

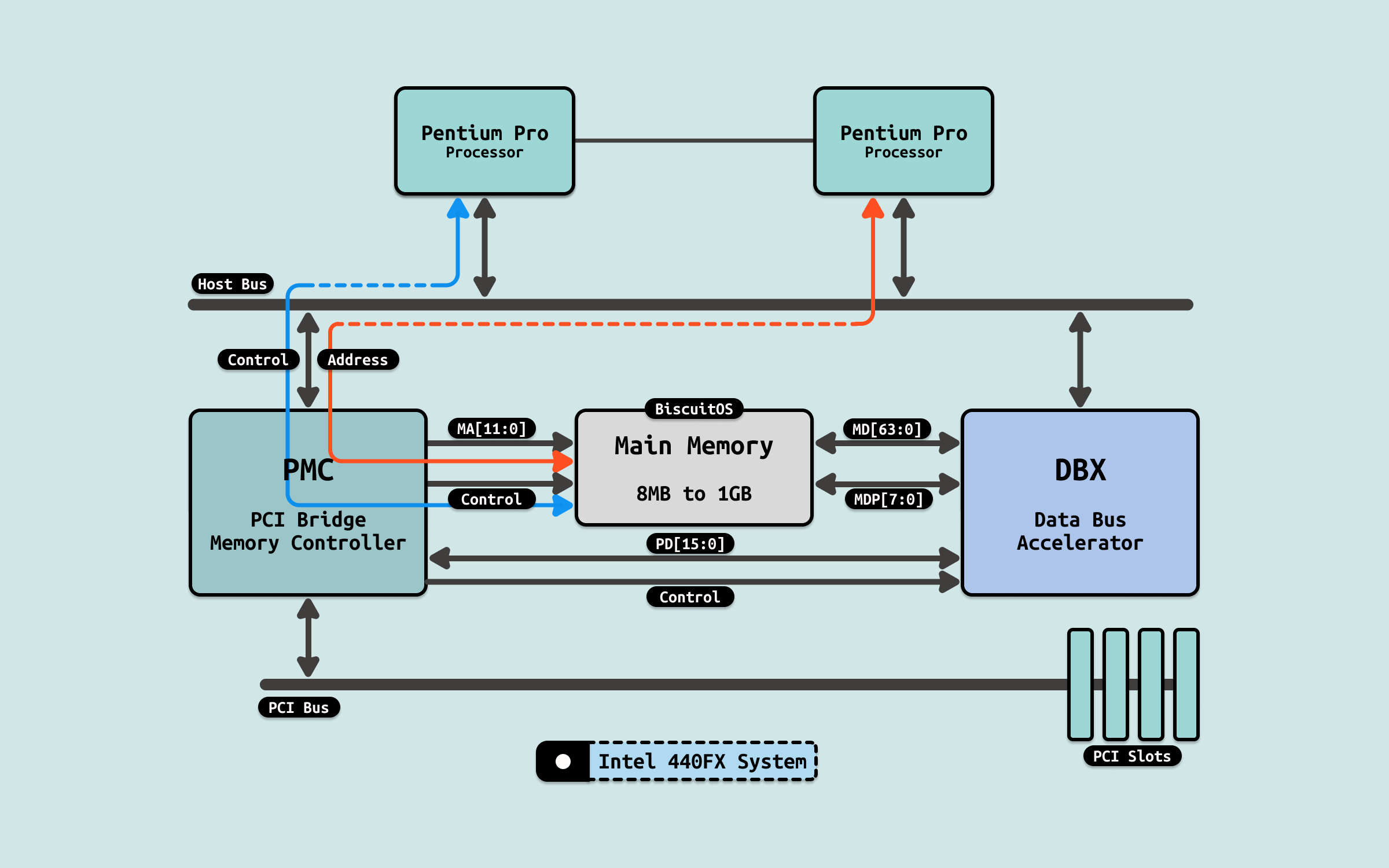
在早期系统了,所有的 CPU 通过共享总线 FSB 与北桥相连,北桥芯片上连接内存控制器和南桥,CPU 要访问内存就必须要通过北桥,再经过内存控制器,才能访问到 DIMM 内存. 此时 CPU 在访问完一次内存之后,需要一定的时间间隔才能执行下一次内存访问,这里的时间间隔包括: L(CAS 延时)、tRCD(RAS 到 CAS 延时)、tRP(预充电有效周期) 等. 因此在早期系统里,内存带宽受限与 FSB 总线和北桥.
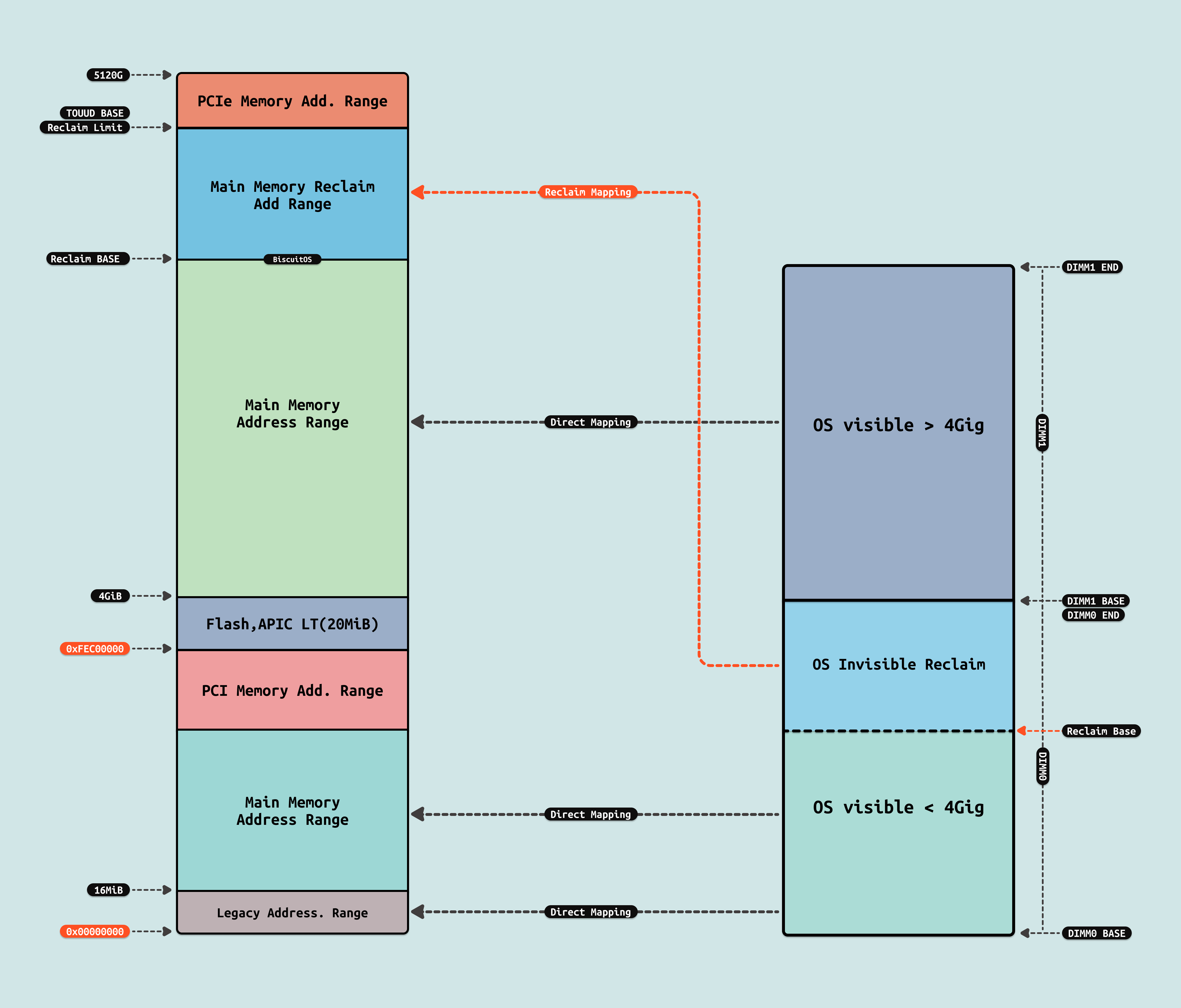
在这种架构下,早期的硬件将 DIMM 内存直接映射到连续的系统物理地址空间里,因此 CPU 看到连续的物理内存来自同一块 DIMM. 结合程序的局部性原理,程序会把代码和数据都放在连续的物理内存上,并且 CACHE 也会根据局部性原理将连续的物理内存预加载到 CACHE 里,因此程序都会放到同一个 DIMM 上,因此系统只能串行的访问内存. 此时内存带宽为:
- 总带宽 = 单条内存带宽
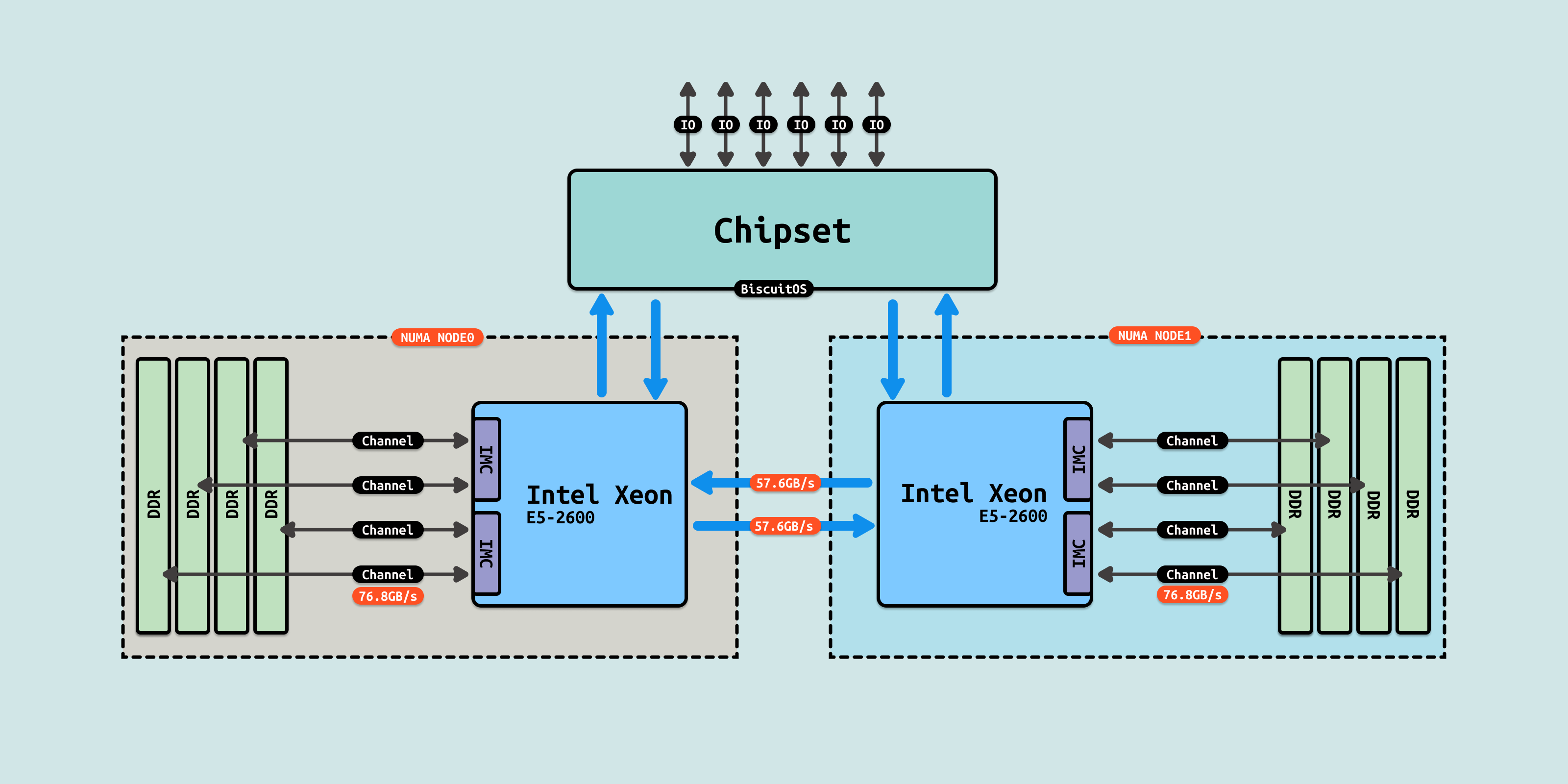
随机技术不断的发展,多核 CPU 不断出现,传统的 FSB 总线已经无法满足多核场景,Intel 针对该场景提出了 QPI 和 UPI 多 Socket 互联技术. 此时内存控制器已经集成到 CPU Die 内部,CPU 可以直接访问内存控制器,进而访问到 DIMM 内存. 由于 CPU Die 内核心数不断的增加,CPU Die 内部出现了两个内存控制器(IMC), 每个内存控制器通过多个通道(Channel)连接到多个 DIMM 插槽. 此时如果数据存储在不同的 DIMM 上,那么内存控制器可以并行读取这些数据,因此此时内存带宽计算如下:
- 总带宽 = 单条内存条带宽 * 通道数
虽然出现了多通道技术,结合程序的局部性原理,程序会把代码数据放到连续的物理内存上,并且 CACHE 也会根据局部性原理将连续的物理内存加载到 CACHE 里,因此程序大概率会访问同一个 DIMM 上,因此系统依旧还是得串行访问某个 DIMM. 因此多通道技术并没有带来性能的明显提升.
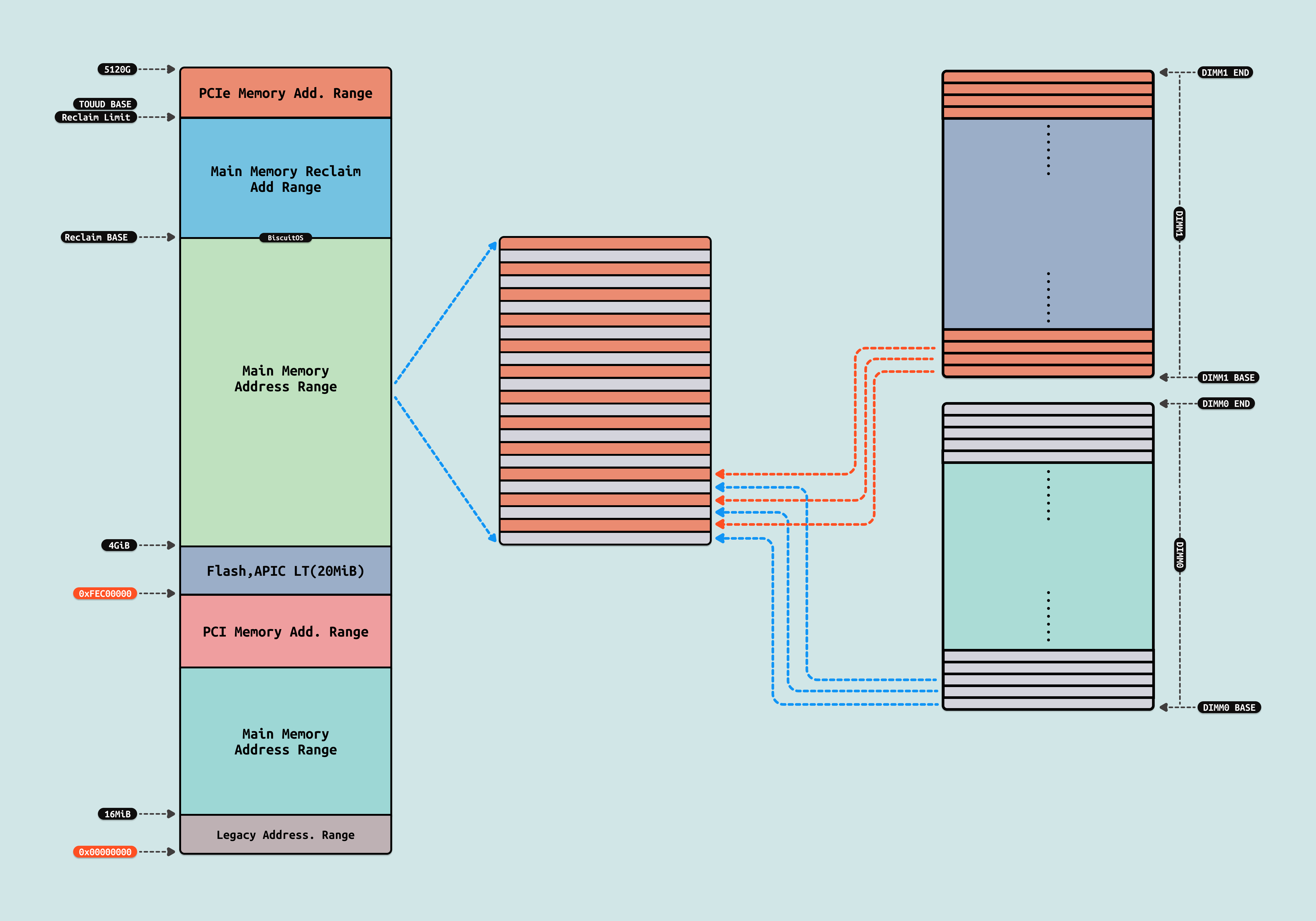
现代 CPU 微架构支持三通道或四通道内存,这允许内存控制器同时访问多个 DIMM. 为了让系统更好的享受多通道带来的带宽优势,硬件引入了内存交织(Memory Interleaving)技术. 其最大的特点是连续的系统物理内存被交织映射到所有的 DIMM 上,通俗来讲就是物理地址第一个 512B 来自 DIMM0,第二个 512B 来自 DIMM1,第三个 512B 来自 DIMM2,以此类推. 内存交织的优势是 CPU 可以在读取或写入一个 DIMM 同时,立即访问下一个 DIMM 上的数据, 这样可以充分享受高带宽的优势,是系统整体性能提升. 此时程序依旧将程序放到连续的物理内存上,CACHE 依旧根据局部性原理将连续的物理内存加载到缓存里,但此时这些操作可以在多个 DIMM 上并行进行.
SUMA and NUMA Interleaving
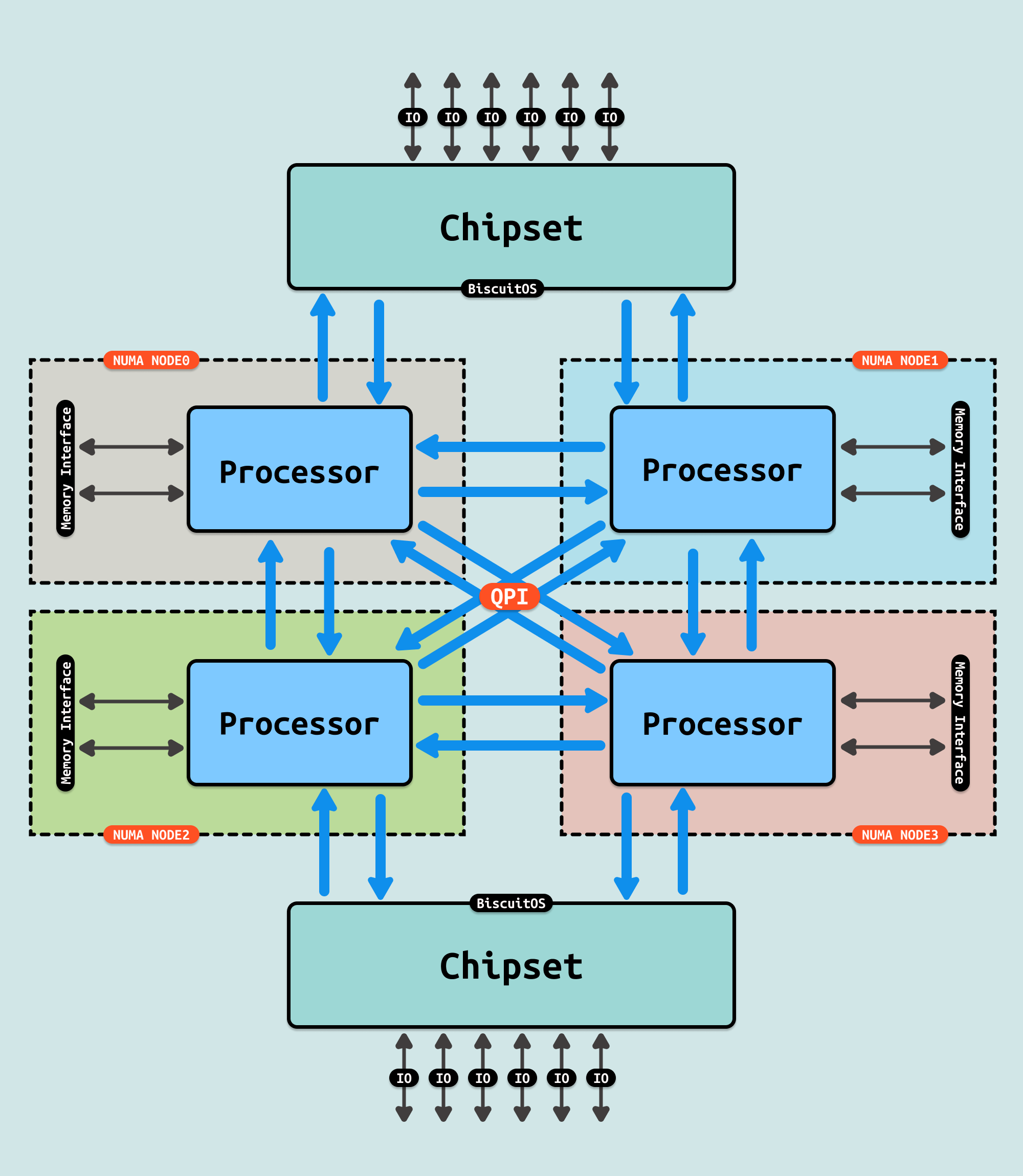
在现代 CPU 中都存在多个 NUMA NODE,每个 NUMA NODE 内存在一个或者多个内存控制器,每个内存控制器存在多个 Channel, 同时内存也被划分为本地内存和远端内存,系统出于性能考虑就会让 CPU 尽可能的访问本地内存,这样会让该节点的 CPU 争抢优先的 Channel 带宽. 在有的场景下,高带宽的收益远远大于低延迟,系统希望尽可能将物理内存散落到不同的 Channel 上, 因此出现了一种类似 SMP 的系统配置, 这种配置称为节点交错(Node Interleaving). 该选项通常可以在系统BIOS中进行配置,并使操作系统和任何 NUMA 感知(NUMA Aware)和优化的应用程序将系统视为传统的 SMP 系统.
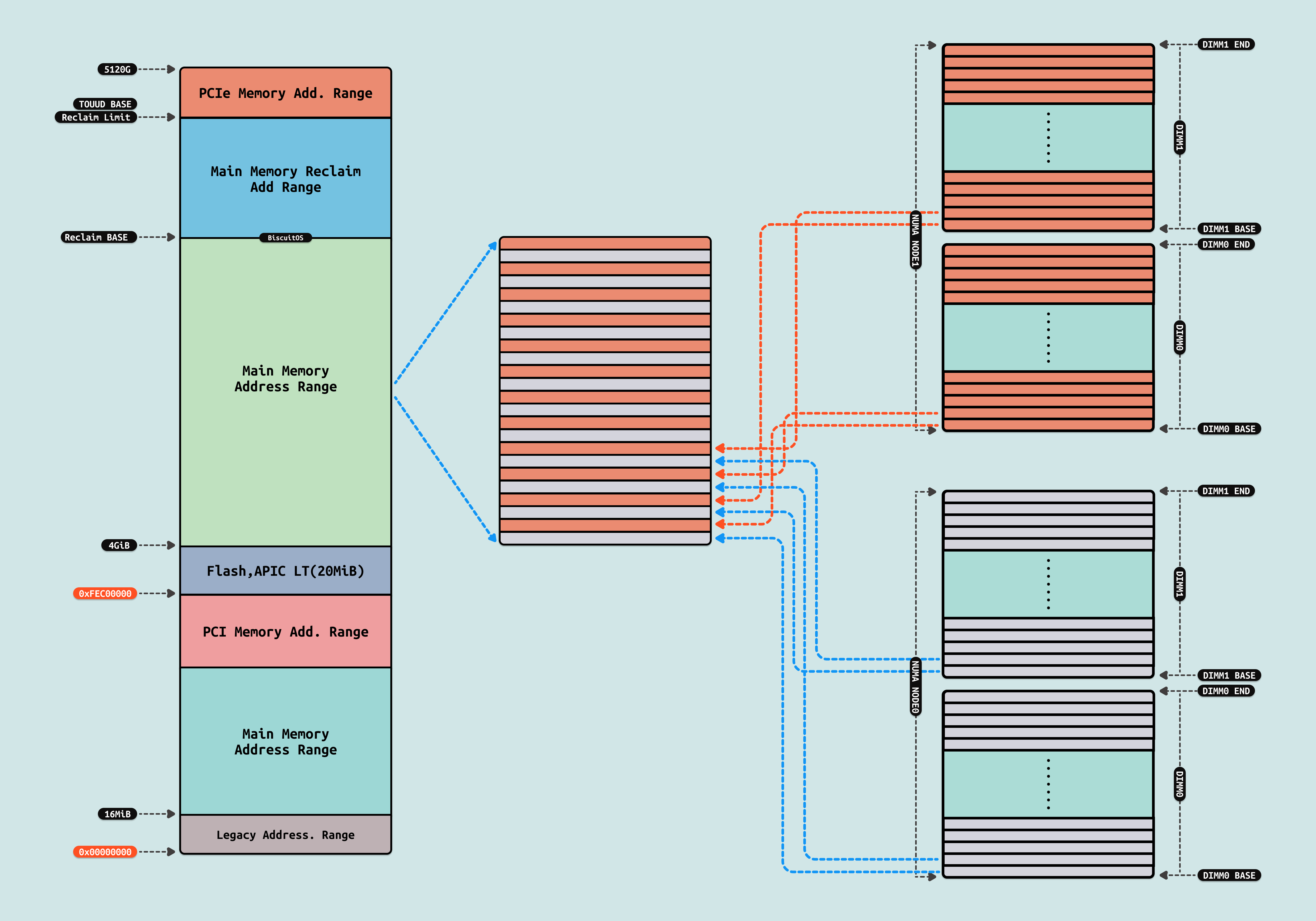
当启用节点交错时,系统将成为一个充分统一内存架构(Sufficiently Uniform Memory Architecture,SUMA) 配置,其中内存被分割成4KB 的可寻址区域,并通过循环方式从每个节点进行映射,从而将系统物理地址空间分布到各个节点中. SUMA 模式的特点:
- 内存交织(Interleaving): 在 SUMA 模式下,每个节点的内存被交织排列,系统会以循环的方式将各个 NUMA 节点的内存段组合在一起. 这种交织机制会将内存以较小的块(例如 4KB)分配到不同的 NUMA 节点,使得系统的物理内存地址空间看起来是连续的
- 统一地址空间: 虽然内存物理上位于不同的 NUMA 节点,但通过 SUMA 模式,操作系统和应用程序会将这些内存视为一个统一的、连续的物理地址空间
- 类似SMP的行为 在 SUMA 模式下,系统表现得更像是一个对称多处理系统(SMP),即所有处理器均匀地访问所有内存,减少了对特定内存区域的偏好

在大多数场景,系统对访问内存的延时有很高的要求,这个时候会将程序绑定到指定 CPU 上运行,因此尽可能的访问本地内存,避免访问远端内存. 比较新的 CPU 硬件支持 NUMA 或者 SNC,每个 NUMA NODE 上都存在一个或者多个内存控制器,每个内存控制器存在多个 Channel. 在禁用 SUMA 的情况下,每个 NUMA NODE 节点内部,硬件仍可以将多个内存控制器和多个内存通道之间进行通道级别的内存交织,以此构成 NUMA NODE 内连续的物理地址空间, 其优势在于:
- 提高带宽: 交织可以最大化多个通道的并行访问能力,因为每次内存访问都会分布到不同的通道上,这样可以在同一时间内利用所有通道的带宽
- 降低延迟: 由于内存地址被分布到多个通道,CPU 无需等待单个内存通道完成读/写操作,从而可以更快地处理内存请求,减少内存访问的延迟

在禁用 SUMA 的多 NUMA 架构下,每个 NUMA NODE 节点 DIMM 映射到系统物理地址空间,形成系统物理地址空间里连续物理,系统物理地址空间的物理内存也被划分成不同的区域,每个区域可以理解为软件层面的 NUMA NODE. 软件层面的 NUMA NODE 的物理内存由物理 NUMA NODE 内多个 Channel 交织映射而成,例如软件层面 NUMA NODE0 的地址第一个 512B 由硬件 NUMA NODE0 DIMM0 的第一个 512B 映射而来,软件层面的第二个 512B 有硬件 NUMA NODE0 DIMM1 的第一个 512B 映射而来,以此类推.

在支持 SNC 的架构里,每个 NUMA NODE 有一个内存控制器,每个内存控制器包含多个 Channel,因此在 NUMA NODE 内可以做 Channel 级别的 Interleaving,这样可以最大化的并行访问内存,另外可以享受更低的延迟.
Intel Roadmap

内存控制器以交织模式在 DIMM 之间分配数据,允许内存控制器访问每个 DIMM 来获得较小的数据块,而不是访问单个 DIMM 来获取整个数据块,这为内存控制器提供更多带宽用于跨通道访问相同数量的数据. 因此内存访问需要: 多内存控制器、多通道、多 Rank、多 Bank 上,这样交织访问. 上图是 Intel Xeon Sapphire Rapid CPU, 每个 CPU 具有四个内存控制器,每个内存控制器有两个 Channel,每个 Channel 有两根 DIMM. 通过 Interleaving 可以享受四个内存控制器,两个 channel 并行访问数据,因此当个内存访问最大带宽的理论值为:
- 4800(MT/s) * 64(bit) / 8(bit/Byte) = 307200 MBps
在内存通道的 Interleave 中会有 Interleave group 的形成,而在一个 Interleave group 中会首先检查同样容量,同样 rank 数目的最大内存通道数,这个最大通道数的区域会组成一个 Interleave group. 而不平衡的内存插法会在第一次的遍历之后剩下一部分 DIMM 或者内存容量,剩下的内存容量,会按照同样的方法重复进行 Interleave 的分组. 以此类推可能会得到不同 Interleave group, 而每个 group 内部的通道数,capacity 都可能存在的差异,因此内存访问的性能就会出现不同的结果. 所以出于性能考虑,有以下建议:
- 所有的内存通道建议有同样的内存容量和同样的 RANK 数量
- 在一个处理器上的所有内存通道建议有同样的内存配置
控制 NUMA 的 Intel BIOS 选项
- NUMA OFF: 1 NUMA Cluster Per Node
- NUMA ON:
- SNC Disable(1 NUMA Cluster Per Socket): 建议设定为 2-Way Interleaving
- SNC Enable(2 NUMA Cluster per Socket): 不会影响整体的内存带宽,通过与就近的 IMC 进行亲和,优势在于局部性好,但是有些极端场景会更差. 但是整体的 LLC/MEM 时延可能会更小, 另外的优点就是 mesh 上的信息更小了. 建议不设置内存控制器交织,也就是保持 1-Way Interleaving.