

目录
Linux TLB 机制
TLB 使用教程
TLB 调试工具
TLB 应用场景
TLB 进阶研究


初识 TLB

什么是 TLB? TLB 用来干什么? TLB 学了有什么用? 要怎么才能用好 TLB 提高程序的性能呢? 问题太多,先从一个实践案例讲起,其在 BiscuitOS 上的部署逻辑是:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] Modify PTE with/without FLUSH TLB --->
<*> Modify PTE with/without FLUSH TLB on Userspace --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-MODIFY-PTE-default/
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-MODIFY-PTE-APP-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make prepare
make buildBiscuitOS-TLB-FLUSH-MODIFY-PTE-default Source Code on Gitee
BiscuitOS-TLB-FLUSH-MODIFY-PTE-APP-default Source Code on Gitee
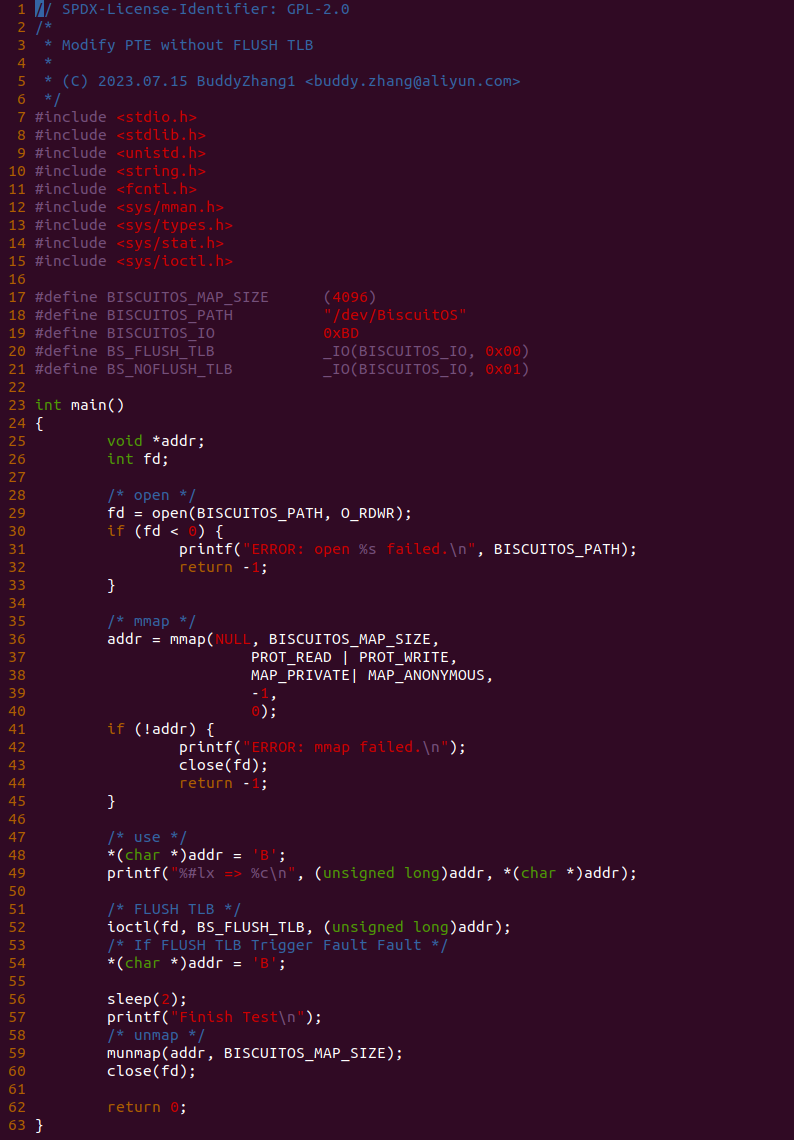
实践案例由两部分组成,其一是用户空间程序,其通过 open 函数打开 “/dev/BiscuitOS” 节点,然后调用 mmap 函数分配一段内存,然后在 48 行向虚拟内存写入 ‘B’, 然后在 52 行调用 ioctl() 函数向内核空间发起 BS_FLUSH_TLB 请求,该请求会将虚拟内存的权限修改为只读,然后刷新 TLB,最后在 54 行再次对虚拟内存执行写操作。
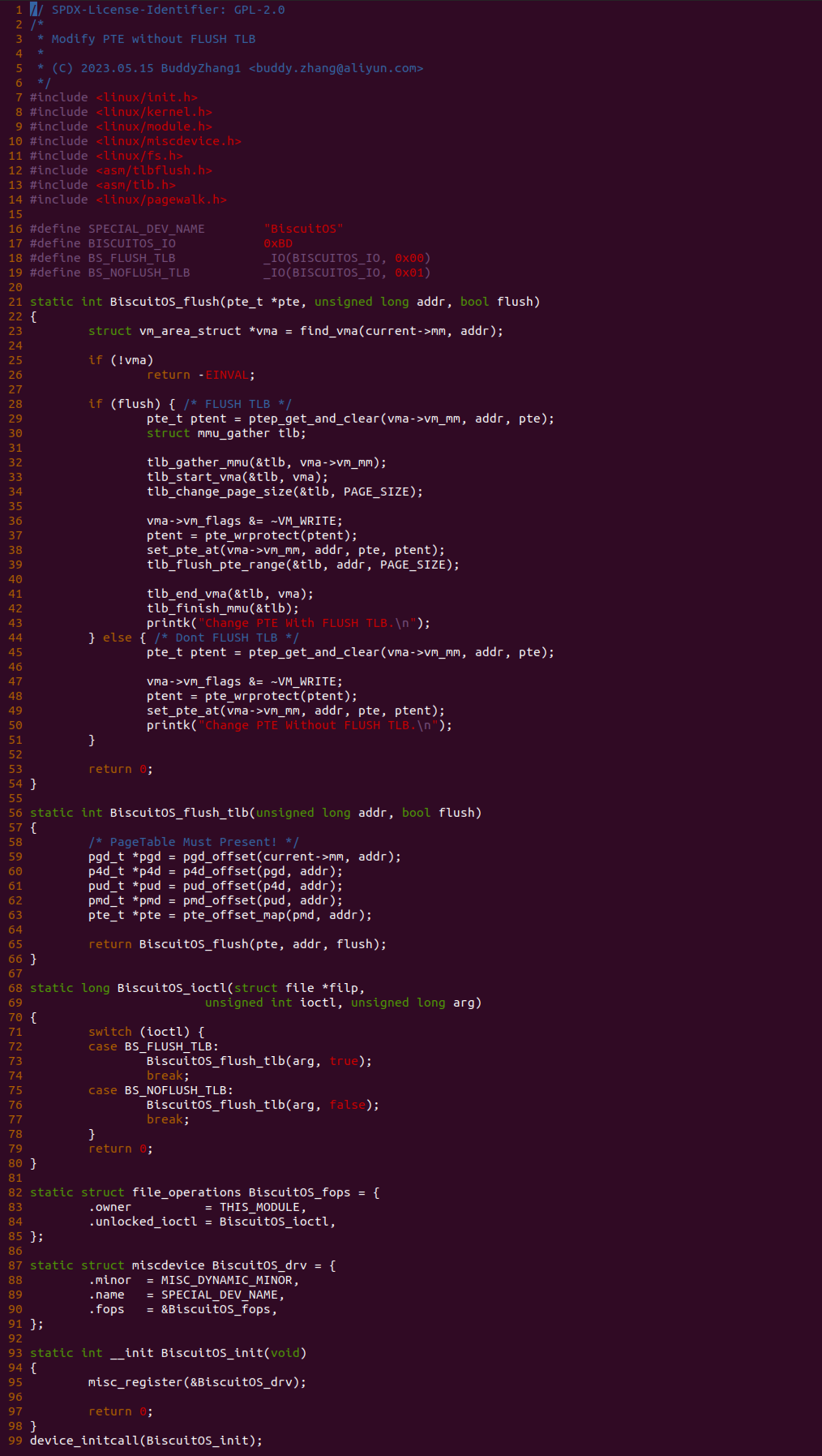
实践案例的另外一部分是一个内核模块,其由一个 MSIC 驱动构成,其在 Linux 生成 “/dev/BiscuitOS” 节点,对该节点提供了 ioctl 接口,当用户空间打开该节点,然后调用 ioctl 函数之后会调用到 BiscuitOS_ioctl() 函数,BiscuitOS_ioctl() 函数支持 BS_FLUSH_TLB 和 BS_NOFLUSH_TLB 请求,其中 BS_FLUSH_TLB 请求会修改虚拟地址的页表为只读,并且会刷新对应的 TLB; BS_NOFLUSH_TLB 请求只会修改虚拟地址对应的页表为只读,且不会刷新 TLB。BiscuitOS_flush() 函数为修改 PTE 页表的核心函数,28-43 行代码用于修改 PTE 页表为只读,并刷新 TLB; 45-50 行代码只修改 PTE 页表为只读. 那么接下来先实践用户空间下发 BS_FLUSH_TLB 请求的情况:
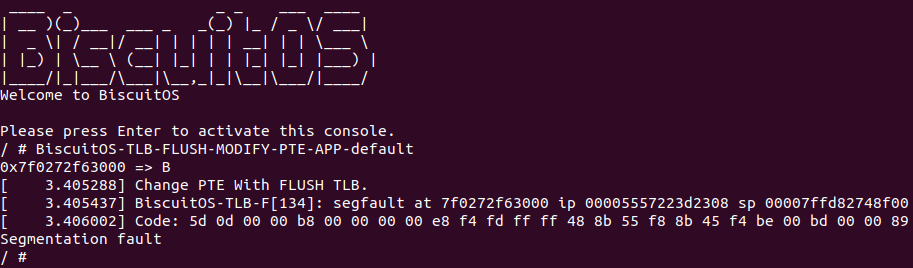
BiscuitOS 启动之后,运行应用程序 BiscuitOS-TLB-FLUSH-MODIFY-PTE-APP-default,此时可以看到对只读内存写操作时会触发系统异常,最后程序因为 Segmentation fault 退出. 那么接下来修改应用程序,将 52 行 ioctl() 函数的请求替换成 BS_NOFLUSH_TLB,然后再次实践:
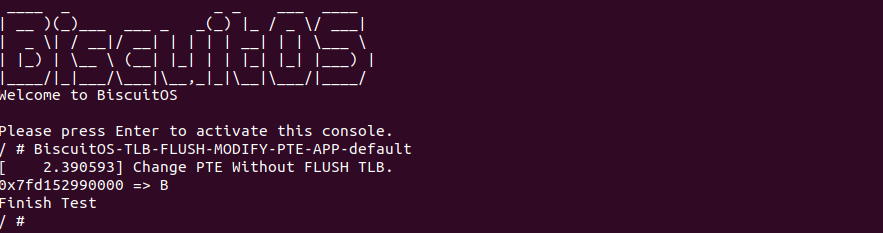
BiscuitOS 启动之后,运行应用程序 BiscuitOS-TLB-FLUSH-MODIFY-PTE-APP-default,此时可以看到 Change PTE Without FLUSH TLB 字符串已经打印,说明此时只修改了 PTE 页表并没有刷新 TLB,那么 TLB 里依旧存储着虚拟地址与旧 PTE 的映射,因此此时应用程序对只读内存还是可写。通过这个实践案例,让开发者更加了解修改页表之后及时刷新 TLB 重要性. 那么接下来通过本文一步步解开 TLB 神秘面纱。

TLB 通识知识
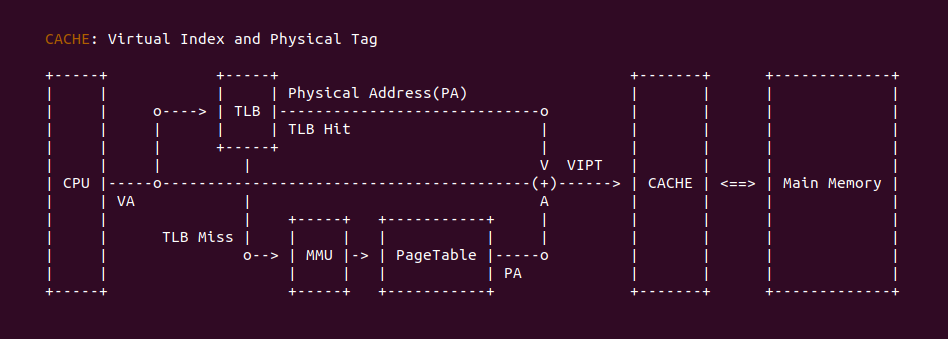
在现代计算机系统中,Translation-Lookaside Buffer(TLB) 扮演着重要的角色,用于加速虚拟地址到物理地址的转换过程. TLB 作为一种硬件缓存,通过存储最近使用的页表项,提供了快速的地址转换,从而提高系统性能. 本文将从多个角度介绍 TLB 的作用、工作原理和相关考虑因素. TLB 作为硬件缓存在计算机系统中发挥了重要的作用. 它的主要功能包括:
- 提高地址转换性能: TLB 存储了最近使用的页表项,使得在虚拟地址到物理地址的转换过程中可以快速查找并获取正确的物理地址,避免了频繁访问内存或缓存的开销
- 减少内存访问次数: 通过缓存页表项,TLB 可以减少对主存的访问次数,从而提高系统响应速度和吞吐量
- 提高处理器效率: 由于 TLB 能够减少地址转换的时间,处理器可以更快地访问和处理数据,提高整体的计算效率
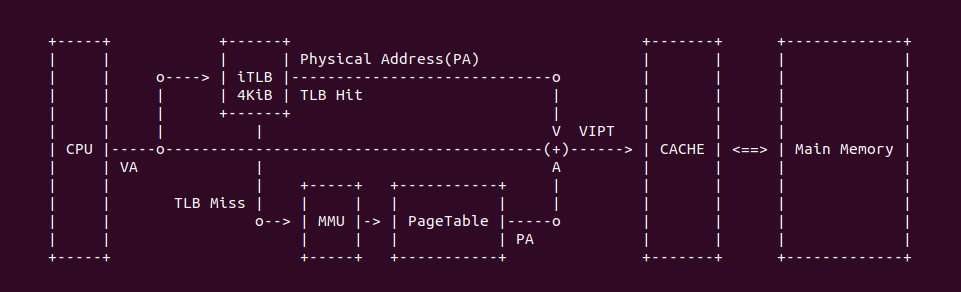
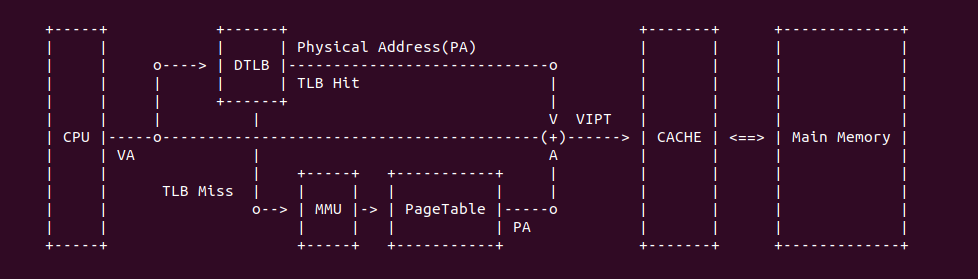
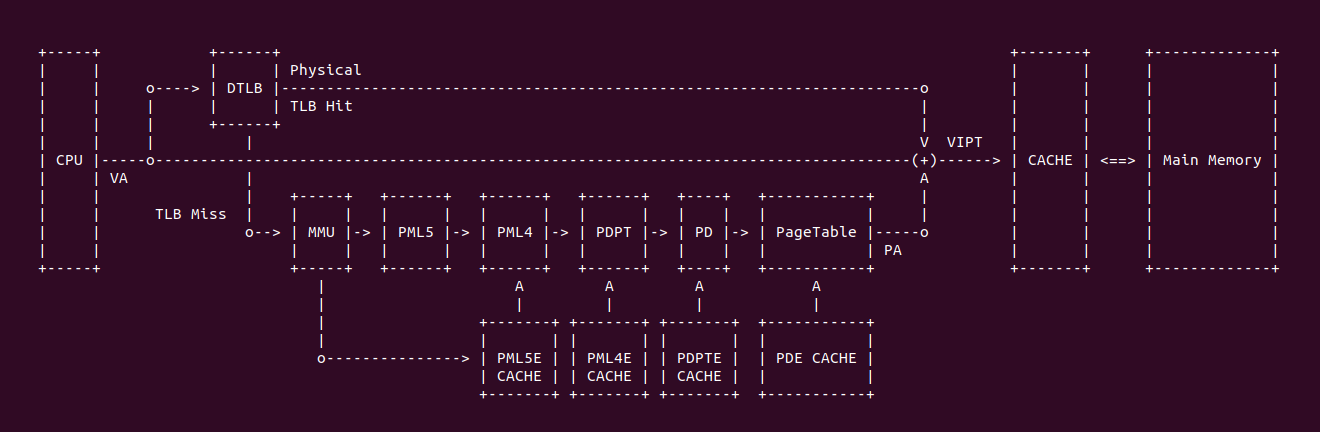
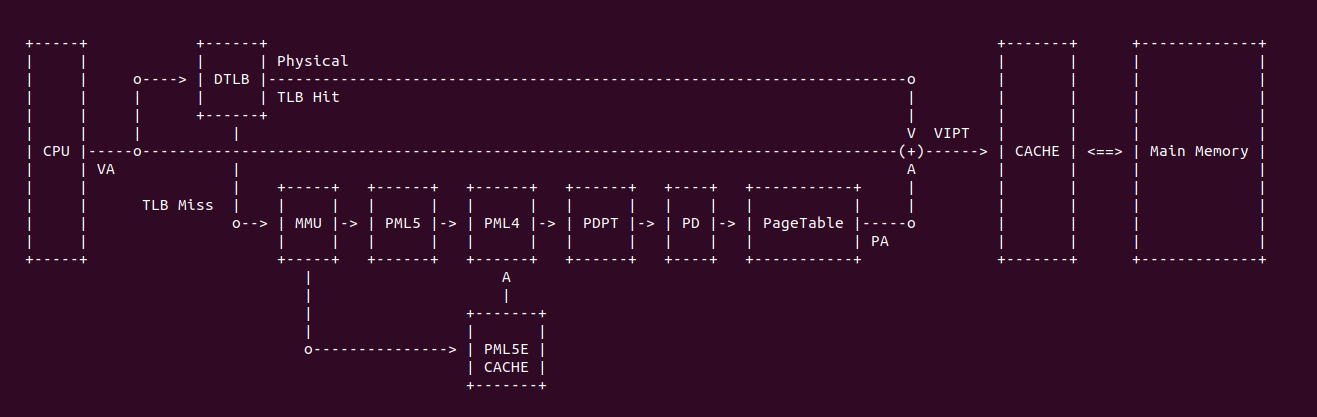
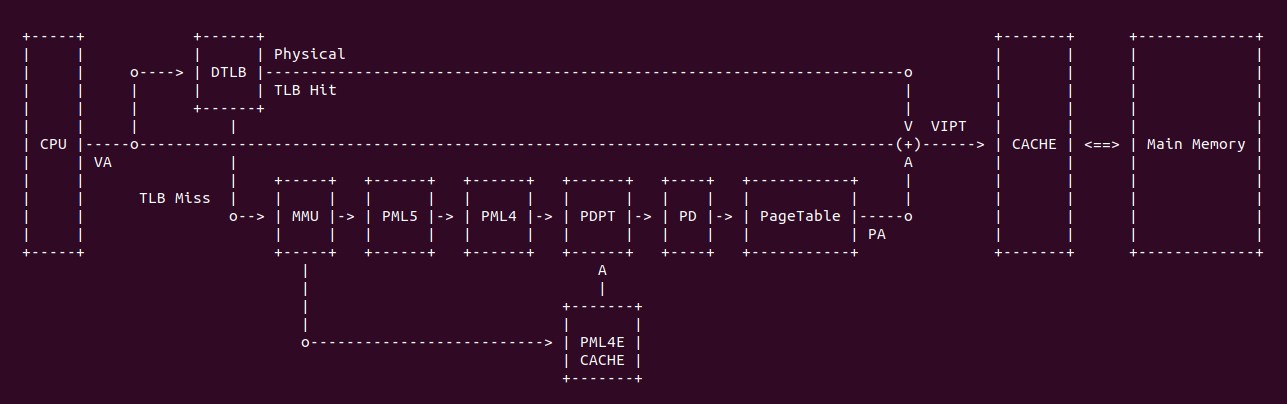
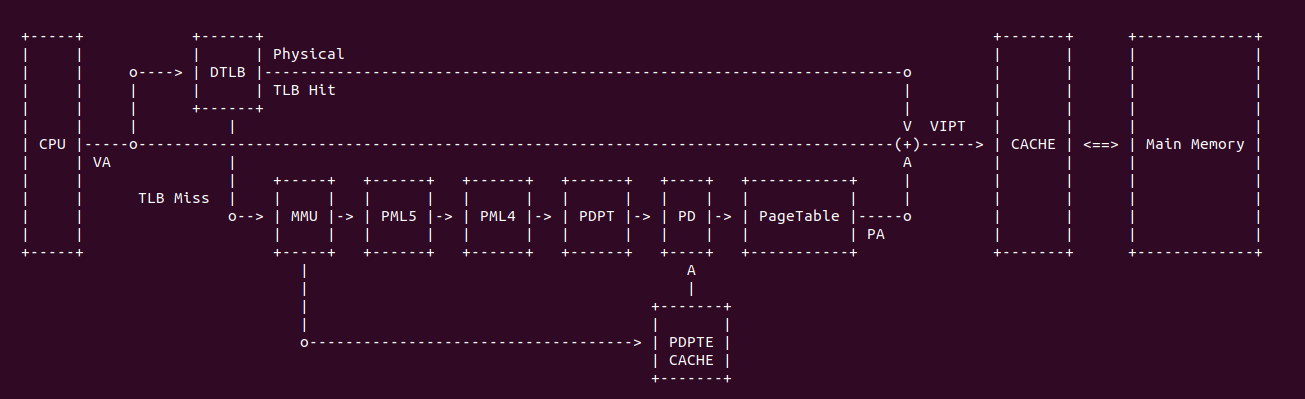
上图是一个典型的 TLB 硬件在系统的布局,当 CPU 发送一个虚拟地址(VA),首先发送到 TLB 里进行查询,如果 TLB Entry 包含了 VA 到 PA 的映射关系,那么 TLB Hit 直接获得物理地址(PA); 如果 TLB 里面没有 VA 对应的映射,那么 TLB Miss,TLB 将虚拟地址发送给 MMU,MMU 通过查询页表(PageTable)找到对应的物理地址。当获得物理地址之后可以结合 CACHE 的 VIPT(Virtual Index Physical Tag) 机制从 CACHE 里查看 VA 对应的内容. 查询页表(Consule PageTable) 相比 TLB 是一个超级耗时的操作,因此 TLB Hit 能提高处理器效率.
TLB 硬件结构
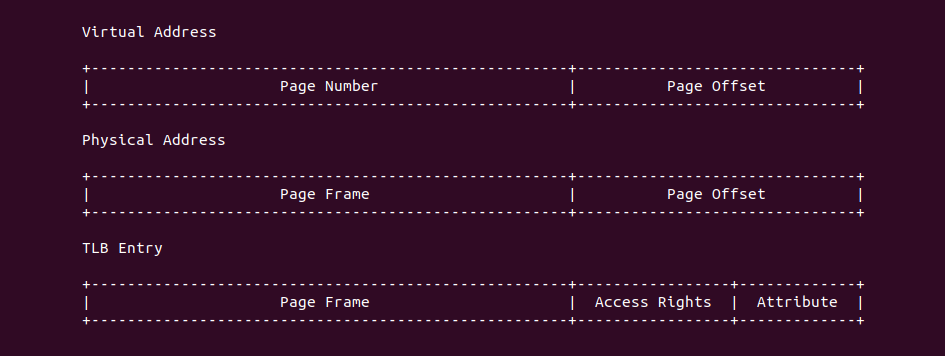
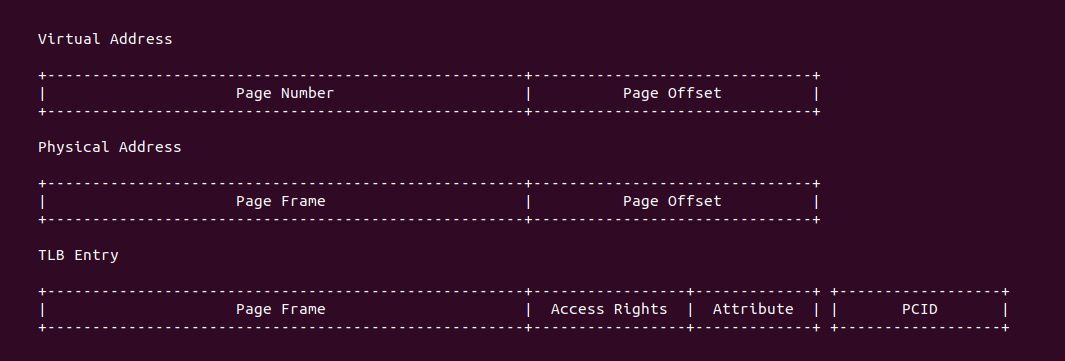
TLB 的硬件组成与具体的架构有关,但本节抛开架构之间的差异抽象的描述 TLB 的硬件组成。内核支持的页大小为 PAGE_SIZE(默认为 4KiB 为例), 那么虚拟地址的 [12: MSB] 字段称为 页号(Page Number), 虚拟地址的 [0: 11] 则称为页内偏移(Page Offset); 对于物理地址的 [12: MSB] 字段称为页帧(Page Frame), 物理地址的 [0: 11] 也称为页内偏移(Page Offset). TLB 内由一个个 Entry 组成,这些 Entry 称为 TLB Entry(TLB 项),其内容来自虚拟地址对应的最后一级页表项,包括了物理页帧(Page Frame)、访问权限(Access Right) 以及 Attribute 域. 由于不同架构的差异,TLB Entry 在 TLB 内部的组成因虚拟地址映射存在差异,主流分为三种方式: 直接映射方式、全相联映射、组相联映射,那么接下来分别介绍:
直接映射(Direct-mapped)
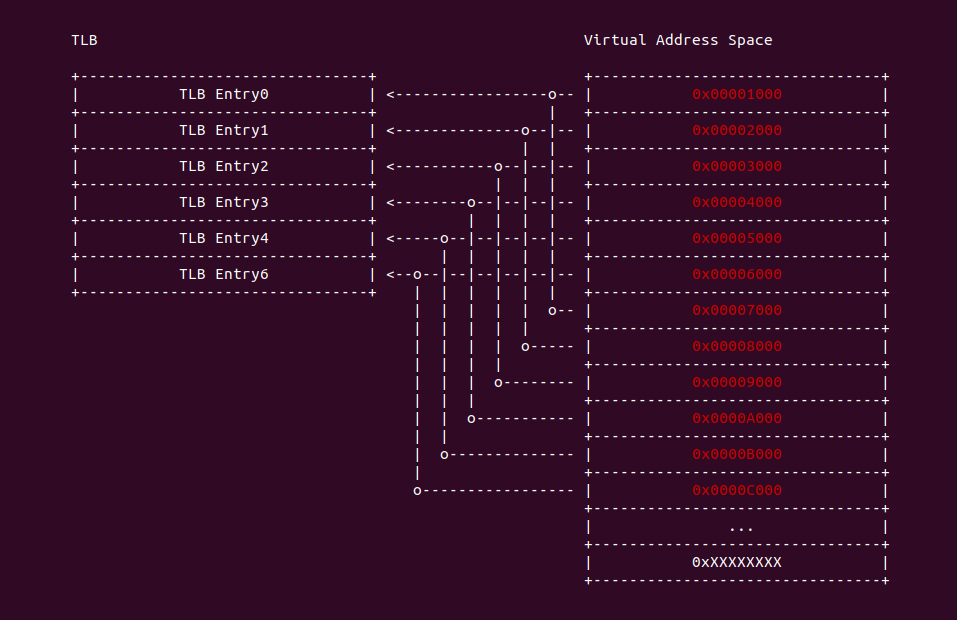
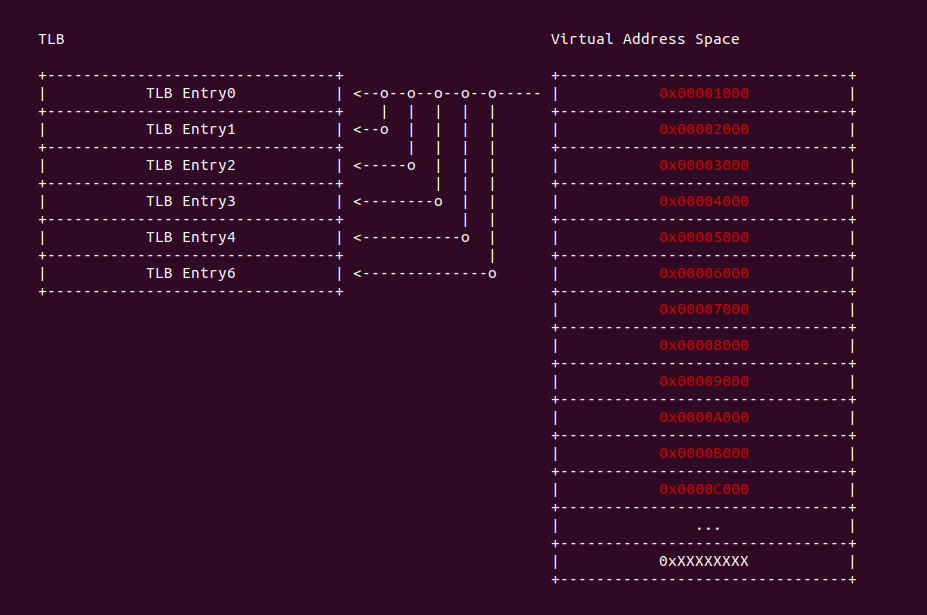
直接映射(Direct-mapped): 指的是每一个虚拟地址只能映射到 TLB 中唯一的 TLB Entry,这里的虚拟地址指的是已经按 PAGE_SIZE 对齐之后的地址,因此可以理解为每个 Page Number 与 TLB Entry 一一映射,可以从上图案例看出,虚拟地址 0x00001000 的 Page Number 为 1,那么其映射 TLB Entry0,同理虚拟地址 0x00002000 的 Page Number 为 2,那么映射 TLB Entry1. 直接映射具有一下优缺点:
- 优点: 硬件设计简单、成本低
- 缺点: 灵活性差,虚拟地址只能映射到固定的 CACHE Line 上,很容易与同一个 TLB Entry 的虚拟地址冲突,从而引起 TLB 颠簸. TLB 容量比较大才能显示其优势.
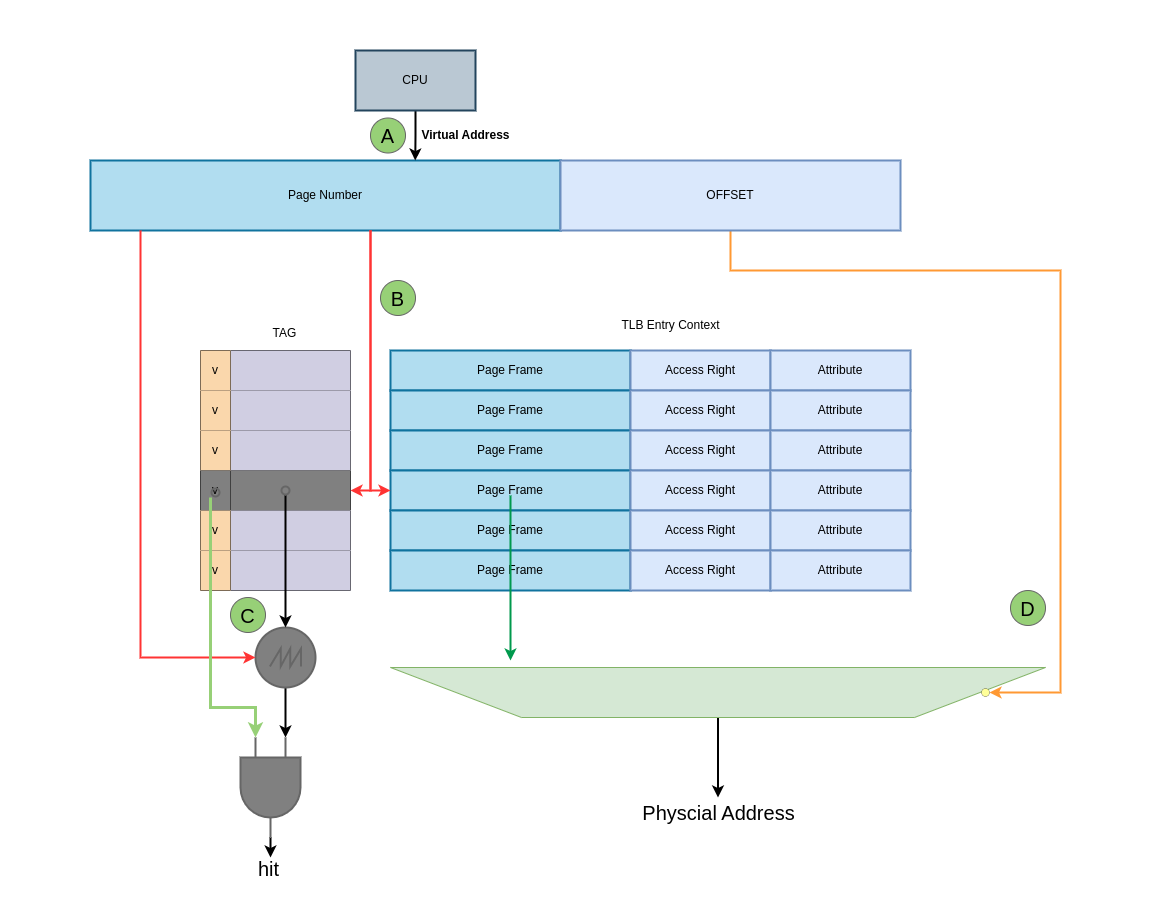
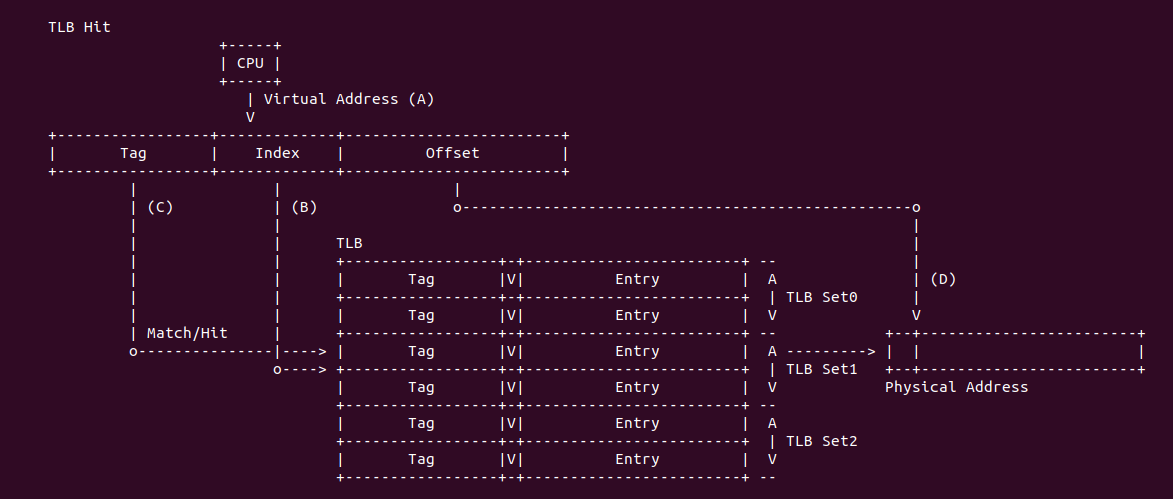
假设 TLB 具有 64 Entry,TLB 缓存的页大小为 4KiB,TLB Entry 由两部分组成,一部分是 TLB Entry Context 域,其包含了缓存最后一级页表的 Page Frame、Access Rights 以及 PageTable Attribute; 另外一部分就是 TLB Entry Tag 字段,该字段来自虚拟地址的 [18: MAX). 结合上图,那么 TLB 的处理流程如下:
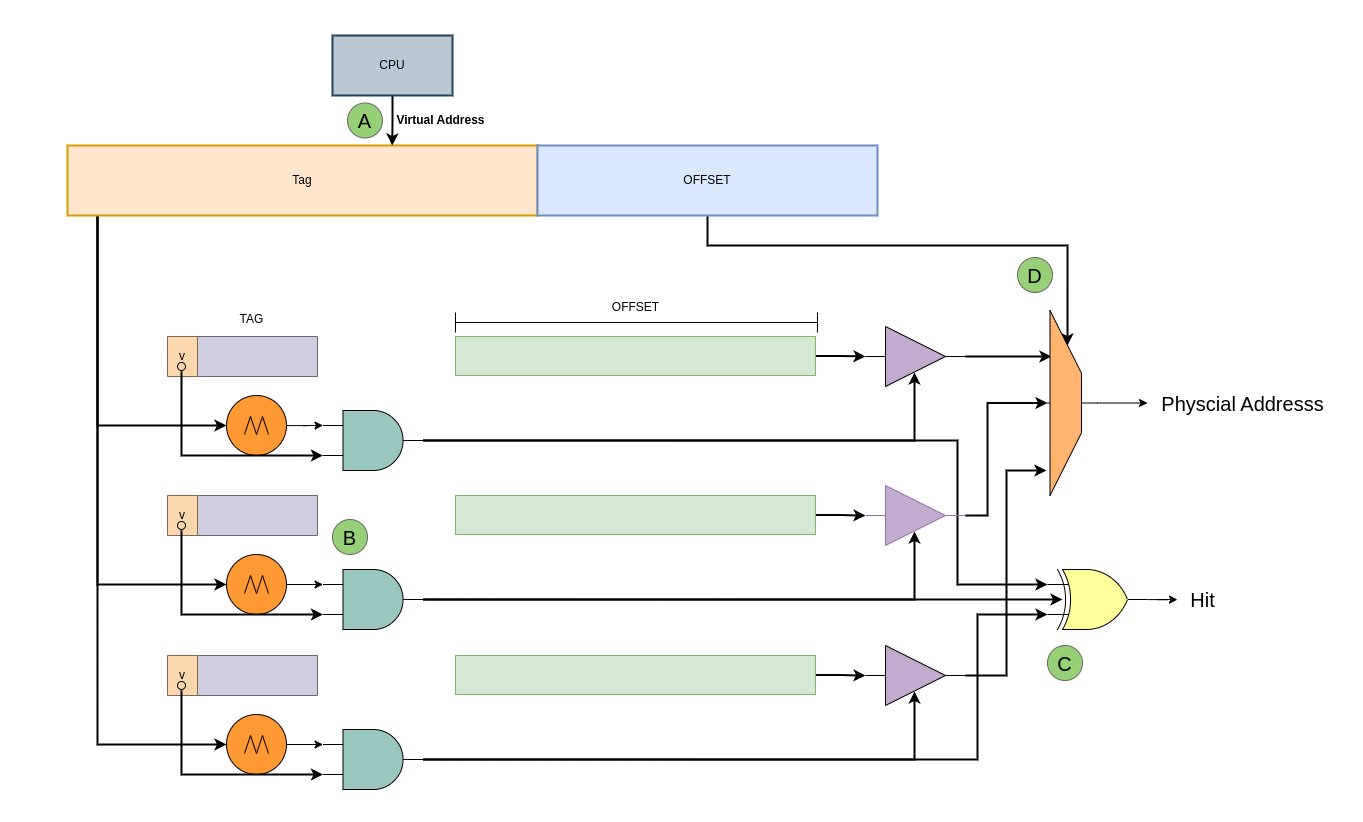
- A: CPU 发送一个虚拟地址,虚拟地址会被分作三部分: [0: 11] Page Offset、[12: 17] TLB Index 以及 [18: MAX) TLB Tag
- B: TLB 从虚拟地址中截取 [12: 17] TLB Index 字段,然后在 TLB 中找到对应的 TLB Entry
- C: TLB 将找到的 TLB Entry 的 TLB Tag 字段与虚拟地址的 [18: MAX) 字段进行匹配,如果匹配上即为 TLB Hit; 反之为 TLB Miss
- D: 当 TLB Hit 之后,TLB 从 TLB Entry 中取出 Page Frame,并与虚拟地址的 Page Offset 字段组成最终的物理地址。在这过程中 TLB 还会从 TLB Entry 的 Access Rights 和 Attribute 进行检查,确认对物理地址有权访问.
- E: 当 TLB Miss 之后,硬件 MMU 会查询页表找到最终的物理地址,并将最后一级页表内容加载到 TLB.
全相联映射(Full-associative)
全相联映射(Full-associative): 指 TLB Entry 和虚拟地址之间没有任何关系,也就是说一个虚拟地址可以所有的 TLB Entry 关联. 这种关联方式使得 TLB Entry 的利用率达到最大. 但是延迟可能相当大,因为每次 CPU 请求,TLB 硬件都把虚拟地址和 TLB Entry 逐一比较,直到 TLB Hit 或者所有 TLB Entry 都比较完。特别随着 CPU 缓存越来越大,需要比较大量的 TLB 表项,所以这种组织方式适合容量小的 TLB. 全相联映射的优缺点如下:
- 优点: 灵活性好,TLB Entry 一旦空闲就可以加载新的 Translation
- 缺点: 速度慢、硬件成本高,每次 TLB 访问需要依次遍历.
假设 TLB 具有 64 TLB Entry,TLB 缓存页的大小为 4KiB,TLB Entry 由两部分组成,一部分是 TLB Entry Context 域,其包含了缓存最后一级页表的 Page Frame、Access Rights 以及 PageTable Attribute; 另外一部分就是 TLB Entry Tag 字段,该字段来自虚拟地址的 [12: MAX). 结合上图,那么 TLB 的处理流程如下:
- A: CPU 发送一个虚拟地址,虚拟地址会被分作两部分: [0: 11] Page Offset 和 [12: MAX) TLB Tag
- B: TLB 从虚拟地址中截取 [12: MAX) 字段逐次与 TLB Entry 的 TLB Tag 字段进行比较
- C: 如何 TLB 将找到的 TLB Entry 的 TLB Tag 字段与虚拟地址的 [12: MAX) 字段匹配,那么即为 TLB Hit
- D: 当虚拟地址与 TLB Tag 匹配成功,那么 TLB 还会从 TLB Entry 的 Access Rights 和 Attribute 进行检查,确认对物理地址有权访问. 检查通过之后 TLB Entry 的 Page Frame 字段与虚拟地址的 Page Offset 组成最终的物理地址.
- E: 当虚拟地址与所有的 TLB Entry 比较之后都没有匹配成功,那么 TLB Miss,硬件 MMU 会查询页表找到最终的物理地址,并将最后一级页表内容加载到 TLB, 此时 TLB 会找一个空闲的 TLB Entry 存储该映射.
组相联映射(Set-associative)
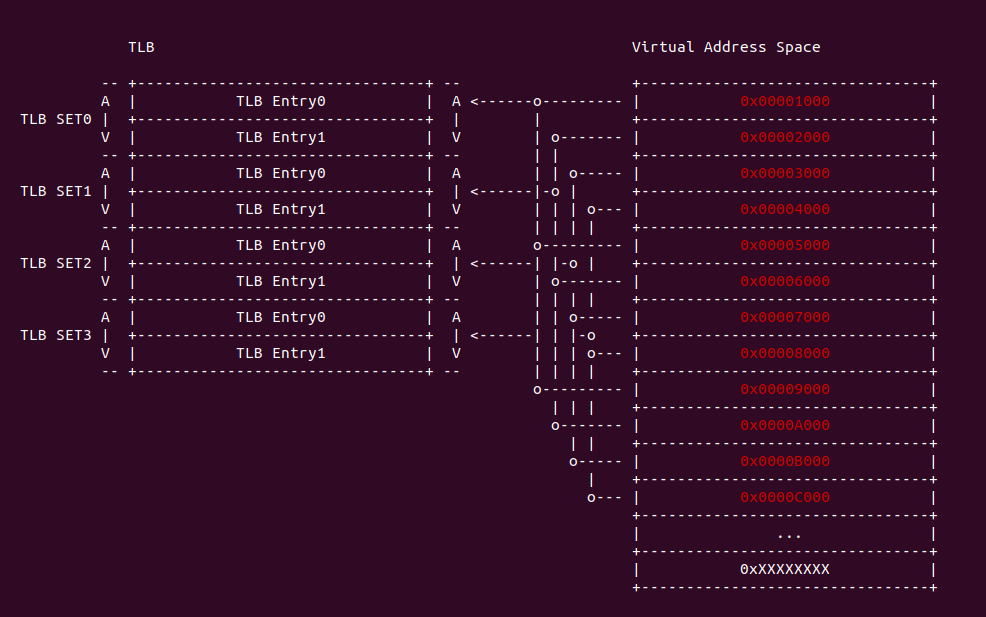
组相联映射(Set-associative): 是直接映射和全映射的折中方案,将多个 TLB Entry 组成一个组称为 TLB Set, 每个虚拟地址(按页对齐)只能映射到一个 TLB Set, 但可以映射到 TLB Set 里任何一个 TLB Entry. 另外相邻的两个虚拟地址(按页对齐)只能映射到相邻的的 TLB Set. 组相联映射很好的解决了全相联内部比较效率低和直接映射匹配冲突问题。
组相联映射的硬件是一个立体结构,通常称为 X-entries, Y-way set associative, 那是指 TLB 有 Y 个面,也可以理解为每个 TLB Set 里包含了 Y 个 TLB Entry,那么 TLB 一共具有 X/Y 个 TLB Set. 假设 TLB 是 “64-entries, 4-way set associative”, 且映射的页大小为 4KiB,TLB Entry 由两部分组成,一部分是 TLB Entry Context 域,其包含了缓存最后一级页表的 Page Frame、Access Rights 以及 PageTable Attribute; 另外一部分就是 TLB Entry Tag 字段,该字段来自虚拟地址的 [18: MAX). 结合上图,那么 TLB 的处理流程如下:
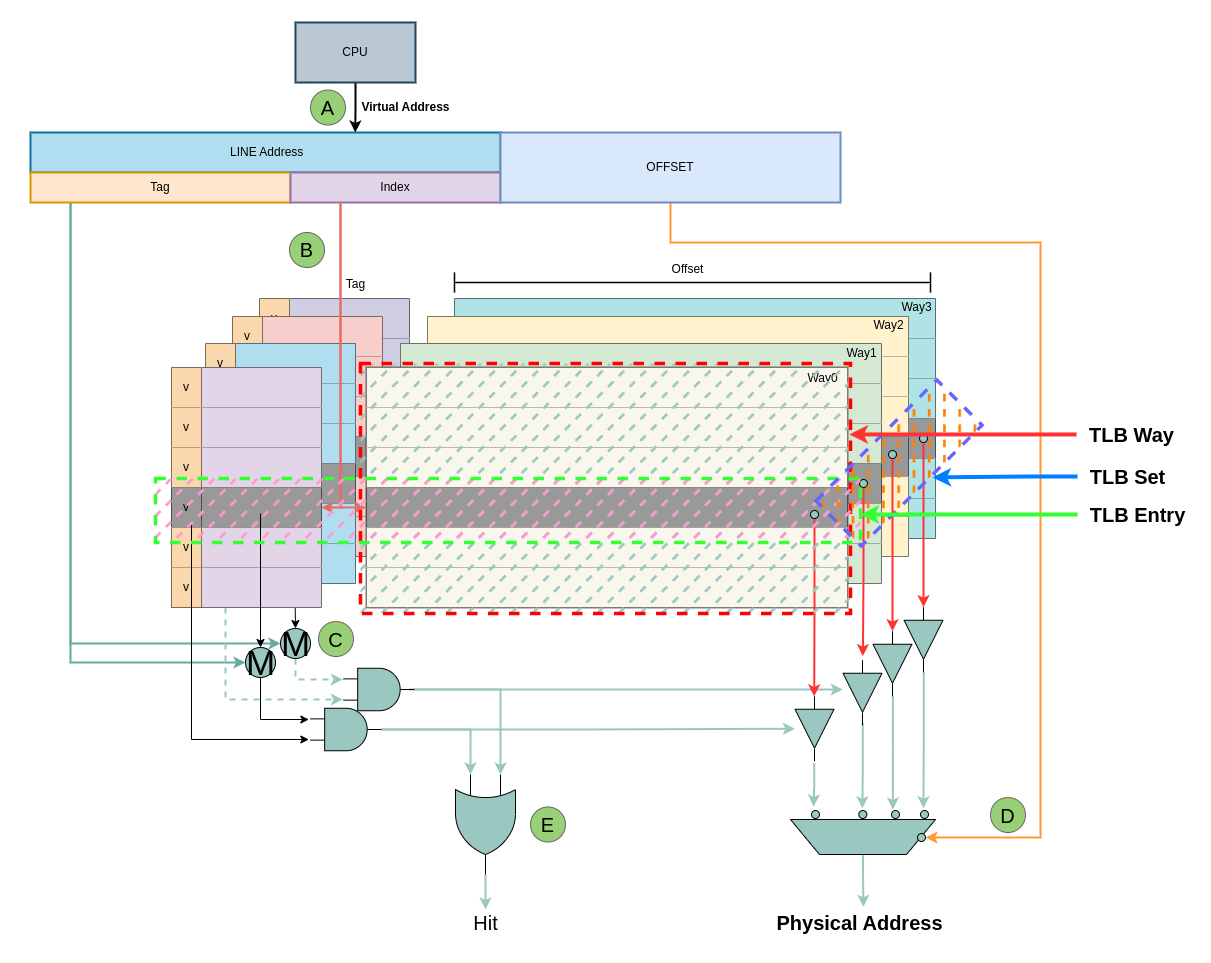
- A: CPU 发送一个虚拟地址,虚拟地址会被分作三部分: [0: 11] Page Offset、[12: 15] TLB Set Index 以及 [16: MAX) TLB Tag
- B: TLB 从虚拟地址中截取 [12: 15] TLB Set Index 字段,然后在 TLB 中找到对应的 TLB Set
- C: TLB 将找到的 TLB Set 里所有 TLB Entry 的 TLB Tag 字段逐次与虚拟地址的 [16: MAX) 字段进行匹配,如果匹配上即为 TLB Hit
- D: 当 TLB Hit 之后,TLB 从 TLB Entry 中取出 Page Frame,并与虚拟地址的 Page Offset 字段组成最终的物理地址。在这过程中 TLB 还会从 TLB Entry 的 Access Rights 和 Attribute 进行检查,确认对物理地址有权访问.
- E: 当 TLB Set 里所有的 TLB Entry 都与虚拟地址不匹配,那么 TLB Miss 之后,硬件 MMU 会查询页表找到最终的物理地址,并将最后一级页表内容加载到 TLB Set 里任一一个 TLB Entry.
TLB 工作原理
TLB 由于硬件组成的差异,TLB 的工作原理上也存在差异,但其核心功能不会有改变,那么就是提供虚拟地址到最后一级页表的映射,另外 TLB 还提供了以下通用能力:
- 地址查询: 当处理器访问虚拟地址时,TLB 会首先进行查询,检查虚拟地址是否已经存在于 TLB 的缓存中
- 命中与未命中: 如果虚拟地址在 TLB 中找到匹配项,即为命中(TLB hit),TLB 会直接提供对应的物理地址。如果没有找到匹配项,即为未命中(TLB miss)
- 填充与替换: 在 TLB 未命中的情况下,处理器需要访问主存或其他缓存层次结构获取相应的页表项,并将其填充到 TLB 中,以供将来的访问使用。如果 TLB 已满,则可能需要进行替换策略,选择合适的页表项进行替换
- 更新与维护: 当页表发生变化时,TLB 需要及时更新以反映新的映射关系。这通常需要硬件和操作系统之间的协作,以确保 TLB 的一致性和正确性
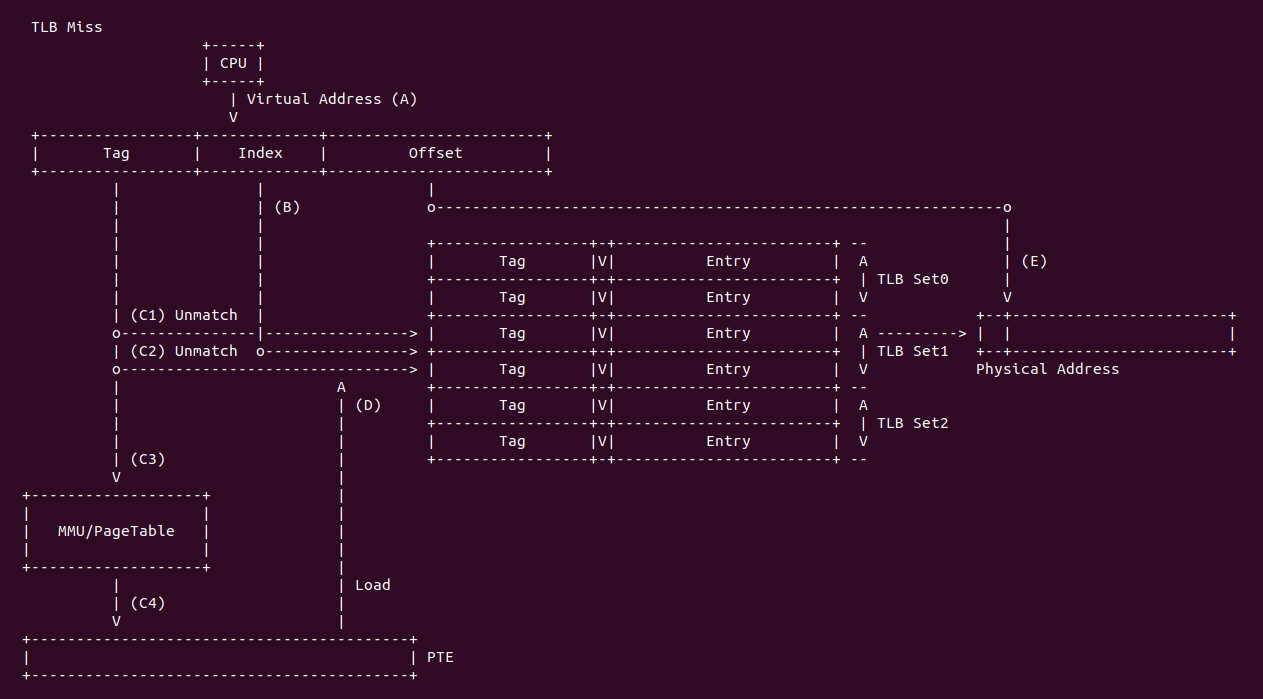
接下来通过对 TLB Miss 场景来了解一下 TLB 的工作原理,在此之前先假设 TLB 是 64-entries, 4-way set associative 设计,虚拟地址采用 32 位,系统支持 3-level 硬件页表, TLB 映射的页大小为 4KiB:
- A: CPU 访问某个虚拟内存,CPU 首先将虚拟地址发送给 TLB
- B: TLB 提取虚拟地址的 [12: 15] 字段作为 TLB Set Index,在 TLB 中找到对应的 TLB Set
- C1: TLB 将虚拟地址的 [16: 31] 字段与 TLB Set 里所有 TLB Entry 的 TLB Tag 逐次进行比较,比较了一半的 TLB Entry 还是没有匹配上
- C2: TLB 与 TLB Set 里最后一个 TLB Entry 的 TLB Tag 进行比较,还是匹配失败,因此判定为 TLB Miss
- C3: TLB 将虚拟地址发送给 MMU,MMU 根据虚拟地址进行页表查询
- C4: MMU 最终查找到最后一级页表,获得 PTE,PTE 包含了 Page Frame、Access Rights 和 Atrribute 信息
- D: MMU 将 PTE 相关的信息合成新的 Entry,然后将其加载到 TLB Set 里任意一个空闲 TLB Entry 里,如果没有空闲的 TLB Entry,那么将按照某种算法将旧的 TLB Entry 淘汰,然后将新的 Entry 加载到该 TLB Entry.
- B: TLB 再次提取虚拟地址的 [12: 15] 字段作为 TLB Set Index,在 TLB 中找到对应的 TLB Set
- C: TLB 与 TLB Set 里每个 TLB Entry 的 TLB Tag 进行比较,那么此时会匹配到一个 TLB Entry,TLB 针对找到的 TLB Entry 进行 Access Right 和 Attribute 检查,检查不通过,那么 CPU 没有权限访问该虚拟地址,并引发异常
- E: 当权限检查通过之后,TLB 从 TLB Entry 中获得 Page Frame,然后与虚拟地址的 Page Offset 一同组成物理地址.
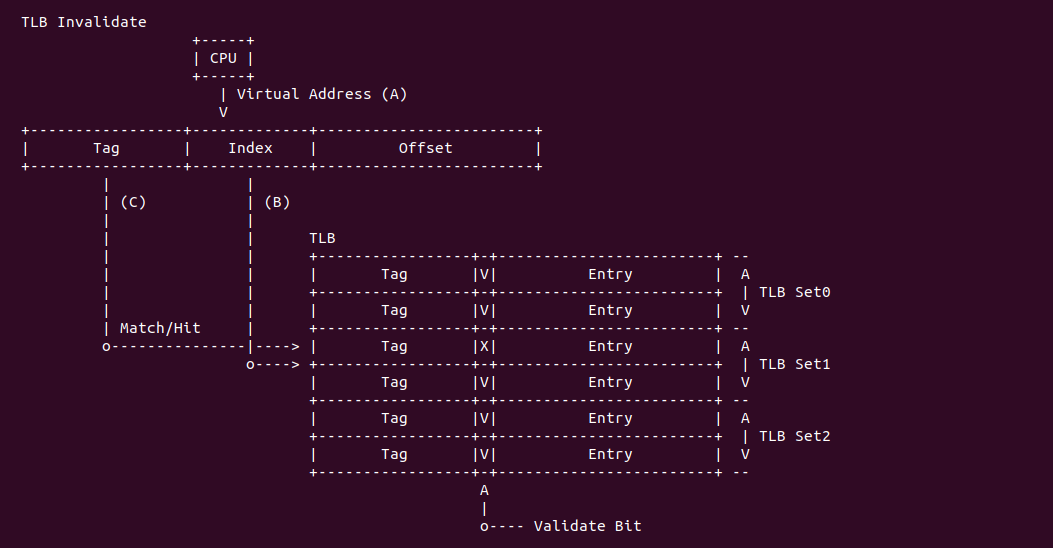
TLB 还需要维护另外一个功能就是更新 TLB,由于 TLB 无法感知内存里页表被修改,因此当软件修改页表之后,需要将原来的 TLB Entry Invalidate,每个架构都会提供特殊的指令来完成 Invalidte Ops。在有的架构里,TLB Miss 之后会触发一个异常,然后由操作系统来处理 TLB Miss, 但有的架构在发生 TLB Miss 之后,由硬件自动处理.
总结: TLB 作为一种硬件缓存,在现代计算机系统中扮演着重要的角色。它通过提供快速的地址转换,提高了系统的性能和效率。设计和优化 TLB 需要综合考虑大小、关联性、命中率和刷新策略等因素。了解 TLB 的作用、工作原理和相关考虑因素,有助于更好地理解计算机系统中的内 现代架构采用不同的 TLB 硬件,但在设计和优化 TLB 时需要考虑如下因数:
- TLB 大小: TLB 的大小直接影响了其容纳的页表项数量。较大的 TLB 可以容纳更多的页表项,减少未命中的概率,但也需要更多的硬件资源和访问时间
- TLB 关联性: TLB 可以具有不同的关联性,如全关联、组关联或直接映射。关联性决定了 TLB 查找的效率和冲突的可能性
- TLB 命中率: TLB 命中率是衡量 TLB 性能的重要指标,高命中率意味着更少的未命中,从而提高地址转换的效率
- TLB 刷新策略: TLB 需要及时更新和刷新以反映页表的变化。刷新策略涉及到硬件和操作系统之间的协作,需要综合考虑性能和一致性。

Intel® X86 架构 TLB 机制

Intel® Core and Xeon TLB Architecture
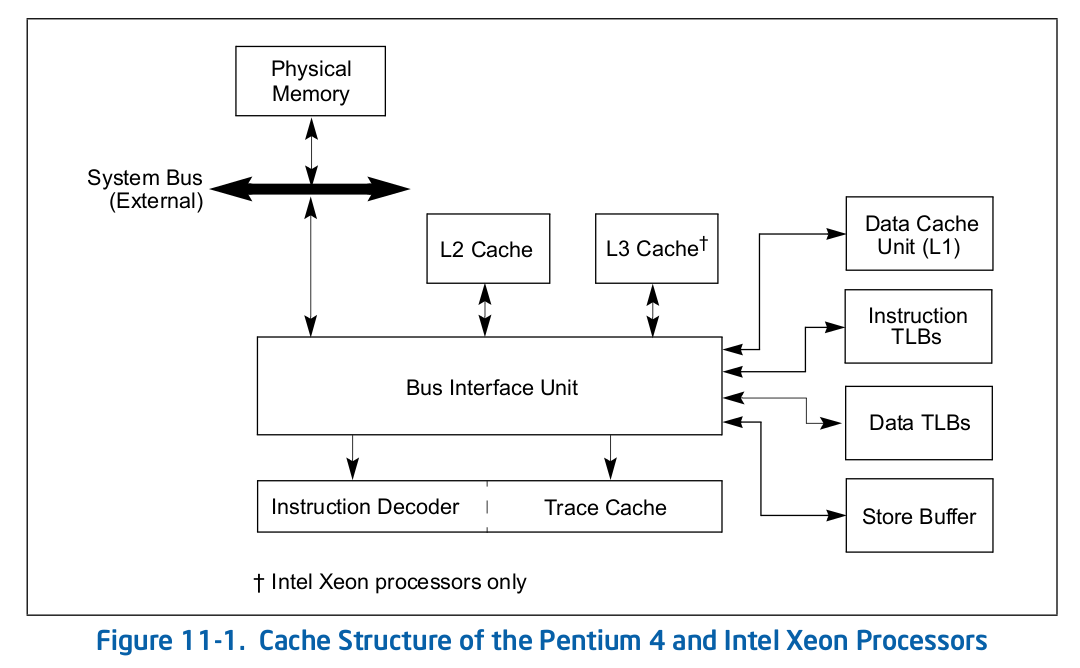
Intel 64 架构和 IA-32 架构的 TLB 系统由缓存 4KiB 页的 Instruction TLB 和 Data TLB, 以及缓存大页(2MiB/1Gig)的 Instruction TLB 和 Data TLB. 另外 Paging-Structure CACHE 也属于 TLB,只是 Paging-Structure 缓存的其他级的 PageTable Entry. Figure 11-1 展示了 Xeon 系列处理器的 TLB 架构组成,可以看到 Xeon 处理器包含了 ITLB 和 DTLB,并且分为小页和大页两种类型. DTLB 和 ITLB 直接连接到了 Bus Insterface Unit, 另外 Xeon 系列处理器并没有包含 STLB.
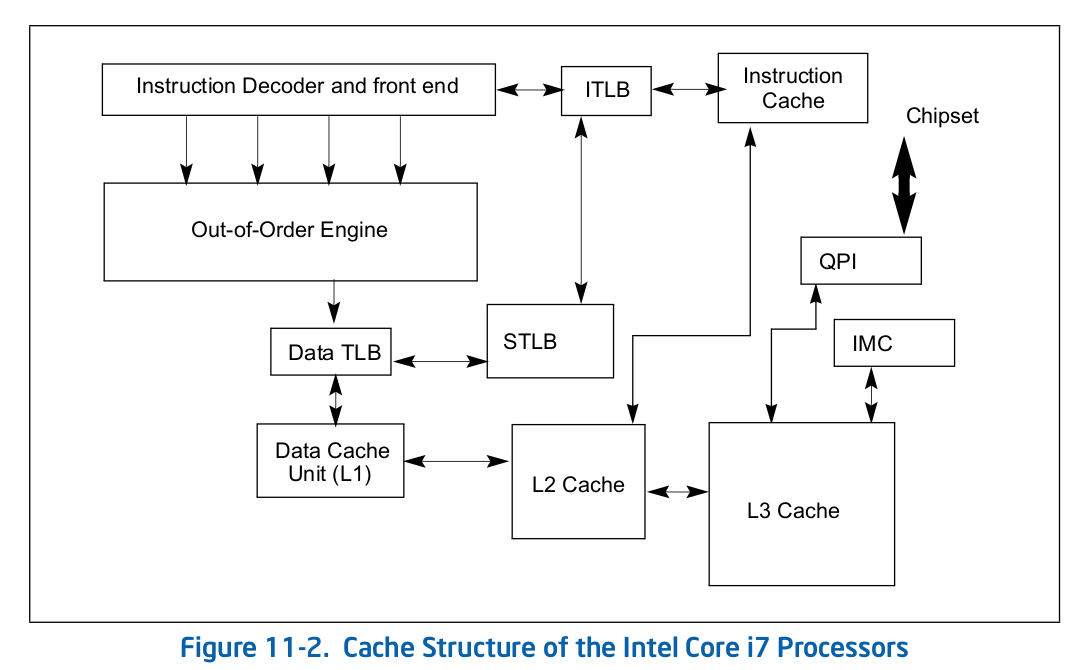
Figure 11-2 展示了 Corei7 系列 TLB 架构组成,Instruction TLB 位于 Instruction Decoder and Front end 与 Instruction CACHE 之间,而 Data TLB 位于 Out-of-Order Engine 与 Data Cache(L1) 之间,这里的 STLB 表示 Second-level Unified TLB(4KiB Pages). 在 Core 系列处理器 TLB 比 CACHE 更靠近 CPU, 并且采用了 2 levels TLB 架构.
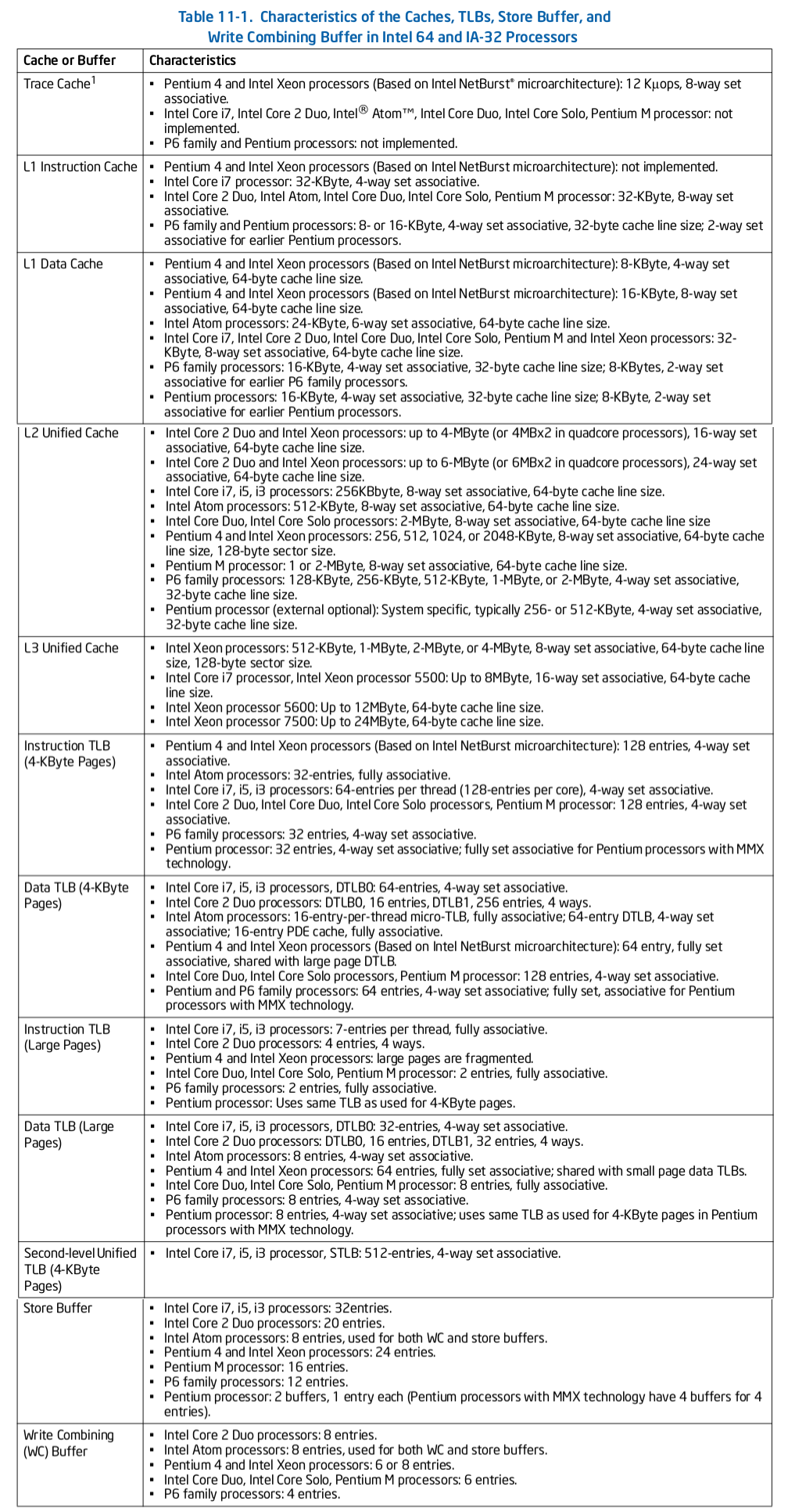
上表显示了不同 Intel 处理器采用 TLB 的信息,可以通过查该表获得某个系列 CPU 的 TLB 硬件信息,信息包括 TLB 缓存的对象和 TLB 大小,例如 Intel Corei7:
- Instruction TLB(4KiB Pages): “64-entries per thread(128-entries per Core), 4-way set associative”,表示其 iTLB-4K 是一个组相联映射 TLB,每个 thread 具有 4 路 16 TLB Set,每个 TLB Set 包含 4 个 TLB Entry
- Instruction TLB(Large Pages): “7-entires per thread, full associative”,表示其 iTLB-Large 是一个全相联映射 TLB,每个 thread 具有 7 TLB Entry
- Data TLB(4KiB Pages): “64-entries, 4-way set associative”, 表示 DTLB-4K 是一个组相联映射 TLB,其具有 4 路 16 组 TLB Set,每个 TLB Set 包含 4 个 TLB Entry
- Data TLB(Large Pages): “32-entries, 4-way set associative”, 表示 DTLB-Large 是一个组相联映射 TLB,其具有 4 路 8 组 TLB Set,每个 TLB Set 包含 4 个 TLB Entry
- Second-level Unified TLB(4KiB Pages): “512-entries, 4-way set associative”, 表示 STLB 是一个组相联映射 TLB,其具有 4 路 128 TLB Set, 每个 TLB Set 包含 4 个 TLB Entry.
Intel® Processor-Context Identifiers(PCIDs)
Processor-Context Identifiers(PCIDs): 是一项功能,用于在处理器中缓存多个线性地址空间的信息。它的主要作用是提高上下文切换时的缓存效率. PCID 允许处理器在不同的线性地址空间之间切换时保留缓存的信息。通过使用不同的 PCID 标识符,处理器可以将不同线性地址空间的缓存信息进行隔离和区分,以避免缓存冲突和数据污染。当软件切换到具有不同 PCID 的不同线性地址空间时,处理器可以继续使用之前缓存的信息,而无需重新加载。
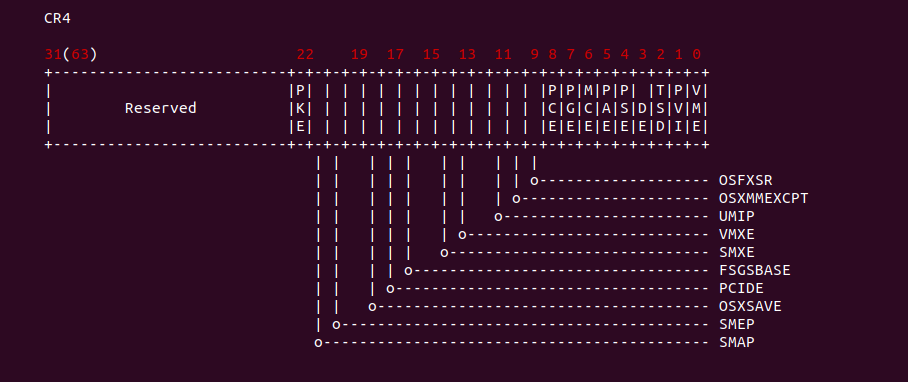
PCID 是一个 12 位标识符。PCID 机制通过 CR4 的 PCIDE 标志位进行控制,当该位清零,那么 PCID 始终为 0x0000; 反之如果 CR4 寄存器 PCIED 标志位置位,那么 CR3 的 [0: 11] 存储当前 PCID 值. 并非所有的处理器运行将 CR4.PCIDE 置为 1. 处理器确保 CR4.PCIDE 只能在 IA-32e 模式下置位,因此 32-bit Paging 和 PAE Paging 仅使用 PCID 为 0000H. 另外只有在 CR3[11: 0] = 0000H 时,软件才能将 CR4.PCIDE 从 0 修改为 1. 通过使用 PCID,处理器能够更有效地管理缓存,提高上下文切换的性能,并减少由于缓存失效引起的延迟。特别是在具有大量线性地址空间的应用程序或多任务环境中,PCID 可以显著提升系统的整体性能。那么 PCID 的应用场景包括:
- 多任务环境: 在多任务操作系统中,不同的任务或进程可能运行在不同的线性地址空间中。PCID 可以使处理器在任务切换时保留缓存信息,从而减少缓存失效带来的性能损失
- 虚拟化: 在虚拟化环境中,多个虚拟机可能同时运行在同一个物理处理器上。每个虚拟机可以使用不同的 PCID 标识符来隔离和区分它们的缓存信息,避免缓存冲突和数据污染,从而提高虚拟化性能
- 内核与用户空间切换: 在操作系统中,内核和用户空间拥有不同的线性地址空间。PCID 可以使处理器在内核与用户空间之间切换时保留缓存信息,减少缓存失效带来的性能开销
- 应用程序运行环境切换: 在某些应用程序中,可能会切换不同的运行环境,例如从用户态切换到内核态,或者从一个安全沙盒环境切换到另一个。PCID 可以帮助处理器在环境切换时保留相关的缓存信息,提高切换效率
总之,PCID 提供了一种机制,使处理器能够在不同的线性地址空间之间缓存信息,并在切换时保留相关的缓存状态,从而提高缓存利用率和系统性能。它特别适用于多任务、虚拟化和操作系统的内核/用户空间切换等场景。
以上是 PCID 带来的便利,那么如果系统不开启 PCID 会带来哪些影响呢? 在 x86 体系结构中,开启和不开启 PCID(Process-Context Identifiers) 的差异主要体现在以下几个方面:
- 缓存效率: 开启 PCID 可以提高缓存的利用效率。当 PCID 被启用时,处理器可以在不同的线性地址空间之间切换时保留缓存的信息。这样在切换地址空间时,处理器可以继续使用之前缓存的数据,而无需重新加载,从而减少缓存失效带来的性能损失。相比之下,如果不开启 PCID,则在每次地址空间切换时,处理器都需要清空缓存,重新加载数据,这会导致较大的性能开销
- 上下文切换速度: 开启 PCID 可以加快上下文切换的速度。上下文切换是在多任务环境中从一个任务切换到另一个任务时发生的操作。当 PCID 启用时,处理器可以在切换任务时保留缓存的信息,从而减少缓存失效的影响,加快任务切换的速度。而如果不开启 PCID,则每次任务切换都需要清空缓存,重新加载数据,导致上下文切换的延迟增加
- 虚拟化性能: 在虚拟化环境中,开启 PCID 可以提高虚拟化性能。通过使用不同的 PCID 标识符,不同的虚拟机可以在同一物理处理器上共享缓存,并避免缓存冲突和数据污染。这可以提高虚拟机的性能和效率。如果不开启 PCID,则每个虚拟机都需要独立地管理缓存,可能导致更多的缓存冲突和性能下降
总的来说,开启 PCID 可以提高缓存效率、加快上下文切换速度,并在虚拟化环境中提供更好的性能。但需要注意的是,并非所有的 x86 处理器都支持 PCID 功能,具体支持情况需要查看处理器的规格说明
PCID(Process-Context Identifiers) 与 TLB(Translation Lookaside Buffer) 之间存在一定的关系。TLB 是一种高速缓存,用于存储最近访问的线性地址到物理地址的映射,以加速地址转换过程。PCID 提供了一种标识符,用于将 TLB 中的条目与特定的线性地址空间关联起来。当处理器执行地址转换时,它会检查 TLB 中的条目,并查找与当前 PCID 相关联的条目。在具有 PCID 支持的系统中,TLB 中的条目通常会包含 PCID 标识符,以便处理器可以根据当前任务或线性地址空间的上下文来选择适当的条目进行地址转换。这样,即使在切换任务或线性地址空间时,TLB 中仍然可以保留相关的缓存条目,从而减少地址转换的开销. PCID 和 TLB 的结合使用可以提高地址转换的效率,尤其在多任务环境、虚拟化场景或操作系统内核/用户空间切换时。通过关联 TLB 条目和 PCID,处理器可以更快速地找到正确的映射关系,避免了频繁的缓存失效和重复的地址转换操作,从而提高系统性能。
Intel® Instruction TLB(4KiB Pages)
指令 TLB(Translation Lookaside Buffer) 是一种高速缓存,用于存储指令地址到物理地址的转换结果。它是处理器中的一部分,用于加速指令地址转换过程。在执行程序时,处理器需要将指令的线性地址转换为物理地址才能正确地访问内存中的指令。这个地址转换过程涉及到页表的查询和映射操作,而 TLB 就是用于缓存这些查询和映射结果的快速查找表。指令 TLB 包含了一组 TLB Entry,每个 Entry 存储了一对线性地址和物理地址的映射关系。当处理器执行指令时,它首先检查指令 TLB 中是否存在与指令地址对应的映射。如果存在映射,处理器可以直接从 TLB 中获取物理地址,从而避免了昂贵的页表查询过程。如果指令 TLB 中不存在对应的映射,处理器将通过查询页表来获取映射关系,并将结果存储到 TLB 中以供后续访问使用.
由于 TLB(Translation Lookaside Buffer) 仅缓存具有转换的线性地址的条目,因此只有当用于转换该页号的每个分页结构条目中的 P(Present) 标志为 1 且保留位为 0 时,才能有 TLB 条目与页号对应。此外,处理器只有在转换过程中用于转换的每个分页结构条目中的访问标志(AccessBit)为 1 时,才会缓存页号的转换; 在缓存转换之前,处理器会将任何不为1的访问标志设置为 1. 如果线性地址的页号对应于与当前 PCID 关联的 TLB 条目,处理器可以使用该 TLB 条目来确定用于访问该线性地址的页框、访问权限和其他属性。在这种情况下,处理器可能实际上不会查询内存中的分页结构。即使软件随后修改内存中的相关分页结构条目,处理器也可以保留未修改的 TLB 条目.
在 X86 架构中,支持 4KiB、2MiB、1Gig 大页,那么当 CPU 发送一个虚拟地址,TLB 如何知道虚拟地址映射的是 4KiB 还是大页? 如果分页结构指定了一个大于 4KiB 的页面大小的转换,一些处理器可能会为该转换缓存多个更小页面的 TLB 条目。每个这样的 TLB 条目将与对应较小页面大小的页号相关联(例如,具有 4 级分页的线性地址的 47 到 12 位),即使该页号的一部分(例如,20到12位)是相对于由分页结构指定的页面的偏移量的一部分。这样一个 TLB 条目中的物理地址的高位是根据用于创建转换的 PDE 中的物理地址派生出来的,而低位则来自创建转换的访问的线性地址。软件无法意识到已经为大页面使用了多个更小页面的多个转换。例如,对该页面上的任何线性地址的转换执行 INVLPG 将使得所有与该转换相关的更小页面的 TLB 条目无效.
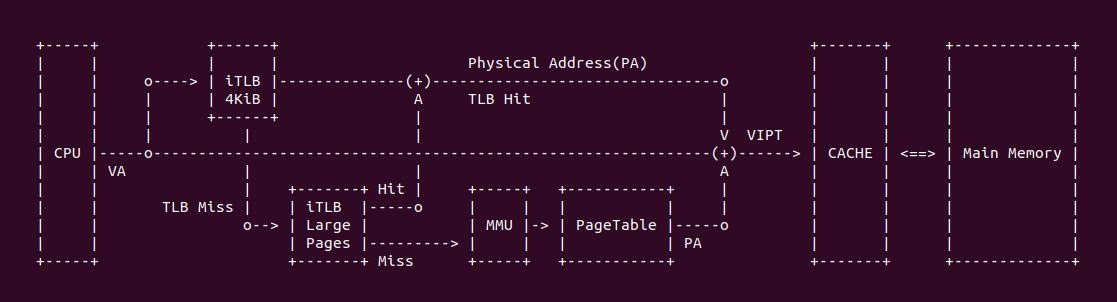
在 X86 架构中,存在 Instruction TLB(4KiB Pages) 和 Instrction TLB(Large Pages),虽然没有明确的文档对两者关系进行描述,但可以猜测某种关系,当 TLB 缓存一个转换关系时,其会根据转换关系来自 PTE 还是非 PTE 进行分类,例如当转换关系来自 PDE,即虚拟地址映射了 2MiB 大页,那么硬件将转换关系存储到 Instruction TLB(Large Pages) 的 TLB Entry,该 TLB Entry 的 Page Frame、Access Rights 和 Attribute 均来自 PDE。当 CPU 访问对应的虚拟地址,TLB 首先在 Instrction TLB(4KiB) 里面查找,如果查找失败则继续到 Instrction TLB(Large Pages) 里进行查找.
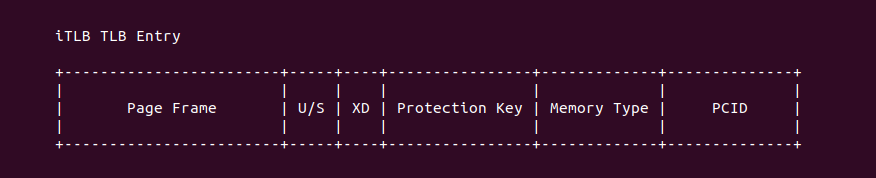
Instruction TLB(4KiB) 的 TLB Entry 组成如上图,其由 4 部分组成,其内容均来自 PTE,每个字段的含义如下:
- Page Frame: 物理地址的 [12: MAX] 字段
- U/S: 指明映射是用户空间虚拟地址(U)还是内核空间虚拟地址(S)
- XD: 指明是否具有可执行权限
- Protection Key: 更细粒度的内存访问控制
- Memory Type: 由于描述映射的内存类型,例如 UC/WC/WB 等
- PCID: 线性空间标识
Instruction TLB(4KiB) 维护的 4KiB PTE 页表的映射,另外结合 iTLB 的硬件结构一般为 组相联映射(Set-Associative), 例如 “64-entries,4-Way Set-associative”,虚拟地址的 [12: 15] 字段查找到 TLB Set 之后,虚拟地址的 [16: MAX) 字段与 TLB Entry 的 Tag 字段进行比较,以此找到对应的 TLB Entry。最后 TLB Entry 是无法感知 PTE 被修改,因此在修改了 PTE 之后需要手动更新 TLB Entry,X86 提供了更新 TLB 的指令 INVLPG/INVPCID, 可以针对虚拟地址进行更新,也可以根据 PCID 进行更新, 在 TLB 里所谓的更新就是将 TLB Entry Invalidate.
Intel® Instruction TLB(Large Pages)
指令 TLB(Translation Lookaside Buffer) 是一种高速缓存,用于存储指令地址到物理地址的转换结果。它是处理器中的一部分,用于加速指令地址转换过程。在执行程序时,处理器需要将指令的线性地址转换为物理地址才能正确地访问内存中的指令。这个地址转换过程涉及到页表的查询和映射操作,而 TLB 就是用于缓存这些查询和映射结果的快速查找表。指令 TLB 包含了一组 TLB Entry,每个 Entry 存储了一对线性地址和物理地址的映射关系。当处理器执行指令时,它首先检查指令 TLB 中是否存在与指令地址对应的映射。如果存在映射,处理器可以直接从 TLB 中获取物理地址,从而避免了昂贵的页表查询过程。如果指令 TLB 中不存在对应的映射,处理器将通过查询页表来获取映射关系,并将结果存储到 TLB 中以供后续访问使用.
由于 TLB(Translation Lookaside Buffer) 仅缓存具有转换的线性地址的条目,因此只有当用于转换该页号的每个分页结构条目中的 P(Present) 标志为 1 且保留位为 0 时,才能有 TLB 条目与页号对应。此外,处理器只有在转换过程中用于转换的每个分页结构条目中的访问标志(AccessBit)为 1 时,才会缓存页号的转换; 在缓存转换之前,处理器会将任何不为1的访问标志设置为 1. 如果线性地址的页号对应于与当前 PCID 关联的 TLB 条目,处理器可以使用该 TLB 条目来确定用于访问该线性地址的页框、访问权限和其他属性。在这种情况下,处理器可能实际上不会查询内存中的分页结构。即使软件随后修改内存中的相关分页结构条目,处理器也可以保留未修改的 TLB 条目.
在 X86 架构中,支持 4KiB、2MiB、1Gig 大页,那么当 CPU 发送一个虚拟地址,TLB 如何知道虚拟地址映射的是 4KiB 还是大页? 如果分页结构指定了一个大于 4KiB 的页面大小的转换,一些处理器可能会为该转换缓存多个更小页面的 TLB 条目。每个这样的 TLB 条目将与对应较小页面大小的页号相关联(例如,具有 4 级分页的线性地址的 47 到 12 位),即使该页号的一部分(例如,20到12位)是相对于由分页结构指定的页面的偏移量的一部分。这样一个 TLB 条目中的物理地址的高位是根据用于创建转换的 PDE 中的物理地址派生出来的,而低位则来自创建转换的访问的线性地址。软件无法意识到已经为大页面使用了多个更小页面的多个转换。例如,对该页面上的任何线性地址的转换执行 INVLPG 将使得所有与该转换相关的更小页面的 TLB 条目无效.
在 X86 架构中,存在 Instruction TLB(4KiB Pages) 和 Instrction TLB(Large Pages),虽然没有明确的文档对两者关系进行描述,但可以猜测某种关系,当 TLB 缓存一个转换关系时,其会根据转换关系来自 PTE 还是非 PTE 进行分类,例如当转换关系来自 PDE,即虚拟地址映射了 2MiB 大页,那么硬件将转换关系存储到 Instruction TLB(Large Pages) 的 TLB Entry,该 TLB Entry 的 Page Frame、Access Rights 和 Attribute 均来自 PDE。当 CPU 访问对应的虚拟地址,TLB 首先在 Instrction TLB(4KiB) 里面查找,如果查找失败则继续到 Instrction TLB(Large Pages) 里进行查找.
Instruction TLB(Large Pages) 的 TLB Entry 组成如上图,其由 4 部分组成,其内容均来自 PDE/PDPTE,每个字段的含义如下:
- Page Frame: 物理地址的 [12: MAX] 字段
- U/S: 指明映射是用户空间虚拟地址(U)还是内核空间虚拟地址(S)
- XD: 指明是否具有可执行权限
- Protection Key: 更细粒度的内存访问控制
- Memory Type: 由于描述映射的内存类型,例如 UC/WC/WB 等
- PCID: 线性空间标识
Instruction TLB(Large Pages) 维护的 2M/1G PDE/PDPTE 页表的映射,另外结合 iTLB 的硬件结构一般为 全相联映射(Full-Associative), 例如 “7-entries Per thread,Full-associative”,虚拟地址的 [21: MAX) 字段逐次与所有 TLB Entry 的 Tag 字段进行比较,以此找到对应的 TLB Entry。最后 TLB Entry 是无法感知 PDE/PDPTE 被修改,因此在修改了 PDE/PDPTE 之后需要手动更新 TLB Entry,X86 提供了更新 TLB 的指令 INVLPG/INVPCID, 可以针对虚拟地址进行更新,也可以根据 PCID 进行更新, 在 TLB 里所谓的更新就是将 TLB Entry Invalidate.
Intel® Data TLB(4KiB Pages)
数据 TLB(Translation Lookaside Buffer) 是处理器中的一种高速缓存,用于存储数据地址到物理地址的转换结果。它类似于指令 TLB,但用于数据访问的地址转换。当处理器执行数据访问操作时,需要将数据的线性地址转换为物理地址以正确访问内存。这个地址转换过程涉及到页表的查询和映射操作,数据 TLB 就是用于缓存这些查询和映射结果的快速查找表。数据 TLB 包含一组 TLB Entry,每个 Entry 存储数据地址到物理地址的映射关系。当处理器执行数据访问时,它首先检查数据 TLB 中是否存在与数据地址对应的映射。如果存在映射,处理器可以直接从 TLB 中获取物理地址,从而避免了昂贵的页表查询过程。如果数据 TLB 中不存在对应的映射,处理器将通过查询页表来获取映射关系,并将结果存储到 TLB 中以供后续访问使用.
由于 TLB(Translation Lookaside Buffer) 仅缓存具有转换的线性地址的条目,因此只有当用于转换该页号的每个分页结构条目中的 P(Present) 标志为 1 且保留位为 0 时,才能有 TLB 条目与页号对应。此外,处理器只有在转换过程中用于转换的每个分页结构条目中的访问标志(AccessBit)为 1 时,才会缓存页号的转换; 在缓存转换之前,处理器会将任何不为1的访问标志设置为 1. 如果线性地址的页号对应于与当前 PCID 关联的 TLB 条目,处理器可以使用该 TLB 条目来确定用于访问该线性地址的页框、访问权限和其他属性。在这种情况下,处理器可能实际上不会查询内存中的分页结构。即使软件随后修改内存中的相关分页结构条目,处理器也可以保留未修改的 TLB 条目.
在 X86 架构中,支持 4KiB、2MiB、1Gig 大页,那么当 CPU 发送一个虚拟地址,TLB 如何知道虚拟地址映射的是 4KiB 还是大页? 如果分页结构指定了一个大于 4KiB 的页面大小的转换,一些处理器可能会为该转换缓存多个更小页面的 TLB 条目。每个这样的 TLB 条目将与对应较小页面大小的页号相关联(例如,具有 4 级分页的线性地址的 47 到 12 位),即使该页号的一部分(例如,20到12位)是相对于由分页结构指定的页面的偏移量的一部分。这样一个 TLB 条目中的物理地址的高位是根据用于创建转换的 PDE 中的物理地址派生出来的,而低位则来自创建转换的访问的线性地址。软件无法意识到已经为大页面使用了多个更小页面的多个转换。例如,对该页面上的任何线性地址的转换执行 INVLPG 将使得所有与该转换相关的更小页面的 TLB 条目无效.
在 X86 架构中,存在 Data TLB(4KiB Pages) 和 Data TLB(Large Pages),虽然没有明确的文档对两者关系进行描述,但可以猜测某种关系,当 TLB 缓存一个转换关系时,其会根据转换关系来自 PTE 还是非 PTE 进行分类,例如当转换关系来自 PDE/PDPTE,即虚拟地址映射了 2MiB/1Gig 大页,那么硬件将转换关系存储到 Data TLB(Large Pages) 的 TLB Entry,该 TLB Entry 的 Page Frame、Access Rights 和 Attribute 均来自 PDE/PDPTE。当 CPU 访问对应的虚拟地址,TLB 首先在 Data TLB(4KiB) 里面查找,如果查找失败则继续到 Data TLB(Large Pages) 里进行查找.

Data TLB(4KiB) 的 TLB Entry 组成如上图,其由 4 部分组成,其内容均来自 PTE,每个字段的含义如下:
- Page Frame: 物理地址的 [12: MAX] 字段
- R/W: 指明映射具有读写权限
- U/S: 指明映射是用户空间虚拟地址(U)还是内核空间虚拟地址(S)
- XD: 指明是否具有可执行权限
- Protection Key: 更细粒度的内存访问控制
- Dirty: 指明物理页内容是否被修改
- Memory Type: 由于描述映射的内存类型,例如 UC/WC/WB 等
- PCID: 线性空间标识
Data TLB(4KiB) 维护的 4KiB PTE 页表的映射,另外结合 DTLB 的硬件结构一般为 组相联映射(Set-Associative), 例如 “64-entries,4-Way Set-associative”,虚拟地址的 [12: 15] 字段查找到 TLB Set 之后,虚拟地址的 [16: MAX) 字段与 TLB Entry 的 Tag 字段进行比较,以此找到对应的 TLB Entry。最后 TLB Entry 是无法感知 PTE 被修改,因此在修改了 PTE 之后需要手动更新 TLB Entry,X86 提供了更新 TLB 的指令 INVLPG/INVPCID, 可以针对虚拟地址进行更新,也可以根据 PCID 进行更新, 在 TLB 里所谓的更新就是将 TLB Entry Invalidate.
Intel® Data TLB(Large Pages)
数据 TLB(Translation Lookaside Buffer) 是处理器中的一种高速缓存,用于存储数据地址到物理地址的转换结果。它类似于指令 TLB,但用于数据访问的地址转换。当处理器执行数据访问操作时,需要将数据的线性地址转换为物理地址以正确访问内存。这个地址转换过程涉及到页表的查询和映射操作,数据 TLB 就是用于缓存这些查询和映射结果的快速查找表。数据 TLB 包含一组 TLB Entry,每个 Entry 存储数据地址到物理地址的映射关系。当处理器执行数据访问时,它首先检查数据 TLB 中是否存在与数据地址对应的映射。如果存在映射,处理器可以直接从 TLB 中获取物理地址,从而避免了昂贵的页表查询过程。如果数据 TLB 中不存在对应的映射,处理器将通过查询页表来获取映射关系,并将结果存储到 TLB 中以供后续访问使用.
由于 TLB(Translation Lookaside Buffer) 仅缓存具有转换的线性地址的条目,因此只有当用于转换该页号的每个分页结构条目中的 P(Present) 标志为 1 且保留位为 0 时,才能有 TLB 条目与页号对应。此外,处理器只有在转换过程中用于转换的每个分页结构条目中的访问标志(AccessBit)为 1 时,才会缓存页号的转换; 在缓存转换之前,处理器会将任何不为1的访问标志设置为 1. 如果线性地址的页号对应于与当前 PCID 关联的 TLB 条目,处理器可以使用该 TLB 条目来确定用于访问该线性地址的页框、访问权限和其他属性。在这种情况下,处理器可能实际上不会查询内存中的分页结构。即使软件随后修改内存中的相关分页结构条目,处理器也可以保留未修改的 TLB 条目.
在 X86 架构中,支持 4KiB、2MiB、1Gig 大页,那么当 CPU 发送一个虚拟地址,TLB 如何知道虚拟地址映射的是 4KiB 还是大页? 如果分页结构指定了一个大于 4KiB 的页面大小的转换,一些处理器可能会为该转换缓存多个更小页面的 TLB 条目。每个这样的 TLB 条目将与对应较小页面大小的页号相关联(例如,具有 4 级分页的线性地址的 47 到 12 位),即使该页号的一部分(例如,20到12位)是相对于由分页结构指定的页面的偏移量的一部分。这样一个 TLB 条目中的物理地址的高位是根据用于创建转换的 PDE 中的物理地址派生出来的,而低位则来自创建转换的访问的线性地址。软件无法意识到已经为大页面使用了多个更小页面的多个转换。例如,对该页面上的任何线性地址的转换执行 INVLPG 将使得所有与该转换相关的更小页面的 TLB 条目无效.
在 X86 架构中,存在 Data TLB(4KiB Pages) 和 Data TLB(Large Pages),虽然没有明确的文档对两者关系进行描述,但可以猜测某种关系,当 TLB 缓存一个转换关系时,其会根据转换关系来自 PTE 还是非 PTE 进行分类,例如当转换关系来自 PDE/PDPTE,即虚拟地址映射了 2MiB/1Gig 大页,那么硬件将转换关系存储到 Data TLB(Large Pages) 的 TLB Entry,该 TLB Entry 的 Page Frame、Access Rights 和 Attribute 均来自 PDE/PDPTE。当 CPU 访问对应的虚拟地址,TLB 首先在 Data TLB(4KiB) 里面查找,如果查找失败则继续到 Data TLB(Large Pages) 里进行查找.
Data TLB(Large Pages) 的 TLB Entry 组成如上图,其由 4 部分组成,其内容均来自 PDE/PDPTE,每个字段的含义如下:
- Page Frame: 物理地址的 [12: MAX] 字段
- R/W: 指明映射具有读写权限
- U/S: 指明映射是用户空间虚拟地址(U)还是内核空间虚拟地址(S)
- XD: 指明是否具有可执行权限
- Protection Key: 更细粒度的内存访问控制
- Dirty: 指明物理页内容是否被修改
- Memory Type: 由于描述映射的内存类型,例如 UC/WC/WB 等
- PCID: 线性空间标识
Data TLB(Large Pages) 维护的 2MiB/1Gig PDE/PDPTE 页表的映射,另外结合 DTLB 的硬件结构一般为 组相联映射(Set-Associative), 例如 “32-entries,4-Way Set-associative”,虚拟地址的 [12: 14] 字段查找到 TLB Set 之后,虚拟地址的 [20: MAX) 字段与 TLB Entry 的 Tag 字段进行比较,以此找到对应的 TLB Entry。最后 TLB Entry 是无法感知 PTE 被修改,因此在修改了 PTE 之后需要手动更新 TLB Entry,X86 提供了更新 TLB 的指令 INVLPG/INVPCID, 可以针对虚拟地址进行更新,也可以根据 PCID 进行更新, 在 TLB 里所谓的更新就是将 TLB Entry Invalidate.
Intel® Second-Level Unified TLB(4KiB Pages)
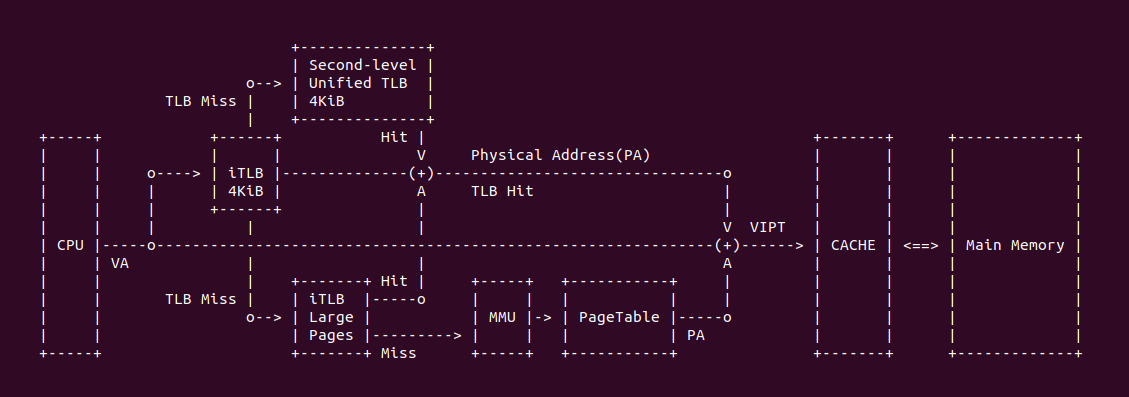
在 x86 体系结构中,Second-level Unified TLB(二级统一TLB) 是一种高速缓存,用于存储和加速地址转换过程中的页表查找结果。它作为主 TLB(Primary TLB) 的补充,提供更大的容量和更高的效率。主 TLB 是处理器中的第一级 TLB,用于缓存常用的地址转换结果。然而,由于 TLB 的大小和性能限制,无法完全容纳所有的地址转换映射。为了提高覆盖率和性能,x86 架构引入了二级统一 TLB 作为主 TLB 的扩展。二级统一 TLB 是一个辅助 TLB,它与主 TLB 配合工作,用于缓存额外的地址转换映射。它可以提供更大的容量和更高的覆盖率,以减少 TLB 缺失(TLB miss) 的频率。Intel Core-i7 处理器提供了一个 Second-level Unified TLB, 其硬件结构是 512-entries, 4-way set associative.

Intel® Paging-Structure CACHEs
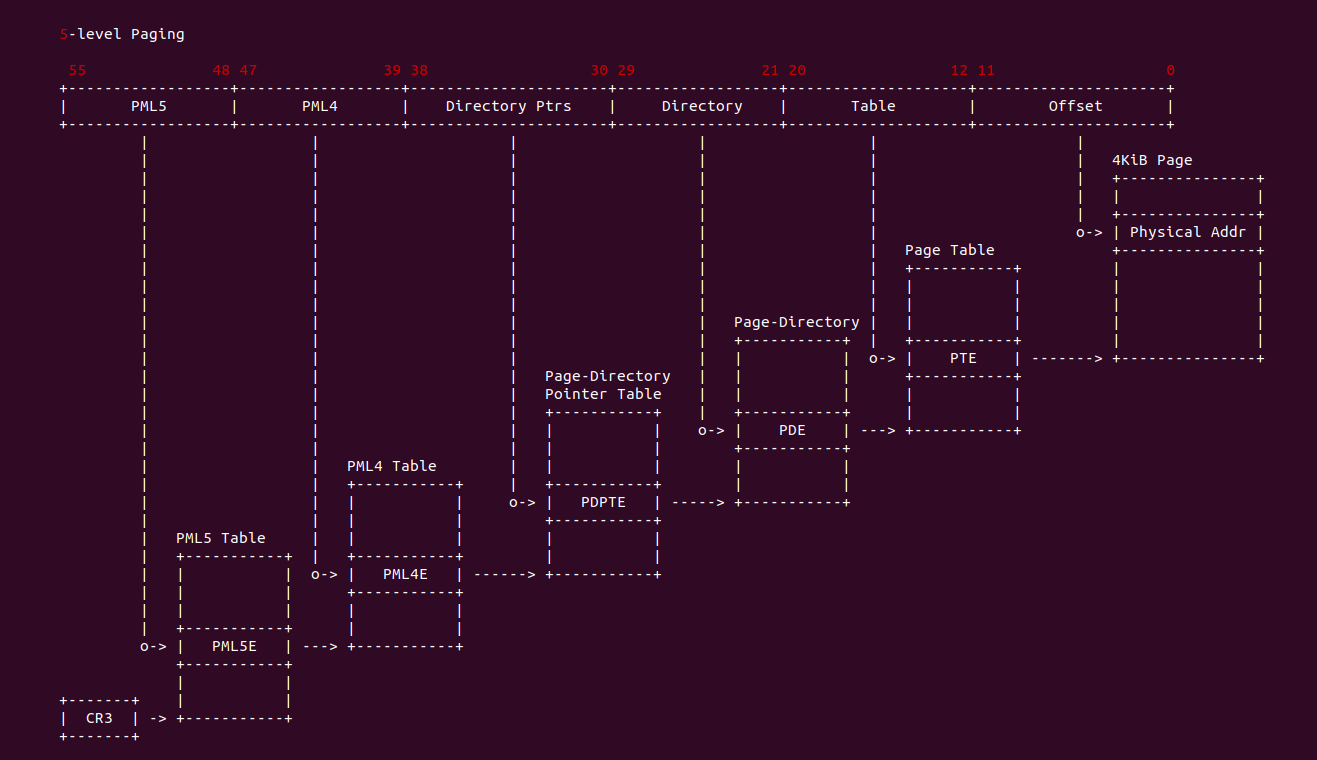
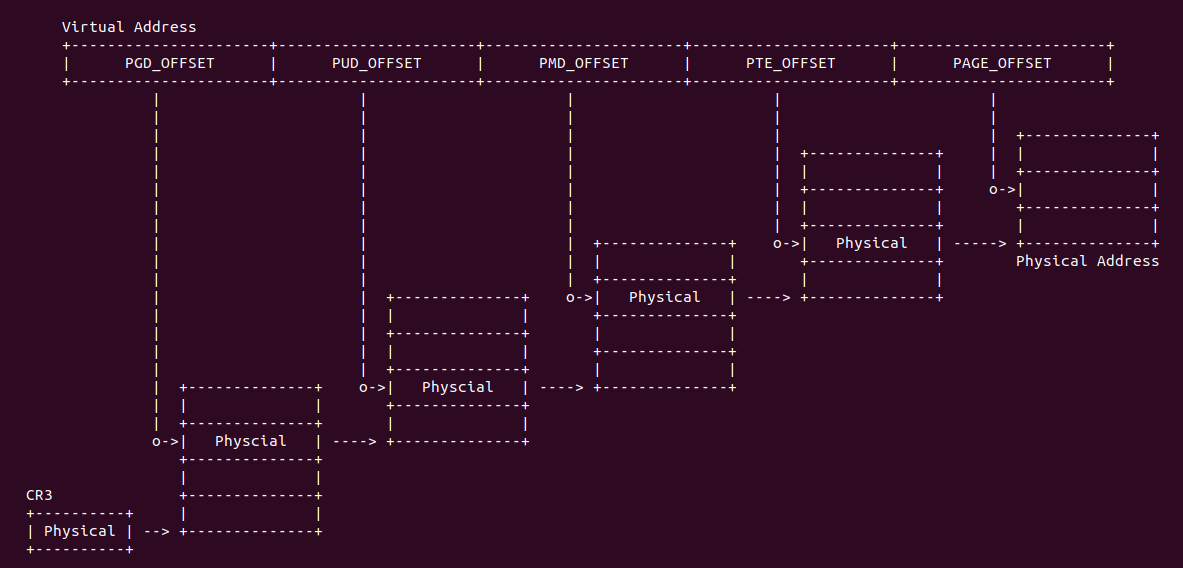
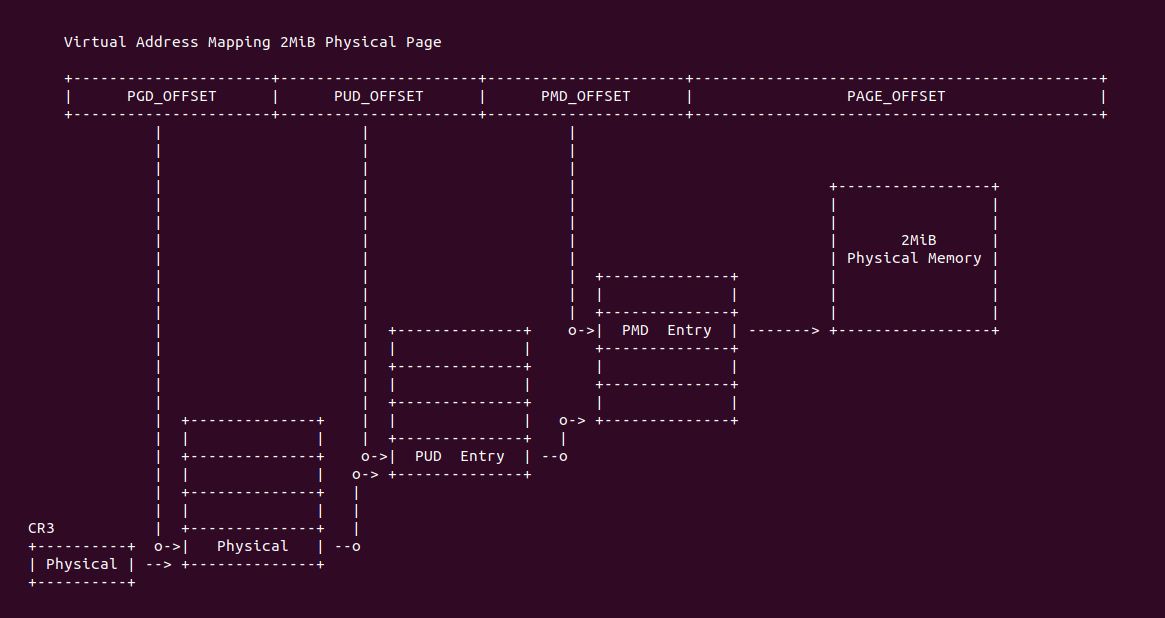
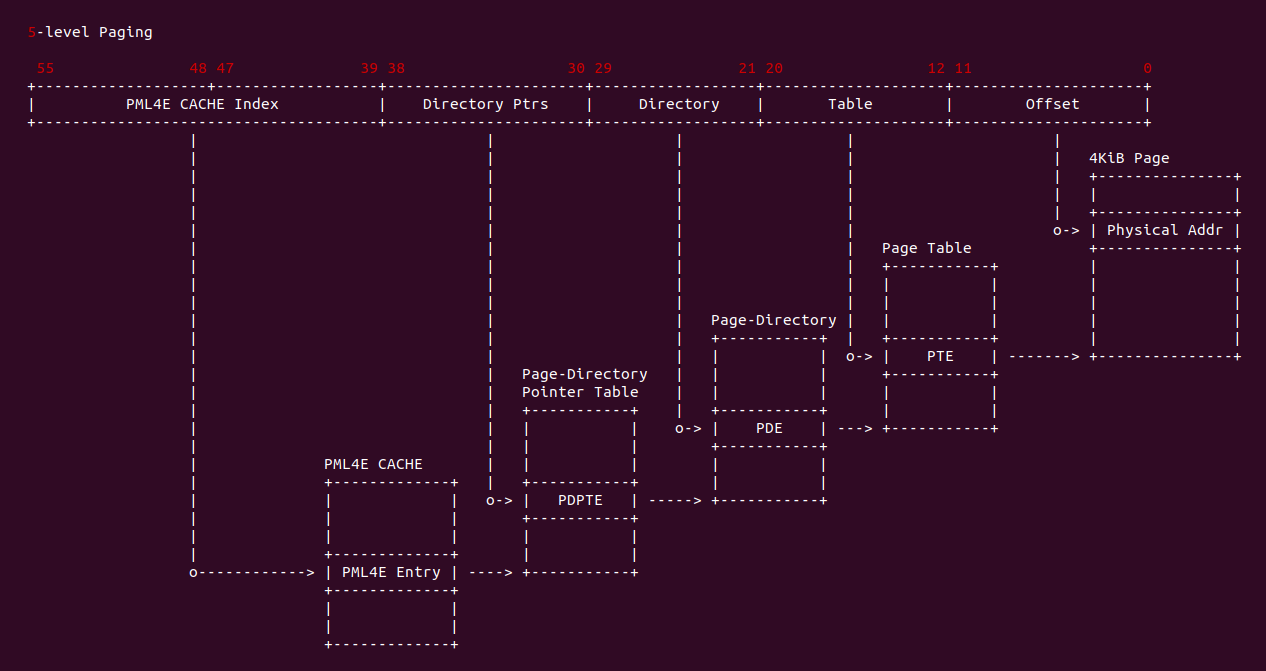
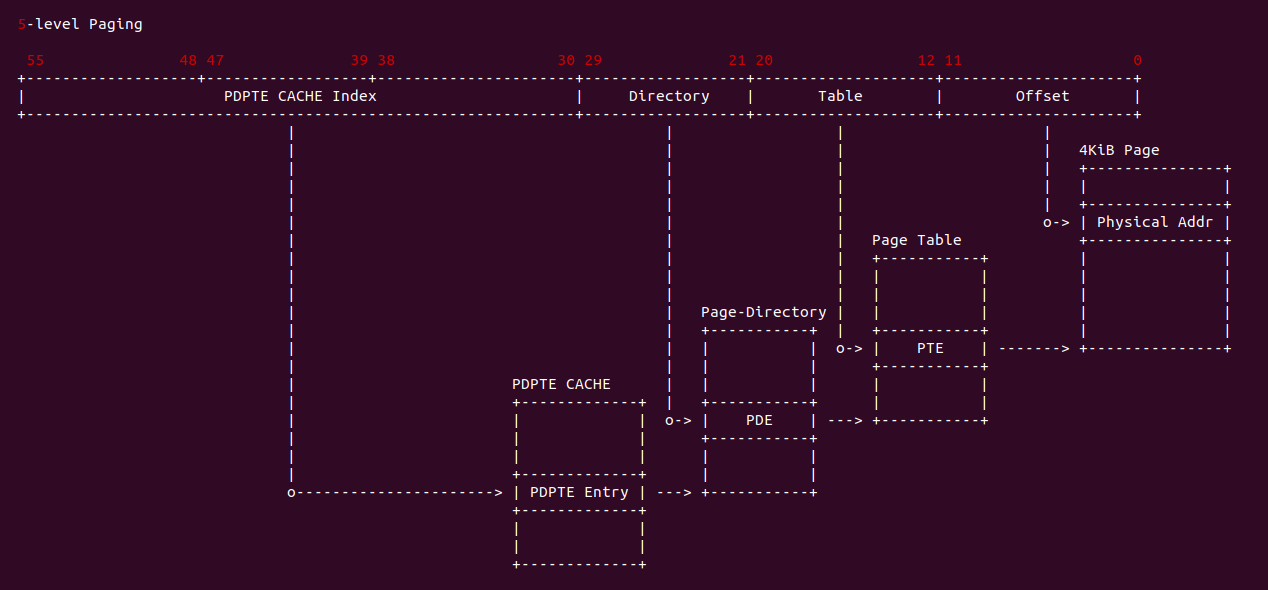
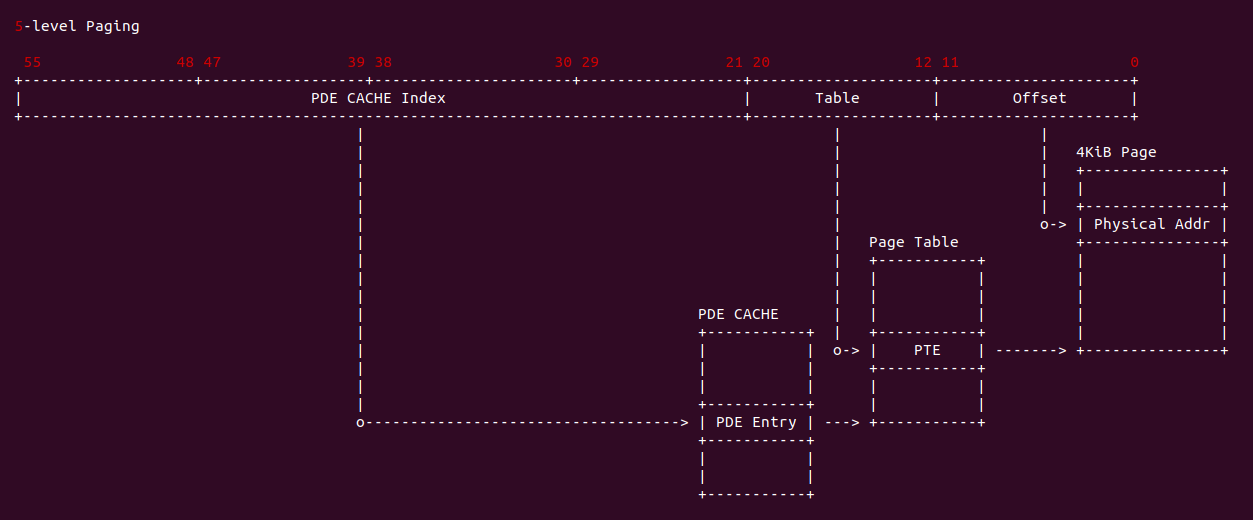
在 X86 支持 5-level 页表的架构中,硬件地址有效位达到 56bit,当开启分页之后,一个虚拟地址通过查页表(Consule PageTable)方式,需要查询五级页表, 其查询过程如下:
- A: CR3 寄存器存储了页表的基地址(物理地址),MMU 提取虚拟地址 [48: 55] 字段作为 PML5 页表的索引,查找对应的 PML5E(PML5 Entry), PML5E 存储 PML4 页表的基地址(物理地址)
- B: MMU 从虚拟地址提取 [39: 47] 字段作为 PML4 页表的索引,查找对应的 PML4E(PML4 Entry), PML4E 存储 Page-Directory Pointer Table(PDPT 页表)的基地址(物理地址)
- C: MMU 继续从虚拟地址提取 [30: 38] 字段作为 PDTE 页表的索引,查找对应的 PDPTE(PDPT Entry), PDPTE 存储 Page-Director Table(PD 页表)的基地址(物理地址)
- D: MMU 继续从虚拟地址提取 [21: 29] 字段作为 PD 页表的索引,查找对应的 PDE(PD Entry), PDE 存储 Page Table 的基地址
- E: MMU 继续从虚拟地址提取 [12: 20] 字段作为 Page Table 的索引,查找对应的 PTE(Page Table Entry), PTE 存储物理页的基地址
- F: MMU 最后从虚拟地址提取 [0: 11] 字段作为页内偏移,与 PTE 中的物理页基地址组成最终的物理地址.
在 TLB Miss 的场景下,MMU 必须通过查询页表才能找到虚拟地址映射的物理地址,并且页表都是存储在内存里,那么可以知道查询一次需要的开销相对与 TLB Hit 来说是相当最大的,但页表查询又是无法避免的操作。Intel 提出了 Paging-Structure CACHE 机制来加速页表的查询,该机制与 TLB 机制类似,TLB 是缓存虚拟地址与最后一级页表 Entry 的映射关系,而 Paging-Structre CACHE 则缓存虚拟地址与每一级页表 Entry 映射关系,那么 Paging-Structure CACHE 则包括了一套 CACHE,分别是:
MMU 在查询页表过程中,可以从虚拟地址中截取一段作为 Paging-Structure CACHE 的 CACHE Tag 找到某一级页表项. Paging-Structure CACHE 的存在大大加速了页表查询速度,MMU 可以在不访问内存的情况下获得页表项。由于 Paging-Structre CACHE 只缓存虚拟地址与页表项的映射关系,因此 Paging-Structure CACHE 不会缓存页表项中 PS 标志位置位的页表项,因为这类页表项以及被 TLB 缓存. 但页表被访问即页表项的 Access 标志位置位,那么该页表项会被加载到 Paging-structure. 最后 Paging-Structure CACHE 是无法感知页表项被修改,因此需要软件在页表项更新之后显示更新 Paging-Structure CACHE.
Paging-Structure CACHE Usage
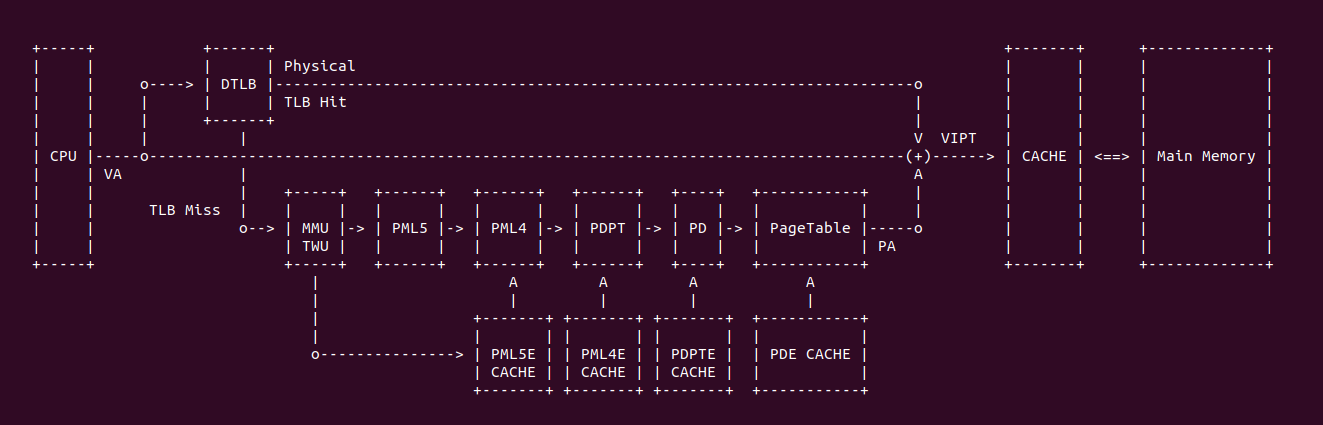
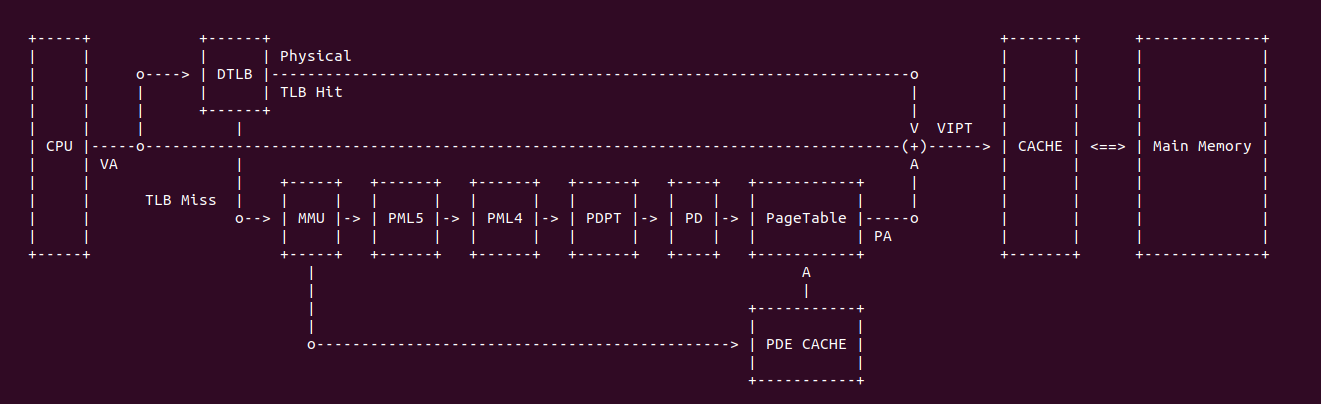
当 CPU 发送一个虚拟地址请求之后,TLB 查询无果之后,TLB 将该虚拟地址传送给 MMU,MMU 借助 Paging-Structure CACHE 加速页表的遍历,其处理流程如下:
- A: CPU 发送一个虚拟地址到 TLB,如果处理器找到一个 TLB 条目,该条目对应于线性地址的页号,并且与当前 PCID 相关联(或者是全局的), 则可以使用该条目中的物理地址、访问权限和其他属性
- B: 如果处理器没有找到相关的 TLB 条目,则可以使用线性地址的高位来选择与当前 PCID 相关联的 PDE 缓存(PDE CACHE) 中的条目。然后可以使用该条目来完成转换过程(定位 PTE 等),就好像已经遍历了对应于 PDE 缓存(PDE CACHE)条目的 PDE
- C: 如果处理器没有找到相关的 PDE 缓存(PDE CACHE)条目,则可以使用线性地址的高位(对于 4 级分页,为 [47 : 30] 位; 对于 5 级分页,为 [56 : 30]位) 来选择与当前 PCID 相关联的 PDPTE 缓存(PDPTE CACHE) 中的条目。然后可以使用该条目来完成转换过程(定位 PDE 等),就好像已经遍历了对应于 PDPTE 缓存(PDPTE CACHE)条目的 PDPTE、PML4E 和 PML5(对于 5 级分页)
- D: 如果处理器没有找到 PDPTE 缓存(PDPTE CACHE)条目,则可以使用线性地址的高位(对于 4 级分页,为 [47 : 39] 位; 对于 5 级分页,为 [56 : 39] 位) 来选择与当前 PCID 相关联的 PML4E 缓存(PML4E CACHE) 中的条目。然后可以使用该条目来完成转换过程(定位 PDPTE 等),就好像已经遍历了对应的 PML4E
- E: 对于 5 级分页,如果处理器没有找到对应的 PML4E 缓存(PML4E CACHE)条目,则可以使用线性地址的 [56 : 48] 位来选择与当前 PCID 相关联的 PML5E 缓存(PML5E CACHE)中的条目。然后可以使用该条目来完成转换过程(定位 PML4E 等),就好像已经遍历了对应的 PML5E
通过使用 Paging-Structure CACHE,处理器可以避免频繁的页表访问和内存访问,从而加快地址转换的速度。它提供了一种快速的缓存机制,使得常用的页表条目可以快速地被重用。需要注意的是,具体的分页结构缓存实现可能因处理器型号和体系结构的不同而有所不同。不同级别的分页结构缓存(如 PDPTE 缓存、PDE 缓存等)可能存在于不同的硬件层次上。因此对于特定的 x86 体系结构和处理器,请参考其相关的文档和规格说明以了解详细的细节。
Intel® PML5E CACHE
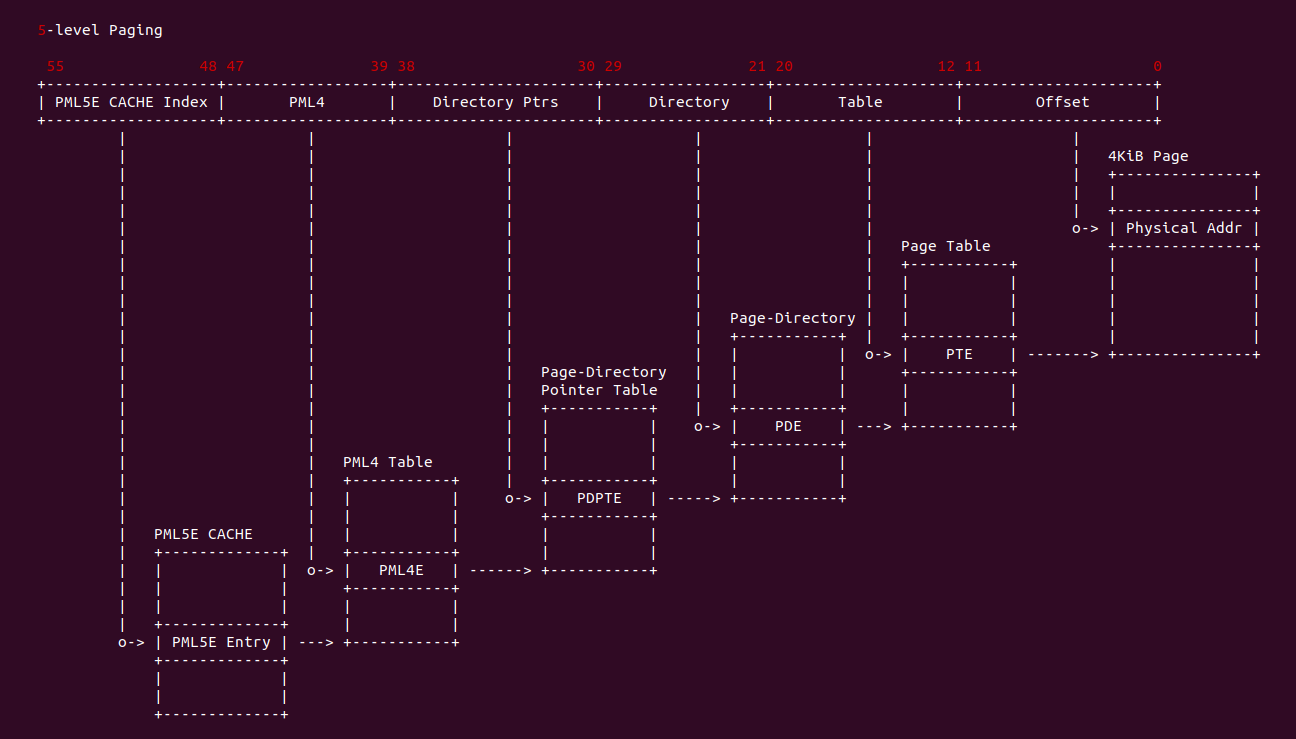
PML5E CACHE 用于缓存虚拟地址到 PML4 页表物理基地址信息,如果处理器没有找到对应的 PML4E 缓存(PML4E CACHE)条目,则可以使用线性地址的 [56 : 48] 位来选择与当前 PCID 相关联的 PML5E 缓存(PML5E CACHE)中的条目。然后可以使用该条目来完成转换过程(定位 PML4E 等),就好像已经遍历了对应的 PML5E.

- Page Frame: PML4 页表物理地址的 [12: MAX] 字段
- R/W: 指明映射具有读写权限
- U/S: 指明映射是用户空间虚拟地址(U)还是内核空间虚拟地址(S)
- XD: 指明是否具有可执行权限
- PCD/PWT: 用于指明映射的 Memory Type
- PCID: 线性空间标识
以下是处理器可能如何使用 PML5E 缓存(PML5E CACHE)的详细说明:
- 如果处理器对于某个线性地址有一个 PML5E 缓存(PML5E CACHE) 条目,它可以在转换线性地址时使用该条目(而不是内存中的 PML5E)
- 处理器不会创建 PML5E CACHE 条目,除非 PML5E 中的 P 标志为 1 且所有保留位为 0
- 处理器不会创建 PML5E CACHE 条目,除非 PML5E 中的访问标志为 1; 在缓存转换之前,如果访问标志尚未为 1,处理器会将其设置为 1
- 即使没有任何线性地址的转换会使用该条目(例如,因为所引用的 PML4 表中所有条目的 P 标志都为 0),处理器也可能创建 PML5E CACHE 条目
- 如果处理器创建了 PML5E CACHE 条目,处理器可以在将来的转换中使用该条目,直到发生以下情况之一:
- 该条目被清除(例如,因为在缓存更新期间发生了页表更改)
- 该条目被标记为无效(例如,通过将相应的 PML5E 条目中的 P 标志设置为 0)
- 该条目被替换为存储其他线性地址的转换
- 处理器重新启动或发生上下文切换
请注意,上述内容是关于处理器如何使用 PML5E CACHE 的一般说明。具体的实现和行为可能因处理器型号和体系结构的不同而有所不同。因此对于特定的 x86 体系结构和处理器,请参考相关的文档和规格说明以了解详细的细节.
Intel® PML4E CACHE
PML4E CACHE 用于缓存虚拟地址到 Page-Directory Pointer 页表物理基地址信息,如果处理器没有找到 PDPTE 缓存(PDPTE CACHE)条目,则可以使用线性地址的高位(对于 4 级分页,为 [47 : 39] 位; 对于 5 级分页,为 [56 : 39] 位) 来选择与当前 PCID 相关联的 PML4E 缓存(PML4E CACHE) 中的条目。然后可以使用该条目来完成转换过程(定位 PDPTE 等),就好像已经遍历了对应的 PML4E.

- Page Frame: Page-Directory Pointer 页表物理地址的 [12: MAX] 字段
- R/W: 指明映射具有读写权限
- U/S: 指明映射是用户空间虚拟地址(U)还是内核空间虚拟地址(S)
- XD: 指明是否具有可执行权限
- PCD/PWT: 用于指明映射的 Memory Type
- PCID: 线性空间标识
以下是处理器可能如何使用 PML4E CACHE 的详细说明:
- 如果处理器对于某个线性地址有一个 PML4E CACHE 条目,它可以在转换线性地址时使用该条目(而不是内存中的 PML5E 和 PML4E)
- 处理器只有在内存中的 PML5E 和 PML4E 的 P 标志都为 1 且所有保留位为 0 时,才会创建 PML4E CACHE 条目
- 处理器只有在内存中的 PML5E 和 PML4E 的访问标志都为 1 时,才会创建 PML4E CACHE 条目; 在缓存转换之前,处理器会设置任何访问标志,以确保它们都为 1
- 即使没有任何线性地址的转换会使用该条目(例如,因为所引用的页目录指针表中所有条目的 P 标志都为 0),处理器也可能创建 PML4E CACHE 条目
- 如果处理器创建了 PML4E CACHE 条目,即使软件随后修改了内存中相应的 PML4E,处理器也可能保留该条目不变
请注意,上述内容是关于处理器如何使用 PML4E CACHE 的一般说明。具体的实现和行为可能因处理器型号和体系结构的不同而有所不同。因此对于特定的 x86 体系结构和处理器,请参考相关的文档和规格说明以了解详细的细节。
Intel® PDPTE CACHE
PDPTE CACHE 用于缓存虚拟地址到 Page-Directory 页表物理基地址信息,如果处理器没有找到相关的 PDE 缓存(PDE CACHE)条目,则可以使用线性地址的高位(对于 4 级分页,为 [47 : 30] 位; 对于 5 级分页,为 [56 : 30]位) 来选择与当前 PCID 相关联的 PDPTE 缓存(PDPTE CACHE) 中的条目。然后可以使用该条目来完成转换过程(定位 PDE 等),就好像已经遍历了对应于 PDPTE 缓存(PDPTE CACHE)条目的 PDPTE、PML4E 和 PML5(对于 5 级分页).

- Page Frame: Page-Directory 页表物理地址的 [12: MAX] 字段(不映射 1Gig 大页)
- R/W: 指明映射具有读写权限
- U/S: 指明映射是用户空间虚拟地址(U)还是内核空间虚拟地址(S)
- XD: 指明是否具有可执行权限
- PCD/PWT: 用于指明映射的 Memory Type
- PCID: 线性空间标识
以下内容详细说明了处理器可能如何使用 PDPTE 缓存:
- 如果处理器对于某个线性地址有一个 PDPTE CACHE 条目,它可以在转换线性地址时使用该条目(而不是内存中的 PML5E、PML4E 和 PDPTE)
- 处理器只有在内存中的 PML5E、PML4E 和 PDPTE 的 P 标志都为 1、PS 标志为 0 且所有保留位为 0 时,才会创建 PDPTE CACHE 条目
- 处理器只有在内存中的 PML5E、PML4E 和 PDPTE 的访问标志都为 1 时,才会创建 PDPTE 缓存条目; 在缓存转换之前,如果访问标志尚未为 1,处理器会将其设置为 1
- 即使没有任何线性地址的转换会使用该条目,处理器也可能创建 PDPTE CACHE 条目
- 如果处理器创建了 PDPTE CACHE 条目,即使软件随后修改了内存中相应的 PML5E、PML4E 或 PDPTE,处理器也可能保留该条目不变
请注意,上述内容是关于处理器如何使用 PDPTE CACHE 的一般说明。具体的实现和行为可能因处理器型号和体系结构的不同而有所不同。因此对于特定的 x86 体系结构和处理器,请参考相关的文档和规格说明以了解详细的细节。
Intel® PDE CACHE
PDE CACHE 用于缓存虚拟地址到 Page 页表物理基地址信息,如果处理器没有找到相关的 TLB 条目,则可以使用线性地址的高位来选择与当前 PCID 相关联的 PDE 缓存(PDE CACHE) 中的条目。然后可以使用该条目来完成转换过程(定位 PTE 等),就好像已经遍历了对应于 PDE 缓存(PDE CACHE)条目的 PDE. 就好像已经遍历了对应于 PDE 缓存(PDE CACHE)条目的 PDE、PDPTE、PML4E 和 PML5(对于 5 级分页).

- Page Frame: Page 页表物理地址的 [12: MAX] 字段(不映射 2MiB 大页)
- R/W: 指明映射具有读写权限
- U/S: 指明映射是用户空间虚拟地址(U)还是内核空间虚拟地址(S)
- XD: 指明是否具有可执行权限
- PCD/PWT: 用于指明映射的 Memory Type
- PCID: 线性空间标识
以下是处理器可能如何使用 PDE CACHE 的详细说明(下面对于 PML5E、PML4E 和 PDPTE 的引用仅适用于 4 级分页和 5 级分页,具体取决于情况):
- 如果处理器对于某个线性地址有一个 PDE CACHE 条目,它可以在转换线性地址时使用该条目(而不是内存中的 PML5E、PML4E、PDPTE 和 PDE)
- 处理器只有在内存中的 PML5E、PML4E、PDPTE 和 PDE 的 P 标志都为 1、PS 标志为 0 且所有保留位为 0 时,才会创建 PDE CACHE条目
- 处理器只有在内存中的 PML5E、PML4E、PDPTE 和 PDE 的访问标志都为 1 时,才会创建 PDE CACHE 条目; 在缓存转换之前,如果访问标志尚未为 1,处理器会将其设置为 1
- 即使没有任何线性地址的转换会使用该条目,处理器也可能创建 PDE CACHE 条目
- 如果处理器创建了 PDE CACHE 条目,即使软件随后修改了内存中相应的 PML5E、PML4E、PDPTE 或 PDE,处理器也可能保留该条目不变
请注意,上述内容是关于处理器如何使用 PDE CACHE 的一般说明。具体的实现和行为可能因处理器型号和体系结构的不同而有所不同。因此对于特定的 x86 体系结构和处理器,请参考相关的文档和规格说明以了解详细的细节.
Paging-Structure CACHE 总结
页表结构条目中的信息可以包含在其他被原始条目引用的页表结构缓存条目中。例如如果 PML4E 中的 R/W 标志为0,则任何来自被该 PML4E 引用的页目录指针表中的 PDPTE 的 PDPTE 缓存条目中的 R/W 标志也将为 0。这是因为每个这样的 PDPTE 缓存条目的 R/W 标志是逻辑与运算,取决于相应的 PML4E 和 PDPTE 中的 R/W 标志.
页表结构缓存只包含引用其他页表结构(而不是映射页面)的页表结构条目的信息。由于在这些页表结构条目中不使用 G 标志,全局页面特性不会影响页表结构缓存的行为。处理器可能会在页表结构缓存中创建用于预取所需的翻译条目,以及由于推测执行而产生的访问,这些访问实际上不会在执行的代码路径中发生。由逻辑处理器在页表结构缓存中创建的任何条目都与当前PCID相关联。处理器可以选择实现或不实现任何页表结构缓存。软件既不应该依赖于它们的存在,也不应该依赖于它们的缺失。处理器可以随时使这些缓存条目无效。由于处理器可能在翻译时创建缓存条目,并且在之后对内存中的页表结构进行修改后不对其进行更新,因此在引起此类修改时,软件应当适当地使缓存条目无效.

Intel® Invalidate TLB and Paging-Structure CACHE
在 X86 架构,硬件自动完成了 TLB Entry 的填充和替换,处理器在转换线性地址时可能会在 TLB 和页表结构缓存中创建条目,并且即使用于创建这些条目的页表结构已被修改,它们仍可能保留这些条目。为了确保线性地址转换使用修改后的页表结构,软件应采取措施使可能包含已被修改的信息的任何缓存条目无效。以下指令使 TLB 和页表结构缓存的条目无效化:
- INVLPG(无效化页) 指令: 该指令接受一个操作数,即线性地址(虚拟地址)。该指令会使与该线性地址对应的页号相关的任何 TLB 条目无效化,同时也会使与该页号相关的全局 TLB 条目无效化(不考虑PCID)。此外该指令还会使与当前 PCID 相关的所有页表结构缓存中的条目无效化,不管它们对应的线性地址是什么
- INVPCID(无效化 PCID) 指令: 该指令的操作基于指令操作数,包括 INVPCID 类型和 INVPCID 描述符。目前定义了四种 INVPCID 类型:
- 单个地址(Individual-address): 如果 INVPCID 类型为 0,逻辑处理器将使与 INVPCID 描述符中指定的 PCID 相关联且将用于转换 INVPCID 描述符中指定的线性地址的映射失效(除了全局映射)。此指令还可以使全局映射失效,并使与其他 PCID 和其他线性地址相关联的映射失效
- 单个上下文(Single-context): 如果 INVPCID 类型为 1,逻辑处理器将使与 INVPCID 描述符中指定的 PCID 相关联的所有映射(除了全局映射)失效。此指令还可以使全局映射失效,并使与其他 PCID 相关联的映射失效
- 所有上下文,包括全局映射(All-context, including globals): 如果 INVPCID 类型为 2,逻辑处理器将使与所有 PCID 相关联的映射(包括全局映射)失效
- 所有上下文(All-context): 如果 INVPCID 类型为 3,逻辑处理器将使与所有 PCID 相关联的所有映射(除了全局映射)失效. 此指令还可以使全局映射失效.
- MOV 到 CR4 寄存器: 指令的行为取决于被修改的位:
- 如果指令改变了 CR4.PGE 的值(从 0 变为 1),它会使所有 TLB 条目(包括全局条目) 和所有页表结构缓存中的条目(对于所有 PCID)无效化
- 如果指令将 CR4.PCIDE 的值从 1 改变为 0,它会使所有 TLB 条目和所有页表结构缓存中的条目(对于所有 PCID)无效化
- 如果指令改变了 CR4.PAE 的值,它会使与当前 PCID 相关联的所有 TLB 条目和所有页表结构缓存中的条目无效化
- 如果指令将 CR4.SMEP 的值从 0 改变为 1,它会使与当前 PCID 相关联的所有 TLB 条目和所有页表结构缓存中的条目无效化
- 任务切换: 如果任务切换导致 CR3 的值发生变化,它会使与 PCID 000H相关联的所有 TLB 条目(除了全局页)无效化,并使与 PCID 000H 相关联的所有页表结构缓存中的条目无效化
- VMX转换
Invalidate Example
处理器始终可以自由地使TLB和页表结构缓存中的其他条目无效化。以下是一些示例(其他指令和操作可能会使 TLB 和页表结构缓存中的条目无效化,但下述指令是推荐的):
- INVLPG 可以使与其线性地址操作数对应的页之外的 TLB 条目无效化. 它可以使与当前 PCID 不同的 PCID 相关联的 TLB 条目和页表结构缓存条目无效化
- INVPCID 可以使与指定的线性地址对应的页之外的 TLB 条目无效化. 它可以使与指定的 PCID 不同的 PCID 相关联的 TLB 条目和页表结构缓存条目无效化
- MOV 到 CR0 可能会使 TLB 条目无效化,即使 CR0.PG 没有改变. 例如,如果修改了 CR0.CD 或 CR0.NW
- MOV 到 CR3 可能会使全局页的 TLB 条目无效化. 如果 “CR4.PCIDE = 1” 且指令源操作数的第 63 位为 0,则可能会使与 “CR4.PCIDE = 1” 且位于指令源操作数的第 63 位为 1 的 PCID 相关联的 TLB 条目和页表结构缓存条目无效化
- MOV 到 CR4 可能会在更改 CR4.PSE 或将 CR4.SMEP 从 1 更改为 0 时使 TLB 条目无效化. 在支持超线程技术的处理器上,一个逻辑处理器上的无效化操作可能会使其他逻辑处理器使用的 TLB 和页表结构缓存中的条目无效化
除了上述指令,页故障也会使 TLB 和页表结构缓存中的条目无效化. 特别地,由于尝试使用线性地址而导致的页故障异常会使与当前 PCID 相关联且与线性地址对应的页号的 TLB 条目无效化。它还会使与当前 PCID 相关联且用于该线性地址的所有页表结构缓存条目无效化。这些无效化操作确保如果页故障异常不是由于内存中的页表结构内容引起的(因此是由于在修改页表结构后未使缓存的条目无效化),则在重新执行故障指令时不会再次发生该异常. 某些处理器可能选择为由页表结构指定的使用大于 4KiB 的页面的翻译缓存多个较小页面的TLB 条目。软件无法知道是否为大页面使用了多个较小页面的多个翻译。INVLPG 指令和页故障提供了与使用单个 TLB 条目时相同的保证: 它们使与页表结构指定的翻译相对应的所有 TLB 条目无效化.
Recommanded TLB Invalidation
在内核里,可以使用如下指令或场景使 TLB 或者 Paging-Structure CACHE 无效,内核里有通用的做法,但 X86 架构下关于软件何时应执行无效化操作的一些建议:
- 如果软件修改了映射页面的页表项(而不是引用另一个页表),应针对使用该页表项进行翻译的具有页号的每个线性地址执行 INVLPG 指令
- 如果软件修改了引用其他页表的页表项,可以根据受修改的页表项控制的翻译类型和数量采用以下方法之一:
- 对于每个具有翻译的页号,执行 INVLPG 指令。但是如果没有使用该页表项的页号具有翻译(例如,因为受修改的页表项引用的页表中的所有条目的 P 标志为 0),则至少需要执行一次 INVLPG 指令
- 如果修改的页表项不控制全局页面,则执行 MOV 到 CR3 指令
- 执行 MOV 到 CR4 指令以修改 CR4.PGE
- 如果 “CR4.PCIDE = 1” 且软件修改的页表项不映射页面或 G 标志(位 8)为 0,并且该页表项可能用于当前 PCID 以外的 PCID,则需要执行其他步骤:
- 执行 MOV 到 CR4 指令以修改 CR4.PGE,可以立即执行或在再次使用任何受影响的 PCID 之前执行。例如软件可以为使用受影响 PCID 的进程使用不同的(以前未使用的)PCID
- 对于每个受影响的 PCID,执行 MOV 到 CR3 指令将其设置为当前 PCID(并加载相应的 PML4 表的地址). 如果修改的页表项不控制全局页面且 MOV 到 CR3 指令的源操作数的位 63 为 0,则不需要进一步的步骤。否则对于使用该页表项进行翻译的具有页号的每个线性地址,执行 INVLPG 指令; 如果没有使用该页表项的页号具有翻译,则至少执行一次 INVLPG 指令
- 如果使用 PAE 分页的软件修改了 PDPTE,则应重新加载 CR3 以确保修改后的 PDPTE 加载到相应的 PDPTE 寄存器中
- 如果页表结构的性质使得单个条目可以用于多个目的,软件应为所有这些目的执行无效化操作。例如如果单个条目可能同时用作 PDE 和 PTE,可能需要使用两个(或多个)线性地址执行 INVLPG 指令,一个用于将条目用作 PDE,一个用于将其用作 PTE。或者可以使用 MOV 到 CR3 或 MOV 到 CR4 指令
- 如果软件修改了页表结构,使得用于 4K 字节线性地址范围的页面大小发生变化,则 TLB 中可能包含地址范围的多个翻译。地址范围内的线性地址引用可能使用其中任何一个翻译。希望避免这种不确定性的软件不应以一种方式写入页表项,即同时更改页面大小和页面框、访问权限或其他属性的线性地址。相反可以采用以下算法: 首先清除相关页表项(例如 PDE)中的 P 标志,然后无效化受影响线性地址的任何翻译,最后修改相关的页表项以设置 P 标志并为新的页面大小建立修改后的翻译
- 在执行将先前用于不同线性地址空间(例如,CR3 的位 [51 : 12] 具有不同值)的 PCID 的 MOV 到 CR3 指令时,应清除源操作数的位 63,以确保无效化可能已经为先前的线性地址空间缓存的任何信息。这假设两个线性地址空间使用相同的全局页面,因此无需无效化任何全局 TLB 条目。如果情况不是如此,软件应通过执行 MOV 到 CR4 指令以修改 CR4.PGE 来无效化这些条目。
TLB Invalidate Fault
之前的文档描述了如何使 TLB 或者 Paing-Structure CACHE 无效,如果在上面的场景中没有进行 Invalidate 操作,那么将会导致异常,以下情况描述了软件选择不执行无效化操作的情况及可能的后果:
- 如果修改了页表项的 P 标志从 0 变为 1,则无需执行无效化操作。这是因为在 P 标志为 0 的页表项中不会创建任何 TLB 条目或页表缓存条目的信息
- 如果修改了页表项的访问标志从 0 变为 1,则无需执行无效化操作(假设上一次访问标志从 1 变为 0 时已执行了无效化操作)。这是因为在访问标志为 0 的页表项中不会创建任何 TLB 条目或页表缓存条目的信息
- 如果修改了页表项的 R/W 标志从 0 变为 1,不执行无效化操作可能会导致虚假页故障异常(例如,对写访问的尝试)但不会产生其他不良行为。这样的异常对于每个受影响的线性地址最多发生一次.
- 如果 “CR4.SMEP = 0” 并且修改了页表项将 U/S 标志从 0 变为 1,不执行无效化操作可能会导致虚假页故障异常(例如,对用户模式访问的尝试)但不会产生其他不良行为。这样的异常对于每个受影响的线性地址最多发生一次
- 如果修改了页表项的 XD 标志从 1 变为 0,不执行无效化操作可能会导致虚假页故障异常(例如,对指令获取的尝试)但不会产生其他不良行为。这样的异常对于每个受影响的线性地址最多发生一次
- 如果修改了页表项的访问标志从 1 变为 0,不执行无效化操作可能导致处理器在后续访问使用该页表项进行翻译的线性地址时不设置该位。软件不能将该位被清除解释为指示该访问未发生
- 如果软件修改了将线性地址的最终物理地址(PTE 或 PS 标志为 1 的页表项)标识为修改脏位从 1 变为 0 的页表项,不执行无效化操作可能导致处理器在后续写访问使用该页表项进行翻译的线性地址时不设置该位。软件不能将该位被清除解释为指示该写入未发生
- 在使用地址进行指令获取的过程中,读取页表项可能会在先前写入该页表项之前执行,如果在写入和指令获取之间没有序列化指令
- 单个页表项可能包含在页表缓存中的多个条目中缓存的信息的情。由于这些缓存中的所有条目都会被执行 INVLPG 指令无效化,因此不需要通过多次执行 INVLPG 来无效化这些多个缓存条目,仅仅为了无效化目的(可能需要多次执行 INVLPG 来无效化多个 TLB 条目)
Delayed TLB Invalidation
在某些情况下,必要的 TLB 无效化操作可能会被延迟。软件开发人员应该了解,在修改页表项和执行前面建议的无效化指令之间,处理器可能会使用基于旧值或新值的页表项进行翻译。以下情况描述了延迟无效化操作可能引起的一些潜在后果:
- 如果将页表项的 P 标志从 1 改为 0,对于由该项控制其翻译的线性地址的访问可能会引发页故障异常,也可能不会引发
- 如果将页表项的 R/W 标志从 0 改为 1,对于由该项控制其翻译的线性地址的写访问可能会引发页故障异常,也可能不会引发
- 如果将页表项的 U/S 标志从 0 改为 1,对于由该项控制其翻译的线性地址的用户模式访问可能会引发页故障异常,也可能不会引发
- 如果将页表项的 XD 标志从 1 改为 0,对于由该项控制其翻译的线性地址的指令获取可能会引发页故障异常,也可能不会引发
访问大于四字的数据的 x87 指令或 SSE 指令可能使用多个内存访问来实现。如果此类指令向内存存储数据且延迟了无效化操作,其中一些访问可能会完成(写入内存),而另一些可能会引发页故障异常。在这种情况下,即使整个指令导致了故障,已完成的访问的效果对软件来说可能是可见的。在某些情况下,延迟无效化操作的后果可能不会对软件产生不良影响。例如,在释放线性地址空间的一部分(通过标记页表项为不存在)时,如果软件不重新分配该线性地址空间的那部分或与之关联的内存,使用 INVLPG 进行无效化操作可能会被延迟。然而由于推测执行(或错误的软件),在无效化操作发生之前,可能会对已释放的线性地址空间进行访问。在这种情况下,可能会发生以下情况:
- 对已释放的线性地址空间可能会进行读取操作。因此,对于具有读取副作用的地址范围,无效化操作不应被延迟
- 处理器可能会长时间保留 TLB 和页表缓存中的条目。软件不应假设处理器不会使用与线性地址关联的条目,仅仅因为时间过去了
- 处理器可能会在没有任何线性地址使用该条目的情况下创建一个页表缓存条目。因此,如果软件将一个页表中的所有条目标记为“不存在”,处理器可能会随后为引用该页表的 PDE 创建一个 PDE 缓存条目(假设 PDE 本身标记为”存在”)
- 如果软件尝试写入已释放的线性地址空间,处理器可能不会生成页故障. (这样的尝试很可能是由软件错误引起的)因此,先前与已释放的线性地址空间相关联的页帧可能被重用,而软件可能无法察觉到这种情况
Intel® TLB Related Instruction
在 Intel 架构里,TLB 的填充和 TLB 异常处理都是硬件自动完成的,并且 TLB 硬件上无法感知软件修改了页表,因此提供了 TLB Invalidate 指令,用于软件修改页表情况下更新 TLB,这里的 TLB 更新指的就是 Invalidate TLB Entry. 具体命令如下:
INVLPG—Invalidate TLB Entries
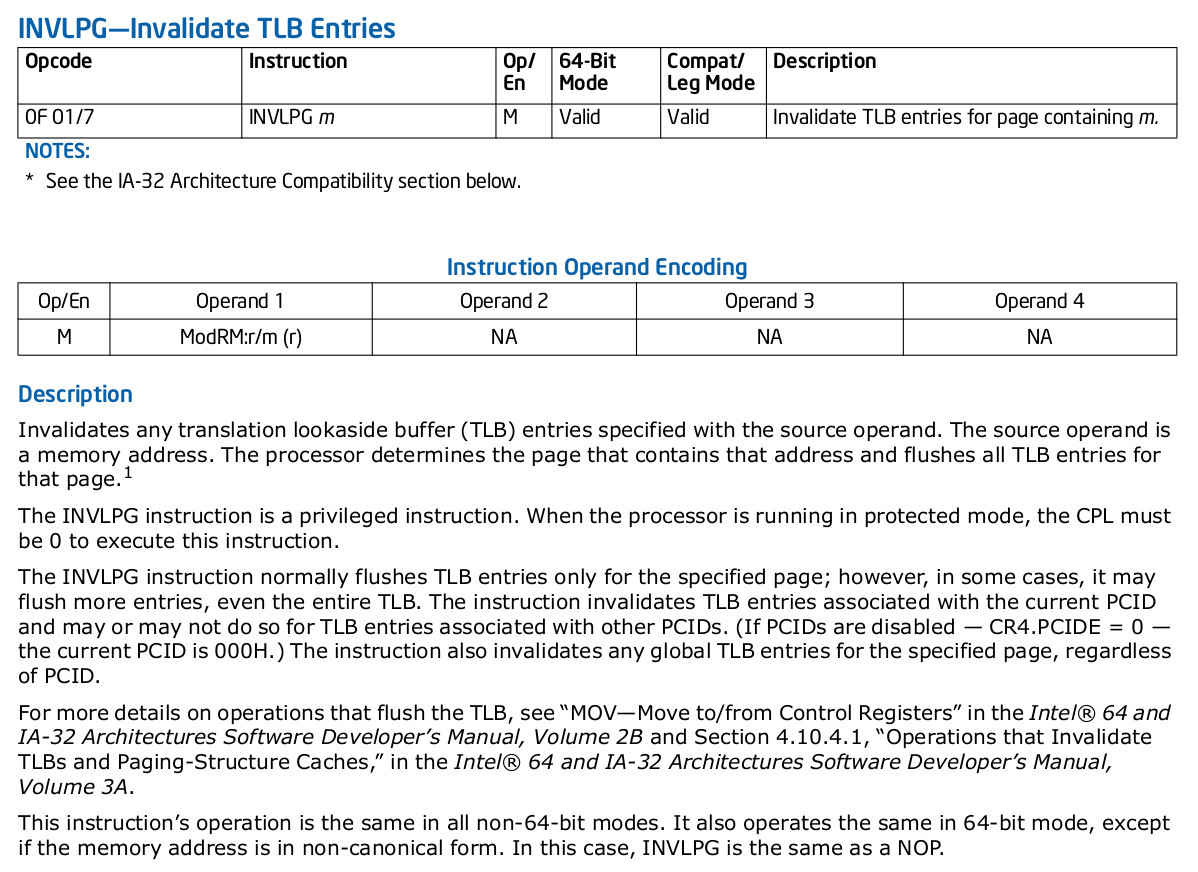
INVLPG 指令: 无效虚拟地址对应的 TLB Entry。源操作数是一个内存地址。处理器确定包含该地址的页面,并清除该页面的所有 TLB 条目。INVLPG 指令是一条特权指令。当处理器在保护模式下运行时,CPL 必须为 0 才能执行此指令。INVLPG 指令通常只清除指定页面的 TLB 条目; 然而在某些情况下,它可能会清除更多的条目,甚至是整个TLB。该指令使与当前 PCID 关联的 TLB 条目无效,对于与其他 PCID 关联的 TLB 条目可能会或可能不会这样做(如果禁用了 PCID - CR4.PCIDE = 0,则当前 PCID 为 000H)。该指令还无效化指定页面的任何全局 TLB 条目,而不考虑 PCID。
INVLPG 指令的使用如上图,该指令只能在内核空间使用,其参数是一个虚拟地址. 内核里 tlb_flush() 函数最终会调用到该函数,用于刷新一个虚拟地址对应的 TLB Entry. 开发者可以通过一个实践案例了解内核调用 INVLPG 指令的逻辑,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] TLB FLUSH: Adjust VMA Protection(mprotect) --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-MPROTECT-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
实践案例是一个用户空间程序,其映射了一段可读可写的虚拟内存,然后对虚拟内存写入字符串 “Hello BiscuitOS” 之后,调用 mprotect() 函数修改了虚拟内存的页表属性,将其设置为只读。由于修改了页表,那么内核需要将虚拟地址对应的 TLB Entry Invalidate。那么接下来现在 BiscuitOS 实践该案例:
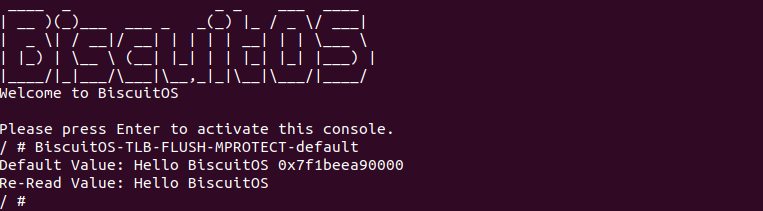
BiscuitOS 启动完毕之后,运行应用程序 BiscuitOS-TLB-FLUSH-MPROTECT-default,可以看到打印了字符串 “Hello BiscuitOS”, 软件上并没有任何感知 TLB Invalidate 动作,那么看看内核是如何将虚拟地址对应的 TLB Entry Invalidate?
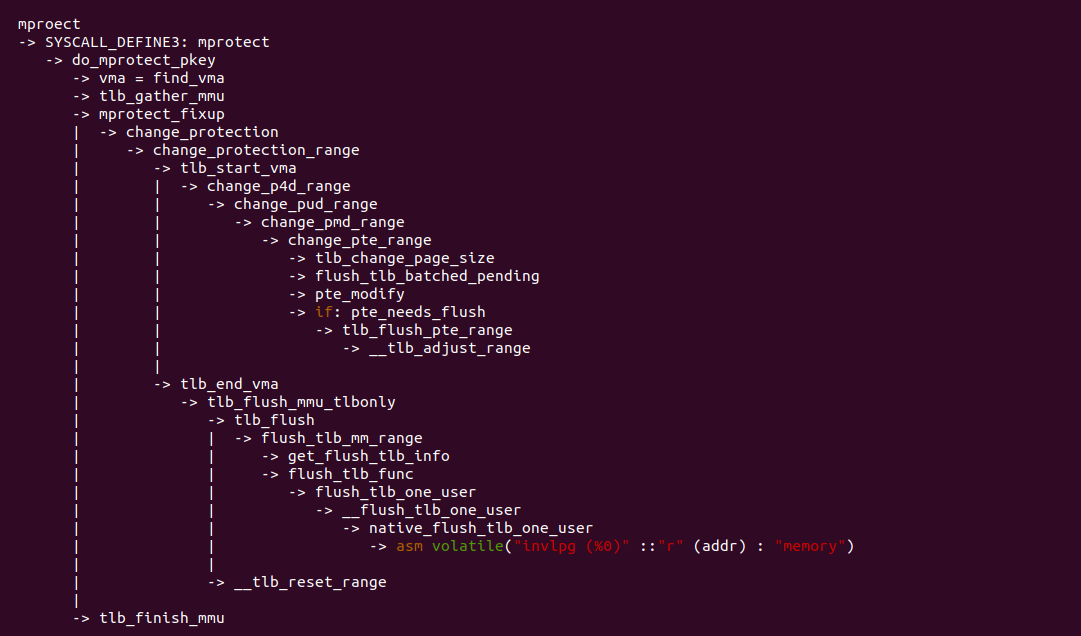
通过对 mprotect 函数的系统调用路径跟踪,可以看到 mprotect 修改完页表内容之后,还是调用 tlb_flush() 去更新虚拟地址对应的 TLB Entry,最终还是调用到 INVLPG 指令完成 TLB Entry Invalidate.
INVPCID—Invalidate Process-Context Identifier
INVPCID 指令: 根据进程上下文标识符(PCID),无效 TLB 和页表结构缓存中的映射. 无效化基于寄存器操作数中指定的 INVPCID 类型和内存操作数中指定的 INVPCID 描述符. 在 64 位模式外,寄存器操作数始终为 32 位,不论 CS.D 的值如何。在 64 位模式下,寄存器操作数为 64 位。当前定义了四种 INVPCID 类型:
- 单地址无效化: 如果 INVPCID 类型为 0,则逻辑处理器无效化线性地址和 INVPCID 描述符中指定的 PCID 的映射,但全局翻译除外。在某些情况下,该指令可能还会无效化全局翻译或其他线性地址(或其他 PCID)的映射
- 单上下文无效化: 如果 INVPCID 类型为 1,则逻辑处理器无效化与 INVPCID 描述符中指定的 PCID 相关联的所有映射,但全局翻译除外。在某些情况下,该指令可能还会无效化全局翻译或其他 PCID 的映射
- 所有上下文无效化, 包括全局翻译: 如果 INVPCID 类型为 2,则逻辑处理器无效化与任何 PCID 相关联的所有映射,包括全局翻译
- 所有上下文无效化: 如果 INVPCID 类型为 3,则逻辑处理器无效化与任何 PCID 相关联的所有映射,但全局翻译除外。在某些情况下,该指令可能还会无效化全局翻译

INVPCID 描述符由 128 位组成,包括一个 PCID 和一个线性地址,如图所示。对于 INVPCID 类型 0,在 64 位模式外,处理器使用完整的 64 位线性地址; 其他 INVPCID 类型不使用线性地址。
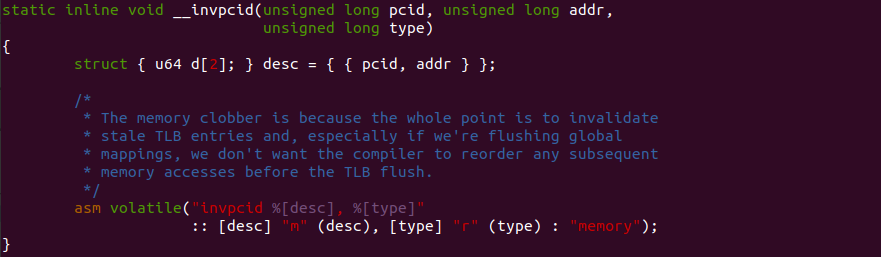
在 Linux 内核中,__invpcid() 函数通常用于处理上下文切换、进程销毁或修改映射关系的操作。它被用来无效化特定 PCID 的 TLB 和页表结构缓存中的映射,以确保新的映射能够正确生效。这对于保持内核和用户空间之间的内存隔离以及处理虚拟地址空间的动态变化非常重要. 该函数最终通过内嵌汇编调用 INVPCID 指令,可以看到 desc 构造 128 bit 参数的过程.
MMU Gather Mechanism
在 TLB 工作原理 章节分析过,TLB 硬件可以自动完成 TLB Entry 填充和替换,但 TLB 硬件无法感知软件对页表的修改,因此软件需要对 TLB Entry 进行更新操作,这里的 TLB Entry 更新具体指的是 TLB Entry Invalidate 操作。Linux 中的 MMU Gather 机制是一种用于优化内存管理单元(MMU)操作的机制。它主要用于减少在执行一系列内存操作时对 MMU 进行多次刷新的开销,从而提高内存访问的效率。在传统的操作系统中,当进行一系列内存操作(如页表修改、TLB 刷新等)时,每个操作都会导致对 MMU 进行刷新,这会带来一定的开销. MMU Gather 机制通过将多个内存操作合并为一个操作,减少了刷新 MMU 的次数,从而提高了系统性能。在讲解 MMU Gather 机制原理之前,可以先通过一个实践案例感受一下其工作方式,实践案例在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] TLB FLUSH: Adjust VMA Protection(mprotect) --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-MPROTECT-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
实践案例是一个用户空间程序,其映射了一段可读可写的虚拟内存,然后对虚拟内存写入字符串 “Hello BiscuitOS” 之后,调用 mprotect() 函数修改了虚拟内存的页表属性,将其设置为只读。由于修改了页表,那么内核需要将虚拟地址对应的 TLB Entry Invalidate。那 么接下来现在 BiscuitOS 实践该案例:
BiscuitOS 启动完毕之后,运行应用程序 BiscuitOS-TLB-FLUSH-MPROTECT-default,可以看到打印了字符串 “Hello BiscuitOS”, 软件>上并没有任何感知 TLB Invalidate 动作,那么看看内核是如何将虚拟地址对应的 TLB Entry Invalidate?
通过对 mprotect 函数的系统调用路径跟踪,可以看到 mprotect 修改完页表内容之后,还是调用 tlb_flush() 去更新虚拟地址对应的 TLB Entry,最终还是调用到 INVLPG 指令完成 TLB Entry Invalidate. 通过实践案例和源码分析,可以看到 MMU Gather 在修改页表前后调用 tlb_start_vma() 和 tlb_end_vma() 函数对来收集需要更新 TLB 的虚拟内存范围,然后使用 tlb_end_vma() 或者 tlb_finish_vma() 一次性刷新所有的 TLB,减少了刷新 MMU 的次数,从而提高了系统性能.
MMU Gather 原理
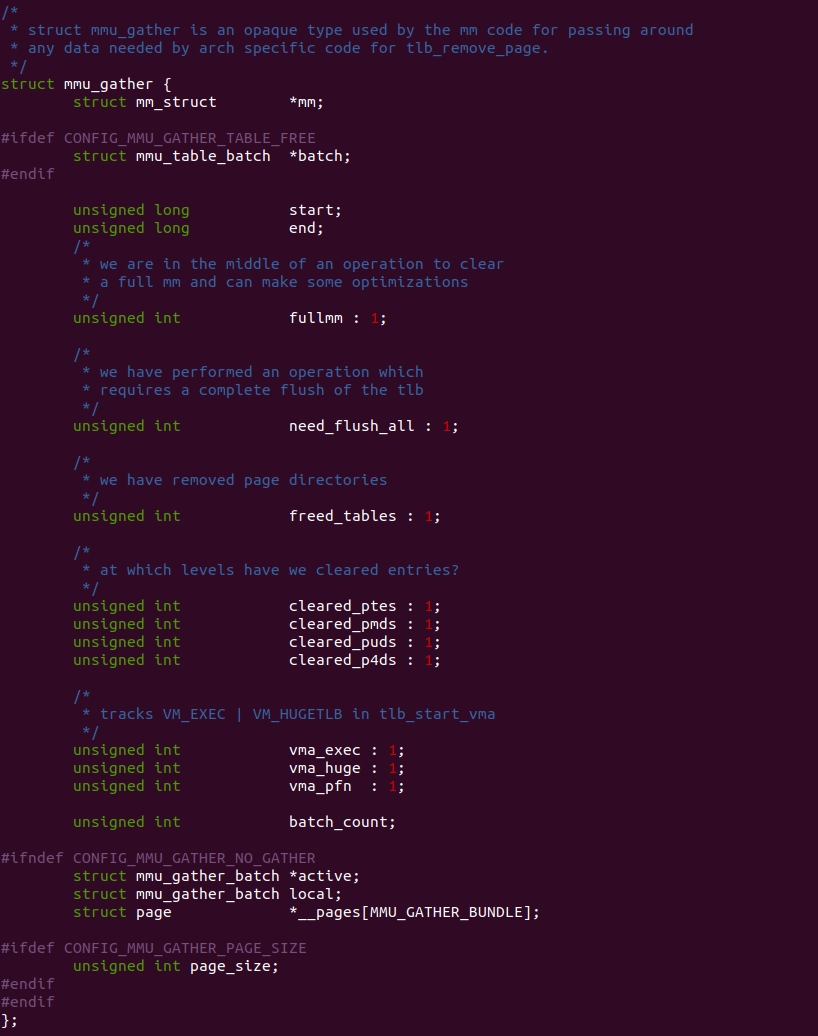
在 Linux 中,MMU Gather 机制使用 struct mmu_gather 数据结构在进行页表操作期间,收集需要更新的页表项和相关的 TLB 刷新操作,以确保内存管理的一致性,其定义在 “include/linux/mm.h”头文件中。以下是 “struct mmu_gather” 的一些重要成员及其含义:
- mm: 指向与操作相关的内存描述符(struct mm_struct)的指针。mm_struct 表示进程的地址空间和相关的页表信息
- batch: 指一次批处理的页面数量,表示在进行页表项更新时一次性处理的页面数目
- fullmm: 指示是否需要完全刷新 TLB。如果设置为 1,则需要进行全局 TLB 刷新
- need_flush_all: 指示在页表项更新过程中是否需要执行全局TLB刷新
- cleared_ptes: 指示是否刷新对应的 PTE 页表
- cleared_pmds: 指示是否刷新对应的 PMD 页表
- cleared_puds: 指示是否刷新对应的 PUD 页表
- cleared_p4ds: 指示是否刷新对应的 P4D 页表
- start/end: 表示需要更新的页表范围的起始地址和结束地址
- vma_exec: 指示 VMA 是否具有可执行权限
- vma_huge: 指示 VMA 是否属于大页映射
- vma_pfn: 指示 VMA 是否来自设备管理的内存
- batch_count: 于记录在批量页表更新过程中所处理的页表项的数量
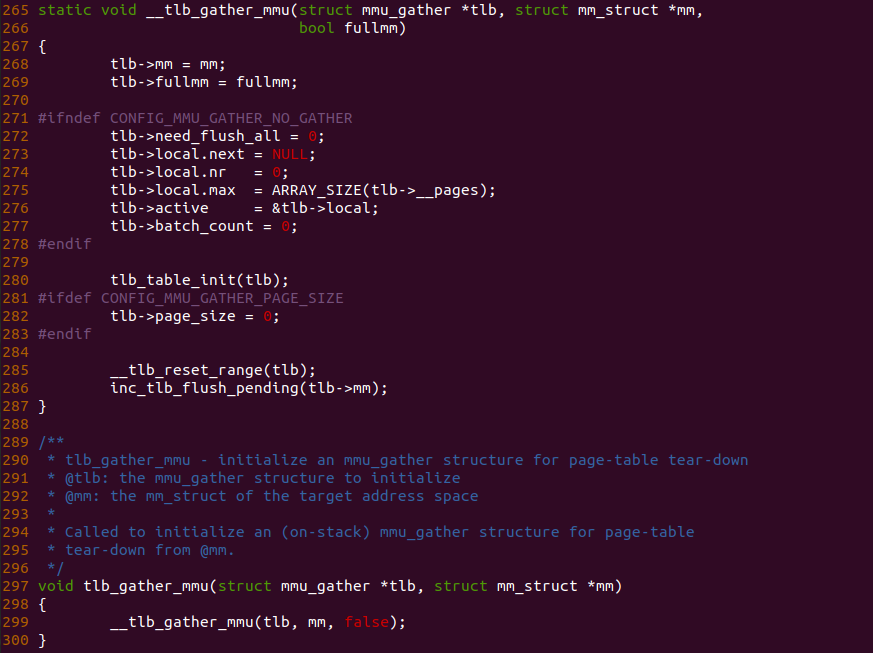
在使用 MMU Gather 聚合 TLB 刷新操作前,需要调用 tlb_gather_mmu() 函数初始化和启动 TLB 更新操作。该函数的主要作用是创建并初始化一个 “struct mmu_gather” 数据结构,该结构用于跟踪和管理页表项的批量更新。struct mmu_gather 结构存储了与页表更新相关的信息和状态。具体而言,tlb_gather_mmu 函数执行以下主要任务:
- 初始化一个 struct mmu_gather 结构体对象,用于跟踪页表项的批量更新
- 获取当前 CPU 的页表上下文,并将其存储在 mmu_gather 结构的 mm 成员中
- 设置 need_flush_all 标志为 false,表示在开始批量更新之前不需要刷新整个 TLB
- 设置 cleared_ptes 和 cleared_pmds 为零,表示在开始批量更新之前还未清除任何页表项
- 启用页表项更新追踪,并将 batch_count 设置为零,以准备记录处理的页表项数量
- 返回初始化好的 struct mmu_gather 结构体对象,供后续的页表更新操作使用。
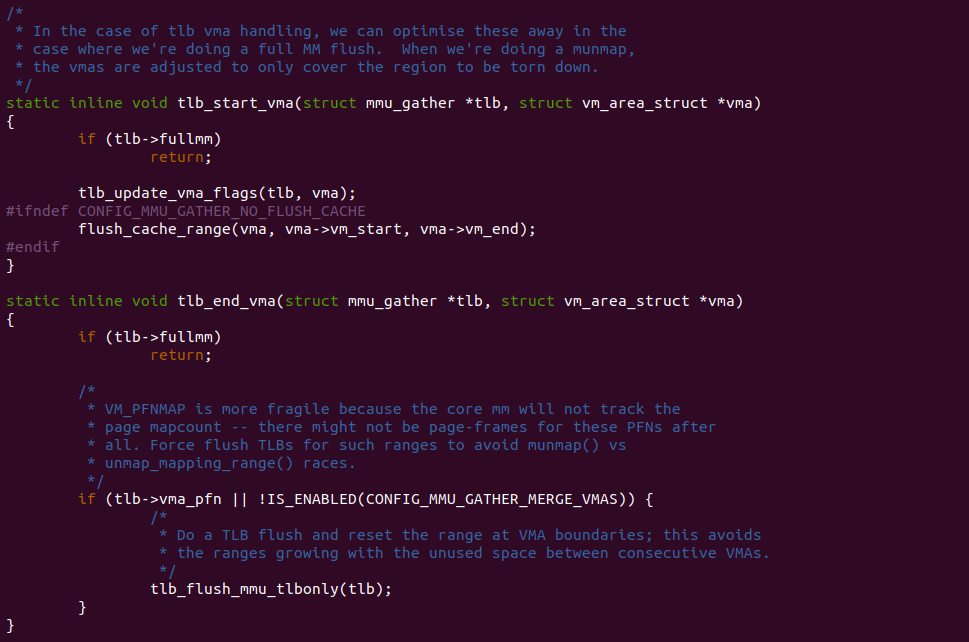
tlb_start_vma 函数的主要作用是初始化并准备处理特定 VMA 的 TLB 更新。TLB 是用于存储虚拟地址到物理地址的转换结果的硬件缓存,用于加速地址转换过程。当涉及到虚拟内存区域的更改时,例如映射或解除映射页面,需要更新 TLB 以反映这些更改. 具体而言,tlb_start_vma 函数执行以下主要任务:
- 如果 TLB 的更新是针对整个内存管理(full MM flush)进行的,则直接返回,无需进行后续的操作
- 通过调用 tlb_update_vma_flags 函数,将 VMA 的属性信息设置到 TLB 更新操作中。这些属性信息包括读写权限、执行权限等
- 在没有定义 CONFIG_MMU_GATHER_NO_FLUSH_CACHE 宏的情况下,调用 flush_cache_range 函数,刷新与 VMA 相关的缓存区域
tlb_end_vma 函数用于结束处理虚拟内存区域(VMA)的 TLB 更新操作. 如果进行的是完整的内存管理(full MM flush),则直接返回; 否则根据条件判断是否执行 TLB 刷新操作,并在 VMA 边界处重新设置 TLB 的处理范围。这样可以确保 TLB 中的转换结果是准确的,并避免不必要的 TLB 条目增长, 其主要任务:
- 如果 TLB 的更新是针对整个内存管理(full MM flush)进行的,则直接返回,无需进行后续的操作
- 在不满足 CONFIG_MMU_GATHER_MERGE_VMAS 宏定义条件的情况下,或者存在 vma_pfn(用于标记 VMA 是否为 PFNMAP 类型)时,执行以下操作:
- 进行 TLB 刷新,清除 TLB 中与 VMA 相关的条目,确保 TLB 中的转换结果是准确和最新的
- 在 VMA 边界处重新设置 TLB 的处理范围,以避免连续的 VMA 之间存在未使用空间导致范围增长
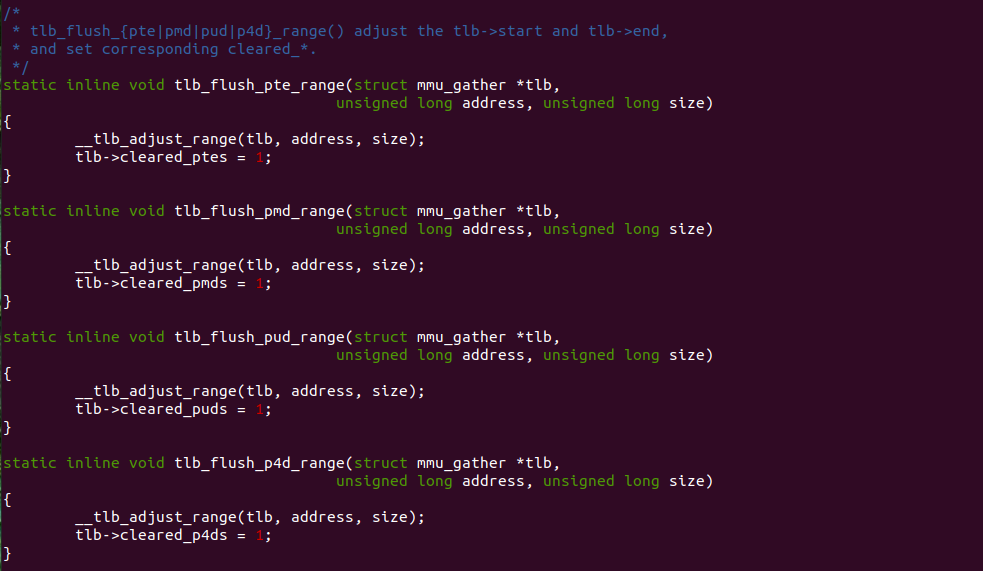
tlb_flush_X_range 函数用于记录 TLB 刷新的范围,MMU Gather 在遍历页表过程中,记录每次遍历的虚拟地址方位,其具体含义如下:
- tlb_flush_pte_range: 函数记录 PTE 作为最后一级页表对应的 TLB Entry 范围
- tlb_flush_pmd_range: 函数记录 PDE 作为最后一级页表对应的 TLB Entry 范围
- tlb_flush_pud_range: 函数记录 PUD 作为最后一级页表对应的 TLB Entry 范围
- tlb_flush_p4d_range: 函数记录 P4D 作为最后一级页表对应的 TLB Entry 范围
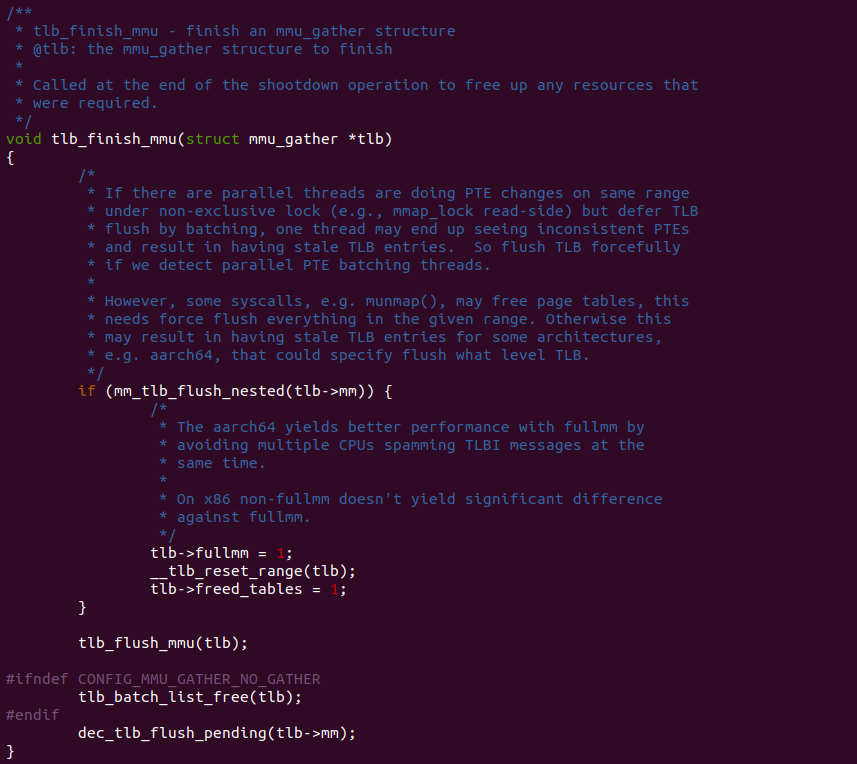
tlb_finish_mmu 函数用于在 MMU 操作的结束阶段完成 “mmu_gather” 记录的内容进行实际的更新操作. 函数首先通过调用 mm_tlb_flush_nested 来检测是否存在并发的 PTE 批处理线程。在某些情况下,多个线程可能在相同的范围内进行 PTE 更改,但使用非独占锁(如 mmap_lock 的读取端). 这可能导致某个线程看到不一致的 PTE 并产生过期的 TLB 条目。因此如果检测到并发的 PTE 批处理线程,就需要强制刷新 TLB。接下来,根据架构的不同,如果 mm_tlb_flush_nested 返回值为真,表示需要进行全局 TLB 刷新。此时将 tlb->fullmm 设置为 1,表示需要进行全局刷新。然后调用 __tlb_reset_range 函数重置 TLB 的范围,并将 tlb->freed_tables 设置为 1,表示已释放页表。接着调用 tlb_flush_mmu 函数刷新 TLB,确保最新的页表转换结果生效。最后根据配置的选项,在非 CONFIG_MMU_GATHER_NO_GATHER 情况下,调用 tlb_batch_list_free 函数释放tlb中的批处理列表。然后通过调用 dec_tlb_flush_pending 减少 tlb->mm 中的 TLB 刷新挂起计数。
不同架构最终 FLUSH TLB 的指令可能不同,在 X86 架构中,FLUSH TLB 最终会调用到 INVLPG 指令,该指令将虚拟地址对应的 TLB Entry Invalidate. 至此 MMU Gather 聚集刷新 TLB Entry 的主要函数已经介绍完毕,那么接下来介绍开发者如何使用 MMU Gather 机制刷新 TLB.
MMU Gather 使用
MMU Gather 的目将多次 TLB 刷新聚集到一起进行刷新,以此提升 MMU 刷新的效率,另外由于最终调用的刷新指令只能在内核空间使用,因此开发者想要使用 MMU Gather 机制,只能在内核中使用,并且是针对软件修改页表的场景,那么通过一个实践案例介绍 MMU Gather 机制使用方法,其在 BiscuitOS 部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] TLB FLUSH --->
<*> TLB FLUSH on Userspace --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-default/
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-APP-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build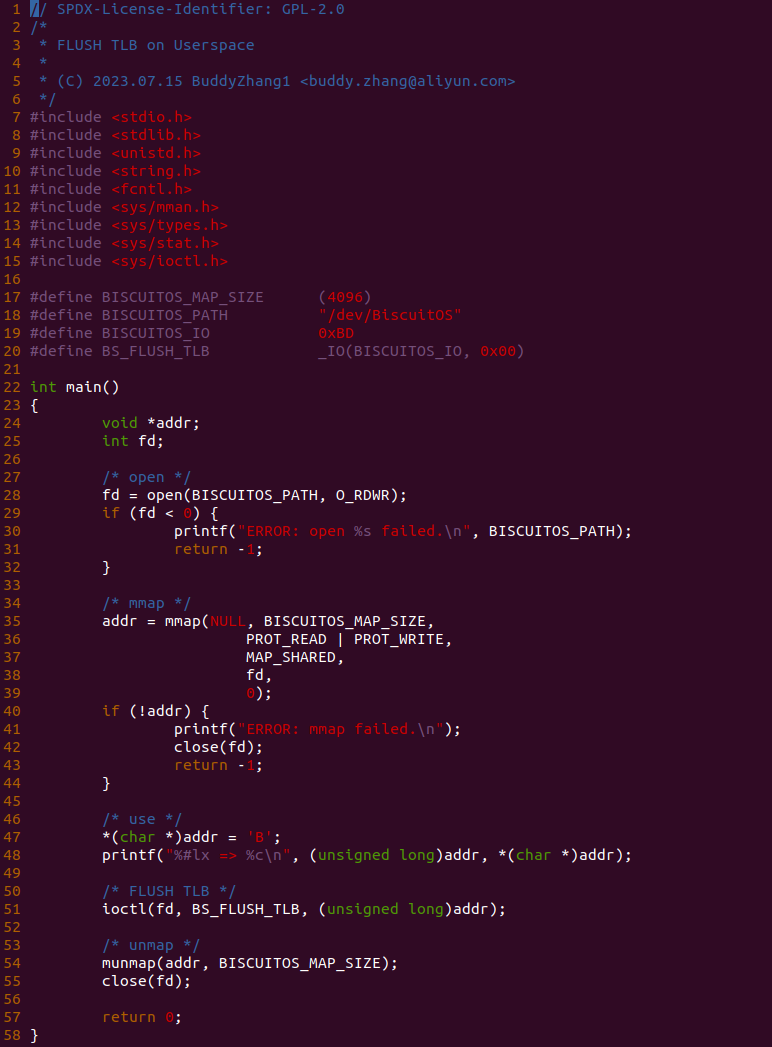
实践案例由两部分组成,其中一部分是上图的用户空间应用程序。应用程序的逻辑很简单,分配一段虚拟内存,并在 47 行通过缺页映射到物理内存,并在 51 行调用 ioctl() 函数向 “/dev/BiscuitOS” 节点发送 BS_FLUSH_TLB 请求.
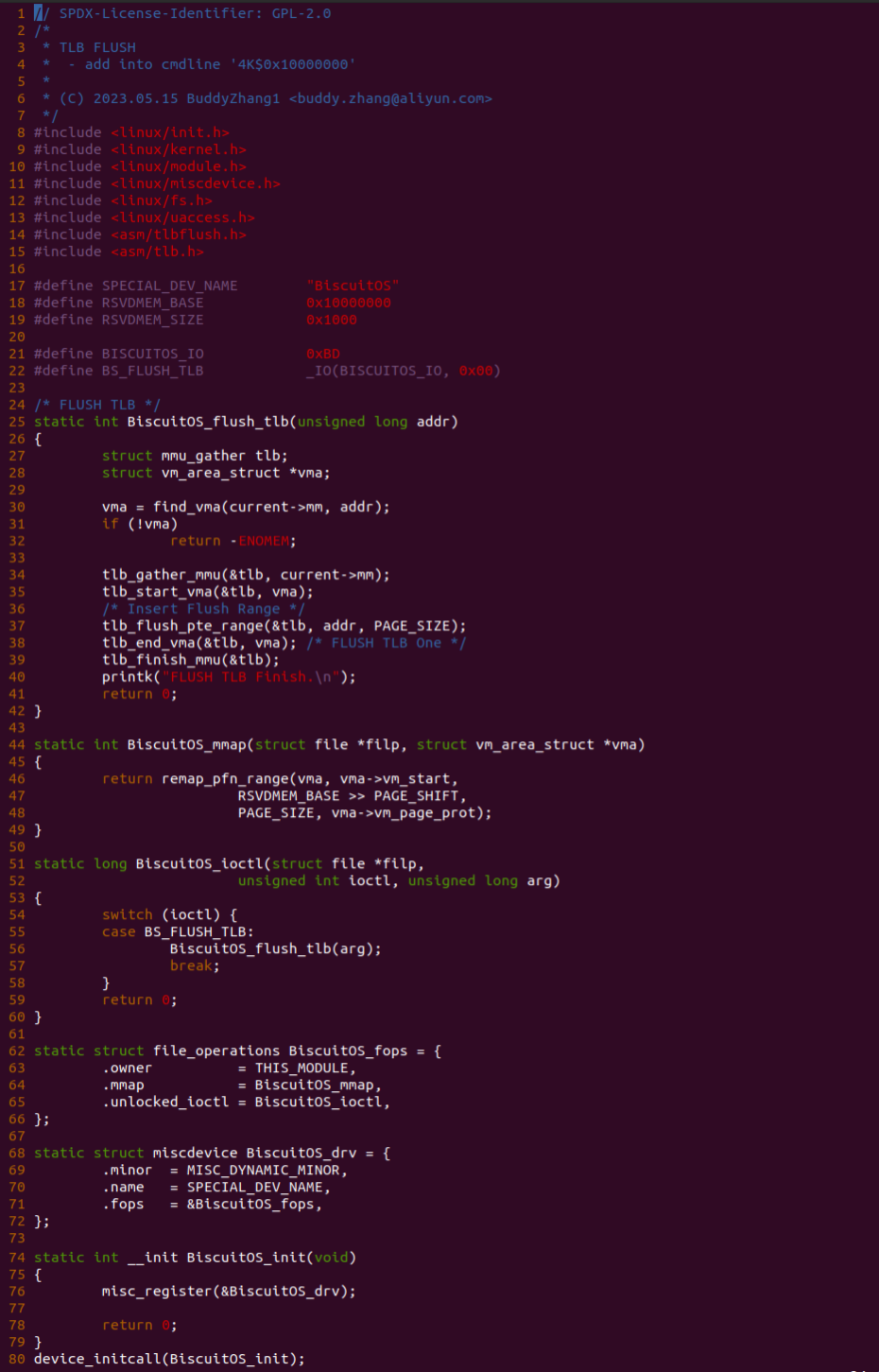
实践案例的另外一部分是一个内核空间模块,模块由一个 MSIC 驱动构成,其向用户空间透出 “/dev/BiscuitOS” 节点,并对节点提供了 mmap 和 unlocked_ioctl 接口,其中 mmap 对应 BiscuitOS_mmap() 函数实现分配虚拟内存就建立页表映射到物理内存上; 另外 unlocked_ioctl 对应 BiscuitOS_ioctl() 函数,其实现 BS_FLUSH_TLB 请求接口,当用户空间通过 “/dev/BiscuitOS” 节点的 ioctl() 函数下发 BS_FLUSH_TLB 请求就会调用到 BiscuitOS_flush_tlb() 函数。
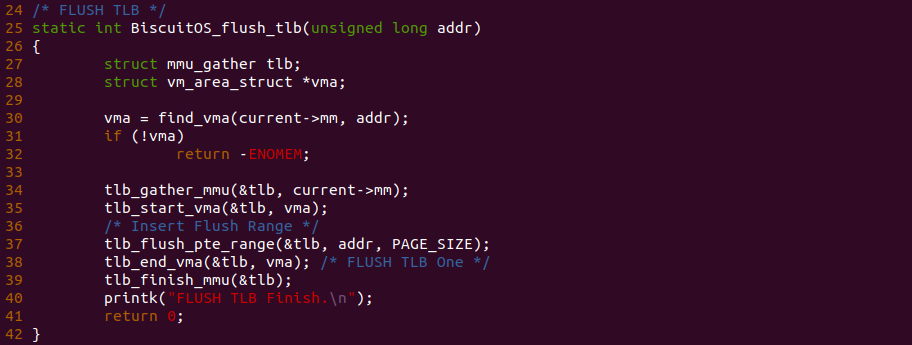
BiscuitOS_flush_tlb() 函数的实现逻辑即是内核里 FLUSH TLB 的标准做法,因此可以按顺序以此调用这些函数实现多个 TLB 刷新:
- find_vma() 找到虚拟地址对应的 VMA 和 mm 数据结构
- tlb_gather_mmu() 用户初始化 mmu_gather 数据结构,准备一次新的多个 TLB 刷新
- tlb_start_vma() 用于修改页表之前
- tlb_flush_pte_range() 记录被修改页表的虚拟地址范围
- tlb_end_vma() 用于结束页表修改处
- tlb_finish_mmu() 用于最终的 FLUSH TLB 操作
通过上面的一套函数可以实现对一段虚拟内存的 TLB 刷新。可能在实际运用过程中需要遍历页表操作,以及 TLB 刷新之后通过 MMU notifier 机制通知其他子系统. 总之以上便是一个最简单的刷 TLB 模型,开发者可以结合需求进行使用.

TLB/PCIDs Flsuh Mechanism
Linux 提供了一套接口用于刷新 TLB 和 PCIDs, 这些接口有的可以将所有的 CPU 的 TLB 都刷新,有的针对一个虚拟地址刷新对应的 TLB Entry。在 X86 架构,提供了 INVLPG 和 INVPCID 指令进行最终的刷新操作,不同的架构提供的指令可能不同,但 Linux 提供了统一的接口实现 TLB 刷新,那么本节介绍相关的 TLB/PCID FLUSH 接口.
FLUSH TLB
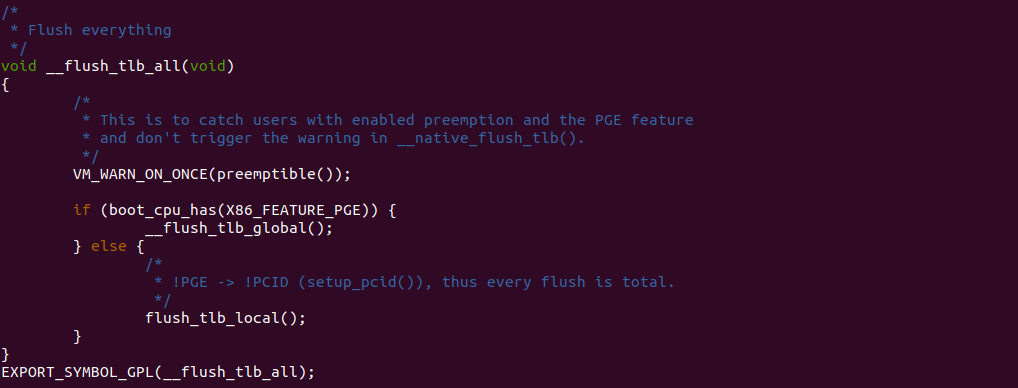
__flush_tlb_all 函数可以将所有的 TLB 无效,函数会向每个处理器发送一个特殊的指令(比如 INVLPG)来清除 TLB 中的所有条目,使得后续的内存访问将会重新进行地址转换。这个函数通常在内核进行全局 TLB 刷新时使用,例如在修改页表、更改进程上下文或者进行系统调用时, 该函数已经 EXPORT_SYMBOL_GPL 导出,因此可以作用到内核模块.

flush_tlb_local 函数用于将本地 TLB 全部刷新. 在后续的内存访问中,CPU 将重新执行地址转换,以获取最新的虚拟地址到物理地址的映射关系. 该函数通常在内核中的页表操作或地址空间切换过程中被调用,以确保 TLB 的一致性和正确性。通过刷新 TLB,可以确保使用最新的页表映射,避免使用过期或无效的映射结果。需要注意的是,flush_tlb_local 函数仅刷新本地 CPU 的 TLB,而不涉及其他 CPU 的 TLB.
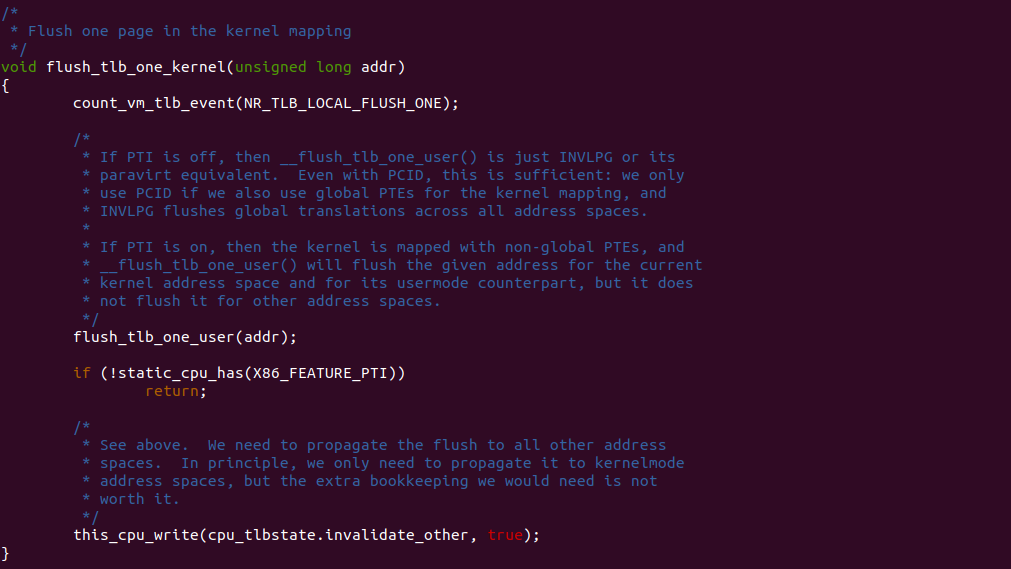
flush_tlb_one_kernel 函数的作用刷新单个内核页表项对应的 TLB Entry. 当内核修改了页表项,例如更改页面权限或取消映射,需要确保 TLB 中不保留过时的转换结果。该函数将使用 invlpg 指令(Invalidate Page)来刷新 TLB 中指定内核页表项的转换结果。通常情况下,这个函数会在对内核页表项进行更改后被调用,以确保 TLB 中的转换结果与最新的页表项一致。这样后续的内核内存访问将会使用最新的页表项进行地址转换,避免错误的访问或权限问题.

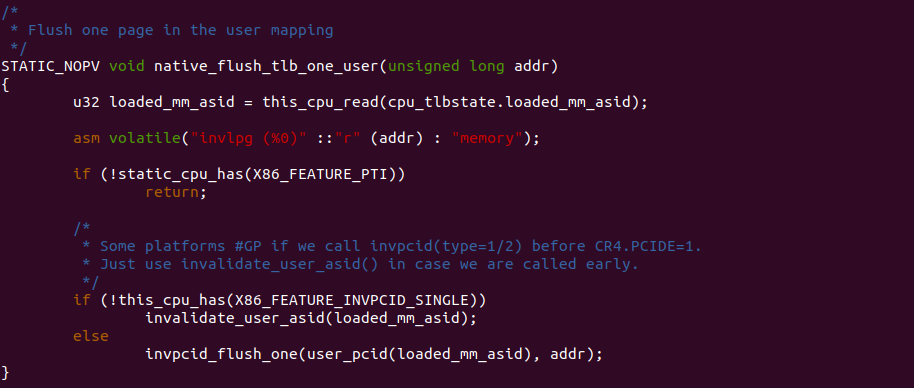
flush_tlb_one_user 函数的作用是刷新单个用户空间页表对应的 TLB Entry. 当用户空间修改了页表项,例如更改页面权限或取消映射,需要确保 TLB 中不保留过时的转换结果。该函数将使用 invlpg 指令(Invalidate Page)来刷新 TLB 中指定用户空间页表项的转换结果。通常情况下这个函数会在对用户空间页表项进行更改后被调用,以确保 TLB 中的转换结果与最新的页表项一致。这样后续的用户空间内存访问将会使用最新的页表项进行地址转换,避免错误的访问或权限问题.

flush_tlb_multi 函数的作用是刷新多个 TLB 缓存。它通过遍历指定的线性地址范围,调用底层的架构特定函数来刷新 TLB。不同的架构可能有不同的底层实现方式,但它们的目标都是将指定范围内的 TLB中 的转换结果标记为无效。该函数通常在需要刷新多个 TLB 的情况下被调用,例如在修改了一段连续的页表项或映射关系时。通过刷新多个 TLB,确保涉及到修改的页表项或映射关系的转换结果都是最新的,以避免旧的页表项或映射关系导致的地址转换错误或权限问题.
FLUSH PCID

INVPCID 指令根据进程上下文标识符(PCID),无效 TLB 和页表结构缓存中的映射. 无效化基于寄存器操作数中指定的 INVPCID 类型和内存操作数中指定的 INVPCID 描述符. 在 64 位模式外,寄存器操作数始终为 32 位,不论 CS.D 的值如何。在 64 位模式下,寄存器操作数为 64 位。当前定义了四种 INVPCID 类型:
- 单地址无效化: 如果 INVPCID 类型为 0,则逻辑处理器无效化线性地址和 INVPCID 描述符中指定的 PCID 的映射,但全局翻译除 外。在某些情况下,该指令可能还会无效化全局翻译或其他线性地址(或其他 PCID)的映射
- 单上下文无效化: 如果 INVPCID 类型为 1,则逻辑处理器无效化与 INVPCID 描述符中指定的 PCID 相关联的所有映射,但全局翻 译除外。在某些情况下,该指令可能还会无效化全局翻译或其他 PCID 的映射
- 所有上下文无效化, 包括全局翻译: 如果 INVPCID 类型为 2,则逻辑处理器无效化与任何 PCID 相关联的所有映射,包括全局翻>译
- 所有上下文无效化: 如果 INVPCID 类型为 3,则逻辑处理器无效化与任何 PCID 相关联的所有映射,但全局翻译除外。在某些情>况下,该指令可能还会无效化全局翻译

invpcid_flush_one 函数的用于将与 PCID(ASID) 关联的单线性地址的 TLB 缓存失效操作。它通过使用 INVPCID 指令,通知处理器将指定 PCID(ASID) 的 TLB 缓存项无效化。这样当对应的地址空间再次被访问时,处理器将重新加载最新的映射关系,以确保地址转换的正确性。该函数通常在地址空间销毁或修改页表项时被调用,以保持 TLB 的一致性。它遍历所有处理器核心上的TLB缓存,并使用 INVPCID 指令将指定 ASID 的 TLB 项失效.

invpcid_flush_single_context 函数的作用是通知处理器将指定上下文的 TLB 缓存项无效化。这样当对应的进程或地址空间再次被访问时,处理器将重新加载最新的映射关系,以确保地址转换的正确性。该函数在涉及更改特定上下文的页表或销毁上下文时使用,以保持 TLB 的一致性。它遍历所有处理器核心上的 TLB 缓存,并使用 invpcid 指令将指定上下文的 TLB 项失效.

invpcid_flush_all 函数通过使用 INVPCID 指令,通知处理器将所有上下文的 TLB 缓存项无效化。这样所有进程或地址空间的映射关系都将被失效,当它们再次被访问时,处理器将重新加载最新的映射关系,以确保地址转换的正确性。该函数在需要刷新所有核心上的 TLB 缓存时使用,以确保所有处理器核心的 TLB 都是最新的。它遍历所有处理器核心上的 TLB 缓存,并使用 INVPCID 指令将所有上下文的 TLB 项失效。

invpcid_flush_all_nonglobals 函数通过使用 INVPCID 指令,通知处理器将所有非全局上下文的 TLB 缓存项无效化。非全局上下文是指那些与全局上下文不同的上下文,这些上下文在进程切换时不会自动刷新,需要手动进行失效操作。该函数遍历所有非全局上下文的上下文标识符,并使用 INVPCID 指令将它们的 TLB 缓存项失效。这样所有非全局上下文的映射关系都将被失效,当它们再次被访问时,处理器将重新加载最新的映射关系,以确保地址转换的正确性。
TLB FLUSH 数据统计
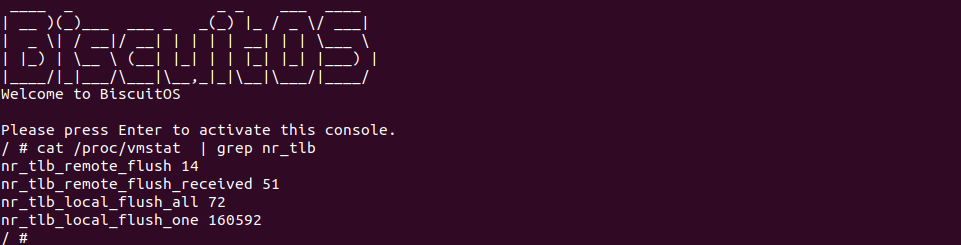
在 Linux 操作系统中,/proc/vmstat 接口提供了有关虚拟内存统计信息的实时数据。它是一个虚拟文件,可以通过读取该文件来获取有关系统虚拟内存使用情况的统计信息. 该接口提供了关于 TLB FLHSU 的多个统计,具体如下:
- nr_tlb_remote_flush: 统计了远程刷新的 TLB 项数量
- nr_tlb_remote_flush_received: 统计了接收到的远程 TLB 刷新请求的数量
- nr_tlb_local_flush_all: 统计了本地 TLB 全局刷新的次数
- nr_tlb_local_flush_one: 统计了本地TLB单页刷新的次数
Linux 统计上面的数据需要打开 CONFIG_DEBUG_TLBFLUSH 宏, VM_EVENT 会新增: NR_TLB_REMOTE_FLUSH、NR_TLB_LOCAL_FLUSH_ALL、NR_TLB_LOCAL_FLUSH_ONE 和 NR_TLB_REMOTE_FLUSH_RECEIVED, 那么接下来分析四个计数在何处进行统计:
NR_TLB_LOCAL_FLUSH_ONE
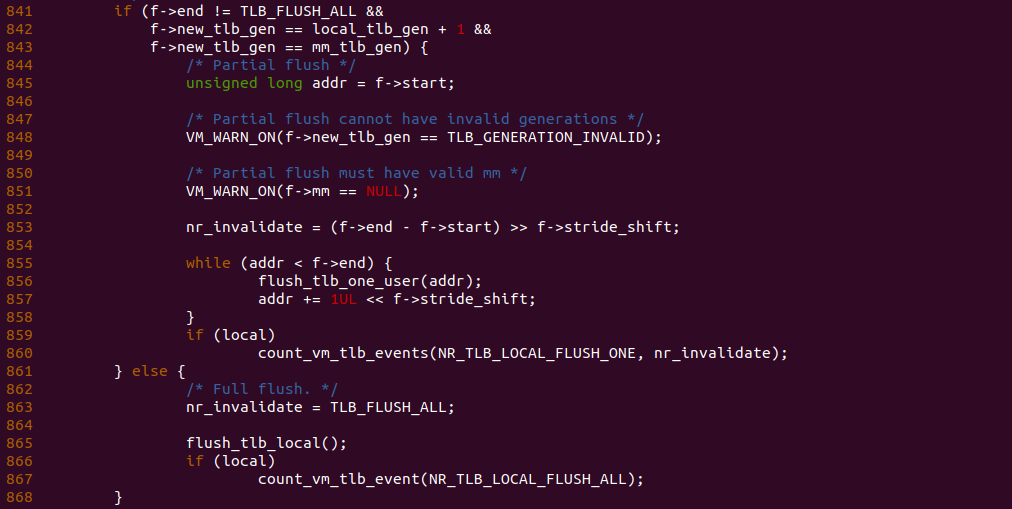
flush_tlb_func 函数用户实际的 TLB FLUSH 操作,其内部存在上图的逻辑,函数在 841 行判断逻辑,如果判断到调用者只是想刷新单个 TLB Entry,那么进入 845 行逻辑,在 TLB FLUSH 完毕之后,函数会在 860 行调用 count_vm_tlb_events 函数增加 NR_TLB_LOCAL_FLUSH_ONE 的计数,每次增加 nr_invalidate.
flush_tlb_one_kernel 函数的作用刷新单个内核页表项对应的 TLB Entry. 当内核修改了页表项,例如更改页面权限或取消映射,需要确保 TLB 中不保留过时的转换结果, 因此函数也会调用 count_vm_tlb_event 函数对 NR_TLB_LOCAL_FLUSH_ONE 计数加一.
NR_TLB_LOCAL_FLUSH_ALL
flush_tlb_func 函数用户实际的 TLB FLUSH 操作,其内部存在上图的逻辑,函数在 841 行判断逻辑,如果判断到调用者想将所有的 TLB 都刷新,那么进入 862 行逻辑,在 TLB FLUSH 完毕之后,函数会在 866 行调用 count_vm_tlb_events 函数对 NR_TLB_LOCAL_FLUSH_ALL 计数加一.
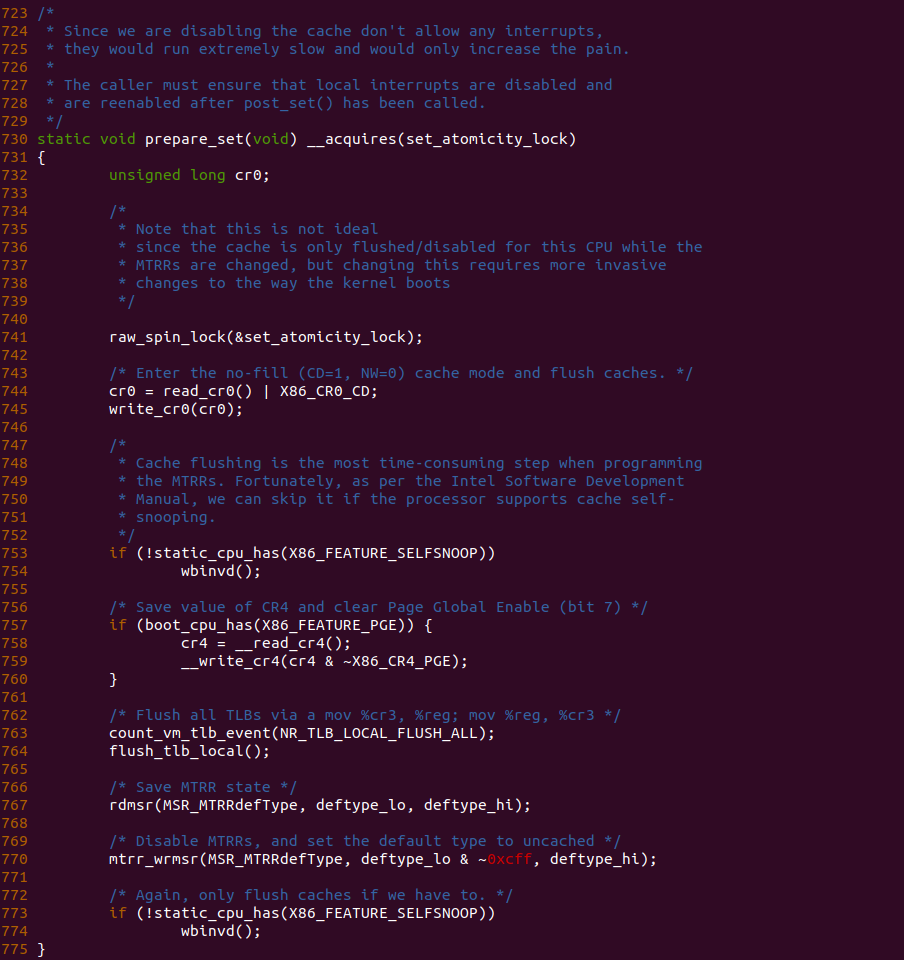
prepare_set 函数是设置 MTRRs 之前的准备,其中就包括 764 行的 flush_tlb_locl() 函数,该函数会将所有的 TLB 无效,因此函数在 763 行调用 count_vm_tlb_event 函数对 NR_TLB_LOCAL_FLUSH_ALL 计数加一.
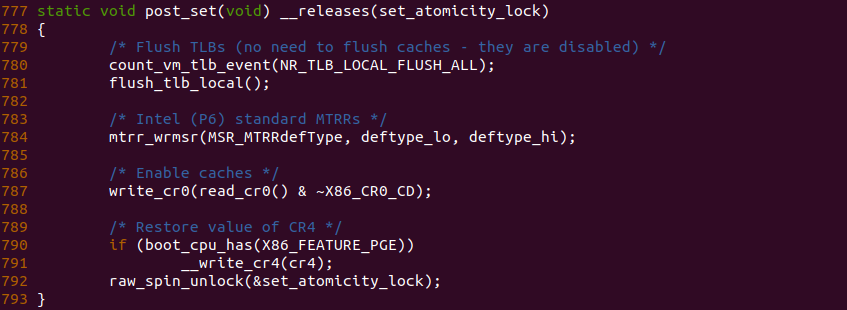
post_set 函数的设置 MTRRs 之后的收尾操作,函数在 784 行再次对 MTRRs 进行写操作,因此需要在写之前将所有的 TLB 无效,那么函数在 781 行调用 flush_tlb_local() 刷新了 TLB,因此这里可以调用 count_vm_tlb_event 函数将 NR_TLB_LOCAL_FLUSH_ALL 计数加一.
NR_TLB_REMOTE_FLUSH
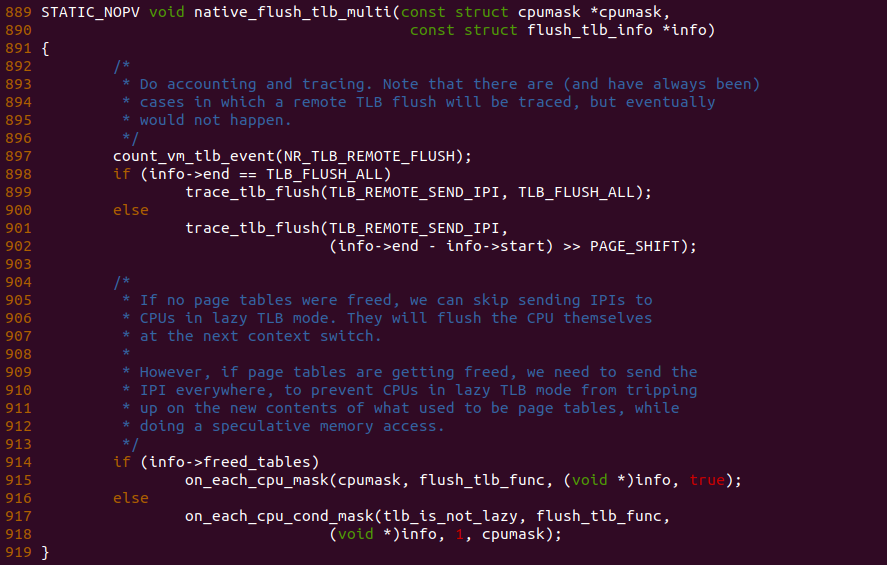
native_flush_tlb_multi 和 flush_tlb_multi 函数用于刷新多个 CPU 的 TLB 缓存,也就是远端(Remote) TLB. 那么函数在 897 行调用 count_vm_tlb_event 函数对 NR_TLB_REMOTE_FLUSH 计数加一操作,接下来调用在每个 CPU 上执行 flush_tlb_func 函数.

flush_tlb_all 函数用于刷新所有 CPU 的 TLB,那么调用该函数的 CPU 称为 LOCAL CPU,那么其他 CPU 称为 Remote CPU,那么 Remote CPU 的 TLB 也称为 Remote TLB, 因此函数可以调用 count_vm_tlb_event 函数对 NR_TLB_REMOTE_FLUSH 计数加一.
NR_TLB_REMOTE_FLUSH_RECEIVED

do_flush_tlb_all 函数用于将本地的 TLB 刷新,但是由其他 CPU 发起调用,那么该 CPU 是收到 TLB FLUSH 请求之后才刷新的,因此该处可以调用 count_vm_tlb_event 函数对 NR_TLB_REMOTE_FLUSH_RECEIVED 计数加一操作.
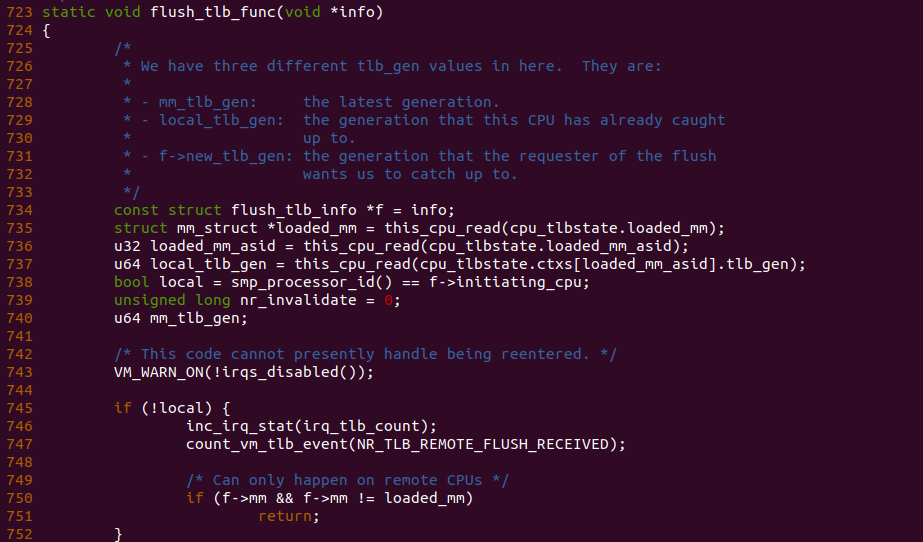
flush_tlb_func 函数是 FLUSH TLB 实际处理函数,函数在 745 行发现 local 为 false,那么表示是其它 CPU 发起的 FLUSH TLB 动作,因此可以在 747 行调用 count_vm_tlb_event 函数对 NR_TLB_REMOTE_FLUSH_RECEIVED 计数加一.

Single TLB Flush Ceiling Mechanism
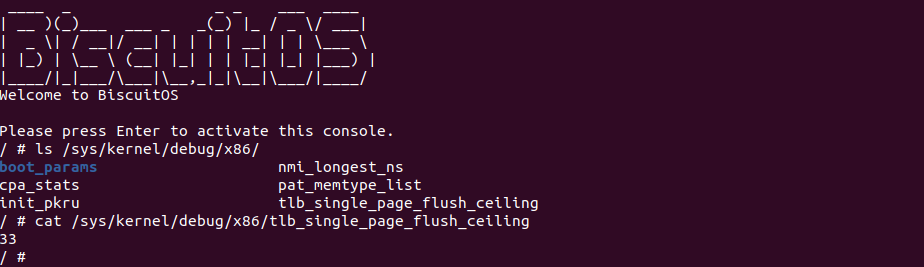
在 Linux 中存在 tlb_single_page_flush_ceiling 节点,其位于 X86 debugfs 目录下,该节点作为单独刷新 TLB 阈值。那么内核为什么要添加该节点呢,本节对该问题进行研究. 当内核取消映射或修改一段内存的属性时,有两种选择:
- 使用两个指令的序列刷新整个 TLB。这是一个快速的操作,但会造成副作用: 除了我们要刷新的区域外,其他区域的 TLB 条目也会被破坏,需要稍后重新填充,带来一定的开销
- 使用 INVLPG 指令逐个无效化单个页面. 这可能需要更多的指令,但是它是一种更精确的操作,不会对其他 TLB 条目造成副作用
两种方法都各有好处,选择使用哪种方法取决于以下几个因素:
- 执行刷新的大小: 如果刷新整个地址空间,通过刷新整个 TLB 显然比进行 2^48/PAGE_SIZE 个单独的刷新要好
- TLB的内容: 如果 TLB 为空,则执行全局刷新不会造成任何副作用,所有的单独刷新都会变成无用功
- TLB的大小: TLB 越大,使用全局刷新造成的副作用就越大。因此,TLB 越大,单独刷新就越具有吸引力. 数据和指令有不同的 TLB,不同的页面大小也有各自的 TLB
- 微体系结构: 在现代 CPU 上,TLB 已经成为一个多级缓存,相对于单页刷新,全局刷新变得更加昂贵
显然内核无法知道所有这些事情,特别是在给定刷新期间 TLB 的内容。刷新的大小也会根据工作负载而大大变化。基本上没有正确的选择点。如果在性能分析中看到 INVLPG 指令(或靠近它的指令)的使用频率很高,可能会进行太多的单独无效化操作。如果认为单独无效化调用太频繁,可以降低可调整的值:
/sys/kernel/debug/x86/tlb_single_page_flush_ceiling这将导致我们在更多的情况下进行全局刷新。将其降低为 0 将禁用单独刷新的使用。将其设置为 1 是一个非常保守的设置,在正常情况下不应该需要为 0。尽管在 x86 架构上,单个单独刷新保证刷新了完整的 2MB 大小的页面,但 hugetlbfs 总是使用全局刷新。THP 与普通内存处理方式完全相同。在性能分析中,您可能会在 flush_tlb_mm_range() 函数中看到 INVLPG 操作,或者可以使用 trace_tlb_flush() 跟踪点来确定刷新操作的持续时间。
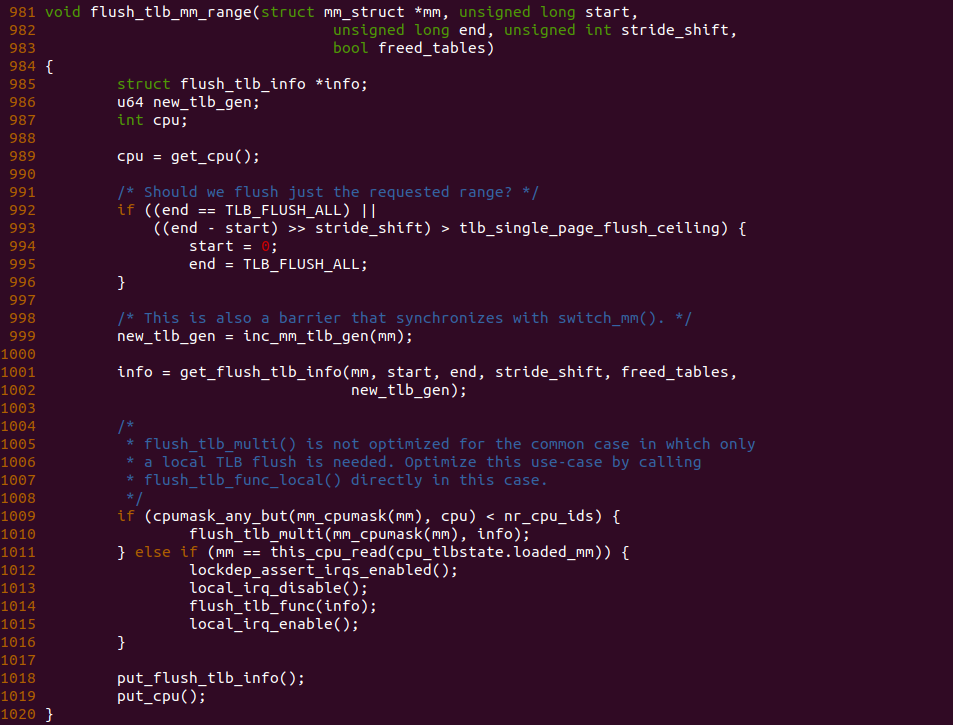
flush_tlb_mm_range 函数用户实际的 TLB FLUSH 操作,假设只对一个 4KiB 区域进行刷新,但是 tlb_single_page_flush_ceiling 节点设置为 0,那么函数在 993 行的逻辑一致成立,那么函数进入 994 行分支将 TLB 刷新的范围设置为 TLB_FLUSH_ALL. 那么此时会将整个 TLB 都刷新了. 由此可以见 tlb_single_page_flush_ceiling 节点是一个单刷粒度阈值.

TLB Flush Nofitifer Mechanism
MMU Notifier Mechanism 是一种用于内核和用户空间之间通信的机制。它提供了一种机制,允许内核在内存映射发生变化时通知用户空间。这种变化可能包括页面的分配、释放、保护属性的更改等。MMU 通知机制通过注册回调函数来实现。当发生与内存映射相关的事件时,内核会调用这些回调函数来通知用户空间。用户空间可以在回调函数中执行相应的操作,例如更新页表、刷新缓存等。那么当系统刷新 TLB 时,MMU 如何通知其他进程的,那么本文对该问题进行详细研究,依照惯例,首先通过一个实践案例介绍该机制如何实践,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] TLB FLUSH Notify Mechansim --->
<*> TLB FLUSH on Userspace --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-NOTIFY-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make prepare
make build
实践案例由两部分组成,其中一部分是上图的用户空间应用程序。应用程序的逻辑很简单,分配一段虚拟内存,并在 47 行通过缺页映射 到物理内存,并在 51 行调用 ioctl() 函数向 “/dev/BiscuitOS” 节点发送 BS_FLUSH_TLB 请求.
实践案例的另外一部分是一个内核空间模块,模块由一个 MSIC 驱动构成,其向用户空间透出 “/dev/BiscuitOS” 节点,并对节点提供了 mmap 和 unlocked_ioctl 接口,其中 mmap 对应 BiscuitOS_mmap() 函数实现分配虚拟内存就建立页表映射到物理内存上; 另外 unlocked_ioctl 对应 BiscuitOS_ioctl() 函数,其实现 BS_FLUSH_TLB 请求接口,当用户空间通过 “/dev/BiscuitOS” 节点的 ioctl() 函数下发 BS_FLUSH_TLB 请求就会调用到 BiscuitOS_flush_tlb() 函数。
对于 MMU 通知机制,模块首先在 BiscuitOS_open() 函数,也就是用户空间调用 open 函数时会调用到该函数,此时在 114-115 行调用 mmu_notifier_register 函数注册了一个监听接口,当有通知事件时,会调用 BiscuitOS_notifier_ops 定义的处理函数,可以在 54-52 行看到定义了三个监听处理函数,当收到 Invalidate 通知之后。接着在 BiscuitOS_flush_tlb 函数内部,如果要监听一段代码里的 MMU 事件,需要在 72 行调用 mmu_notifier_range_init 函数监听一段内存区域的变动,75 行的 mmu_notifier_invalidate_range_start 函数和 84 行的 mmu_notifier_invalidate_range_end 函数设定了监听访问,只要这段代码执行过程中让 [addr, addr + PAGE_SIZE] 的区域 Invalidate,那么就会调用刚刚注册的监听函数。那么接下来在 BiscuitOS 上事件该案例:
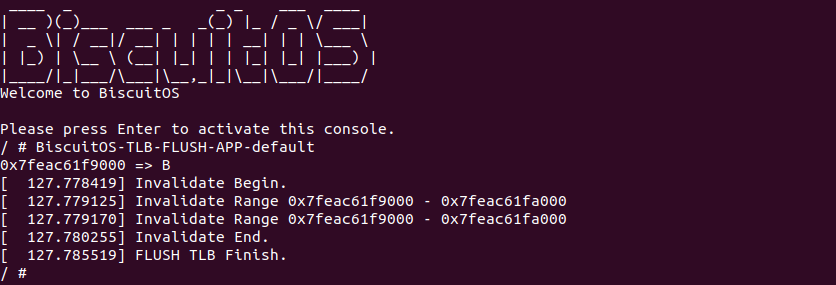
当 BiscuitOS 启动之后,运行程序 BiscuitOS-TLB-FLUSH-APP-default,可以看到内核模块捕捉到内核对虚拟地址 0x7feac61f9000 执行 TLB FLUSH 的动作,另外当调用 mmu_notifier_invalidate_range_start 时 BiscuitOS_invalidate_range_start 函数被调用,另外 mmu_notifier_invalidate_range_end 被调用时,BiscuitOS_invalidate_range_end 函数随后被调用,可以看到在 FLUSH TLB 时模块在通知联上捕获到 Invalidate Message,因此 BiscuitOS_invalidate_range 函数被调用. 上图实践符合预期,那么接下来看看其实现原理:

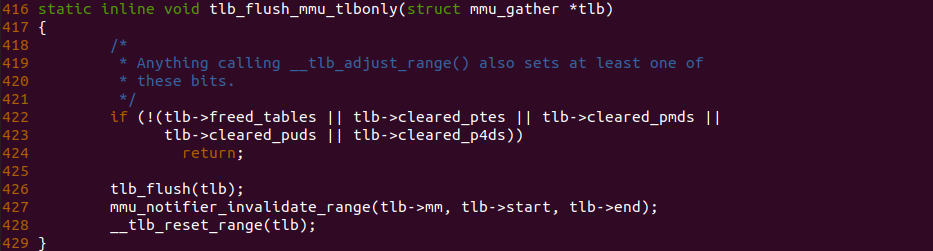
内核会调用 tlb_finish_mmu 函数完成最终的 TLB FLUSH,从该函数的调用链可以看到最终调用到 tlb_flush_mmu_tlbonly,其在调用完 tlb_flush() 执行真正的 FLUSH TLB 动作之后,调用了 mmu_notifier_invalidate_range 函数向 mm 对应的进程发送了 Invalidate 消息,因此内核模块可以监听到 TLB FLUSH 动作. 通过上面的案例和原理分析,开发者可以根据实际需求使用该通知链捕获 TLB FLUSH 动作.

CPUID 工具查看 TLB 硬件信息
要查看 TLB 相关的信息,可以使用 cpuid 指令和相应的 CPUID 功能码来获取。在 x86 架构的 Linux 系统中,可以通过编写程序或使用特定的命令行工具来执行 cpuid 指令并解析返回的结果。以下是一种常见的方法:
- 使用编程语言(如 C 或 C++)编写一个程序来执行 cpuid 指令并解析返回的结果。可以使用 cpuid 指令的内联汇编或使用相关的库函数(如cpuid.h)来执行该指令。通过读取特定的寄存器(如 EAX、EBX、ECX、EDX)中的值,可以获取与 TLB 相关的信息
- 使用命令行工具(如 cpuid 或 lscpu)来获取 TLB 相关的信息。这些工具可以在 Linux 系统中执行,并以易于阅读的格式显示 CPU 的功能和特性
CPUID 命令
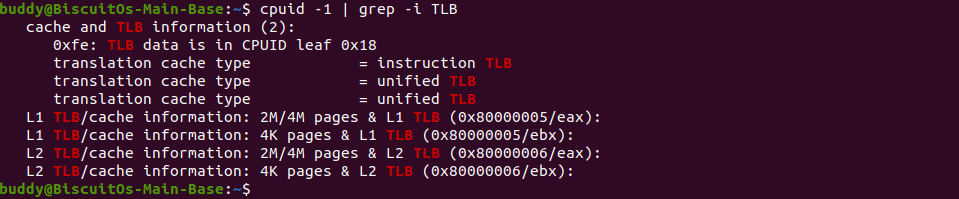
cpuid -1cpuid -1 命令用于执行 CPUID 功能码为 1 的操作,并显示与 CPU 相关的详细信息。CPUID 功能码 1 返回有关处理器的基本信息,包括处理器类型、系列、型号、扩展特性和支持的指令集。运行 cpuid -1 命令将显示以下信息(可能因CPU型号和架构而有所差异):
- Vendor ID: 供应商标识,表示处理器制造商(如Intel、AMD 等)
- CPU Family、Model、Stepping: 处理器系列、型号和步进信息
- Extended Features: 扩展特性,包括支持的指令集和其他功能(如 SSE、AVX 等)
- Cache Information: 缓存信息,包括L1、L2和L3缓存的大小、关联性和其他特性
- TLB Information: TLB 信息,包括 L1、L2 TLB 的大小、类型
- Processor Frequency: 处理器频率
- Thermal and Power Management: 热管理和功耗管理特性
通过运行 cpuid -1 命令,可以快速了解 CPU 的一般特性和功能,帮助识别处理器的型号和功能集,并为系统优化和调试提供有用的信息。如上图可以通过该命令获得 TLB 相关的信息.
CPUID Program
可以在 C/C++ 程序中调用 CPUID 指令获得 CPUID 相关信息,那么 TLB 大小相关信息存储在 CPUID 里,因此可以在程序中获得 TLB 的信息,BiscuitOS 提供了一个实践案例介绍如何在程序中使用 CPUID,那么通过这个实践案例了解其在使用方法,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] CPUID: Utility to read CPUIDs from x86 processors --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-CPUID-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build使用 “make download” 获得源码之后,main.c 是核心源码,开发者可以自行参考,其核心是按照 X86 CPUID 寄存器的读写逻辑,读写执行的 CPUID 寄存器,其中包括包含 X86 TLB Information 的 CPUID 寄存器,那么接下来在 BiscuitOS 上直接实践该案例:
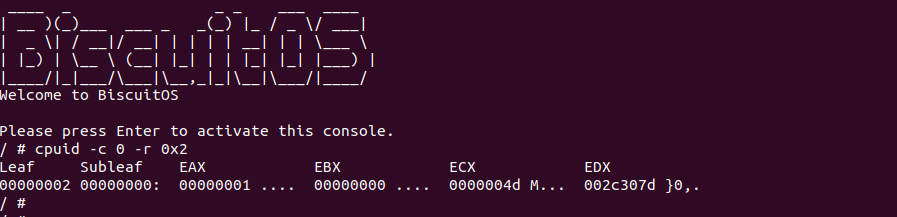
BiscuitOS 运行之后,使用 cpuid 程序,其 c 参数用于指明从读取哪个 CPU 的 CPUID 寄存器,r 参数则指明 CPUID 寄存器,如上图就是读取 “CPUID EAX=2” 的寄存器,该寄存器里面包含了 TLB Information. 那么接下来了解一下 CPUID EAX=2 寄存器:

上图的大致意思说的是当执行 CPUID 指令时,EAX 为 0x2 时,那么 EBX/ECX/EDX 里面就会存储 TLB 相关的信息,具体的信息如下:

CPUID EAX=2 的使用提供了上面的案例,例如当执行指令之后,EAX、EBX、ECX 和 EDX 的值如上图,那么首先看 EAX 的值为 0x665B5001, 由于最低字节为为 01, 那么 EAX 的值可以忽略; EDX 的值为 0x007A7000H,那么 0x7A 查询上表可以知道系统包含了 “56-KByte 2nd level cache, 8-way set associative, with a sectored, 64-byte cache line size”, 同理 0x70 查询上表可以知道系统包含了 “Trace cache: 12 K - μop, 8-way set associative”. 不同的架构值存在差异,也可以看到上图有很多 TLB 相关的信息,因此可以通过 CPUID 工具获得 TLB 硬件结构相关信息.
Perf 工具记录 TLB hit/miss
Perf 是 Linux 的一款性能分析工具,能够进行函数级和指令级的检测,可以用来分析程序中热点函数的 CPU 占用率,从而定位性能瓶颈。Perf 也能检测系统 TLB Hit 和 Miss 率,从而提供优化方向的数据指标。本节重点描述 Perf 与 TLB 相关的分析:
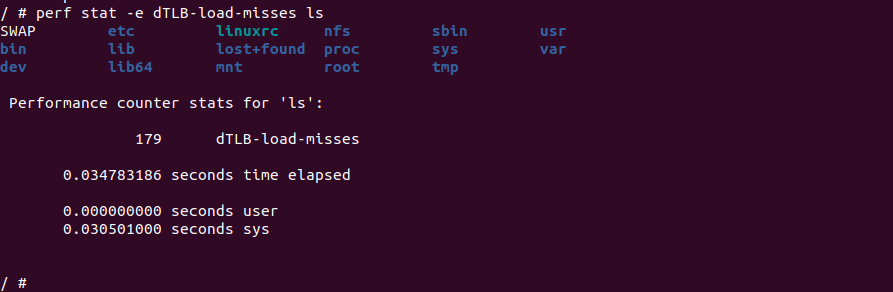
perf stat -e dTLB-load-misses ${APP}perf stat 命令中的 dTLB-load-misses 事件监听的是数据 TLB 的加载(load)未命中(miss)事件. 数据 TLB 是 CPU 中用于存储虚拟地址到物理地址的转换信息的高速缓存。当程序访问一个虚拟地址,而该地址的转换信息不在数据 TLB 中时,就会发生数据 TLB 加载未命中。这时 CPU 需要访问内存来获取相应的转换信息,将其加载到数据 TLB 中,然后再进行地址转换。通过使用 perf stat -e dTLB-load-misses 命令,可以监测程序执行期间发生的数据 TLB 加载未命中的次数。这个事件的统计结果可以帮助分析程序的内存访问模式,了解数据 TLB 的效率以及对性能优化进行定位。
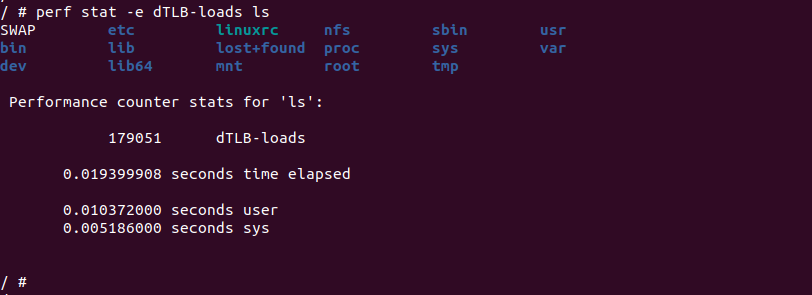
perf stat -e dTLB-loads ${APP}perf stat 命令中的 dTLB-loads 事件监听的是数据 TLB 的加载(load)事件。数据 TLB 是 CPU 中的一个高速缓存,用于存储虚拟地址到物理地址的转换信息。当程序访问一个虚拟地址时,CPU 会首先查找数据 TLB,如果转换信息存在于数据 TLB 中,则可以直接进行地址转换,从而提高访问效率。而如果数据 TLB 中不存在所需的转换信息,则会发生数据 TLB 加载事件。通过使用 perf stat -e dTLB-loads 命令,可以统计程序执行期间发生的数据 TLB 加载事件的次数。这个事件的统计结果可以帮助分析程序的内存访问模式和数据 TLB 的效率,以及进行性能调优和优化.
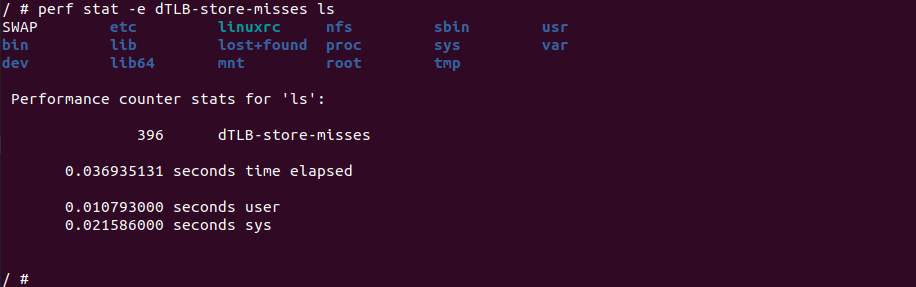
perf stat -e dTLB-store-misses ${APP}perf stat 命令中的 dTLB-store-misses 事件监听的是数据 TLB 的存储(store)缺失事件。数据 TLB 是 CPU 中的一个高速缓存,用于存储虚拟地址到物理地址的转换信息。当程序执行写操作并访问一个虚拟地址时,CPU 会首先查找数据 TLB,如果转换信息存在于数据 TLB 中,则可以直接进行地址转换和写入操作。而如果数据 TLB 中不存在所需的转换信息,则会发生数据 TLB 的存储缺失事件。通过使用 perf stat -e dTLB-store-misses 命令,可以统计程序执行期间发生的数据 TLB 的存储缺失事件的次数。这个事件的统计结果可以帮助分析程序的内存访问模式和数据 TLB 的效率,以及进行性能调优和优化。
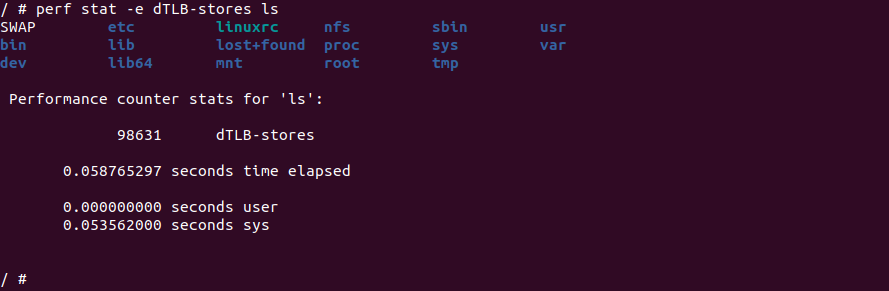
perf stat -e dTLB-stores ${APP}perf stat 命令中的 dTLB-stores 事件监听的是数据 TLB 的存储(store)操作。数据 TLB 是 CPU 中的一个高速缓存,用于存储虚拟地址到物理地址的转换信息。当程序执行写操作并访问一个虚拟地址时,CPU 会首先查找数据 TLB,如果转换信息存在于数据 TLB 中,则可以直接进行地址转换和写入操作。dTLB-stores 事件统计的是程序执行期间发生的数据 TLB 的存储操作的次数。通过使用 perf stat -e dTLB-stores 命令,可以获取程序执行期间数据 TLB 的存储操作次数的统计结果。这个事件的统计信息可以帮助我们了解程序中写操作的频率和数据 TLB 的使用情况,有助于进行性能分析和优化。
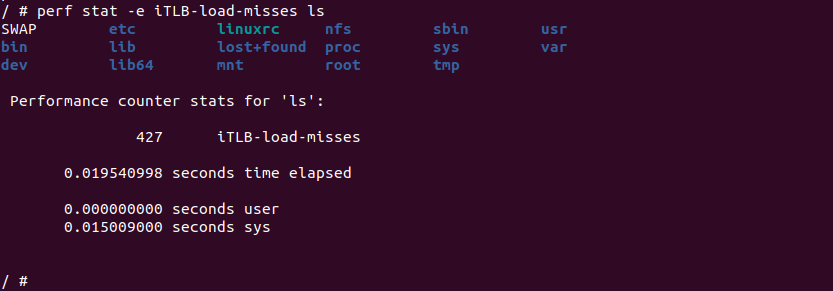
perf stat -e iTLB-load-misses ${APP}perf stat 命令中的 iTLB-load-misses 事件监听的是指令 TLB 的加载(load)操作中的缺失(miss)次数。指令 TLB 是 CPU 中的一个高速缓存,用于存储虚拟地址到物理地址的转换信息,针对指令的加载操作。当程序执行指令时,CPU 会根据指令的虚拟地址查找指令 TLB,如果转换信息不在指令 TLB 中,则发生了指令 TLB 的缺失,CPU 需要通过访问页表等方式获取正确的转换信息。iTLB-load-misses 事件统计的就是程序执行期间发生的指令 TLB 缺失的次数。通过使用 perf stat -e iTLB-load-misses 命令,可以获取程序执行期间指令 TLB 缺失次数的统计结果。这个事件的统计信息可以帮助我们了解程序中指令访问的频率和指令 TLB 的使用情况,有助于进行性能分析和优化。
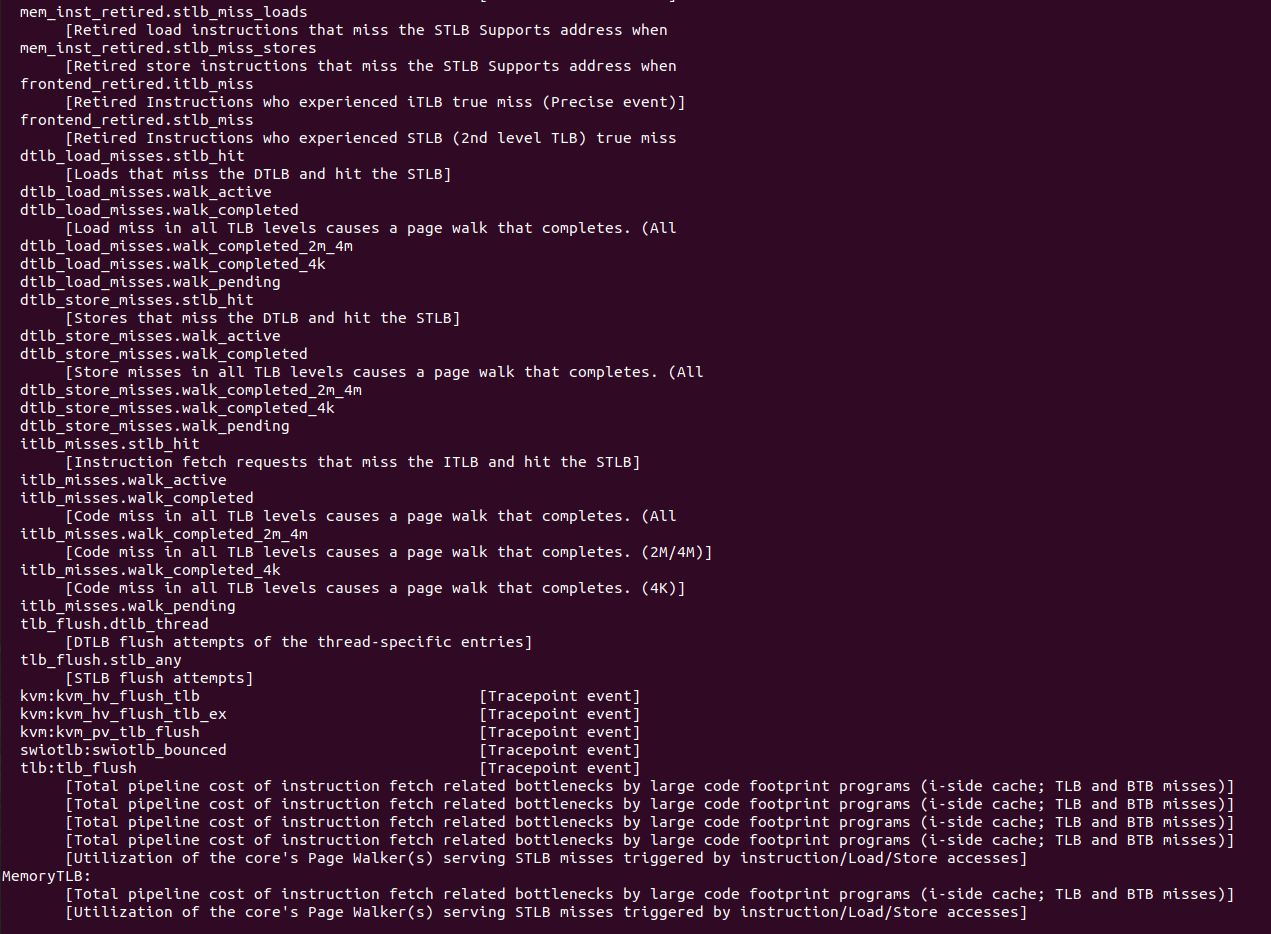
perf stat -e ${EVENT} ${APP}perf 工具还支持更多与 TLB 相关的事件,但由于硬件的差异,有的事件不支持,开发者可以使用上面的命令对这些事件进行监听,这里就不逐一进行介绍. 支持 perf 工具对 TLB 提供的信息进而优化程序性能.

QEMU 虚拟机查看 TLB 映射关系
QEMU 监控器 是 QEMU 与实现用户交互的一种控制台,一般用于为 QEMU 模拟器提供较为复杂的功能,包括如下: 为客户机添加和移除一些媒体镜像(如 CD-ROM) 暂停和继续客户机的运行,快照的建立和删除 从磁盘文件中保持和恢复客户机状态, 其中也包括查看 TLB 内部 TLB Entry 的内容:
上图是 DTLB Entry 的内容结构,其由 4 部分组成,其内容均来自 PTE,每个字段的含义如下:
- Page Frame: 物理地址的 [12: MAX] 字段
- R/W: 指明映射具有读写权限
- U/S: 指明映射是用户空间虚拟地址(U)还是内核空间虚拟地址(S)
- XD: 指明是否具有可执行权限
- Protection Key: 更细粒度的内存访问控制
- Dirty: 指明物理页内容是否被修改
- Memory Type: 由于描述映射的内存类型,例如 UC/WC/WB 等
- PCID: 线性空间标识

QEMU Monitor 工具可以查看虚拟机的 TLB Entry 内容,当 QEMU 进入监听模式之后,其使用 info tlb 获得所有的 TLB 映射关系,打印的信息结构为: 虚拟地址 : Page Frame : Access : Attribute

Madvise: MADV_FREE 场景
在 Linux 里提供了 madvise 机制,其作用是向内核提供有关内存区域的建议。允许应用程序向内核传递关于内存使用模式的信息,以便内核可以根据这些建议来优化内存管理。MADV_FREE 是其中一种建议,用于告诉内核特定的内存区域不再被进程使用,并且可以释放底层物理内存资源。那么该过程会涉及页表的释放,因此可能会触发 TLB FLUSH,那么接下来通过一个实践案例体验 MADV_FREE 建议 FLUSH TLB 的过程,实践案例在 BiscuitOS 里的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] TLB FLUSH on MADV_FREE --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-MADV-FREE-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build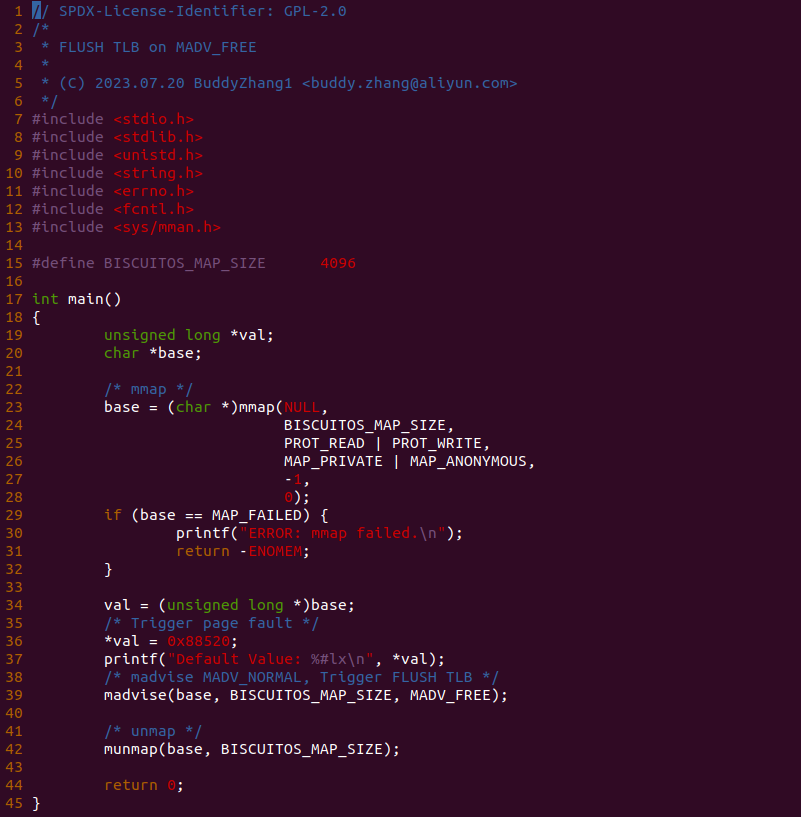
实践案例是一个用户空间程序,其映射了一段可读可写的虚拟内存,然后对虚拟内存写入 0x88520 之后,调用 madvise() 函数对虚拟地址建议 MAVD_FREE, 即释放虚拟内存对应的物理内存,那么会将对应的页表页清空,即修改页表,那么会触发 TLB FLUSH。接下来现在 BiscuitOS 实践该案例:
BiscuitOS 启动完毕之后,运行应用程序 BiscuitOS-TLB-FLUSH-MADV-FREE-default,可以看到打印了 0x88520, 软件上并没有任何感知 TLB Invalidate 动作,那么看看内核是如何将虚拟地址对应的 TLB Entry Invalidate?
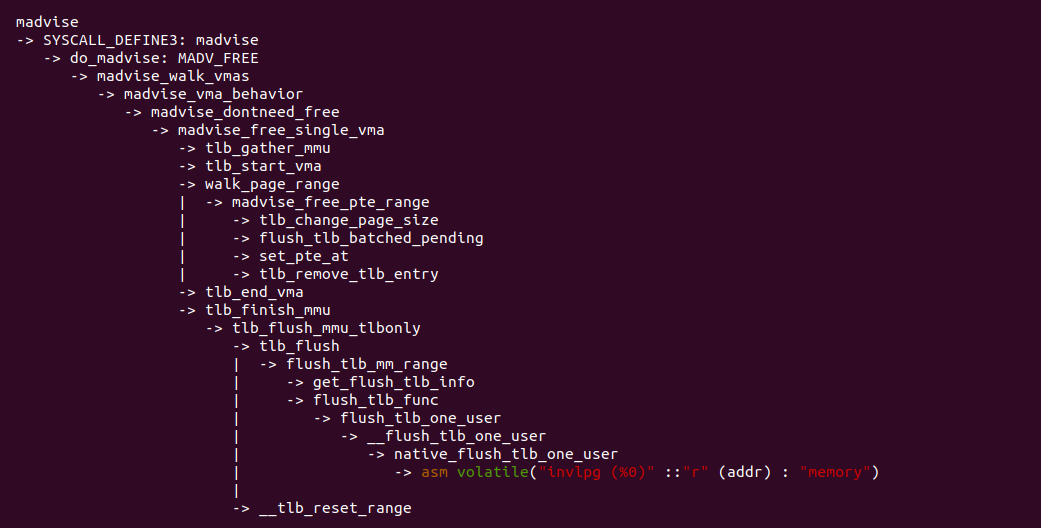
madvise 函数经过系统调用进入到内核,在 do_madvise() 函数里面处理 MAVD_FREE 建议,最终调用 madvise_free_single_vma() 函数,里面涉及到更新页表,然后刷新 TLB,依旧按照 MMU Gather 机制的流程来刷新 TLB. 该场景也是很常见的场景,程序会主动释放不需要的物理内存,因此会涉及到页表修改,那么需要及时更新 TLB.
Madvise: MADV_DONTNEED/MADV_DONTNEED_LOCKED 场景
在 Linux 里提供了 madvise 机制,其作用是向内核提供有关内存区域的建议。允许应用程序向内核传递关于内存使用模式的信息,以便内核可以根据这些建议来优化内存管理。MADV_DONTNEED 是其中一种建议,用于在进程不再使用某个内存区域时,建议内核将该区域的物理页面释放回系统,以便供其他进程使用。那么该过程会涉及页表的释放,因此可能会触发 TLB FLUSH,那么接下来通过一个实践案例体验 MADV_DONTNEED 建议 FLUSH TLB 的过程,实践案例在 BiscuitOS 里的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] TLB FLUSH on MADV_DONTNEED --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-MADV-DONTNEED-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-TLB-FLUSH-MADV-DONTNEED-default Source Code on Gitee
实践案例是一个用户空间程序,其映射了一段可读可写的虚拟内存,然后对虚拟内存写入 0x88520 之后,调用 madvise() 函数对虚拟地址建议 MAVD_DONTNEED, 即释放虚拟内存对应的物理内存,那么会将对应的页表页清空,即修改页表,那么会触发 TLB FLUSH。接下来现在 BiscuitOS 实践该案例:
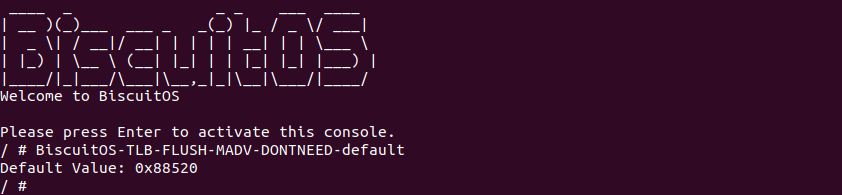
BiscuitOS 启动完毕之后,运行应用程序 BiscuitOS-TLB-FLUSH-MADV-DONTNEED-default,可以看到打印了 0x88520, 软件上并没有任何感知 TLB Invalidate 动作,那么看看内核是如何将虚拟地址对应的 TLB Entry Invalidate?
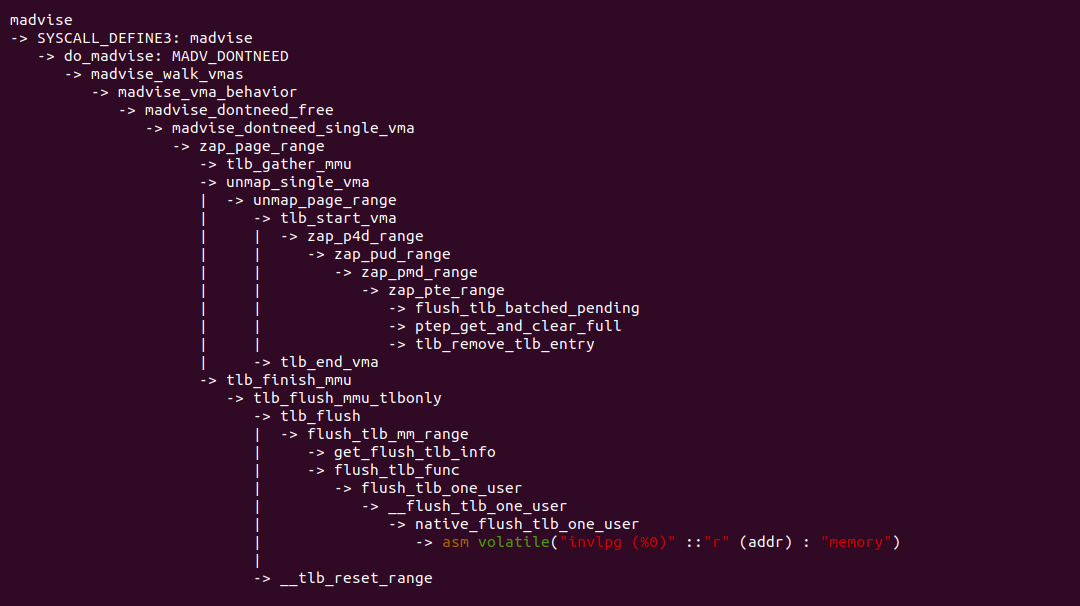
madvise 函数经过系统调用进入到内核,在 do_madvise() 函数里面处理 MAVD_DONTNEED 建议,最终调用 madvise_dontneed_single_vma() 函数,里面涉及到更新页表,然后刷新 TLB,依旧按照 MMU Gather 机制的流程来刷新 TLB. 该场景也是很常见的场景,程序会主动释放不需要的物理内存,因此会涉及到页表修改,那么需要及时更新 TLB.
Madvise: MADV_PAGEOUT SWAPOUT 场景
在 Linux 里提供了 madvise 机制,其作用是向内核提供有关内存区域的建议。允许应用程序向内核传递关于内存使用模式的信息,以便内核可以根据这些建议来优化内存管理。MADV_PAGEOUT 是其中一种建议,是告诉内核将指定的内存区域的页面移出物理内存,以释放内存资源。那么该过程会涉及页表的释放,因此可能会触发 TLB FLUSH,那么接下来通过一个实践案例体验 MADV_PAGEOUT 建议 FLUSH TLB 的过程,实践案例在 BiscuitOS 里的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] TLB FLUSH on MADV_PAGEOUT --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-MADV-PAGEOUT-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make buildBiscuitOS-TLB-FLUSH-MADV-PAGEOUT-default Source Code on Gitee
实践案例是一个用户空间程序,其映射了一段可读可写的虚拟内存,然后对虚拟内存写入 0x88520 之后,调用 madvise() 函数对虚拟地址建议 MAVD_PAGEOUT, 即将虚拟地址对应的物理地址 SWAP OUT 到 SWAP SPACE 上,这样会涉及修改页表,那么会触发 TLB FLUSH。接下来现在 BiscuitOS 实践该案例:
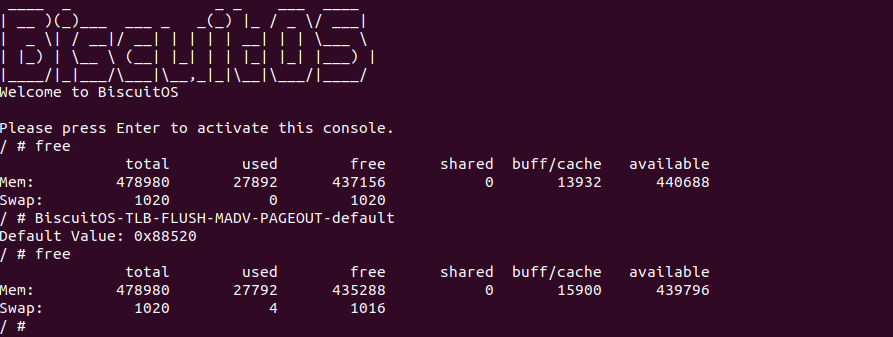
BiscuitOS 启动完毕之后,运行应用程序 BiscuitOS-TLB-FLUSH-MADV-PAGEOUT-default,可以看到打印了 0x88520, 另外使用 free 命令可以看到 SWAP Space 新增了一个物理页,因此页表被修改,但软件上并没有任何感知 TLB Invalidate 动作,那么看看内核是如何将虚拟地址对应的 TLB Entry Invalidate?
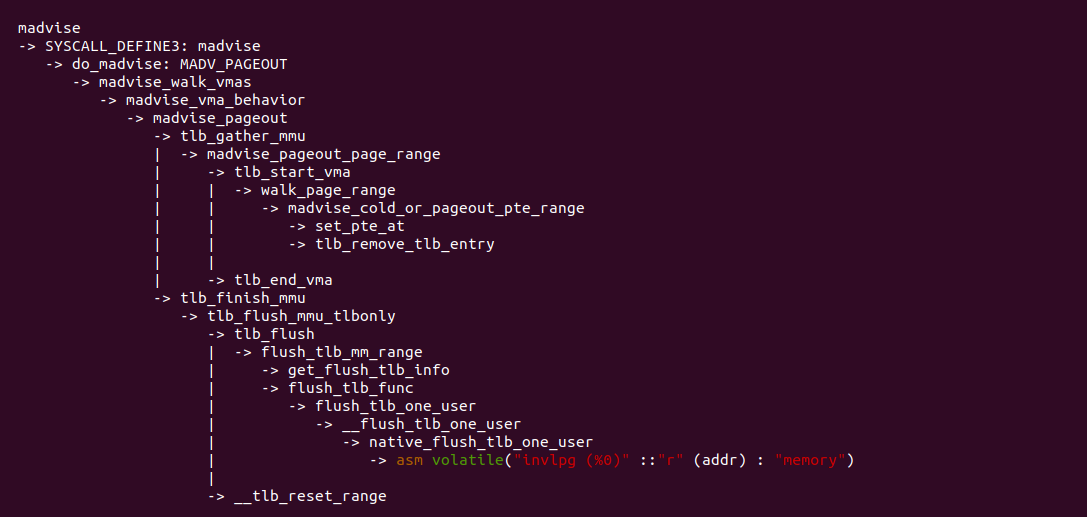
madvise 函数经过系统调用进入到内核,在 do_madvise() 函数里面处理 MAVD_PAGEOUT 建议,最终调用 madvise_pageout() 函数,里面涉及到更新页表,然后刷新 TLB,依旧按照 MMU Gather 机制的流程来刷新 TLB. 该场景也是很常见的场景,程序会主动释放不需要的物理内存,因此会涉及到页表修改,那么需要及时更新 TLB.
Madvise: MADV_COLD 冷页场景
在 Linux 里提供了 madvise 机制,其作用是向内核提供有关内存区域的建议。允许应用程序向内核传递关于内存使用模式的信息,以便内核可以根据这些建议来优化内存管理。MADV_COLD 是其中一种建议,于指示内核将内存区域标记为冷(cold),即该区域的页面很可能长时间未被访问。那么该过程会涉及页表修改,因此可能会触发 TLB FLUSH,那么接下来通过一个实践案例体验 MADV_COLD 建议 FLUSH TLB 的过程,实践案例在 BiscuitOS 里的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] TLB FLUSH on MADV_COLD --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-MADV-COLD-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
实践案例是一个用户空间程序,其映射了一段可读可写的虚拟内存,然后对虚拟内存写入 0x88520 之后,调用 madvise() 函数对虚拟地址建议 MAVD_COLD, 即将虚拟地址标记为 COLD 区域,这样会涉及修改页表,那么会触发 TLB FLUSH。接下来现在 BiscuitOS 实践该案例:
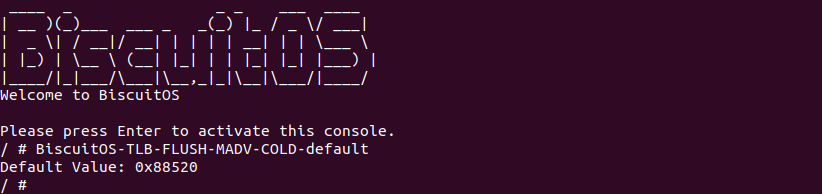
BiscuitOS 启动完毕之后,运行应用程序 BiscuitOS-TLB-FLUSH-MADV-COLD-default,可以看到打印了 0x88520, 软件上并没有任何感知 TLB Invalidate 动作,那么看看内核是如何将虚拟地址对应的 TLB Entry Invalidate?
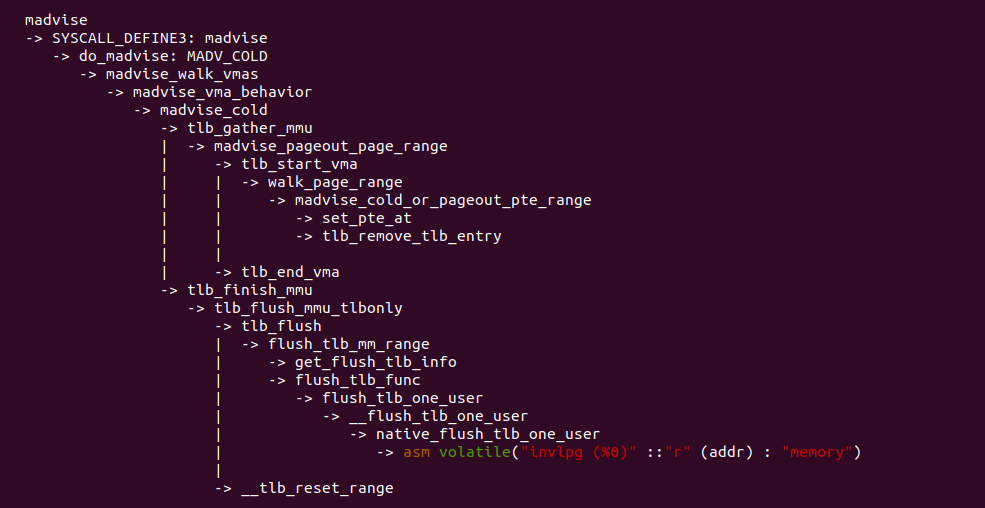
madvise 函数经过系统调用进入到内核,在 do_madvise() 函数里面处理 MAVD_COLD 建议,最终调用 madvise_cold() 函数,里面涉及到更新页表,然后刷新 TLB,依旧按照 MMU Gather 机制的流程来刷新 TLB. 该场景也是很常见的场景,程序会主动释放不需要的物理内存,因此会涉及到页表修改,那么需要及时更新 TLB.

Mprotect: Change Page Attribute 场景
在 Linux 里提供了 mprotect 机制,其作用是更改内存区域的保护属性。内存区域的保护属性存储在页表内,那么 mprotect 会修改页表,因此涉及到 FLUSH TLB 操作。mprotect 可以修改的保护权限包括: 可读、可写、可执行、不可访问。那么接下来通过一个实践案例体验 mprotect 修改保护属性导致的 FLUSH TLB 的过程,实践案例在 BiscuitOS 里的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] TLB FLUSH: Adjust VMA Protection(mprotect) --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-MPROTECT-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build
实践案例是一个用户空间程序,其映射了一段可读可写的虚拟内存,然后对虚拟内存写入字符串 “Hello BiscuitOS” 之后,调用 mprotect() 函数修改了虚拟内存的页表属性,将其设置为只读。由于修改了页表,那么内核需要将虚拟地址对应的 TLB Entry Invalidate。那 么接下来现在 BiscuitOS 实践该案例:
BiscuitOS 启动完毕之后,运行应用程序 BiscuitOS-TLB-FLUSH-MPROTECT-default,可以看到打印了字符串 “Hello BiscuitOS”, 软件上并没有任何感知 TLB Invalidate 动作,那么看看内核是如何将虚拟地址对应的 TLB Entry Invalidate?
通过对 mprotect 函数的系统调用路径跟踪,可以看到 mprotect 修改完页表内容之后,还是调用 tlb_flush() 去更新虚拟地址对应的 TLB Entry,最终还是调用到 INVLPG 指令完成 TLB Entry Invalidate.
MTRRs 物理区域 Memory Type 设置场景
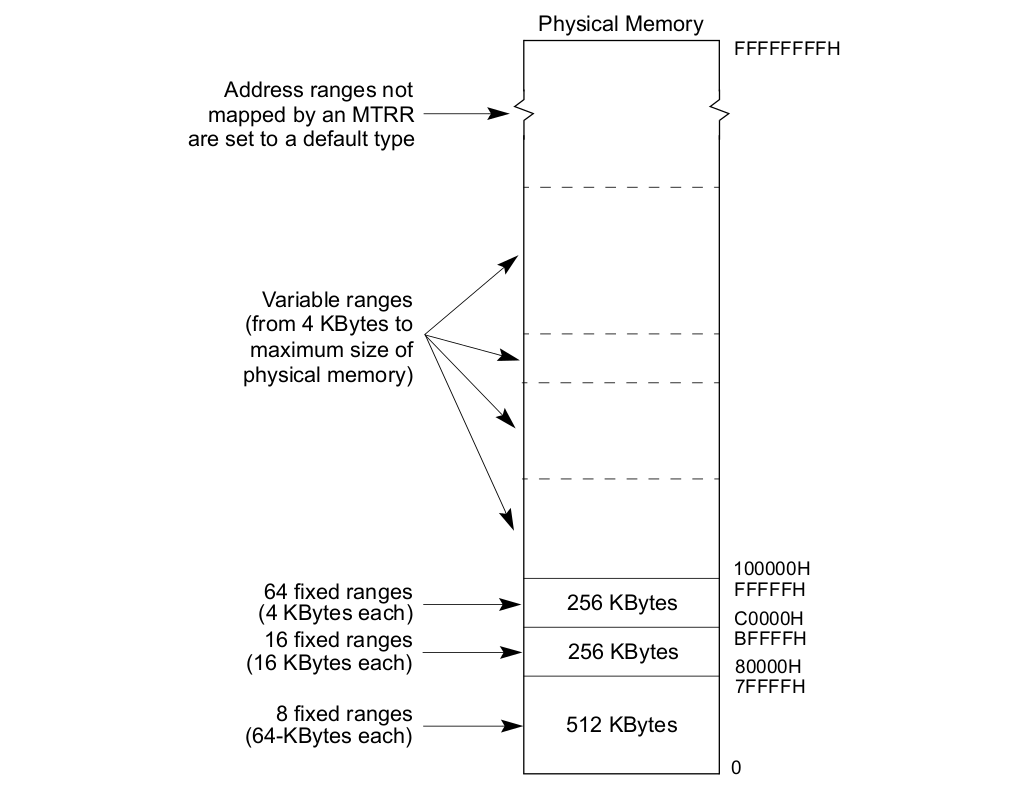
MTRRs(The memory type range registers): Intel® 在 P6 之后向系统提供了 MTRRs 技术,MTRRs 运行为 RAM、ROM、Frame-Buffer 内存和 MMIO 对应的物理区域设置不同的 Memory Type. MTRRs 机制通过提供一系列的 MSR 寄存器用于指定物理区域范围和 Memory Type,上表描述了 MTRR 映射物理区域的范围,可以分为三类:
- 固定物理区域 MTRRs(Fixed MTRRs), MTRRs 提供了多个 MSR 寄存器,这些寄存器针对固定的物理区域可以设置指定的 Memory Type
- 可变物理区域 MTRRs(Variable MTRRs), MTRRs 提供了多对 MSR 寄存器,每一对寄存器可以设置物理区域和 Memory Type
- 默认 MTRR(Default MTRRs), MTRRs 提供了一个 MSR 用于设置默认的 Memory Type,针对不在前两种覆盖范围的物理区域,均采用默认的 Memory Type.
prepare_set 函数是设置 MTRRs 之前的准备,可以看到在 770 行调用 mtrr_wrmsr() 函数之前在 764 行调用 flush_tlb_local() 函数将所有的 TLB 刷新,以此所有的 CPU 在 MTRRs 生效之后都访问新的 TLB 内容.
post_set 函数是设置 MTRRs 之后的收尾,可以看到 784 行在调用 mtrr_wrmsr() 函数使 MTRRs 生效之前,在 781 行调用 flush_tlb_local() 函数再次刷新所有 TLB,最后确保 MTRRs 最终生效之后,所有的 CPU 都访问新的 TLB 内容.
TLB Shootdown
TLB Shootdown 是一种处理 TLB 缓存失效的机制。TLB 是一个硬件高速缓存,用于存储虚拟地址到物理地址的映射关系。当操作系统修改了页表或进行内存管理操作时,可能会导致 TLB 中的映射信息过期或无效,需要进行 TLB 缓存的失效(invalidation)。TLB Shootdown 是指通过通知其他 CPU 或处理器核心将其 TLB 中的特定或全部条目无效,以确保内存映射的一致性。这通常发生在以下情况下:
- 内核修改了一个页面的访问权限或映射关系
- 一个页面被删除或重新映射到不同的物理地址
- 在多处理器系统中,一个 CPU 更新了页表并需要通知其他 CPU 更新它们的 TLB。
当发生 TLB Shootdown 时,操作系统需要协调各个 CPU 或处理器核心之间的通信,以确保正确的 TLB 缓存失效。这可能涉及中断、同步原语、IPI(Inter-Processor Interrupt) 等机制。TLB Shootdown 是一项复杂的任务,其效率对系统性能和多核并发操作的影响非常重要。因此,在设计和实现操作系统内存管理和多处理器机制时,需要充分考虑和优化 TLB Shootdown 的策略和实现,以提高系统的性能和响应性。那么接下来通过一个实践案例了解什么是 TLB Shootdown,实践案例在 BiscuitOS 部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] TLB Shootdown --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-SHOOTDOWN-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build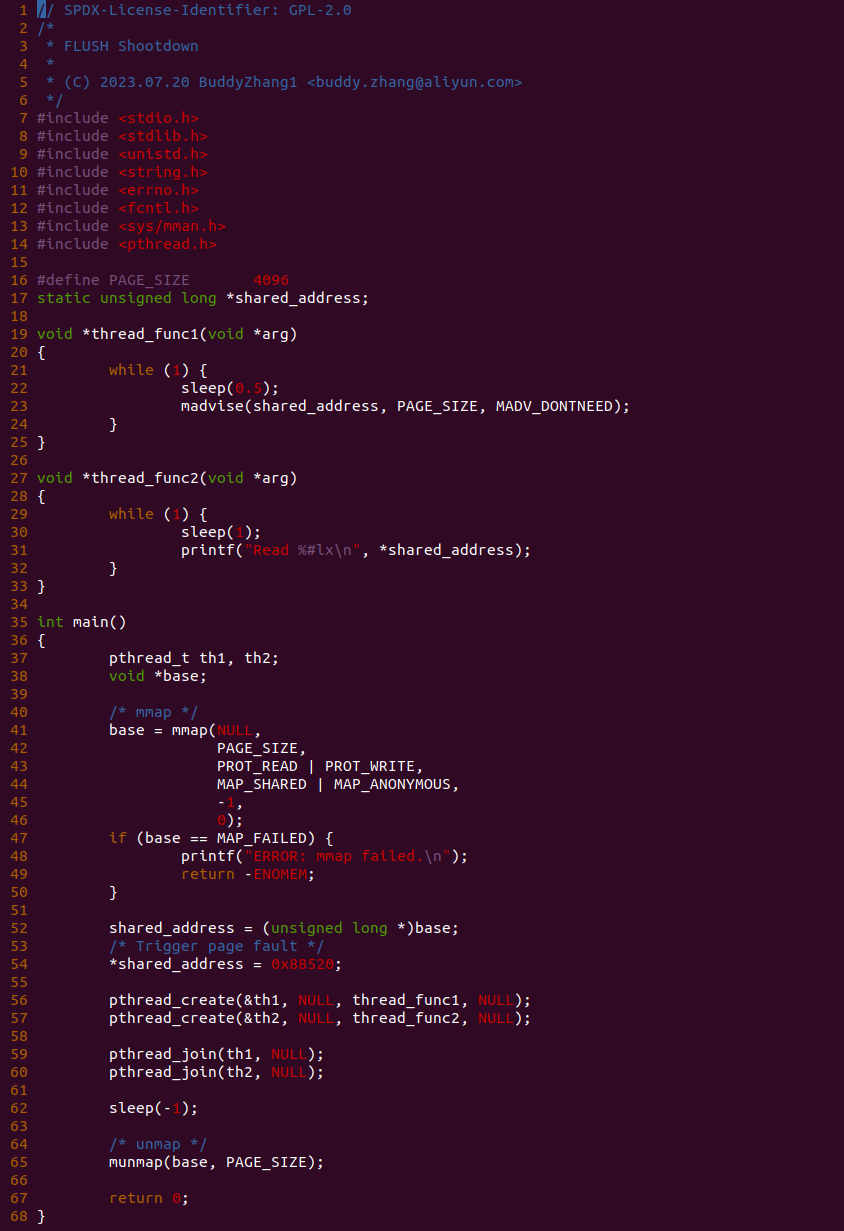
实践案例是一个用户空间程序,程序首先分配一段虚拟内存,然后对虚拟内存写入 0x88520, 接着启动两个线程,线程 th1 每隔 0.5 秒将共享的虚拟内存对应的物理内存释放,而另外一个线程 th2 每隔 1 秒读取虚拟内存, 如此循环下去。那么接下来在 BiscuitOS 上实践该案例:
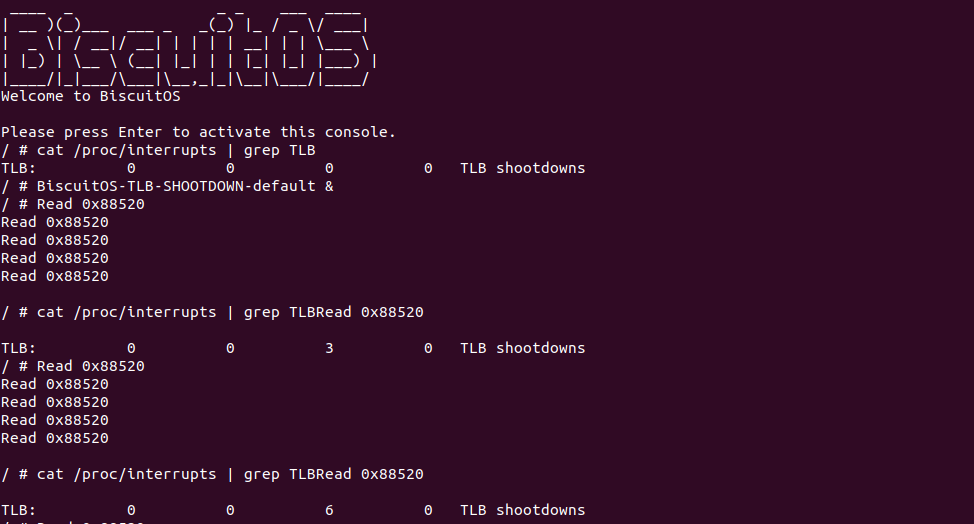
BiscuitOS 启动完毕之后,首先查看 TLB Shootdown 中断,可以看到一开始 4 个 CPU 都没有收到任何 TLB Shootdown 中断,接着后台运行应用程序 BiscuitOS-TLB-SHOOTDOWN-default,可以线程从共享内存中读到 0x88520, 并且发现线程每当读取一次内存,那么 TLB Shootdown 中断就加一. 通过实践案例发现一个线程执行 FLUSH TLB 的时候同时也将其他包含该虚拟地址映射的 TLB 也刷新,那么在案例中,另外一个线程对虚拟地址也有访问,那么其 TLB 内部也缓存了映射关系,那么其中一个线程 FLUSH TLB 的时候,也要通知另外一个线程去 FLUSH TLB. 在 X86 架构,当 TLB 刷新时,其他 CPU TLB 也有副本时,硬件会产生 TLB Shootdown 中断,该中断是一个硬中断. 在 x86 架构中,TLB Shootdown 中断是一种特殊的中断,用于处理与 TLB FLUSH 相关的操作。当需要刷新或失效 TLB 条目时,内核会触发 TLB Shootdown 中断,以确保处理器上的 TLB 与内存的一致性. TLB Shootdown 中断通常由以下情况触发:
- 进程切换: 当一个进程切换到另一个进程时,内核需要刷新当前进程的 TLB 条目,以避免进程间的地址空间冲突
- 内存映射更改: 当内存映射发生更改,例如通过 mmap 函数映射新的内存区域或释放内存区域时,内核需要刷新相关的 TLB 条目
- 多核同步: 在多核系统中,当一个核心修改了共享内存区域的权限或映射关系时,其他核心的 TLB 条目需要进行更新
TLB Shootdown 中断允许内核通知处理器执行 TLB 条目的刷新或失效。处理器收到 TLB Shootdown 中断后,会根据内核提供的信息执行相应的操作,如刷新 TLB 条目或使其失效。这样处理器就能够保持与内核的一致性,避免使用过时的 TLB 条目。另外一点是大量的上下文切换导致频繁的 TLB 失效,引发大量的 TLB Shootdown 中断,因此在某些场景中应该避免该问题,另外虚拟机也需要避免大量的 TLB Shootdown. TLB Related Video 提供了几个关于 TLB Shootdown 的描述.
修改页表不刷新 TLB 引起的问题研究
TLB 的主要作用是缓存虚拟地址与最后一级页表的映射关系,如果修改页表之后不刷新 TLB 会引起什么问题呢? 通过上文的学习知道 TLB 是无法感知软件对 PTE 页表的修改的,因此需要使用 MMU Gather 等机制来刷新 TLB。本文就研究一下修改 PTE 页表不刷新 TLB 的影响,依旧从一个实践案例开始,其在 BiscuitOS 上的部署逻辑如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] Modify PTE with/without FLUSH TLB --->
<*> Modify PTE with/without FLUSH TLB on Userspace --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-MODIFY-PTE-default/
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-MODIFY-PTE-APP-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make prepare
make buildBiscuitOS-TLB-FLUSH-MODIFY-PTE-default Source Code on Gitee
BiscuitOS-TLB-FLUSH-MODIFY-PTE-APP-default Source Code on Gitee
实践案例由两部分组成,其一是用户空间程序,其通过 open 函数打开 “/dev/BiscuitOS” 节点,然后调用 mmap 函数分配一段内存,然后在 48 行向虚拟内存写入 ‘B’, 然后在 52 行调用 ioctl() 函数向内核空间发起 BS_FLUSH_TLB 请求,该请求会将虚拟内存的权限修改为只读,然后刷新 TLB,最后在 54 行再次对虚拟内存执行写操作。
实践案例的另外一部分是一个内核模块,其由一个 MSIC 驱动构成,其在 Linux 生成 “/dev/BiscuitOS” 节点,对该节点提供了 ioctl 接口,当用户空间打开该节点,然后调用 ioctl 函数之后会调用到 BiscuitOS_ioctl() 函数,BiscuitOS_ioctl() 函数支持 BS_FLUSH_TLB 和 BS_NOFLUSH_TLB 请求,其中 BS_FLUSH_TLB 请求会修改虚拟地址的页表为只读,并且会刷新对应的 TLB; BS_NOFLUSH_TLB 请求只会修改虚拟地址对应的页表为只读,且不会刷新 TLB。BiscuitOS_flush() 函数为修改 PTE 页表的核心函数,28-43 行代码用于修改 PTE 页表为只读,并刷新 TLB; 45-50 行代码只修改 PTE 页表为只读. 那么接下来先实践用户空间下发 BS_FLUSH_TLB 请求的情况:
BiscuitOS 启动之后,运行应用程序 BiscuitOS-TLB-FLUSH-MODIFY-PTE-APP-default,此时可以看到对只读内存写操作时会触发系统异常,最后程序因为 Segmentation fault 退出. 那么接下来修改应用程序,将 52 行 ioctl() 函数的请求替换成 BS_NOFLUSH_TLB,然后再次实践:
BiscuitOS 启动之后,运行应用程序 BiscuitOS-TLB-FLUSH-MODIFY-PTE-APP-default,此时可以看到 Change PTE Without FLUSH TLB 字符串已经打印,说明此时只修改了 PTE 页表并没有刷新 TLB,那么 TLB 里依旧存储着虚拟地址与旧 PTE 的映射,因此此时应用程序对只读内存还是可写。通过这个实践案例,让开发者更加了解修改页表之后及时刷新 TLB 重要性. 刷新 TLB 的意义在于确保 CPU 的地址转换信息与内存中的实际映射保持一致。TLB 是 CPU 的高速缓存,用于加速虚拟地址到物理地址的转换过程。当 CPU 执行指令时,需要将虚拟地址转换为对应的物理地址,这个过程涉及到查找 TLB 中的映射表。TLB 中的映射表在以下情况下可能变得不准确或过时:
- 内存映射的修改: 当操作系统或应用程序更改了内存映射关系,例如调用 mmap()、munmap() 等函数,导致页表或页面映射发生变化
- 多处理器环境下的竞争条件: 在多处理器系统中,不同的 CPU 可能同时修改相同的内存映射,这可能导致 TLB 中的映射表变得不一致
因此,为了确保地址转换的准确性,必须定期刷新 TLB。TLB 刷新会使 TLB 中的映射表无效,让 CPU 重新从页表或其他缓存中获取最新的地址映射信息。通常 TLB 刷新发生在以下情况:
- 内核更新页表: 当内核修改进程的页表信息时,会触发 TLB 刷新
- 进程上下文切换: 当操作系统从一个进程切换到另一个进程时,会触发 TLB 刷新,以确保新进程的地址映射正确。
- 硬件辅助: 某些处理器提供硬件支持,允许在特定情况下手动触发 TLB 刷新。
刷新 TLB 确保了虚拟地址的正确映射,从而保证程序执行时的地址转换的准确性和性能。在多处理器环境下,TLB 刷新还有助于避免因不一致的映射表导致的竞争条件和数据不一致性问题。因此,TLB 刷新是操作系统和硬件系统中的一个重要操作,用于维护地址转换的一致性和正确性。
ASID vs PCID
在 Linux 中,ASID 和 PCID 都是用于管理地址空间的标识符,但它们在不同的场景下起作用,并且有一些差异。
- ASID(Address Space ID): ASID 是一种用于标识不同地址空间的编号。每个进程在内核中都有一个唯一的 ASID。当操作系统进行进程上下文切换时,会切换 ASID,以便 CPU 知道正在处理的是哪个进程的地址空间。ASID 的主要作用是在进程切换时加速 TLB 刷新。TLB 是 CPU 的高速缓存,用于加速虚拟地址到物理地址的转换。当进程切换时,需要刷新 TLB,否则可能导致地址转换出现错误。ASID 的引入使得 CPU 可以更有效地刷新 TLB,避免了不必要的全局 TLB 刷新,从而提高了性能
- PCID(Process Context IDentifier): PCID 是用于标识不同进程上下文的编号。在支持 Intel 的 Extended Page Table(EPT)或 AMD 的 Nested Page Table(NPT) 的虚拟化环境中,每个虚拟机或每个进程都有一个唯一的 PCID。PCID 允许 CPU 在虚拟化环境下缓存多个不同进程的页表信息,从而提高了虚拟地址到物理地址的转换效率。PCID 的主要作用是加速虚拟化环境中的地址转换,特别是在进程上下文切换时,避免频繁刷新页表
- ASID 用于标识不同的进程地址空间,用于进程切换时的 TLB 刷新
- PCID 用于标识不同的进程上下文,用于虚拟化环境中的地址转换
虽然 ASID 和 PCID 在不同的场景下起作用,但它们的目标都是加速地址转换过程,提高系统的性能和效率。在支持的硬件和内核环境中,它们可以共同发挥作用,提供更好的性能和虚拟化支持.
ASID
在 x86 架构下,ASID(Address Space ID) 用于标识不同的进程或地址空间。x86 架构中的 ASID 是通过 CR3 寄存器的低 12 位来表示的。CR3 寄存器是用于存储当前进程的页表基地址(Page Directory Base Address),它是地址转换的关键之一。在 CR3 寄存器的低 12 位中,存储了 ASID 的值,这个值被称为 Process Context Identifier(PCID)。在 x86 架构中,PCID 的范围是 0 到 4095,共有 4096 个不同的 ASID。在进行进程上下文切换时,操作系统会将新进程的页表基地址加载到 CR3 寄存器中,并且更新 ASID 的值,以便 CPU 能够区分不同进程的地址空间。当进行进程切换后,之前进程的 ASID 就失效了,而新进程的 ASID 将生效。ASID 的引入使得 CPU 可以更有效地刷新 TLB,避免了不必要的全局 TLB 刷新,从而提高了地址转换的性能和效率。
PCID
在 x86 架构下,PCID(Process Context Identifier) 用于标识 TLB 中的页表项是否有效。PCID 是在 Intel 架构中引入的一项优化技术,它允许 CPU 在 TLB 中缓存多个页表,以减少 TLB 刷新的开销。在 x86 架构中,PCID 是通过 CR3 寄存器的高 12 位来表示的。CR3 寄存器是用于存储当前进程的页表基地址(Page Directory Base Address),它是地址转换的关键之一。CR3 寄存器的高 12 位用来存储 PCID 的值,范围是 1 到 4095,共有 4095 个不同的 PCID。PCID 的值为 0 时表示禁用 PCID 特性,即所有的 TLB 项都是全局的,没有关联任何特定的 PCID。在使用 PCID 特性时,每个进程都可以拥有自己的 PCID 值,并且可以在TLB中缓存不同的页表。当进行进程切换时,操作系统会更新 CR3 寄存器中的页表基地址,并根据新的 PCID 值刷新 TLB,以确保 TLB 中的页表项与当前进程的页表一致。PCID 的引入使得 TLB 刷新更加高效,减少了不必要的 TLB 刷新开销,从而提高了地址转换的性能和效率。
Hugetlbfs Page 与 TLB 关系
在 Linux 中,hugetlbfs 是一种特殊的文件系统,用于向用户空间提供并管理大页(Huge Pages)。大页是指比标准页(通常为4KiB)更大的页,可以是 2MB、1GB 或其他大尺寸的页。大页主要用于优化内存管理,特别是在处理大规模的内存映射时,如数据库、虚拟机等应用场景。相较于小页,大页能够减少页表项的数量,从而降低了TLB 的压力。
例如一个 2MiB 的大页,其大小等于 512 个 4KiB 页,那么 512 个 4KiB 页需要 512 个 PTE 进行映射,那么 TLB 需要 512 个 TLB Entry 映射与 PTE 的关系; 2MiB 大页只需要一个 PMD 进行映射,那么 TLB 只需一个 LargeTLB 的 TLB Entry 进行描述虚拟地址到 2MiB 物理页的映射。同理 1Gig 的大页占用一个 LargeTLB 的 TLB Entry 就能描述 1G 虚拟内存与 1G 物理内存的映射关系。
在有的架构是不存在 LargeTLB 的,那么映射一个 2MiB 大页的时候,TLB 还是会将 2MiB 虚拟内存映射拆分成 4KiB 虚拟区域进行映射,但在 X86 架构下,其存在 LargeTLB 硬件,那么 4KiB 页映射放在普通的 TLB 硬件里,而大页全部放在 LargeTLB 里. 但一个 CPU 访问一个虚拟地址时,首先截取虚拟地址的 [12: MAX] 字段在 TLB 里进行查找,如果 TLB Miss,那么截取虚拟地址 [21: MAX] 字段在 LargeTLB 里进行查找,此时就会 TLB Hit,那么就可以获得虚拟地址与 PDE/PDPTE 的映射关系,最终找到对应的物理内存.
在有的架构如果对一个大页对应的 TLB FLUSH,那么会将相关的所有 TLB Entry 都刷新,但在 X86 架构只需对 LargeTLB 里面的 TLB Entry 进行刷新,因此大页的 TLB 刷新效率还是很高的,这样会避免很多的 TLB Shutdown 产生,提高了虚拟机或者多线程程序的运行效率. 以上便是对 Hugetlb 与 TLB 的分析.
TLB Related Paper
Intel IA32 Development Manual
Paging: Faster Translation(TLBs)
Optimizing Main-Memory Join On Modern Hardware

TLB Related Video
Translation Look Aside Buffer | TLB | Disadvantage of Paging
Translation Lookaside Buffer(TLB) in Operating System
Virtual Memory: TLB Example
TLB(Translation Look Aside Buffer) In Virtual Memory
Translation Lookaside Buffer
TLB Shootdown
Torwards a More Scalable KVM Hypervisor by WanpengLi.mp4
TLB 实践教程
BiscuitOS 目前支持对 TLB 场景的实践,开发者可以参考本节在 BiscuitOS 上实践案例. 在实践之前,开发者需要准备一个 Linux 6.0 X86 架构实践环境,可以参考:
部署完毕之后,针对 TLB 的实践,需要 BiscuitOS 使用 make menuconfig 选择如下配置:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] TLB: Translation-Lookaside Buffer --->
[*] TLB FLUSH: Adjust VMA Protection(mprotect) --->
# 源码目录
# Module
cd BiscuitOS/output/linux-6.0-x86_64/package/BiscuitOS-TLB-FLUSH-MPROTECT-default/
# 部署源码
make download
# 在 BiscuitOS 中实践
make build通过上面的命令,开发者可以获得指定的源码目录,使用 “make download” 命令可以下载实践用的源码, 然后使用 tree 命令可以看到>实践源码 main.c 和编译脚本 Makefile. 接下来在当前目录继续使用 “make build” 进行源码编译、打包并在 BiscuitOS 上实践:
BiscuitOS 运行之后,可以直接运行 RunBiscuitOS.sh 脚本直接运行实践所需的所有步骤,开发者只需在意最后的运行结果,可以提升>实践效率。以上便是最简单的实践,具体实践案例存在差异,以实践文档介绍为准.