

在个人计算机微处理器架构中,英特尔的 QuickPath Interconnect(QPI) 是一种点对点的处理器互连技术,从 2008 年开始替代了在 Xeon、Itanium 以及某些桌面平台上的前端总线(FSB). 它提高了可扩展性和可用带宽. 在正式命名为 QPI 之前,英特尔称其为通用系统接口(CSI), 更早的版本被称为又一个协议(YAP)和YAP+.
FSB 是一种共享总线,所有的处理器核心、内存和其他系统资源都通过这个总线进行通信。随着多核处理器的普及和处理器核心数量的增加,FSB 成为了一个显著的性能瓶颈. 因为所有的数据传输都必须通过这一个总线,多个核心同时访问数据时会相互竞争带宽,导致严重的拥堵和延迟. 随着处理器速度的增加,FSB 的带宽成为限制整体系统性能的一个因素。尽管前端总线的频率得到了提升,但它仍然无法满足高性能计算和高速存储之间的数据传输需求.
与 FSB 不同,QPI 提供了点对点的连接,允许直接连接处理器和内存控制器或其他处理器. 这种设计减少了数据传输路径,降低了延迟,提高了数据传输效率。每个处理器或核心可以直接访问连接到其上的内存,而不必通过一个共享总线,这在多处理器配置中特别有效. QPI 支持非一致性内存访问(NUMA),这使得在多处理器系统中,每个处理器都可以访问自己最近的内存,从而提高内存访问速度和总体性能。这对于数据中心和高性能计算应用尤其重要.

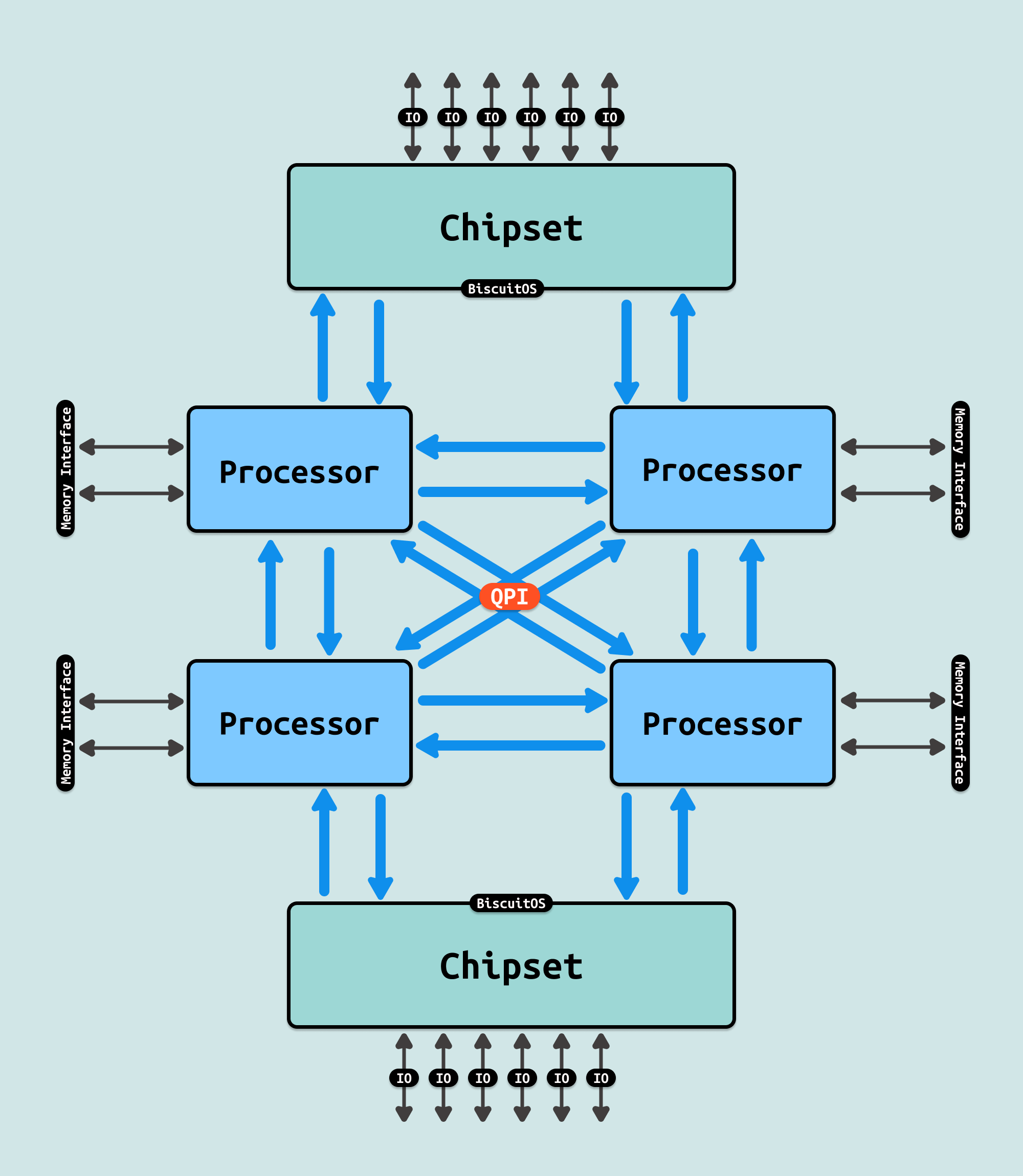
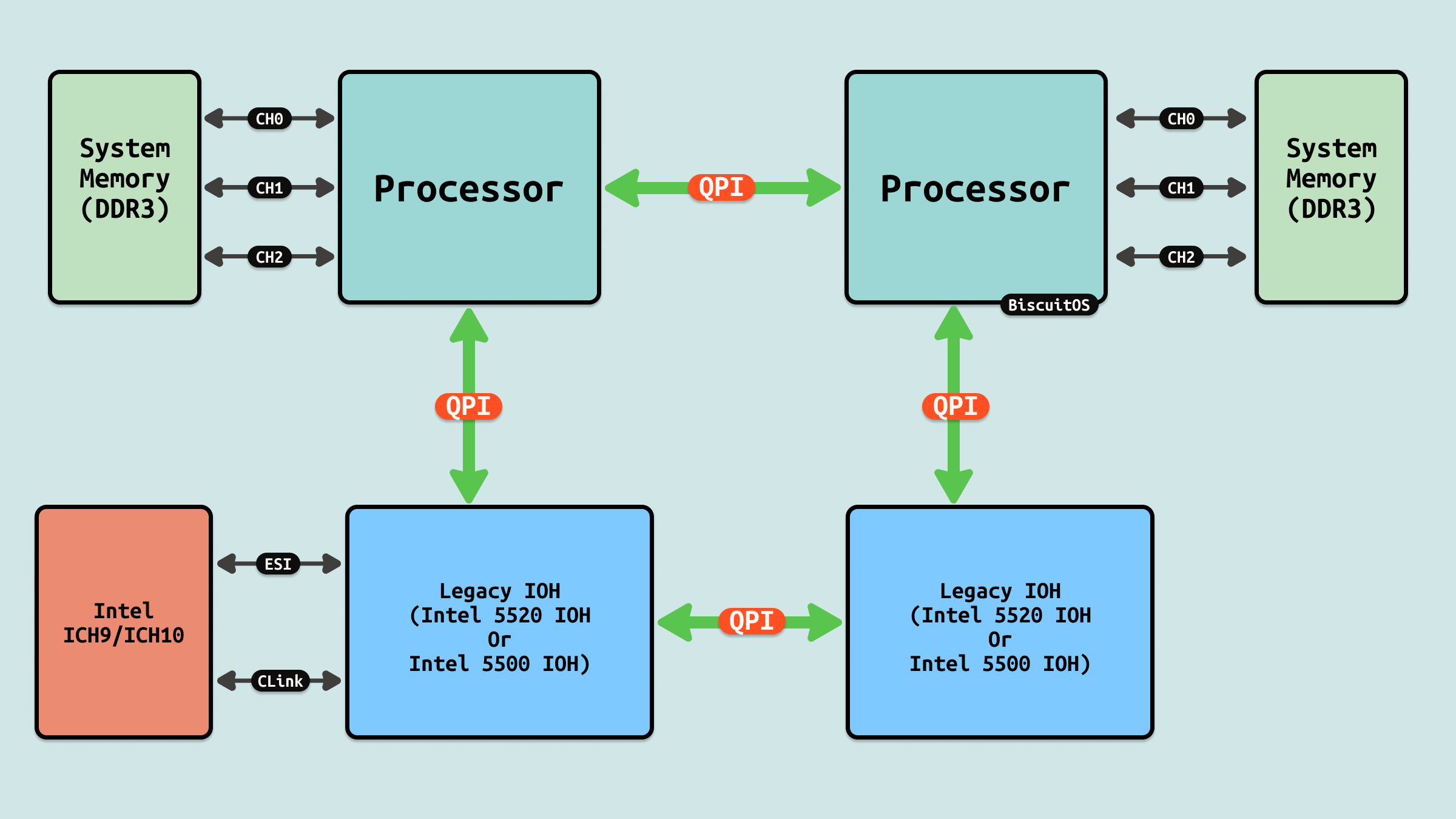
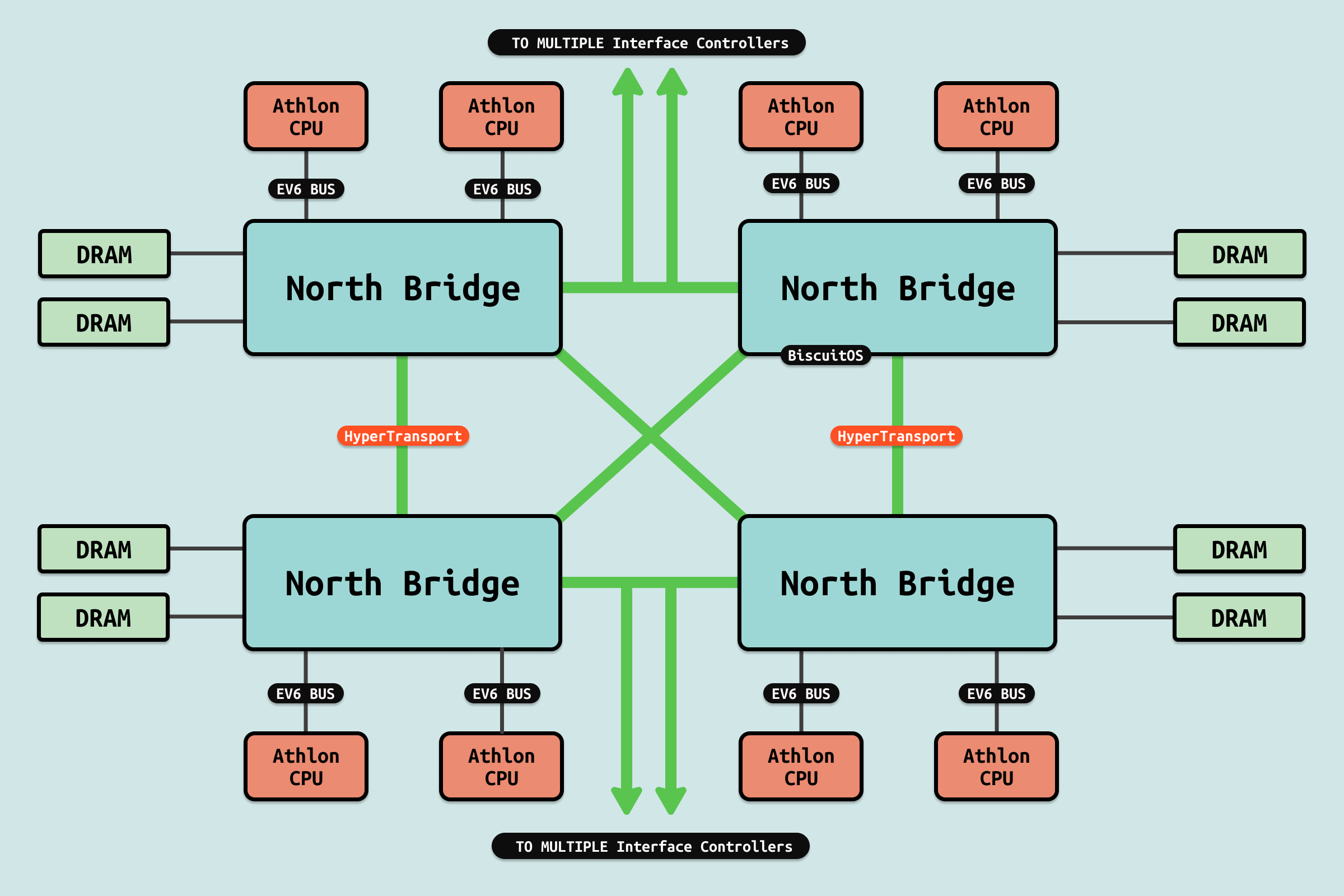
在单处理器主板上的最简单形式中,一个 QPI 用于将处理器连接到 IO 中心(例如将 Intel Core i7 连接到 X58). 在更复杂的架构实例中,单独的 QPI 链接对连接一个或多个处理器以及一个或多个 IO 中心或路由中心,形成主板上的网络,允许所有组件通过网络访问其他组件. 因此可以看到 QPI 是用于多个 Socket(Package) 间互联的方式,并不是 Package 内部物理核之间的互联方式. 如图服务器支持 4 个 Socket,可以将 4 个封装(Package) 插入到主板上,Socket 之间就是通过 QPI 互联.
QPI 发展史

QPI 1.1 是在 Sandy Bridge-EP(Romley) 推出的一种显著改进的版本. 其通过 QPI 总线将两个 Sandy Bridge-EP Package 连接在一起.
英特尔首次在 2008 年 11 月通过 Intel Core i7-9xx 和 X58 芯片组为桌面处理器交付了 QPI. QPI 在 2009 年 3 月的代号为 Nehalem 的 Xeon 处理器和 2010 年 2 月的代号为 Tukwila 的 Itanium 处理器中推出.
QPI 被设计来与 AMD 自 2003 年起使用的 HyperTransport 竞争. AMD 通过其 HyperTransport 技术提供了类似的优势,这促使 Intel 需要一种更快、更高效的互连技术来保持竞争力.
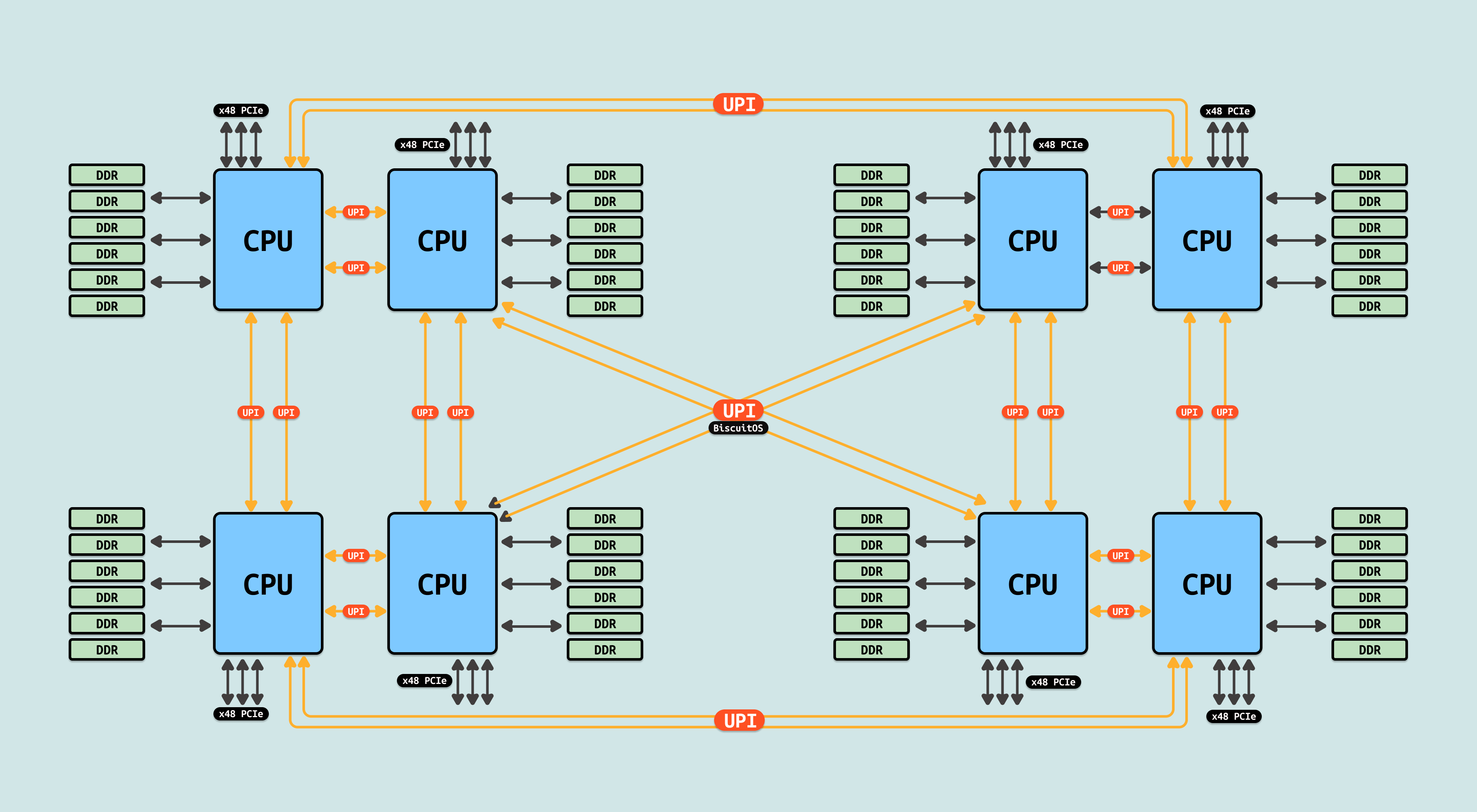
在基于 LGA 3647 插槽的 Skylake-SP Xeon 处理器中,QPI 被英特尔的 Ultra Path Interconnect(UPI) 所取代. 尽管有时被称为“总线”,QPI 实际上是一个点对点的互连, 也就是负责两个 Package 之间的互联. Intel QPI 总线主要用于以下系列的 Intel 处理器:
- Intel Core i7: 部分高端的 Core i7 处理器,特别是首次采用 Nehalem 微架构的 i7-9xx 系列处理器使用了 QPI 以提供更高的带宽和更低的延迟.

- Intel Xeon: 自 Nehalem 微架构开始,包括 Nehalem, Westmere, Sandy Bridge, Ivy Bridge 以及 Haswell 微架构的 Xeon 处理器广泛采用了 QPI. 这些处理器通常用于需要高性能、高吞吐量和低延迟的服务器和工作站.

- Intel Itanium: 用于高端计算的 Itanium 处理器也使用 QPI,例如 2010 年推出的代号为 Tukwila 的 Itanium 处理器.
QPI 实现
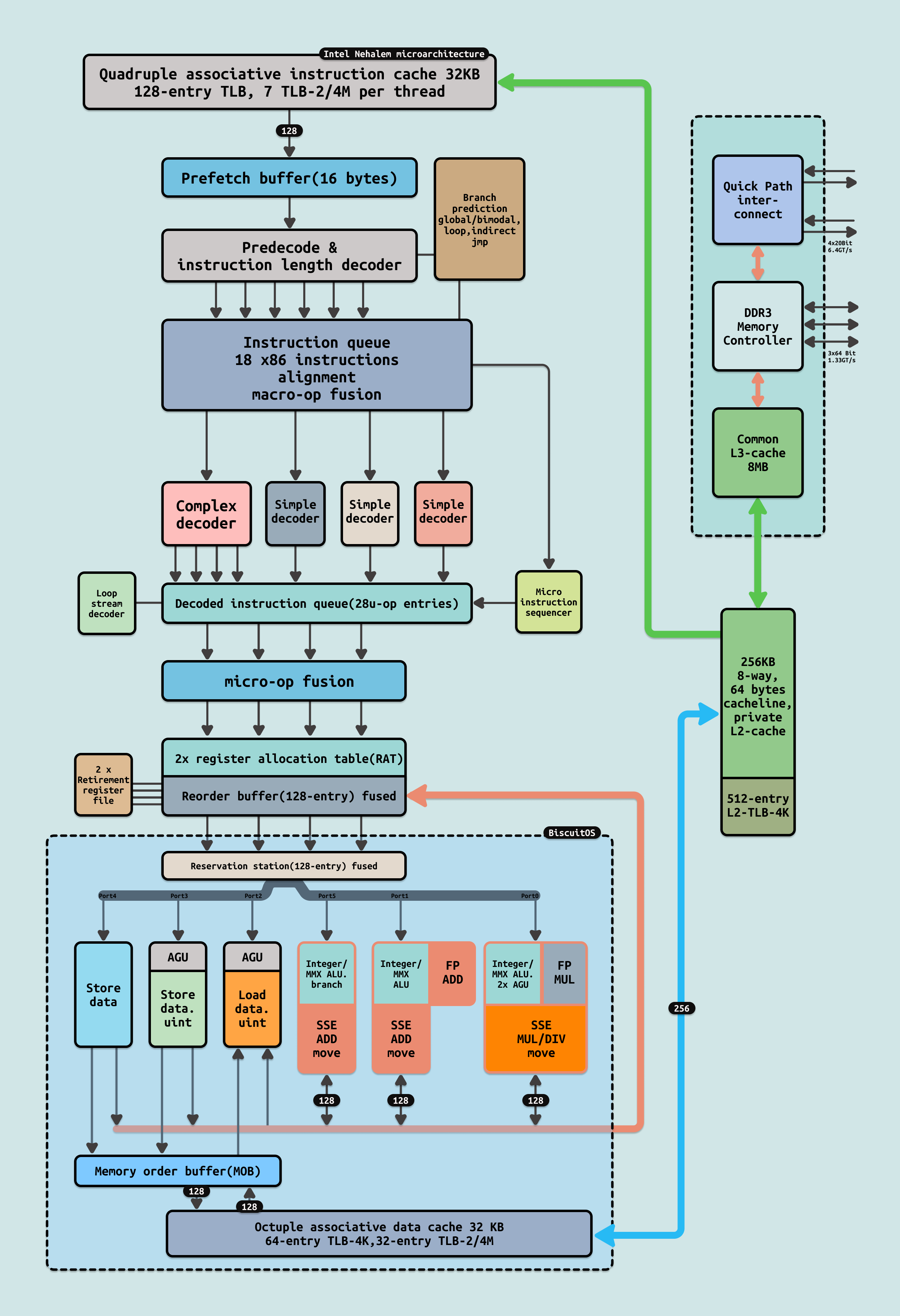
每个 QPI 包括两个 20 通道的点对点数据链接,一个方向一个(全双工),每个方向有一对单独的时钟,总共 42 个信号. 每个信号都是一对差分对,所以总的引脚数是 84 个. 20 个数据通道被划分为四个”象限”,每个象限 5 个通道. 传输的基本单位是 80 位的 flit,其中包含8位用于错误检测,8 位用于”链路层头部”,64 位用于数据. 在两个时钟周期内传输一个 80 位的 flit(四个 20 位的传输,每个时钟周期两次)。QPI 的带宽是通过计算每个方向上每两个时钟周期传输 64 位(8 字节)的数据来传输的.
尽管最初的实现使用单个四象限链接,QPI 规范允许其他实现。每个象限可以独立使用. 在高可靠性服务器上,QPI 链接可以在降级模式下运行. 如果 20+1 个信号中的一个或多个失败,接口将使用剩余的 10+1 或甚至 5+1 个信号运行,即使时钟失败也可以将时钟重新分配给数据信号. Nehalem 的初始实现使用了完整的四象限界面,实现了 25.6GB/s(6.4GT/s × 1B × 4),这正好是英特尔在 X48 芯片组中使用的 1600 MHz FSB 的理论带宽的两倍.
尽管一些高端的 Core i7 处理器暴露了 QPI,其他”主流”的 Nehalem 桌面和移动处理器,这些处理器用于单插槽主板(例如 LGA 1156 的 Core i3, Core i5 以及来自 Lynnfield/Clarksfield 和后继家族的其他 Core i7 处理器)不会外露 QPI,因为这些处理器不是为多插槽系统设计的. 然而,这些芯片内部使用 QPI 与 uncore 通信,uncore 是芯片的一部分,包含内存控制器、CPU 侧的 PCI Express 和 GPU. uncore 可能与 CPU 核心位于同一芯片上,例如在基于 Westmere 的 Clarkdale/Arrandale 上就是一个单独的芯片.
在 2009 年之后的单插槽芯片中,从 Lynnfield、Clarksfield、Clarkdale 和 Arrandale 开始,传统的北桥功能被集成到这些处理器中,因此它们通过较慢的 DMI 和 PCI Express 接口进行外部通信. 虽然桌面和移动的 Sandy Bridge 处理器中不存在 Core-uncore QPI 链接(例如在 Clarkdale上),但芯片上的内核之间的内部环形互连也是基于 QPI 原理的,至少在缓存一致性方面是这样.
频率规格
QPI 是一个同步电路,其工作频率为 2.4GHz、2.93GHz、3.2GHz、3.6GHz、4.0GHz 或 4.8GHz(3.6GHz 和 4.0GHz 频率是在 Sandy Bridge-E/EP 平台引入的,4.8GHz 则是在 Haswell-E/EP 平台引入的). 某一特定链接的时钟频率取决于链路两端组件的能力和印刷电路板上信号路径的信号特性。非极端的 Core i7 9xx 处理器在标准参考时钟下限制为 2.4 GHz 频率.
位传输发生在时钟的上升沿和下降沿,因此传输速率是时钟频率的两倍. Intel 通过仅计算每个 80 位 flit 中的 64 位数据有效载荷来描述数据吞吐量(以 GB/s 表示). 然而因为单向的发送和接收链接对可以同时活动,Intel 将结果翻倍。因此,Intel 描述一个工作在 3.2GHz 时钟下的 20 通道 QPI 链路对(发送和接收)具有 25.6GB/s 的数据速率。2.4 GHz 的时钟频率产生的数据速率为 19.2 GB/s。更一般地,按照这个定义,一个双链路的 20 通道 QPI 每个时钟周期传输八字节,每个方向四字节. 速率的计算如下:
3.2 GHz
× 2 位/赫兹 (双倍数据速率)
× 16(20) (数据位/QPI 链路宽度)
× 2 (单向发送和接收同时操作)
÷ 8 (位/字节)
= 25.6 GB/sQPI 协议
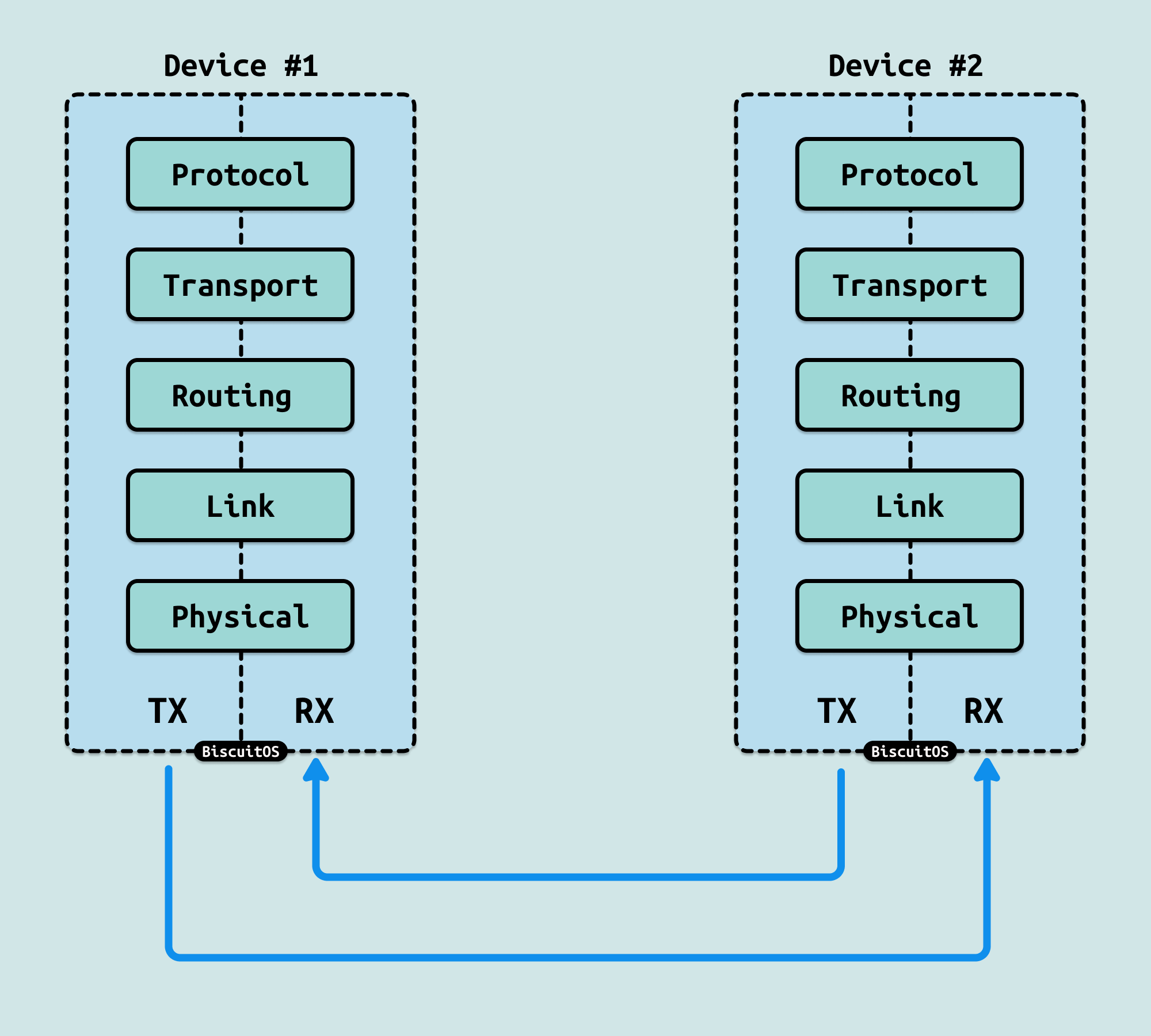
QPI 被定义为一个五层架构,包括独立的物理层、链路层、路由层、传输层和协议层。在只用于点对点QPI使用且不需要转发的设备中,如 Core i7-9xx 和 Xeon DP 处理器,传输层不存在,路由层也非常简单. 《Intel® QuickPath Interconnect》
- 物理层: 物理层包括实际的电线和差分发射器与接收器,以及传输和接收物理层单元的最底层逻辑。物理层单元是 20 位的 “phit”. 当所有 20 个通道可用时,物理层使用单个时钟边缘传输一个 20 位的 “phit”,或者在 QPI 因故障被重新配置时使用 10 个或 5 个通道. 需要注意的是,除了数据信号外,还有一个时钟信号从发射器传送到接收器(这简化了时钟恢复但增加了额外的引脚).
- 链路层: 链路层负责发送和接收 80 位的 flits. 每个 flit 作为四个 20 位 phits 发送到物理层。每个 flit 包含由链路层发射器生成的 8 位 CRC 和 72 位有效载荷. 如果链路层接收器检测到 CRC 错误,接收器通过成对返回链路上的一个 flit 通知发射器,然后发射器重新发送 flit. 链路层实施信用/借记方案的流量控制,以防止接收器缓冲区溢出。链路层支持六种不同类别的消息,以便高层区分数据 flits 和非数据消息,主要是为了维护缓存一致性。在复杂的 QuickPath 架构实现中,链路层可以配置为为不同类别维护独立的流量和流量控制.
- 路由层: 路由层发送一个由 8 位头部和 64 位有效载荷组成的 72 位单元。头部包含目的地和消息类型。当路由层接收到一个单元时,它会检查其路由表以确定该单元是否已到达其目的地。如果是,则将其传递给下一层。如果不是,则将其发送到正确的出站 QPI. 对于只有一个 QPI 的设备,路由层非常简单。对于更复杂的实现,路由层的路由表更加复杂,并会动态修改以避免 QPI 链接失败.
- 传输层: 传输层在只用于点对点连接的设备中不需要且不存在。这包括 Core i7. 传输层在 QPI 网络中从其他可能未直接连接的设备(即数据可能已通过一个中间设备路由)的同级设备发送和接收数据。传输层验证数据是否完整,如果不完整,它会向其同级请求重传.
- 协议层: 协议层代表设备发送和接收数据包, 典型的数据包是一个内存缓存行. 协议层还通过发送和接收相关消息参与维护缓存一致性.