

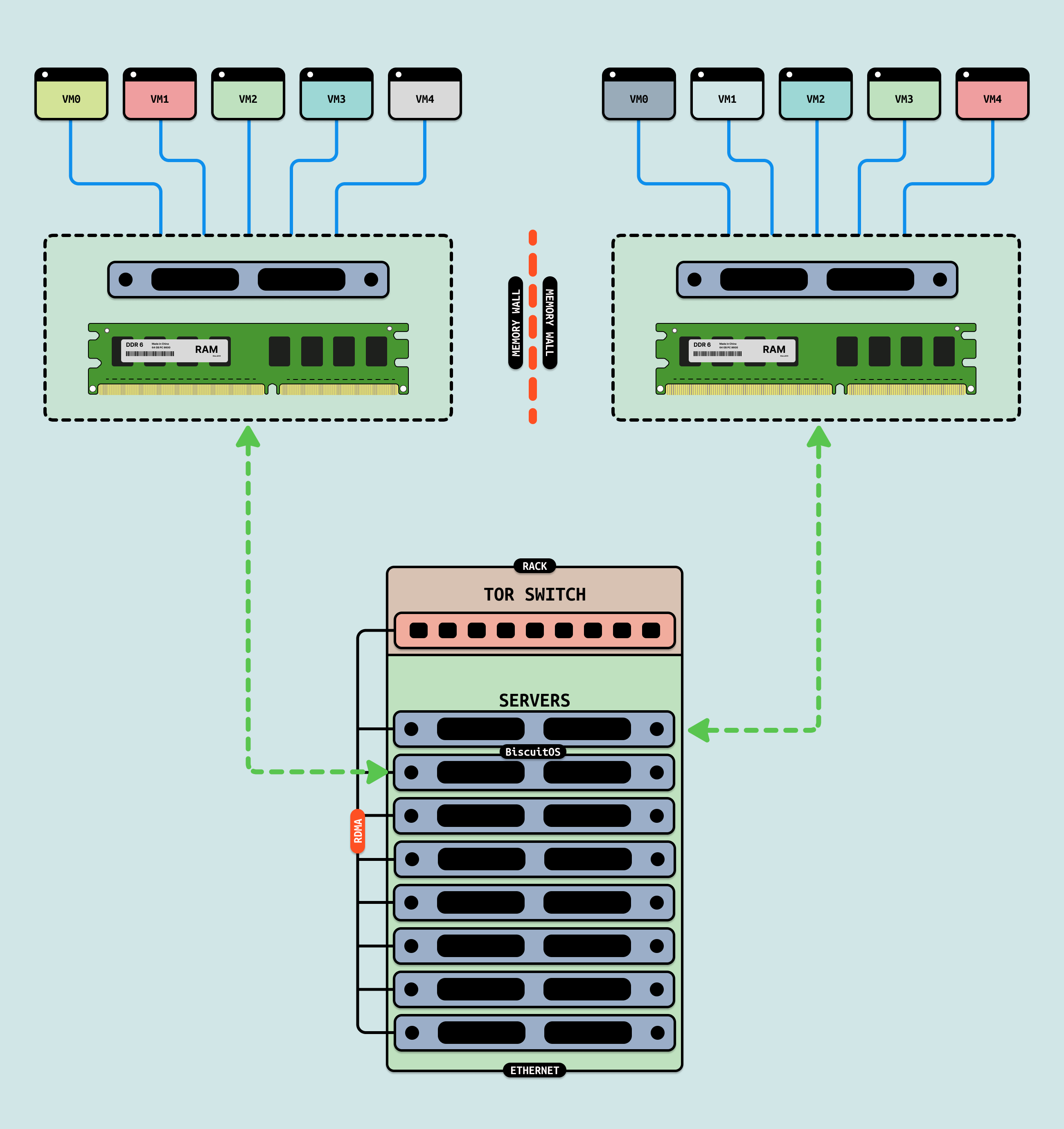
传统的云厂商将单机的内存、CPU 等资源虚拟化成多份提供用户,用户在虚拟机内部只能看到隔离的资源. 微软 Azure 的研究表明,在其云上,内存容量利用率平均仅为 40% 左右,而运行的虚拟机中有一半从未访问超过一半的内存, 因此从这个数据可以看出两个问题,虚拟机上大部分的内存都是浪费的,另外虚拟机的内存自来一个个内存孤岛, 所谓内存孤岛就是只有单机可以使用的内存.
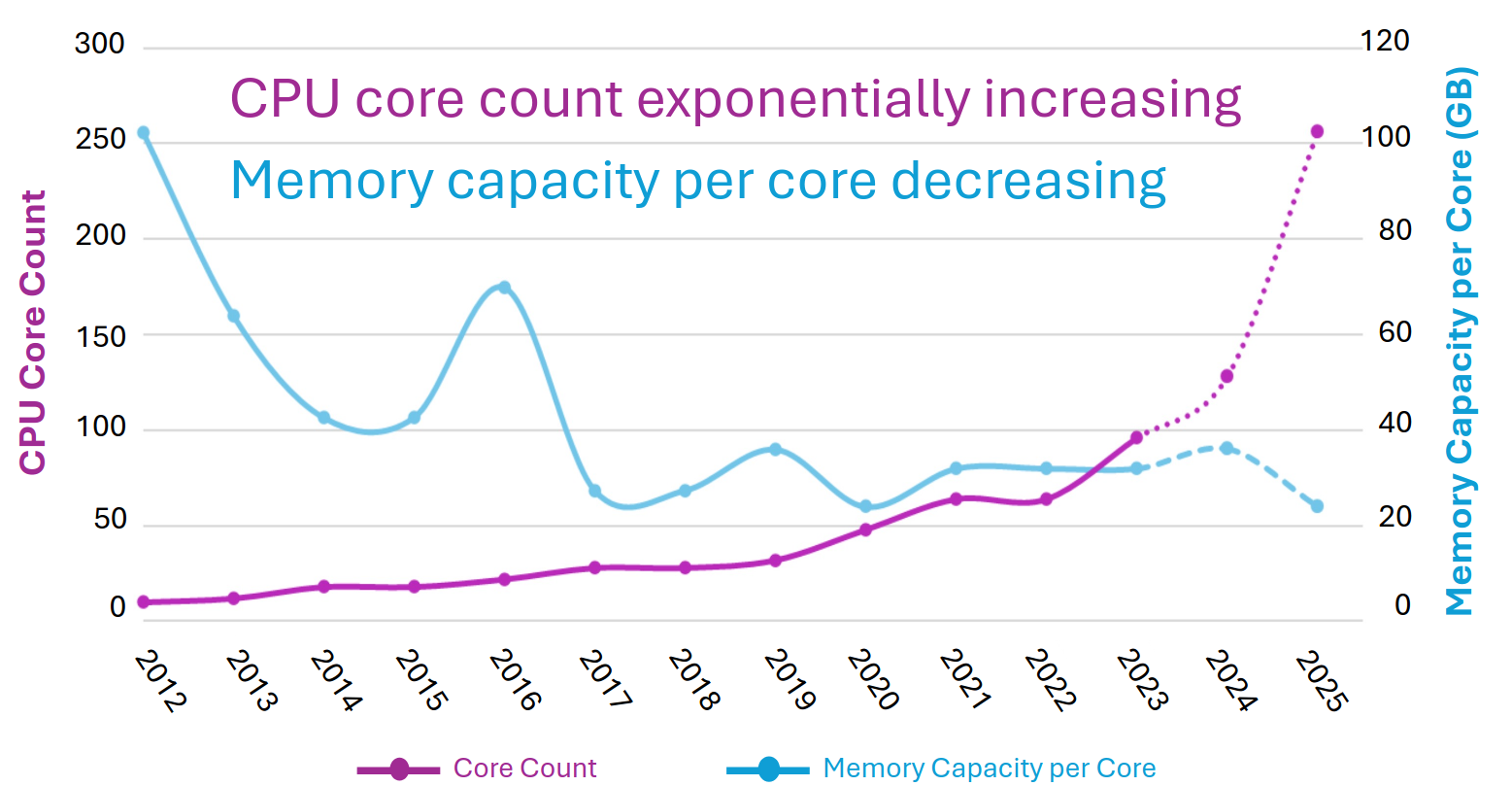
从成本角度来看,随着时间推移,大约十年前,CPU 曾经占数据中心基础设施工作负载基本服务器成本的一半左右. HPC 系统在内核上的强度更高,而在内存上的强度则更低. 内存约占系统成本的 15%, 主板约占 10%, 本地存储(即磁盘驱动器)约占 5% 到 10%, 具体取决于磁盘的容量或速度. 其余部分由电源、网络接口和机箱组成. 在很多情况下,网络接口已经在主板上,因此除了想要更快的以太网或 InfiniBand 接口的情况外,成本已经捆绑在一起.
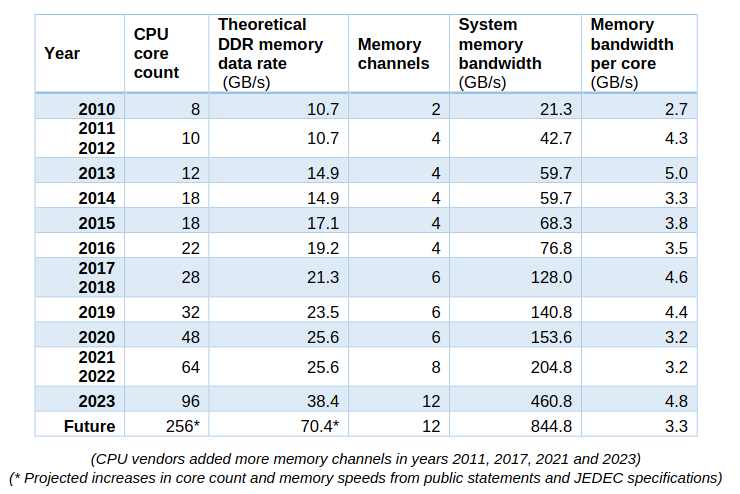
随着时间的推移,闪存被添加到系统中,服务器的主内存成本飙升至顶峰(但相对于其他组件的价格有所下降),随着 AMD 的重新进入,X86 CPU 又回到了竞争. 因此通用服务器的服务器成本饼中的相对切片大小在这里和那里扩大和缩小. 根据配置,CPU 和主内存各占系统成本的三分之一左右,而如今内存通常比 CPU 更昂贵, 对于超大规模和云建设者来说,内存绝对是最昂贵的项目,因为 X86 CPU 上的竞争更加激烈,从而降低了成本.
据英特尔称,CPU 仍占 IT 设备功耗预算的 32% 左右,内存仅消耗 14%,外围设备成本约为 20%,主板约为 10%,磁盘驱动器约为 5%(闪存是功耗预算派的外围部分). 包括计算、存储和网络在内的 IT 设备消耗的功耗不到一半,而电源调节、照明、安全系统和其他方面数据中心设施消耗了一半多一点,这给出了相当可怜的 1.8 的电源使用效率. 典型的超大规模和云构建者数据中心的 PUE 约为 1.2.
通过前面的分析可以总结出,内存的容量越大成本越高,整体功耗越大,但有效率却越低,因此在云场景中合理的应用内存可以减低内存成本,又可以充分的售卖内存资源. 为了达到这个目录,本文重点介绍 CXL 方案的引入如何解决这个问题.
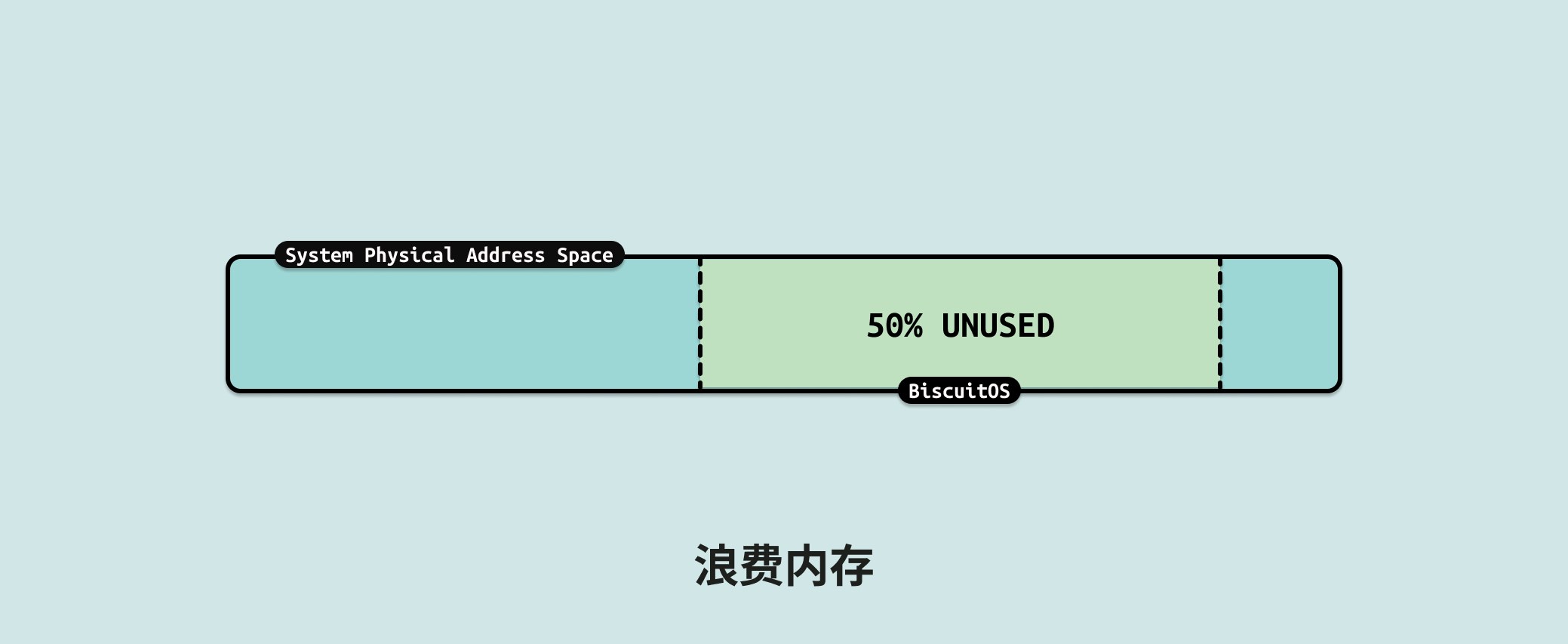
微软 Azure 的研究表明,在其云上,内存容量利用率平均仅为 40% 左右,而运行的虚拟机中有一半从未访问超过一半的内存. 这个数据说明了虚拟机里大部分内存都是未使用的内存,因此可以有两个方案解决:
- 按需分配: 虚拟机只有真正使用内存的时候,才为虚拟机分配内存,这样可以按需分配将浪费降到最低,也可以最大限度的售卖内存资源. 但该方案有明确的缺点,虚拟机只有使用内存的时候才去分配,这会带来很大的访问延迟,对延敏感的客户会有极大的影响. 另外将内存资源超量售卖,当内存挤兑的时候会出现有的虚拟机无法分配到内存. 因此该方案适用于内存延迟不敏感和低访问频率的客户, 这类客户如:
- 大数据分析: 大数据分析任务(如 MapReduce、Hadoop、Spark)通常处理大量数据,要求高内存容量来存储中间结果、缓存数据等. 需要大容量内存来提高数据处理效率和减少磁盘 I/O,但对延迟要求较低,因为数据处理可以被分批执行. 例如数据挖掘、机器学习模型训练、大规模数据集分析
- 数据仓库和 OLAP: 在线分析处理(OLAP)系统和数据仓库需要将大量数据加载到内存中以加速查询和分析. 需要大容量内存来缓存和处理数据集,但查询可以容忍一定的延迟. 例如商业智能(BI)应用、报表生成、复杂查询分析
- 虚拟桌面基础架构(VDI): VDI 解决方案需要支持多个用户会话,每个会话可能需要大量内存以运行应用程序, 高内存容量是关键,以支持多个并发用户和应用程序,但单个会话对内存访问的延迟不敏感. 例如远程桌面服务、虚拟工作站
- 内存缓存和存储: 某些内存缓存系统需要大容量内存来存储缓存数据,但数据访问可以容忍一定的延迟. 例如分布式缓存系统、大型对象存储缓存
- 图形渲染和视频处理: 复杂的图形渲染和视频处理任务可以利用大容量内存来处理大型数据集和素材. 需要大容量内存来存储纹理、模型和视频帧,对延迟不敏感,因为处理通常是批处理或异步进行. 例如 3D 渲染、视频特效处理、动画制作
- 科学计算和仿真: 科学计算和仿真需要处理大量数据,通常需要大内存来存储模拟数据, 大容量内存来支持复杂计算,但往往可以通过优化算法和数据访问模式来减少内存延迟的影响. 例如气候模拟、基因组分析、物理仿真
- 冷页回收: 虚拟机启动的时候,可以分配全量的内存或者按需分配内存,将虚拟机长时间不访问的内存进行回收,当虚拟机再次访问被回收的内存时,再将其换入,这样可以将释放的内存资源进行售卖, 可以将内存资源有效的利用起来. 但该方案存在明显的缺点,对于延迟敏感性用户影响很大,另外当出现内存挤兑的时候,有的客户会因为内存分配失败而宕机,另外回收的介质也会对用户构成影响,如果回收介质是 SWAP,那么换入的延迟会显著增加,如果回收的介质是 ZSWAP,那么换入的延迟会有所减低,但会消耗本机内存. 因此该方案适用于内存延迟不敏感和低访问频率的客户,这类客户如:
- 批处理任务: 批处理任务通常是非交互式的,可以在后台运行,具有较长的运行时间. 这些任务通常依赖于 CPU 计算能力而不是频繁的内存访问, 例如日志分析、数据清洗、视频转码等
- 数据存档和备份: 这些任务主要涉及大量数据的读取和写入,通常是顺序访问, 其内存的使用主要用于缓冲和缓存,延迟不是主要瓶颈, 例如数据备份、恢复任务、归档处理
- 简单的 Web 服务: 对于一些简单的 Web 服务,主要瓶颈在于网络 I/O 而不是内存访问, 这类应用程序通常对内存的需求较低,适合运行在轻量级虚拟机或容器中, 例如静态网站托管、简单的 API 服务
- 流媒体传输: 流媒体服务需要稳定的带宽和 I/O 性能,但对内存延迟要求不高, 内存主要用于缓冲流媒体数据,延迟的影响较小. 例如视频流服务、音频流服务
- 脚本和自动化任务: 自动化脚本和任务调度通常是短期运行的,并且对实时性能要求不高, 这类任务通常只需要少量内存来执行逻辑操作. 例如系统维护脚本、定期报告生成
- 低频率的数据库查询: 某些数据库工作负载,特别是读密集型查询,可能对内存延迟不敏感. 在数据库缓存机制有效的情况下,内存访问频率较低. 例如数据仓库查询、OLAP(在线分析处理)
通过上面的分析,主流处理以上问题的方案中还是存在美中不足,虽然很好的解决了资源浪费的问题,但更多的延迟和内存挤兑风险让人们不敢轻易采用这些方案. 接下来引入 CXL 方案来优化这些问题,CXL 内存的特点是高带宽、低延迟(相对 PCIe 低延迟,相对 DDR 高延迟)、价格远低于 DDR 和 CXL 池化能力.
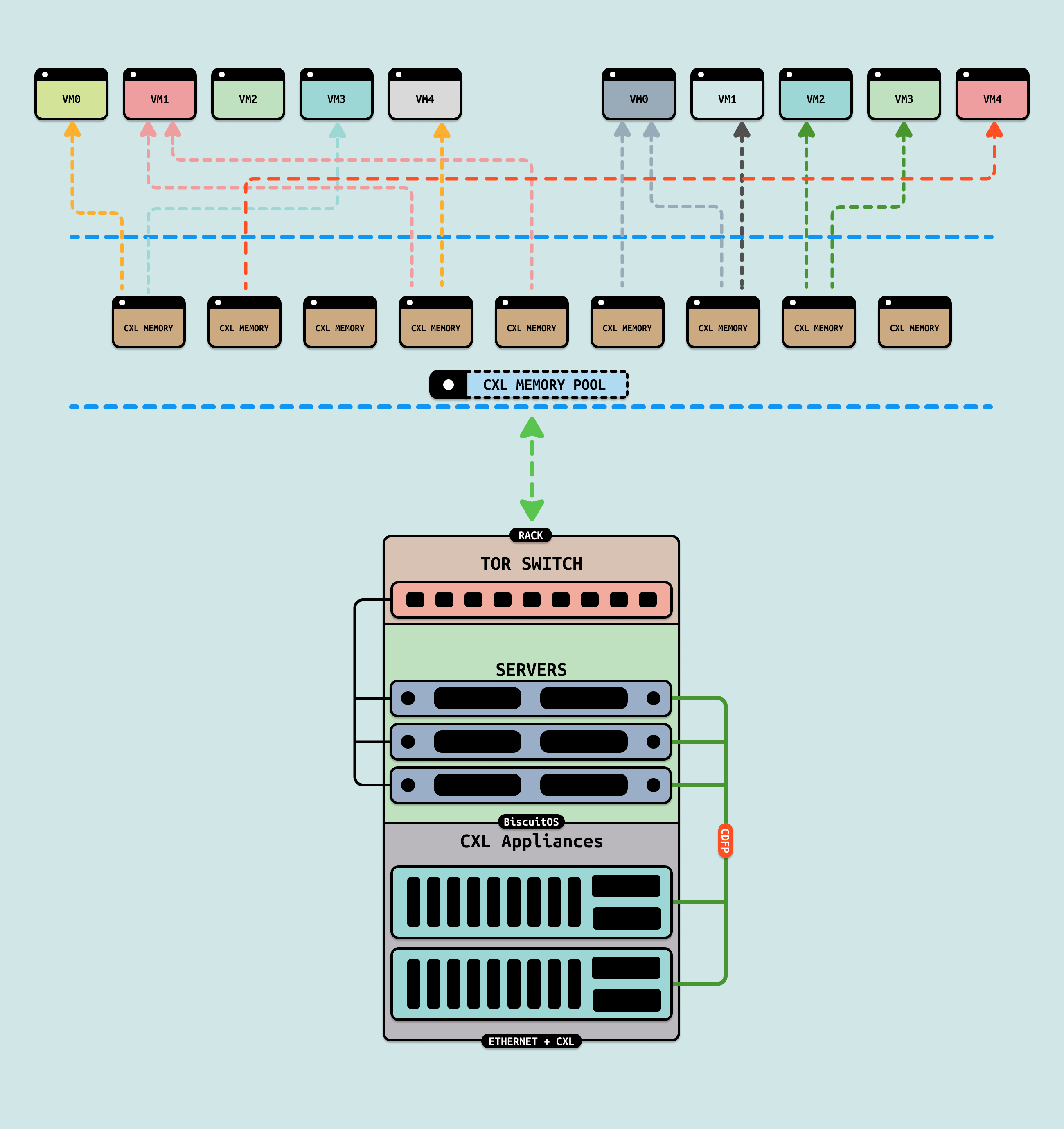
CXL 2.0 支持 CXL 内存池化能力,另外 CXL 内存支持热插拔能力,那么 CXL 服务器维护池化的 CXL 内存,当虚拟机或者物理主机需要扩容时,CXL 可以通过热插的方式为其扩充内存. 当虚拟机或者物理机不需要物理内存时,可以动态缩容,这样可以充分利用内存资源。主机和虚拟机的扩容存在一定的差异,具体如下:
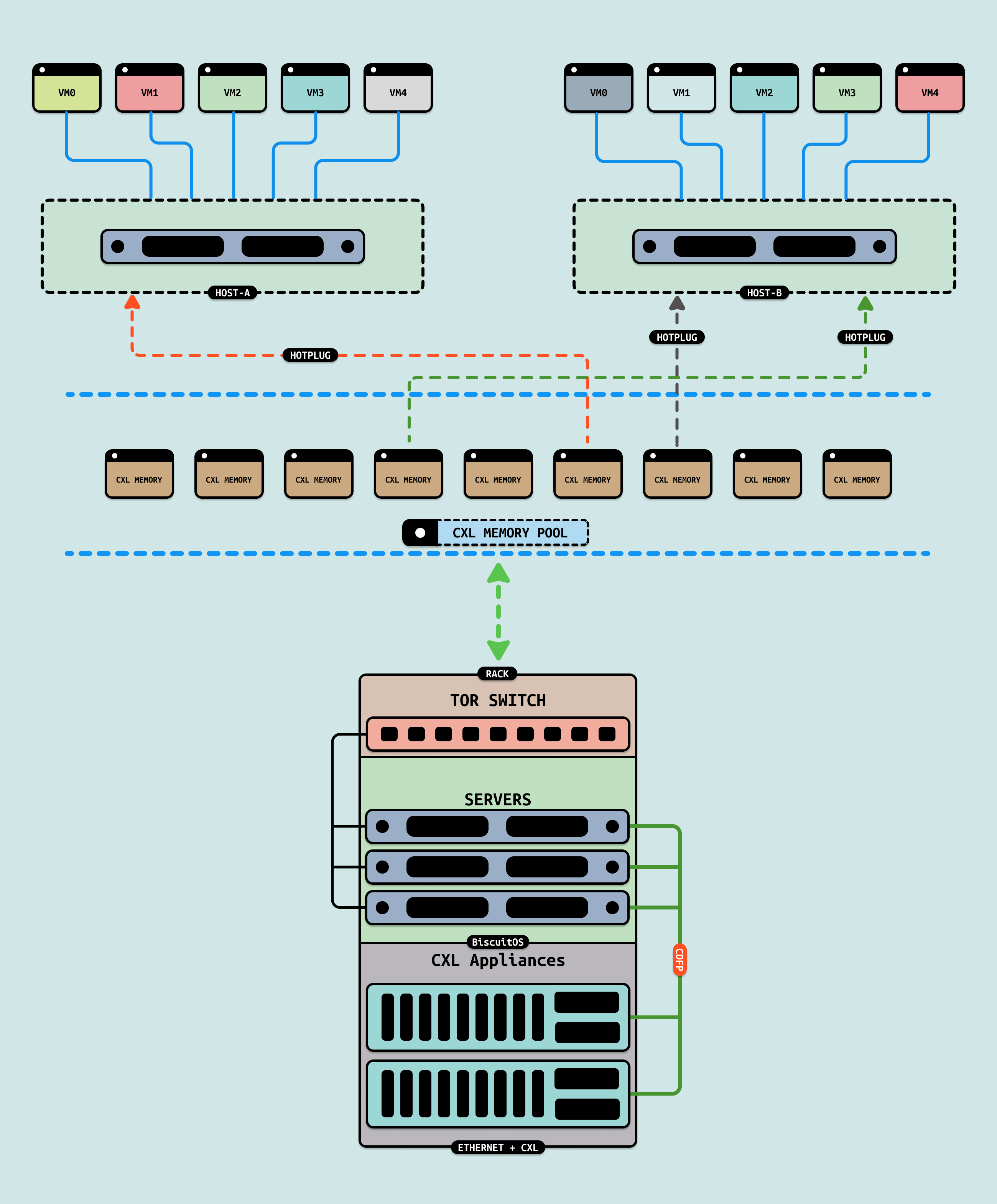
当物理主机出现内存挤兑问题,或者内存紧缺的时候,可以将 CXL 内存以 SYSTEM-RAM 的方式热插到系统,这种方式插入的好处是可以提供大容量的高带宽、低价内存,并且新加的内存被放在一个 CPULESS NUMA 节点上,受系统内存管理机制管理,上层的应用程序和内核线程无感.
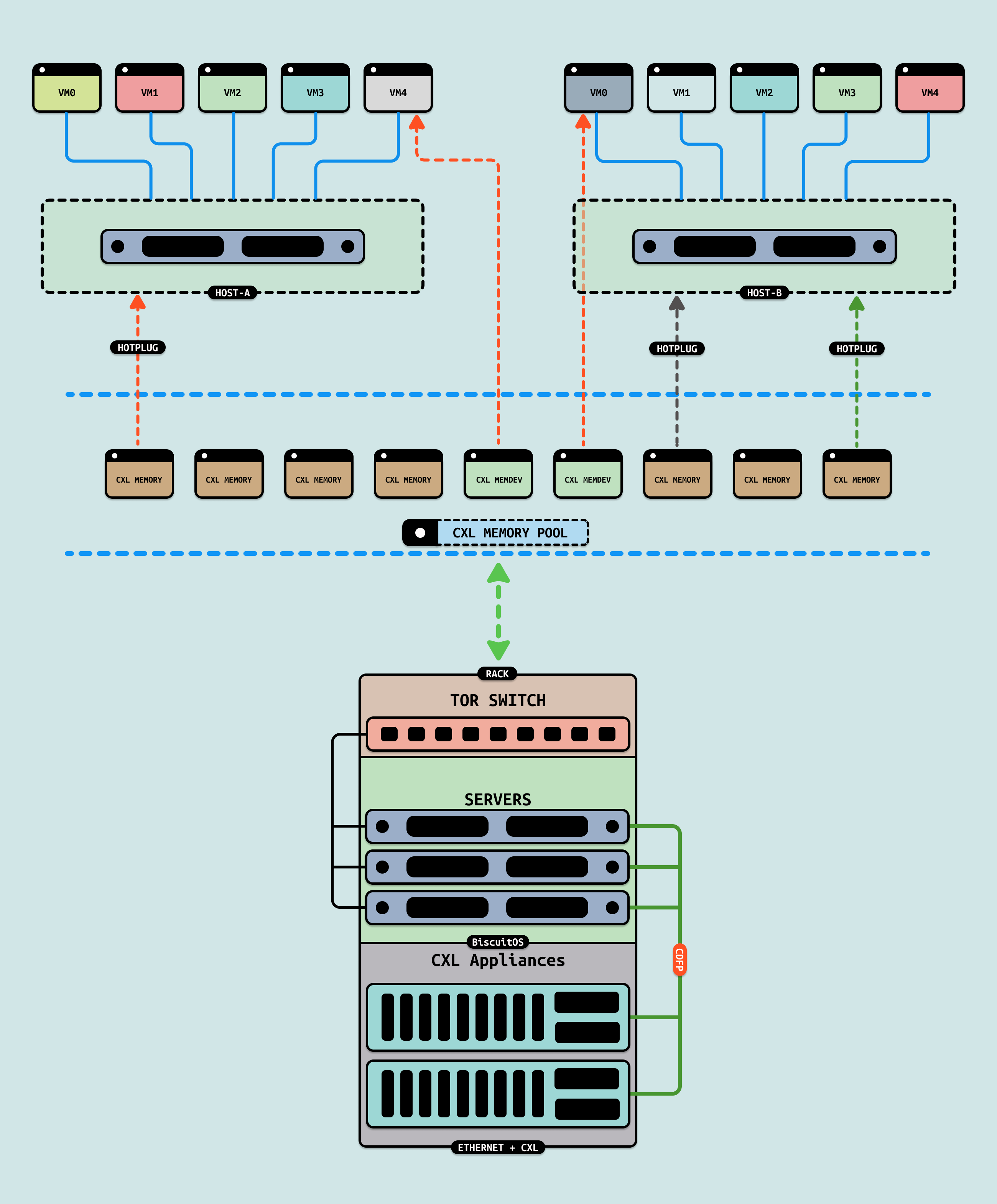
当虚拟机在运行中需要使用大量的内存,可以在虚拟机启动之前,将 CXL 内存以 DEVDAX 的方式热插到主机,在虚拟机启动时,将该 DEVDAX 模式下的 CXL 内存映射为虚拟机的内存,这样虚拟机使用远超物理机的内存. 如果虚拟机运行过程中需要扩容,可以直接将 CXL SYSTEM-RAM 模式的内存提供给虚拟机,也可以将 CXL DEVDAX 模式的内存提供给虚拟机. 接下来通过一个实践案例讲解上诉过程,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd /BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] Intel Q35
[*] Support Host CPU Feature Passthrough
[*] CXL: Compute Express Link
CXL Hardware Topology (CXL2.0: x1 VCS + x1 Type DDR) --->
[*] Package --->
[*] HETEROGENEOUS MEMORY MANAGEMENT
[*] CXL VM: DEVDAX --->
# 配置完毕保存,然后进行部署
make
# 切换到实践案例所在目录
cd output/linux-6.10-x86_64/package/BiscuitOS-CXL-VM-DEVDAX-default
# 准备依赖工具
make prepare
# 编译实践案例
make download
make build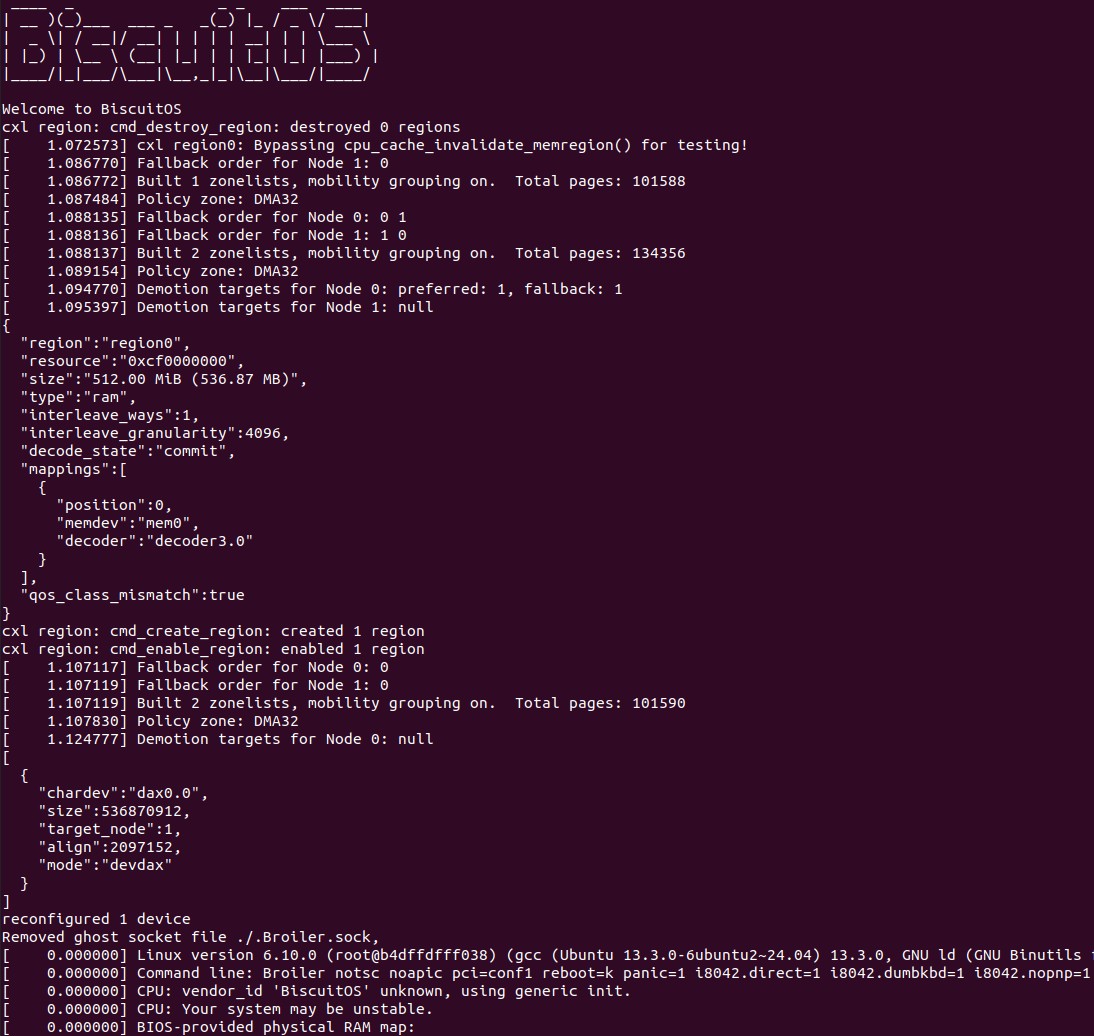
BiscuitOS 启动之后,会将 CXL REGION 配置为 DEVDAX,然后将 DEVDAX 提供给虚拟机作为其内存. HOST 主机可以将 DEVDAX 设备通过 mmap 方式映射作为虚拟机内存,虚拟机并不感知内存来自 CXL 还是 DDR,可以采用这种方式拓展虚拟机内存.
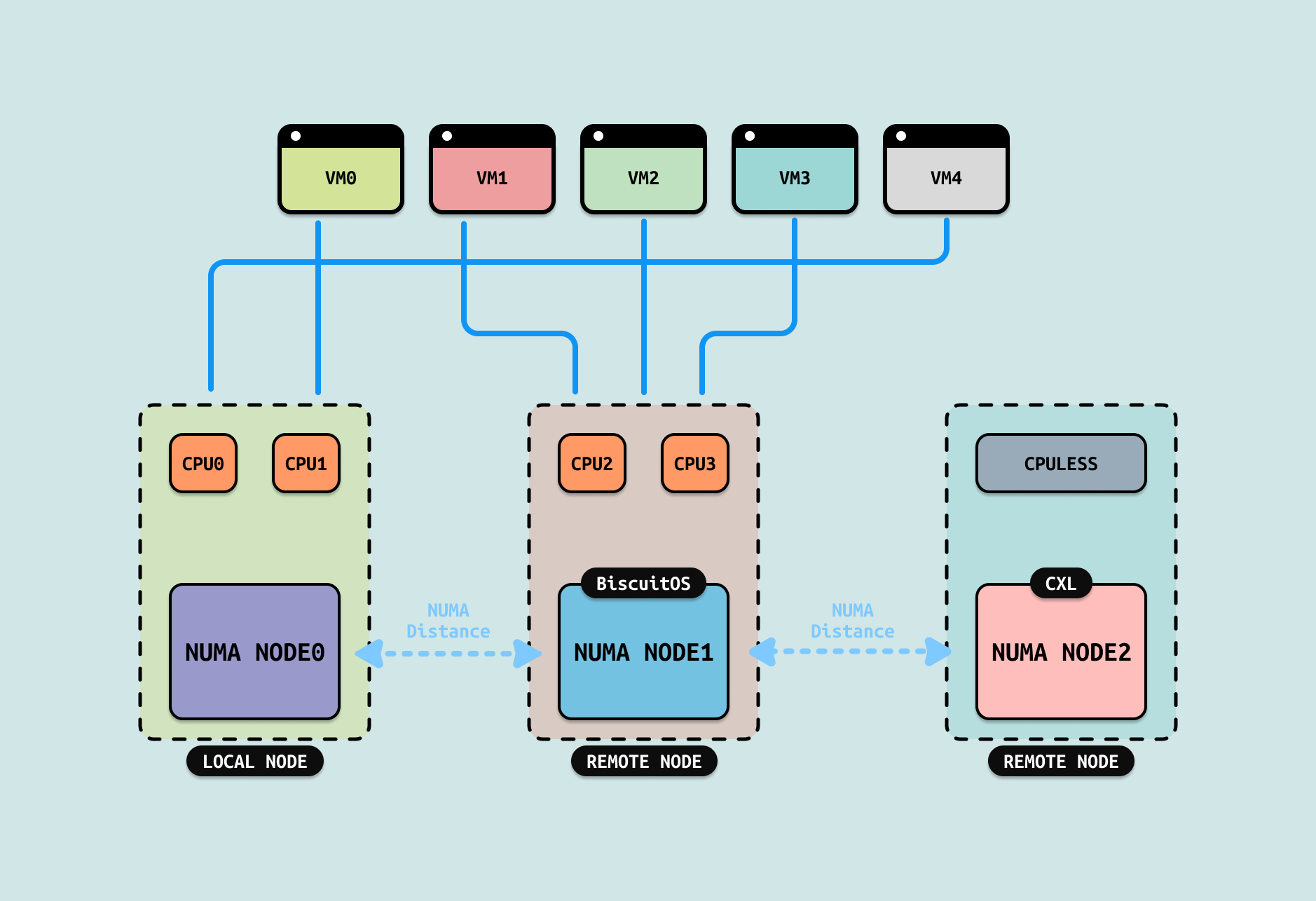
CXL 以 SYSTEM-RAM 作为系统物理内存时,系统会将 CXL 内存划分到一个独立的 CPULESS NUNA 节点上,由于 CXL 内存带宽高,但延迟比 DDR 高,因此访问 CXL 内存的速度比 DDR 慢,因此可以将 DDR 当做快速内存,而 CXL 则当做慢速内存,这就是 Linux Tiered Memory(分层) 机制,在该机制中,内核会让热页尽可以的放在 DDR 中,而将冷页放到了 CXL 中.
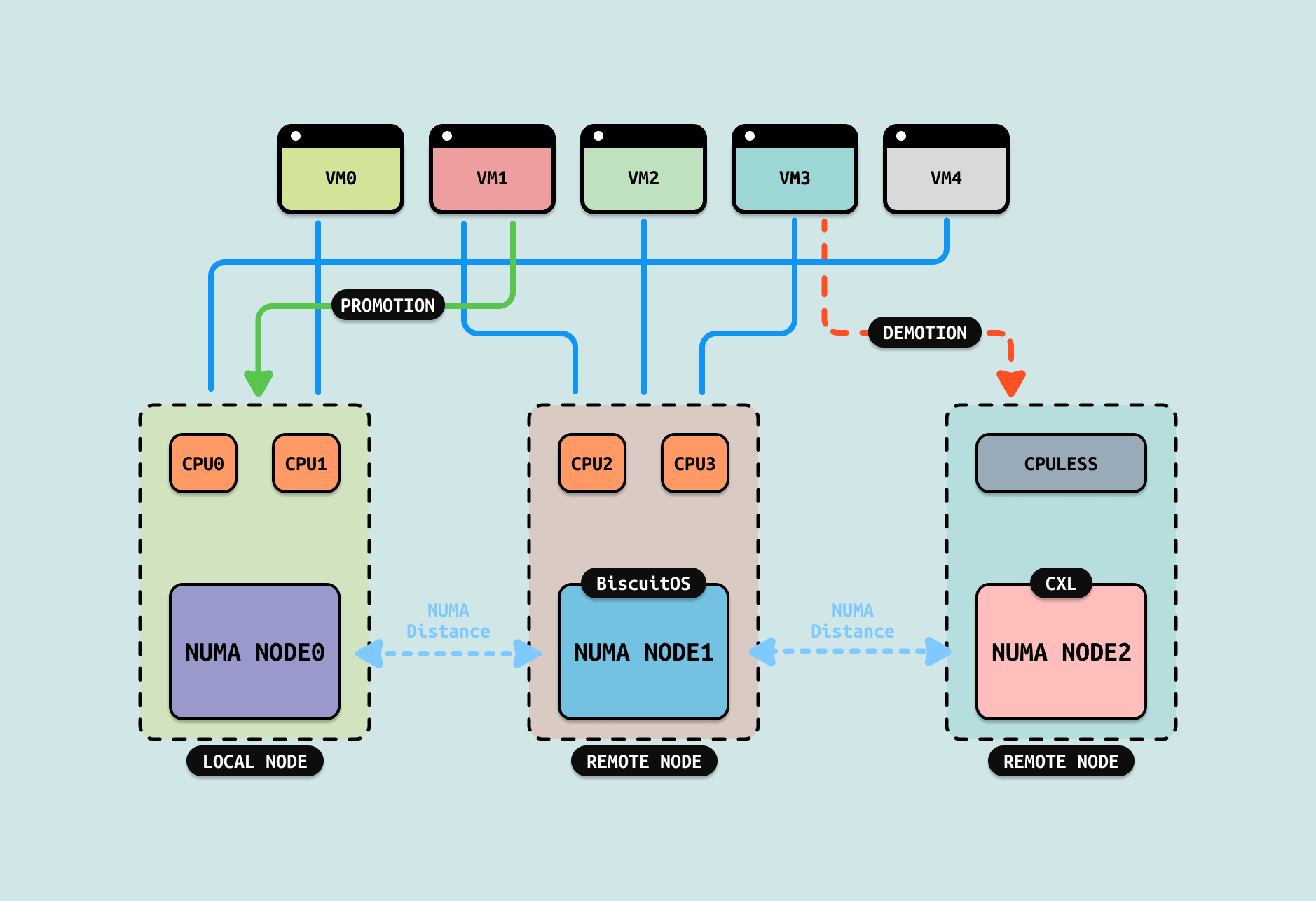
有了分层内存机制(Tiered Memory), 可以在 HOST 主机上分配 CXL 内存,并以 SYSTEM-RAM 的模式存在,当虚拟机需要回收冷页时,可以不将其回收到 SWAP,而是将其降级(DEMOTION) 到 CXL 内存,而热页则继续留在 DDR 内存里. 当再次访问回收的冷页,则将 CXL 中的内存升级(PROMOTION) 到 DDR 内存里,升级(PROMOTION) 的延迟远比换入(SWAP IN). 通过这样的办法可以很好解决回收带来的问题.
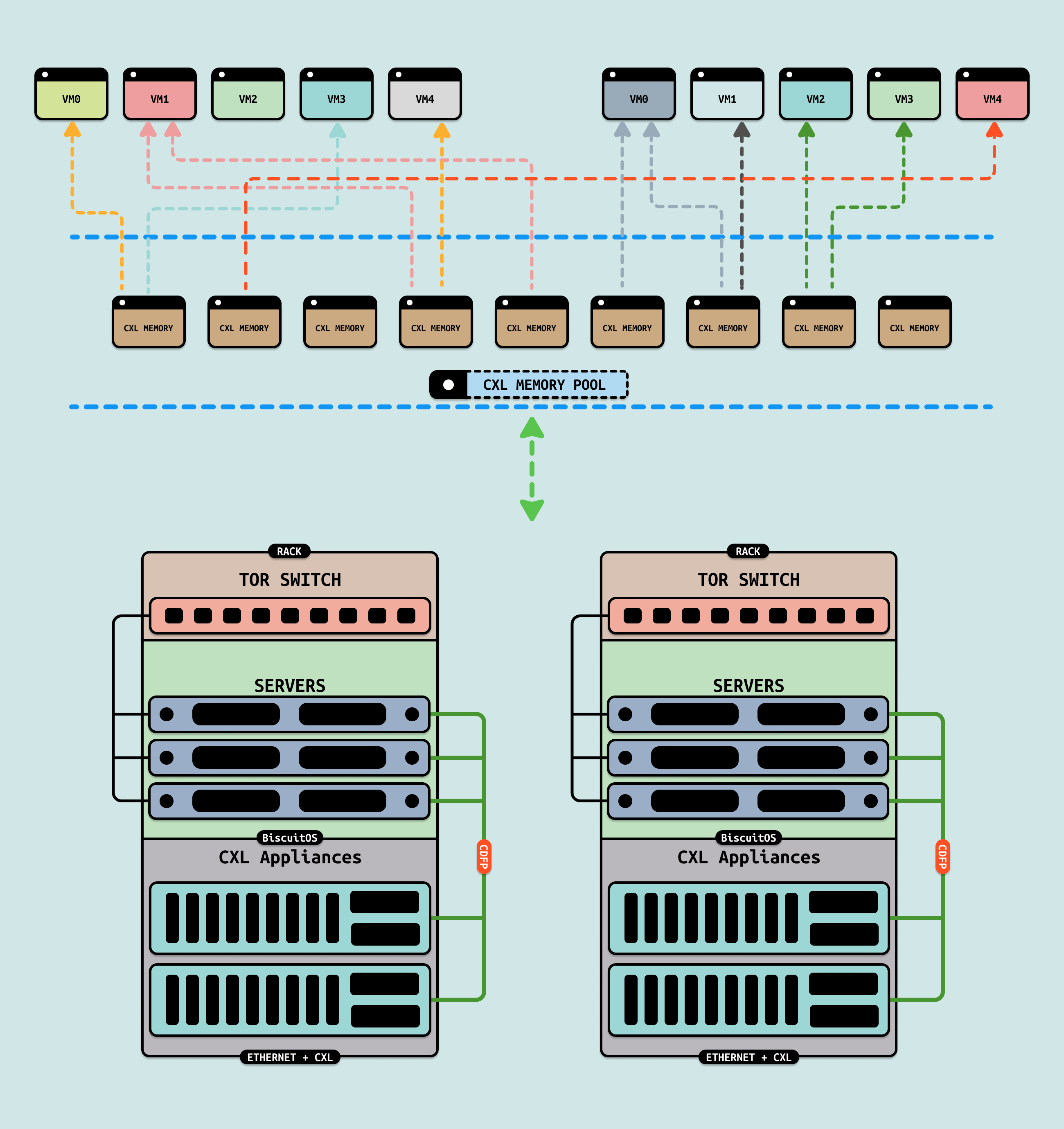
CXL 2.0 引入了 CXL 内存池化的功能,其重点提供了 Pooling 和 Sharing 的能力,前面的热插拔其实应用了 CXL 内存池化的提供弹性且隔离内存能力. 对于 CXL 内存池子的 Sharing 功能,其在虚拟化场景也有一定的应用前景, 由于硬件条件的限制这里只对方案进行介绍. 虚拟机热迁移(Live Migration)是指在不关闭或中断虚拟机的情况下,将其从一台物理主机迁移到另一台物理主机的过程, 常见的热迁移包括: “Pre-Copy 迁移” 和 “Post-Copy 迁移”. 热迁移的核心是将虚拟机数据分成状态部分和虚拟机内存部分. 当使用 Pre-Copy 迁移时,其工作流程如下:
- 初始内存复制: 在迁移开始时,虚拟机的内存页面会被复制到目标主机, 这一阶段虚拟机继续在源主机上运行
- 增量复制: 在内存复制的过程中,虚拟机仍在运行,并且可能会修改一些内存页面, 对于这些被修改的页面,Pre-Copy 会在后台进行增量复制, 这个过程可能会多次重复.
- 停止和复制:当增量复制的内存页面数量减少到一定程度时,虚拟机会短暂停止,以便将最后的内存差异复制到目标主机
- 切换:完成所有内存页面的传输后,虚拟机将在目标主机上恢复运行
可以看出,如果虚拟机的内存超级大,并且热迁移过程中虚拟机一直在访问内存,那么第一步和第二步会话费大量的时间,这也成为了 “Pre-Copy” 的瓶颈. 如果将虚拟机的内存替换成 CXL DEVDAX 模式的内存,那么发生 Pre-Copy 时,其流程如下:
- 拷贝虚拟机状态: 在迁移开始时,只拷贝虚拟机状态部分到目标主机运行,虚拟机继续在源端主机运行
- 热插 CXL 内存: 通过 CXL 内存池化 Sharing 功能,直接将 CXL DEVDAX 查到目的端虚拟机进行共享
- 停止: 虚拟机短暂停止
- 切换: 虚拟机在目标主机上恢复运行
从上面的流程可以看出,CXL 内存池的 Sharing 功能让源端和目的端虚拟机共享 CXL DEVDAX,也就不需要拷贝内存,直接 ZEROCOPY,对于超大内存的虚拟机来说,其可以节省大量的时间和消耗. 对于 “Post-Copy” 也是类似,将内存拷贝替换成 Zero-Copy 可以节省大量的时间.
