

目录
Multild Die For MCM
NUMA Software
ACPI With NUMA: HMB/SRAT
NUMA FALLBACK Mechanism
NUMA BALACNING SCHEDULE
NUMA MEMORY Policy
Tiered Memory with NUMA
NUMA Fault
CPULess NUMA
Hotplug with NUMA
PCIe(DMA) with NUMA
CXL with NUMA
HBM with NUMA
NUMA Tools Union
libnuma: numactl/numastate/numademo
numasate
lmbench
NUMA Optimize on Intel/AMD
NUMA Underpinning
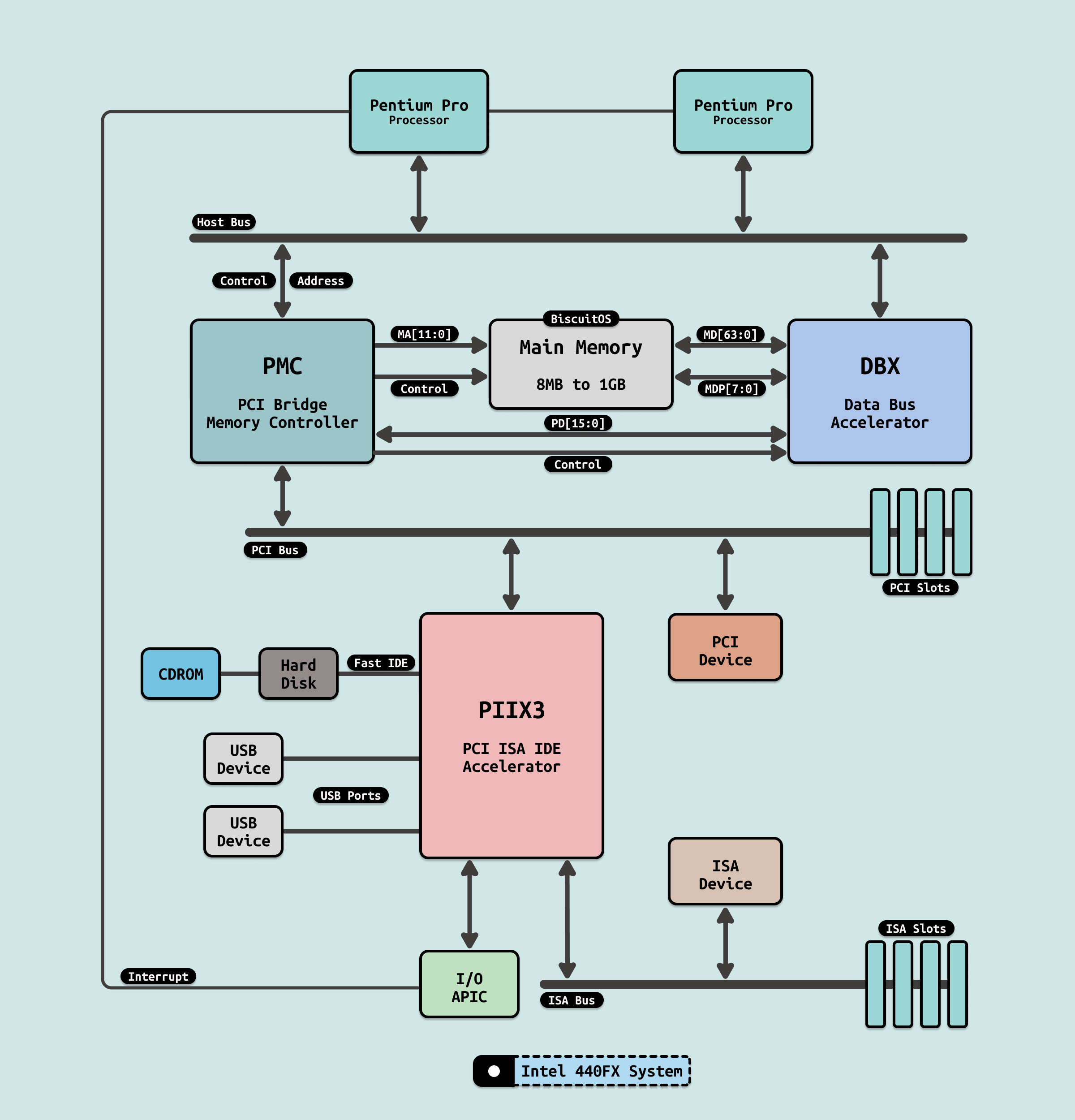
在早期的计算机,其采用单处理器架构,即一个 CPU 只有一个物理核,并且主板上只有插一块 CPU Package. 随着技术的进步,主板上可以插入更多的 CPU package,这是 CPU 内部依旧是单物理核结构,多处理器系统的出现,它们能够同时处理多个任务,显著提高了计算效率. 最初这些多处理器系统采用的是对称多处理(SMP)架构,所有的处理器共享同一块内存资源,每个处理器都可以平等地访问所有的内存,比如典型的 Intel i440FX 架构,所有的处理器共享系统总线(FSB).
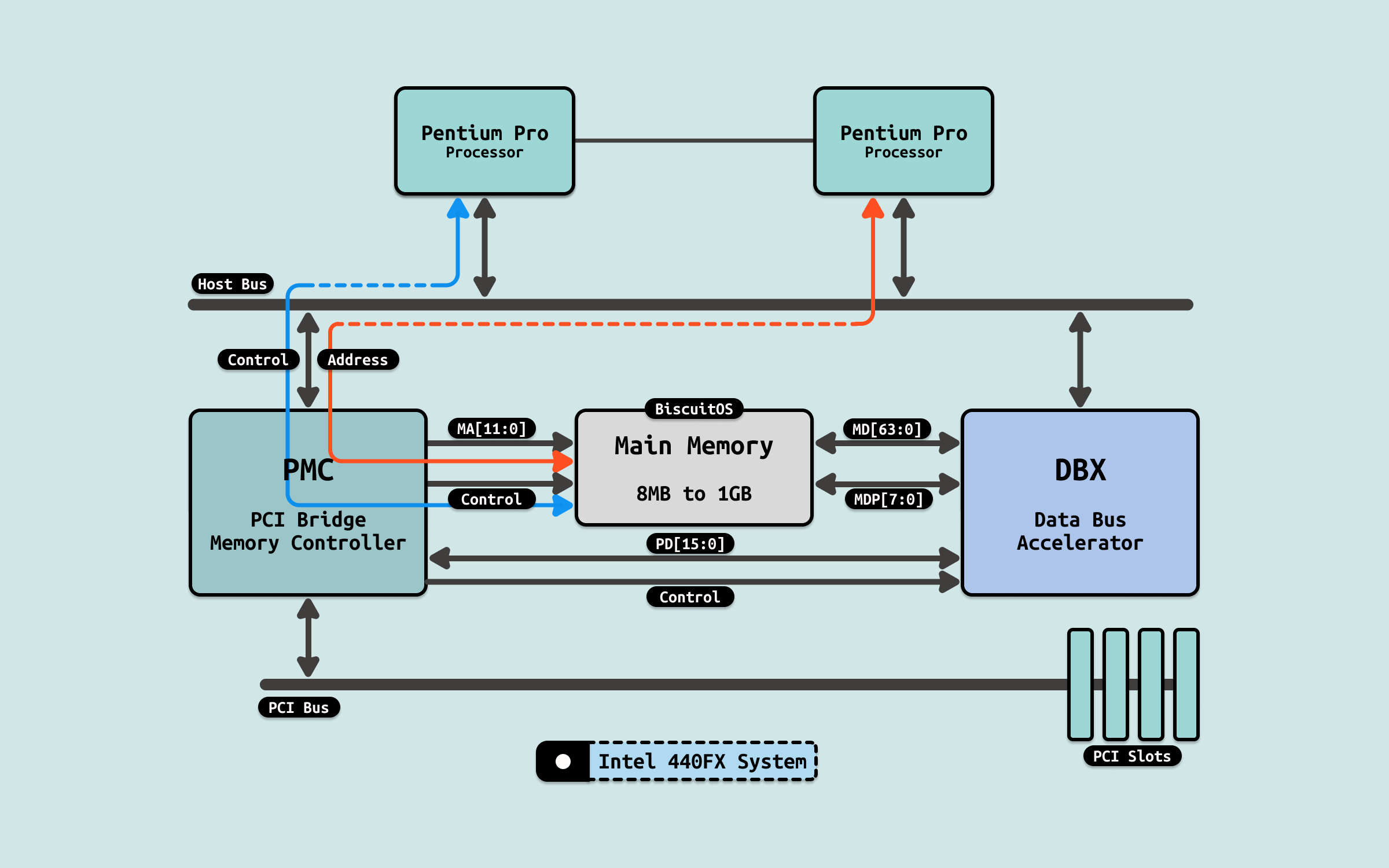
在这种架构下,内存控制器和内存并没有集成到 CPU 内部,CPU 访问内存需要通过共享总线(FSB) 经由内存控制器(PMC) 才能访问到物理内存, 可以看到所有处理器访问内存的距离都是一样的,因此称这类架构为统一内存访问架构(Uniform Memory Access: UMA). 在 UMA 架构下,所有处理器(CPU) 访问内存的延迟(Latency)是一致的.

然而,随着处理器核心数量的增长,SMP 架构暴露出了性能瓶颈, 其中 FSB 共享总线带宽影响最明显,Intel 为此不断改进,引入了双独立共享总线(Dual Independent Buses: DIB)和基于高速互联(Dedicated High-Speed Interconnects: DHSI) 的四独立共享 FSB 总线. 但竞争对手 AMD 推出的 HyperTransport 总线直接取消了北桥,将内存控制器集成到 CPU 内部, 大大降低了多核芯带来的性能瓶颈,Intel 随后也将内存控制器集成到 CPU 内部, 至此共享总线模式退出舞台.
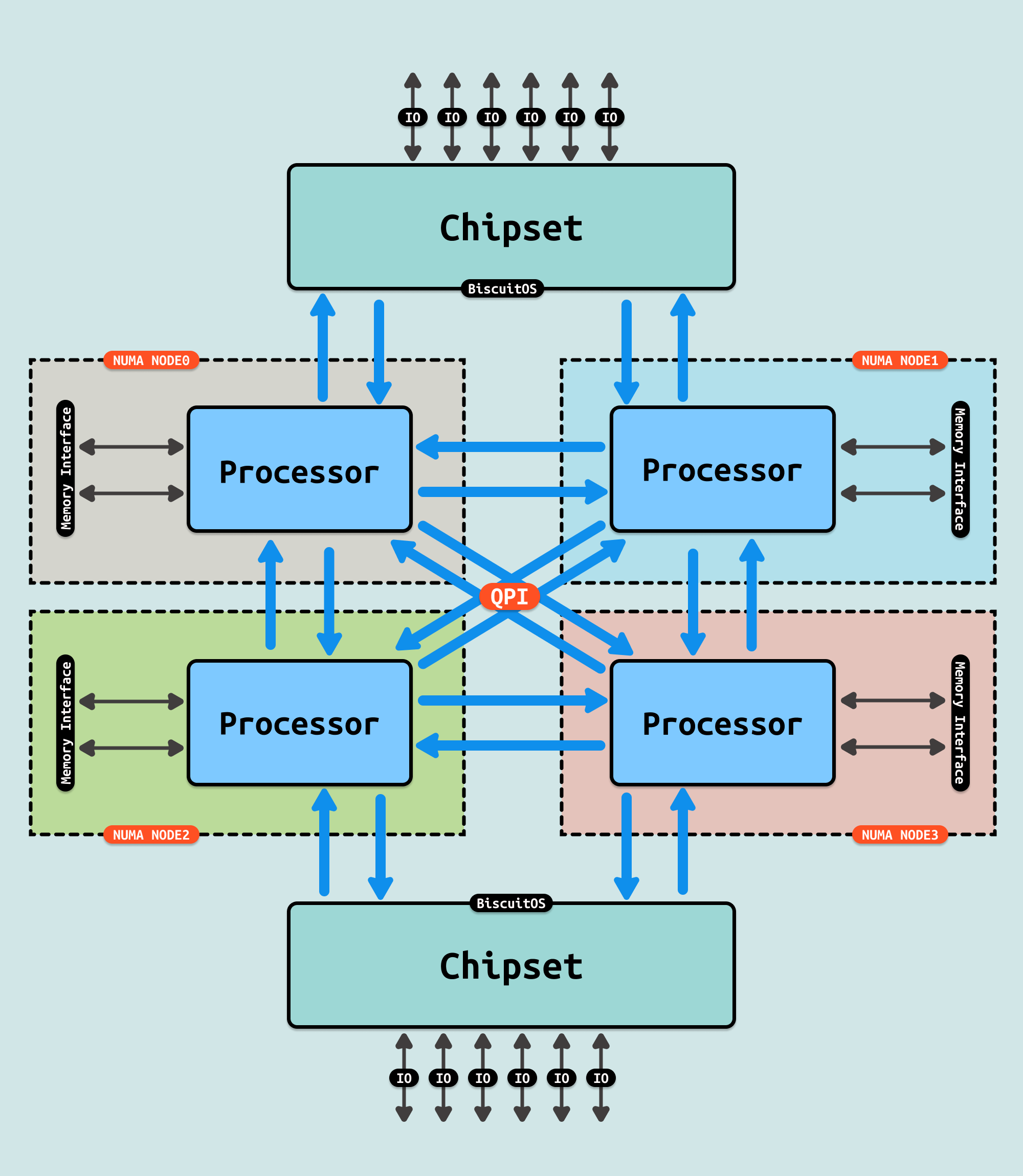
X86 将内存控制器集成到 CPU 内部之后,Intel 尽可能提高 CPU 频率来提升性能,受限于工艺和技术,提升频率有一定的限度,于是提出拼核心数来提升性能,早期的拼核心数的方式是在主板上加入更多的 Socket,让多个处理器通过 QPI 总线互联. 每个 Socket 都有自己的内存控制器,内存控制器连接内存条(DIMM). 由于 QPI 总线互联模式的出现,处理器可以访问本 Socket 内部的内存,也需要跨 Socket 去访问其他 Socket 的内存. X86 顺势推出了非一致性内存访问(Non-uniform Memory Access: NUMA)架构, 在 NUMA 架构下,将一个 Socket 称为一个独立的 NUMA 节点(NUMA NODE), 本 Socket 的内存称为本地内存(Local Memory), 而需要跨 NUMA 才能访问到的内存称为远端内存(Remote Memory).

随机架构进一步演进,Die 内被塞入更多的物理核,物理核之间通过 RingBus 总线连接在一起,该总线与 FSB 共享总线类似,每个 Ring 上连接一个内存控制器,这条总线也被称为 IMC Bus. 但随着 Die 内存塞入的物理核越来越多,为了保证延迟,一个 Ring 已经不够用,于是出现了 1.5 个 Ring 和 2 个 Ring 的架构,多出来的 Ring 也连接到一个内存控制器里,因此一个 Package 里出现了两个内存控制器的情况. CPU 不仅跨 Socket 访问远端内存会带来性能损耗,Die 内的物理核跨 Ring 访问内存控制器也会有一定的性能损耗.
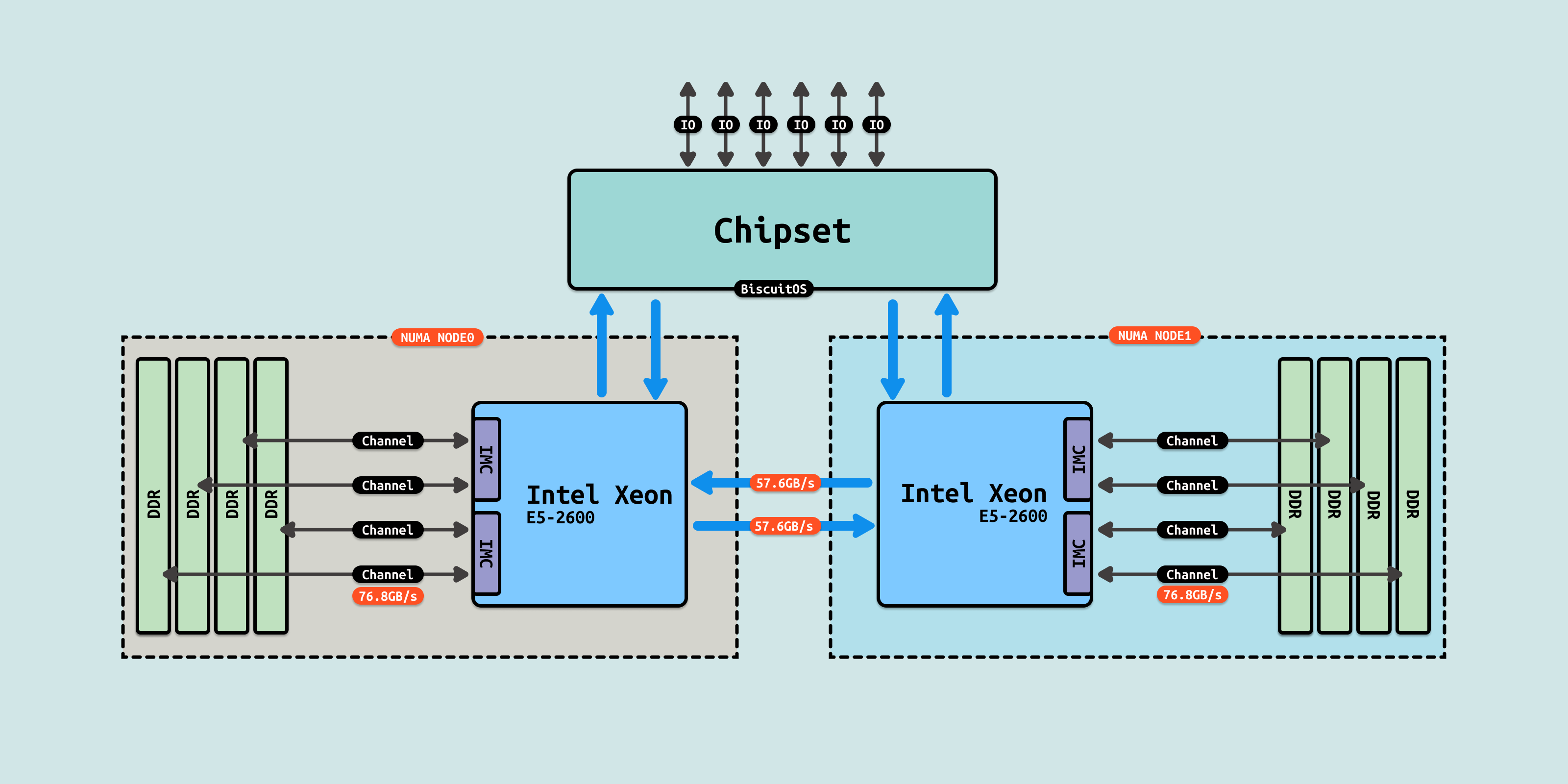
以 Intel Xeon 2600 V4 系列 CPU 来看,两个 Socket 之间通过各自一条 9.6GT/s 的 QPI 总线互联. 每个处理器内部具有两个内存控制器,并且每个内存控制器有两个内存通道(Channel), 每个内存通道最多支持 3 根内存条(DIMM). 理论上 Socket 支持 76.8GB/s 的内存带宽,而两个 QPI link,每个 QPI link 有 9.6GT/s(~57.6GB/s) 的速率,如果跨 Socket 访问,那么 QPI link 已经出现了瓶颈.

随着 Die 内核心数的不断增多,RingBus 已经称为了性能瓶颈,在 Intel Xeon Skylake 引入了 Mesh 总线. 由于这种架构的变化,导致内存的访问变得更加复杂. 在 Mesh 总线上,每个节点的维度(连接数量)为 2、3 或者 4,相邻节点称为一跳(Hop), 两个节点之间 Hop 个数称为跳数(Hop Count),每一跳都需要消耗时间,两个节点之间的跳数越少,延迟越低. 因此在 Mesh 总线架构里,两个 IMC(内存控制器) 也有了 Local/Remote 的区别,在保证兼容性的前提和性能导向的纠结中,系统允许用户进行更灵活的内存访问架构划分, 因此 “NUMA 之上的 NUMA” 的 SNC(Sub-NUMA Clustering) 概念孕育而生.
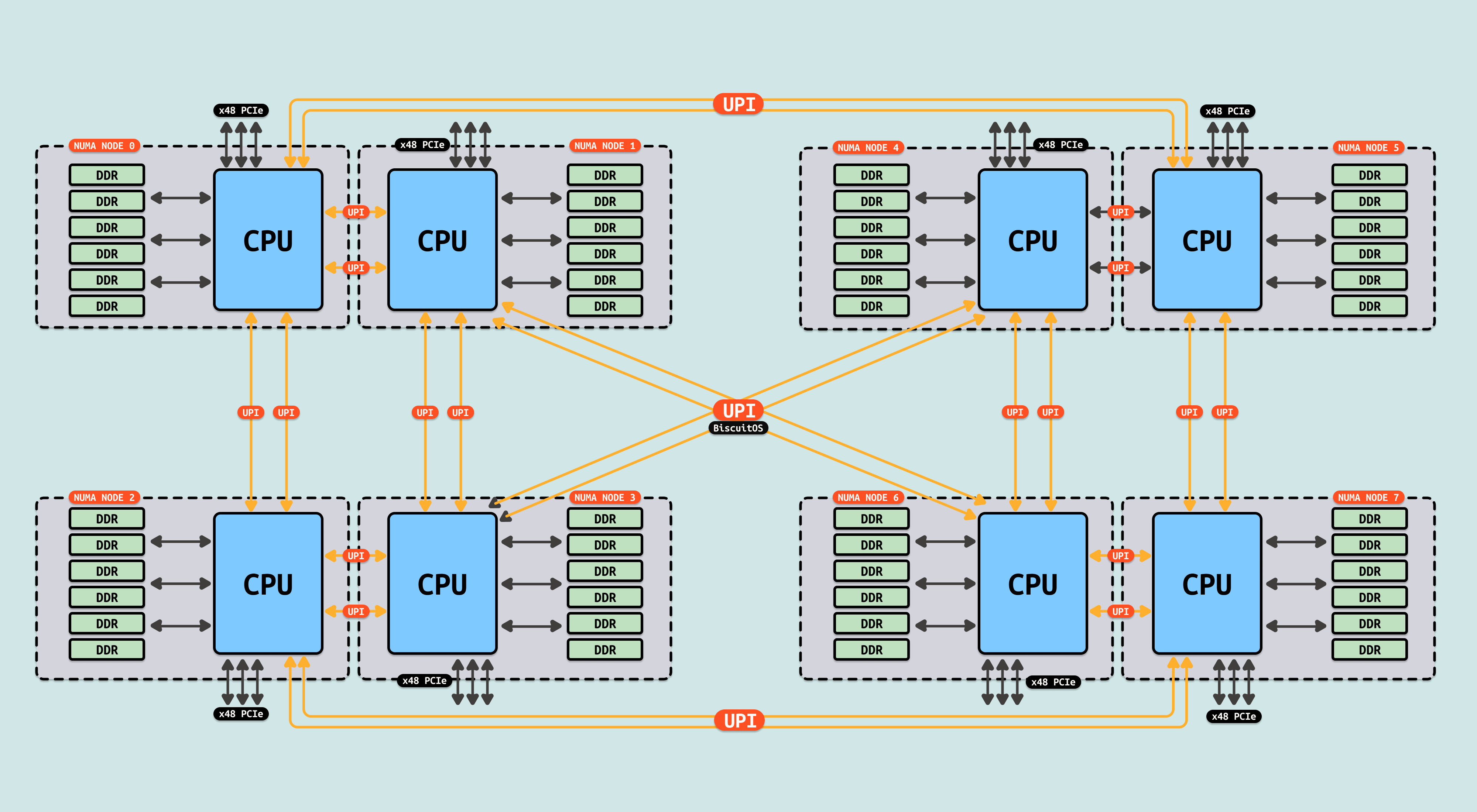
为了提升 Socket 之间的互联效率,QPI 总线升级为 UPI 总线,其可以提供高达 10.4GT/s(QPI 9.6GT/s), 约为 41.6GB/s, 这对跨 Socket 的内存访问是有益的. 以上便是 NUMA 的基本原理,在分析 NUMA 性能优化时,应该基于实际的 CPU 架构进行优化,后续的内容将对 Intel 和 AMD 进行详细的分析.