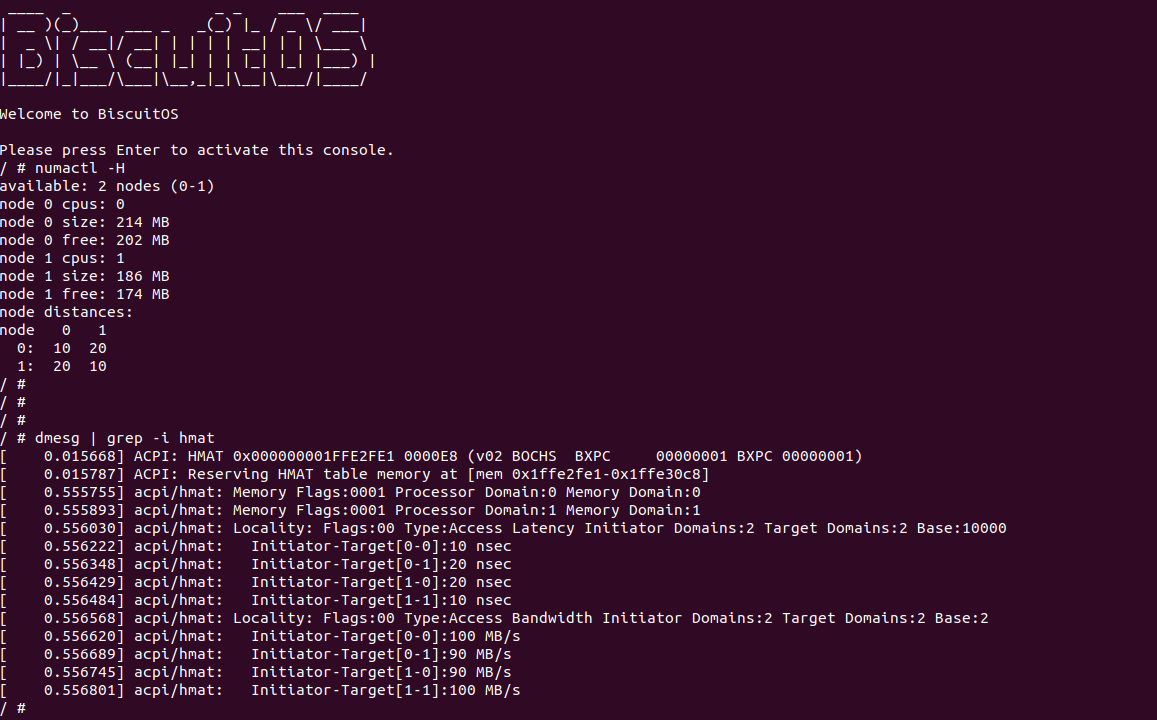
SNC(Sub-NUMA Clustering)是一种内存架构优化技术,最早在 Intel Xeon Scalable Skylake 其处理器中引入. 在 Skylake 内部集成了更多的物理核,其使用 Mesh 总线将所有的物理核和内存控制器(IMC) 连接. 相邻物理核之间的距离称为一跳(Hop),物理核之间通过跳数(Hop Count) 描述之间的距离或延时(Latency). 同理, 物理核与内存控制器之间的跳数越小,那么访问内存延时就越小. 由于 Mesh 总线的对角线没有相连,因此在双内存控制器的架构里,物理核到两个内存控制器的跳数并不相同, 因此内存控制器也出现了本地和远端的区分.

对于 Skylake 之间的处理器,一个 Socket 就是一个独立的 NUMA NODE,但对于 Skylake 处理器,其将 Socket 的 NUMA 域进一步分割成更小的 NUMA NODE, 通过增加内存的局部性来减低内存访问延时. 如图其内部存在两个内存控制器,可以将其换分成两个 SNC Domain,Domain 内的内存称为本地内存(Local Memory),相对的 Domain 外的内存称为远端内存(Remote Memory). 物理核访问本地内存的延时要小于远端内存. SNC 的特点如下:
- 减少内存访问延迟: SNC 通过将单一的 NUMA 节点进一步分成多个较小的子 NUMA 节点,使处理器在本地 NUMA 节点内存区域内的访问更加快速,减少跨 NUMA 节点访问的延迟
- 改进缓存局部性: SNC 分割了每个 NUMA 节点的缓存区,使得每个 SNC 域的缓存更贴近本地内存. 这意味着缓存访问更快,并且处理器可以更高效地访问其本地的数据
- NUMA 拓扑的优化: SNC 会将缓存、内存控制器等资源进行逻辑分组,每个组称为一个 SNC 域. 不同的 SNC 域会有独立的资源,从而提高系统的并行处理能力
- 操作系统支持: SNC 的拓扑信息可以通过 ACPI HMAT(Heterogeneous Memory Attribute Table)等机制暴露给操作系统. 操作系统通过这些信息来优化任务调度和内存分配,使任务尽量在本地 SNC 域运行,进一步提升性能
- 硬件要求: SNC 需要处理器和内存控制器对称布置,通常在多核服务器处理器(如 Intel Xeon Scalable)中实现

ACPI HMAT(Heterogeneous Memory Attribute Table,异构内存属性表) 提供关于系统中内存拓扑结构的详细信息,特别是与带宽、延迟和内存设备之间的关系. HMAT 的目的是帮助操作系统在具有异构内存的系统中进行优化内存管理,例如在多 NUMA 节点和混合存储(如 DRAM、HBM 和 NVDIMM)系统中. 在 SNC 架构了,可以根据 HMAT 表对程序进行优化, 例如上图中,NUMA NODE 0 与 1 属于同一个 Socket 里的两个 SNC 域,因此其延时远低于跨 Socket NUMA 的延时, 因此在优化程序性能时,尽可能将程序划分到某个 SNC NODE 上,避免跨 SNC 和 Socket 内存访问.
Latency and Bandwidth

在 CPU 厂商中对 SNC 的表述为: “改善了对 LLC 的平均延迟”,那么 SNC 是 BIOS 中隐藏的 Turbo 功能? 基于 《基于 Sub-NUMA 处理器拓扑的内存数据库任务调度》 中发布的性能数据,在默认的 NUMA 配置下(SNC 为开启), Socket0(S0) 和 Socket1(S1) 之间的延迟差异如上.

启用 SNC 后, Socket0 包含了两个 NUMA NODE,分别是 NODE0 和 NODE1, Socket1 包含两个 NUMA NODE,分别是 NODE2 和 NODE3. 这些逻辑分区是实际的 NUMA NODE. 尽管不同的内存控制器和缓存域位于同一个芯片上,但缓存机制和内存控制器的非交织访问模式在域之间创建了非统一的内存访问模式. 因此当从同一插槽内的另一个 Remote NUMA 节点获取内存时,延迟会增加. 通过将内存地址从本地内存控制器映射到最近的 LLC,SNC 确实降低了本地 NUMA 延迟,与默认 NUMA 配置相比,启用 SNC 后,本地 NUMA 的延迟平均下降了 6% 到 7%. 以 NUMA 节点 0 为例,启用 SNC 后,它的内存延迟为 74.2 ns,而在 SNC 未启用的情况下,访问延迟为 80.8 ns。因此 SNC 将 NUMA 节点 0 的内存延迟降低了 7.5%.
性能数据显示,由 NUMA NODE0 和 NODE2 处理的远程连接表现优于 SNC 禁用状态,而 NUMA 节点 1 和节点 3 的表现则不如 SNC 禁用状态. 报告的同一插槽内远程节点的延迟非常有趣,可能显示了互连架构的独特行为. 然而英特尔并未分享关于 Ultra Path Interconnect(UPI)框架的详细信息. 会注意到 NUMA 节点 0 之上有一个具有两个 UPI 连接的控制器,而 NUMA 节点 1 之上有一个具有单个 UPI 连接的控制器. 可能单个 UPI 在网格上的 I/O 流量阻塞较多,而具有两个连接的 UPI 控制器能够更好地管理数据流动.
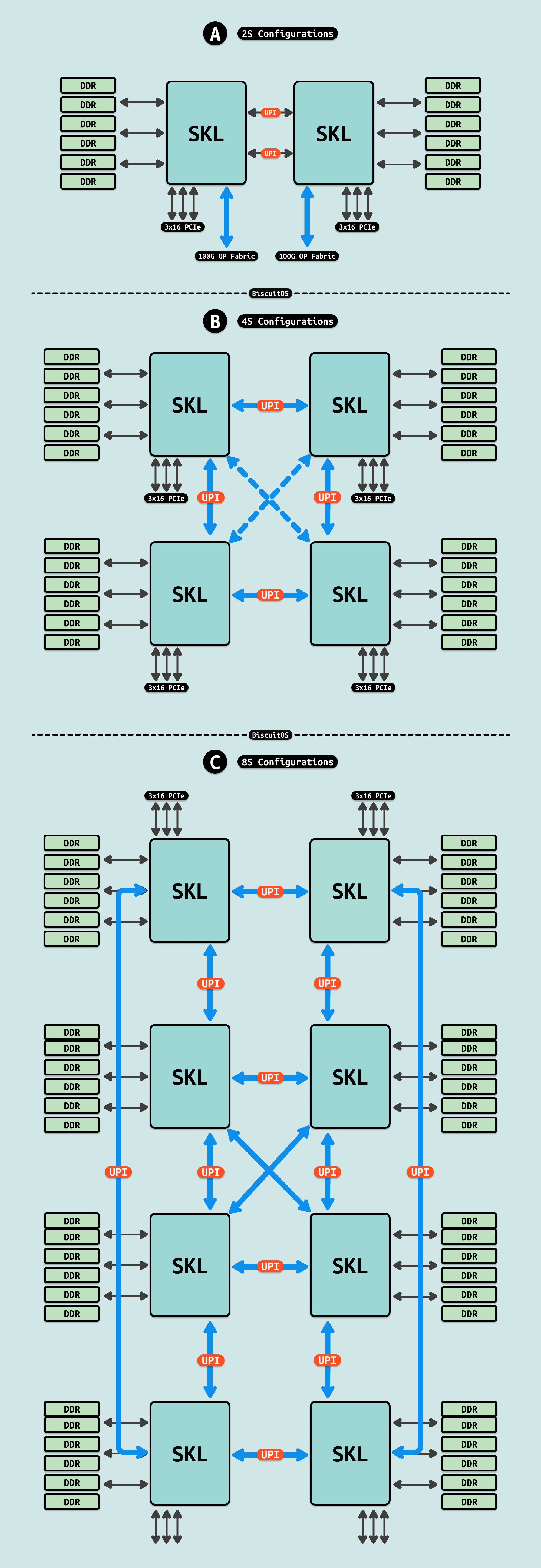
Skylake CPU 型号具有两到三个 UPI 链路, 每个 UPI 链路是一个点对点的全双工连接,每个方向有独立的通道. UPI 链路的理论传输速度为 10.4 Gigatransfers per second(GT/s),这相当于 20.8 gigabytes per second(GB/s). 研究中使用的 Intel Xeon Platinum 8180 处理器包含三个 UPI 链路,理论上可以提供 62.4 GB/s 的聚合带宽. 一个控制器具有两个 UPI 链路,另一个控制器具有一个 UPI 链路. 研究论文显示,与远程节点通信时,平均带宽大约为 34.4 GB/s. 由于有关 UPI 通信模式的信息有限,在默认 NUMA 节点下,系统只使用了两个 UPI 链路. 默认 NUMA 下,内存跨内存控制器交错,因此必须从两个内存控制器中检索内存,因此系统使用了两个 UPI 控制器.

启用 SNC 后,系统停止将整个内存范围交错分配给 CPU 包内的两个内存控制器,而是给了每个内存控制器分配内存范围的子集. 每个内存控制器有三个通道,将 NUMA 节点的带宽分为两半. 测试系统使用了 DDR4 2666 MHz(21.3 GB/s)的内存模块,理论上每个 SNC NUMA 节点可以提供 63.9 GB/s 的带宽. 在查看研究结果时,默认 NUMA 节点提供了 111 GB/s(6 个通道).

启用 SNC 后,每个 NUMA 节点的带宽应大约为 55.5 GB/s,但测试结果报告为 58 GB/s. 由于工作负载的隔离,SNC 将局部带宽平均提高了 4.5%,从而减少了其他 I/O 操作在网格上的阻塞情况. 同样的改进也发生在同一 Socket 上的 NUMA 节点. 因此,SNC 是为高度优化的工作负载挤出最后一点性能的绝佳方式. 如果工作负载在核心数量和内存容量上适合较小的 NUMA 节点,那么它可以预期在延迟上获得 7% 的提升,并且内存带宽提升 4%. 如果在每个工作节点中部署两个运行不同工作负载的工作线程,它们都可以从额外可获得的带宽中受益. 如果你只部署一个工作负载,那么你就剥夺了该工作负载一半可获得的带宽. 该工作负载仍然可以访问远程内存容量,并有可能获得更多带宽,但是否做出明智的决定并选择合适的 NUMA 节点,取决于 NUMA 调度器或应用程序的判断.
Intel Xeon Scalable SNC
SNC 与 Haswell 引入的 Cluster-on-Die(COD)特性类似,但两者之间存在一些差异. SNC 在处理器内部创建两个本地化域,通过将来自本地内存控制器的地址映射到与该内存控制器更靠近的一半 LLC Slices,而将映射到另一个内存控制器的地址映射到另一半 LLC 切片中. 通过这种地址映射机制,在 SNC 域中的核运行的进程使用来自同一 SNC 域中的内存控制器时,观察到的 LLC 和内存延迟较低,而访问映射到另一个 SNC 域的地址时延迟会增加.
与 COD 机制不同的是,COD 允许缓存行在每个 Cluster 的 LLC 中都有副本,而在 SNC 中,每个地址在 LLC 中都有唯一的位置,且不会在 LLC 切片之间复制. 此外,地址在 LLC 中的本地化仅适用于映射到同一 Socket 中内存控制器的地址. 所有映射到远程 Socket 内存的地址在 LLC 切片中均匀分布,与 SNC 模式无关. 因此,即使在 SNC 模式下, Socket 上所有核心都可以使用整个 LLC 容量,且通过 CPUID 报告的 LLC 容量不受 SNC 模式的影响.
上图显示了一个由 SNC 域 0 和 SNC 域 1 组成的双集群配置,以及它们相关的核心、LLC 和内存控制器. 每个 SNC 域包含 Socket 上一半的处理器、一半的 LLC 切片和一个具有三个 DDR4 通道的内存控制器. Core、LLC 和内存在域中的亲和性通过操作系统的 NUMA 亲和性参数表达,操作系统可以考虑 SNC 域在调度任务和分配进程内存时的作用,从而优化性能. SNC 要求内存不能以细粒度方式跨内存控制器交错. 此外,SNC 模式需要通过 BIOS 启用,以便每个 Socket 暴露两个 SNC 域,并设置资源亲和性和延迟参数,以便与 NUMA 原语一起使用.
Intel® Xeon® Processor Scalable Family Technical Overview
Intel Xeon Max Series SNC
Intel Xeon Max Series 是 Sapphire Rapids 微架构的一个高端版本,专门针对对内存带宽有高需求的工作负载,比如高性能计算 (HPC)、人工智能 (AI)、大数据分析等. Intel Xeon Scalable Processor SPR 是 Sapphire Rapids 系列的标准版本,它们都共享相同的核心微架构和技术改进,比如 Compute Express Link (CXL) 和增强的 PCIe 通道.

随着时间的推移,处理器、内存控制器、互连结构和支持基础设施的密度在芯片上不断增加,而几何尺寸变得越来越小. 这导致数据从芯片的一端移动到另一端所需的时间增加. 最初使用的是统一内存访问(UMA)域,并且在系统中仍然可以选择这种架构. 它提供了一个在所有内存控制器之间交错的单一连续地址空间. 然而 UMA 并没有为最近资源的数据流动提供优化. 这通常通过处理器亲和性来完成,处理器亲和性是一种用于指定某个软件线程使用哪一个处理器的方式. 因此,当所有内核属于 UMA 域时,它们对最后一级缓存和内存的访问是平等的. 在这种情况下,可能会出现处理器访问位于芯片另一侧的内存控制器或最后一级缓存切片,而不是访问最近的资源的情况.
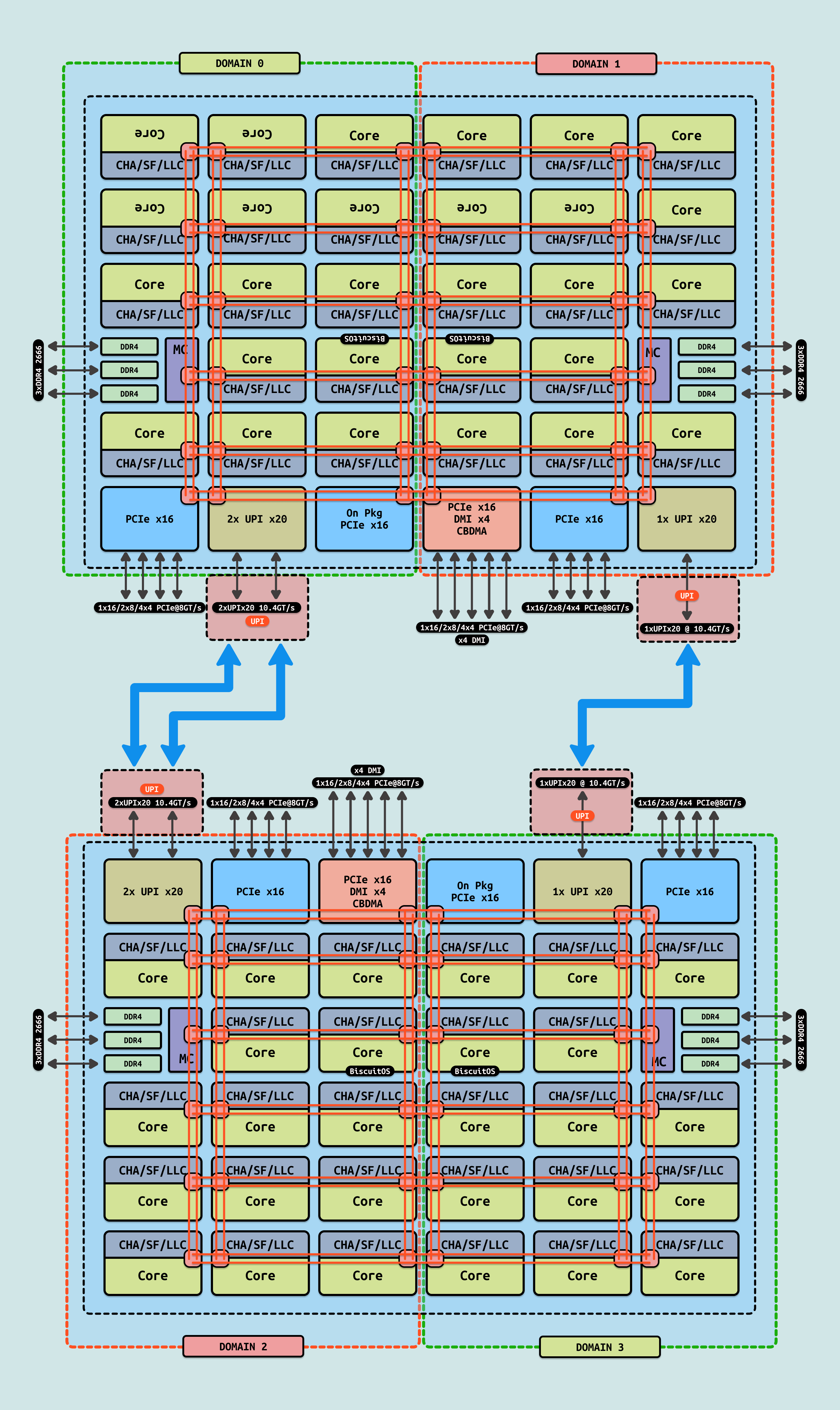
为了减少芯片上数据移动的延迟,引入了 Sub-NUMA Clusters(SNC). 在双 Cluster 的 SNC(SNC-2)中,处理器内存在两个本地化域, 每个域都有来自本地内存控制器和本地最后一级缓存(LLC)切片的映射地址. 本地域中的处理器将使用本地内存控制器和本地LLC 切片. 本地域中的处理器在访问映射到同一 SNC 域的内存时,会观察到比访问映射到其他 SNC 域外的位置更低的 LLC 和内存延迟. SNC 为 LLC 中的每个地址分配了一个唯一的位置,并且在 LLC Bank 中不会重复. 每个 SNC 域中 LLC 的地址本地化仅适用于映射到同一 Socket 中内存控制器的地址. 所有映射到远程 Socket 内存的地址在所有 LLC Bank 中均匀分布,且与 SNC 模式无关. 因此即使在 SNC 模式下,每个核心仍然可以使用 Socket 上的整个 LLC 容量,并且通过 CPUID 报告的 LLC 容量不受 SNC 模式的影响.

上图展示了一个由 SNC Domain0 和 SNC Domain1 组成的双 Cluster 配置,以及与其相关的核心、LLC 和内存控制器. 每个 SNC 域包含 Socket 上半数的处理器、半数的 LLC Bank 以及一个与其相关的 DDR 通道的内存控制器. Core、LLC 和内存的亲和性通过操作系统中的 NUMA 亲和性参数表达,操作系统可以在任务调度和内存分配中考虑 SNC 域,以实现最佳性能.

最新一代的硅芯片提供了 2 Domain 或 4 Domain 版本的 SNC. SNC 需要在 BIOS 级别启用,并要求内存对称分布,同时软件也需要进行优化以充分利用 SNC 功能, 如果这些条件能够满足,那么 SNC 将提供所有操作模式中最佳的性能.
Technical Overview Of The Intel® Xeon® Scalable processor Max Series
BiscuitOS 实践 SNC
BiscuitOS 目前以及支持 SNC 的实践,其基于 QEMU 提供的 HMAT 机制实现 Latency 和 Bandwidth 模拟,开发者可以参考如下步骤进行实践:
# 切换到 BiscuitOS 项目目录
cd BiscuitOS
# 选择开发环境,如果已经选择过可以跳过,这里与 linux 6.10 X86 为例
make linux-6.10-x86_64_defconfig
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
[*] NUMA(Non-uniform Memory Access)
NUMA Hardware Topology (x2 SNC NUMA NODE with Mesh(Xeon Skylake-SP)) --->
[*] HMAT NUMA Latency AND Bandwidth
# 配置完毕保存,然后进行部署
make
# 运行 BiscuitOS
cd BiscuitOS/output/linux-6.10-x86_64
./RunBiscuitOS.sh