

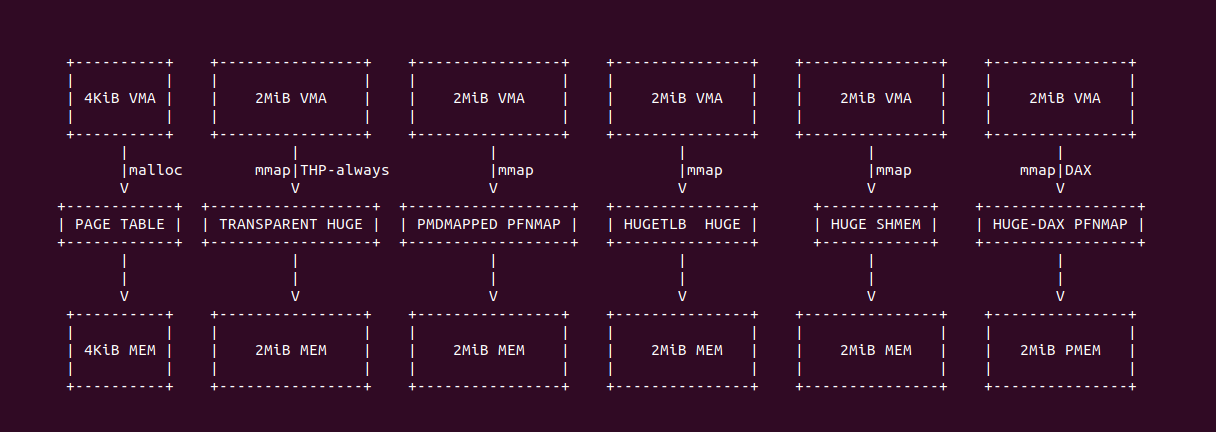
在 Linux 里,用户进程可以使用 malloc/mmap 分配虚拟内存,通常情况下虚拟内存最终映射到 4KiB 的物理内存上. 用户进程的虚拟内存除了可以映射 4KiB 的物理内存,其也可以映射更大粒度的物理大页,映射大页的好处简单来说就是节省页表内存开销和减少 TLB Entry 占用,从而降低内存峰值带来的性能损耗。目前 Linux 支持用户空间虚拟内存映射 2MiB/1Gig 物理大页的方法有:
- 透明大页方案: 可以自动、无需修改应用程序代码的情况下,将零散的 4KiB 物理页映射迁移合并成 2MiB 物理页映射, 减少 TLB 缺失从而提供应用程序和系统的整体性能.
- PMDMAPPED PFNMAP 方案: 在驱动模块的支持下,应用程序将虚拟内存直接映射到 2MiB 的系统预留物理内存上,优点是应用自我内存管理,减少 TLB 缺失.
- HUGETLB 方案: 系统提供的大页池化机制,应用程序可以从大页池子中获得 2MiB/1Gig 物理页,然后将进程虚拟内存映射到 HugeTLB 大页上,核心优点就是减少 TLB 缺失.
- 共享大页内存方案: 多个进程在使用共享内存时,可以采用共享内存大页,这样有利于减少 TLB 缺失和内存消耗.
- HUGE-DAX 方案: 在支持 PMEM 的系统里,用户进程可以将虚拟内存直接映射到 2MiB 区域的 PMEM 内存上,同样可以减少 TLB 缺失.
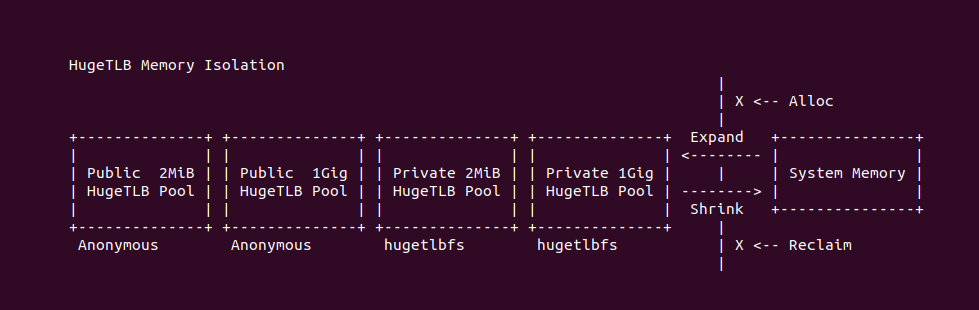
虽然系统支持多种应用程序虚拟内存映射 2MiB 物理内存的方案,有的是针对特定场景,而有的是需要过多的前置条件,但对于 HugeTLB 机制来说,其具有普适性,可以应用到很多场景,并且可以做到对应用程序透明. HugeTLB 机制将物理大页维持在内存池内,内存池和系统管理的物理内存是相互独立的,也就是说 HugeTLB 机制可以控制的内存池子的伸缩,另外系统在通用内存的分配和回收时,内存池子的内存不受影响。HugeTLB 机制默认建立两个公共的大页内存池子,其也支持基于 Hugetlbfs 文件系统建立 N 个私有的大页内存池子,最后应用程序可以从指定的大页池子中分配映射 2MiB/1Gig 的物理大页.
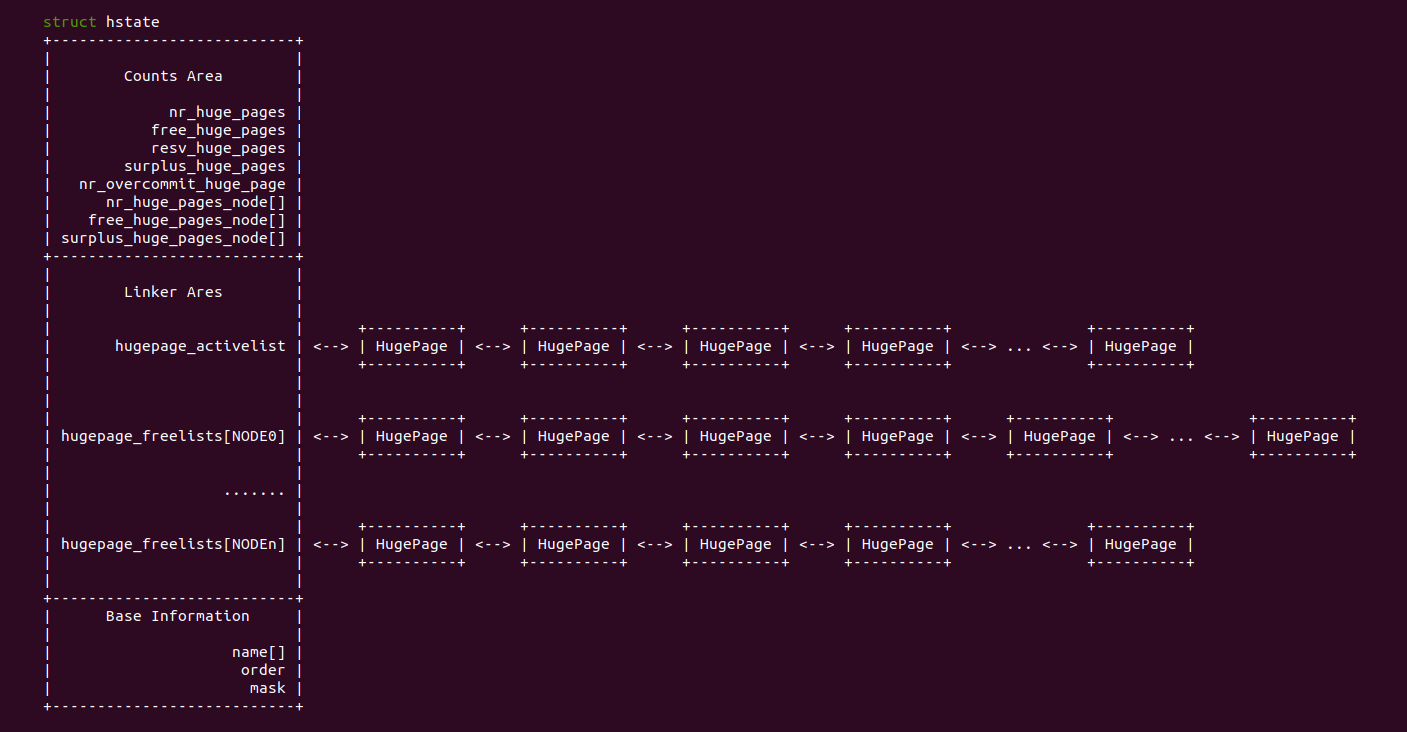
HugeTLB 大页池子使用 STRUCT hstate 数据结构进行维护,其成员记录了某种粒度 HugeTLB 大页的使用情况,并维护了两类链表,其中一个链表维护了已经分配出去的 HugeTLB 大页,另外一类链表是为每个 NUMA NODE 维护的没有使用的 HugeTLB 大页。HugeTLB 大页存在多种状态,分别是: 空闲状态(HugePages_Free)、预留状态(HugePages_Rsvd) 、超发状态(HugePages_Surp) 以及激活状态(Active).
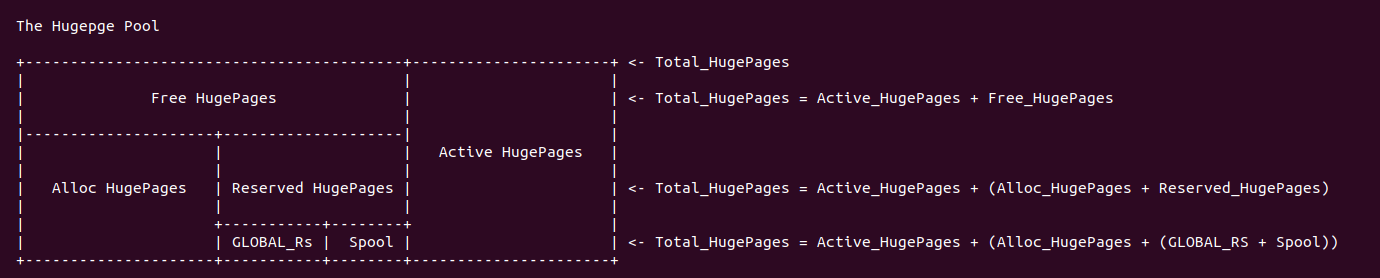
HugeTLB 大页池子使用不同的成员统计大页内存的使用情况,这些统计量让系统知道 HugeTLB 池子里大页使用情况, 并且各成员之间存在如下关系:
- nr_huge_pages: 该成员用于指明在指定粒度的大页内存池子中总共包含大页的数量
- max_huge_pages: 该成员用于指明指定粒度大页内存池子中固定大页的数量, 所谓固定大页就是一次性从系统中分配,并一直维护在大页内存池子中,不会被动态释放会系统的大页.
- free_huge_pages: 该成员用于表示指定粒度大页内存池子中空闲大页的数量,空闲但不代表可用(可能被预留)
- resv_huge_page: 该成员用于表示指定粒度大页内存池子中预留池子的大页数量, 预留表示已经分配但未被真正使用的大页
- nr_overcommit_huge_pages: 该成员用于指明指定粒度大页能可以超发大页的数量,即最多可以从系统动态申请大页的数量
- suplus_huge_pages: 该成员用于表示指定粒度大页内存池子中通过超发机制动态分配的大页数量
# 指定粒度 HugeTLB 大页池子大页总数: nr_huge_pages
nr_huge_pages = max_huge_pages + surplus_huge_pages
# 指定粒度 HugeTLB 大页池子固定大页总数: Persistent HugePages
max_huge_pages = nr_huge_pages - surplus_huge_pages
# 指定粒度 HugeTLB 大页池子超发大页总数: Surplus HugePages
surplus_huge_pages = nr_huge_pages - max_huge_pages
# 指定粒度 HugeTLB 大页池子可分配大页数量:
nr_Alloc_HugePage = free_huge_pages - resv_huge_pages + (nr_overcommit_huge_pages - surplus_huge_pages)
# 指定粒度 HugeTLB 大页池子还可以超发大页数量:
nr_may_Surplus_pages = nr_overcommit_huge_pages - surplus_huge_pages
# 指定粒度 HugeTLB 大页池子激活(正在使用)大页总数:
nr_active_pages = nr_huge_pages - free_huge_pages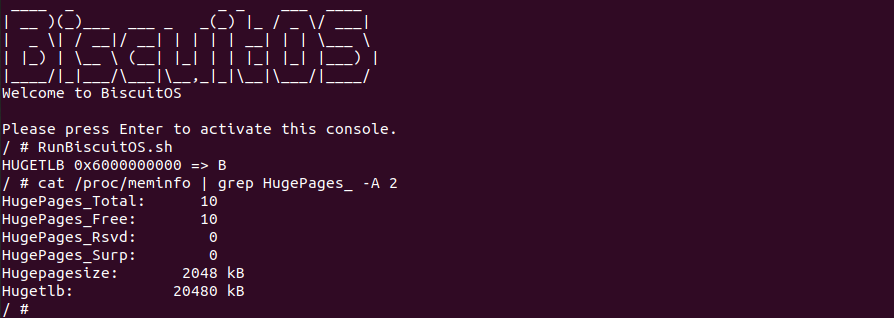
在 Linux 系统里,可以通过 ‘/proc/meminfo’ 查看系统默认粒度 HugeTLB 大页池子的使用情况,其中 HugePages_Total 对应 nr_huge_pages 成员,HugePages_Free 对应 free_huge_pages 成员,HugePages_Rsvd 对应 resv_huge_page 成员,HugePages_Surp 对应 suplus_huge_pages 成员。对于某种粒度的大页池子内存情况,可以在 “/sys/kernel/mm/hugepages” 目录下查看.
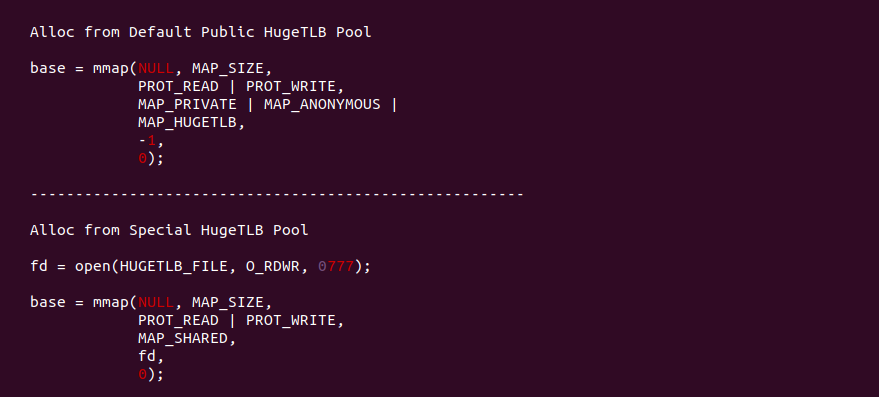
用户进程可以使用两种方式分配 HugeTLB 大页,两种都基于 mmap 函数进行分配. 首先是从系统公共 HugeTLB 大页池子中分配大页,其核心是使用 MAP_ANONYMOUS 和 MAP_HUGETLB 标志,另外也可以使用 MAP_HUGETLB_64KB、MAP_HUGETLB_2MB、MAP_HUGETLB_4-MB、MAP_HUGETLB_32MB 和 MAP_HUGETLB_1G 选择不同粒度的 HugeTLB 大页; 第二种方式则利用 Hugetlbfs 文件系统,通过在挂载 Hugetlbfs 文件系统的目录下创建或打开文件,然后将文件映射到进程地址空间即可.
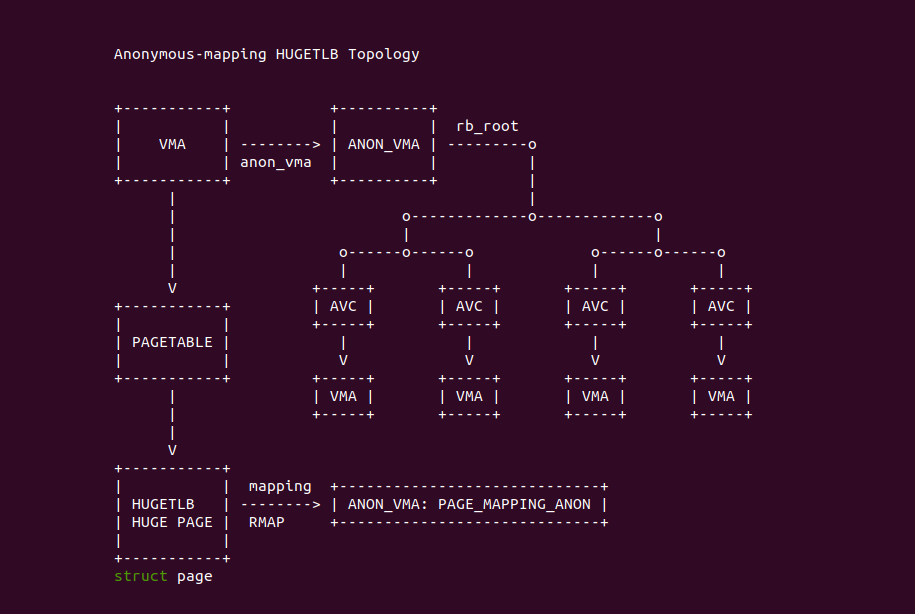
用户进程采用匿名映射(Anonymous Mapping)与 HugeTLB 建立页表映射之后,HUGETLB 大页与用户进程之间也建立逆向映射关系,那么正向映射、逆向映射、进程与 HugeTLB 之间的关系如上图: 每个 VMA 的 anon_vma(AV) 成员维护着一颗红黑树,红黑树上的节点 AVC 指向了映射到该 HugeTLB 大页的 VMA,VMA 的虚拟内存可以通过页表获得映射的 HugeTLB 大页,HugeTLB 大页的 mapping 指向了 anon_vma(AV),那么 HugeTLB 可以遍历 AV 的红黑树知道哪些进程(VMA) 映射到自身.
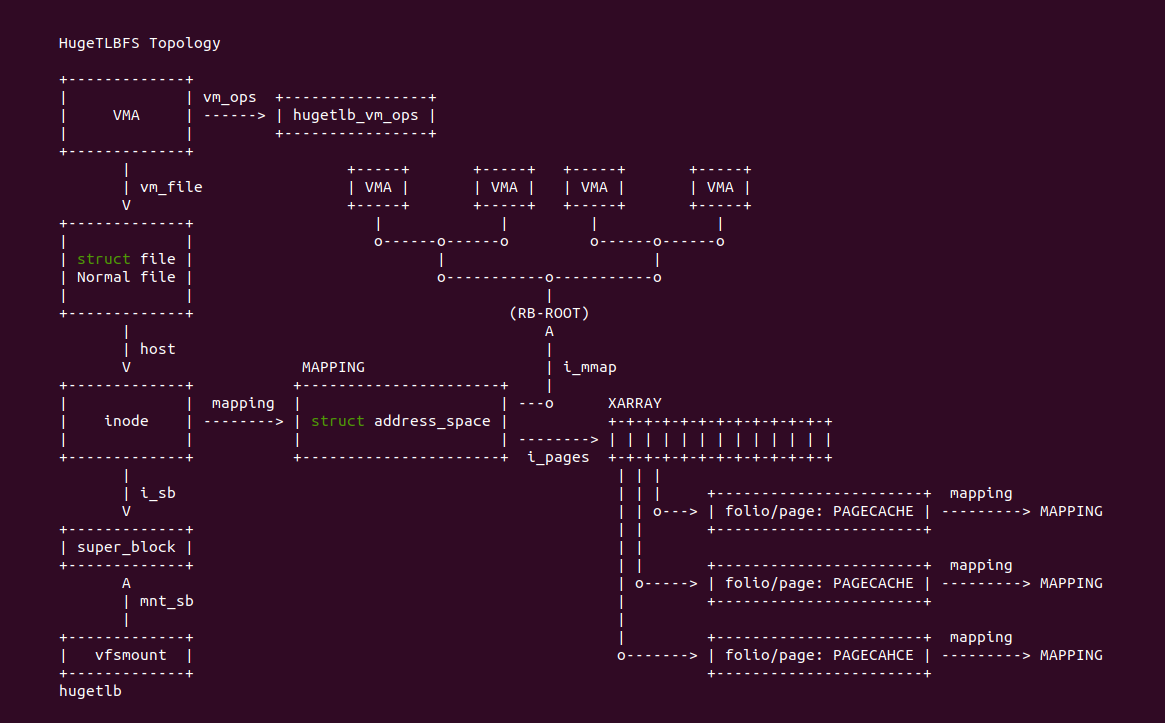
用户进程采用文件映射(File-Mapping) 与 HugeTLB 建立页表映射之后,HUGETLB 大页与用户进程之间也建立逆向映射关系,那么正向映射、逆向映射、进程 与 HugeTLB 之间的关系如上图: 每个 VMA 对应一个 Hugetlbfs 文件, 该文件对应唯一的 STRUCT inode, 其成员 STRUCT address_space 维护了所有的映射,其中 i_mmap 维护的红黑树记录了那些进程(VMA) 映射到该文件,然后 i_pages 维护的 XARRAY 数组知道 PAGECACHE(HugeTLB 大页) 与文件偏移的关系,最后 HugeTLB 大页的 mapping 指向了 STRUCT address_space. 因此 HugeTLB 大页可以遍历 address_space 维护的红黑树知道那些进程映射到自身.
HugeTLB 预留
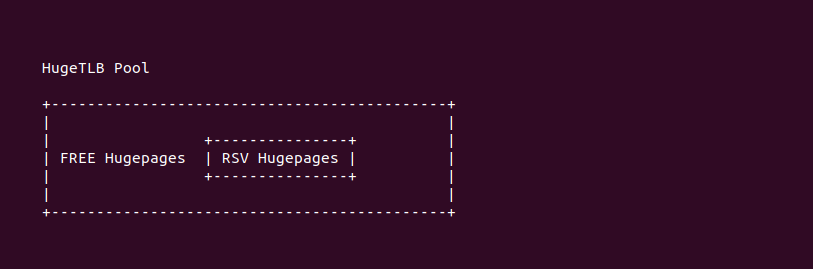
当用户进程通过上面的方式分配指定粒度 HugeTLB 时,进程不仅会分配一段虚拟内存,并且会从大页池子中预留指定数量的 HugeTLB 大页,虽然此时虚拟内存并没有与 HugeTLB 大页建立映射,但 HugeTLB 一旦预留就不能被分配,直到进程真正访问到这段内存,被预留的 HugeTLB 才会转换成激活态的 HugeTLB. 这样做的目的是防止 HugeTLB 大页内存发生缺页时分配不出内存导致核心进程异常退出,保证 HugeTLB 大页池子分配的可靠。但预留 HugeTLB 策略也带来了另外一个问题,就是进程预留了很多大页,但真正使用的很少,而且系统内存特别紧缺也无法回收 HugeTLB,这就出现旱的旱死涝的涝死. 为了缓解这个问题,可以在分配时使用 MAP_NORESERVE 标志不让进程预留 HugeTLB 大页.
HugeTLB 超发
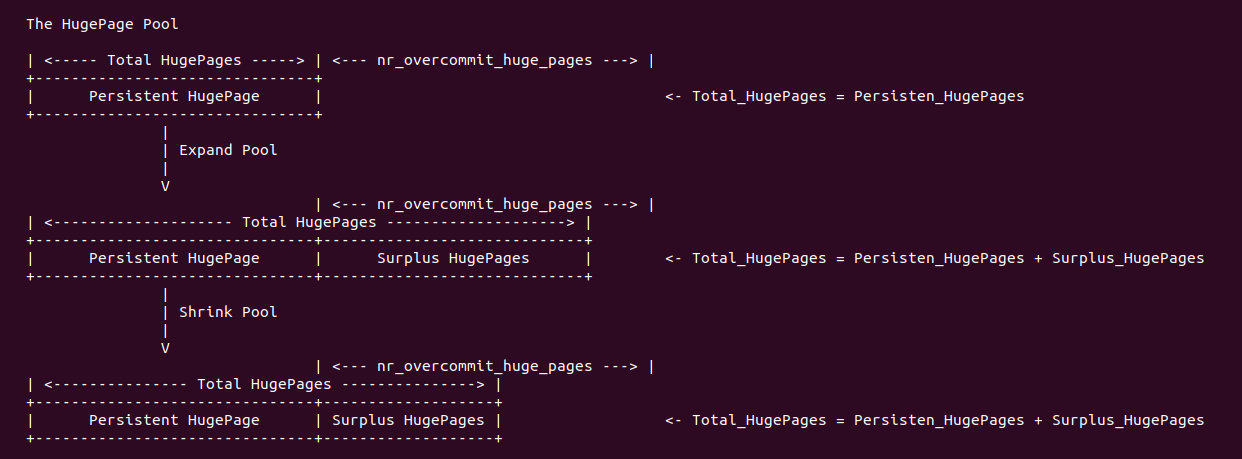
HugeTLB 大页池子可以一次性从系统中申请多个大页,这些大页只有 HugeTLB 大页池子主动释放的时候,系统才能回收,否则就算系统内存资源紧缺也无可奈何,这里将这种方式申请的大页称为 HugeTLB 固定大页(Persistent HugePages). HugeTLB 固定大页的多少直接会影响内存紧缺场景下的性能,那么为了解决这个问题,HugeTLB 大页池子也支持另外一种方法申请大页,简单来说就是需要的时候从系统申请,不需要的时候释放会系统,这类型的大页称为超发大页(Surplus Hugepages). 超发大页虽好,但也有一定问题,例如动态从系统申请导致 HugeTLB 大页申请慢,另外不采用预留机制的场景可能出现无大页可用从而导致进程崩溃, 因此超发大页的时候应该结合实际情况进行使用. Linux 有很多使用 HugeTLB 大页的场景,比较经典的使用场景总结如下:


LazyALLOC 方式分配 HugeTLB 大页内存
LazyALLOC 也支持对 HugeTLB 大页内存的分配,HugeTLB 大页内存在用户进程里使用很广,例如 MMAP 映射区内存等,LazyALLOC 的特点是当进程访问虚拟内存时才会去分配 HugeTLB 内存。那么接下来通过一个实践案例介绍如何使用 LazyALLOC 分配 HugeTLB 大页内存,实践案例在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] Paging Mechanism --->
[*] USER LAZYALLOC: HugeTLB Memory --->
# 部署实践案例
make
# 源码目录
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-PAGING-VM-LAZYALLOC-HUGETLB-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-PAGING-VM-LAZYALLOC-HUGETLB-default Source Code on Gitee
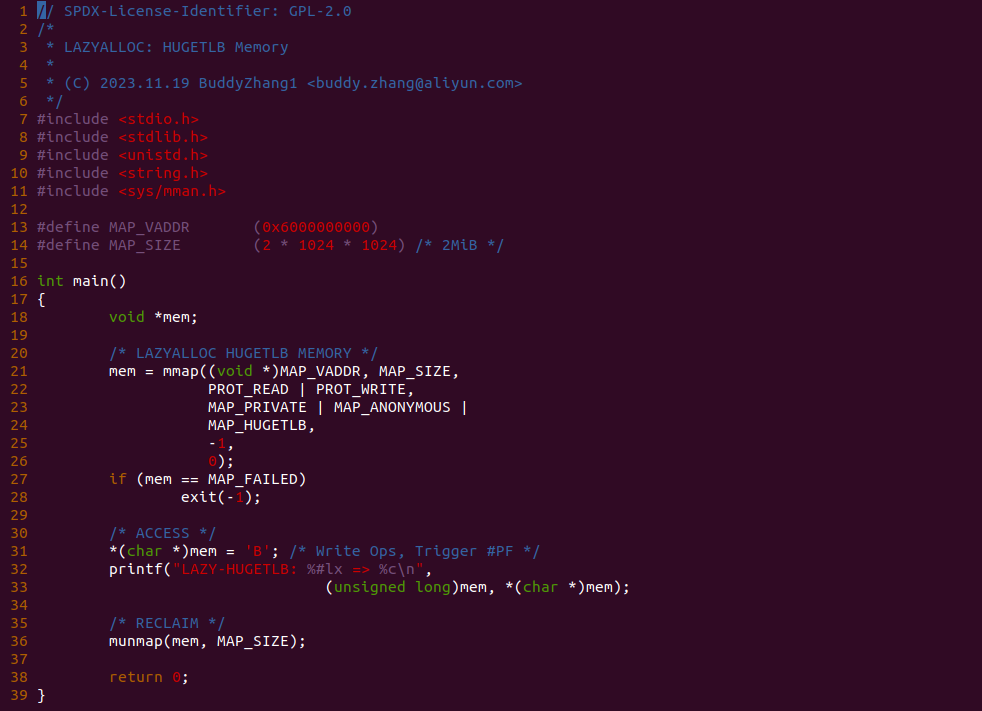
实践案例由一个应用程序构成,程序首先在 21 行调用 mmap 函数分配 2MiB 的虚拟内存,由于其使用了 MAP_PRIVATE、MAP_ANONYMOUS 和 MAP_HUGETLB, 那么这段虚拟内存就是 HugeTLB 内存,另外没有使用 MAP_POPULATE 标志,那么意味着在分配虚拟内存的同时不会分配物理内存,那么进程访问这段虚拟内存会触发缺页. 函数接着在 31 行对虚拟内存进行写操作,但由于页表没有建立,因此此时会触发缺页,最后测试完毕之后将资源进行回收,以上便是一个最简单的实践案案例,为了验证 31 行处没有发生缺页,可以在 31 行处添加 BS_DEBUG 开关:


接着在内核内存缺页流程必经之路上任意位置加上 BS_DEBUG 函数,以此观察内存在某个函数里的流动,例如上图在 exc_page_fault 函数的 1506 行加上 bs_debug 打印,以此确认内存是向哪个函数流动,接下来执行如下命令进行实践:
# 编译应用程序
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-PAGING-VM-LAZYALLOC-HUGETLB-default/
# 编译内核
make kernel
# 编程程序
make build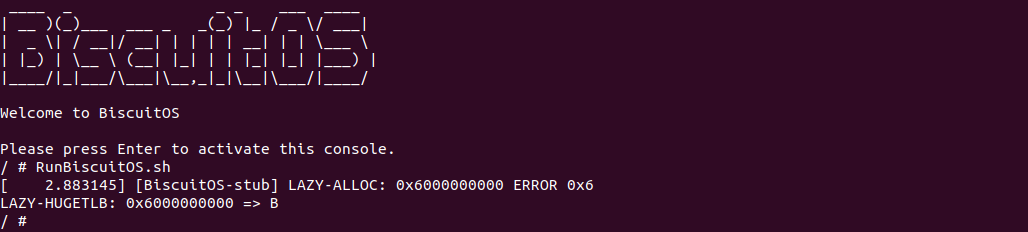
BiscuitOS 启动之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了运行实践案例所需的全部命令,可以看到应用程序运行之后,系统并打印缺页相关的信息,说明进程在分配虚拟内存的时候仅仅分配了虚拟内存. 以上便是 LazyAlloc 的一种使用场景.

PreALLOC 方式分配 HugeTLB 大页内存
PreALLOC 也支持对 HugeTLB 大页内存的分配,HugeTLB 大页内存在用户进程里使用很广,例如 MMAP 映射区内存等,PreALLOC 的特点可以让进程更快的访问虚拟内存。那么接下来通过一个实践案例介绍如何使用 PreALLOC 分配 HugeTLB 大页内存,实践案例在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] Paging Mechanism --->
[*] USER PREALLOC: HugeTLB Memory --->
# 部署实践案例
make
# 源码目录
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-PAGING-VM-PREALLOC-HUGETLB-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-PAGING-VM-PREALLOC-HUGETLB-default Source Code on Gitee
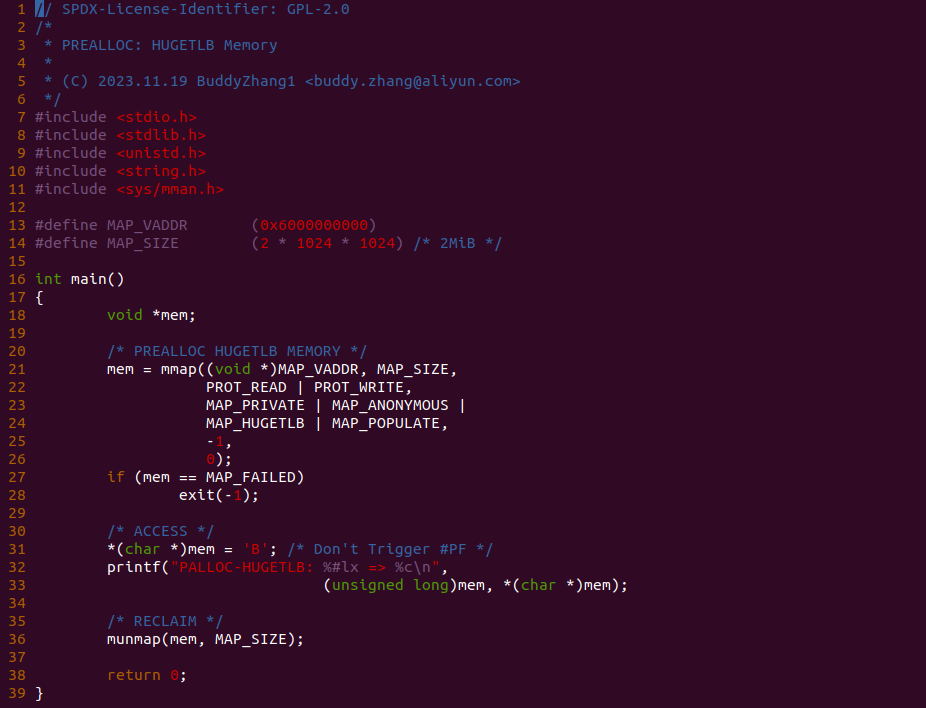
实践案例由一个应用程序构成,程序首先在 21 行调用 mmap 函数分配 2MiB 的虚拟内存,由于其使用了 MAP_PRIVATE、MAP_ANONYMOUS 和 MAP_HUGETLB, 那么这段虚拟内存就是 HugeTLB 内存,另外还使用了 MAP_POPULATE 标志,那么意味着在分配虚拟内存的同时也会分配物理内存,并建立相应的页表映射. 函数接着在 31 行对虚拟内存进行写操作,但由于页表已经建立,因此此时不会触发缺页,最后测试完毕之后将资源进行回收,以上便是一个最简单的实践案案例,为了验证 31 行处没有发生缺页,可以在 31 行处添加 BS_DEBUG 开关:


接着在内核内存缺页流程必经之路上任意位置加上 BS_DEBUG 函数,以此观察内存在某个函数里的流动,例如上图在 exc_page_fault 函数的 1506 行加上 bs_debug 打印,以此确认内存是向哪个函数流动,接下来执行如下命令进行实践:
# 编译应用程序
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-PAGING-VM-PREALLOC-HUGETLB-default/
# 编译内核
make kernel
# 编程程序
make build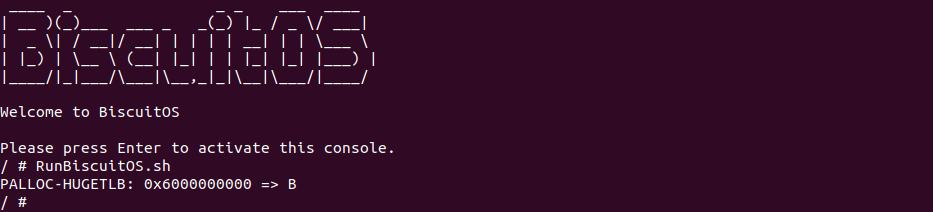
BiscuitOS 启动之后,直接运行 RunBiscuitOS.sh 脚本,脚本里包含了运行实践案例所需的全部命令,可以看到应用程序运行之后,系统并没有打印缺页相关的信息,为了更好证明实践案例的可靠性,开发者可以将 mmap 函数的 MAP_POPULATE 标志去掉之后再实践:
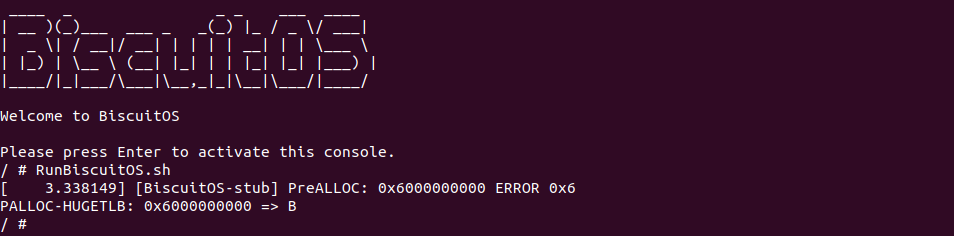
通过对比实践可以看出,当 mmap 里去掉 MAP_POPULATE 标志之后,访问虚拟内存缺失引起了缺页异常,因此再次证明实践案例确实在分配虚拟内存的同时也分配了物理内存,并建立页表映射. 以上便是 PreALLOC 的一种使用场景.