


在 Intel Gen Xeon Scalable Processors 系列中,从第四代 SPR(Sapphire Rapids) 开始支持 CXL1.0/CXL1.1, 第五代 EMR(Emerald Rapids) 只支持 CXL1.0/CXL1.1, 第六代 GNR(Granite Rapids) 开始支持 CXL2.0. CXL 支持 Type1/2/3 3 种设备,其中 CXL Type3 设备作为内存拓展,可为系统提供除 DDR 之外的低速内存. Intel GNR 对 CXL Type3 内存拓展存在三种模式:
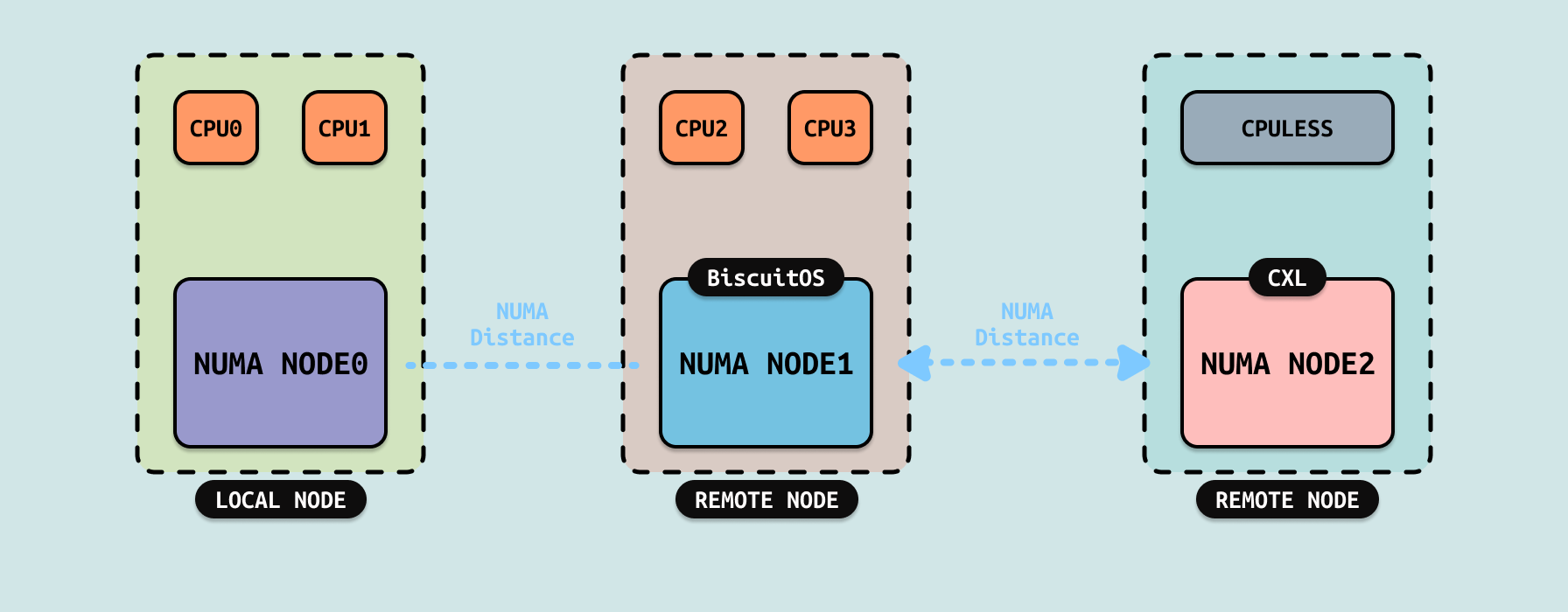
Tiered Mode: CXL Type3 设备以 SYSTEM-RAM 模式插入系统,并以独立的 CPULESS NUMA NODE 节点存在,系统将 DDR 所在的 NUMA NODE 成为快速内存,而将 CXL 所在的内存成为低速内存,操作系统在软件层面会将经常访问的热页(Hot Page)放在 DDR,而将不常访问的冷页(Cold Page)放到 CXL 上,并基于 NUMA Balancing 根据页的冷热程度在 DDR 和 CXL 进行升级(PROMOTION)和降级(DEMOTION). Tiered 模式的优点:
- 扩展内存容量: 通过将 CXL 内存作为远内存使用,可以显著扩展系统的总内存容量
- 成本效益: CXL 内存通常比本地 DRAM 更便宜,Tiered 模式提供了一种经济高效的内存扩展方案
- 灵活性: 软件可以根据工作负载的需求,动态调整数据在本地 DRAM 和 CXL 内存之间的分布
由软件辅助实现内存分层,数据迁移以 4KB 页面为单位,具有更高的灵活性,但会引入一定的性能开销. 软件需要实现内存分层管理逻辑,增加了系统的复杂性, Tiered 模式依赖于操作系统的 Tiered Memory 功能,需要特定的内核版本和配置. 其应用场景:
- 内存密集型应用: 如大数据分析、虚拟化、数据库等需要大容量内存的应用
- 成本敏感型场景: 在需要扩展内存容量但预算有限的情况下,CXL 内存提供了一种经济高效的解决方案
- 动态工作负载: 工作负载的内存访问模式动态变化,需要灵活的内存管理策略
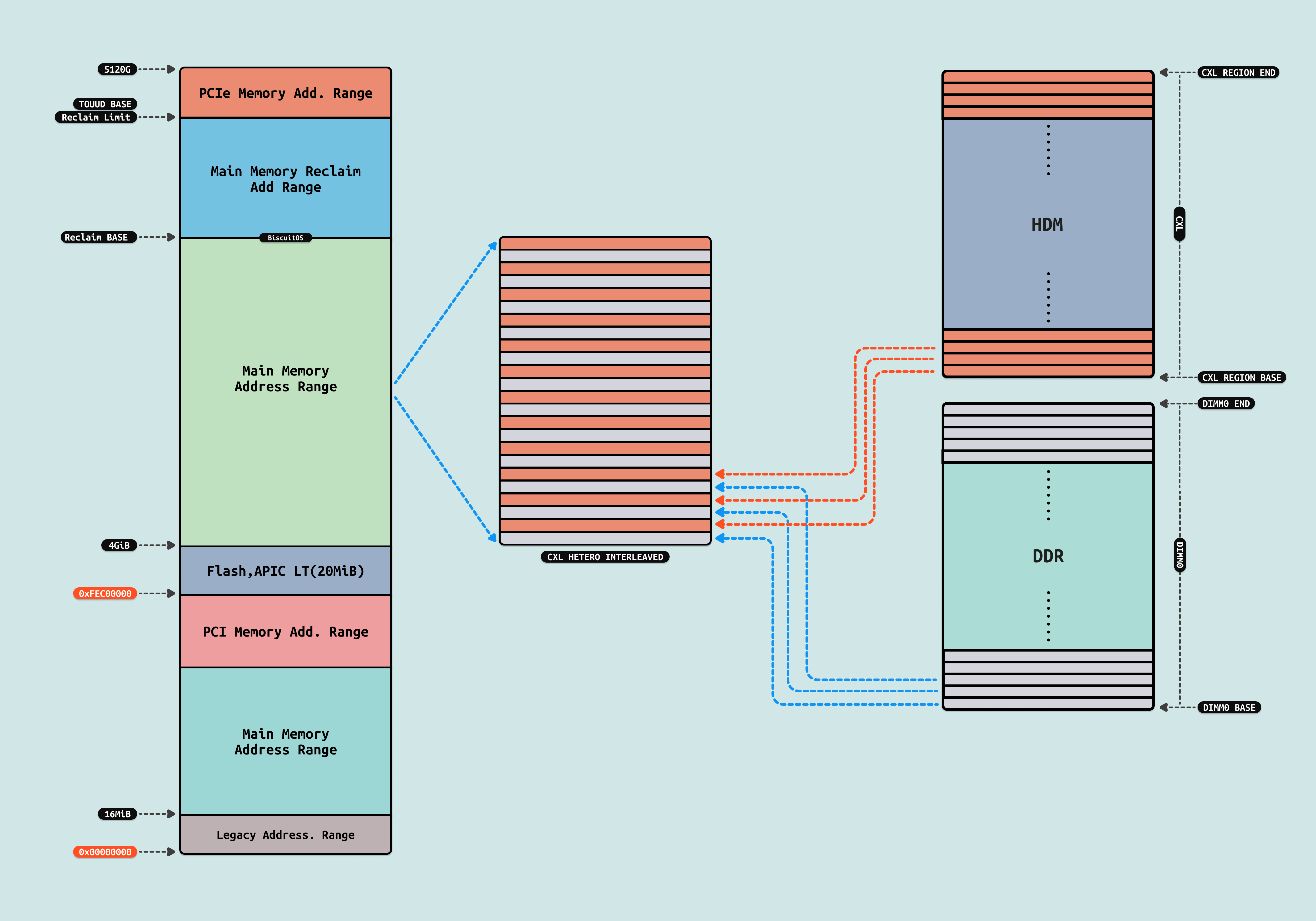
HETERO INTERLEAVING MODE: 通过硬件实现内存地址的交织(interleaving),将本地 DRAM 和 CXL 内存的地址空间混合在一起,从而优化内存访问的并行性和带宽利用率. 内存地址的交织由硬件(如内存控制器)自动完成,无需软件干预. 通过将内存地址均匀分布在本地 DRAM 和 CXL 内存中,可以提高内存访问的并行性,从而提升整体性能. 硬件将本地 DRAM 和 CXL 内存的地址空间混合在一起,形成一个统一的内存地址空间. 通过交织,内存访问请求被均匀分布到本地 DRAM 和 CXL 内存中,避免了单一内存资源的瓶颈. Hetero Interleaved 模式仅在配备 P-cores 的 Xeon 6 6900/6700 系列处理器上支持,而在配备 E-cores 的型号上不支持. Hetero Interleaved 模式的优势:
- 提高内存带宽利用率: 通过将内存访问请求均匀分布到本地 DRAM 和 CXL 内存中,可以更充分地利用两者的带宽
- 降低访问延迟: 交织技术可以减少单一内存资源的访问压力,从而降低整体访问延迟
- 简化软件管理: 由于内存交织由硬件自动完成,软件无需感知内存的分布,简化了开发和优化工作
传统的非交织内存访问模式通常会将内存地址连续分配到本地 DRAM 或 CXL 内存中,这可能导致访问负载不均衡,进而影响性能, 而 Hetero Interleaved 模式通过硬件实现内存地址的交织. 内存访问请求被均匀分布到本地 DRAM 和 CXL 内存中,避免了单一资源的瓶颈. 交织技术可以同时利用多个内存通道,提高内存访问的并行性. 由于交织由硬件完成,软件无需额外的优化或管理. 其应用场景如下:
- 高性能计算: 需要高内存带宽和低延迟的应用,如科学计算、人工智能训练等
- 内存密集型工作负载: 需要同时访问大量数据的应用,如数据库、大数据分析等
- 混合内存架构: 在系统中同时使用本地 DRAM 和 CXL 内存的场景,Hetero Interleaved 模式可以优化两者的协同工作
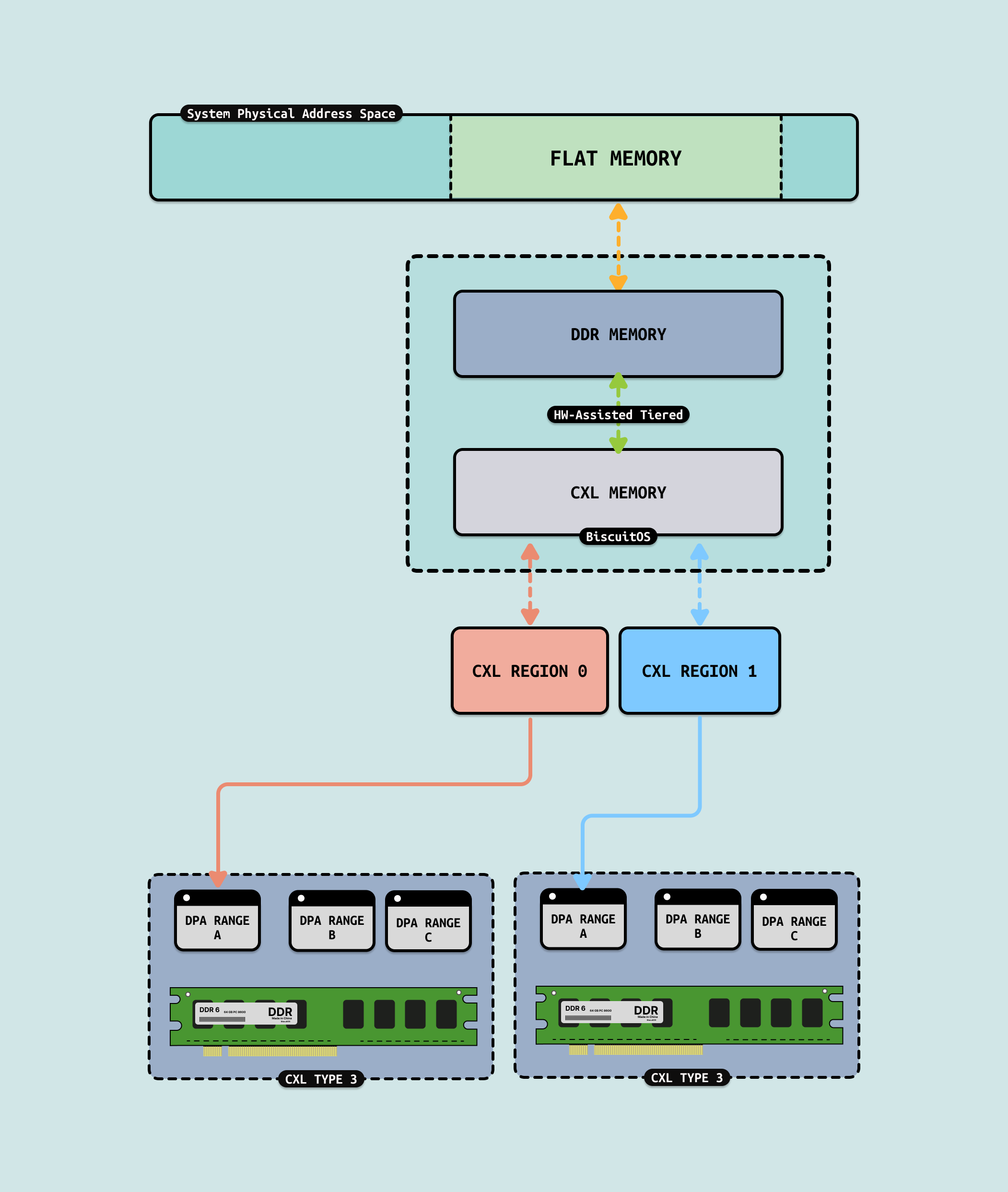
FLAT MODE: 通过硬件辅助的方式,将本地 DDR 内存和 CXL 内存 统一管理,形成一个单一的内存区域. FLAT 模式通过硬件(如内存控制器)自动管理内存的分层,将热数据(频繁访问的数据)放置在性能更高的本地 DDR 内存中,而将冷数据(较少访问的数据)放置在性能稍低的 CXL 内存中. 与操作系统软件的 Tiered Memory 机制相比,操作系统和应用程序无需感知内存的分层管理,硬件会自动完成数据的迁移和优化,这意味着开发者无需修改代码或调整系统配置,即可享受内存分层的性能优势. FLAT 模式将本地 DDR 内存和 CXL 内存视为一个连续的内存地址空间. 操作系统和应用程序看到的是一个单一的内存池,而不需要区分本地内存和远程内存, 这种设计简化了内存的管理和分配,减少了软件层面的复杂性. FLAT 模式支持本地 DDR 内存和 CXL 内存以 1:1 的比例配置,例如如果系统有 512GB 的本地 DDR 内存,那么可以扩展 512GB 的 CXL 内存,形成一个总计 1TB 的统一内存池. FLAT 模式的优势:
- 性能优化: 通过硬件自动将热数据保留在本地 DDR 内存中,确保关键工作负载的高性能
- 容量扩展: 通过 CXL 内存扩展系统总内存容量,满足内存密集型应用的需求
- 成本效益: CXL 内存通常比本地 DDR 内存更便宜,FLAT 模式允许用户以较低的成本扩展内存容量
- 简化开发: 对软件完全透明,开发者无需修改代码即可利用 FLAT 模式的优势
Linux 的 Tiered Memory 需要软件参与数据迁移和管理,这会引入额外的开销和复杂性,而 FLAT 模式通过硬件实现内存分层. 硬件辅助的数据迁移比软件实现更高效, 硬件可以更精细地管理数据(如以 64B 为单位),而操作系统通常以 4KB 页面为单位管理数据. 最后 FLAT 对软件完全透明,无需修改应用程序或操作系统配置. 那么 FLAT 模式的应用场景:
- 内存密集型应用: 如大数据分析、人工智能训练、虚拟化等需要大容量内存的应用
- 成本敏感型场景: 在需要扩展内存容量但预算有限的情况下,CXL 内存提供了一种经济高效的解决方案
- 高性能计算: 通过硬件辅助的内存分层,确保关键工作负载的高性能
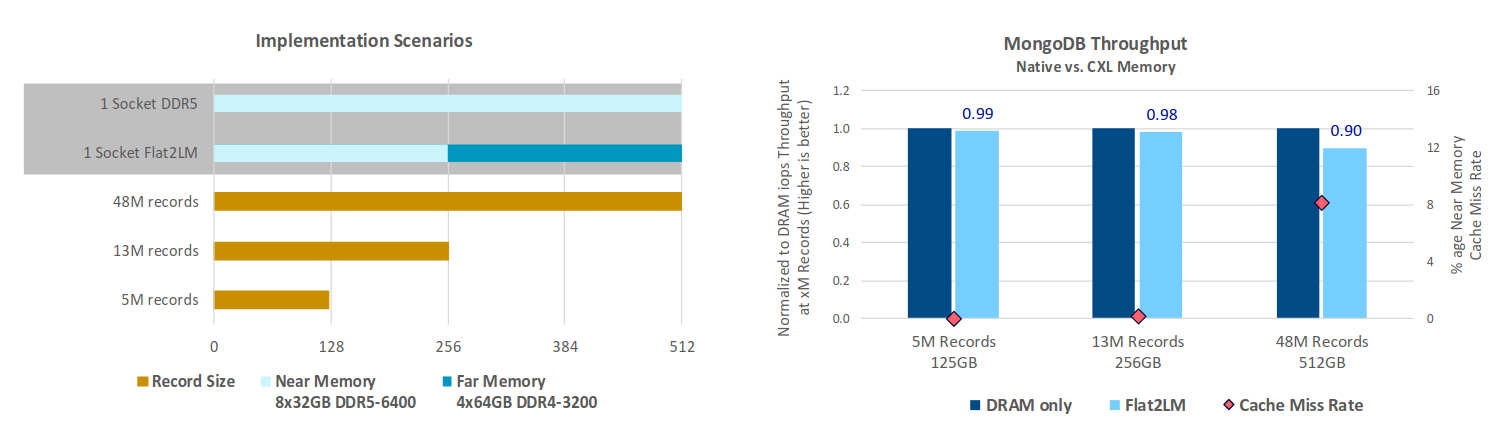
通过 CXL 技术,用户可以继续使用现有的 DDR4 内存模块,而无需额外购买新的内存硬件,这种设计降低了总体拥有成本(TCO),因为用户无需完全替换现有基础设施. CXL 提供了一种高效的内存扩展方式,允许 DDR4 内存与 CXL 内存共存,并通过统一的接口进行管理. 虽然重复使用 DDR4 内存模块可能会导致轻微的性能下降(例如由于 CXL 内存的延迟略高于本地 DDR4 内存),但这种性能损失是可以接受的,因为用户可以节省硬件成本. CXL 技术通过硬件实现内存管理,无需依赖操作系统的数据分层功能. 这意味着没有额外的操作系统开销(如上下文切换、页面迁移等),从而提高了整体效率. 与基于操作系统的数据分层(通常以 4KB 页面为单位迁移数据)相比,CXL 以更小的数据单位(64B)进行数据传输,从而显著降低了延迟.
