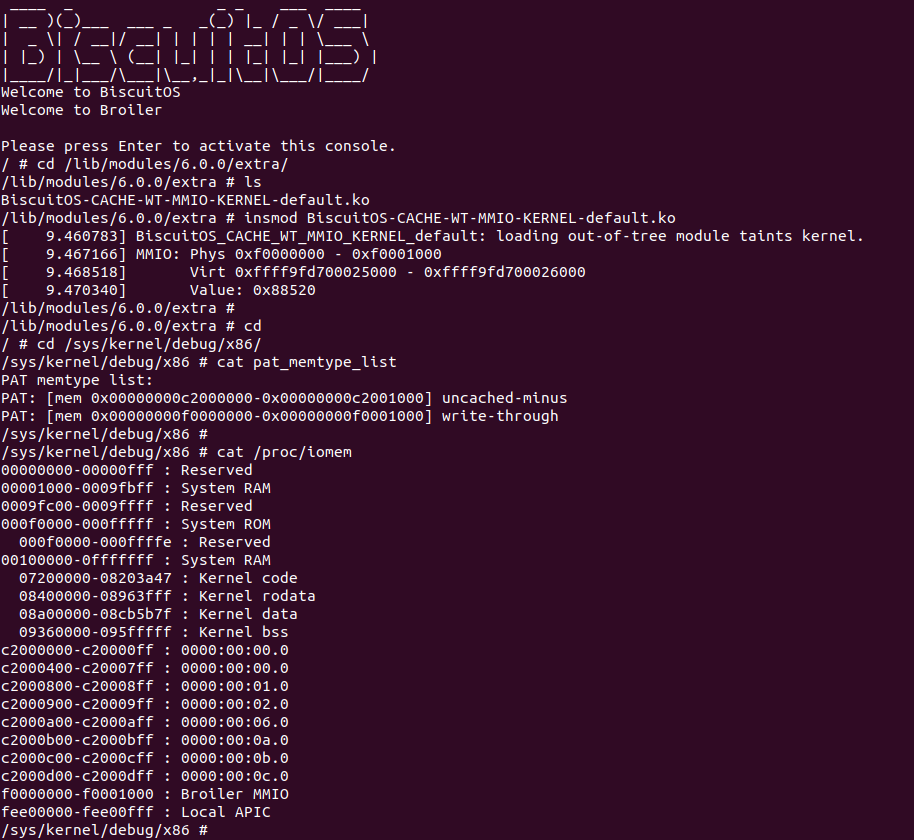
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-WT-MMIO-KERNEL-default.ko 模块之后,从打印的内核信息可以看出模块已经映射了 MMIO,并且向 MMIO 写入 0x88520 之后可以读出正确的数据,最后查看 ‘/sys/kernel/debug/x86/pat_memtype_list’ 节点查看系统 MMIO memory_type 信息,可以看到模块映射的 MMIO [0xF0000000, 0xF0001000] 为 write-through, 另外查看 ‘/proc/iomem’ 节点查看物理地址空间信息,可以看到 [0xF0000000, 0xF0001000) 为 Broiler MMIO 区域, 实践符合预期. 接下来一个实践案例用于介绍如何将用户空间虚拟地址映射成 WT 的 MMIO,BiscuitOS 部署逻辑如下:
用户空间虚拟地址映射 WT MMIO
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] WriteThrough(WT): Mapping WT MMIO on Userspace --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WT-MMIO-USERSPACE-default
# 部署源码
make download
# 在 BiscuitOS/Broiler 中实践
make broilerBiscuitOS-CACHE-WT-MMIO-USERSPACE-default Source Code on Gitee
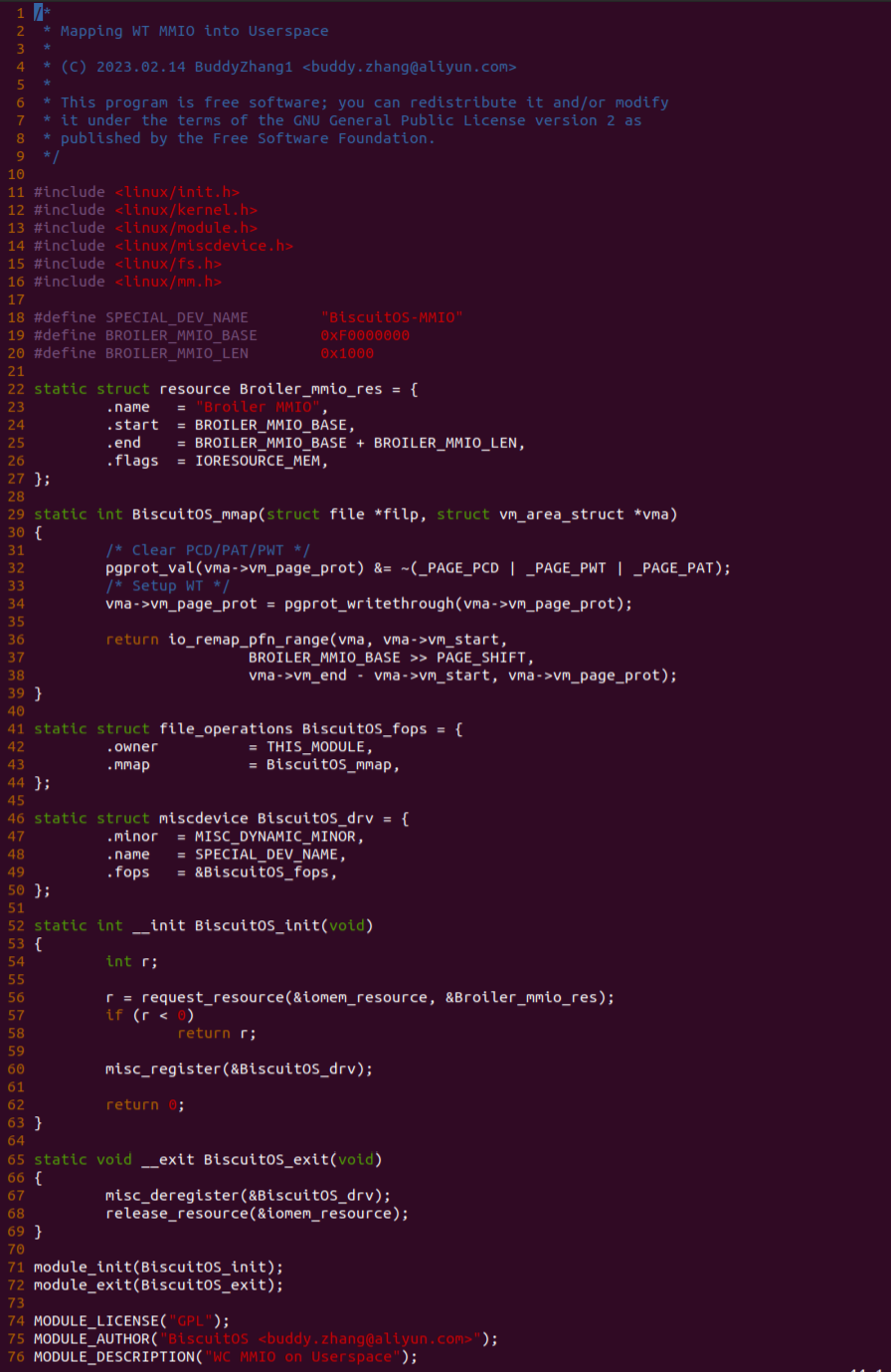
实践案例由两个部分组成,main.c 为内核模块部分,负责映射 MMIO 的底层逻辑。模块首先在 22-26 行定义了 MMIO 区域的信息,然后在 56-57 行通过调用 request_resource() 函数将 MMIO 区域添加到系统物理地址空间树里。模块通过注册一个 MISC 驱动,向用户空间提供 “/dev/BiscuitOS-MMIO” 接口,用户空间程序打开该接口,并调用 mmap() 映射 MMIO 时会调用到模块的 BiscuitOS_mmap() 函数,该函数首先在 32 行将虚拟地址对应的页表属性里的 _PAGE_PAT、_PAGE_PCD 和 _PAGE_PWT 标志清除,然后在 34 行调用 pgport_writethrough() 函数,将 WT 属性赋值到 vm_page_prot 成员,接下来调用 io_remap_pfn_range() 函数进行虚拟地址到 MMIO 的映射工作。映射完毕之后用户空间虚拟地址就可以以 WT 方式访问 MMIO.
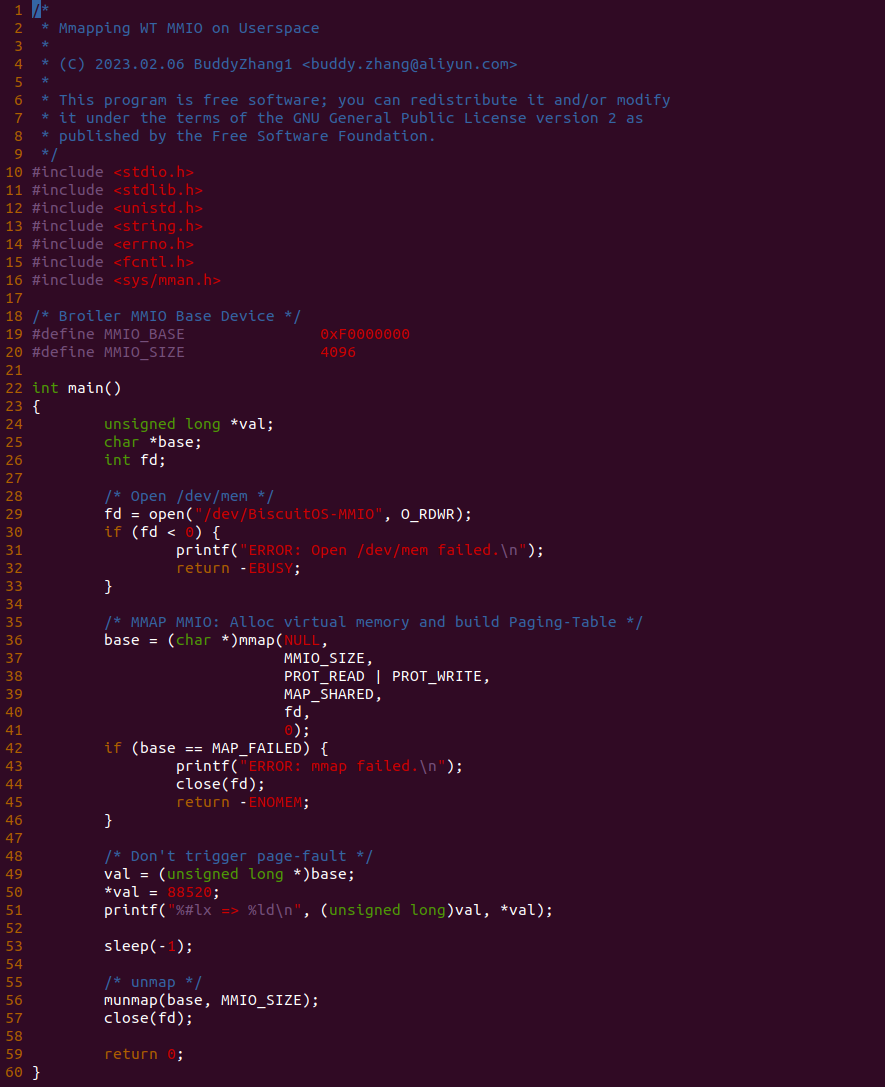
实践案例的另外一部分位于 app.c 内,其为用户空间程序,用于映射虚拟地址到 MMIO 并进行访问. 程序首先在 29 行通过 open() 函数打开 “/dev/BiscuitOS-MMIO” 节点,然后在 36-46 通过 mmap() 函数将进程地址空间的虚拟地址映射到 MMIO,接下来在 49-51 行对映射之后对 MMIO 进行访问,最后在 56-57 行释放相应的资源. 源码分析完毕之后在 BiscuitOS 进行实践,由于 MMIO 绑定在具体的硬件上,此时可以使用 Broiler 进行模块,直接使用 “make broiler” 命令进行实践:
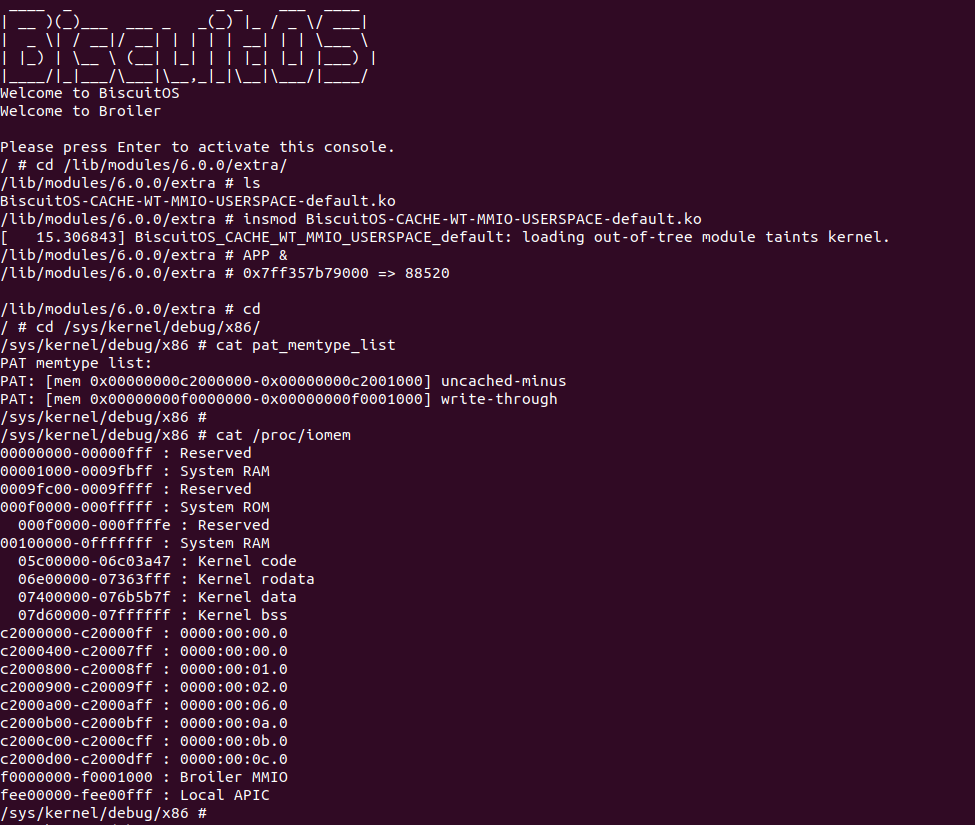
BiscuitOS Broiler 运行之后加载 BiscuitOS-CACHE-WT-MMIO-USERSPACE-default.ko, 接着运行用户态程序 APP,这里以后台方式运行,因此查看其他有用信息,运行之后可以看到正常访问 MMIO。接下来查看 /sys/kernel/debug/x86/pat_memtype_list 节点,可以看到 [0xF0000000, 0xF0001000) 区域映射为 write-through,最后查看 /proc/iomem 系统物理地址空间,可以看到 Broiler MMIO 对应的区域正好是 [0xF0000000, 0xF0001000)。实践结果符合预期. 那么接下来对普通物理内存映射为 WC 场景进行实践:
用户空间虚拟内存映射 WT 物理内存
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] WriteThrough(WT): Mapping WT Memory on Userspace --->
-*- CACHE User-Page for Kernel Stub (Basic) --->
# 进入源码目录
# Userspace: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WT-MEM-USERSPACE-default/
# Kernel: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default/
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WT-MEM-USERSPACE-default/
# 部署源码
make prepare
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-WT-MEM-USERSPACE-default Source Code on Gitee
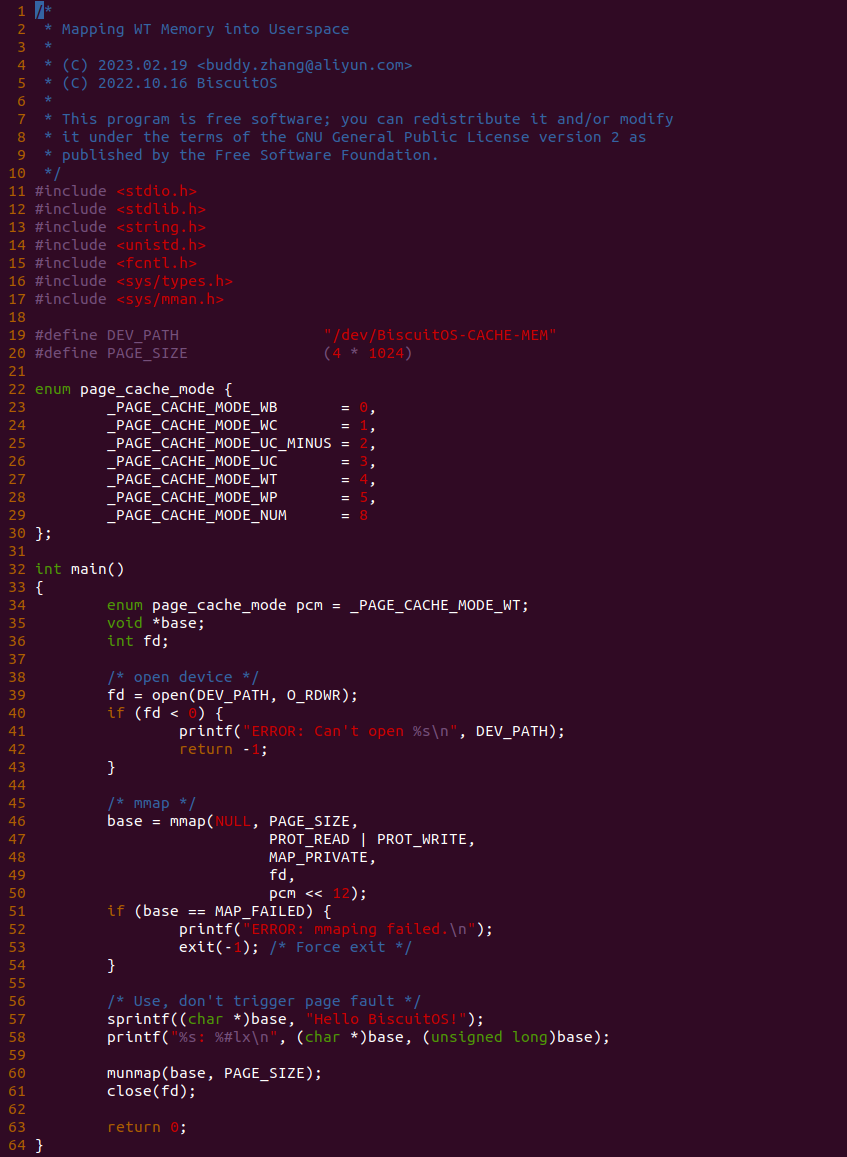
源码分成两部分,其中一部分为用户空间程序(上图所示), 用户空间代码的主要功能是映射一段虚拟内存,并将其缓存类型设置为 WT. 函数首先在 34 行将 pcm 变量设置为 _PAGE_CACHE_MODE_WT, 然后在 39 行打开 “/dev/BiscuitOS-CACHE” 节点,并基于该节点映射长度为 PAGE_SIZE 的虚拟内存,此时在函数 50 行将 pcm 传入到 mmap() 函数,映射完毕后函数在 58-59 行使用 WT 的内存,使用完毕在 61-62 行解除映射并关闭文件。
BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default Source Code on Gitee
源码的另外一部分位于内核空间,其主要功能是进行实际的映射任务。模块通过一个 MISC 驱动进行实现,其提供了 mmap 接口 BiscuitOS_mmap(), 当用户空间基于 “/dev/BiscuitOS-CACHE” 节点调用 mmap() 函数时,BiscuitOS_mmap() 函数就会别调用。模块首先在 60 行调用 mtrr_add() 函数将 [MTRR_MEM_BASE, MTRR_MEM_SIZE + MTRR_MEM_BASE) 区域的 MTRR 设置为 WB. 模块接着在 33 行在用户空间调用 mmap() 函数时从 vma 的 vm_pgoff 成员中获得 PAGE CACHE MODE 信息,接着在 36 行将 vma_page_prot 成员中移除 _PAGE_PCD、_PAGE_PWT 和 _PAGE_PAT 属性,并在 39 行调用 cachemode2protval() 函数将 PAGE CACHE MODE 转换成对应的页表属性,并重新存储到 vma 的 vm_page_prot, 以此作为用于空间设置的 memory type 页表属性,最后模块在 41 行调用 remap_pfn_range() 函数为虚拟内存建立页表并映射到 MTRR_MEM_BASE 对应的物理内存上. 接下来在 BiscuitOS 上实践该案例:
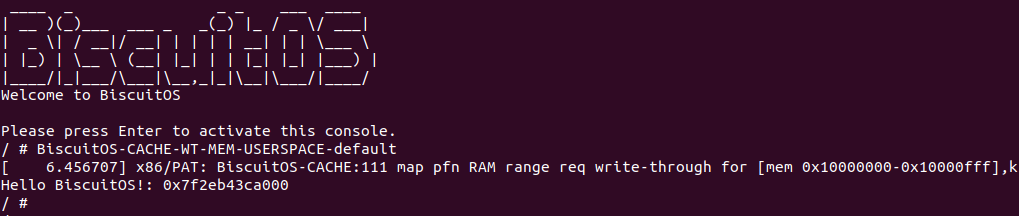
BiscuitOS 运行之后, 执行应用程序 BiscuitOS-CACHE-WT-MEM-USERSPACE-default,此时系统提示了程序预期将 [0x10000000-0x10000fff] 为 write-through,但是系统还是将对应的 memory type 设置为 write-back, 这个与预期不符合. 查看内核模块源码的 3 行提示需要将 [0x10000000, 0x10200000) 进行预留,那么在 CMDLINE(CMDLINE 位于 RunBiscuitOS.sh 文件中) 中添加预留字段后再次实践:
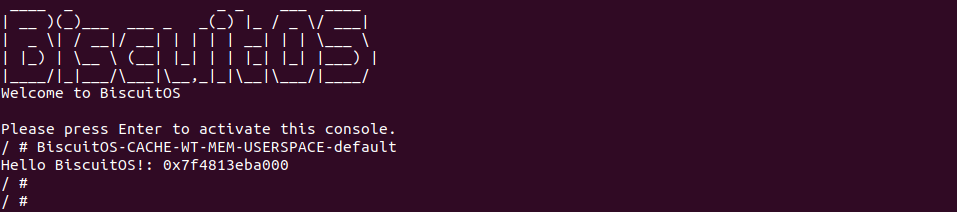
BiscuitOS 在次运行之后,运行应用程序,可以看到系统没有再提示修改信息了,那么用户进程已经成功将一段物理内存的 memory type 设置为 WT. 实践符合预期,那么接下来实践内核空间虚拟地址映射 WT 物理内存:
内核空间虚拟内存映射 WT 物理内存
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] WriteThrough(WT): Mapping WT Memory on Kernel --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WT-MEM-KERNEL-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
实践案例主要目的是在内核空间申请一段内存之后,将对应的虚拟地址以 WT 的方式映射到物理内存,并进行访问。案例在 21-25 行通过 __get_free_page() 函数分配一个物理页并获得对应的虚拟地址,然后在 28 行调用 _set_memory_wt() 函数进行 WT 方式的映射,案例接着在 30-33 行对映射之后的虚拟地址进行访问。最后在 36-37 行回收设置,值得注意的是当将内核空间虚拟地址设置为非 WB 之后,在回收时要主动设置为 WB, 接下来在 BiscuitOS 上实践该案例:
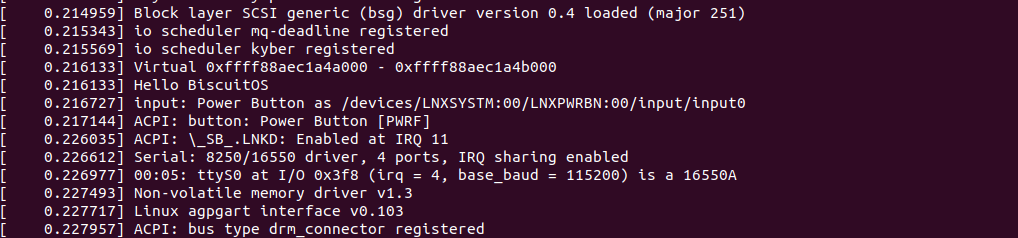
BiscuitOS 系统启动过程中,可以看到 dmesg 打印字符串 “Hello BiscuitOS”, 以及相应的虚拟地址,符合预期.
Write-Back (WB)
Write Back (WB): 回写类型,该类型会缓存读写请求。当 Read CACHE Hit 时直接从 CACHE Line 中读取数据,当 Read CACHE Miss 时先进行 CACHE Fill,然后再从 CACHE Line 中读取数据; 当 Write CACHE Hit 时,尽可能只更新 CACHE Line 的数据, 当 Write CACHE Miss 时会 CACHE Fills,并尽可能只更新 CACHE Line 中的数据. 当 WB 类型时预测读是允许的,并且 Write Combining 也是允许的。WB 类型内存由于写请求尽可能在 CACHE Line 中进行,很大程度上缓解了总线拥堵的问题. 与 WT 类型不同的是当写请求时不是立即写入到内存,而是尽可能的只写如到 CACHE Line,直到 Write-Back 信号到来时才把缓存中已经修改的数据更新到内存。Write-Back 操作可能发生在 CACHE 已经满的请求下,需要新分配一个 CACHE Line,那么被淘汰的 CACHE Line 就会执行 Write-Back 操作. 另外 CACHE 一致性协议针对其他核对 M 状态的 CACHE Line 进行读时也会触发 Write-Back 操作. WB 可以提供最好的性能,但其要求采用该类型的设备具有监听(snoop)内存访问,以此维护内存和 CACHE 的一致性. 那么接下来通过一组实践案例介绍内核和用户空间如何使用 WB 类型的内存:
用户空间虚拟地址映射 WB MMIO
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] WriteBack(WB): Mapping WB MMIO on Userspace --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WB-MMIO-USERSPACE-default
# 部署源码
make download
# 在 BiscuitOS/Broiler 中实践
make broilerBiscuitOS-CACHE-WB-MMIO-USERSPACE-default Source Code on Gitee
实践案例由两个部分组成,main.c 为内核模块部分,负责映射 MMIO 的底层逻辑。模块首先在 22-26 行定义了 MMIO 区域的信息,然后在 56-57 行通过调用 request_resource() 函数将 MMIO 区域添加到系统物理地址空间树里。模块通过注册一个 MISC 驱动,向用户空间提供 “/dev/BiscuitOS-MMIO” 接口,用户空间程序打开该接口,并调用 mmap() 映射 MMIO 时会调用到模块的 BiscuitOS_mmap() 函数,该函数首先在 32 行将虚拟地址对应的页表属性里的 _PAGE_PAT、_PAGE_PCD 和 _PAGE_PWT 标志清除,然后在 34 行调用 cachemode2protval() 函数,将 WB 属性赋值到 vm_page_prot 成员,接下来调用 io_remap_pfn_range() 函数进行虚拟地址到 MMIO 的映射工作。映射完毕之后用户空间虚拟地址就可以以 WB 方式访问 MMIO.
实践案例的另外一部分位于 app.c 内,其为用户空间程序,用于映射虚拟地址到 MMIO 并进行访问. 程序首先在 29 行通过 open() 函数打开 “/dev/BiscuitOS-MMIO” 节点,然后在 36-46 通过 mmap() 函数将进程地址空间的虚拟地址映射到 MMIO,接下来在 49-51 行对映射之后对 MMIO 进行访问,最后在 56-57 行释放相应的资源. 源码分析完毕之后在 BiscuitOS 进行实践,由于 MMIO 绑定在具体的硬件上,此时可以使用 Broiler 进行模块,直接使用 “make broiler” 命令进行实践:
BiscuitOS Broiler 运行之后加载 BiscuitOS-CACHE-WB-MMIO-USERSPACE-default.ko, 接着运行用户态程序 APP,这里以后台方式运行,因此查看其他有用信息,运行之后可以看到正常访问 MMIO。接下来查看 /sys/kernel/debug/x86/pat_memtype_list 节点,可以看到 [0xF0000000, 0xF0001000) 区域映射为 uncached-minus,最后查看 /proc/iomem 系统物理地址空间,可以看到 Broiler MMIO 对应的区域正好是 [0xF0000000, 0xF0001000)。实践结果不符合预期,具体原因见. 那么接下来对普通物理内存映射为 WB 场景进行实践:
用户空间虚拟内存映射 WB 物理内存
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] WriteBack(WB): Mapping WB Memory on Userspace --->
-*- CACHE User-Page for Kernel Stub (Basic) --->
# 进入源码目录
# Userspace: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WB-MEM-USERSPACE-default/
# Kernel: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default/
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WB-MEM-USERSPACE-default/
# 部署源码
make prepare
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-WB-MEM-USERSPACE-default Source Code on Gitee
源码分成两部分,其中一部分为用户空间程序(上图所示), 用户空间代码的主要功能是映射一段虚拟内存,并将其缓存类型设置为 WB. 函数首先在 34 行将 pcm 变量设置为 _PAGE_CACHE_MODE_WB, 然后在 39 行打开 “/dev/BiscuitOS-CACHE” 节点,并基于该节点映射长度为 PAGE_SIZE 的虚拟内存,此时在函数 50 行将 pcm 传入到 mmap() 函数,映射完毕后函数在 58-59 行使用 WB 的内存,使用完毕在 61-62 行解除映射并关闭文件。
BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default Source Code on Gitee
源码的另外一部分位于内核空间,其主要功能是进行实际的映射任务。模块通过一个 MISC 驱动进行实现,其提供了 mmap 接口 BiscuitOS_mmap(), 当用户空间基于 “/dev/BiscuitOS-CACHE” 节点调用 mmap() 函数时,BiscuitOS_mmap() 函数就会别调用。模块首先在 60 行调用 mtrr_add() 函数将 [MTRR_MEM_BASE, MTRR_MEM_SIZE + MTRR_MEM_BASE) 区域的 MTRR 设置为 WB. 模块接着在 33 行在用户空间调用 mmap() 函数时从 vma 的 vm_pgoff 成员中获得 PAGE CACHE MODE 信息,接着在 36 行将 vma_page_prot 成员中移除 _PAGE_PCD、_PAGE_PWT 和 _PAGE_PAT 属性,并在 39 行调用 cachemode2protval() 函数将 PAGE CACHE MODE 转换成对应的页表属性,并重新存储到 vma 的 vm_page_prot, 以此作为用于空间设置的 memory type 页表属性,最后模块在 41 行调用 remap_pfn_range() 函数为虚拟内存建立页表并映射到 MTRR_MEM_BASE 对应的物理内存上. 接下来在 BiscuitOS 上实践该案例:
BiscuitOS 在次运行之后,运行应用程序,可以看到系统没有再提示修改信息,那么用户进程已经成功将一段物理内存的 memory type 设置为 WB. 实践符合预期,那么接下来实践内核空间虚拟地址映射 WB 物理内存:
内核空间虚拟内存映射 WB 物理内存
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] WriteBack(WB): Mapping WB Memory on Kernel --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WB-MEM-KERNEL-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build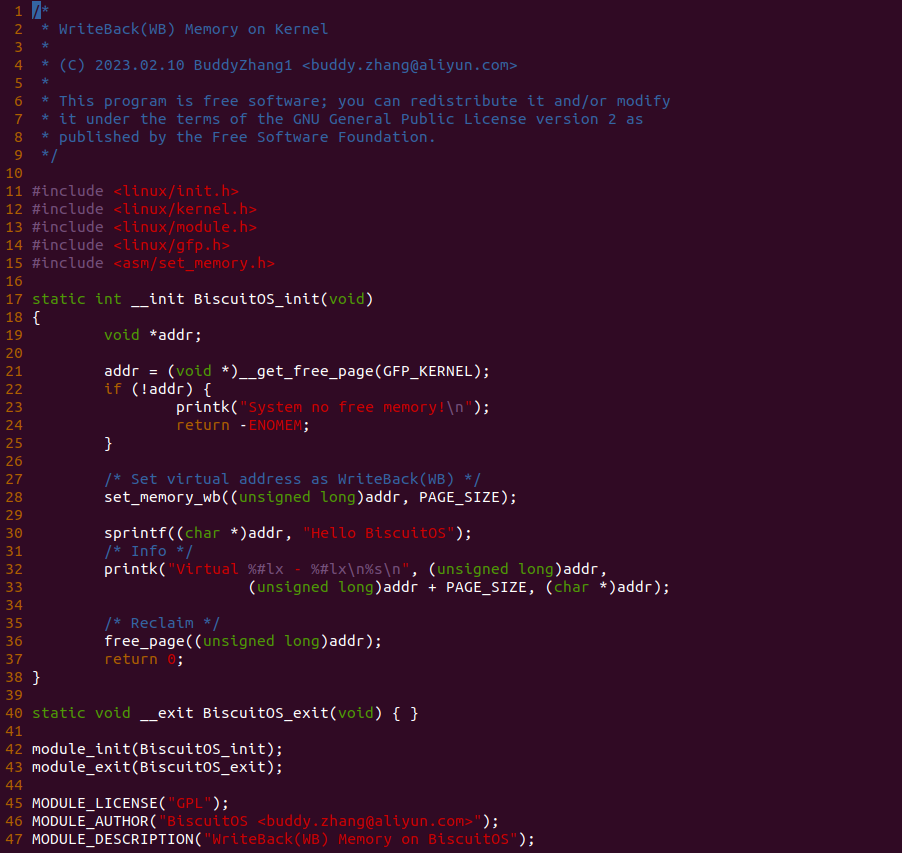
实践案例主要目的是在内核空间申请一段内存之后,将对应的虚拟地址以 WB 的方式映射到物理内存,并进行访问。案例在 21-25 行通过 __get_free_page() 函数分配一个物理页并获得对应的虚拟地址,然后在 28 行调用 set_memory_wb() 函数进行 WB 方式的映射,案例接着在 30-33 行对映射之后的虚拟地址进行访问。最后在 36-37 行回收设置, 接下来在 BiscuitOS 上实践该案例:
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-WB-MEM-KERNEL-default.ko 模块,可以看到系统可以使用 WB 的虚拟内存,并打印字符串 “Hello BiscuitOS”, 符合预期.
Write-Protected (WP)
Write Protected (WP): 写保护类型,该类型读请求从 CACHE Line 中获得数据,当 Read CACHE Miss 时触发 CACHE Fill. 但写请求会广播到总线,让其他 CPU 缓存副本的 CACHE Line 在总线上的数据全部无效,这个场景优点类似于所有 CPU 对一个 Shared 状态的 CACHE Line 进行写操作时,每个 CPU 都有将 CACHE Line 设置为 Modify 的可能,但此时采用 WP 的 CPU 会让其他 CPU 的 Modify 都无效,只有自己的 CACHE Line 可以设置为 Modify。另外 WP 时分支读是允许的, 那么接下来通过一组实践案例介绍内核和用户空间如何使用 WP 类型的内存:
用户空间虚拟内存映射 WP 物理内存
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] WriteProtected(WP): Mapping WP Memory on Userspace --->
-*- CACHE User-Page for Kernel Stub (Basic) --->
# 进入源码目录
# Userspace: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WP-MEM-USERSPACE-default/
# Kernel: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default/
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WP-MEM-USERSPACE-default/
# 部署源码
make prepare
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-WP-MEM-USERSPACE-default Source Code on Gitee
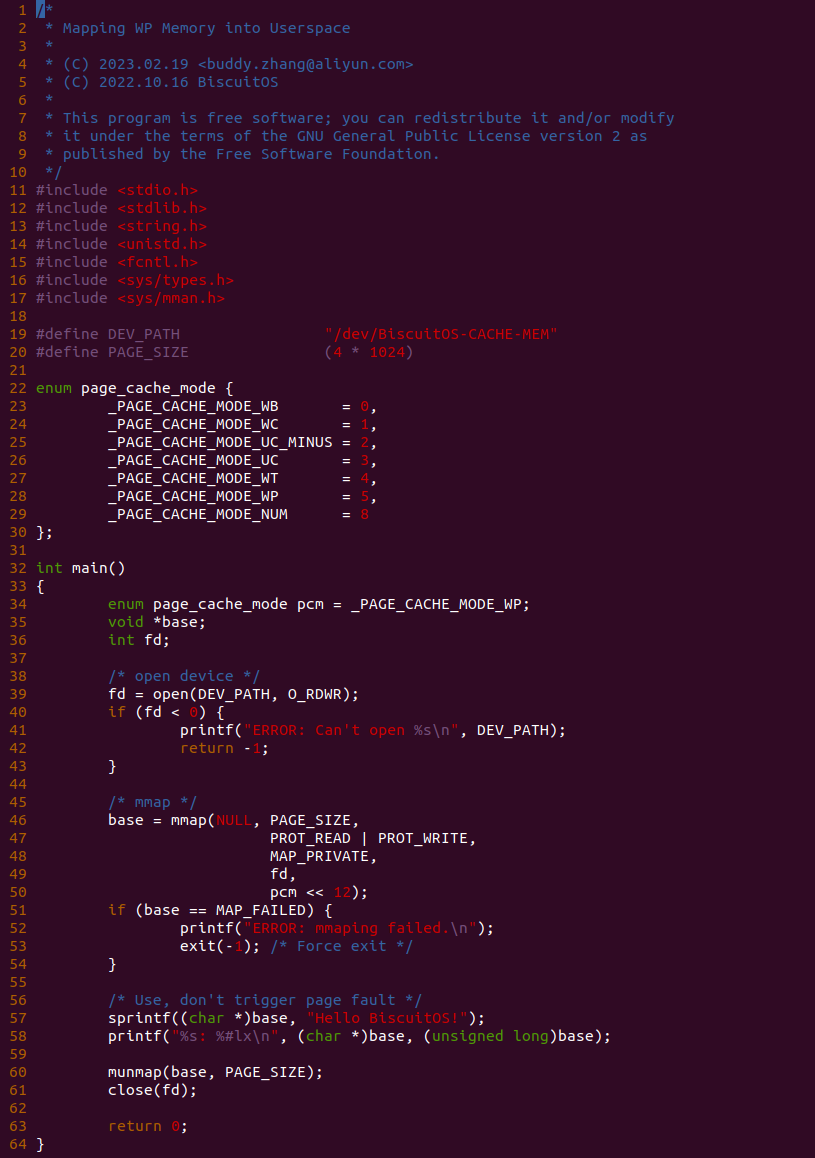
源码分成两部分,其中一部分为用户空间程序(上图所示), 用户空间代码的主要功能是映射一段虚拟内存,并将其缓存类型设置为 WP. 函数首先在 34 行将 pcm 变量设置为 _PAGE_CACHE_MODE_WP, 然后在 39 行打开 “/dev/BiscuitOS-CACHE” 节点,并基于该节点映射长度为 PAGE_SIZE 的虚拟内存,此时在函数 50 行将 pcm 传入到 mmap() 函数,映射完毕后函数在 58-59 行使用 WP 的内存,使用完毕在 61-62 行解除映射并关闭文件。
BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default Source Code on Gitee
源码的另外一部分位于内核空间,其主要功能是进行实际的映射任务。模块通过一个 MISC 驱动进行实现,其提供了 mmap 接口 BiscuitOS_mmap(), 当用户空间基于 “/dev/BiscuitOS-CACHE” 节点调用 mmap() 函数时,BiscuitOS_mmap() 函数就会别调用。模块首先在 60 行调用 mtrr_add() 函数将 [MTRR_MEM_BASE, MTRR_MEM_SIZE + MTRR_MEM_BASE) 区域的 MTRR 设置为 WB. 模块接着在 33 行在用户空间调用 mmap() 函数时从 vma 的 vm_pgoff 成员中获得 PAGE CACHE MODE 信息,接着在 36 行将 vma_page_prot 成员中移除 _PAGE_PCD、_PAGE_PWT 和 _PAGE_PAT 属性,并在 39 行调用 cachemode2protval() 函数将 PAGE CACHE MODE 转换成对应的页表属性,并重新存储到 vma 的 vm_page_prot, 以此作为用于空间设置的 memory type 页表属性,最后模块在 41 行调用 remap_pfn_range() 函数为虚拟内存建立页表并映射到 MTRR_MEM_BASE 对应的物理内存上. 接下来在 BiscuitOS 上实践该案例:
BiscuitOS 运行之后, 执行应用程序 BiscuitOS-CACHE-WP-MEM-USERSPACE-default,此时系统提示了程序预期将 [0x10000000-0x10000fff] 为 write-protected,但是系统还是将对应的 memory type 设置为 write-back, 这个与预期不符合. 查看内核模块源码的 3 行提示需要将 [0x10000000, 0x10200000) 进行预留,那么在 CMDLINE(CMDLINE 位于 RunBiscuitOS.sh 文件中) 中添加预留字段后再次实践:
BiscuitOS 在次运行之后,运行应用程序,可以看到系统没有再提示修改信息,那么用户进程已经成功将一段物理内存的 memory type 设置为 WP. 实践符合预期,那么接下来实践内核空间虚拟地址映射 WP 物理内存:
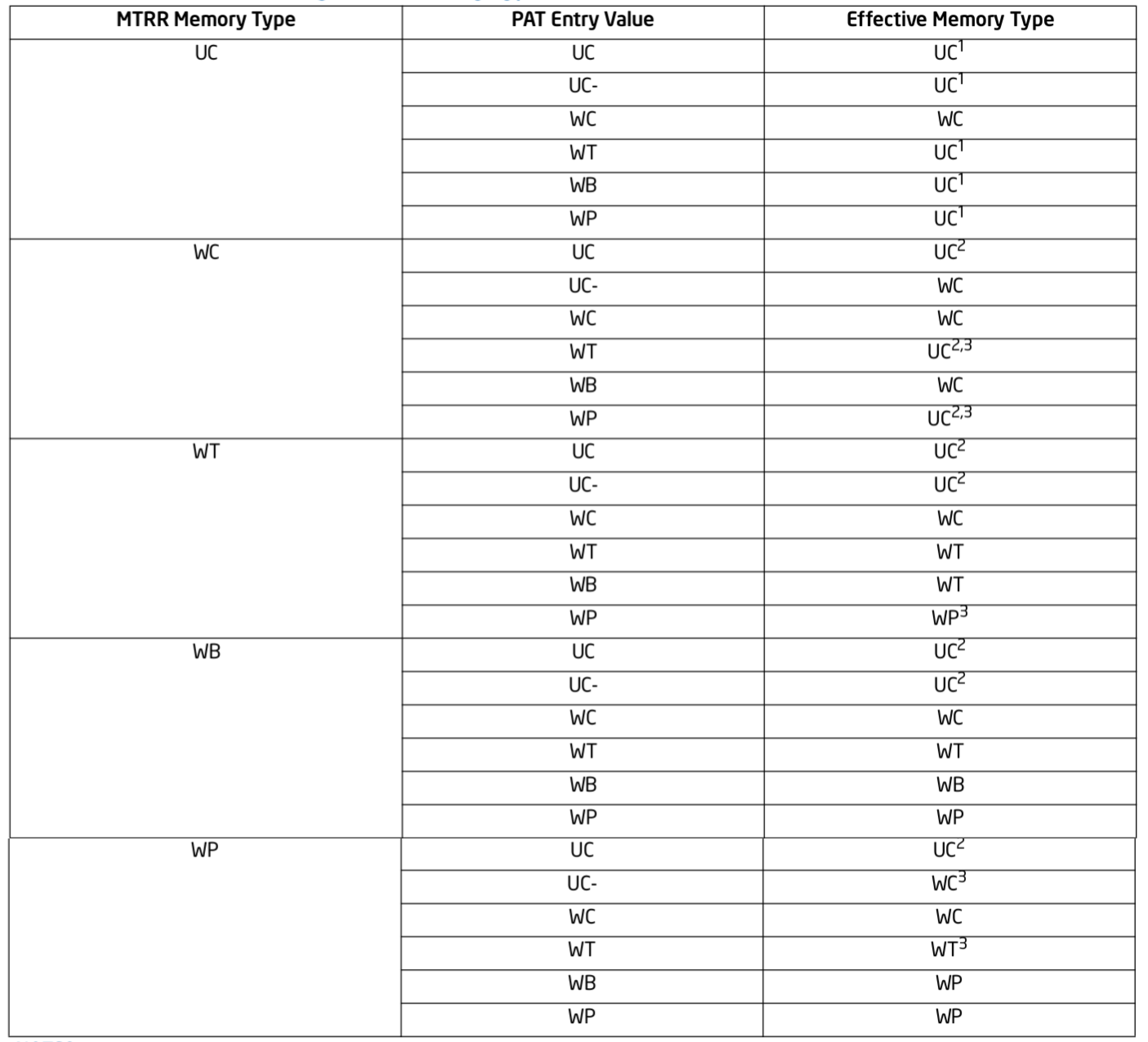
UC/UC-/WC/WT/WB/WP 横向对比
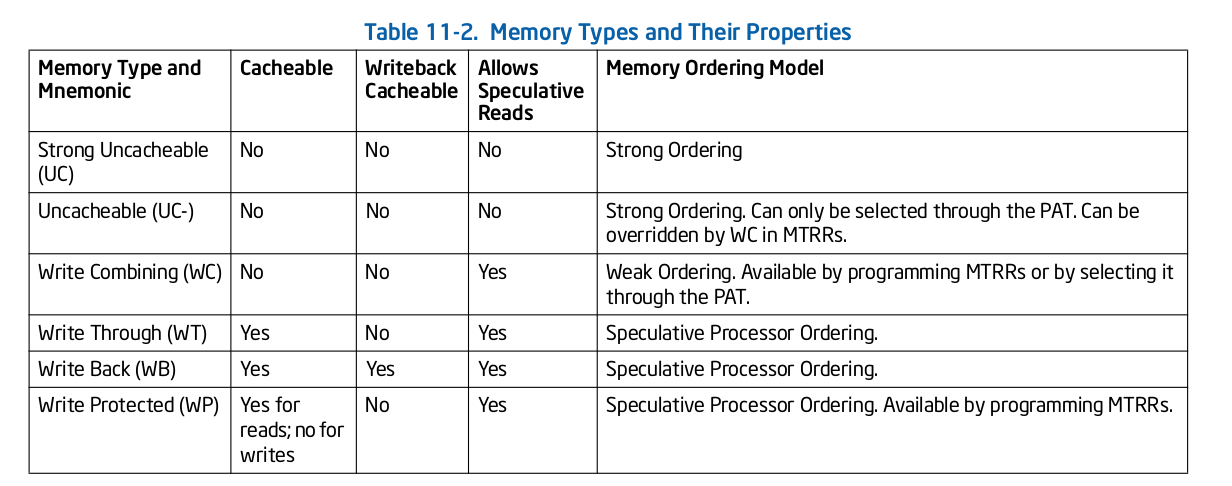
本节对不同的 memory type 进行横向对比,在上表中对于 Read/Write 请求是否缓存,UC、UC-、WC 全部不缓存,WT、WB 全部缓存,WP 只对读请求进行缓存; 只有 WB 支持 Writeback 不一定访问内存,其余类型 Write 都会访问内存; UC、UC- 不支持分支读预测功能,其余都支持分支读预测功能;
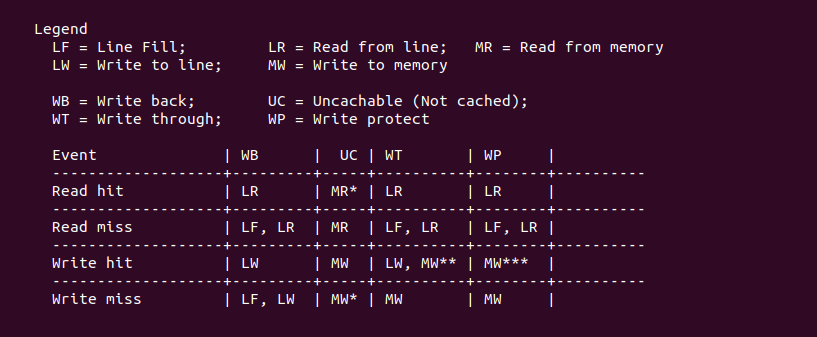
上图展示的是当 Read/Write Hit/Miss 时不同 memory type 的动作: WB Read/Write hit 仅仅访问 CACHE Line,而 Read/Write Miss 时都会先触发 CACHE Fill,然后在访问缓存; UC Read/Write 无视 Hit/Miss,直接访问内存; WT Read Hit 只访问 CACHE Line,Write Hit 是不仅访问 CACHE Line,还会更新内存,Read Miss 是先触发 CACHE Fill 再访问 CACHE Line,Write Miss 时仅仅访问内存; WP Read Hit 直接访问 CACHE Line,Read Miss 触发 CACHE Fille 再访问 CACHE Line,Write Hit 时直接访问内存并让其他 CACHE Line 副本 Invalid,Write Miss 直接访问内存.
Memory Type 适用场景
不同的 Memory Type 适用与不同的场景,本节用于分析系统推荐的 memory type 场景, 总结如下:
- 普通物理内存(不包括 Frame Buffer) memory type 均采用 WB.
- 具有 IO Agent 且能维护 CACHE 一致性的外设,其能 DMA 的物理内存 memory type 采用 WB.
- MMIO 采用 UC/UC-
- Dual-ported Memory 可以采用 UC/UC-/WT/WC
- Frame Buffer 可以采用 UC/UC-/WT/WC. 其特点就是大量的写而很少的读操作.
Uncacahed Memory 编程
Intel® CACHE Coherency Protocol
在 Intel 64 和 IA-32 架构里,L1 Data CACHE、L2 和 L3 Unified CACHE 支持 MESI(Modify、Exclusive、Shared、Invalid) CACHE Line 状态,以此维护 CACHE 一致性. L1 Data CACHE、L2 和 L3 Unified CACHE 的每个 CACHE Line 具有两个 MESI 状态,每个 CACHE Line 可以标记为上图中的四种状态。同理在 X86 架构下 MESI 状态对软件依旧透明. 在 L1 Instruction CACHE 因为是只读的,因此 CACHE Line 只支持了 SI(Shared、Invalid) 状态。在多核架构里,IA-32 和 Intel 64 架构有能力监听(Snoop) 其他处理器访问内存和各自内部 CACHE. 处理器利用监听能力,保证了其内部的 CACHE 与内存和其他处理其内部 CACHE 的一致性.
Intel P6 之后的架构,原子操作不再发出任何的 LOCK# 信号,一切都由 CACHE 一致性协议完成。上图是典型的多核架构下的 CACHE 缓存结构,L1/L2 CACHE 为 CORE 私有 CACHE,L3 则由同一个 Socket 上的多个 Core 共享的,那么就存在 CACHE Coherent 问题,通过之前的文章可以知道,硬件通过 MESI 机制保证 CACHE Coherent。对于 X86 则使用了增强版 MESIF, F 代表 Forwarding. 引入 F 的原因是对于一个处于 Shared 状态的 CACHE Line,在多个 Core 中都有一份备份,那么有一个新的 Core 需要读取该 CACHE Line 内存中数据,发现多个 Core 都有副本,那么此时由哪个 Core 提供副本呢? 如果每个 Core 都应答新 Core 会造成冗余数据,所以将 S 状态下的某个 Core 的 CACHE Line 标记为 F,并且只由 F 负责应答,通常最后持有备份的为 F.
Intel® MTRRs Technology
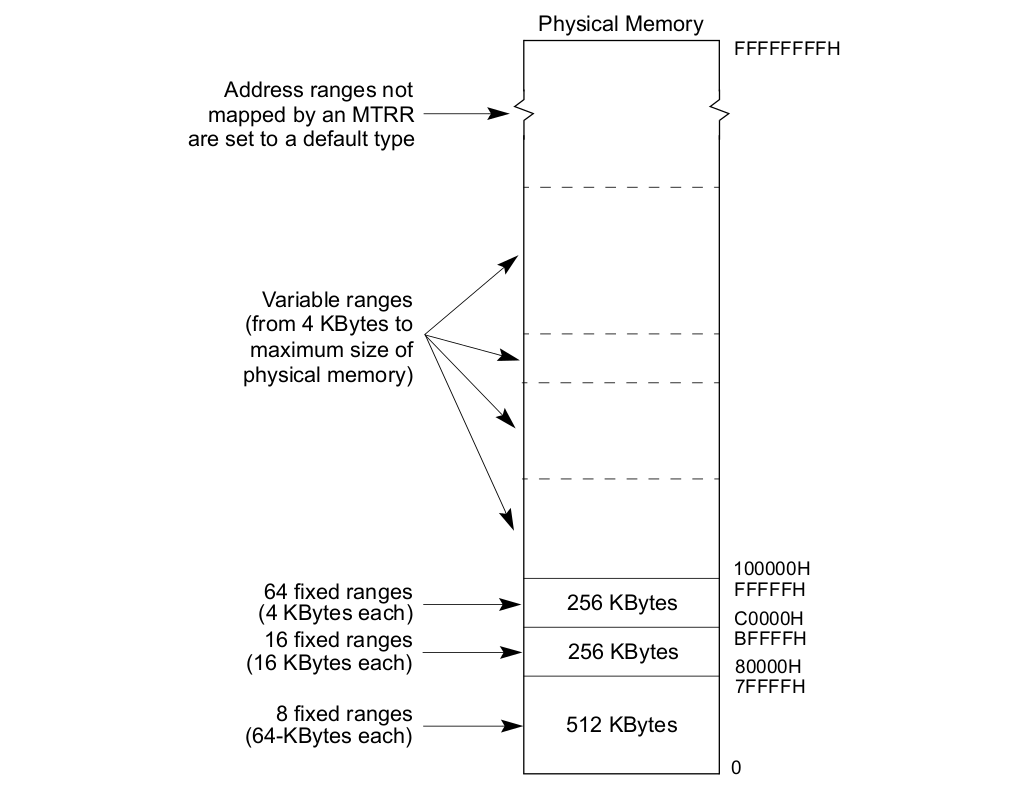
MTRRs The memory type range registers: Intel® 在 P6 之后向系统提供了 MTRRs 技术,MTRRs 运行为 RAM、ROM、Frame-Buffer 内存和 MMIO 对应的物理区域设置不同的 Memory Type. MTRRs 机制通过提供一系列的 MSR 寄存器用于指定物理区域范围和 Memory Type,上表描述了 MTRR 映射物理区域的范围,可以分为三类:
- 固定物理区域 MTRRs(Fixed MTRRs), MTRRs 提供了多个 MSR 寄存器,这些寄存器针对固定的物理区域可以设置指定的 Memory Type
- 可变物理区域 MTRRs(Variable MTRRs), MTRRs 提供了多对 MSR 寄存器,每一对寄存器可以设置物理区域和 Memory Type
- 默认 MTRR(Default MTRRs), MTRRs 提供了一个 MSR 用于设置默认的 Memory Type,针对不在前两种覆盖范围的物理区域,均采用默认的 Memory Type.
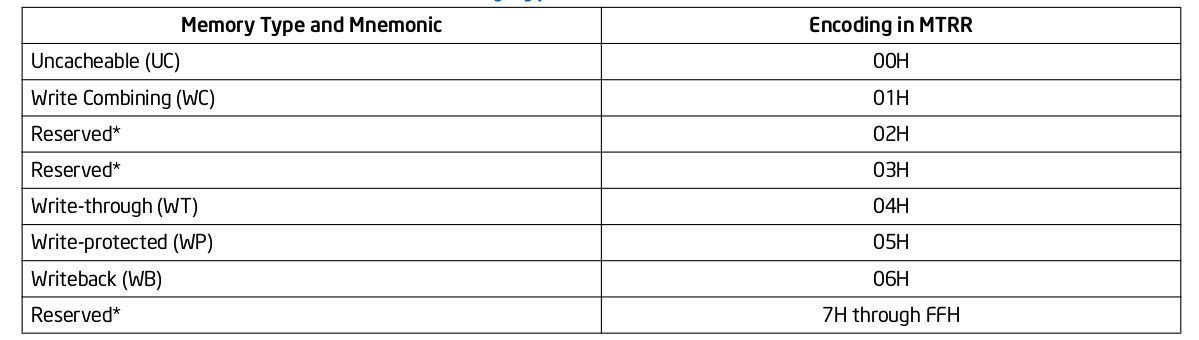
上表描述了 MTRRs 可以配置的 Memory Type 种类,以及每种类型的编码. MTRRs 支持 UC、WC、WT、WP 和 WB 五种 Memory Type,当在 MTRRs 寄存器中配置了 Reserved 之后会引起 general-protection exception (#GP). 当系统 Reset 之后,硬件会 Disable 所有的 Fixed 和 variable MTRRs,并将所有物理区域设置为 Uncached,因此系统初始化需要为指定的物理区域设置指定的 Memory Type, 典型的做法是 BIOS 负责 MTRRs 的初始化,然后操作系统或软件再结合 PAT 设置最终的 Memory Type。PAT(Page Attribute Table) 技术可以提供页级的 Memory Type 设置能力,PAT 与 MTRRs 组合形成最终的 Memory Type,因此 MTRRs 机制只是设置物理区域的 Memory Type,但不能决定最终的 Memory Type。
MTRR Memory type 指明通过 MTRRs 机制对某段物理区域设置的 Memory Type,PAT Entry Value 通过页表的 PAT、PWT、PAT 属性进行设置的 Memory Type,两者结合形成 Effective Memory Type, 其为最终生效的 Memory Type.
MTRRs Feature Identification
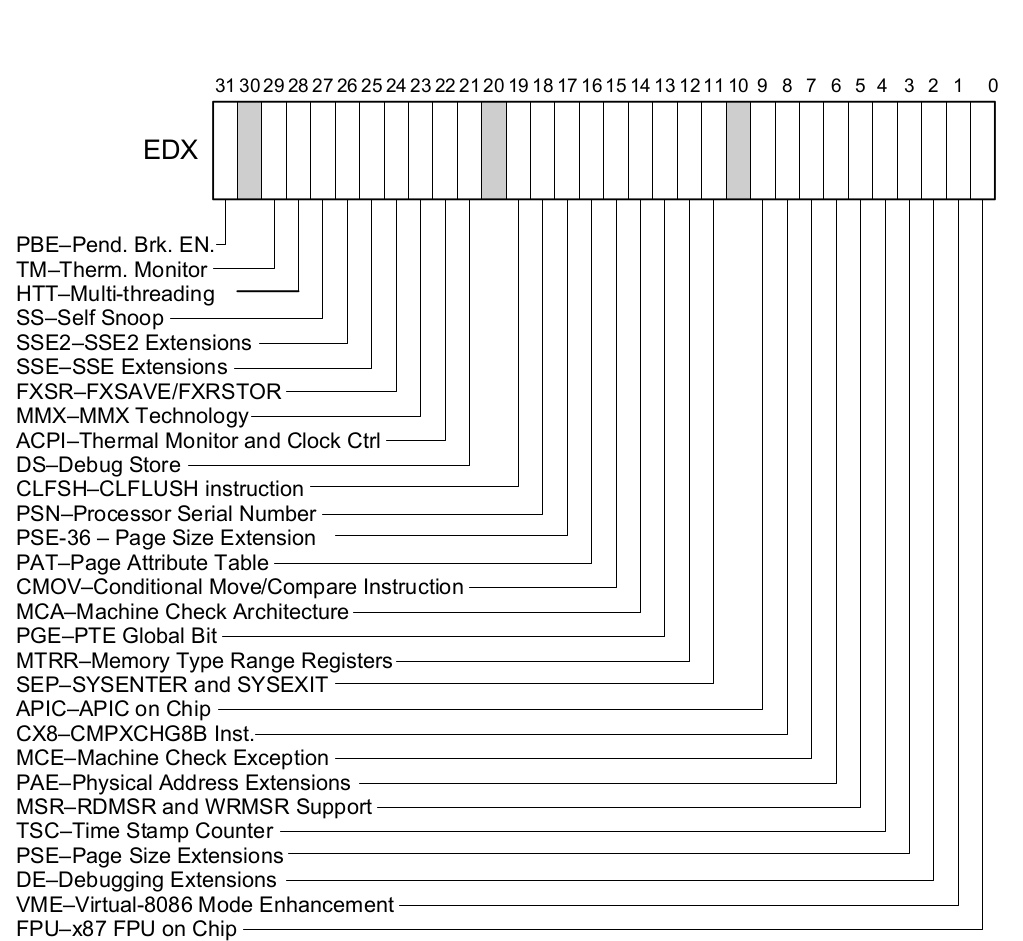
系统是否启用 MTRRs 机制可以通过查看 CPUID 指令(EAX=01H), 当指令返回时可以查看 EDX 寄存器,Bit12 MTRR 指明是否启用 MTRRs 机制,如果该标志位置位,那么 MTRRcap MSR 寄存器记录了 MTRRs 所支持的 Memory Type,以及多少个可变 MTRRs 寄存器等信息; 反之该标志位清零,那么系统不支持 MTRRs 机制.
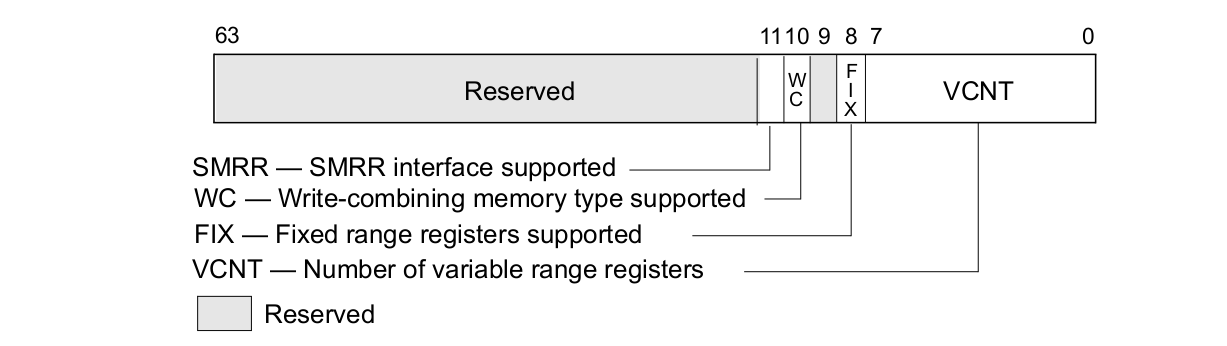
当系统支持 MTRRs 机制之后,可以从 IA32_MTRRCAP 寄存器获得更多 MTRRs 机制信息. 上图为该寄存器的位图: WC 标志位指明系统是否支持 Write-Combining Memory Type,当置位时系统支持 WC Memory Type, 反之不支持 WC Memory Type; FIX 标志位用于指明 MTRRs 是否支持固定物理区域 MTRR,如果支持那么 MTRRs 提供了一些列的 MSR 寄存器 (IA32_MTRR_FIX64K_00000 - IA32_MTRR_FIX4K_0F8000),这些寄存器可以设置固定物理区域的 Memory Type; SMRR 标志位指明是否支持 System-Management Range Register 机制; VCNT 字段指明系统支持可变 MTRRs 寄存器的数量.
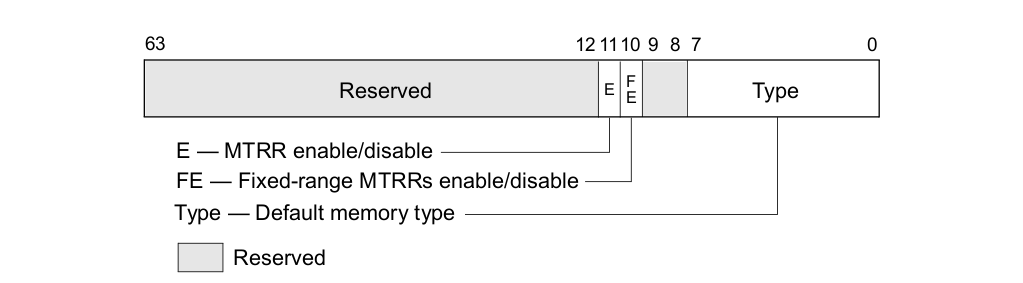
对于系统物理区域既不属于固定物理区域 MTRRs 又不属于可变物理区域 MTRRs 管理的区域,系统使用默认 MTRRs 方式设置这些物理区域的 Memory Type。MTRRs 提供了 IA32_MTRR_DEF_TYPE 寄存器用于配置默认的 Memory Type,上图为该 MSR 寄存器的位图. E 标志位用于控制是否使能 MTRR 机制,当标志位置位,那么系统使能 MTRR 机制,反之当标志位清零,那么系统关闭 MTRR 机制; FE 标志位用于控制开启或关闭固定物理区域 MTRRs, 当标志位置位,那么系统启用固定物理区域 MTRRs,反之关闭固定物理区域 MTRRs; Type 字段用于指明默认的 Memory Type,Intel 推荐对不存在物理内存的物理区域的 Memory Type 设置为 UC,那么可以将 Default Memory Type 设置为 UC.
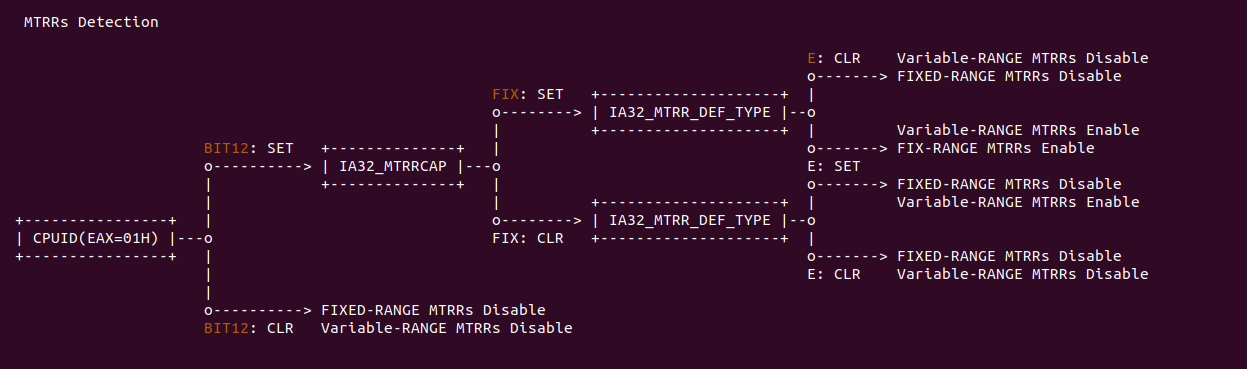
通过上面的分析,系统需要通过检查 CPUID、IA32_MTRRCAP、IA32_MTRR_DEF_TYPE 寄存器相互配合,才能获得系统支持 MTRRs 机制的情况。如果 CPUID 就检测不支持 MTRR,那么剩余两个寄存器就没必要检查.
固定物理区域 MTRRs
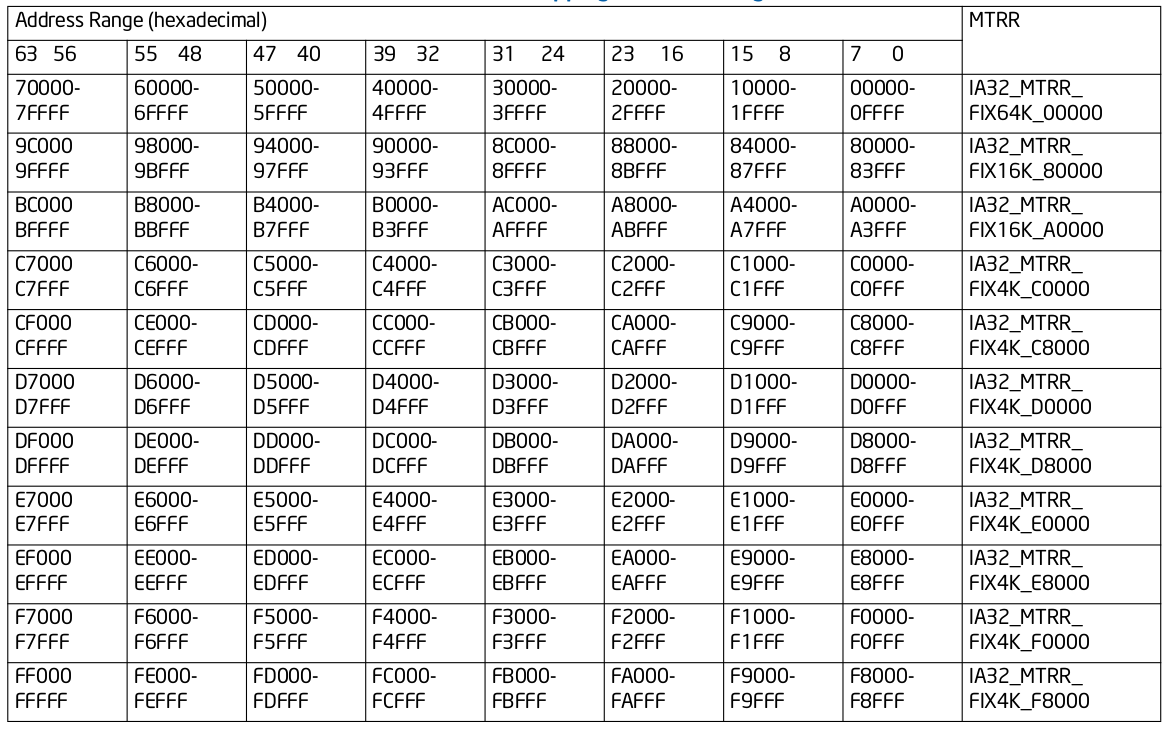
当系统使能 FIXED-RANGE MTRRs 之后,系统提供了一系列的寄存器用于配置固定物理区域的 Memory Type,例如上图的 IA32_MTRR_FIX64L_00000 寄存器,其用于设置 [0x00000, 0x80000) 区域的 Memory Type,并且将寄存器划分为 8 个区域,每个区域的长度为 64KiB,并且 BIt0 到 BIT7 表示第一个 64KiB 区域,也就是 [0x00000, 0x10000) 物理区域,以此类推,操作系统或者 BIOS 可以向每个字段写入指定的 Memory Type,Memory Type 的编码如下表:
向字段写入不支持的 Memory Type 会引起 general-protection exception (#GP). IA32_MTRR_FIX16K_80000 至 IA32_MTRR_FIX16K_A0000 寄存器集按 16KiB 粒度设置了 [0x80000, 0xC0000) 物理区域 Memory Type. IA32_MTRR_FIX4K_C0000 至 IA32_MTRR_FIX4K_F8000 寄存器集按 4KiB 粒度设置了 [0xC0000, 0x100000) 物理区域的 Memory Type.
可变物理区域 MTRRs
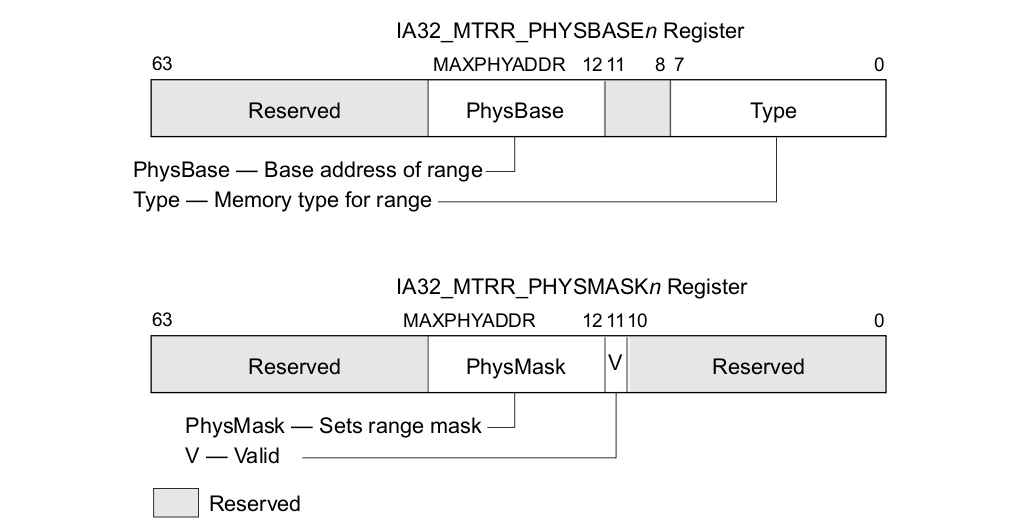
当系统置位 IA32_MTRR_DEF_TYPE 寄存器的 E 标志位,那么系统使能 Variable-RANGE MTRRs,另外在 IA32_MTRRCAP 寄存器的 VCNT 字段指令了系统所支持 Variable-RANGE MTRRs 寄存器的数量. 每个 Variable-RANGE MTRRs 寄存器由两个寄存器配对组成,分别是上图的 IA32_MTRR_PHYSBASEn 和 IA32_MTRR_PHYSMASKn 寄存器。IA32_MTRR_PHYSBASEn 寄存器的 PhysBase 字段用于指明物理区域的起始地址,该地址按 PAGE_SIZE 进行对其,Type 字段用于设置该区域的 Memory Type. IA32_MTRR_PHYSMASKn 寄存器的 PhysMask 字段用于设置物理区域掩码,与 PhysBase 字段值一起计算出可变物理区域的长度,V 字段指明了设置是否有效. 那么接下来通过一个实践案例讲解如何使用 MTRR 设置 Memory Type:
MTRR 设置 Memory Type
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] WriteCombining(WC): Mapping WC Memory on Userspace --->
-*- CACHE User-Page for Kernel Stub (Basic) --->
# 进入源码目录
# Userspace: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WC-MEM-USERSPACE-default/
# Kernel: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default/
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WC-MEM-USERSPACE-default/
# 部署源码
make prepare
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-WC-MEM-USERSPACE-default Source Code on Gitee
源码分成两部分,其中一部分为用户空间程序(上图所示), 用户空间代码的主要功能是映射一段虚拟内存,并将其缓存类型设置为 WC. 函数首先在 34 行将 pcm 变量设置为 _PAGE_CACHE_MODE_WC, 然后在 39 行打开 “/dev/BiscuitOS-CACHE” 节点,并基于该节点映射长度为 PAGE_SIZE 的虚拟内存,此时在函数 50 行将 pcm 传入到 mmap() 函数,映射完毕后函数在 58-59 行使用 WC 的内存,使用完毕在 61-62 行解除映射并关闭文件。
BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default Source Code on Gitee
源码的另外一部分位于内核空间,其主要功能是进行实际的映射任务。模块通过一个 MISC 驱动进行实现,模块在 60 行调用 mtrr_add() 函数设置 [MTRR_MEM_BASE, MTRR_MEM_BASE + MTRR_MEM_SIZE) 区域 Memory Type 为 WB. 模块提供了 mmap 接口 BiscuitOS_mmap(), 当用户空间基于 “/dev/BiscuitOS-CACHE” 节点调用 mmap() 函数时,BiscuitOS_mmap() 函数就会别调用。模块首先在 60 行调用 mtrr_add() 函数将 [MTRR_MEM_BASE, MTRR_MEM_SIZE + MTRR_MEM_BASE) 区域的 MTRR 设置为 WB. 模块接着在 33 行在用户空间调用 mmap() 函数时从 vma 的 vm_pgoff 成员中获得 PAGE CACHE MODE 信息,接着在 36 行将 vma_page_prot 成员中移除 _PAGE_PCD、_PAGE_PWT 和 _PAGE_PAT 属性,并在 39 行调用 cachemode2protval() 函数将 PAGE CACHE MODE 转换成对应的页表属性,并重新存储到 vma 的 vm_page_prot, 以此作为用于空间设置的 memory type 页表属性,最后模块在 41 行调用 remap_pfn_range() 函数为虚拟内存建立页表并映射到 MTRR_MEM_BASE 对应的物理内存上. 接下来在 BiscuitOS 上实践该案例:
BiscuitOS 运行之后, 执行应用程序 BiscuitOS-CACHE-WC-MEM-USERSPACE-default,此时系统提示了程序预期将 [0x10000000-0x10000fff] 为 write-combining,但是系统还是将对应的 memory type 设置为 write-back, 这个与预期不符合. 查看内核模块源码的 3 行提示需要将 [0x10000000, 0x10200000) 进行预留,那么在 CMDLINE(CMDLINE 位于 RunBiscuitOS.sh 文件中) 中添加预留字段后再次实践:
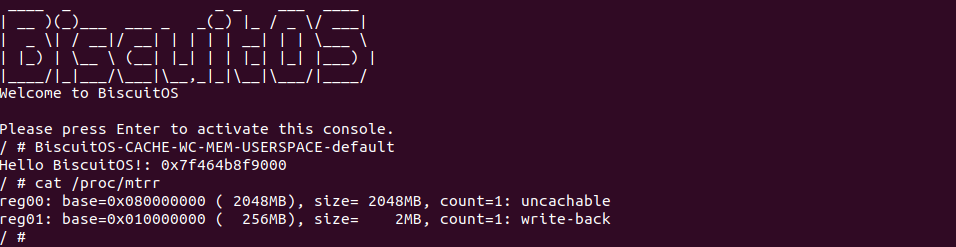
BiscuitOS 在次运行之后,运行应用程序,可以看到系统没有再提示修改信息了,那么用户进程已经成功将一段物理内存的 memory type 设置为 WC. 接着查看 “/proc/mtrr” 节点,可以看到 0x10000000 起始的 2MiB 区域都是 WB,实践符合预期. 通过实践可以看出内核通过 mtrr_add() 函数可以实现对指定物理区域设置 Memory Type,接下来查看其函数调用逻辑:
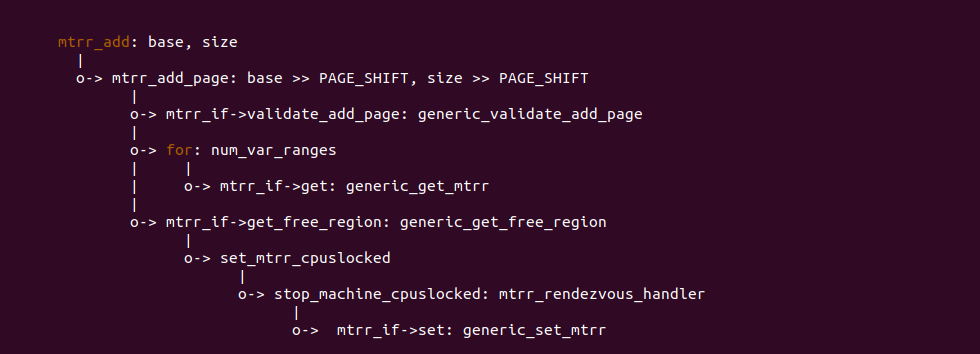
mtrr_add() 函数的调用逻辑如上,核心步骤是通过 generic_get_free_region() 函数获得一个空闲的 Variable-RANGE MTRRs 寄存器组,然后调用 generic_set_mtrr() 函数设置相应的 MTRRs 寄存器,其函数逻辑如下:
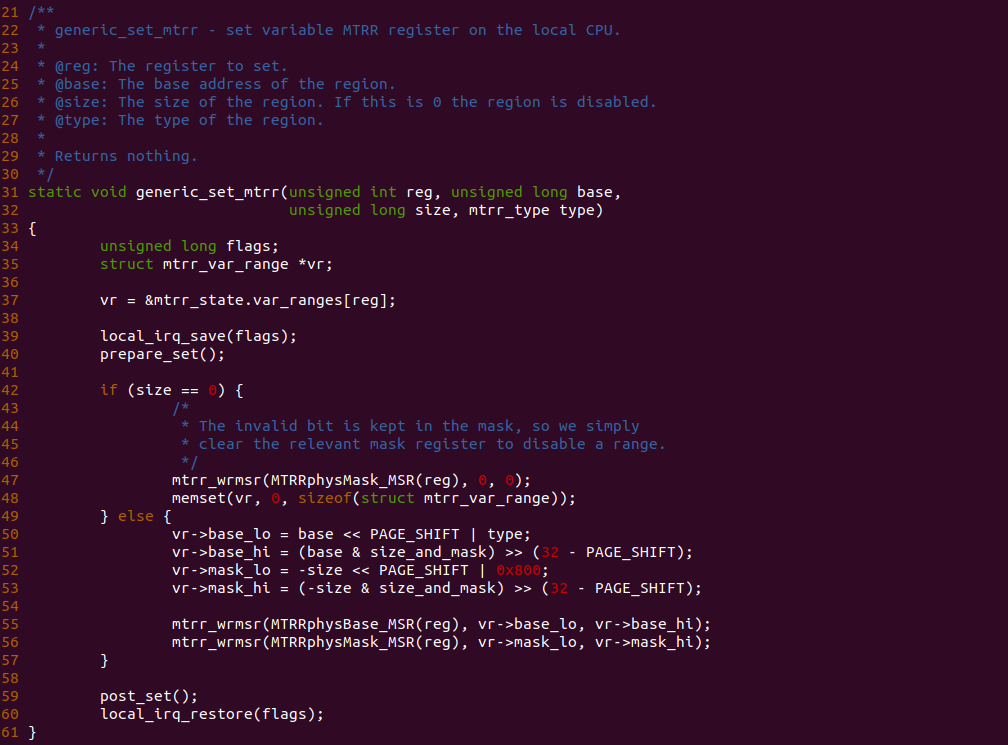
generic_set_mtrr() 函数的核心步骤在 50-56 行,可以看出函数是如何构造 IA32_MTRR_PHYSBASEn 寄存器的 PhysBase 字段和 IA32_MTRR_PHYSMASKn 寄存器的 PhysMask 字段,设置完毕之后同个mtrr_wrmsr() 函数写入相应的寄存器内。在设置 MTRR 寄存器过程中,分别调用 prepare_set() 函数和 post_set() 函数保证设置生效.
Interface with /proc/mtrr
Linux 提供了 /proc/mtrr 接口可以以 ASCII 的方式对指定物理区域的 MTRRs 进行读取和写入,该接口一般给系统管理员使用. 可以通过写入一段字符串实现实现对某段物理内存的 MTRR 设置,也可以通过 cat 该节点获得当前系统设置的 MTRR 信息,如上图,regN 表示系统第 N+1 个物理区域, base 字段表示物理区域的起始地址,size 字段表示物理区域的长度,接下来的区域表示 Memory Type,最后 count 字段表示物理区域的数量.
通过 echo 命令向 /proc/mtrr 接口写入一段字符串,可以动态设置某段物理区域的 Memory Type,接口支持写入的参数包括 base、size、type 字段,其中 base 表示物理区域的起始物理地址,size 表示物理区域的长度、type 表示需要设置 Memory Type 的种类,接口目前支持的 Memory Type 包括: write-combining、write-back、write-through、uncachable.
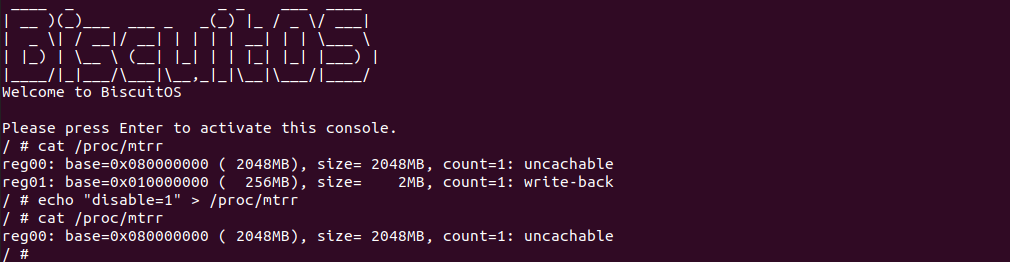
“/proc/mtrr” 接口也支持移除某段物理区域的 MTRRs 设置,可以通过向接口写入字符串 “disable=N”, 其中 N 表示物理区域 regN 的标号 N,例如上图向移除 reg01, 那么此时 N 为 1,于是可以向接口写入 “disable=1” 即可移除 reg01 的 MTRRs 设置.
IOCTL with MTRRs
用户空间除了可以直接使用 echo 和 cat 命令对 MTRRs 设置进行读取和写入,也可以在代码里通过 IOCTL 实现对物理区域 MTRRs 的读取和写入. 其原理 /proc/mtrr 节点向用户空间提供了 ioctl 接口,因此代码里可以实现 MTRRs 的读取写入,接下来通过案例讲解 ioctl 的使用, 其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] MTRRs: Read MTRRs via IOCTL on Userspace --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-MTRR-IOCTL-READ-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-MTRR-IOCTL-READ-default Source Code on Gitee
源码很精简,程序首先在 64 行通过 open() 函数打开 “/proc/mtrr” 节点,然后在 74 行通过 ioctl() 函数结合 MTRRIOC_GET_ENTRY 获得一个有效的 Entry,然后使用 for 循环遍历每个 Entry。struct mtrr_gentry 数据结构里维护的 regnum、base、size 和 type 成员,详细描述了 MTRRs 维护的一段物理区域,程序在 82 行结合 mtrr_strings[] 字符数组和 type 成员,最终打印了每段物理区域的 Memory Type 信息。接下来在 BiscuitOS 上实际运行案例:
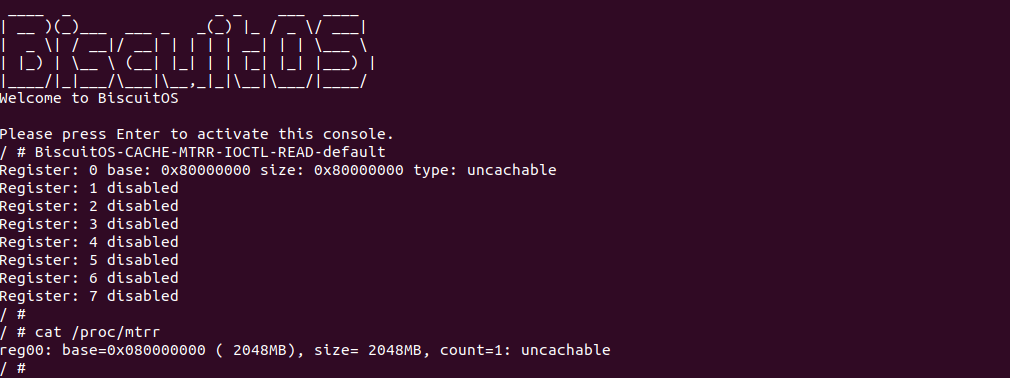
BiscuitOS 启动之后,运行 BiscuitOS-CACHE-MTRR-IOCTL-READ-default 应用程序,可以看到其打印了 MTRRs 所有 Region,无论 Region 是否真的维护物理区域,统统打印,可以看到 Region0 的起始地址为 0x80000000, 长度为 0x80000000, 该区域的 Memory Type 是 uncachable. 同时使用 cat 查看 “/proc/mtrr” 节点,打印的信息一致,实践符合预期. 接下来通过案例讲解 ioctl 实现 mtrrs 写入功能,其在 BiscuitOS 上部署逻辑如下:
IOCTL with MTRRs Type 2
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] MTRRs: Write MTRRs via IOCTL on Userspace --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-MTRR-IOCTL-WRITE-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-MTRR-IOCTL-WRITE-default Source Code on Gitee
源码很精简,程序首先在 69-75 行从传入 argv 参数中获得 base、size 和 type 信息,并存储在 struct mtrr_sentry 数据结构里,因此程序运行的时候必须包含以上三个参数,否则程序直接异常退出. 程序在 72-80 行会对传入的 type 信息进行检查,查看是否符合 mtrr_strings[] 定义的可用类型。程序接着在 82 行调用 open() 函数打开 “/proc/mtrr” 节点,打开成功之后在 92 行调用 ioctl() 函数,并传入 MTRRIOC_ADD_ENTRY 参数,因此将新增的 Entry 传入到系统 MTRRs 子系统,如果 ioctl() 函数执行成功,那么说明新增物理区域的 Memory Type 设置成功,那么只要节点没有关闭,就可以通过 “/proc/mtrr” 节点查看新增的区域,因此在 99 行为了调试进行无限睡眠,那么接下来在 BiscuitOS 上实际运行案例:
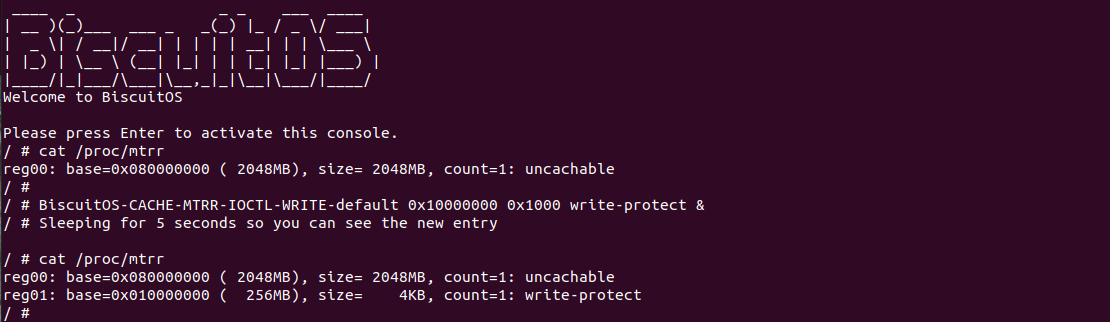
BiscuitOS 启动之后,首先查看 “/proc/mtrr” 节点,以此获得当前系统维护的 MTRRs 物理区域,接着运行 BiscuitOS-CACHE-MTRR-IOCTL-WRITE-default,并传入三个参数,第一个参数表示物理区域的起始物理地址,第二个参数表示物理区域的长度,最后一个参数表示需要设置的 Memory Type,为了调试效果,此时压后台运行。程序运行之后查看 “/proc/mtrr” 可以看到新增的物理区域 [0x10000000, 0x10001000) 的 Memory Type 已经设置为 write-protect, 符合预期.
Intel® PAT Technology
PAT (Page Attribute Table) 技术是拓展了 IA-32 页表属性,可以基于页表设置线性地址映射物理内存的 Memory Type. 对比 MTRRs 机制,MTTRs 可以看成是基于物理区域设置物理内存的 Memory Type,而 PAT 是基于线性地址(等同于虚拟地址)设置映射物理内存的 Memory Type。PAT 需要配合 MTRRs 才能使用, PAT 可以设置 Memory Type,MTRRs 也可以设置 Memory Type,只有两种机制设置的 Memory Type 组合才能形成最终生效的 Memory Type.
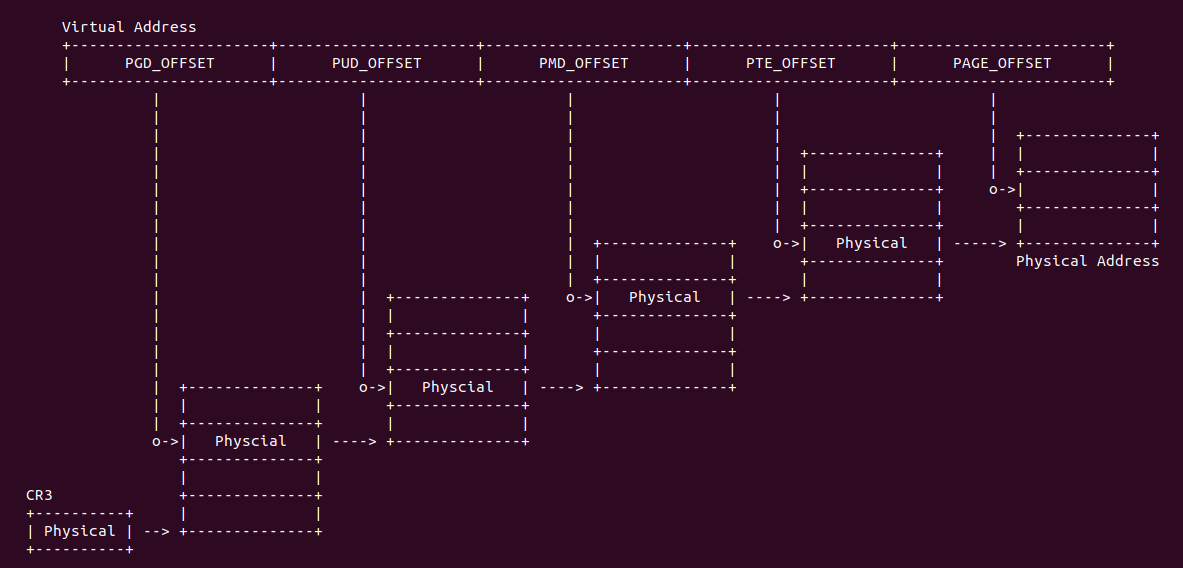
在 Intel 架构下,支持 3-/4-/5-level 级页表,可以映射虚拟地址(线性地址)到物理地址,PAT 按照线性地址映物理地址的粒度设置 Memory Type,那么 PAT 支持的线性地址粒度可以是 4KiB、2MiB、4MiB(i386 Only)、1Gig 以及 512Gig.
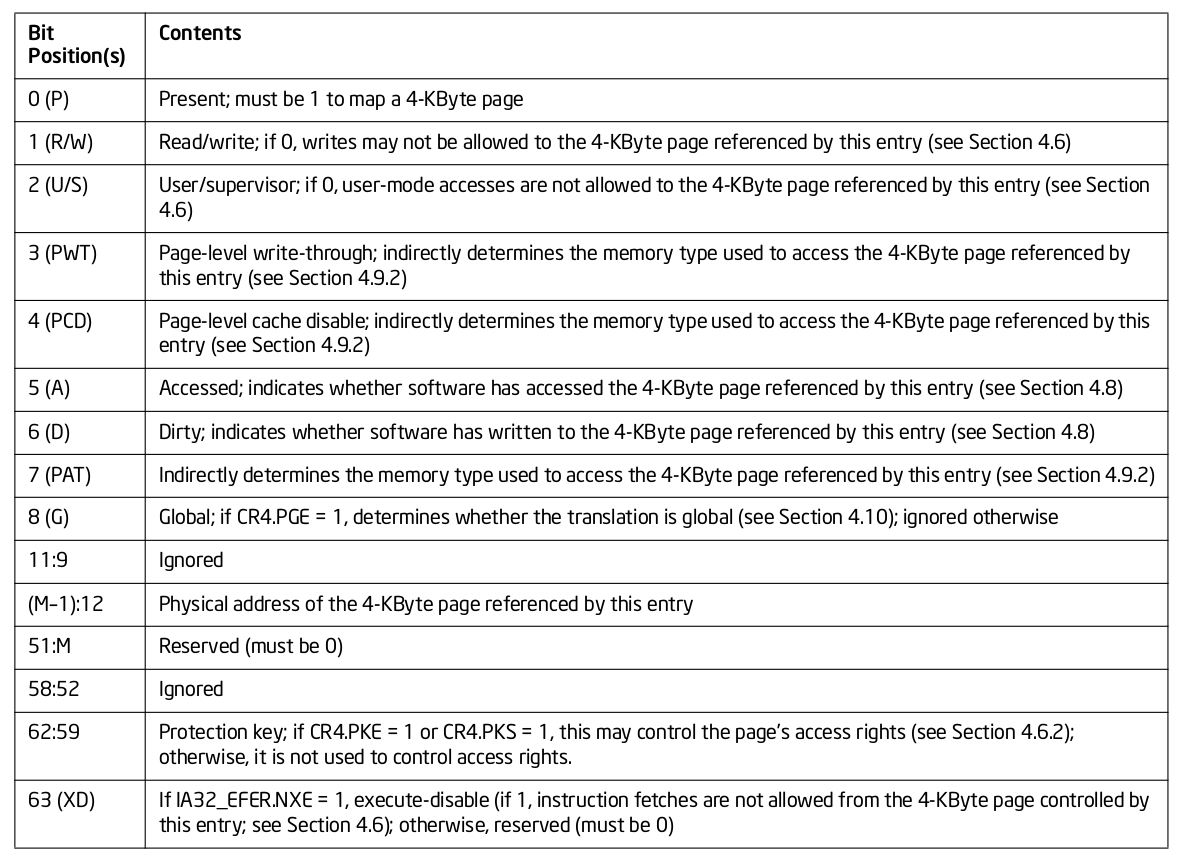
例如 PAT 按 4KiB 线性地址设置映射物理内存的 Memory Type,那么在 PTE 页表中存在 PWT、PCD、PAT 三个标志位,系统或者软件可以通过设置 3 个标志位,使映射的物理内存采用不同的 Memory Type. 假设 PAT 按 2MiB 线性地址设置映射物理内存的 Memory Type,那么 PDE 页表中的 PWT、PCD、PAT 三个标志位起作用, 其他粒度依次类推.
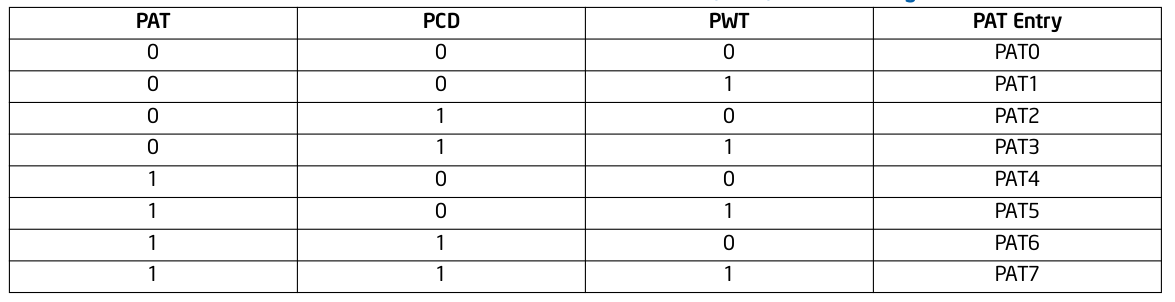
页表中的 PAT、PCD、PWD 排列组合可以形成不同的 PAT Entry, 每个 PAT Entry 对应不同的编码值. 页表中设置好三个标志位之后,PAT 机制会根据 PAT Entry 找到对应的编码.

PAT 采用 IA32_PAT MSR 寄存器为了所有的 PAT Entry,上图为该寄存器的位图,每 8 bit 一组,从低到高依次为 Entry 编号,页表中的 PAT、PCD、PWT 组合选择的 PAT Entry X 即该寄存器里的 PAx. 系统在初始化过程中,会为每个 PAx 填入 Memory Type 对应的编码,也就是说 PAx 里可以灵活的填入系统所规划的 Memory Type.
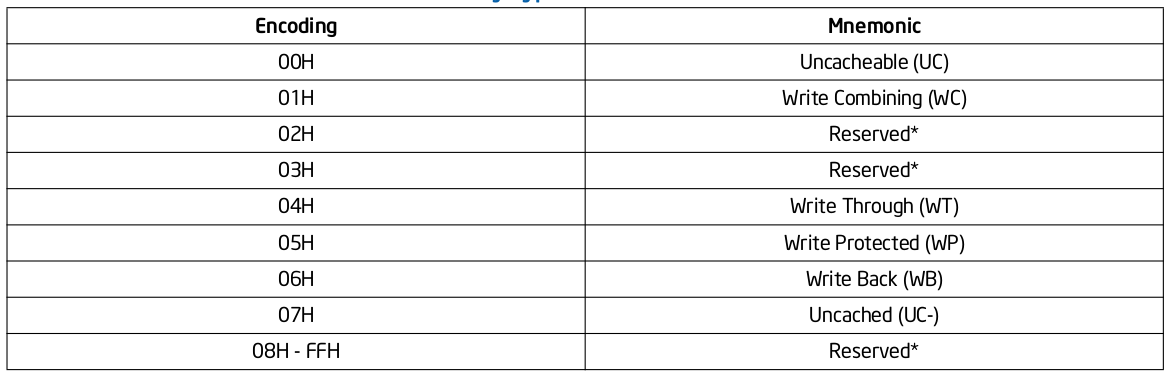
IA32_PAT MSR 寄存器每组 PAx 所支持的 Memory Type 编码如上图,例如系统软件想让 PA0 里的 Memory Type 为 WT,那么 PA0 里的值为 04H,另外页表向将虚拟地址映射的物理内存 Memory Type 设置为 WT,那么页表的 PAT、PCD、PWT 组合选择 PAT0 即可, 这样极大的提高了 PAT 设置的灵活性.
当通过页表的 PAT、PWT、PCD 三个标志位选择了线性地址映射物理内存的 Memory Type 之后,该 Memory Type 还不是最终生效的 Memory Type,硬件上会找到线性地址映射物理内存对应的 MTRRs 设置,从而获得 MTRRs 对应的 Memory Type,此时硬件将 MTRRs 和 PAT 获得的 Memory Type 按上表结合生成最终的 Memory Type. 接下来通过一个实践案例了解 PAT 机制的使用方法, 其在 BiscuitOS 上部署逻辑如下:
PAT 设置 MeType
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] WriteCombining(WC): Mapping WC Memory on Userspace --->
-*- CACHE User-Page for Kernel Stub (Basic) --->
# 进入源码目录
# Userspace: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WC-MEM-USERSPACE-default/
# Kernel: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default/
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-WC-MEM-USERSPACE-default/
# 部署源码
make prepare
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-WC-MEM-USERSPACE-default Source Code on Gitee
源码分成两部分,其中一部分为用户空间程序(上图所示), 用户空间代码的主要功能是映射一段虚拟内存,并将其缓存类型设置为 WC. 函数首先在 34 行将 pcm 变量设置为 _PAGE_CACHE_MODE_WC, 然后在 39 行打开 “/dev/BiscuitOS-CACHE” 节点,并基于该节点映射长度为 PAGE_SIZE 的虚拟内存,此时在函数 50 行将 pcm 传入到 mmap() 函数,映射完毕后函数在 58-59 行使用 WC 的内存,使用完毕在 61-62 行解除映射并关闭文件。
BiscuitOS-CACHE-USER-PAGE-Kernel-Stub-default Source Code on Gitee
源码的另外一部分位于内核空间,其主要功能是进行实际的映射任务。模块通过一个 MISC 驱动进行实现,模块在 60 行调用 mtrr_add() 函数设置 [MTRR_MEM_BASE, MTRR_MEM_BASE + MTRR_MEM_SIZE) 区域 Memory Type 为 WB. 模块提供了 mmap 接口 BiscuitOS_mmap(), 当用户空间基于 “/dev/BiscuitOS-CACHE” 节点调用 mmap() 函数时,BiscuitOS_mmap() 函数就会别调用。模块首先在 60 行调用 mtrr_add() 函数将 [MTRR_MEM_BASE, MTRR_MEM_SIZE + MTRR_MEM_BASE) 区域的 MTRR 设置为 WB. 模块接着在 33 行在用户空间调用 mmap() 函数时从 vma 的 vm_pgoff 成员中获得 PAGE CACHE MODE 信息,接着在 36 行将 vma_page_prot 成员中移除 _PAGE_PCD、_PAGE_PWT 和 _PAGE_PAT 属性,并在 39 行调用 cachemode2protval() 函数将 PAGE CACHE MODE 转换成对应的页表属性,并重新存储到 vma 的 vm_page_prot, 以此作为用于空间设置的 memory type 页表属性,最后模块在 41 行调用 remap_pfn_range() 函数为虚拟内存建立页表并映射到 MTRR_MEM_BASE 对应的物理内存上. 接下来在 BiscuitOS 上实践该案例:
BiscuitOS 运行之后, 执行应用程序 BiscuitOS-CACHE-WC-MEM-USERSPACE-default,此时系统提示了程序预期将 [0x10000000-0x10000fff] 为 write-combining,但是系统还是将对应的 memory type 设置为 write-back, 这个与预期不符合. 查看内核模块源码的 3 行提示需要将 [0x10000000, 0x10200000) 进行预留,那么在 CMDLINE(CMDLINE 位于 RunBiscuitOS.sh 文件中) 中添加预留字段后再次实践:
BiscuitOS 在次运行之后,运行应用程序,可以看到系统没有再提示修改信息了,那么用户进程已经成功将一段物理内存的 memory type 设置为 WC. 接着查看 “/proc/mtrr” 节点,可以看到 0x10000000 起始的 2MiB 区域都是 WB,实践符合预期. 通过上面的实践,PAT 核心设置发生在内核模块调用了 cachemode2protval() 函数,该函数的逻辑实现了页表 PAT、PCD、PWT 三个标志位依据 Memory Type 反向选择 PAT Entry,这是因为系统在初始化过程中,已经将三个标志位与 PAT Entry,以及 PAT Entry 内 Memory Type 的关系固化在 cachemode2protval() 函数逻辑了,开发者仅仅传入所需的 Memory Type 即可.
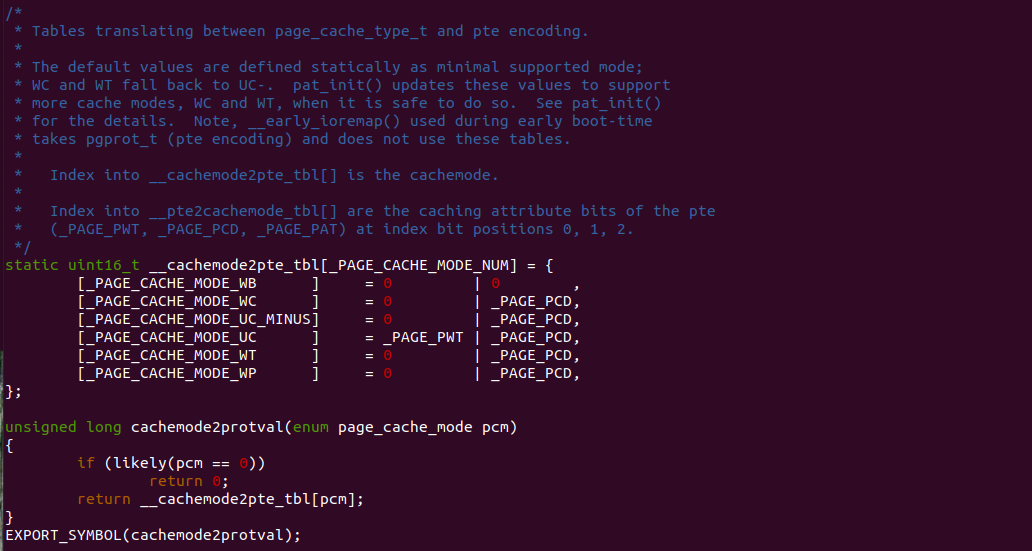
cachemode2protval() 函数的逻辑如上,目前支持的 PAT ENTRY MODE 有 _PAGE_CA-CHE_MODE_WB、_PAGE_CACHE_MODE_WC、_PAGE_CACHE_MODE_UC_MINUS、_PAGE_CACHE_MODE_UC、_PAGE_CACHE_MODE_WT 和 _PAGE_CACHE_MODE_WP, 只需向函数传入这些值,函数就可以获得页表 PAT、PCD、PWT 三个标志位的集合, 程序接下来就是将三个标志位写入最终的页表即可。
PAT RB-TREEs/Page CACHE Mode
PAT 可以按线性地址粒度设置映射物理内存的 Memory Type,PAT 如何避免不同虚拟地址映射到同一物理内存时采用不同的 Memory Type? 针对 PAT 机制,内核将物理地址空间划分成了 MMIO 和普通内存进行不同的管理。对于 MMIO,PAT 采用了一颗区间树(特殊功能的红黑树),将物理区域维护在区间树里,每个区间都有各自的 Memory Type。当新增一段 MMIO 的 Memory Type,PAT 机制首先在区间树中查找是否有重叠的区域,如果有重叠的区域,那么继续检查是否存在 Memory Type 不一致的情况,如果出现则报错,如果相同则调整区间的范围. 如果没有重叠的区域,那么在区间树中新增加一个区域; 对于普通内存,PAT 首先查看物理内存是否有对应的 struct page, 如果存在那么从 struct page 的 flags 字段中截取 memorytype 字段,该字段就是当前物理内存对应的 Memory Type,然后与 PAT 需要设置的 Memory Type 进行比对,如果相同则不做处理,反之如果不相同,那么系统将报错.
PAT 机制向用户空间提供了 “/sys/kernel/debug/x86/pat_memtype_list” 接口,该接口可以查看 MMIO 物理区域 Memory Type 的情况,例如在上图的案例里,运行 BiscuitOS_CACHE_WT_MMIO_USERSPACE_default 之后程序将映射 MMIO 的 Memory Type 为 WT(write-through), 可以查看该接口,看到 MMIO [0xF0000000, 0xF0001000) 区域的 Memory Type 为 write-through.
对于物理内存,当将物理内存设置为原先默认的 Memory Type 不同时,系统都会进行提示,例如上图的将物理内存的 Memory Type 有 WB 设置为 WT,内核就会弹出提示,并阻止了本次改动.
Intel® CACHE Related Instruction
Intel® 64/IA-32 架构提供了一些列的指令管理 L1、L2、L3 CACHE. INVD 和 WBINVD 只有内核才可用使用,其作用与 L1、L2、L3 或者所有 CACHE. PREFETCHh、CLFLUSH 和 CLFLUSHOP 指令提供粒度的 CACHE 控制,用户空间进程和内核都可以使用。MOVNTI、MOVNTQ、MOVNTDQ、MOVNTPS、MOVNTPD 无时间跟踪的指令同样提供了更多粒度的 CACHE 控制,用户空间进程和内核同样都可以使用. 那么接下来分别对这些指令进行详细讲解:
INVD Instruction
INVD 指令将所有的 CACHE 标记为无效,但不会触发 Write-Back 操作,因此 Modify 状态的 CACHE Line 数据并不会更新到内存,导致数据未同步的数据丢失. INVD 指令只能在内核空间运行,该指令应用的场景是 CACHE 用于 CACHE Line 里面缓存了临时内存的内容,系统需要 Invalid CACHE Line 的内容而不是 Write-back 操作. 接下来通过一个实践案例讲解如何使用该指令, 其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] CACHE Instruction(X86): INVD - Invalidate Internal CACHE --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-INSTRUCT-INVD-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build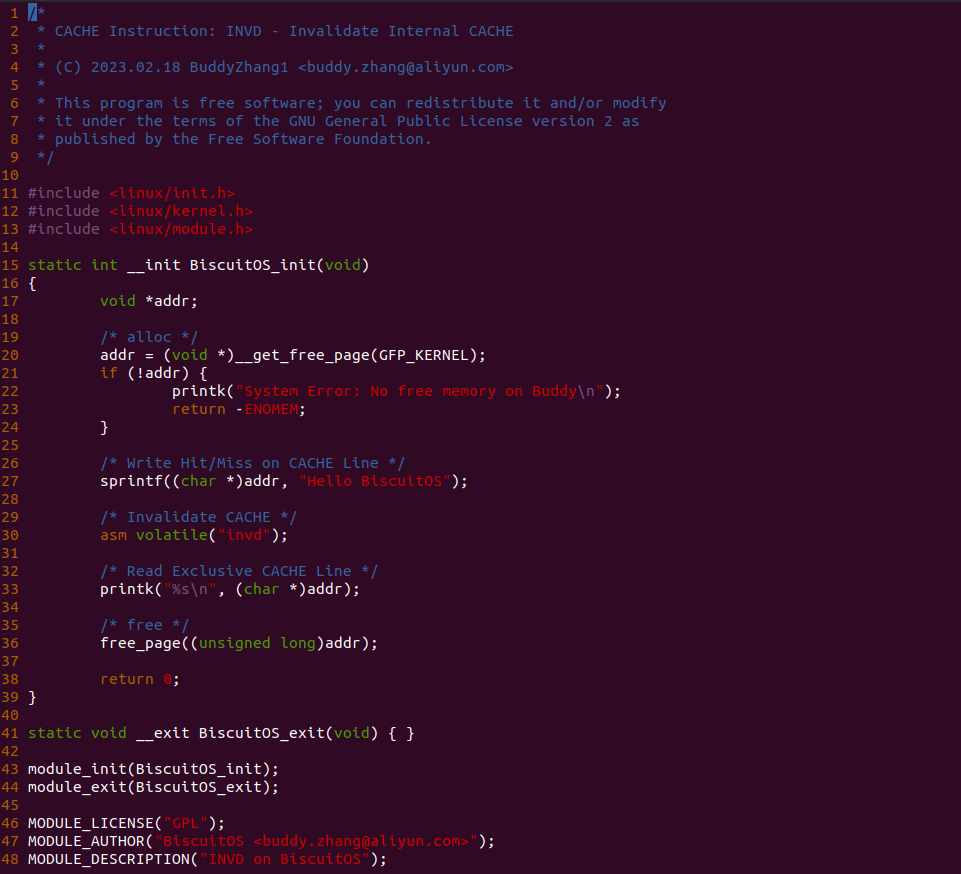
源码很精简,通过一个内核模块进行讲解,模块首先在 20 行通过 __get_free_page() 函数分配一个物理页,并将物理页对应的虚拟地址存储到 addr 变量里,接着在 27 行使用这段内存。模块在 30 行使用内嵌汇编的方式调用了 INVD 指令,并在 33 行再次使用这段内存,最后在 36 行调用 free_page() 函数释放这段内存. 调用 INVD 指令之后在次访问内存会比不调用 INVD 指令快. 接下来在 BiscuitOS 上实践该案例:
BiscuitOS 启动之后,加载 BiscuitOS-CACHE-INSTRUCT-INVD-default.ko 模块,可以看到内核成功打印了字符串,符合预期.
WBINVD Instruction
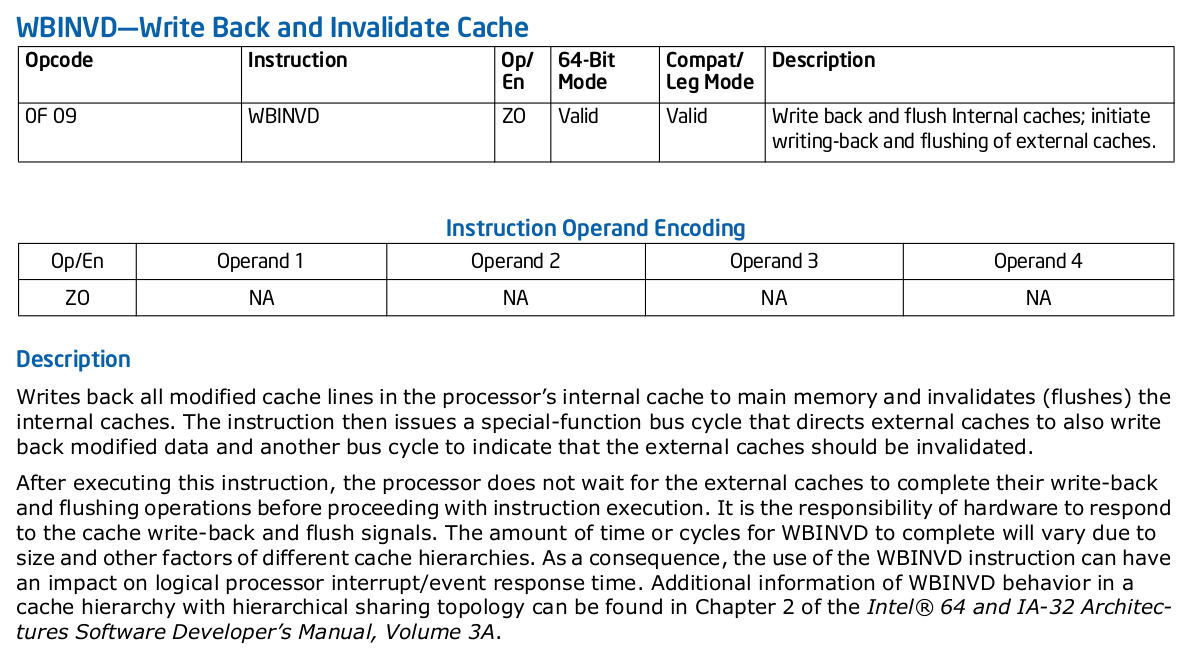
WBINVD 指令先将所有 Modify 状态的 CACHE Line 更新到内存,然后将所有的 CACHE LINE 标记为无效. 由于 Write-Back 操作的存在,该指令会导致系统总线阻塞. 指令的执行无需等待 Write-back 和 Invalid 操作完成,硬件上会应答操作的完成. WBINVD 指令同样只运行在内核空间. 接下来通过一个实践案例讲解如何使用该指令, 其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] CACHE Instruction(X86): WBINVD - WriteBack and Invalidate CACHE --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-INSTRUCT-WBINVD-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-INSTRUCT-WBINVD-default Source Code on Gitee
源码很精简,通过一个内核模块进行讲解,模块首先在 20 行通过 __get_free_page() 函数分配一个物理页,并将物理页对应的虚拟地址存储到 addr 变量里,接着在 27 行使用这段内存。模块在 30 行调用 wbinvd_on_all_cpus() 函数,函数底层调用 WBINVD 指令,并在 34 行再次使用这段内存,最后在 37 行调用 free_page() 函数释放这段内存. 调用 WBINVD 指令会将已经修改的 CACHE Line 刷新到内存里. 接下来在 BiscuitOS 上实践该案例:
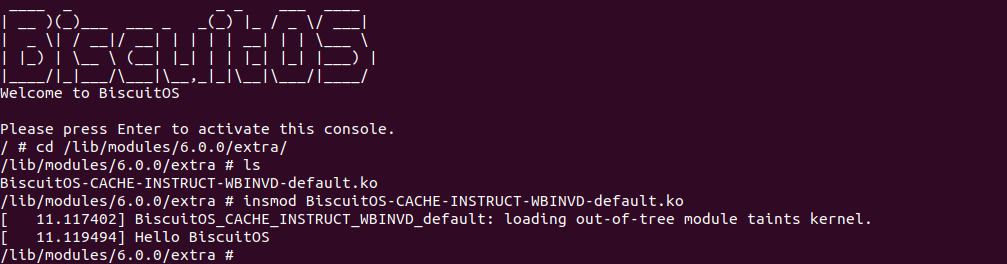
BiscuitOS 启动之后,加载 BiscuitOS-CACHE-INSTRUCT-WBINVD-default.ko 模块,可以看到内核成功打印了字符串,符合预期.
WBNOINVD Instruction
WBNOINVD 指令将所有 Modify 状态的 CACHE Line 更新到内存,但不会使所有的 CACHE LINE 无效. 指令执行之后软件无需等待所有 Write-Back 操作完成,其他 CACHE Line 完成 Write-Back 操作之后会自动进行应答,以此硬件确认指令执行完成. 接下来通过一个实践案例讲解如何使用该指令, 其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] CACHE Instruction(X86): WBNOINVD - WriteBack and Don't Invalidate CACHE --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-INSTRUCT-WBNOINVD-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-INSTRUCT-WBNOINVD-default Source Code on Gitee
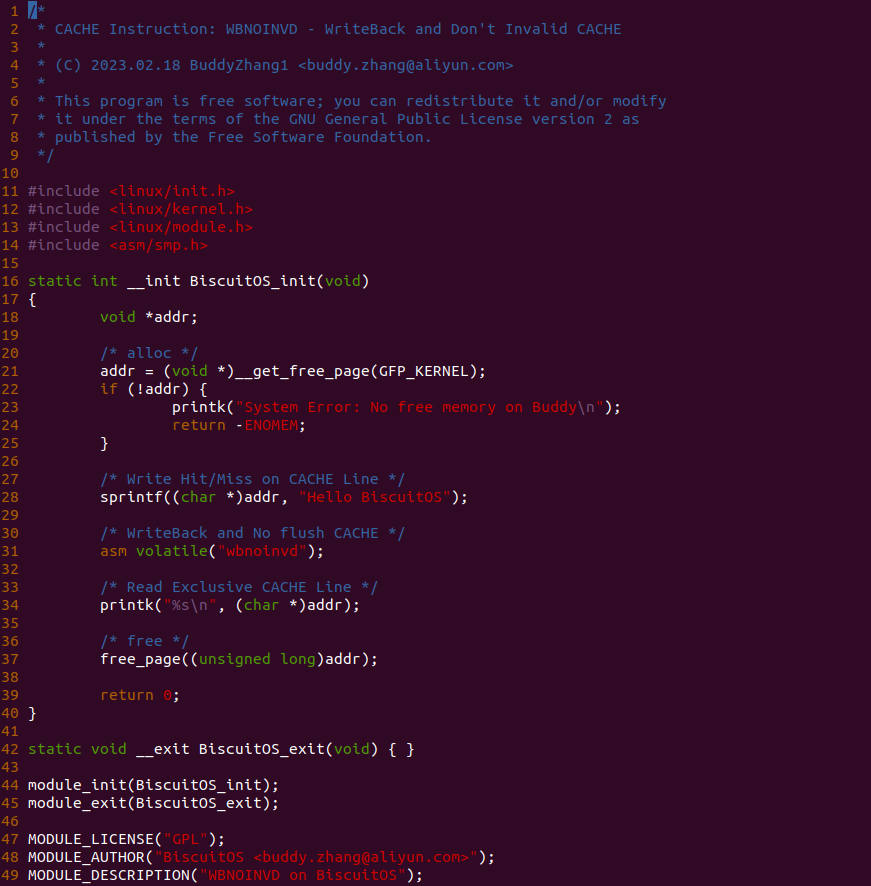
源码很精简,通过一个内核模块进行讲解,模块首先在 20 行通过 __get_free_page() 函数分配一个物理页,并将物理页对应的虚拟地址存储到 addr 变量里,接着在 27 行使用这段内存。模块在 30 行通过内嵌汇编的方式调用了 WBNOINVD 指令,并在 34 行再次使用这段内存,最后在 37 行调用 free_page() 函数释放这段内存. 调用 WBNOINVD 指令会将已经修改的 CACHE Line 刷新到内存里. 接下来在 BiscuitOS 上实践该案例:
BiscuitOS 启动之后,加载 BiscuitOS_CACHE_INSTRUCT_WBNOINVD_default.ko 模块,可以看到内核成功打印了字符串,符合预期.
CLFLUSH Instruction
CLFLUSH 指令基于虚拟地址, 如果 CACHE Line 的状态是 Modify,那么先执行 Write-Back 将 CACHE Line 内容刷新到内存里,然后将包含内容的 CACHE Line 全部置为 Invalid. CLFLUSH 指令一般用于准备读取新数据的场景. 接下来通过一个实践案例讲解如何使用该指令, 其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] CACHE Instruction(X86): CLFLUSH - Flush CACHE Line --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-INSTRUCT-CLFLUSH-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-INSTRUCT-CLFLUSH-default Source Code on Gitee
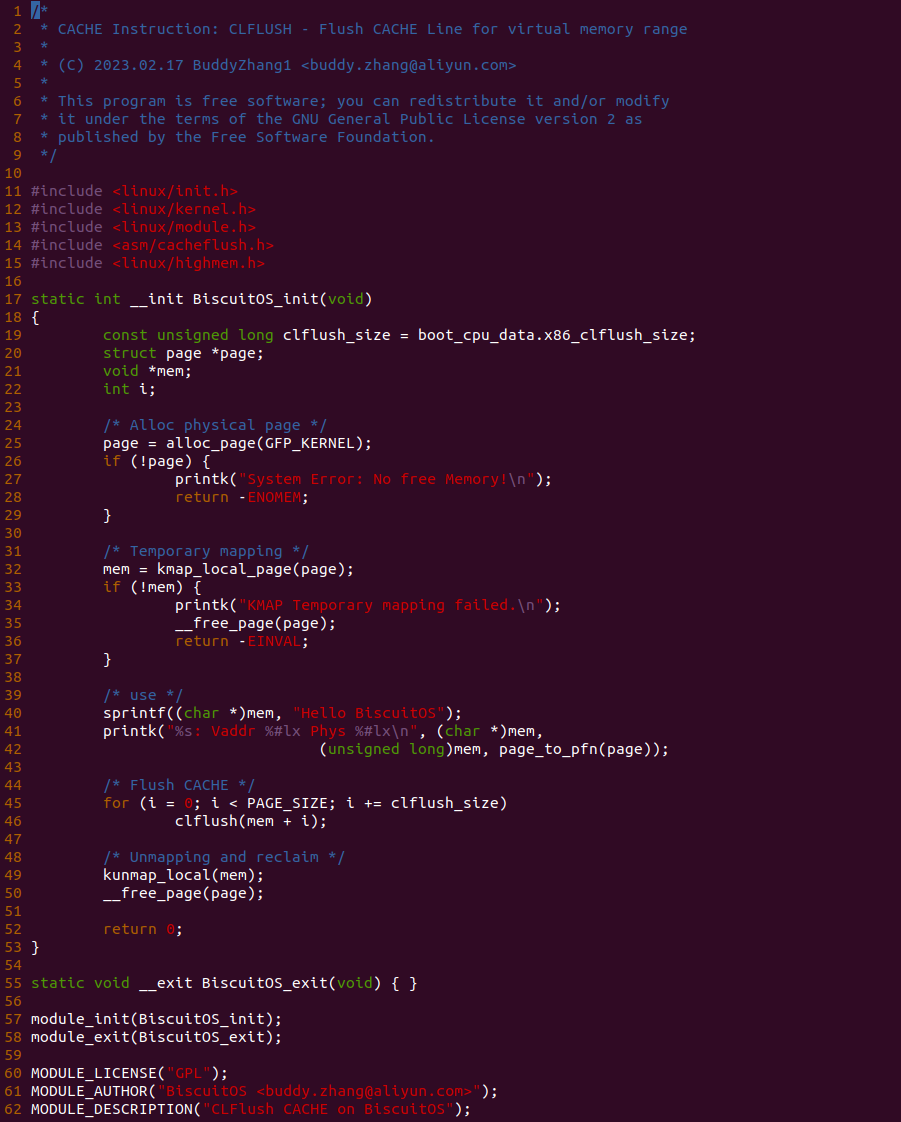
源码很精简,通过一个内核模块进行讲解,模块首先在 25 行调用 alloc_page() 分配一个物理页,然后在 32 行调用 kmap_local_page() 函数将物理页临时映射到内核空间,并在 40 行使用内存,接着在 45-46 行按 CACHE Line Size 的粒度循环调用 clflush() 函数将虚拟地址对应的 CACHE Line 进行刷新. 最后模块在 49 行调用 kunmap_local() 函数解除了物理页的临时映射,并调用 __free_page() 函数回收物理页. clflush() 函数最终调用到 CLFLUSH 指令并将修改的内容更新到内存,这在临时映射的场景有效果. 接下来在 BiscuitOS 上实践该案例:
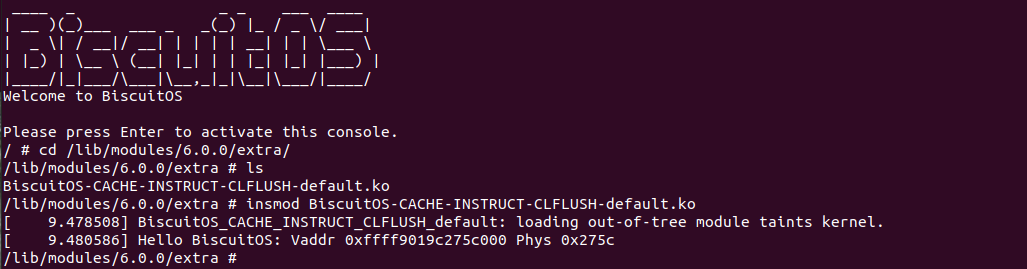
BiscuitOS 启动之后,加载 BiscuitOS-CACHE-INSTRUCT-CLFLUSH-default.ko 模块,可以看到内核成功打印了字符串,符合预期.
CLFLUSHOPT Instruction
CLFLUSHOPT 指令基于虚拟地址进行 CACHE Line 刷新, 如果 CACHE Line 的状态是 Modify,那么先执行 Write-Back 将 CACHE Line 内容刷新到内存里,然后将包含内容的 CACHE Line 全部置为 Invalid. CLFLUSHOPT 指令一般用于准备读取新数据的场景. 接下来通过一个实践案例讲解如何使用该指令, 其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] CACHE Instruction(X86): CLFLUSHOPT - Flush CACHE Line Optimized --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-INSTRUCT-CLFLUSHOPT-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-INSTRUCT-CLFLUSHOPT-default Source Code on Gitee
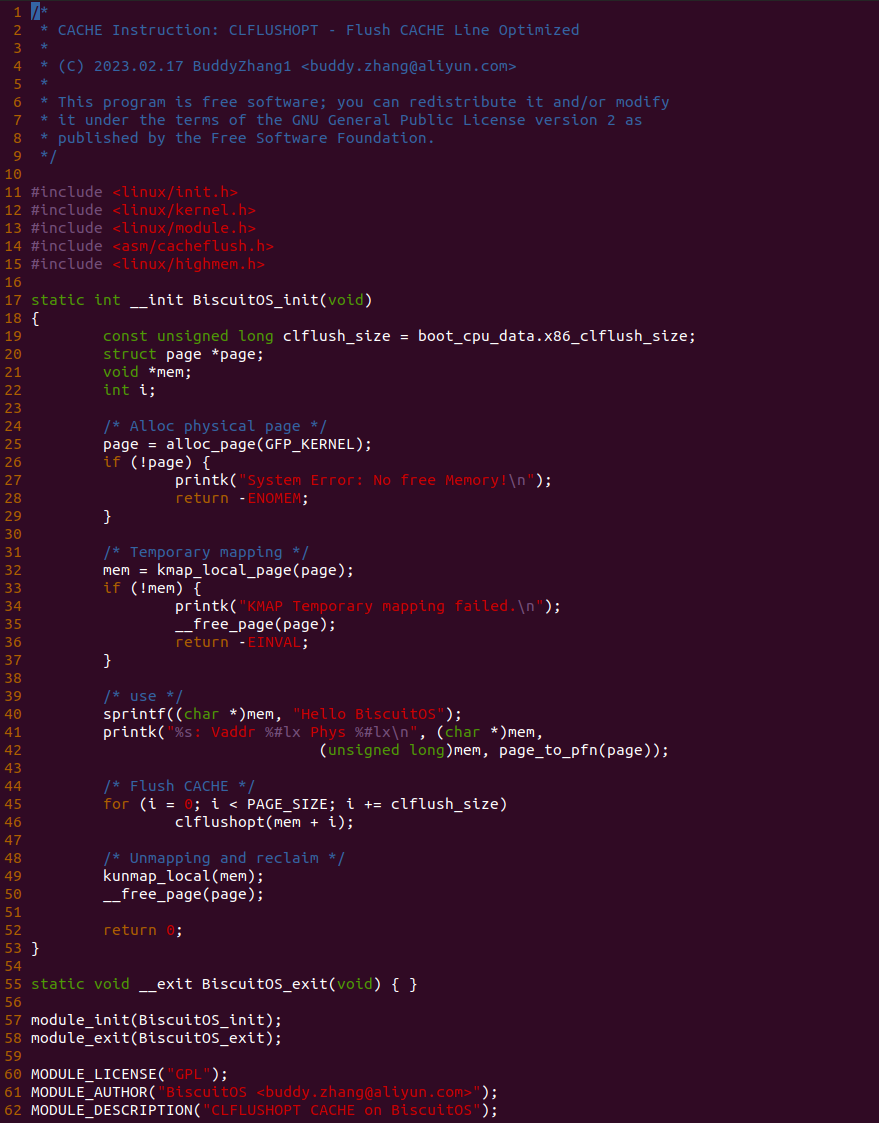
源码很精简,通过一个内核模块进行讲解,模块首先在 25 行调用 alloc_page() 分配一个物理页,然后在 32 行调用 kmap_local_page() 函数将物理页临时映射到内核空间,并在 40 行使用内存,接着在 45-46 行按 CACHE Line Size 的粒度循环调用 clflushopt() 函数将虚拟地址对应的 CACHE Line 进行刷新. 最后模块在 49 行调用 kunmap_local() 函数解除了物理页的临时映射,并调用 __free_page() 函数回收物理页. clflushopt() 函数最终调用到 CLFLUSHOPT 指令并将修改的内容更新到内存,这在临时映射的场景有效果. 接下来在 BiscuitOS 上实践该案例:
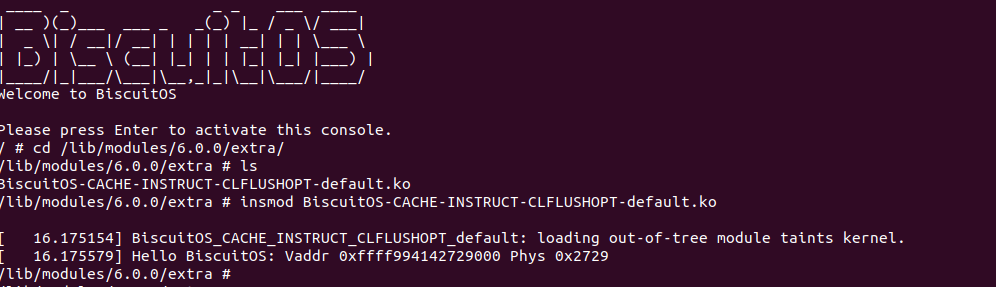
BiscuitOS 启动之后,加载 BiscuitOS-CACHE-INSTRUCT-CLFLUSHOPT-default.ko 模块,可以看到内核成功打印了字符串,符合预期.
CLWB Instruction
CLWB 指令基于虚拟地址进行 WriteBack 操作,将数据从 CACHE Line 中刷新到内存里, WBNOINVD 或者 WBINVD 指令都有 WriteBack 操作,但是针对所有的 CACHE,而 CLWB 可以按 CACHE Line 的粒度进行 WriteBack 操作. 该指令用于同步外设同步数据的场景。接下来通过一个实践案例讲解如何使用该指令, 其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] CACHE Instruction(X86): CLWB - WriteBack CACHE Line --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-INSTRUCT-CLWB-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
源码很精简,通过一个内核模块进行讲解,模块首先在 25 行调用 alloc_page() 分配一个物理页,然后在 32 行调用 kmap_local_page() 函数将物理页临时映射到内核空间,并在 40 行使用内存,接着在 45-46 行按 CACHE Line Size 的粒度循环调用 clwb() 函数将虚拟地址对应的 CACHE Line 进行 WriteBack 操作. 最后模块在 49 行调用 kunmap_local() 函数解除了物理页的临时映射,并调用 __free_page() 函数回收物理页. clwb() 函数最终调用到 CLWB 指令并将修改的内容更新到内存,这在临时映射的场景有效果. 接下来在 BiscuitOS 上实践该案例:
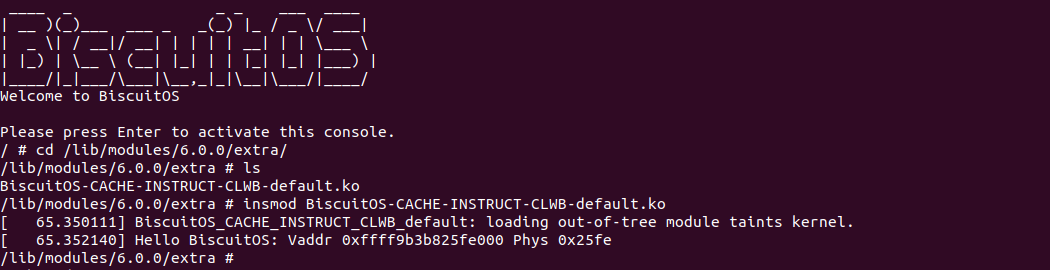
BiscuitOS 启动之后,加载 BiscuitOS-CACHE-INSTRUCT-CLWB-default.ko 模块,可以看到内核成功打印了字符串,符合预期.
PREFETCHh Instruction
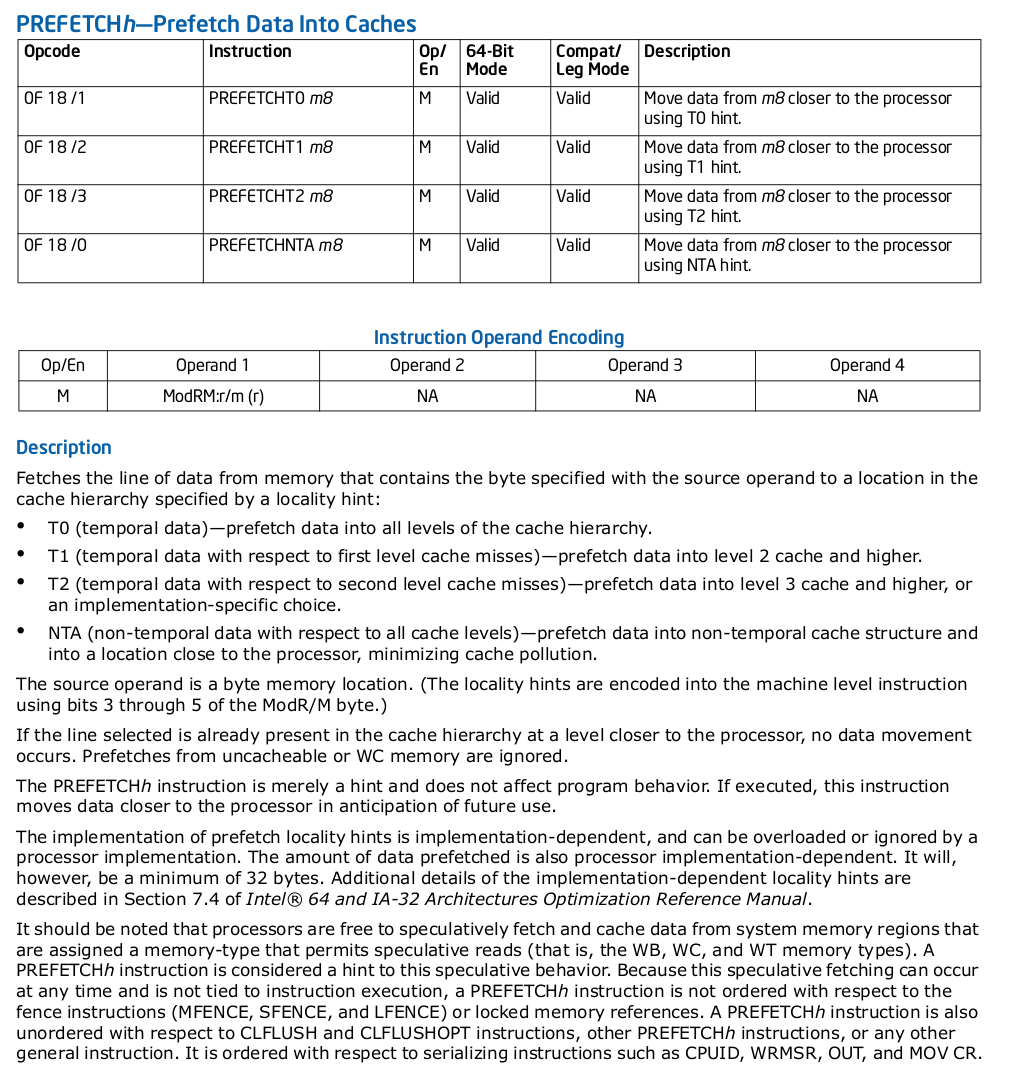
PREFETCHh 指令用于将内存中的 Data Block 加载到 CACHE Line 中,有预取的作用,指令可以按不用的要求进行预期. 接下来通过一个实践案例讲解如何使用该指令, 其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] CACHE Instruction(X86): PREFETCH - Prefetch Data into CACHE --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-INSTRUCT-PREFETCH-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-INSTRUCT-PREFETCH-default Source Code on Gitee
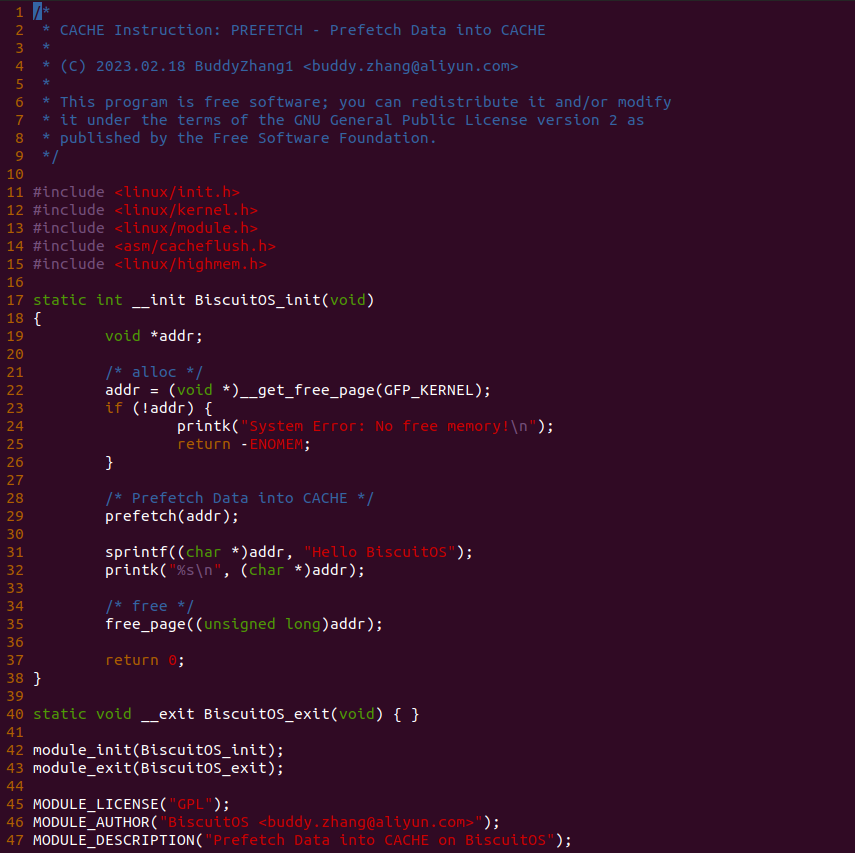
源码很精简,通过一个内核模块进行讲解,模块首先在 25 行调用 __get_free_page() 分配一个物理页并获得物理也对应的虚拟地址,然后在 29 行调用 prefetch() 函数将物理页预先加载到 CACHE Line 中,接着在 31-32 行使用内存,最后在 35 行调用 free_page() 函数释放物理页. prefetch() 函数最终会调用到 PREFETCH 指令, 该指令适用于需要加速读的场景. 接下来在 BiscuitOS 上实践该案例:
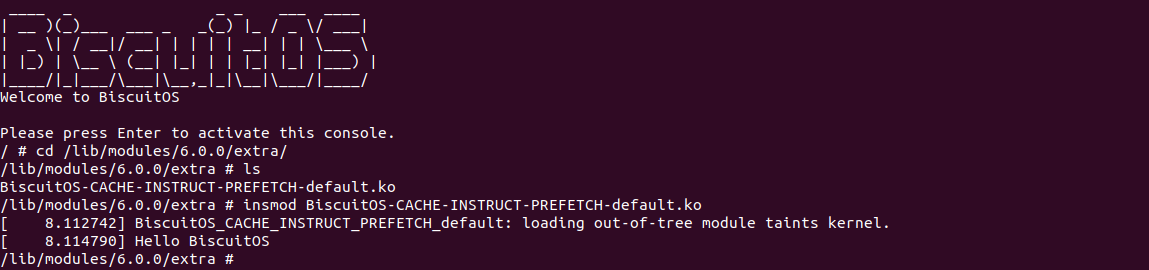
BiscuitOS 启动之后,加载 BiscuitOS-CACHE-INSTRUCT-PREFETCH-default.ko 模块,可以看到内核成功打印了字符串,符合预期.
PREFETCHW Instruction
PREFETCHW 指令用于将内存中的 Data Block 加载到 L1/L2 CACHE Line 中,是该 CACHE Line 的其他数据无效. 接下来通过一个实践案例讲解如何使用该指令, 其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] CACHE Instruction(X86): PREFETCHW - Prefetch Data into CACHE in Anticipation of a Write --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-INSTRUCT-PREFETCHW-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-INSTRUCT-PREFETCHW-default Source Code on Gitee
源码很精简,通过一个内核模块进行讲解,模块首先在 23 行调用 __get_free_page() 分配一个物理页并获得物理也对应的虚拟地址,然后在 30 行调用 prefetchw() 函数将物理页预先加载到 CACHE Line 中,接着在 32-33 行使用内存,最后在 36 行调用 free_page() 函数释放物理页. prefetchw() 函数最终会调用到 PREFETCHW 指令, 该指令适用于需要加速读的场景. 接下来在 BiscuitOS 上实践该案例:
BiscuitOS 启动之后,加载 BiscuitOS-CACHE-INSTRUCT-PREFETCHW-default.ko 模块,可以看到内核成功打印了字符串,符合预期.
MOVNTI Instruction
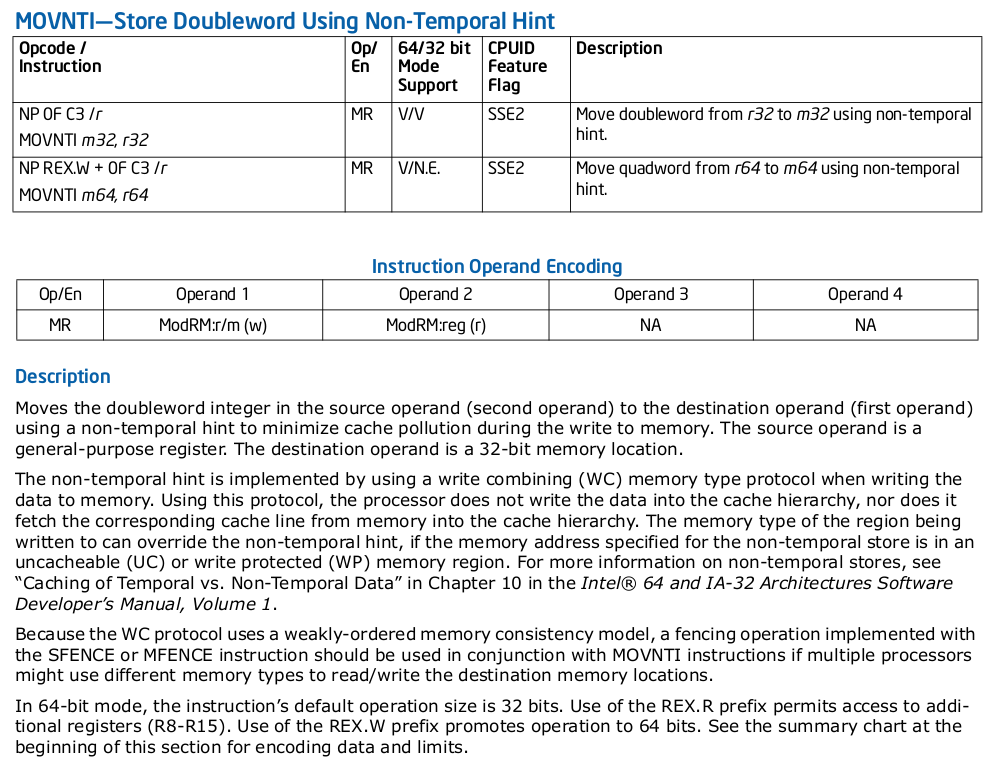
MOVNTI 指令用于非时间限定最小化使用 CACHE 的方式使 CPU 写 DoubleWord 数据到内存,其实现基于 WriteCombining Memory Type,CPU 在写内存时可以尽可能推迟写操作. 其基于 Non-Temporal Hit 硬件,在内存搬运过程中尽可能不使用 CACHE. 接下来通过一个实践案例讲解如何使用该指令, 其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] CACHE Instruction(X86): MOVNTI - Store Doubleword Using No-Temporal Hint --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-INSTRUCT-MOVNTI-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-INSTRUCT-MOVNTI-default Source Code on Gitee
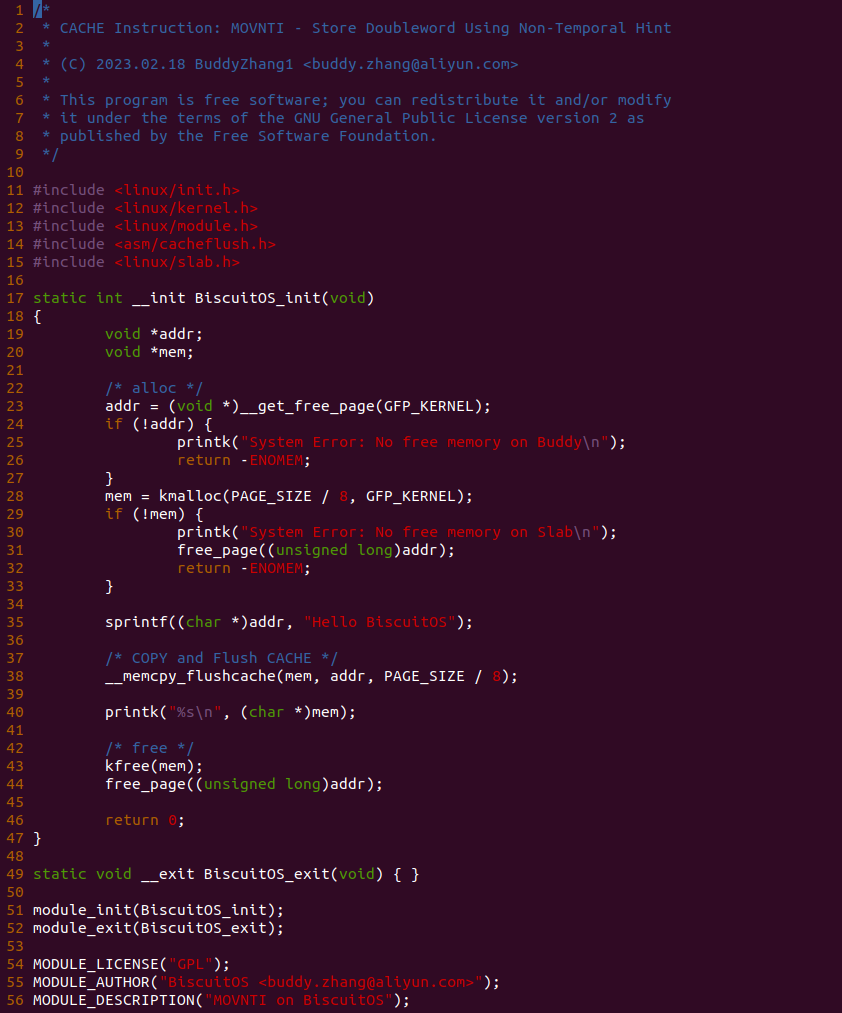
源码很精简,通过一个内核模块进行讲解,模块首先在 23 行调用 __get_free_page() 分配一个物理页并获得物理也对应的虚拟地址,然后在 28 行调用 kmalloc() 函数分配一段内存,接下来向物理页写入字符串。模块在 38 行调用 __memory_flushcache() 函数在物理页和 mem 对应的内存之间拷贝数据,此时是向 mem 写入动作,拷贝完毕之后打印 mem 的内容,最后模块在 43-44 行调用 kfree() 和 free_page() 函数回收内存. 接下来在 BiscuitOS 上实践该案例:
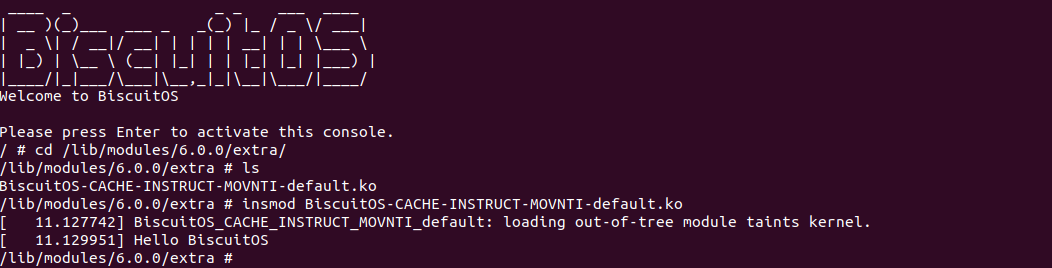
BiscuitOS 启动之后,加载 BiscuitOS-CACHE-INSTRUCT-MOVNTI-default.ko 模块,可以看到内核成功打印了字符串,符合预期.
Intel® Split_lock Check Technology
在现代 Intel 架构里,原子操作不再是简单的通过 #LOCK 锁住总线的方式,而是在多核架构下,通过 MESIF 硬件上实现原子操作,简单的说单一原子操作已经不需要发送 #LOCK 信号锁总线,而是可以无锁的实现原子操作,具体描述可以参考下文:
但也存在特殊情况,当对一个跨 CACHE Line 的数据进行原子操作时,硬件 MESIF 无法保证原子性,那么还是需要发送 #LOCK 信号锁住总线,突然的锁总线对性能带来了极大跳转,作为开发者应该尽量避免对跨 CACHE Line 的数据进行原子操作,另外一方面 Intel 架构在硬件上提供了 Split lock 检测机制,用于检测跨 CACHE Line 的原子操作。那么接下来通过一个实践案例讲解该机制如何运行, 实践案例在 BiscuitOS 的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Split lock detect --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-SPLIT-LOCK-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build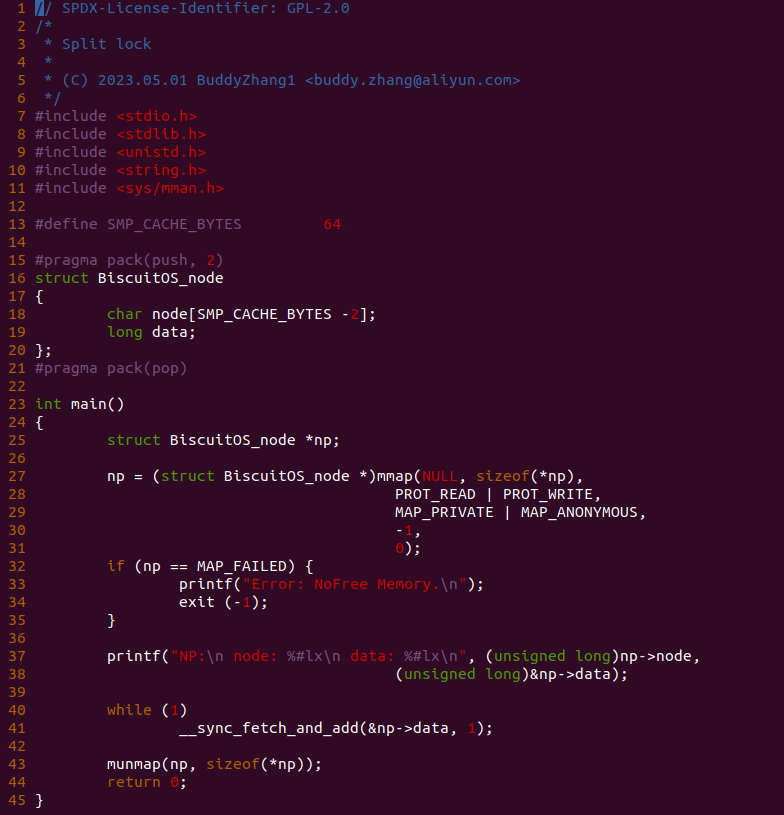
实践案例有一个用户空间程序组成,程序定义了一个数据结构体 struct BiscuitOS_nod, 其包含了两个成员: node 和 data, 由于采用 “#pragma” 关键字,那么会出现 data 的地址并没有对其,而是紧贴 node 之后,那么会出现 data 横跨两个 CACHE Line. 程序通过 mmap() 函数为 np 变量分配内存,其是一个指向 struct BiscuitOS_node 的指针,分配成功之后在 40-41 行循环执行 __sync_fetch_and_add() 函数,该函数是对 np->data 成员执行一次原子加 1 操作。那么接下来在 BiscuitOS 上进行实践:
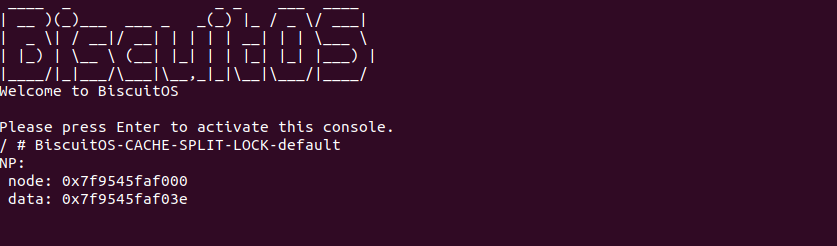
BiscuitOS 运行之后,运行 BiscuitOS-CACHE-SPLIT-LOCK-default,此时可以看到 data 成员的地址确实横跨了两个 CACHE Line,但此时系统并没有发送其他情况。这个情况也符合预期,Split lock Detect 硬件功能不是所有的 Intel 架构上都有,其在特定的 CPU 架构上采用,如果开发者的 CPU 架构上包含了 Split lock detect 功能,那么此时内核会打印如下信息:
[8978.593816] x86/split lock detection: #AC: BiscuitOS-CACHE-SPLIT-LOCK-default/83426 took a split_lock trap at address: 0x7f9545faf03e有了 Split lock Detect 检查机制之后,内核可以检查到系统运行时跨 CACHE Line 的操作,当检查到该行为之后,Linux 提供了多种处理机制,内核最终采用何种机制可以通过 CMDLINE 进行配置:
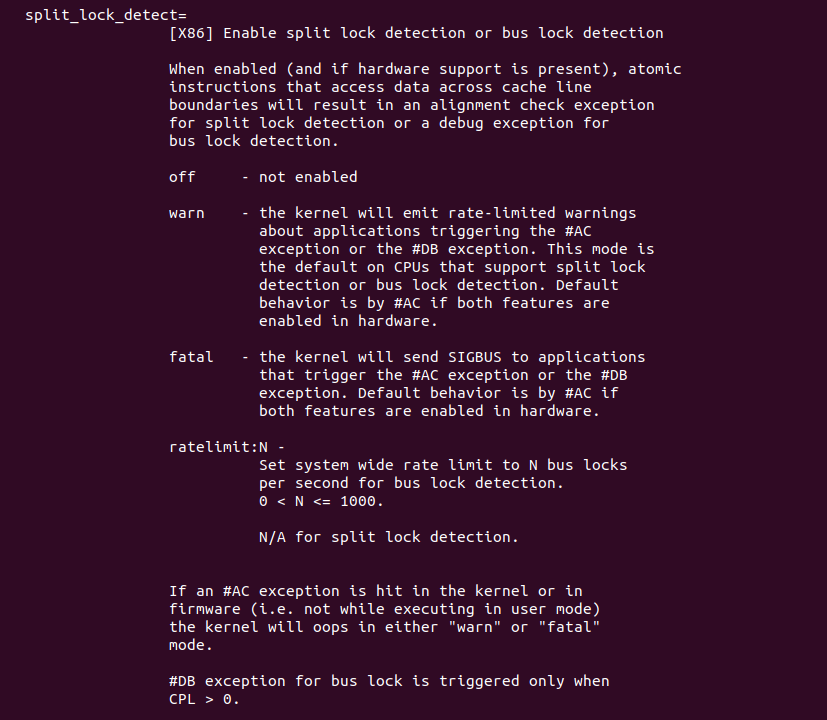
内核提供了上图几种策略用于处理 Split lock detect 检查到跨 CACHE Line 原子操作, 每种策略都会对系统性能产生极大的影响,开发者可以参考进行选择:
- off: 视而不见,就是检查到也不做任何处理,那么 #LOCK 总线的操作会降低系统性能
- warn: 广而告之, 仅仅是发出警告,不做更多操作
- fatal: 天降正义,直接向触发的应用程序发 SIGBUS 信号触发 #AC 异常或 #DB 异常. 如果是内核触发,视为致命错误,直接导致系统崩溃.
- retelimit: 类似于 warn 选项,但是限制日志消息的频率,以避免填满日志系统.
有了上面几个选项之后,开发者可以根据实际情况使用 Split lock detect 机制,接下来对 Split lock 进一步研究, SDM 中是这么描述 Split lock Detect 机制,split lock 是指任何操作数跨越两个缓存行的原子操作. 由于操作数跨越了两个 CACHE Line 且操作必须是原子的,所以系统在 CPU 访问两个缓存行时会锁总线. 在总线锁定期间,来自其他 CPU 或总线代理的总线访问请求都被阻塞,阻塞其他 CPU 的总线访问加上配置总线锁定协议的开销,不仅会降低单个 CPU 性能,还会降低整个系统性能。
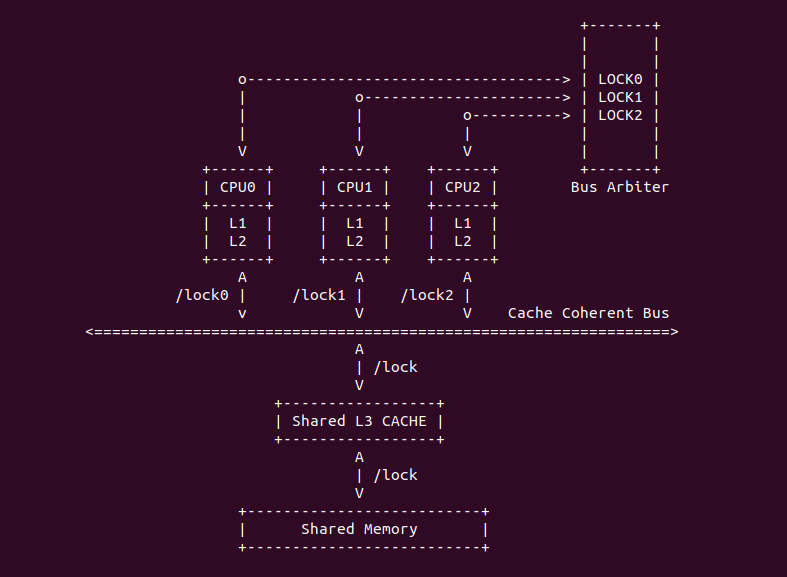
如果操作数可以被缓存且全部包含在同一行中,那么在 Intel P6 和最近的处理器上,原子操作通过更少的缓存锁定进行优化。如果检查到 split lock 操作并且开发者修复了问题,是操作数可以在同一个 CACHE Line 里进行操作,那么原子操作将通过 MESIF 就可以实现原子操作,而不是去锁定更昂贵的总线操作,去除 Split lock 可以提供整体性能.

Intel 多核处理器支持在系统内存中的位置上进行锁定的原子操作,例如下列指令使用内存目标操作形式时,可以在这些命令前面加上 LOCK 指令前缀: ADD、ADC、AND、BTC、BTR、BTS、CMPXCH、CMPXCH8B、CMPXCHG16B、DEC、INC、NEG、NOT、OR、SBB、SUB、XOR、XADD 和 XCHG. 上图是实践案例对应的汇编代码,可以看到 __sync_fetch_and_add() 函数对应的汇编代码,可以看到 ADDQ 指令前面的 LOCK 指令.
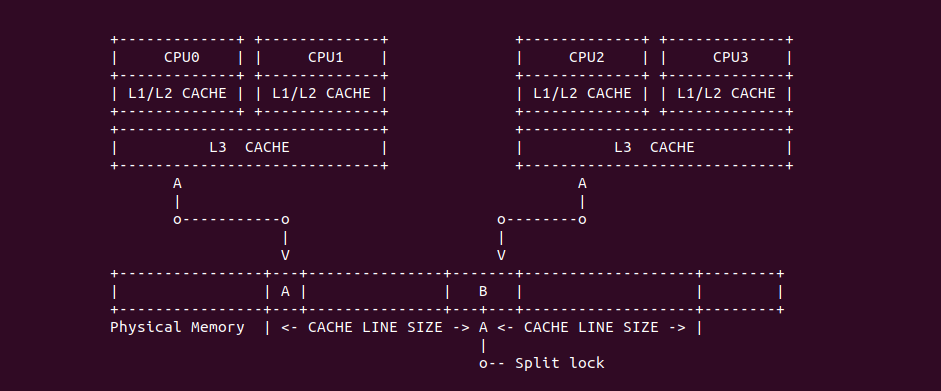
Intel 引入了 Split lock Detect 硬件机制,在不良对齐的原子操作影响整个系统性能之前,通过对齐检查(#AC)异常来检测分割锁定. 对于构建集成实时系统设计者来说,这个能力是至关重要的. 在实时系统里,在某些核上运行 “不受信任” 的代码,硬实时不能承受来自不受信任程序的任何总线锁定,以此带来的损害实时性能。到目前为止,架构师无法部署这些解决方案,因为他们没有办法防止 “不受信任” 的代码生成分 Split lock 和锁总线, 以阻止硬实时代码在总线锁定期间访问内存. 这种能力在云场景中找到了用途,在一个客户端运行 split lock 的原子操作锁总线,导致其他核无法访问共享内存,这可能会导致系统性能降低. 另外 Split lock 可能会开放一个安全漏洞,恶意用户代码可以通过执行带有 Split lock 的原子操作减缓整个系统的速度。对 Split lock detect 机制分析已经完成,那么通过几个实际的案例分析 Split lock 带来的问题:

Intel® RDT Technology
RDT(Resource Director Technology) 提供了两种能力: 监控和分配。该技术旨在通过一系列的 CPU 指令从而允许用户直接对每个 CPU 核心的 L2 缓存、L3 缓存(LLC) 以及内存带宽进行监控和分配, 包括缓存分配技术(Cache Allocation Technology, CAT)、代码和数据优先级(Code and Data Prioritization, CDP) 以及内存带宽分配(Memory Bandwidth Allocation, MBA). Linux Kernel 4.10 引入了 Intel RDT 实现架构,基于 resctrl 文件系统提供了 L3 CAT(Cache Allocation Technology)、L3 CDP(Code and Data Prioritization),以及 L2 CAT, 并且 Linux Kernel 4.12 进一步实现支持了 MBA(Memory Bandwidth Allocation) 内存带宽分配技术。RDT分为5个功能模块:
- Cache Monitoring Technology (CMT) 缓存检测技术
- Cache Allocation Technology (CAT) 缓存分配技术
- Memory Bandwidth Monitoring (MBM) 内存带宽监测
- Memory Bandwidth Allocation (MBA) 内存带宽分配
- Code and Data Prioritization (CDP) 代码和数据优先级
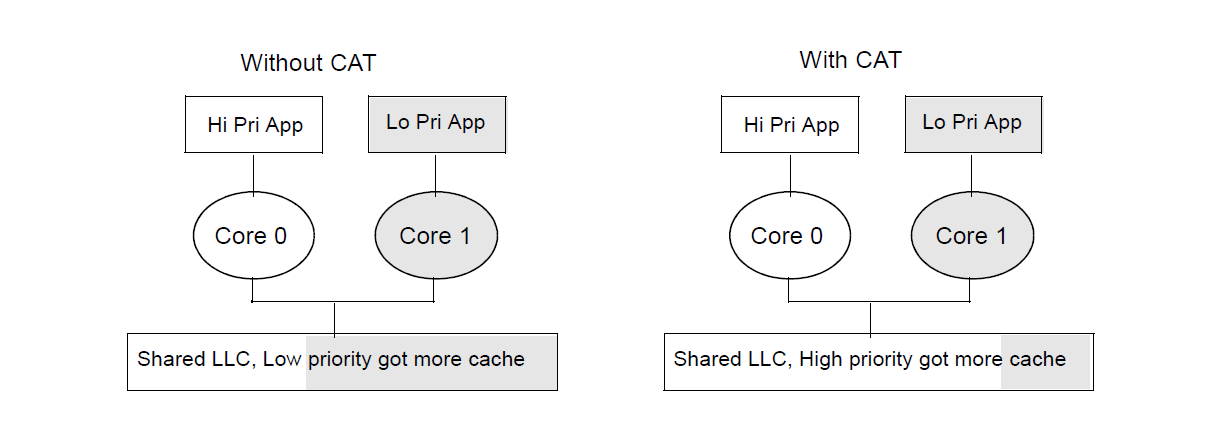
在 LLC 隔离研究 章节对 LLC 噪音问题进行了讲解, 简单的总结就是在虚拟化环境中,宿主机的资源(包括 CPU CACHE 和内存带宽) 都是共享的。这引入一个问题就是: 如果有一个过度消耗 CACHE 的应用耗尽了 L3 缓存或者大量的内存带宽,将无法保障其他虚拟机应用的性能,这种问题称为 noisy neighbor. 以往解决方法是通过控制虚拟机逻辑资源 (cgroup) 但是调整粒度太粗,并且无法控制处理器缓存这样敏感而且稀缺的资源, 为此 Intel 推出了 RDT 技术。
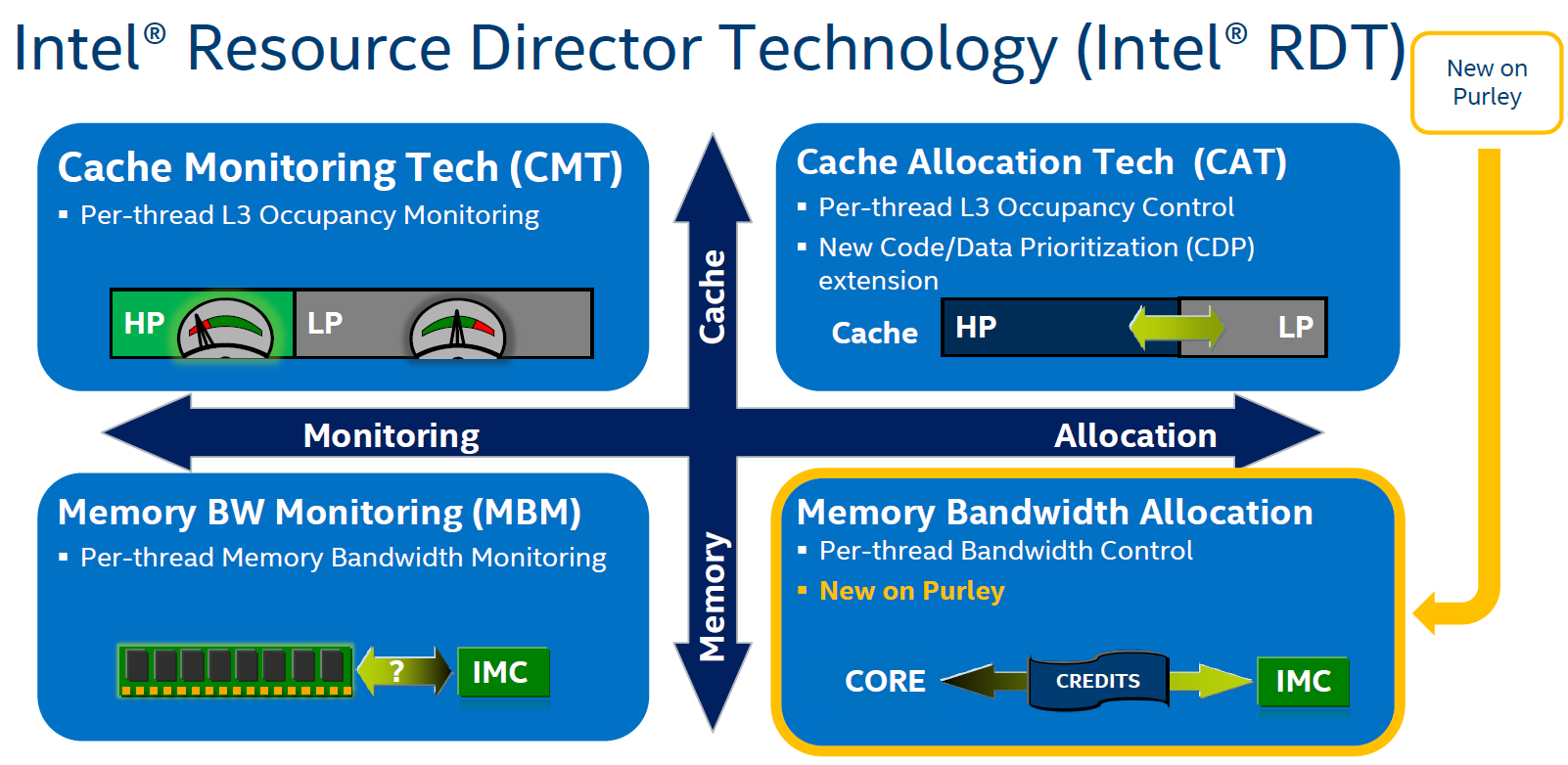
缓存分配技术 CAT(Cache Allocation Technology) 的核心目标是基于服务级别(Class of Service, COS 或 CLOS)来实现资源分配。应用程序或者独立线程可以按照处理器提供的一系列服务级别来标记, 这样就会按照应用程序和线程的服务分类来限制和分配其使用的缓存。每个 CLOS 可以使用能力掩码(capacity bitmasks, CBMs)来标志并在服务分类中指定覆盖(overlap)或隔离(isolation)的程度。对于每个逻辑处理器,都有一个寄存器(被称为 IA32_PQR_ASSOC MSR或PQR)来允许操作系统(OS)或虚拟机管理器(VMM)在应用程序、线程、虚拟机(VM)调度(scheduled)的时候指定它的 CLOS. RDT 允许 OS 或 VMM 监控线程、应用或 VM 使用的 CACHE/内存带宽,通过分析 CACHE/内存带宽使用率,OS 或 VMM 可以优化调度策略提高效能,使得高级优化技术可以实现.
RDT 术语
RMID: OS 或 VMM 会给每个应用或虚拟机标记一个软件定义的 ID,叫做 RMID(Resource Monitoring ID),通过 RMID 可以同时监控运行在多处理器上相互独立的线程,注意这里是指应用线程而是不是硬件的 core。每个处理器可用的 RMIDs 数量是不一样的,这个可以通过 CPUID 指令获取得到,RMID 数量不一样意味着可以监控独立线程的数量会有差异,如果一个系统上运行过多的线程可能会导致不能监控到所有线程的资源使用。此外线程可以被独立监控,也可以按组的方式进行监控:
- 多个线程可以标记为相同的 RMID
- 同一个虚拟机下的所有线程可以标记为相同的 RMID
- 同样一个应用下的所有线程可以标记为相同的 RMID

绑定 RMID 到线程的动作由 OS/VMM 来完成, 每个 CPU core 上存在一个 IA32_PQR_ASSOC MSR 寄存器,获取监控数据也是通过 MSR 来实现的: IA32_QM_EVTSEL 设置 RMID 和 Event ID,硬件就会查看特定数据,并通过 IA32_QM_CTR MSR 返回结果。这个 IA32_QM_CTR MSR 的 E/U 位表示 Error 和 Unavailable,如果数据合法就不会设置这两个位,则数据就可以被软件使用.
CLOS: CAT 中引入了一个中间结构叫做 CLOS (Class of Service),可以理解为资源控制标签。此外每个 CLOS 定义了 CBM(capacity bitmasks),CLOS 和 CBM一起,确定有多少 CACHE 可以被这个 CLOS 使用。Intel 提供了 intel-cmt-cat 工具合集,可以不需要内核支持,直接使用 CAT/CMT/MBM/CDP 功能,BiscuitOS 已经支持该工具,其部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Intel CACHE tools: CMT and CAT U+ --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-Intel-CMT-CAT-github/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
当安装完毕之后,在 BiscuitOS 上或者 Host 上运行 RDT,在运行之前可能需要指定运行依赖库,可以使用 “export LD_LIBRARY_PATH=/lib”, RDT 主要提供了 pqos 工具,如上图,我的开发机上没有 RDT 硬件,因此没法运行起来。那么在接下来的章节会介绍 RDT 的具体使用.
CMT/MBM/MBA 使用
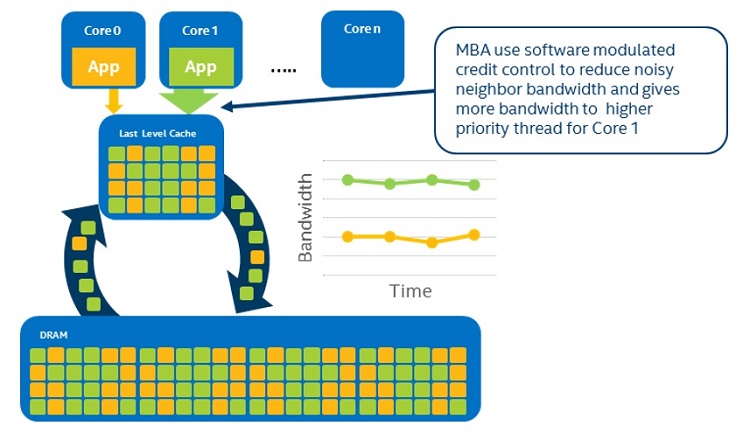
pqos -m all:0-11监控 CORE 0-11 的所有事件(本地内存带宽,异地内存带宽,LLC空间使用率)
pqos -m llc:0,2,6监控 CORE0,2,6 的 LLC
pqos -m "mbl:0-2;mbr:3,4,5"监控 CORE0-2 的本地内存带宽,CORE3-5 的异地内存带宽.
pqos -m "all:[0-11];llc:[12,13,14];mbl:[15-17,20]"监控 CORE 组的事件. 监控虚拟机使用情况,假设一个主机上运行 3 个虚拟机,每个虚拟机分配 CORE 的情况如下:
- VM0 - COREs 0-2
- VM1 - COREs 3-5
- VM2 - COREs 6-8
pqos -m "all:[0-2],[3-5],[6-8];"
# 输出
CORE IPC MISSES LLC[KB] MBL[MB/s] MBR[MB/s]
0-2 0.69 3k 1120.0 0.0 0.0
3-5 1.62 10k 3520.0 0.0 0.0
6-8 0.49 1k 1040.0 0.0 0.0监控每个虚拟机事件. 输出如上,每一行表示一个虚拟机资源使用情况.
pqos -s显示当前资源分配配置.
pqos -e "mba:1=50;mba:2=70;"设置 COS1 可使用 50%,设置 COS2 可使用70%.
pqos -e "mba:1=80;mba@0,1:2=64;mba@2-3:3=85"设置 COS1 运行在所有 SOCEKTS 上,COS2 运行在 SOCEKT0 和 SOCKET1 上,COS3 运行在 SOCKET2 和 SOCKET3 上.
Kernel 直接使用 RDT
上面是传统的通过 MSR 方式来使用 RDT,还可以通过操作系统内核的方式来使用 RDT,这也是业务上常用的方式,不过需要内核支持.
cat /proc/cpuinfo | grep cat_l3确认 kernel 和 CPU 均支持 CAT
mount -t resctrl resctrl /sys/fs/resctrl系统不会自动开启 resctrl 的用户接口,需要手工开启
mkdir /sys/fs/resctrl/ptest创建一个新的LLC分配策略
echo "L3:0=1” > /sys/fs/resctrl/ptest/schemata修改 LLC 分配策略,这里分配测 L3 cache 策略是 1 个 CACHE way.
echo 768 > /sys/fs/resctrl/ptest/tasks绑定一个 LLC 策略到进程,假定 PID 为 768. 这样就将 768 的进程 LLC 资源限制在了 1 个 CACHE way 上而不能使用更多.
Intel® CAT Technology

在云计算环境,多租户虚拟机会运行多种不同类型的应用,所以确保一致的性能和优先级划分确保重要应用运行是巨大的挑战。在多核处理器系统中,共享资源例如最后一级高速缓存(LLC,Last Level Cache)、共享IO设备、共享内存带宽的分配和使用是关系到应用性能的关键。一些应用(如后台视频流和转码应用)会过度使用高速缓存,导致降低更重要应用的性能, 例如下图中 Noisy neighbor 的 App[0] (运行在CPU核心0上)消耗了过多的末级高速缓存,影响了 CPU 核心 1 上运行的 App[1] 。这是因为通常根据先到先得的分配原则:
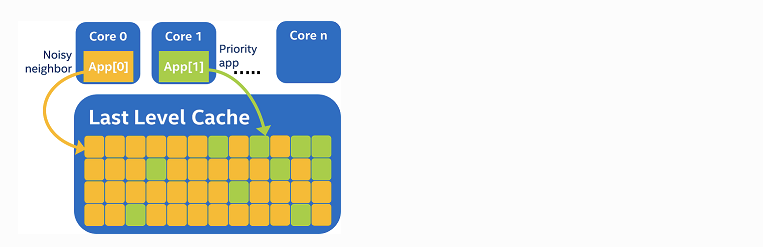
高速缓存分配技术(CAT)提供了软件可编程控制,以控制特定线程、应用、虚拟机或容器等消耗的高速缓存空间。可支持操作系统保护重要的进程,支持管理程序即使在 noisy 环境中也可以对重要虚拟机进行优先级划分。CAT 基本机制:
- 通过 CPUID 枚举 CAT 功能和相关LLC 分配支持的能力
- 支持操作系统/管理程序将应用划分成不同服务类 (CLOS) 并为不同 CLOS 指定可用末级高速缓存量的接口, 这些接口都基于特定型号寄存器 MSR.
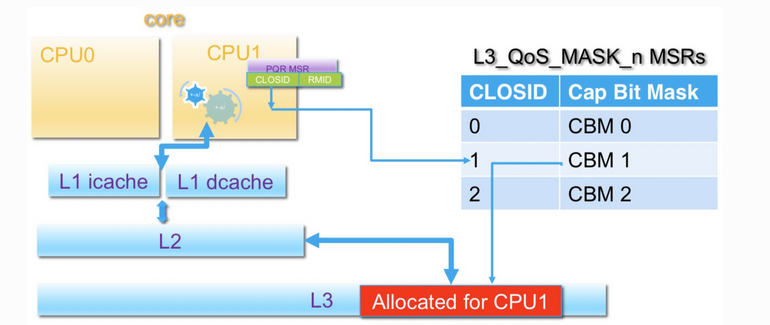
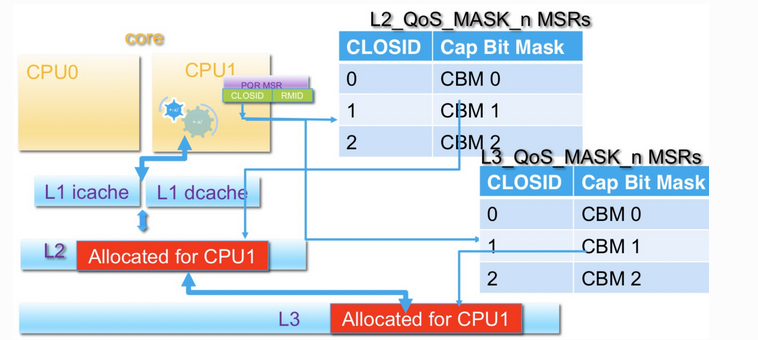
Intel 在 Haswell 志强处理器首次引入 CAT L3 功能,并且在后续的 Broadwell 和 Skylake 系列上得到增强改进。未来 x86 处理器还将引入 CAT L2功能,对共享的 L2 缓存进行类似的分配管理技术. 上图为 CAT 硬件架构, 有了以上的了解,继续分析与 CAT 相关的概念:
CLOS: 高速缓存分配技术引入一种名为服务类(CLOS)的中间接口,可以为资源控制标记,线程/应用/虚拟机/容器在该标记内进行分组。CLOS 包含相关资源容量位掩码(CBM),来说明特定的CLOS能够使用多少高速缓存.
使用模式: 通过高速缓存分配技术(Cache Allocation Technology, CAT) 功能提供的可伸缩接口可以创建出大量的使用模式,包括对重要应用程序的优先级以及隔离应用程序降低干扰。在使用 CAT 功能的底层软件,例如 OS 或 VMM 使用如下步骤实现:
- 通过 CPUID 检查 CPU 是否支持 CAT: CPUID 的 leaf 0x10 提供了 CAT 功能的能力的详细信息
- 配置服务分类(the class of service, CLOS)定义了通过 MSRs 可提供的资源范围(缓存空间)
- 每一个逻辑线程都有响应的一个可用的逻辑 CLOS
- 当 OS/VMM 将一个线程或 VCPU 加载到 CPU 核心中,将通过 IA32_PQR_ASSOC MSR 来更新 CPU 核心的 CLOS,以确保这个资源是通过步骤2(配置的服务分类)来控制其使用的资源.
更高层次的软件,例如一个调度框架(Kubernetes)或者管理员层次的工具可以通过 OS/VMM 激活硬件能力, 对于给定应用程序指定可用的缓存是通过 MSR 所包含 能力掩码(capacity bitmasks, CBMs )来设置的:
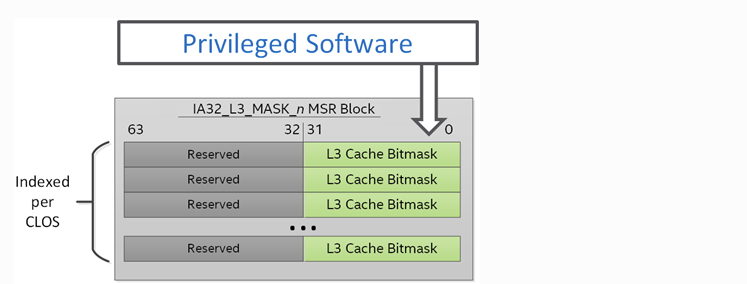
通过 MSR 的 IA32_L3_MASK_n 可以配置 CLOS 的 L3 容量位掩码,这里 n 表示 CLOS 编号,在 CBMs 中的值表示了可用缓存量以及重叠或隔离程度. 例如下图 CLOS[1] 的可用缓存小于 CLOS[3],即优先级较低.

在 LLC 中,如果应用程序没有相互覆盖或者 VM 没有竞争缓存空间的情况下,系统不会使用独立的缓存分区,而是可以动态更新任何需要修改的资源。使用覆盖位掩码(overlapping bitmasks)(在上图中的 CLOS[2] 和 CLOS[3])通常可能比隔离情况更能达到较高的带宽,并且依然具备了相关优先级: 因为比使用完全隔离的分区,可以动态按需更新资源可以获得更大的 LLC。这可能是适合很多线程/应用/VM 并发运行的模型。关联软件线程和 CLOS 是通过 IA32_PQR_ASSOC MSR 实现的,为每个硬件线程做了定义:
另一种可选的方法是不激活操作系统和 VMM 的 CLOS 直接 pin 到硬件线程的方式,而是采用软件线程 pin 到硬件线程上; 不过建议激活 OS/VMM 的方式避免需要 pin 应用线程。在开始评估截断,pin 模式可以通过 RDT工具 来实现,这个工具提供了Linux 系统的线程监控和通过关联 Resource Monitoring IDs (RMIDs) 和 每个硬件线程的 CLOS 控制资源使用。
CAT技术的应用场景: CAT 缓存分配技术在很多领域有广泛适应性,具备动态更新的伸缩和重叠(overlapped)、隔离(isolated)配置,可以将一个设备在不同应用领域轮转共享使用:
- 数据中心的云计算主机 - 在同时运行着 noisy neighbors 的主机上保障重要虚拟机或容器的资源使用
- 公有/私有云 - 保护重要的基础架构 VM(例如VPN to bridge连接私有和公有云)能够提供稳定的网络服务
- 数据中心基础架构 - 确保虚拟交换机能够稳定服务
- 通讯 - 确保网络应用的性能和后台任务稳定运行
- 内容分发(CDN) - 提供内容分发应用的带宽稳定
- 网络 - 基于 DPDK 的高性能应用能够不受 noisy neighbor 干扰
- 工业控制 - 实时环境确保重要代码部分能够符合要求稳定运行
CAT 使用
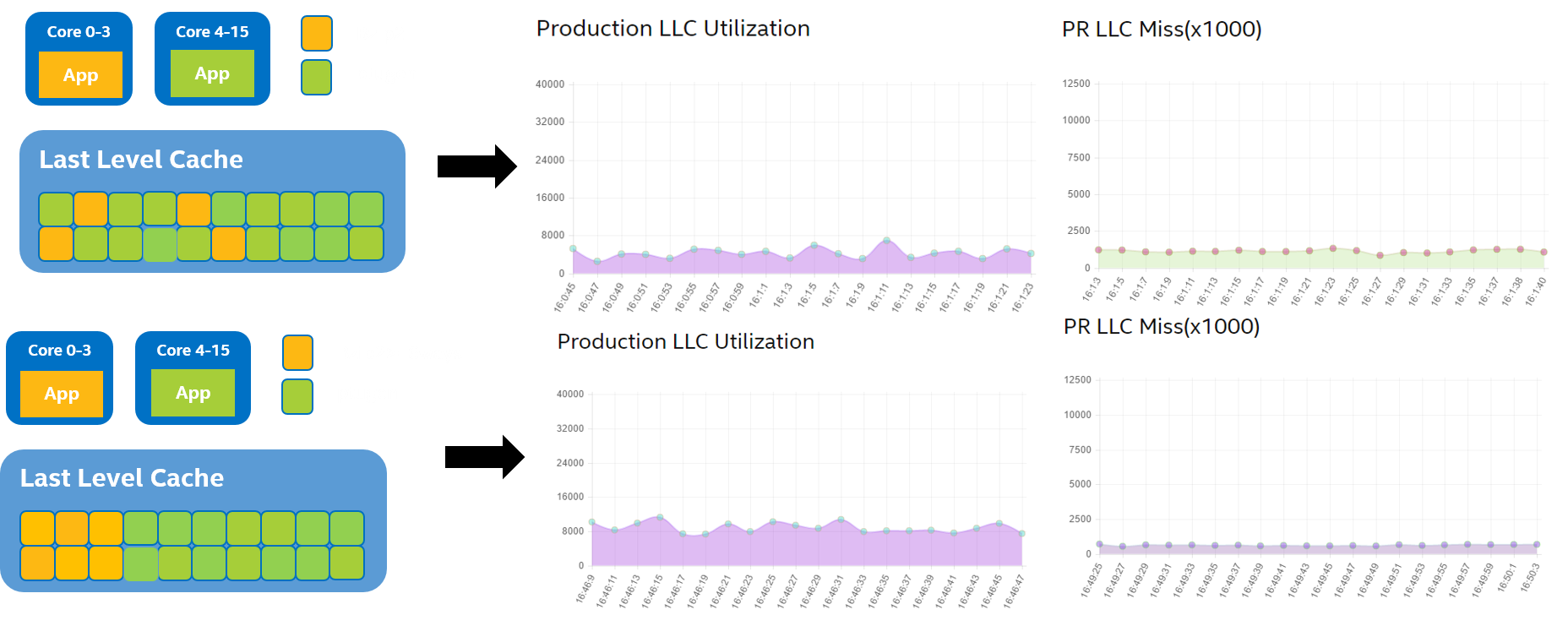
在安装了 Intel RDT-CAT 组件之后,编译之后获得主要的工具 PQOS, 可以使用 PQOS 进行配置 CAT,那么接下来本节用于介绍 CAT-PQOS 使用:
pqos -e "llc:1=0x000f;llc:2=0x0ff0;"设置 COS1 到前 4 个 CACHE ways,设置 COS2 到接下去 8 个 CACHE ways.
pqos -e "llc:1=0x000f;llc@0,1:2=0x0ff0;llc@2-3:3=0x3c"设置 COS1 到所有 SOCKETS,COS2 到 SOCKET0 和 SOCKET1,COS3 到 SOCKET 2 和 SOCKET3.
pqos -a "llc:1=0,2,6-10;llc:2=1;"设置 CORE0,2,6,10 到 COS1, CORE2 到 COS 2.
pqos -R l3cdp-on
pqos -R l3cdp-off使用/禁用 L3 CDP
pqos -e "llc:1d=0xfff;llc:1c=0xfff00;"使用 L3CDP 设置,设置 COS1 代码和数据位. CAT 完整使用案例,宿主机运行 3 个虚拟机,每个虚拟机分配 3 个 CORE 和不同优先级如下, VM0 有最高优先级分配独立的 8 个LLC way. VM1 分配 6 个,VM2 分配 4 个,其中 VM1 和 VM2 共享 2 个 way.
- VM0 - COREs 0-2 (P5)
- VM1 - COREs 3-5 (P2)
- VM2 - COREs 6-8 (P1)
pqos -e "llc:1=0x00ff;llc:2=0x3f00;llc:3=0xf000;"首先设置 3 个 CLOS 掩码位, COS1 到前 8 个 CACHE way,COS2 和 COS3 共享 12-13 2 个 CACHE Way,COS2 独占 8-11 4 个 CACHE way; COS3 独占 14-15 2 个 CACHE Way.
pqos -a "llc:1=0-2;llc:2=3-5;llc:3=6-8;"然后将 CLOS 关联到 VM 运行的 COREs 上,VM0 运行在 0-2 CPU 上,那么将 CLOS1 与 CPU 0-2 绑定,然后将 CLOS2 与 CPU 3-5 绑定,最后将 CLOS3 与 CPU 6-8 绑定,支持 CAT 已经为 VM0、VM1 和 VM2 分配好了 LLC CACHE.

Intel® DDIO Technology
随着大数据和云计算的爆炸式增长,宽带的普及以及个人终端网络数据的日益提高,对电信服务节点和数据中心的数据交换能力和网络带宽提出了更高的要求。数据中心本身对虚拟化功能的需求也增加了更多的网络带宽需求。电信服务节点和数据中心为了应付这种需求,需要对内部的各种服务器资源进行升级。在这种环境下,Intel 提出了 Intel® DDIO(Data Direct I/O) 的技术, 该技术的主要目的就是让服务器能更快处理网络接口的数据,提高系统整体的吞吐率,降低延迟,同时减少能源的消耗。
网卡发送数据
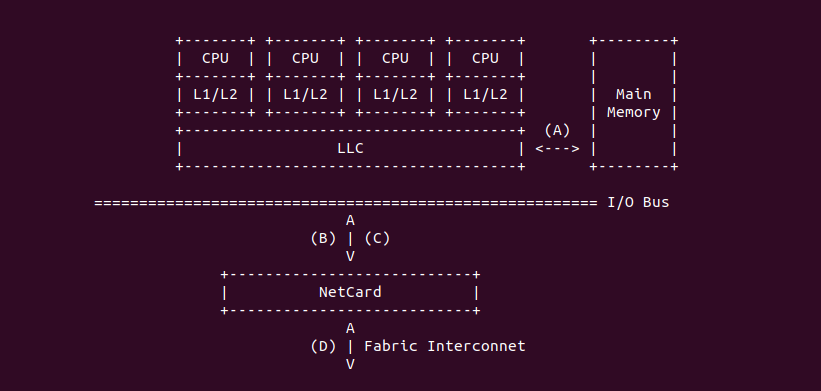
在没有 DDIO 技术下,为了将一个数据报文发送到网络上,那么需要经过如下步骤:
- A: CPU 软件上分配一段内存,然后将其从内存读取到 CPU 内存,更新数据并填充相应的报文描述符,然后写回到内存中
- B: CPU 通知网卡有新的数据需要发送
- C: 网卡收到通知之后从内存指定位置将内容 DMA 到网卡内部
- D: 网卡最后将数据发送到网络上.
上述即为一个简单的网卡发包过程,由于报文和控制结构体位于内存,CPU 对其进行更新时会触发以此 CACHE Miss,然后将数据读取到 CACHE 中,然后才能更新报文和控制结构体,之后通过 NIC 来读取报文. NIC 收到报文传递到网络的通知之后,NIC 首先要读取控制结构体进而知道报文在内存的位置,由于 CPU 刚访问过报文和控制结构体,因此还缓存在 CACHE 里并且做了更新,很有可能 CACHE 还没有来得及将更新的数据写入到内存中。因此当 NIC 发起一个对内存的读请求时,很有可能这个请求发送到 CACHE 系统中(因为在 Intel 架构,外设具有 Snoop 能力), CACHE 系统会把数据写回到内存,然后内存控制器把数据写到 PCIe 总线上,因此发生了多次内存的读写.
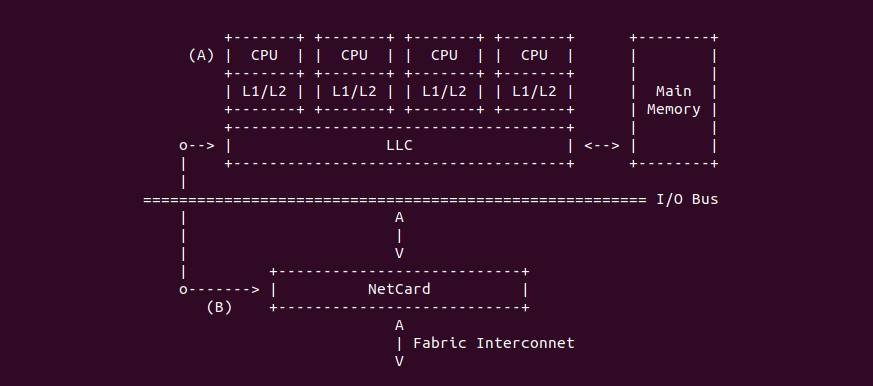
当采用 Intel DDIO 技术之后,处理器更新报文和控制结构体依旧和之前一样,但由于 DDIO 的引入,CPU 一开始就把内存中的数据缓存到 CACHE 中,因此减少了内存读取时间. NIC 收到有报文需要传递到网络的通知之后,通过 PCIe 总线把控制结构体和报文发送 NIC 内部,利用 DDIO 技术,I/O 访问可以直接将 CACHE 的内容送到 PCIe 总线上,这样减少了 CACHE 写回时等待的时间. 由此可见,由于 DDIO 技术的引入,网卡的读操作减少访问内存的次数,因此提高了访问效率,减少了报文转发的延迟。在理想状况下,NIC 和 CPU 无需内存访问,直接通过访问 CACHE 就可以完成更新数据,把数据发送到 NIC 内部,进而发送到网络上的所有操作.
网卡接受数据
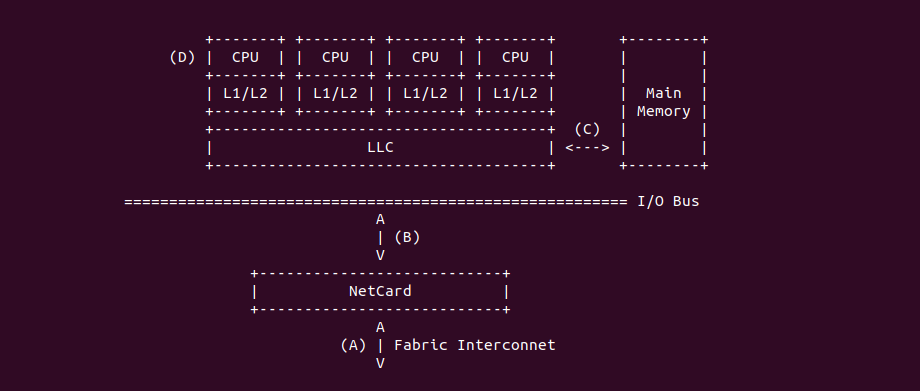
在没有 DDIO 技术下,从网络上接受一个报文,需要经过如下步骤:
- A: CPU 预先分配一段内存
- B: NIC 从网络上收到报文,通过 PCIe 总线 DMA 把报文和控制结构体送到原先分配的内存
- C: NIC 通知驱动或者软件进行处理
- D: CPU 收到通知之后到预先分配的内存读取数据进行处理
上述即为一个简单的网卡收包过程,报文和控制结构体通过 PCIe 总线 DMA 搬运到内存中,如果该内存恰好缓存在 CACHE 中,则需要等待 CACHE 把内容写回到内存中,然后才能把报文和控制结构体 DMA 到内存中. CPU 收到 NIC 的新报文通知之后,CPU 去内存读取控制结构体和相应的报文,CACHE 一定 Miss. 之所以 CACHE 一定 Miss ,是因为确保最新的数据一定来自内存. 通过上面的分析收报文发生多次内存访问和 CACHE Miss.
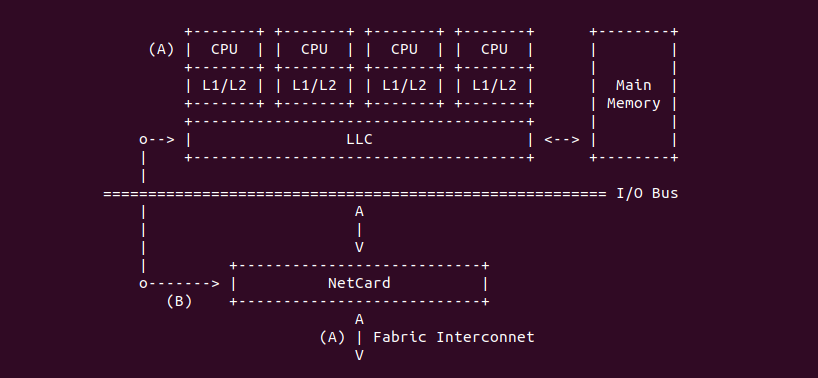
当采用 Intel DDIO 技术之后,NIC 收到报文和控制结构体之后,直接将报文和控制结构体通过 PCIe 总线直接 DMA 搬运到 CACHE 中。同理 CPU 也会提前分配一段内存用于接受这些数据,如果 CACHE 里正好缓存了这段内存,那么 DDIO 直接更新 CACHE 里面的内容; 如果 CPU 没有缓存这段内存,那么 DDIO 直接从 LLC CACHE 中分配一块区域,将数据搬运到这段 CACHE 里. DDIO 搬运完毕之后通知 CPU,CPU 发起对预先分配的内存进行访问,由于此时数据都在 CACHE 里,那么 CPU 直接从 CACHE 中获取数据。由此可以看,DDIO 技术在 CPU 和外设交换数据时,减少了 CPU 对内存的访问次数,也减少了 CACHE 回写的等待,提高了系统的吞吐率和数据的交换延迟.
总结: DDIO 技术使外部网卡和 CPU 通过 LLC CACHE 直接交换数据,减少了内存相应慢速的部件,这样就增加了 CPU 处理网络报文的速度,减少网络报文在服务器端处理延迟。但也会带来一些问题,例如因为网络报文直接存储在 LLC CACHE 中,因此需要大容量的 CACHE,另外 DDIO 是硬件上分配 LLC CACHE 的,可能会与软件 RDT(CAT) 分配 LLC CACHE 冲突,导致性能降低问题等. 但 DDIO 带来的益处显而易见的,因此开发者可以根据实际场景而定,至此 DDIO 技术研究完毕.

Intel® CHA Architecture
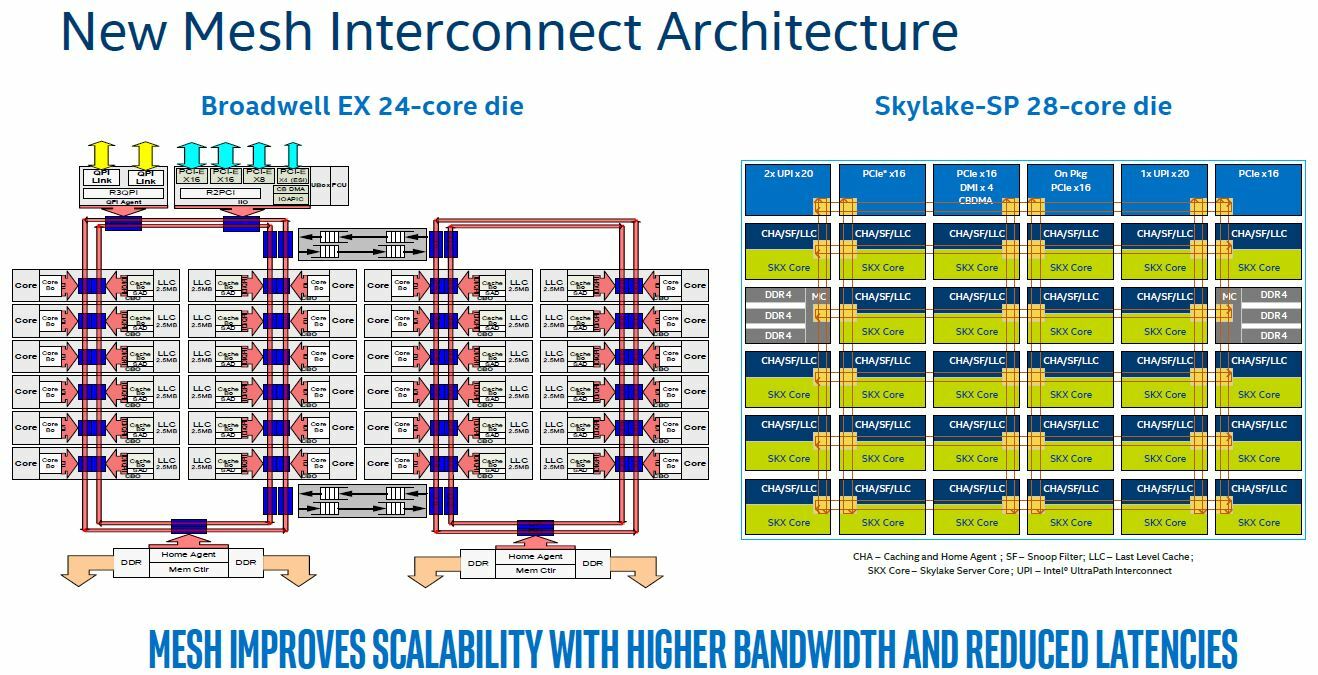
在 Skylake 之前的 Xeon 处理器中,CPU、LLC 缓存、内存控制器、I/O 控制器和 Socket 直接互联的端口都是通过芯片上的环形架构进行连接,当 Socket 上的核心数增加时,这会带来延迟和带宽限制的缺点。为了解决这个问题,在 Skylake 采用了一种网状架构,包括一些列的垂直和水平路径,允许通过最短路径从一个核心通信到另外一个核心。此外每个核心和 LLC CACHE Chip 都有一个组合的缓存和代理 (CHA), 用于处理地址映射和信息路由,并在网格中提供资源的可伸缩性.
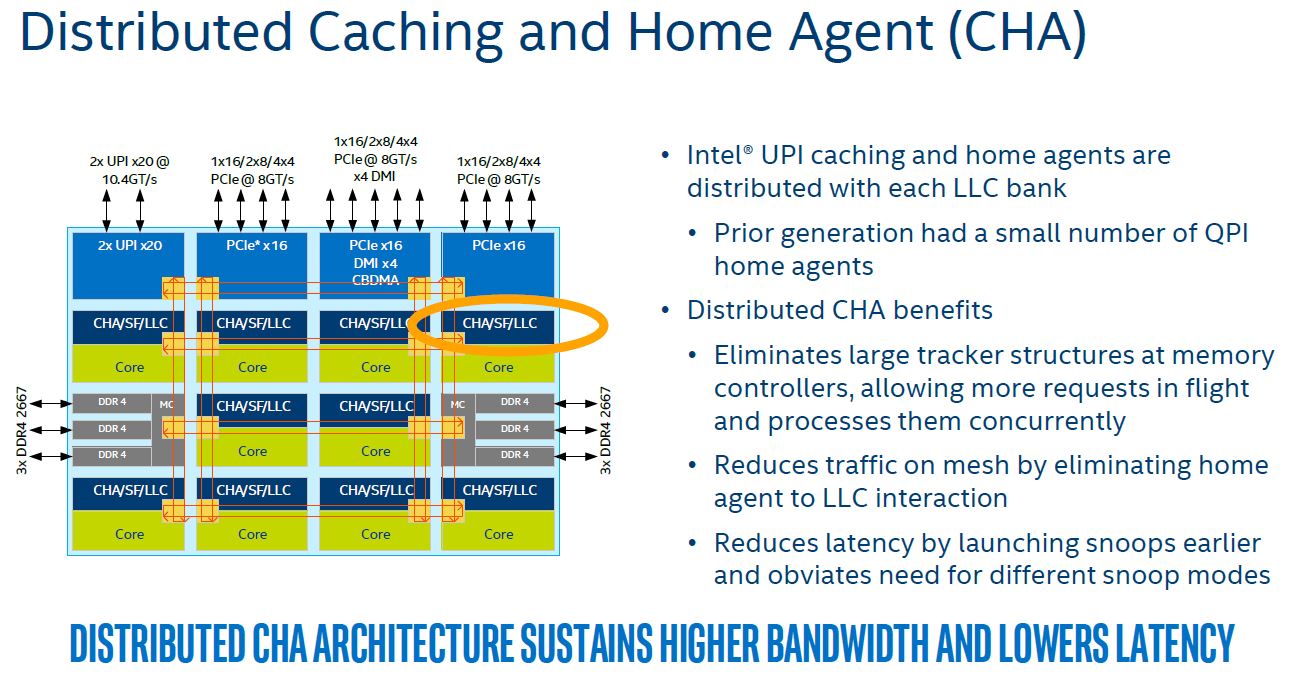
CHA: CA and Home Agent,CA 指的是 Coherent Agent. 在某些情况下,CA 被称为缓存代理,尽管实际上不需要 CA 具体缓存,它是提供网格接口到 LLC 和核心的内部逻辑单元。在 Skylake 架构中,CHA 是分布到每个 CORE 上的,CHA 的编号与 CORE 的编号相同. CHA 用于保存一些 CACHE 的 Meta 信息,管理 LLC 和 L2 CACHE.

Intel® Non-Temporal Hit Technology
在传统的数据拷贝流程里,需要 CPU 介入,那么会先将 CPU 把源端和目的端内存缓存到 CACHE 中,然经过 CPU 使用 MOV 指令进行数据搬运,由于搬运过程中 CPU 会依次访问源端和目的端,那么 CACHE 中被源端和目的端的内存数据填充,当 CPU 拷贝完毕之后,CPU 大概率不会直接访问目的端的内存,那么 CACHE 里会存在大量不需要近期使用的 CACHE Line。
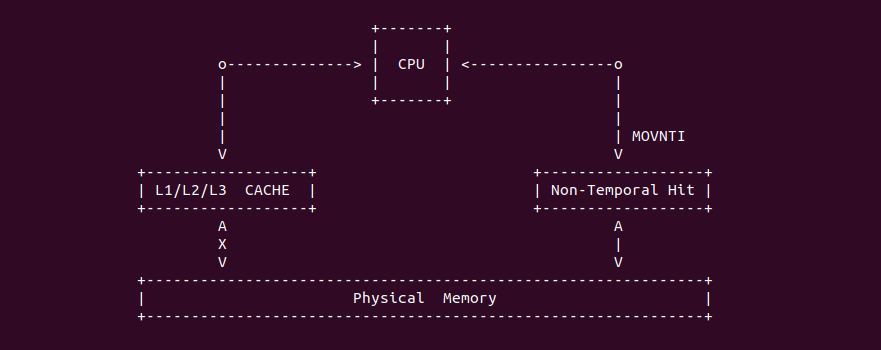
为了减少内存拷贝时 MOV 指令带来的 CACHE 污染,Intel 提供了 Non-Temporal Hit 硬件模块,该模块的特点是向系统提供 MOVNTI 指令,并在 CPU 搬运内存过程中尽可能少使用 CACHE,而是使用 Non-Temporal Hit 缓存数据,待搬运完毕之后由于内存里的数据是最新的,CACHE 里的数据可能不是最新的,因此需要软件刷新 CACHE. 更多内容可以参考:
Linux CACHE 机制
CACHE MODE on MMIO
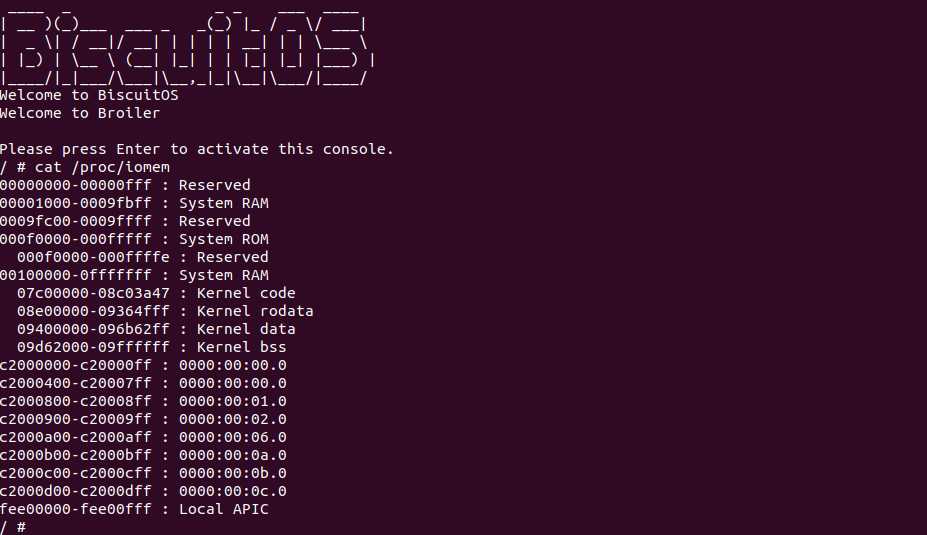
在 Linux 中物理地址地址空间主要由物理内存 RAM 和 MMIO 组成,其中 MMIO 是外设的 IO 映射到地址空间形成,可以通过 “/proc/iomem” 节点查看系统物理地址空间。在 X86 架构中,外设的 IO 既可以映射到物理地址空间,然后像普通内存一样进行访问,同样外设也可以将 IO 映射到 IO 空间,然后使用 IN/OUT 系列指令进行访问. 在 X86 IO 空间和物理地址空间是两个独立的空间, 外设可以根据自己的需求在硬件设计的时候规划 IO 映射到哪个空间. 例如 PCI/PCIe 设备可以将其 BAR 空间映射到 IO 空间形成 IO 端口,也可以映射到物理地址空间形成 MMIO. 如果从管理者角度将 MMIO 进行划分,那么可以分成两类: 系统管理的 MMIO 和设备管理的 MMIO(DEVMMIO). 系统管理的 MMIO 是由系统提供统一的接口,各模块子系统和用户进程都可以访问 MMIO; 设备管理的 MMIO(DEVMEM) 是由设备管理的 MMIO,需要通过指定的接口为特殊功能提供 MMIO.
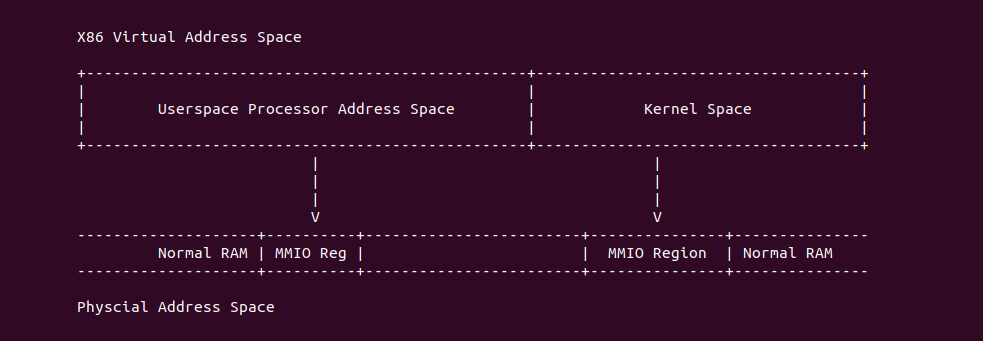
当外设 IO 以 MMIO 方式映射到物理地址空间,无论是系统管理的 MMIO 还是设备管理的 MMIO(DEVMMIO),用户进程或者内核线程需要访问 MMIO 时,需要将各自空间的虚拟地址通过页表映射到 MMIO 上,映射完毕之后可以通过访问虚拟地址进而访问 MMIO. 由于映射的存在,因此可以修改映射时的 CACHE Mode. 本节用于描述 MMIO 映射过程中如何设置 CACHE MODE:
内核空间 CACHE MODE 与系统管理的 MMIO
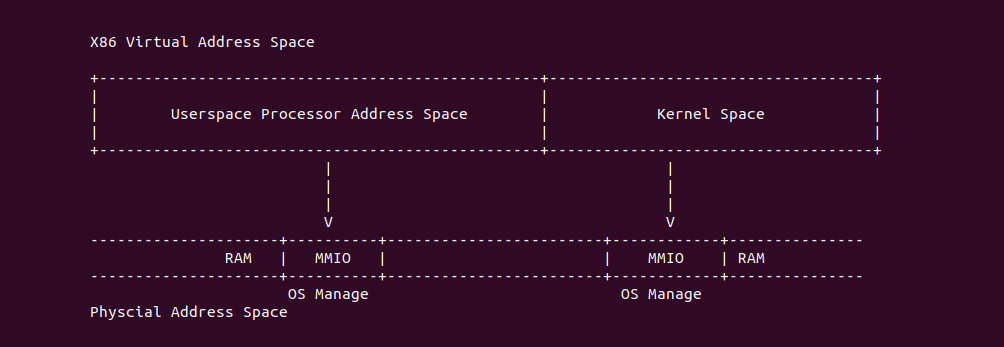
在 Linux 中,外设将其 IO 映射到系统物理地址空间之后形成了 MMIO,系统统一管理 MMIO,并在内核空间提供了统一的接口管理、分配、映射和回收 MMIO. 内核线程可以通过统一的接口分配到 MMIO,然后将内核空间虚拟地址映射到 MMIO,因此在映射过程中可以根据需求配置不同的 CACHE Mode,那么系统是如何实现 MMIO CACHE MODE 配置呢? 首先通过一个实践案例了解问题的背景,然后再进一步源码分析,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] IOREMAP: CACHE MODE with IOREMAP Mechanism --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-IOREMAP-default/
# 部署源码
make download
# 在 Broiler 中实践
make broiler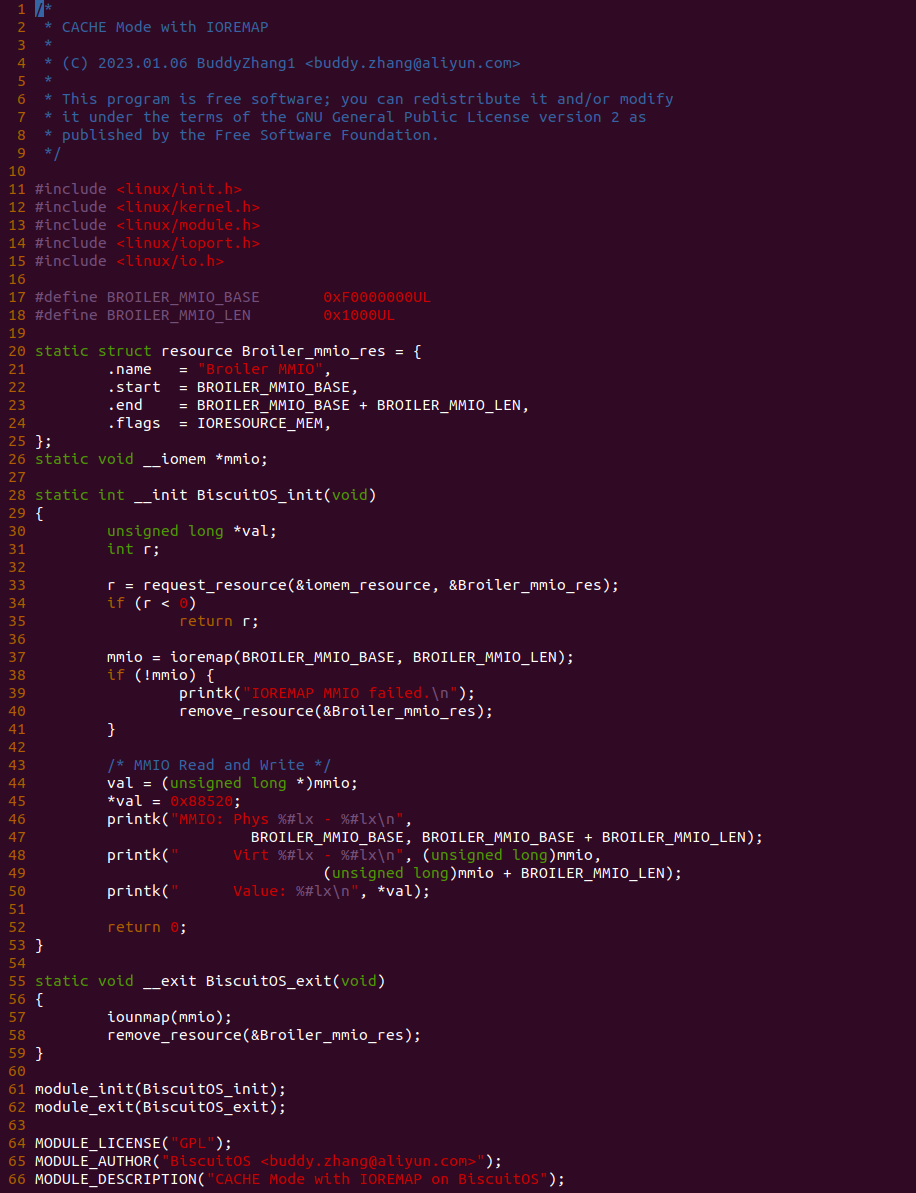
源码很精简,通过一个内核模块进行讲解,模块首先在 20-25 行描述了 MMIO 资源信息,然后在 33-35 行通过调用 request_resource() 函数将该 MMIO 资源注册到系统物理空间资源树,接着模块在 37 行调用 ioremap() 函数将 BROILER_MMIO_BASE 起始长度为 BROILER_MMIO_LEN 的 MMIO 区域映射到内核空间,并将映射之后的虚拟地址存储在 mmio 变量里,接下来就是在 43-50 行对 MMIO 进行访问。由于需要外设才能完成实践,因此可以使用 Broiler 进行实践,直接执行命令 “make broiler”,其在 Broiler 上的实践如下:
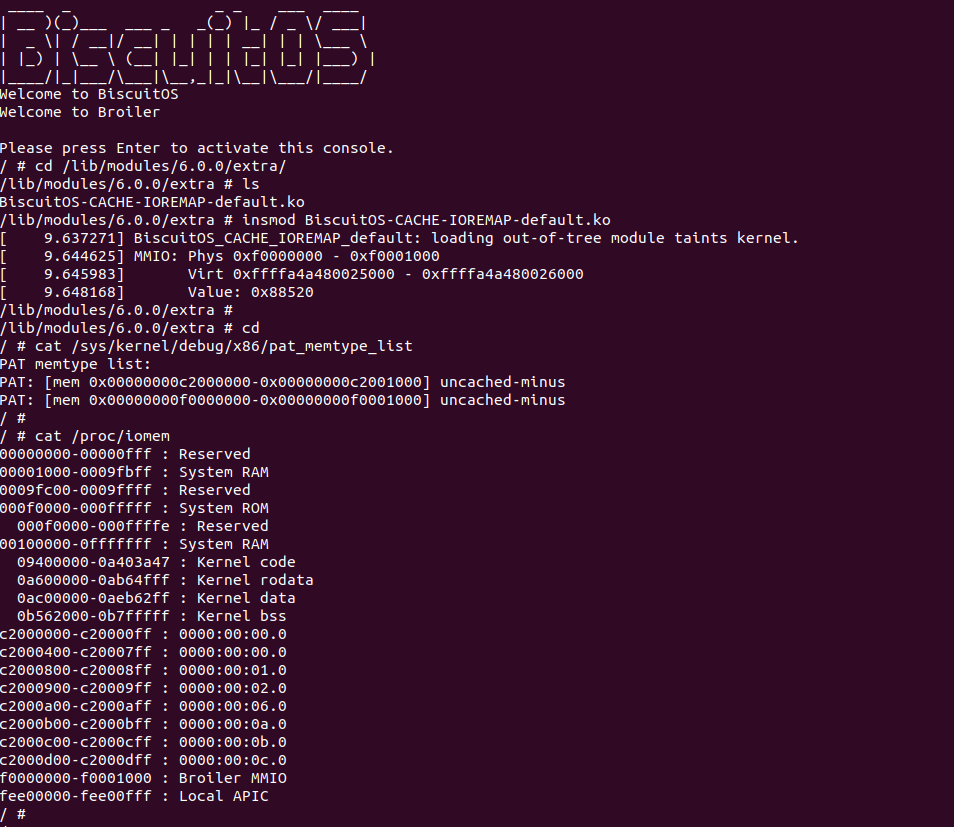
BiscuitOS 启动之后,加载 BiscuitOS-CACHE-IOREMAP-default.ko 模块,可以看到系统可以访问 MMIO,可以看到对应的虚拟地址和物理地址,并看到 MMIO 写入然后读出的值 0x88520. 接着查看 pat_memtype_list 节点,可以看到 [0xF0000000, 0xF0001000) 区域映射为 uncached-minus, 这里的 uncached-minus 指的是什么呢? 通过对前面的学习,可以知道这是映射 MMIO 采用的 Memory Type,也就是 CACHE Mode,此时映射 MMIO 采用了 UC 的模式,即映射时不采用任何 CACHE,CPU 直接对 MMIO 进行访问, 那么 MMIO 的 CACHE MODE 如何规划的?另外 IOREMAP 机制是否可以通过其他 CACHE MODE? 接下来本节进一步分析这些问题.
当内核空间将虚拟地址通过页表映射到 MMIO 区域,那么 CPU 可以通过访问虚拟地址就可以访问到 MMIO,与普通内存一样,依据映射的 Memory Type 不同,CPU 访问虚拟地址时不一定能访问到真实的 MMIO,因为 CPU 和物理地址空间之间还存在 CACHE。假设映射 MMIO 时 Memory Type 采用了 Writeback,当 CPU 向 MMIO 写操作时,所写的数据不是立即写入到 MMIO 的,而是写入到 CACHE 里,只有当 CPU 对 MMIO 发起读或者 CACHE Line 收到 Writeback 信号,那么 CACHE 中的数据才会被真正写到 MMIO 中,如果所写的数据一直在 CACHE 中,此时设备对 MMIO 中的数据进行读时,此时会出现 Device 看到的时旧数据,而最新的数据还在 CACHE 里,因此对应 MMIO 的映射需要选择正确的 Memory Type.
如果设备有 Snoop 总线的能力,即可以检测到 CPU 对内存发起的读写请求,那么当系统将内核空间虚拟地址映射 MMIO 的 Memory Type 设置为 Write Back 时,当 CPU 对 MMIO 进行写操作时,所写的数据会被缓存在 CACHE 里而不被写到 MMIO,此时如果设备需要读取 MMIO 中的值,由于其具有 snoop 能力,那么其可以知道 CACHE 中缓存了数据,此时向总线上发起 Write-back 和 Invalid 信息,那么设备就可以从 MMIO 中读取最新的值,另外由于 Invalid 信息,当 CPU 再次读对应的数据时,其会从 MMIO 中加载最新的数据.
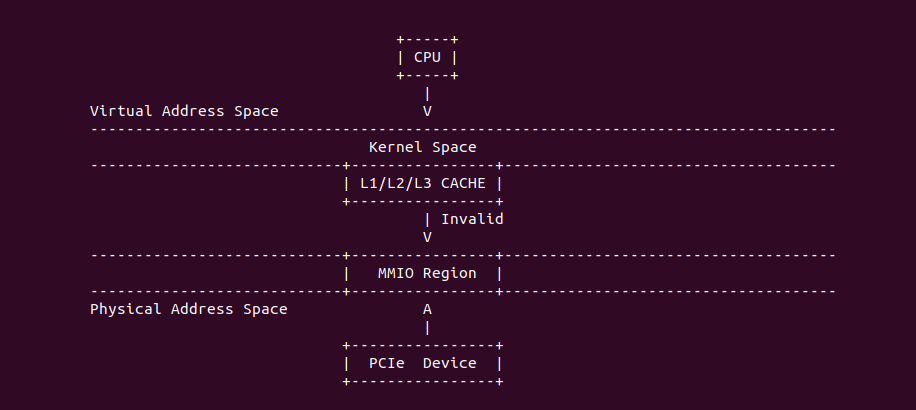
如果设备没有 Snoop 总线的能力,那么设备无法感知 CPU 什么时候访问了 MMIO,但此时可以将内核空间虚拟地址映射 MMIO 的 Memory Type 设置为 Write-Through, 那么 CPU 对 MMIO 发起写操作的时候,所写的数据缓存在 CACHE 的同时也会被写如到 MMIO 里,那么设备一定可以读取到 MMIO 最新值,但会存在一个问题,当设备更新了 MMIO 的数据,之后 CPU 发起 MMIO 读请求时,由于 CACHE Line 中存有数据并 CACHE hit,CPU 并不会到 MMIO 上读取真正的数据,因此造成数据差异。但在有的场景可以采用 Write-through Memory Type,CPU 进行大量的写操作,读请求的概率特别小,当读之前可以先 Invalid CACHE Line,以此获得最新的数据.
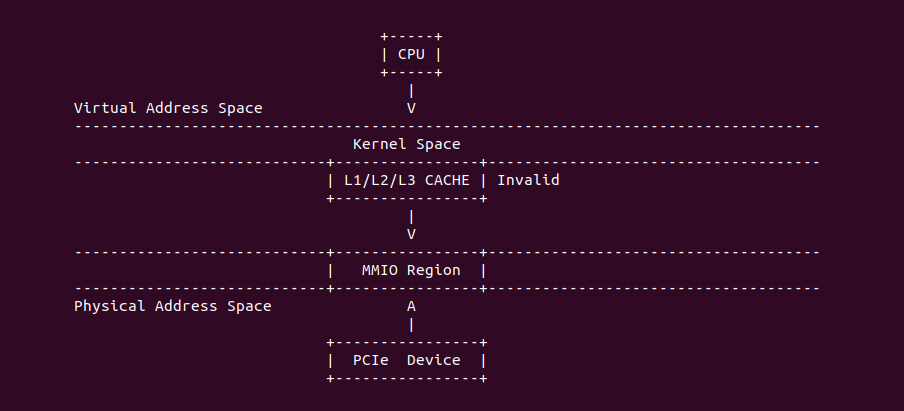
如果设备没有 Snoop 总线的能力,那么设备无法感知 CPU 什么时候访问了 MMIO,那么最好的方案就是将内核空间虚拟地址映射 MMIO 的 Memory Type 设置为 Uncached 或者 Strong Uncached,那么 CPU 访问 MMIO 不会被 CACHE 缓存,CPU 直接写数据到 MMIO 和直接从 MMIO 读数据,那么外设看到的 MMIO 数据与 CPU 看到的一致.
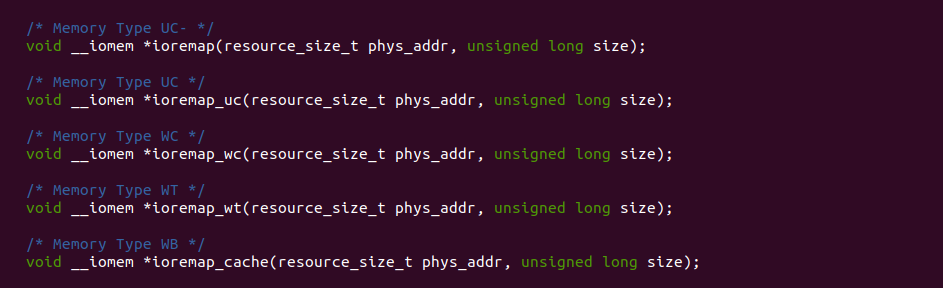
通过上面的分析,内核空间虚拟地址映射 MMIO 的 Memory Type 可以根据场景不同选择 WB、WC、WT 和 UC/UC-, IOREMAP 机制作为映射 MMIO 的通用接口,其也提供多种满足不同的 Memory Type 的接口,例如映射 WB 类型 MMIO 的 ioremap_cache() 函数, 整理了 IOREMAP 机制映射不同 Memory Type 的实践案例,具体见:
IOREMAP 映射过程
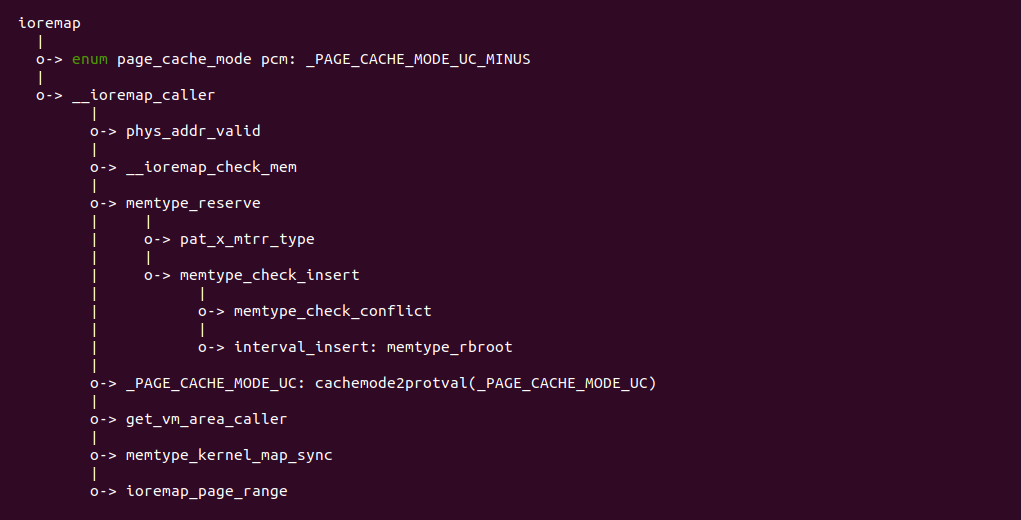
ioremap() 函数的主题流程如上图,其他类似函数的流程差异在于 enum page_cache_mode 的选择,例如选择映射 WB 的 MMIO,那么这里会选择 _PAGE_CACHE_MODE_WB. 接下来的逻辑都是一致的,IOREMAP 机制会通过调用 memtype_reserve() 函数将 MMIO 区域的 Memory Type 维护在一颗区间树里面,通过函数 pat_x_mtrr_type() 或者有效的 Memory Type,然后调用 memtype_check_insert() 函数检查是否与其他 MMIO 区域重叠,如果重叠,那么采用重叠的 Memory Type,最后将 MMIO 区域插入到区间树 memtype_rbroot。IOREMAP 机制根据 Memory Type 选择不同的 PAT 页表属性,并调用 get_vm_area_caller() 从 VMALLOC 区域中获得一段可用的虚拟内存,接下来调用 memtype_kernel_map_sync() 函数同步 Memory Type,但对 MMIO 不进行同步,最后调用 ioremap_page_range() 函数建立虚拟地址到 MMIO 的映射,并采用指定的 Memory Type. 接下来通过一个案例讲解 IOREMAP 如何修改 Memory Type,其在 BiscuitOS 中的部署如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] IOREMAP: Change CACHE Mode with IOREMAP Mechanism --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-IOREMAP-CHANGE-MEMTYPE-default/
# 部署源码
make download
# 在 Broiler 中实践
make broilerBiscuitOS-CACHE-IOREMAP-CHANGE-MEMTYPE-default Source Code on Gitee
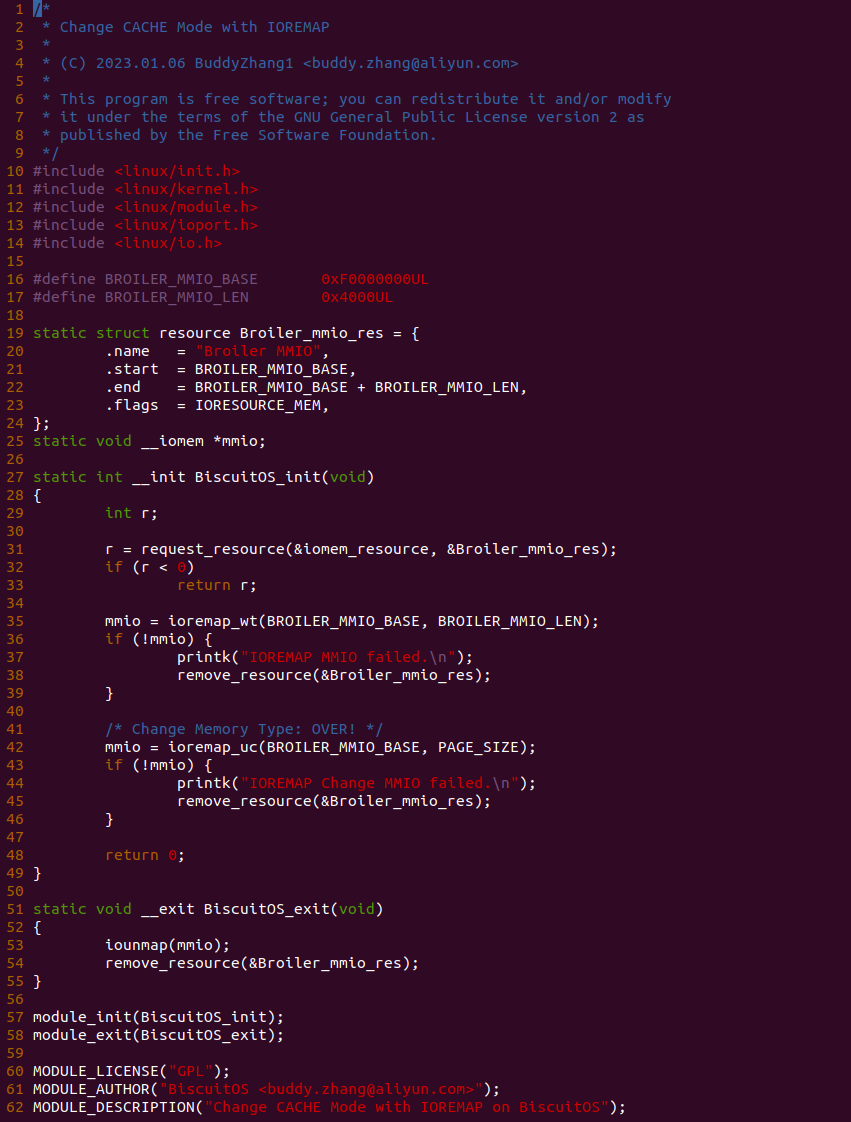
源码很精简,通过一个内核模块进行讲解,模块首先在 20-25 行描述了 MMIO 资源信息,然后在 33-35 行通过调用 request_resource() 函数将该 MMIO 资源注册到系统物理空间资源树,接着模块在 35 行调用 ioremap_wt() 函数将 BROILER_MMIO_BASE 起始长度为 BROILER_MMIO_LEN 的 MMIO 区域映射到内核空间,并且 Memory Type 为 WT,并将映射之后的虚拟地址存储在 mmio 变量里,接下来就是在 42 行调用 ioremap_uc() 函数改变 MMIO Memory Type 为 UC。由于需要外设才能完成实践,因此可以使用 Broiler 进行实践,直接执行命令 “make broiler”,其在 Broiler 上的实践如下:
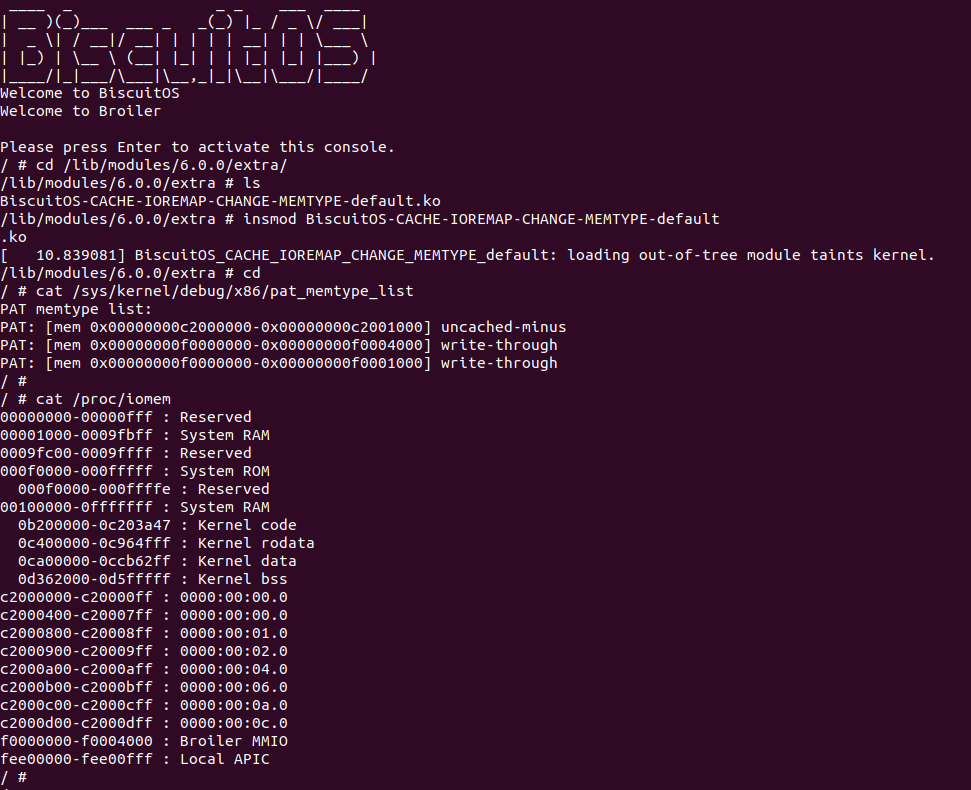
当 BiscuitOS 运行之后,加载 BiscuitOS-CACHE-IOREMAP-CHANGE-MEMTYPE-default.ko 模块,接下来查看 pat_memtype_list 节点,以此查看系统 MMIO 区域采用的 Memory Type,此时看到 [0xF0000000, 0xF0004000) 区域 Memory Type 为 write-through, 但 [0xF0000000, 0xF0001000) 区域 Memory Type 为 write-through, 此时 IOREMAP 并没有修改 Memory Type 成功,从另外一个层面思考,如果一个物理地址被多个虚拟地址映射,如果每个都映射不同的 Memory Type,这样会引起混乱,因此 IOREMAP 在这种场景下的做法如下:
IOREMAP 在 85 行调用 interval_iter_first() 函数在 memtype_rbroot 区间树内查找包含 [start, end) 的区间,当找到之后获取该区间的 Memory Type,该场景下新的 Memory Type 和当前 Memory Type 不相等,且新的 Memory Type 不为空,那么 IOREMAP 的做法是将新修改 MMIO 区域的 Memory Type 覆盖成当前 Memory Type,以此保证不同虚拟地址映射同一个 MMIO 时 Memory Type 是一致的. IOREMAP 在 95 行调用 interval_iter_next() 函数将新增加的区域插入到区间树内. 最后就看到实践过程中看到的新增的区域为独立区域,但 Memory Type 与当前一致.
在 __ioremap_caller() 函数主体逻辑里,IOREMAP 机制根据 CACHE MODE 为映射构造不同的页表属性,CACHE MODE 通过 cachemode2protval() 函数转换成页表对应的 PAT 属性集,最终拼接成映射所需的页表属性集. 另外可以看出 IOREMAP 机制只支持 WT、WC、WB、UC 和 UC-,默认 CACHE MODE 为 UC.

当 IOREMAP 机制解除虚拟地址对 MMIO 的映射时,需要将映射 Memory Type 一同解除,其代码流程如上图,IOREMAP 首先调用 find_vma_area() 函数找到对应的 vm_struct 数据结构,然后获得对应的物理地址,接下来通过调用 memtype_free() 函数移除 MMIO 区域的 Memory Type,最后调用 remove_vm_area() 函数是否虚拟内存.
用户空间 CACHE MODE 与系统管理的 MMIO
在 Linux 中,外设将其 IO 映射到系统物理地址空间之后形成了 MMIO,系统统一管理 MMIO,并在内核空间提供了统一的接口管理、分配、映射和回收 MMIO. 用户进程可以通过统一的接口分配到 MMIO,然后将用户空间虚拟地址映射到 MMIO,因此在映射过程中可以根据需求配置不同的 CACHE Mode,那么系统是如何实现 MMIO CACHE MODE 配置呢? 首先通过一个实践案例了解问题的背景,然后再进一步源码分析,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] MMIO: CACHE MODE with MMIO (Recommend) --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-MMIO-default/
# 部署源码
make download
# 在 Broiler 中实践
make broiler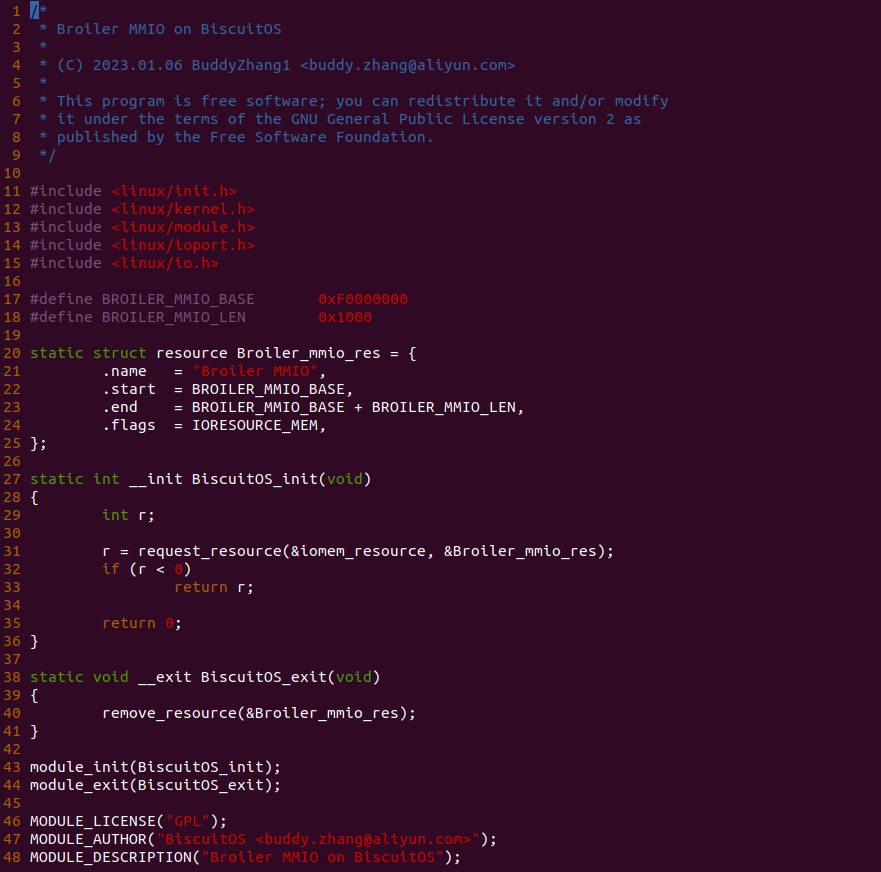
实践案例由两部分组成,内核部分如上图,主要目的是向系统物理地址总线树注册 MMIO 信息,模块在 20-25 行通过 struct resource 数据结构描述了 MMIO 的信息,接着在 31 行调用 request_resource() 函数注册到 iomem_resource 资源树. 如果 Linux 启动默认已经将 MMIO 资源注册到系统,那么不需要额外使用模块进行注册.
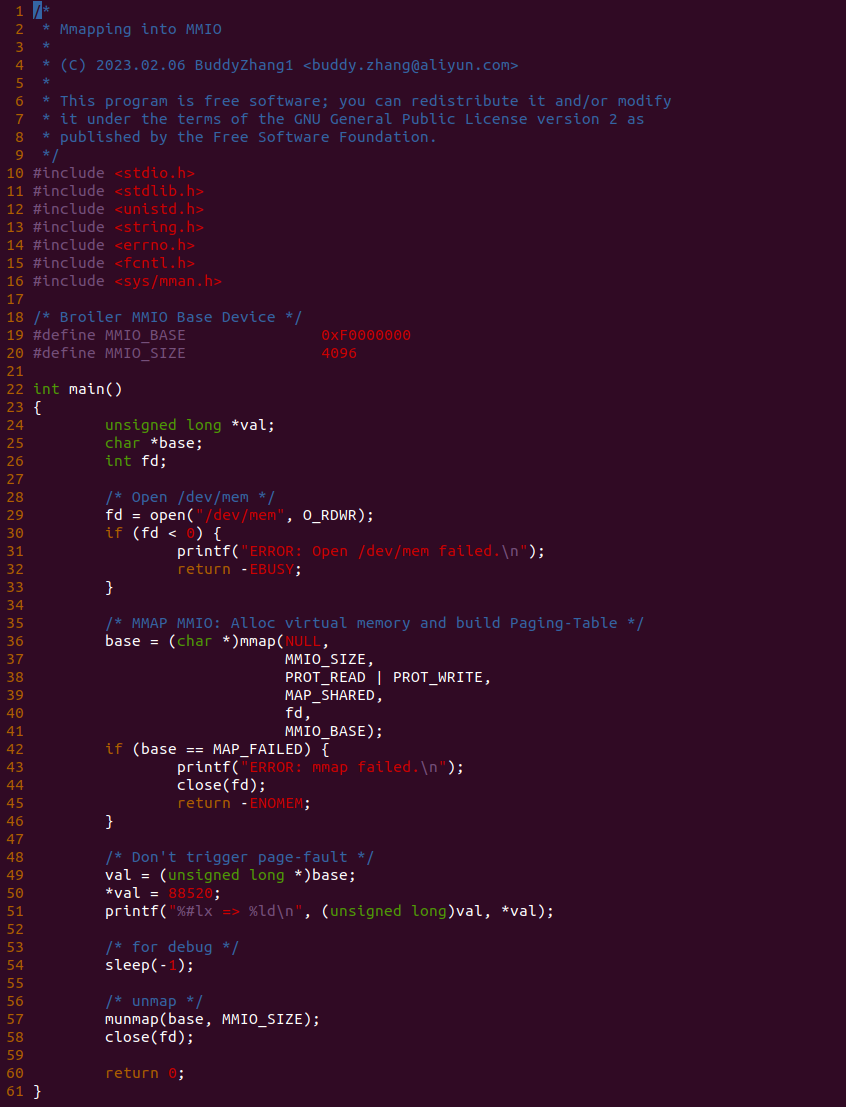
实践案例的核心有一个应用程序组成,程序实现如上图. 在 29 行函数调用 open() 函数打开 ‘/dev/mem’ 节点,然后在 36-46 行调用 mmap() 函数将 MMIO 区域映射到进程的地址空间,可以看到 mmap() 函数的最后一个参数是 MMIO_BASE, 即映射物理地址的起始地址. 接下来就是对映射之后的 MMIO 进行访问,最后就是解除映射以及关闭 ‘/dev/mem’ 节点. 由于需要硬件支撑才能完成实践,因此可以在 Broiler 上进行实践,直接运行 ‘make broiler’ 命令即可:
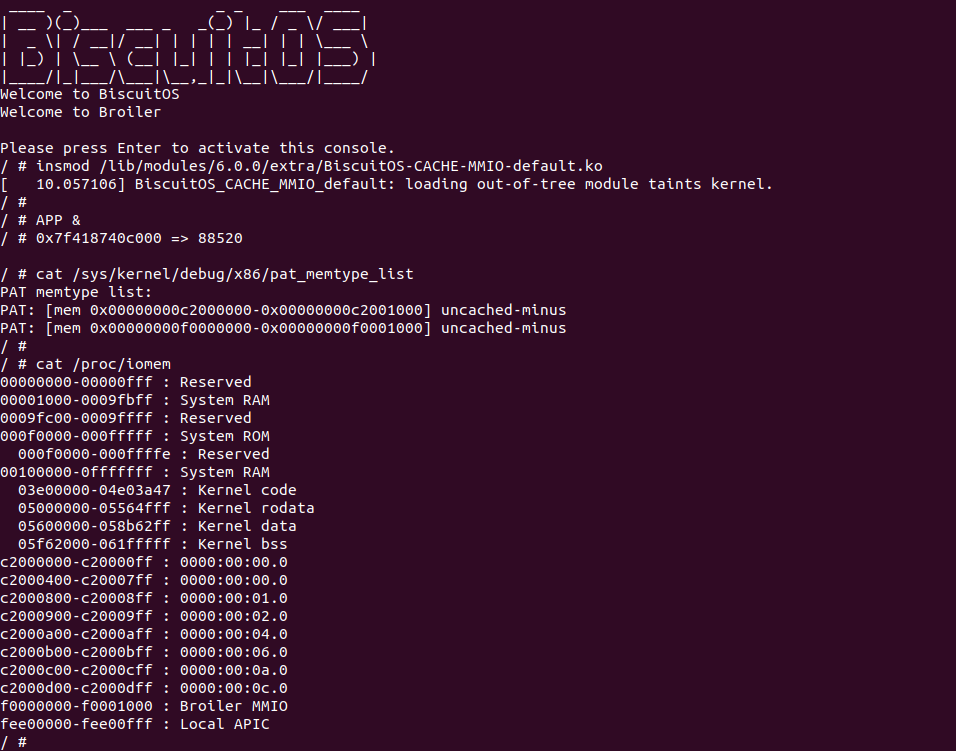
当 BiscuitOS 运行之后,加载 BiscuitOS-CACHE-MMIO-default.ko 模块,接下来查看 pat_memtype_list 节点,以此查看系统 MMIO 区域采用的 Memory Type,此时看到 [0xF0000000, 0xF0001000) 区域 Memory Type 为 uncached-minus, 实践符合预期,那么接下来分析整个流程如何将映射 的 CACHE MODE 设置为 uncached-minus.
当应用程序打开 ‘/dev/mem’ 节点之后,其最终调用到 ‘drivers/char/mem.c’ 文件的 open_mem() 函数,函数主要将 f_mapping 设置为 iomem_get_mapping. 应用程序调用 mmap() 函数,其最终会调用到该文件的 mmap_mem() 函数,该函数首先设置页表属性,这里调用了 pgprot_noncached() 函数设置了 UC- 的页表属性,接着通过 remap_pfn_range() 函数进行页表的建立,建立过程中也会调用 track_pfn_remap() 函数检查 MMIO 的 CACHE MODE 是否冲突,如果冲突则沿用当前的 CACHE MODE.
用户空间 CACHE MODE 与设备管理的 MMIO(DEVMEM)
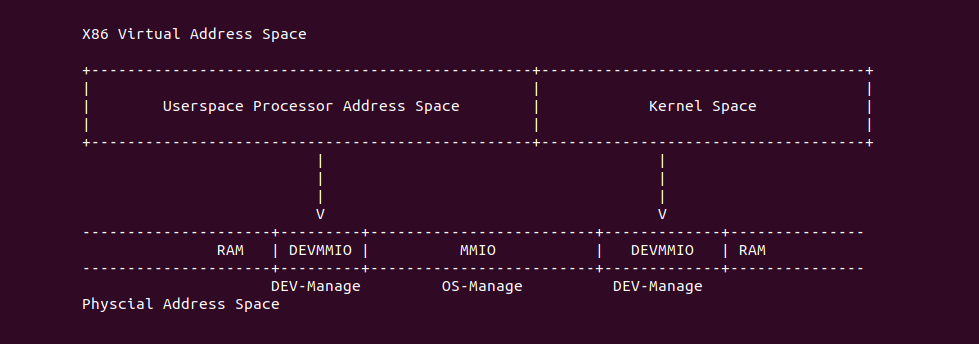
从管理角度 MMIO 可以分为系统管理的 MMIO 和设备管理的 MMIO(DEVMEM), 本节讲解设备管理的 MMIO(DEVMEM), 用户进程或内核线程想访问设备管理的 MMIO,那么同样需要将其虚拟地址映射到 MMIO 上,此时可以在页表中配置所需的 CACHE Mode,接下来先通过一个实践案例了解整个映射过程,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] MMIO: CACHE MODE with DEVMMIO (Recommend) --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-DEVMMIO-default/
# 部署源码
make download
# 在 Broiler 中实践
make broiler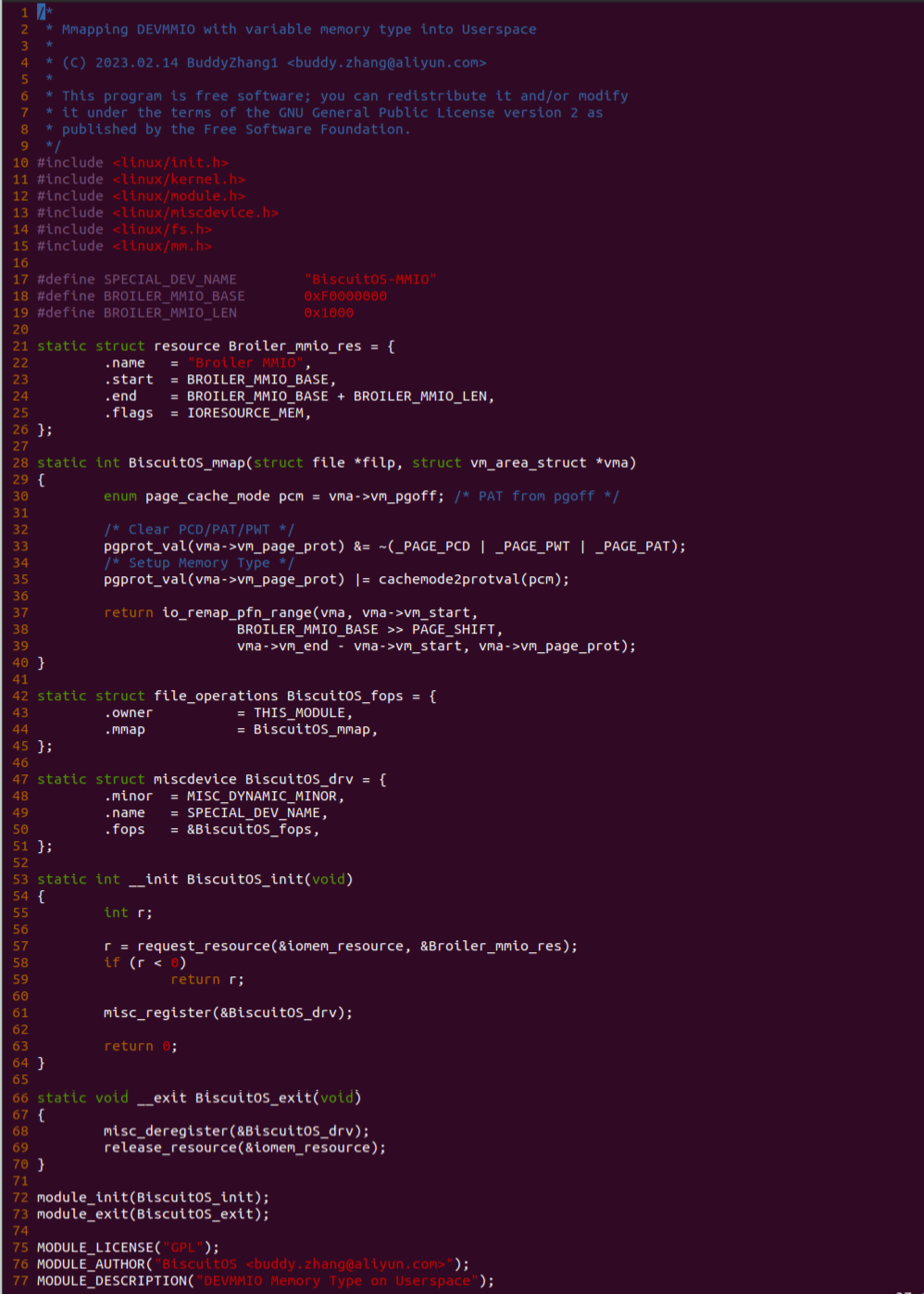
实践案例由两部分组成,内核部分如上图,模块在 21-26 行通过 struct resource 数据结构描述了 MMIO 信息,然后通过一个 MISC 框架向用户空间提供 “/dev/BiscuitOS-MMIO” 接口,框架仅实现了 mmap 接口,因此当用户进程调用 mmap() 函数之后会调用到 BiscuitOS_mmap() 函数。在 BiscuitOS_mmap() 函数里首先在 33 行将页表的 PAT 属性清除,然后将 vma 的 vm_pgoff 中存储的 enum page_cache_mode 信息,通过 cachemode2protval() 函数转换成页表的 PAT 属性集,并与 vma 的 vm_page_prot 合并成最终的页表属性集,函数最终调用 io_remap_pfn_range() 函数建立最终的页表.
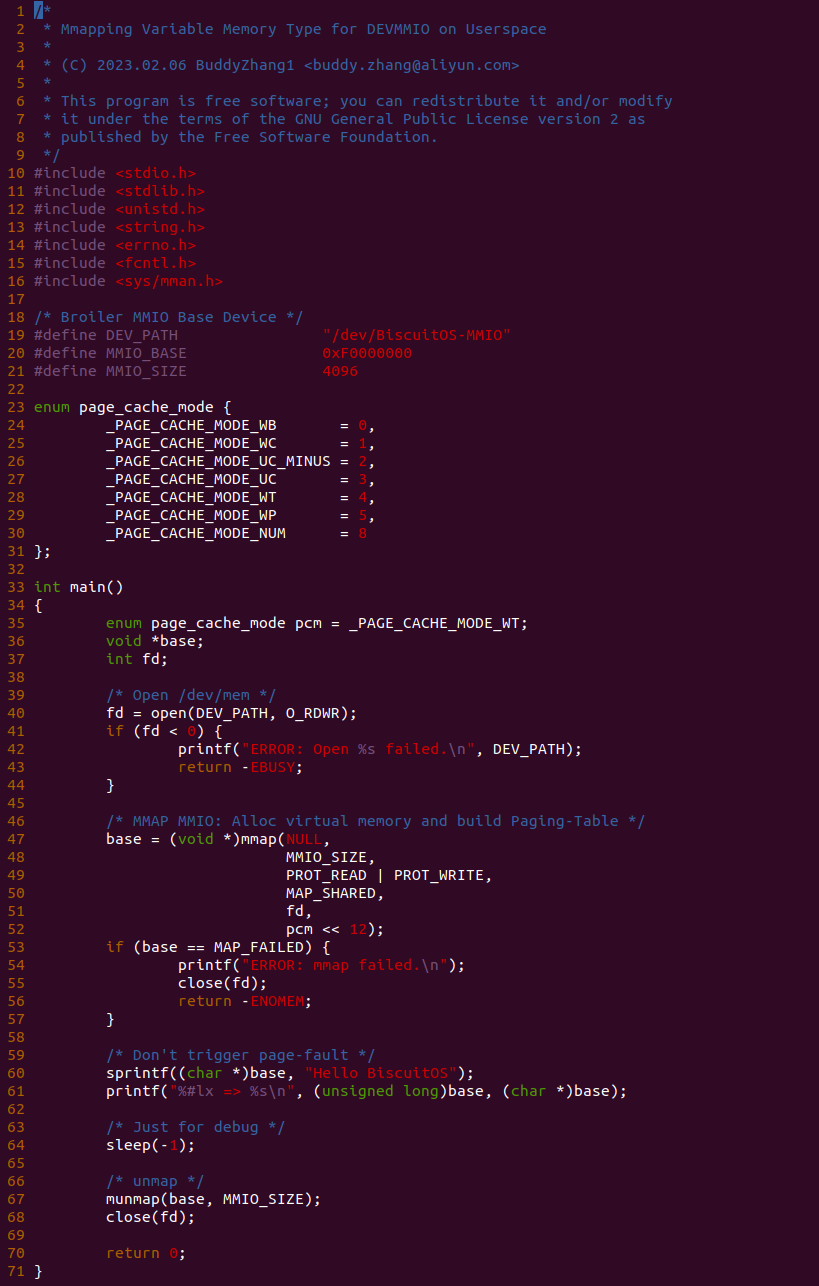
实践案例的另外一部分由应用程序组成,程序实现如上图. 程序首先在 23-31 行定义了多种 CACHE MODE,并在 35 行将 CACHE MODE 设置为 WT,接着在 40 行函数调用 open() 函数打开 ‘/dev/BiscuitOS-MMIO’ 节点,然后在 47-57 行调用 mmap() 函数将 MMIO 区域映射到进程的地址空间,可以看到 mmap() 函数的最后一个参数是 ‘pcm « 12’, 即将 CACHE MODE 传入到设备. 接下来就是对映射之后的 MMIO 进行访问,最后就是解除映射以及关闭 ‘/dev/BiscuitOS-MMIO’ 节点. 由于需要硬件支撑才能完成实践,因此可以在 Broiler 上进行实践,直接运行 ‘make broiler’ 命令即可:
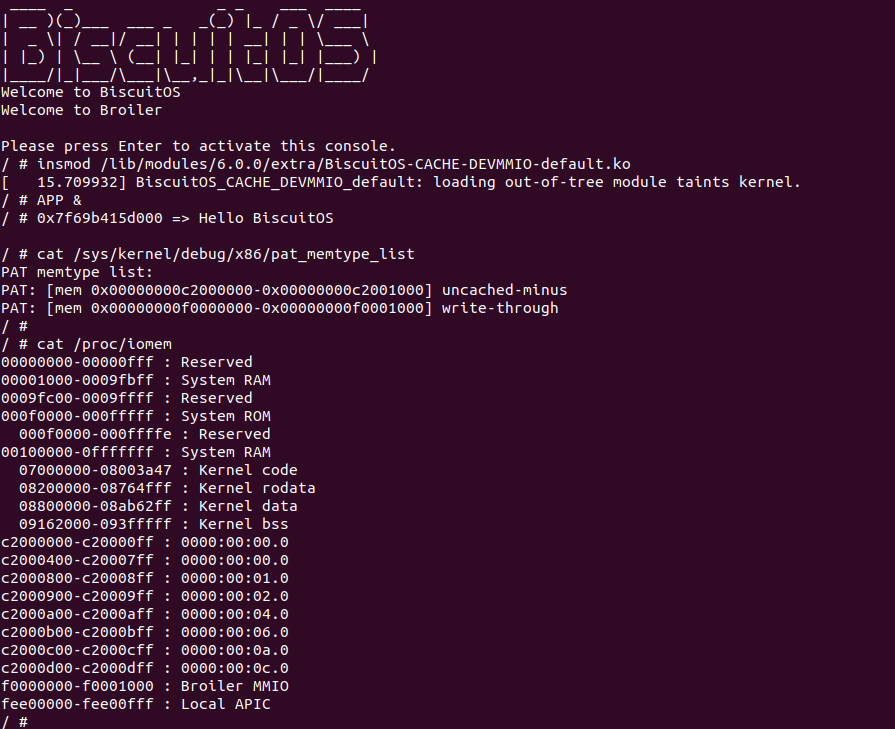
当 BiscuitOS 运行之后,加载 BiscuitOS-CACHE-DEVMMIO-default.ko 模块,接下来查看 pat_memtype_list 节点,以此查看系统 MMIO 区域采用的 Memory Type,此时看到 [0xF0000000, 0xF0001000) 区域 Memory Type 为 write-through, 实践符合预期.
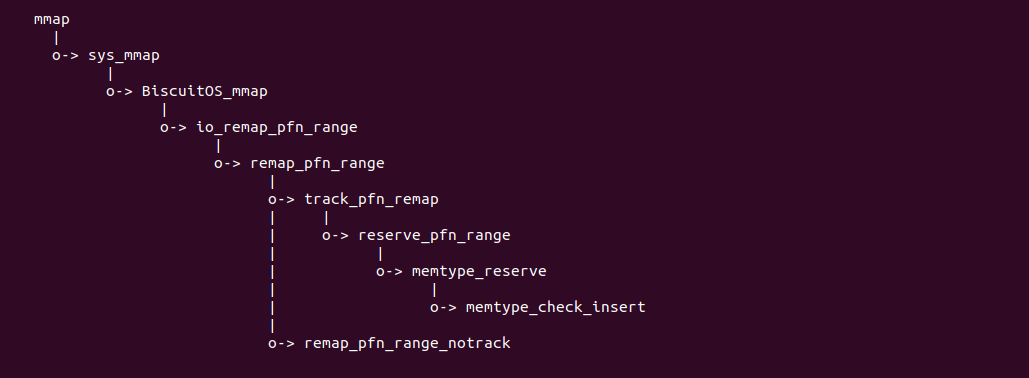
当用户进程调用 mmap() 映射 MMIO 时,最终会调用到 BiscuitOS_mmap() 函数,函数核心是调用 io_remap_pfn_range() 函数,但其只是 remap_pfn_range() 的一层包装,那么核心做了两个事,第一件事就是通过调用 track_pfn_range() 函数在 memtype_rbroot 区间树中查看指定的 MMIO 区域是否存在,如果存储其对应的 CACHE Mode 是否与预期要设置的 CACHE MODE 冲突,如果冲突那么系统将提示并预期的 CACHE Mode 设置为当前 CACHE Mode. 第二件事就是建立页表,其调用 remap_pfn_range_notrack() 函数,该函数会将预期的 CACHE Mode 最终写入到页表里.
CACHE MODE on MEMORY

在 Linux 中,物理地址空间主要由 RAM 和外设映射的 MMIO 组成,物理内存提供了系统运行时存储程序代码和运行数据的功能,如果将物理内存从管理者角度可以分为: 系统管理的物理内存、设备管理的物理内存和系统预留的物理内存。系统管理的物理内存由 struct page 进行表述,并由系统统一管理,提供给内核线程和用户进程使用, 设备管理的物理内存(DEVMEM)同样由 struct page 进行描述,但有设备进行统一管理,为特定的功能/任务提供内存, 系统预留的物理内存(RSVDMEM)不具有 struct page, 只能通过 PFN 或物理地址进行管理,有设备独立管理,系统无法直接管理,为特定的功能或任务提供内存.
用户空间的进程或者内核线程想要访问这三类物理内存,都需要将其虚拟地址映射与物理内存建立页表,页表建立完毕之后才能访问到物理内存。当虚拟地址映射到物理内存之后,其可以使用不同的 Memory Type 满足不同的 CACHE Mode,不同的 CACHE Mode 会对程序执行效率有很大的影响,开发者因根据场景的需求选择正确的 CACHE Mode,本节用于讲解虚拟内存映射三类物理内存时如何配置所需的 CACHE Mode:
CACHE Mode 与系统管理的物理内存
在 Linux 中有系统通过不同的内存管理器管理一类物理内存,并提供统一的接口为内核子系统和用户空间进程提供物理内存,那么简称这类物理内存为系统管理的物理内存. 用户进程或者内核线程首先通过统一的内存分配器从系统获得物理内存,然后将其虚拟地址映射到物理内存上,在映射过程中可以根据场景配置不同的 CACHE Mode,那么系统是如何实现 CACHE Mode 配置逻辑呢? 首先通过一个实践案例了解相应的场景,然后再进一步源码分析,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] RAM: CACHE Mode on Direct Mapping Area --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-RAM-DIRECT-MAPPING-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-RAM-DIRECT-MAPPING-default Source Code on Gitee
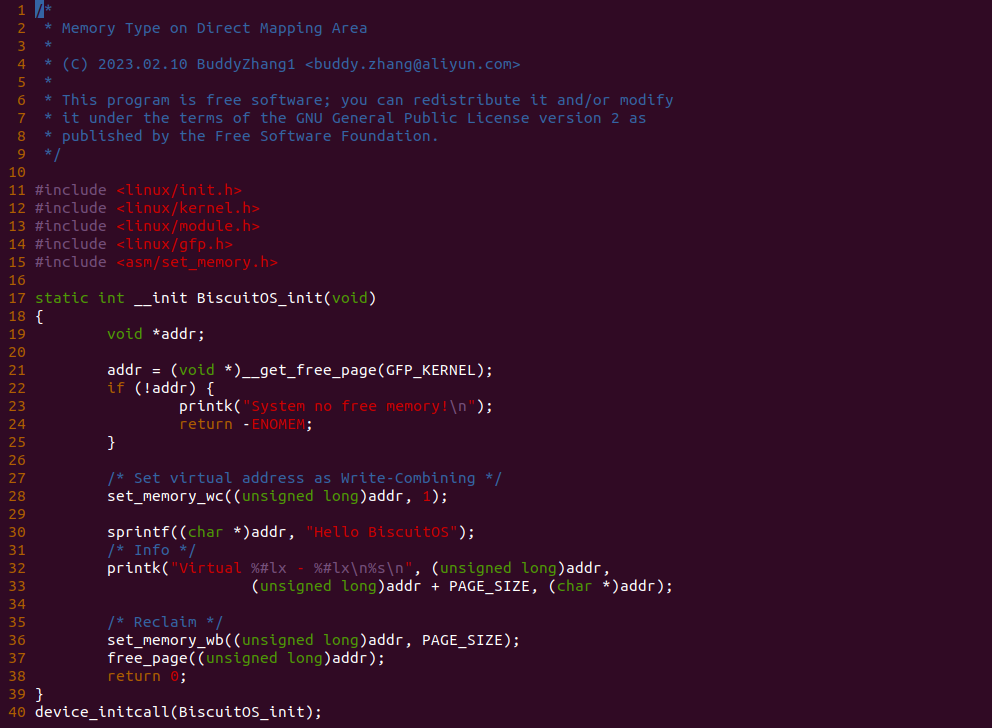
实践案例主要目的是在内核空间申请一段内存之后,将对应的虚拟地址以 WC 的方式映射到物理内存,并进行访问。案例在 21-25 行通过 __get_free_page() 函数分配一个物理页并获得对应的虚拟地址,然后在 28 行调用 set_memory_wc() 函数进行 WC 方式的映射,案例接着在 30-33 行对映射之后的虚拟地址进行访问。最后在 36-37 行回收设置,值得注意的是当将内核空间虚拟地址设置为非 WB 之后,在回收时要主动设置为 WB, 接下来在 BiscuitOS 上实践该案例:
BiscuitOS 系统启动过程中,可以看到 dmesg 打印字符串 “Hello BiscuitOS”, 以及相应的虚拟地址。通过这个案例可以看到 Linux 如何为内核空间虚拟地址设置 CACHE Mode,核心函数是 set_memory_wc() 函数。Linux 提供了一些列的函数用于内核空间虚拟地址设置不同的 CACHE Mode.
Linux 提供了 set_memory_X() 系列函数为内核虚拟地址映射物理地址时,提供丰富接口实现 CACHE Mode 的选择,例如 UC、WT、WC、WB 等,更多详细的实践案例可以参考如下:
内核虚拟地址映射过程
内核虚拟地址设置 Memory Type 有两种方式,第一种是在建立线性映射的时候,内核统配置为 WB; 第二种是通过 set_memory_X() 系列函数修改已经建立映射的内存,这里重点介绍第二种,上图是该系列的通用流程,核心分作三部分,第一部分是将 Memory Type 记录到 struct page,第二部分是修改页表,第三部是刷新虚拟内存对应的 CACHE Line. memory_reserve() 函数根据不同的 enum page_cache_mode 计算出页表属性,然后在 reserve_ram_pages_type() 函数找到物理地址对应的 struct page, 然后将 Memory Type 信息存储在 struct page 的 flags 成员里,具体可以从 get_page_memtype()/set_page_memtype() 函数得知具体的逻辑. 接下来通过调用 __change_page_attr_set_clr() 函数修改了对应页表的属性,最后调用 cpa_flush() 函数,其最终会调用 clflushopt() 函数,其在 X86 架构里会调用 CLFLUSHOPT 指令针对虚拟地址刷新 CACHE Line.
set_page_memtype()/get_page_memtype() 函数可以看到 RAM 的 Memory Type 存储在 struct page 的 flags 成员里. 从 124-129 行定了不同 Memory Type 在 struct page flags 成员的位置,例如 UC- 位于 PG_uncached 位置, 因此可以利用 PageUncache() 函数判断一个物理页对应的 CACHE Mode 是否为 UC-. 另外从宏的定义来看,目前 Linux 可以动态修改 RAM CACHE Mode 只包括 WB、WT、WC 和 UC- 四种类型,其他类型都无法动态修改.
__change_page_attr() 函数在 set_memory_X() 函数流程里的主要目的就是修改页表,函数根据页表的粒度,如果是 4KiB 页,那么直接在 526-557 的分支直接修改 PTE 页表的属性,譬如 552 行直接调用 set_pte_atomic() 函数直接原子修改页表. 另外如果页表的粒度是大页,那么在 563 行调用 should_split_large_page() 函数判断是否对大页进行页表修改,如果是调用 split_large_page() 函数,如果只是修改了大页中的一个页或几个页,那么需要将大页拆分成多个小页,然后将需要修改的物理页更新其 CACHE Mode.
修改 CACHE MODE 最后一步就是刷新已经修改物理页对应的 CACHE Line 和 TLB,函数在 375 行进行判断之后可以对单个 CPU 刷 TLB,也可以对所有 CPU 刷 TLB,刷完 TLB 之后继续刷 CACHE Line,由于虚拟地址都是内核空间虚拟地址,且都是线性映射区的虚拟地址,因此只会出现一个虚拟地址对应一个物理地址的情况,因此直接找到对应的页表,如果页表存在,那么调用 clflush_cache_range_opt() 函数将虚拟地址对应的 CACHE Line 全部刷掉. 通过上面的分析,set_memory_X() 系列提供的接口具有限制性功能:
- 只能针对内核线性映射区的虚拟地址,其他 VMALLOC 等区域的虚拟地址不能使用
- 接口只能动态修改 WB、WC、WT 和 UC- 四种类型的 CACHE MODE
- RAM 的 CACHE Mode 存储在 struct page 的 flags 里
CACHE Mode 与设备管理的物理内存(DEVMEM)
在 Linux 中存在一类物理内存,由设备统一从系统中申请,并独立管理物理内存的分配回收等任务。这类物理内存由 struct page 进行描述,从系统角度来看这类物理内存已经在使用中,无法进行回收再使用. 从设备角度来看这类物理内存可以享受系统提供的多种内存管理功能,也可以按特定的需求进行使用。设备可以将内核虚拟地址映射到这类物理地址之后进行访问,也可以将进程虚拟地址映射到这类物理内存之后再访问,因此在映射过程中可以根据需求采用指定的 CACHE Mode,以此满足场景需求. 接下来通过一个实践案例讲解用户空间如何修改映射到设备管理物理内存的 CACHE Mode,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] RAM: CACHE Mode on DEVMEM --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-RAM-DEVMEM-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build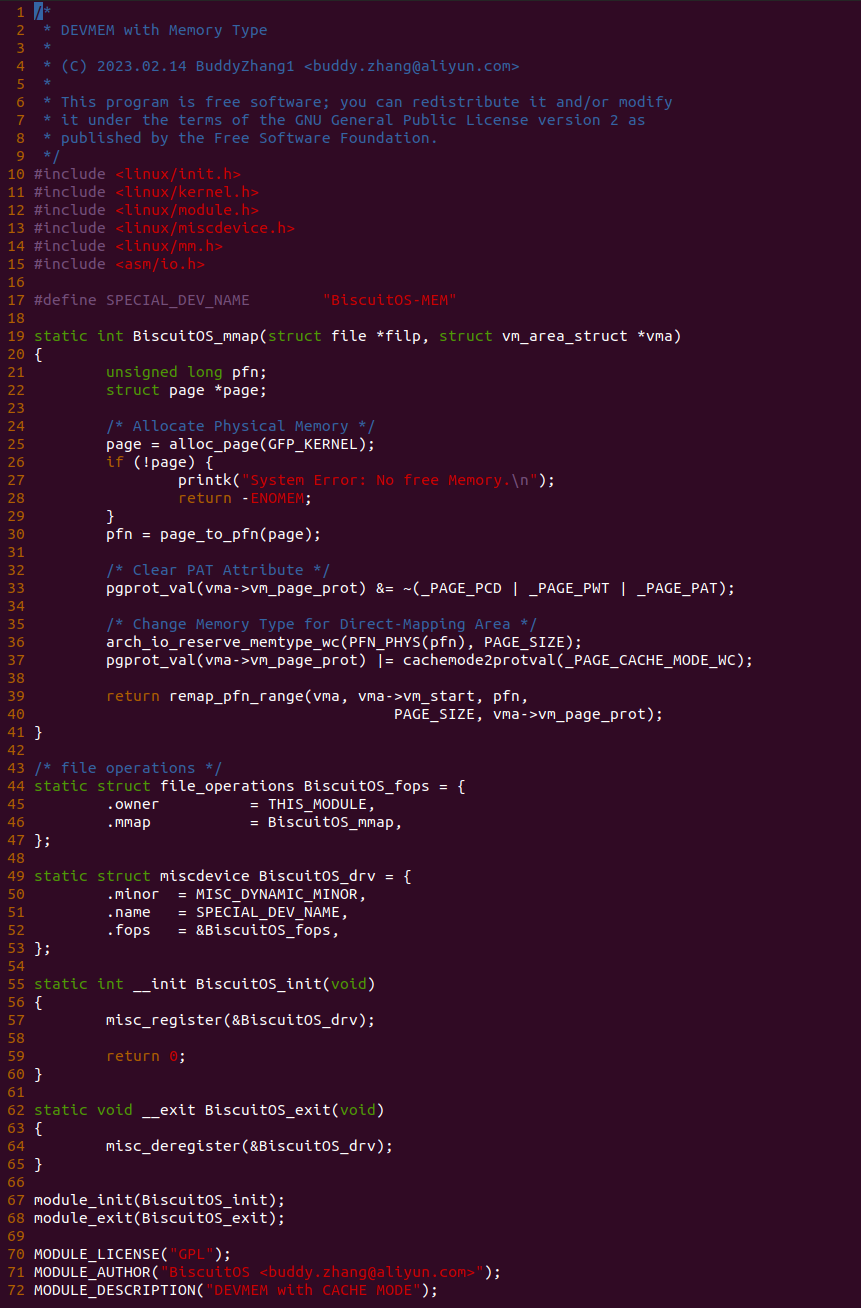
实践案例由两部分组成,上图展示了内核模块部分,模块基于 MISC 驱动框架向用户空间提供了 “/dev/BiscuitOS-MEM” 接口,接口提供了 mmap 实现,当用户空间打开接着并调用 mmap() 函数之后,其最终会调用到 BiscuitOS_mmap() 函数. 在 BiscuitOS_mmap() 函数中,函数首先在 25-30 行通过调用 alloc_page() 分配一个物理页,然后获得物理页对应的 PFN,接着在 33 行将映射页表的 PAT 属性集清除,然后在 36 行调用 arch_io_reserve_memtype_wc() 函数调整物理页对应的线性映射区的 CACHE Mode 为 WC,确保映射物理页的所有 CACHE Mode 都是 WC. 函数接着在 37 行根据实际需求,将映射页表的 PAT 属性集设置为 WC,最后函数调用 remap_pfn_range() 函数建立页表.
实践案例的另外一部分是用户空间的代码,在程序中,首先在 28 行通过 open() 函数打开 “/dev/BiscuitOS-MEM” 节点,然后在 35 行调用 mmap() 函数映射一段设备内存到用户空间,接着在 46-48 行使用内存,最后在 50-52 行归还内存. 接下来在 BiscuitOS 上进行实践:
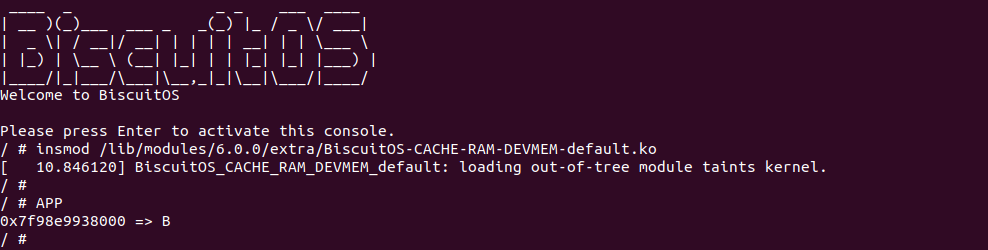
BiscuitOS 系统启动过程中,先加载 BiscuitOS-CACHE-RAM-DEVMEM-default.ko 模块,然后在运行 APP 程序,可以看到应用空间进程可以使用从设备分配的物理内存,实践符合预期. 上面分析源码的时候,需要确保映射到 DEVMEM 物理页的虚拟内存,其 CACHE Mode 都要保持一致,那么开发者可以进一步实践,将内核模块 37 行的 _PAGE_CACHE_MODE_WC 修改为其他 CACHE MODE 试试,例如修改为 _PAGE_CACHE_MODE_WT, 然后在 BiscuitOS 上实践如下:
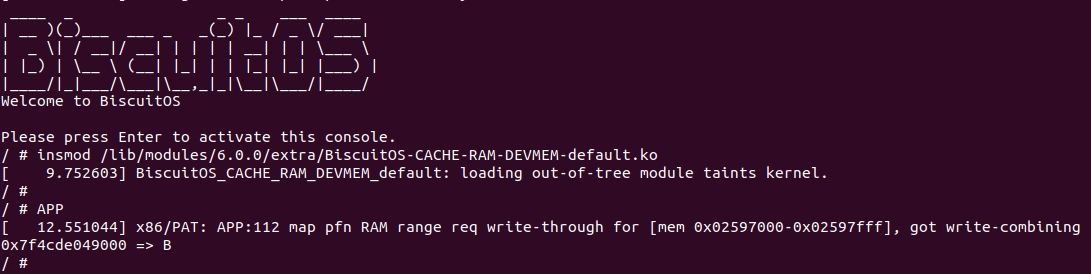
BiscuitOS 系统启动之后,加载完驱动之后运行 APP,此时系统打印字符串 x86/PAT: APP:112 map pfn RAM range req write-through for [mem 0x02597000-0x02597fff], got write-combining, 意思就是新建立的映射想采用 WT,但当前对应物理页的 CACHE Mode 为 WC,为了保持 CACHE Mode 的一致性,因此需要将 CACHE Mode 设置为 WC,因此应用程序最终以 WC 的方式映射了物理页.
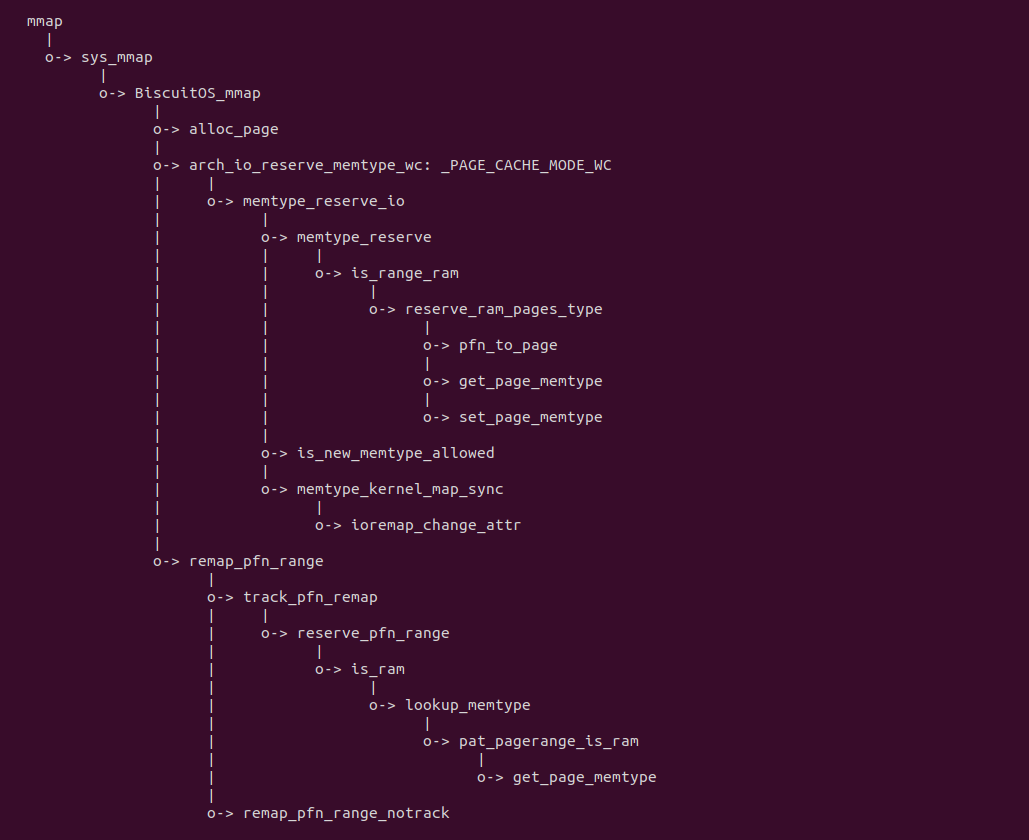
用户空间进程映射设备管理物理内存的逻辑调用如上图,核心三个动作. 第一个动作是 arch_io_reserve_memtype() 函数里的 memtype_reserve() 函数,该函数用于将新的 CACHE Mode 通过 set_page_memtype() 函数存储到物理页对应的 struct page 数据结构 flags 成员里. 第二个动作是 arch_io_reserve_memtype() 函数里的 memtype_kernel_map_sync() 函数,该函数根据预期的 CACHE Mode,将线性映射区的虚拟地址对应的页表 PAT 集合设置为预期的 CACHE Mode. 通过前两个动作可以确保映射到当前物理页的 CACHE Mode 都是与预期 CACHE Mode 一致。最后一个动作就是建立进程虚拟地址到物理页的页表,并将页表的 PAT 集合设置为预期的 CACHE Mode. 三个动作下来进程映射的 DEVMEM 也可以采用预期的 CACHE Mode. 上面的实践案例只是展示了进程 mmap() 调用时就分配 DEVMEM 和建立页表,那么进程想在访问内存时才建立映射和设置 CACHE Mode,即缺页的时候才建立映射和 CACHE Mode,那么 DEVMEM 由该如何做呢? 接下来还是先通过实践案例感受一下具体的场景,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] RAM: CACHE Mode on DEVMEM Page-Faulting --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-RAM-DEVMEM-PAGE-FAULT-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-RAM-DEVMEM-PAGE-FAULT-default Source Code on Gitee

实践案例由两部分组成,上图展示了内核模块部分,模块基于 MISC 驱动框架向用户空间提供了 “/dev/BiscuitOS-MEM” 接口,接口提供了 mmap 实现,mmap 接口只设置了 “vma->vm_ops” 接口,该接口指向 BiscuitOS_vm_ops, 其提供了 fault 接口 vm_fault, 因此当发生缺页的时候最终调用到 vm_fault() 函数. vm_fault() 函数在 22 行获得缺页的虚拟地址,然后在 28-34 行分配一个物理页然后获得对应的 PFN,接着在 37 行清除原先页表中的 PAT 属性. 函数接下来继续调用 arch_io_reserve_memtype_wc() 函数调整了物理页对应线性映射区的 CACHE Mode 为 WC,确保映射物理页的所有 CACHE Mode 都是 WC. 函数在 41 行重新设置了映射的 PAT 属性集为 _PAGE_CACHE_MODE_WC. 接着在 44-46 行调用 vm_insert_page() 函数建立相应的页表,最后在 49-51 行做一下缺页处理的收尾动作.
实践案例的另外一部分是用户空间的代码,在程序中,首先在 28 行通过 open() 函数打开 “/dev/BiscuitOS-MEM” 节点,然后在 35 行调用 mmap() 函数映射一段设备内存到用户空间,接着在 46-48 行使用内存,最后在 50-52 行归还内存. 接下来在 BiscuitOS 上进行实践:
BiscuitOS 系统启动过程中,先加载 BiscuitOS-CACHE-RAM-DEVMEM-PAGE_FAULT-default.ko 模块,然后在运行 APP 程序,可以看到应用空间进程可以使用从设备分配的物理内存,实践符合预期. 上面分析源码的时候,需要确保映射到 DEVMEM 物理页的虚拟内存,其 CACHE Mode 都要保持一致,那么开发者可以进一步实践,将内核模块 41 行的 _PAGE_CACHE_MODE_WC 修改为其他 CACHE MODE 试试,例如修改为 _PAGE_CACHE_MODE_WT, 然后在 BiscuitOS 上实践如下:
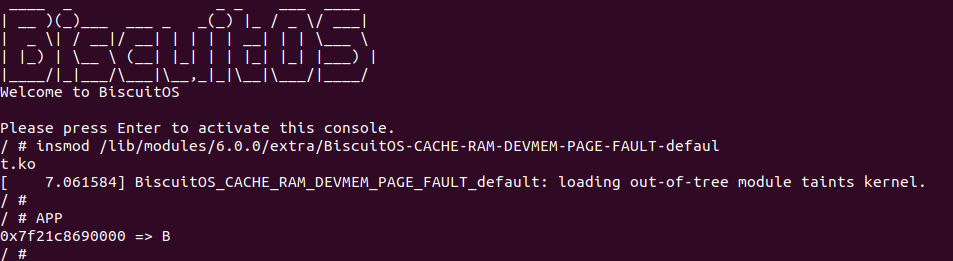
BiscuitOS 系统启动之后,加载完驱动之后运行 APP,此时系统并没有向之前分析那样打印字符串 x86/PAT: APP:112 map pfn RAM range req write-through for [mem 0x02597000-0x02597fff], got write-combining, 那么是不是意味着映射物理页的 CACHE Mode 不一致? 接下来源码分析一下:
基于前面的分析,当发生 Page fault 的时候,系统最终会调用到 vm_fault() 函数,其实现三个功能,第一个功能是通过 alloc_page() 函数提供 DEVMEM,第二个功能是 arch_io_reserve_memtype_wc() 调整物理页线性映射区的 CACHE Mode 为 WC,并修改线性映射区的页表 PAT 属性. 低三个功能是 vm_insert_page() 函数为发生缺页的用户空间虚拟地址建立页表,其通过 get_lock_pte() 函数获得对应的 PTE 页表之后,调用 insert_page_into_pte_locked() 函数建立最终页表,该页表的 PAT 属性集就是设备配置的 _PAGE_CACHE_MODE_WC。通过上面的分析确实没有对 CACHE Mode 的统一性进行检测,这里容易出现不同的虚拟地址采用不同的 CACHE Mode 映射同一个物理内存现象,该问题需要紧跟主线社区的处理进度.
CACHE Mode 与系统预留物理内存(RSVDMEM)
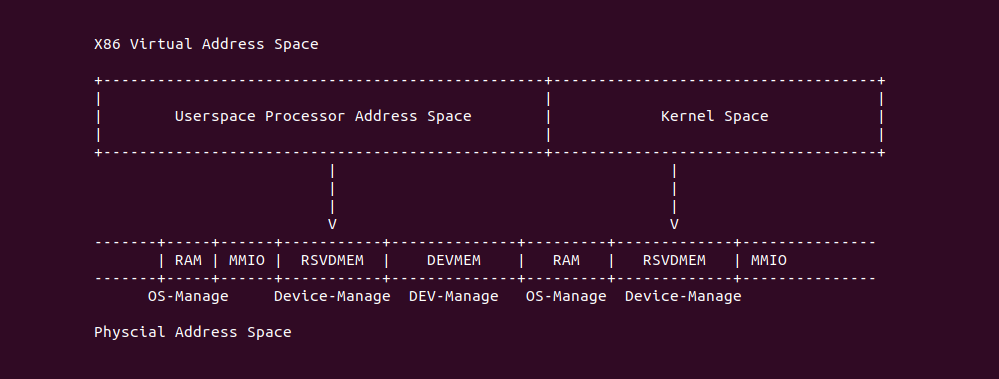
在 Linux 中存在一类物理内存,这里物理内存在系统启动早期就进行预留,系统看不到也管不到这里物理内存,因此系统无法直接使用这里物理内存,因此这类物理内存是没有对应的 struct page,只有物理地址和 PFN. 这里将系统预留物理内存简称为 RSVDMEM,RSVDMEM 一般有设备进行管理,以供特殊功能使用,用户空间可以通过设备建立映射访问到 RSVDMEM,因此建立映射过程中也可以指定 CACHE Mode,以此满足特定场景需求. 接下来通过一个实践案例讲解用户空间如何修改映射到 RSVDMEM 的 CACHE Mode, 其在 BiscuitOS 中的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] RAM: CACHE Mode on RSVDMEM --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-RAM-RSVDMEM-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build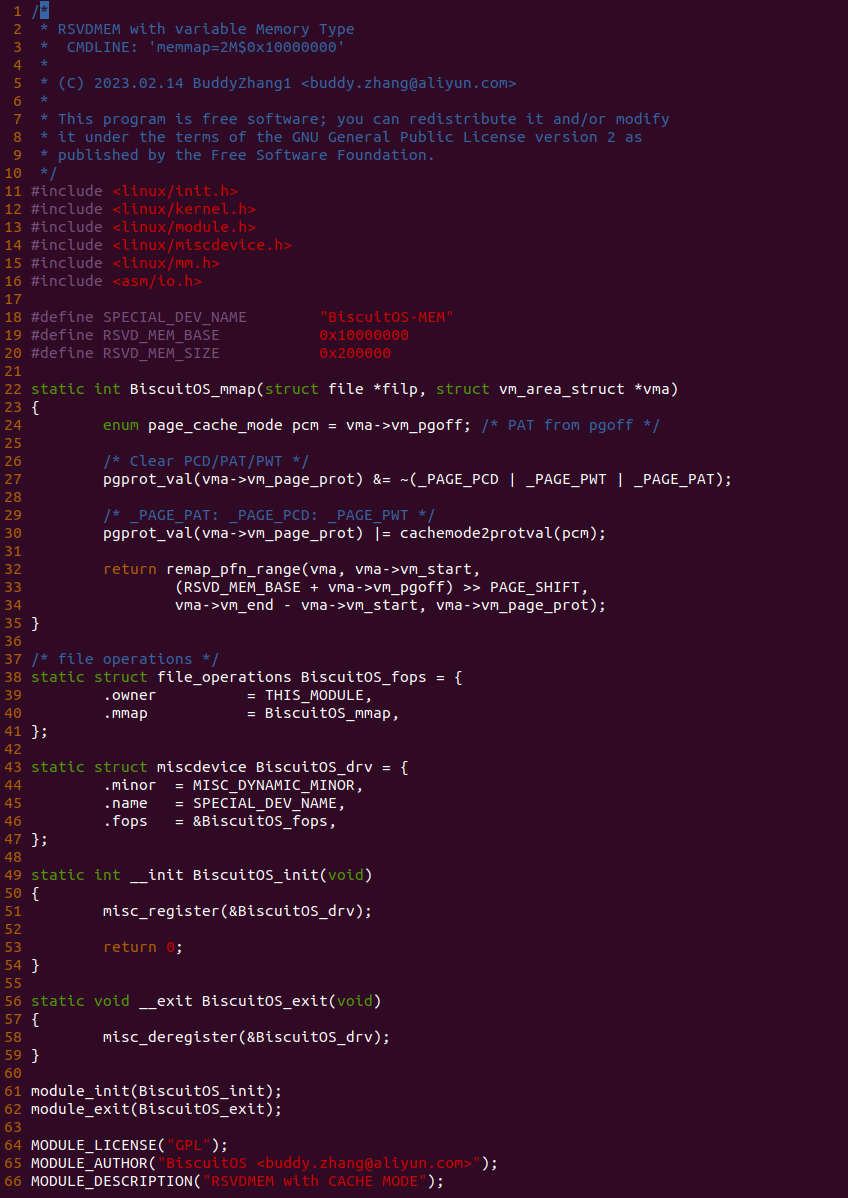
实践案例由两部分组成,上图展示了内核模块部分,模块基于 MISC 驱动框架向用户空间提供了 “/dev/BiscuitOS-MEM” 接口,接口提供了 mmap 实现,当用户空间打开接着并调用 mmap() 函数之后,其最终会调用到 BiscuitOS_mmap() 函数. 在 BiscuitOS_mmap() 函数中,模块在第 3 行提示需要在 CMDLINE 中添加 ‘memmap=2M$0x10000000’ 字段,以此将 [0x10000000, 0x10200000) 区域作为系统预留区域。函数接着在 26 行清除页表里的 PAT 属性集,然后在 29 行调用 cachemode2protval() 函数设置指定的 PAT 集, 最后函数在 31 行调用 remap_pfn_range() 函数建立页表映射.
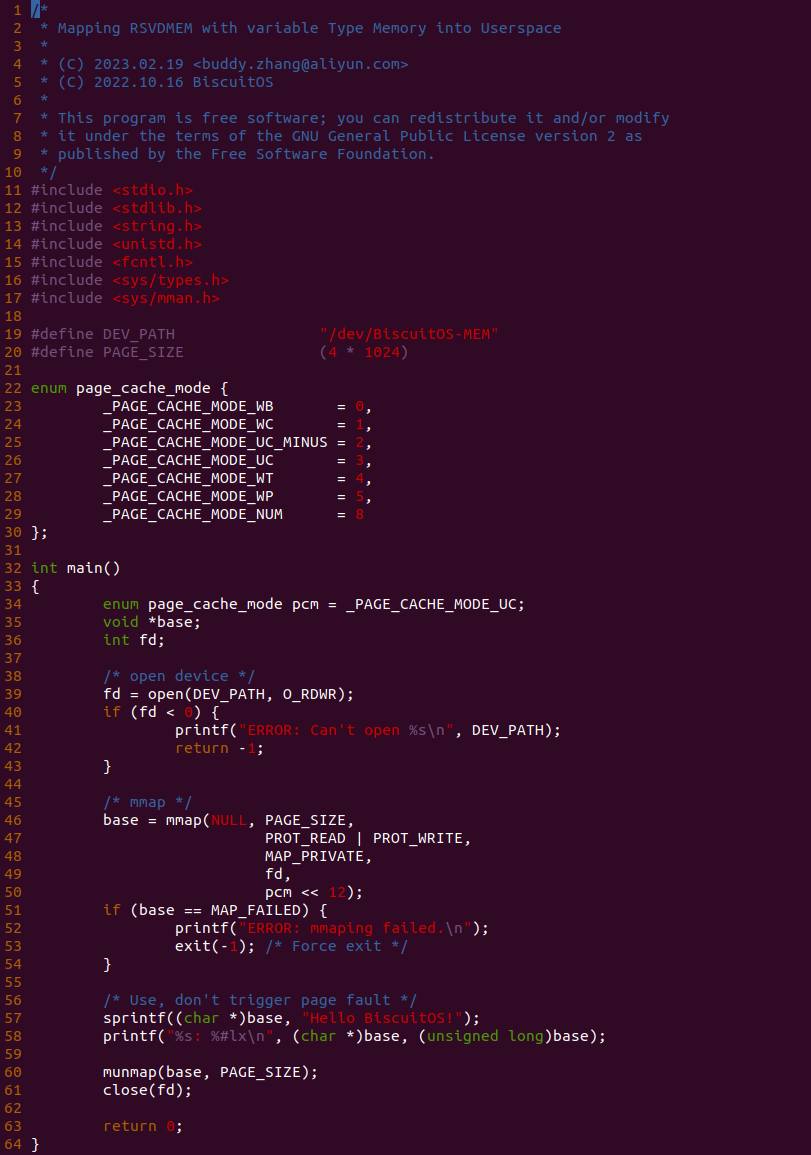
实践案例的另外一部分是用户空间的代码,在程序 22-30 行定义了支持的 CACHE Mode 种类,并在 34 行将 CACHE Mode 设置为 _PAGE_CACHE_MODE_UC。 函数在 39 行通过 open() 函数打开 “/dev/BiscuitOS-MEM” 节点,然后在 46 行调用 mmap() 函数映射一段设备内存到用户空间,并在 50 行将 pcm 变量传入,接着在 56-58 行使用内存,最后在 60-62 行归还内存. 接下来在 BiscuitOS 上进行实践:
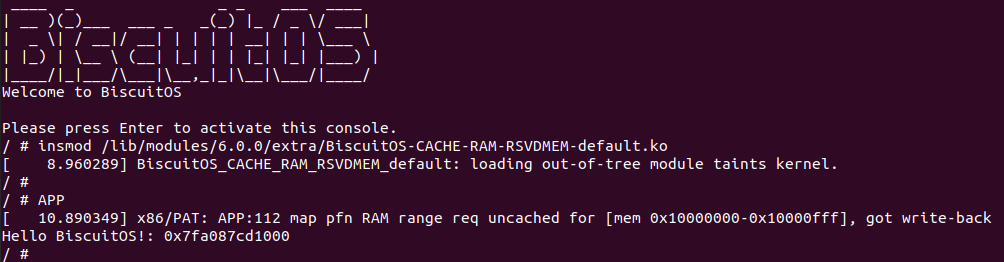
BiscuitOS 系统启动后,先加载 BiscuitOS-CACHE-RAM-RSVD-default.ko 模块,然后在运行 APP 程序,此时系统打印 x86/PAT: APP:112 map pfn RAM range req uncached for [mem 0x10000000-0x10000fff], got write-back, 意思就是系统阻止了将 CACHE Mode 设置为 UC,因此当前的 CACHE Mode 为 WB. 回想起源码里提示的需要将物理区域设置为系统预留区域,因此在 CMDLINE 中添加 ‘memmap=2M$0x10000000’, 再次在 BiscuitOS 上实践:
BiscuitOS 启动完毕之后,加载 BiscuitOS-CACHE-RAM-RSVD-default.ko 模块,然后在运行 APP 程序, 此时系统没有提示 CACHE Mode 异常信息了,此时查看 pat_memtype_list 表,可以看到 [mem 0x10000000-0x10000fff] 区域的 CACHE Mode 已经是 UC. 实践符合预期,那么来看看具体的代码调用逻辑:
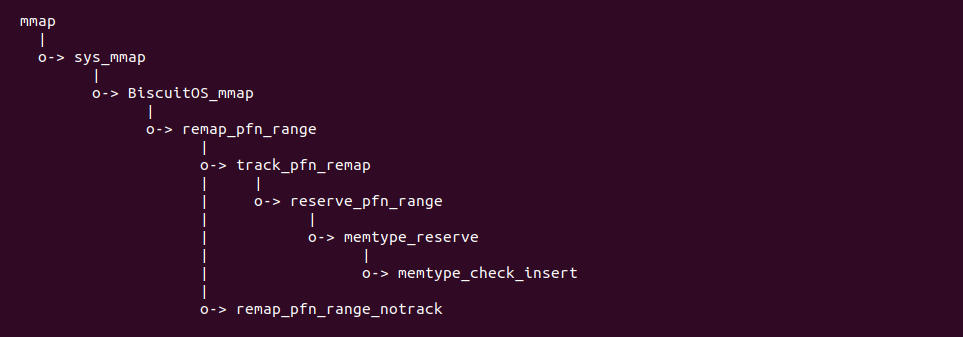
RSVDMEM CACHE MODE 设置流程如上图,由于默认情况下 RSVDMEM 没有被任何虚拟地址映射,因此不存在默认的 CACHE Mode,因此 BiscuitOS_mmap() 函数调用 remap_pfn_range() 函数建立映射时,track_pfn_remap() 函数检测到 RSVDMEM 为非 RAM,然后最终调用 memtype_check_insert() 函数将 RSVDMEM 的 CACHE Mode 添加到 memtype_rbroot 区间树进行维护,因此最后可以在 pat_memtype_list 表中看到 [mem 0x10000000-0x10000fff] 区域的 CACHE Mode 为 UC.

CACHE MODE Coherent
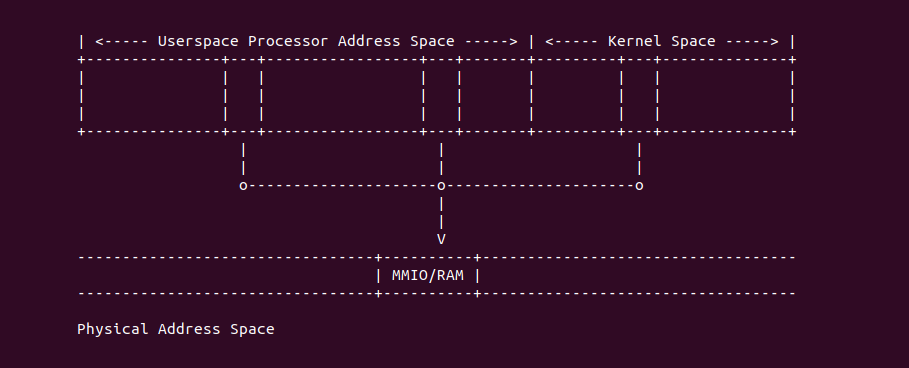
在 Linux 中经常会出现用户进程将其地址空间的虚拟地址映射到一个物理页,同时其他进程以及内核线程也会将其虚拟内存映射到同一个物理页上,那么这样就存在一个问题,每个虚拟地址到物理内存的映射都由页表控制,假设每个映射都有自己的 CACHE Mode,例如其中一个使用 WT 方式映射,另外一个使用 WC 映射,那么这将给系统和硬件造成混乱,到底是回写还是通写?从根本上来说,一个物理页只能存在一种 CACHE Mode,因此无论虚拟地址如何映射都不能打破这个规则,否则将造成行为错乱。那么 Linux 如何确保一个物理页的 CACHE Mode 一致呢? 本节从物理内存的管理者角度来进行分析:
总结: 通过 CACHE MODE 在不同场景的分析,总结来说 RSVDMEM、OSMMIO 和 DEVMMIO 可以通过系统提供的 RB 区间树维护 CACHE MODE 的一致性,确保重叠区域与当前 CACHE MODE 保持一致; 系统在 CACHE MODE 对 DEVMEM 提供了一定程度的支持,可以防止无缺页场景下 CACHE MODE 的一致性,但在缺页场景下,系统无法保证 DEVMEM 的 CACHE MODE 一致. 最后就是 OSMEM 场景,大部分场景系统认为 OSMEM 都是 WB 的,因此无需主动进行保证,但在 VMALLOC 场景映射非 WB 时,系统并不能保证 OSMEM 的 CACHE MODE 一致。最后需要对不能保证 CACHE MODE 一致的场景提交相应的补丁修复.
CACHE Mode Coherent with RSVDMEM
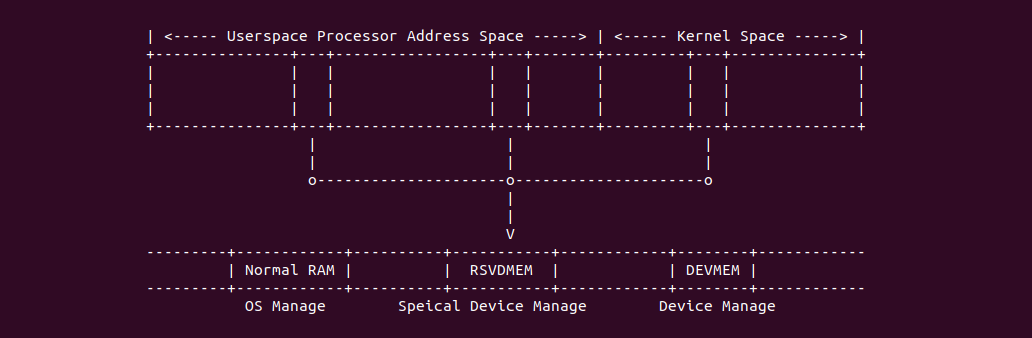
在 Linux 中存在一类物理内存,这里物理内存在系统启动早期就进行预留,系统看不到也管不到这里物理内存,因此系统无法直接使用这里物理内存,这类物理内存是没有对应的 struct page,只有物理地址和 PFN. 这里将系统预留物理内存简称为 RSVDMEM,RSVDMEM 一般有设备进行管理,以供特殊功能使用,用户空间可以通过设备建立映射访问到 RSVDMEM, 那么多个用户空间进程同时对同一个 RSVDMEM 建立映射时,如何保证 CACHE Mode 的一致呢? 为了研究这个问题,从一个实践案例先感受问题的场景,然后在进一步进行分析,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Coherent: CACHE Mode Coherent for RSVDMEM --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-MODE-COHERENT-RSVDMEM-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-MODE-COHERENT-RSVDMEM-default Source Code on Gitee
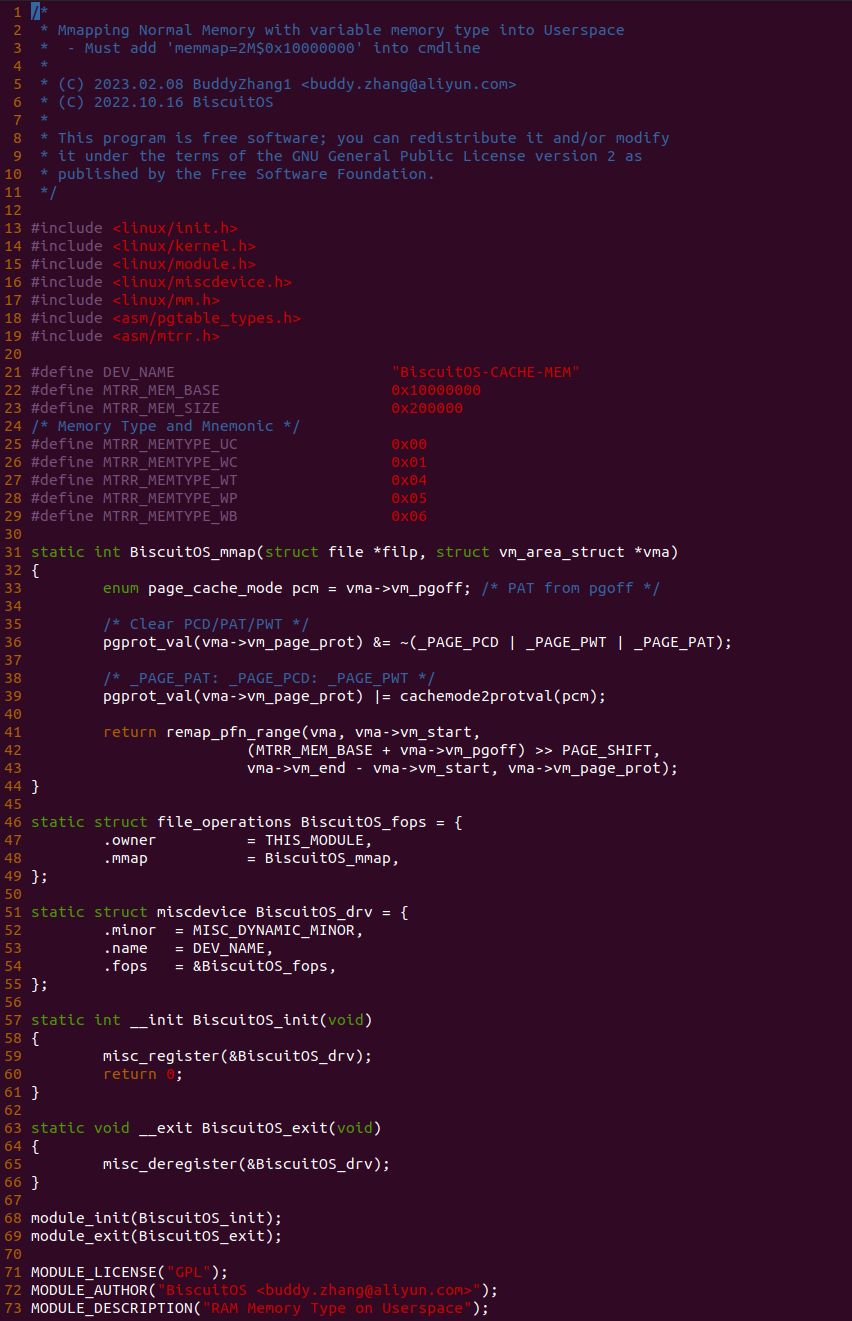
案例由两部分组成,一部分位于内核模块组成,另外一部分由用户空间进程组成。上图为内核模块部分,模块提供了 MSIC 字符设备框架,并向用户空间提供了 mmap 接口,用户空间打开 ‘/dev/BiscuitOS-CACHE-MEM’ 之后,调用 mmap() 函数就能调用到 BiscuitOS_mmap() 函数。在 BiscuitOS_mmap() 函数里,模块在 36 行首先移除配置的页表属性的 PAT 标志位,然后从 vma 的 vm_pgoff 中解析出 enum page_cache_mode 信息,并传入 cachemode2protval() 获得 CACHE Mode 对应的页表 PAT 标志集合,最后在 41 行调用 remap_pfn_range() 函数建立页表映射. 最后值得注意的是 3 行注释部分提示需要将 [0x10000000, 0x10200000) 区域作为系统预留内存加入到 CMDLINE 里.
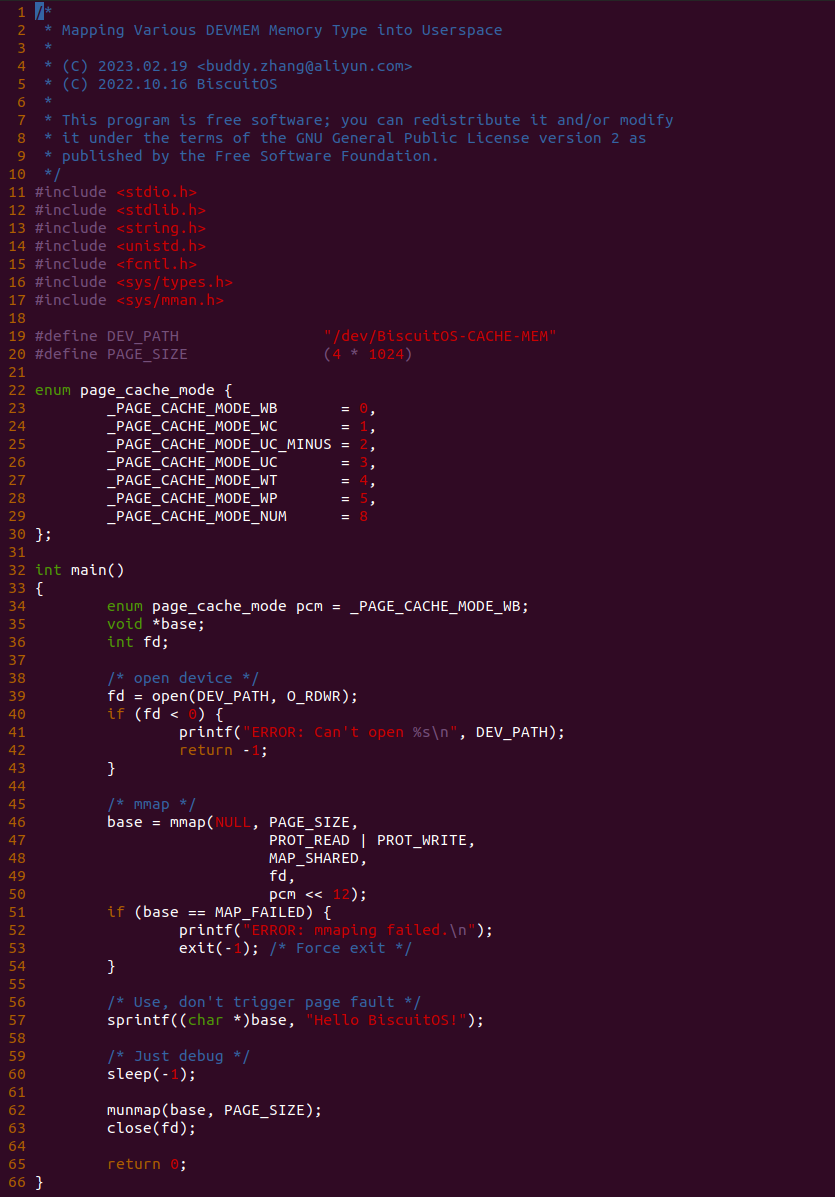
案例的另外一部分是由两个用户空间进程进行组成的,app.c 负责向映射的物理内存写如字符串,app1.c 负责从映射的同一个物理页中读取字符串. app.c 程序如上图,程序首先在 34 行配置了 CACHE MODE 为 WB,目前支持的 CACHE MODE 有 WC、WT、WB、WP、UC 和 UC-, 程序接着在 39 行通过 open() 函数打开 ‘/dev/BiscuitOS-CACHE-MEM’ 节点,接着在 46-54 行通过 mmap() 函数映射一段物理内存,并将 CACHE Mode 通过 pgoff 参数传入到内核。映射完毕之后在 57 行向内存写入字符串 “Hello BiscuitOS”,最后在 62-63 行解除映射和关闭节点.
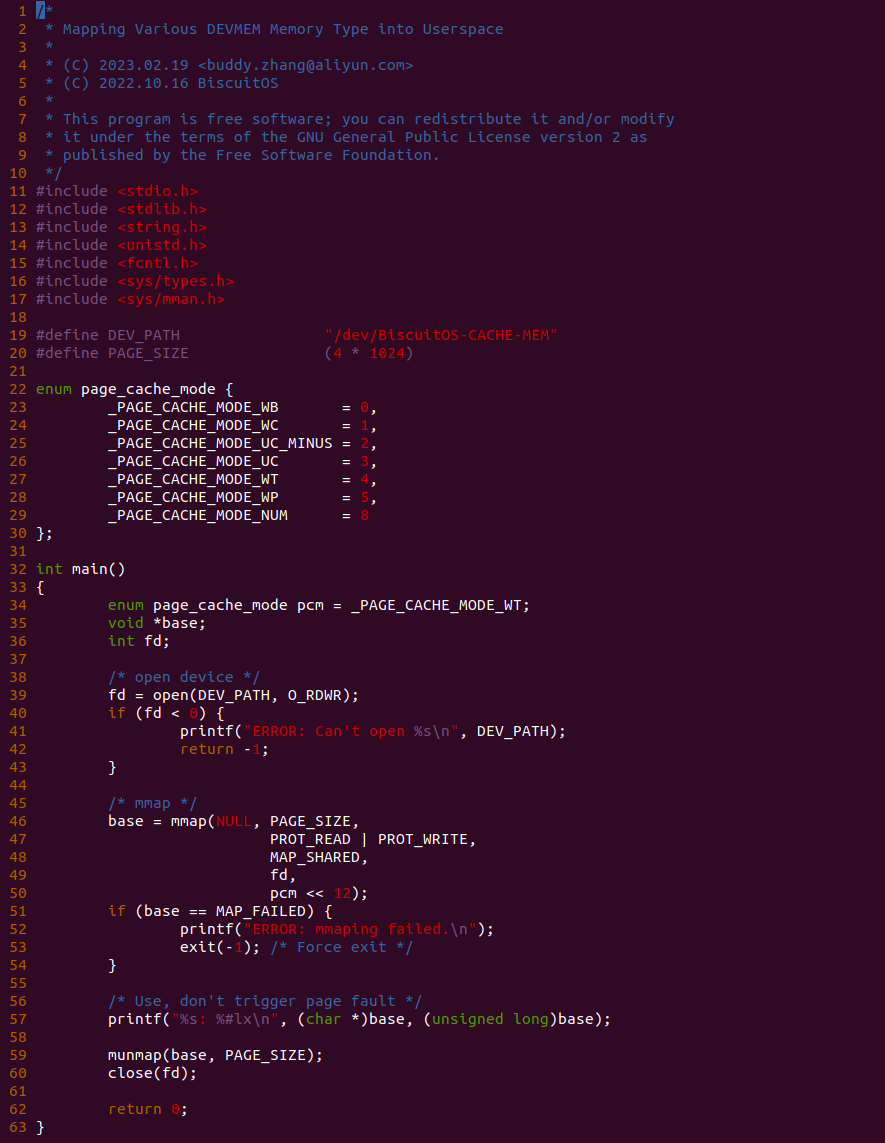
app1.c 程序如上图,程序首先在 34 行配置了 CACHE MODE 为 WT, 程序接着在 39 行通过 open() 函数打开 ‘/dev/BiscuitOS-CACHE-MEM’ 节点,接着在 46-54 行通过 mmap() 函数映射一段物理内存,并将 CACHE Mode 通过 pgoff 参数传入到内核。映射完毕之后在 57 行从内存中读取字符串,最后在 59-60 行解除映射和关闭节点. 接下来就是在 BiscuitOS 上实践该案例:
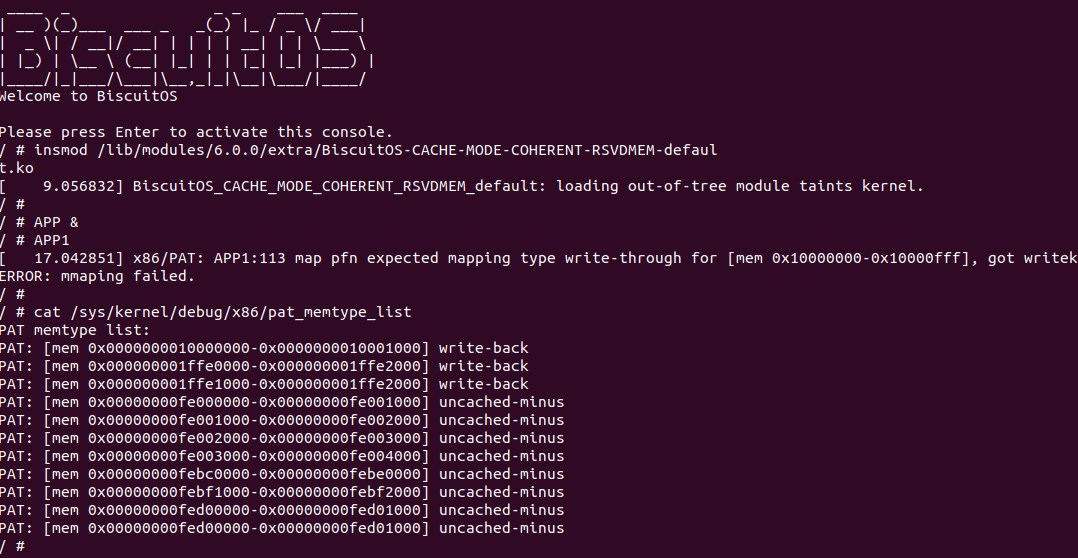
BiscuitOS 系统启动之后,加载 BiscuitOS-CACHE-MODE-COHERENT-RSVDMEM-default.ko, 然后后台运行 APP 应用程序,接着运行 APP1,此时可以看到系统提示 x86/PAT: APP:113 map pfn RAM range req uncached for [mem 0x10000000-0x10000fff], got write-back, 意思就是 APP1 像将映射的 CACHE Mode 设置为 Write-through,但该物理页已经被映射为 Write-Back 了,因此需要将映射保持当前类型,因此 APP1 映射的 CACHE MODE 设置为 WB. 进一步实践,将 app.c 映射的 CACHE Mode 设置为 WC 或者 UC、UC-,然后再次在 BiscuitOS 上实践:
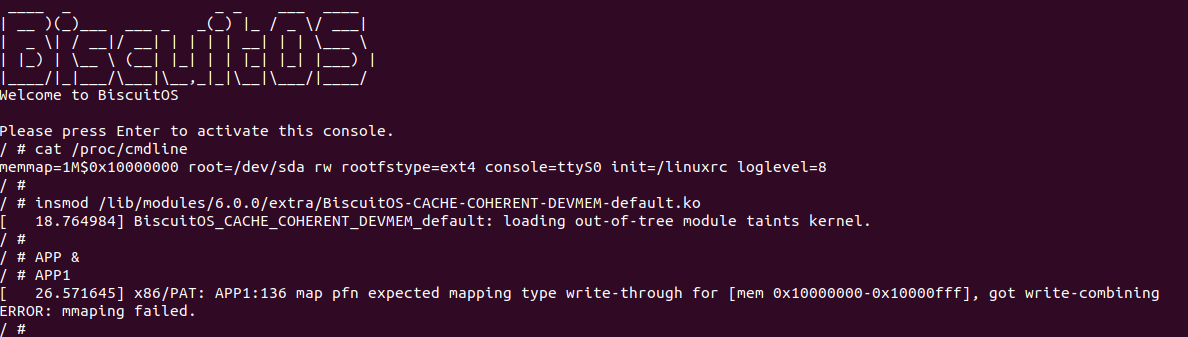
当把 app.c 的 CACHE Mode 设置为 WC 之后,再次在 BiscuitOS 上实践还是发现 APP1 运行的时候,此时可以看到系统提示 x86/PAT: APP:135 map pfn RAM range req write-through for [mem 0x10000000-0x10000fff], got write-combining, 意思就是 APP1 向将映射的 CACHE Mode 设置为 Write-through,但该物理页已经被映射为 Write-Combining 了,因此需要将映射保持当前类型,因此 APP1 映射的 CACHE MODE 设置为 WC. 最后将 app.c 的 CACHE Mode 统一设置为 WT,继续实践:
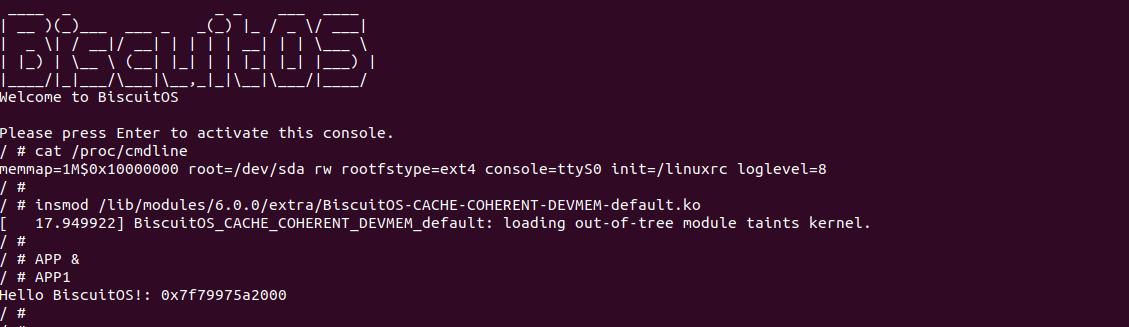
当把 app.c 的 CACHE Mode 和 app1.c 统一为 WT 之后,再次运行 BiscuitOS,此时 APP 和 APP1 都可以正常运行,没有任何移除提示,最后读出字符串 “Hello BiscuitOS”。实践符合预期,那么接下来分析背后的 Linux 逻辑.
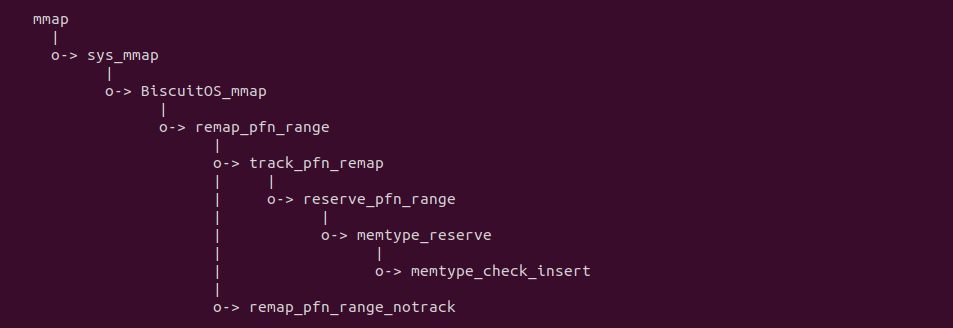
对于 RSVDMEM 调用 mmap() 函数最终会调用到 BiscuitOS_mmap() 函数,然后使用 remap_pfn_range() 函数建立映射,其内部首先调用 track_pfn_remap() 函数, 由于 RSVDMEM 对应系统来说不是 RAM,因此调用到 reserve_pfn_range() 函数,并进入 memtype_reserve() 函数,
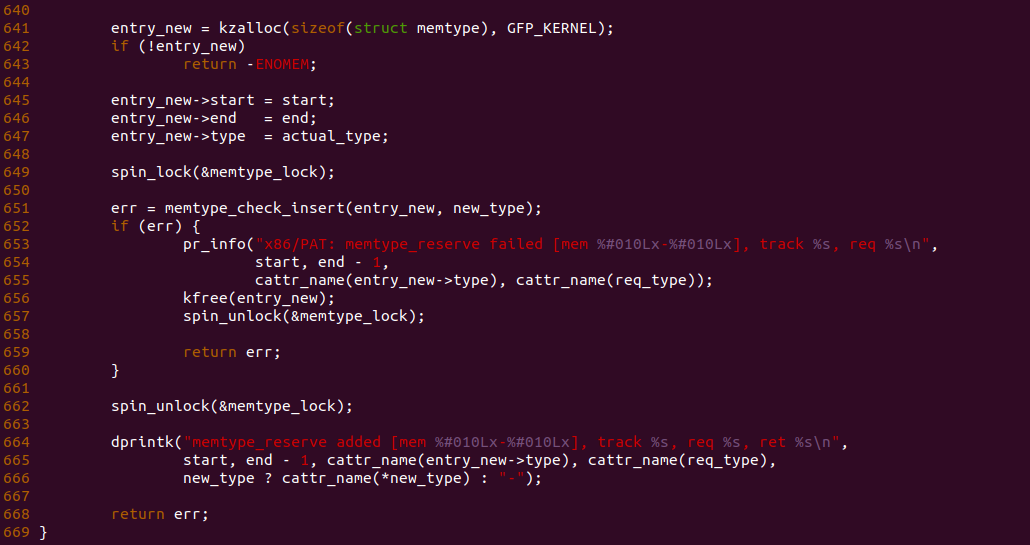
在 memtype_reserve() 函数内部,由于 RSVDMEM 对系统来说不是系统 RAM,那么其不会进入 is_range_ram 的分支,而是进入 641 之后的分支,其在 651 行调用 memtype_check_insert() 函数会在 memtype_rbroot 区间树内部查找 RSVDMEM 区域是否已经在内,如果在就取出对应的 Memory Type,并进行比较,如果发现不一致函数会将当前 Memory Type 覆盖期盼的 Memory Type.
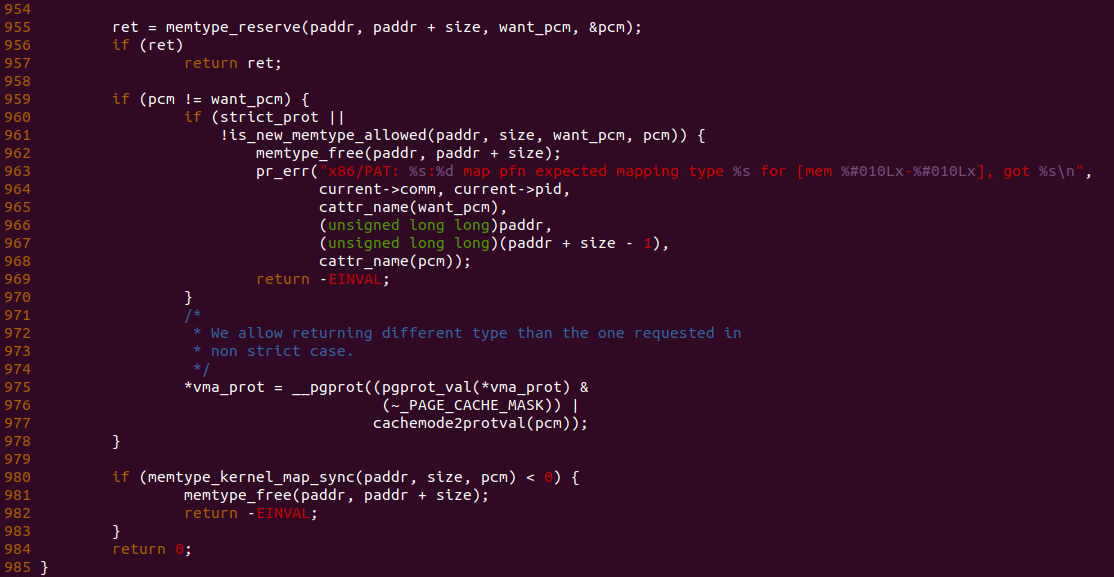
memtype_check_insert() 函数执行完毕回退到 reserve_pfn_range() 函数,其在 959 行对当前的 Memory Type 和预期的 Memory Type 进行比较,如果不相同那么进入 960 分支,然后打印 Memory Type 修改失败信息,最后返回 -EINVAL, 最终导致第二个程序执行时发生 Bus error。这样确保了映射 RSVDMEM 时保持不同虚拟地址映射时的 CACHE Mode 都是一致的. 因此 RSVDMEM 是可以保证 CACHE Mode 一致的.
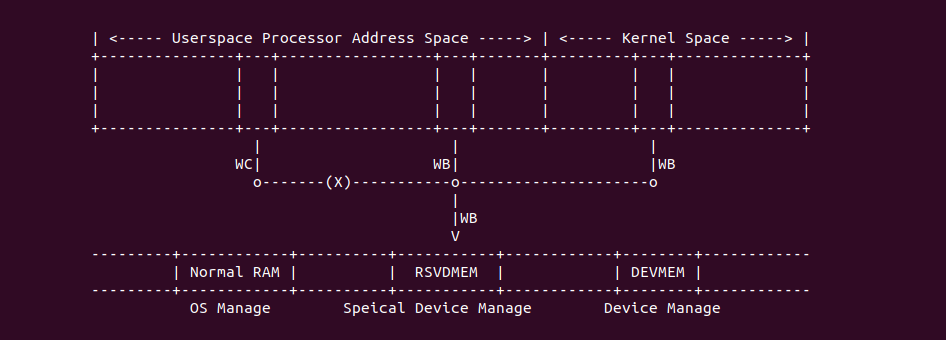
通过上述分析,当用户进程或者内核线程映射 RSVDMEM 时,系统原有机制是可以确保不同虚拟地址采用同样的 CACHE Mode 映射到同一个 RSVDMEM,当新建映射的预期 CACHE Mode 与当前不一致时,系统会将预期的 CACHE Mode 修改为当前采用的 CACHE Mode,以此保证同一个 RSVDMEM 只有一个 CACHE Mode.
CACHE Mode Coherent With DEVMEM
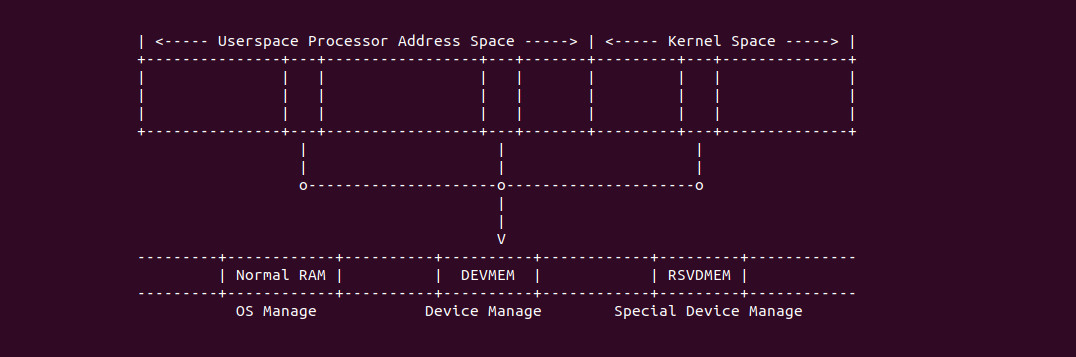
在 Linux 中存在一类物理内存,由设备统一从系统中申请,并独立管理物理内存的分配回收等任务。这类物理内存由 struct page 进行描述,从系统角度来看这类物理内存已经在使用中,无法进行回收再使用. 从设备角度来看这类物理内存可以享受系统提供的多种内存管理功能,也可以按特定的需求进行使用。设备可以将内核虚拟地址映射到这类物理地址之后进行访问,也可以将进程虚拟地址映射到这类物理内存之后再访问,因此在映射过程中可以根据需求采用指定的 CACHE Mode. 当多个用户空间进程同时对同一个 DEVMEM 建立映射时,如何保证 CACHE Mode 的一致呢? 为了研究这个问题,从一个实践案例先感受问题的场景,然后再进一步分析具体的逻辑,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Coherent: CACHE MODE Coherent for DEVMEM --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-MODE-COHERENT-DEVMEM-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-MODE-COHERENT-DEVMEM-default Source Code on Gitee
实践案例由两部分组成,上图展示了内核模块部分,模块基于 MISC 驱动框架向用户空间提供了 “/dev/BiscuitOS-MEM” 接口,接口提供了 mmap 实现,当用户空间打开接着并调用 mmap() 函数之后,其最终会调用到 BiscuitOS_mmap() 函数. 在 BiscuitOS_mmap() 函数中,函数首先在 25-30 行通过调用 alloc_page() 分配一个物理页,然后获得物理页对应的 PFN,接着在 33 行将映射页表的 PAT 属性集清除,然后在 36 行调用 arch_io_reserve_memtype_wc() 函数调整物理页对应的线性映射区的 CACHE Mode 为 WC,确保映射物理页的所有 CACHE Mode 都是 WC. 函数接着在 37 行根据实际需求,将映射页表的 PAT 属性集设置为 WC,最后函数调用 remap_pfn_range() 函数建立页表.
实践案例的另外一部分是用户空间的代码,在程序中,首先在 28 行通过 open() 函数打开 “/dev/BiscuitOS-MEM” 节点,然后在 35 行调用 mmap() 函数映射一段设备内存到用户空间,接着在 46-48 行使用内存,最后在 50-52 行归还内存. 接下来在 BiscuitOS 上进行实践:
BiscuitOS 系统启动过程中,先加载 BiscuitOS-CACHE-RAM-DEVMEM-default.ko 模块,然后在运行 APP 程序,可以看到应用空间进程可以使用从设备分配的物理内存,实践符合预期. 上面分析源码的时候,需要确保映射到 DEVMEM 物理页的虚拟内存,其 CACHE Mode 都要保持一致,那么开发者可以进一步实践,将内核模块 37 行的 _PAGE_CACHE_MODE_WC 修改为其他 CACHE MODE 试试,例如修改为 _PAGE_CACHE_MODE_WT, 然后在 BiscuitOS 上实践如下:
BiscuitOS 系统启动之后,加载完驱动之后运行 APP,此时系统打印字符串 x86/PAT: APP:112 map pfn RAM range req write-through for [mem 0x02597000-0x02597fff], got write-combining, 意思就是新建立的映射想采用 WT,但当前对应物理页的 CACHE Mode 为 WC,为了保持 CACHE Mode 的一致性,因此需要将 CACHE Mode 设置为 WC,因此应用程序最终以 WC 的方式映射了物理页.
用户空间进程映射设备管理物理内存的逻辑调用如上图,核心三个动作. 第一个动作是 arch_io_reserve_memtype() 函数里的 memtype_reserve() 函数,该函数用于将新的 CACHE Mode 通过 set_page_memtype() 函数存储到物理页对应的 struct page 数据结构 flags 成员里. 第二个动作是 arch_io_reserve_memtype() 函数里的 memtype_kernel_map_sync() 函数,该函数根据预期的 CACHE Mode,将线性映射区的虚拟地址对应的页表 PAT 集合设置为预期的 CACHE Mode. 通过前两个动作可以确保映射到当前物理页的 CACHE Mode 都是与预期 CACHE Mode 一致。最后一个动作就是建立进程虚拟地址到物理页的页表,并将页表的 PAT 集合设置为预期的 CACHE Mode.
此时会调用 track_pfn_remap() 函数对 CACHE Mode 的一致性进行检测,其最终从 get_page_memtype() 获得 CACHE Mode,然后回到 reserve_pfn_range() 函数检测是否一致,函数 941-950 行对 CACHE Mode 进行检测,如果不一致就进行提示,并将预期的 CACHE Mode 修改为当前正在使用的 CACHE Mode. DEVMEM 还存在另外一个场景,就是缺页的时候设置 CACHE Mode, 接下来继续分析该场景, 其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Coherent: CACHE MODE Coherent for DEVMEM on Page-Fault --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-MODE-COHERENT-DEVMEM-PAGE-FAULT-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-MODE-COHERENT-DEVMEM-PAGE-FAULT-default Source Code on Gitee
实践案例由两部分组成,上图展示了内核模块部分,模块基于 MISC 驱动框架向用户空间提供了 “/dev/BiscuitOS-MEM” 接口,接口提供了 mmap 实现,mmap 接口只设置了 “vma->vm_ops” 接口,该接口指向 BiscuitOS_vm_ops, 其提供了 fault 接口 vm_fault, 因此当发生缺页的时候最终调用到 vm_fault() 函数. vm_fault() 函数在 22 行获得缺页的虚拟地址,然后在 28-34 行分配一个物理页然后获得对应的 PFN,接着在 37 行清除原先页表中的 PAT 属性. 函数接下来继续调用 arch_io_reserve_memtype_wc() 函数调整了物理页对应线性映射区的 CACHE Mode 为 WC,确保映射物理页的所有 CACHE Mode 都是 WC. 函数在 41 行重新设置了映射的 PAT 属性集为 _PAGE_CACHE_MODE_WC. 接着在 44-46 行调用 vm_insert_page() 函数建立相应的页表,最后在 49-51 行做一下缺页处理的收尾动作.
实践案例的另外一部分是用户空间的代码,在程序中,首先在 28 行通过 open() 函数打开 “/dev/BiscuitOS-MEM” 节点,然后在 35 行调用 mmap() 函数映射一段设备内存到用户空间,接着在 46-48 行使用内存,最后在 50-52 行归还内存. 接下来在 BiscuitOS 上进行实践:
BiscuitOS 系统启动过程中,先加载 BiscuitOS-CACHE-RAM-DEVMEM-PAGE_FAULT-default.ko 模块,然后在运行 APP 程序,可以看到应用空间进程可以使用从设备分配的物理内存,实践符合预期. 上面分析源码的时候,需要确保映射到 DEVMEM 物理页的虚拟内存,其 CACHE Mode 都要保持一致,那么开发者可以进一步实践,将内核模块 41 行的 _PAGE_CACHE_MODE_WC 修改为其他 CACHE MODE 试试,例如修改为 _PAGE_CACHE_MODE_WT, 然后在 BiscuitOS 上实践如下:
BiscuitOS 系统启动之后,加载完驱动之后运行 APP,此时系统并没有向之前分析那样打印字符串 x86/PAT: APP:112 map pfn RAM range req write-through for [mem 0x02597000-0x02597fff], got write-combining, 那么是不是意味着映射物理页的 CACHE Mode 不一致? 接下来源码分析一下:
基于前面的分析,当发生 Page fault 的时候,系统最终会调用到 vm_fault() 函数,其实现三个功能,第一个功能是通过 alloc_page() 函数提供 DEVMEM,第二个功能是 arch_io_reserve_memtype_wc() 调整物理页线性映射区的 CACHE Mode 为 WC,并修改线性映射区的页表 PAT 属性. 低三个功能是 vm_insert_page() 函数为发生缺页的用户空间虚拟地址建立页表,其通过 get_lock_pte() 函数获得对应的 PTE 页表之后,调用 insert_page_into_pte_locked() 函数建立最终页表,该页表的 PAT 属性集就是设备配置的 _PAGE_CACHE_MODE_WC。通过上面的分析确实没有对 CACHE Mode 的统一性进行检测,这里容易出现不同的虚拟地址采用不同的 CACHE Mode 映射同一个物理内存现象,该问题需要紧跟主线社区的处理进度.
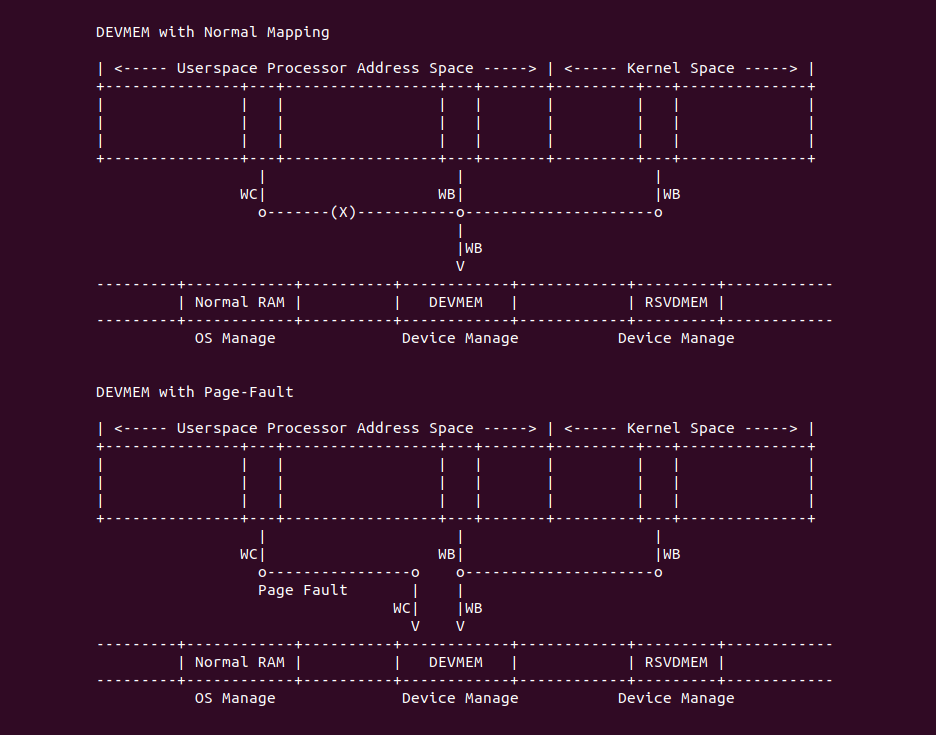
通过上面分析,非缺页模式下,DEVMEM 是可以维护多个虚拟地址映射到同一个物理内存时,CACHE Mode 保持一致. 但如果在缺页模式下,DEVMEM 无法保证多个虚拟地址映射到同一个物理地址 CACHE MODE 一致.
CACHE Mode Coherent With OSMEM
在 Linux 中有系统通过不同的内存管理器管理一类物理内存,并提供统一的接口为内核子系统和用户空间进程提供物理内存,那么简称这类物理内存为系统管理的物理内存 OSMEM. 用户进程或者内核线程首先通过统一的内存分配器从系统获得物理内存,然后将其虚拟地址映射到物理内存上,在映射过程中可以根据场景配置不同的 CACHE Mode,那么多个虚拟地址映射到 OSMEM 时,系统如何保持 CACHE MODE 一致呢? 首先通过一个实践案例了解相应的场景,然后再进一步源码分析,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Coherent: CACHE MODE Coherent for OSMEM --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-MODE-COHERENT-OSMEM-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-MODE-COHERENT-OSMEM-default Source Code on Gitee
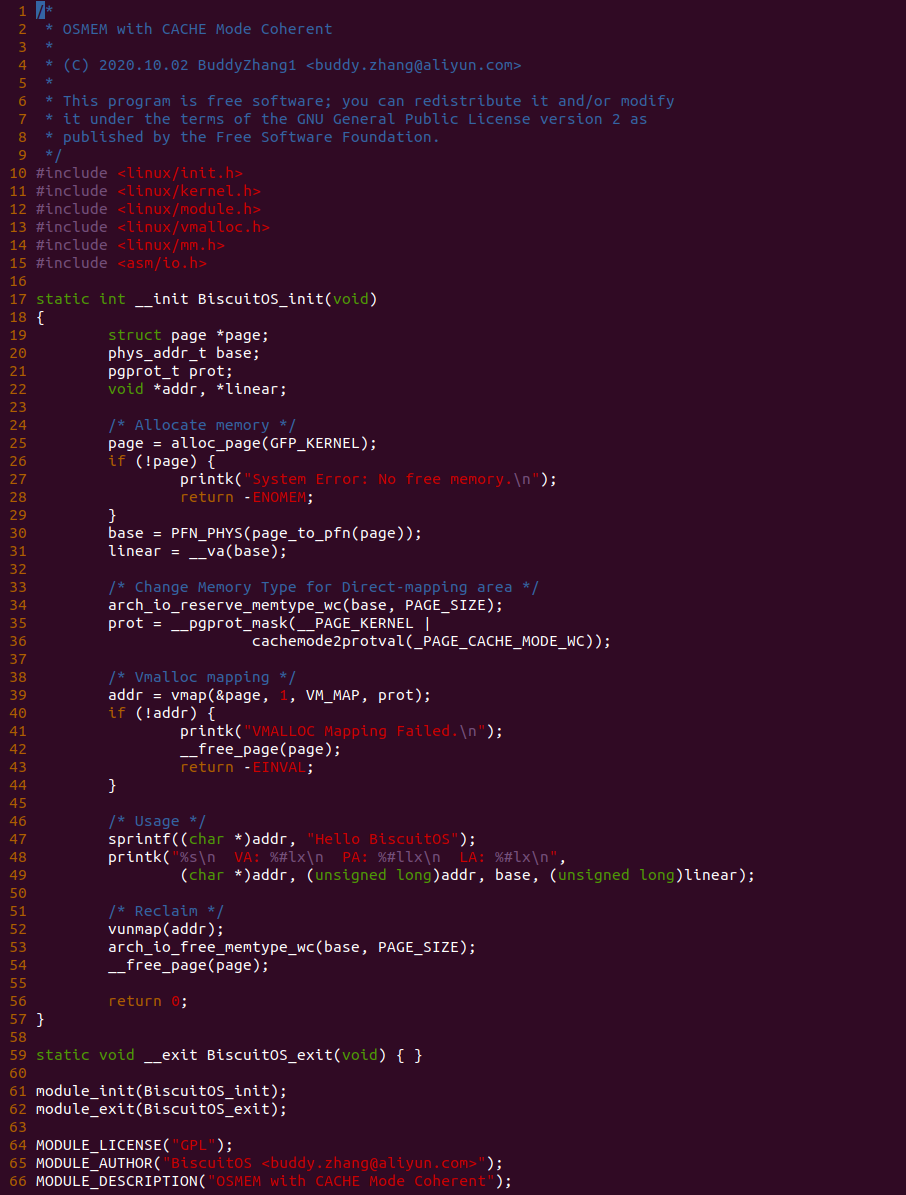
实践案例由一个内核模块组成,其通过 VMALLOC 分配器提供的接口将 VMALLOC 区域的虚拟内存映射到物理页上. 模块首先在 25-30 行从 Buddy 分配器中分配一个物理页,并获得物理页对应的 PFN,这里隐含的物理页被一个线性映射区的内核虚拟地址映射, 31 行将线性映射区虚拟地址存储在 linear 变量. 模块接着在 34 行调用 arch_io_reserve_memtype_wc() 函数将物理页对应的线性映射区的页表修改为 WC,并在 35 设置所需的 CACHE MODE 放到页表里,模块接着在 39-44 行调用 vmap() 函数将 VMALLOC 虚拟内存映射到物理页上,此时物理页被两个虚拟内存映射,最后在 47-54 行使用了内存并回收内存。接下来在 BiscuitOS 上进行实践:
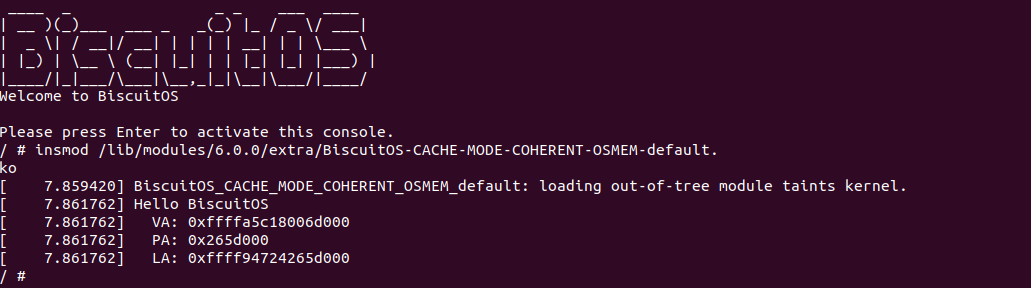
BiscuitOS 系统启动过程中,先加载 BiscuitOS-CACHE-MODE-COHERENT-OSMEM-default.ko 模块,此时模块打印了物理的物理地址和虚拟地址,以及线性映射的虚拟地址,并可以正常使用内存. 实践符合预期,那么接下来将模块 35 行的 CACHE MODE 修改为 _PAGE_CACHE_MODE_WT, 然后再此时实践:
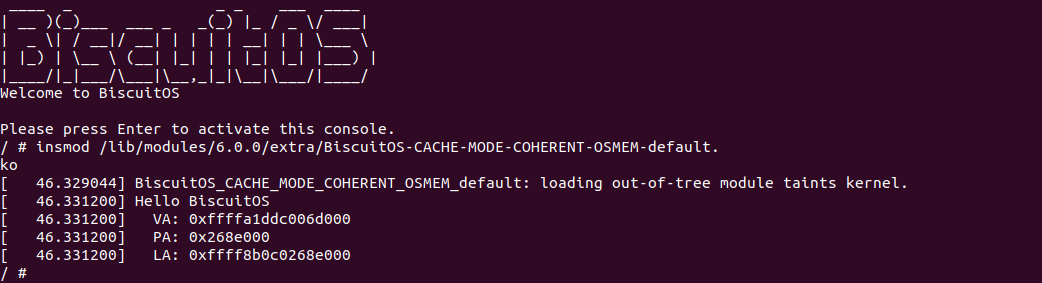
BiscuitOS 系统启动之后,加载驱动,此时系统并没有向之前分析那样打印字符串 x86/PAT: APP:112 map pfn RAM range req write-through for [mem 0x02597000-0x02597fff], got write-combining, 那么是不是意味着映射物理页的 CACHE Mode 不一致? 实践与预期不符合,那么接下来从源码角度进行分析:
假设代码要拦截非一致的 CACHE MODE,那么只可能在配置完所需的 CACHE MODE 之后,那么拦截点应该从 vmap() 函数进行分析,函数由两部分组成,第一部分是 get_vm_area_caller() 函数,其目的是从 VMALLOC 管理的区域中找到一块空闲的虚拟内存. 第二部分是 vmap_pages_range() 函数,其目的是将 VMALLOC 虚拟地址映射到物理页上,查看其调用路径并没有发现任何 CACHE MODE 检查逻辑,那么此处也存在漏洞,需要向主线社区提交修复方案.
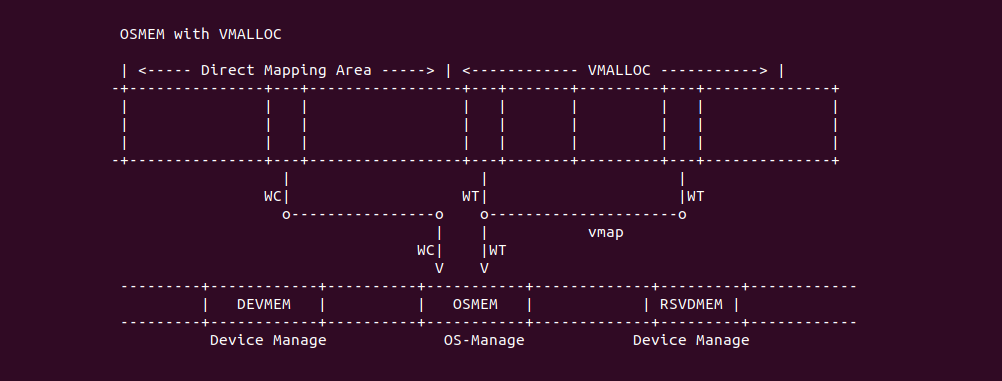
总结: 通过上面的实践分析,系统管理的物理内存大部分都是使用默认的 WB 进行映射,因此通用的接口并不会出现 CACHE MODE 不一致的问题,但如果在特殊场景对 OSMEM 设置了 CACHE MODE 之后,新设置的 CACHE MODE 会与线性映射区的 CACHE MODE 冲突,但 OS 并没有进一步防止 CACHE MODE 不一致,而是无视,因此需要对这个漏洞进行修复.
CACHE Mode Coherent With OSMMIO
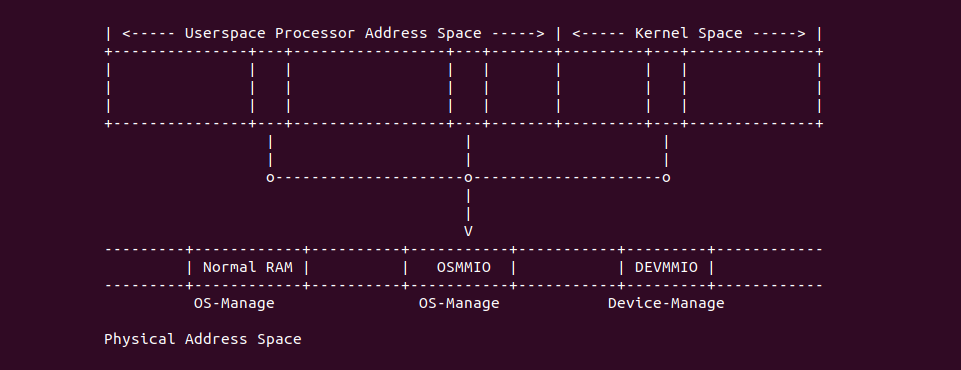
在 Linux 中,外设将其 IO 映射到系统物理地址空间之后形成了 MMIO,系统统一管理 MMIO,并在内核空间提供了统一的接口管理、分配、映射和回收 MMIO. 内核线程可以通过统一的接口分配到 MMIO,然后将内核空间虚拟地址映射到 MMIO,因此在映射过程中可以根据需求配置不同的 CACHE Mode. 内核为内核线程提供而来 IOREMAP 接口用于映射 OSMMIO,在映射过程中可以配置所需的 CACHE MODE,那么 OS 如何保证 CACHE MODE 的一致呢? 首先通过一个实践案例了解问题背景,然后在进一步源码分析根本原因,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] IOREMAP: Change CACHE Mode with IOREMAP Mechanism --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-IOREMAP-CHANGE-MEMTYPE-default/
# 部署源码
make download
# 在 Broiler 中实践
make broilerBiscuitOS-CACHE-IOREMAP-CHANGE-MEMTYPE-default Source Code on Gitee
源码很精简,通过一个内核模块进行讲解,模块首先在 20-25 行描述了 MMIO 资源信息,然后在 33-35 行通过调用 request_resource() 函数将该 MMIO 资源注册到系统物理空间资源树,接着模块在 35 行调用 ioremap_wt() 函数将 BROILER_MMIO_BASE 起始长度为 BROILER_MMIO_LEN 的 MMIO 区域映射到内核空间,并且 Memory Type 为 WT,并将映射之后的虚拟地址存储在 mmio 变量里,接下来就是在 42 行调用 ioremap_uc() 函数改变 MMIO Memory Type 为 UC。由于需要外设才能完成实践,因此可以使用 Broiler 进行实践,直接执行命令 “make broiler”,其在 Broiler 上的实践如下:
当 BiscuitOS 运行之后,加载 BiscuitOS-CACHE-IOREMAP-CHANGE-MEMTYPE-default.ko 模块,接下来查看 pat_memtype_list 节点,以此查看系统 MMIO 区域采用的 Memory Type,此时看到 [0xF0000000, 0xF0004000) 区域 Memory Type 为 write-through, 但 [0xF0000000, 0xF0001000) 区域 Memory Type 为 write-through, 此时 IOREMAP 并没有修改 Memory Type 成功,从另外一个层面思考,如果一个物理地址被多个虚拟地址映射,如果每个都映射不同的 Memory Type,这样会引起混乱,因此 IOREMAP 在这种场景下的做法如下:
IOREMAP 在 85 行调用 interval_iter_first() 函数在 memtype_rbroot 区间树内查找包含 [start, end) 的区间,当找到之后获取该区间的 Memory Type,该场景下新的 Memory Type 和当前 Memory Type 不相等,且新的 Memory Type 不为空,那么 IOREMAP 的做法是将新修改 MMIO 区域的 Memory Type 覆盖成当前 Memory Type,以此保证不同虚拟地址映射同一个 MMIO 时 Memory Type 是一致的. IOREMAP 在 95 行调用 interval_iter_next() 函数将新增加的区域插入到区间树内. 最后就看到实践过程中看到的新增的区域为独立区域,但 Memory Type 与当前一致.
在 __ioremap_caller() 函数主体逻辑里,IOREMAP 机制根据 CACHE MODE 为映射构造不同的页表属性,CACHE MODE 通过 cachemode2protval() 函数转换成页表对应的 PAT 属性集,最终拼接成映射所需的页表属性集. 另外可以看出 IOREMAP 机制只支持 WT、WC、WB、UC 和 UC-,默认 CACHE MODE 为 UC.
当 IOREMAP 机制解除虚拟地址对 MMIO 的映射时,需要将映射 Memory Type 一同解除,其代码流程如上图,IOREMAP 首先调用 find_vma_area() 函数找到对应的 vm_struct 数据结构,然后获得对应的物理地址,接下来通过调用 memtype_free() 函数移除 MMIO 区域的 Memory Type,最后调用 remove_vm_area() 函数是否虚拟内存.
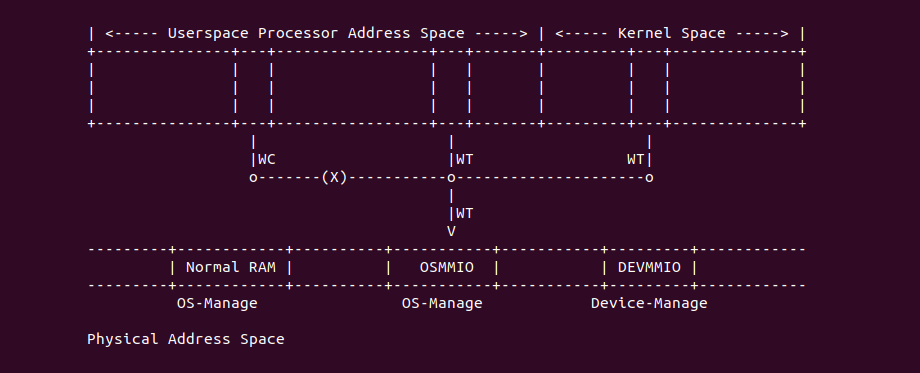
总结: IOREMAP 机制可以确保 OSMMIO 不会出现 CACHE MODE 不一致的情况,其依赖 memtype_rbroot 区域树维护的信息,确保预期的 CACHE MODE 最终和当前 CACHE MODE 一致. 因此内核线程可以放心使用 IOREMAP 提供的接口配置不同的 CACHE MODE.
CACHE Mode Coherent With DEVMMIO
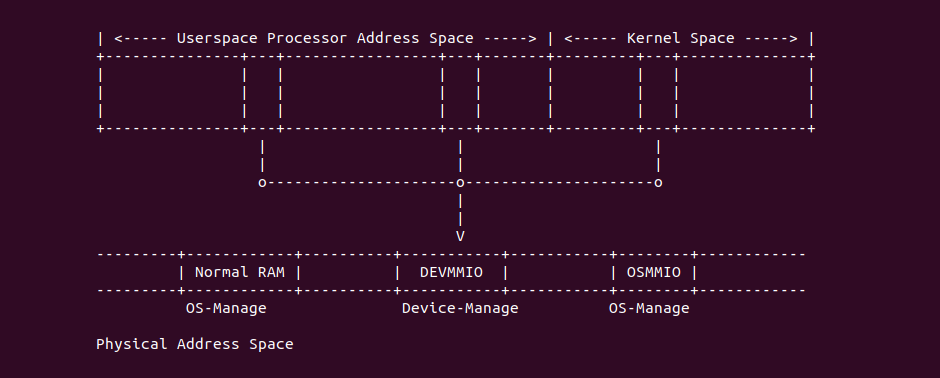
从管理角度 MMIO 可以分为系统管理的 MMIO 和设备管理的 MMIO(DEVMEM), 本节讲解设备管理的 MMIO(DEVMEM), 用户进程或内核线程想访问设备管理的 MMIO,那么同样需要将其虚拟地址映射到 MMIO 上,此时可以在页表中配置所需的 CACHE Mode. 当多个用户进程将其虚拟地址映射到 MMIO 之后,系统如何保证 CACHE MODE 是一致的? 接下来先通过一个实践案例了解整个映射过程,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] Coherent: CACHE MODE Coherent for DEVMMIO --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-MODE-COHERENT-DEVMMIO-default/
# 部署源码
make download
# 在 Broiler 中实践
make broilerBiscuitOS-CACHE-MODE-COHERENT-DEVMMIO-default Source Code on Gitee
实践案例由两部分组成,内核部分如上图,模块在 21-26 行通过 struct resource 数据结构描述了 MMIO 信息,然后通过一个 MISC 框架向用户空间提供 “/dev/BiscuitOS-MMIO” 接口,框架仅实现了 mmap 接口,因此当用户进程调用 mmap() 函数之后会调用到 BiscuitOS_mmap() 函数。在 BiscuitOS_mmap() 函数里首先在 33 行将页表的 PAT 属性清除,然后将 vma 的 vm_pgoff 中存储的 enum page_cache_mode 信息,通过 cachemode2protval() 函数转换成页表的 PAT 属性集,并与 vma 的 vm_page_prot 合并成最终的页表属性集,函数最终调用 io_remap_pfn_range() 函数建立最终的页表.
实践案例的另外一部分由两个应用程序组成,程序实现如上图. 应用程序为 app.c 和 app1.c,两个程度的代码基本相同,只有在 35 行处有差异. 程序首先在 23-31 行定义了多种 CACHE MODE,并在 35 行设置要映射的 CACHE MODE, app.c 设置为 WT,app1.c 则设置为 WC,接着在 40 行函数调用 open() 函数打开 ‘/dev/BiscuitOS-MMIO’ 节点,然后在 47-57 行调用 mmap() 函数将 MMIO 区域映射到进程的地址空间,可以看到 mmap() 函数的最后一个参数是 ‘pcm « 12’, 即将 CACHE MODE 传入到设备. 接下来就是对映射之后的 MMIO 进行访问,最后就是解除映射以及关闭 ‘/dev/BiscuitOS-MMIO’ 节点. 由于需要硬件支撑才能完成实践,因此可以在 Broiler 上进行实践,直接运行 ‘make broiler’ 命令即可:
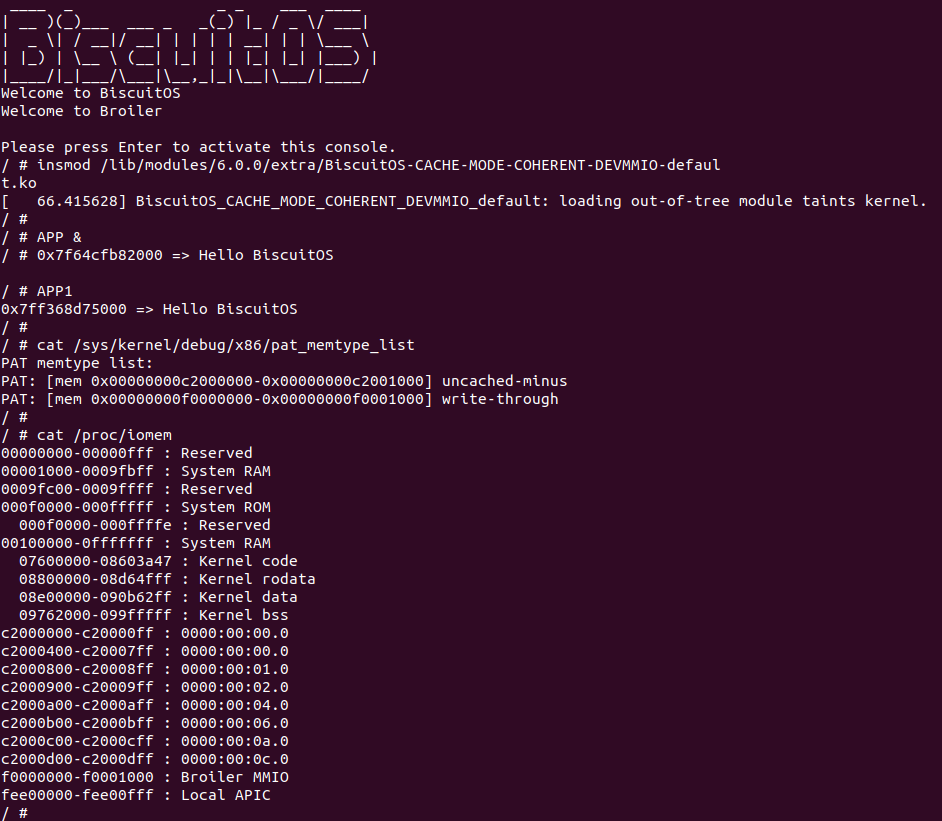
当 BiscuitOS 运行之后,加载 BiscuitOS-CACHE-MODE-COHERENT-DEVMMIO-default.ko 模块,然后运行 APP 和 APP1 程序,可以看到可以正常访问, 接下来查看 pat_memtype_list 节点,以此查看系统 MMIO 区域采用的 Memory Type,此时看到 [0xF0000000, 0xF0001000) 区域 Memory Type 为 write-through, APP1 设置的 CACHE MODE 失效了, 实践不符合预期. 接下来通过代码进一步分析:
当用户进程调用 mmap() 映射 MMIO 时,最终会调用到 BiscuitOS_mmap() 函数,函数核心是调用 io_remap_pfn_range() 函数,但其只是 remap_pfn_range() 的一层包装,那么核心做了两个事,第一件事就是通过调用 track_pfn_range() 函数在 memtype_rbroot 区间树中查看指定的 MMIO 区域是否存在,如果存储其对应的 CACHE Mode 是否与预期要设置的 CACHE MODE 冲突,如果冲突那么系统将提示并预期的 CACHE Mode 设置为当前 CACHE Mode. 第二件事就是建立页表,其调用 remap_pfn_range_notrack() 函数,该函数会将预期的 CACHE Mode 最终写入到页表里.
在 memtype_check_insert() 函数会调用 memtype_check_conflict() 函数,该函数从 memtype_rbroot 区间树中获得区间当前的 Memory Type,然后与预期的 Memoy Type 进行比较,如果不相同则进入 92 行之后的逻辑,因此此时 newtype 不为空,那么函数使用当前 Memory Type 区覆盖预期的 Memory Type,这样就可以保证 CACHE Mode 的一致.
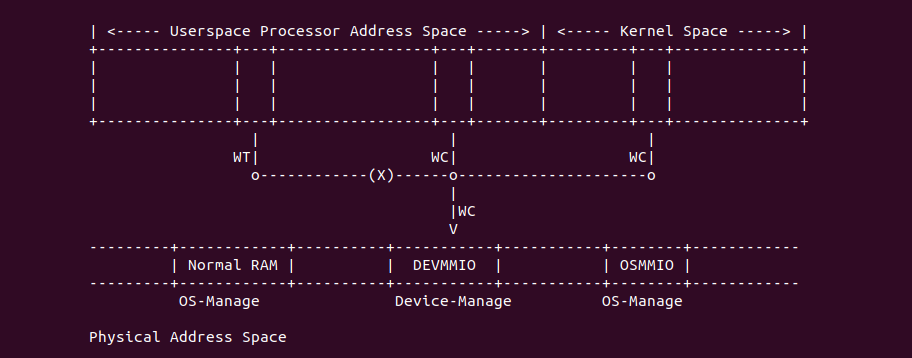
总结: DEVMMIO 是可以确保在多个虚拟地址之间保持 CACHE Mode 一致的,当新建立的页表的 CACHE Mode 与当前正在使用的 CACHE Mode 冲突时,DEVMMIO 将继续采用正在使用的 CACHE Mode,然后将预期的 CACHE MODE 修改为当前 CACHE MODE.

CACHE on PageTable
当系统开启保护模式之后,系统直接访问的内存由物理内存变成了虚拟内存,虚拟内存就想其名字一样,并不是真实的内存,而是硬件提供的一种内存访问机制。在没有虚拟内存之前,系统直接访问物理内存,那么所有进程都可以看到同一个物理内存,那么对于多个进程的内存使用和保护带来了很多问题。虚拟内存出现之后,每个进程都有自己的内存空间,而且进程独占自己的内存空间,另外虚拟内存具有保护机制,可以防止进程的无权限的非法操作。虚拟内存硬件上通过一些列分层的映射关系与物理内存建立连续,这里可以将映射关系称为页表. 因此在现代操作系统里,CPU 直接访问虚拟内存,然后由硬件基于页表透明的转换成对指定物理内存的访问.
页表在不同的架构中组成存在一定的差异,但其主要由两部分组成,第一部分是物理地址偏移,其记录了下一级页表的物理地址偏移或者物理内存起始地址偏移,基于分层的页表结构,页表分成了很多级,每一级页表都会记录下一级页表对应物理地址的偏移,最后一级页表则记录物理页起始物理地址偏移; 第二部分则是页属性(Page Attribute),其存在很多字段,每个字段用于控制虚拟内存对物理内存的访问,例如只读、只有用户进程可以访问、CACHE Mode 等. 结合 CACHE 的主题,本节主要讲解页表如何控制 CACHE MODE.
在《Intel® Page Attribute Table(PAT) Technology》 和《Intel® Memory Type Range Registers(MTRRs) Technology》 章节分析过,在 X86 架构, 硬件上提供了 PAT 和 MTRRs 机制可以在页表粒度控制一段虚拟内存的 CACHE Mode,其原理是 MTRRs 机制设置了某段物理内存的 CACHE Mode,然后软件上可以通过在页表的 PAT 字段指定 CACHE Mode,硬件上会将两个 CACHE Mode 进行合并给出最终的 CACHE Mode. 由于 MTRRs 在系统启动的时候将所有的物理内存都设置成 WB,那么开发者可以通过在页表中配置指定的 PAT 就可以配置某段虚拟内存的 CACHE Mode.
例如 PAT 按 4KiB 线性地址设置映射物理内存的 CACHE Mode,那么在 PTE 页表中存在 PWT、PCD、PAT 三个标志位,系统或者软件可以通过设置 3 个标志位,使映射的物理内存采用不同的 CACHE Mode. 假设 PAT 按 2MiB 线性地址设置映射物理内存的 CACHE Mode,那么 PDE 页表中的 PWT、PCD、PAT 三个标志位起作用, 其他粒度依次类推.
页表中的 PAT、PCD、PWD 排列组合可以形成不同的 PAT Entry, 每个 PAT Entry 对应不同的编码值. 页表中设置好三个标志位之后,PAT 机制会根据 PAT Entry 找到对应的编码.
PAT 采用 IA32_PAT MSR 寄存器为了所有的 PAT Entry,上图为该寄存器的位图,每 8 bit 一组,从低到高依次为 Entry 编号,页表中的 PAT、PCD、PWT 组合选择的 PAT Entry X 即该寄存器里的 PAx. 系统在初始化过程中,会为每个 PAx 填入 CACHE Mode 对应的编码,也就是说 PAx 里可以灵活的填入系统所规划的 CACHE Mode.
IA32_PAT MSR 寄存器每组 PAx 所支持的 CACHE Mode 编码如上图,例如系统软件想让 PA0 里的 CACHE Mode 为 WT,那么 PA0 里的值为 04H,另外页表向将虚拟地址映射的物理内存 CACHE Mode 设置为 WT,那么页表的 PAT、PCD、PWT 组合选择 PAT0 即可, 这样极大的提高了 PAT 设置的灵活性.
当通过页表的 PAT、PWT、PCD 三个标志位选择了线性地址映射物理内存的 CACHE Mode 之后,该 CACHE Mode 还不是最终生效的 CACHE Mode,硬件上会找到线性地址映射物理内存对应的 MTRRs 设置,从而获得 MTRRs 对应的 CACHE Mode,此时硬件将 MTRRs 和 PAT 获得的 CACHE Mode 按上表结合生成最终的 CACHE Mode. 接下来从不同的角度,对 CACHE Mode 对 Page Table 的影响进行分析,并提供多个实践案例讲解如何对涉及内容的使用:
CACHE Mode on PageTable PAT Attribute
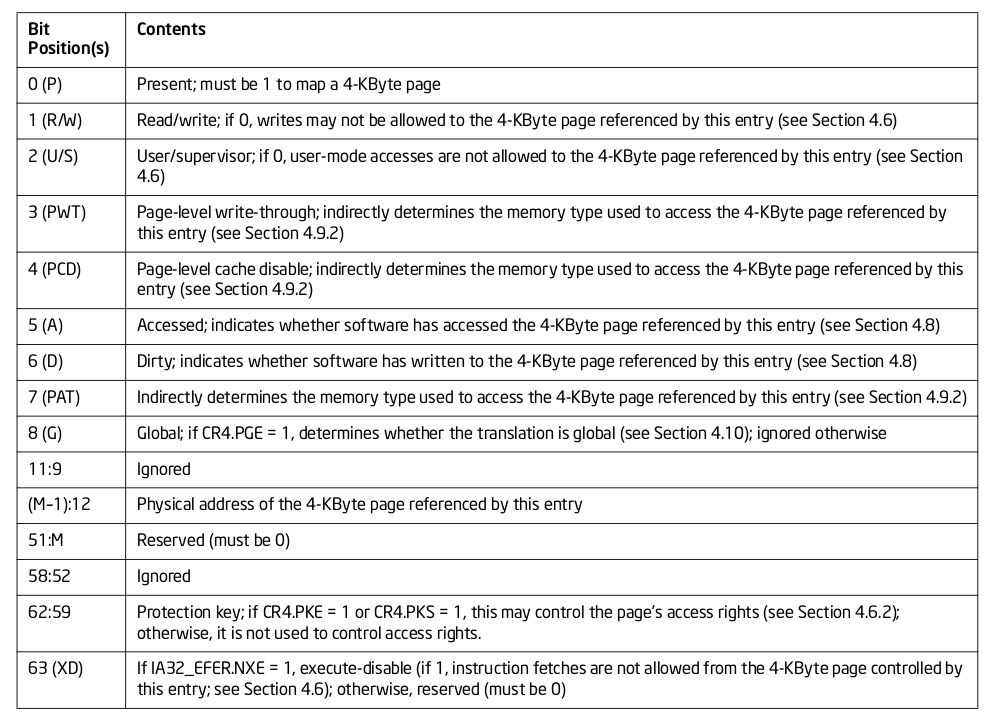
通过上面的分析,那么接下来分析 X86 架构下 Linux 如何通过页表控制虚拟内存的 CACHE MODE. 上图是 X86 架构中最后一级页表 PTE 的位图, 页表映射了 4KiB 的物理页,其中 Bit7 为 PAT 标志位、Bit4 为 PCD 标志位以及 Bit3 为 PWT 标志位,三者结合可以定义 4KiB 虚拟内存的 CACHE Mode,那么接下来通过一个实践案例讲解如何通过 PAT 标志集合配置 4KiB 虚拟内存的 CACHE MODE, 其在 BiscuitOS 上的部署逻辑是:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] PAGE Table: Setup CACHE Mode [Default] --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-PAGE-TABLE-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build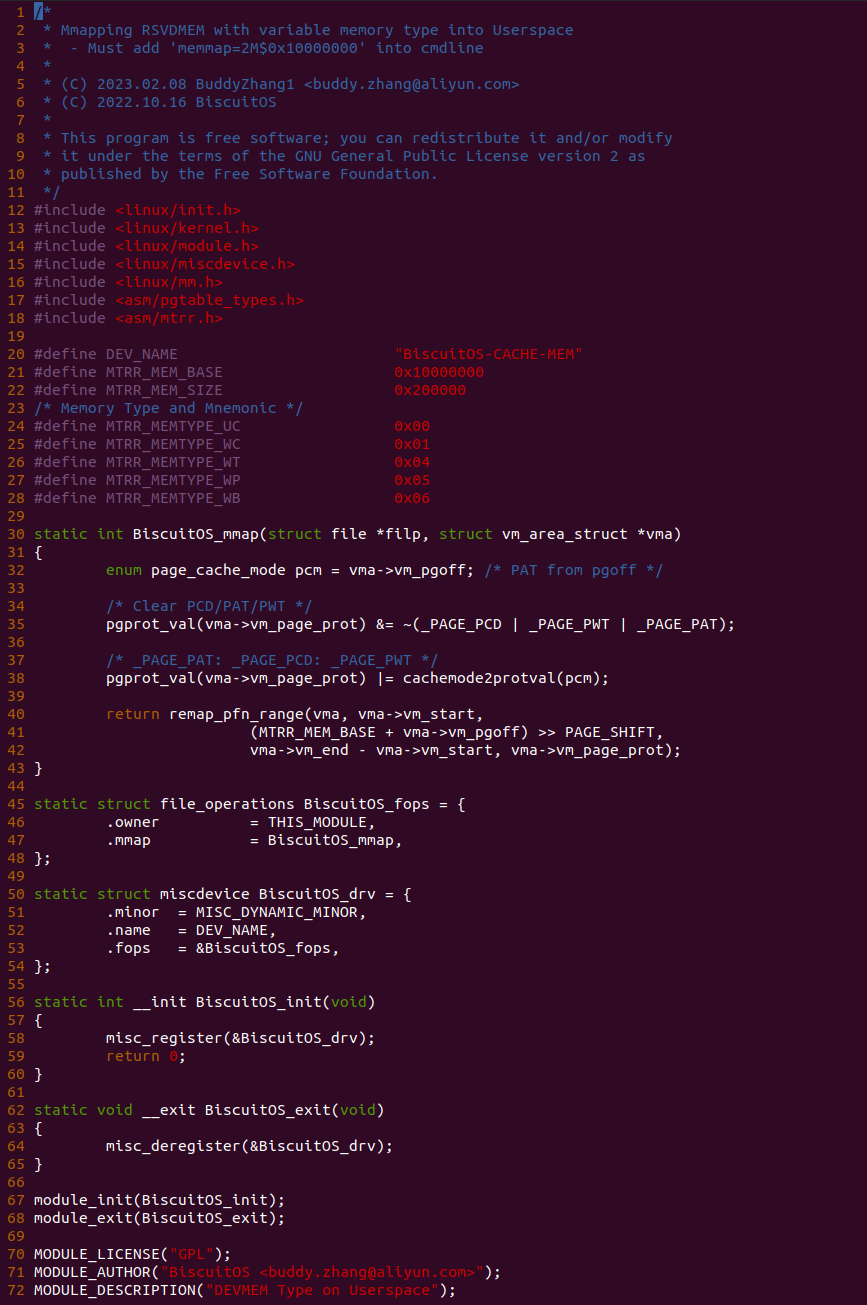
实践案例由两部分组成,内核部分部分如上图,模块主体由一个 MSIC 设备构成,其向用户空间提供了 mmap 接口,当用户空间打开设备节点 “/dev/BiscuitOS-CACHE-MEM” 之后,调用 mmap() 函数最终会调用到 BiscuitOS_mmap() 函数。在 BiscuitOS_mmap() 函数中,32 行从 VMA 的 vm_pgoff 成员中获得用户空间传递来的 CACHE MODE, 进程将虚拟地址配置的页表信息存储在 VMA 的 vm_page_prot 成员里,因此 35 行先将页表里的 PAT 属性集先清除掉,然后在 38 行调用 cachemode2protval() 函数将用户空间传递的 CACHE Mode 转换成对应的 PAT 属性集,并存储在 vm_page_prot 成员里,函数最后调用 remap_pfn_range() 函数将虚拟地址与 MTRR_MEM_BASE 物理内存建立页表,并将 vm_page_prot 值填充到页表里.
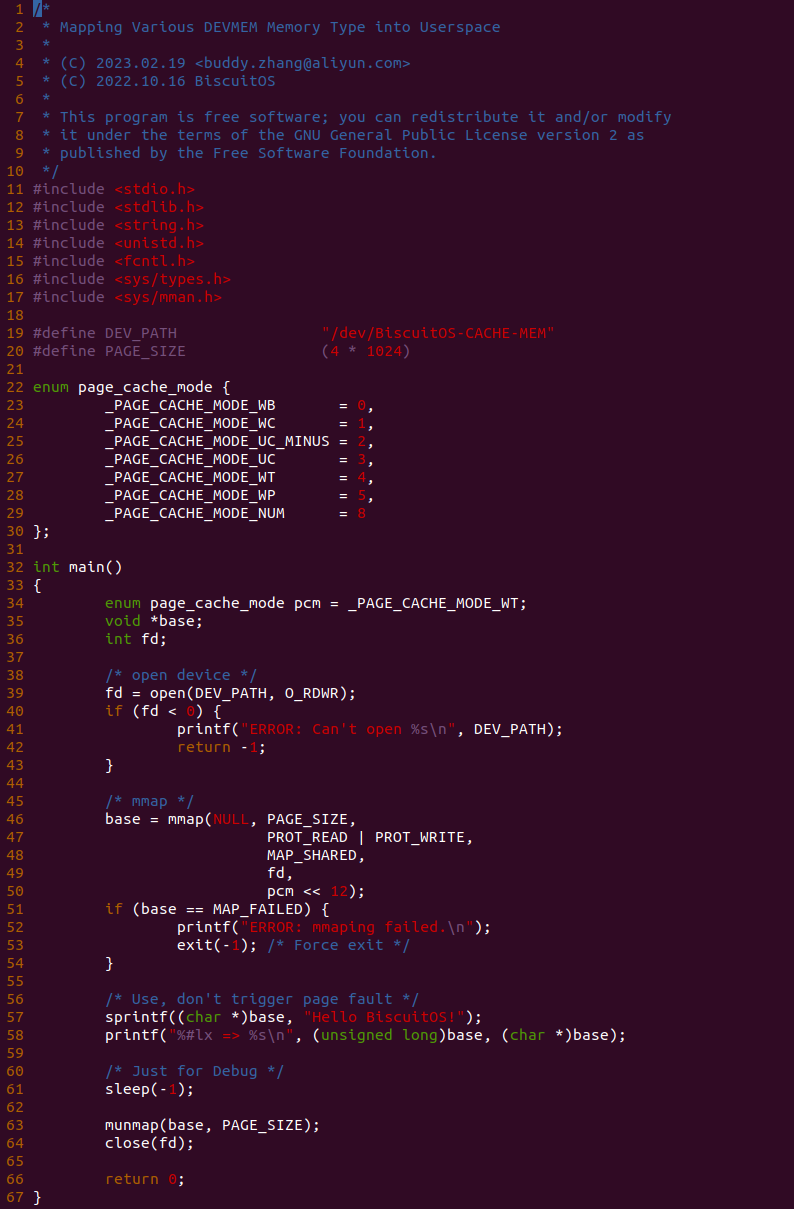
实践案例的另外一部分是一个应用程序,其在 22-30 行定义了多个 CACHE MODE,然后在 34 行将虚拟内存需要配置的 CACHE Mode 设置为 WT,接着在 39 行通过 open() 函数打开 “/dev/BiscuitOS-CACHE-MEM” 节点,然后调用 mmap() 函数进行内存分配,此时将 CACHE Mode 传递到 mmap() 函数最后一个参数,当映射成功之后就是在 57-58 行使用内存,最后使用完毕之后释放内存, 为了进行代码延时,在 61 行调用 “sleep(-1)” 是程序不退出. 接下来在 BiscuitOS 上实践案例,实践之前记得在 RunBiscuitOS.sh 脚本里的 CMDLINE 添加 “memmap=2M$0x10000000” 字段:
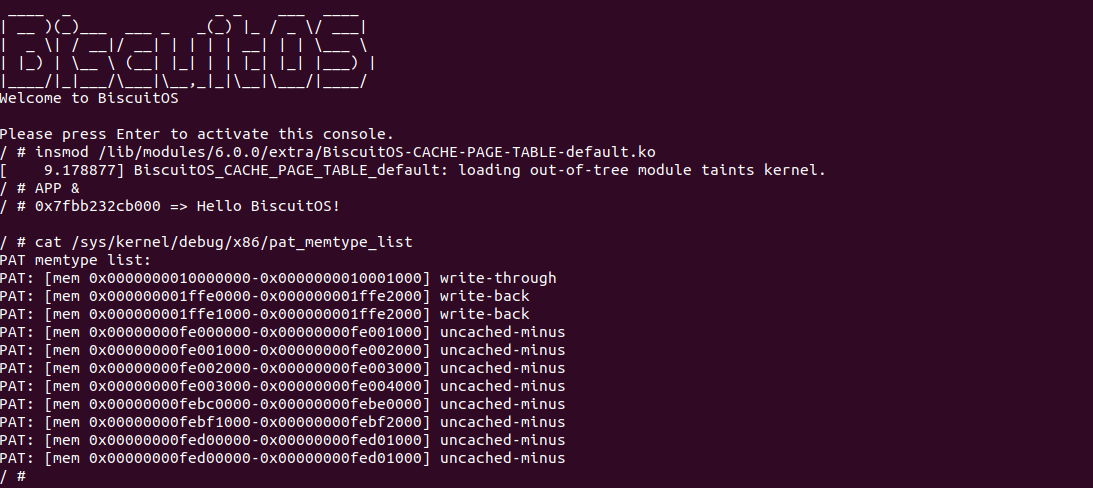
当 BiscuitOS 运行之后,加载 BiscuitOS-CACHE-PAGE-TABLE-default.ko 模块,然后运行后台运行 APP,可以看到可以正常访问, 接下来查看 pat_memtype_list 节点,此时看到 [0x10000000, 0x10001000) 区域 CACHE Mode 为 write-through, 实践不符合预期. 接下来通过代码进一步分析:
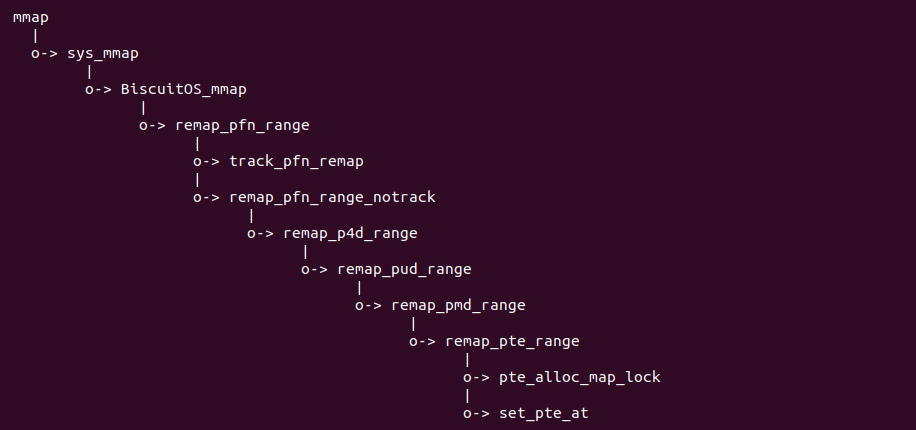
当用户空间打开 “/dev/BiscuitOS-CACHE-MEM” 节点之后,然后调用 mmap() 函数,其最终会调用到 BiscuitOS_mmap() 函数,函数的核心是通过调用 remap_pfn_range() 函数实现的,其中 track_pfn_remap() 函数检查映射物理区域的 CACHE MODE,并将物理区域的 CACHE Mode 信息添加到系统 RBTree 里,remap_pfn_range_notrack() 函数的目的是建立页表,可以看出函数的逻辑是在一级一级的查询页表,直到查到最后一级页表 PTE 时将 BiscuitOS_mmap() 配置的 PAT 属性集与页表属性一同写入到 PTE Entry 里. 当页表建立完毕之后,应用程序不需要通过缺页异常就可以直接访问虚拟内存.
在 X86 架构支持的 4-Level 或 5-level 页表的场景,CR3 寄存器存储了当前进程所使用页表的入口,也就是 MMU 在遍历页表时首先从 CR3 获得第一级页表的信息。上图是 CR3 寄存器的位图,可以看到其也包含了 PWT 和 PCD 标志位,标志位用于指明下一级页表对应物理页的 Memory Type(CACHE MODE), 细心的读者可能发现其没有 PAT 标志位,那么基于这种情况,架构采用了另外一种计算方式:
当不支持 PAT 是,PCD 和 PWT 标志位结合 MTRRs 计算出有效的 Memory Type,例如上图中 MTRRs 将某段物理内存区域的 Memory Type 设置为 WB,那么此时 CR3 寄存器里 PCD 和 PWT 标志位都清零,那么最终下一级页表的物理页 Memory Type 为 WB. 同理依次查看其他级页表:
在 5-Level 页表架构中,CR3 指向了 PML5 页表所在的物理页,PML5 页表的 Entry 指向了下一级页表 PML4, 上图是 PML5 页表的位图,可以看到其只包含了 PCD 和 PWT 标志位,那么不支持 PAT 标志位,因此只需 PCD、PWT 和 MTRRs 就可以计算出 PML4 页表所在物理页的 Memory Type.

上图为 PML4 页表的位图,其也只包含了 PWT 和 PCD 标志位,PML4 Entry 指向了 PDPTE 页表,同理 PWT、PCD 和 MTRRs 就可以计算出 PDPTE 页表所在物理页的 Memory Type.

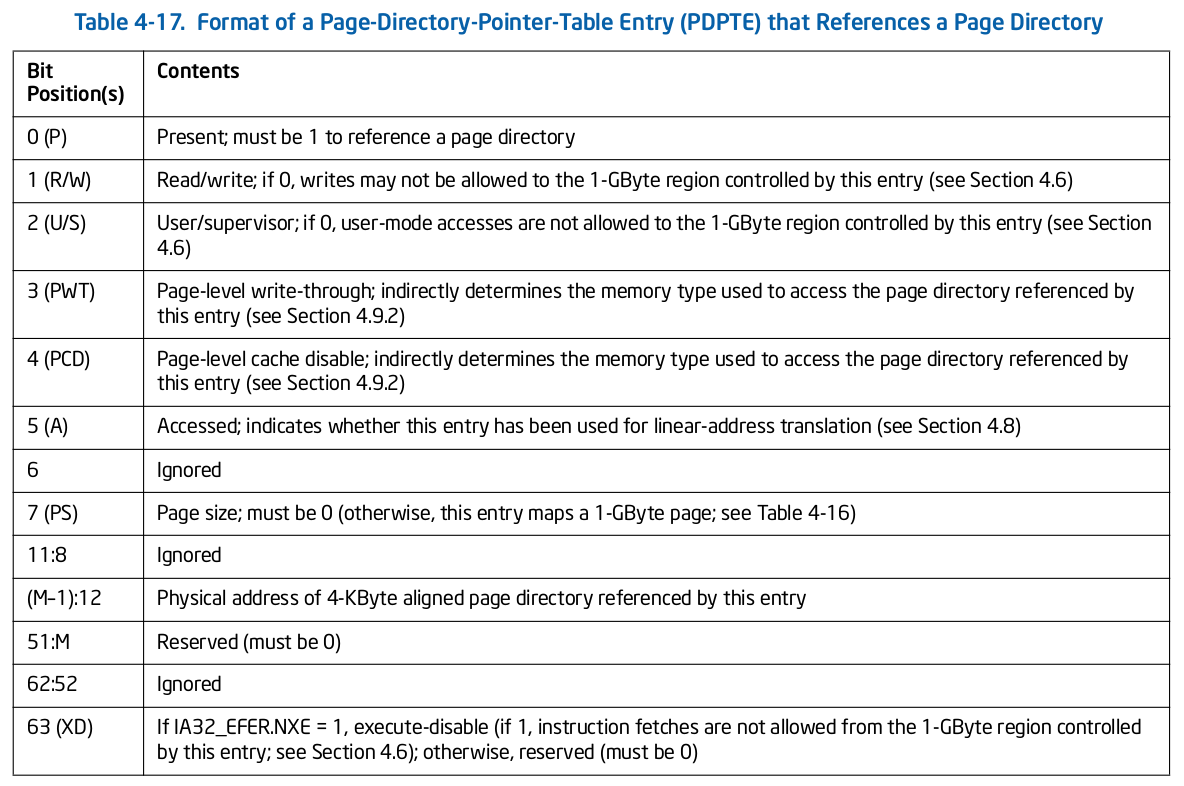
PDPTE 页表存在两种位图,当 PS 标志位置位之后,那么 PDPTE 则用于映射 1Gig 的内存区域,那么其包含了 PAT、PCD 和 PWT 标志位,那么 1Gig 物理页的 Memory Type 需要 PAT、PCD、PWT 和 MTRRs 计算; 当 PS 标志位清零,那么 PDPTE Entry 指向下一级页表 Page-Directory 页表的物理页.
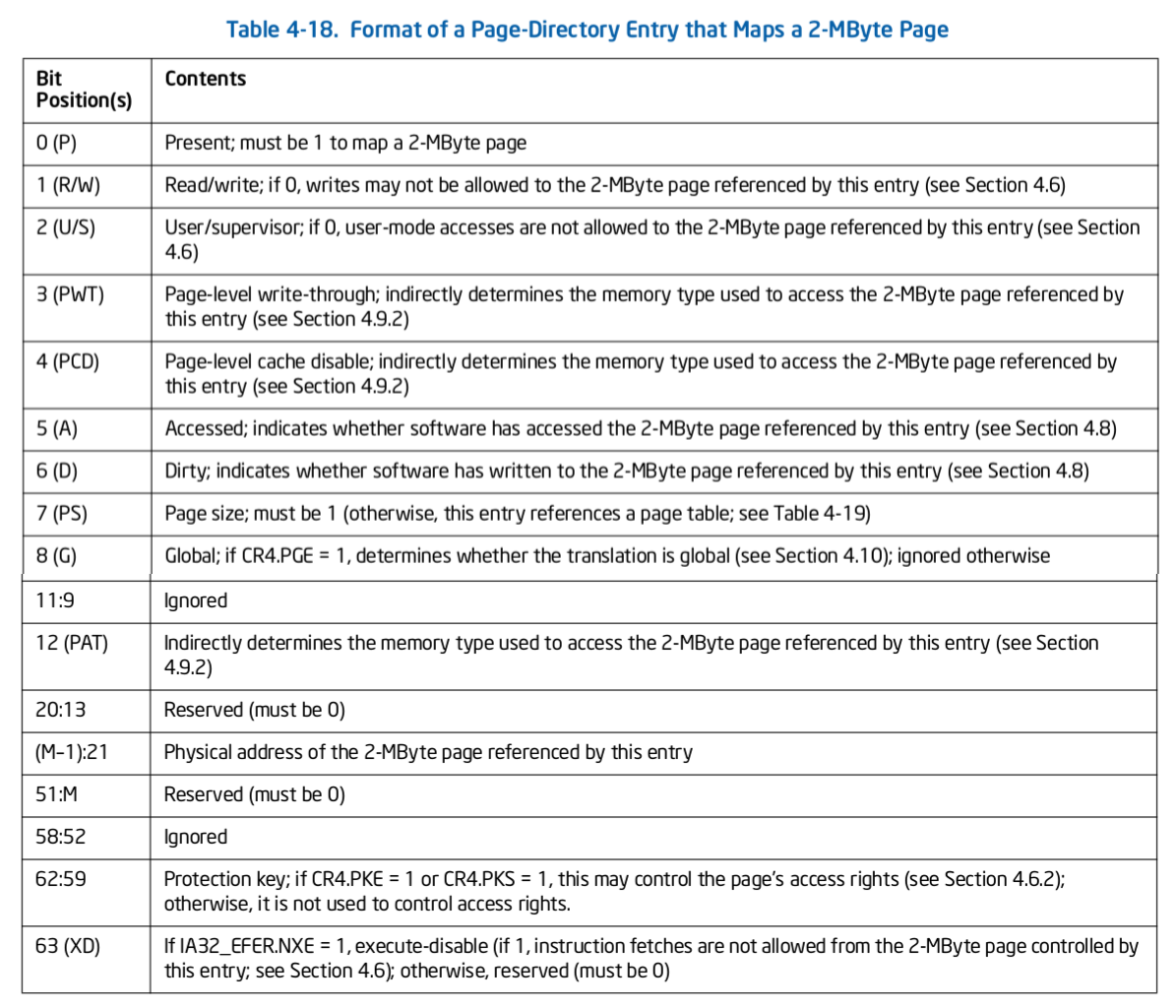

Page-Directory 页表存在两种位图,当 PS 标志位置位,那么 Page-Directory 映射 2MiB 的内存区域,那么其包含了 PAT、PCD 和 PWT 标志位,因此 2MiB 物理页的 Memory Type 需要 PAT、PCD、PWT 和 MTRRs 共同计算; 当 PS 标志位清零,那么 Page-Directory Entry 指向下一级页表 PTE 页表的物理页.

PTE 页表的每个 Entry 映射一个 4KiB 物理页,其 Entry 的位图如上图,可以看到其包含 PAT、PCD 和 PWT 标志位,那么 4KiB 物理页的 Memory Type 需要通过 PCD、PWT、PAT 和 MTRRs 标志位一同计算. 以上便是 CACHE Mode 与 X86 页表之间的关系,接下来分析基于上面的原理,Linux 是如何实现不同 Memory Type 设置.
CACHE Mode on 2MiB PageTable PAT Attribute
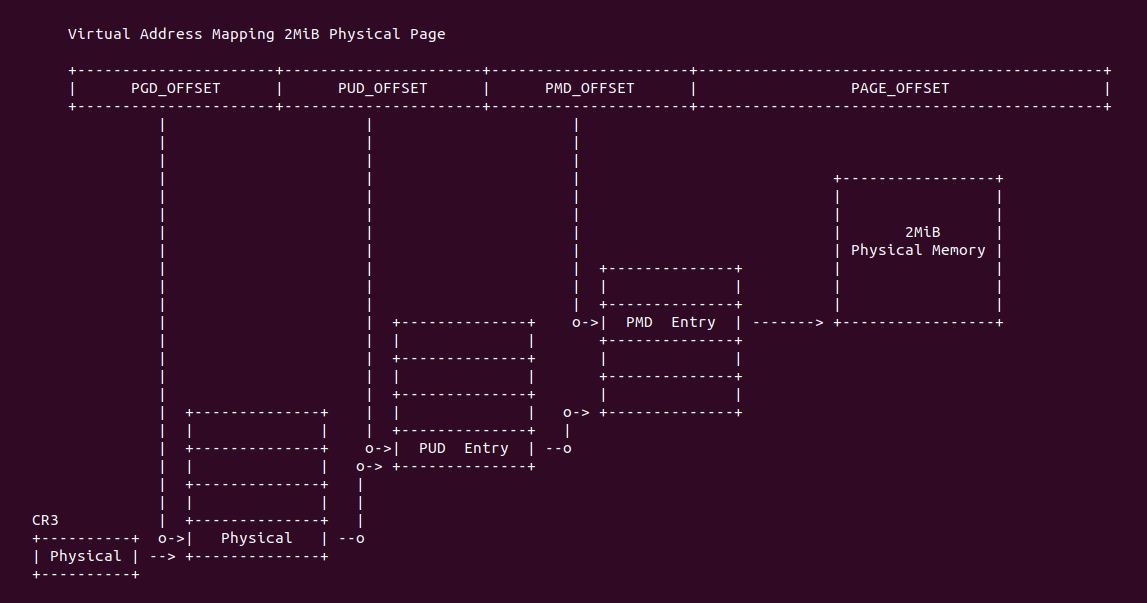
X86 架构支持 2MiB 粒度的页表映射,其使用 Page-Directory Table 维护了很多 PMD Entry,每个 PMD Entry 指向一个 2MiB 的物理区域或者下一级 PTE 页表,因此与其他页表一样,当 PMD Entry 指向 2MiB 物理页时,PMD Entry 内包含了 2MiB 物理页的页帧号以及页表属性,其中就包含了 PAT 相关的信息.
上图是 X86 架构 Page-Directory Entry 的位图,也就是 PMD Entry 的位图,可以看到 PS 标志位必须置位,以此表明页表用于映射 2MiB 物理区域,上图中可以看到 PAT 属性集分别是 PAT、PCD 和 PWT 标志位,那么接下来通过一个实践案例了解一下 PAT 如何影响 2MiB 页表的映射,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] PAGE Table: Setup CACHE Mode on 2MiB RSVDMEM APP --->
<*> PAGE Table: Setup CACHE Mode on 2MiB RSVDMEM --->
# 源码目录
# Module 部分: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-PAGE-TABLE-RSVDMEM-2M-default/
# 用户空间部分: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-PAGE-TABLE-RSVDMEM-2M-APP-default/
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-PAGE-TABLE-RSVDMEM-2M-APP-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make prepare
make buildBiscuitOS-CACHE-PAGE-TABLE-RSVDMEM-2M-default Source Code on Gitee
BiscuitOS-CACHE-PAGE-TABLE-RSVDMEM-2M-APP-default Source Code on Gitee
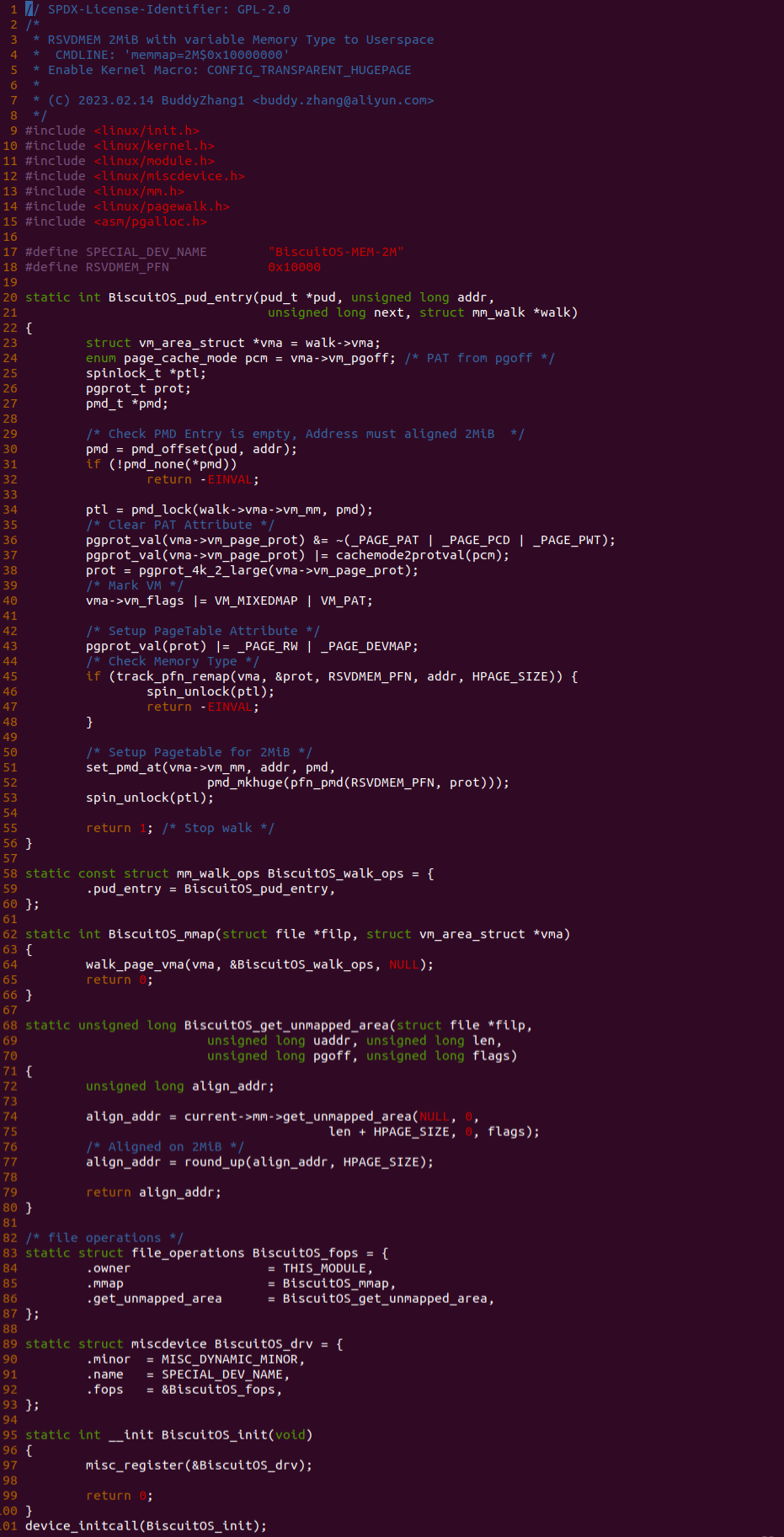
实践案例由两部分组成,内核部分部分如上图,模块主体由一个 MSIC 设备构成,其向用户空间提供了 mmap 接口,当用户空间打开设备节点 “/dev/BiscuitOS-MEM-2M” 之后,调用 mmap() 函数最终会调用到 BiscuitOS_mmap() 函数。在 BiscuitOS_mmap() 函数中,其只提供了 walk_page_vma() 函数,该函数用于遍历页表,向该函数传入了 BiscuitOS_walk_ops, 可以在 58-60 行看到其仅仅提供了 pud_entry 的实现接口,那么 walk_page_vma() 在遍历到 PUD 页表的时候会调用 BiscuitOS_pud_entry() 函数. BiscuitOS_pud_entry() 函数的主要功能是建立 2MiB 页表映射. 在 30 行调用 pmd_offset() 函数从 PUD 页表中获得 PMD Entry,并调用 pmd_none() 查看 PMD Entry 是否为空,如果不为空,那么表示 PMD Entry 映射了非 2MiB 的页,但此时认为 PMD Entry 为空,因此非空情况直接返回 EINVAL。PMD Entry 为空的情况,在 34 行获得 PMD Entry 的锁,接着 36-38 行用于对 VMA 中自带的 PageTable 属性进行处理,36 行将 PageTable 的 PAT 属性标志全部清除,然后在 37 行调用 cachemode2protval() 函数将用户空间设置的 PAGE MODE 转换成页表 PAT 属性集,然后填充到 VMA 的 vm_page_prot 成员里。由于 vm_page_prot 默认存储 4KiB 页表属性集,因此在 38 行调用 pgprot_4k_2_large() 函数转换成 2MiB 页表属性集. 模块在 40 行向 VMA 添加了 VM_MIXEDMAP 和 VM_PAT 标志,以此告诉 Memory Mapping 机制此次映射是一个特殊的映射,会修改页表的 PAT 属性,需要特殊的处理。43 行向页表中添加了 _PAGE_RW 和 _PAGE_DEVMAP 标志,以此让映射区有读写的权限,_PAGE_DEVMAP 用于表示 DEVMEM 或者 RSVDMEM. 45 行调用 tack_pfn_remap() 函数的目的是检查即将映射物理内存 CACHE Mode 是否和用户空间配置的 CACHE Mode 存在冲突,如果存在,那么保持当前的 CACHE Mode. 最后 51-52 行调用 set_pmd_at() 函数填充 PMD Entry,使其映射 2MiB 的物理内存区域. 最后的最后解除锁.
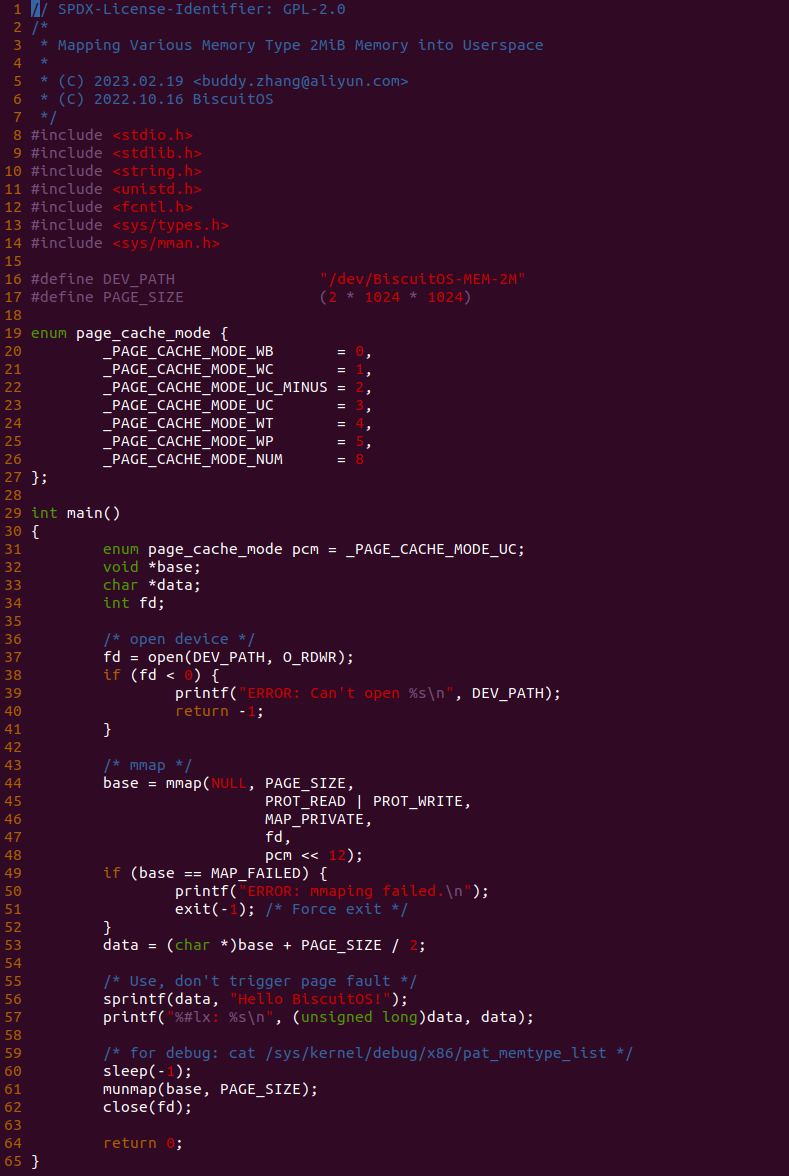
实践案例的另外一部分是一个应用程序,其在 19-27 行定义了多个 CACHE MODE,然后在 31 行将虚拟内存需要配置的 CACHE Mode 设置为 UC,接着在 37 行通过 open() 函数打开 “/dev/BiscuitOS-CACHE-MEM” 节点,然后调用 mmap() 函数进行内存分配,此时将 CACHE Mode 传递到 mmap() 函数最后一个参数,当映射成功之后就是在 56-57 行使用内存, 此时访问 1MiB 处的内存,最后使用完毕之后释放内存, 为了进行代码调试,在 60 行调用 “sleep(-1)” 是程序不退出. 接下来在 BiscuitOS 上实践案例,实践之前记得在 RunBiscuitOS.sh 脚本里的 CMDLINE 添加 “memmap=2M$0x10000000” 字段:
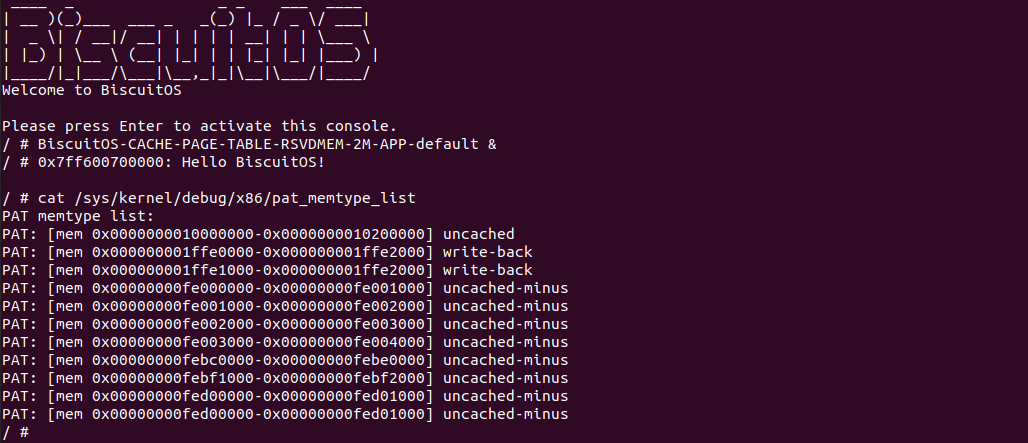
当 BiscuitOS 运行之后,后台运行 BiscuitOS-CACHE-PAGE-TABLE-RSVDMEM-2M-APP-default,可以看到可以正常访问, 接下来查看 pat_memtype_list 节点,此时看到 [0x10000000, 0x10200000) 区域 CACHE Mode 为 uncached, 实践符合预期. 接下来分析一下其实现的原理:
案例代码的函数调用逻辑如上,用户空间调用 mmap() 之后最终调用到 BiscuitOS_mmap() 函数,其调用 walk_page_vma() 函数依次遍历页表,最终遍历到 PUD 页表,此时调用 walk_pud_range() 函数,该函数内可以调用到钩子函数从而进入到 BiscuitOS_pud_entry() 函数,接下来就是建立页表的核心逻辑.
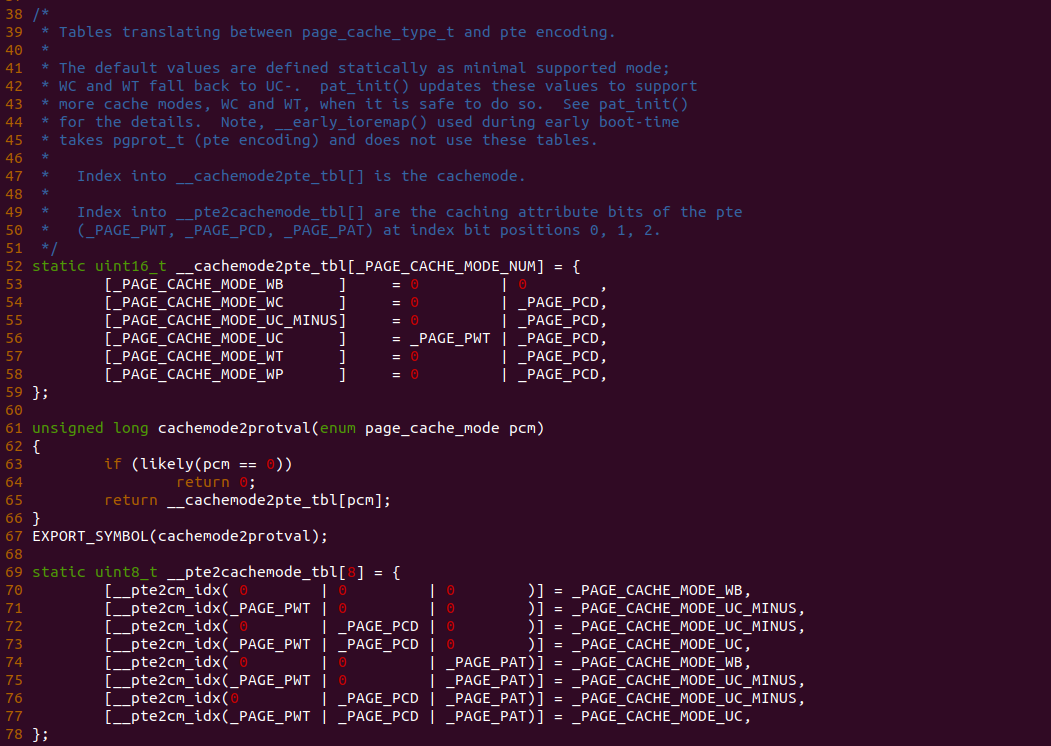
在 X86 架构中,由于 CACHE Mode(Memory Type) 是由 PAT 和 MTRRs 两种机制共同决定的,MTRRs 一般由 BIOS 设置或者在内核启动早期设置,PAT 则根据 IA32_PAT_MSR 寄存器配置,内核为了软件层面使用方便,将三者的关系通过 cachemode2protval() 函数进行转换,软件可以直接传入 page_cache_mode 系统就可以计算出所需的 PAT 页表属性集合.
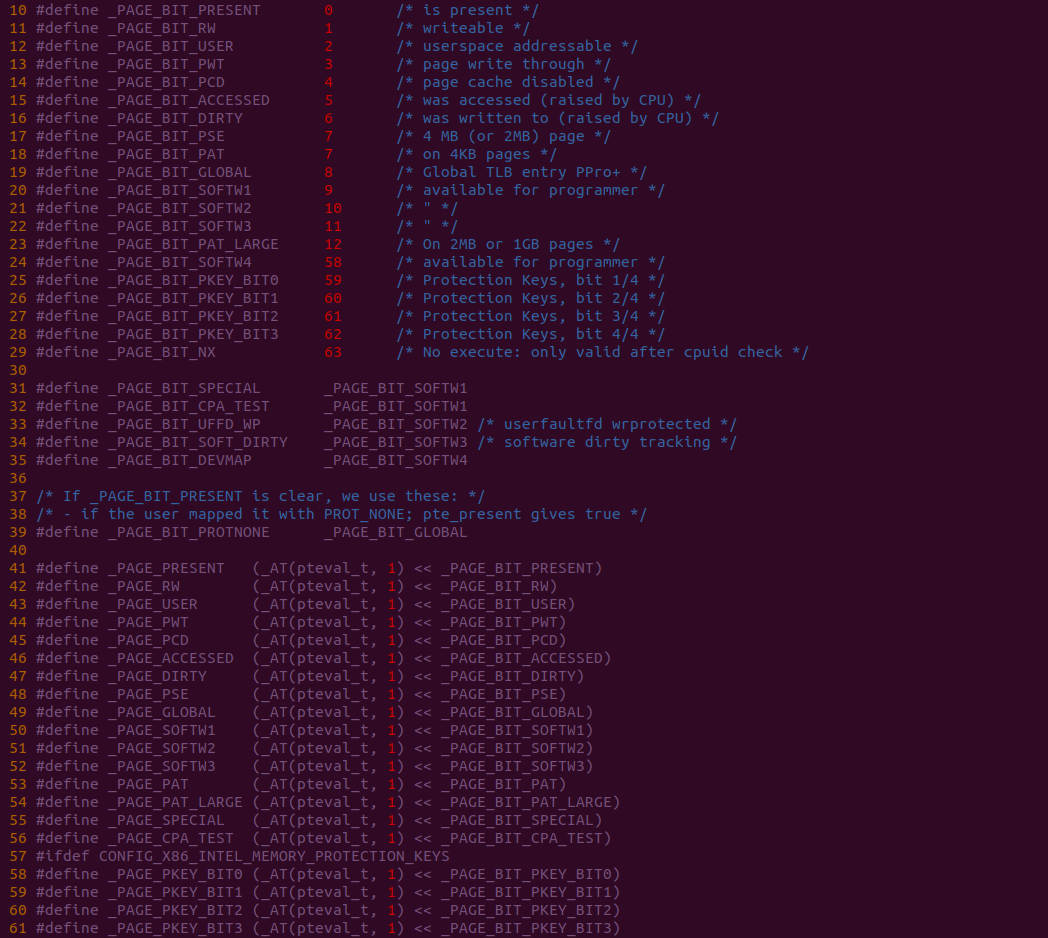
内核定义了多个页表相关的宏,其中可以看到 PAT 相关的 _PAGE_PAT、_PAGE_PWT、_PAGE_PCD 以及 _PAGE_PAT_LARGE 标志位,由于 4KiB 页表与 2MiB 大页的 PAT 标志位位置不同,因此内核提供了 _PAGE_PAT 和 _PAGE_PAT_LARGE. 默认情况下 Memory Mapping 机制传递的页表属性都是 4KiB 页表的,因此内核提供了 pgprot_4k_2_large() 函数用于 4KiB 页表属性与 2MiB 页表属性的转换.
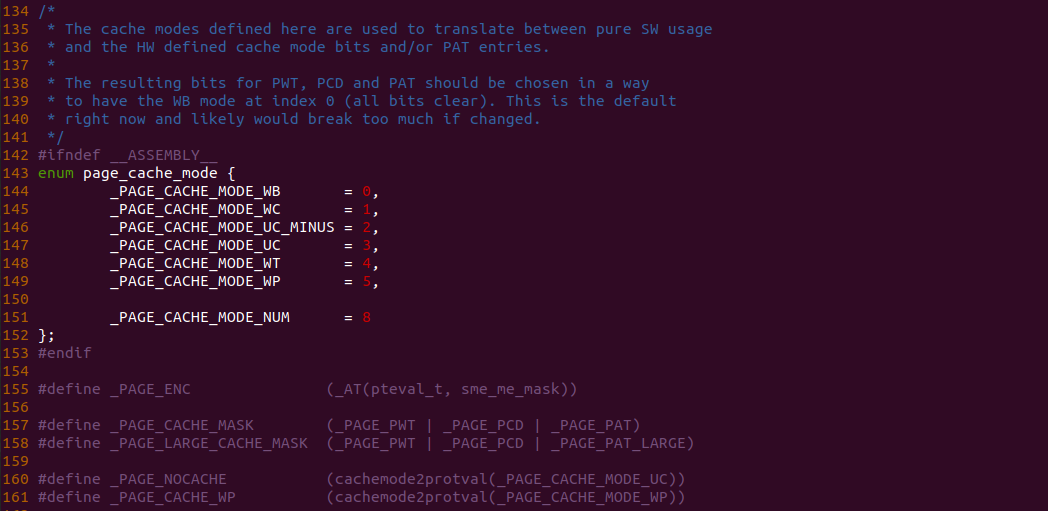
内核定义了 page_cache_mode,其包含了 WB、WC、UC、UC_MINUS、WT 和 WP CACHE Mode,这些构成了 Linux X86 架构最基础的 CACHE MODE,然后结合 cachemode2protval() 函数内核构造多种页表属性集合,例如 _PAGE_NOCACHE 指明页表为 UC, _PAGE_CACHE_WP 指明页表为 WP 的. 至此可以在内核中查看使用了这些宏的地方,以此查看更多的应用场景.
CACHE Mode on 1Gig PageTable PAT Attribute
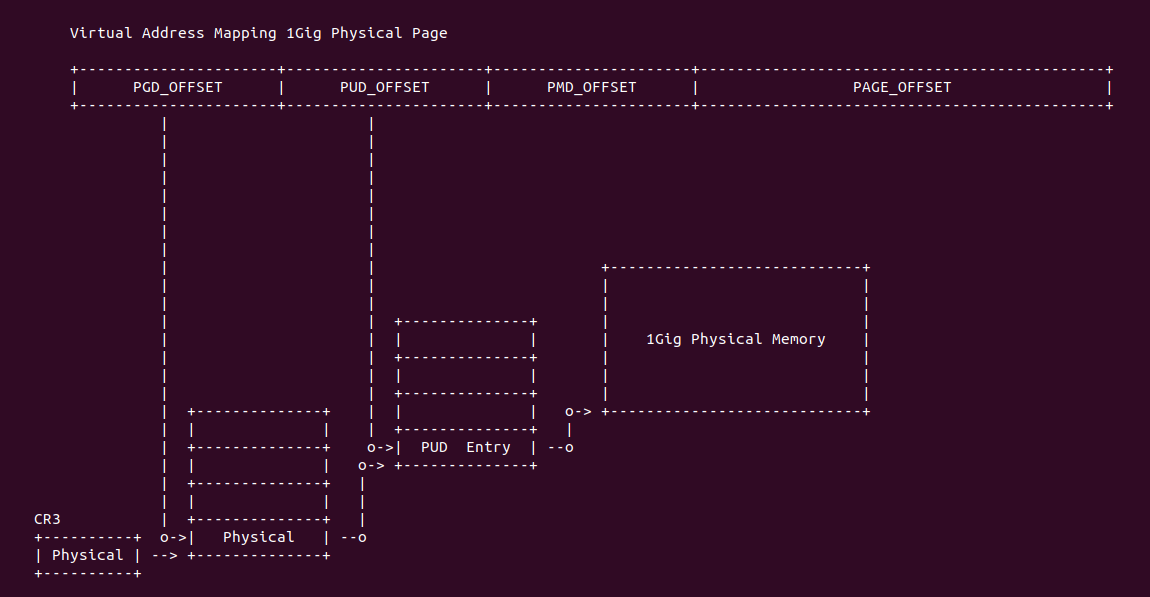
X86 架构支持 1Gig 粒度的页表映射,其使用 Page-Directory-Pointer Table 维护了很多 PUD Entry,每个 PUD Entry 指向一个 1Gig 的物理区域或者下一级 PMD 页表,因此与其他页表一样,当 PUD Entry 指向 1Gig 物理页时,PUD Entry 内包含了 1Gig 物理页的页帧号以及页表属性,其中就包含了 PAT 相关的信息.
上图是 X86 架构 Page-Directory-Pointer Entry 的位图,也就是 PUD Entry 的位图,可以看到 PS 标志位必须置位,以此表明页表用于映射 1Gig 物理区域,上图中可以看到 PAT 属性集分别是 PAT、PCD 和 PWT 标志位,那么接下来通过一个实践案例了解一下 PAT 如何影响 1Gig 页表的映射,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] PAGE Table: Setup CACHE Mode on 1Gig RSVDMEM APP --->
<*> PAGE Table: Setup CACHE Mode on 1Gig RSVDMEM --->
# 源码目录
# Module 部分: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-PAGE-TABLE-RSVDMEM-1G-default/
# 用户空间部分: BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-PAGE-TABLE-RSVDMEM-1G-APP-default/
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-PAGE-TABLE-RSVDMEM-1G-APP-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make prepare
make buildBiscuitOS-CACHE-PAGE-TABLE-RSVDMEM-1G-default Source Code on Gitee
BiscuitOS-CACHE-PAGE-TABLE-RSVDMEM-1G-APP-default Source Code on Gitee

实践案例由两部分组成,内核部分部分如上图,模块主体由一个 MSIC 设备构成,其向用户空间提供了 mmap 接口,当用户空间打开设备节点 “/dev/BiscuitOS-MEM-1G” 之后,调用 mmap() 函数最终会调用到 BiscuitOS_mmap() 函数。在 BiscuitOS_mmap() 函数中,其只提供了 walk_page_vma() 函数,该函数用于遍历页表,向该函数传入了 BiscuitOS_walk_ops, 可以在 58-60 行看到其仅仅提供了 p4d_entry 的实现接口,那么 walk_page_vma() 在遍历到 P4D 页表的时候会调用 BiscuitOS_p4d_entry() 函数. BiscuitOS_p4d_entry() 函数的主要功能是建立 1Gig 页表映射. 在 31 行调用 pud_offset() 函数从 P4D 页表中获得 PUD Entry,并调用 pud_none() 查看 PUD Entry 是否为空,如果不为空,那么表示 PUD Entry 映射了非 1Gig 的页,但此时认为 PUD Entry 为空,因此非空情况直接返回 EINVAL。PUD Entry 为空的情况,在 35 行获得 PUD Entry 的锁,接着 37-39 行用于对 VMA 中自带的 PageTable 属性进行处理,37 行将 PageTable 的 PAT 属性标志全部清除,然后在 38 行调用 cachemode2protval() 函数将用户空间设置的 PAGE MODE 转换成页表 PAT 属性集,然后填充到 VMA 的 vm_page_prot 成员里。由于 vm_page_prot 默认存储 4KiB 页表属性集,因此在 38 行调用 pgprot_4k_2_large() 函数转换成 1Gig 页表属性集. 模块在 41 行向 VMA 添加了 VM_MIXEDMAP 和 VM_PAT 标志,以此告诉 Memory Mapping 机制此次映射是一个特殊的映射,会修改页表的 PAT 属性,需要特殊的处理。44 行向页表中添加了 _PAGE_RW 和 _PAGE_DEVMAP 标志,以此让映射区有读写的权限,_PAGE_DEVMAP 用于表示 DEVMEM 或者 RSVDMEM. 46 行调用 tack_pfn_remap() 函数的目的是检查即将映射物理内存 CACHE Mode 是否和用户空间配置的 CACHE Mode 存在冲突,如果存在,那么保持当前的 CACHE Mode. 最后 52-53 行调用 set_pud_at() 函数填充 PUD Entry,使其映射 1Gig 的物理内存区域. 最后的最后解除锁.
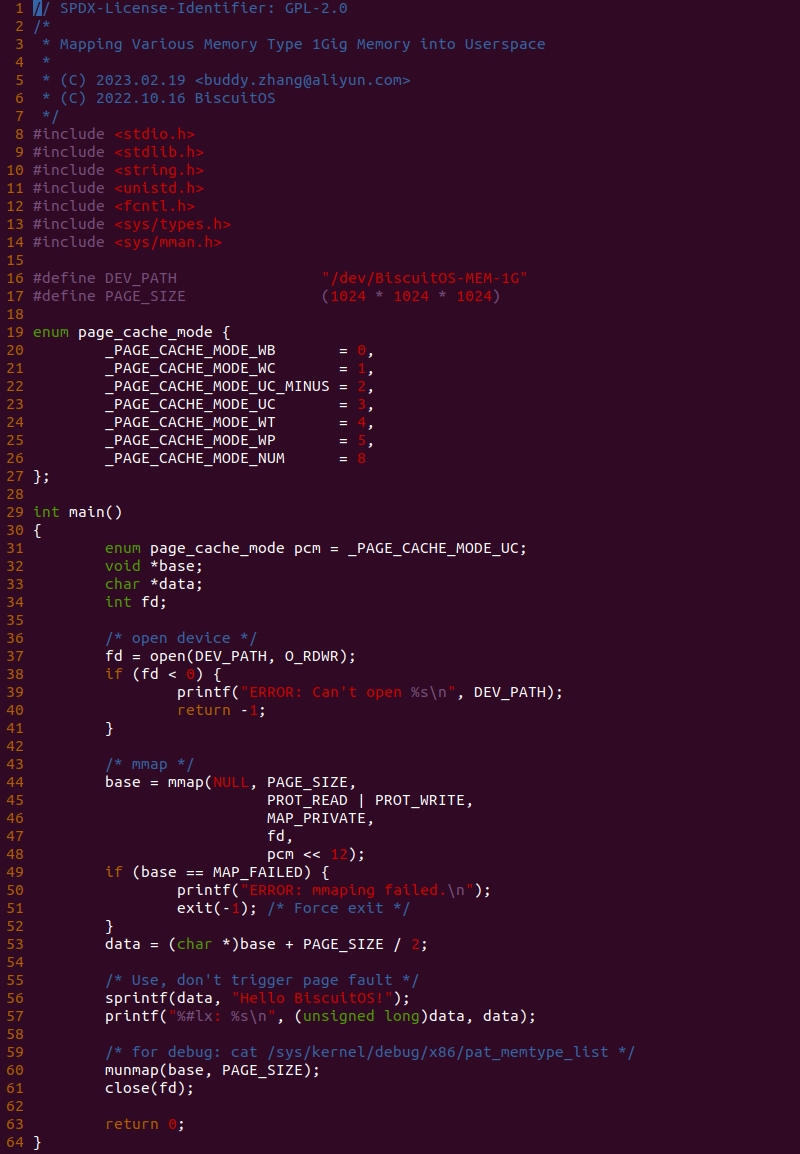
实践案例的另外一部分是一个应用程序,其在 19-27 行定义了多个 CACHE MODE,然后在 31 行将虚拟内存需要配置的 CACHE Mode 设置为 UC,接着在 37 行通过 open() 函数打开 “/dev/BiscuitOS-CACHE-MEM” 节点,然后调用 mmap() 函数进行内存分配,此时将 CACHE Mode 传递到 mmap() 函数最后一个参数,当映射成功之后就是在 56-57 行使用内存, 此时访问 512MiB 处的内存,最后使用完毕之后释放内存, 为了进行代码调试,在 60 行调用 “sleep(-1)” 是程序不退出. 接下来在 BiscuitOS 上实践案例,实践之前记得在 RunBiscuitOS.sh 脚本里的 CMDLINE 添加 “memmap=1G$0x100000000” 字段:
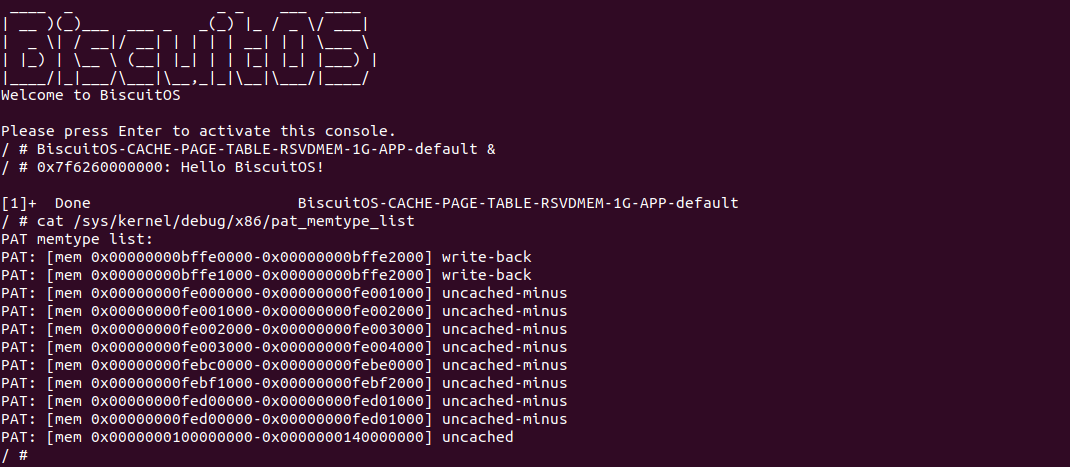
当 BiscuitOS 运行之后,后台运行 BiscuitOS-CACHE-PAGE-TABLE-RSVDMEM-1G-APP-default,可以看到可以正常访问, 接下来查看 pat_memtype_list 节点,此时看到 [0x100000000, 0x140000000) 区域 CACHE Mode 为 uncached, 实践符合预期. 接下来分析一下其实现的原理:
案例代码的函数调用逻辑如上,用户空间调用 mmap() 之后最终调用到 BiscuitOS_mmap() 函数,其调用 walk_page_vma() 函数依次遍历页表,最终遍历到 P4D 页表,此时调用 walk_p4d_range() 函数,该函数内可以调用到钩子函数从而进入到 BiscuitOS_p4d_entry() 函数,接下来就是建立页表的核心逻辑.
在 X86 架构中,由于 CACHE Mode(Memory Type) 是由 PAT 和 MTRRs 两种机制共同决定的,MTRRs 一般由 BIOS 设置或者在内核启动早期设置,PAT 则根据 IA32_PAT_MSR 寄存器配置,内核为了软件层面使用方便,将三者的关系通过 cachemode2protval() 函数进行转换,软件可以直接传入 page_cache_mode 系统就可以计算出所需的 PAT 页表属性集合.
内核定义了多个页表相关的宏,其中可以看到 PAT 相关的 _PAGE_PAT、_PAGE_PWT、_PAGE_PCD 以及 _PAGE_PAT_LARGE 标志位,由于 4KiB 页表与 2MiB 大页的 PAT 标志位位置不同,因此内核提供了 _PAGE_PAT 和 _PAGE_PAT_LARGE. 默认情况下 Memory Mapping 机制传递的页表属性都是 4KiB 页表的,因此内核提供了 pgprot_4k_2_large() 函数用于 4KiB 页表属性与 2MiB 页表属性的转换.
内核定义了 page_cache_mode,其包含了 WB、WC、UC、UC_MINUS、WT 和 WP CACHE Mode,这些构成了 Linux X86 架构最基础的 CACHE MODE,然后结合 cachemode2protval() 函数内核构造多种页表属性集合,例如 _PAGE_NOCACHE 指明页表为 UC, _PAGE_CACHE_WP 指明页表为 WP 的. 至此可以在内核中查看使用了这些宏的地方,以此查看更多的应用场景.

CACAHE on Memory Allocator
在 Linux 中,将虚拟内存按 PAGE_SIZE 划分成多个区域,并从低地址到高地址的顺序给区域编号,该编程称为页号 Page Number. 同理将物理内存也按 PAGE_SIZE 划分成多个区域,并从低地址到高地址的的顺序给区域编号,该编号称为页帧号 PFN(Page Frame Number). Linux 使用 struct page 数据结构描述一个物理页,并使用 Buddy 分配器基于 struct page 数据结构管理所有可用的物理内存,其他子系统可以通过 Buddy 分配器获得可用的物理内存,然后根据各自需求进行使用,有的将用户空间虚拟地址映射到物理内存上,有的直接在内核空间访问物理页。Linux 同时也存在其他类型的内存分配器,例如分配连续虚拟内存但物理内存不连续的 VMALLOC 分配器,以及 FIXMAP 分配器为固定的虚拟内存建立物理内存的映射。无论哪种分配器,只有存在虚拟地址映射物理内存的过程,都会涉及 CACHE MODE 使用,因此本节用于分析 Linux 不同内存分配器如何处理 CACHE MODE.
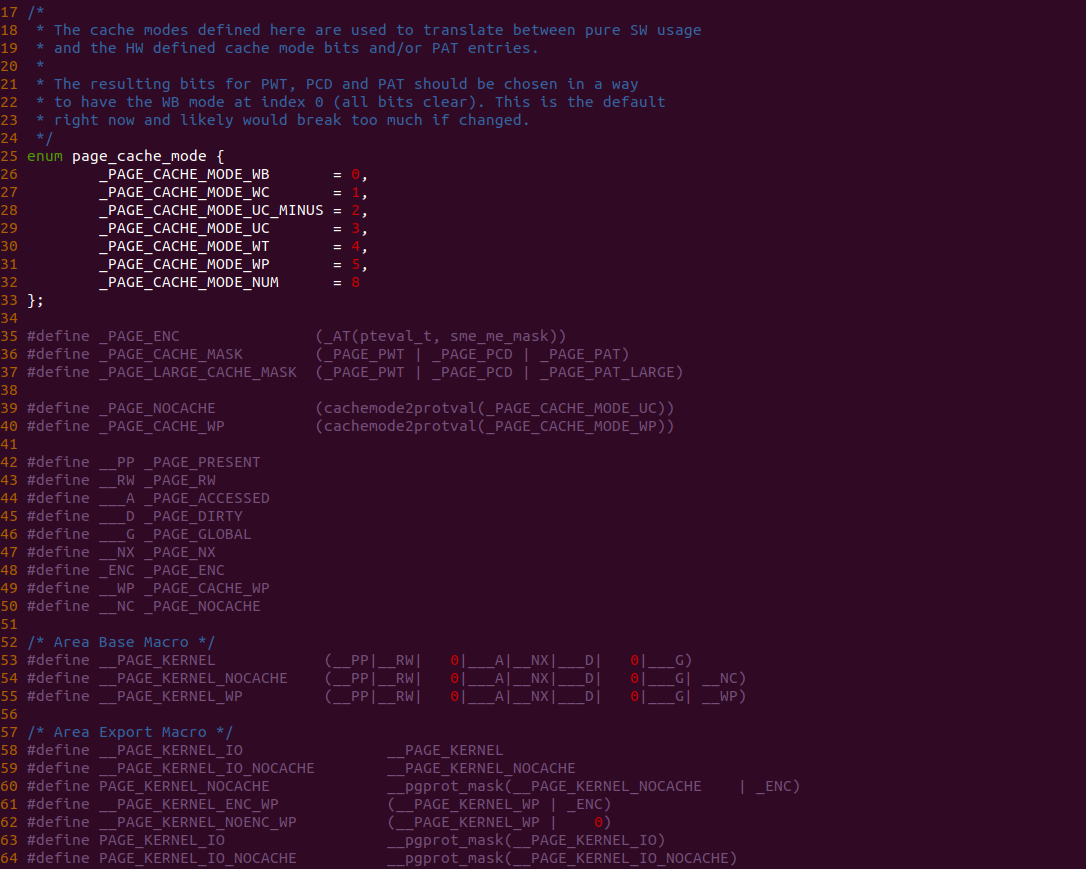
Linux 定义了 enum page_cache_mode 枚举体,共定义了 6 种 CACHE MODE,并结合 cachemode2protval() 函数,可以将 CACHE MODE 转换成页表里的 PAT 属性集,并向内核提供了两个基础的宏: _PAGE_NOCACHE 和 _PAGE_CACHE_WP, 基于两个基础的宏,内核一共构建了多个宏,用于构造不同的页表属性宏,可以方便系统创建不同的映射,例如 PAGE_KERNEL_IO_NOCACHE 宏就可以构建 UC 的映射,那么接下来从分配器和页表宏的角度分析其在 Linux 内的应用:
CACHE Mode on Permanent Mapping Memory Allocator
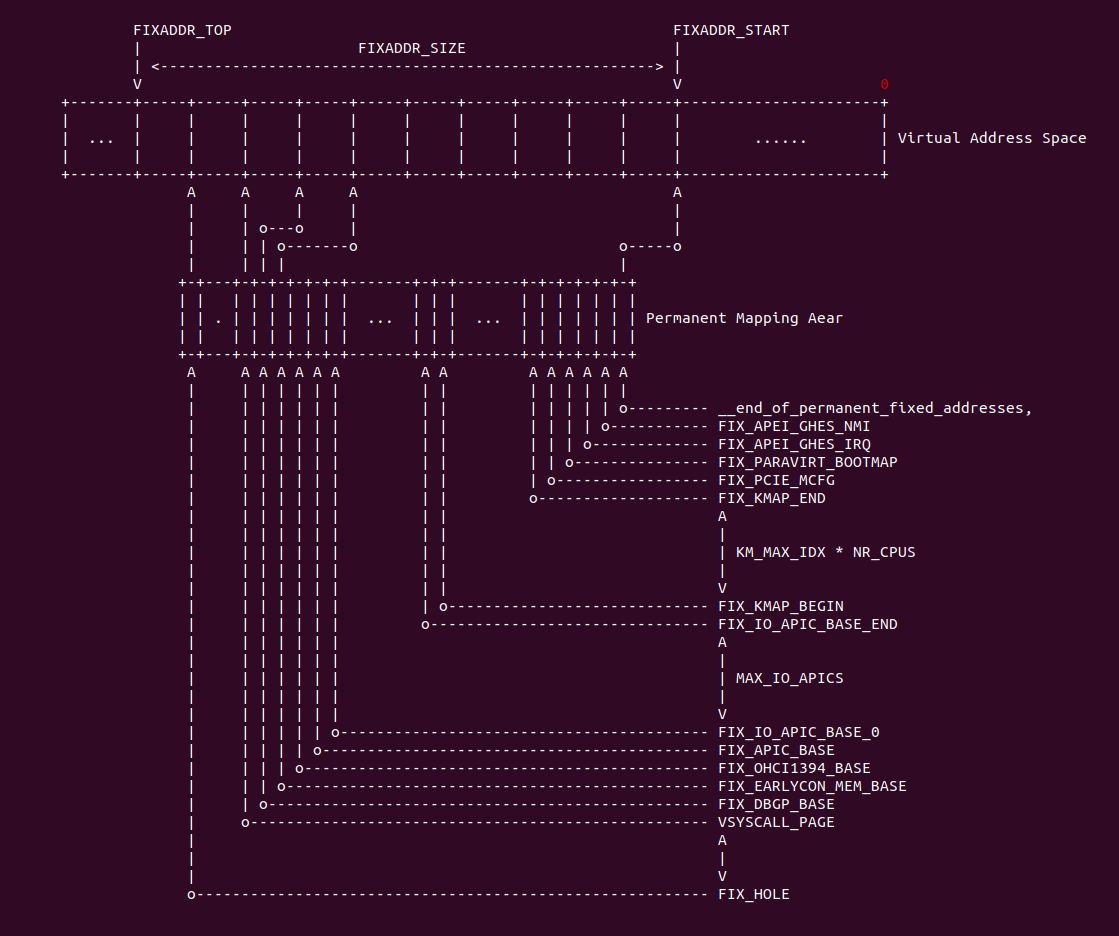
Permanent Mapping Memory Allocator 称为永久映射内存分配器, 其属于固定映射内存分配器的一个分支,其特点就是在编译阶段就可以确定某段虚拟地址分配给特定的功能使用。从实现角度来看,永久映射内存分配器通过在编译阶段从内核的虚地址地址空间占用一段虚拟内存,再等到系统运行之后,通过将这个区域的某段虚拟地址映射到特定的物理内存或者外设寄存器上,只要不释放那么这段映射会永久有效. 永久映射分配器也会为 MMIO 分配内存,因此需要根据 MMIO 的特点建立不同 CACHE Mode 的映射,接下来先通过一个实践案例讲解永久映射分配器如何建立不同 CACHE Mode 映射,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate
[*] CACHE --->
[*] Allocator: Permanent Mapping with CACHE --->
# 源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-ALLOC-PERMANENT-default/
# 部署源码
make download
# 在 Broiler 中实践
make broilerBiscuitOS-CACHE-ALLOC-PERMANENT-default Source Code on Gitee
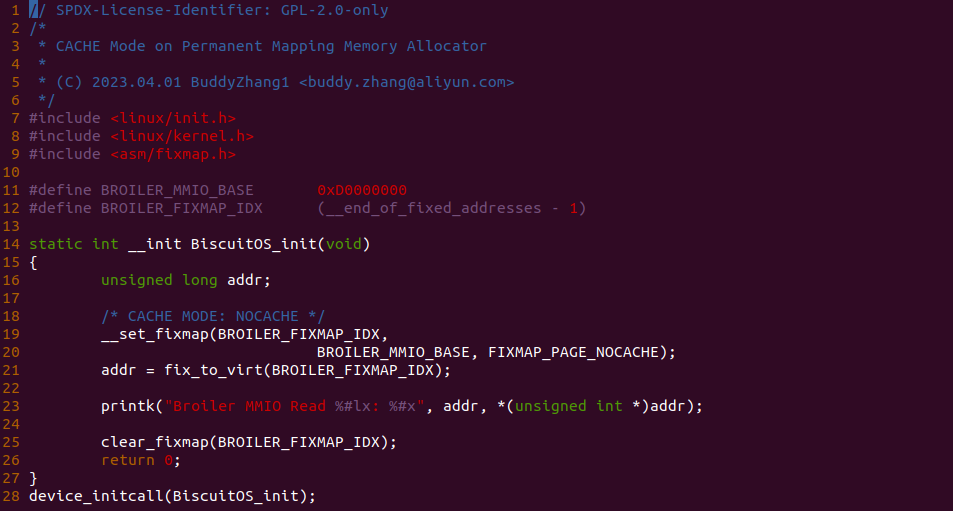
上图为案例使用的代码,内核启动过程中会调用 BiscuitOS_init() 函数,函数在 19-20 行调用 __set_fixmap() 函数建立固定映射,此时因此采用 FIXMAP_PAGE_NOCACHE 属性,建立完毕之后在 21 行调用 fix_to_virt() 函数获得固定映射的虚拟地址,接下来在 23 行使用内存,使用完毕之后调用 clear_fixmap() 函数解除映射和回收内存. 接下来进行实践,由于实践需要访问 MMIO,那么可以在 Broiler 上实践,直接运行命令 “make broiler”:
当 Broiler 运行之后,由于实践案例是在 Broiler 启动时加载的,此时通过 dmesg 查看打印的 log,可以看到案例运行并访问了 MMIO, 实践符合预期。接下来通过源码分析整个映射过程:
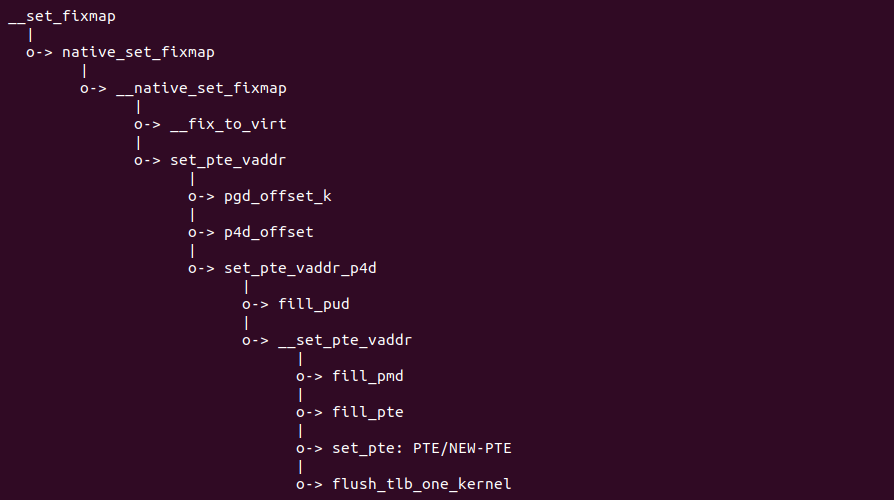
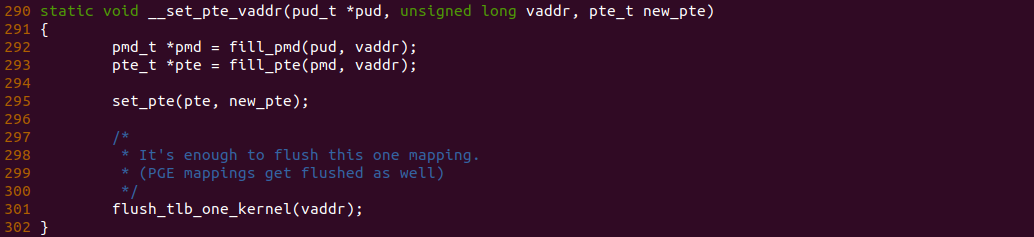
__setup_fixmap() 函数流程如上图,核心流程是 __set_pte_vaddr() 函数,其实现如上图,其调用 set_pte() 函数直接将 new_pte 写入到 PTE 里,因此回到程序,向函数传入了 FIXMAP_PAGE_NOCACHE, 其定义如下:
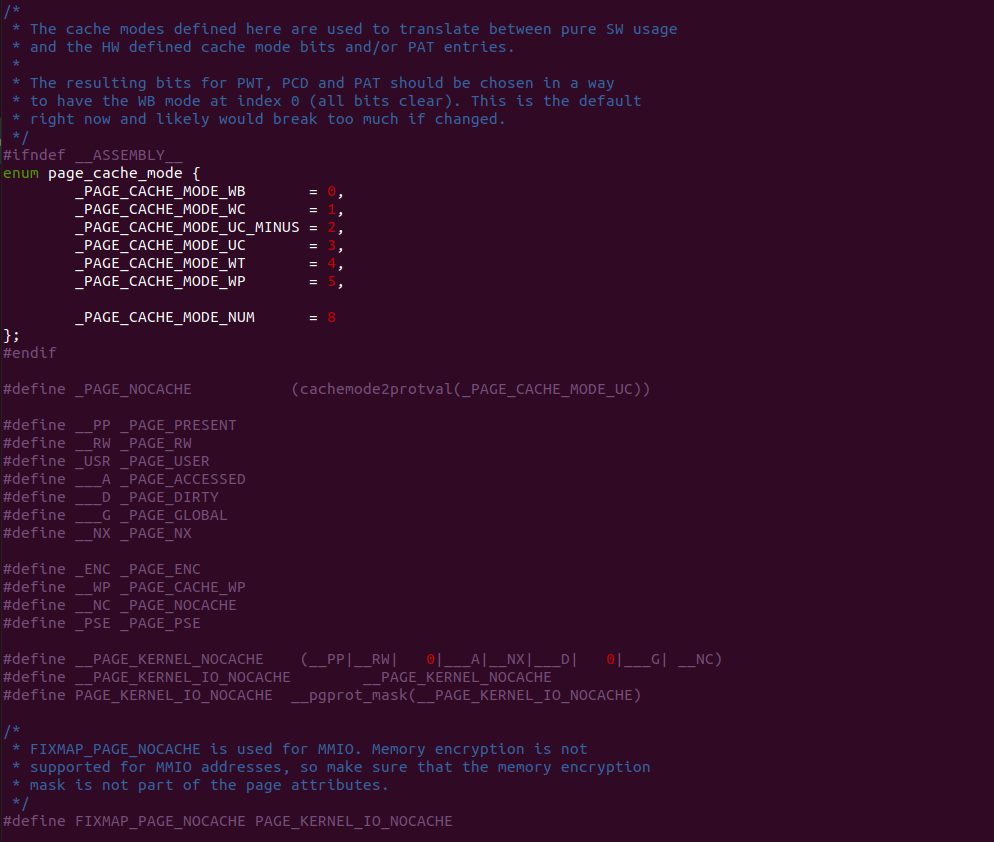
可以看到 FIXMAP_PAGE_NOCACHE 宏由 PAGE_KERNEL_IO_NOCACHE 构成,其页表属性包含了 _PAGE_PRESENT、_PAGE_RW、_PAGE_ACCESSED、_PAGE_DIRTY、_PAGE_NX、_PAGE_GLOBAL、_PAGE_NOCACHE。其中 _PAGE_NOCACHE 由 cachemode2protval() 函数和 _PAGE_CACHE_MODE_UC 结合生成的页表属性集合,其中 cachemode2protval() 函数用于将 CACHE MODE 转换成 PAT 页表属性集. 通过上面的分析已经知道整个永久映射分配器设置 CACHE Mode 的流程,接下来查看一下 Linux 内核实际应用的场景:
IOAPIC 场景
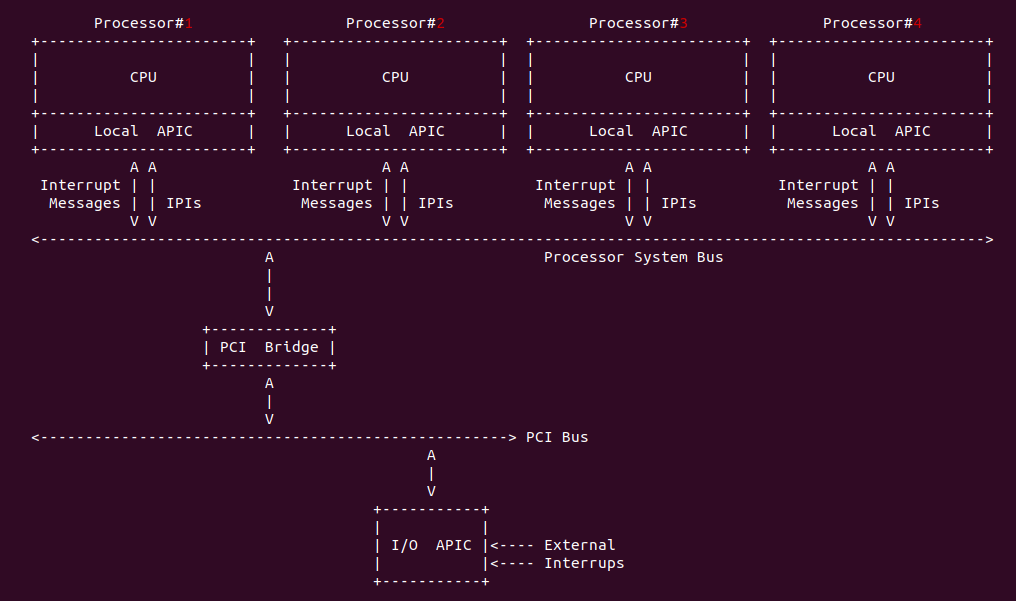
IOAPIC 是 X86 架构上为相应外设中断的可编程高级中断控制器,其内部包含了很多控制寄存器,X86 会将其内部寄存器映射到物理地址空间,形成 MMIO 区域,并且内核需要在启动早期就需要访问 IOAPIC 寄存器,因此系统将 PERMANENT 区域映射到 IOAPIC 寄存器,这样系统就可以使用固定的虚拟地址访问到 IOAPIC,但由于这些寄存器是 MMIO 形式的,因此需要使用 NOCACHE 方式映射
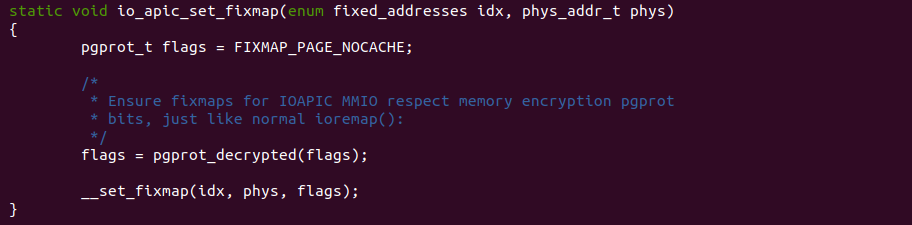
因此出现上图的代码逻辑. 系统调用 io_apic_set_fixmap() 函数将固定映射虚拟内存映射到 IOAPIC 的 MMIO 寄存器, 可以看到函数直接将页表属性设置为 FIXMAP_PAGE_NOCACHE.
总结: 通过上面的实践和理论的分析,且由于永久映射分配器的特殊性,其可以映射 OSMEM、RSVDMEM 和外设 MMIO,因此面对复杂的场景,要求永久映射分配器可以为不同的场景提供不同的页表,以此满足不同的 CACHE MODE 需求.
CACHE Mode on VMALLOC Memory Allocator
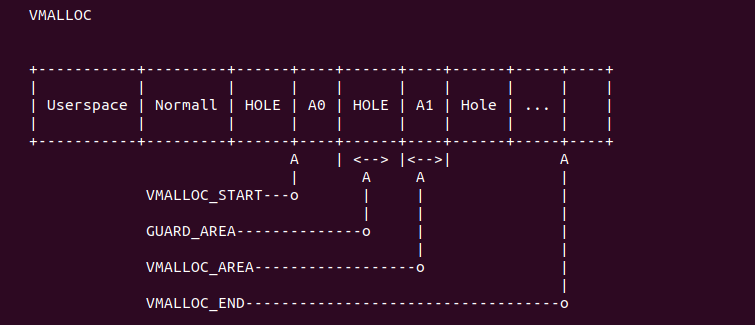
VMALLOC 内存分配器(Virtual Memory Allocator) 提供的内存存在虚拟地址连续物理内存不连续的特点。Linux 将内核空间 [VMALLOC_START, VMALLOC_END) 的虚拟区域归 VMALLOC 分配器管理,当分配内存时从该区域获得一段连续的虚拟内存,然后从 Buddy 分配器中分配多个离散的 4KiB 物理页,然后建立页表映射,最终形成了虚拟连续物理不连续的内存。由于存在映射,因此 VMALLOC 分配器是可以控制映射的 CACHE Mode,那么先通过一个实践案例感受 VMALLOC 分配器如何控制 CACHE Mode,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Allocator: VMALLOC with CACHE --->
# 源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-ALLOC-VMALLOC-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
实践案例通过一个内核模块进行展示,模块主要实现从 VMALLOC 区域分配一段虚拟内存并映射到新分配的物理页上. 模块安装时调用 BiscuitOS_init() 函数,18 行调用 page_alloc() 函数分配一个物理页,25 行调用 vmap() 函数从 VMALLOC 分配一段虚拟内存,然后建立 PAGE_KERNEL_NOCACHE 的页表,最后返回建立映射之后的虚拟内存。33-34 行使用这段虚拟内存,使用完毕之后在 37 行调用 vfree() 函数释放 VMALLOC 内存和解除映射,最后在 40 行调用 __free_page() 函数回收物理页. 接下来在 BiscuitOS 上实践该案例:
当 BiscuitOS 运行之后,加载模块 BiscuitOS-CACHE-ALLOC-VMALLOC-default.ko,加载之后可以看到打印 “Hello BiscuitOS” 字符串,说明可以正常使用分配的内存,实践符合预期。接下来通过源码分析整个映射过程:
vmap() 函数的流程如上图,核心包括 vma_pages_pte_range() 为虚拟内存建立页表,以及 arch_sync_kernel_mappings() 函数,该函数用于保证分配物理内存对应的线性映射和 vmap() 映射 CACHE MODE 的一致性。通过上面的分析可以知道 VMALLOC 分配器可以通过 vmap() 函数的 prot 参数指定所需的 CACHE MODE, 例如案例中的 PAGE_KERNEL_NOCACHE, vmap() 函数还可以根据需求采用不同的 CACHE Mode.
可以看到 PAGE_KERNEL_NOCACHE 的定义,其页表属性包含了 _PAGE_PRESENT、_PAGE_RW、_PAGE_ACCESSED、_PAGE_DIRTY、_PAGE_NX、_PAGE_GLOBAL、_PAGE_NOCACHE。其中 _PAGE_NOCACHE 由 cachemode2protval() 函数和 _PAGE_CACHE_MODE_UC 结合生成的页表属性集合,其中 cachemode2protval() 函数用于将 CACHE MODE 转换成 PAT 页表属性集. 通过上面的分析已经知道整个永久映射分配器设置 CACHE Mode 的流程,接下来查看一下 Linux 内核实际应用的场景:
AGP: GPU 场景

AGP(Accelerate Graphical Port) 加速图形接口。随着显示芯片的发展,PCI 总线日益无法满足其需求, 英特尔于 1996 年 7 月正式推出了AGP 接口,它是一种显示 AGP 显卡图片卡专用的局部总线。严格的说,AGP 不能称为总线,它与 PCI 总线不同,因为它是点对点连接,即连接控制芯片和 AGP 显示卡,但在习惯上我们依然称其为 AGP 总线。AGP 接口是基于 PCI 2.1 版规范并进行扩充修改而成,工作频率为 66MHz。AGP 总线直接与主板的北桥芯片相连,且通过该接口让显示芯片与系统主内存直接相连,避免了窄带宽的 PCI 总线形成的系统瓶颈,增加 3D 图形数据传输速度,同时在显存不足的情况下还可以调用系统主内存。所以它拥有很高的传输速率,这是 PCI 等总线无法与其相比拟的。
agp_remap() 函数用于重新映射 AGP 显卡的地址空间,由于 AGP 显卡地址空间是 MMIO,因此在映射时为了保持 CACHE 一致性,会将虚拟内存映射为 NOCACHE 的,因此在 arg_remap() 函数中在 95 行调用 vmap() 函数映射时采用了 PAGE_AGP, 该宏其实就是 PAGE_KERNEL_NOCACHE. 通过上面案例的分析,当内核需要访问外设的 MMIO 时,其会通过 VMALLOC 分配器提供一块虚拟内存,然后使用 vmap() 函数建立虚拟内存到物理地址的映射,此时可以感觉物理地址的属性采用不同的 CACHE MODE,对于 MMIO 且没有 snoop 能力的外设来说,CACHE MODE 采用 NOCACHE 最佳.
总结: 通过上面的实践理论分析,VMALLOC 分配器可以根据实际场景的需求,在映射页表时采用不同的 CACHE MODE,以此满足场景的需求,同时也给系统带来了很多灵活性.
EARLY RSVDMEM/MMIO Memory Allocator
Early IO/RSVD-MEM Memory Allocator 称为早期 IO/预留内存分配器,其属于固定映射内存分配器的一个分支,其目的是内核启动早期需要访问外设寄存器或预留内存,这个时候 IOREMAP 机制还没有建立,于是内核在这个阶段为外设的 MMIO 和预留内存做临时映射,当其任务完毕之后,内核会销毁该分配器, 然后专用功能完备的 IOREMAP 分配器, 那么分配器也属于临时映射分配器. 由于需要将虚拟内存映射到 RSVDMEM 或者 MMIO 上,因此分配器也会涉及设置页表的 CACHE Mode,那么先通过一个实践案例感受 EARLY IO/RSVDMEM 分配器如何控制 CACHE Mode,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Allocator: EARLY IO/RSVDMEM with CACHE --->
# 源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-ALLOC-EARLY-IORSVDMEM-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-ALLOC-EARLY-IORSVDMEM-default Source Code on Gitee
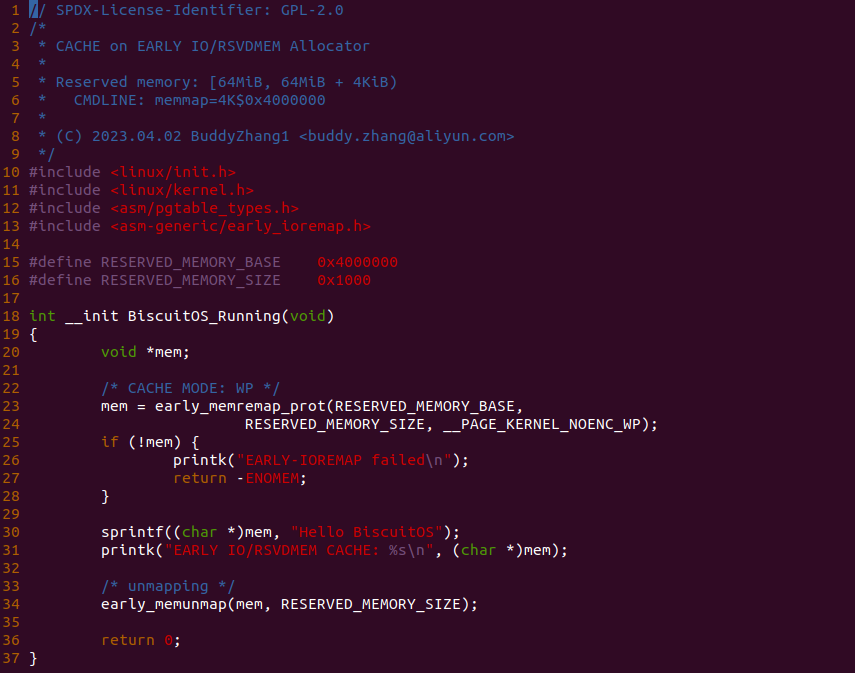
实践案例通过一个内核模块进行展示, 模块主要任务是在内核启动早期,通过映射访问 RSVDMEM. RSVDMEM 的范围是 [0x4000000, 0x4001000), 模块在 23 行调用 early_memremap_prot() 函数为 RSVDMEM 建立页表映射,此时页表属性为 __PAGE_KERNEL_NOENC_WP, 映射成功之后在 30-31 行使用内存,最后使用完毕之后在 34 行调用 early_memunmap() 函数解除映射和回收内存. 接下来在 BiscuitOS 上实践该案例:
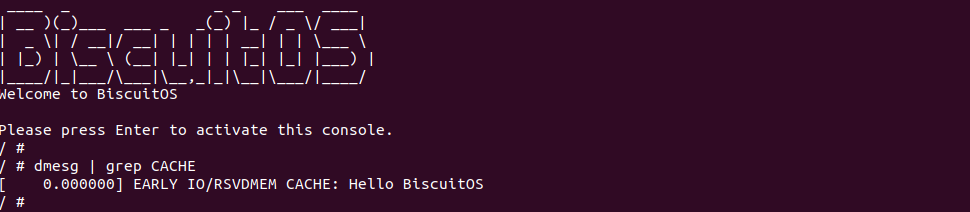
当 BiscuitOS 运行之后,由于案例是在内核启动早期就运行的,因此在 dmesg 里查看相关的打印信息,可以看到模块打印的字符串,实践符合预期,接下来通过源码分析整个过程:
early_memremap_prot() 函数的流程如上图,核心函数为 __early_ioremap() 函数,该函数通过 early_ioremap_pte() 函数获得虚拟地址对应的 PTE,然后通过 set_pte() 函数建立页表,此时页表属性里包含了 __PAGE_KERNEL_NOENC_WP 和 RSVDMEM 信息,最后调用 flush_tlb_one_kernel() 刷新一下 TLB. 通过上面的分析,early_memremap_prot() 函数还可以使用其他页表属性集来配置不同的 CACHE MODE,例如 PAGE_KERNEL_NOCACHE 就可以配置为 UC.
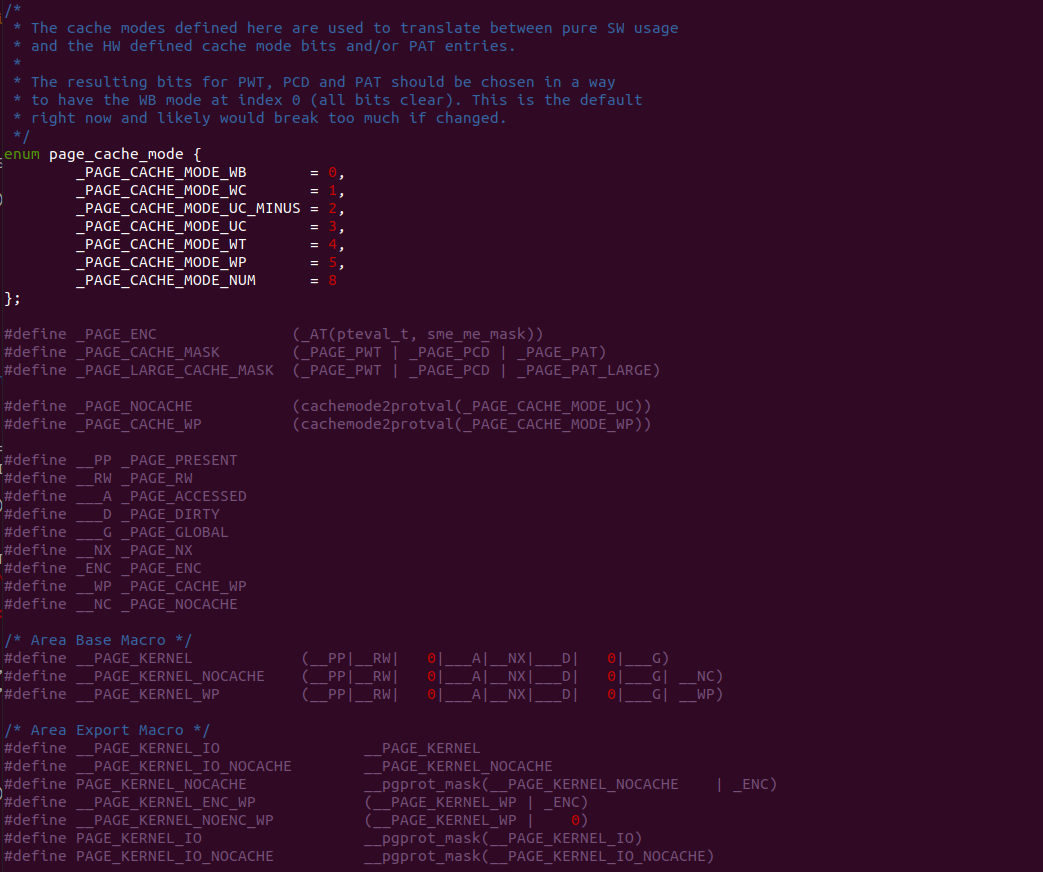
可以看到 __PAGE_KERNEL_NOENC_WP 的定义,其页表属性包含了 _PAGE_PRESENT、_PAGE_RW、_PAGE_ACCESSED、_PAGE_DIRTY、_PAGE_NX、_PAGE_GLOBAL、_PAGE_CACHE_WP。其中 _PAGE_CACHE_WP 由 cachemode2protval() 函数和 _PAGE_CACHE_MODE_WB 结合生成的页表属性集合,其中 cachemode2protval() 函数用于将 CACHE MODE 转换成 PAT 页表属性集. 通过上面的分析已经知道整个永久映射分配器设置 CACHE Mode 的流程,接下来查看一下 Linux 内核实际应用的场景:
AMD 加密内存场景

AMD Zen 处理器不单单会在架构上全面超越奔腾,它还会支持全新的内存加密(memory encryption),可以让处理器特别是云服务器第一次得到全程软硬加密掩护,而这一点即便 Intel 目前也没有做到. AMD 的这一技能来自与 ARM 相助之后打造的 AMD安详处理赏罚器(AMD Security Processor),借助硬件 SHA 安详算法,支持安全内存加密(SME)、安全加密假造化(SEV)两种方法。SME 模式下,AMD 安全处理赏罚器会在数据写入内存时,行使 AES-128 秘钥进行加密,并且每次系统重置后都随机生成新的秘钥,运行在 CPU 上的任何软件都不行能读取加密内存. SEV 模式下,传统令牌加密体系中,造假机监督器(Hypervisor) 泄密的条目将不复存在。监督器和运行在统一主板上的客户端资源、独立客户负载完全断绝,代码和数据将分离标志、独立加密,访问的时的如果加密标志错误,不能访问内存只能看到加密状态.
对于加密内存,在软件建立映射的时候需要添加 WP 的 CACHE Mode,以此结合硬件加密属性,达到软硬加密的效果。__sme_early_enc_dec() 函数用于 SME 模式下内存的加密拷贝,可以看到 114-117 行调用 early_memremap_decrypted_wp() 函数映射加密内存,此时 CACHE MODE 为 WB,而目的端的内存映射则无需 WB。函数最后在 131-137 行对内存进行拷贝.
总结: 通过上面实践和理论的分析,在早期对外设或者 RSVDMEM 访问时,IOREMAP 机制尚未工作,EARLY IO/RSVDMEM 分配器可以根据实际场景的需求选择不同的 CACHE MODE,为早期的特定初始化场景提供了很多便利.

Flush CACHE on X86 Linux
在 CACHE Coherent 章节曾分析过,在 SMP 多核架构中,为了保持 CPU 之间看到 CACHE 数据是一致的, 硬件上采用 MESI 机制进行保证,软件无需任何操作,这样做的本质是 CPU 具有 Snoop 总线的能力。但在实际场景中,CPU 之间数据访问要一致可能 MESI 机制无法保证,需要提供额外的软件通过 Flush CACHE 进行保证。那么什么场景下需要 Flush CACHE 呢?
- 在多线程环境下,为了保证线程间的数据一致性,线程在写入数据之后需要将数据刷新到内存,当其他线程读取数据时确保数据从内存中读到最新的.
- 在加密场算法中,为了防止缓存侧信道攻击,需要在加密过程中将数据刷新到内存,以避免数据被缓存从而被攻击者利用
- 在性能测试场景,为了避免缓命中带来的干扰,需要主动刷新缓存,以确保每次测试数据都从内存读取
- 在 DMA 场景,对于没有 Snoop 能力的外设,在进行 DMA 搬运时需要刷新数据,以确保 CPU 和外设看到内存数据是一致的
- 当物理内存存在多个虚拟内存映射时,为了避免 CACHE 别名问题,在访问完毕之后 FLUSH CACHE.
- 内核采用特殊硬件尽量避免污染 CACHE 的方式拷贝数据,拷贝完毕之后需要刷新数据保证 CPU 读到最新的数据

为了能够提供 FLUSH CACHE 能力,硬件上在 CACHE Line 的 Tag 域添加了两个标志位: Validate 和 Dirty. Validate 标志位表示 CACHE Line 中的数据是否有效,当 Validate 标志位置位表示 CACHE Line 中的数据有效, 反之标志位清零表示 CACHE Line 无效; Dirty 标志位表示 CACHE Line 中的数据与下一级存储是否一致,当 Dirty 标志位置位,那么表示与下一级存储数据不一致,反之标志位清零则表示与下一级存储数据一致. 当有了两个标志位之后,CACHE 新增了三种操作:
- CLEAN: 检查内存对应 CACHE Line 的 Dirty Bit,如果置位则将 CACHE Line 的数据写回下一级存储,并将 Dirty 标志位清零.
- Invalid: 检查内存对应 CACHE Line 的 Validate Bit,如果置位则清零,以此使 CACHE Line 无效
- FLUSH: 对内存对应的 CACHE Line,先执行 CLEAN,然后再 Invalid 操作.

Intel X86 架构提供了以上指令用于刷新 CACHE Line,根据 MESI 原理的研究,FLUSH 可以直接将 CACHE Line 切换成 Invalidate,也可以先将 CACHE Line 中的数据 WriteBack 到内存之后再 Invalidate. 这些指令可以针对单个虚拟地址,也针对所有的 L1/L2/L3 CACHE, 以上指令的含义如下:
- CLFLUSH: 刷新虚拟地址对应的 L1/L2/L3 CACHE Line,先 WriteBack 再 Invalidate
- CLFLUSHOPT: 刷新虚拟地址对应的 L1/L2/L3 CACHE Line,先 WriteBack 再 Invalidate
- CLWB: WriteBack 虚拟地址对应 L1/L2/L3 CACHE Line.
- WBINVD: WriteBack 全部 L1/L2/L3 CACHE Line, 并 Invalidate CACHE Line
- WBNOINVD: WriteBack 全部 L1/L2/L3 CACHE Line, 但不 Invalidate CACHE Line
- INVD: 全部 L1/L2/L3 CACHE Line Invalidate.
结合 X86 提供的指令,以及 FLUSH CACHE 的原理,那么接下来通过对几个特殊场景的分析,以此进一步了解 FLUSH CACHE 的意义以及重要性.
CACHE 别名场景 FLUSH CACHE
当 CACHE Line 采用 Virtual Index 时,可能会出现同一个物理地址被多个虚拟地址映射,这些虚拟地址具有同步的 Virtual Index,因此 CACHE 别名问题的本质是一个物理地址被映射到多个 CACHE Line. 在 X86 架构 L1 CACHE 采用的是 VIPT 的方式,因此也会出现 CACHE 别名问题,那么在实际场景中,CACHE 别名问题如何体现? 接下来先通过一个实践案例进行讲解,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] FLUSH CACHE: Flush for Alias --->
# 源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-FLUSH-CACHE-Alias-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-FLUSH-CACHE-Alias-default Source Code on Gitee
实践案例通过两部分组成,其中一部分是内核模块,其通过 MISC 框架向用户空间提供 OnDemand 方式分配的内存. 模块的核心在 BiscuitOS_ioctl() 函数,当用户空间调用 ioctl() 函数并传入 BISCUITOS_ONDEMAND 参数时,其会进入 30 行分支,分支首先调用 get_user_pages() 函数,该函数可以通过 GUP 方式为虚拟地址分配物理页并建立页表映射,然后在 35-37 行模块调用 kmap_local_page() 函数将新分配的物理页临时映射到内核空间,并向物理页写入 “Hello BiscuitOS” 字符串,当写入完毕之后,模块在 40-41 行按 CACHE Line Size 的粒度使用 clflush() 函数将临时映射对应的 CACHE Line 刷新到内存,最后模块调用 kunmap_local() 解除临时映射.
案例的另外部分是一个应用程序,程序首先在 25 行打开内核模块提供的 “/dev/BiscuitOS” 节点,然后在 32 行处调用 mmap() 函数分配一段虚拟内存,接着在 43 行调用 ioctl() 函数并传入 BISCUITOS_ONDEMAND 参数,以此让模块按 OnDemand 的方式为虚拟内存分配物理内存并建立页表映射,最后在 51 行使用内存。接下来就是在 BiscuitOS 上实践案例:
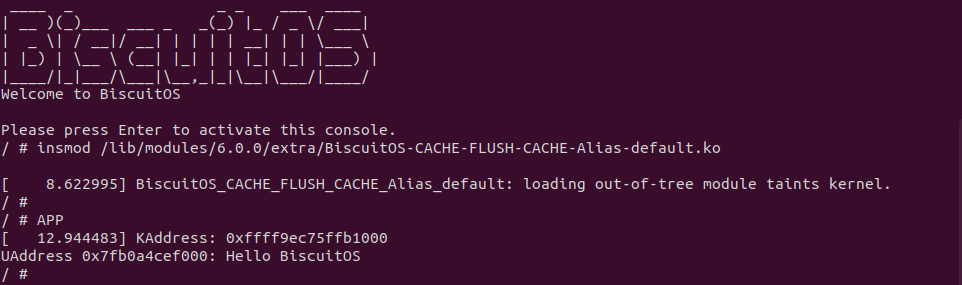
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-FLUSH-CACHE-Alias-default.ko 驱动,然后运行 APP,可以看到此时两个不同的虚拟地址对物理内存进行访问,应用程序读到了内核线程写入的 “Hello BiscuitOS” 字符串,实践看似没有任何差异的地方,但在会看一下内核模块部分刷 CACHE 的动作。
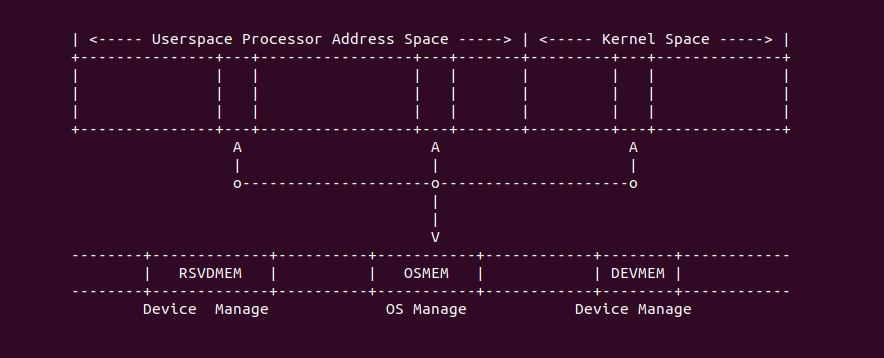
实践案例中展示了一个别名问题,应用程序在使用 OnDemand 方式分配内存时,内核模块分配物理内存之后,调用 kmap_local_page() 函数对物理页建立临时映射,此时内核使用了一个内核空间的虚拟地址访问物理页,此时根据 MESI 可以知道 CPU 访问的数据被加载指定的 CACHE Line 中,紧接着应用程序对虚拟内存进行访问,此时应用程序使用用户空间的虚拟地址对物理内存进行访问,此时用户态的 CPU 也会将数据加载到指定的 CACHE Line 中。这里如果要引发别名问题的前提是 CACHE 使用 VIPT 或 VIVT,在 X86 中 L1 CACHE 采用 VIPT,L2/L3 采用 PIPT,因此只有 L1 CACHE 会发生别名问题,此时两个不同的虚拟地址对同一个物理内存发起访问,两者的 Virtual Index 不一定相同,因此很可能同一个物理地址被加载到不同的 CACHE Line。为了解决这个问题,模块在 kmap_local_page() 映射使用完虚拟地址之后,主动调用 clflush() 函数 Flush CACHE Line,那么修改的数据都会同步到物理内存里,这样可以保证同一时间只有一个虚拟地址访问物理页,这样可以大大避免别名问题. 因此在别名场景,FLUSH CACHE 是很有必要的操作.
总结: 类似的场景还有很多,本质上因为内核采用线性映射可以访问基本所有的物理内存,如果用户空间访问物理内存过程中内核访问了物理页,那么就需要使用 FLUSH CACHE 避免别名问题. OnDemand 场景、临时映射场景,VMALLOC 为用户分配场景都是会出现别名的场景,不止可以通过 FLUSH CACHE 解决别名问题,还可以通过顺序访问和禁止内核访问分配给用户空间物理页.
内存拷贝场景 FLUSH CACHE
在 Linux 中内存拷贝是由 CPU 使用 MOV 指令将源端内存搬运到目的端内存,在搬运过程中,被访问的内存会被缓存到 CACHE,然后由 CPU 访问,对于大量的内存拷贝会导致 CACHE 内很多 CACHE Line 被拷贝的内存占用,这里称为CACHE 污染. 为了减低内存拷贝中的 CACHE 污染, X86 架构提供了 Non-Temporal Hit 机制,该机制下 CPU 可以尽可能不使用 CACHE 缓存拷贝的数据,而是使用 Non-Temproal Hit 缓存这些数据,当拷贝完毕之后,CACHE 的命中率依旧很高. 那么先通过一个实践案例感受一下 MOVNTI 如何拷贝数据,然后再分析为什么和 Flush CACHE 有关, 案例在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] FLUSH CACHE: Flush for MOVNTI --->
# 源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-FLUSH-CACHE-MOVNTI-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-FLUSH-CACHE-MOVNTI-default Source Code on Gitee
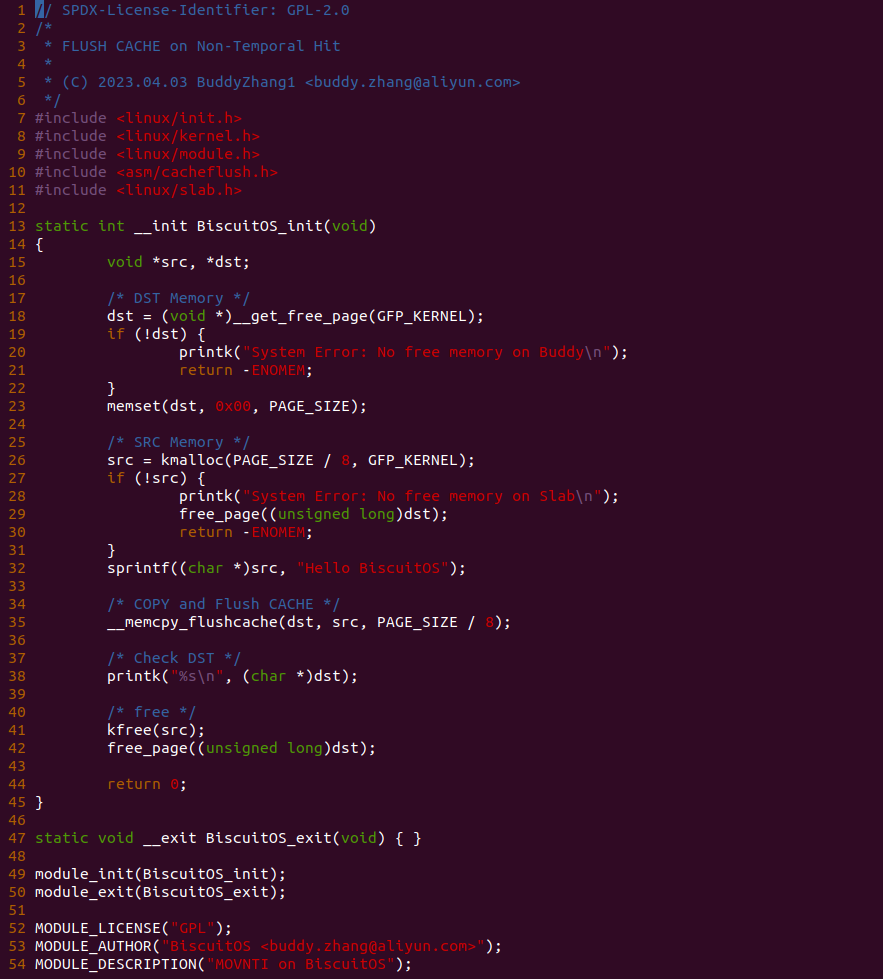
实践案例通过一个内核模块组成,模块的主要功能就是使用 MOVNTI 指令搬运内存。模块在 18-32 行分配源端和目的端内存,然后在 35 行调用 __memcpy_flushcache() 函数进行内存拷贝,最后打印拷贝的数据,最后归还资源. 接着在 BiscuitOS 上实践该案例:
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-FLUSH-CACHE-MOVNTI-default.ko 驱动,此时可以看到拷贝的数据正确。通过该案例只是看到一个新的函数 __memcpy_flushcache() 可以进行数据数据拷贝,那么其与 FLUSH CACHE 有什么关系呢? 如果直接展示场景案例会很复杂,这里从简单的代码一步一步接近复杂,这样开发者比较好容易整个技术过程. 接下来查看函数的实现:
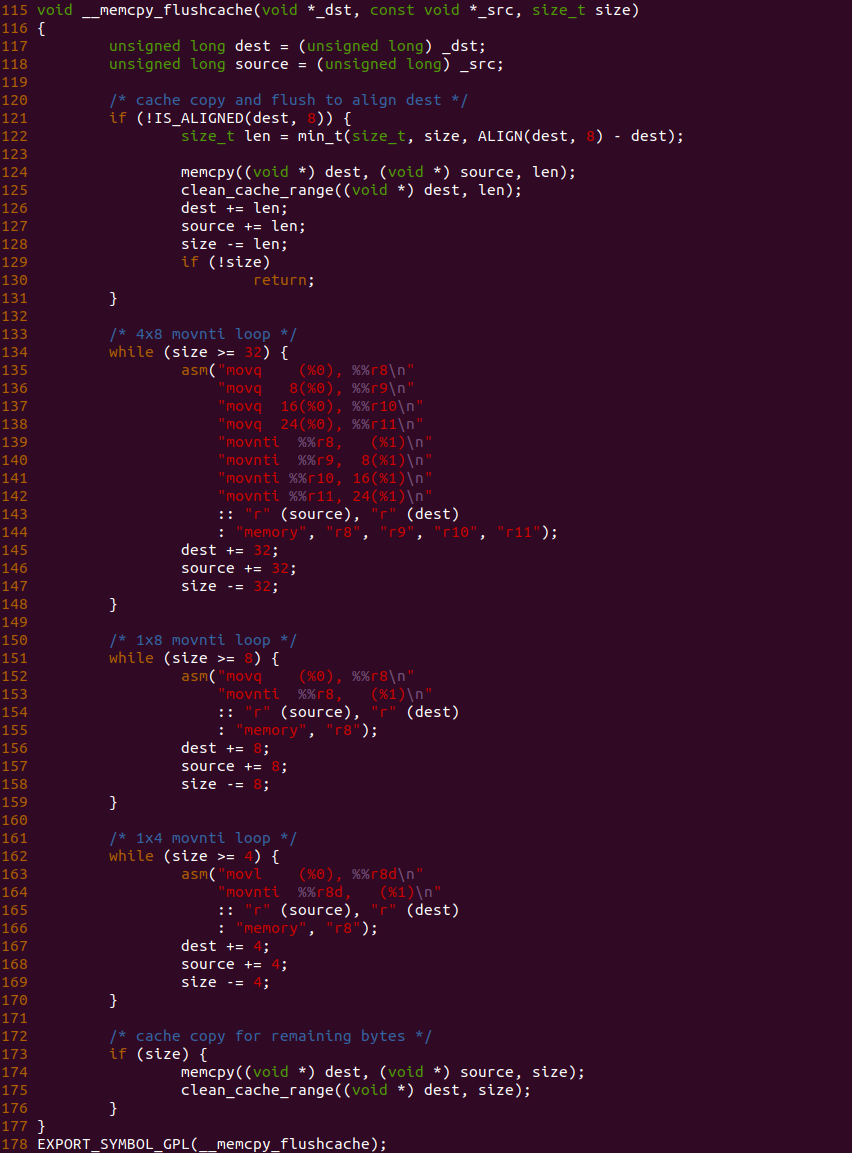
函数的实现过程虽然很复杂,但核心逻辑为 134-147 行,其调用内嵌汇编代码,代码首先对没有对其的数据使用 movq 进行拷贝,但对对齐的数据则采用 movnti 进行拷贝,对齐的数据拷贝完毕之后再对结尾不对齐的数据再单独拷贝. 以上便是函数的全部逻辑,经过分析也不是很复杂,那么回到原始问题,为什么使用 MOVNTI 之后需要 FLUSH CACHE?
在分析 MOVNTI 的搬运内存过程,假设 CPU 访问了一段物理内存 A 之后,A 的内容被缓存到 CACHE 中,此时 CPU 调用 MOVNTI 指令拷贝数据,并且物理内存 A 是 MOVNTI 拷贝的目的端,那么 MOVNTI 在拷贝内存时会尽可能的不污染 CACHE,那么拷贝完毕之后会出现 CACHE 中缓存物理内存 A 的内容不是最新的,最新的内容是由 MOVNTI 写入的,因此需要需要主动 FLUSH CACHE,保证 CPU 可以访问到最新的数据. MOVNTI 的使用场景很多,最常见的就是 copy_from_user 场景, 可以在下面章节详细了解.
总结: 在使用 MOVNTI 的场景,在享用 MOVNTI 提供的便利时,也要通过软件方式确保 CPU 访问到最新的内容, 可以通过对需要访问的数据进行 FLUSH CACHE 动作.
Non-Snoop DMA 场景 FLUSH CACHE
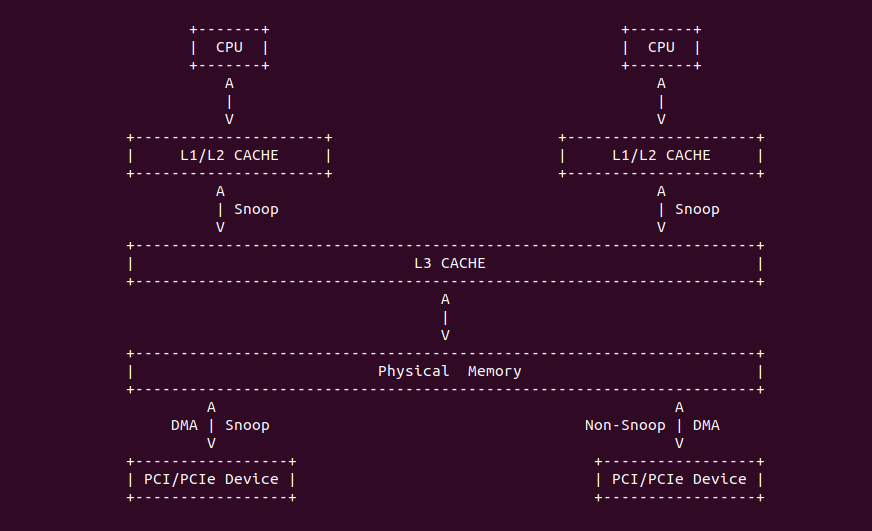
在多核架构下,CPU 之间都具有 Snoop 总线的能力,即可以监听到其他 CPU 对内存的访问,因此可以通过 MESI 硬件确保 CPU 之间的 CACHE 一致性. 对于 PCI/PCIe 外设,其通过 DMA 方式与 CPU 交换数据,因此会出现 CPU 和外设同时访问同一块物理内存的场景,如果外设也具有 Snoop 能力,那么在 DMA 搬运过程中,可以确保 CPU 与外设看到内存的数据都是最新的。但对于没有 Snoop 能力的外设来说,一般做法是 CPU 将 DMA 使用的物理内存映射为 UC(Uncachable) 的,这样可以保证 CPU 看到物理内存是最新的. UC 固然好,但比起 WB 性能严重降低,为了提供 CPU 访问 DMA 内存的效率,CPU 依旧采用 WB,但 CPU 采用流式 DMA 方式访问 DMA 物理内存,那么 CPU 如何确保 CACHE 一致性呢? 开发者可以先通过一个实践案例感受一下什么是流式,然后再分析其如何保证 CPU 访问的数据是最新的,实践案例在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support BiscuitOS Hardware Emulate --->
[*] Package --->
[*] CACHE --->
[*] FLUSH CACHE: Flush for DMA --->
# 源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-FLUSH-CACHE-DMA-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-FLUSH-CACHE-DMA-default Source Code on Gitee

实践案例由两部分组成,其中一部分为内核模块,其是一个 PCIe 设备的驱动,用于实现 DMA 搬运. 模块通过 MISC 框架向用户空间提供 “/dev/Broiler-DMA” 节点,并提供了该节点的读写接口. 当用户空间对该节点发起读操作时,内核最终调用到 BiscuitOS_read() 函数,函数在 95 行调用 dma_map_single() 函数采用流式映射 DMA 内存,接着在 99 行调用 dma_sync_single_for_cpu() 函数将 CPU 访问 DMA BUFFER 产生的 CACHE 全部 Invalid,因此确保 DMA BUFFER 里面的内容已经是最新的,然后在 102 行调用 dma_ops() 函数发起 PCIe 设备到 DDR 的 DMA 搬运,然后调用 wait_for_completion() 函数等待 DMA 完成,当搬运完成之后会收到设备发来的 MSIX 中断,并调用 dma_unmap_single() 函数解除 DMA 内存映射,最后 108 行调用 copy_to_user() 将数据搬运到用户空间; 同理当用户空间对该节点发起写操作,那么内核最终会调用到 BiscuitOS_write() 函数,函数在 67 行调用 copy_from_user() 函数从用户空间拷贝数据到 DMA BUFFER 内存里,然后在 72 行调用 dma_map_single() 函数进行 DMA 映射,并在 76 行调用 dma_sync_single_for_device() 函数 CLEAN CPU 的 CACHE,这样确保 DMA BUFFER 的内容是最新的,接下来调用 dma_ops() 执行 DDR 到 PCI 设备的 DMA 搬运,搬运完毕之后收到 PCI 外设的 MSIX 中断,之后在 85 行调用 dma_unmap_single() 函数解除映射. 另外模块在 186 行通过 __get_free_page() 函数申请了用于 CPU 和外设共同访问的 DMA 内存,CPU 在执行 copy_to_user() 和 copy_from_user() 过程中会将用户空间的数据拷贝到内核空间,此时 CPU 使用内核空间的虚拟地址会将 DMA Buffer 的内容缓存到 CACHE 中.
实践案例的另外一部分由应用程序组成,其在 27 行通过 open() 函数打开了 “/dev/Broiler-DMA” 节点,然后在 34 行调用 write() 函数向节点写入 str 字符串,接着在 42 行调用 read() 函数从节点读入数据,最后展示读到的数据。接下来在 Broiler 上进行实践, 直接运行 ‘make broiler’:
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-FLUSH-CACHE-DMA-default.ko 驱动,可以看到驱动正确加载,接下来压后台方式运行 APP,等待 10s 左右应用程序从驱动中读到字符串,这些字符串来自外设 DMA 到内存的内容. 整个过程的实践符合预期,那么接下来分析一下上面的场景如何存在 CACHE 一致性问题,以及流式 DMA 如何保证 CPU 和外设之间数据一致性的。
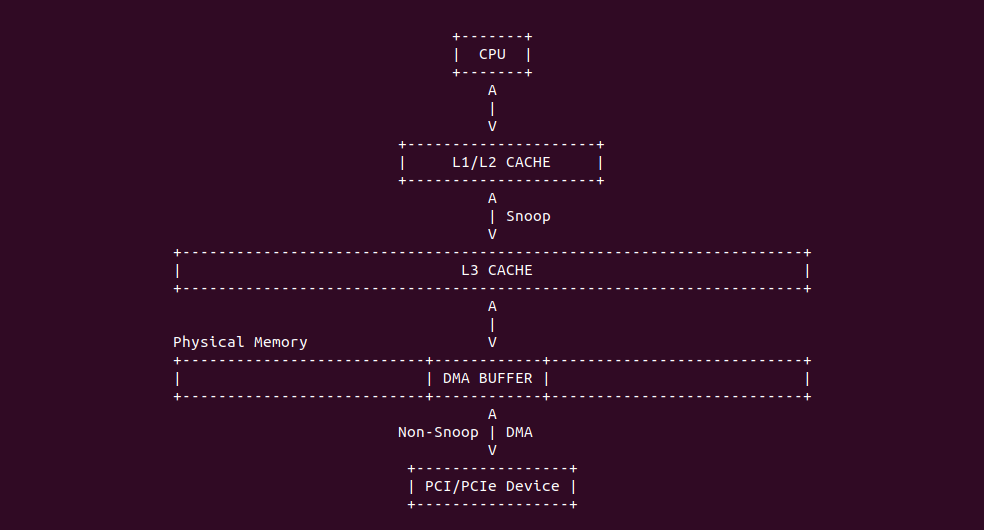
正如案例程序,其申请了一段物理内存 “bpdev->dma_buffer”, 这段内存有两个用途,第一个用途是用于与用户空间交换数据的缓存,因此 copy_to_user()/copy_from_user() 操作 CPU 会通过内核地址访问这段内存,因此这段内存会被缓存到 CACHE; 第二个用途是 CPU 和外设之间 DMA 搬运的内存。由于 CPU 映射这段内存采用 WB,并且外设也没有 Snoop 能力,那么在 DMA 搬运前后需要软件保持 CACHE 一致性,接下来分析案例如何实现 CACHE 是一致的:
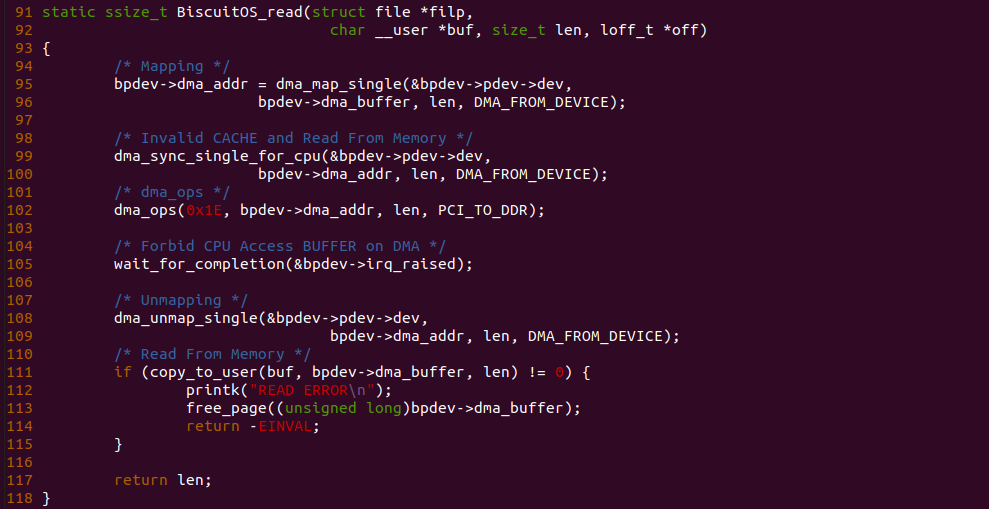
当应用程序发起 Read 请求之后,案例通过 dma_map_single() 函数建立 CPU 到 DMA BUFFER(DDR) 的映射,此时 CACHE MODE 是 WB 的,为了 CPU 可以从 DMA BUFFER 中读到最新的数据,案例调用 dma_sync_single_for_cpu() 函数将 DMA BUFFER 对应的 CACHE Line 无效,这样 CPU 下次在读 DMA BUFFER 时就直接从 Memory 上读取。假设 DMA 搬运还没有结束,那么 CPU 访问了 DMA BUFFER,那么这样会导致 CACHE 缓存了 DMA BUFFER 的内容,那么 DMA 搬运完毕之后还是无法读到最新的数据,因此案例在发起 DMA 搬运之后调用 wait_for_completion() 函数,等到 DMA 搬运完毕通过 MSIX 中断通知驱动之后,驱动才让 CPU 对 DMA 发起读操作。当 DMA 搬运完毕之后,DMA BUFFER 里面的内容已经是最新的,并且 CPU 接下来访问 DMA BUFFER 时是从 Memory 读取,因此最后调用 copy_to_user() 函数可以将最新的数据传递到用户空间.
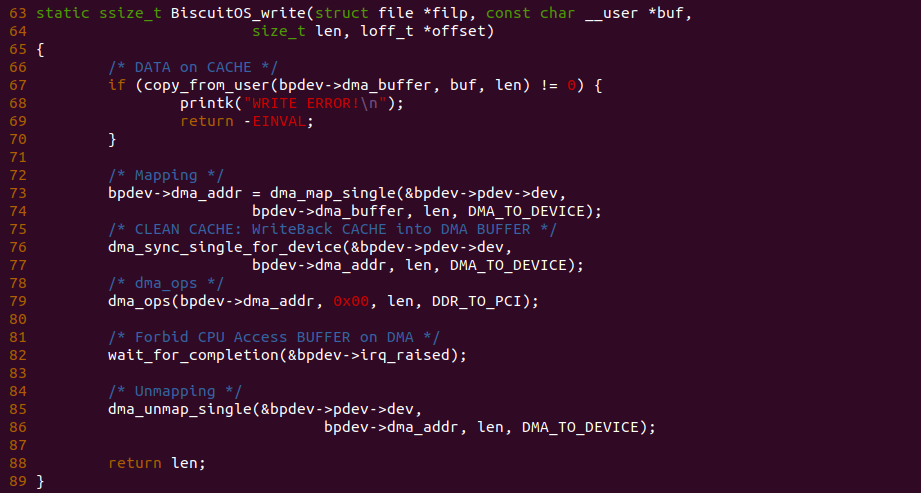
当应用程序发起 Write 请求之后,案例首先通过 copy_from_user() 函数将用户空间数据拷贝 DMA BUFFER,此时会将 DMA BUFFER 内容缓存到 CACHE 里。案例接着在 73 行调用 dma_map_single() 函数建立了 DMA BUFFER 映射,此时映射也是 WB 的,并且 CACHE 中缓存了 DMA BUFFER 的内容,因此在 DMA 之前需要将 CACHE 中的内容刷新到 DMA BUFFER 里,确保 DMA BUFFER 上的数据是最新的,因此案例在 76 行调用 dma_sync_single_for_device() 函数进行 CLEAN CACHE 的操作,此时 DMA BUFFER 数据已经是最新的,接下来搬运 DMA 即可,但同样也会遇到一个问题,就是 DMA 搬运没有完成时,CPU 又访问了 DMA BUFFER,这样就会造成数据变脏,因此案例的做法是在 DMA 搬运开始之后调用 wait_for_completion() 函数,也就是收到设备 MSIX 中断之后才可以执行接下来的 DMA BUFFER 操作,最后就是调用 dma_unmap_single() 函数解除映射.
总结: 在 DMA 搬运过程中,开发者需要确保 DMA BUFFER 数据最新,因此调用函数显示的 FLUSH CACHE,另外也要确保 DMA 搬运过程中不要对 DMA BUFFER 进行访问。通过上面操作就可以在 Non-Snoop 能力的外设上进行安全的 DMA 搬运.
多线程场景数据同步场景 FLUSH CACHE
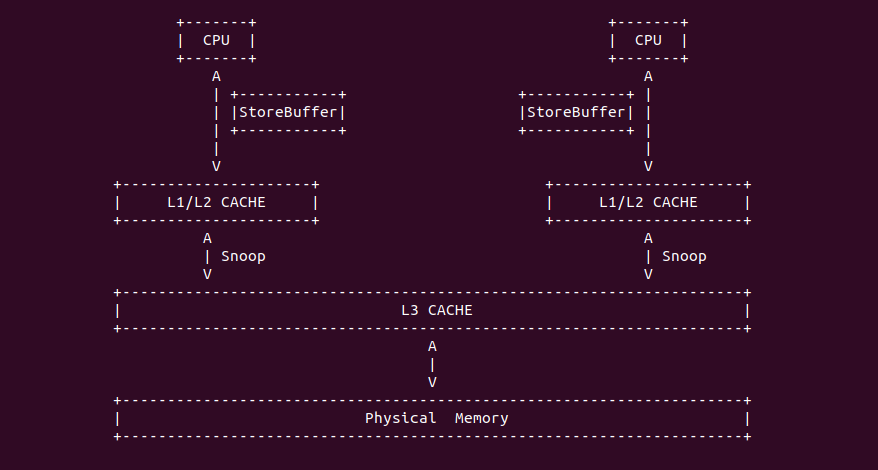
在多核多线程的场景中,线程之间往往会共享数据,那么不同的线程同时对共享数据进行访问,硬件上 MESI 可以确保 CACHE 一致性,但由于在 X86 中存在 Store Buffer,CPU 的写操作可能缓存在 Store Buffer 里,并没有刷新到 CACHE 里,此时其他的 CPU 通过 MESI 机制只能确保 CACHE 里看到的内容一致,这样就会出现其他进程读不到最新的数据,这个问题的一个解法是使用内存屏障确保 Store Buffer 里的数据更新的 CACHE,然后再通过 MESI 保证 CACHE 一致性; 这里采用另外一种方式,就是当线程执行写操作之后,直接进行 CLEAN CACHE 操作,这样最新的数据就会从 Store Buffer 进入到 Memory 里,其他线程从 Memory 中获得最新的数据,这样就可以确保数据一致性. 那么接下来通过一个实践案例感受这种方案如何实现,其在 BiscuitOS 上的实现逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
[*] Package --->
[*] CACHE --->
[*] FLUSH CACHE: Flush for Thread --->
# 源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-FLUSH-CACHE-THREAD-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-FLUSH-CACHE-THREAD-default Source Code on Gitee
实践案例由一个应用程序组成,其在不同的物理 Core 上运行两个线程同时访问资源。程序 22-37 为线程 A 所做的事,可以看到核心在 34-35 行对共享资源 shared_memory 进行读操作; 同理程序 40-57 行为线程 B 所做的事,其核心为 52-55 行对共享资源进行写操作,当在写操作之后调用 _mm_clflush() 函数将写入的内容刷新到内存. 最后统计两个线程完成任务的总耗时,那么接下来在 BiscuitOS 上实践该案例:
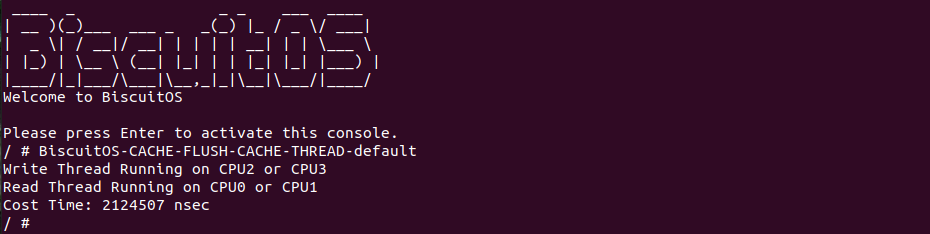
BiscuitOS 运行之后,运行程序 BiscuitOS-CACHE-FLUSH-CACHE-THREAD-default,此时可以看到 THREAD-A 运行在 CPU3 上,而 THREAD-B 运行在 CPU1 上,此时两个线程在不同的物理 CORE 上,那么他们并不共享 L1/L2 CACHE,仅仅共享 L3 CACHE. 此时 THREAD-A 写入数据之后就 CLEAN 了自己的 CACHE,那么 THREAD-B 就可以从 Memory 中获得最新的数据,这样做法的好处就是可以确保线程读到的内容总是最新的,但缺点也很明显,每次 CLEAN 会严重影响程序的性能,开发者可以将 _mm_clflush() 函数移除之后再进行验证:
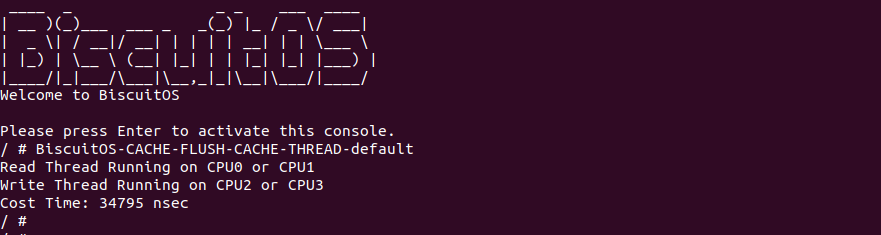
BiscuitOS 在次运行之后,可以看到程序花费极少的时间就完成了,虽然很快但会由于内存顺序导致线程之间共享数据出现异常的结果,这样的错误并没有违反 MESI CACHE Coherent 机制,但在内存序上引起了问题,如果不刷 CACHE 就需要加内存屏障保序.
总结: 在多线程访问共享数据时,对共享数据写操作之后需要 CLEAN CACHE,确保其他线程可以访问到最新的数据,以此避免数据还在 Store Buffer 里.
CACHE on Copy User Mechanism

在 Linux 虚拟内存被划分为用户空间和内核空间,这样做的好处是访问用户进程和内核线程的非法访问。但有的场景,需要在两个空间之间数据交换,实现的办法很多,其中最常见的就是 Copy User 机制,正如上图当从用户空间拷贝数据到内核空间使用 copy_from_user, 同理从内核空间拷贝数据到用户空间使用 copy_to_user. Copy User 原理很简单,查看源码就会发现其核心就是 memcpy 函数,memcpy 也是很常使用的函数,其如何实现跨越空间隔离呢? 不同的架构可能做法不同,但在 X86 架构,其提供了一个硬件 MX,其在启用的时候可以拦截用户空间和内核空间数据拷贝,但在执行 Copy User 机制时,动态关闭 MX 功能,就可以实现 memcpy 正常的数据拷贝,拷贝完成之后在开启 MX 功能即可。COPY USER 机制的原理是不是很简单,有时了解底层机制之后复杂的东西无处遁形.
回到本文的整体,COPY USER 机制如何与 CACHE 有关? 这里先分析一种场景,当从用户空间拷贝数据到内核空间,两个虚拟虚拟映射不同的物理内存,然后CPU 使用 MOV 指令进行数据搬运,整个用户进程和内核线程都可以直接从 CACAHE 中搬运数据,因为 MOV 指令经过 CPU 的,不像 DMA 那种不经过 CPU 的. 那么还是没回答 COPY 与 CACHE 的关系,继续进行分析:
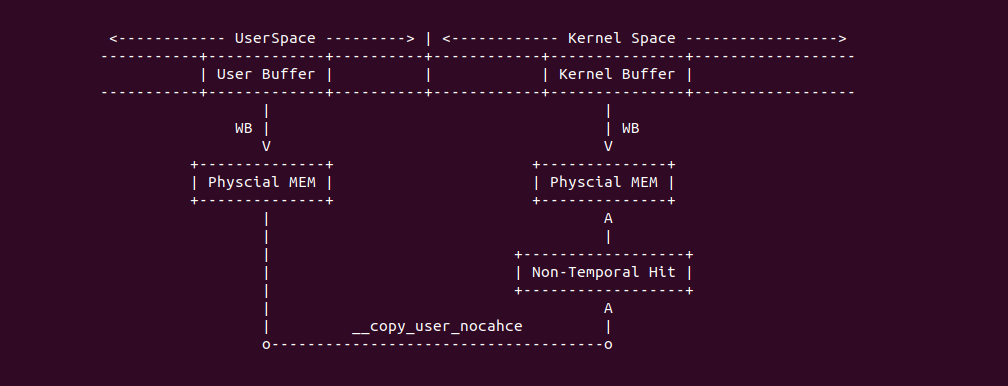
在 X86 架构中,存在一种辅助数据拷贝的硬件 Non-Temporal Hit,众所周知,MOV 类的数据拷贝都是 CPU 直接介入搬运的,那么搬运过程就是顺序的访问内存,这样会造成大量的 CACHE 无效,并且拷贝过程的更新的 CACHE 对接下来程序执行无意,因此称这种行为为 CACHE 污染. 为了解决这个问题,架构提供了 MOVNTI 系列指令,其利用 Non-Temporal Hit 在数据拷贝时会尽可能不污染 CACHE 完成数据拷贝,但也存在一个问题,虽然不污染 CACHE 的将 Memory 内存更新了,但内核原先映射这段 Memory 的 CACHE 中的数据不是最新的,因此在使用 MOVNTI 指令之后需要刷新 CACHE 操作. 会到本节的内容,在接下来的内容将会展开讲解 MOVNTI 与 CACHE 在 COPY USER 中的应用:
CACHE SCENE: IOVEC Copy Data from Userspcae[Default]
当用户空间需要对文件连续进行写操作,一般方案是通过多次 write 操作完成,但每次 write 都是一次系统调用,多次 write 增加了很多系统消耗. Linux 提供了 IOVEC 机制,其将多次 Write/Read 操作合成一次,然后仅仅通过一次系统调用即可完成之前多次的系统调用,这将大大提升文件的读写效率,那么先通过一个实践案例了解 IOVEC 机制如何使用,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
[*] Package --->
[*] CACHE --->
[*] CACHE SCENE: IOVEC Copy Data from Userspcae[Default] --->
# 源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-SCENE-IOVEC-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
实践案例由两部分组成,其中一部分是一个内核模块,其通过 MISC 框架向用户空间提供 “/dev/BiscuitOS-IOV” 节点,并为节点提供了 Write 接口,当用户空间打开节点并向该节点执行写操作,那么最终会调用 BiscuitOS_write_iter() 函数,函数通过调用 copy_from_iter() 函数将用户空间的写数据最终拷贝到 buffer 变量里,最后在 28 行打印拷贝到的数据.
实践案例的另外一部分是一个应用程序,其定义了 struct iovec 数组,并包含另个成员,程序在 29 行调用 open() 函数打开了 “/dev/BiscuitOS-IOV” 节点,然后程序在 35-38 行分别描述了两次写操作的位置、长度和内容,最后程序在 39 行调用 writev() 函数进行聚集写操作。接下来在 BiscuitOS 上实践该案例:
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-SCENE-IOVEC-default.ko 驱动,然后运行 APP 程序,此时看到内核空间打印字符串 “IOV-DATA: Hello BiscuitOS”, 用户空间自己成功向用户空间写入数据,实践符合预期,那么接下来看看 IOVEC 的实现原理:
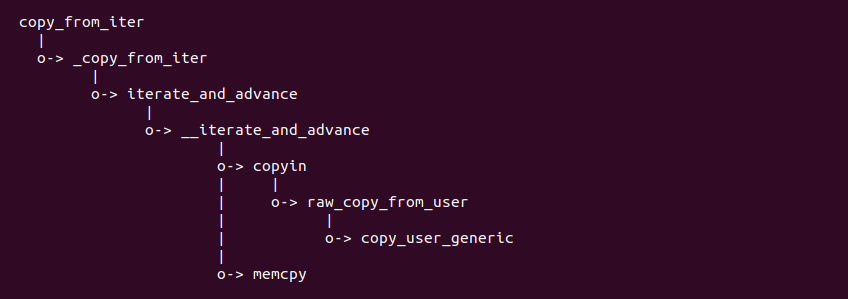
上图是 copy_from_iter() 函数的逻辑,函数主要分为两部分,第一部分是使用 __iterate_and_advance() 函数遍历用户空间传递下来的写集合 struct iovec 的每个成员,第二部是对每次遍历过程中调用 copy_user_generic() 函数进行用户空间到内核空间的拷贝,通过之前的分析可以知道拷贝的时候系统关闭了 SMAP 硬件功能,那么可以直接使用 MOV 指令在用户空间和内核空间拷贝数据,不会被拦截,当拷贝完毕之后在开启 SMAP 硬件功能防止跨区域拷贝.
上图提供了 copy_user_generic_string() 一种在用户空间和内核空间之间拷贝数据的实现,了解 SMAP 原理的可以知道 ASM_STAC 用于关闭 SMAP 硬件机制,然后接下来就是通过 MOV 系列指令进行数据搬运,搬运完毕之后调用 ASM_CLAC 开启 SMAP 硬件拦截机制,这就是 COPY USER 机制的核心,是不是比想象中的简单多了。通过上面的分析了解了 IOVEC 的实现原理,接下来的章节继续分析其与 CACHE 的研究.
CACHE SCENE: IOVEC NOCACHE/FLUSH Copy Data from Userspcae
通过前面的分析,了解了 IOVEC 机制的使用和背后逻辑,其核心通过 MOV 指令在用户空间和内核空间之间搬运内存,并且这个搬运是由 CPU 参与的,因此内核空间 MOV 的目的端 CPU 也会访问,那么 CPU 会将目的端的虚拟内存缓存到 CACHE. 试想一下 CPU 使用 MOV 指令将数据搬运到内核空间之后很大概率不会直接去访问这些数据,那么目的端的内存缓存到 CACHE 的意义不是很大,并且由于目的端内存被大量缓存到 CACHE,原先的 CACHE 会被淘汰出去,对于 CPU 接下来要访问的内容很可能发生大量的 CACHE Miss,这种行为可以称为 CACHE 污染,为了解决这个问题,X86 架构提供了 MOVNTI 指令.
MOVNTI 指令使用了 Non-Temporal Hit 存储搬运过程中的数据,尽量避免污染目的端的 CACHE,但搬运完毕之后 CPU 继续执行时不会发生大量的 CACHE Miss,那么接下来通过一个实践案例了解 MONTI 在 COPY USER 场景的使用,其在 BiscuitOS 的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
[*] Package --->
[*] CACHE --->
[*] CACHE SCENE: IOVEC NOCACHE Copy Data from Userspcae --->
# 源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-SCENE-IOVEC-NOCACHE-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-SCENE-IOVEC-NOCACHE-default Source Code on Gitee
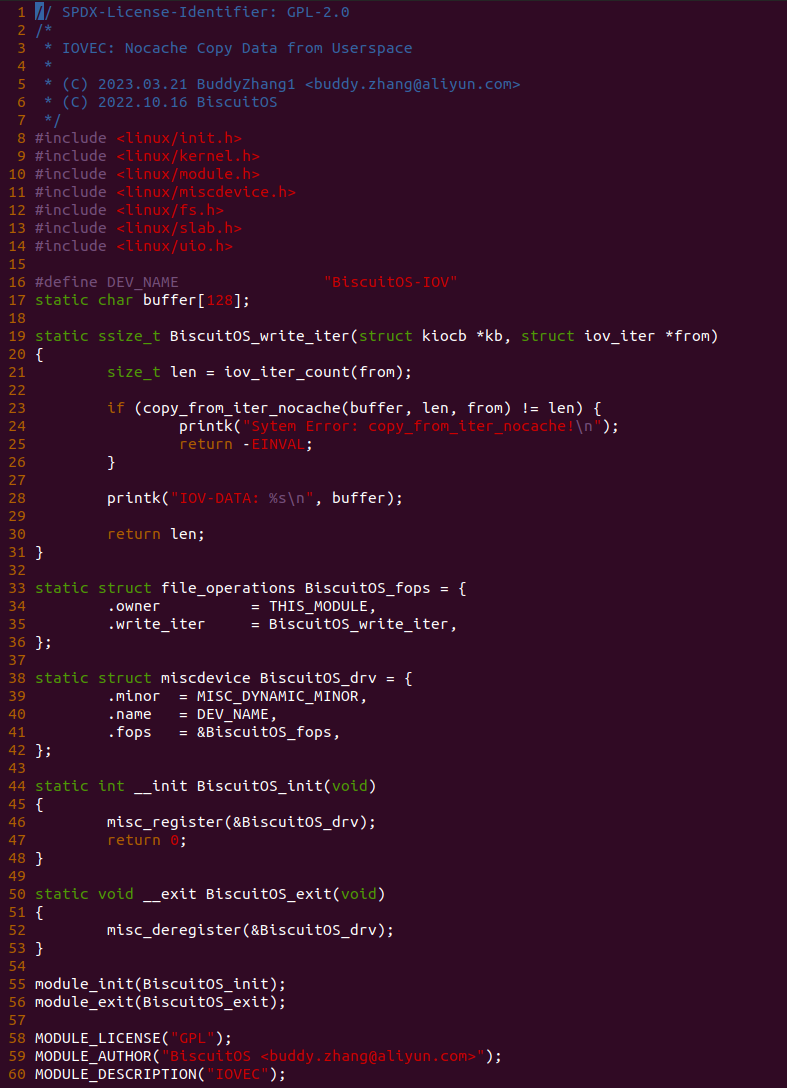
实践案例由两部分组成,其中一部分是一个内核模块,其通过 MISC 框架向用户空间提供 “/dev/BiscuitOS-IOV” 节点,并为节点提供了 Write 接口,当用户空间打开节点并向该节点执行写操作,那么最终会调用 BiscuitOS_write_iter() 函数,函数通过调用 copy_from_iter_nocache() 函数将用户空间的写数据最终拷贝到 buffer 变量里,最后在 28 行打印拷贝到的数据.
实践案例的另外一部分是一个应用程序,其定义了 struct iovec 数组,并包含另个成员,程序在 29 行调用 open() 函数打开了 “/dev/BiscuitOS-IOV” 节点,然后程序在 35-38 行分别描述了两次写操作的位置、长度和内容,最后程序在 39 行调用 writev() 函数进行聚集写操作。接下来在 BiscuitOS 上实践该案例:
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-SCENE-IOVEC-NOCACHE-default.ko 驱动,然后运行 APP 程序,此时看到内核空间打印字符串 “IOV-DATA: Hello BiscuitOS”, 用户空间自己成功向用户空间写入数据,实践符合预期,那么接下来看看 NOCACHE IOVEC 的实现原理:
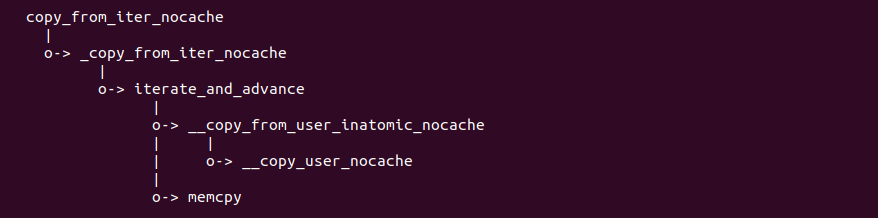
上图是 copy_from_iter_nocache() 函数的逻辑,函数主要分为两部分,第一部分是使用 iterate_and_advance() 函数遍历用户空间传递下来的写集合 struct iovec 的每个成员,第二部是对每次遍历过程中调用 __copy_user_nocache() 函数进行用户空间到内核空间的拷贝,通过之前的分析可以知道拷贝的时候系统关闭了 SMAP 硬件功能,那么可以直接使用 MOVNTI 指令在用户空间和内核空间拷贝数据,不会被拦截,当拷贝完毕之后在开启 SMAP 硬件功能防止跨区域拷贝.
上图提供了 __copy_user_nocache() 一种在用户空间和内核空间之间拷贝数据的实现,了解 SMAP 原理的可以知道 ASM_STAC 用于关闭 SMAP 硬件机制,然后接下来就是通过 MOVNTI 系列指令进行数据搬运,搬运完毕之后调用 ASM_CLAC 开启 SMAP 硬件拦截机制,这就是 COPY USER 机制的核心,是不是比想象中的简单多了, 另外从汇编代码可以看出搬运的时候采用了 MOV 和 MOVNTI 指令,因此还是会污染到少部分 CACHE. 通过上面的分析了解了 NOCACHE IOVEC 的实现原理,当 MOVNTI 指令搬运完数据之后,存在一个问题,Memory 里已经是最新的了,但 CACHE 里可能不是最新的,因此接下来继续分析 MOVNTI 处理该问题的方案.
CACHE SCENE: IOVEC NOCACHE/FLUSH Copy Data from Userspcae
MONTI 指令在内存搬运过程中,减少了 CACHE 污染,对系统运行带来了正面收益,但 MOVNTI 也存在一个问题,在有的场景中,CPU 可能对搬运之后的数据进行访问,那么此时 MOVNTI 搬运之后的内存是最新的,但 CPU 里并没有 Snoop 到内存有修改,这也是 MOVNTI 的特点之一,因此 CPU 此时继续对目的端内存访问可能会访问到 CACHE 中的旧数据,因此在这个场景可以在 MOVNTI 之后进行 FLUSH CACHE,使 CPU 访问到最新的数据,那么接下来通过一个实践案例了解如何使用这个特性,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
[*] Package --->
[*] CACHE --->
[*] CACHE SCENE: IOVEC NOCACHE/FLUSH Copy Data from Userspcae --->
# 源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-SCENE-IOVEC-NOCACHE-FLUSH-CACHE-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-SCENE-IOVEC-NOCACHE-FLUSH-CACHE-default Source Code on Gitee
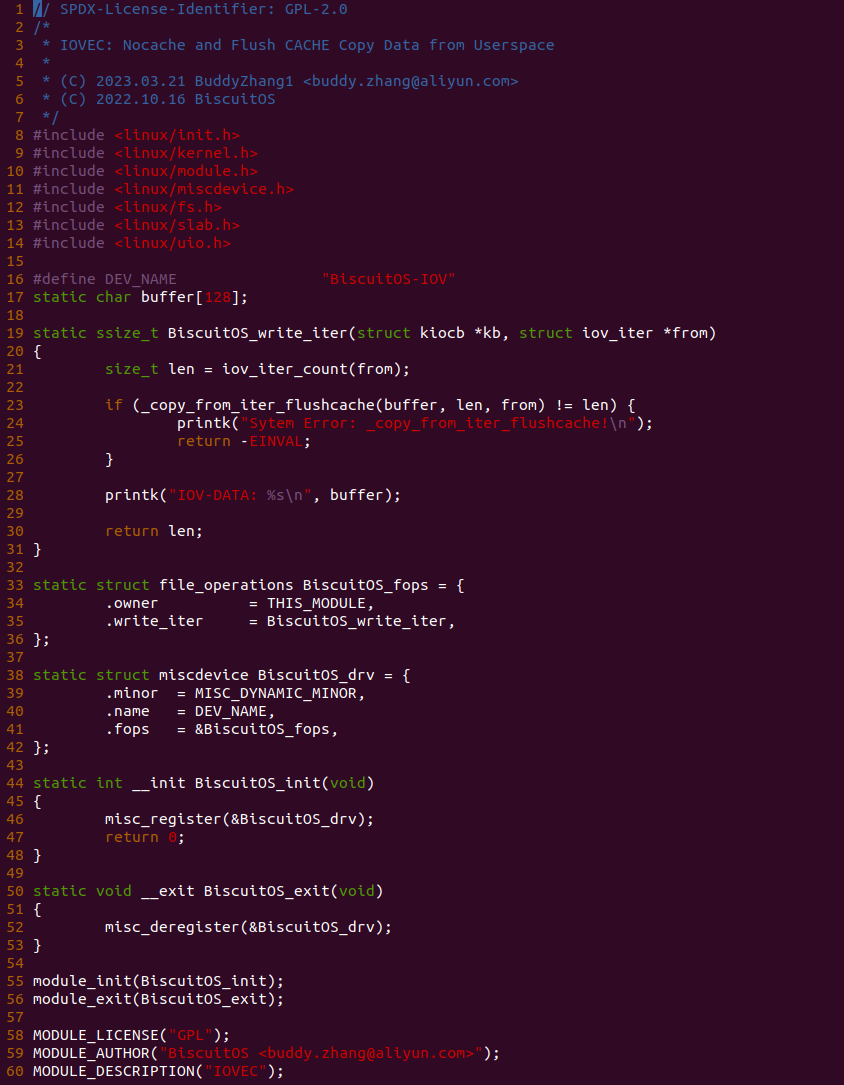
实践案例由两部分组成,其中一部分是一个内核模块,其通过 MISC 框架向用户空间提供 “/dev/BiscuitOS-IOV” 节点,并为节点提供了 Write 接口,当用户空间打开节点并向该节点执行写操作,那么最终会调用 BiscuitOS_write_iter() 函数,函数通过调用 _copy_from_iter_flushcache() 函数将用户空间的写数据最终拷贝到 buffer 变量里,最后在 28 行打印拷贝到的数据.
实践案例的另外一部分是一个应用程序,其定义了 struct iovec 数组,并包含另个成员,程序在 29 行调用 open() 函数打开了 “/dev/BiscuitOS-IOV” 节点,然后程序在 35-38 行分别描述了两次写操作的位置、长度和内容,最后程序在 39 行调用 writev() 函数进行聚集写操作。接下来在 BiscuitOS 上实践该案例:
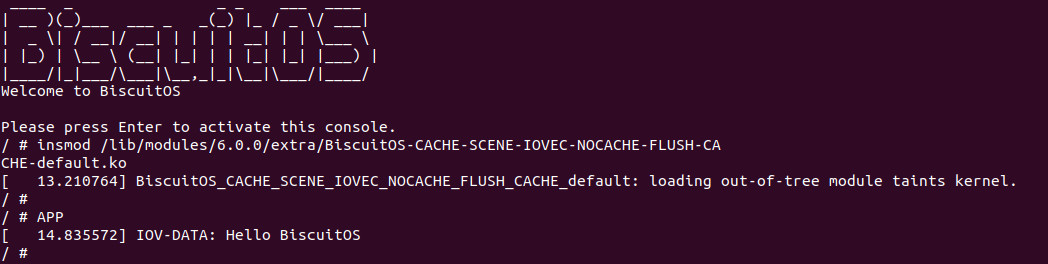
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-SCENE-IOVEC-NOCACHE-FLUSH-CACHE-default.ko 驱动,然后运行 APP 程序,此时看到内核空间打印字符串 “IOV-DATA: Hello BiscuitOS”, 用户空间自己成功向用户空间写入数据,实践符合预期,那么接下来看看 NOCACHE FLUSH CACHE IOVEC 的实现原理:
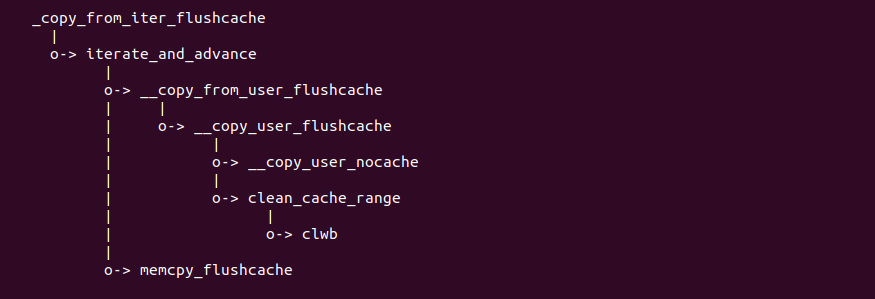
上图是 _copy_from_iter_flushcache() 函数的逻辑,函数主要分为两部分,第一部分是使用 iterate_and_advance() 函数遍历用户空间传递下来的写集合 struct iovec 的每个成员,第二部是对每次遍历过程中调用 __copy_user_nocache() 函数进行用户空间到内核空间的拷贝,通过之前的分析可以知道拷贝的时候系统关闭了 SMAP 硬件功能,那么可以直接使用 MOVNTI 指令在用户空间和内核空间拷贝数据,不会被拦截,当拷贝完毕之后在开启 SMAP 硬件功能防止跨区域拷贝, 最后调用 clwb() 函数进行 FLUSH CACHE.
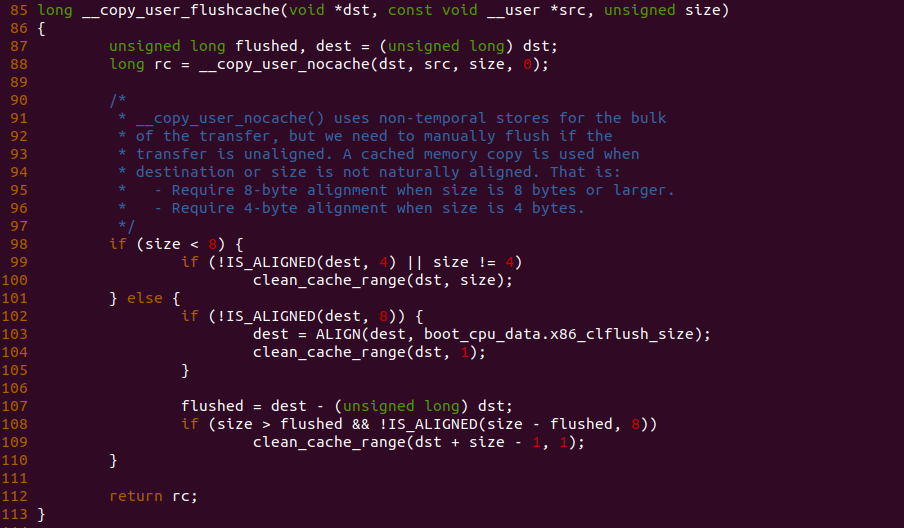
上图是 __copy_user_flushcache() 函数实现原理,可以看到 __copy_user_nocache() 函数调用 MOVNTI 拷贝完毕之后,才是内存里的数据是最新的,CACHE 的数据旧的,因此函数调用 clean_cache_range() 函数将对应的 CACHE Line Flush 到内存,底层通过调用 CLWB 指令完成,对更改的 CACHE Line 采用 WriteBack,然后再 Invalidate. 通过上面的分析,已经将 IOVEC 机制与 CACHE 的关系,开发者可以根据场景灵活使用该机制.
CACHE SCENE: copy_{from}_user [Default]
分析完 IOVEC 机制之后,很多情况下都是直接对节点发起单次的读写操作,那么接下来看看单次读写操作时,用户空间和内核空间如何交换数据的. 首先通过一个实践案例了解应用的场景,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
[*] Package --->
[*] CACHE --->
[*] CACHE SCENE: copy_{from}_user [Default] --->
# 源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-SCENE-COPY-USER-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-SCENE-COPY-USER-default Source Code on Gitee
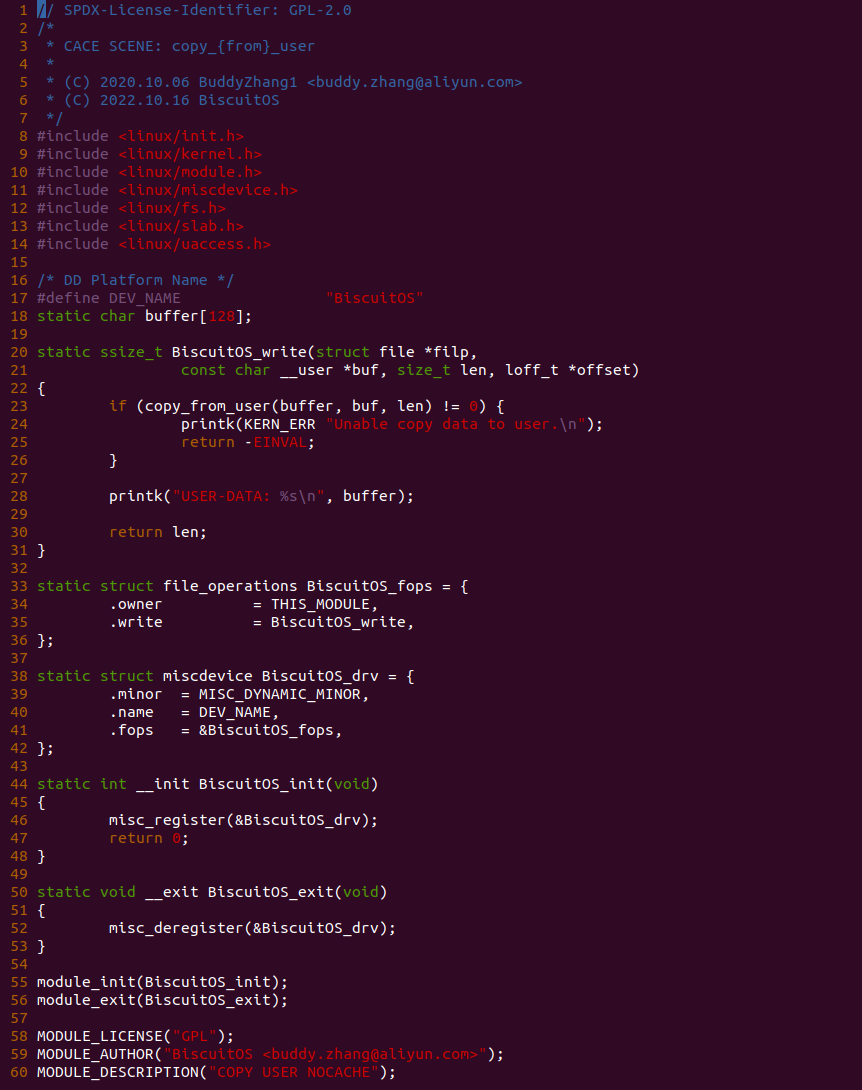
实践案例由两部分组成,其中一部分是一个内核模块,其通过 MISC 框架向用户空间提供 “/dev/BiscuitOS” 节点,并为节点提供了 Write 接口,当用户空间打开节点并向该节点执行写操作,那么最终会调用 BiscuitOS_write_iter() 函数,函数通过调用 copy_from_user() 函数将用户空间的写数据最终拷贝到 buffer 变量里,最后在 28 行打印拷贝到的数据.
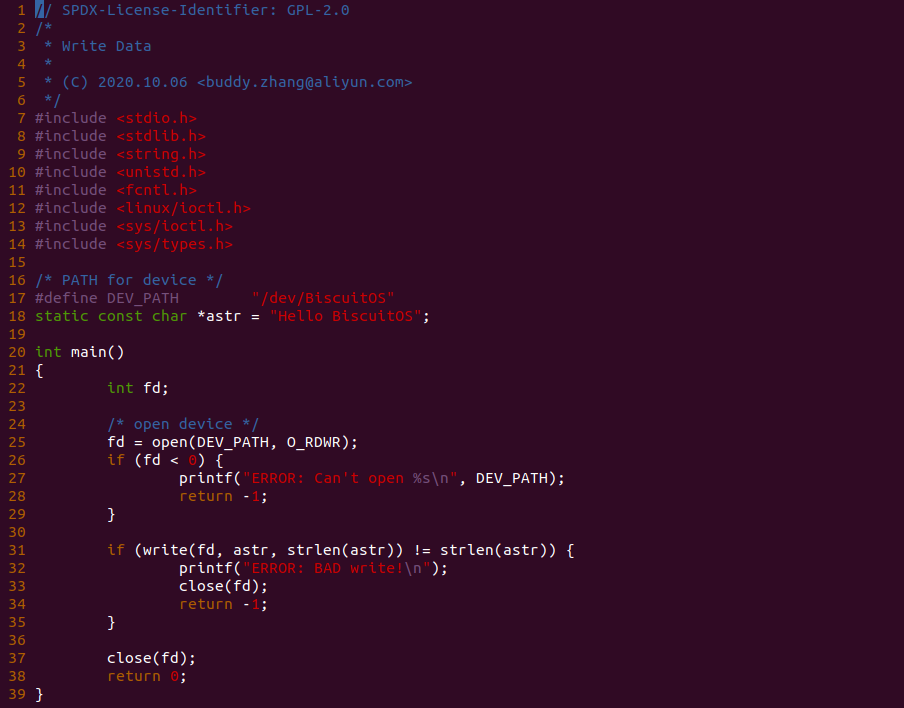
实践案例的另外一部分是一个应用程序,程序在 25 行调用 open() 函数打开了 “/dev/BiscuitOS” 节点,然后程序在 31 行调用 write() 函数进行聚集写操作。接下来在 BiscuitOS 上实践该案例:
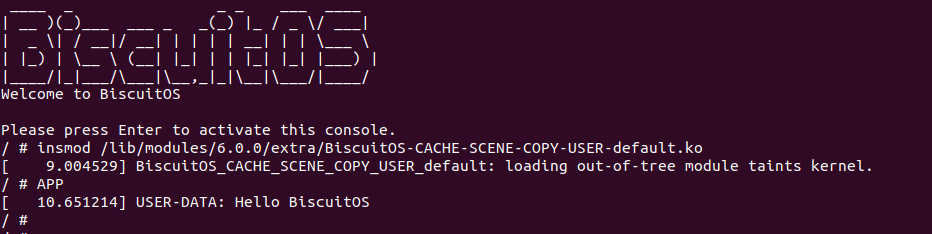
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-SCENE-COPY-USER-default.ko 驱动,然后运行 APP 程序,此时看到内核空间打印字符串 “USER-DATA: Hello BiscuitOS”, 用户空间自己成功向用户空间写入数据,实践符合预期,那么接下来看看 copy_from_user 的实现原理:
上图是 copy_from_user() 函数调用逻辑,其核心实现 copy_user_generic_string() 函数, 该函数是一个汇编函数,之前分析过 X86 中采用 SMAP 硬件保证用户空间和内核空间之间不会越界访问,因此在函数执行之处调用 ASM_STAC 关闭 SMAP 功能,然后调用 MOV 指令进行拷贝,拷贝完毕之后再调用 ASM_CLAC 开启 SMAP 功能,这就是函数的核心逻辑. 分析完基础的场景之后,接下来继续分析如何使用 CACHE 来优化这个过程.
CACHE SCENE: copy_{from}_user NOCACHE
通过前面的分析,了解了 COPY USER 机制的使用和背后逻辑,其核心通过 MOV 指令在用户空间和内核空间之间搬运内存,并且这个搬运是由 CPU 参与的,因此内核空间 MOV 的目的端 CPU 也会访问,那么 CPU 会将目的端的虚拟内存缓存到 CACHE. 试想一下 CPU 使用 MOV 指令将数据搬运到内核空间之后很大概率不会直接去访问这些数据,那么目的端的内存缓存到 CACHE 的意义不是很大,并且由于目的端内存被大量缓存到 CACHE,原先的 CACHE 会被淘汰出去,对于 CPU 接下来要访问的内容很可能发生大量的 CACHE Miss,这种行为可以称为 CACHE 污染,为了解决这个问题,X86 架构提供了 MOVNTI 指令.
MOVNTI 指令使用了 Non-Temporal Hit 存储搬运过程中的数据,尽量避免污染目的端的 CACHE,但搬运完毕之后 CPU 继续执行时不会发生大量的 CACHE Miss,那么接下来通过一个实践案例了解 MONTI 在 COPY USER 场景的使用,其在 BiscuitOS 的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
[*] Package --->
[*] CACHE --->
[*] CACHE SCENE: copy_{from}_user NOCACH --->
# 源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-SCENE-COPY-USER-NOCACHE-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-SCENE-COPY-USER-NOCACHE-default Source Code on Gitee
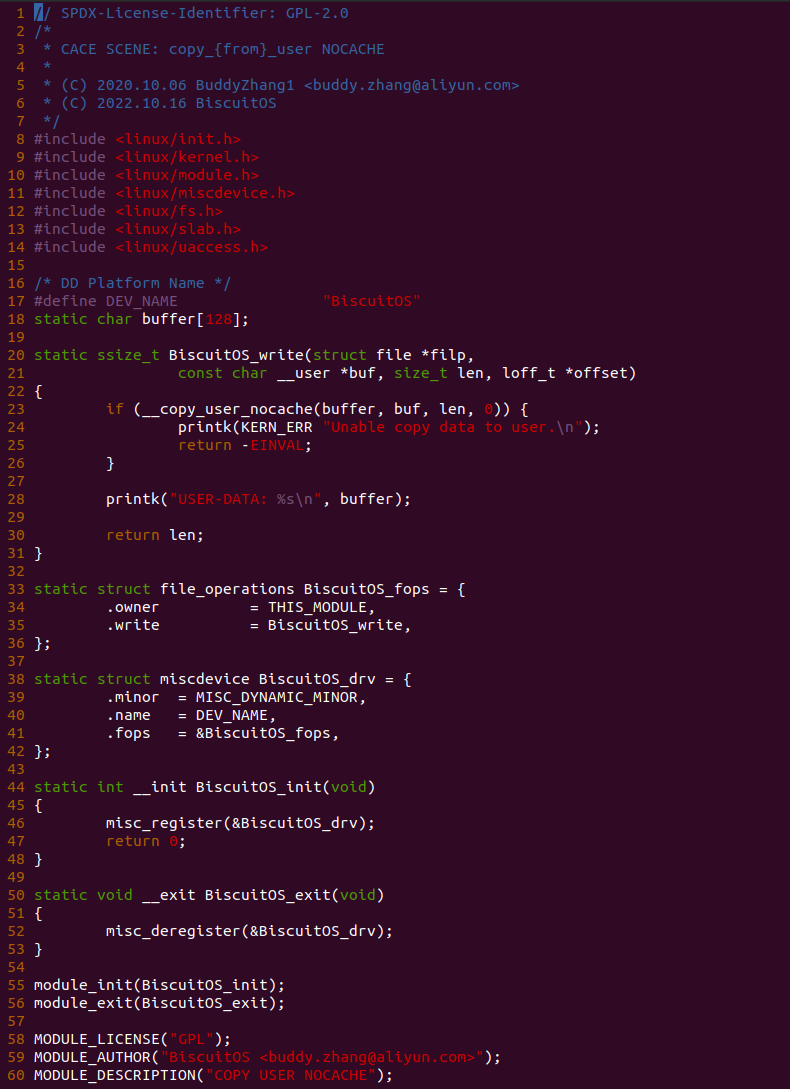
实践案例由两部分组成,其中一部分是一个内核模块,其通过 MISC 框架向用户空间提供 “/dev/BiscuitOS” 节点,并为节点提供了 Write 接口,当用户空间打开节点并向该节点执行写操作,那么最终会调用 BiscuitOS_write_iter() 函数,函数通过调用 __copy_user_nocache() 函数将用户空间的写数据最终拷贝到 buffer 变量里,最后在 28 行打印拷贝到的数据.
实践案例的另外一部分是一个应用程序,程序在 25 行调用 open() 函数打开了 “/dev/BiscuitOS” 节点,然后程序在 31 行调用 write() 函数进行聚集写操作。接下来在 BiscuitOS 上实践该案例:
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-SCENE-COPY-USER-NOCACHE-default.ko 驱动,然后运行 APP 程序,此时看到内核空间打印字符串 “USER-DATA: Hello BiscuitOS”, 用户空间自己成功向用户空间写入数据,实践符合预期,那么接下来看看 __copy_user_nocache 的实现原理:
上图是 __copy_user_nocache() 函数实现逻辑,该函数是一个汇编函数,之前分析过 X86 中采用 SMAP 硬件保证用户空间和内核空间之间不会越界访问,因此在函数执行之处调用 ASM_STAC 关闭 SMAP 功能,然后调用 MOV 和 MOVNTI 指令进行拷贝,拷贝完毕之后再调用 ASM_CLAC 开启 SMAP 功能. 由于 MOVNTI 指令的使用,在有的场景中,CPU 拷贝完数据之后并不会对数据进行访问,那么该场景下使用 MOVNTI 是最合适,该指令最低程度污染 CACHE,使 CPU 接下来的访问不会发生大量的 CACHE Miss.
CACHE SCENE: copy_{from}_user Flush CACHE
MONTI 指令在内存搬运过程中,减少了 CACHE 污染,对系统运行带来了正面收益,但 MOVNTI 也存在一个问题,在有的场景中,CPU 可能对搬运之后的数据进行访问,那么此时 MOVNTI 搬运之后的内存是最新的,但 CPU 里并没有 Snoop 到内存有修改,这也是 MOVNTI 的特点之一,因此 CPU 此时继续对目的端内存访问可能会访问到 CACHE 中的旧数据,因此在这个场景可以在 MOVNTI 之后进行 FLUSH CACHE,使 CPU 访问到最新的数据,那么接下来通过一个实践案例了解如何使用这个特性,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
[*] Package --->
[*] CACHE --->
[*] CACHE SCENE: copy_{from}_user Userspace --->
-*- CACHE SCENE: copy_{from}_user Flush CACHE --->
# 源码目录
# Module
# BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-SCENE-COPY-USER-FLUSH-CACHE-default/
# APP
# BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-SCENE-COPY-USER-USERSPACE-default/
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-SCENE-COPY-USER-USERSPACE-default/
# 部署源码
make prepare
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-SCENE-COPY-USER-USERSPACE-default Source Code on Gitee BiscuitOS-CACHE-SCENE-COPY-USER-FLUSH-CACHE-default Source Code on Gitee
实践案例由两部分组成,其中一部分是一个内核模块,其通过 MISC 框架向用户空间提供 “/dev/BiscuitOS” 节点,并为节点提供了 Write 接口,当用户空间打开节点并向该节点执行写操作,那么最终会调用 BiscuitOS_write_iter() 函数,函数通过调用 __copy_user_flushcache() 函数将用户空间的写数据最终拷贝到 buffer 变量里,最后在 27 行打印拷贝到的数据.
实践案例的另外一部分是一个应用程序,程序在 25 行调用 open() 函数打开了 “/dev/BiscuitOS” 节点,然后程序在 31 行调用 write() 函数进行聚集写操作。接下来在 BiscuitOS 上实践该案例:
BiscuitOS 运行之后,内核模块是直接编译进内核的,因此无需加载直接运行 APP 程序,此时看到内核空间打印字符串 “USER-DATA: Hello BiscuitOS”, 用户空间自己成功向用户空间写入数据,实践符合预期,那么接下来看看 __copy_user_flushcache 的实现原理:
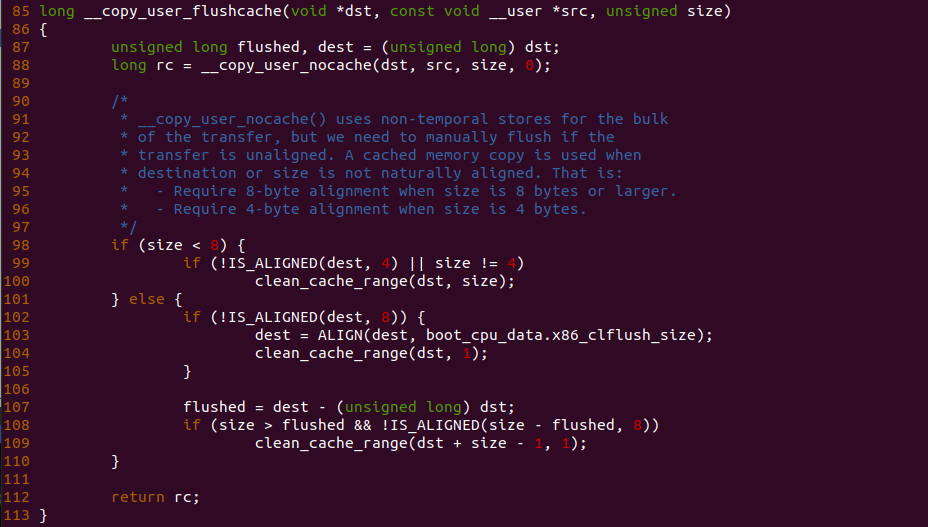
上图是函数的实现过程,函数首先在 88 行调用 __copy_user_nocache() 函数从用户空间拷贝数据,该函数之前已经分析过,拷贝完毕之后,CACHE 中的数据还是旧的,因此根据实际情况需要 FLUSH CACHE,此时调用 clean_cache_range() 函数刷新 CACHE,这样就可以确保 CPU 访问到最新的数据.
CACHE CPA Mechanism
CPA(Change Page Attribute) Mechanism: 是 Linux 提供的一种动态修改页表属性机制,由于在 Linux 支持同一个物理内存上被多个虚拟内存映射,因此当修改了其中一个映射中页表属性,CPA 机制可以确保其余的映射页表属性同步修改或者不影响正常使用. CPA 可支持修改的页表属性很多,但本节只重点研究对 PAT 属性的修改.
在之前的讨论中也多次提到,页表中存在 PAT/PCD/PWT 三个标志位联合作用,影响映射的 CACHE MODE, 另外当一个物理页被多个虚拟内存映射的时候,需要确保所有映射到同一个物理页的 CACHE MODE 是一致的,不然会出现有的有的映射为 WB,而有的映射为 WT,这会引起 CACHE 缓存策略的混乱。另外 CPA 作用的范围是对已经建立映射的页表进行修改,而不是在页表建立的时候进行修改,那么在什么场景中需要使用 CPA 进行修改呢?
在 Linux 中,内核为了方便管理所有物理内存,会从内核空间起始地址到物理内存起始地址,连续建立覆盖所有物理内存的映射,映射采用了默认的 CACHE Mode WB,WB 确保了内核以最高性能访问内存,因此每个物理内存都被内核空间虚拟内存映射 (这里的物理内存只包括内核可以使用的物理内存). 线性映射只是确保了内核可以访问所有的物理内存,但不代表内核将所有物理内存占为己有,无论是内核还是用户进程需要直接或间接通过 Buddy 之后分配物理内存之后该物理内存才真正被占用。
由于线性映射的存在,默认情况下线性映射由 4KiB 页表拼成,但如果物理内存按 2MiB 或者 1Gig 连续,那么线性映射时会采用 2MiB 或 1Gig 页表. 首先分析最简单的场景,当用户进程分配一段虚拟内存,其可以主动与物理内存建立映射,或者通过缺页时在与物理内存建立映射,无论那种方式,系统都会通过 Buddy 分配器分配一个可用的物理页,然后建立页表映射,最后用户进程就可以使用内存,这个时候物理页是存在两种映射,如下图:
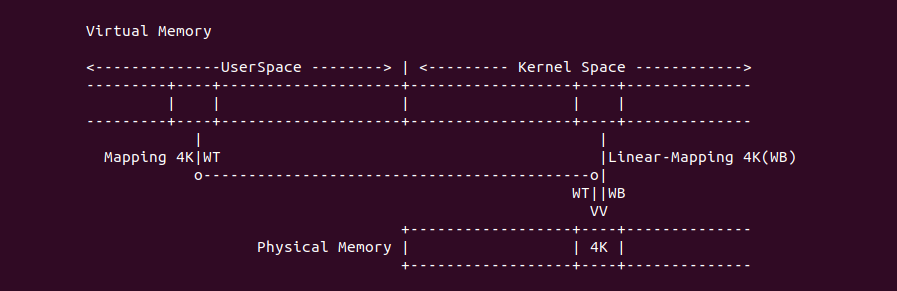
正如上图所示,应用程序建立与物理内存的映射之后,此时物理内存存在两个映射,一个是用户空间的虚拟地址映射,另外一个来自内核空间的虚拟地址线性映射,如果此时两种映射都采用 WB,那么不存在问题,但如果其中用户进程需要采用 WT,那么此时会出现同一个物理地址即采用了 WB 又采用了 WT,这是不合理的,解决这个问题的办法如下:
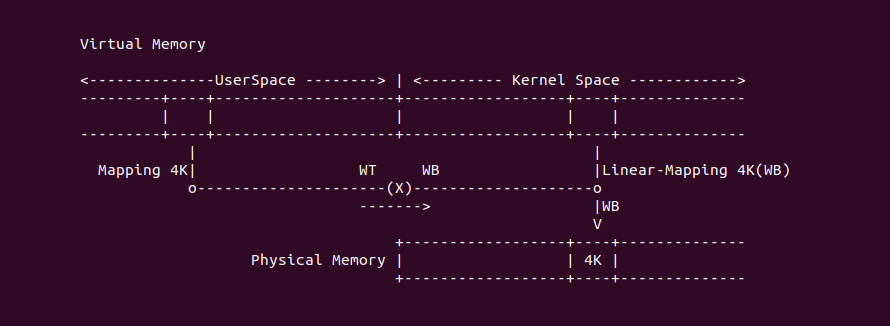
Linux 基于物理内存维护 CACHE Mode 的一致性,当发现映射的 CACHE Mode 不同时,可以保留当前的 CACHE Mode,禁止新建立映射所采用的 CACHE Mode,例如上图应用程序想映射 WT 的映射,但此时物理内存已经采用了 WB 映射模式,那么需要阻止新建映射的 CACHE Mode,并将新建映射的 CACHE Mode 采用当前的 CACHE Mode. Linux 内核在物理内存的 CACHE Mode 信息存储在 struct page 的 flags 指定域里,可以确保物理内存 CACHE Mode 的唯一性。
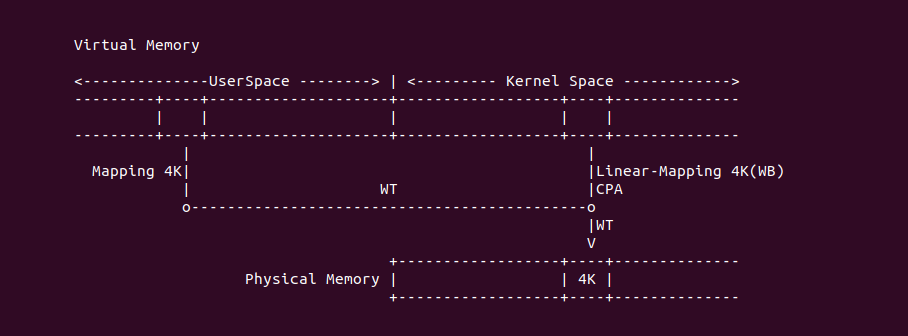
但在有的场景,确实需要采用新建立映射的 CACHE Mode,因此这个时候就需要借助 CPA 机制,该机制会修线性映射的 CACHE Mode,使其与新建立的 CACHE Mode 一致,这样物理页就可以使用新的 CACHE Mode。由于 CPA 修改了线性映射的 CACHE Mode,需要 FLUSH 对应的内核虚拟内存.
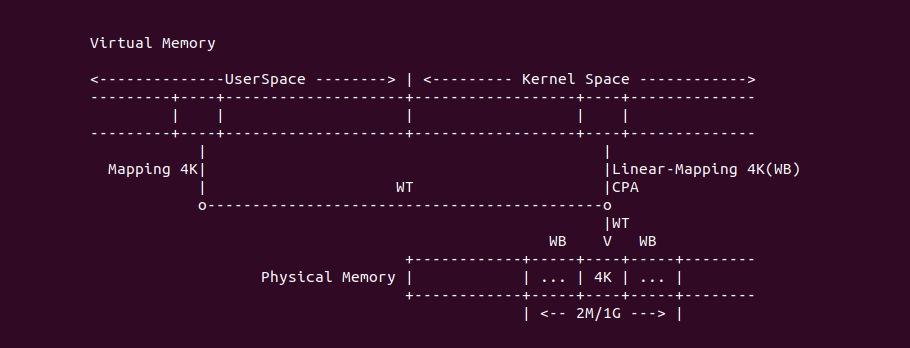
CPA 机制不仅仅修改 CACHE Mode 这么简单,继续讨论线性映射的 CACHE Mode 问题,之前分析了解到线性映射存在 2M 或者 1G 的映射,如果应用程序分配的 4K 物理页正好属于 2M/1G 大页中的一个 4K 页,那么应用程序映射的 4K 采用的 CACHE Mode 就和同属一个大页的其他 4K 物理页采用不同的 CACHE Mode,那么此时需求将原有的大页线性映射拆分成小页. 通过上面的分析基本了解了 CPA 与 CACHE 的关系,那么接下来先通过一个实践案例感受 CPA 的使用方法,案例在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] CPA: Change Page Attribute with CACHE --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-CPA-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build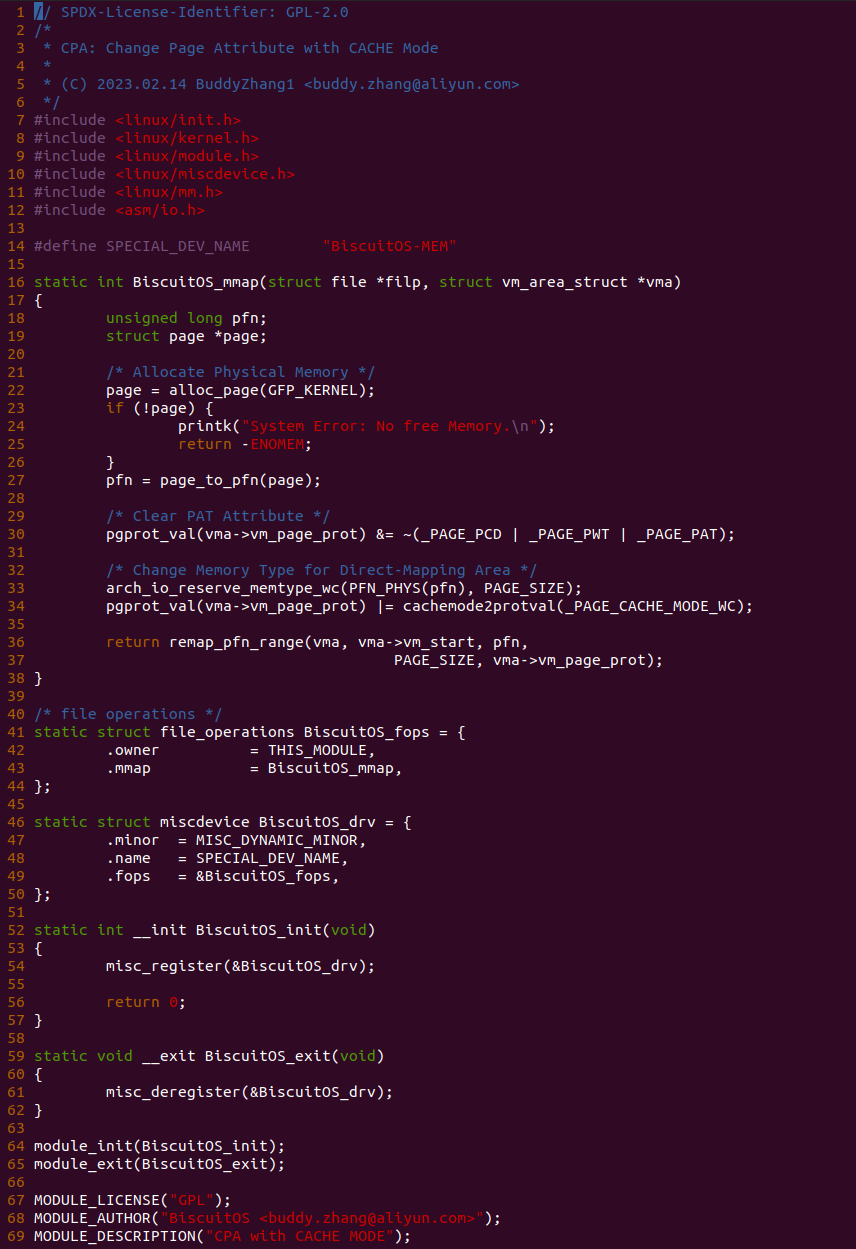
实践案例由两部分组成,上图展示了内核模块部分,模块基于 MISC 驱动框架向用户空间提供了 “/dev/BiscuitOS-MEM” 接口,接口提供了 mmap 实现,当用户空间打开接着并调用 mmap() 函数之后,其最终会调用到 BiscuitOS_mmap() 函数. 在 BiscuitOS_mmap() 函数中,函数首先在 22-27 行通过调用 alloc_page() 分配一个物理页,然后获得物理页对应的 PFN,接着在 30 行将映射页表的 PAT 属性集清除,然后在 33 行调用 arch_io_reserve_memtype_wc() 函数调整物理页对应的线性映射区的 CACHE Mode 为 WC,确保映射物理页的所有 CACHE Mode 都是 WC. 函数接着在 34 行根据实际需求,将映射页表的 PAT 属性集设置为 WC,最后函数调用 remap_pfn_range() 函数建立页表.
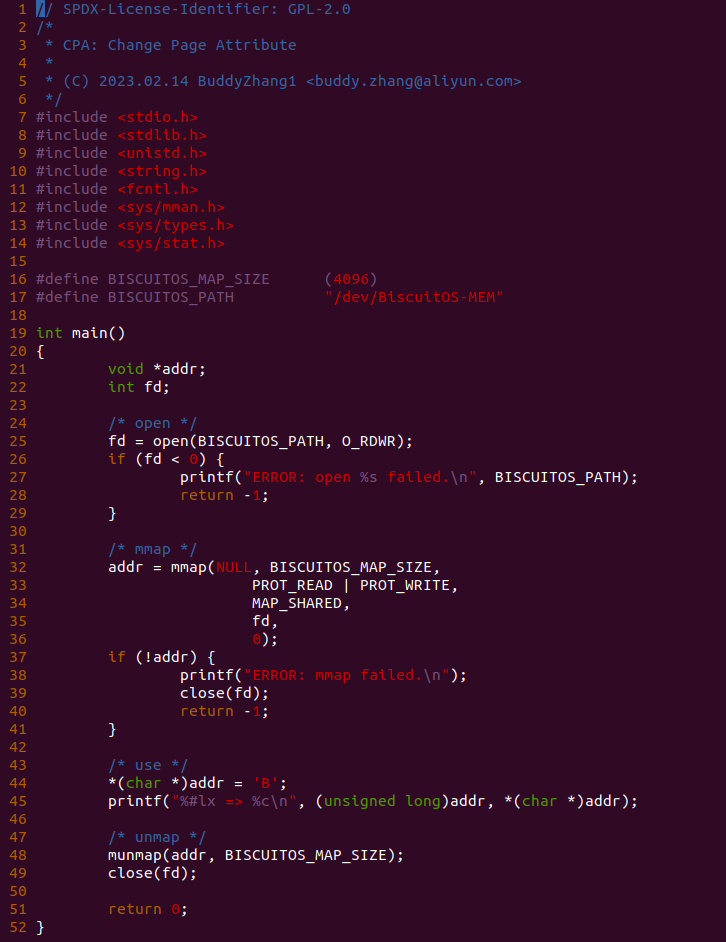
实践案例的另外一部分是用户空间的代码,在程序中,首先在 25 行通过 open() 函数打开 “/dev/BiscuitOS-MEM” 节点,然后在 32 行调用 mmap() 函数映射一段设备内存到用户空间,接着在 43-45 行使用内存,最后在 48-49 行归还内存. 接下来在 BiscuitOS 上进行实践:
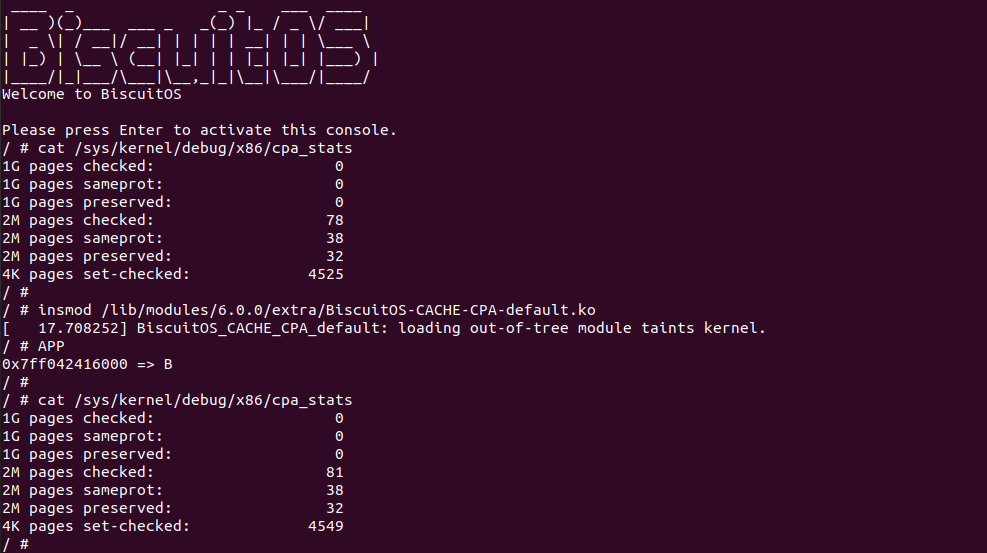
BiscuitOS 系统启动之后,首先查看 cpa_stats 节点信息,该信息是 CPA 机制用于统计修改页表操作的统计,接着加载 BiscuitOS-CACHE-CPA-default.ko 模块,最后运行 APP,此时可以正确使用内存,系统并没有报 Memory Type 移除的信息,说明应用程序映射 WC 生效了. 开发者可以进一步实践,将内核模块 34 行的 _PAGE_CACHE_MODE_WC 修改为其他 CACHE MODE 试试,例如修改为 _PAGE_CACHE_MODE_WT, 然后在 BiscuitOS 上实践如下:
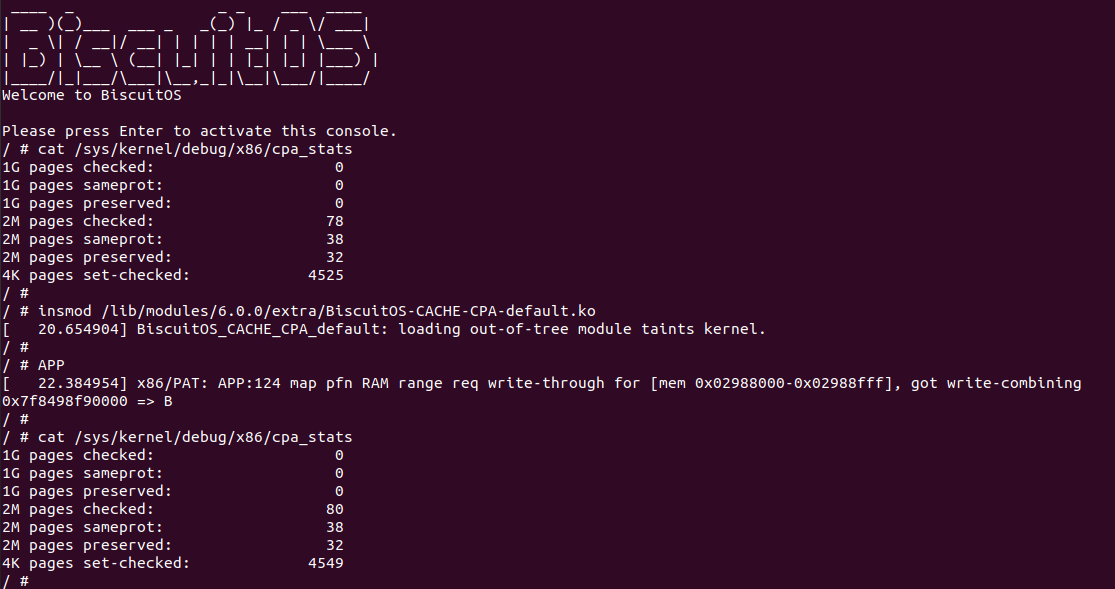
BiscuitOS 系统启动之后,加载完驱动之后运行 APP,此时系统打印字符串 x86/PAT: APP:124 map pfn RAM range req write-through for [mem 0x02988000-0x02988fff], got write-combining, 意思就是新建立的映射想采用 WT,但当前对应物理页的 CACHE Mode 为 WC,为了保持 CACHE Mode 的一致性,因此需要将 CACHE Mode 设置为 WC,因此应用程序最终以 WC 的方式映射了物理页. 通过上面的实践说明之前的 CPA 确实保证了物理内存 CACHE Mode 的一致.
用户空间进程映射设备管理物理内存的逻辑调用如上图,核心三个动作. 第一个动作是 arch_io_reserve_memtype() 函数里的 memtype_reserve() 函数,该函数用于将新的 CACHE Mode 通过 set_page_memtype() 函数存储到物理页对应的 struct page 数据结构 flags 成员里. 第二个动作是 arch_io_reserve_memtype() 函数里的 memtype_kernel_map_sync() 函数,该函数根据预期的 CACHE Mode,将线性映射区的虚拟地址对应的页表 PAT 集合设置为预期的 CACHE Mode. 通过前两个动作可以确保映射到当前物理页的 CACHE Mode 都是与预期 CACHE Mode 一致。最后一个动作就是建立进程虚拟地址到物理页的页表,并将页表的 PAT 集合设置为预期的 CACHE Mode. 三个动作下来进程映射的 DEVMEM 也可以采用预期的 CACHE Mode. 通过上面的分析可以看到 CPA 在其中起到的作用有两个,一个是保持物理内存的 CACHE Mode 一致,另外一个功能是记录系统 Change Page Attribute 的数据,那么接下来分析 CPA 中关于 CACHE 实现机理.
内核提供了一套接口函数,主要两个作用,首先将虚拟内存对应的物理内存 CACHE Mode 设置为指定的类型,第二个作用是修改虚拟内存已经建立页表的属性,其中就包括页表 PAT 属性集合. 那么接下来详细分析 set_memory_wc() 函数的实现过程来一探 CPA 机制:
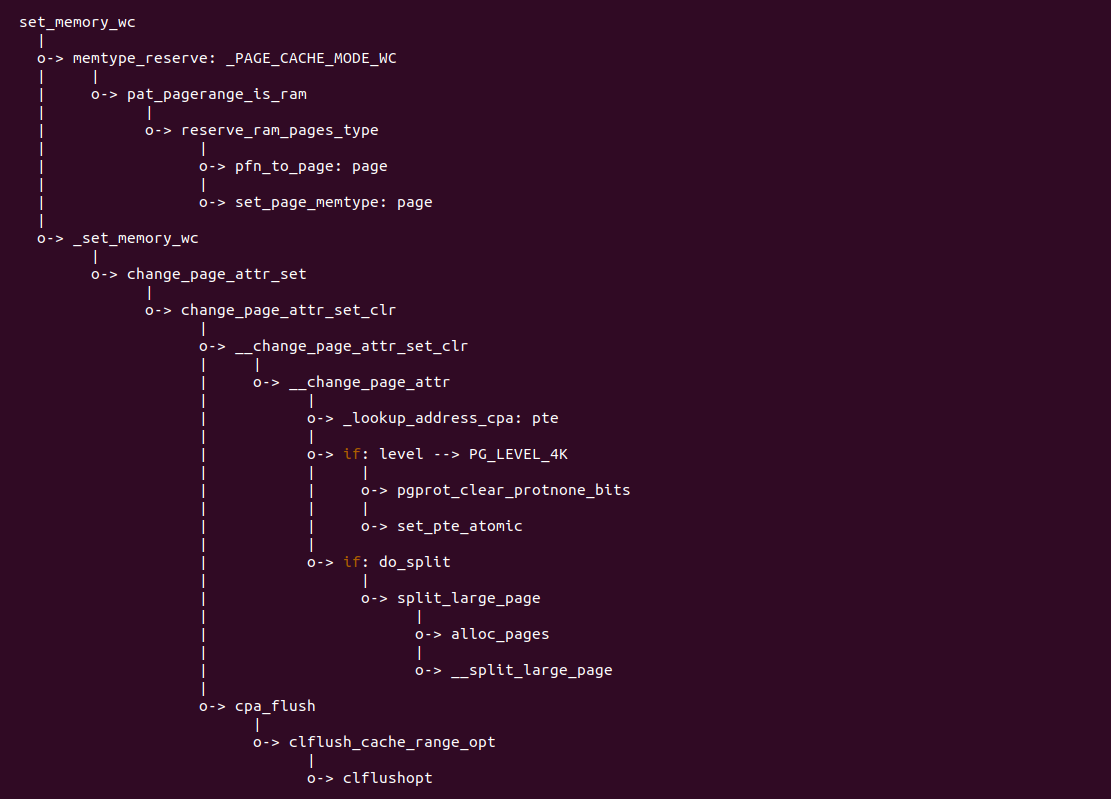
set_memory_wc() 函数的实现逻辑如上,分作两个部分,第一部分的核心是 reserve_ram_page_type() 函数,物理内存的 CACHE Mode 信息存储在 struct page 的 flags 成员里,此处从软件上确保物理页的 CACHE Mode 信息统一; 第二部份是 change_page_attr_clr() 函数,其实现对线性映射页表属性进行修改,如果映射时是一个巨型页,那么还需要将巨型页拆分成 4K 页,最后设置完页表之后需要调用 cpa_flush() 函数对虚拟内存 FLUSH CACHE.
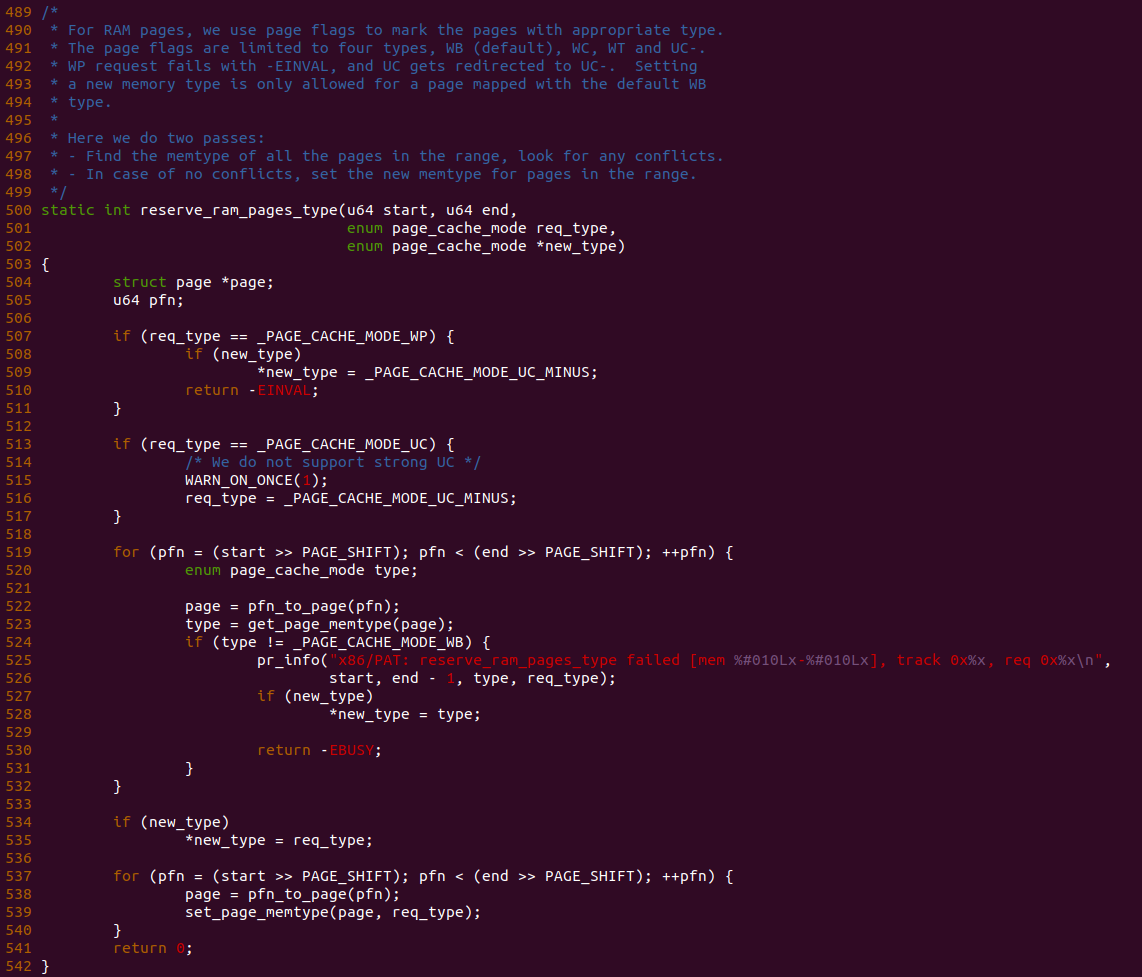
set_momory_wc() 函数第一部分的核心函数 reserve_ram_pages_type() 实现逻辑如上,函数确保物理内存的 CACHE MODE 不能修改为 WP,其二是如果将物理内存的 CACHE MODE 修改为 UC,那么会警告,然后调整为 UC-. 检查通过之后就是找到物理页对应的 struct page, 并从 struct page 的 flags 成员获得当前物理页的 CACHE MODE,如果此时 CACHE MODE 不是 WB,那么系统会报错,因此内核现在只支持 WB 的物理内存切换成其他 CACHE MODE,最后函数在 538 行调用 set_page_memtype() 函数将当前物理页的 CACHE MODE 修改该指定的类型.
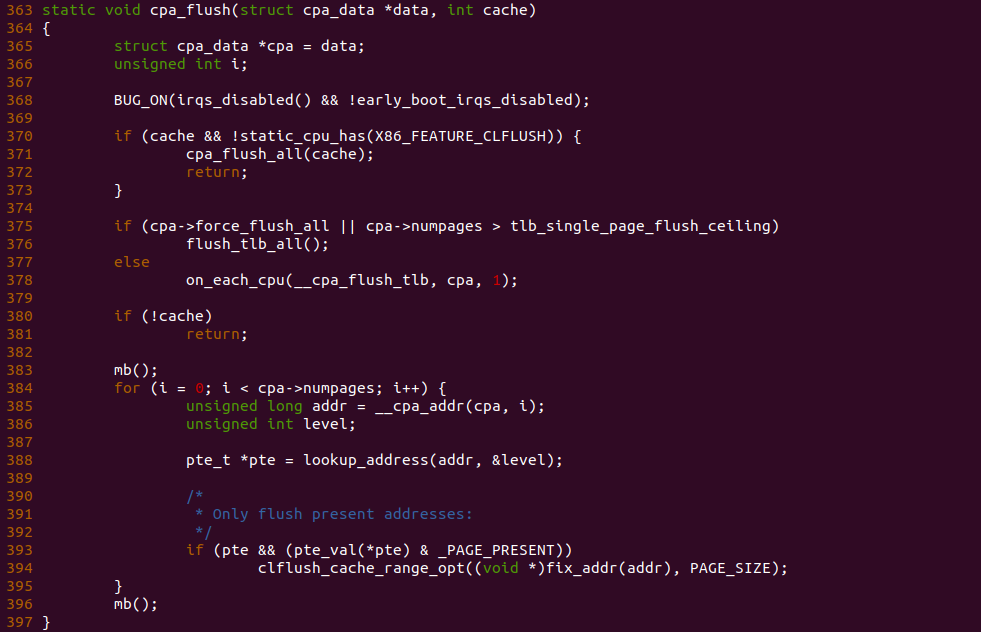
set_memory_wc() 函数的另外一个核心就是修改页表属性,这里不做过多介绍,主要涉及页表的修改,另外就是 FLUSH CACHE 部分,由于 CPU 访问通过线性映射的虚拟地址访问物理页,其会被缓存在 CACHE 中,如果此时修改了页表属性,那么需要将虚拟内存中对应的 CACHE Line 无效,那么通过 cpa_flush() 函数实现,其实现原理如上图,第一部分是 375-378 的 FLUSH TLB,第二部分是调用 clflush_cache_range_opt() 函数刷虚拟内存对应的 CACHE,其核心通过 CLFLUSH_OPT 指令实现. 至此 CPA 与 CACHE 的代码逻辑已经分析完毕.
CPA 机制向用户空间提供了 “/sys/kernel/debug/x86/cpa_stats” 接口,该接口记录了当前系统修改页表的统计,按页表粒度分作三类.
CACHE-Info Interface
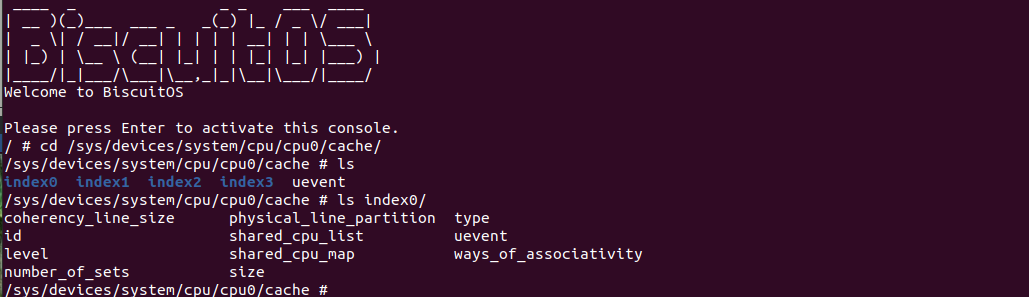
CACHE-Info Interface 是 Linux 内核向用户空间提供用于获取系统 CACHE 组织信息,例如系统包括所有级 CACHE,每一级 CACHE 的 CACHE Line 大小、Set 数量等信息。通过这些信息用户可以更便捷的获得 CACHE 的信息,并加以使用. 接下来先介绍各节点的含义:
/sys/devices/system/cpu/cpuX/cache 目录下展示的是 CPUX 所使用的 CACHE 信息,其中 indexX 表示不同 Level 的 CACHE,其中 index0/index1 表示 L1 CACHE, L1 CACHE 包含了 Instruction CACHE 和 Data CACHE. index2 表示 L2 CACHE,以及 index3 表示 L3 CACHE。现代 Intel CPU 包含了 L1/L2/L3 CACHE。

进入 indexX 之后就是每一级 CACHE 具体信息,基本包含了上图节点,各成员的含义:
- coherency_line_size: 该级 CACHE Line Size 的大小,主流的值为 64
- id: CACHE ID,ID 为 0 为表示 L1 Data CACHE, ID 为 1 表示 L1 Instruction CACHE,ID 为 2 表示 L2 CACHE,ID 为 3 表示 L3 CACHE.
- ways_of_associativity: 组相联映射中 CACHE 的路数
- number_of_sets: 组相联映射中 CACHE 包含的组数
- physical_line_partition: 缓存的物理分区情况
- shared_cpu_list: 能够共享该缓存的 CPU 核列表,在 X86 中两个逻辑核共享 L1/L2
- shared_cpu_map: 能够共享该缓存的 CPU bitmap.
- size: 缓存的大小
- type: 缓存类型,可以是 Instruction、Data 和 Unified
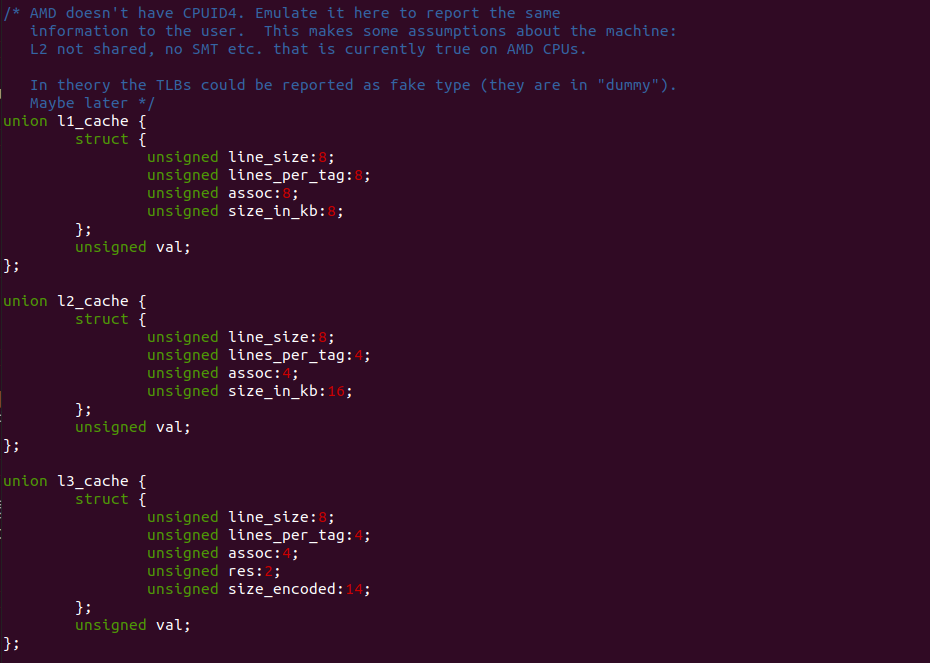
CACHE-INFO 相关的代码实现位于 “arch/x86/kernel/cpu/cacheinfo.c”, 其定义了三个数据结构分别描述 L1/L2/L3 CACHE, 可以通过 init_intel_cacheinfo() 函数查看其初始化过程,内核基于上个数据结构,将其导入到 sys 文件系统中, 以便上文各接口使用.

在 Intel 架构中,各级 CACHE 的信息存储在 CPUID 里(EAX=0x4H), 内核可以通过连续从 CPUID(EAX=0x4H) 处读出所有 CACHE 的信息,例如第一次 CPUID 读出的信息是 L1 Data CACHE, 第二次读出的是 L1 Instruction CACHE,第三次读出的是 L2 CACHE,下一次读出的是 L3 CACHE。每次使用 CPUID 读出 CACHE 信息时,EBX、ECX 和 EDX 都包含了 CACHE 相关的信息,这些信息用于填充 struct l1_cache、l2_cache 和 l3_cache 数据结构体.
CACHE 调试工具合集
Perf with CACHE
Perf 是 Linux 的一款性能分析工具,能够进行函数级和指令级的检测,可以用来分析程序中热点函数的 CPU 占用率,从而定位性能瓶颈。Perf 也能检测系统 CACHE Hit 和 Miss 率,从而提供优化方向的数据指标。本节重点描述 Perf 与 CACHE 相关的分析,具体如下:
Perf 工具的安装部署
BiscuitOS 默认支持 Perf 工具的部署,其部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] Perf Tools --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-perf-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
主流发行版上部署 Perf 工具如下:
# Ubuntu/Debian
sudo apt install linux-tools-common linux-tools-generic linux-tools-`uname -r`
# Add Permission
# 1. Add 'kernel.perf_event_paranoid = -1' on /etc/sysctl.conf
# 2. Set /proc/sys/kernel/perf_event_paranoid
echo -1 > /proc/sys/kernel/perf_event_paranoid
# CentOS
sudo yum install perf
Perf 测试代码部署
Perf 测试代码是针对 perf 工具使用时,最大限度展示工具功能性,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Analysis/Diagnosis Tools: Perf --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-TOOLS-PREF-default/
# 部署源码/解决依赖
make download
make prepare
# 在 BiscuitOS 中实践
make build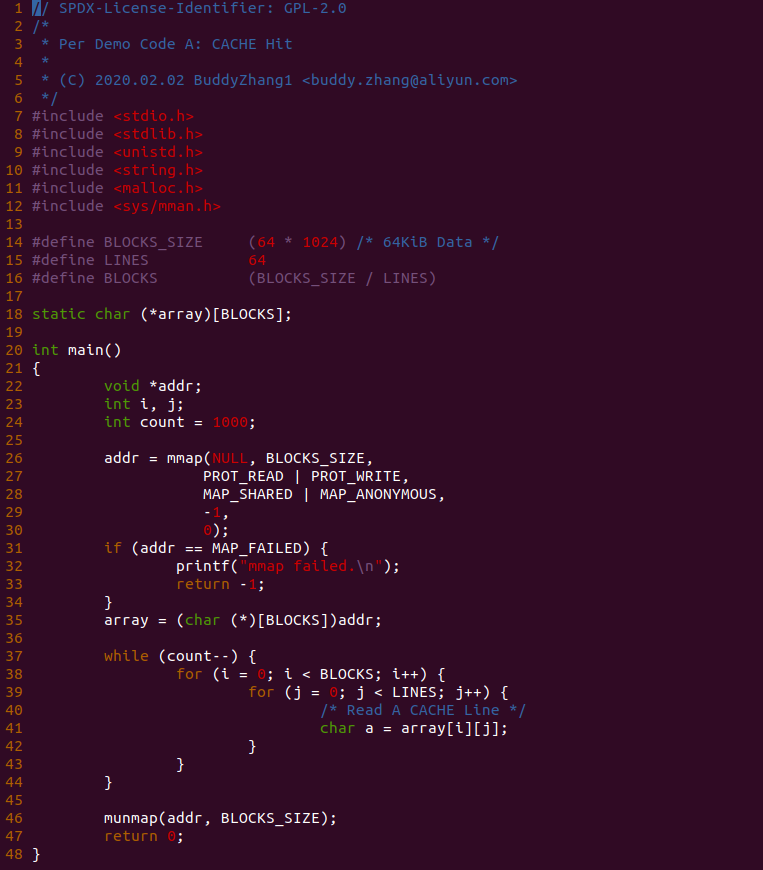
测试代码由两个用户空间程序组成,上图为 main-A.c 的源码. 源码的目的很简单,通过 mmap 分配 64KiB 的内存,然后在 36-43 行顺序将内存的数据取出.
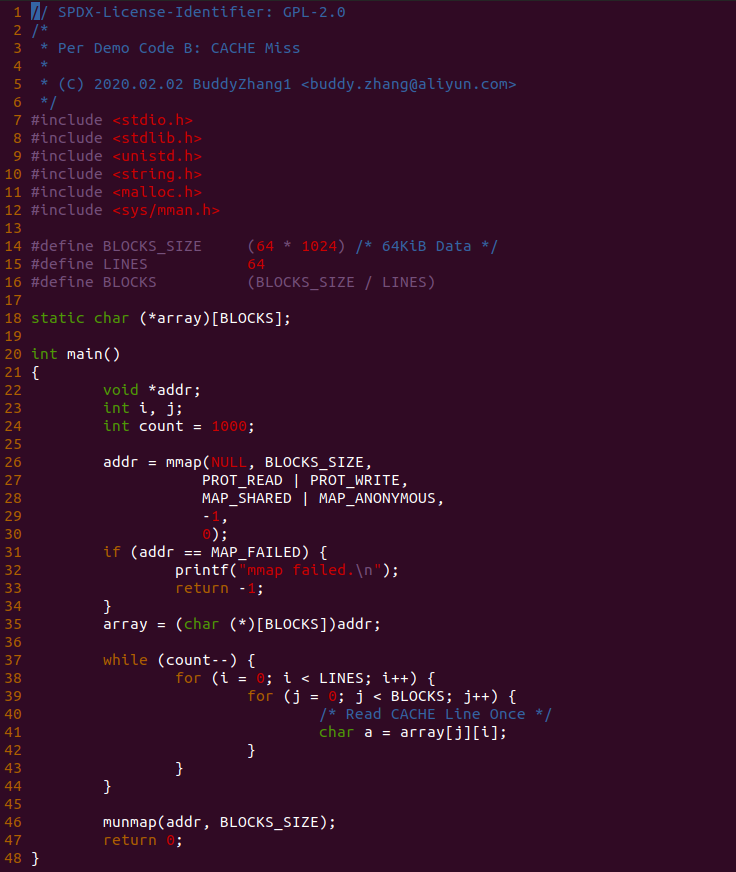
上图为测试代码 main-B.c,其实现与 main-A.c 一致,只是在 36-43 行遍历内存时采用了不同的逻辑.
main-A.c 采用的遍历方式是按顺序的访问数组中的内容,即将前 64 个字节依次访问完毕之后,继续顺序访问下一个 64 字节. 而 main-B.c 遍历是先将内存分成 64 个字节的块,然后先访问所有块的第一成员,然后访问所有块的第二个成员,依次类推。从结果来看都是遍历的同样大小的内存,那么接下来使用 perf 分析两个程序之间的性能差异.
抓取 L1 CACHE Hit/Miss 数据
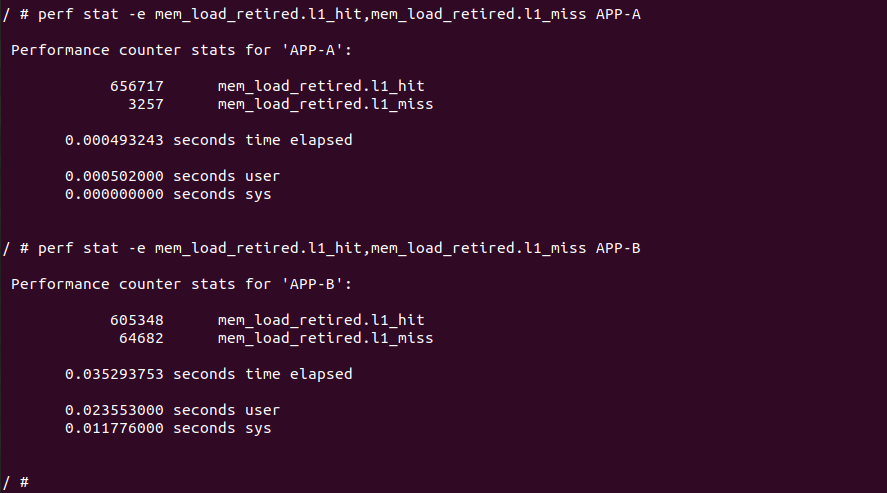
perf stat -e mem_load_retired.l1_hit,mem_load_retired.l1_miss ${APP}perf 可以捕获程序运行时 L1 CACHE Miss/Hit 数量, 其中 mem_load_retired.l1_hit 字段用于检查 L1 CACHE 的 Hit 数量,mem_load_retired.l1_miss 用于检测 L1 CACHE 的 Miss 数量. 开发者可以利用该工具分析程序运行的 L1 命中率,通过增加 L1 的命中率提供程序性能, 该数据也是性能优化的数据依据. 上图中使用 perf 工具检测 APP-A 和 APP-B 执行时 L1 命中率,可以看到 APP-A 的 hit 的数量远远大约 APP-B,另外 APP-A 的 miss 数远远小于 APP-B,最终从程序时间体现了两者之间的差异,APP-A 的性能优于 APP-B.
抓取 L2 CACHE Hit/Miss 数据
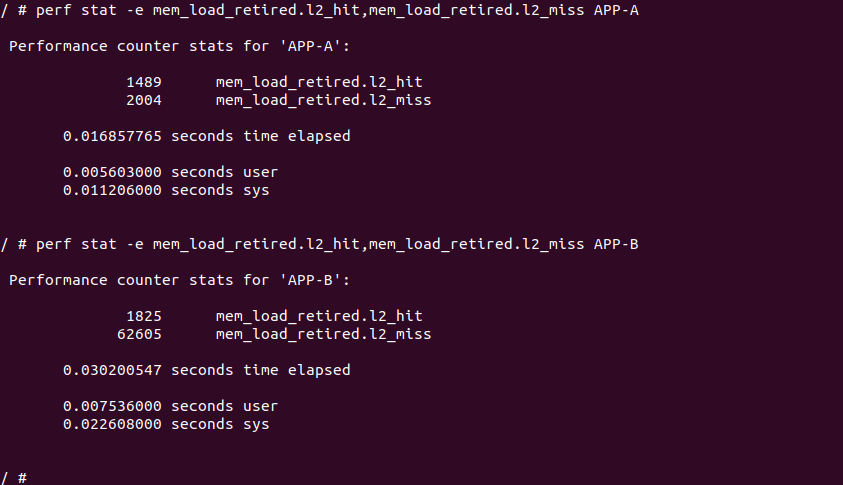
perf stat -e mem_load_retired.l2_hit,mem_load_retired.l2_miss ${APP}perf 可以捕获程序运行时 L2 CACHE Miss/Hit 数量, 其中 mem_load_retired.l2_hit 字段用于检查 L2 CACHE 的 Hit 数量,mem_load_retired.l2_miss 用于检测 L2 CACHE 的 Miss 数量. 开发者可以利用该工具分析程序运行的 L2 命中率,通过增加 L2 的命中率提供程序性能, 该数据也是性能优化的数据依据. 上图中使用 perf 工具检测 APP-A 和 APP-B 程序运行时的 L2 命中率,可以看到 APP-A hit 的数量远大于 APP-B,同时也可以看到 APP-A 运行耗时比 APP-B 少很多,因此可以推断两种算法在 L2 上的差异.
抓取 L3 CACHE Hit/Miss 数据
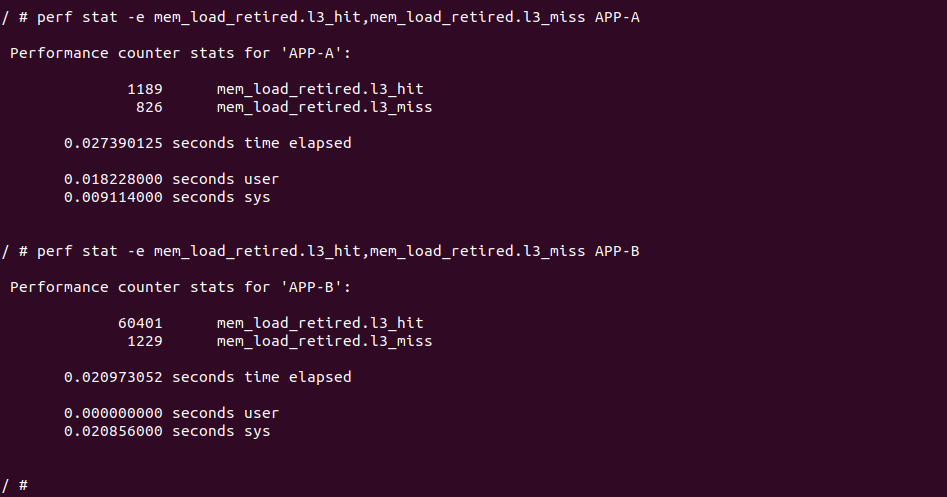
perf stat -e mem_load_retired.l3_hit,mem_load_retired.l3_miss ${APP}perf 可以捕获程序运行时 L3 CACHE Miss/Hit 数量, 其中 mem_load_retired.l3_hit 字段用于检查 L3 CACHE 的 Hit 数量,mem_load_retired.l3_miss 用于检测 L3 CACHE 的 Miss 数量. 开发者可以利用该工具分析程序运行的 L3 命中率,通过增加 L3 的命中率提供程序性能, 该数据也是性能优化的数据依据. 上图中使用 perf 工具检测APP-A 和 APP-B 程序运行时的 L3 命中率,可以看到 APP-A hit 的数量大于 APP-B,同时也可以看到 APP-A 运行耗时比 APP-B 少很多,因此可以推断两种算法在 L3 上的差异.
抓取程序 Miss 数据
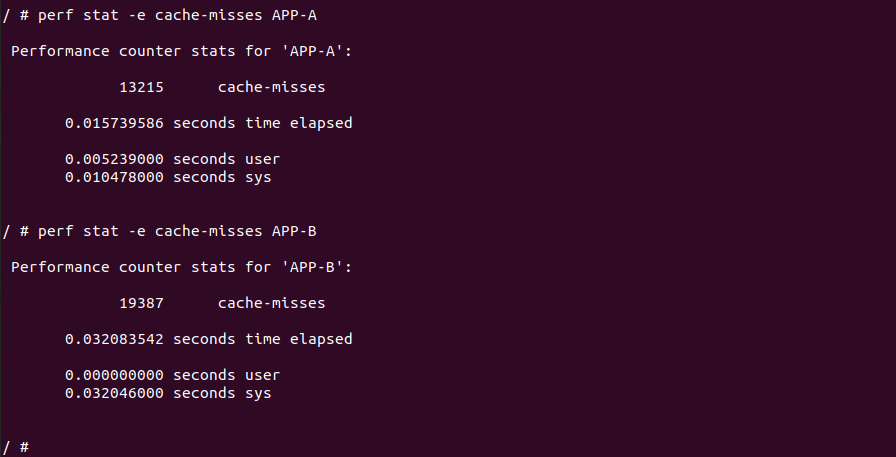
perf stat -e cache-misses ${APP}perf 可以捕获程序运行时 Miss 数据, 其中 cache-misses 字段用于检测程序 Miss 数量, 其包括了所有级 CACHE 的 Miss 数. 例如上图执行 APP-A 和 APP-B 时造成 cache-miss 的数量,可以看出 APP-A 的算法 Miss 数据明显少于 APP-B 的算法,另外检测时需要确保 “/proc/sys/kernel/kptr_restrict” 节点为 0. 因此通过不断减少应用程序 cache-miss 数量可以提升程序性能.
抓取程序应用 CACHE 数据
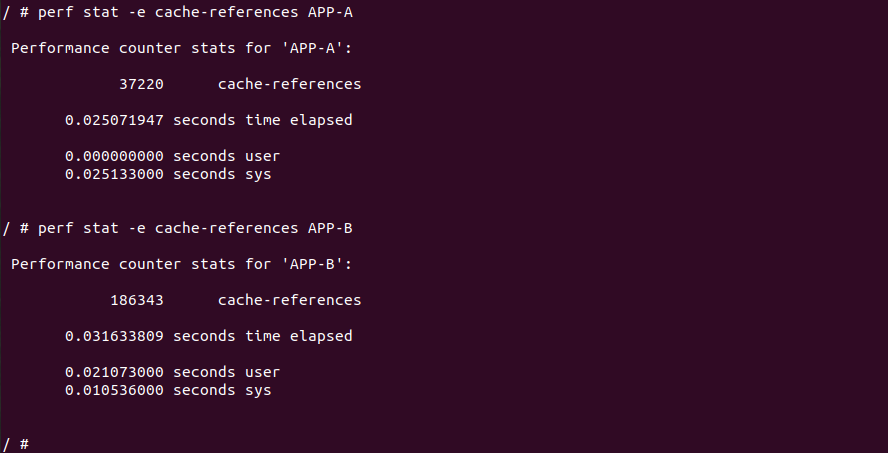
perf stat -e cache-references ${APP}perf 可以捕获程序运行时 CPU 访问 CACHE 的总数, 使用关键字 cache-references. 这个计数器可以用来衡量程序对缓存的使用情况,以及是否存在大量的 CACHE 访问导致性能问题. 如果 cache-references 计数器的值很高,说明程序使用了大量的 CACHE, 但不代表性能就好。如果该值与 CPU 周期计数器 cycles 相比较,可以计算出访问效率,从而更好的优化程序性能. 例如上图运行 APP-A 和 APP-B 时,APP-B 的 CACHE 访问数比 APP-A 好,但最终 APP-A 的耗时更少. 另外检测时需要确保 “/proc/sys/kernel/kptr_restrict” 节点为 0.
抓取应用程序 CACHE Miss 的位置
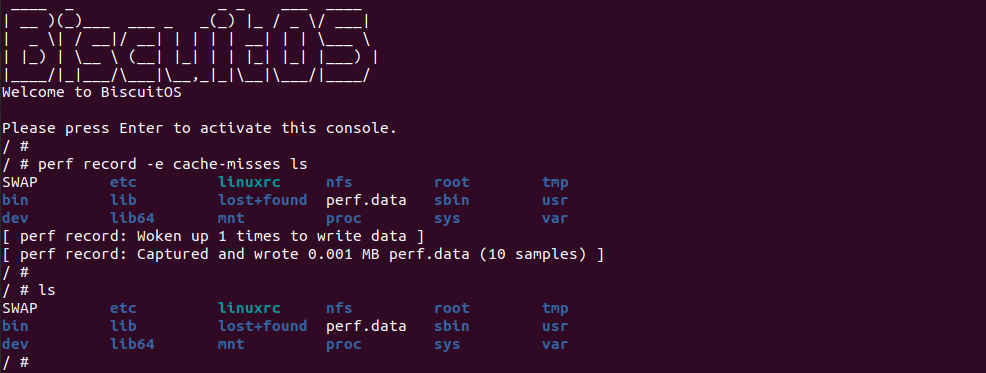
# 抓取 cache-misses event
perf record -e cache-misses ${APP}
# 解析数据
perf report perf.dataperf 可以监听 APP 程序运行发生 CACHE Miss 的位置, 会将生成的数据保存在当前目录的 perf.data 文件里,然后使用 perf report 进行查看. 另外需要内核打开 CONFIG_BPF_SYSCALL.
perf.data 文件可以使用 perf report 进行分析,默认情况下,perf report 会展示一个简单的文本用户界面(TUI),以便浏览收集的数据。–stdio 选项提供简单的文本输出。例如上图列出了数据收集的时间和位置,标题部分还包括了硬件和软件以及用于收集数据命令的详细信息. 在标题信息之后是一个排序的列表,显示与事件关联的指令位于哪些函数中。在这个情况下,应用程序在 main 函数占据了 85% 以上的样本. 列表中排名第二的函数是内核函数 clear_page_c_e, 可以看到其带有 “[k]” 属性,因此说明该函数是内核函数.
当想了解某个函数中哪些代码与缓存 Miss 有关的更多信息,Perf annotate 可以提供更多详细的信息,正如上图所示,perf annotate 输出的左列显示与该指令相关的采样百分比,右列显示了混合源代码和汇编代码,也可以使用光标键浏览输出,使用 H 查看样本最多的最热门指令。
列出 perf 支持的 CACHE 事件
perf list cache- L1-dcache-load-misses: L1 Data CACHE 读取 Miss 数
- L1-dcache-loads: L1 Data CACHE 读取数
- L1-dcache-stores: L1 Data CACHE 写入数
- L1-dcache-store-misses: L1 Data CACHE 写入 Miss 数
- L1-dcache-prefetches: L1 Data CACHE 预取数
- L1-icache-load-misses: L1 Instruction CACHE 读取 Miss 数
- LLC-load-misses: 最后一级 CACHE 读取 Miss 数
- LLC-loads: 最后一级 CACHE 读取数
- LLC-prefetches: 最后一级 CACHE 预读数
- LLC-store-misses: 最后一级 CACHE 写入 Miss 数
- LLC-stores: 最后一级缓存写入数
抓捕 L1 Data CACHE 读取 Miss 数
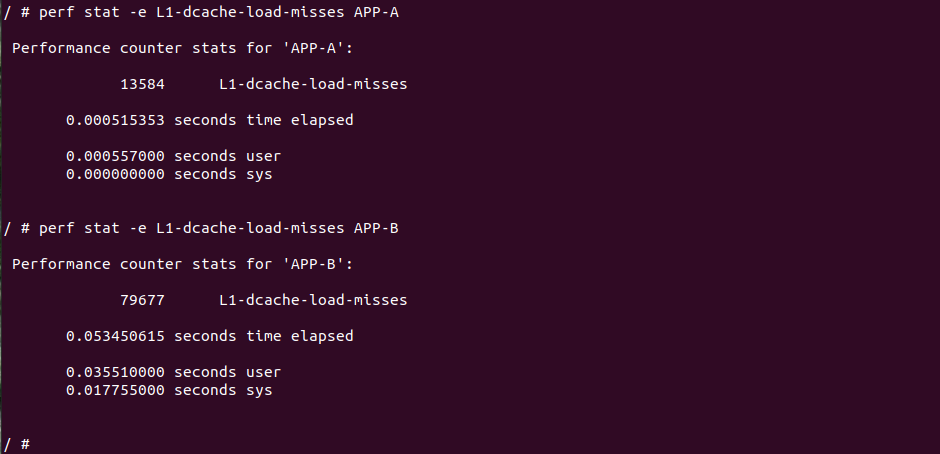
perf stat -e L1-dcache-load-misses ${APP}perf 结合 L1-dcache-load-misses 字段可以捕获应用程序在 L1 Data CACHE 读请求时发生 CACHE Miss 的数据, 该指标可以用来评估程序访问 CACHE 的效率,Miss 越少,说明程序的 CACHE 利用率越高,访问速度也更快. 从图中可以看出 APP-A 算法比 APP-B 算法更少的 L1 Data CACHE 缺失,因此说明 CPU 访问 APP-A 的数据很大概率缓存在 L1D CACHE 里,这样 APP-A 的运行速率越快.
抓捕 L1 Data CACHE 读取数
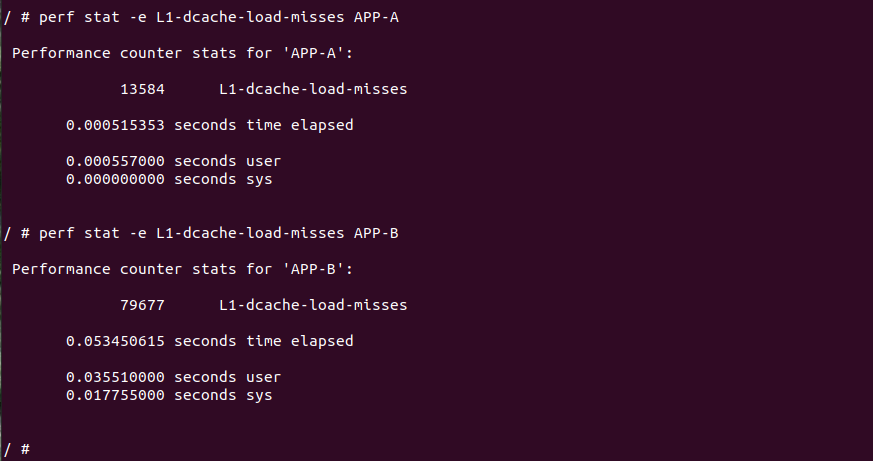
perf stat -e L1-dcache-loads ${APP}perf 结合 L1-dcache-loads 字段可以捕获应用程序在 L1 Data CACHE 加载的数据,该计数可以帮助开发者了解程序中的 L1D CACHE 的命中情况,从而优化程序的性能.
捕获 L1 Data CACHE 中缓存替换的数据
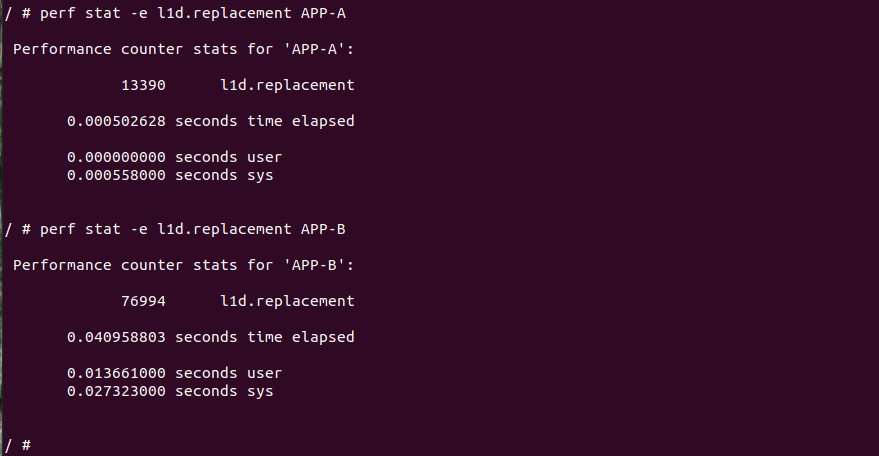
perf stat -e l1d.replacement ${APP}l1d.replacement 是 perf 工具与 L1D CACHE 中替换操作相关的计数器。L1D CACHE 是处理器中最快的 CACHE,它的大小有限,那么当 L1D CACHE 满的时候,需要将某些 CACHE Line 替换出去,为新的数据腾出空间. 这个替换操作可能会对程序的性能才生一定的影响,因此需要进行监控和分析. 当 l1d.replacement 计数较高,说明程序中有较多的 CACHE Replacement 操作,可能需要优化程序的数据访问模式来减少替换操作,提高程序的性能. 例如 APP-A 的算法比 APP-B 的算法有更少的 l1d.replacement 计数, 并从程序的执行时间来看 APP-A 的运行时间比 APP-B 少.
捕获 L1 Data CACHE 中因为缓存满 MISS 且被阻塞的数据
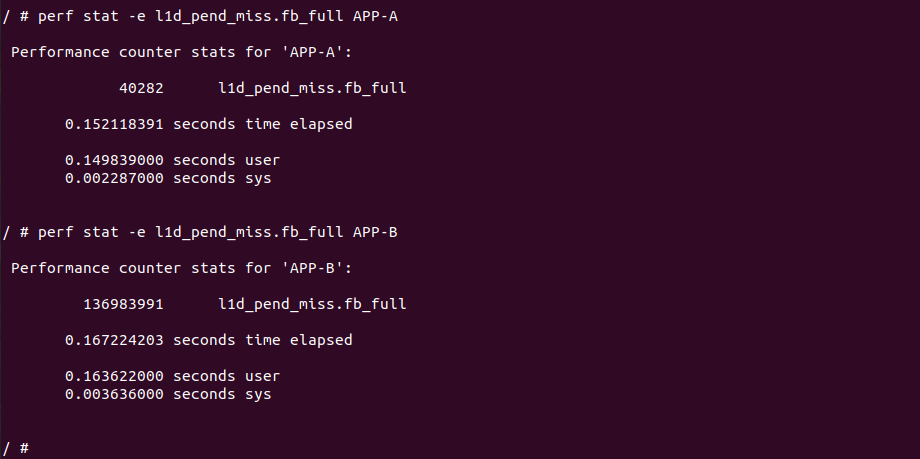
perf stat -e l1d_pend_miss.fb_full ${APP}l1d_pend_miss.fb_full 是 perf 工具用于记录 L1D CACHE 中被挂起的 MISS 数. 当数据不再 L1D CACHE 且 L1D CACHE 满掉,那么将会发生 CACHE Miss,且访问会被阻塞,直到所需的数据被加载到 L1D CACHE,因此可以使用 l1d_pend_miss.fb_full 获得被阻塞的 Miss 计数. 该计数是一个重要的性能计数器,可用于评估 L1D CACHE 的效率和性能. 例如 APP-A 比 APP-B 的算法发生极少的 CACHE Miss 阻塞, 在结合程序耗时,因此 APP-A 的算法优于 APP-B.
捕获 L1 Data CACHE 中因为缓存满 MISS 且被阻塞时间段数据
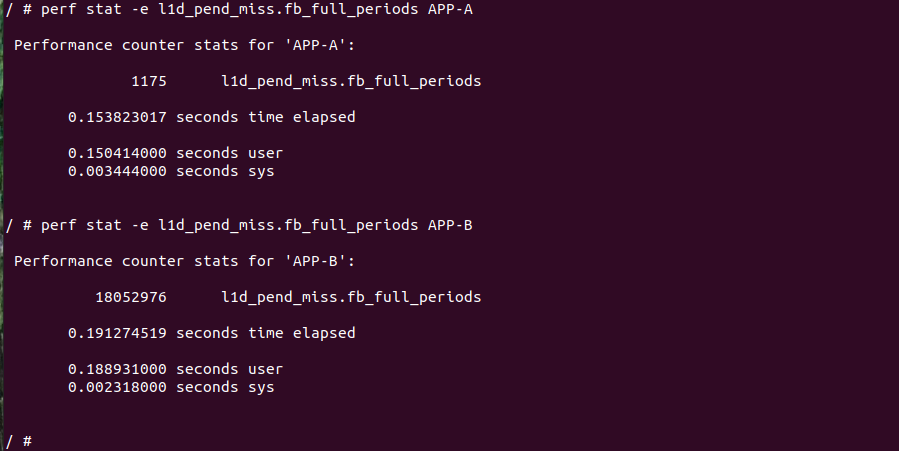
perf stat -e l1d_pend_miss.fb_full_periods ${APP}l1d_pend_miss.fb_full_periods 是 perf 工具用于记录 L1D CACHE 中被挂起的 MISS 时间段数. 当数据不再 L1D CACHE 且 L1D CACHE 满掉,那么将会发生 CACHE Miss,且访问会被阻塞,直到所需的数据被加载到 L1D CACHE,因此可以使用 l1d_pend_miss.fb_full_periods 获得被阻塞的 Miss 时间段数,即占用了多少个时钟周期. 该计数是一个重要的性能计数器,可用于评估 L1D CACHE 的效率和性能. 例如 APP-A 比 APP-B 的算法发生极短的 CACHE Miss 时间片, 在结合程序耗时,因此 APP-A 的算法优于 APP-B.
捕获因 L2 CACHE Stall 导致 L1D CACHE 被阻塞的计数
perf stat -e l1d_pend_miss.l2_stall ${APP}l1d_pend_miss.l2_stall 是 perf 工具用于统计 L1D CACHE 因为 L2 CACHE 无法及时处理导致被挂起的 MISS 计数. CACHE Stall 表示 CACHE 请求太多, 导致请求无法被及时处理而被挂起. 当 L1D CACHE 中发生 CACHE MISS,那么会去 L2 CACHE 中进行查找,但是由于 L2 CACHE 的请求太多,且未处理的请求达到了一定数量,那么 L1D CACHE 的请求会被挂起。l1d_pend_miss.l2_stall 就是用于统计这类事件的数量. 该数据是用来评估 L2 CACHE 性能的瓶颈,以及优化程序的内存访问模式,以减少由于 L2 CACHE 请求 Stall 导致的 L1D CACHE 挂起的情况. 例如 APP-A L1D CACHE Pend 数就远远比 APP-B 的低,因此需要 APP-B 的内存访问算法.
捕获 L1D CACHE Miss 是被 Pending 的数据
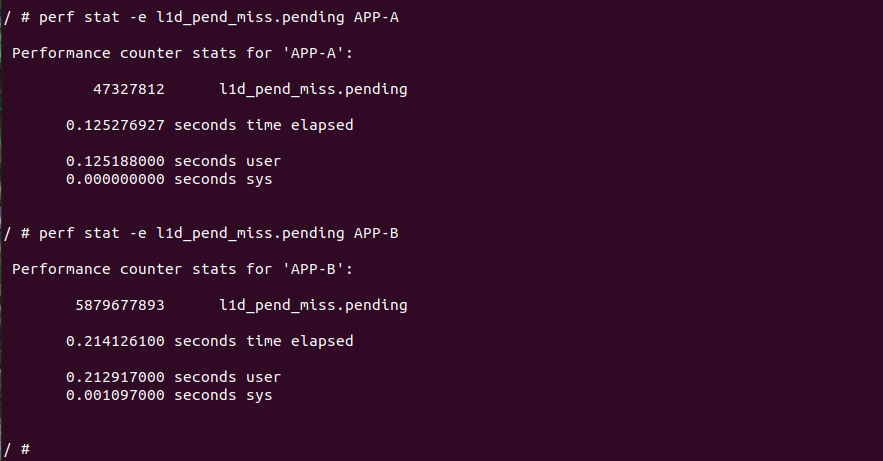
perf stat -e l1d_pend_miss.pending ${APP}l1d_pend_miss.pending 是 perf 工具用于统计程序 L1D CACHE 发生 CACHE Miss 时,CPU 需要等待数据从内存或其他 CACHE 中读取的次数. 这个计数通常反应程序访问内存的效率和延迟情况,对于优化程序性能和减少延迟非常有效。具体来说,l1d_pend_miss.pending 计数越高,表示 CPU 处理器需要等待数据的次数越多,程序效率越低,延迟越大. 例如上图中 APP-A 算法延时就比 APP-B 好很多.
捕获 L1D CACHE Miss 是被 Pending 的时钟周期数
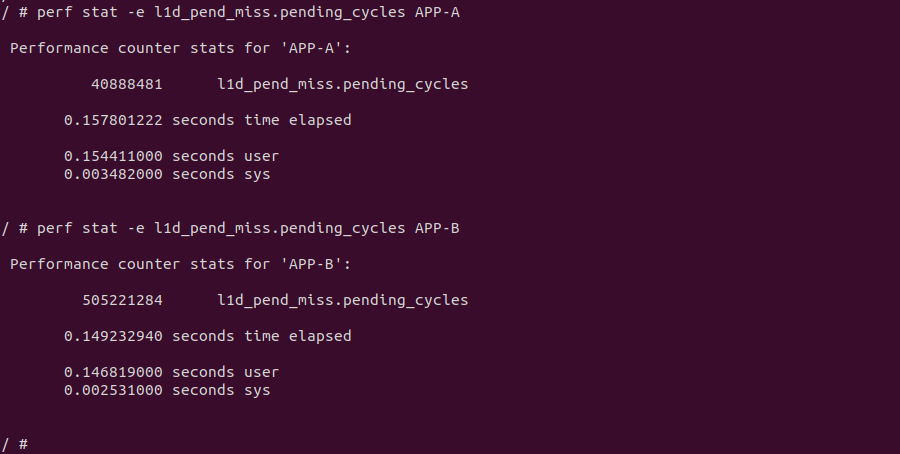
perf stat -e l1d_pend_miss.pending_cycles ${APP}l1d_pend_miss.pending_cycles 是 perf 工具用于统计程序 L1D CACHE 发生 CACHE Miss 时,CPU 需要等待数据从内存或其他 CACHE 中读取的周期数. 这个计数通常反应程序访问内存的效率和延迟情况,对于优化程序性能和减少延迟非常有效。具体来说,l1d_pend_miss.pending_cycles 计数越高,表示 CPU 处理器花费在等待数据的时间越高,程序效率越低,延迟越大. 例如上图中 APP-A 算法延时就比 APP-B 好很多.
捕获 L1D CACHE Miss 导致 CPU 循环周期数
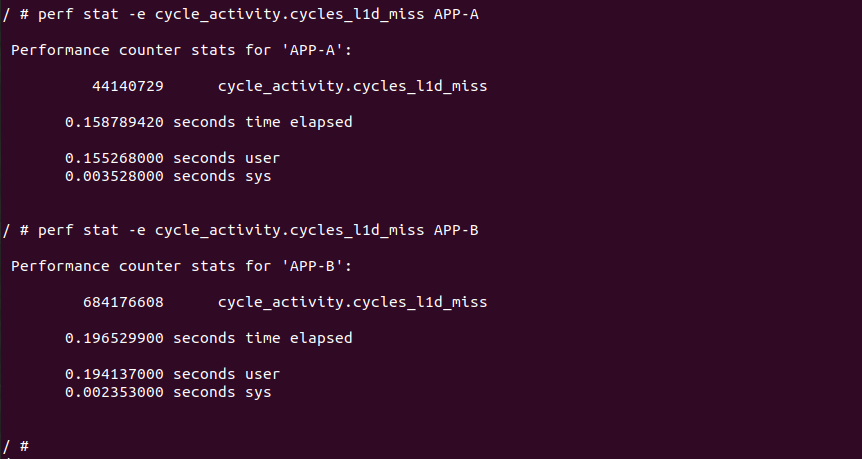
perf stat -e cycle_activity.cycles_l1d_miss ${APP}cycle_activity.cycles_l1d_miss 是 perf 工具用于统计程序 L1D CACHE 发生 CACHE Miss 时,统计 CPU 循环周期数. L1D CACHE 是离 CPU 最近的 CACHE,当 CPU 访问的数据不在 L1D CACHE,导致 CACHE Miss,那么 CPU 需要从更慢的内存或者 CACHE 中读取数据,这会导致 CPU 浪费一些循环周期。因此 cycle_activity.cycles_l1d_miss 可以用于诊断程序中存在 L1D CACHE MISS 的问题,帮助开发者优化性能. 例如 APP-A 算法比 APP-B 有较少的循环周期。
捕获 L1D CACHE Miss 导致 CPU 循环周期停顿数
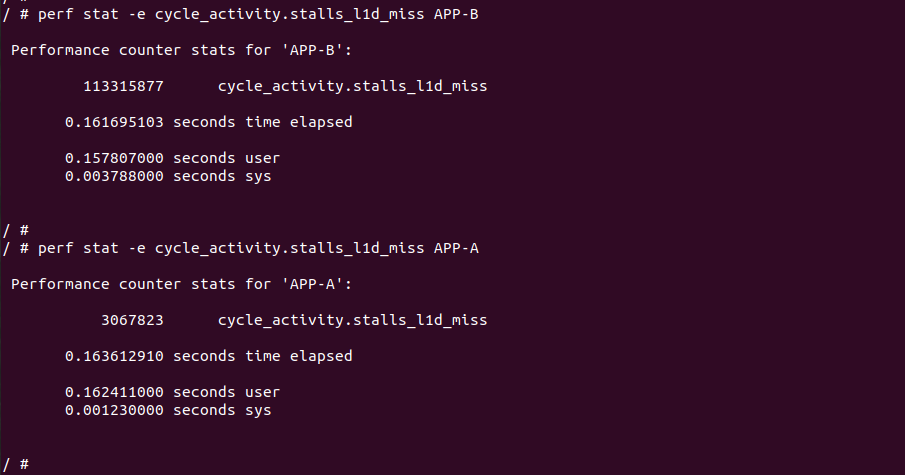
perf stat -e cycle_activity.stalls_l1d_miss ${APP}cycle_activity.stalls_l1d_miss 是 perf 工具用于统计程序 L1D CACHE 发生 CACHE Miss 时,统计 CPU 循环周期停顿数. L1D CACHE 是离 CPU 最近的 CACHE,当 CPU 访问的数据不在 L1D CACHE,导致 CACHE Miss,那么 CPU 需要从更慢的内存或者 CACHE 中读取数据,在此期间,CPU 不能继续执行后续指令,而是必须停顿等待数据返回,这种停顿称为循环周期停顿。因此 cycle_activity.stalls_l1d_miss 可以用于分析程序因 L1D CACHE Miss 导致循环周期停顿的情况,帮助开发者优化程序. 例如 APP-A 算法比 APP-B 有较少的循环周期停顿。
捕获 L2 CACHE 加载 CACHE Line 数量
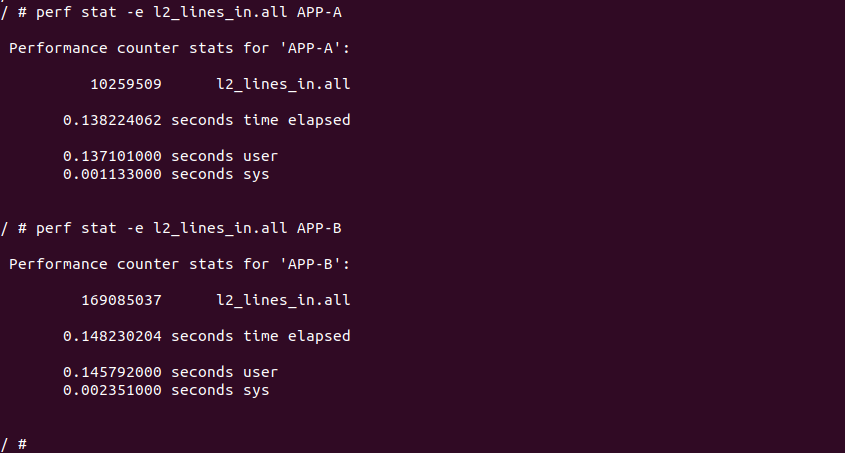
perf stat -e l2_lines_in.all ${APP}l2_lines_in.all 是 perf 统计应用程序使用 L2 CACHE 的情况,其通过统计 L2 CACHE 加载 CACHE Line 的数量来体现。该数据可以帮助开发者了解 L2 CACHE 的使用情况和性能,因为 L2 CACHE 的 CACHE Line 从内存或者 L3 中读取,因此其加载的数量对系统的性能有很大的影响。如果 L2 CACHE 加载 CACHE Line 数量很高,则会导致 L2 CACHE 过度使用,从而降低系统性能。相反如果 L2 CACHE 加载的 CACHE Line 数量过低,则可能会导致 L2 CACHE 未被充分利用,从而浪费了系统资源. 例如上图中 APP-A 和 APP-B 的 L2 CACHE 加载 CACHE Line 数量都不低,但 APP-A 的更合理,说明 APP-A 的数据访问基本在 L1D CACHE 就可以解决. 开发者可以根据该数据判断是否需要优化系统的缓存配置或者其他方面也提高系统性能.
捕获 L2 CACHE 非静默写入 CACHE Line 数量
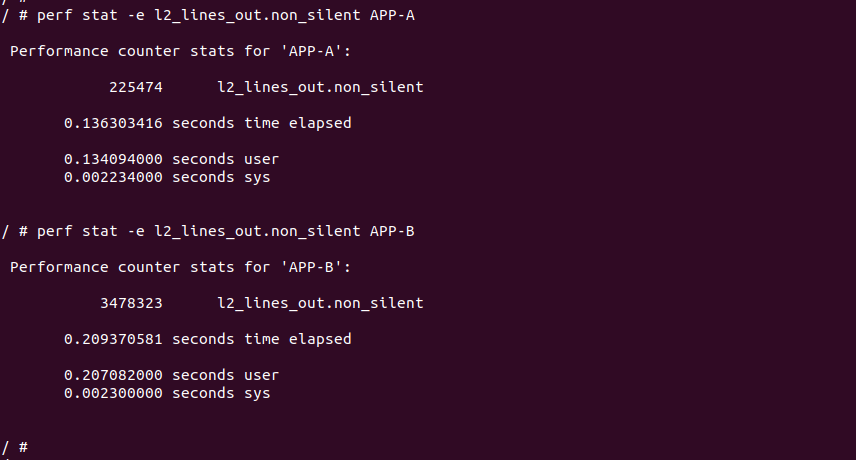
perf stat -e l2_lines_out.non_silent ${APP}l2_lines_out.non_silent 是 perf 统计因应用程序运行导致 L2 CACHE 被写入的 CACHE Line 数量,但不包括静默写入(静默写入: 即没有导致任何 CACHE Line 被替换的写入操作) 的 CACHE Line. 该事件可以用来衡量应用程序对 L2 CACHE 的写入压力,以及缓存替换算法的效率。较高的 l2_lines_out.non_silent 值可能会导致 L2 CACHE 性能瓶颈,需要优化缓存访问模式或增加缓存大小.
捕获 L2 CACHE 静默写入 CACHE Line 数量
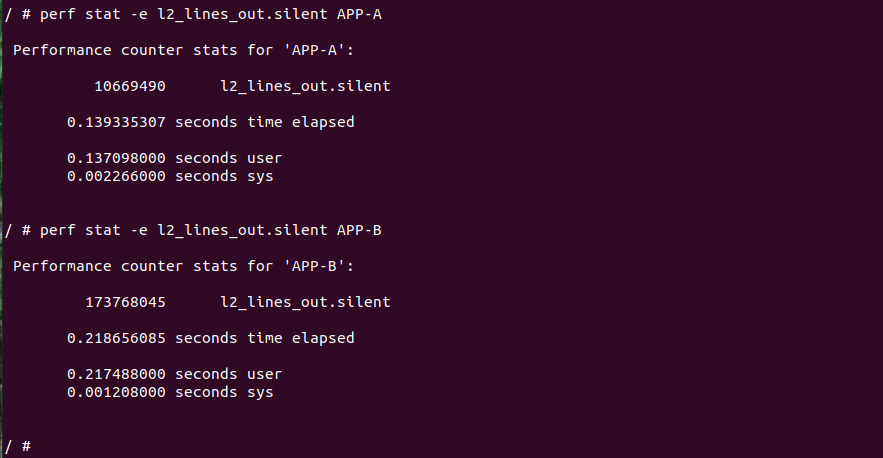
perf stat -e l2_lines_out.silent ${APP}l2_lines_out.silent 是 perf 统计因应用程序运行导致 L2 CACHE 被静默写入的 CACHE Line 数量,静默写入: 即没有导致任何 CACHE Line 被替换的写入操作。该事件可以用来衡量应用程序对 L2 CACHE 的写入压力,但它不计入 CACHE 替换算法的开销。较高的 l2_lines_out.silent 值可能表明应用程序的 CACHE 写入操作较为频繁,但是缓存替换算法比较高效。这个指标通常与 l2_lines_out.non_silent 一起使用,以提供完整的 CACHE 访问模式和性能分析.
捕获 L2 CACHE 硬件预期 CACHE Line 数量
perf stat -e l2_lines_out.useless_hwpf ${APP}l2_lines_out.useless_hwpf 是 perf 统计应用程序运行时 L2 CACHE 被硬件预取器预取的 CACHE Line 数量,但这些 CACHE Line 并没有被使用的数量。硬件预取器是用来提高 CACHE 访问性能的机制,它可以在程序访问一个 CACHE Line 之前,预先将相邻的 CACHE Line 加载到 CACHE,以便程序访问相邻 CACHE Line 是 CACHE Hit。但如果程序没有使用这些预取的 CACHE Line,那么他们是无用的,且浪费空间和带宽的. 较高的 l2_lines_out.useless_hwpf 值可能表明程序内存访问模式不适合硬件预取机制,或者硬件预取机制没有被充分利用. 上图中可以看出 APP-A 和 APP-B 未被使用的预取 CACHE Line 数量差不多,因此硬件预取机制不是影响程序算法的原因.
捕获 L2 CACHE 代码读操作数量
perf stat -e l2_rqsts.all_code_rd ${APP}l2_rqsts.all_code_rd 是 perf 统计应用程序运行时在 L2 CACHE 里代码读操作数量。该数值可以用来评估应用程序中代码访问的局部性和 L2 CACHE 缓存的命中率,该值也可以用来识别代码访问密集的区域,并优化代码以提高 L2 缓存的命中率. 例如在上图中 APP-A 比 APP-B 相比有较少的 L2 CACHE 代码访问量,也说明 APP-A 在 L1I CACHE 中的命中率很高.
捕获 L2 CACHE OnDemand 数据读数量
perf stat -e l2_rqsts.all_demand_data_rd ${APP}l2_rqsts.all_demand_data_rd 是 perf 统计应用程序运行时需要从 L2 CACHE 读取所需数据的数量. 它可以用来评估应用程序中数据访问的局部性和 L2 CACHE 命中率。基于 OnDemand 数据读操作指的是 CPU 在执行程序过程中需要从内存读取数据的操作,该操作是由程序控制流所导致的。该计数器可以用于识别程序中哪些数据结构或者数据集合正在频繁访问,并帮助优化程序以提高 L2 CACHE 命中率,以便更快地访问内存中的数据.
捕获 L2 CACHE OnDemand 请求 Miss 数量
perf stat -e l2_rqsts.all_demand_miss ${APP}l2_rqsts.all_demand_miss 是 perf 统计应用程序运行时需要从 L2 CACHE 读取数据发送 CACHE Miss 的计数,也就是需要从 L3 CACHE 或内存读取数据的计数. 该计数可以评估系统的内存子系统性能, 如果 l2_rqsts.all_demand_miss 计数器值很高,那么表示系统中存在大量的内存访问,这可能导致性能瓶颈,因此性能调优的过程中需要关注 l2_rqsts.all_demand_miss 计数器的值. 如图 APP-A 的算法就比 APP-B 的算法能实现较少的 L2 CACHE Miss, 因此内存访问次数会较少,最后体现在程序耗时会变少.
捕获 L2 CACHE 请求数量
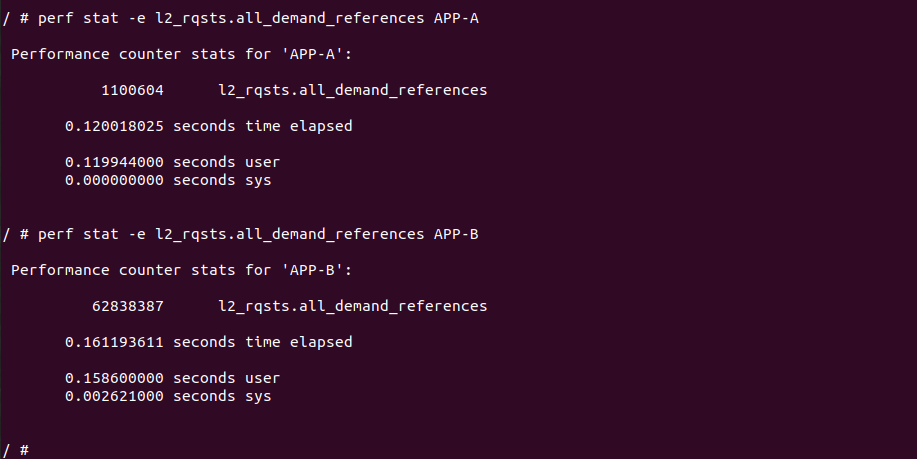
perf stat -e l2_rqsts.all_demand_references ${APP}l2_rqsts.all_demand_references 是 perf 统计应用程序运行时对 L2 CACHE 的请求数,包括 Hit 和 Miss 的计数。该计数可以用于评估系统的内存子系统性能,如果 l2_rqsts.all_demand_references 计数较高,那么意味着系统存在大量的内存访问和 L2 CACHE 使用,这可能导致性能瓶颈,因此通过观察 l2_rqsts.all_demand_references 计数器值,可以帮助评估系统中内存子系统的性能,从而进行优化和调优. 例如上图中 APP-A 的算法就比 APP-B 有较少的 L2 CACHE 使用,因为 APP-A 算法有较高的 L1D CACHE 使用率,因此性能优于 APP-B 的算法.
捕获 L2 CACHE RFO 请求数量
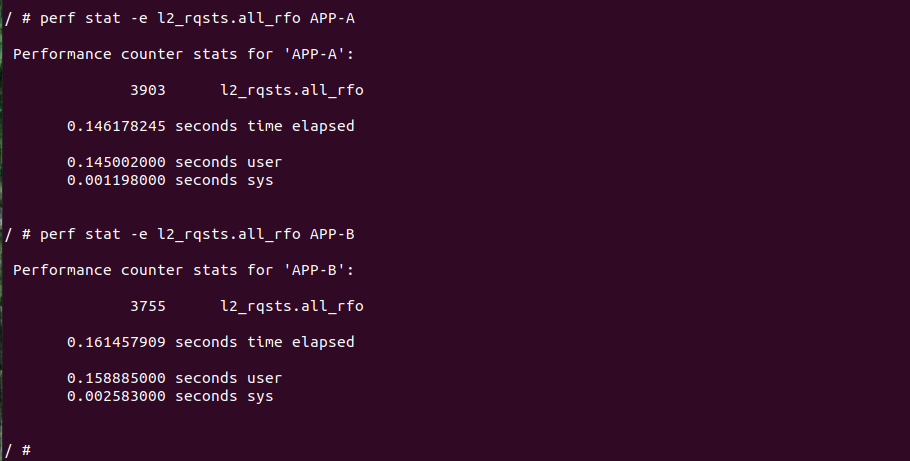
perf stat -e l2_rqsts.all_rfo ${APP}l2_rqsts.all_rfo 是 perf 统计应用程序运行时对 L2 CACHE 的 RFO 请求计数,RFO 是一种内存访问模式,当 CPU 需要修改一个数据块时,它会发送一个 RFO 请求到 L2 CACHE,以获取 CACHE Line 所有权并进行修改。与其他内存访问模式相比,RFO 请求通常需要更长时间来完成,因为它需要在 L2 CACHE 和主存之间进行数据传输和同步,因此如果 l2_rqsts.all_rfo 计数很高,表明系统中存在大量的 RFO 请求,这可能导致性能问题和瓶颈。通过观察 l2_rqsts.all_rfo 计数值,可以帮助开发者对程序进行优化和调优。
捕获 L2 CACHE 读取指令命中数量
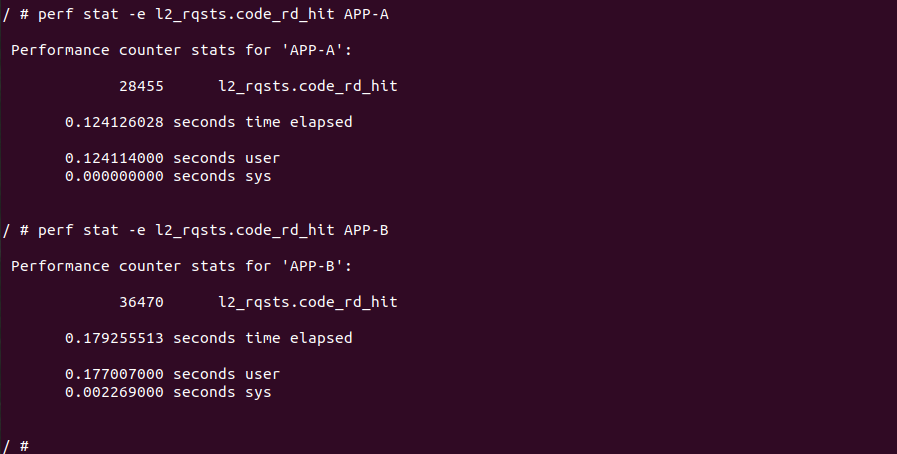
perf stat -e l2_rqsts.code_rd_hit ${APP}l2_rqsts.code_rd_hit 是 perf 统计应用程序运行时从 L2 CACHE 中读取指令命中的计数。在计算机 CACHE 系统里,为了提高 CPU 执行指令的效率,指令会被缓存到 CACHE 中,当 CPU 需要访问指令时,它首先在 L1 Instruction CACHE 中查找指令,如果指令不在 L1I CACHE,那么就到 L2 CACHE 中查找。如果指令在 L2 CACHE 中,那么称为读取命中 (read-hit), 否则称为读取未命中 (read-miss). 因此如果 l2_rqsts.code_rd_hit 计数很高,说明应用程序的指令缓存效率很高,可以提高 CPU 的执行效率,通过观察该值可以帮助评估内存子系统的性能,以及识别潜在的瓶颈.
捕获 L2 CACHE 读取指令不命中数量
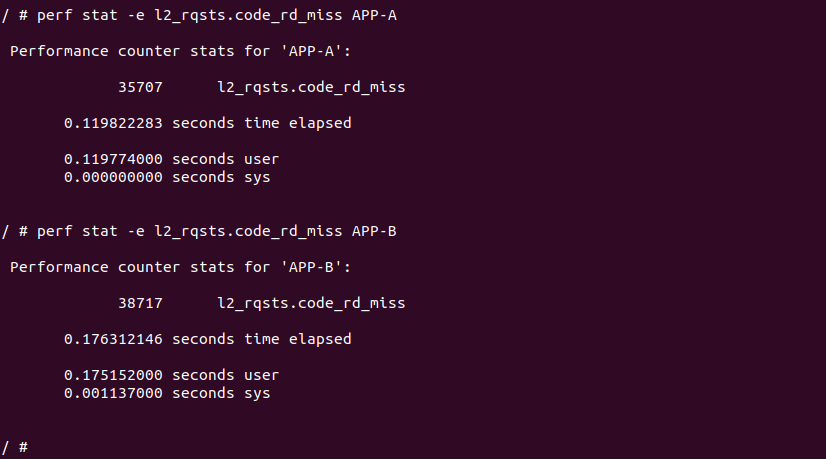
perf stat -e l2_rqsts.code_rd_miss ${APP}l2_rqsts.code_rd_miss 是 perf 统计应用程序运行时从 L2 CACHE 中读取指令不命中的计数。在计算机 CACHE 系统里,为了提高 CPU 执行指令的效率,指令会被缓存到 CACHE 中,当 CPU 需要访问指令时,它首先在 L1 Instruction CACHE 中查找指令,如果指令不在 L1I CACHE,那么就到 L2 CACHE 中查找。如果指令在 L2 CACHE 中,那么称为读取命中 (read-hit), 否则称为读取未命中 (read-miss). 因此如果 l2_rqsts.code_rd_miss 计数很高,说明应用程序的指令不在 L2 CACHE 的情况很多. 该计数器可以用来评估代码的执行效率,较高的缺失数通常意味着较慢的执行速度.
捕获 L2 CACHE 读所需数据的命中数量
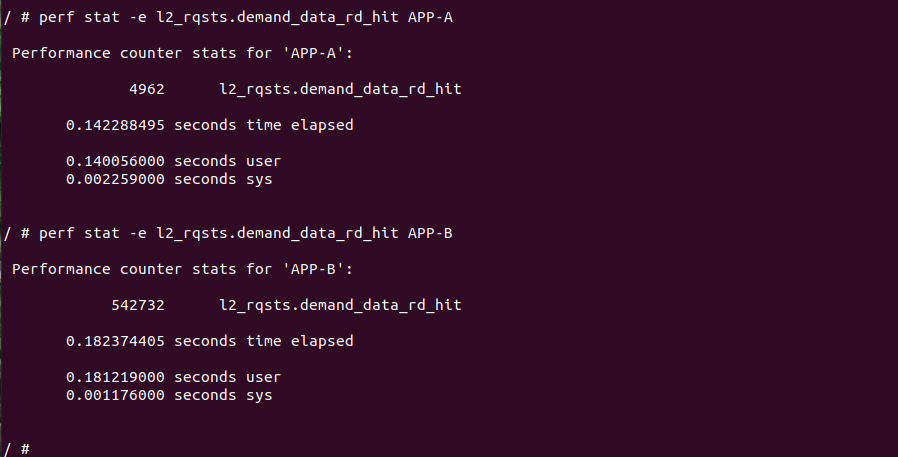
perf stat -e l2_rqsts.demand_data_rd_hit ${APP}l2_rqsts.demand_data_rd_hit 是 perf 统计应用程序运行时从 L2 CACHE 中读取数据是命中计数. 具体来说,计数器在 L2 CACHE 中发生数据读取需求,其请求的数据已经被加载到 L2 CACHE 中,因此无需从内存或者 L3 CACHE 中加载。这个计数器可以用来评估 L2 CACHE 的命中率,以及应用程序对 L2 CACHE 的使用情况。命中率高意味着较少的延迟和更好的性能.
捕获 L2 CACHE 读所需数据的缺失数量
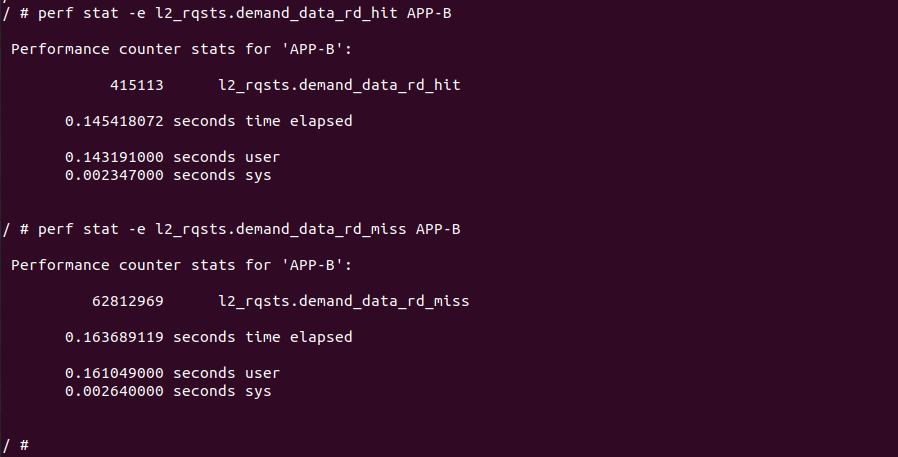
perf stat -e l2_rqsts.demand_data_rd_miss ${APP}l2_rqsts.demand_data_rd_miss 是 perf 统计应用程序运行时从 L2 CACHE 中读取数据是缺失计数. 具体来说,计数器在 L2 CACHE 中发生数据读取需求,其请求的数据没有被加载到 L2 CACHE 中,因此需从内存或者 L3 CACHE 中加载。该计数器可以帮助开发者确定程序在访问内存时是否存在瓶颈,并优化代码以提高性能. 例如上图中,APP-A 的算法比 APP-B 算法有较少的缺失数,因此 APP-B 的访问方式需要进行改进。
捕获 L2 CACHE RFO 请求命中数量
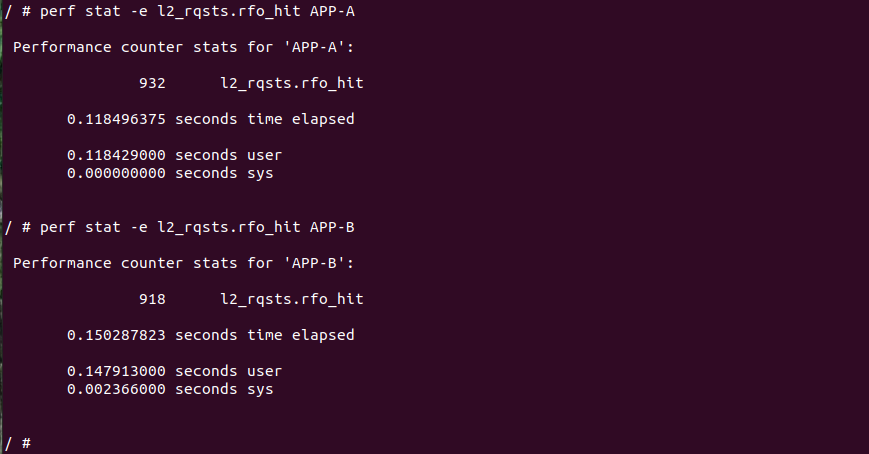
perf stat -e l2_rqsts.rfo_hit ${APP}l2_rqsts.rfo_hit 是 perf 统计应用程序运行时对 L2 CACHE 的 RFO 请求命中计数,RFO 是一种内存访问模式,当 CPU 需要修改一个数据块时,它会发送一个 RFO 请求到 L2 CACHE,以获取 CACHE Line 所有权并进行修改。与其他内存访问模式相比,RFO 请求通常需要更长时间来完成,因为它需要在 L2 CACHE 和主存之间进行数据传输和同步. 该计数器可以帮助开发者确认程序中的 RFO 请求是否存在 L2 缓存中有效使用,以及为了提高程序性能,是否需要优化 RFO 请求的使用方式。它还可以用于确认哪些程序模块会受到 RFO 请求导致的性能影响.
捕获 L2 CACHE RFO 请求缺失数量
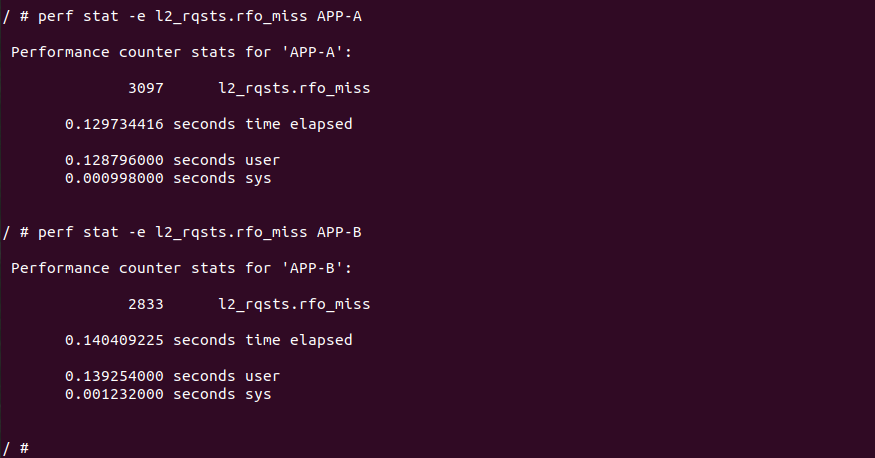
perf stat -e l2_rqsts.rfo_miss ${APP}l2_rqsts.rfo_miss 是 perf 统计应用程序运行时对 L2 CACHE 的 RFO 请求缺失计数,RFO 是一种内存访问模式,当 CPU 需要修改一个数据块时,它会发送一个 RFO 请求到 L2 CACHE,以获取 CACHE Line 所有权并进行修改。与其他内存访问模式相比,RFO 请求通常需要更长时间来完成,因为它需要在 L2 CACHE 和主存之间进行数据传输和同步. 该计数器可以帮助开发者确认程序中的 RFO 请求不存在 L2 缓存中的数量,以及为了提高程序性能,是否需要优化 RFO 请求的使用方式。它还可以用于确认哪些程序模块会受到 RFO 请求导致的性能影响.
捕获 L2 CACHE SWPF 请求命中数量
perf stat -e l2_rqsts.swpf_hit ${APP}l2_rqsts.swpf_hit 是 perf 统计应用程序运行时对 L2 CACHE 的 SWPF 请求命中数. SWPF 请求指的是 Store-to-Write-BACK,其是一种特殊类型的存储请求,用于将 CACHE 中已经被修改的缓存写回到内存中。由于这些 CACHE Line 是已修改的,因此写回操作通常需要写到内存,因此有较高的延迟。通过 SWPF 请求,可以将这些操作从任何可能延迟程序执行的路径中隔离出来,而从提高程序的整体性能. 计数器可以帮助开发者人员了解程序中的 SWPF 请求如何影响 L2 缓存性能,并确定哪些代码路径中的 SWPF 请求是主要的性能瓶颈。通过优化 SWPF 请求和使用更好的缓存预期策略,可以改善缓存的性能,并减少 L2 CACHE 的延迟.
捕获 L2 CACHE SWPF 请求缺失数量
perf stat -e l2_rqsts.swpf_miss ${APP}l2_rqsts.swpf_miss 是 perf 统计应用程序运行时对 L2 CACHE 的 SWPF 请求缺失数. SWPF 请求指的是 Store-to-Write-BACK,其是一种特殊类型的存储请求,用于将 CACHE 中已经被修改的缓存写回到内存中。由于这些 CACHE Line 是已修改的,因此写回操作通常需要写到内存,因此有较高的延迟。通过 SWPF 请求,可以将这些操作从任何可能延迟程序执行的路径中隔离出来,而从提高程序的整体性能. 计数器可以帮助开发者人员了解程序中的 SWPF 请求如何影响 L2 缓存性能,并确定哪些代码路径中的 SWPF 请求是主要的性能瓶颈。可以帮助定位需要更好的预期策略或更大的 CACHE 容量的代码段.
捕获 L2 CACHE WriteBack 数量
perf stat -e l2_trans.l2_wb ${APP}l2_trans.l2_wb 是 perf 统计应用程序运行时对 L2 CACHE 写操作之后发生回写(WriteBack) 的计数. L2 CACHE 回写发生时,CACHE Line 中的数据会被回写到内存,以便其他处理器可以访问该数据。这个计数器可以帮助开发者了解程序中写操作的数量,以及缓存容量是否足够。如果 CACHE 的回写数量过多,可能需要考虑增加缓存容量或者优化代码,减少写操作.
捕获 L2 CACHE Miss 占用的周期数
perf stat -e cycle_activity.cycles_l2_miss ${APP}cycle_activity.cycles_l2_miss 是 perf 统计应用程序运行时 L2 CACHE Miss 所占的周期计数. 该计数通常和其他计数一同使用,以帮助分析程序的性能瓶颈和优化机会. 例如上图 APP-A 算法就比 APP-B 有较少的 L2 CACHE Miss 周期数,因此性能由于 APP-B.
捕获 L2 CACHE Miss 导致 CPU 停顿的周期数
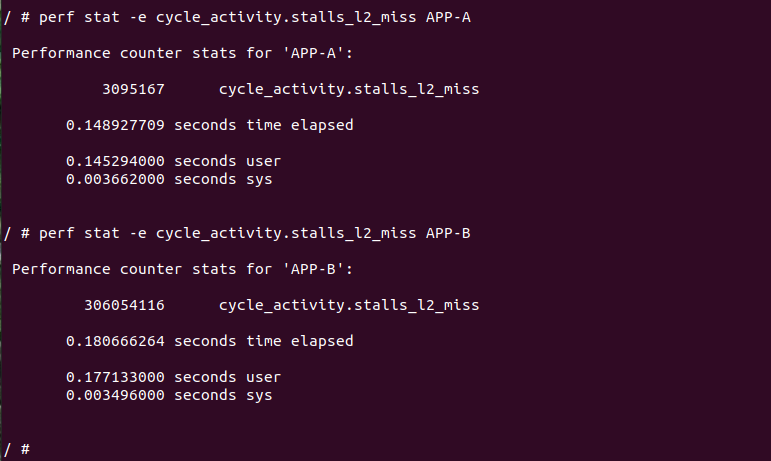
perf stat -e cycle_activity.stalls_l2_miss ${APP}cycle_activity.stalls_l2_miss 是 perf 统计应用程序运行时因 L2 CACHE Miss 导致 CPU 流水线停顿 (Stalls) 的时钟周期数。这个计数器可以帮助分析程序中由于 L2 CACHE Miss 导致性能瓶颈。流水线停顿指 CPU 等待某些资源准备好之前暂停执行指令的情况,这会导致 CPU 的效率下降,并增加程序的执行时间。L2 CACHE Miss 是一种常见的流水线停顿原因,因为它需要 CPU 等待从主存中获得数据,而这需要花费很长时间. 例如上图可以看出 APP-A 算法比 APP-B 有更少的 Stalls 周期,因此性能由于 APP-B.
捕获 L3 CACHE Hit 时内存负载计数
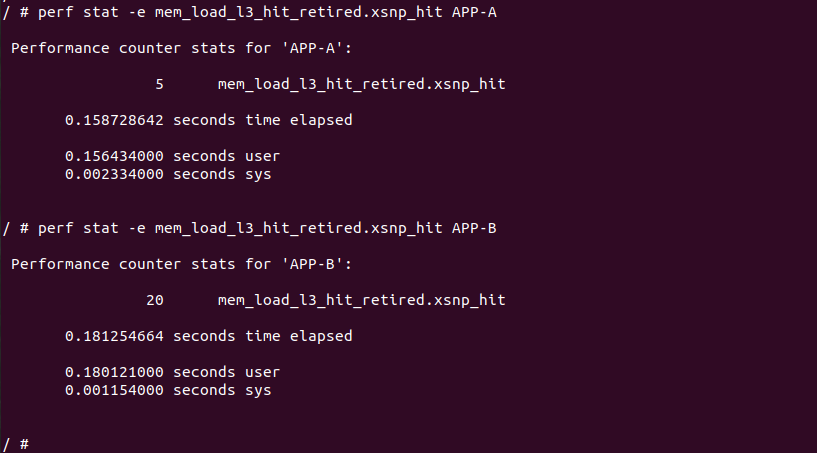
perf stat -e mem_load_l3_hit_retired.xsnp_hit ${APP}mem_load_l3_hit_retired.xsnp_hit 是 perf 统计应用程序运行时 L3 CACHE 命中时由于远程数据请求返回的 CACHE Line 中包含了许多数据而导致的内存负载操作计数. 在 Intel 处理器中,该实践由于 L3 CACHE 的 CACHE Line 中发现除了被请求的数据之外的数据而发生。这可能是由于缓存行被其他 CPU 请求的其他数据占用而被强制淘汰出缓存,然而再次请求数据时缓存行被填满,包含更多数据. 这个计数器可以帮助开发者分析代码中内存访问的效率。如果程序中有太多的内存操作,这会导致 CACHE Line 被强制淘汰并且需要从内存中读取更多数据,这会导致性能下降,并增加程序的执行时间。通过使用该计数器,可以识别程序中可能导致性能瓶颈的内存访问,并对其进行优化,以提高程序的效率.
捕获 L3 CACHE Hit 但位于其他 CPU 的计数
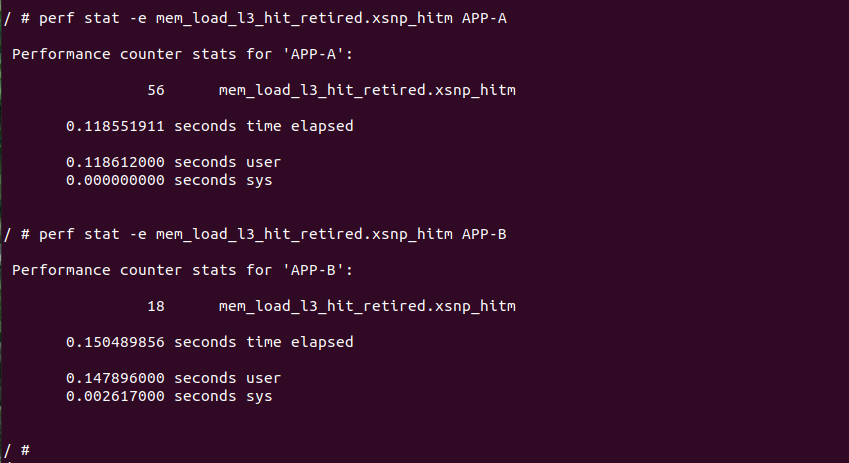
perf stat -e mem_load_l3_hit_retired.xsnp_hitm ${APP}mem_load_l3_hit_retired.xsnp_hitm 是 perf 统计应用程序运行时 L3 CACHE 读取数据时,由于相应的数据已经在其他 CPU 的 L3 CACHE 中,因此可以直接从其他 CPU 缓存获取数据的情况。这些操作被称为 xsnp_hitm, 其中 xsnp 表示 exclusive Snoop,意思是当执行访问时,系统会先检查其他核心 L3 CACHE 是否已经包含了相应的数据,如果是则直接从那里读取数据,从而避免从内存中读取数据,从而提高访问速度.
捕获 L3 CACHE 远端 Miss 且本地 Miss 计数
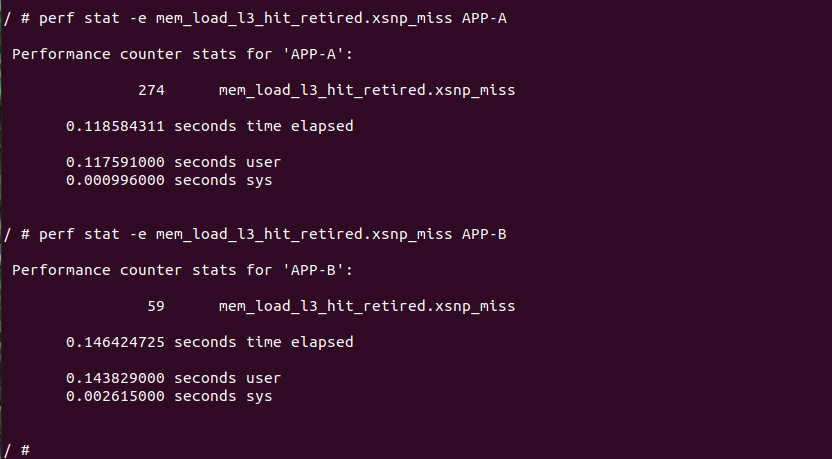
perf stat -e mem_load_l3_hit_retired.xsnp_miss ${APP}mem_load_l3_hit_retired.xsnp_miss 是 perf 统计应用程序运行时请求 XSNP 的加载操作 (表示远端 L3 CACHE Miss),但是在本地 L3 CACHE Miss 计数. 这个事件通常被用于检测在 NUMA 系统中的 CACHE 效率问题。例如如果一个程序经常较高的 mem_load_l3_hit_retired.xsnp_miss,那么可能需要调整程序或者系统配置以优化缓存访问.
捕获 L3 CACHE 远端 Miss 但本地 Hit 计数
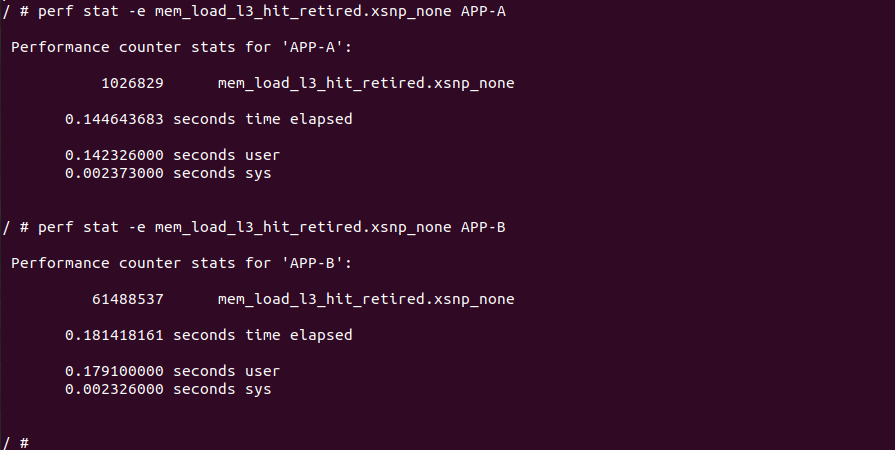
perf stat -e mem_load_l3_hit_retired.xsnp_none ${APP}mem_load_l3_hit_retired.xsnp_none 是 perf 统计应用程序运行时请求 XSNP 的加载操作 (表示远端 L3 CACHE Miss),但是在本地 L3 CACHE Hit 计数. 该事件通常用于检测在 NUMA 系统中的缓存效率问题,如果一个应用程序经常出现较高的 mem_load_l3_hit_retired.xsnp_none, 则说明程序的 CACHE 访问已经是很高效,但可能需要进一步优化以避免不必要的跨节点访问。因此通过监控该计数,可以帮助开发者优化应用程序的性能.
捕获 L3 CACHE Miss 占用的周期数
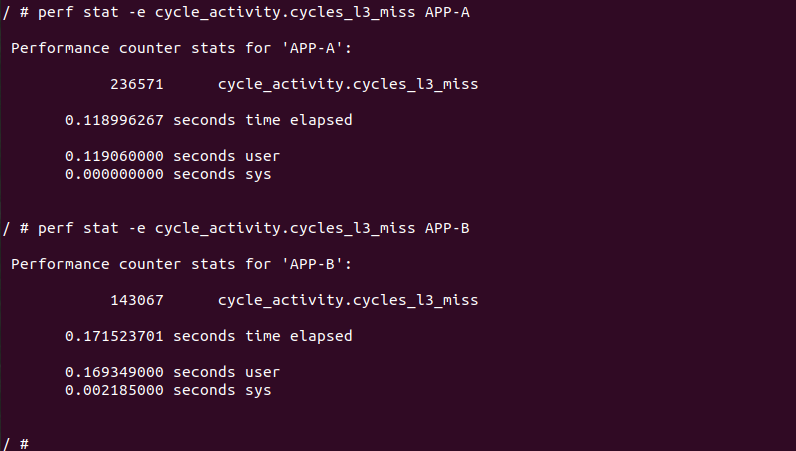
perf stat -e cycle_activity.cycles_l3_miss ${APP}cycle_activity.cycles_l3_miss 是 perf 统计应用程序运行时 L3 CACHE Miss 所占的周期计数. 该计数通常和其他计数一同使用,以帮助分析程序的性能瓶颈和优化机会. 例如上图 APP-A 算法就比 APP-B 有较少的 L3 CACHE Miss 周期数,因此性能由于 APP-B.
捕获 L3 CACHE Miss 导致 CPU 停顿的周期数
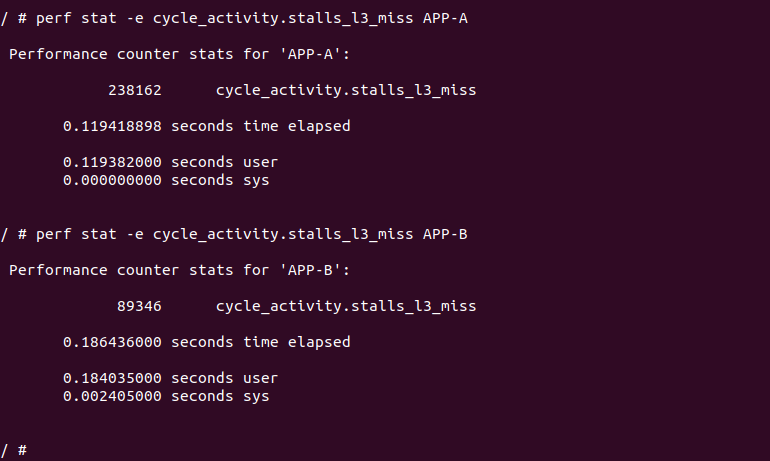
perf stat -e cycle_activity.stalls_l3_miss ${APP}cycle_activity.stalls_l3_miss 是 perf 统计应用程序运行时因 L3 CACHE Miss 导致 CPU 流水线停顿 (Stalls) 的时钟周期数。这个计数器可以帮助分析程序中由于 L3 CACHE Miss 导致性能瓶颈。流水线停顿指 CPU 等待某些资源准备好之前暂停执行指令的情况,这会导致 CPU 的效率下降,并增加程序的执行时间。L3 CACHE Miss 是一种常见的流水线停顿原因,因为它需要 CPU 等待从主存中获得数据,而这需要花费很长时间. 例如上图可以看出 APP-A 算法比 APP-B 有更少的 Stalls 周期,因此性能由于 APP-B.
捕获 L3 CACHE 读请求 Miss 从内存中读取计数
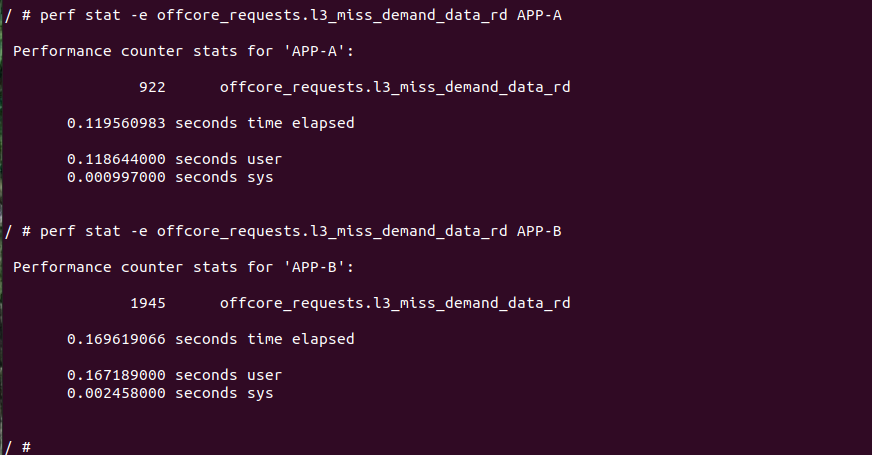
perf stat -e offcore_requests.l3_miss_demand_data_rd ${APP}offcore_requests.l3_miss_demand_data_rd 是 perf 统计应用程序运行时在一定时间内向 L3 CACHE 发出的读请求中,由于数据为命中而需要从内存读取的占比。通过监控 offcore_requests.l3_miss_demand_data_rd 计数,可以了解 CPU 中有多少实践花费在 L3 CACHE 未命中的读取请求上,从而发现 L3 CACHE 性能瓶颈和程序的访问策略是否能够优化.
捕获 L3 CACHE 读请求 Miss 从内存加载周期数
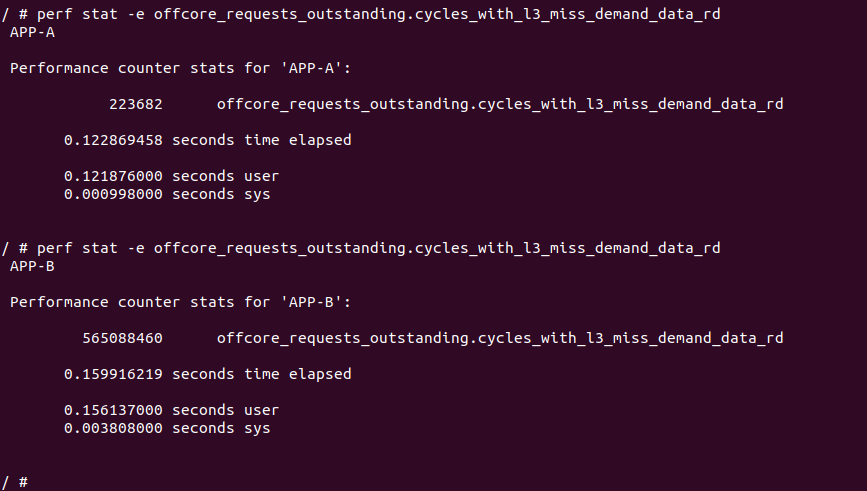
perf stat -e offcore_requests_outstanding.cycles_with_l3_miss_demand_data_rd ${APP}offcore_requests_outstanding.cycles_with_l3_miss_demand_data_rd 是 perf 统计应用程序运行时 L3 CACHE Miss 时需要从内存读取数据的周期计数. 当 L3 CACHE Miss 而从内存加载数据时,CPU 需要等待多个时钟周期,直到从内存中读取到数据,并将其存储到 L3 CACHE 中。通过监控该计数,可以帮助开发者发现性能瓶颈.
抓捕 L1 Data CACHE 写入数
perf stat -e L1-dcache-stores ${APP}perf 结合 L1-dcache-stores 字段可以捕获应用程序在 L1 Data CACHE 写请求的数据.
抓捕 L1 Instruction CACHE 读取 Miss 数
perf stat -e L1-icache-load-misses ${APP}perf 结合 L1-icache-load-misses 字段可以捕获应用程序在 L1 Instruction CACHE 读请求时发生 CACHE Miss 的数据.

Valgrind with CACHE
Valgrind 是一套 Linux 开源仿真调试工具集合,包含 Memcheck、Callgrind、Cachegrind、Helgrind 等多个工具。其中 Cachegrind 用于检查程序中缓存使用出现的问题. Cachegrind 模拟程序如何与机器的缓存层次结构和分支预测器进行交互。它模拟具有独立的第一级指令和数据高速缓存(L1I 和 L1D)的机器,由统一的二级缓存(L2)支持。这完全符合许多现代机器的配置。然而,一些现代机器具有三或四级缓存。对于这些机器(在 Cachegrind 可以自动检测缓存配置的情况下)Cachegrind 模拟一级和最后一级缓存. 本节重点描述 Valgrind 与 CACHE 相关的分析,具体如下:
Valgrind 工具的安装部署
# Ubuntu
sudo apt-get install valgrind
sudo apt-get install kcachegrind
Cachegrind 测试代码部署
Perf 测试代码是针对 perf 工具使用时,最大限度展示工具功能性,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Analysis/Diagnosis Tools: Valgrind --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-TOOLS-VALGRIND-default/
# 部署源码/解决依赖
make download
# 在 BiscuitOS 中实践
make
tree
测试代码由两个用户空间程序组成,上图为 main-A.c 的源码. 源码的目的很简单,通过 mmap 分配 64KiB 的内存,然后在 36-43 行顺序将内存的数据取出.
上图为测试代码 main-B.c,其实现与 main-A.c 一致,只是在 36-43 行遍历内存时采用了不同的逻辑.
main-A.c 采用的遍历方式是按顺序的访问数组中的内容,即将前 64 个字节依次访问完毕之后,继续顺序访问下一个 64 字节. 而 main-B.c 遍历是先将内存分成 64 个字节的块,然后先访问所有块的第一成员,然后访问所有块的第二个成员,依次类推。从结果来看都是遍历的同样大小的内存,那么接下来使用 Valgrind 分析两个程序之间的性能差异.
Valgrind 基础使用
valgrind --tool=cachegrind ${APP}Cachegrind 模拟您的程序与机器缓存等级和(可选)分支预测单元的互动。它跟踪模拟的一级指令和数据缓存的用量以便探测不良代码与这一级缓存的互动; 最高一级,可以是二级或者三级缓存,用来跟踪对主内存的访问。因此,使用 Cachegrind 运行的程序速度比正常运行时要慢 20-100 倍. 要运行 Cachegrind 请执行以下命令,使用您要用 Cachegrind 简要描述的程序替换 APP. Cachegrind 可以为整个程序以及该程序中的每个功能收集统计数据:
- 一级指令缓存读取(或者执行的指令)和读取缺失,最后一级缓存指令读取缺失
- 数据缓存读取(或者内存读取),读取缺失,以及最高一级缓存数据读取缺失
- 数据缓存写入(或者内存写入),写 ur 缺失,以及最高一级缓存数据写入缺失
- 已执行和无法预测的条件分支
- 已执行和无法预测的间接分支
cg_annotate profiling 分析
Cachegrind 输出控制台的这些统计数据信息小结,并在文件(默认为 cachegrind.out.pid,其中pid 为您运行 Cachegrind 的程序的进程 ID)中写入更详细的配置信息。该文件可由 cg_annotate 进行进一步的处理:
cg_annotate cachegrind.out.pid
cg_annotate 是一个 profiling 工具,用于分析应用程序的性能瓶颈和优化方案,它会根据已经生成的 profiling 数据,对每个函数进行分析并输出一下信息:
- I1 CACHE/D1 CACHE/LL CACHE 的信息
- Command: 函数名称
- Data file: Profiling 文件名字
- Events recorded: Cachegrind 捕获的事件
- Events shown: 表示使用了哪些性能计数器来分析性能瓶颈
- Events sort order: 对性能计数器进行排序
- Thresholds: 函数最小调用次数,即调用阈值,与计数器一一对应
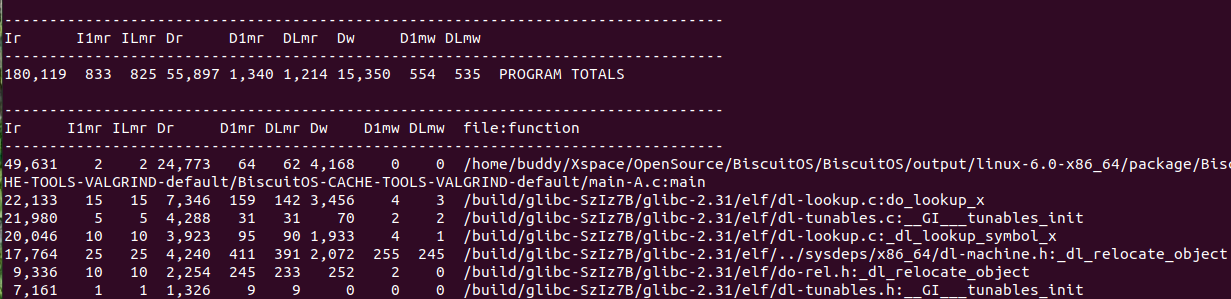
cg_annotate 输出的另外一段区域是各函数的性能统计计数,其从 Events recorded 描述的计数器进行统计输出,可以通过这段信息分析出是哪些函数导致性能瓶颈的. 每个字段的含义如下:
- Ir: Instruction Retired 即指令数
- I1mr: L1 Instruction CACHE read miss: 即 L1I CACHE 读取未命中数
- ILmr: L1 Instruction CACHE Line read miss L1I CACHE Line 读取未命中数
- Dr: Data read 数据读取数
- D1mr: L1 Data CACHE read misses: L1D CACHE 读取未命中数
- DLmr: L1 Data CACHE Line read miss: L1D CACHE Line 读未命中数
- Dw: Data write 即数据写入数
- D1mw: L1 Data CACHE write miss: L1D CACHE 写未命中数
- DLmw: L1 Data CACHE Line write miss: L1D CACHE Line 写未命中数
cg_diff profiling 分析
Cacahegrind 工具集合还提供了 cg_diff 工具,该工具可以对两个 cachegrind.out.pid 文件进行比较,以此发现两次性能 Profiling 之间的差异,其使用如下:
cg_diff OLD.cachegrind.out.pid NEW.cachegrind.out.pid
cg_diff 工具可以快速对两次 profiling 之间函数调用从 Event 事件进行对比,工具输出的信息如上图,其中各字段的含义如下:
- desc: Files compared:: 进行对比的 Profiling 文件
- cmd: Profiling 所针对的命令
- events: cg_diff 所对比的数据项目
- fl: 所对比函数所在的文件
- fn: 所对比的函数
- 0 0 0 0 0 0: 对比项输出的结果
cg_diff 通过对有所的函数按对比项目一一进行对比,这样可以快速发现性能瓶颈点,开发者后续可以根据对比数据进行优化.
kcachegrind profiling 分析
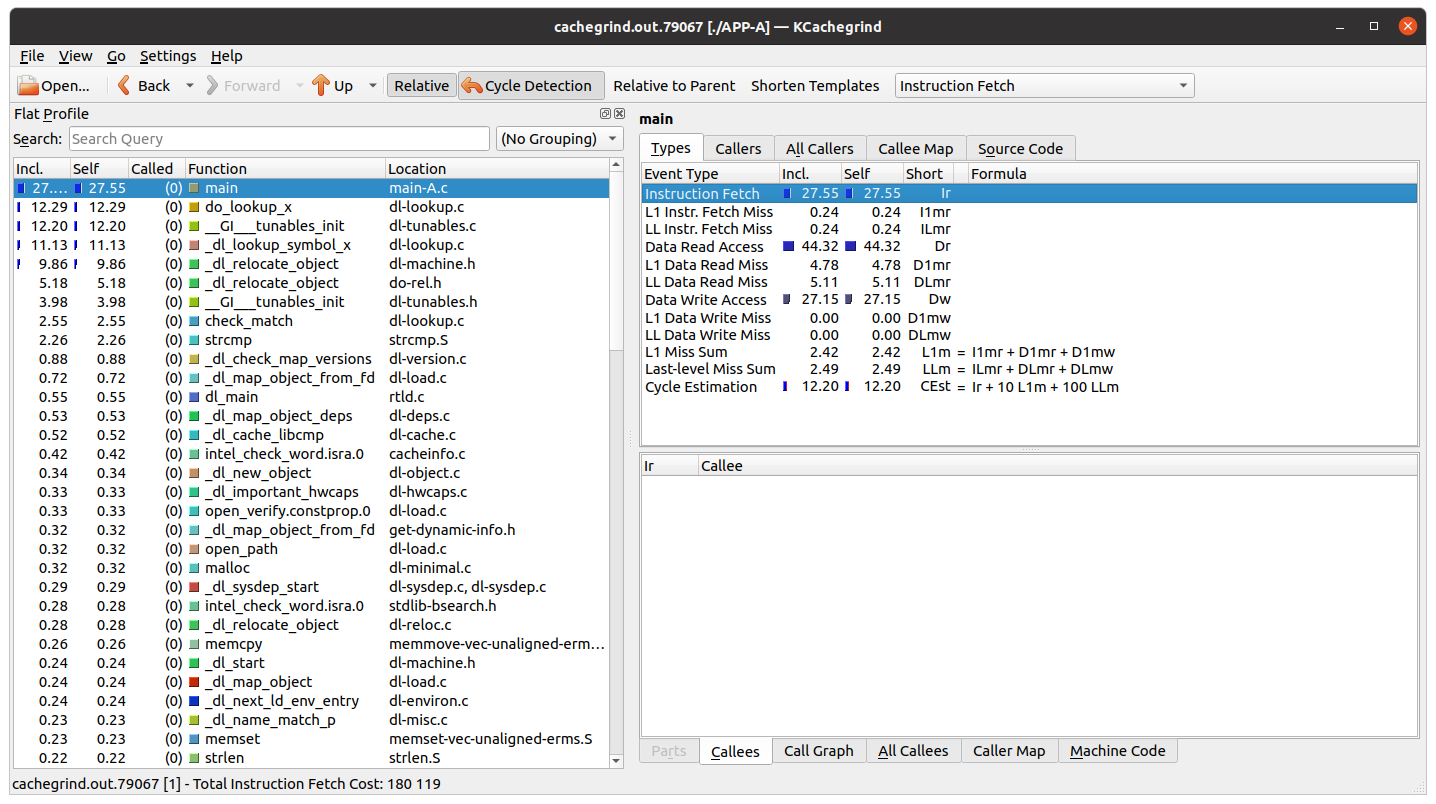
kcachegrind 工具是一个图形化的性能分析工具,用于分析 cachegrind 产生的 profiling 数据,其包括 CPU 使用率、内存使用情况和代码热点,也包括 L1 CACHE 和 LL CACHE 的命中率情况。它可以通过调用图、函数图和热点图等视图来帮助开发者了解应用程序的性能瓶颈,从而优化和改进应用程序的性能. 其使用命令如下:
kcachegrind cachegrind.out.pid
kcachegrind 的 Types 面板输出了 L1 CACHE 和 LL CACHE 读写命中数据与不命中数. Event Type 描述计数器表示的事件名称; Incl. 表示 Inclusive,即一个函数或者事件自身执行的时间总和,以及它所调用的所有子函数或代码块的执行时间总和; Self 表示一个函数或者代码块自身的执行时间,而不包括所调用的子函数或代码段的执行时间; Short 表示 Event 事件的缩写. kcachegrind 可以描述的事件具体如下:
- Instruct Fetch: 指令预取事件
- L1 Instr. Fetch Miss: L1I CACHE 指令未命中率
- LL Instr. Fetch Miss: LL CACHE 指令未命中率
- Data Read Access: 读取内存概率
- L1 Data Read Miss: L1D CACHE 读取未命中率
- LL Data Read Miss: LL CACHE 读取未命中率
- Data Write Access: 写入内存概率
- L1 Data Write Miss: L1D CACHE 写入未命中率
- LL Data Write Miss: LL CACHE 写入未命中率
- L1 Miss Sum: L1 CACHE 未命中率
- Last-level Miss Sum: LL CACHE 未命中率
- Cycle Estimation: 执行周期评估,它通过 CPU 执行程序花费的时间来评估每条指令执行所需的时钟周期

Kcachegrind 的 Shorten Templates 提供了多个事件过滤项目,当选择其中一个选项之后,Kcachegrind 的最左边的面板将展示每个函数针对选项的数据,例如此时选择 L1 Data Write Miss, 那么面板将显示每个函数在 L1 Data CACHE 里写未命中的统计数据. 对于左边的面板 Incl. 表示 Inclusive,即一个函数或者事件自身执行的时间总和,以及它所调用的所有子函数或代码块的执行时间总和; Self 表示一个函数或者代码块自身的执行时间,而不包括所调用的子函数或代码段的执行时间; Function 表示调用的函数名称,Location 表示函数所在的文件.
设置 Cachegrind 模拟的 L1 Instruction CACHE 大小
Cachegrind 可以模拟程序如何与机器的缓存层次结构和分支预测器进行交互,并提供了对 L1 Instruction CACHE 的模拟,可以使用如下命令进行 L1 Instruction CACHE 大小修改:
valgrind --tool=cachegrind --I1=${size},${associativity},${line_size} ${APP}I1 字段提供了对 L1 Instruction CACHE 指令进行定制,其包括三个参数: size 表示 CACHE 的大小; associativity 表示 CACHE 的路数; line_size 表示 CACHE Line Size 的大小。例如上图的 L1 Instruction CACHE 设置为 8 路 CACHE Line Size 为 64B, 大小为 32K 的 L1I CACHE.
设置 Cachegrind 模拟的 L1 Data CACHE 大小
Cachegrind 可以模拟程序如何与机器的缓存层次结构和分支预测器进行交互,并提供了对 L1 Data CACHE 的模拟,可以使用如下命令进行 L1 Data CACHE 大小修改:
valgrind --tool=cachegrind --D1=${size},${associativity},${line_size} ${APP}D1 字段提供了对 L1 Data CACHE 指令进行定制,其包括三个参数: size 表示 CACHE 的大小; associativity 表示 CACHE 的路数; line_size 表示 CACHE Line Size 的大小。例如上图的 L1 Data CACHE 设置为 12 路 CACHE Line Size 为 64B, 大小为 48K 的 L1D CACHE.
设置 Cachegrind 模拟的 LL CACHE 大小
Cachegrind 可以模拟程序如何与机器的缓存层次结构和分支预测器进行交互,并提供了对 LL CACHE 的模拟,可以使用如下命令进行 LL CACHE 大小修改:
valgrind --tool=cachegrind --LL=${size},${associativity},${line_size} ${APP}LL 字段提供了对 LL CACHE 指令进行定制,其包括三个参数: size 表示 CACHE 的大小; associativity 表示 CACHE 的路数; line_size 表示 CACHE Line Size 的大小。例如上图的 LL Data CACHE 设置为 16 路 CACHE Line Size 为 64B, 大小为 16M 的 LL CACHE.
取用/禁用 CACHE Miss 统计
Cachegrind 可以模拟程序如何与机器的缓存层次结构和分支预测器进行交互,并提供对 CACHE Miss 的统计,CACHE Miss 有助于分析程序的性能瓶颈,可以使用如下命令进行配置:
valgrind --tool=cachegrind --cache-sim=${yes,no} ${APP}cache-sim 字段作为 CACHE Miss 统计的开关,其支持 yes 和 no 两个值,默认情况下为 yes,可以开启 CACHE Miss 的统计,no 为关闭 CACHE Miss 的统计。例如上图,从两者的输出可以看出 cache-sim 为 yes 的时候输出了 L1I/L1D/LL CACHE 的 CACHE Miss 数据.

likwid: likwid-perfctr

likwid(Like I Knew what I am doing): 是一种用于性能分析和调优的工具,它可以帮助用户测试 CPU 性能、内存带宽、缓存性能等指标,同时还可以分析应用程序的瓶颈和性能问题。该工具支持多种操作系统,并提供了多种命令行和 API 接口,方便用户进行性能测试和优化。其包含如下工具集合:
- likwid-perfctr: 用于性能计数器的管理和控制,可测量 CPU 性能、内存带宽、缓存性能等.
- likwid-mpirun: 用户 MPI 并行程序的管理和控制,可测量 MPI 程序的性能,并通过不同的调度器和分配器实现负载均衡.
- likwid-pin: 用于将应用程序绑定到特定的 CPU 核心上,以控制和优化应用程序的性能.
- likwid-topology: 用于显示系统的拓扑结构,包括 CPU 核心、内存控制器、缓存层次等.
- likwid-bench: 用于进行基准测试,测量 CPU、内存、缓存等各种性能指标.
- likwid-powermeter: 用于测量系统的能耗和功耗,可帮助用户优化系统能耗和性能.
- likwid-perfscope: 用于可视化性能数和瓶颈分析,可以生成图表和报表.
likwid 提供了很多有用的工具帮助开发者分析程序的性能,本文更加关心 likwid 为 CACHE 带来的红利,那么接下来详细分析如何使用 likwid 提供的工具分析 CACHE:
likwid 工具安装
Ubuntu/Debian 等发行版支持 likwid 工具包,可以直接使用如下命令安装:
sudo apt-get install likwidlikwid 也支持源码安装,likwid github 链接https://github.com/RRZE-HPC/likwid, e.g:
VERSION=stable
wget http://ftp.fau.de/pub/likwid/likwid-$VERSION.tar.gz
tar -xaf likwid-$VERSION.tar.gz
cd likwid-XXX
make
sudo make install # sudo required to install the access daemon with proper permissions安装完毕之后,可以运行 likwid 提供的多个工具:
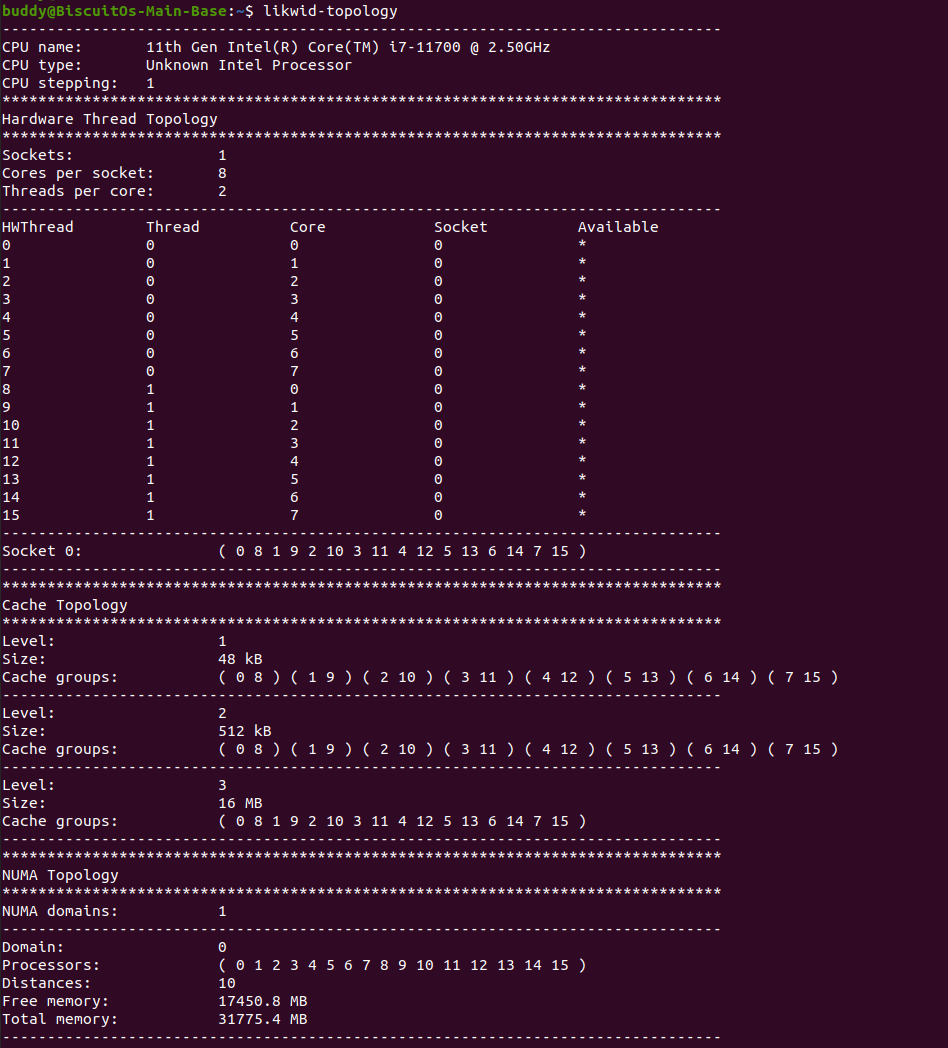
likwid 测试代码部署
likwid 工具提供了 API 函数,可以针对某段代码进行 CACHE 性能测试,计数通过 likwid-perfctr 进行封装,BiscuitOS 提供了基础使用逻辑,开发者可以在代码里参考使用,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Analysis/Diagnosis Tools: Likwid --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-TOOLS-LIKWID-default/
# 部署源码/解决依赖
make download
# 在 BiscuitOS 中实践
make
tree
使用 likwid 对某段代码进行性能测试,可以参考上图的应用程序,其在 20 行调用 LIKWID_MARKER_INIT 宏用于初始化 LIKWID 工具库,包括启用性能计数器、检查 CPU 支持的功能. 41 行调用 LIKWID_MARKER_START() 函数与 50 行调用 LIKWID_MARKER_STOP() 函数之间的区域就是性能测试的区域,最后 52 行调用 LIKWID_MARKER_CLOSE 宏关闭 LIKWID 工具库,包括停止性能计数器等. 接下来直接编译源码,并在 Host 机器上直接运行,命令如下:
likwid-perfctr -C 2 -g L3 -m ./BiscuitOS-CACHE-TOOLS-LIKWID-default
由于 Host 机器硬件上不支持某些计数器,如果开发者使用的是服务器,那么可能会在运行 likwid-perfctr 之后输出实践案例代码里 L3 性能数据,那么基于该案例继续介绍 likwid 提供的不同工具使用方法。
likwid-perfctr 测试 CACHE 性能
likwid-perfctr: 用于性能计数器的管理和控制,可测量 CPU 性能、内存带宽、缓存性能等, 本节重点介绍其如何测试 CACHE 性能.
likwid-perfctr -C 2 -g L1 -m ./BiscuitOS-CACHE-TOOLS-LIKWID-default-g L1 字段用于测试程序在 L1 CACHE 的性能.
likwid-perfctr -C 2 -g L2 -m ./BiscuitOS-CACHE-TOOLS-LIKWID-default-g L2 字段用于测试程序在 L2 CACHE 的性能.
likwid-perfctr -C 2 -g L3 -m ./BiscuitOS-CACHE-TOOLS-LIKWID-default-g L3 字段用于测试程序在 L3 CACHE 的性能.
likwid-perfctr -C 2 -g CACHE -m ./BiscuitOS-CACHE-TOOLS-LIKWID-default-g CACHE 字段用于测试程序所有层 CACHE 的性能.
likwid-perfctr -e-e 命令列出了 likwid-perfctr 可以监听的事件,对应支持的事件,可以使用 “-g” 命令进行监听即可,那么其还可以监听的 CACHE 事件如下:
CORE_POWER_LVL1_TURBO_LICENSE, 0x28, 0x18, PMC
L1D_PEND_MISS_PENDING, 0x48, 0x1, PMC
L1D_PEND_MISS_FB_FULL, 0x48, 0x2, PMC
L1D_PEND_MISS_PENDING_CYCLES, 0x48, 0x1, PMC, THRESHOLD=0x1
L1D_PEND_MISS_FB_FULL_PERIODS, 0x48, 0x2, PMC, THRESHOLD=0x1|EDGEDETECT=0x1
L1D_PEND_MISS_L2_STALL, 0x48, 0x4, PMC
L1D_REPLACEMENT, 0x51, 0x1, PMC
CYCLE_ACTIVITY_CYCLES_L1D_MISS, 0xA3, 0x8, PMC, THRESHOLD=0x8
CYCLE_ACTIVITY_STALLS_L1D_MISS, 0xA3, 0xC, PMC, THRESHOLD=0xC
MEM_LOAD_RETIRED_L1_HIT, 0xD1, 0x1, PMC
MEM_LOAD_RETIRED_L1_MISS, 0xD1, 0x8, PMC
MEM_LOAD_RETIRED_L1_ALL, 0xD1, 0x9, PMC
L2_TRANS_L1D_WB, 0xF0, 0x10, PMC
L2_RQSTS_DEMAND_DATA_RD_MISS, 0x24, 0x21, PMC
L2_RQSTS_RFO_MISS, 0x24, 0x22, PMC
L2_RQSTS_CODE_RD_MISS, 0x24, 0x24, PMC
L2_RQSTS_ALL_DEMAND_MISS, 0x24, 0x27, PMC
L2_RQSTS_SWPF_MISS, 0x24, 0x28, PMC
L2_RQSTS_DEMAND_DATA_RD_HIT, 0x24, 0xC1, PMC
L2_RQSTS_RFO_HIT, 0x24, 0xC2, PMC
L2_RQSTS_CODE_RD_HIT, 0x24, 0xC4, PMC
L2_RQSTS_SWPF_HIT, 0x24, 0xC8, PMC
L2_RQSTS_ALL_DEMAND_DATA_RD, 0x24, 0xE1, PMC
L2_RQSTS_ALL_RFO, 0x24, 0xE2, PMC
L2_RQSTS_ALL_CODE_RD, 0x24, 0xE4, PMC
L2_RQSTS_ALL_DEMAND_REFERENCES, 0x24, 0xE7, PMC
L2_RQSTS_MISS, 0x24, 0x2F, PMC
L2_RQSTS_REFERENCES, 0x24, 0xEF, PMC
CORE_POWER_LVL2_TURBO_LICENSE, 0x28, 0x20, PMC
L1D_PEND_MISS_L2_STALL, 0x48, 0x4, PMC
CYCLE_ACTIVITY_CYCLES_L2_MISS, 0xA3, 0x1, PMC, THRESHOLD=0x1
CYCLE_ACTIVITY_STALLS_L2_MISS, 0xA3, 0x5, PMC, THRESHOLD=0x5
MEM_LOAD_RETIRED_L2_HIT, 0xD1, 0x2, PMC
MEM_LOAD_RETIRED_L2_MISS, 0xD1, 0x10, PMC
MEM_LOAD_RETIRED_L2_ALL, 0xD1, 0x12, PMC
L2_TRANS_DEMAND_DATA_RD, 0xF0, 0x1, PMC
L2_TRANS_RFO, 0xF0, 0x2, PMC
L2_TRANS_CODE_RD, 0xF0, 0x4, PMC
L2_TRANS_ALL_PF, 0xF0, 0x8, PMC
L2_TRANS_L1D_WB, 0xF0, 0x10, PMC
L2_TRANS_L2_FILL, 0xF0, 0x20, PMC
L2_TRANS_L2_WB, 0xF0, 0x40, PMC
L2_TRANS_ALL_REQUESTS, 0xF0, 0x80, PMC
L2_LINES_IN_ALL, 0xF1, 0x1F, PMC
L2_LINES_OUT_SILENT, 0xF2, 0x1, PMC
L2_LINES_OUT_NON_SILENT, 0xF2, 0x2, PMC
L2_LINES_OUT_USELESS_HWPF, 0xF2, 0x4, PMC
OFFCORE_REQUESTS_OUTSTANDING_CYCLES_WITH_L3_MISS_DEMAND_DATA_RD, 0x60, 0x10, PMC, THRESHOLD=0x1
CYCLE_ACTIVITY_CYCLES_L3_MISS, 0xA3, 0x2, PMC, THRESHOLD=0x2
CYCLE_ACTIVITY_STALLS_L3_MISS, 0xA3, 0x6, PMC, THRESHOLD=0x6
OFFCORE_REQUESTS_L3_MISS_DEMAND_DATA_RD, 0xB0, 0x10, PMC
MEM_LOAD_RETIRED_L3_HIT, 0xD1, 0x4, PMC
MEM_LOAD_RETIRED_L3_MISS, 0xD1, 0x20, PMC
MEM_LOAD_RETIRED_L3_ALL, 0xD1, 0x24, PMC
MEM_LOAD_L3_HIT_RETIRED_XSNP_MISS, 0xD2, 0x1, PMC
MEM_LOAD_L3_HIT_RETIRED_XSNP_HIT, 0xD2, 0x2, PMC
MEM_LOAD_L3_HIT_RETIRED_XSNP_HITM, 0xD2, 0x4, PMC
MEM_LOAD_L3_HIT_RETIRED_XSNP_NONE, 0xD2, 0x8, PMC
LONGEST_LAT_CACHE_MISS, 0x2E, 0x1, PMC
ICACHE_16B_IFDATA_STALL, 0x80, 0x4, PMC
ICACHE_64B_IFTAG_HIT, 0x83, 0x1, PMC
ICACHE_64B_IFTAG_MISS, 0x83, 0x2, PMC
ICACHE_64B_IFTAG_ALL, 0x83, 0x3, PMC
ICACHE_64B_IFTAG_STALL, 0x83, 0x4, PMC
likwid-topology CACHE 拓扑结构
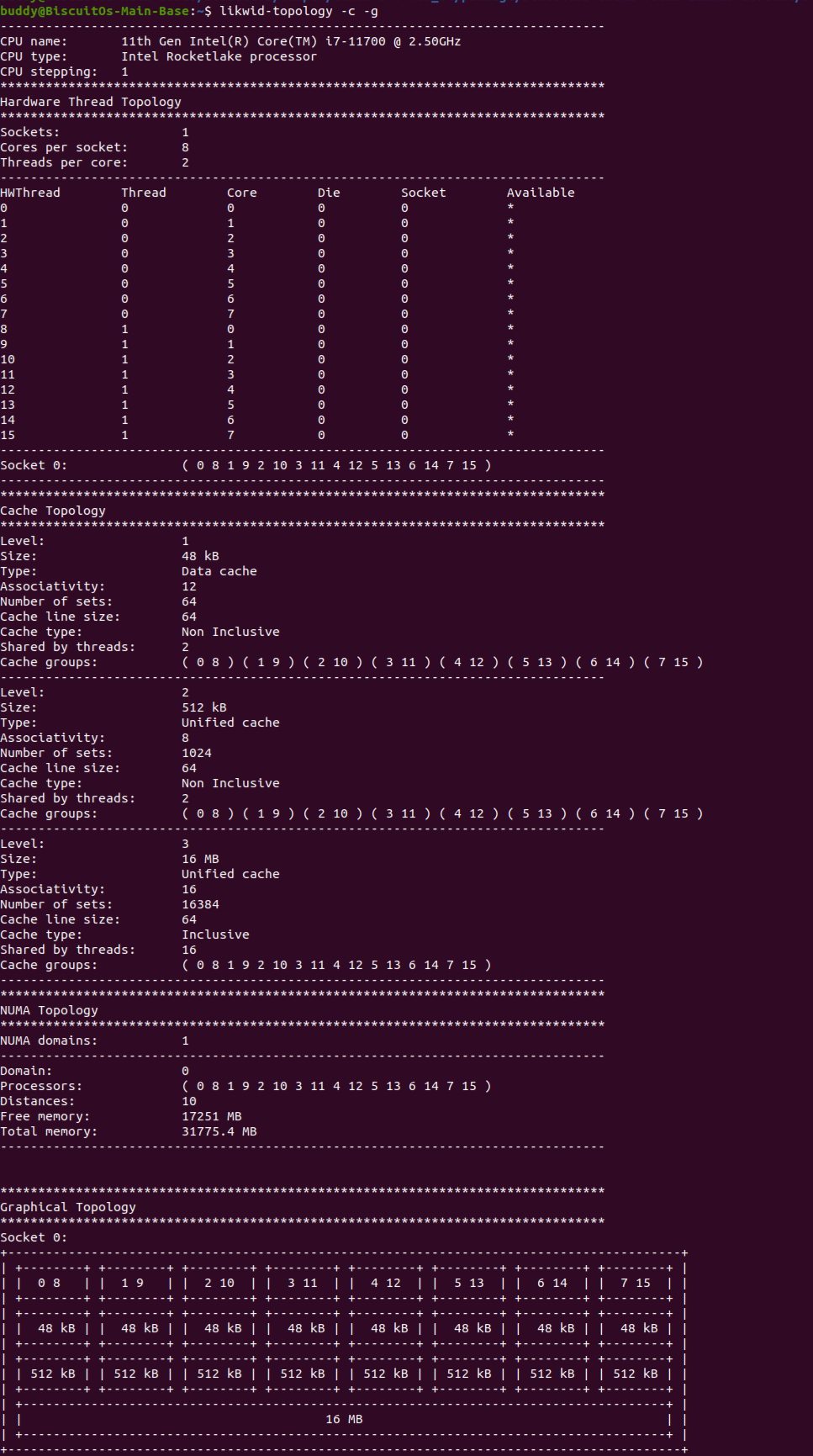
likwid-topology 工具可以显示系统的拓扑结构,包括 CPU 核心、内存控制器和 CACHE 等,那么本节研究该工具显示 CACHE 的拓扑结构:
likwid-topology -c -glikwid-topology -c 命令可以显示 CACHE 的拓扑结构, “-g” 选项可以图形化显示,可以看到各级 CACHE 的信息,包括 CACHE Level、CACHE associativity、Sets 等.
likwid-bench CACHE 基准测试
likwid-bench 工具可以提供性能基准测试,包括 CPU、内存和 CACHE 的性能指标,那么本节介绍如何使用 likwid-bench 测试 CACHE 基准性能.
likwid-bench -t ${ITEM} -w S${OBJ}:${SIZE} ./${APP}ITEM 表示基准测试的项目,目前与 CACHE 相关的有 “clcopy(CACHE Line Copy)”、”clload(CACHE Line Load)” 以及 “clstore(CACHE Line Store)”, OBJ 表示基础测试的位置: 0(主内存)、1(L1 CACHE)、2(L2 CACHE)、3(L3 CACHE); SIZE 表示测试的数据大小,单位可以是 GB、MB、KB、B; APP 可以是测试的应用程序,那么具体给出一些案例:
likwid-bench -t clcopy -w S3:10MB ./BiscuitOS-CACHE-TOOLS-LIKWID-default对 L3 CACHE 的 CACHE Line Copy 进行 10MB 的基准测试
likwid-bench -t clstore -w S2:10MB ./BiscuitOS-CACHE-TOOLS-LIKWID-default对 L2 CACHE 的 CACHE Line Store 进行 10MB 的基准测试
likwid-bench -t clload -w S1:10MB ./BiscuitOS-CACHE-TOOLS-LIKWID-default对 L1 CACHE 的 CACHE Line Load 进行 10MB 的基准测试,测试完毕之后都会输出相关测试报告. 如上图所示,性能测试数据很详细,包括了 CACHE 多个性能的基准信息.


OProfile: Performance System profiler

PAPI
PAPI 是田纳西大学创新计算实验室开发的一组可以在多个处理器平台上对硬件性能计数器进行访问的标准接口,它的目标是方便用户在程序运行时监测和采集由硬件性能计数器记录的处理器事件信息。开发者可以使用其提供的 high/low api 对程序某一段的使用时钟周期数、执行指令数、L1/L2 cache miss/access 数、TLB miss 数等等都统计出来,使开发者能够直观的了解到程序的局部性如何。PAPI 支持一百多个事件,其标准事件分为 4 类:
- 存储层次访问事件
- 周期与指令计数:
- 功能部件与流水状态事件
- CACHE 一致性事件
PAPI 提供了两类接口访问硬件性能计数器: 一类是比较简单的高层接口用于完成基本的计数测量,另一类是可编程的底层接口能够满足用户的复杂的监测需求。PAPI 高层接口提供了一些访问硬件性能计数器所需的基本功能,例如配置计数器、启动计数、停止计数、读取计数器的数值等。高层接口只能利用 PAPI 预制事件,而不能够通过配置计数器去监测超出预制事件覆盖范围以外的处理器原生事件。不过 PAPI 高层接口能够直接返回在程序测评中最经常使用的一些性能指标,例如每个周期执行完成的指令数、每秒执行完成的浮点指令/浮点操作数、程序的运行时间等; 另外,高层接口还能获取一些系统信息,例如处理器能够支持的硬件性能计数器的个数等。不同于高层接口只能使用 PAPI 预制事件,PAPI 底层接口能够直接使用原生事件对程序运行时的处理器硬件行为进行监测。用户可以将一个或多个原生事件组成一个事件组(Event Set),然后通过设置硬件性能计数器对事件组中所有的原生事件同时进行监测,进而根据监测结果分析程序的性能问题,例如通过同时采集每秒执行完成的浮点指令数和 L1 Cache 失效次数就有助于分析是否是因为 L1 Cache 的命中率不高导致了程序浮点性能的下降。需要注意的是事件组中的原生事件个数不能够超过处理器所能支持的硬件性能计数器个数. 本文重点介绍 PAPI 测试 CACHE 性能相关的内容,从以下几个方面进行讲解:
PAPI 工具安装
Ubunt/Debian 发行版支持命令直接安装,安装完毕之后 PAPI 工具和相关的库会被安装,使用如下命令:
sudo apt install -y papi-tools papi-examples另外也可以从PAPI 官网下载源码,可以参考如下命令:
# Download papi-7.0.1.tar.gz
# TAR
tar -xf papi-7.0.1.tar.gz
cd api-7.0.1/src/
./configure
make
make fulltest
sudo make install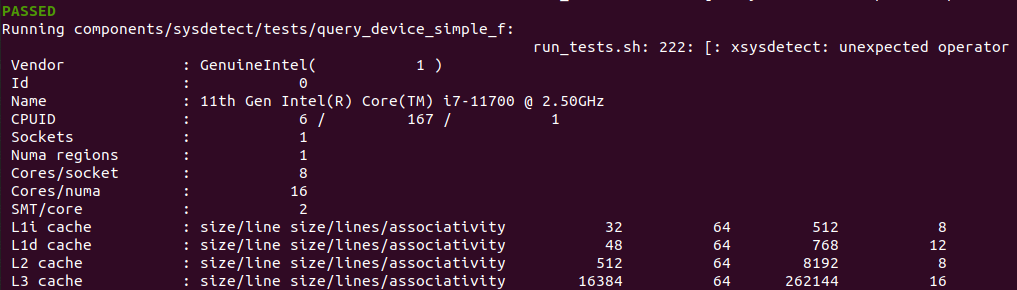

编译过程中,可以执行 “make fulltest” 检测机器支持哪些事件和计数器,最后进行安装,安装完毕之后系统内可以看到多个 papi 工具集合。
PAPI 测试代码部署
PAPI 底层接口能够直接使用原生事件对程序运行时的处理器硬件行为进行监测。用户可以将一个或多个原生事件组成一个事件组(Event Set),然后通过设置硬件性能计数器对事件组中所有的原生事件同时进行监测,进而根据监测结果分析程序的性能问题,例如通过同时采集每秒执行完成的浮点指令数和 L1 Cache 失效次数就有助于分析是否是因为 L1 Cache 的命中率不高导致了程序浮点性能的下降。BiscuitOS 提供了基础使用逻辑,开发者可以在代码里参考使用,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Analysis/Diagnosis Tools: PAPI --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-TOOLS-PAPI-default/
# 部署源码/解决依赖
make download
# 在 BiscuitOS 中实践
make
tree
实践案例是一个用户空间程序,为了使用 PAPI 进行源码级检测,可以参考案例程序的做法,首先在 30 行调用 PAPI_library_init() 函数加载 PAPI 的动态库,然后在需要测试性能的代码前后添加检测启动和停止的函数,例如 47 行调用 PAPI_start_counters() 函数,以及 62 行调用 PAPI_stop_counters() 函数。另外在 47 行传入了 papi_counter[] 数组,数组里包含了需要监听的事件,例如 21 行定了需要监听 PAPI_L1_TCM、PAPI_L2_TCM 和 PAPI_L3_TCM 事件,当监听完毕之后数据存储在 values[] 数组了,67-72 行将监听数据进行打印。最后就是编译的时候加上 “-lpapi” 选项. 最后就是运行实践案例.

可能实践案例运行时会遇到上诉错误,此时可以使用 papi_avail 命令查看当前机器支持的事件,那么将可用的事件填入 papi_counter[] 数组即可. PAPI 目前支持与 CACHE 相关的事件有:
PAPI_L1_DCM /*Level 1 data cache misses */
PAPI_L1_ICM /*Level 1 instruction cache misses */
PAPI_L2_DCM /*Level 2 data cache misses */
PAPI_L2_ICM /*Level 2 instruction cache misses */
PAPI_L3_DCM /*Level 3 data cache misses */
PAPI_L3_ICM /*Level 3 instruction cache misses */
PAPI_L1_TCM /*Level 1 total cache misses */
PAPI_L2_TCM /*Level 2 total cache misses */
PAPI_L3_TCM /*Level 3 total cache misses */
PAPI_CA_SNP /*Snoops */
PAPI_CA_SHR /*Request for shared cache line (SMP) */
PAPI_CA_CLN /*Request for clean cache line (SMP) */
PAPI_CA_INV /*Request for cache line Invalidation (SMP) */
PAPI_CA_ITV /*Request for cache line Intervention (SMP) */
PAPI_L3_LDM /*Level 3 load misses */
PAPI_L3_STM /*Level 3 store misses */
PAPI_L1_LDM /*Level 1 load misses */
PAPI_L1_STM /*Level 1 store misses */
PAPI_L2_LDM /*Level 2 load misses */
PAPI_L2_STM /*Level 2 store misses */
PAPI_PRF_DM /*Prefetch data instruction caused a miss */
PAPI_L3_DCH /*Level 3 Data Cache Hit */
PAPI_L1_DCH /*L1 D Cache Hit */
PAPI_L2_DCH /*L2 D Cache Hit */
PAPI_L1_DCA /*L1 D Cache Access */
PAPI_L2_DCA /*L2 D Cache Access */
PAPI_L3_DCA /*L3 D Cache Access */
PAPI_L1_DCR /*L1 D Cache Read */
PAPI_L2_DCR /*L2 D Cache Read */
PAPI_L3_DCR /*L3 D Cache Read */
PAPI_L1_DCW /*L1 D Cache Write */
PAPI_L2_DCW /*L2 D Cache Write */
PAPI_L3_DCW /*L3 D Cache Write */
PAPI_L1_ICH /*L1 instruction cache hits */
PAPI_L2_ICH /*L2 instruction cache hits */
PAPI_L3_ICH /*L3 instruction cache hits */
PAPI_L1_ICA /*L1 instruction cache accesses */
PAPI_L2_ICA /*L2 instruction cache accesses */
PAPI_L3_ICA /*L3 instruction cache accesses */
PAPI_L1_ICR /*L1 instruction cache reads */
PAPI_L2_ICR /*L2 instruction cache reads */
PAPI_L3_ICR /*L3 instruction cache reads */
PAPI_L1_ICW /*L1 instruction cache writes */
PAPI_L2_ICW /*L2 instruction cache writes */
PAPI_L3_ICW /*L3 instruction cache writes */
PAPI_L1_TCH /*L1 total cache hits */
PAPI_L2_TCH /*L2 total cache hits */
PAPI_L3_TCH /*L3 total cache hits */
PAPI_L1_TCA /*L1 total cache accesses */
PAPI_L2_TCA /*L2 total cache accesses */
PAPI_L3_TCA /*L3 total cache accesses */
PAPI_L1_TCR /*L1 total cache reads */
PAPI_L2_TCR /*L2 total cache reads */
PAPI_L3_TCR /*L3 total cache reads */
PAPI_L1_TCW /*L1 total cache writes */
PAPI_L2_TCW /*L2 total cache writes */
PAPI_L3_TCW /*L3 total cache writes */
PAPI: papi_avail 获得支持的事件
PAPI 提供了 papi_avali 工具,用于获得当前机器支持的事件,对于所支持的事件可以在 PAPI 底层接口中进行监听。papi_aval 还提供了多个参数用于打印指定的事件,例如:
- –l1: 查看机器支持的 L1 CACHE 相关事件
- –l2: 查看机器支持的 L2 CACHE 相关事件
- –l3: 查看机器支持的 L3 CACHE 相关事件
- –cache 查看机制支持的 CACHE 相关事件
- -e: 打印指定事件的具体信息
PAPI: papi_cost 测试 CACHE 事件性能
PAPI 提供了 papi_cost 接口和 papi_cost() 函数接口,可以用于计算当前运行代码段的 CPU 时间和事件计数器耗时,其特点就是可以嵌入到代码中,对某段代码进行计算,另外其可以针对其中的某个事件进行监听,那么其也可以对 CACHE 事件进行监听,接下来通过一个案例介绍如何在代码中使用 papi_cost() 监听 CACHE 事件, 其在 BiscuitOS 的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Analysis/Diagnosis Tools: PAPI-COST --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-TOOLS-PAPI-COST-default/
# 部署源码/解决依赖
make download
# 在 BiscuitOS 中实践
make
treeBiscuitOS-CACHE-TOOLS-PAPI-COST-default Source Code on Gitee
事件案例是一个应用程序,为了需要使用 PAPI COST,那么首先在 30 行调用 PAPI_library_init() 函数加载 PAPI 动态库,然后 34 行调用 PAPI_create_eventset() 函数创建监听事件集合,36 行可以使用 PAPI_add_event() 函数添加监听事件,例如对 PAPI_L1_DCH 事件进行监听,接下来是 49 和 65 行成对调用 PAPI_start() 函数和 PAPI_stop() 函数对代码段进行监听。最后监听完毕之后在 66-68 行进行收尾工作. 编译过程中需要添加 “-lpapi” 动态库,最后运行事件案例:

使用 papi_cost 命令运行程序,可以看到运行并没有预期的结果,原因是本机没有相应的硬件支持,对于开发者有硬件支持的环境,此时可以输出相应的性能和监听事件信息.
PAPI: papi_mem_info 查看 CACHE 硬件信息
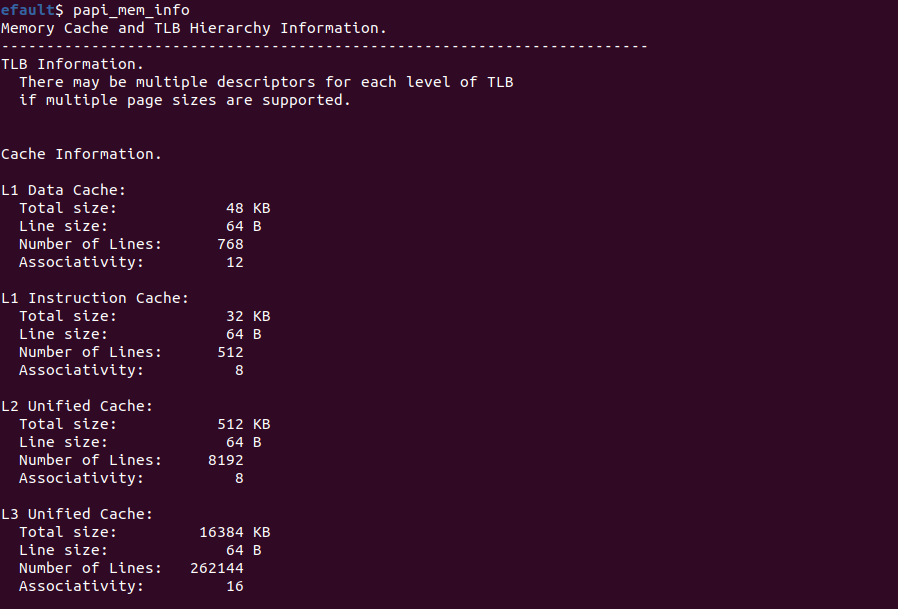
PAPI 提供的 papi_mem_info 命令可以用于查看系统 CACHE 硬件系统,其会列出每一级 CACHE 的大小、CACHE Line Size 大小、CACHE Line 数量以及 CACHE Way 数量.
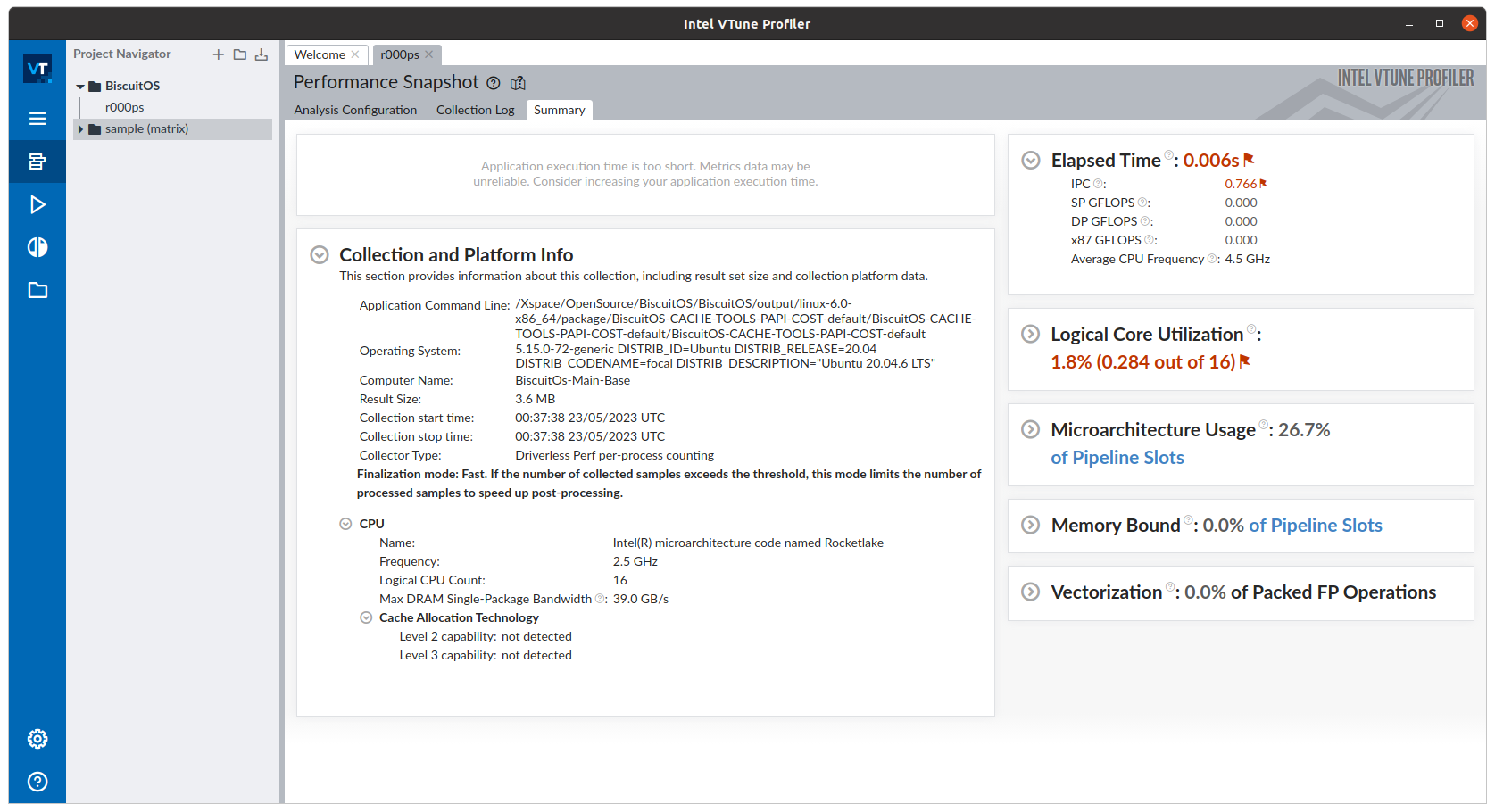
Intel VTune Performance Analyzer
Intel VTune 是一款高级性能分析工具,用于调试和优化应用程序的性能,它可以帮助开发者分析应用程序的性能瓶颈,并提供详细的性能数据和建议,以优化代码和提高应用程序的性能。该工具支持多种平台和编程语言,并提供多种性能分析技术,包括 CPU、内存、I/O 和网络处理等方面分析。Intel VTune 也可以分析 CACHE 的使用情况,包括但不限于 CACHE 命中率等,该工具支持在多平台上安装使用,具体安装可以参考:
例如在 Ubuntu 上安装完毕之后,直接运行 vtune-gui 可以启动桌面版程序,其可以对多种性能进行测试,例如内存访问、CACHE 命中率等,在工具界面上点击 Application 加载需要测试的程序,然后在右边选择要测试的项目,例如选择内存访问,这里包含了 CACHE 的检查,点击底部的按钮会进行测试:
测试运行完毕之后,工具会输出相关的性能测试数据,可以看到内存带宽相关的数据,其中可以看到 LLC CACHE 命令率之类的,在支持 LLC RDT 和 L2 RDT 的机器会输出更多的 CACHE 相关的数据.
Perf CACHE 2 CACHE
perf c2c(Perf CACHE 2 CACHE): 是一种针对 Intel CPU 的性能分析工具,用于分析 CPU 缓存的性能,它可以测试缓存的命中率、缓存行的使用情况和缓存的性能指标。具体来说,perf c2c 通过分析 CPU 对 CACHE 的访问情况,可以测量不同级 CACHE 的命中率、缓存行的使用情况、缓存行间的竞争情况等,从而帮助开发人员定位和优化程序中的 CACHE 访问问题。不是所有的 Intel 机器都支持 C2C 功能,可以使用如下命令确认:
perf list | grep c2c如果显示 c2c,那么硬件上支持,可以继续查看下文 perf c2c 的使用方法。那么开发者可以使用 perf stat 或者 perf record 对 CACHE 信息进行收集,如下:
# 收集 LLC CACHE hit 和 miss 数
perf c2c record -e LLC-loads -e LLC-load-misses ${EXEC-PROGRAM}
# 收集 CACHE miss 和 hit 数,以及读写命中数
perf stat -e c2c/misses/ -e c2c/hits/ -e c2c/wr_hits/ -e c2c/rd_hits ${EXEC-PROGRAM}当采集完程序运行的 CACHE 之后,会在当前目录生成 perf.data 文件,可以使用如下命令解析采集的数据:
perf c2c report
perf c2c 可以输出程序执行过程中监听事件的信息,比如 LLC CACHE 的命中率和 Miss 率等, 开发者可以利用这些数据对自己的程序进行优化。由于本机不支持 c2c 功能,这里不做实践讲解。开发者可以使用如下命令查看 perf c2c 支持的事件:
perf c2c record -e list
Get CACHE configuration value
getconf 是 Linux 系统提供的一个工具,可获取系统的配置信息。它可以获得系统参数和限制,如系统页大小、最大进程数、最大打开文件数等等,同时 getconf 还可以获取特定的系统变量值,如 _POSIX_VERSION、_XOPEN_VERSION 等. getconf 工具也可以用来获得系统 CACHE 信息,具体命令如下:
getconf -a | grep CACHE
从图中可以看到各级 CACHE 的大小、CACHE Way 以及 CACHE LINE SIZE 等.
CACHE BUG/Fault
CACHE Mode 一致问题: 记一次内核提交过程
什么是 CACHE Mode 一致性? 它与 CACHE 一致性有什么区别? CACHE 一致性性是硬件保证多核 CPU 之间 CACHE 看到的数据一致; CACHE Mode 一致性指的是 Linux 可以将多个虚拟地址映射到同一个物理页上,需要保证所有的映射采用同样的 Memory Type. CACHE Mode 详细描述参看【CACHE Mode Coherent】. 开发者首先通过一个实践案例了解原始问题,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] CACHE --->
[*] Coherent: CACHE MODE Coherent for DEVMEM on Page-Fault --->
# 进入源码目录
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-MODE-COHERENT-DEVMEM-PAGE-FAULT-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-MODE-COHERENT-DEVMEM-PAGE-FAULT-default Source Code on Gitee
实践案例由两部分组成,上图展示了内核模块部分,模块基于 MISC 驱动框架向用户空间提供了 “/dev/BiscuitOS-MEM” 接口,接口提供了 mmap 实现,mmap 接口只设置了 “vma->vm_ops” 接口,该接口指向 BiscuitOS_vm_ops, 其提供了 fault 接口 vm_fault, 因此当发生缺页的时候最终调用到 vm_fault() 函数. vm_fault() 函数在 22 行获得缺页的虚拟地址,然后在 28-34 行分配一个物理页然后获得对应的 PFN,接着在 37 行清除原先页表中的 PAT 属性. 函数接下来继续调用 arch_io_reserve_memtype_wc() 函数调整了物理页对应线性映射区的 CACHE Mode 为 WC,确保映射物理页的所有 CACHE Mode 都是 WC. 函数在 41 行重新设置了映射的 PAT 属性集为 _PAGE_CACHE_MODE_WC. 接着在 44-46 行调用 vm_insert_page() 函数建立相应的页表,最后在 49-51 行做一下缺页处理的收尾动作.
实践案例的另外一部分是用户空间的代码,在程序中,首先在 28 行通过 open() 函数打开 “/dev/BiscuitOS-MEM” 节点,然后在 35 行调用 mmap() 函数映射一段设备内存到用户空间,接着在 46-48 行使用内存,最后在 50-52 行归还内存. 接下来在 BiscuitOS 上进行实践:
BiscuitOS 系统启动过程中,先加载 BiscuitOS-CACHE-RAM-DEVMEM-PAGE_FAULT-default.ko 模块,然后在运行 APP 程序,可以看到应用空间进程可以使用从设备分配的物理内存,实践符合预期. 上面分析源码的时候,需要确保映射到 DEVMEM 物理页的虚拟内存,其 CACHE Mode 都要保持一致,那么开发者可以进一步实践,将内核模块 41 行的 _PAGE_CACHE_MODE_WC 修改为其他 CACHE MODE 试试,例如修改为 _PAGE_CACHE_MODE_WT, 然后在 BiscuitOS 上实践如下:
BiscuitOS 系统启动之后,加载完驱动之后运行 APP,此时系统并没有向之前分析那样打印字符串 x86/PAT: APP:112 map pfn RAM range req write-through for [mem 0x02597000-0x02597fff], got write-combining, 那么是不是意味着映射物理页的 CACHE Mode 不一致? 接下来源码分析一下:
基于前面的分析,当发生 Page fault 的时候,系统最终会调用到 vm_fault() 函数,其实现三个功能,第一个功能是通过 alloc_page() 函数提供 DEVMEM,第二个功能是 arch_io_reserve_memtype_wc() 调整物理页线性映射区的 CACHE Mode 为 WC,并修改线性映射区的页表 PAT 属性. 低三个功能是 vm_insert_page() 函数为发生缺页的用户空间虚拟地址建立页表,其通过 get_lock_pte() 函数获得对应的 PTE 页表之后,调用 insert_page_into_pte_locked() 函数建立最终页表,该页表的 PAT 属性集就是设备配置的 _PAGE_CACHE_MODE_WC。通过上面的分析确实没有对 CACHE Mode 的统一性进行检测,这里容易出现不同的虚拟地址采用不同的 CACHE Mode 映射同一个物理内存现象,该问题需要紧跟主线社区的处理进度.
通过上面分析,非缺页模式下,DEVMEM 是可以维护多个虚拟地址映射到同一个物理内存时,CACHE Mode 保持一致. 但如果在缺页模式下,DEVMEM 无法保证多个虚拟地址映射到同一个物理地址 CACHE MODE 一致. 以上便是 CACHE MODE Coherent 问题,那么接下来将该问题提交 Linux 上游社区,对于如何提交补丁,这里有一篇很好的文章: 【如何提交patch 到内核】.

接下来就是和社区的拉扯,需要去说服 Manintainer 接受这个 patch,有时可能开发者提交的补丁很久没有得到回应,可以再发一封内容为 “Frindly ping”, 这样会增加被 maintainer 看到的概率.

Split lock 引起的性能降低问题
开发者在查看本节内容之前需要先了解 CACHE locking 机制与原子操作 和 Intel® Split_lock Check Technology 两个章节,分别介绍了多核架构下的原子操作实现,以及 Intel 用于检测 Split Lock 的硬件机制. 有了两片文章的基础之后,一起来看一个有 Split lock 引起的问题.
问题场景来自 LWN: The search for the correct amount of split-lock misery, 事情起因是一个名为 “pibberflibbits” 的 GitHub 用户发布了一份 bug report,称 Linux 上的 God of War(战神) 游戏的性能变得 “低得离谱”, 参与讨论的人们花了一点时间,最终发现问题出在 split-lock 的这个额外惩罚上。为什么 Split lock 会引起这个问题呢? 那是因为在 linux 5.7 内核版本中,内核对 split lock 提供了三种策略,也就是之前分析的可以在 CMDLINE 的 split_lock_detect 字段,该字段可以设置当硬件检查到 split lock 之后采取的策略,一共四种策略:
- off: 视而不见,就是检查到也不做任何处理,那么 #LOCK 总线的操作会降低系统性能
- warn: 广而告之, 仅仅是发出警告,不做更多操作
- fatal: 天降正义,直接向触发的应用程序发 SIGBUS 信号触发 #AC 异常或 #DB 异常. 如果是内核触发,视为致命错误,直接导致系统崩溃.
- retelimit: 类似于 warn 选项,但是限制日志消息的频率,以避免填满日志系统.
期初希望 warning 模式足以提醒用户注意这个问题,并让软件得到正确的修复,同时不影响系统的整体性能。但由于 5.19 内核开发周期,似乎对于去除 split-lock 操作并没有太大的进展,拒绝服务(denial-of-service) 的问题还是和之前一样,因此内核采取了更强硬的立场来可知 split-lock. 其中的一个选项就是将 split-lock 默认处理策略切换成 fatal 模式,但这会是一个非常严厉的解决方案。同时 Tony Luck 采取了不同的方案,他写了一个 patch,标题是 “make life miserable for split lockers”, 该 patch 会修改 warning 模式,并对 split-lock 的进程进行惩罚,但不会真正去 kill 进程。相反在检测到 split-lock 时让进程受到 10ms 级别的 delay,并且通过 semaphore 保证序列执行。当选择这种模式时,使用了 split-lock 的恶意程序仍然会拖慢自己执行的速度,但对整个系统不再有太大的影响,这一改动在 5.19 合并窗口期合入.
一个名为 “pibberflibbits” 的 GitHub 用户发布了一份 bug report,称 Linux 上的 God of War(战神) 游戏的性能变得 “低得离谱”, 参与讨论的人们花了一点时间,最终发现问题出在 split-lock 的这个额外惩罚上。显然,战神并不满足于仅使用普通的 lock,所以游戏中使用了许多 split locking。Luck 的 patch 确实达到了预期的目的,战神玩家现在是过得很痛苦。不过 Guilherme G. Piccoli 并没有庆祝这场对战神的胜利; 相反他发布了一个 patch,认为 “不应该修改 default 配置选项,让旧的应用或者专有软件表现下降,尤其是原有的 config 选项能正常工作的情况下”。这个 patch 对 warn 模式恢复到了的旧的行为,并增加了一个新的 seq 模式,该模式会像现在的 warn 模式一样拖慢 split-lock 用户的速度。warn 模式仍然是默认的,这就解除了游戏界的苦难. 对这一改动的意见不太一致, Luck 指出游戏玩家可以通过在内核命令行上用 split_lock_detect=off 重启,就能直接禁用 split-lock 检测, 如果要增加 seq 模式,那么也应该是默认的。他还建议向《战神》的发行商提交一个 bug,从而让其 fix 它自己的问题.
不过,Luck 认为 split-lock 会给其他进程(除了这个有责任的进程之外)制造了痛苦,而目前的模式 “在多用户系统上非常有效”。他建议也许可以开发某种启发式方法,让这些折腾用户的行为就限制在多用户系统中。不过,最终 Thomas Gleixner 给出了明确的答案,他指出,默认情况下拖慢 split-lock 的速度,这是发行版中可以做出的唯一选择; 其他任何方案都会产生一个容易被利用的拒绝服务漏洞, 所以拖慢速度的做法需要保留。”减少受攻击的暴露面,会比某个应用程序出现问题要更重要”。不过他确实建议说,可以添加一个 sysctl 开关来控制 split-lock 的检测; 这就可以让那些使用这种出现了的应用程序的用户能回到以前的性能,而不需要弄清楚如何改变 kernel 命令行参数,也不需要重启他们的系统。
虚拟化环境 split-lock 问题
前面分析了物理主机上的内核和用户态程序产生 split-lock 的处理逻辑,那么在虚拟化场景中,split-lock 来自 Guest OS,那么 Host 如何检测? 怎么避免对其他 Guest 的影响? 如果直接在 Host 上 Enable bus lock ratelimit,可能会影响没有准备号的 Guest。如果直接把 split-lock 的检测开关暴露给 Guest,Host 或其他 Guest 处理等问题. CPU 可以在 VMX mode 下支持 split lock 检测的 #AC trap,后面具体怎么做有 Hyperisor 决定。大部分 Hyperisor 会直接把 trap 转发给 Guest 中,如果 Guest 没有准备好,可能会产生 crash.
Guest 中尝试 Split lock 操作,会 VM-EXIT 到 KVM 中,如果硬件不支持 split-lock 检测或者为 legacy #AC,会把 #AC 注入给 Guest 处理; 如果硬件支持 split lock 检测, 那么会根据配置产生警告,甚至尝试 SIGBUS. Guest 进行 Bus lock 后会发送 VM-EXIT 到 KVM 里,KVM 通知 QEMU,vCPU 线程会主动进行 sleep 降频.
总结: 在支持 Split lock 检测的平台,开发者最好在 warning 模式下将程序中的 split-lock 都清除,否则由于系统对 split-lock 处理模式转换,程序性能可能被严重影响.
CACHE 进阶研究

Coherent/Streaming DMA
DMA 是不需要 CPU 参与下外设与内存之间的数据拷贝行为. DMA 可以是外设内存搬运到内存,也可以是内存搬运到外设,由于不需要 CPU 介入,当 DMA 搬运完毕之后会通过中断通知 CPU.通过之前的分析,在多核架构中,硬件通过 MESI 机制保证了多个 CPU 之间 CACHE 一致性,对于外设其只能看到内存,并不能看到 CACHE 里面的内容,因此在 DMA 搬运的时候,内存最新的数据还在 CACHE 里,那么 DMA 搬运的数据就是旧的数据,这样是不符合期望的。通过之前的分析,CPU 是因为有了 Snoop 总线的能力,所以才能保证 CACHE 的一致性,那么如果也给外设赋予 Snoop 能力,那么是不是也可以保证数据一致呢? 本文通过三个章节来分析不同场景下 DMA 如何保证数据一致.
Coherent DMA
Coherent DMA(一致性 DMA): 指的是外设做 DMA 时可以保证 CPU 和外设看到的内存是一致的。不同架构实现 Coherent DMA 方式存在差异,但达到的效果是一致的,也就是当外设进行 DMA 搬运之前,外设知道内存里的数据是否为最新的。在有的架构(.e.g. ARM), 外设是没有 Snoop 总线的能力,因此架构会将所有 Coherent DMA 使用的内存映射为 Nocache 的,那么 CPU 访问 DMA 使用的物理内存时不再使用 CACHE,物理内存里可以保持最新的数据; 在有的架构(.e.g. X86), 外设有 Snoop 总线能力,因此架构会将所有 Coherent DMA 使用的内存映射为 WriteBack,那么 CPU 访问 DMA 使用的物理内存同样使用 CACHE,当外设需要 DMA 搬运时,硬件自动将对应的 CACHE Line Flush 到内存,那么同样可以保证内存里的数据是最新的。那么接下来先通过一个实践案例来感受 Coherent DMA 的使用, 其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
[*] BiscuitOS PCI/PCIe DMA with MSIX Interrupt --->
[*] Package --->
[*] CACHE --->
[*] DMA: DMA Coherent(WB/UC) Memory --->
# 源码目录
# Module
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-DMA-COHERENT-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
实践案例有一个内核模块构成,模块主体有一个 PCIe 驱动构成,这里不做过多细节描写,主要看 Broiler_pci_probe() 函数,在 159 行调用 dma_alloc_coherent() 函数分配一段长 DMA_BUFFER_LEN 的物理内存,物理内存用于 DMA 使用,并简称这段物理内存为 DMA 内存,DMA 内存对应的物理地址存储在 bpdev->dma_addr, 内核映射到 DMA 内存的虚拟地址存储在 bpdev->dma_buffer 里,该虚拟地址是 CPU 访问 DMA 物理内存使用。167-177 行是模块执行的 DMA 操作,其中 168 行调用 memset 将 DMA 内存清零,然后在 169 行执行 DMA 操作,将外设内存拷贝到 DMA 内存. 模块接着在 172 行向 DMA 内存写入 “Hello BiscuitOS” 字符串,然后执行 DMA 操作,将 DMA 内存搬运到外设; 最后模块在 176 行再次将 DMA 内存清零,并执行 DMA 操作,将外设内存拷贝到 DMA 内存里。每次 DMA 操作完成之后,外设都会发送一个中断给系统,系统收到中断之后调用 42 行的中断处理函数,中断处理函数的逻辑就是将 DMA 内存打印出来. 那么接下来在 BiscuitOS 上实践该案例:
BiscuitOS 系统启动之后,加载 BiscuitOS-CACHE-DMA-COHERENT-default.ko 模块,可以看到模块一共收到三次中断,第一次收到中断时 DMA 内存的数据正好是外设搬运到内存的; 第二次收到中断时 DMA 内存正好是搬运到外设的内容; 最后一次中断是从外设 DMA 搬运回来的内存,内容正好是上一次写入的,实践结果符合预期。那么回到今天的主题,Coherent DMA 与 CACHE 的关系,接下来从源码进行实践分析:
上图最左边是 Coherent DMA 映射的流程,其核心完成两个流程,第一个是分配一段连续的物理内存,第二个是建立页表映射到连续物理内存上。__dma_direct_alloc_pages() 函数完成了连续物理内存的分配,但在有的架构物理内存可能来自高端物理内存,由于高端内存没有建立页表,因此需要调用 dma_common_contiguous_remap() 函数进行页表映射; 但在有的架构不存在高端内存,物理内存来自线性映射区,页表已经建立. 最后就是根据不同架构外设是否具有 Snoop 能力选择 DMA 内存是 CACHE 还是 NoCACHE. 在 X86 架构中,外设具有 Snoop 能力的,并且不存在高端内存,那么 DMA 内存来自线性映射区,并且映射采用 WriteBack,因此在 X86 架构里 DMA 内存是 Cacheable; 但在 ARM 架构里,外设没有 Snoop 能力,那么系统将 DMA 内存映射为 Nocache 的.
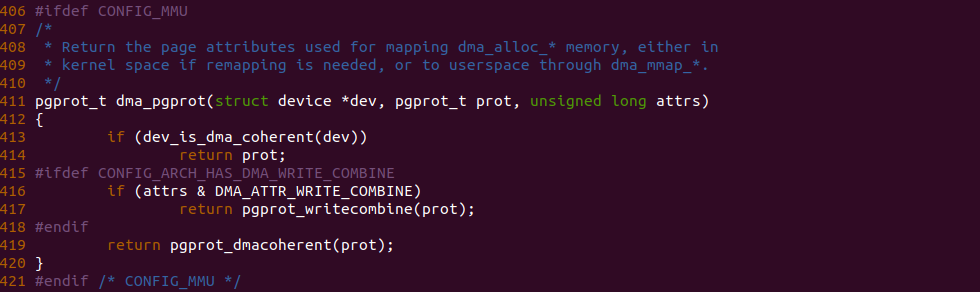
在 X86 架构里,由于外设具备 Snoop 能力,因此可以将 DMA 内存映射为 Cacheable 的, 并且内存都来自线性映射区,因此直接采用 WriteBack 属性; 但对于 ARM 架构,由于不具备 Snoop 能力,因此 dma_pgprot() 函数则返回 pgprot_dmacoherent(), 该函数会将 DMA 内存映射为 NOCACHE. 另外从函数的定义可以看出,Coherent DMA 还可以支持 WriteCombining 的 DMA 内存.
总结: Coherent DMA 是一种可以保证 DMA 内存数据一致性的方案,在不同的架构中,外设具有 Snoop 能力,那么 DMA 内存可以直接使用 Cacheable 的 WB 内存; 外设不具备 Snoop 能力,那么 DMA 内存直接使用 Uncachable 的 UC 或者 WC 内存. 无论采用 Uncachable 还是 Cacheable,外设在进行 DMA 操作时 DMA 内存的数据已经是最新的!
Streaming DMA
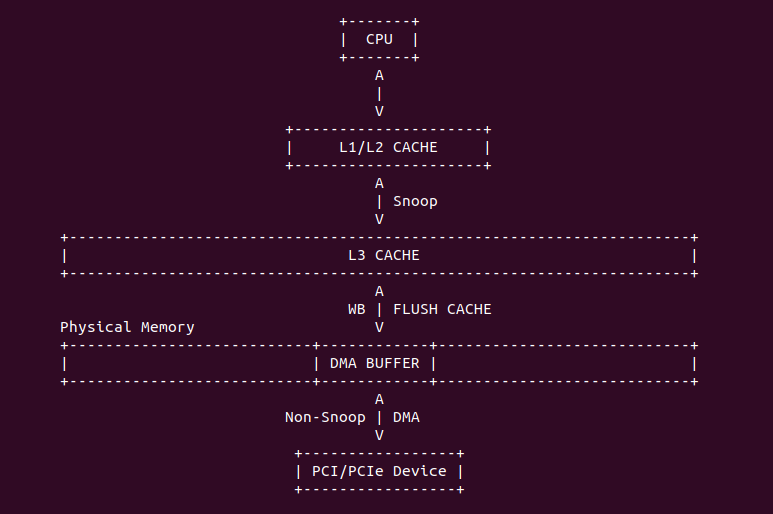
继续上面的分析,在有的架构中,例如 ARM 架构中,其外设没有 Snoop 的能力,为了在 DMA 搬运时保证 DMA 内存最新,那么其会将 DMA 内存映射为 Uncachable 的,然后使用 Coherent DMA 进行 DMA 搬运,这样虽然能解决问题,但由于 Uncachable 映射会导致 CPU 访问 DMA 内存时,无法使用 CACHE 带来的好处,即 CPU 访问都需要到内存中获得数据,处理完毕之后还要将数据再次写入内存,与 WB 类型的内存相比,性能会带来极大的影响,为了让 DMA 内存也可以享受 CACHE 带来的好处,在这类架构中可以使用 Streaming DMA(流式 DMA).
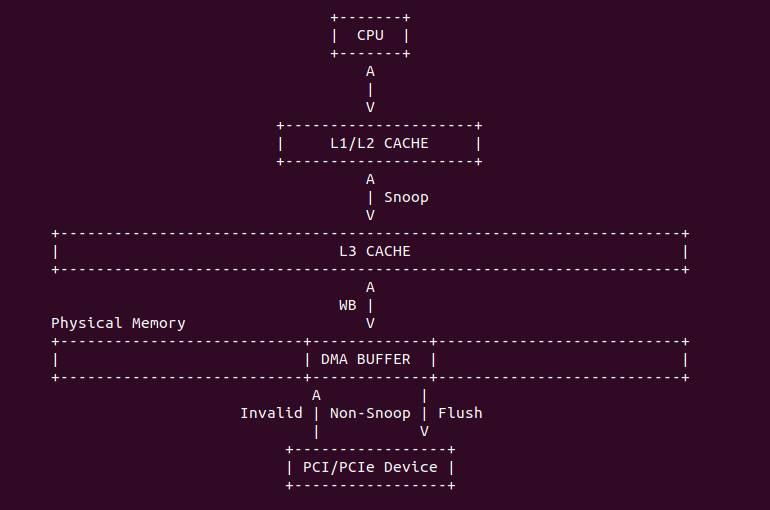
Streaming DMA(流式 DMA) 可以理解为软件保证了 DMA 内存一致. 当需要 DMA 搬运到外设,那么软件提前 Flush CACHE DMA 内存,将最新的内容写到 DMA 内存, 那么 DMA 搬运最新内存到外设; 当需要 DMA 搬运到内存,那么软件提前 Invalid DMA 内存,DMA 搬运完毕之后 CPU 可以从 DMA 内存里读取到最新的数据. DMA 搬运过程中,软件需要确保 CPU 不要对 DMA 内存进行访问. 那么接下来通过一个实践案例了解 Streaming DMA 如何使用,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
[*] BiscuitOS PCI/PCIe DMA with MSIX Interrupt --->
[*] Package --->
[*] CACHE --->
[*] DMA: DMA Streaming(WB/UC) Memory --->
# 源码目录
# Module
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-DMA-STREAMING-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
实践案例由两部分组成,其中一部分是一个内存模块,模块的主体是一个 PCIe 驱动,本文不做详细讲解. 在模块 195 行调用 __get_free_page() 函数分配一个物理页作为 DMA 内存,此时 DMA 内存是 WriteBack Cacheable 的内存。模块中使用 MSIC 框架向用户空间提供了 “/dev/Broiler-DMA” 节点,可以对节点进行读写操作. 另外当完成以此 DMA 操作之后,外设都会向内核发送一个中断,中断处理函数使用 Broiler_msix_handle() 函数.
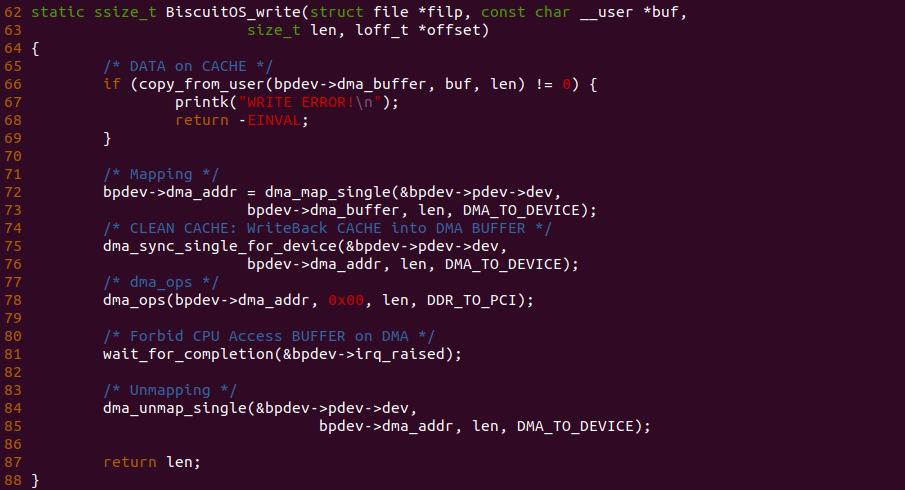
当用户空间向 “/dev/Broiler-DMA” 执行写操作之后,最终会调用到 BiscuitOS_write() 函数,函数首先将用户空间数据通过 copy_from_user() 函数拷贝到 DMA 内存,然后调用 dma_map_single() 建立内核空间到 DMA 内存的映射,接着调用 dma_sync_single_for_device() 函数,该函数对 DMA 内存对应的 CACHE 进行 FLUSH CACHE 操作,使 DMA 内存的数据是最新的. 接下来在 78 行调用 dma_ops() 进行 DMA 搬运,并在 81 行调用 wait_for_completion() 函数等待 DMA 搬运的完成,当 DMA 搬运完成之后调用 dma_unmap_single() 函数解除内核对 DMA 内存的映射.
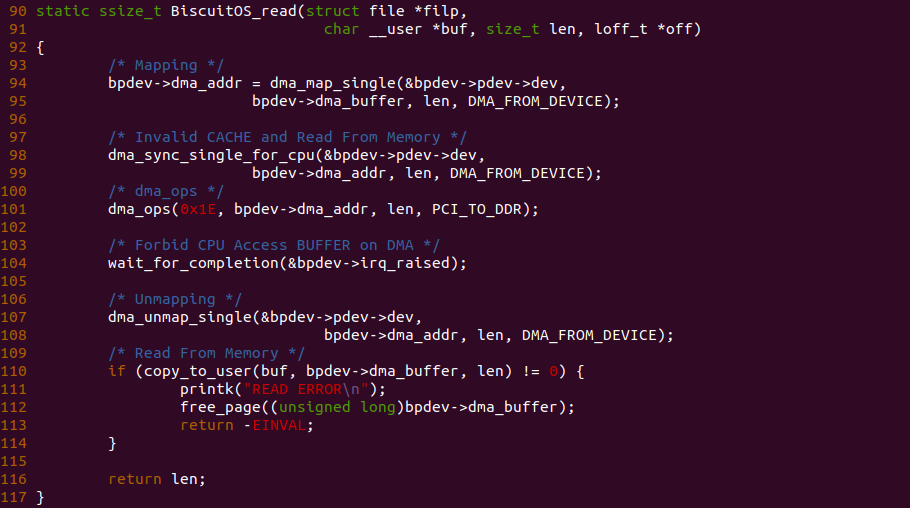
同理当用户空间向 “/dev/Broiler-DMA” 执行读操作之后,最终会调用到 BiscuitOS_read() 函数,该函数首先调用 dma_map_single() 函数建立内核到 DMA 内存的映射,然后调用 dma_sync_single_for_cpu() 函数将 DMA 内存对应的 CACHE Line Invalidate,接着调用 dma_ops() 函数进行 DMA 搬运,并通过 wait_for_completion() 函数等到 DMA 搬运完成,在没有完成之前就一直等待. DMA 搬运完成之后,调用 dma_unmap_single() 函数解除 DMA 内存的映射,由于之前 Invalidate 操作,当前 DMA 内存里的数据是最新的,并且 CPU 将会直接访问 DMA 内存而不是 CACHE。因此在最后调用 copy_to_user() 函数将数据拷贝到用户空间.
实践案例的另外一部分是一个用户空间的程序,程序通过 open() 函数打开 “/dev/Broiler-DMA” 节点,然后对节点分别进行读写操作,最后将读到的内容打印出来. 那么接下来在 BiscuitOS 上实践该案例:
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-DMA-STREAMING-default.ko 驱动,并运行 APP 程序,可以看到从外设读到字符串 “DMA Context: :) The Home of BiscuitOS: http://www.biscuitOS.cn”, 实践符合预期。那么接下来继续分析 Streaming DMA 如何在 Cacheable 内存实现 DMA 搬运.
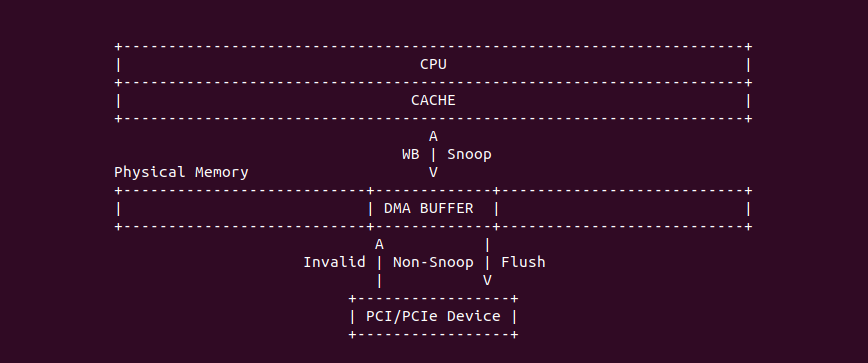
与 Coherent DMA 相比,Streaming DMA 需要软件自己维护 DMA 内存的一致性,通过上面的实例也看到, 具体做法是:
- DMA TO DEVICE: 当 DMA 搬运 DMA 内存到外设时,CPU CACHE 缓存这 DMA 内存的最新数据,此时 DMA 内存数据是旧的,因此需要将这些 CACHE Line 执行 FLUSH CACHE 操作,让最新的数据都回写到 DMA 内存里,那么接下来 DMA 搬运到外设的内存就是最新的,模块里使用了 dma_sync_single_for_device() 函数完成 FLUSH CACHE 操作.
- DMA FROM DEVICE: 当 DMA 搬运外设数据到 DMA 内存时,CPU CACHE 同样缓存 DMA 内存最新的数据,并且会一直访问 CACHE 里面的数据,此时需要向这些 CACHE Line 执行 Invalidate CACHE 操作,让 CPU 可以访问 DMA 内存,那么此时执行完 DMA 搬运之后,DMA 内存里的数据是最新的,CPU 接下来访问会从 DMA 内存中获得,可以确保 CPU 访问到最新的数据.
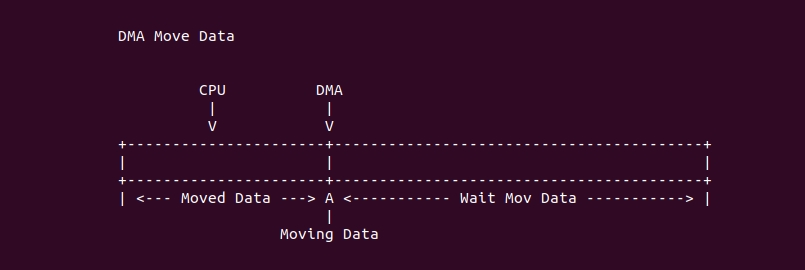
在 Streaming DMA 中虽然有软件通过 Flush/Invalidate CACHE 保证 DMA 内存是最新的,但还是会存在一种情况,就是 DMA 搬运过程中,CPU 访问了刚搬运完的数据,那么被访问的 DMA 内存处是最新的数据,而已经搬运到外设里面的数据已经变成旧数据。为了防止该问题的出现,软件上需要保证一次 DMA 操作的原子性,例如在实践案例中,通过使用 Completion 机制进行保证,也就是在 DMA 操作开始之后,CPU 就必须等待 Completion 完成之后才能对 DMA 内存进行读写操作。开发者可能已经发现了,在实践案例中,DMA 搬运完成之后外设向系统发送一个中断,中断函数里就是将 Completion 设置为完成,这样才能继续其他的 DMA 操作.
总结: Streaming DMA 通过软件的方案,使 DMA 内存可以 Cacheable,这样将大大提高内存访问效率。另外 Invalidate 和 Flush CACHE 也给开发者们提供了一个很好的场景去理解何时刷 CACHE. 最后在 X86 架构中,由于硬件负责 DMA Buffer 数据的一致,那么无需通过软件进行保证,可以直接使用 Coherent Cache 完成高效率的 DMA 操作.
DMA-BUF/DMA-Pool
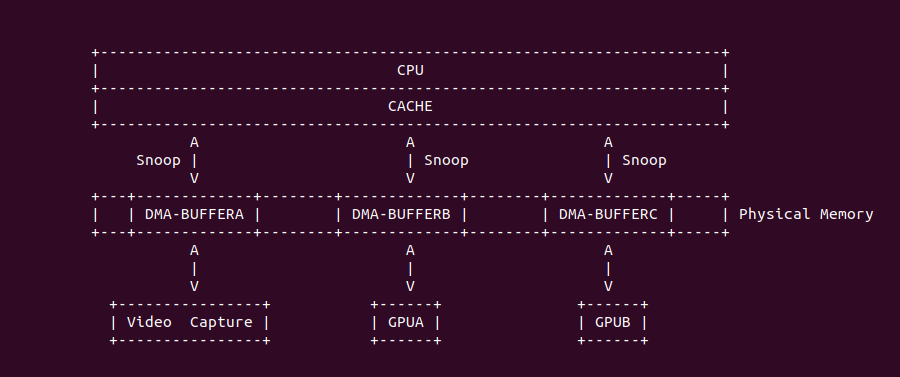
什么 DMA-BUF? 为什么会出现 DMA-BUF 技术? 要回答这个问题先来看一个场景,如上图: 在某个系统里存在三个外设,第一个外设是 Video Capture, 用于从摄像头捕获视频流; 第二个外设是 GPUA, 用于将 Video Capture 采集的数据进行处理并进行显示; 第三个外设是 GPUB,与 GPUA 具有相同的目的. 那么看一下数据的流向: 首先 Video Capture 通过摄像头采集数据之后,通过 DMA 搬运到 DMA 内存 DMA-BUFFERA,然后 CPU 通过搬运将 DMA-BUFFERA 的内存搬运到 DMA-BUFFERB 和 DMA-BUFFERC, 搬运完毕之后 GPUA 和 GPUB 在通过 DMA 搬运到各自的外设里面进行处理,一套操作下来 CPU 进行了两次搬运,但搬运的内容没有变化,另外外设是否可以直接从 DMA-BUFFERA 通过 DMA 搬运到各自的外设?
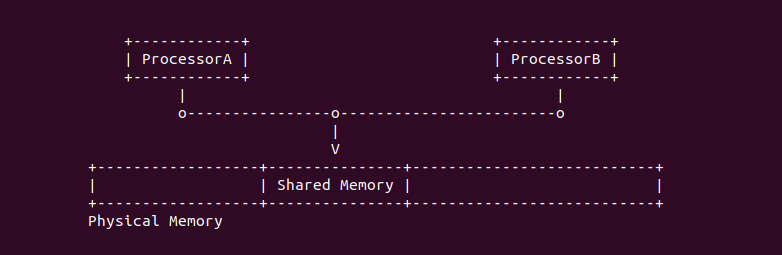
为了弄明白这个问题,我门需要更加深入的理解没有 DMA-BUF 框架之前的痛点。在做共享内存时,可以将不同进程的虚拟地址映射到同一个物理内存,并使用其他通行机制保证进程之间的内存共享。但对于外设之间如何共享物理内存呢?
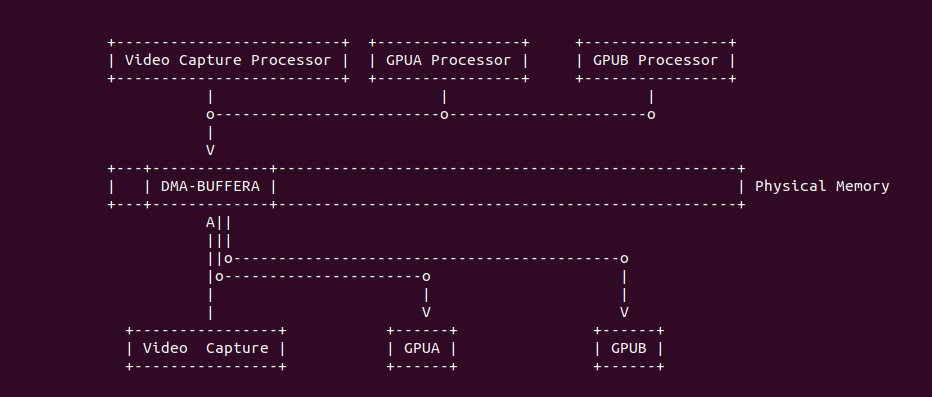
参考用户进程共享内存的方案,每个外设都用一个用户进程,并将各自进程的虚拟内存映射到共享的 DMA 内存 DMA-BUFFERA 上,当 Video Capture 采集到数据,并通知 Video Capture Processor 之后,Video Capture Processor 通过 DMA 搬运将数据从 Video Capture 搬运到 DMA 内存 DMA-BUFFERA 上,然后 Video Capture Processor 通过共享机制通过 GPUA Processor 和 GPUB Processor 取处理新的数据. GPUA Processor 和 GPUB Processor 收到消息之后,让 DMA 搬运 DMA-BUFFERA 的数据到各自的外设内,然后进行处理. 遇上操作 CPU 并没有做无效的内存搬运,都只进行 DMA 搬运.
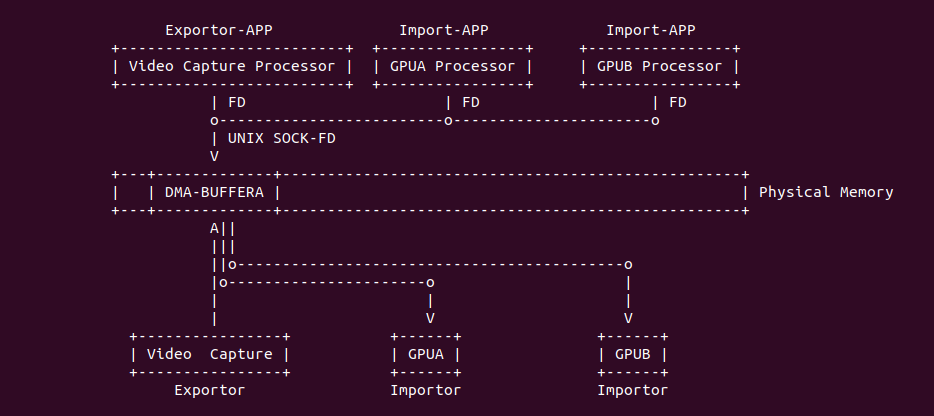
在 DMA-BUF 框架没有出来之前,各种外设都采用不同的方案来实现不同外设之间的内存共享,DMA-BUF 出现之后,希望通过一个完善的方案实现不同外设之间共享内存的方案,其实现如上: DMA-BUF 采用 CS 框架,将共享内存的管理者称为 Exportor(生产者), 然后将使用共享内存的称为 Importor(消费者),Exportor 和 Importor 在用户空间通过 Unix Sock-FD 实现对物理内存的共享。DMA-BUF 框架提供了一套完整的接口实现设备之间的内存共享,接下来先通过一个实践案例感受一下 DMA-BUF 是如何使用的,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
[*] BiscuitOS PCI/PCIe DMA-BUF --->
[*] Package --->
[*] CACHE --->
[*] DMA: DMA-BUF(WB/UC) Memory --->
# 源码目录
# Module
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-DMA-BUF-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
实践案例有三个内核模块和三个应用程序构成,APP-Export-Capture.c 和 DMABUF-Export-Capture.c 分别是 Video Capture 设备的内核模块和应用程序,其是一个 Exportor 源码; APP-Import-GPUA.c 和 DMABUF-Import-GPUA.c 分别是 GPUA 设备的内核模块和应用程序,其是一个 Importor; APP-Import-GPUB.c 和 DMABUF-Import-GPUB.c 分别是 GPUB 设备的内核模块和应用程序,其也是一个 Importor. 由于篇幅有限,这里只做部分代码展示,完整代码请看上面链接.
DMA-BUF Exportor
Video Capture 设备的内核模块在初始化时,在 294 行通过 dma_alloc_coherent() 函数分配了一段 Coherent DMA 内存,然后在 304-314 行是 DMA-BUF 架构需要填充的数据,其中 Video Capture 提供了 BiscuitOS_exp_dmabuf_ops, 也就是作为一个 Exportor,当 Importor 申请共享内存式,DMA-BUF 的分配行为.
Video Capture 作为 Exportor 提供了 map_dma_buf 接口和 unmap_dma_buf 接口,当 Importor 申请映射 DMA-BUF 的共享内存时,DMA-BUF 会调用到 BiscuitOS_map_dma_buf() 函数,该函数为每次 Importor 申请分配了一个 struct sg_table, 其将分配共享内存信息填充到 struct sg_table 数据结构里,其中共享内存的物理地址在 145 行通过 sg_dma_address() 函数进行填充,而共享物理内存区域的长度则通过 144 行的 sg_dma_len() 函数进行填充。当 Importor 使用完毕之后解除对共享物理内存的映射,此时 DMA-BUF 框架会调用到 BiscuitOS_unmap_dma_buf() 函数,该函数将对应的 struct sg_table 释放和销毁即可. 另外通过 BiscuitOS_mmap() 接口可以将 Exportor 共享内存映射到 Exportor 对应的用户进程虚拟内存.
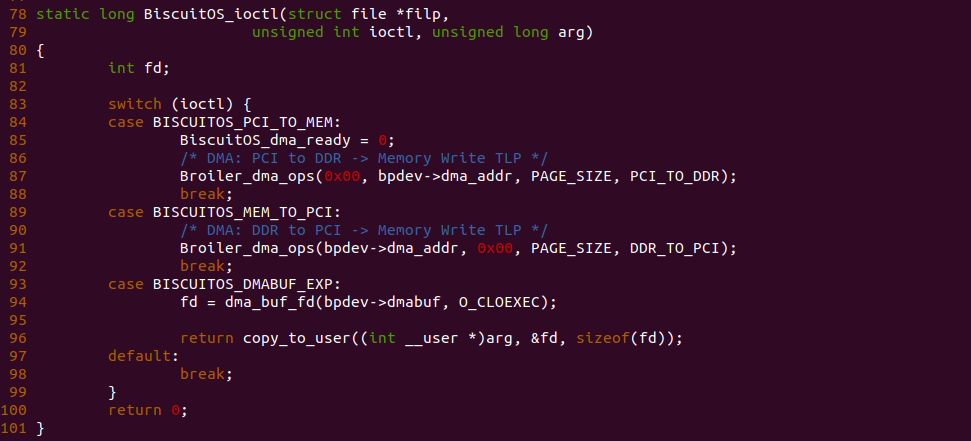
为了实现不同进程之间的内存共享,这里使用了 Unix SockFD 方案,DMA-BUF 通过提供 dma_buf_fd() 函数获得共享物理内存使用的 FD,然后用户进程通过 ioctl() 接口读取该 FD.
APP-Export-Capture.c 作为 Exportor 服务端 APP 接口,与其他 Importor APP 进行交互,目的是实现 Unix SockFD 的传递,以此实现 DMA 内存的共享. 函数首先在 97 行通过 open() 函数与 Video Capture 模块取得联系,然后在 102 行通过 ioctl() 函数获得共享物理内存的 Unix SockFD,存储在变量 dmabuf_fd. 接着程序通过 while() 循环进入监听阶段,一旦有 Client Importor 请求时,Exportor Server 通过 send_fd() 函数将共享 DMA 内存的 Unix SockFD 传递给请求者,然后在 116 行从 Video Capture 设备上 DMA 搬运最新抓取到的数据到共享的 DMA 内存. 以此往复服务多个 Importor.
DMA-BUF Import
GPUA 和 GPUB 都是相同的设备,其目的都是从 DMA 内存搬运数据到设备内部进行处理,处理完毕之后直接显示。他们两个都是 Importor,其内核模块需要实现对共享物理内存 FD 的解析,其在上图 102-108 行逻辑,Importor 应用程序获得共享内存的 FD 之后,通过 dma_buf_get() 函数,将 fd 转换成对应的 struct dma_buf 数据结构,该数据结构是 DMA-BUF 管理共享物理内存使用,与 Exportor 使用是同一个 struct dma_buf. 当需要进行 DMA 搬运到设备时,其执行 77-100 行的代码逻辑,首先通过 dma_buf_attach() 函数将 GPA 设备 Attach 到 DMA-BUF 上,然后通过 dma_buf_map_attachment() 函数获得共享内存使用的 struct sg_table, 共享 DMA 内存信息全部存储在里面,那么通过 sg_dma_address() 获得了共享 DMA 内存的物理地址,接下来就是使用该物理地址进行 DMA 操作,DMA 操作完毕之后将 GPU 设备从 DMA-BUF 上解除,并是否 sg_table,至此一次 DMA 搬运完成.
Importor 对应的应用程序如上,其核心目的就是获得共享 DMA 内存的 FD,然后传递给 Import 模块并进行 DMA 操作. 程序通过 open() 函数与 GPU 模块取得联系,然后通过 sock_setup() 函数从 Exportor 获得共享内存的 Unix SockFD,然后在 101 行通过 ioctl() 传递给 GPU 模块. 程序接下来 104-116 行将其虚拟内存映射到共享 DMA 内存上,然后打印共享内存里面的信息,最后在 117 行下发 DMA 搬运到设备的命令. GPUB Importor 实现和这类似. 那么接下来在 BiscuitOS 上实践该案例:
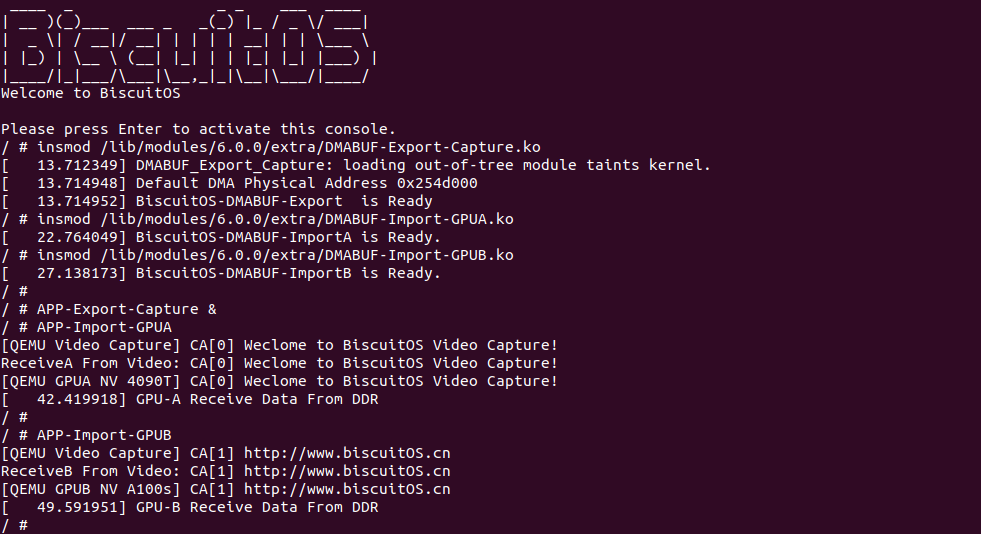
BiscuitOS 运行之后,将 Exportor 和 Importor 的驱动加载完毕之后,后台运行 APP-Export-Capture 进程,该进程为服务进程,然后运行 APP-Import-GPUA 进程,可以看到 Video Capture 采集到原始数据 “Weclome to BiscuitOS Video Capture!”, 然后将其通过 DMA搬运到共享 DMA 内存上,此时 GPUA 从 Exportor 处获得共享 FD 之后将其进程的虚拟内存映射到共享 DMA 内存上,然后打印共享 DMA 内存的内容,可以看到 Capture 设备已经 DMA 搬运成功了,接下来就是将共享 DMA 内存的数据搬运到 GPUA 内部,然后 GPUA 处理完毕之后进行显示,此时显示的数据也正好是 Capture 捕获的数据,因此可以看到整条链路是通畅的。同理运行 Import GPUB 也可以看到同样的效果. 实践符合预期,接下来不对 DMA-BUF 实现细节进行分析,因为本文研究的是 CACHE 相关的,那么接下来研究一下 DMA-BUF 和 CACHE 相关的话题.
在之前的 Coherent/Streaming DMA 章节分析过,在有的架构例如 X86 架构,外设是具有 Snoop 总线能力,因此硬件可以确保 DMA 搬运时 DMA 内存是最新的,但在有的架构例如 ARM 架构,外设就没有 Snoop 能力,那么可以将 DMA 内存映射为 Nocache 的,或者使用 Streaming DMA 进行 DMA 搬运,软件上确保 DMA 内存是最新的。在 DMA-BUF 架构里同样存在上述问题,如果一个 DMA-BUF 共享的 DMA 内存映射时采用了 Nocache,或者共享的 DMA 内存指由外设使用,CPU 不会访问 DMA 内存,那么无需考虑 CACHE 一致性问题.
通过上面的分析可知,当 DMA-BUF 使用了 Coherent DMA 作为 DMA 内存,那么 DMA-BUF 无需在软件层面保持 CACHE 一致性,但如果 DMA-BUF 使用了 Streaming DMA 之后,并且 CPU 也会使用 Cacheable 的方式访问 DMA 内存,那么这个时候 DMA-BUF 需要软件维护 CACHE 一致性。与 Streaming DMA 一样,Importor 在映射共享 DMA 内存时,调用 dma_buf_map_attachment() 函数,该函数一个重要功能就是同步 CACHE:
- 当 Importor 需要搬运共享 DMA 内存到设备,那么 dma_buf_map_attachment() 函数会将共享 DMA 内存在 CACHE 中的内容刷新到共享 DMA 内存里,此时共享 DMA 内存里的数据是最新的,可以进行 DMA 搬运。
- 当 Importor 需要从外设搬运数据到共享 DMA 内存,那么 dma_buf_map_attachment() 函数会将共享 DMA 内存在 CACHE 中的内容 Invalidate,当搬运完成之后,CPU 就会从共享 DMA 内存里读取最新的数据.
总结: DMA-BUF 提供了设备之间共享 DMA 内存的框架,使不同的外设可以便捷统一的共享 DMA 内存,并方便系统的管理。另外 DMA-BUF 框架从软件层面保证了 CACHE 的一致性,并让 DMA 搬运最新的数据.
DMA-Pool Framework
DMA-Pool 框架是内核提供了一种内存池化方案,其预先分配一定数量的物理内存,然后申请者可以直接从 DMA-Pool 池子中快速获得物理内存,属于静态分配的一种,无需向动态分配方案需要经过漫长的分配路径才能分配到所需的内存。DMA-Pool 与其他 DMA 接口不同的是,其提供小粒度的物理内存(PAGE_SIZE),适用于频繁分配使用和释放的场景,可以加速小粒度内存的分配,DMA-Pool 不仅可以为内核子系统提供内存,其还可以为外设提供 DMA 内存. 本节的重点不是介绍 DMA-Pool 的实现,而是研究其与 CACHE 之间的关系,那么接下来先通过一个实践案例感受一下 DMA-Pool 如何使用,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
[*] BiscuitOS PCI/PCIe DMA with MSIX Interrupt --->
[*] Package --->
[*] CACHE --->
[*] DMA: DMA-POOL(WB/UC) Memory --->
# 源码目录
# Module
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-DMA-POOL-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build实践案例源码如上链接,其一个应用程序和一个内核模块组成,其中内核模块是有一个 PCIe 设备驱动为主体,其通过 MISC 框架向用户空间提供了 “/dev/BiscuitOS-DMA-Pool” 接口,并实现 mmap 和 ioctl 接口,应用程序可以通过 mmap() 函数从 DMA-Pool 中申请内存,并映射到进程的地址空间. 用户进程通过 ioctl 实现 DMA 操作,可以操控 DMA 内存和外设之间进行 DMA 搬运.
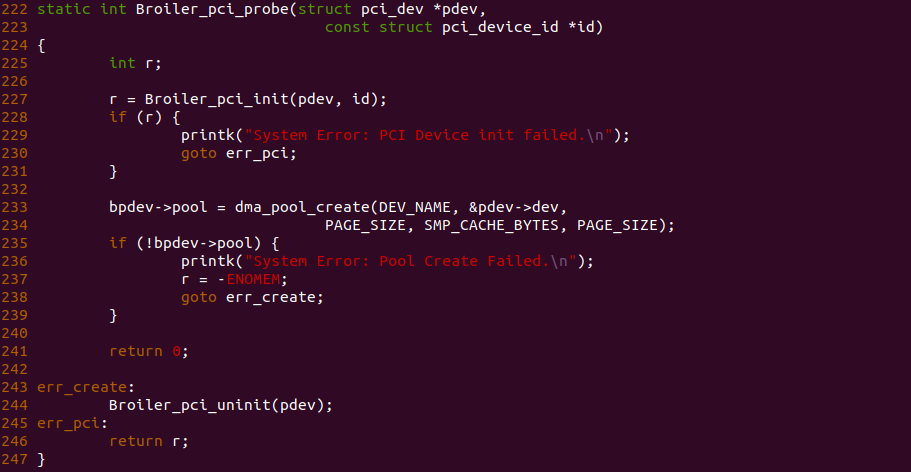
内核模块在 Probe 阶段通过 dma_pool_create() 函数创建了一个 DMA-Pool 池子,该池子用于分配 PAGE_SIZE 粒度的物理内存,并且分配的物理内存都按 SMP_CACHE_BYTES 进行对齐.
内核模块通过 MISC 框架向用户空间提供了 “/dev/BiscuitOS-DMA-Pool” 接口,当在用户空间调用 mmap() 函数时,最终会调用到 BiscuitOS_mmap() 函数,函数在 70 行通过 dma_pool_zalloc() 函数从 DMA-Pool 里分配内存,分配内存大小为 PAGE_SIZE,分配成功之后调用 remap_pfn_range() 函数将物理内存映射到进程的地址空间. 用户进程可以通过 ioctl() 向模块传递请求,模块支持 BISCUITOS_DMA_TO_DEVICE 和 BISCUITOS_DMA_FROM_DEVICE 两种请求. 当请求是 BISCUITOS_DMA_TO_DEVICE 时,模块会将 DMA 内存通过 DMA 搬运到外设上,而请求为 BISCUITOS_DMA_FROM_DEVICE 时,模块会从外设搬运数据到 DMA 内存里. 这里的 DMA 内存就是 BiscuitOS_mmap() 函数里分配的内存.
应用程序首先通过 open() 函数打开 “/dev/BiscuitOS-DMA-Pool” 节点,然后调用 mmap() 函数从 DMA-Pool 里分配内存并映射到用户空间,接下来 48-49 行应用程序让模块将外设内的数据通过 DMA 搬运到新分配的内存里,然后在用户空间打印内存里面的数据. 接下来 52-53 行程序修改 DMA 内存里面的数据,然后让模块将新写入的数据通过 DMA 搬运到外设,搬运完毕之后,程序又在 56-58 行将 DMA 内存清空,然后让模块将外设的数据通过 DMA 搬运到 DMA 内存里,最后在用户空间打印出来. 接下来在 BiscuitOS 上实践该案例:
BiscuitOS 运行之后,加载 BiscuitOS-CACHE-DMA-POOL-default.ko 模块,然后运行 APP,可以看到第一次成功读取数据,第二次打印正面 DMA 搬运成功, 实践结果符合预期。那么接下来分析 DMA-Pool 与 CACHE 的关系.
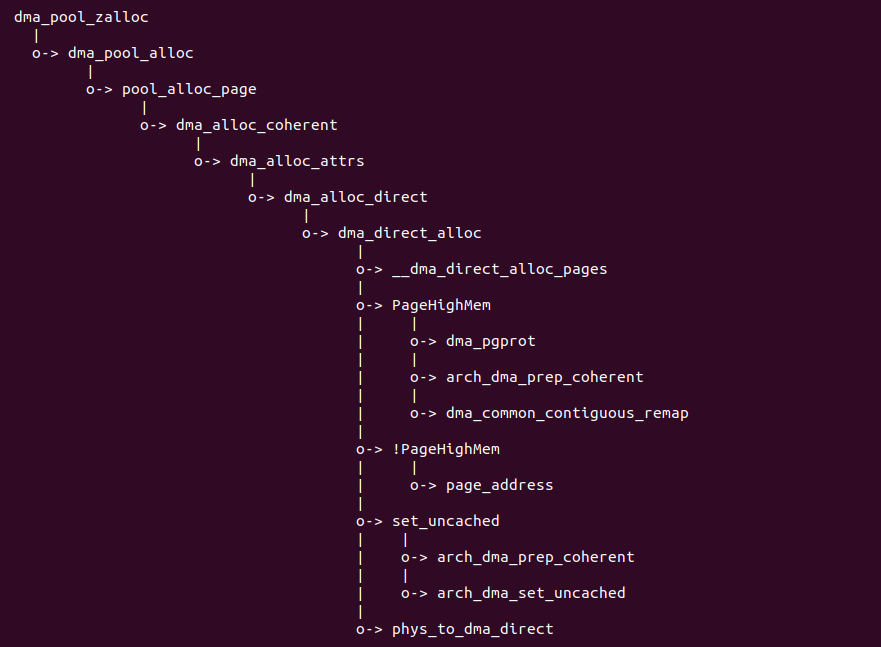
DMA-Pool 内存分配的核心是 dma_pool_zalloc() 函数,其核心实现是 dma_alloc_coherent() 函数分配的一致性 DMA 内存,在之前分析过,不同架构 Coherent DMA 的 CACHE 一致性策略不同,例如在 ARM 架构中,外设是不具备 Snoop 能力的,因此分配的一致性 DMA 内存都是 Uncache; 但在 X86 架构,外设具有 Snoop 能力,因此分配的 DMA 内存可以是 Cacheable。但无论何种架构,DMA-Pool 分配的内存都是 Coherent DMA,因此软件无效负责 CACHE 一致性问题. 但软件需要关注另外一个问题:
该问题是 DMA 常见的问题,就是 DMA 搬运过程中,需要防止 CPU 访问已经搬运的内存,只有 DMA 搬运完毕之后,CPU 才能访问 DMA 内存。在实践案例里,模块在 BISCUITOS_DMA_TO_DEVICE 和 BISCUITOS_DMA_FROM_DEVICE 搬运 DMA 内存时,均使用 Complete 机制确保 DMA 搬运完成,DMA 搬运完成之后会通过 MSIX 中断告知系统,模块收到中断之后才认为 DMA 搬运完成,那么这时才允许 CPU 访问 DMA 内存.
总结: 由于 DMA-Pool 分配的内存来自 Coherent DMA 内存,那么硬件可以确保 CACHE 一致性,软件只需确保 CPU 不会访问正在访问的 DMA 内存.
CACHE with DMA IOMMU
在传统的非 IOMMU 架构中,外设需要和 CPU 交互数据可以通过 DMA 搬运完成,由于外设只能看到连续的物理内存,并不能像 CPU 一样通过分页机制使用虚拟连续物理不连续的内存,外设在做 DMA 搬运时只能老老实实的将数据搬运到连续的物理内存上, 这里为什么说是老老实实呢? 进一步考虑,DMA 搬运对于 PCIe 设备来说就是以此 Memory Read/Write TLP, 只要指定好目的地址、长度和方向之后,就可以实现数据搬运,那么外设也可以使用离散的物理内存,只是需要将原来一次 TLP 拆分成多次,并且这个外设管理上带来很多不便,另外 DMA 搬运是需要考虑性能的,如果能一次性拷贝完成,那么从管理和性能上都会带来正向收益,综上原因,在非 IOMMU 架构 DMA 搬运需要连续的物理内存.
IOMMU 机制目的是外设也具有和 CPU 一样使用分页能力,外设可以使用连续的外设虚拟内存,并映射到不连续的物理内存上,就想 CPU 使用的虚拟内存,其可以映射到不同的物理内存上. 由于 IOMMU 之后,外设可以直接使用 IOVA 地址,无需关系物理内存是否连续,在 DMA 搬运之后直接使用,IOMMU 硬件会向自动查询页表,最终找到对应的物理内存,然后进行 Memory Read/Write TLP 实现 DMA 搬运。本文不会对 IOMMU 细节进行讲解,而是分析 CACHE 与 IOMMU 的关系,那么接下来先通过一个实践案例感受一下 IOMMU 机制下如何进行 DMA 操作的,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
-*- Intel Q35 --->
-*- vIOMMU
-*- BiscuitOS PCI/PCIe DMA with MSIX Interrupt
[*] Package --->
[*] CACHE --->
[*] DMA: DMA IOMMU(WB/UC) Memory --->
# 源码目录
# Module
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-DMA-IOMMU-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build实践案例由一个内核模块组成,完整的源码如上。模块基于一个 PCIe 驱动构建,其内部通过 IOMMU 机制映射了一段 DMA 内存,然后进行 DMA 搬运,每当 DMA 搬运完成外设都会发送一个 MSIX 中断通知系统. 由于源码篇幅较大,这里这对核心部分进行讲解:
上图是 IOMMU 映射临时物理内存的过程,可以看到 170 行模块从系统分配了 PAGE_NR 个零散的物理页,每个物理页都存储在 bpdev.pages[] 数组里,物理页对应的虚拟地址存储在 bpdev.dma_buffer[] 数组. 模块在 180 行设置了外设使用的外设虚拟地址的起始地址,这里设置为 IOMMU_BASE, 接下来 181-192 行,模块将外设的虚拟地址映射到零散的物理页上,模块在 182 行获得物理页的页帧号,然后在 184 行调用 iommu_map() 函数将 IOVA 外设虚拟地址映射到物理页上. 通过上面的操作,外设已经已经可以 IOVA 虚拟内存.
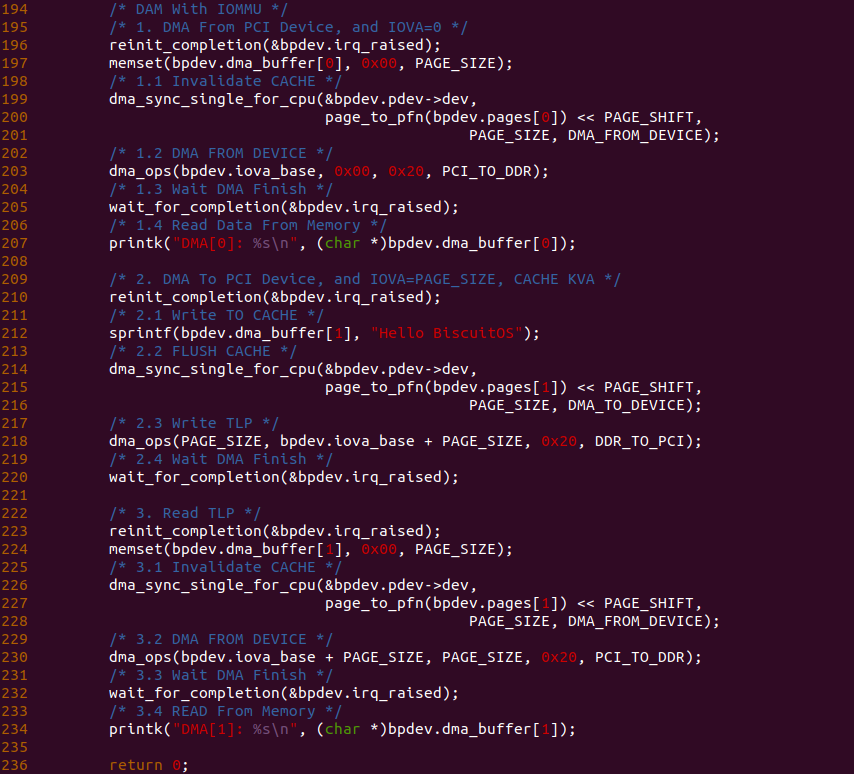
上图是 IOMMU 模式下,外设进行 DMA 搬运的过程。模块在 196 行调用 reinit_completion() 函数设置以此完成任务,然后调用 memset 将 DMA 内存清零,接着在 199 行调用 dma_sync_single_for_cpu() 函数将 CPU 刚刚访问的 DMA 内存对应的 CACHE,进行以此 FLUSH,以此保持 DMA 内存最新数据,接下来在 203 行调用 dma_ops() 函数进行 DMA 搬运,模块在 205 行通过 wait_for_completion() 函数等待 DMA 搬运完成,搬运完成之后从 DMA 内存中读区最新的数据. 同理接下来完成了两次 DMA 操作,先是将 CPU 写入 DMA 内存的数据搬运到外设,然后再将外设的内存搬运到 DMA 内存,最后将 DMA 内存内容进行打印. 那么接下来在 BiscuitOS 上进行实践:
当 BiscuitOS 运行之后,加载 BiscuitOS-CACHE-DMA-IOMMU-default.ko 驱动,可以看到模块从外设两次 DMA 搬运之后读到的数据,符合预期。那么接下分析 IOMMU 与 CACHE 的关系:
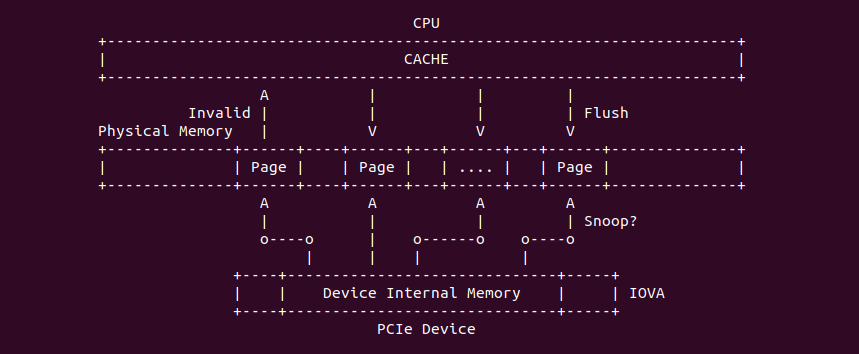
在使用 IOMMU 硬件模式下的 DMA 搬运与 CACHE 没有正向关系,首先取决于外设是否具有 Snoop 总线的能力,如果有 Snoop 能力,那么就向 Coherent DMA 一样,硬件会保证 CACHE 一致性,无需软件干预; 如果外设没有 Snoop 能力,那么要没使用 Coherent DMA,使 DMA 内存为 Uncacheable 的,这样硬件也可以确保 CACHE 一致性. 如果想让 DMA 内存也具备 Cachable 能力,那么可以使用 Streaming DMA,那么需要遵循下面规则:
- DMA TO DEVICE: 当 DMA 搬运 DMA 内存到设备时,如果 CPU 已经访问过 DMA 内存,那么需要调用 dma_sync_single_for_cpu() 函数将访问过的 DMA 内存对应的 CACHE,执行 FLUSH CACHE 操作,以此让 CPU 访问的最新数据更新到 DMA 内存. 一旦开始执行 DMA 搬运时,需要在软件上防止 CPU 访问 DMA 内存,以此访问 CPU 污染 DMA 内存.
- DMA FROM DEVICE: 当 DMA 从外设搬运数据到 DMA 内存之前,需要将 CPU 访问 DMA 内存被缓存到 CACHE 中的 CACHE Line,执行以此 Invalidate 操作,并且软件层面上防止 CPU 在 DMA 搬运过程中访问 DMA 内存。当 DMA 搬运完毕之后,CPU 访问 DMA 内存时,不再从 CACHE 中而是从 DMA 内存中读取最新的数据.
总结: IOMMU 提供了外设使用连续的虚拟地址映射到离散的物理内存能力,这在碎片化严重的场景下能带来很多优势。经过分析,IOMMU 映射的物理内存如果来自 Coherent DMA 内存,那么软件无需确保 CACHE 一致性,硬件自动保证; 如果 IOMMU 映射的物理内存来自 Streaming DMA 内存,那么需要软件确保 CACHE 的一致性. 最后与其他 DMA 操作一致,需要防止 CPU 访问正在 DMA 操作的 DMA 内存.
CACHE Aligment 研究
什么是 CACHE Alignment 问题? CACHE Alignment 对普通开发者有什么影响? 为了讲解 CACHE Alignment 问题,开发者可以先从一个实践案例切入,实际感受一下什么是 CACHE Alignment 问题,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
(4) CPU Number --->
[*] Package --->
[*] CACHE --->
[*] Alignment: False Sharing --->
# 源码目录
# Module
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-ALIGN-FALSE-SHARING-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-ALIGN-FALSE-SHARING-default Source Code on Gitee
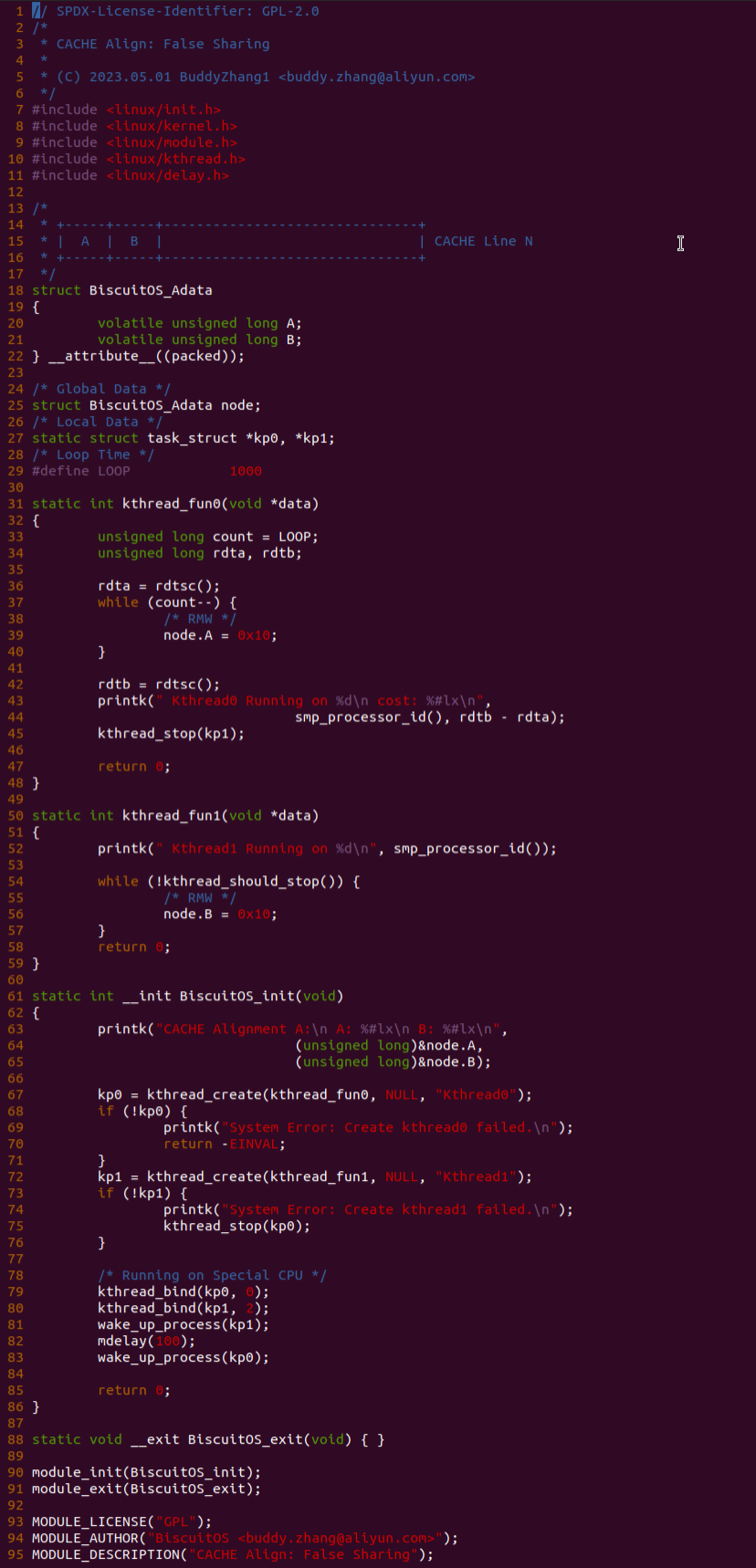
实践案例由两个内核模块组成,上图为 main-A.c 源码. 模块在 18-19 行定义了数据结构 struct BiscuitOS_Adata, 其特点就是其成员 A 和 B 都位于同一个 CACHE Line 内,何为同一个 CACHE Line? 就是如果 CPU 访问了 A 或者 B,那么系统会自动加 A 所在内存 SMP_CACHE_BYTES 个字节全部加载到 CACHE 里,也就是 CPU 访问 A 或者 B,那么 A 和 B 同时都会被加载到同一个 CACHE Line 内. 模块创建了两个内核线程 kp0 和 kp1,kp0 在 CPU0 上访问 A 成员 LOOP 次,kp1 在 CPU2 上连续访问 B 成员,知道 kp0 读取完成,kp1 线程停止运行. 此时记录在 kp0 上访问 LOOP 次 A 成员的时间.
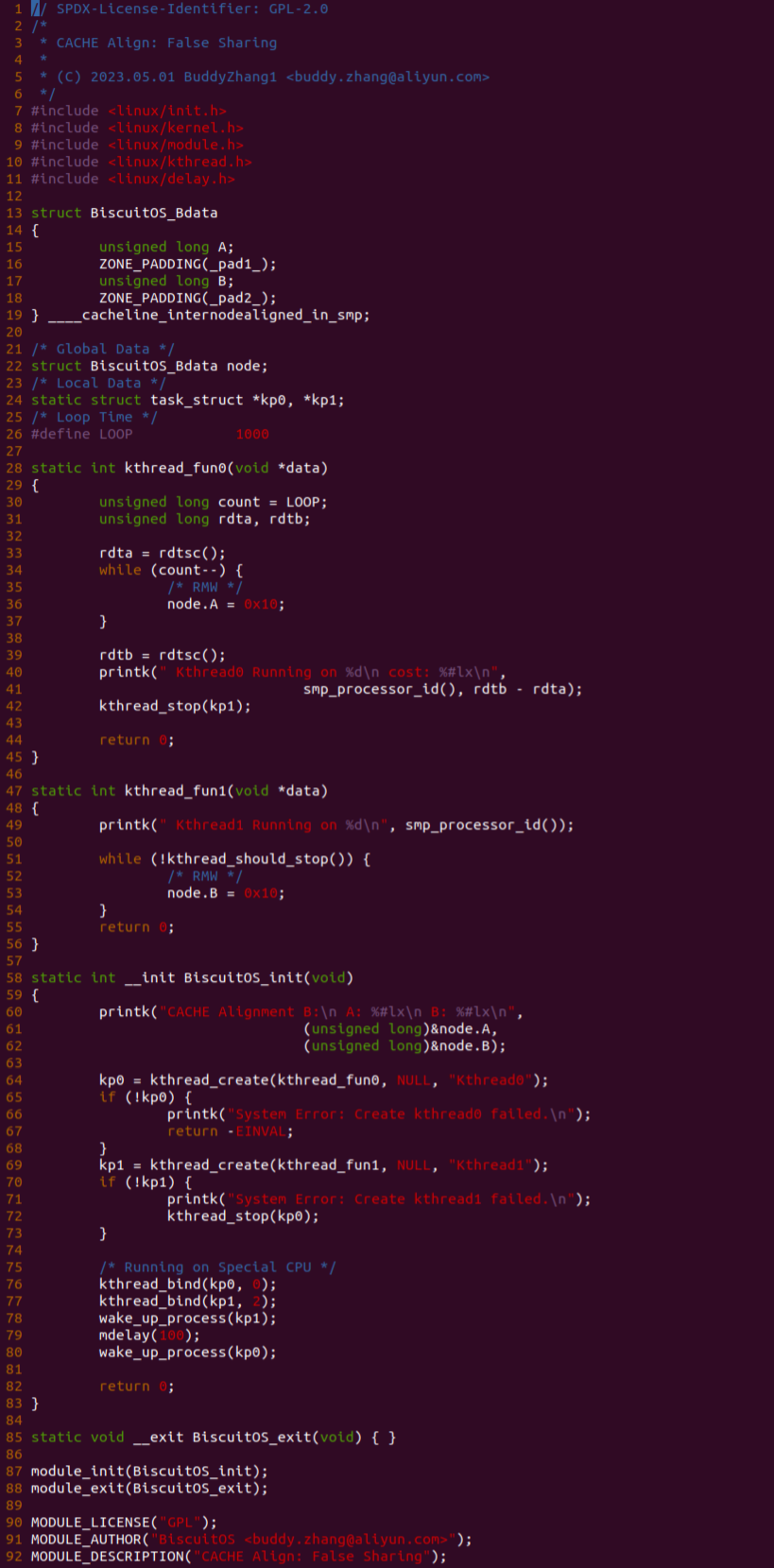
上图为 main-B.c 的源码,其实现逻辑和 main-A.c 的一致,唯一不同的是模块在定义数据结构 struct BiscuitOS_Bdata 时,将成员 A 和成员 B 放到了两个不同的 CACHE Line 里。其他逻辑都与 main-A.c 一致,那么接下来在 BiscuitOS 上实践案例:
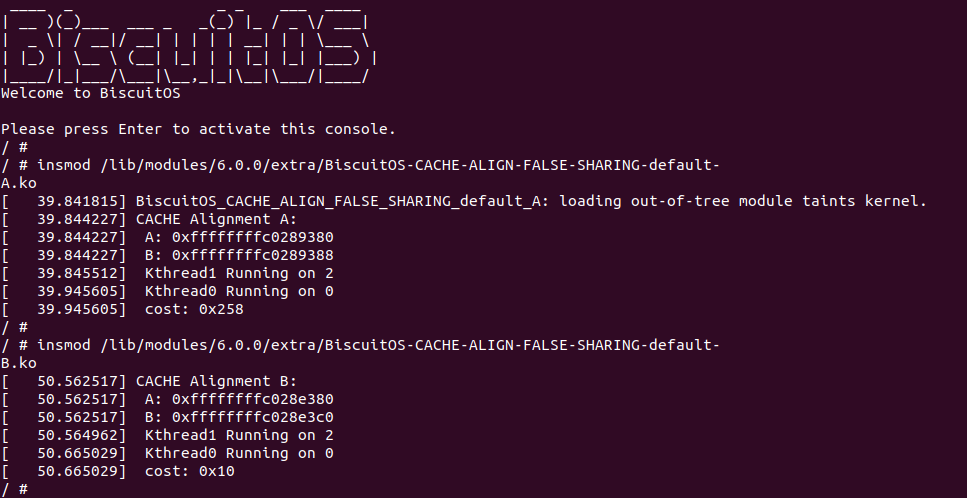
BiscuitOS 运行之后,首先加载 BiscuitOS-CACHE-ALIGN-FALSE-SHARING-default-A.ko 模块,可以看到 LOOP 之后总共耗时 0x258, 然后加载 BiscuitOS-CACHE-ALIGN-FALSE-SHARING-default-B.ko,可以看到 LOOP 之后总耗时居然只有 0x10. 那么是什么原因导致的?另外从这个现象是不是大家开始感受到性能优化的魅力?一个好的性能优化能让程序健步如飞。话不多说一起来揭开这个神秘面纱.
通过 CACHE 一致性 MESI 协议的学习,可以知道在 main-A.c 中 struct BiscuitOS_Adata 定义的 A 和 B 成员,都位于同一个 CACHE Line Size 区域内,那么任何一个 CPU 访问了 A 或者 B,那么 A 和 B 都会同时被加载到指定 CPU 的 L1/L2/L3 CACHE 里,这里先对 main-A.c 的场景进行分析:
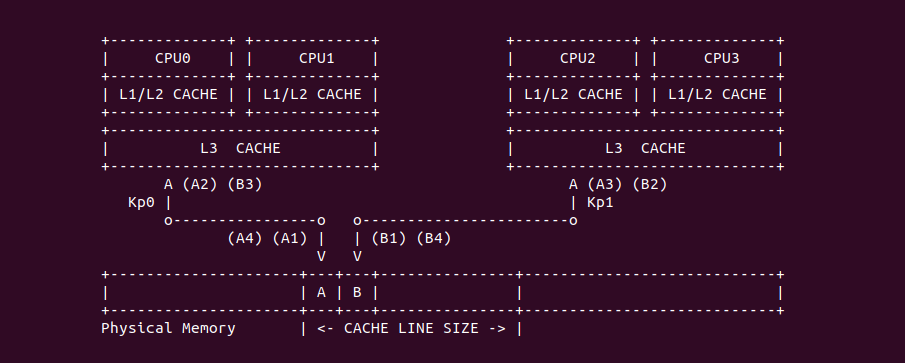
从实践案例代码可以看到 Kp0 内核线程现在 CPU 0 上运行,运行到某个时间段 Kp1 内核线程在 CPU2 上运行,并不断循环,那么细化每次访问过程:
- A1: Kp0 开始在 CPU0 上运行,并通过 RMW 方式访问 A 成员,CPU0 先向总线发起读请求,其他 CPU 发现自己没有 A 的副本,那么 CPU0 直接从内存里读取 A. 由于 A 和 B 位于同一个 CACHE LINE Size 区域内,因此 A 和 B 会同时被加载到 CPU0 的 CACHE 里.
- A2: CPU0 将 A 加载到 CACHE 之后,并将 CACHE Line 状态标记为 Exclusive,接着 CPU0 修改 A 成员,那么将 A 所在 CACHE Line 状态标记为 Dirty 和 Modify. 由于 Kp1 还没有运行,那么接下来的循环,CPU0 只在 CACHE 里访问 A 成员.
- A3: Kp1 开始在 CPU2 上运行,CPU2 准备读取 B 成员,并向总线发起读请求,此时 CPU0 应答总线,CPU2 收到应答之后知道 CPU0 上 B 的副本且 CACHE Line 的状态是 Modify,那么 CPU2 发起的 Read Invalidate 请求.
- A4: CPU0 收到了 CPU2 发送的 Read Invalidate 信号,然后找打对应的 CACHE Line,此时 CACHE Line 的状态是 Modify,那么发起 WriteBack 请求,将 A、B 所在的 CACHE Line 内容回写到内存.
- B1: CPU2 收到 CPU0 WriteBack 完成的信号之后,从内存将 B 成员加载到自己的 CACHE 里,由于 A 和 B 同属一个 CACHE Line Size 区域内,因此 A 和 B 都被加载到 CPU2 的 CACHE 里,此时 CPU2 将 CACHE Line 状态标记为 Exclusive.
- B2: 接下来 CPU2 修改了 B 的值,那么将 B 对应的 CACHE Line 状态修改为 Modify 和 Dirty,并在接循环访问 B 过程中,CPU2 直接在 CACHE 里访问 B.
- B3: CPU0 继续自己的循环,开始新以此对 A 成员的访问,此时发现自己的 CACHE 里 A 对应的 CACHE Line 是 Invalidate 的,那么向总线发起了读请求,此时 CPU2 收到信号之后知道 A 的副本位于其 CACHE 内,那么应答了 CPU0,CPU0 收到 CPU2 的应答之后,知道其 CACHE Line 的状态已经是 Modify,那么发起了 Read Invalidate 信号.
- B4: CPU2 收到 Read Invalidate 信号,检查 A 副本对应的 CACHE Line 状态是 Dirty 和 Modify,那么执行 WriteBack 请求,A 和 B 所在 CACHE Line 内容被回写到内存。
- A1: 又回到 A1 的逻辑,此时收到 WriteBack 完成的信号,那么从新开始加载 A 成员到 CPU0 的 CACHE 里,依次往复.
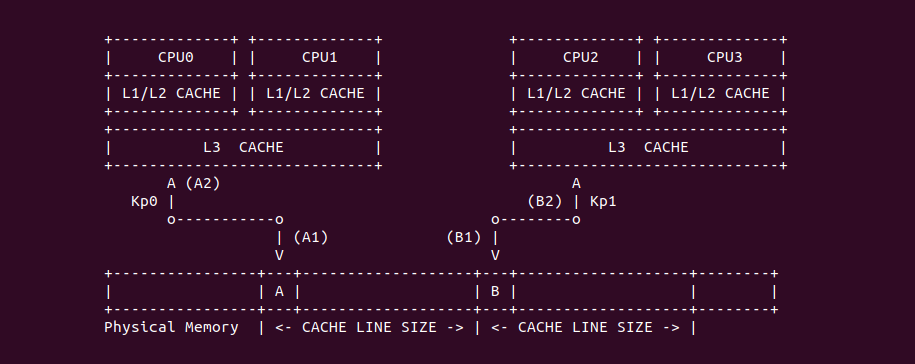
接下来分析一下 main-B.c 里 Kp0 和 Kp1 线程的场景,同理 Kp0 运行在 CPU0 运行,运行到某个时间段 Kp1 内核线程在 CPU2 上运行,并不断循环,那么细化每次访问过程:
- A1: kp0 内核线程在 CPU0 上运行,CPU0 访问 A,但发现其 CACHE 里没有 A,因此发生 CACHE Miss,然后向总线发起 Read 请求。其他 CPU 收到请求之后,发现其没有 A 的副本,因此直接应答. CPU0 收到总线的应答之后发现其他 CPU 也没有 A 的副本,因此直接发起读分配方式,从内存加载 A,此时由于 A 和 B 在不同的 CACHE Line Size 区域,因此只有 A 所在的 CACHE Line 加载到 CPU0 的 CACHE 里.
- A2: CPU0 对 A 变量进行修改,并将修改的值更新到 CACHE,并将对应的 CACHE Line 状态标记为 Modify 和 Dirty,但由于 CACHE 是 WriteBack 的,因此不会立即将 CACHE Line 的数据更新到内存里. 那么接下来 LOOP 循环里 CPU0 对 A 的访问都只发生在 CACHE 里.
- B1: kp1 内核线程在 CPU2 上运行,CPU2 访问 B, 但发现其 CACHE 里没有 B,因此发生 CACHE Miss,然后向总线发起 Read 请求。其他 CPU 收到请求之后,发现其没有 B 的副本,因此直接应答. CPU0 收到总线的应答之后发现其他 CPU 也没有 B 的副本,因此直接发起读分配方式,从内存加载 B,此时由于 B 和 A 在不同的 CACHE Line Size 区域,因此只需将 B 所在的 CACHE Line 加载到 CPU2 的 CACHE 里.
- B2: CPU2 对 B 变量进行修改,并将修改的值更新到 CACHE,然后将对应的 CACHE Line 状态标记为 Modify 和 Dirty, 但由于 CACHE 是 WriteBack 的,因此不会立即将 CACHE Line 的数据更新到内存里。那么接下来的 LOOP 循环里 CPU2 对 B 的访问都只在 CACHE 里.
总结: 通过对上面的细节进行分析,开发者有没有发现,硬件所做的事远远比软件看到的更多,因此理解硬件的工作原理对底层开发及其重要。回到 main-A.c 和 main-B.c 两个模块,只是因为将变量进行重新布局,就带来了性能极大提升,因此开发者在开发过程中对于此类问题需要多思考. 接下来分析内核里存在该问题的场景,并分析内核的解决办法:
伪共享 False Sharing
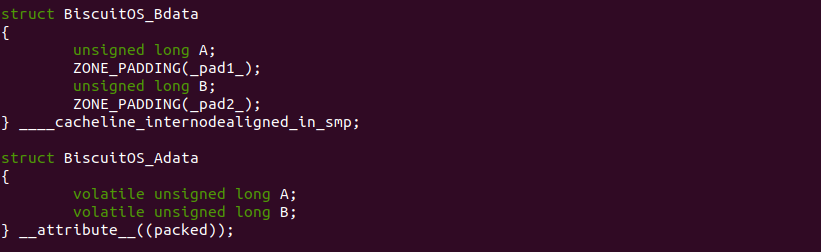
CACHE Alignment 带来的第一个问题就是伪共享. 在 Linux 内核里,所有内核线程都共享内核空间的数据,也就是对于一些共享数据,其可以在不同的 CPU 上运行,相比用户空间线程共享的数据,其只能在指定 CPU 的 CACHE 里访问,因此这个问题只出现在内核线程. 就拿上节案例进行讲解,struct BiscuitOS_Adata 数据结构定义的全局共享数据,如果出现不同的内核线程分别访问 A 和 B,那么在时间维度碰撞时,可能就会出现 CACHE 被不断的淘汰和重入现象,虽然所有内核线程都可以共享这个数据,但没有带上正向的收益,因此可以称这种现象为伪共享 False Sharing, 但伪共享是时间维度上的事,如果同一个内核线程对 A,B 进行访问,那么同样也能带来性能上的正向收益.
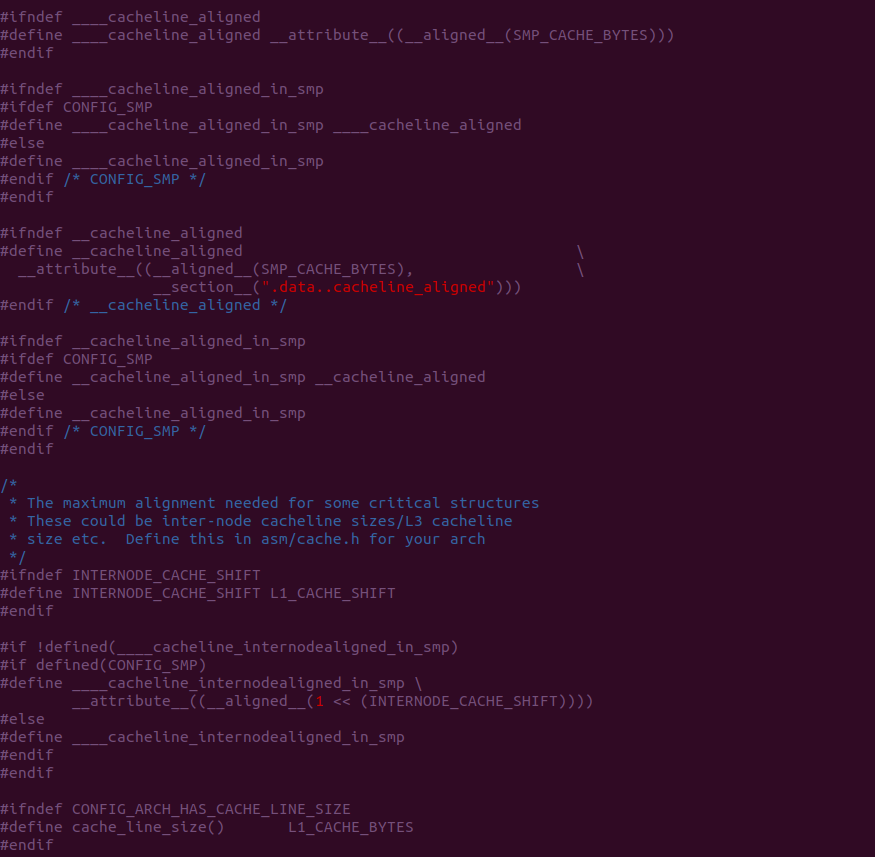
内核解决伪共享的方法是使用 GCC 提供的 __attribute__ 机制在编译链接时将指定的数据划分到不同的 CACHE Line 里,假设开发者的内核全局变量会频繁被同时加载到不同的 CPU 上运行,那么需要将这类热点变量放在不同的 CACHE Line 里。内核提供了 __cacheline_aligned、 __cacheline_aligned_in_smp 和 ____cacheline_internodealigned_in_smp 等多个宏,可以在内核源码进行查找看看其使用场景:
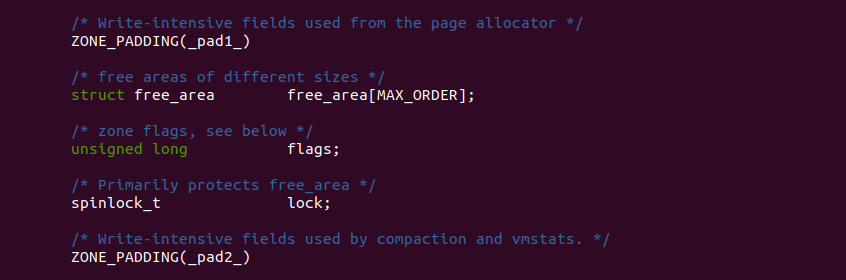
内核里 struct zone 数据结构内部,使用 ZONE_PADDING(_pad1_) 和 ZONE_PADDING(_pad2_) 定义了 flags、lock 和 free_area[] 数组,是其都位于同一个 CACHE Line 里,可以想象这段代码的场景,当多个内核线程都向从 ZONE 的 free_area[] 上分配内存,但首先需要获得 lock 锁,只有正在访问 free_area[] 的线程让出 lock,那么其他线程才有机会抢到 lock. 设想一下这里为什么需要将 lock 和 free_area[] 进行绑定了,例如 CPU0 获得 lock 锁,那么开始访问 free_area[] 数组,并修改了 free_area[] 数组,此时 CPU0 上的 CACHE Line 是 Modify 和 Dirty,此时其他 CPU 访问 lock 的状态,但访问 free_area[] 的 CPU 向让出 lock,但此时其他进程又占有 lock,那么这就进入死锁. 现实 lock 和 free_area 在同一个 CACHE Line 里,那么当 CPU 访问完 free_area[] 之后,由于 lock 也在自己的 CACHE Line 里,不用和其他 CPU 抢,那么直接解除锁即可.
DMA Alignment
通过前几篇对 DMA 分析中,得出一个结论,当 DMA 搬运过程中,软件上需要防止 CPU DMA 内存,这样可以确保 DMA 搬运的数据是最新的。但百密一疏,如上图的情况,就算软件上防止 DMA 搬运过程中,CPU 不允许访问 DMA 内存,但如果某个变量和 DMA 内存同属于一个 CACHE Line Size 区域,那么其也会引起 DMA 搬运到非预期数据: 当 DMA 从外设搬运内容到 DMA 内存,那么系统会将 A 所在的 CACHE Line 数据都标记为 Invalidate,并且软件上禁止 CPU 访问 DMA 内存,此时 DMA 开始搬运,由于 DMA 每次搬运的数据长度小于 CACHE Line Size,那么当 DMA 搬运到上图位置,此时内存里 A 所在 CACHE Line Size 数据是最新的。此时 CPU 突然访问了 A 变量,那么 A 在内存里的数据会被缓存到 CACHE 里,此时也会将一部分已经搬运的 DMA 内存和为搬运的 DMA 内存都缓存到 CACHE 里,那么接下来 DMA 搬运完毕之后,CPU 去访问 DMA 内存,由于与 A 位于同一个 CACHE Line 的 DMA 内存已经在 CACHE 里,那么 CPU 不会去内存里读取最新的数据,而是在 CACHE 里读取,此时 CACHE 里包含了 DMA 内存的新数据和旧数据,因此 CPU 会出现访问旧数据的情况。

为了解决这个问题,软件在分配 DMA 内存时需要进行对其,例如上图在有的架构使用 ARCH_DMA_MINALIGN 宏进行对齐设置. 当 DMA 内存对齐之后,软件就可以防止 DMA 内存被污染问题, 因此开发者在使用 DMA 内存时一定要注意这个问题.
CACHE Bin and Cache Colouring
开发者也许听说过 Page Colouring 或者 SLAB 着色 术语,那么他们和 CACHE Colouring 有什么区别呢? 另外 CACHE Colouring 主要是解决什么问题,以及为什么现在很少听到 Colouring 技术了? 带着这些问题,我门先从一个 Colouring 实践案例来一步步了解今天的主题 Page/CACHE Colouring 技术, 实践案例在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
(4096) Memory Size(MiB)
(hugepagesz=1G hugepages=1) CMDLINE on Kernel
[*] Package --->
[*] CACHE --->
[*] Colouring: CACHE Bin and CACHE Colouring --->
# 源码目录
# Module
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-COLOURING-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build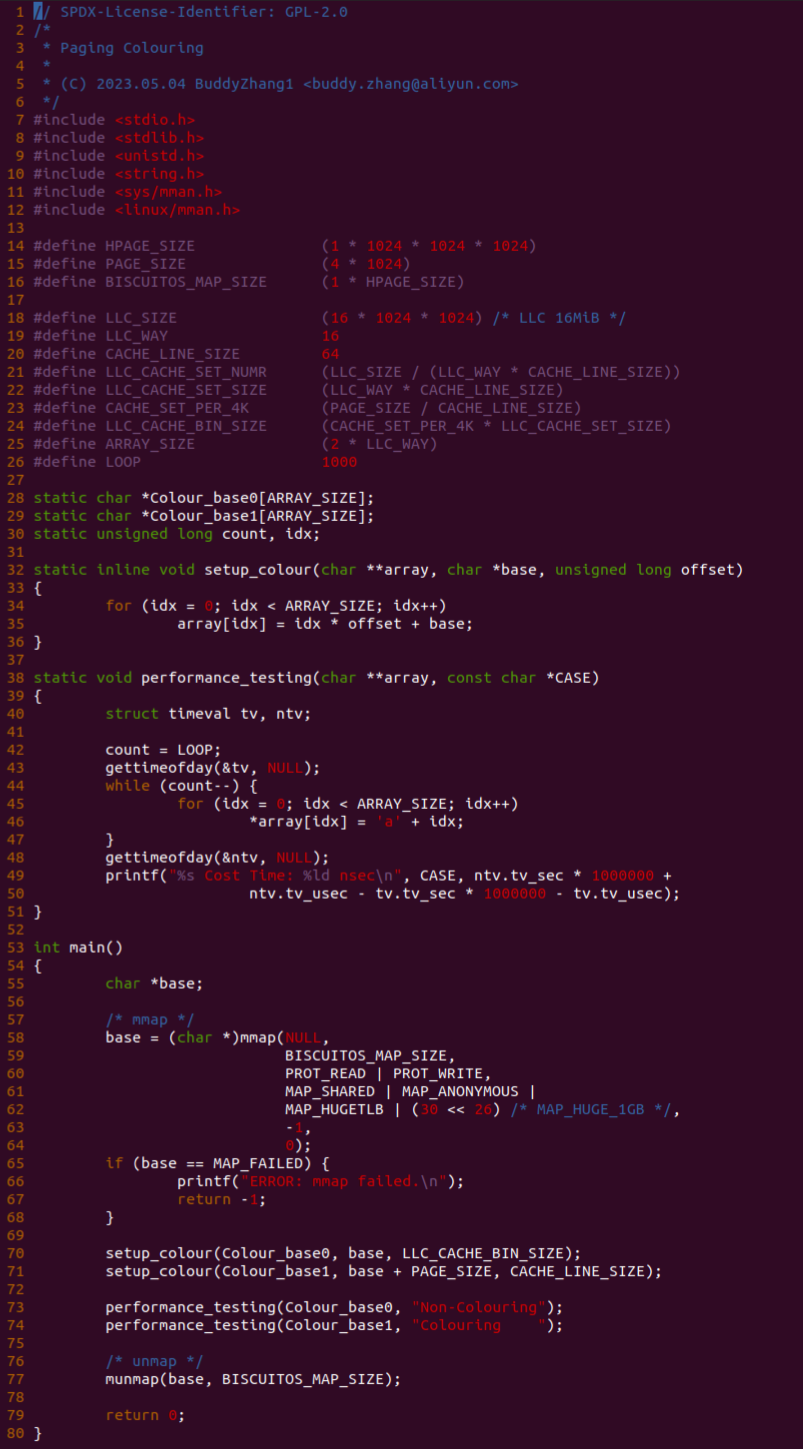
实践案例是一个用户空间的程序,逻辑很简单,定义了两个数组 Colour_base0[] 和 Colour_base1[], 并申请了一个匿名大页,Colour_base0[] 按 LLC_CACHE_BIN_SIZE 为粒度从匿名大页起始处连续采集 ARRAY_SIZE 个虚拟地址,将这些虚拟地址存储到数组里; Colour_base1[] 则按 CACHE_LINE_SIZE 粒度从大页起始虚拟地址之后 PAGE_SIZE 处连续采集 ARRAY_SIZE 个虚拟地址; 接下来将两个数组传入 performance_testing() 函数里进行性能测试,测试的逻辑是循环 LOOP 次,每次程序都会遍历访问数组的每个成员,最后统计循环耗时. 两个数组的数据量是相同的,按理来说性能差异应该很小。那么接下来在 BiscuitOS 上实践该案例:
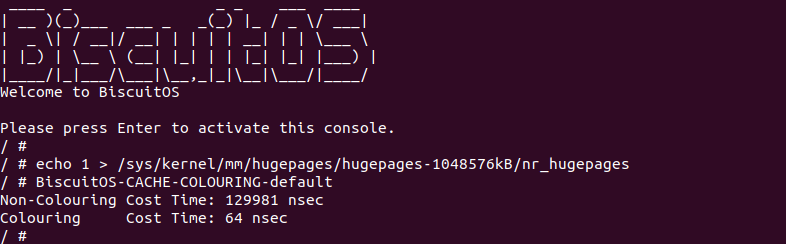
BiscuitOS 运行之后,向内核申请一个 1G 的 Hugetlb 大页,然后运行测试程序,可以看到两侧测试性能差异巨大。回看程序,都是访问相同的数据量,为什么会存在这么大的性能差异,答案是 CACHE Colouring, 是不是很魔法,明明软件上没有任何差异的操作,结果天差地别。那么接下来一起揭开神秘面纱.
现在计算机架构中,一般采用 L1/L2/L3 分级的 CACHE,并且都采用组相连(Set-associative) 方式缓存 CACHE Line,也就是内存中相邻的两个 Data Block 一定会加载到相邻的两个 CACHE Set 中,这点是理解 CACHE Colouring 技术的关键,如上图 Data Block1 加载到 CACHE SET1,那么 Data Block0 一定加载到 CACHE SET0,Data Block2 一定加载到 CACHE SET2. 另外组相联的一个 CACHE SET 内包含多个 CACHE LINE,一个 Data Block 会加载到指定的 CACHE SET,但不确定加载到 CACHE SET 内哪个 CACHE Line.
CACHE Colouring 技术只针对 Physical Index 的 CACHE,在现代计算机架构中,L1 CACHE 一般采用 VIPT,而 L2/L3 CACHE 采用 PIPT,因此 CACHE Colouring 技术针对 L2/L3 CACHE. 具备这两个前提条件,开发者是不是已经发现一个问题,一个 Data Block 会被加载到指定的 CACHE SET?
回想一下 PIPT(Physical Index Physical Tag) 匹配机制,CACHE 机制获得一个物理地址之后,从物理地址指定字段获得 Index,然后在 CACHE 中找到对应的 CACHE SET,接下来从物理地址取出 TAG 字段,然后与 CACHE SET 里所有的 CACHE Line 的 TAG 字段进行匹配,如果命中则 CACHE Hit, 否则 CACHE Miss。因此在 PIPT 中,对于一个物理地址,是可以知道其加载到哪个 CACHE SET 的。

接下来通过一个实际的案例进行讲解,在实践环境里,L3 CACHE 的大小为 16777216Bytes(16MiB),CACHE WAY 为 16,CACHE SIZE 为 64Bytes, 那么一下公式成立:
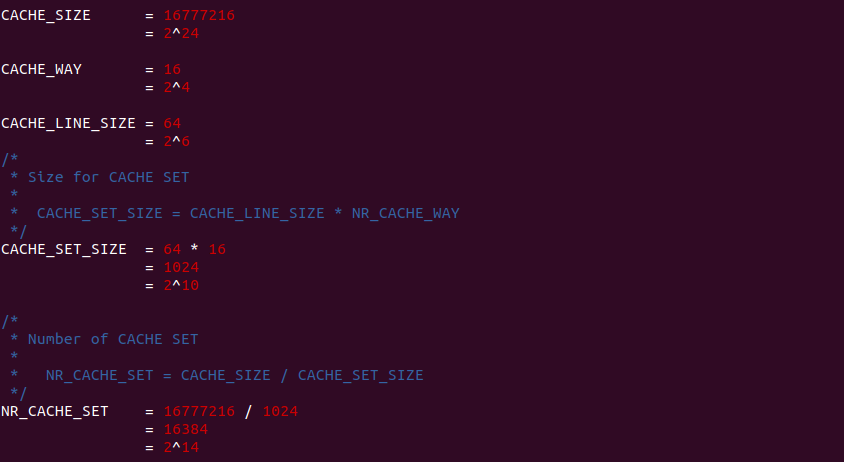
通过计算 LLC CACHE 总共包含了 16K 个 CACHE SET,每个 CACHE SET 里面包含了 16 个 CACHE Line,因此内存的一个 Data Block 会加载到指定的 CACHE SET 里,但是不知道最后使用 CACHE SET 里 16 个 CACHE Line 中的哪个.

在上面的案例中,对于一个物理地址,其 [0:5] 字段用于在 CACHE Line 寻址数据用,由于 CACHE Line Size 是 64Bytes,因此需要 6bit 才能在 64 字节空间寻址; [6:19] 字段用于确认物理地址加载到 CACHE SET 的位置, 由于 LLC CACHE 总共有 16K 个 CACHE SET,因此需要使用物理地址的 14Bite 寻址 CACHE SET 位置; [20:63] 字段用于确认 CACHE SET 里的 16 个 CACHE Line 导致使用了哪个 CACHE Line. 由于上面的的分析,只要给定一个物理地址,就知道这个物理地址所在 Data Block 会被加载到哪个 CACHE SET。
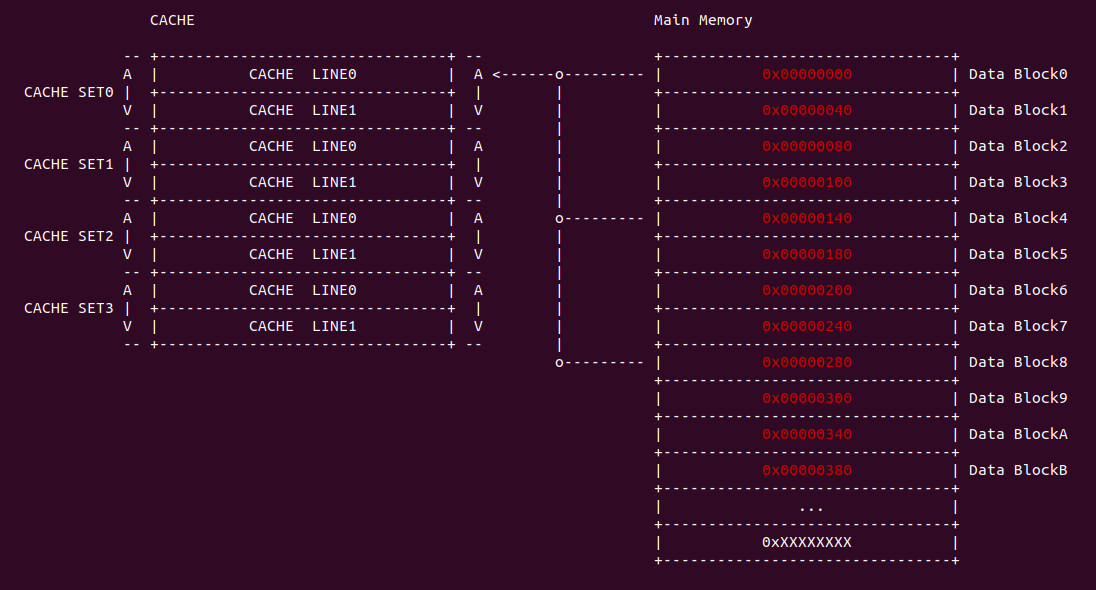
继续分析案例,开发者有没有发现,如果系统同时访问 [6:19] 字段相同的物理内存,那么物理内存对应的 Data Block 都会加载到同一个 CACHE SET 里,当访问 Data Block 数量超过 CACHE WAY 时,那么 CACHE SET 就会根据淘汰算法,将 CACHE SET 内的某些 CACHE Line 淘汰,然后将 CACHE Line 加载新访问的 Data Block, 随着访问量变大,CACHE SET 内将会发生大量的 CACHE Line 淘汰操作,然而此时其他 CACHE SET 却空闲着. 这个也就是本节实践案例,Colour_base0[] 数组里就是 [6:19] 字段相同的内存,而 Colour_base1[] 数组则是 [6:19] 不相同的地址,因此大量的 CACHE 淘汰导致 Colour_base0[] 数组的性能极差. 那么该如何避免软件开发中该类问题呢? 这时就需要使用 CACHE Colouring 技术. 在介绍该技术之前在了解另外一个专业术语 CACHE Bin.
CACHE BIN
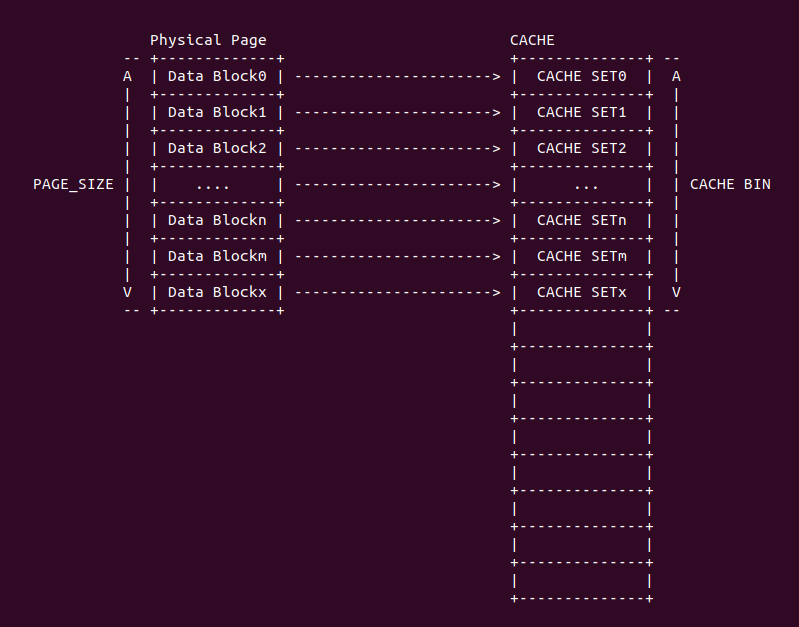
CACHE BIN 是一个软件概念,对于一个物理页来说,它包含了 PAGE_SIZE/CACHE_LINE_SIZE 个 Data Block,每个 Data Block 会映射到一个 CACHE SET 里,相邻的 Data Block 一定会映射到相邻的两个 CACHE SET 里,因此物理页的全部 Data Block 会被加载连续的 CACHE SET 里,因此将这块连续的 CACHE SET 称为 CACHE BIN. 因此 CACHE BIN 就是一个物理页占用的一段 CACHE SET 区域,因此一定存在如下关系:
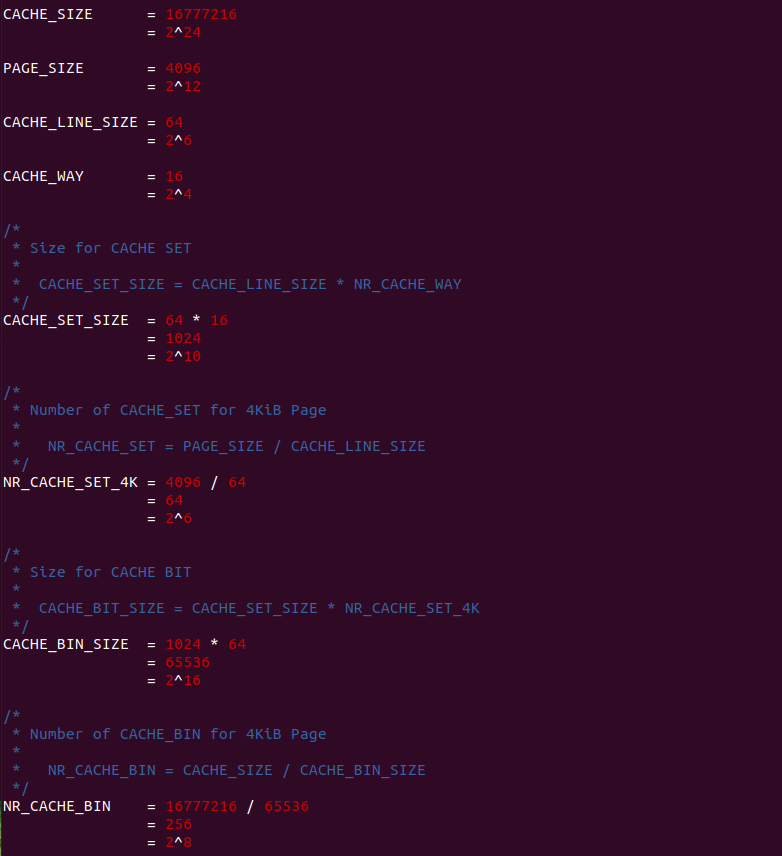
通过上面的公式,可以知道在案例中,4KiB 物理页占用了 64 个 CACHE SET,且一个 CACHE BIN 的大小为 65536B,也就是 64K,最后 CACHE 一共包含 256 个 CACHE BIN. 当有了上面的公式,那么是不是只要物理地址相差 64K 的两个物理页使用的 CACHE 会使用同样的 CACHE BIN? 答案是可能的,就算其他 CACHE BIN 很空,但相差 CACHE BIN SIZE 的两个物理页就是会争抢同一个 CACHE BIN,为了解决这个办法,可以使用 CACHE Colouring 技术避免这类问题.

基于上面的案例,对于一个物理地址,其 [0:5] 字段用于在 CACHE Line 内寻址数据,由于 CACHE Line Size 是 64Bytes,因此需要 64 bit 才能在64 字节空间寻址; CACHE BIN 此时是 4KiB 物理页所用的 CACHE SET 合集,一个 CACHE BIN 内包含 64 个 CACHE SET,因此需要 6 Bit 才能遍历一个 CACHE BIN 里的所有 CACHE SET,因此使用 [6:11] 字段作为 CACHE SET Offset; 由于系统中对于 4K 物理页存在 256 个 CACHE BIN,那么需要 8 bit 来寻址所有的 CACHE BIN,因此物理地址的 [12:19] 作为 CACHE BIN Index; 最后就是作为 CACHE Tag 字段,用于在 CACHE Line 里寻找 CACHE Line.
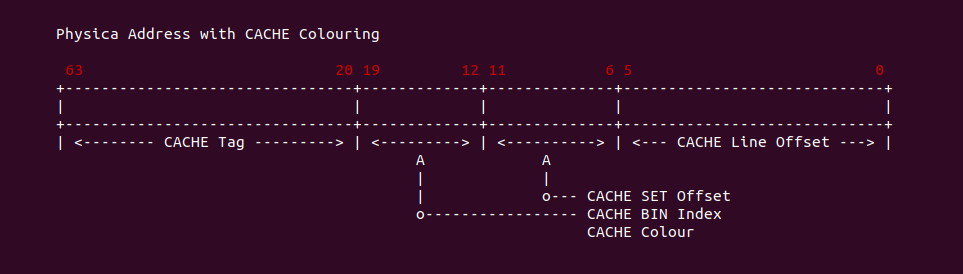
通过上面的分析,对于一个 CACHE,其 CACHE BIN 的数量就是 CACHE Colour 的数量,例如在本例中,CACHE 有 256 中颜色. 对于一个 4KiB 物理页来说,其可以着 256 种颜色,在有些地方也称为 Page Colour. 对于两个物理页,只要颜色不同,就不会被加载到同一个 CACHE BIN 内,因此就不会出现因为大量的 CACHE 替换导致性能降低,这就是 CACHE Colouring 技术用途所在. 同理对于大页 (1Gig/2MiB), 同样适用与 CACHE Colouring,只是 CACHE BIN 的大小不同,这里以 2MiB 大页进行说明:
通过上面的计算公式可以知道,对于 2MiB 页 CACHE BIN SIZE 为 33554432(32MiB), 此时 LLC CACHE 大小为 16MiB,那么就是说半个大页就会共用一套 CACHE SET 集合. 随机硬件不断更新,当前 2023 年 LLC CACHE 已经 336MiB 大小,那么可以使用 CACHE Colouring 概念进行分析。由于当前硬件资源受限,只对 4KiB 场景分析, 到此位置 CACHE Colouring 技术已经讲解完成,那么接来下看看内核里是如何使用该技术的:
SLAB 着色
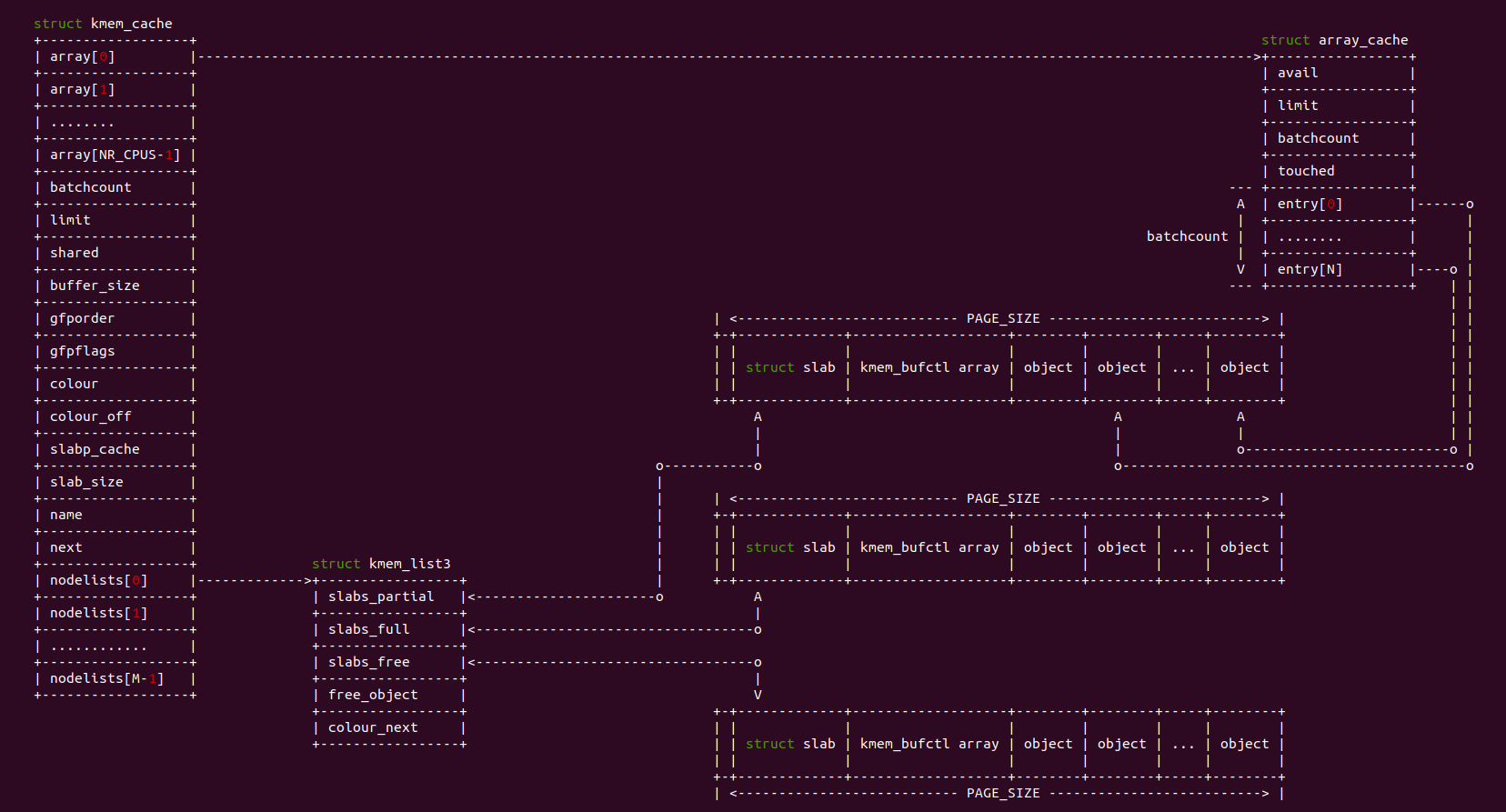
SLAB 分配器是内核用于加速小粒度内存分配,其通过从 Buddy 分配器中分配一个个物理页,并将每个物理页的一部分划分多个小粒度内存,SLAB 称这些小粒度内存为 Object,SLAB 分配器管理这些 Object 的分配和回收,SLAB 将 Object 所在的物理页称为 SLAB Page.
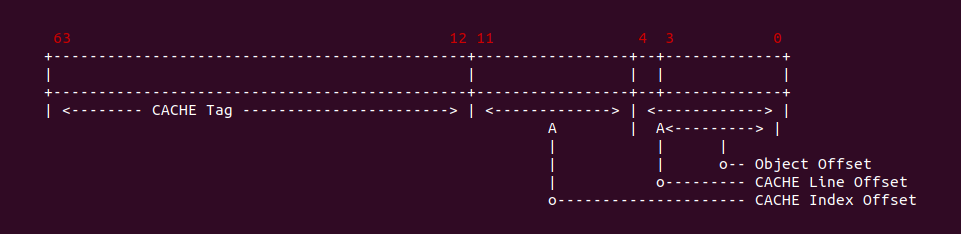
在早些年代,那是 PIPT 的 CACHE 体积较小,而且 CACHE LINE Size 才 32 Bytes,这就会出现物理地址只需 [0:4] 字段作为 CACHE Line Offset 字段,那么 [5:12] 字段也许就可以作为整个 CACHE Index 字段,其中高段的 [X:11] 字段就可能包含 CACHE Bin 字段。因此 SLAB 利用这个特点,直接在一个 SLAB Page 内部进行着色,只要颜色不同,那么不同的 Object 就会使用不同的 CACHE SET.
在 SLAB 分配 SLAB Page 的函数 cache_grow_begin() 中存在上图逻辑, 其着色原理是将 SLAB Page 起始地址加上颜色的偏移,这样做的好处就是每个 SLAB Page 第一个可用的 Object 位置就错开,以此使用不同的 CACHE Bin,这样就会减少 CACHE Line 频繁缓存带来的问题. 回到现在,SLAB 着色正在慢慢被抛弃,首先是因为 PIPT CACHE 的大小越来越大,导致 CACHE WAY 和 CACHE SET 的数量最大,目前 LLC 最大 320M,另外由于 CACHE Line Size 基本采用 64B,对于一个 4KiB 页来说,其 CACHE BIN 字段已经不再物理地址低 12 位以内,也就是说目前 SLAB 着色效果甚微.
CACHE Colouring 总结
前些年 CACHE Colouring 技术如雨后春笋一般,但现在很少有人再提了,主要原因是各大厂商都采用了各自的 CACHE 分配技术,以此合理分配 LLC 资源,例如 Intel RDT 技术等. 回想一下 CACHE Colouring 技术,如果某个程序利用这个特性带来的好处,那么会出现 LLC CACHE 都被它占用,其他进程会被收到严重的性能影响,为了解决这个问题,各大厂商都提出了 LLC 资源隔离方案,让每个进程使用 LLC 时有一定的规则. 本节所将的内容到此为止,但依旧不能阻止我门继续学习 CACHE 的步伐,接下来的专题将会继续研究 LLC 资源隔离技术.
LLC 隔离技术

随着技术的不断进步,在多核年代,CPU 核心数不断增加,每当厂商发布新的 CPU 时,CPU 核数往往是开发者门关心的数据,产商也顺应开发者的需求,不断增加自家产品 CPU 的数量,例如 Intel 的 Xeon 处理器,核数在不断增加,最新的 SPR 已经 48 核 96 线程. 为了提高资源使用率,同一台机器上运行多个应用程序(虚拟机),那么这些应用程序会共享 LLC(Last Level CACHE). 好处就是对于 batch 应用程序需要消耗大量的 LLC,这将导致 LS(Latency Sensitive) 应用程序在读取数据时产生大量的 CACHE Miss,对 LS 应用程序来说 batch 应用程序就是一个 noisy neighbor. 正如上个专题将的 CACHE Colouring 技术,有的程序利用了这个特点,大量消耗 LLC CACHE,导致其他应用程序性能严重降低.
Intel 从 Haswell 微架构开始引入了 RDT(Resource Direct Technology) 技术,其中有一个功能就是 CAT(Cache Allocation Technology), 可以通过设置给不同的 Core 分配不同的 CACHE Way,做到 CACHE 级别的资源隔离. 可以认为 CAT 使得 LLC 变成了一种 QoS(Quality of Service) 的资源. 一个典型的模型就是解决之前提出的 noisy neighbor. 在云服务多租户的场景,一个运行在虚拟机内部的应用不同的读写数据,导致大量的 LLC 占用,导致同一物理机上其他租户虚拟机里 LS 应用需要的数据被 evict 出 LLC,从而导致 LS 应用性能降低.
对不同的应用采用不同的 CAT 策略,那么可以为某些高优先级的程序提供 QoS 服务,而对哪些恶意或者滥用 LLC 资源的应用则带来一定惩罚,以此确保 LLC 资源被合理的应用。Intel 提供了一套软件组件来使用 RDT/CAT 资源,接下来重点介绍 CAT 的使用:
CACHE Locking 机制

CMPXCHG 指令的作用是比较并交换操作,用于在多线程环境下实现原子操作,即保证多个线程同时访问同一个资源时的数据一致性和正确性,避免并发访问造成的数据竞争和不一致性问题。具体而言,CMPXCHG 指令会比较一个内存地址的值和一个寄存器中的值是否相等,如果相等就将寄存器中的值写入该内存地址,否则不执行任何操作。该指令常用于实现线程同步、自旋锁、读写锁、无锁队列等并发算法。CMPXCHG 指令是典型的 RMW(Read-Modify-Write) 操作,那么该指令不止一次对内存访问,那么其是如何实现原子性呢? 其由与 CACHE 有什么关系?
内存总线只有一条独占的,无论是多核还是单核,同一时间只有一个核能够独占总线,占用总线的可以是 CPU 或者 DMA,那么此时将占用者称为 Bus Master. 当 Bus Master 读内存时就会占用总线,读完之后在解除对总线的占用,占用期间其他非 Bus Master 无法访问总线,Bus Master 在一次读内存的中间时刻不会被抢占,只有 Bus Master 完成读内存之后内存总线才会被其他抢占,因此对内存的读是一次原子操作,同理写内存也是一次原子操作. 但对于 CMPXCHG 才做是典型的 RMW 操作,其涉及两次内存访问,读和写是可以分别占用总线,但不是持续的占用总线,为了实现原子性,需要在执行指令前加上 LOCK 前缀, 因此 CMPXCHG 指令执行过程中不会被抢占打断.
在早期的 Intel 架构(P6 之前),原子操作会显式的向系统总线发出 LOCK# 信号,从而获得对应的 CACHE Line 独占权。上图是对该过程的描述,当 CPU 试图获得 CACHE Line 的访问权(读/写),该 CPU 所在的 Core 需要向 Bus 发出一个 LOCK# 信号,BUS 仲裁器将会以 Round Robin(无优先级轮流) 算法选取某个 Core 获取访问权限,每次只允许一个 Core 获取 CACHE Line 的独占权。从现在的角度来看,这种方式的效率是非常低的,首先读写没有进行区分,读的一致性要求弱于写,一个 Core 获得独占权之后,其他 Core 就只能等待,时延高。
Intel P6 之后的架构,原子操作不再发出任何的 LOCK# 信号,一切都由 CACHE 一致性协议完成。上图是典型的多核架构下的 CACHE 缓存结构,L1/L2 CACHE 为 CORE 私有 CACHE,L3 则由同一个 Socket 上的多个 Core 共享的,那么就存在 CACHE Coherent 问题,通过之前的文章可以知道,硬件通过 MESI 机制保证 CACHE Coherent。对于 X86 则使用了增强版 MESIF, F 代表 Forwarding. 引入 F 的原因是对于一个处于 Shared 状态的 CACHE Line,在多个 Core 中都有一份备份,那么有一个新的 Core 需要读取该 CACHE Line 内存中数据,发现多个 Core 都有副本,那么此时由哪个 Core 提供副本呢? 如果每个 Core 都应答新 Core 会造成冗余数据,所以将 S 状态下的某个 Core 的 CACHE Line 标记为 F,并且只由 F 负责应答,通常最后持有备份的为 F.
再回到 CMPXCHG 指令,当两个 Core 同时要对同一个地址执行原子操作,也就是试图修改每个 Core 自己持有的 CACHE Line,假设两个 Core 都持有相同内存地址的 CACHE Line,且 CACHE Line 状态为 S,如果这个时候想要成功执行 CMPXCHG 原子操作,那么首先需要将 CACHE Line 由 S 转换成 E/M, 则需要向其他 Core Invalidate 该内存地址的 CACHE Line,则两个 Core 同时向 RingBus 发出 Invalidate 操作,那么 RingBus 会根据仲裁协议仲裁哪个 Core 能赢得 Invalidate 权利,胜者完成操作,失败者需要接受结果,失败者 Invlidate 自己的 CACHE Line,然后读取胜者修改后的值,然后再次执行 CMPXCHG 原子操作。
至此,MESIF 协议大大降低了读操作的延时,但没有让写变得更慢,同时保持了 CACHE Coherent. 对于原子操作来说,其实锁没有消失,只是转嫁到了 RingBus 的总线仲裁协议中,而且大量的多核同时对一个地址执行原子操作会引起反复的相互 Invalidate 同一个 CACHE Line,造成 PINGPONG 效应,同样会降低性能。只能说基于 CMPXCHG 操作不能滥用,最好还是使用数据地址范围分离模式更好.
接着继续讨论,在上面的情况下,两个 Core 访问 S 状态的 CACHE Line,通过 RingBus 仲裁之后,失败者会向自己发起 Invalidate 操作,为了更高效,Invalidate 机制并没有实现同步操作,而是采用了 Invalidate queue 队列,Invalidate Message 发到 Invalidate queue 之后返回,也就是说 CACHE 的 Invalidate 是异步的,CPU 读取 CACHE 时,不会区检测 Invalidate queue。那么当 CACHE Line 状态是 S 进行写入时,成功者首先占用 RingBus 总线,往总线发 Invalidate Message,此时 RingBus 被独占,其他 Core 必须等待,Invalidate Message 发送完,其他核回 ACK,总线解除,此时 Invalidate Message 已经在失败者的 Invalidate queue 里,此时另外一个核准备对 CACHE Line 写入,这时该核也想发 Invalidate Message,结果发现自己的 Invalidate Queue 中已经有了该 CACHE Line 的 Invalidate Message,于是憋回去将自己的 CACHE Line Invalidate,最后 CACHE Line 状态变成 Invalidate,只有胜利者的 CACHE Line 是 M.
总结: 在 P6 之后,系统通过 MESIF 协议实现了原子操作,无需向系统总线发送 LOCK# 信号,这大大提高了整个系统的性能。但百密一疏,如果原子操作的数据横跨了两个 CACHE Line,那么此时 RingBus 无法确保原子性,系统还是会向总线发起 LOCK# 信号,那么接下来通过 Split lock 章节了解横跨两个 CACHE Line 的原子操作带来的危害:
有趣的 CACHE 别名问题
CACHE Alias(别名) 指: 在采用 VI(Virtual Address Index) 的 CACHE 里,对于映射到同一个物理地址两个虚拟地址,其有不同的 VI 因此会被 CACHE 加载到不同的 CACHE Line. 在 Linux 里存在大量的多个虚拟地址映射到同一个物理地址,那么 Linux 是如何处理 CACHE 别名问题呢? 接下来通过一个实践案例一起了解 Linux 如何解决这种别名问题, 实践案例在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
[*] Package --->
[*] CACHE --->
[*] CACHE Alias: OnDemand GUP --->
# 源码目录
# Module
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-ALIAS-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
实践案例由两部分组成,其实现了一个 OnDemand 的内存分配. 上图为内存模块,其有一个 MISC 框架构成,向用户空间提供了 “/dev/BiscuitOS” 节点,节点提供了 IOCTL 接口,当用户通过 IOCTL 接口写入 CMD 之后,其最后会调用到 BiscuitOS_ioctl() 函数。该函数实现了 BISCUITOS_ONDEMAND 命令,其逻辑分支为 28-39 行所示,分支首先在 30 行调用 get_user_pages() 函数通过 GUP 机制使用户空间虚拟地址映射到物理页,并获得该物理存储在 page 变量里,然后在 34 行调用 kmap_atomic() 函数将物理页临时映射到内核空间,此时内存空间的虚拟地址存储在 addr 变量里,接下来调用 sprintf() 函数将 “Hello BiscuitOS” 数据写入到 addr 对应的内存里,写入完毕之后调用 kunmap_atomic() 函数解除临时映射。
上图为用户空间程序,其在 25 行通过 open() 函数打开 “/dev/BiscuitOS” 节点,然后在 32 行通过 mmap() 分配一段虚拟内存,此时虚拟内存没有映射任何物理内存,接下来在 43 行调用 ioctl() 函数向节点传入 BISCUITOS_ONDEMAND 命令,待命令执行完毕之后,51 行打印虚拟内存的地址和内存里面的内容,最后释放内存关闭节点。那么接下来在 BiscuitOS 上实践该案例:
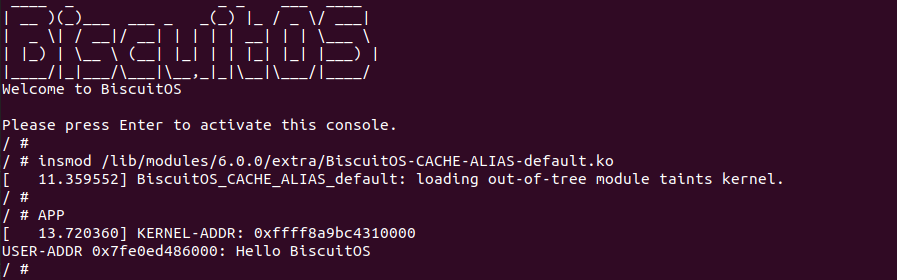
BiscuitOS 运行之后,加载模块并运行 APP,可以看到模块先打印了虚拟地址为 0xffff8a9bc4310000,接着用户进程打印了虚拟地址为 0x7fe0ed486000,并且成功打印了模块写入的内容 “Hello BiscuitOS”, 实践符合预期,那么接下来通过这个案例分析系统如何避免 CACHE 别名问题的.
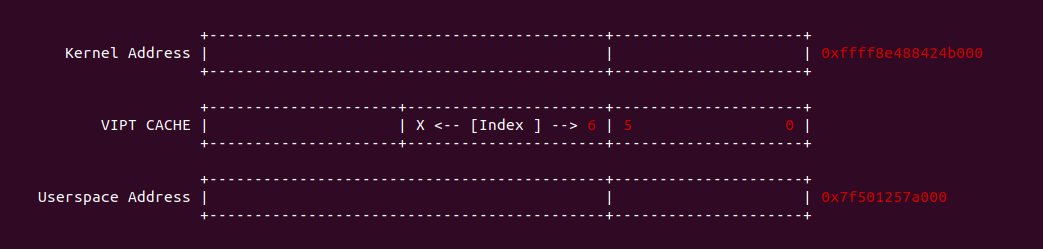
上图是内核空间和用户空间的虚拟地址,另外一个是 VIPT CACHE 对虚拟地址的 Index 索引逻辑,在现代计算机架构中,L1 CACHE 采用 VIPT 组相联 CACHE,而 L2/L3 CACHE 采用 PIPT 组相联 CACHE,因此 L2/L3 CACHE 不存在别名问题,并且 CACHE Line Size 一般为 64B,那么 VIPT CACHE 在计算一个虚拟地址的 CACHE Index 时,其 [0:5] 字段是 CACHE Line 内部查询数据使用,虚拟地址的 [6:X] 字段决定其加载到哪个 CACHE SET,因此 CACHE 的 CACHE SET 数量觉得了 X 的值.
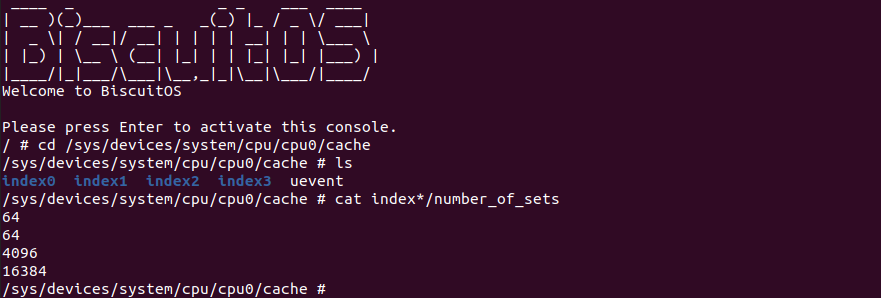
可以通过上图方式查询系统 L1/L2/L3 CACHE 所包含的 CACHE SET 数量,例如上图中前两个是 L1 Data CACHE 和 L1 Instruction CACHE 的 CACHE SET 数量,均为 64. 那么 CACHE 需要在虚拟地址中使用 6Bits 用于寻址 CACHE SET,那么上图中 X 的值为 11.
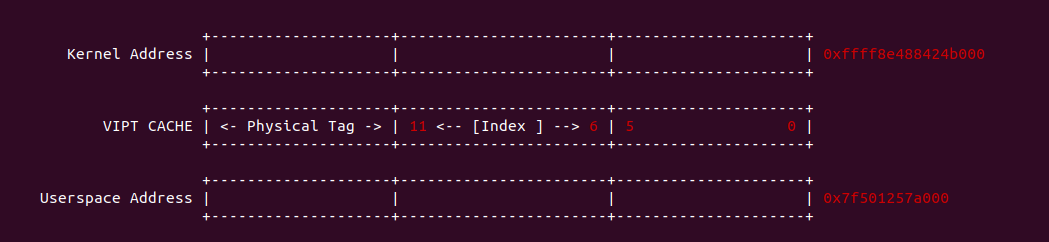
通过上面的分析可以看出,CACHE 使用 [6:11] 字段作为 VI,开发者是否发现 VI 字段位于一个物理页内部,那么无论此时对于内核虚拟地址还是用户虚拟地址,其在物理页内存的偏移都是一致的,那么此时 VI 等价与 PI。另外开发者是否也发现,由于 CACHE 采用了 VIPT,由于两个虚拟地址映射同一个物理页,那么 PT 是一致的,那么 CACHE 可以确保两个虚拟地址最终加载到同一个 CACHE Line 里,从而不存在别名问题. 那么有的开发者继续提出疑问,对于 HugeTlb 2M 或者 1G 大页呢? 该 CACHE 还能避免别名问题吗? 起始这只是一个数字问题:
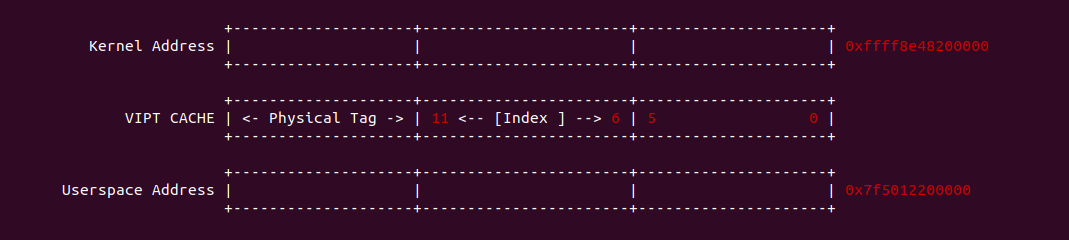
在大页里,其低位都是用来页内寻址的,因此用户空间虚拟地址部分和内核虚拟地址部分,在页内寻址是一致的,也相当于 Physical Index 的效果,因此大页更容易避免在 VIPT CACHE 里别名. 通过上面的分析,以上的分析是否存在巧合? 其实问题的关键在于 “Index” 字段是否落在物理页页内存偏移,如果落在那么 VI 等效与 PI,否则如果 Index 字段超出了页内偏移,那么同样就存在别名问题。
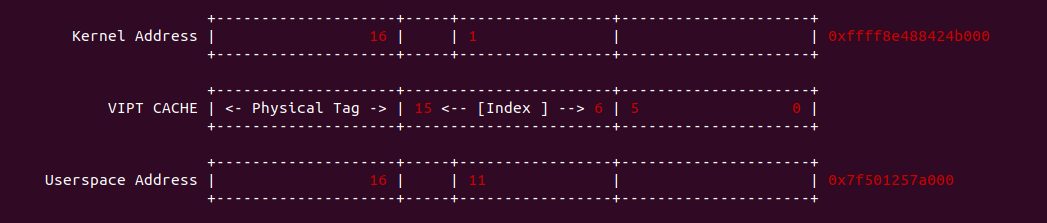
假如在实践案例中,VIPT CACHE 的大小变大,其包含了 N 个 CACHE SET, 需要使用 [6, 15] 字段作为 Virtual Index,那么会发现两个虚拟地址的 [12:15] 字段是不相同的,那么两个虚拟地址会被 CACHE 加载到不同的 CACHE Line,出现别名问题。如果此时别名问题已经无法避免,那么需要软件进行干预,可以做如下操作:
- 软件上避免系统同时访问存在别名的虚拟地址
- 当系统访问完一个存在别名的虚拟地址之后需要主动刷 CACHE
以上只是 YY 的做法,实际架构中 L1 CACHE 硬件避免别名的办法就是确保 CACHE SET 所用的字段位于页内偏移。由于这样的设定,CACHE Line Size 已经固定,所以只能从缩减 CACHE 大小下着手,因此开发者会发现 L1 CACHE 的体积远远小于 L2/L3 CACHE. 至此 CACHE 别名的问题研究完毕.

CACHE 优化案例 A
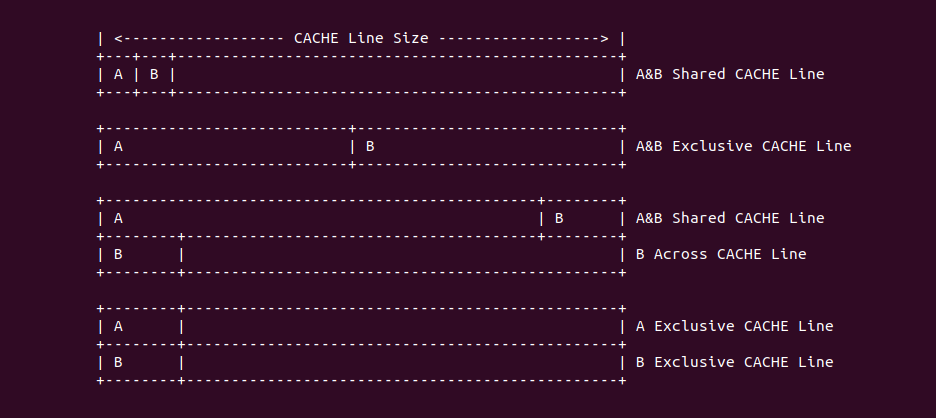
CACHE 优化的出发点之一就是提高 CACHE 的命中率,如果 CPU 访问的数据都在 CACHE 里面,那么对整个系统性能将带来正向收益。内存优化的基本盘就是用空间换时间,那么本节用于研究如何利用空间提升 CACHE 命中率. 上图是数据之间的空间布局关系,第一种关系是 A 与 B 共享一个 CACHE Line,以及第二种 A 与 B 一起独占 CACHE Line,第三种是 A 与 B 共享一个 CACHE Line,并且 B 横跨一个 CACHE Line. 前三种都是紧凑型空间布局,第四种则是 A 与 B 各自独占一个 CACHE Line,其属于松散型空间布局。在之前研究 CACHE 一致性时可知,对于前三种只要访问 A 或 B 其中一个数据,另外一个数据会一同被加载 CACHE Line,也就是 A 与 B 的一致性行为一致; 但对于第四种,A 和 B 是独立的一致性行为. 两种不同的行为会引起什么问题呢? 接下来先通过一个实践案例切身感受一下两者在性能上带来的差异, 实践案例在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
(4) CPU Number --->
[*] Package --->
[*] CACHE --->
[*] Performance: False Sharing --->
# 源码目录
# Module
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-PERFORMANCE-FALSE-SHARING-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-PERFORMANCE-FALSE-SHARING-default Source Code on Gitee
实践案例由两个内核模块组成,上图为 main-A.c 源码. 模块在 18-19 行定义了数据结构 struct BiscuitOS_Adata, 其特点就是其成员 A 和 B 都位于同一个 CACHE Line 内,何为同一个 CACHE Line? 就是如果 CPU 访问了 A 或者 B,那么系统会自动加 A 所在内存 SMP_CACHE_BYTES 个字节全部加载到 CACHE 里,也就是 CPU 访问 A 或者 B,那么 A 和 B 同时都会被加载到同一个 CACHE Line 内. 模块创建了两个内核线程 kp0 和 kp1,kp0 在 CPU0 上访问 A 成员 LOOP 次,kp1 在 CPU2 上连续访问 B 成员,知道 kp0 读取完成,kp1 线程停止运行. 此时记录在 kp0 上访问 LOOP 次 A 成员的时间.
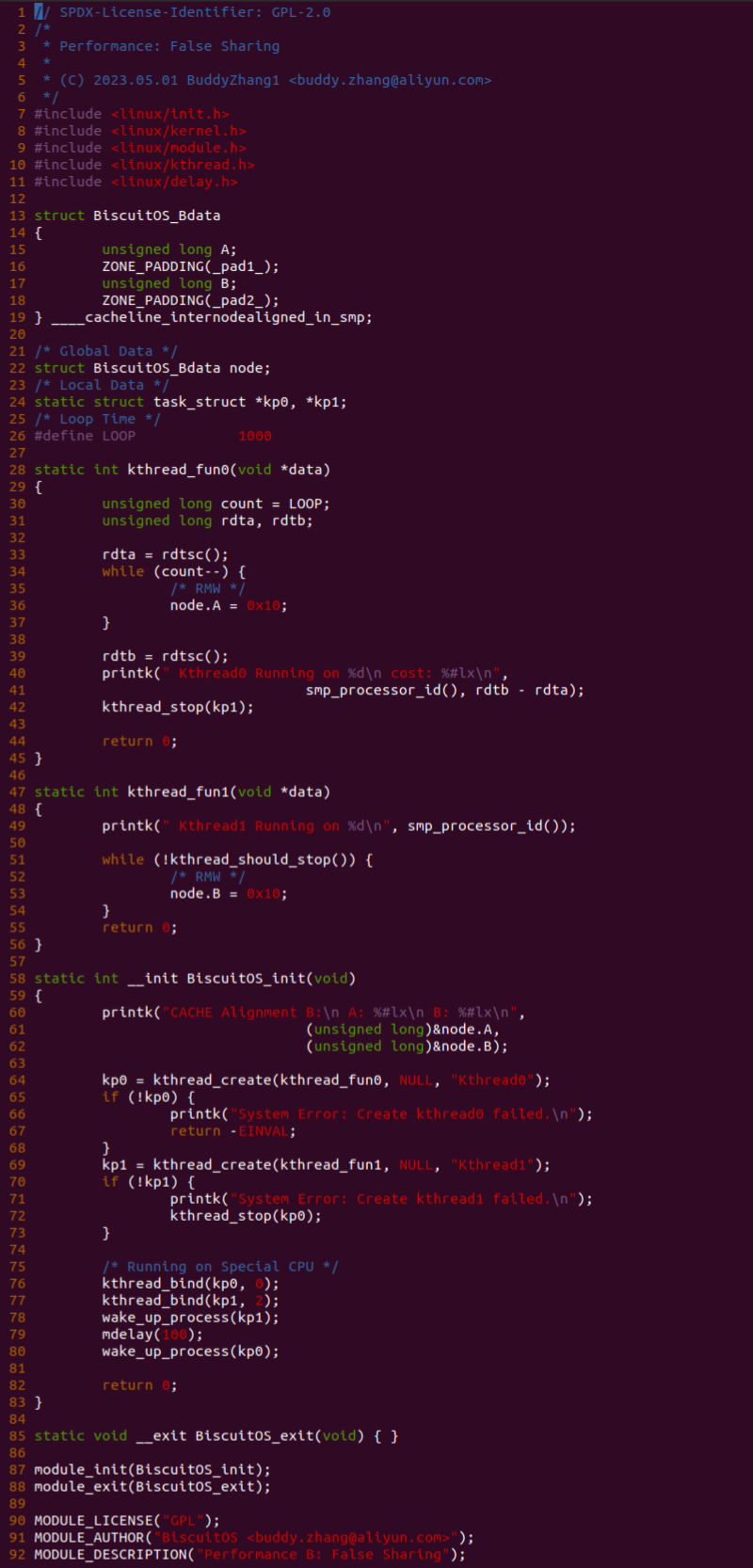
上图为 main-B.c 的源码,其实现逻辑和 main-A.c 的一致,唯一不同的是模块在定义数据结构 struct BiscuitOS_Bdata 时,将成员 A 和成员 B 放到了两个不同的 CACHE Line 里。其他逻辑都与 main-A.c 一致,那么接下来在 BiscuitOS 上实践案例:
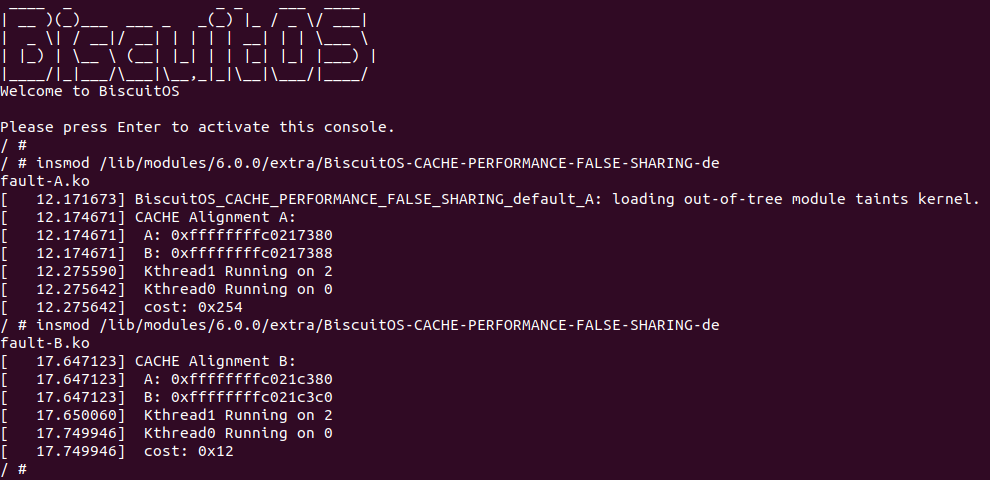
BiscuitOS 运行之后,首先加载 BiscuitOS-CACHE-PERFORMANCE-FALSE-SHARING-default-A.ko 模块,可以看到 LOOP 之后总共耗时 0x254, 然后加载 BiscuitOS-CACHE-PERFORMANCE-FALSE-SHARING-default-B.ko,可以看到 LOOP 之后总耗时居然只有 0x12. 那么是什么原因导致的?另外从这个现象是不是大家开始感受到性能优化的魅力?一个好的性能优化能让程序健步如飞。话不多说一起来揭开这个神秘面纱.
通过 CACHE 一致性 MESI 协议的学习,可以知道在 main-A.c 中 struct BiscuitOS_Adata 定义的 A 和 B 成员,都位于同一个 CACHE Line Size 区域内,那么任何一个 CPU 访问了 A 或者 B,那么 A 和 B 都会同时被加载到指定 CPU 的 L1/L2/L3 CACHE 里,这里先对 main-A.c 的场景进行分析:
从实践案例代码可以看到 Kp0 内核线程现在 CPU 0 上运行,运行到某个时间段 Kp1 内核线程在 CPU2 上运行,并不断循环,那么细化每次访问过程:
- A1: Kp0 开始在 CPU0 上运行,并通过 RMW 方式访问 A 成员,CPU0 先向总线发起读请求,其他 CPU 发现自己没有 A 的副本,那么 CPU0 直接从内存里读取 A. 由于 A 和 B 位于同一个 CACHE LINE Size 区域内,因此 A 和 B 会同时被加载到 CPU0 的 CACHE 里.
- A2: CPU0 将 A 加载到 CACHE 之后,并将 CACHE Line 状态标记为 Exclusive,接着 CPU0 修改 A 成员,那么将 A 所在 CACHE Line 状态标记为 Dirty 和 Modify. 由于 Kp1 还没有运行,那么接下来的循环,CPU0 只在 CACHE 里访问 A 成员.
- A3: Kp1 开始在 CPU2 上运行,CPU2 准备读取 B 成员,并向总线发起读请求,此时 CPU0 应答总线,CPU2 收到应答之后知道 CPU0 上 B 的副本且 CACHE Line 的状态是 Modify,那么 CPU2 发起的 Read Invalidate 请求.
- A4: CPU0 收到了 CPU2 发送的 Read Invalidate 信号,然后找打对应的 CACHE Line,此时 CACHE Line 的状态是 Modify,那么发起 WriteBack 请求,将 A、B 所在的 CACHE Line 内容回写到内存.
- B1: CPU2 收到 CPU0 WriteBack 完成的信号之后,从内存将 B 成员加载到自己的 CACHE 里,由于 A 和 B 同属一个 CACHE Line Size 区域内,因此 A 和 B 都被加载到 CPU2 的 CACHE 里,此时 CPU2 将 CACHE Line 状态标记为 Exclusive.
- B2: 接下来 CPU2 修改了 B 的值,那么将 B 对应的 CACHE Line 状态修改为 Modify 和 Dirty,并在接循环访问 B 过程中,CPU2 直接在 CACHE 里访问 B.
- B3: CPU0 继续自己的循环,开始新以此对 A 成员的访问,此时发现自己的 CACHE 里 A 对应的 CACHE Line 是 Invalidate 的,那么向总线发起了读请求,此时 CPU2 收到信号之后知道 A 的副本位于其 CACHE 内,那么应答了 CPU0,CPU0 收到 CPU2 的应答之后,知道其 CACHE Line 的状态已经是 Modify,那么发起了 Read Invalidate 信号.
- B4: CPU2 收到 Read Invalidate 信号,检查 A 副本对应的 CACHE Line 状态是 Dirty 和 Modify,那么执行 WriteBack 请求,A 和 B 所在 CACHE Line 内容被回写到内存。
- A1: 又回到 A1 的逻辑,此时收到 WriteBack 完成的信号,那么从新开始加载 A 成员到 CPU0 的 CACHE 里,依次往复.
接下来分析一下 main-B.c 里 Kp0 和 Kp1 线程的场景,同理 Kp0 运行在 CPU0 运行,运行到某个时间段 Kp1 内核线程在 CPU2 上运行,并不断循环,那么细化每次访问过程:
- A1: kp0 内核线程在 CPU0 上运行,CPU0 访问 A,但发现其 CACHE 里没有 A,因此发生 CACHE Miss,然后向总线发起 Read 请求。其他 CPU 收到请求之后,发现其没有 A 的副本,因此直接应答. CPU0 收到总线的应答之后发现其他 CPU 也没有 A 的副本,因此直接发起读分配方式,从内存加载 A,此时由于 A 和 B 在不同的 CACHE Line Size 区域,因此只有 A 所在的 CACHE Line 加载到 CPU0 的 CACHE 里.
- A2: CPU0 对 A 变量进行修改,并将修改的值更新到 CACHE,并将对应的 CACHE Line 状态标记为 Modify 和 Dirty,但由于 CACHE 是 WriteBack 的,因此不会立即将 CACHE Line 的数据更新到内存里. 那么接下来 LOOP 循环里 CPU0 对 A 的访问都只发生在 CACHE 里.
- B1: kp1 内核线程在 CPU2 上运行,CPU2 访问 B, 但发现其 CACHE 里没有 B,因此发生 CACHE Miss,然后向总线发起 Read 请求。其他 CPU 收到请求之后,发现其没有 B 的副本,因此直接应答. CPU0 收到总线的应答之后发现其他 CPU 也没有 B 的副本,因此直接发起读分配方式,从内存加载 B,此时由于 B 和 A 在不同的 CACHE Line Size 区域,因此只需将 B 所在的 CACHE Line 加载到 CPU2 的 CACHE 里.
- B2: CPU2 对 B 变量进行修改,并将修改的值更新到 CACHE,然后将对应的 CACHE Line 状态标记为 Modify 和 Dirty, 但由于 CACHE 是 WriteBack 的,因此不会立即将 CACHE Line 的数据更新到内存里。那么接下来的 LOOP 循环里 CPU2 对 B 的访问都只在 CACHE 里.
伪共享 False Sharing
CACHE Alignment 带来的第一个问题就是伪共享. 在 Linux 内核里,所有内核线程都共享内核空间的数据,也就是对于一些共享数据,其可以在不同的 CPU 上运行,相比用户空间线程共享的数据,其只能在指定 CPU 的 CACHE 里访问,因此这个问题只出现在内核线程. 就拿上节案例进行讲解,struct BiscuitOS_Adata 数据结构定义的全局共享数据,如果出现不同的内核线程分别访问 A 和 B,那么在时间维度碰撞时,可能就会出现 CACHE 被不断的淘汰和重入现象,虽然所有内核线程都可以共享这个数据,但没有带上正向的收益,因此可以称这种现象为伪共享 False Sharing, 但伪共享是时间维度上的事,如果同一个内核线程对 A,B 进行访问,那么同样也能带来性能上的正向收益. 所以开发者在开发多线程程序时,不同的线程的数据尽量放到不同的缓存行,避免多线程同时频繁地修改同一个缓存行。
CACHE 优化案例 B
CACHE 的局部性原理指的是计算机程序执行时,对内存中的数据具有一定的局部性,最常用的数据项存储在 CACHE 里,以便快速访问,而不需要每次都去访问内存。具体包括一下两种:
- 时间局部性: 指一个数据项在一段时间内被多次访问的倾向,即在某一时间点访问了某个数据项之后,在接下来的一个时间内该数据可能会被再次访问.
- 空间局部性: 指一个数据项及其附近的数据项在一段时间内被多次访问的倾向,即在某一时间点访问了某个数据项后,在接下来的一段时间内该数据相邻的数据项可能会被访问.
前文展示了空间局部性的应用,将程序的性能得到了极大的优化,那么本文从 CACHE 时间局部性角度对程序进行优化,默认情况下 CACHE 会根据时间局部性将经常使用的数据缓存,以便加速内存的访问,这些都是硬件自动完成,对软件透明。那么在有的场景,程序的分支运行软件是可以预知的,因此可以对这种场景进行优化,充分享受 CACHE 带来的好处。开发者首先通过一个实践案例来了解如何对时间局部性进行利用,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
(4) CPU Number --->
[*] Package --->
[*] CACHE --->
[*] Performance: Prefetch --->
# 源码目录
# Module
cd BiscuitOS/output/linux-X.Y.Z-ARCH/package/BiscuitOS-CACHE-PERFORMANCE-PREFETCH-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-CACHE-PERFORMANCE-PREFETCH-default Source Code on Gitee
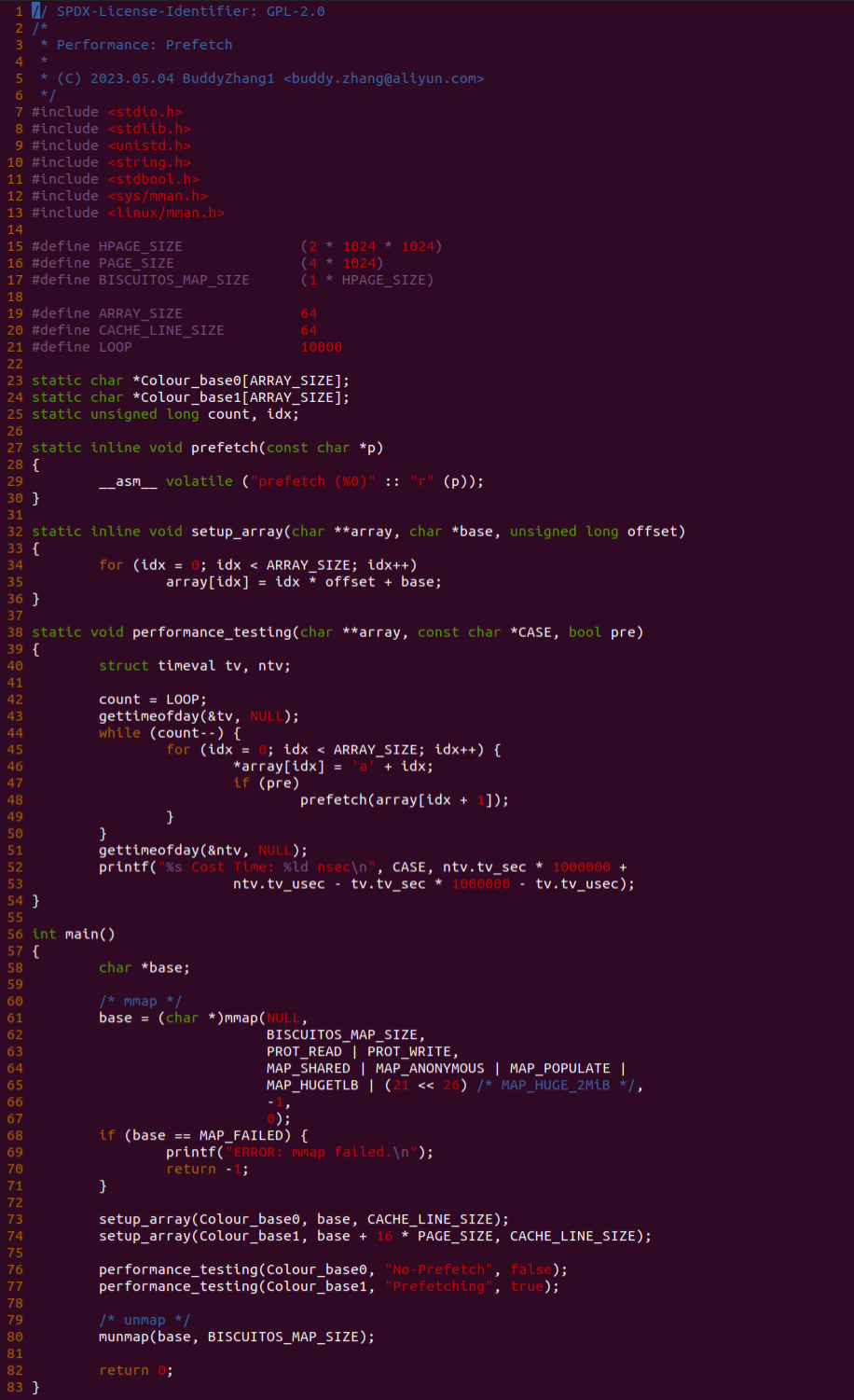
实践案例由一个用户空间程序构成,其首先在 61 行调用 mmap() 函数分配了一个大页,然后在 73 行调用 setup_array() 函数构建了两个长度为 ARRAY_SIZE 个成员的数组,每个成员存储了一个虚拟地址,这些虚拟地址都是相邻 CACHE_LINE_SIZE. 程序接着在 76-77 行调用 performance_testing() 函数对两个数组进行压测,压测函数的实现逻辑很简单,就是重复 LOOP 次读取数组的成员,唯一不同的是当参数 pre 为真时,函数会预取下一个要读的数据到 CACHE。最后测试完毕之后释放内存,那么接下来在 BiscuitOS 上实践该案例:
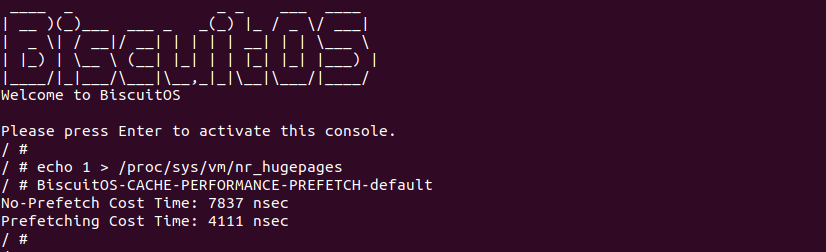
BiscuitOS 运行之后,首先分配一个大页,然后运行测试程序,可以看到预取的程序比不预读的程序快了快一倍,可以看出同样的数据量,采用一定的优化可以得到显著的性能提升,实践符合预期,那么继续研究预取对程序的影响. 现代 CPU 硬件上都会有硬件指令和数据预取机制,也就是根据程序运行状态进行预测,并提前把指令和数据缓存到 CACHE 中,这种硬件预测对连续的内存访问非常有效。但很多情况下,程序对内存的访问是随机的、不规则的、且不连续的,因此硬件预取对随机访问模式很难做出正确的预测,这是需要软件预取。软件预期是一种主动将数据缓存到 CACHE 的技术,以便及时提供给 CPU,以此减少 CPU 停顿,从而降低缓存的不命中率,也提供了 CPU 的使用率, 现代 CPU 提供相应的预取指令:
Windows VC++ 提供的 _mm_prefetch 函数
Linux GCC 提供的 __buildin_prefetch 函数
软件预取也是有代价的,预取操作本身也是一种 CPU 指令,执行它就会占用 CPU 的周期。另外预取的内存数据需要占用 CACHE 空间,因此有的数据会被 CACHE 淘汰,可能导致 CACHE Miss 率上升。另外如果预取的数据没有及时被用到,那么违背了时间局部性原理,那么会带来负优化. 通过上面的实践和分析,开发者可以参考如下建议对预取进行使用:
- 软件预取最好针对特殊必要的场景,明显导致 CPU 停顿的数据进行预取
- 对于循环次数很多的场景,尽量提前预取后面的几次需要访问的数据
- 对于循环次数较少的场景,可以试着在进入循环之前进行预取
CACHE 相关的论文 Paper
Memory System: CACHE, DRAM, DISK - BRUCE JACOB
What Every Programmer Should Know About Memory - Ulrich Drepper
Direct Access,High-Performance Memory Disaggregation with DirectCXL
Meltdown: Reading Kernel Memory from User Space
Memory Barriers: a Hardware View for Software Hackers
Paging: Faster Translations (TLBs)
Accelerating Two-Dimensional Page Walks for Virtualized Systems
Write Combining Memory Implementation Guidelines - Intel
COLORIS: A Dynamic Cache Partitioning System Using Page Coloring
Mastering the DMA and IOMMU APIs
Towards Parctical Page Coloring-based Multi-core Cache Management
THE NEW INTEL XEON SCALABLE PROCESSOR
Optimizing Coherence Traffic in Manycore Processors using Closed-Form Caching/Home Agent Mappings
Pond: CXL-Based Memory Pooling Systems for Cloud Platforms
Intel 64 and IA-32 Architectures Software Developer’s Manual
Intel Architecture Instruction Set Extensions and Future Features
Intel G35 Express Chipset
How to Read a Paper - S.Keshav
那些名叫 CACHE 的非 CACHE
在 Linux 里有很多名字带 CACHE 的术语,有些是与 CACHE 有关,有的却和 CACHE 无关,那么本文一起来聊聊内核里哪些带了 CACHE 的技术.
PAGE CACHE

想必大家都听过 PAGE CACHE 的大名吧,当使用 free 命令时看到的 cache 的数据统计,以及 “cat /proc/meminfo” 时看到的的 Cached 数据,两者都指向 Page CACHE,大家不要被它的名字给迷惑,Page CACHE 不是 Page 的缓存,而是用于缓存的 Page,这么说大家更绕了,那么换另外一个场景进行解释:
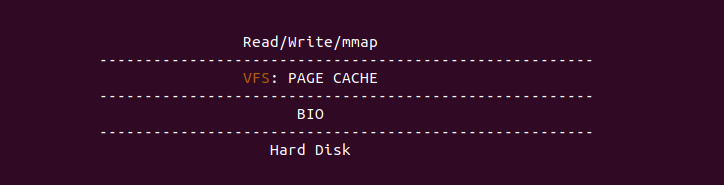
在一个典型 IO 场景中,用户空间的进程与后端磁盘的文件产生关联时,使用 read/write/mmap 库函数时,系统调用下发到 VFS 层之后,VFS 会为请求分配一个 Page 用于存储磁盘读取的数据,那么系统调用不用每次都去访问磁盘,而只需直接访问 Page 里面的数据,待需要同步的时候再将 Page 里的内容更新到磁盘里,这样大大减少了 BIO 层请求的数量,也大大减少了耗时的磁盘访问。因此内核将这个 Page 称为 PAGE CACHE. PAGE CACHE 确实起到了缓存的作用,但与硬件上的 CACHE 没有直接关系,可以认为是两个不同的东西.
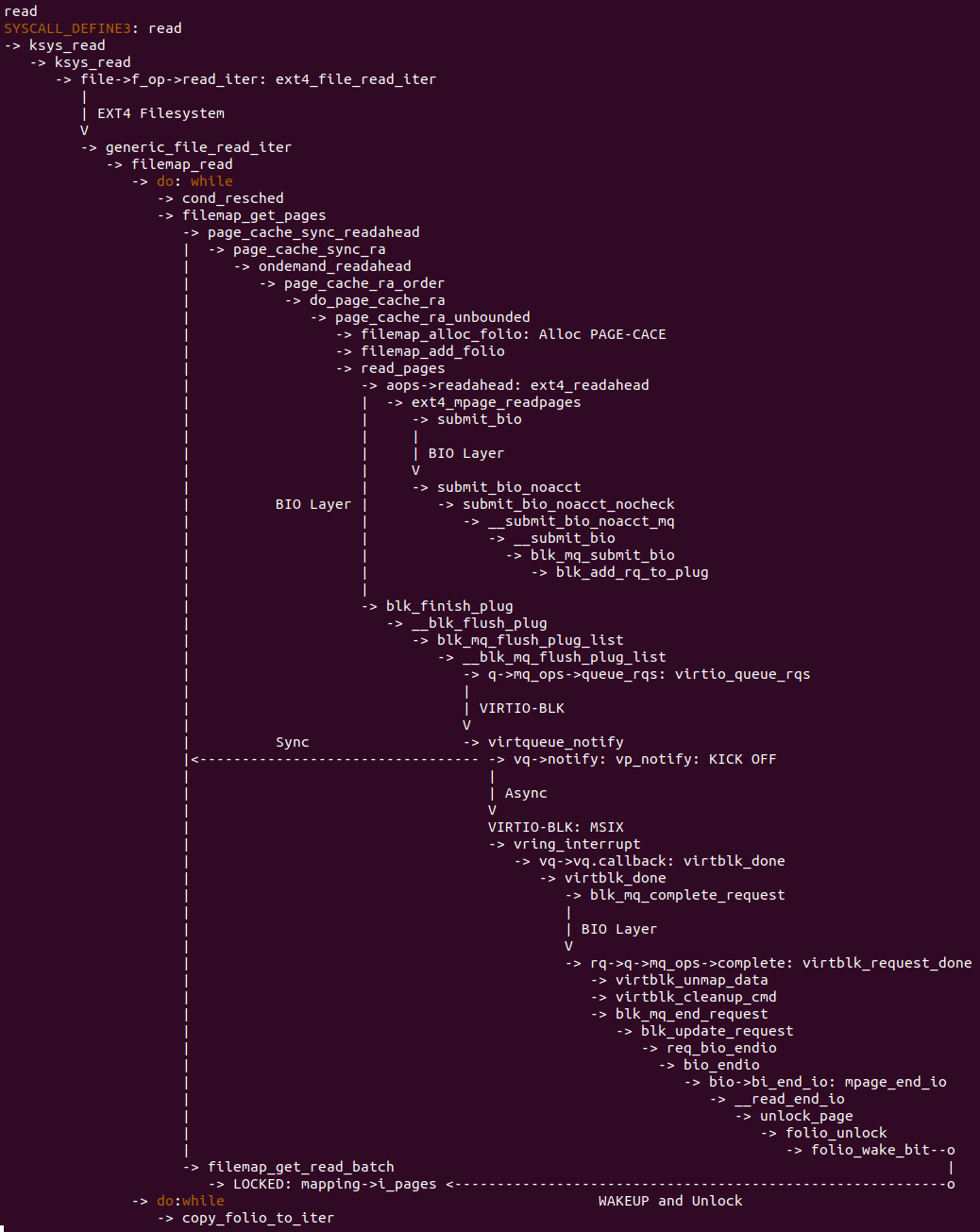
上图是 READ 系统调用的完成路径,可以在路径上看到 PAGE CACHE 的创建(filemap_alloc_folio), 到 PAGE CACHE 的使用(virtqueue_notify), 以及磁盘将数据 DMA 到 PAGE CACHE 之后数据流动(mpage_end_io). 整个过程中 PAGE CACHE 充当了数据缓存的角色。可以简单的认为只要系统访问磁盘就会产生大量的 PAGE CACHE,可以使用如下命令将 PAGE CACHE 清理掉,清理掉的 PAGE CACHE 会将其内容更新到磁盘:
echo 1 > /proc/sys/vm/drop_cachesVMACACHE

在内核每个进程或线程的 struct task_struct 数据结构中存在名为 vmacache 的成员,其目的是加入进程访问虚拟内存。在虚拟内存里,系统使用 struct vm_area_struct 数据结构描述进程使用的一段虚拟内存,这里使用 VMA 表示进程的一段虚拟内存。用户进程的地址空间存在多个独立的 VMA,那么内核将这些 VMA 通过链表和红黑树维护在进程的 struct mm_struct 数据结构里.
每个用户进程都有一个 struct mm_struct 数据结构,用于描述进程的地址空间,其 mmap 成员是一个双链表,用于将进程所有的 VMA 维护在链表里,其 mm_rb 成员是一颗红黑树,按 VMA 起始地址维护在这颗红黑树里。当内核需要通过一个虚拟地址查找进程对应的 VMA,那么其需要到 struct mm_struct 的 mmap 双链表里去查询,也可以去 mm_rb 红黑树里查询,这都需要耗费一定时间才能查询得到。
根据局部性原理,刚被访问的 VMA 还会被再次访问,那么内核将刚访问的 VMA 存储在进程 struct task_struct 的 vmacache 里, 那么该场景下,进程首先区 vmacache 里查找对应的 VMA,如果找到这将会节省很多时间,因此 VMACACHE 的作用是缓存进程热点 VMA, 加速对虚拟地址的操作。VMACACHE 与 CACHE 没有直接联系,因此也很容易被误解.
高速缓存 kmem_cache
内核中分配内存的分配器为 Buddy,但其只能按 PAGE_SIZE 粒度进行分配,对于内核很多场景需要分配很多微小粒度的内存,比如几十个字节大小的内存块,此时如果使用 Buddy 进行分配的化,那么存在两个缺点,首先就是浪费内存,为了小粒度分配一个物理页的内存,非常浪费; 第二个缺点就是速度慢,内核里需要频繁分配小粒度内存。综合两个缺点,内核提供了小粒度分配器 SLAB/SLUB/SLOB, 其特点就是预先从 Buddy 分配器中分配好内存,然后将其切割成小粒度大小的对象,并管理这些空闲对象的分配与回收,那么就可以解决上面的两个缺点:
上图是 SLAB 实现的核心逻辑架构,其包含了 slabp_cache 和 array_cache, slap_cache 用于缓存 SLAB 正在分配的 slab page,其上包含了多个可用的空闲对象; array_cache 是一个数组,SLAB 会从 slab page 里取一部分空闲的 object 到该数组了,那么分配最先从这个数组中获得空闲的对象,另外当内核释放的 object 也存放在该数组里,以便再次被分配。

SLAB 提供了 kmem_cache 用于分配高速缓存,子系统可以根据场景的需求,通过 kmem_cache_create() 函数创建某种粒度的高速缓存,可以使用 kmem_cache_alloc() 函数快速的分配多小粒度的内存. kmem_cache 就是内核经常所说的高速缓存.
DCACHE
DCACHE 指的是 “Dentry cache”, 是 VFS 子系统里用于描述目录的 struct dentry 数据结构的高速缓存,其本质是一种 kmem_cache 创建的长度为 sizeof(struct dentry) 的高速缓存。DCACHE 与 L1 Data CACHE 无关.

CXL
CXL(Compute Express Link): 作为一种全新的开放式互联技术标准,其能够让 CPU 与 GPU、FPGA 或其他加速器之间实现高速高效的互联,从而满足高性能异构计算的要求,并且其维护 CPU 内存空间和连接设备内存之间的一致性。总体而言,其优势高度概括在极高兼容性和内存一致性两方面上. CXL 标准定义了 3 个协议,这些协议通过标准 PCIe 5.0:
- CXL.io: 协议本质上是经过一定改进的 PCIe 5.0 协议,用于初始化、链接、设备的发现和枚举以及寄存器访问,它为 I/O 设备提供了非一致的加载、存储接口.
- CXL.cache: 协议定义了主机和设备之间的交互,允许连接到 CXL 设备使用请求和相应方法以极低的延迟来高效缓存主机内存.
- CXL.memory: 协议提供了主机处理器可以使用 Store/Load 指令访问设备内部的内存,此时主机 CPU 充当主设备,CXL 设备充当从属设备,并且可以支持 PMEM.
作为高速连接, CXL 在 CPU 和连接的 CXL 设备上内存之间维护一个统一的、连贯的内存空间。 这就表明 CPU 和 CXL 设备可以更加高效的交换数据. 在非 CXL 平台,与 CPU 相连的设备想访问内存的话,设备大多使用 DMA,而 CXL 的出现打破了这种限制。CXL 最有代表性的三种设备如下图:
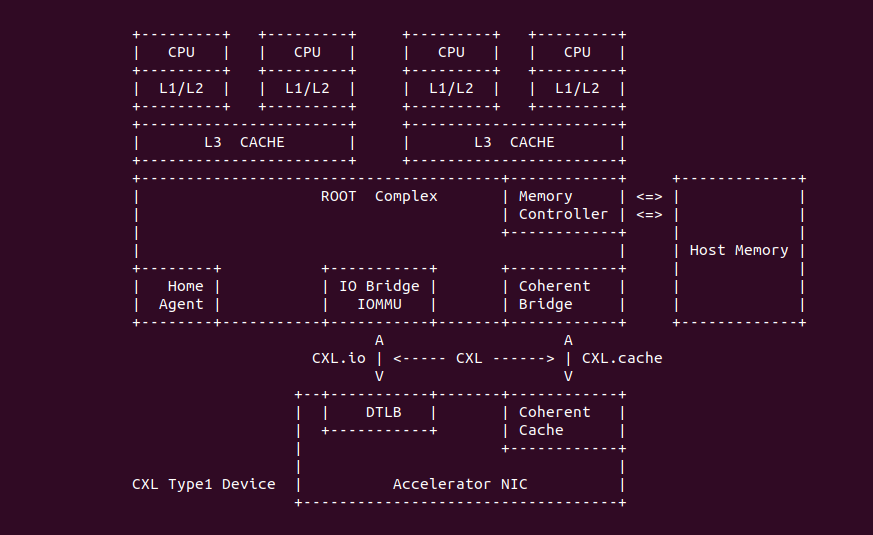
CXL Type1 Device: 支持 CXL.io 和 CXL.cache 协议,这类设备例如 PGAS NIC、NIC Atomics 之类加速卡,这类设备通常缺乏内部内存,但它可以利用 CXL.io 协议和 CXL.cache 协议使用系统内存,CXL 会保证 CACHE 一致性. 在没有 CXL 的场景下,如果设备要使用系统内存,那么需要在 Host 端申请内存,在有的平台需要将这段内存映射为 UC 的,在 X86 平台可以映射为 WB,然后通过 DMA 实现内存访问; 但在有 CXL 场景下,外设可以直接直接访问内存,并不需要关系 CACHE 一致性问题,CXL 已经保证了 CACHE 的一致性.
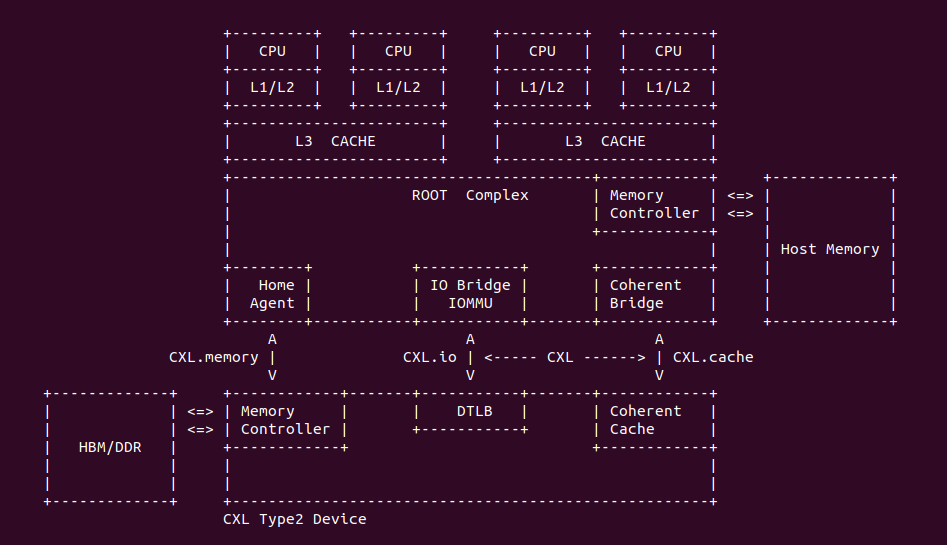
CXL Type2 Device: 支持 CXL.io、CXL.cache 和 CXL.memory 协议。这类设备通常是: CPU、DSP、FPGA 加速卡和 ASIC 卡,它们通常配备设备内部的 DDR 或者 HBM 内存. 三个协议使 CPU 和加速器之间可以相互访问对方的内存,大大提升了异构工作负载.
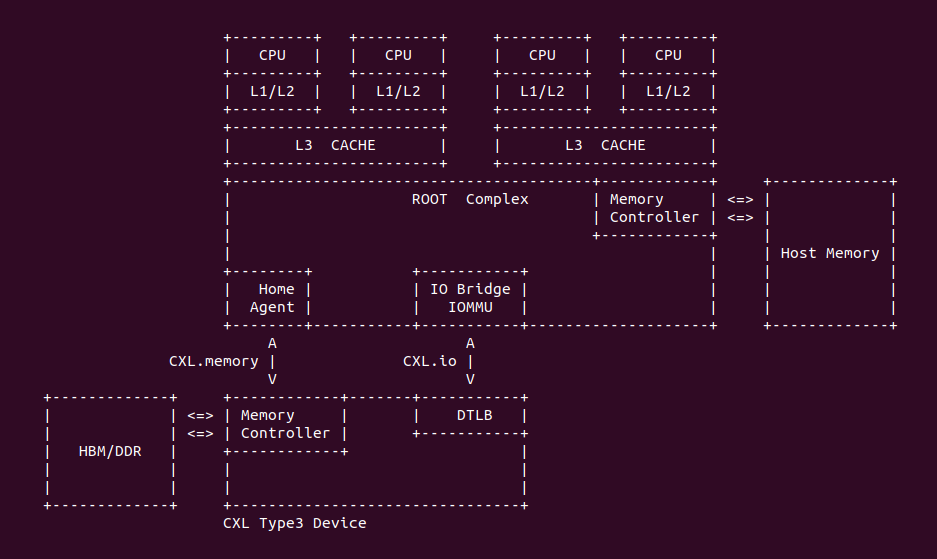
CXL Type 3 Device: 支持 CXL.io 和 CXL.memory, 这类设备通常作为 CPU 内存的拓展,设备内部的内存通过 CXL.memory 协议将内存映射到系统物理地址空间. 另外还可以是一些非易失内存设备 PMEM.

目前市面上开始出现支持 CXL 2.0 的设备,例如 SK 推出的 CXL 2.0 Type3 内存, 其内部有 DDR5 颗粒构成,可以拓展内存用.回到本文的主题 CACHE,CXL 的出现解决了一个重要的问题,支持 CXL 的外设可以像 CPU 一样具有 Snoop 总线的能力,另外设备内部自己也有 CACHE,并且这些 CACHE 可以通过 CXL.cache 协议与系统 CPU 使用的 CACHE 保证 CACHE 的一致性问题,那么这将大大提升对外设共享内存的能力. 本文实践专题支持 CXL 实践,可以添加多个 CXL Type 3 设备, 开发者感兴趣可以进行实践.
CACHE 实践教程
CACHE(OSMEM/DEVMEM/RSVDMEM) on BiscuitOS 实践教程
BiscuitOS 目前支持对 CACHE 在不同类型内存场景的实践,其中内存包括了 OSMEM(系统管理的物理内存)、DEVMEM(设备管理的内存) 和 RSVDMEM(系统预留内存)。在实践之前,开发者需要准备一个 Linux 6.0 X86 架构实践环境,可以参考:
部署完毕之后,针对 CACHE 和物理内存实践,需要 BiscuitOS 使用 make menuconfig 选择如下配置:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough --->
(memmap=2M@0x2000000) CMDLINE on Kernel
[*] Package --->
[*] CACHE --->
[*] RAM: CACHE Mode on RSVDMEM --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-CACHE-RAM-RSVDMEM-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build通过上面的命令,开发者可以获得指定的源码目录,使用 “make download” 命令可以下载实践用的源码, 然后使用 tree 命令可以看到实践源码 main.c 和编译脚本 Makefile. 接下来在当前目录继续使用 “make build” 进行源码编译、打包并在 BiscuitOS 上实践:
BiscuitOS 运行之后,可以直接运行 RunBiscuitOS.sh 脚本直接运行实践所需的所有步骤,开发者只需在意最后的运行结果,可以提升实践效率。以上便是最简单的实践,具体实践案例存在差异,以实践文档介绍为准.
CACHE(DEVMMIO/OSMMIO) on Broiler 实践教程
BiscuitOS 目前支持对 CACHE 在不同的 MMIO 场景的实践,由于 MMIO 来自外设,因此 BiscuitOS 模拟了多种外设,以满足实践需求,实践需要借助 Broiler 项目,该项目可以理解为一个精简版的 QEMU,里面模拟了各种外设,满足 MMIO 和 PCIe 等实践需求,同样开发者需要准备一个 Linux 6.0 X86 架构实践环境,可以参考:
部署完毕之后,针对 CACHE 和物理内存实践,需要 BiscuitOS 使用 make menuconfig 选择如下配置:
cd BiscuitOS
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Support Host CPU Feature Passthrough
[*] Support BiscuitOS Hardware Emulate
[*] Package --->
[*] CACHE --->
[*] MMIO: CACHE MODE with MMIO (Recommend) --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-CACHE-MMIO-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make broiler通过上面的命令,开发者可以获得指定的源码目录,使用 “make download” 命令可以下载实践用的源码, 然后使用 tree 命令可以看到实践源码 main.c 和编译脚本 Makefile. 接下来在当前目录继续使用 “make broiler” 进行源码编译、打包并在 Broiler 上实践:
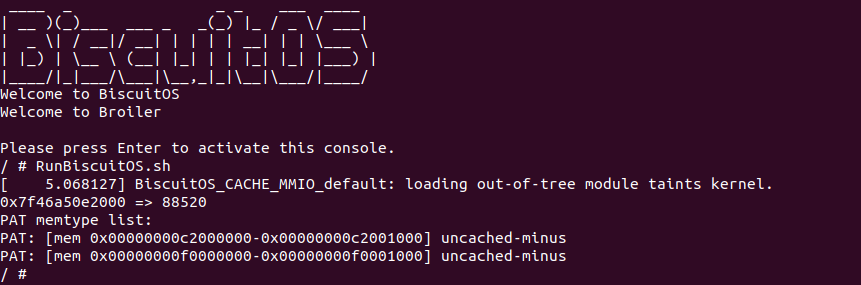
由于使用 “make broiler” 命令,BiscuitOS 运行之后会自动运行 Broiler,待 Broiler 运行之后直接运行 RunBiscuitOS.sh 脚本就可以自动运行实践所需的所有命令,开发者只需查看实践结果即可。具体实践案例存在差异,以实践文档介绍为准.

CACHE(DMA/DMABUFFER/IOMMU) 实践教程
CACHE 使用教程