


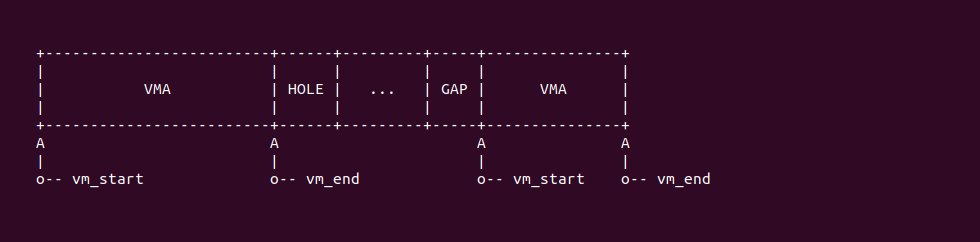
STRUCT vm_area_struct 数据结构的 vm_start 和 vm_end 成员用于描述虚拟区域的起始和结束地址,其描述的范围是: [vm_start, vm_end). 在进程的地址空间里,VMA 之间可以存在相邻和相离的关系,但不会存在重叠和覆盖的情况.
VM_START/VM_END 创建
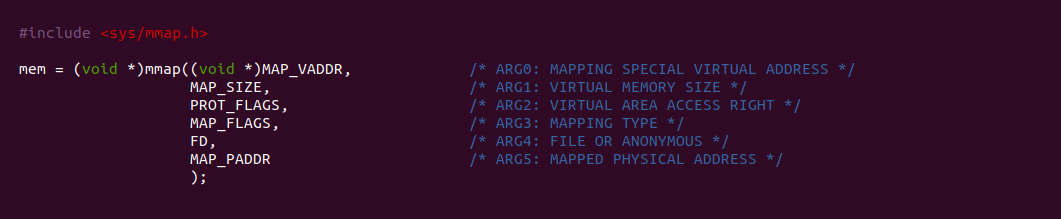
当调用 mmap 系统调用分配一段虚拟内存时,mmap 系统调用支持随机地址分配和固定地址分配. 首先来分析一些随机地址分配,用户空间调用 mmap 系统调用时,会将第一个参数设置为 NULL,那么内核会从进程的虚拟地址空间中按一定规则找到一个空闲区域,该区域就作为新分配的区域. 而固定地址分配则是在 mmap 系统调用的第一个参数上指明从指定虚拟地址处进行分配,该方法虽然可以从指定虚拟内存上分配,但可能存在固定虚拟地址已经被分配出去的情况.
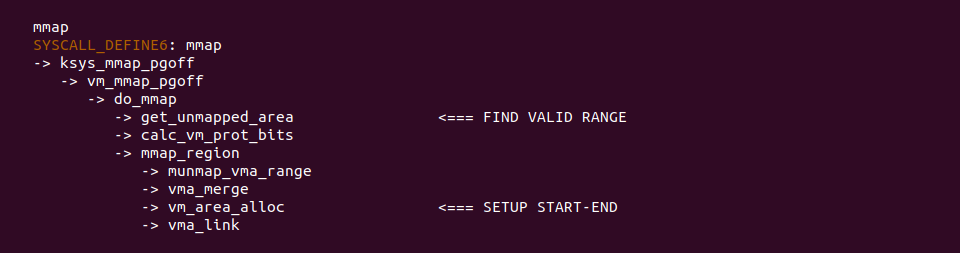
无论采用那种分配方式,mmap 系统调用在代码逻辑上的处理基本类似,首先在 FIND VALID RANGE 处调用 get_unmapped_area 函数从进程虚拟地址空间获得可用的虚拟区域,然后在 SETUP START-END 处调用 vm_area_alloc 函数分配新的 VMA,并将新分配的虚拟内存区域填充到 VMA 的 VM_START 和 VM_END 成员里. 以上便是 VM_START 和 VM_END 的初始化过程,但由于不同架构上的差异,技术细节上存在一定的差异,那么接下来以 X86 为例进行分析:
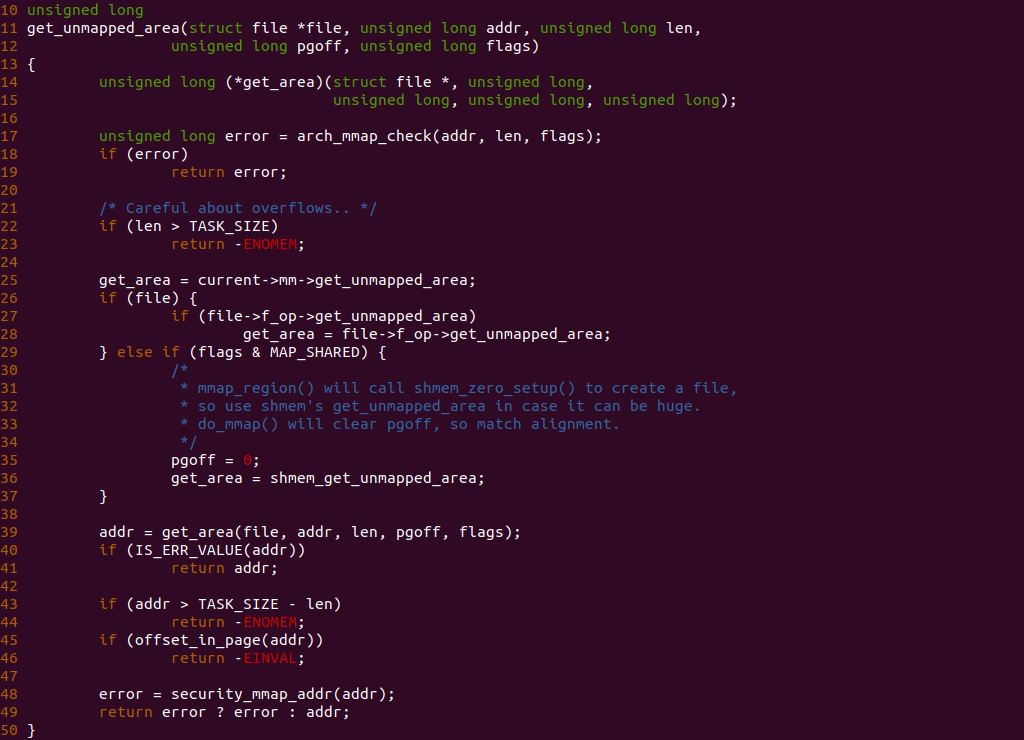
get_unmapped_area 函数是分配新虚拟区域的核心函数,其主要目的是从用户进程地址空间中找到一块空闲的虚拟区域,之前就介绍过,内核将进程的地址空间已经分配的 VMA 维护在进程自己的区间树上,并且区间树记录了其子树最大的 GAP,那么查找一块符合要求的虚拟区域就变得简单,只需从区间树的根节点出发依次查找到叶子节点,只要子树 GAP 符合要求,那么就可以找到找到可分配的区域。但这个方法还存在一定的逻辑问题,当发现子树的 GAP 符合要求,那么先查左子树还是右子树呢? 在有的架构会优先查找右子树,那么这样就会形成从高地址到低地址(TOP TO DOWN)方式分配新的虚拟内存。同理优先左子树,那么可以形成从低地址到高地址(DOWN TO TOP)方式分配新的虚拟内存。有了以上的逻辑再分析函数的实现逻辑:
- 长度检查: 函数首先在 22 行检查需要分配的长度不能超过 TASK_SIZE, TASK_SIZE 是内核空间虚拟地址起始地址,因此这里检查不能超过进程地址空间的极限.
- 获得分配回调函数: 函数在 25 行从进程地址空间获得分配回调接口 get_unmapped_area, 如果虚拟内存使用的是文件映射,那么如果文件提供私有的 get_unmapped_area, 则使用文件映射提供的分配逻辑. 否则既不是文件映射但是匿名的共享内存,则使用 shmem_get_unmapped_area 函数分配虚拟内存,并将 pgoff 设置为 0,这是应为匿名的共享内存虽然也是文件映射的一种,但其文件是伪文件,因此 pgoff 无意义.
- 分配虚拟内存: 函数在 39 行调用 get_area 对应的回调函数进行虚拟内存分配
- 分配结果检查: 函数在 40 行直接检查 get_area 的返回值,如果没有问题直接返回新分配的地址. 如果分配的地址有问题,那么在 43 行检查分配的虚拟内存区域是否已经和内核空间相交,如果相交则返回 ENOMEM. 函数接着在 45 行调用 offset_in_page 函数检查新分配的虚拟地址是否按 PAGE_SIZE 对齐,如果没有按则返回 EINVAL,因为 mmap 系统调用分配的虚拟地址必须按 PAGE_SIZE 对齐.
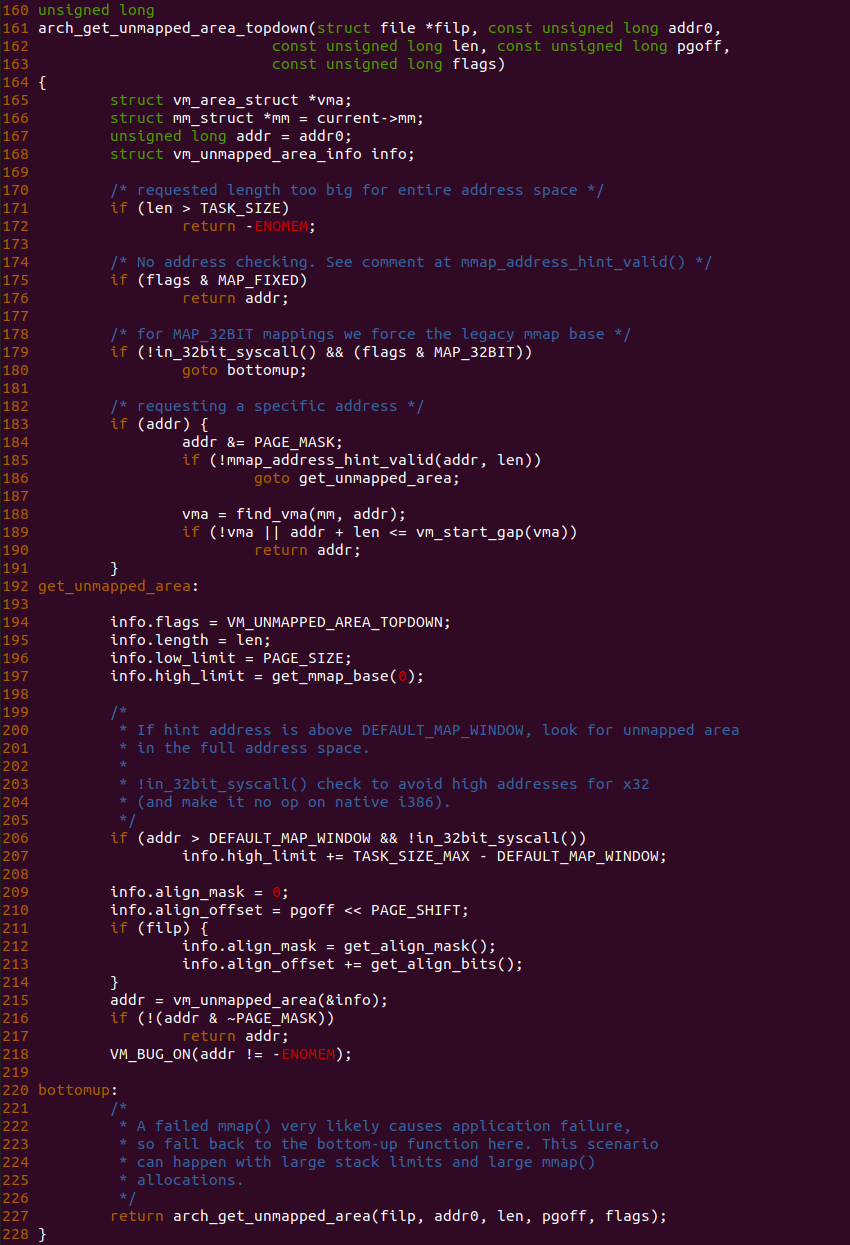
arch_get_unmapped_area_topdown 函数是 X86 架构使用的分配新虚拟内存的逻辑,其采用 TOP TO DOWN 方式进行分配. 经过之前的分析,只要记住在区间树里优先查找右子树即可,然后在分配前后进行一系列检查即可,具体逻辑如下:
- 分配长度检查: 函数在 171 行检查分配的虚拟内存长度不能超过 TASK_SIZE,TASK_SIZE 为内核空间的起始地址,因此当长度超过 TASK_SIZE 之后就说明越界
- 固定地址分配: 函数在 175 行检查到用户进程使用了 MAP_FIXED 标志,该标志指明需要从固定虚拟地址进行分配,那么无需在区间树里进行查找,直接返回该地址即可,后面的逻辑会处理重叠问题.
- 非固定地址分配: 函数在 183 行检查到 addr 值不为零,那么函数先将 addr 按 PAGE_SIZE 对齐,接着 mmap_address_hint_valid 函数检查请求的区域是否超过了用户进程的虚拟地址空间,如果超过则跳转到 get_unmapped_area 处分配一块新的随机区域, 反之则说明新请求的区域不违法,那么继续在 188 行调用 find_vma 函数查找 addr 是否已经包含在已经分配的 VMA,如果发现 VMA 不存在,或者 VMA 存在但新分配的区域在 VMA 的左边 GAP,那么该区域也符合要求,并直接返回 addr.
- 分配虚拟区域: 函数进入 192 行的 get_unmapped_area 分支,然后使用 STRUCT vm_unmapped_area_info 数据结构记录分配过程的中间态信息,函数在 194 行将 VM_UNMAPPED_AREA_TOPDOWN 标志填充到 info.flags 变量,以此表示从顶端到底部的方式进行虚拟内存分配, 分配长度 len 存储在 info.length 里,分配的范围是 [PAGE_SIZE, get_mmap_base(0)), 函数接着在 215 行调用 vm_unmapped_area 函数传入 info 之后进行分配
- 分配结果检查: 函数在 216 行检查分配的虚拟地址是否有效,如果 addr 没有按 PAGE_SIZE 对齐那么说明分配失败,因为会将分配失败的原因填充到 addr 里, 并在 218 行调用 VM_BUG_ON 函数进行报错. 如果 addr 按 PAGE_SIZE 对齐,那么直接返回 addr.
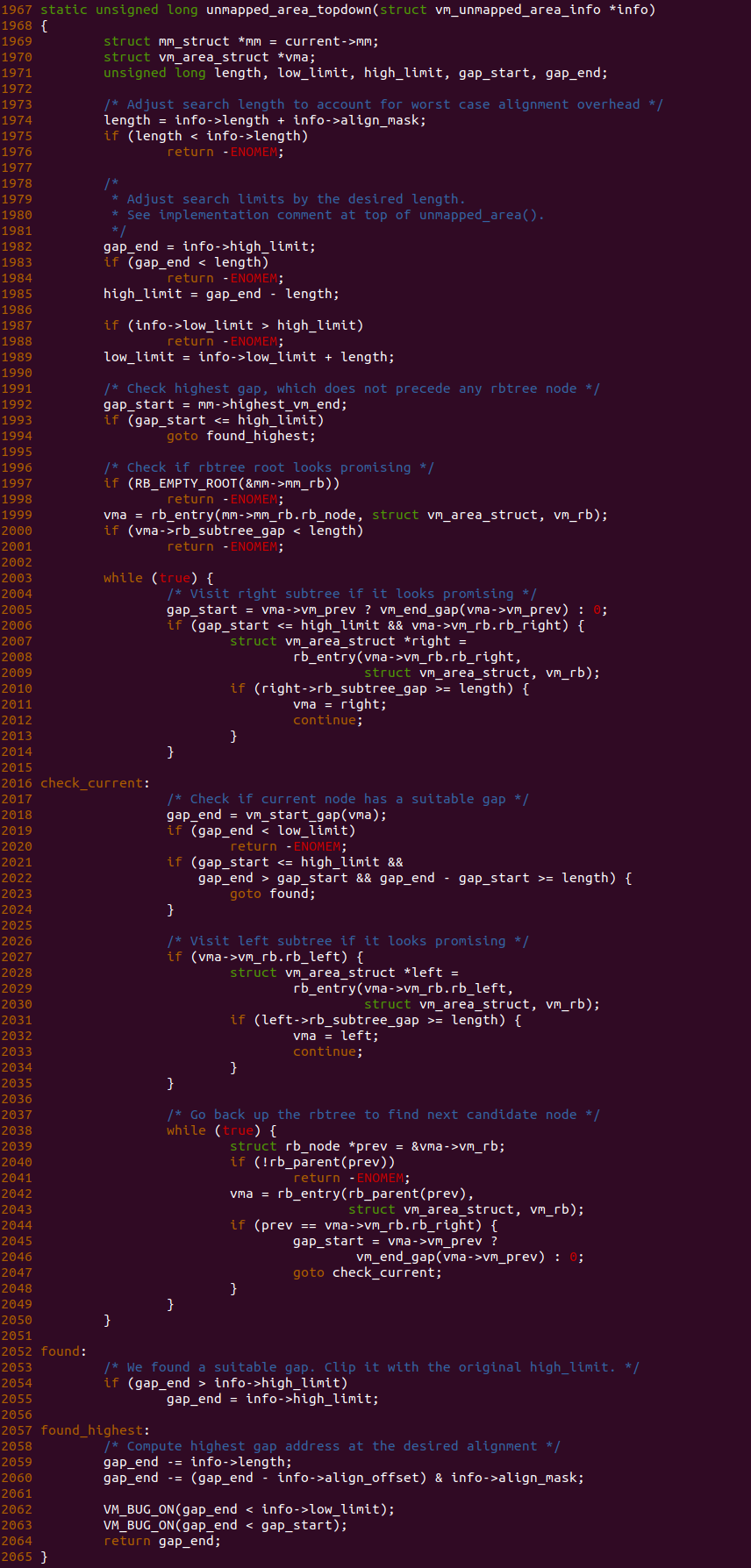
unmapped_area_topdown 函数是 TOPDOWN 分配虚拟内存的核心函数,要掌握该函数,关键是掌握区间树的使用,那么接下来先分析代码,在结合区间树进行讲解:
- 地址范围检查:
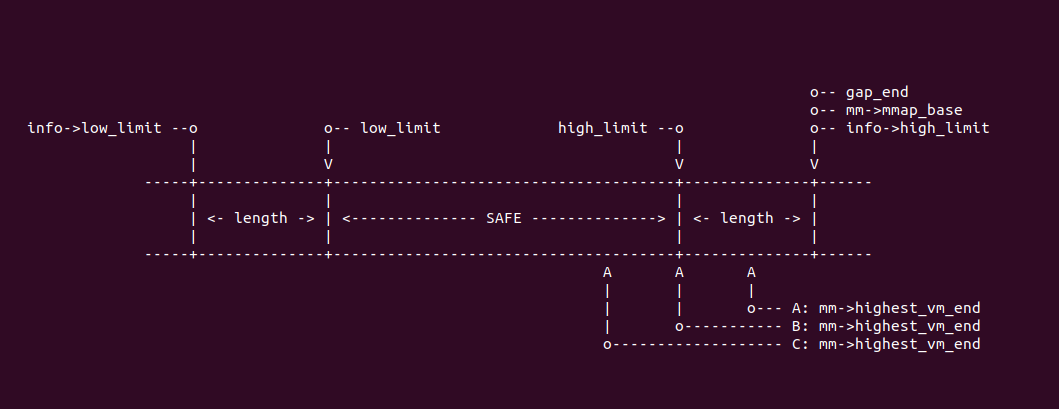 结合上图,函数在 1982-1994 行对分配的虚拟地址范围进行检查,合理的地址范围是 [low_limit, high_limit), 如果此时 ‘mm->highest_vm_end’ 位于 A 点,那么说明新需求区域可能与已分配 VMA 重叠,如果位于 B 点或者 C 点说明区域说明还没有分配,可以直接使用,那么函数直接在 1994 行跳转到 found_highest 处. 反之需要在 A 处查找区间树获得可用的区域.
结合上图,函数在 1982-1994 行对分配的虚拟地址范围进行检查,合理的地址范围是 [low_limit, high_limit), 如果此时 ‘mm->highest_vm_end’ 位于 A 点,那么说明新需求区域可能与已分配 VMA 重叠,如果位于 B 点或者 C 点说明区域说明还没有分配,可以直接使用,那么函数直接在 1994 行跳转到 found_highest 处. 反之需要在 A 处查找区间树获得可用的区域. - 区间树查找:
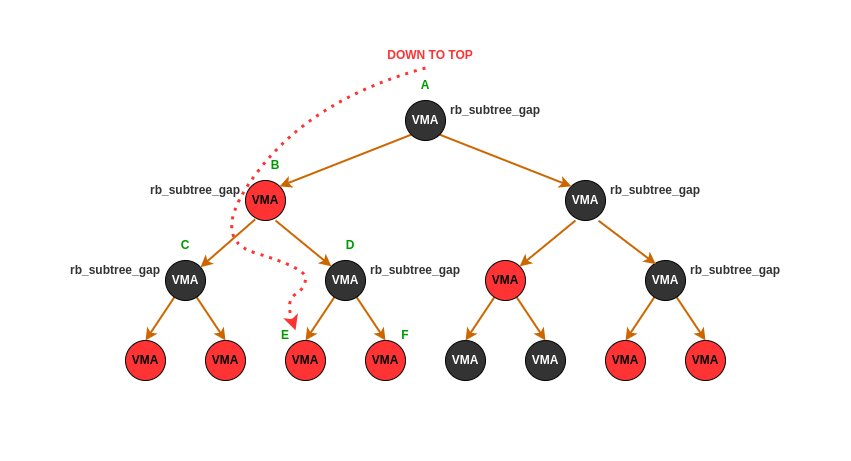 结合上图,函数在 1997-2050 行逻辑就比较容易理解,函数在 1999 行代码的作用是从区间树的根节点开始进行遍历,此时在 2000 行直接检查根节点下子树最大的 GAP 值是否小于需要分配的区域大小,如果小于那么直接说明区间树没有可用的区域进行分配,直接返回 ENOMEM. 反之说明区间树里还有可用的区域,于是执行 WHILE 循环进行遍历. 2005-2014 行的逻辑可以理解为优先从右子树进行查询,如果查询到到的子树的 GAP 小于需求的长度,那么直接跳转到平级的右子树,即 2027-2035 行逻辑,同理左子树的 GAP 小于需要的长度则跳转到更高一级的左子树,以此类推,直到遍历到区间树的叶子,也就是 2018-2023 行逻辑,此时叶子节点的 GAP 符合要求,则从 2023 行跳转到 found 处,反之则跳转到上一级的左子树进行查找.
结合上图,函数在 1997-2050 行逻辑就比较容易理解,函数在 1999 行代码的作用是从区间树的根节点开始进行遍历,此时在 2000 行直接检查根节点下子树最大的 GAP 值是否小于需要分配的区域大小,如果小于那么直接说明区间树没有可用的区域进行分配,直接返回 ENOMEM. 反之说明区间树里还有可用的区域,于是执行 WHILE 循环进行遍历. 2005-2014 行的逻辑可以理解为优先从右子树进行查询,如果查询到到的子树的 GAP 小于需求的长度,那么直接跳转到平级的右子树,即 2027-2035 行逻辑,同理左子树的 GAP 小于需要的长度则跳转到更高一级的左子树,以此类推,直到遍历到区间树的叶子,也就是 2018-2023 行逻辑,此时叶子节点的 GAP 符合要求,则从 2023 行跳转到 found 处,反之则跳转到上一级的左子树进行查找. - 地址检查:
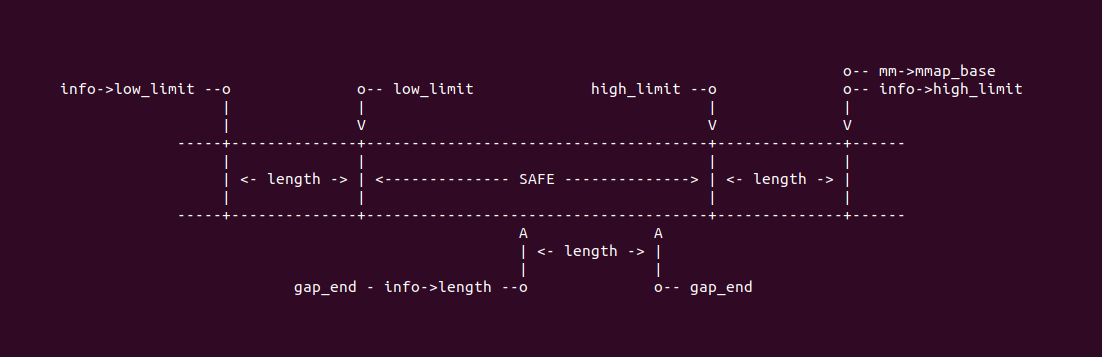 当查找到地址之后,对找到的地址进行检查,此时 gap_end 存储找到的地址,此在 2059 行将 gap_end 减去 info->length 就可以获得可用区域的起始地址,接下来只要检查找到的地址不小于 info->low_limit 和 gap_start 既可以,如果不满足则直接进行 VM_BUG_ON 报错. 最终返回找到的虚拟区域的起始地址.
当查找到地址之后,对找到的地址进行检查,此时 gap_end 存储找到的地址,此在 2059 行将 gap_end 减去 info->length 就可以获得可用区域的起始地址,接下来只要检查找到的地址不小于 info->low_limit 和 gap_start 既可以,如果不满足则直接进行 VM_BUG_ON 报错. 最终返回找到的虚拟区域的起始地址.
固定地址
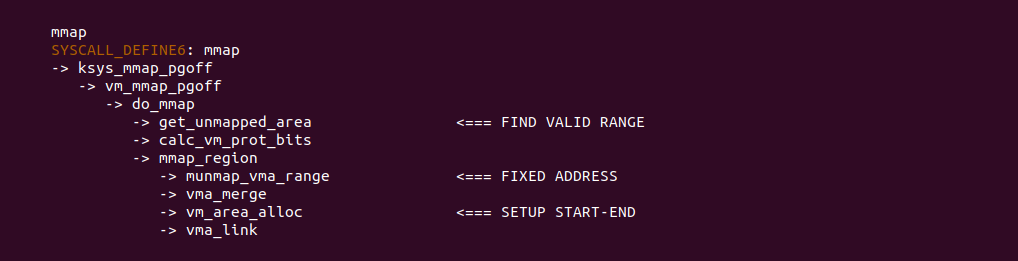
通过之前的分析可以知道,对于从固定地址并不是直接从区间树里进行查找可用的虚拟区域,而是直接就返回虚拟地址的值,那么 SYS_MMAP 系统调用会在 FIXED ADDRESS 处调用 munmap_vma_range 函数将重叠的区域进行移除,然后将该区域分配给应用程序作为新分配内存.
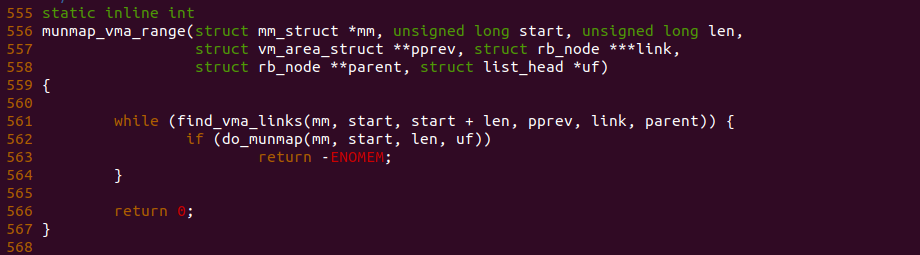
munmap_vma_range 函数的处理逻辑很简单,使用 WHILE 循环调用 find_vma_links 函数获得虚拟地址 start 所在的 VMA,然后调用 do_munmap 函数将重叠的 VMA 进行释放。由于分配的区域横跨多个 VMA,那么需要进行多次释放操作. 那么这样会引入一个问题,如果采用固定映射映射的方式释放了重要的重叠区域,那么这将是得不偿失的,最好的就是既可以从指定虚拟内存区域分配虚拟内存,又不释放任何已经分配的 VMA,即遇到重叠的场景则直接分配失败即可,那么内核提供了 MAP_FIXED_NOREPLACE 标志.
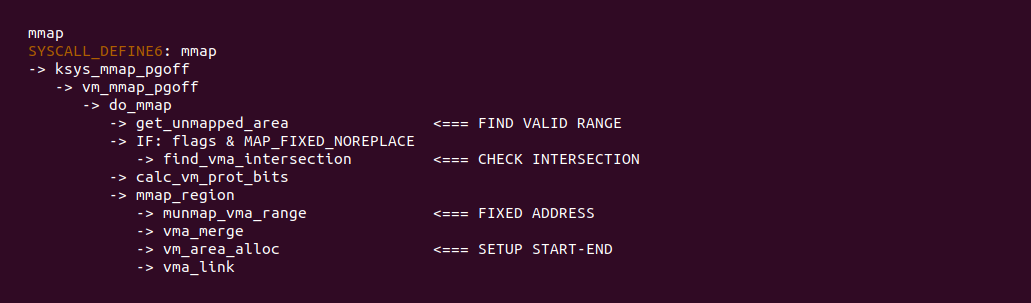
当 SYS_MMAP 系统调用使用 MAP_FIXED_NOREPLACE 标志时,其会在 FIND VALID RANGE 处直接返回地址而不真正去区间树里查找,然后在 CHECK INTERSECTION 处直接调用 find_vma_intersection 函数查看进程所需的固定区域是否与现有的 VMA 存在重叠,如果存在则直接分配失败,反之说明固定分配区域安全.
VM_START/VM_END 设置
当获得可用的虚拟地址之后,内核会在 SETUP START-END 处调用 vm_area_alloc 函数分配一个新的 VMA,然后设置上 VMA 的 VM_START 和 VM_END 成员.
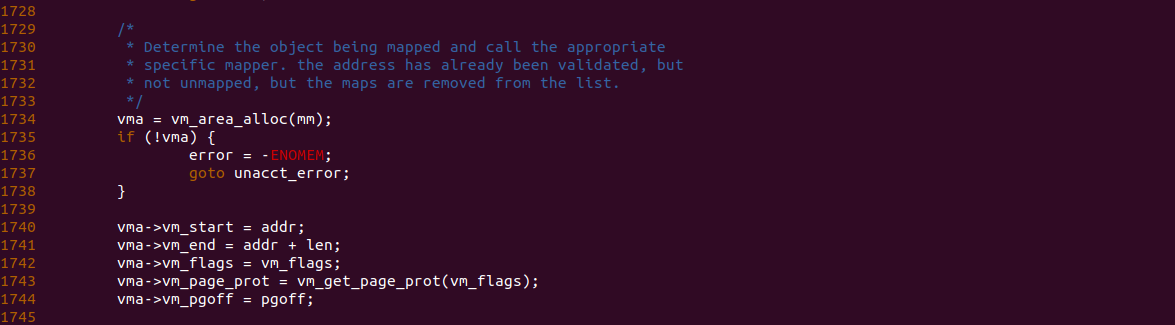
函数在 1734 行调用 vm_area_alloc 函数分配一个新的 VMA,然后在 1740 将分配的新区域的起始地址存储在 VM_START 成员里,接着将新区域的结束地址存储在 VM_END 成员里,以上便是 VM_START 和 VM_END 的来龙去脉,那么接下来通过一个实践案例并结合内存流动工具实践整个过程,实践案例在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] Memory Mapping Mechanism --->
[*] Memory Mapping: AREA NOREPLACE --->
# 部署实践案例
make
# 源码目录
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-MEMORY-MMAP-AREA-NOREPLACE-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-MEMORY-MMAP-AREA-NOREPLACE-default Source Code on Gitee
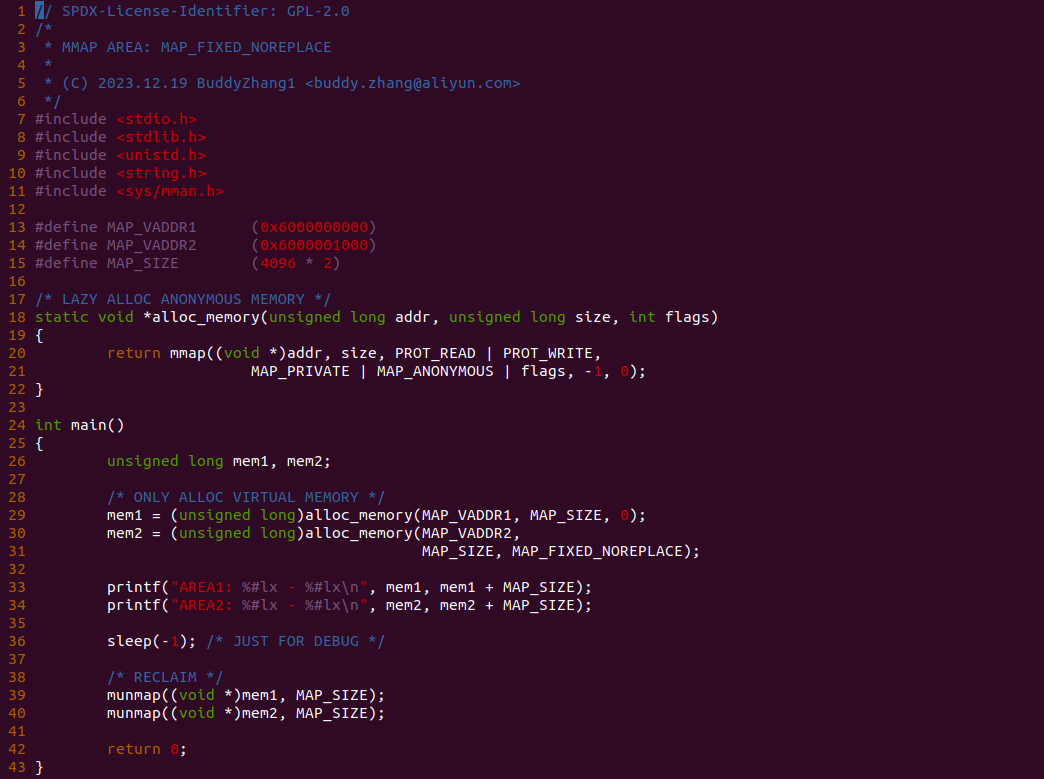
实践案例由一个应用程序构成,程序在 18 行处提供了 alloc_memory 函数,该函数内部是 mmap 系统调用分配一段匿名内存,其中参数 addr 可以指定映射的虚拟地址,size 则指定映射范围的大小,最后 flags 参数则作用与 MAP FLAGS 字段. 在 main 函数里,函数在 29 行和 30 行分别调用了 alloc_memory 函数,并将虚拟地址映射到 MAP_VADDR1 和 MAP_VADDR2,虚拟区域的长度为 8K,从这个分配来看,两个区域中间有一点重叠的区域,即 [0x6000001000, 0x6000002000) 区域,另外后者使用了 MAP_FIXED_NOREPLACE 标志,即在发现固定映射存在重叠时直接返回错误. 其余代码对测试影响不大,那么接下来在 BiscuitOS 上实践该案例:
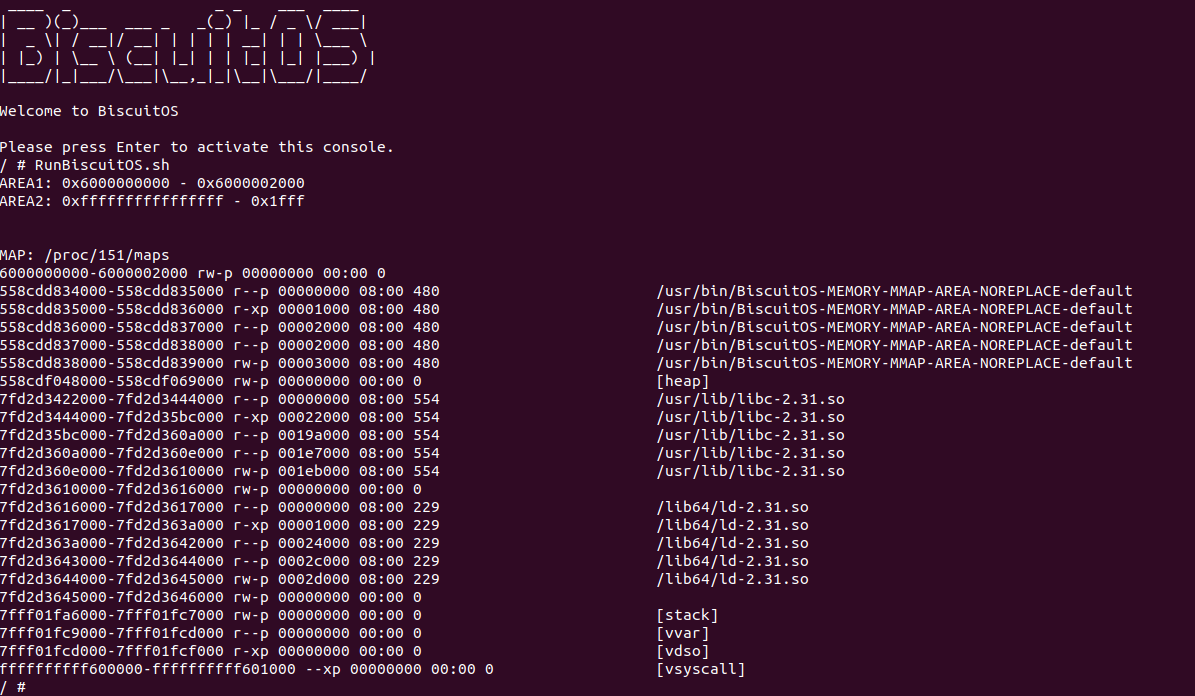
当 BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本可以看到运行实践案例,可以看到 AREA2 的区域并没有映射到指定的虚拟区域上,而是全为 1,那么说明是映射失败,此时查看进程的 “/proc/PID/maps” 文件查看看进程地址空间 VMA 布局,此时看到进程地址空间只有 [0x6000000000, 0x6000002000) 区域,那么可以验证 MAP_FIXED_NOREPLACE 标志确实可以让应用程序安全分配固定虚拟内存. 接着将应用程序再次改进,将代码里 AREA2 的 MAP_FIXED_NOREPLACE 修改为 MAP_FIXED 之后再次实践:

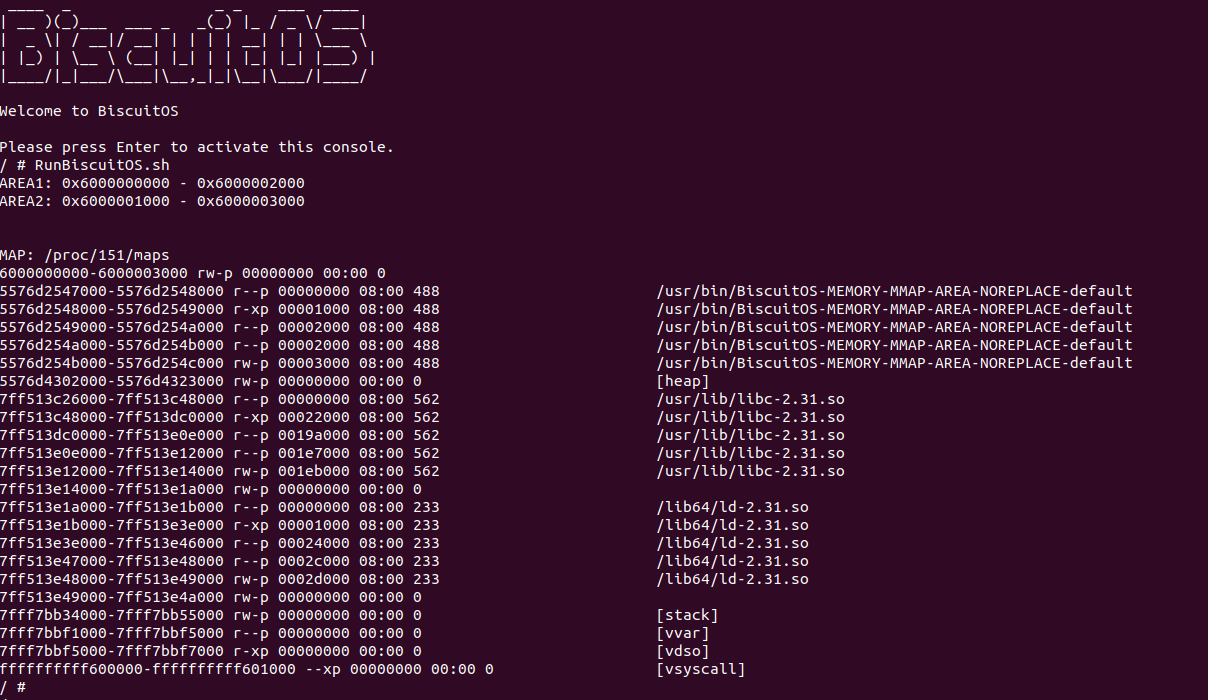
BiscuitOS 运行之后直接运行 RunBiscuitOS.sh 脚本,此时可以看到 AREA2 分配虚拟内存成功,并且区域为 [0x6000001000, 0x6000003000), 此时查看进程的 “/proc/PID/maps” 文件,此时进程的地址空间只有包含一个虚拟区域 [0x6000000000, 0x6000003000), 此时两个区域重叠之后再合并. 接着将应用程序再次改进,将代码里 AREA2 的 MAP_FIXED 标志去掉之后再次实践:

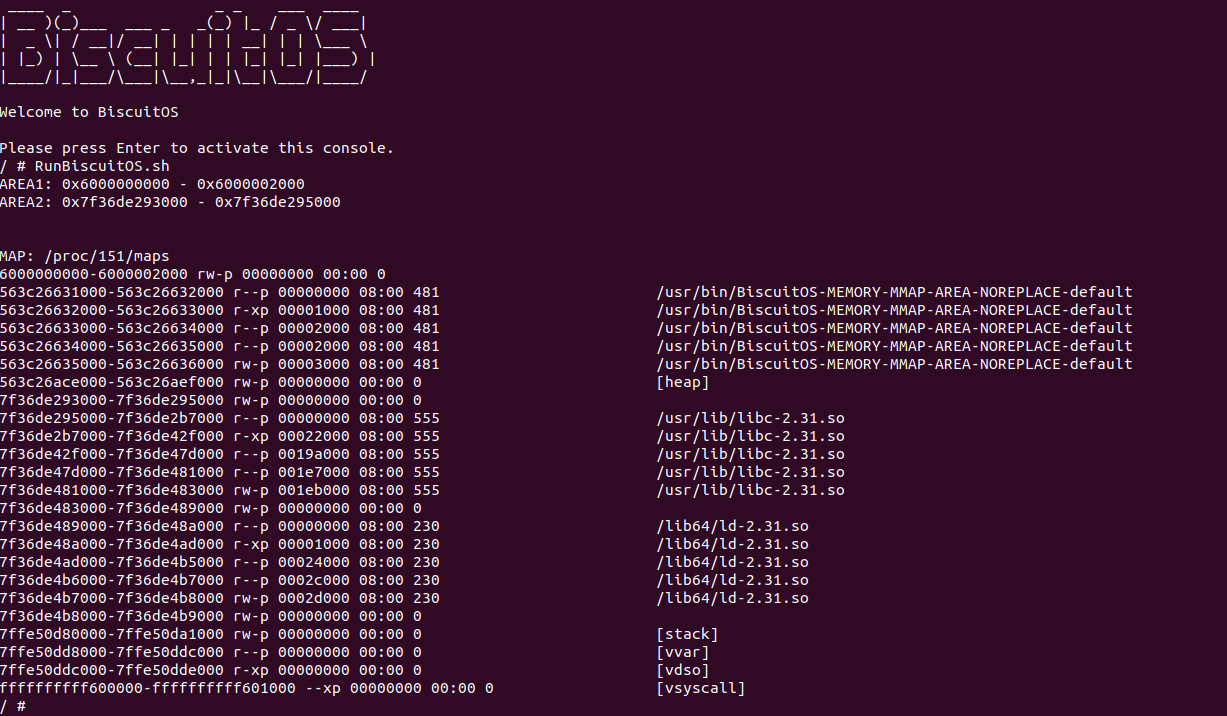
BiscuitOS 运行之后直接运行 RunBiscuitOS.sh 脚本,此时可以看到 AREA2 分配虚拟内存成功,此时虚拟区域不再是指定的虚拟区域, 此时查看进程的 “/proc/PID/maps” 文件,此时进程的地址空间只有包含一个虚拟区域 [0x6000000000, 0x6000002000), 此时两个区域不重叠,且 AREA2 从区间树中找到一块合适的区域进行分配. 以上便是 VM_START/VM_END 的使用场景, 开发者可以使用内存流动工具跟踪一下以上三个场景下的代码逻辑是否与分析的一致.
