

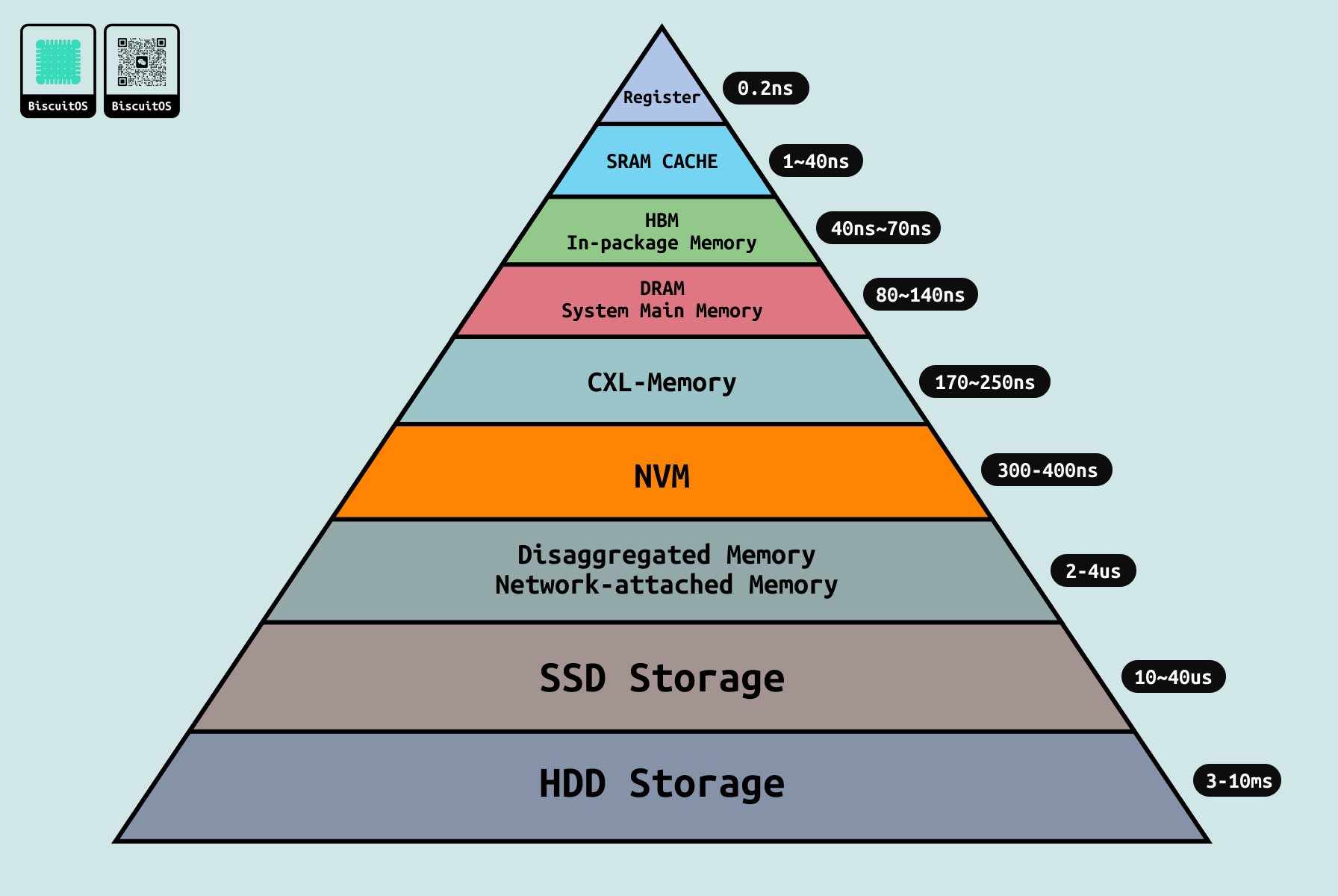
在常见的计算机结构中,系统包含了多种存储介质,例如常见的内存条、磁盘、ROM 等,这些存储介质在计算机体系结构中担任不同角色,系统通过北桥和南桥将这些硬件连接在一起,以此让 CPU 可以访问到这些存储介质。由于不同存储介质离 CPU 的距离不同,导致 CPU 访问不同介质的速度(也可以称为延时(Latency)) 不同,如果将存储介质访问速度进行分类,那么可以得到上图金字塔分布,越靠近金字塔顶端,那么 CPU 访问该存储介质的时延越低,也就是访问速度越快. 金字塔存储介质访问时延如下:
- 寄存器(Register): 离 CPU 最近的存储介质,一般可以认为位于 CPU 内部,用于暂时存储 CPU 运行所需的数据,时延在 0.2ns 左右. 寄存器分为控制寄存器、段寄存器、通用寄存器、标志寄存器等。每个 CPU 都用自己的寄存器组,因此 CPU 可以独立且快速的访问寄存器.
- SRAM CACHE: CACHE 是用于缓存 CPU 经常访问的内存数据,其对软件透明,系统中常见的 CACHE 有 L1 CACHE、L2 CACHE 和 L3 CACHE,其中 L1 CACHE 又可以分为 L1 Data CACHE 和 L1 Instruction CACHE. L1 和 L2 CACHE 一般位于逻辑 CPU 内部,而 L3 CACHE 则位于物理 CPU 上。由于 CACHE 位于 CPU Die 内部,因此访问速度仅次于寄存器。但由于 CACHE 需要保证数据的一致性,以及由于其大小等因此,CACHE 的访问速度依次是: L1 CACHE 快于 L2 CACHE,L2 CACHE 远大于 L3 CACHE.
- HBM(In-Package Memory): 高带宽内存是近些年随着硬件技术的不断创新,引入的堆叠技术设计的新型存储介质,其具有高带宽、低功耗、高容量的特点,其访问速度比 CACHE 慢一些,但比 DDR 快很多. HBM 提供了远超传统 DRAM 的内存带宽, HBM2 可以提供高达 256 GB/s 的带宽,而 HBM2e 和 HBM3 提供的带宽更高. HBM 通过堆叠多个 DRAM 芯片来实现更高的容量。HBM2 典型地堆叠 4 到 8 个 DRAM 芯片,而 HBM2e 和 HBM3 可以堆叠更多芯片,提供更大的存储容量.
- DRAM: DRAM/DDR 作为传统的主内存,负责存储系统所需的数据,其可以提供数 GB 到数百 GB 的容量,访问延时在 80 到 140 纳秒区间。常见的 DDR 包括 DDR4 和 DDR5 等.
- CXL-Memory: CXL 是比较新的连接技术,CXL 支持 Type1、Type2 和 Type3 三种类型的设备,其中 Type3 可以作为与 DDR 类似的存储介质,CXL Type3 设备上可以是 NVM 持久内存颗粒,也可以是易失性内存(Volatile-RAM: DRAM), 由于 CXL 基于 PCIe 构建,常见的 CXL 基于 PCIe5.0 构建,因此访问延迟方面比 DDR 慢,在 170 到 250 ns 区间,但其可以高带宽弥补了延迟高的缺点.
- NVM: 非易失介质,也就是掉电之后数据还可以继续保存一段时间,常见的持久性内存如 Intel 推出的 Optane,NVM 与 DDR 一样插入 DIMM 条连接到系统,因此 NVM 的带宽就受到了 DIMM 的限制,另外 NVM 内部的延时也很高,因此综合下来 NVM 的延时在 300-400 纳秒区间.
- Disaggregated Memory: 解耦内存,其介质可以是 DRAM 或者 NVM,其通过网络与系统进行连接,其提供了高扩展性和高容量,由于设计时提供了高网络带宽,因此该类型内存具有高带宽。但由于网络延迟和网络协议开销,那么导致该类型介质具有高延迟,访问延迟在 2 到 4 微妙.
- SSD Storage: 基于闪存技术的固态硬盘,其可提供数百 MB/s 到数 GB/s,取决于接口类型如 SATA、NVMe. 延时在 10 到 40 微秒区间。SSD 常用于持久性存储数据,适用于存储 OS、应用程序、数据和文件,可以用做 SWAP Space.
- HDD Storage: 机械硬盘,在这些存储介质中延时最大,但其可以提供超低价且超大容量的存储空间,带宽在几十到数百 MB/s. 访问延时在 3 到 10 毫秒之间。常用于大容量数据存储,如档案、备份和大数据.
LOCAL/REMOTE MEMORY
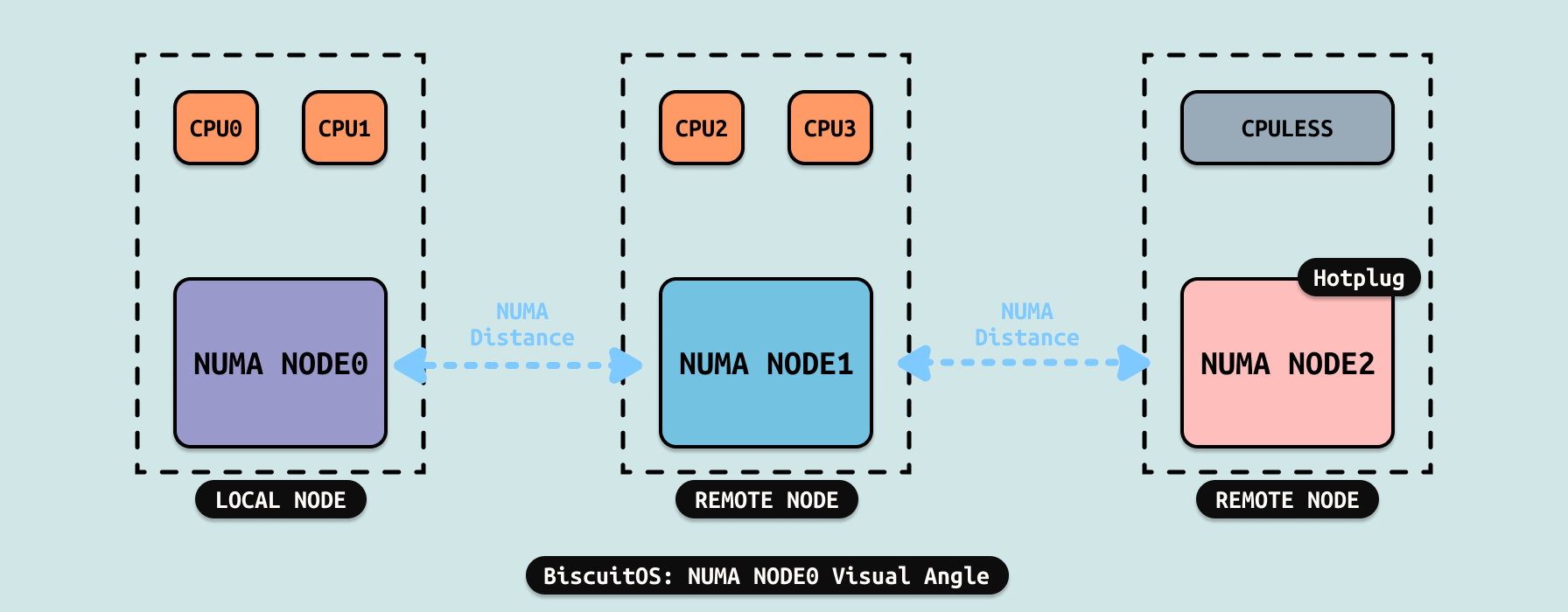
在 NUMA 架构里,系统会根据 CPU 的亲和性将物理内存划分成不同的区域,这些区域称为 NUMA NODE. 每个 CPU 都会绑定到指定的 NUMA NODE 上,此时将该 NUMA NODE 称为 CPU 的本地内存,例如上图中 CPU0 和 CPU1 的本地内存就是 NUMA NODE0,CPU2 和 CPU3 的本地内存就是 NUMA NODE1. 在支持热插拔的系统中,热插的 DIMM 内存会被划分成一个独立的 NUMA NODE,该 NUMA NODE 并不与任何 CPU 进行绑定,例如上图的 NUMA NODE2,其就是 CPULESS(无 CPU 绑定).
NUMA Distance 用于描述两个 NUMA NODE 之间的距离,该距离会影响 CPU 访问内存的延时(Latency), 在 NUMA 里,会将与 CPU 绑定的 NUMA NODE 称为本地节点,相反没有与该 CPU 绑定的 NODE 则称为 REMOTE NODE,例如上图 CPU0 和 CPU1 的本地节点是 NUMA NODE0,而 NUMA NODE1 和 NUMA NODE2 则称为 REMOTE NODE. CPULESS NUMA NODE 是任何 CPU 的 REMOTE NODE.
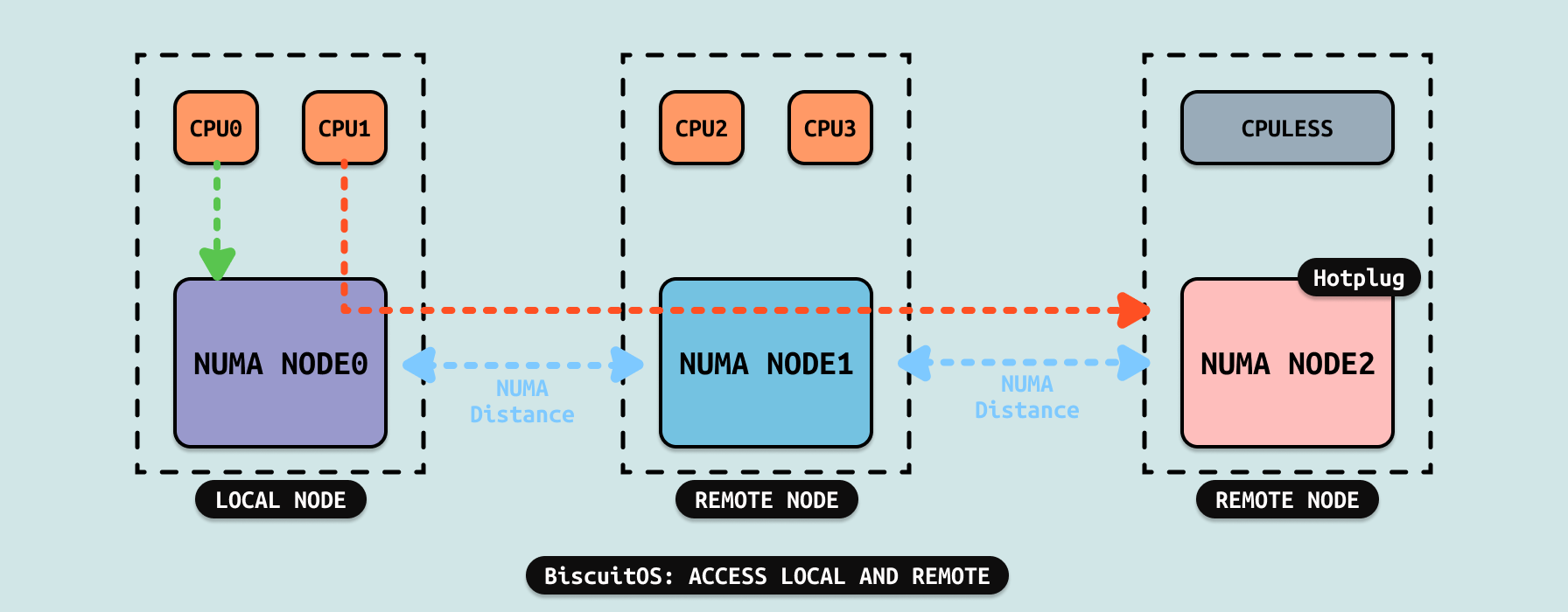
LOCAL NUMA NODE 可以确保绑定的 CPU 访问 NODE 内的内存延时一致,而跨 NUMA 访问 REMOTE NODE 的延时需要依据 NUMA Distance 而定,例如上图中,CPU 访问 LOCAL NUMA NODE0 的延时明显比 CPU1 访问 NUMA NODE2 低的多,同理此时 CPU1 访问 NUMA NODE1 的延时也比 NUMA NODE2 的延时低。通过上面的例子可以看到不同的 NUMA NODE 存在不同的延时,这也是后来 TIERED MEMORY 构建的基础.
FALLBACK AND RECLAIM
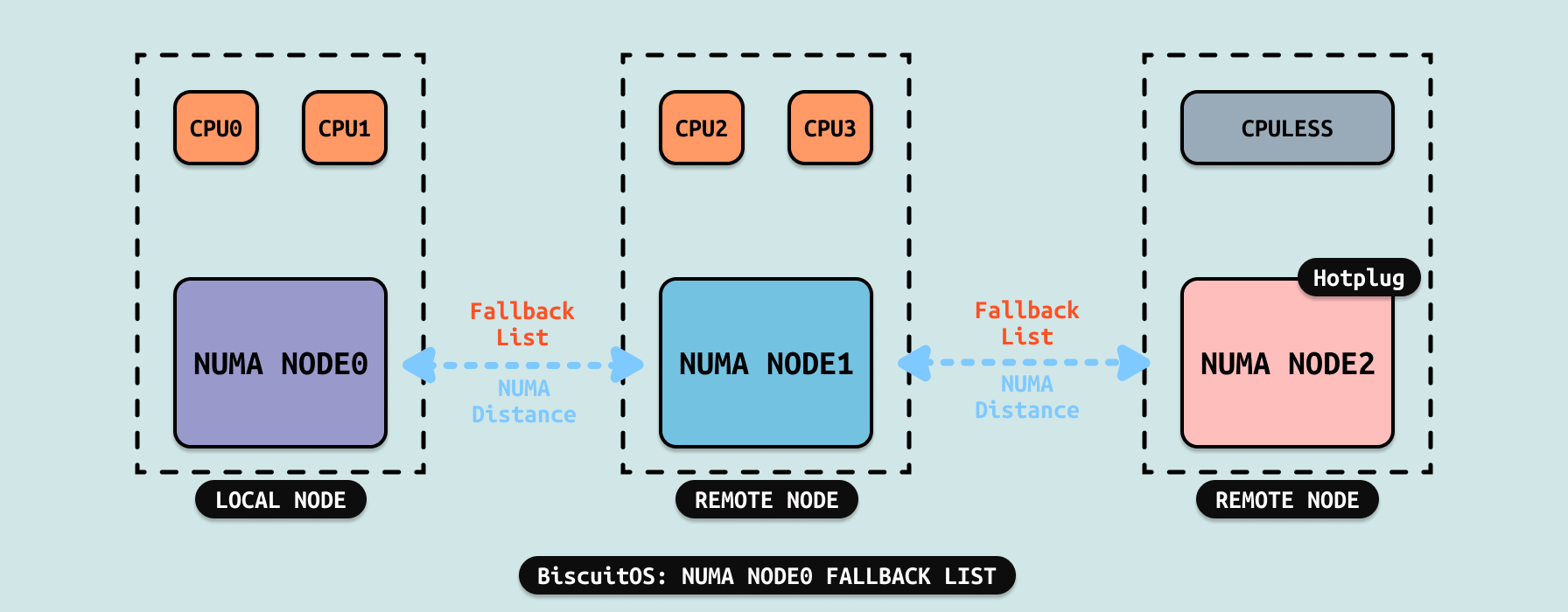
系统优先为 CPU 分配本地内存,但有时本地内存没有空闲内存,那么 CPU 不得不从远端 NUMA NODE 上分配内存. Linux 为每个 NUMA NODE 创建一个 FALLBACK 链表,其会根据 NUMA Distance 为依据,在 FALLBACK 链表上将距离 NUMA NODE 的最近的 NODE 放在链表头,然后距离最远的 NUMA NODE 放到链表尾。例如当本地 NUMA NODE0 没有空闲内存时,系统根据 Fallback 链表从 NUMA NODE1 上分配内存,如果 NUMA NODE1 上也分配不到内存,那么就从下一个 NODE 上分配内存,也就是 NUMA NODE2. 这里可以看到 CPULESS 的 NODE 一直位于 Fallback 链表的末尾.
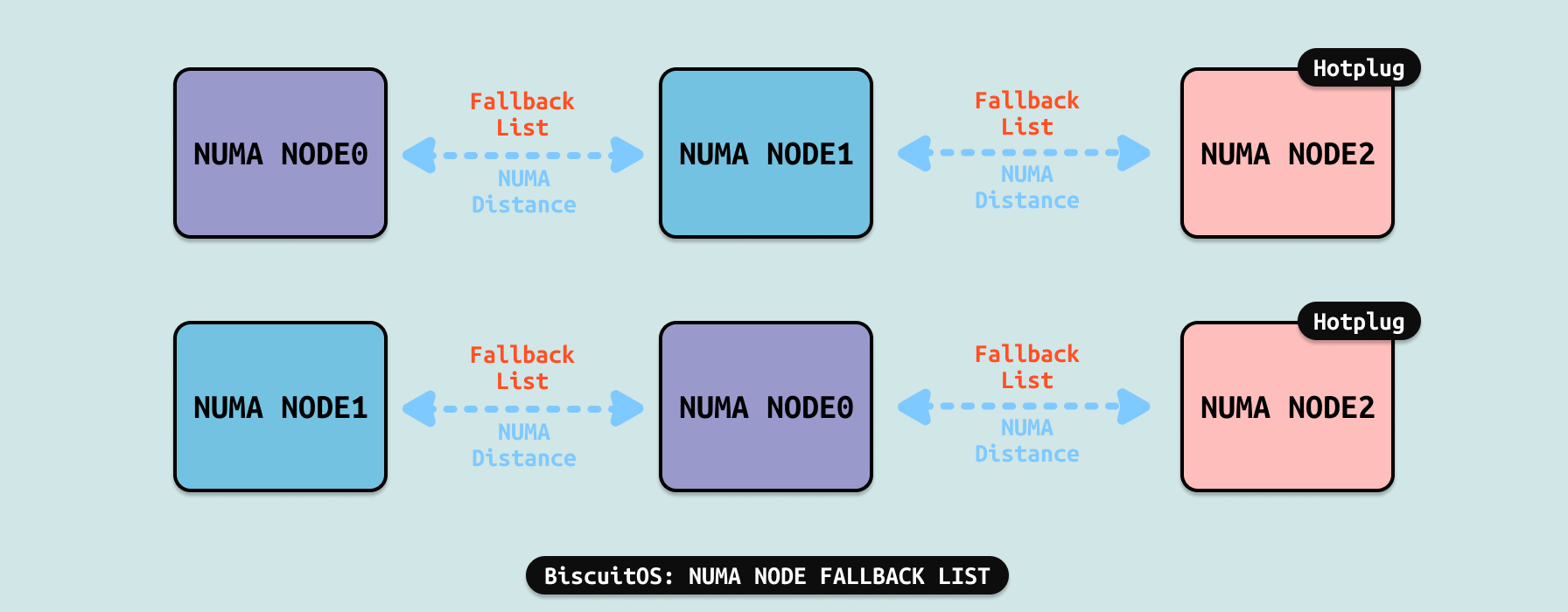
系统会根据 NUMA Disatance 为每个包含 CPU 的 NUMA NODE 创建各自的 Fallback 链表.
- NUMA NODE0 的 Fallback 链表: NUMA NODE1 到 NUMA NODE2
- NUMA NODE1 的 Fallback 链表: NUMA NODE0 到 NUMA NODE2
- NUMA NODE2 没有 Fallback 链表
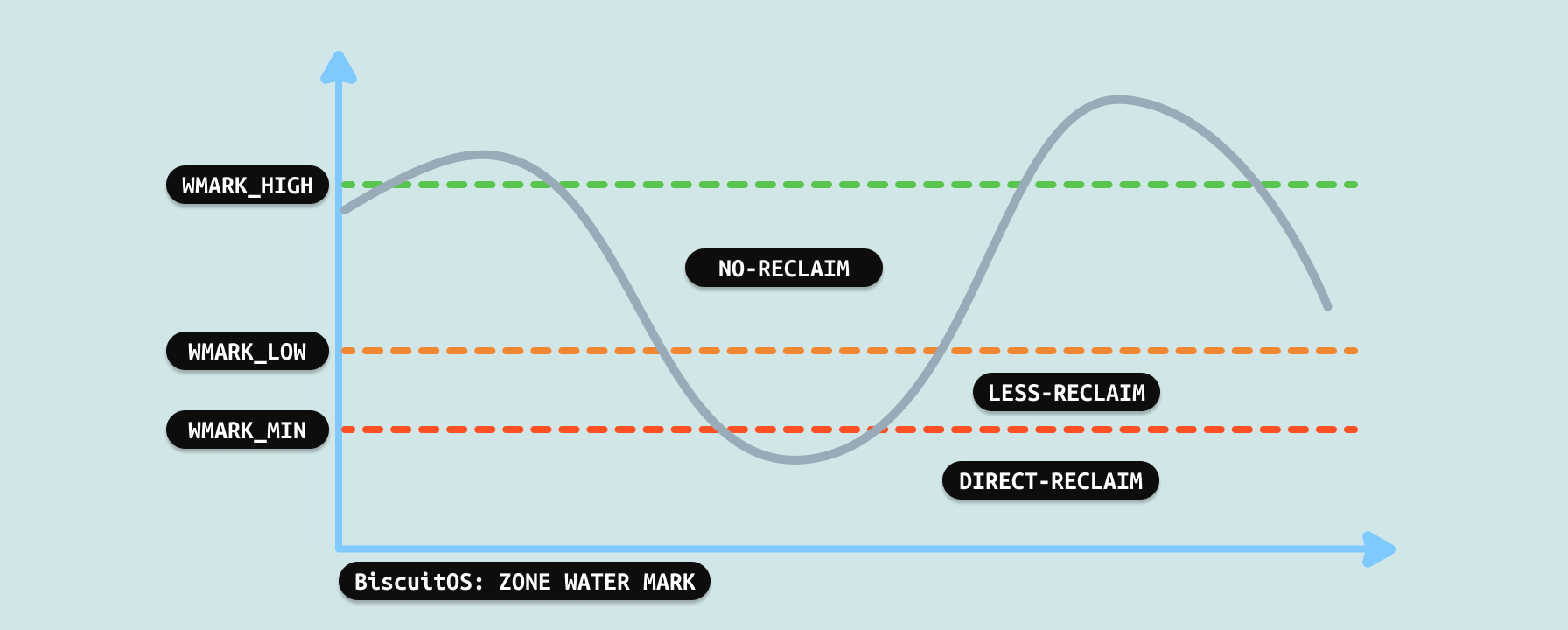
每个 NUMA NODE 上都包含一个或者多个 ZONE,每个 ZONE 管理一定数量的物理内存,ZONE 使用水位线(Water Mark)作为 ZONE 回收的依据:
- 当 ZONE 可用物理内存大于 WARK_HIGH,那么系统不会触发内存回收
- 当 ZONE 可用物理内存小于 WARK_HIGH 但大于 WARK_LOW, 系统会触发一定程度的内存回收
- 当 ZONE 可用物理内存小于 WARK_LOW 但大于 WARK_MIN, 系统会直接触发内存回收
- 当 ZONE 可用物理内存小于 WARK_MIN, 那么系统会触发 OOM
ZONE 触发内存回收之后,会将一部分最近没有使用的物理页交换到 SWAP Space,或者进行内存压缩,那么 ZONE 上就会释放处一些物理内存出来,以缓解系统内存压力。ZONE 内存回收与 NUMA NODE 的 Fallback 链表并不冲突,两者相互互补为调用者可以分配到心意的内存. 接下来继续了解内存回收的冷页:
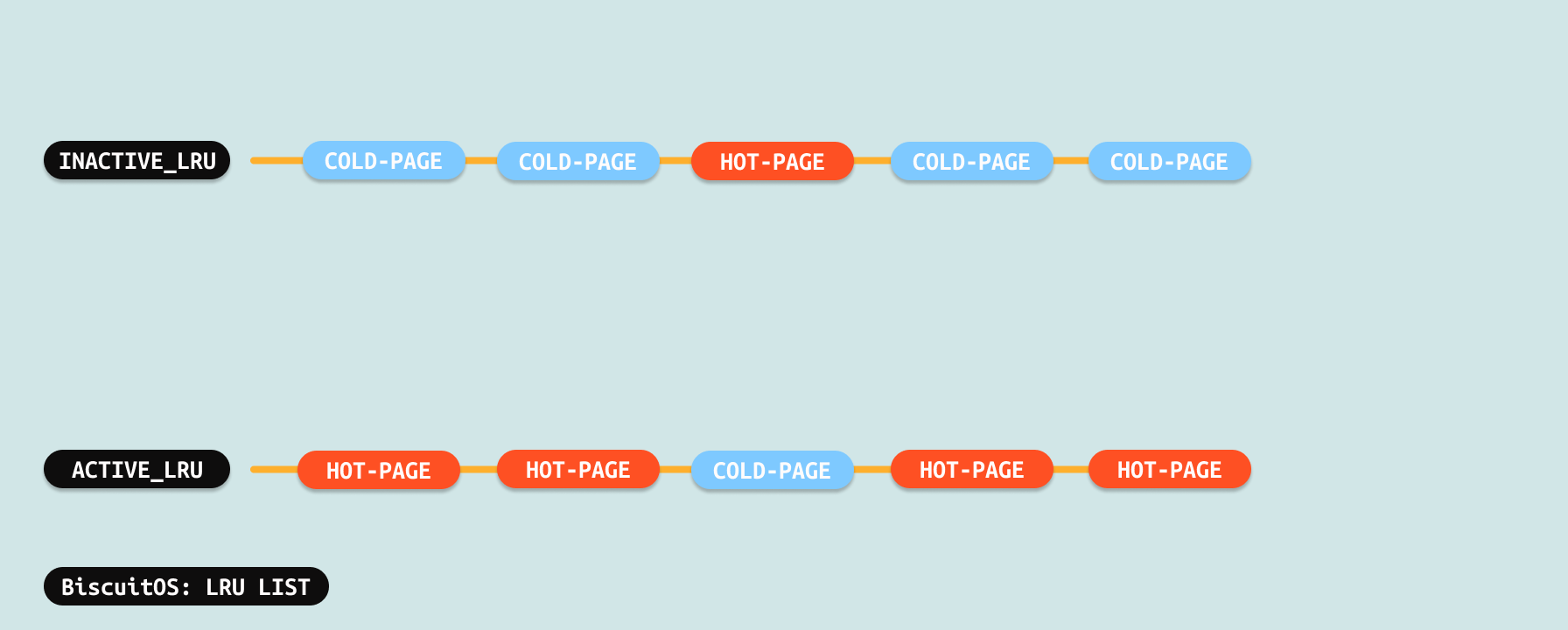
内存回收主要针对是那些分配给用户进程使用的物理页,当一个物理页被分配给用户进程之后,其会被加入到 ACTIVE-LRU 链表,内核会定期调用内核线程进行内存回收,回收的时候其会将 ACTIVE-LRU 链表上的物理页做旧(make old), 被做旧的物理页就变成冷页(COLD PAGE), 冷页的标志是对应页表的 ACCESS 标志位和 Dirty 标志位清零,以及物理页对应 struct page 数据结构 flags 成员的 PG_Reference 清零. 如果冷页被访问或者被写入,那么硬件会自动将对应页表的 ACCESS 标志和 Dirty 标志位置位,冷页就会被成非冷页(这里并没有直接称为热页).
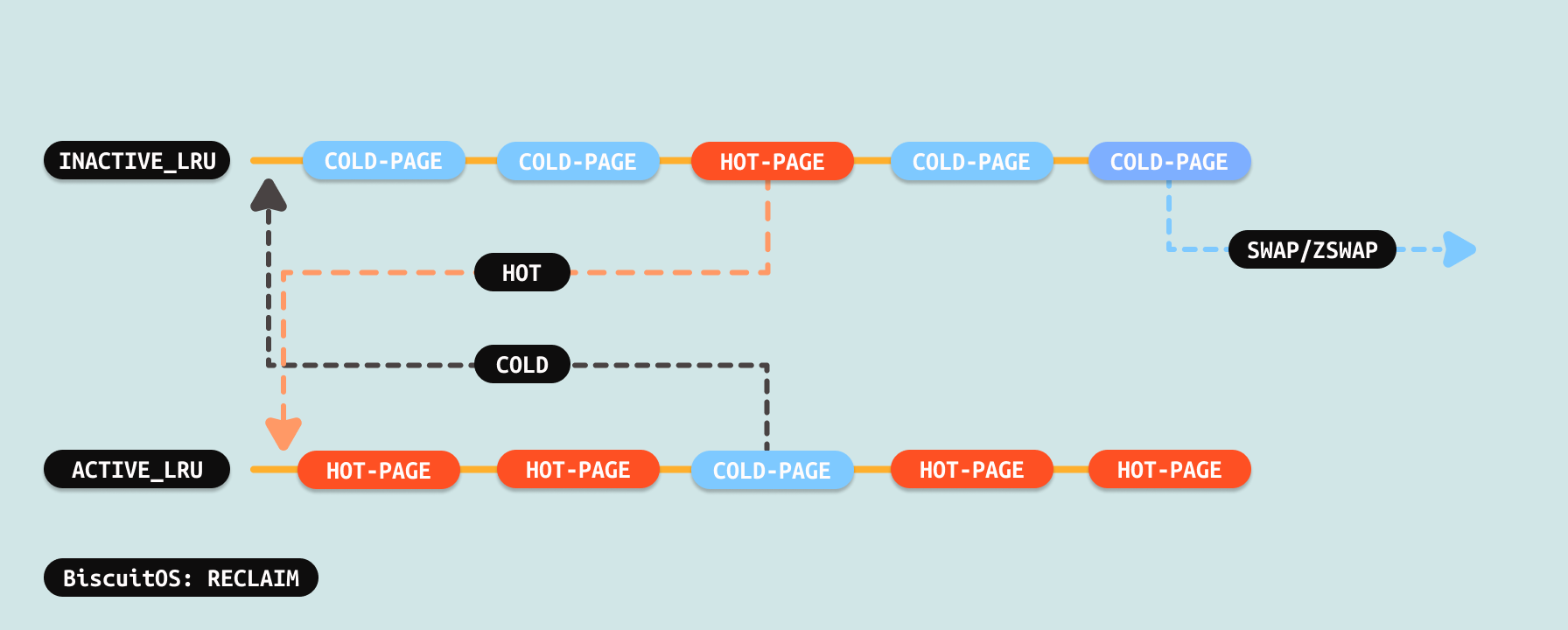
内核回收线程会定期扫描 ACTIVE-LRU 链表,其会将非冷页做旧为冷页,也会将冷页移动到 INACTIVE-LRU 链表. 内核线程还会扫描 INACTIVE-LRU 链表,此时如果遇到非冷页,那么将非冷页移动到 ACTIVE-LRU 链表,而将冷页从 INACTIVE-LRU 链表挪出,并将冷页进行 SWAP 或者 ZSWAP, 待冷页的内容被 SWAP/ZSWAP 之后,系统回收冷页为空闲物理页.
NUMA BALANCING
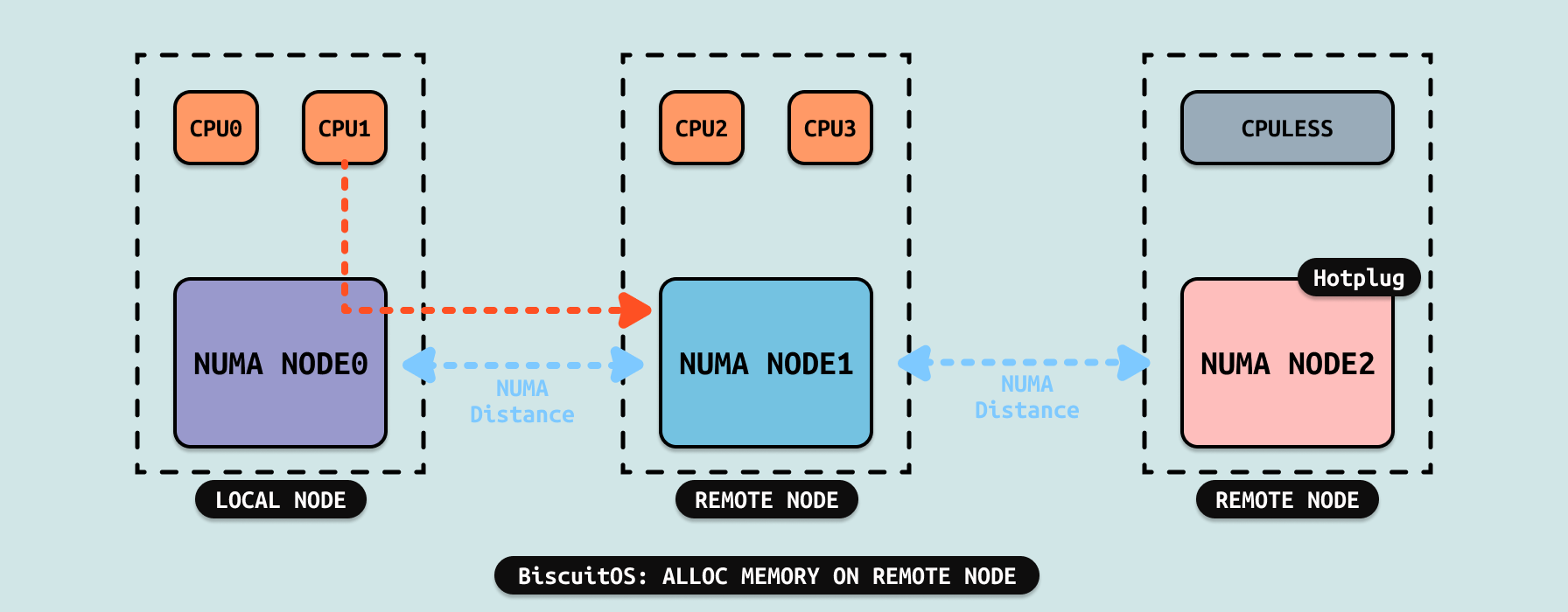
在 Linux 里,当本地内存没有可用物理内存之后,内核会根据 Fallback 链表从其他 NUMA NODE 上分配物理内存,此时本地节点也会触发内存回收. 当某个时刻,CPU 已经“被迫”使用远端内存,但此时本地内存已经有充足物理内存,为了保证系统性能,内核会采用一种称谓 NUMA BALANCING 的机制.
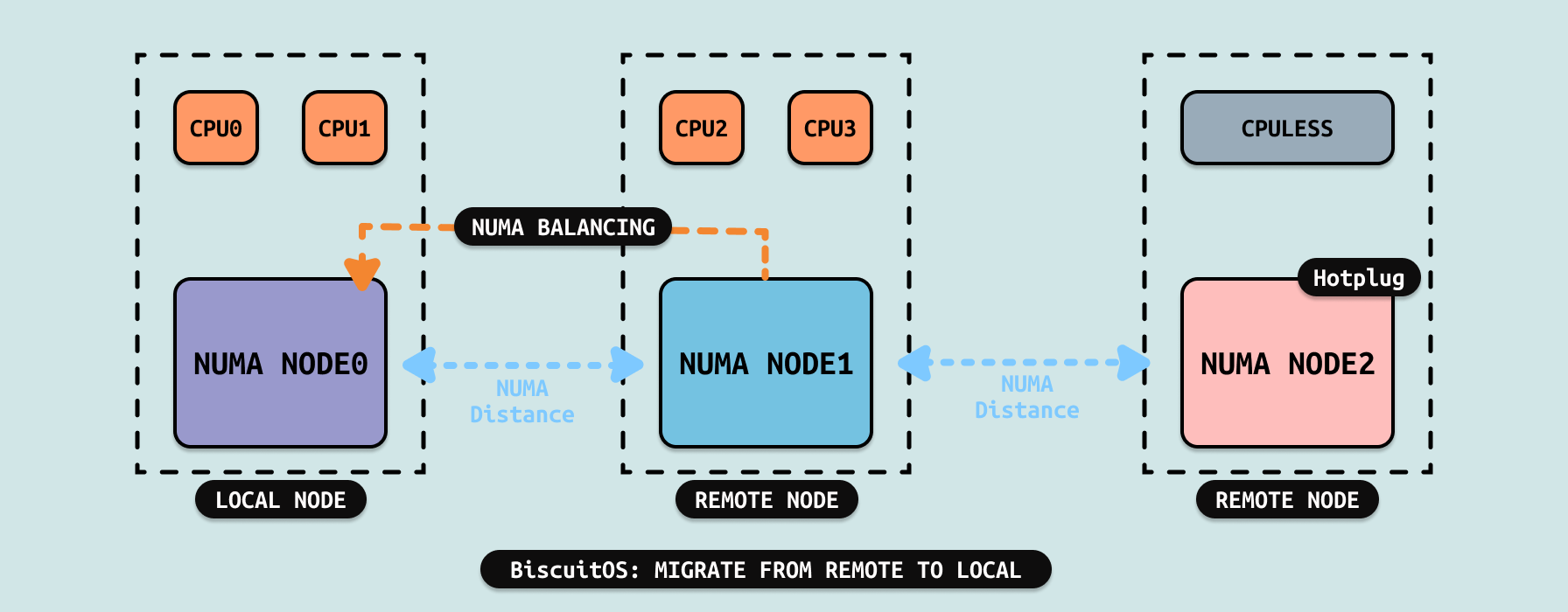
系统会结合 CFS 调度子系统,在进程被调度运行之前遍历整个用户进程的地址空间,查看里面哪些内存来自远端节点,那么会将进程虚拟内存里使用远端内存的页表进行标记,这里将页表标记为 PORT_NONE, 这个过程并不进行实际的页面迁移(Migrate),仅仅进行标记,这个过程就是 NUMA Balancing.
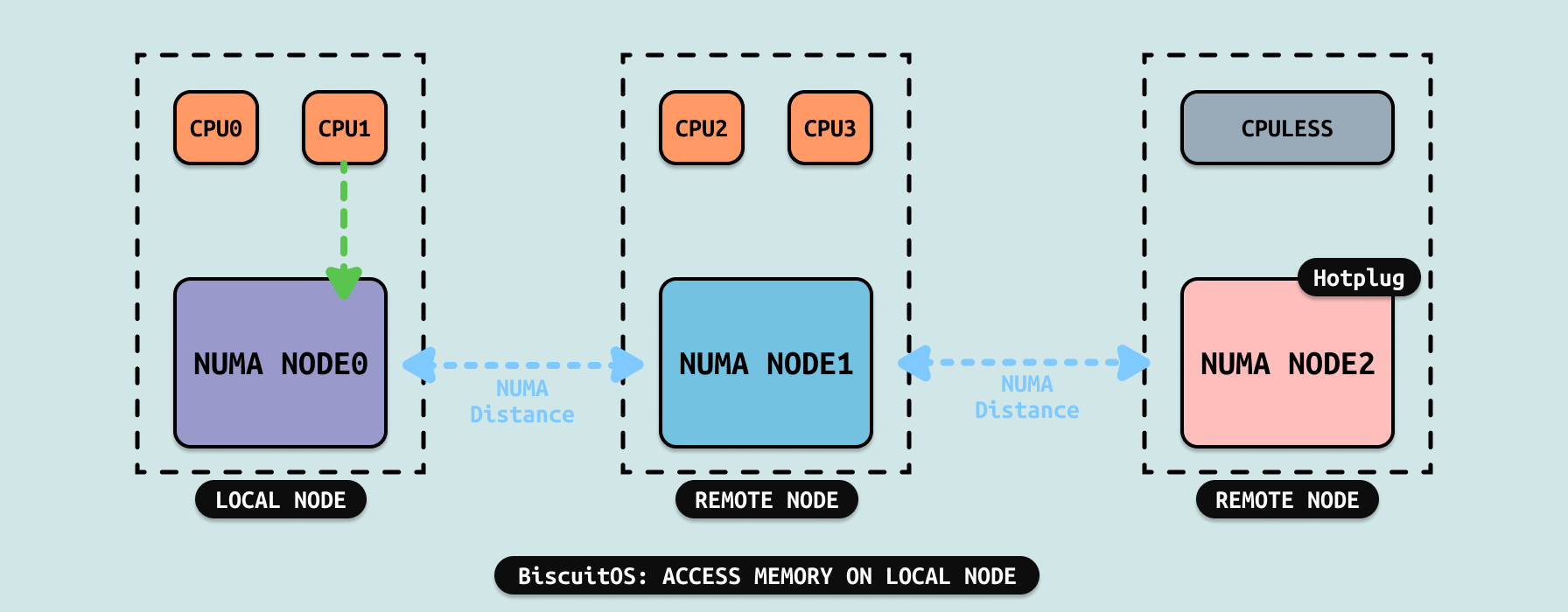
当用户进程再次访问被标记为 PORT_NONE 的内存,MMU 硬件会捕捉并触发缺页异常,缺页异常函数根据页表被标记为 PORT_NONE, 那么知道接下来需要将远端的物理页迁移到本地节点来,因此触发 MIGRATE PAGE,迁移完毕之后 CPU 可以访问本地内存,此时延时将大大降低,整体性能将有所提升.

TIERED MEMORY
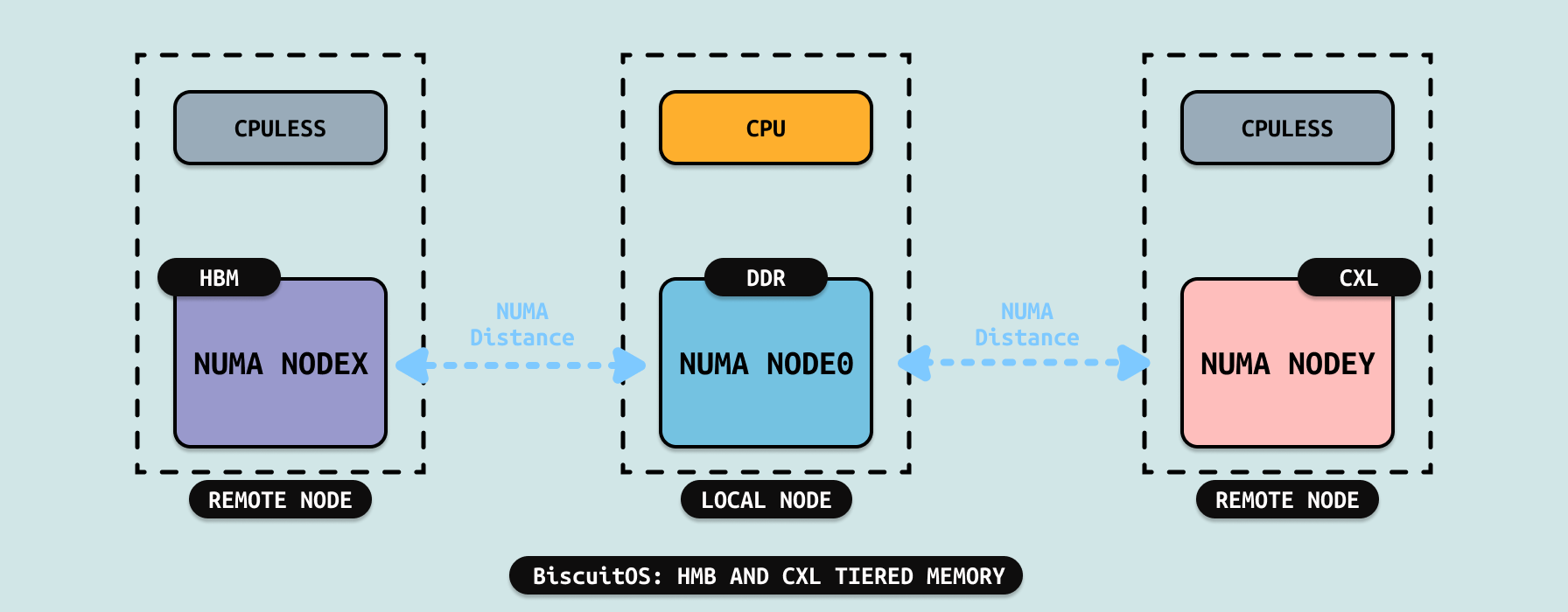
有了前面内容的铺垫,现在给各位开发者介绍分层内存(Tiered Memory), 随着硬件技术的不断更新,随着而来的是为了满足不同需求的存储设备接二连三的出现, HBM 和 CXL 就是两类比较新的存储介质. 从访问延迟的角度看,传统意义的内存 DDR 介于 HBM 和 CXL 之间,Linux 提供了多种机制来使用 HBM 和 CXL,本文介绍其中的一种使用方案. 如上图,系统将 HBM 和 CXL 与独立的 NUMA NODE 出现,并且 NUMA NODE 并不与任何 CPU 进行绑定,而传统意义上的 DDR 所在的 NUMA NODE 则与具体的 CPU 进行绑定,因此对于所有 CPU 而言,HBM 和 CXL 所在的 NUMA NODE 都是 REMOTE NODE.
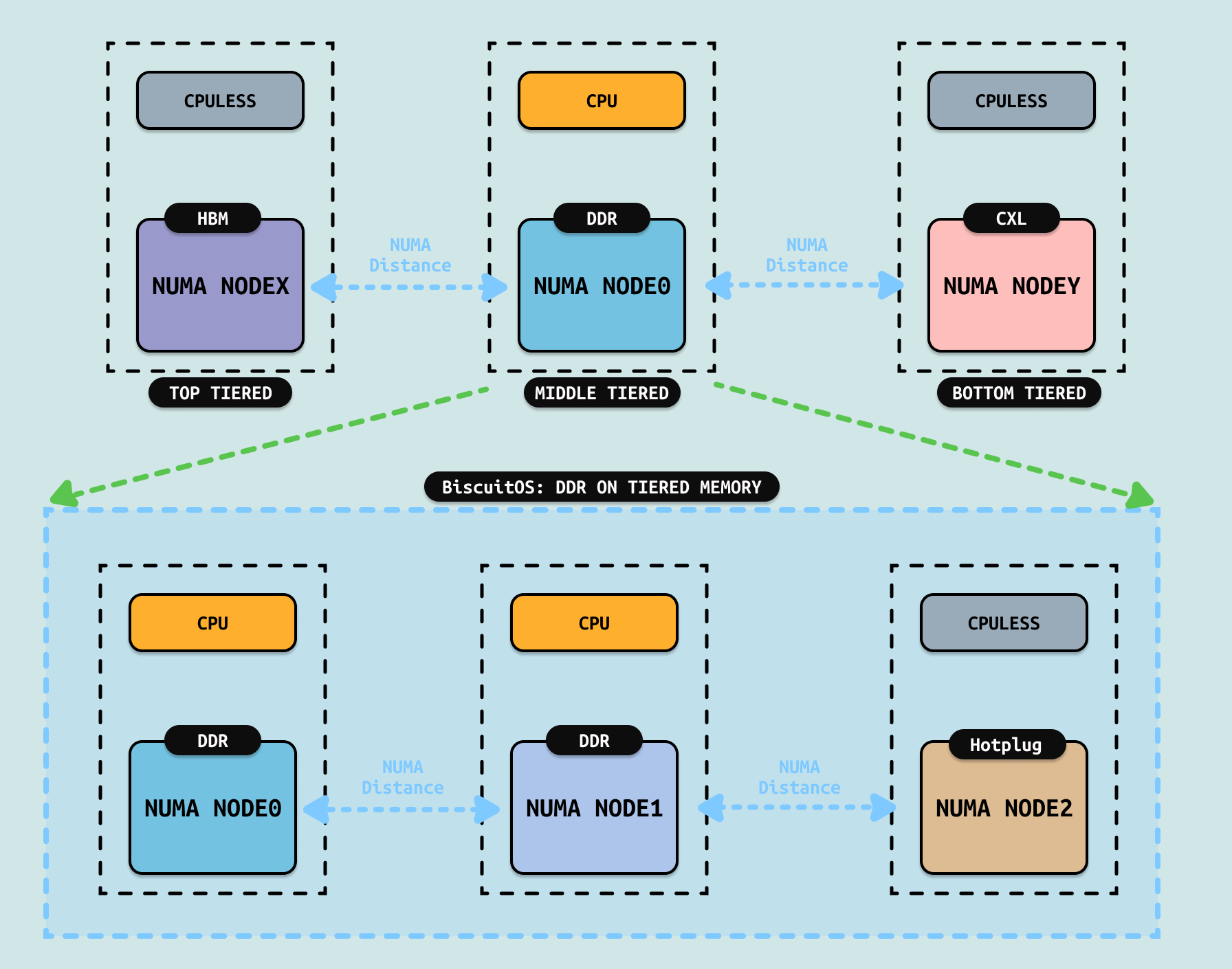
系统将 HBM、DDR 和 CXL 进行分层,其中 HBM 延时最低位于分层内存的顶层(TOP TIERED), CXL 的延时最大,则位于分层内存的底层(BOTTOM TIERED), DDR 则位于分层内存的中层(MIDDLE TIERED). 如果系统中存在多个 CPU 绑定的 DDR NUMA NODE,以及通过热插的 CPULESS DDR NUMA NODE,这些都统一划分到中层(MIDDLE TIERED). 同一层之间不再进行层级划分,因此同一层的逻辑低位一致. Tiered Memory 引入了一些新的概念,在讨论具体细节之前先介绍这些新的概念:
- 冷页(COLD PAGE): 分配给用户空间,位于 LRU 链表上且最近没有被访问的页,这里的冷页与内存回收里的冷页是一致的,因此可以用传统内存管理的角度来看待冷页.
- 热页(HOT PAGE): 在分层内存里,冷页会被降级迁移到 BOTTOM TIERED 内存里,如果对这类页多次访问,那么这个页会变成热页,并会被提升到 MIDDLE TIERED 里. 在 BOTTOM TIERED 的冷页被访问一次或者间隔比较长时间的访问不会变成热页,热页需要短时间内被多次访问.
- 降级(DEMOTION): 将冷页由延迟低的层迁移到延时高的层。例如将冷页由 MIDDLE TIERED 迁移到 BOTTOM TIERED.
- 升级(PROMOTION): 将热页由延迟高的层迁移到延时低的层,例如将热页由 BOTTOM TIERED 迁移到 MIDDLE TIERED.
TIERED DEMOTION
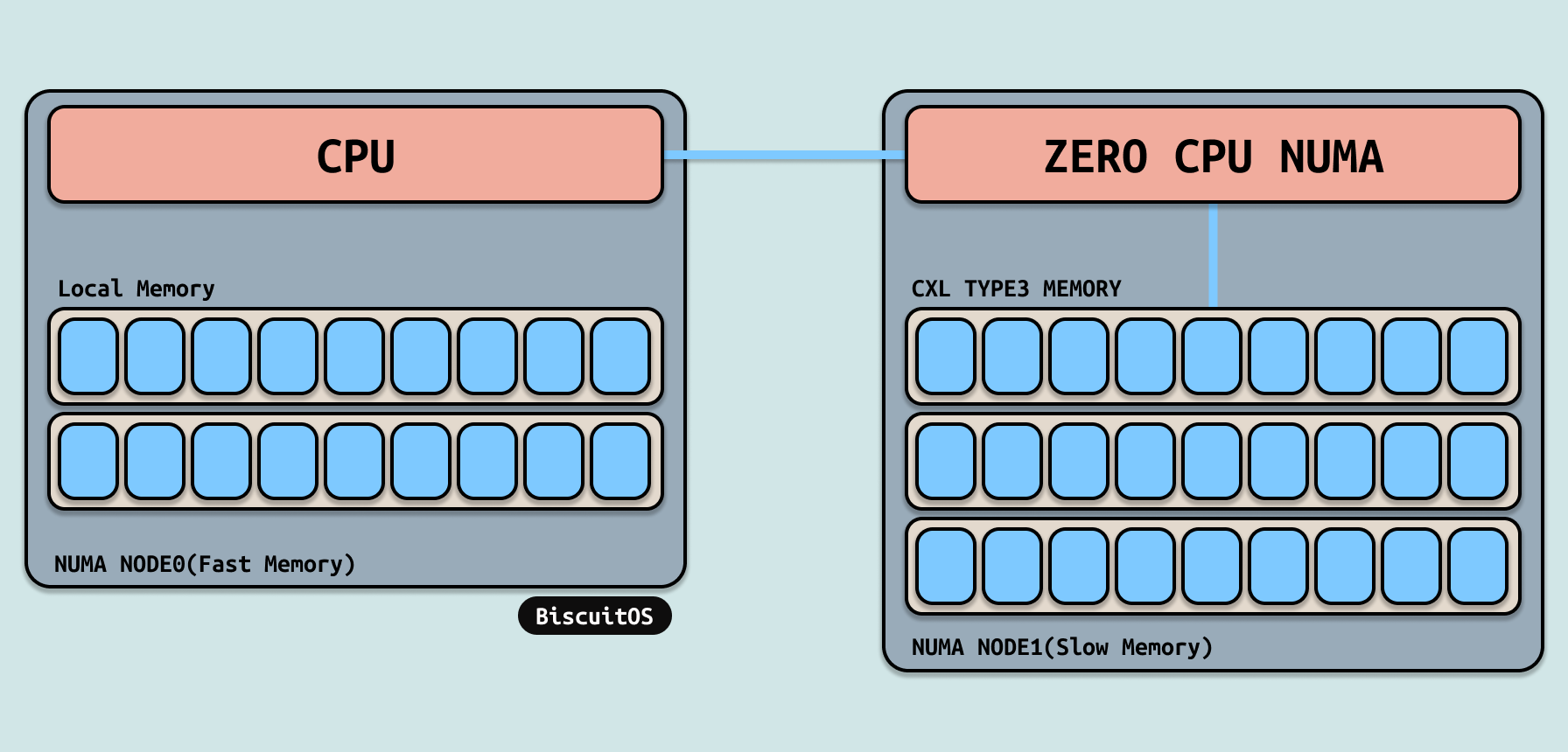
在支持 TIERED MEMORY 的系统了,CXL 的内存被独立划分在一个 CPULESS 的 NUMA NODE 上,并被当做 REMOTE NUMA NODE. 应用程序平时只在本地节点上分配内存,并不会主动到 CXL 所在的节点上分配内存。初始化时,本地节点内存充足, CXL 所在的 NUMA NODE 上内存也充足.
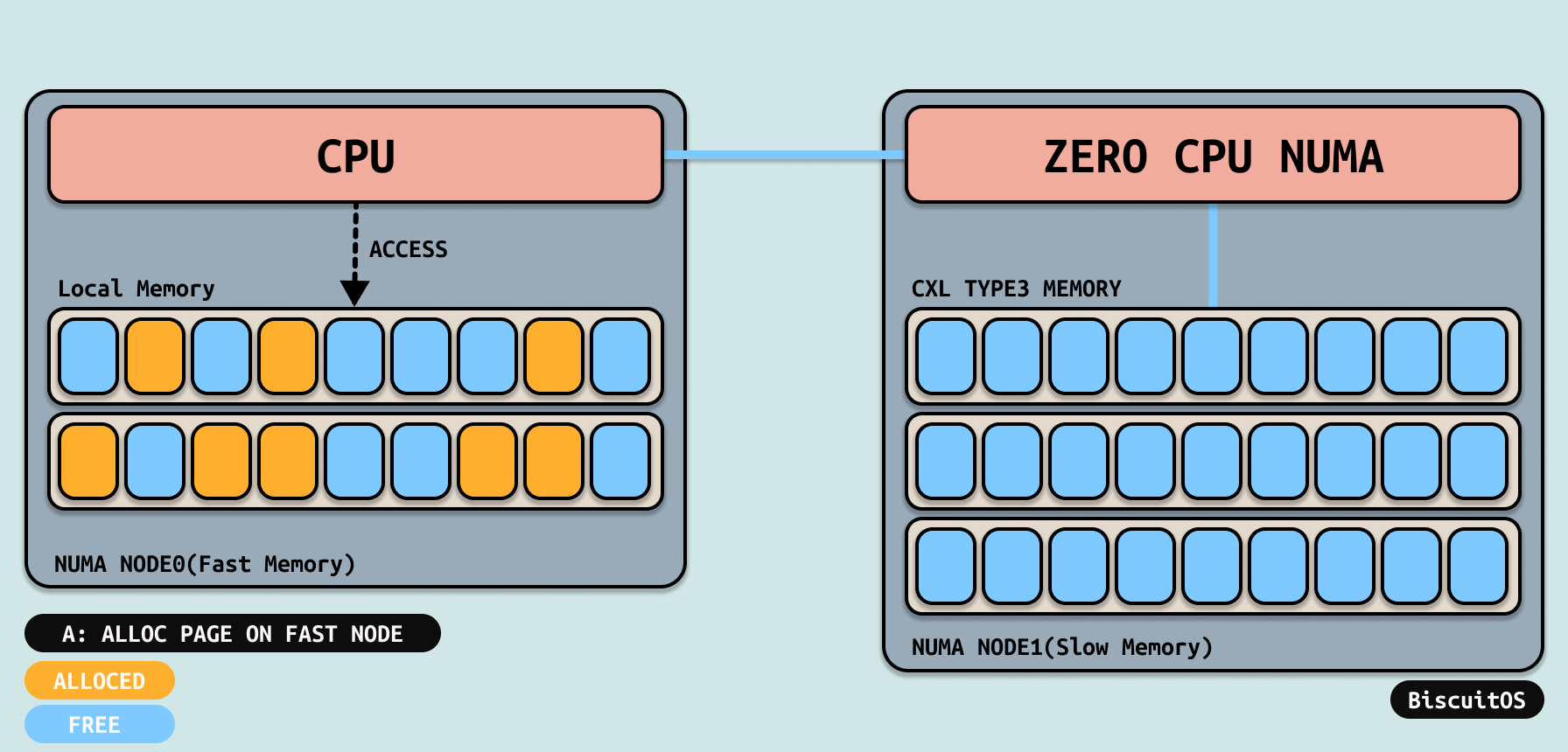
随着应用程序的运行,应用程序从本地节点上分配内存,由于应用程序分配的物理内存是随机的,因此随着应用程序运行时间边长,本地节点内存碎片化严重,导致可用内存越来越低. 此时应用程序会尝试从同一层的 REMOTE NUMA NODE 上分配内存,但其他 REMOTE NUMA NODE 上不没有多少可用的物理内存.
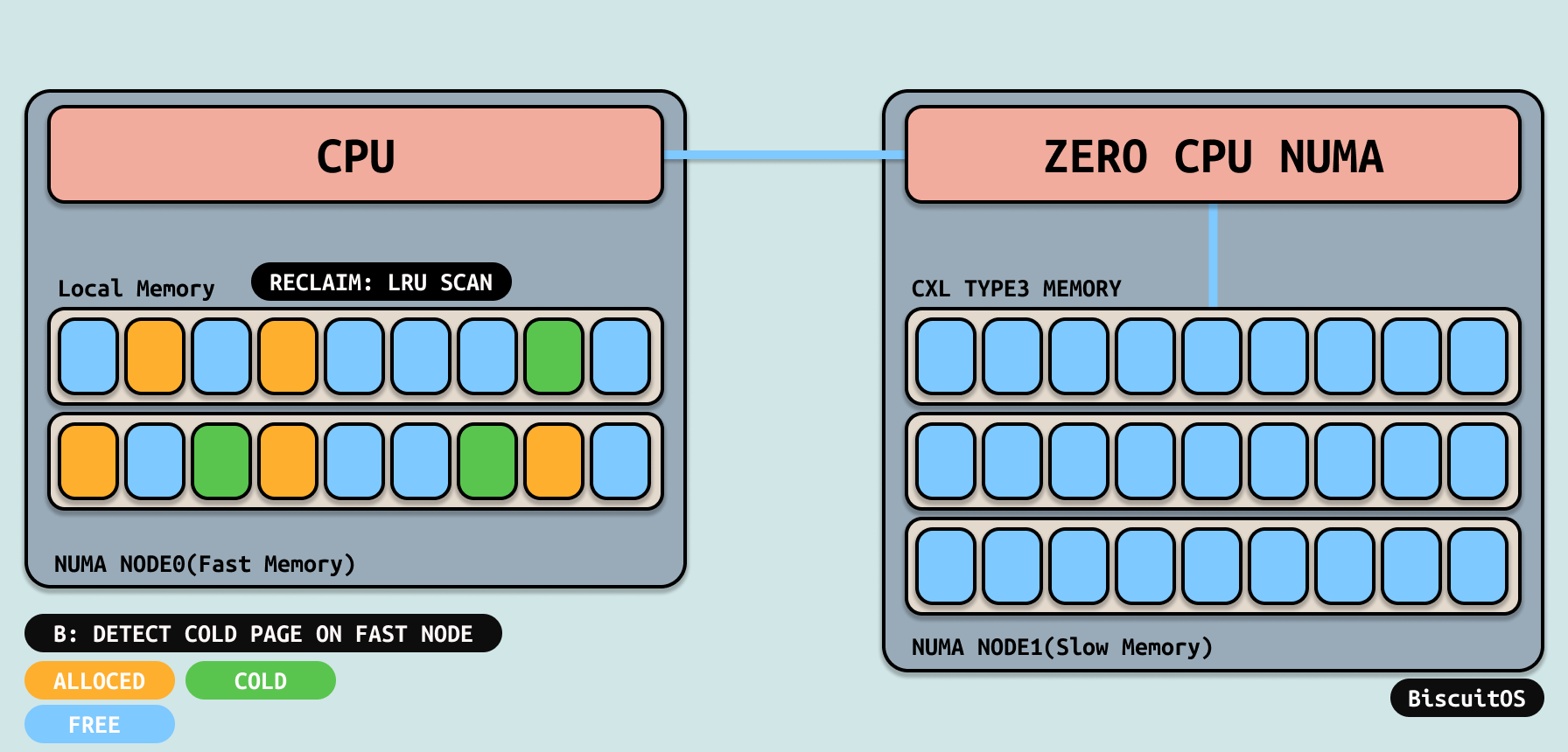
此时系统检查本地节点的水位线,发现水位线已经低于 WMARK_HIGH, 因此内核低力度唤醒内存回收线程进行内存回收,此时可能回收一些内存,但随着运行时间不断变成,水位线已经低于 WMARK_LOW, 内核直接唤醒内核回收线程或者直接进行内存回收.
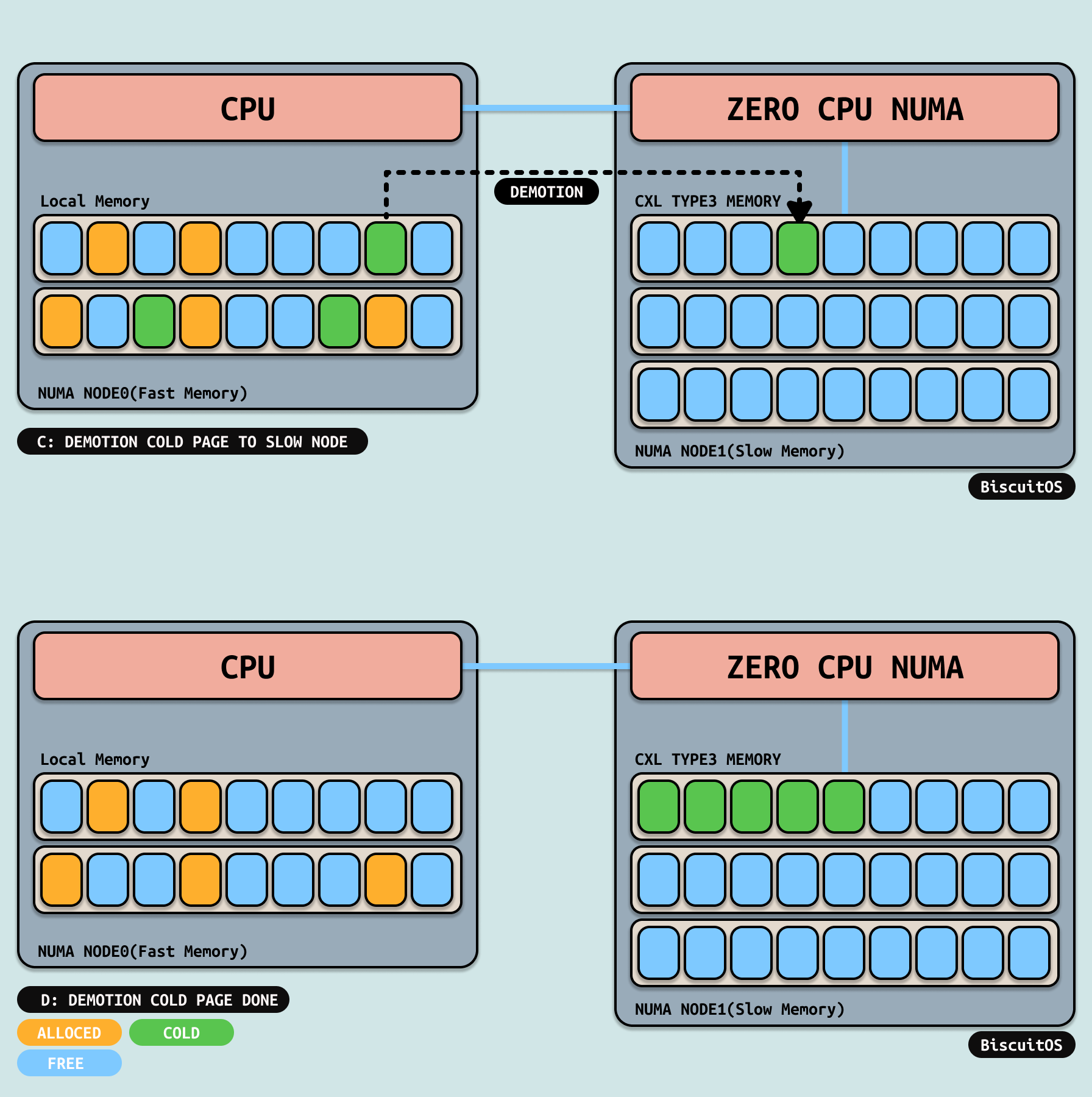
在内存压力很大的情况,内核回收线程会将 INACTIVE-LRU 上的冷页通过MIGRATE PAGE降级到第一层的内存里,例如上图将 DDR 中的冷页迁移到 CXL 所在的 NUMA NODE 上. 降级(Demotion)完毕之后本地内存压力解除,腾挪出更多可用物理内存.
TIERED PROMOTION
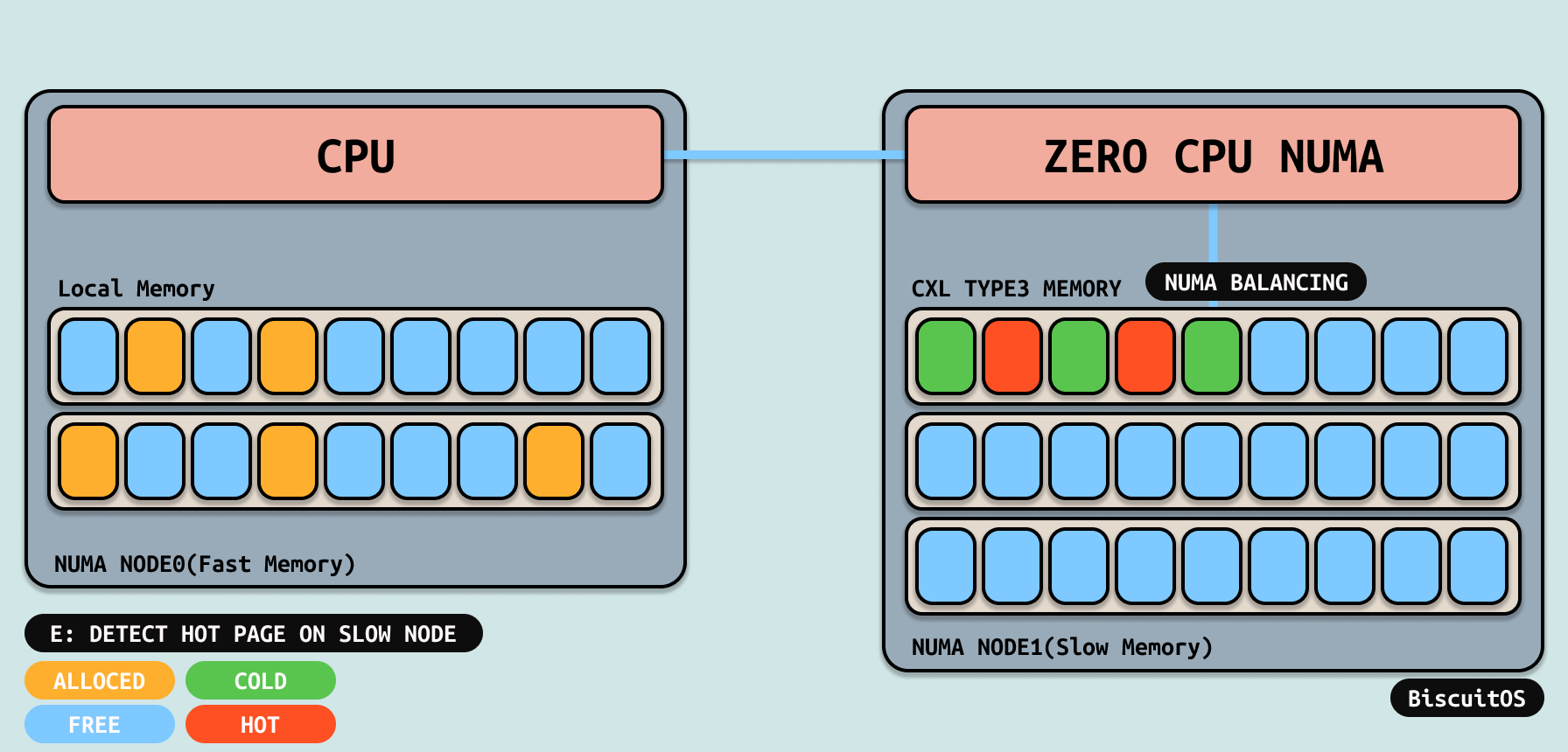
随着运行时间变长,本地节点上空闲内存不断变多,此时如果用户进程继续使用低一层内存的话,应用程序将受到极大影响,因此系统会通过 NUMA Balancing 机制不时的扫描用户进程的地址空间,从中找出被降级的内存,然后将其对应的页表修改为 PORT_NONE, 并且在物理页里记录修改页表的时间,为后续判断热页做准备.
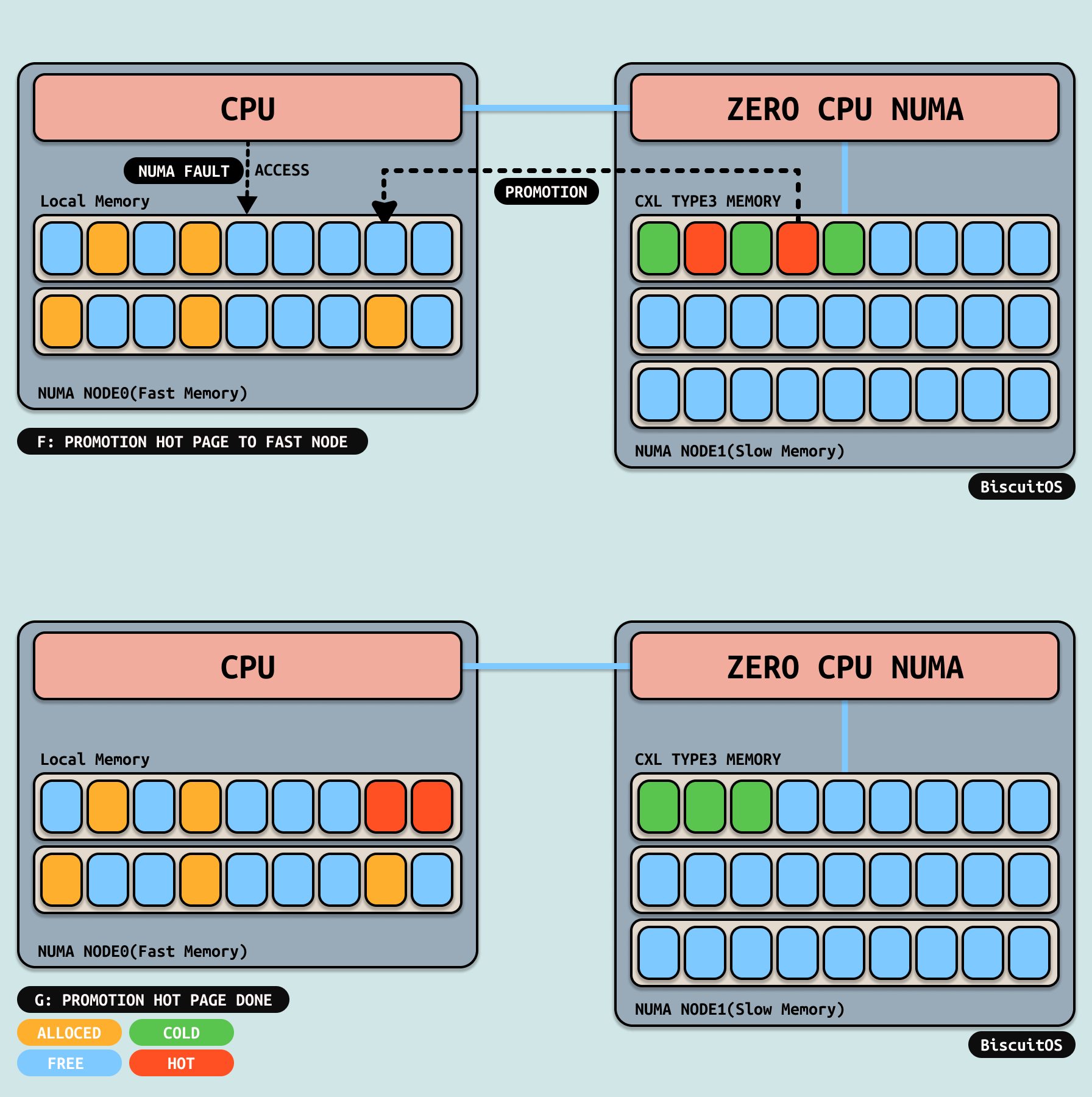
当用户进程再次访问到被标记为 PORT_NONE 的内存时,MMU 会触发缺页异常。在缺页异常处理函数里,通过识别到 PORT_NONE 可以知道需要进行升级操作,此时会判断最近访问时间来确认冷页是否符合要求变成热页. 当确认冷页符合变成热页的条件,那么会将冷页通过 MIGRATE PAGE 机制升级到本地内存,升级(PROMOTION)成功之后,缺页异常处理函数会更新页表,将其指向迁移之后的本地内存,待缺页异常处理函数返回之后,用户进程再次访问这段内存,那么此时访问到本地内存,此时应用程序的性能将大大提升. 此时以此升级(PROMOTION)顺利完成.
TIERED TECHNICAL REALIZATION
通过前面的原理分析,分层内存的实现主要包括三个部分: 降级(DEMOTION)、升级(PROMOTION) 和 热页探测(HOT PAGE DETECT). 接下来从这三面代码细节分析分层内存的实现逻辑:
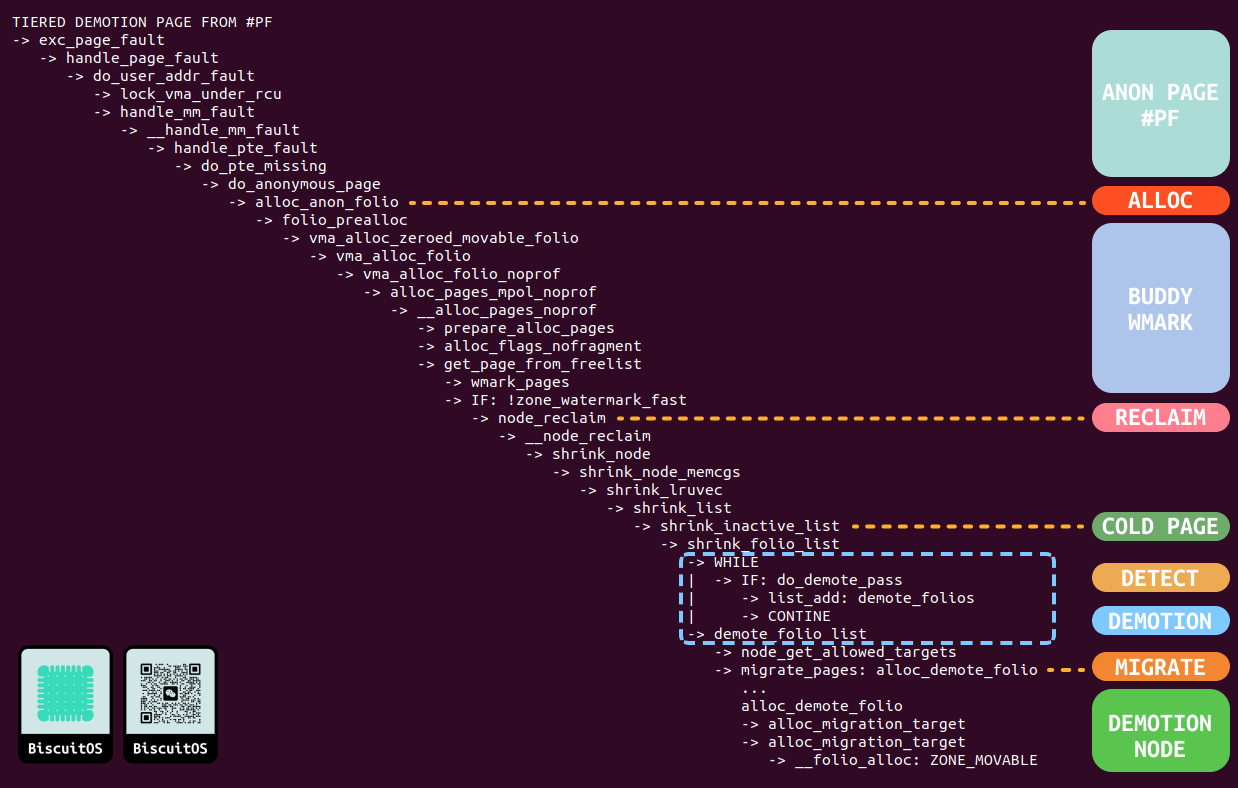
在 Linux 里,触发内存回收的方式很多,例如通过定期唤醒内核回收线程进行内存回收,也可以在从 Buddy 分配器上分配物理内存时,由于可用物理内存低于水位线,直接触发内存回收. 例如上图应用程序通过惰性分配了一段内存,在访问这段内存时触发缺页分配物理内存,其核心逻辑从 node_reclaim 函数开始进入降级(DEMOTION)的核心逻辑,分解如下:
- ANON PAGE #PF: 当访问惰性虚拟内存时,触发缺页异常,其从 exec_page_fault 开始到达 do_anonymous_page 属于匿名内存缺页流程
- ALLOC: 在 do_anonymous_page 里调用 alloc_anon_folio 函数为匿名内存分配物理页, 其会通过一系列的函数从 Buddy 里分配一个物理页
- BUDDY WMARK: 这个阶段主要从 BUDDY 分配器的 FREELIST 里查找可用的物理内存,期间会通过 Fallback 链表从同一层的 REMOTE NODE 上分配物理页。同时也会检查水位线,如果水位线低于 WMARK_LOW 那么直接触发内存回收.
- RECLAIM/COLD PAGE: 此时的内存回收是由 BUDDY 分配器直接触发的,因此其调用 node_reclaim 函数进行内存回收,在此过程中,并没有将 LRU 链表上的物理页做旧,而是直接在 INACTIVE-LRU 链表上查找冷页. 但找到一定数量的冷页之后,调用 shrink_inactive_list 函数将多个冷页进行回收,该函数也是回收的核心.
- DETECT/DEMOTION: 在回收核心处理函数 shrink_inactive_list 函数里,遍历链表里每个物理页,此时检查到 do_demotion_pages 标志之后,函数并不会走内存回收的逻辑,而是又将这些物理页收集到 demotion_folis 链表里,因此看不到对物理页解除映射和清除页表的操作. 最后将 demote_folis 链表传递给 demote_folio_list 函数进行真正的 DEMOTION.
- MIGRATE/DEMOTION NODE: 此时 DEMOTION 将需要需要的降级的物理页进行 MIGRATE PAGE, 在 MIGRATE PAGE 的回调函数 alloc_demote_folio 函数里会从 DEMOTION NODE 上分配一个物理页,并将冷页的内容拷贝到新物理页上,最后更新页表将虚拟内存映射到新物理页上.
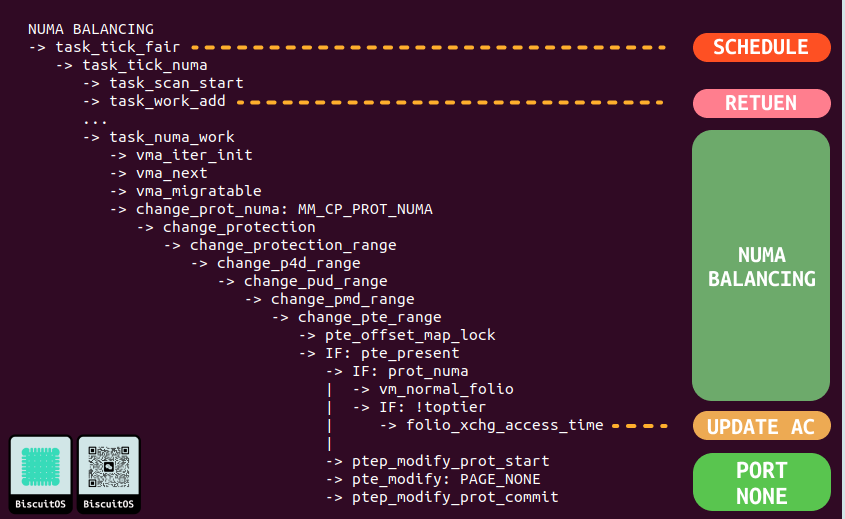
当用户进程所在的本地节点可用内存不断增多,那么为了保证用户进程的性能最大化,内核使用了 NUMA Balancing 机制,该机制会在进程被调度运行是遍历其地址空间,找到被降级的虚拟内存,然后修改其页表为 PORT_NODE. NUMA Balancing 机制只进行标记操作,不做 MIGRAGE PAGE 操作,这样确保不影响调度, 其代码细节如下:
- SCHEDULE/RETUEN: 用户进程会被周期性的调度,那么每次调度时会调用 task_tick_fair 函数(CFS 调度),其会检查调度的时间点是否已经超过下一次运行的 NUAM Balancing,如果时则调用 task_tick_numa 函数唤醒 task_work_add 函数,该函数会在用户进程从内核态返回到用户态时调用其队列里的 WORK,其中一个 WORK 便是 task_numa_work
- NUMA BALANCING: 当 task_numa_work 函数被调用时,其首先检查此时是否已经运行下一次 NUMA Balancing,如果运行才继续执行,其会遍历进程地址空间里所有的 VMA,接着检查可以 MIGRATE 的 VMA,并调用 change_pte 函数修改 VMA 对应的页表,其遍历页表找到最后一级页表 PTE.
- UPDATE AC: 此时调用 change_pte_range 函数,该函数检查修改页表内容为 prot_numa 时,先从 PTE 页表里获得 DEMOTION PAGE,然后将修改的时间更新到对应的 STRUCT page 里
- PORT_NONE: 这个阶段将 PTE 页表修改为 PORT_NONE.
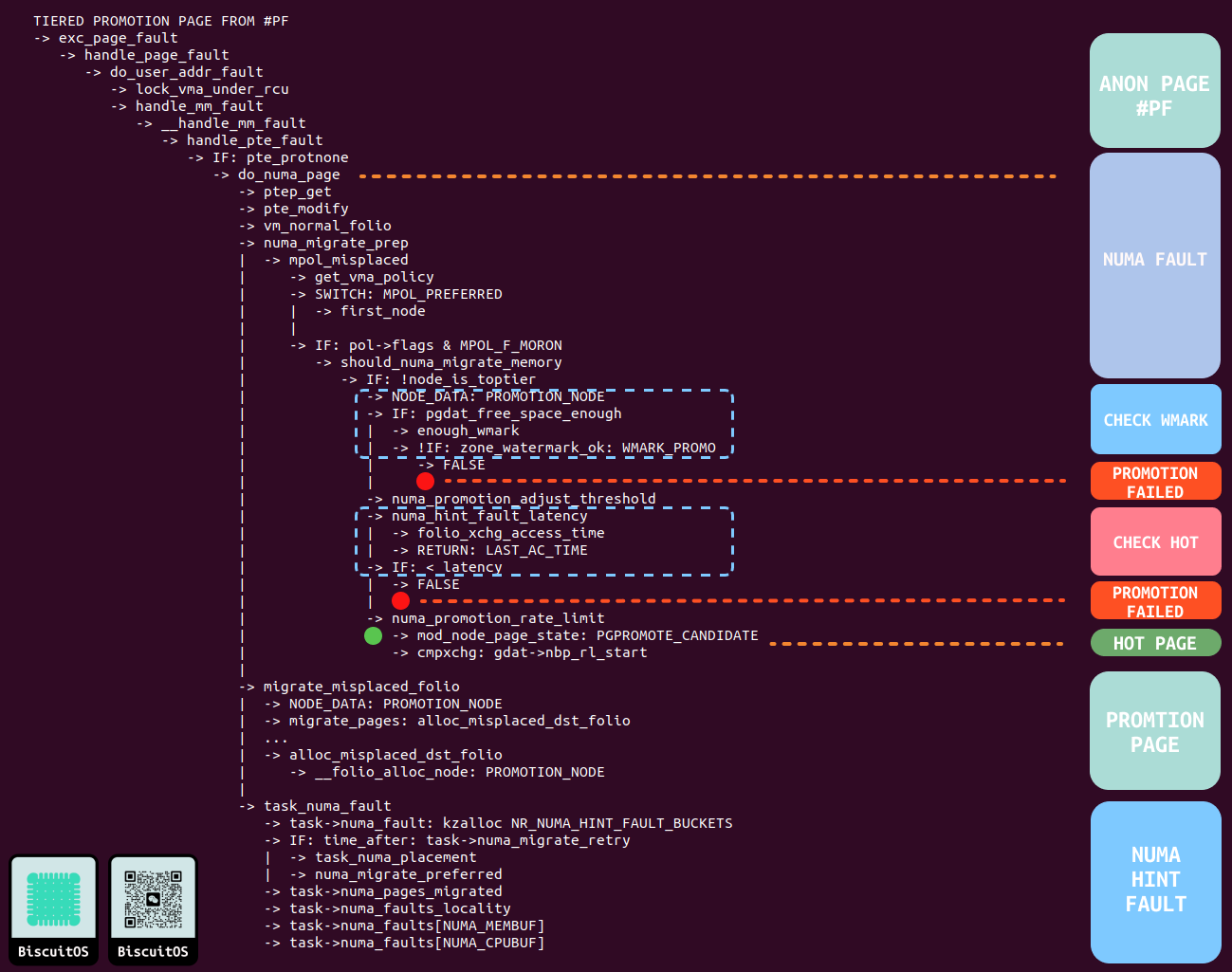
最后阶段就是升级热页(PROMOTION HOT PAGE), 升级的场景很多,比较常见的场景是应用程序再次访问被标记为 PORT_NONE 的内存时,会再次触发缺页异常,缺页异常处理函数通过 PORT_NONE 标记识别到需要升级,接下来如果探测到冷页已经变成热页,那么通过 MIGRATE PAGE 机制进行升级. 除了缺页场景, GUP(Get User Pages) 场景也可以升级. 其核心逻辑是热页的判断,接下来分析代码细节:
- ANON PAGE FAULT: 当应用程序再次访问被标记为 PORT_NONE 的虚拟内存时,MMU 检查到页表异常,于是触发缺页异常。缺页异常处理函数按匿名页的流程进行处理,并在 handle_pte_fault 函数里获得 PTE 页表.
- NUMA FAULT: 检查 PTE 页表内容发现 PORT_NONE 标记,于是调用 do_numa_page 函数进行处理. 函数首先将 PTE 内容修改为正常页表,并从中获得物理页,接着会从物理页里获得 NUMA NODE 的信息,以及当前进程本地 NUMA NODE 信息,如果确认物理页是被降级了,那么接下来调用 numa_migrate_pre
- CHECK WMARK: 升级的 NUMA NODE 也维护了一个水位线,当可用物理内存低于该水位线时,就算物理页已经是热页了,那也不让升级. 如果该检查不过,那么升级失败直接返回.
- CHECK HOT: 当升级的 NUMA NODE 运行升级,接着调用 numa_hint_fault_latency 函数,该函数会从物理页读取上一次被 NUMA Balancing 标记为 PORT_NODE 的时间点,如果该时间到现在的时间值小于一定值,那么该页就认为是热页(HOT PAGE), 因此可以被升级; 反之则被认为是冷页, 不让升级.
- HOT PAGE: 被确认为热页之后,调用 numa_promotion_rate_limit 函数更新 NUMA PROMOTION 相关的统计.
- PROMOTION PAGE: 函数调用 migrate_misplaced_folio 函数进行 PROMOTION,其核心依赖与 MIGRATE PAGE 机制,其回调函数 alloc_misplaced_dst_folio 函数,该函数会在 PROMOTION NODE 里分配物理页,并将虚拟内存映射到新的物理页上.
- NUMA HINT FAULT: 该阶段是 NUMA HINT FAULT 的处理流程,主要是进程对 NUMA 的相关统计,与 PROMOTION 关系不大.
- 升级失败: 当 CHECK WMARK 和 CHECK HOT 失败之后,由于页表已经被更正为指向 DEMOTE NODE,那么下一次 NUMA Balancing 还会对该页表进行 PORT_NONE 标记和更新访问时间.
以上便是分层内存 DEMOTION 和 PROMOTION 核心逻辑,但分层内存还包括 Linux TIERED MEMORY 架构,接下来会在其他文章中进行描述.
TIERED PROMOTION/DEMOTION PRACTICE
BiscuitOS 提供了关于 Tiered 分层内存的 PROMOTION 和 DEMOTION 实践,开发者可以在 BiscuitOS 上进行实践,实践案例在 BiscuitOS 上的部署逻辑如下:
# 切换到 BiscuitOS 项目目录
cd BiscuitOS
# 通过 Kbuild 选择需要部署的应用程序
make menuconfig
[*] DIY BiscuitOS/Broiler Hardware --->
<*> Intel Q35
[*] CXL: Compute Express Link
CXL Hardware Topology (CXL Switch With TYPE3: x1 Volatile Memory(DDR)) --->
[*] Package --->
[*] HETEROGENEOUS MEMORY MANAGEMENT
[*] CXL TIERED MEMORY: DEMOTION AND PROMOTION --->
# 配置完毕保存,然后进行部署
make
# 部署完毕之后,切换到实践案例所在的目录:
cd BiscuitOS/output/linux-6.10-x86_64/package/BiscuitOS-CXL-TIERED-MEMORY-default
# 部署依赖工具
make prepare
# 下载实践源码(第一次部署需要执行)
make download
# 编译并运行实践案例
make build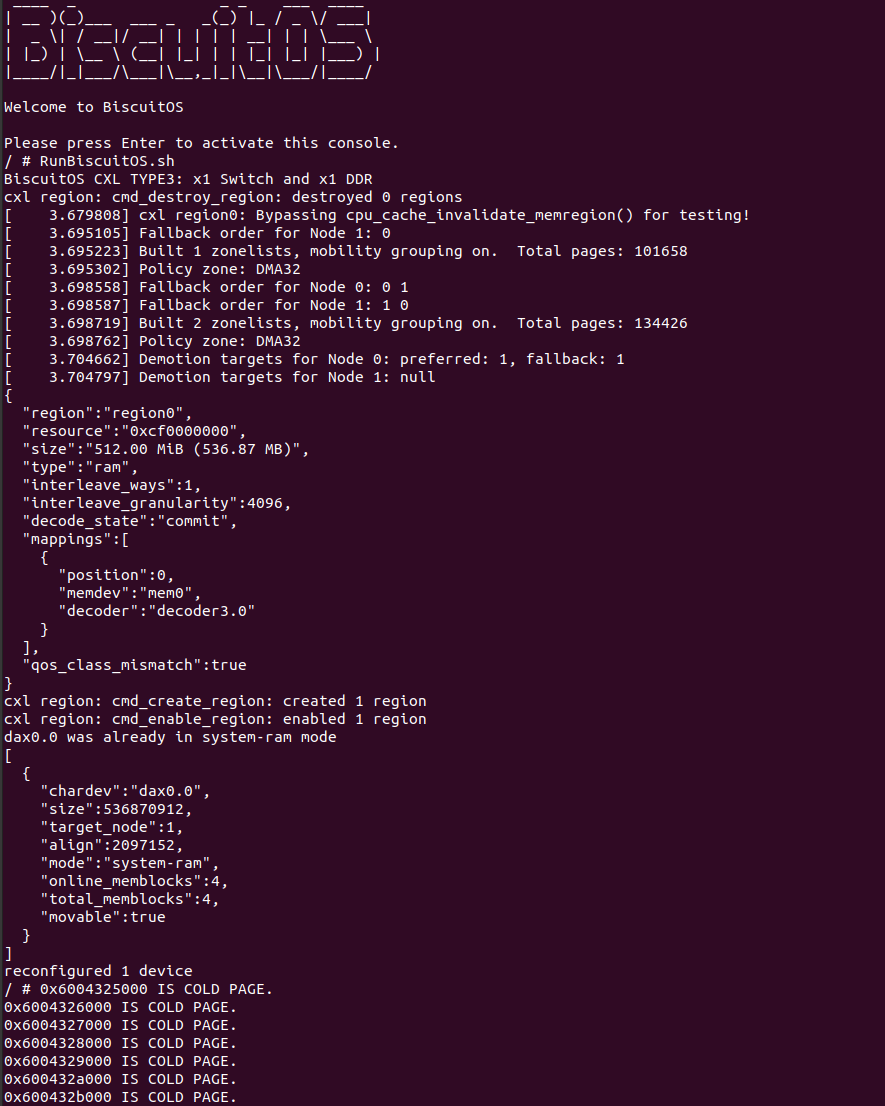
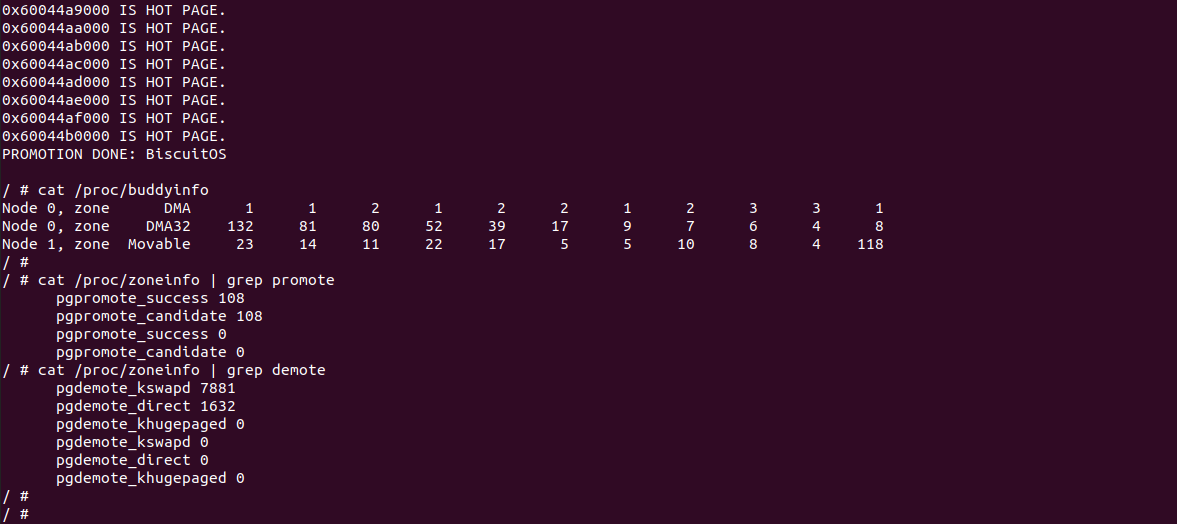
当 BiscuitOS 运行之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含实践所需的所有命令. 可以看到实践案例运行之后,用户进程的内存被降级到 DEMOTION NODE 上,也就是 CXL 所在的 NUMA NODE 上. 待程序运行一段时间之后,经历了 NUMA Balancing,再次对映射冷页的内存进行访问时,冷页慢慢的变成热页,最终全部都回到了 PROMOTION NODE 上. 可以从 /proc/zoneinfo 里面获得 PROMOTION 和 DEMOTION 相关的信息. 接下来分析源码:

实践案例是一个应用程序,四部分组成,分别是: 惰性分配、降级、NUMA Balancing 和 升级,接下里对四部分进行详细描述:
- 惰性分配: 函数 31-42 行,调用 mmap 函数惰性分配匿名内存,31 行 mem 指向匿名内存的起始地址,此时只有分配虚拟内存部分,并没有映射实际的物理内存. 函数在 41 行将 base 指向匿名内存的起始地址,然后将 end 指向匿名内存最后一个页的地址.
- DEMOTION: 函数 45-56 行,函数在 45 行使用 while 循环遍历所有的匿名内存,并按 PAGE_SIZE 的粒度进行遍历,每遍历一个匿名内存页时,函数在 47 行对虚拟内存进行访问,此时会触发缺页,缺页会为虚拟内存分配物理内存并建立页表映射,但由于本地内存不是很充足,Fallback 节点也是不够,那么只能触发内存回收,此时会发生 Demotion 降级,因此有的虚拟内存映射的物理内存来自 DEMOTION NODE. 函数接着在 49 行获得虚拟内存映射的 NUMA NODE 信息,并在 51-52 行发现映射到 DEMOTION NODE,那么将这些虚拟地址记录到 DemotPages[] 数组, 数组最多记录 NR_DEMOT_PAGES 个降级物理页.
- NUMA Balancing: 函数 59-63 行,函数在 59 行使用 WHILE 函数循环 NB_FREQ 次,以此控制 NUMA Balancing 的节奏. 函数在 60 行对匿名内存进行读操作,以此满足 NUMA Balancing 的某些条件,最后就是在 62 行调用 sleep(0.8) 函数,该函数可以实现用户进程每 0.8s 调度一次,该调度评率正好完成 NUMA Balancing.
- PROMOTION: 函数 66-90 行,函数使用 for 循环不停的遍历 DemotPages[] 数组里记录的降级页,直到所有的降级页升级到 PROMOTION NODE 里. 函数在 80 行检查虚拟内存映射的 NUMA NODE 信息,以此判断是否升级成功.
以上便是实践案例的代码逻辑,逻辑简单易懂,可以结合内存流动工具查看内核处理的全部过程. 以上便是本文的全部内容,谢谢收看.