Email: BuddyZhang1 buddy.zhang@aliyun.com
Info: ARM 32 – Linux 5.0
目录

简介
实践简介
俗话说的好 “纸上谈兵终觉浅,绝知此事要躬行”,对于 Linux 内核的学习同样适用,各位 开发者是否看遍了各种经典典籍,但还是对 Linux 不能运用自如。不是开发者不努力,而是 学习 Linux 内核的方法不合适。如何让开发者更有效的学习 Linux 内核其实是作者一直 考虑的问题,经过多年的 Linux 内核开发学习经验,写下了这篇文章和各位开发者分享 如何有效的学习 Linux 内核。
内核实践是作者在 Linux 内核学习中最提倡的学习论,即面对一个全新 Linux 原理或问题, 开发者首先应该做的是如何在有限的实践平台上将原理或问题付诸实践,然后从实践中获得对 Linux 原理和问题的自我认知,有了对问题的自我认知之后再回过头来学习问题对应的原理, 此时,再将原理的认知和实践的认知再投入新的实践中,加入对问题的疑问和想法进行更多的 实践,又从中得到新的认知,有了新的认知之后就产生最原始的求知欲。有了求知欲是一件好 事,凭着这股求知欲去知识里寻找真理,最后问题得到解决,开发者也就学会自主学习的能力, 在经过长期习惯的积累,开发者也就掌握了问题解决的原始能力。
说这么多,那么进入本文的正题。操作系统运作的原理可以简单的总结为 CPU 将位于内存中 的指令和数据加载到 CPU 中运行,重复这个动作,一个操作系统就工作起来。那么可以考虑 这么一个问题,开发者手头正好有一个 Linux 5.x 的内核,想在 ARM 上运行,那么只需将 Linux 5.x 的源码编译汇编成对应平台的指令,然后加载到内存,接着 CPU 读取这些指令, 这样 Linux 就在 ARM 上运行起来了,对一个操作系统就是这么简单的原理工作起来的。 那么本文主要想做的事就是,开发者可以从第一行代码开始编写,然后让这行代码编译汇编 之后加载到内存,之后由 ARM CPU 调用执行,再重复刚刚的操作,这样一行一行代码的添加, Linux 内核就编写和调试出来了。因此,本文就是用于讲解如何从第一行代码开始,如何编写并 调试运行在 ARM 上的 Linux 5.x。
本文适合作为 Linux 5.0 ARM boot 阶段源码实践教程,也适合操作系统从原点实践教程。
实践原理
Linux 源码采用 Kbuild 进行源码的编译汇编,并链接生成可在对应硬件平台上运行的 二进制文件。Linux 从源码到目标平台运行的过程经历了下图所示的过程:
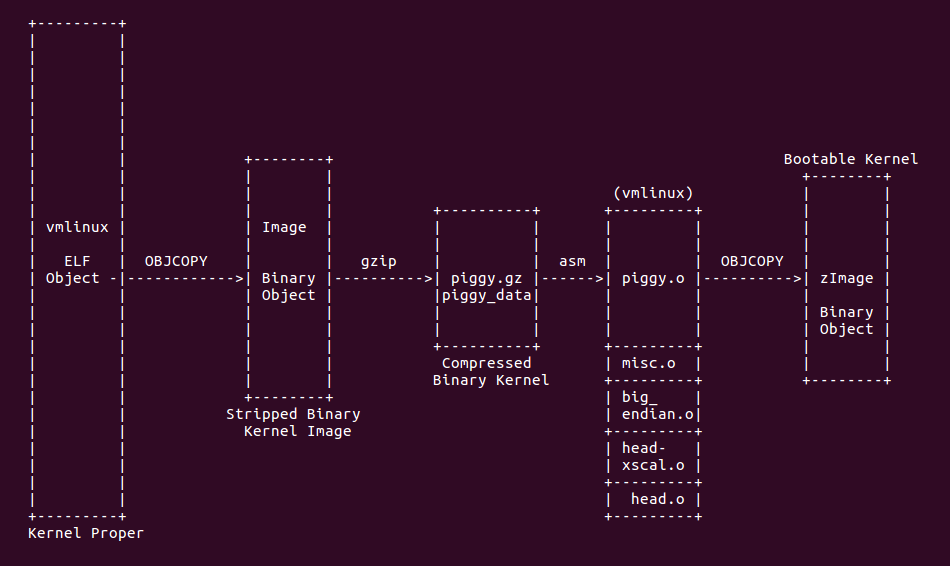
如上图所示,Linux 源码经过 Kbuild 编译系统的编译、汇编、链接之后在源码目录生成 ELF 目标文件 vmlinux。由于 vmlinux 包含了各种数据段,此时还不能在 ARM 上直接运行, 于是使用 OBJCOPY 工具将不必要的段丢弃之后,生成二进制文件 Image。此时的 Image 是可以在 ARM CPU 上直接运行的,但此时 Image 的体积太大,不利于一些历史原因,所以 将 Image 进行压缩,生成 piggy_data 文件,由于最新的内核支持多种压缩方式,所以抛弃 以前的 piggy.gz 叫法。由于压缩之后的文件不能直接在 ARM CPU 上运行,所以需要将压缩 后的内核想办法在内存中解压并能让 ARM CPU 能正确执行解压之后的内存,这部分功能称为 bootstrap,为了让压缩之后的内核具有 bootstrap 功能,于是将 piggy_data 文件包含到 一个汇编文件 piggy.S 里面,然后将 piggy.S 与 bootstrap 功能的源码进行编译、汇编、 链接生成 ELF 文件 vmlinux,开发者要注意,此处的 vmlinux 和之前提到的 vmlinux 不是 同一个文件。此时 vmlinux 由于包含了很多不必要的数据段,不能在 ARM CPU 上直接运行, 于是采用了之前的办法,使用 OBJCOPY 工具将不必要的段都丢弃,最后生成可以在 ARM CPU 上运行的二进制文件 zImage。在实际工程实践中,会遇到 uImage,这个二进制文件是通过 uboot 提供的工具,将 zImage 的头部做了修改,以便于 uboot 加载,但 uImage 和内核 没有多大的关系,所以这里不做讨论。更多详细的细节,请参考文档:
什么位置是 Linux 在 ARM CPU 上运行的起点呢,通过上面的分析可以知道,Linux 最终与 zImage 的形式加载到内存上直接运行,这个阶段的主要任务就是将真正的内核解压到指定 位置,在将 ARM CPU 指向真正内核运行。所以 Linux 加载到 ARM CPU 运行的起点就是 vmlinux 的 bootstrap 功能代码,其源码位于 arch/arm/boot/compressed 目录下,因此 本实践教程以此为原点进行讲解。
实践准备
由于本实践是基于 ARM Linux 5.0,所以开发者还没有搭建源码开发环境,可以参考如下文档:
实践过程中需要用的原理,芯片手册,文档等,请参考如下链接:
芯片手册及文档使用
在 Linux 内核实践中,涉及到很多与硬件相关的操作,这些操作如果只从代码语言层次来 分析是不知道代码的真正意图,这个时候如果会使用芯片手册查看原理的话,不论是代码还是系统 的学习都起到了事半功倍的作用。本节就给开发者介绍如何使用芯片手册。
在代码中往往涉及一些硬件原理操作,特别是汇编代码部分,因此这里使用汇编代码做例子。 本实践基于 ARMv7 Cortex A9MP (Vexpress-a9) 处理器进行讲解。因此开发者应该准备对应 的手册,上一节已经全部列出,开发者自行下载。遇到的问题对应的手册分为以下几类:
硬件资源相关
在开发过程中,开发者总需要了解实践平台的硬件信息,比如内存的大小,内存的总线地址, L1 以及 L2 Cache 的大小,硬件总线架构等信息,这些都可以通过 《Vexpress-a9 Reference Manual》 手册获得。
寄存器级别
开发过程中遇到最多的就是 ARMv7 Cortex A9MP 提供的各种寄存器,CP14,CP15 协处理器簇, 时候需要参看 《ARMv7 Architecture Reference Manual》。
在开发过程,开发者遇到最多的应该就是 CP15 寄存器,其与 VMAS 和 PMAS 有关,在本实践 平台中,CP15 都使用 VMPS 模式下的寄存器簇。
ARM 通用原理
开发过程中遇到很多基础的 ARM 原理,如 ARM 工作模式,中断,内存管理基础知识,可以查看 《ARM Architecture Reference Manual》。国内有好多 ARM 大神写的 ARM 通识性文章也不错,开发者也可以查阅。
ARM 汇编
在 ARM linux 启动的 boot 阶段,基本都是汇编构成的,由于 Linux 使用了很多 GNU 汇编 拓展,当遇到不同的拓展关键字可以查看 《ARM 汇编指令快速查询》,《ARM Architecture Reference Manual》
调试准备
ARMv7 Linux 内核从加载到内存之后运行第一行代码起,需要经历不同的阶段才能将内核正确 启动,因此每个不同的阶段需要采用的方法进行调试实践。本文推荐使用 GDB 进行调试,由于 不同阶段需要对 GDB 进行不同的配置,因此开发者可以根据下面的文档使用 GDB 进行调试:
zImage 实践选择
本文提供了三种实践策略,开发者需要选择其中一种策略进行实践。
策略一
这个策略主要面向对 boot 阶段 ARM Linux 源码实践的开发者,在这个策略中,提供原始 的源码文件进行实践,开发者无需做其他步骤,直接进入下一个章节。
策略二
这个策略主要是由于 arch/arm/boot/compressed 目录下兼容了很多平台,导致源码臃肿, 作者提供了一个干净的源码,里面只包含实际运行的代码,不包含其他无用代码。需要使用这个 策略的开发者首先获得 ARM linux 5.0 开发环境,之前提过制作方法。然后进入到源码的 arch/arm/boot/ 目录,将原始的 compressed 目录删除,然后使用如下命令:
cd arch/arm/boot/
rm -rf compressed/
git clone https://github.com/BiscuitOS/Bootstrap_arm.git compressed策略三
这个策略比较策底,从第一行代码开始编写。其做法与策略二类似,请参考如下步骤:
cd arch/arm/boot/
rm -rf compressed/
git clone https://github.com/BiscuitOS/Bootstrap_arm.git compressed
cd compressed
git reset --hard v0.0.1

实践
最小实践
本小节讲解如何进行最小实践。无论采用何种实践策略,接下来的实践内容都适用。做好的前期 准备之后,开发者首先在源码中加入断点,以方便断点调试。源码位于 arch/arm/boot/compressed/head.S
AR_CLASS( .arm )
start:
.type start,#function
.rept 7
.endr
W(b) 1f
1:
ENTRY(BS_debug)
mov r1, #90
.text接着根据 BiscuitOS/output/linux-5.0-arm32/README.md 提供的编译说明,按如下命令 编译内核:
cd BiscuitOS/output/linux-5.0-arm32/linux/linux
make ARCH=arm CROSS_COMPILE=BiscuitOS/output/linux-5.0-arm32/arm-linux-gnueabi/arm-linux-gnueabi/bin/arm-linux-gnueabi- -j4编译完毕之后,继续参照 BiscuitOS/output/linux-5.0-arm32/README.md 提供的编译说明, 打开两个新的终端,第一个终端中输入如下命令:
cd BiscuitOS/output/linux-5.0-arm32
./RunQemuKernel.sh debug第二个终端中输入如下命令:
BiscuitOS/output/linux-5.0-arm32/arm-linux-gnueabi/arm-linux-gnueabi/bin/arm-linux-gnueabi-gdb -x BiscuitOS/output/linux-5.0-arm32/package/gdb/gdb_zImage
(gdb) b BS_debug
(gdb) c
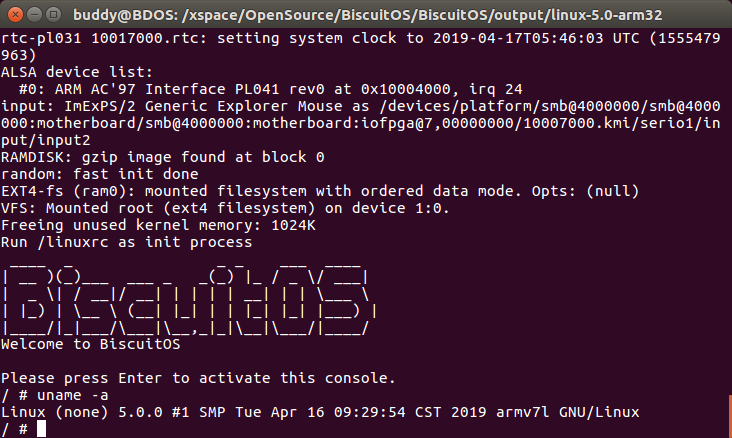
(gdb) info reg实际运行的效果如下:

本实践中,节本调试方法就是这样,在后续的实践中,只介绍实践后的结果,实践过程在此处。
zImage 重定位之前实践
zImage 被加载到内存之后开始在内存上运行,其主要任务就是将压缩的内核在指定位置 进行解压,然后将 CPU 的执行权交给真正的内核进行执行。但 zImage 在执行上面的过程 中,会遇到一个问题,zImage 加载到内存执行,需要对本身进行简单的初始化后运行解压缩 程序,但解压后的内核可能会覆盖 zImage 的数据和代码,因此为了避免这个问题,zImage 在解压内核之前需要将自身重定位到一个安全位置,所谓重定位就是将自身完整拷贝到一个新 的地址继续运行。因此这里就涉及两个过程,zImge 加载到内存进行初始化阶段,以及 zImage 从定位之后解压内核阶段,最后是内核真正运行阶段。本节重点分析实践 zImage 重定位 之前这个阶段。
zImage 入口函数
zImage 初始化阶段源码位于 arch/arm/boot/compressed/ 目录下。根据之前分析的原理可知, 压缩之后的内核会添加 bootstrap 功能之后生成 vmlinux,再经过 OBJCOPY 工具处理生成 zImage。所以可以通过查看 vmlinux 的链接脚本确定 zImage 的入口地址。 zImage 使用 的链接脚本位于 arch/arm/boot/compressed/vmlinux.lds.S, 具体内容如下:
ENTRY(_start)
SECTIONS
{
. = TEXT_START;
_text = .;
.text : {
_start = .;
*(.start)
*(.text)
*(.text.*)
*(.fixup)
*(.gnu.warning)
*(.glue_7t)
*(.glue_7)
}从链接脚本可以知道 vmlinux 链接过程,使用 ENTRY 关键字指定了 vmlinux 的入口地址, 也就是第一行运行的代码,这里设置为 _start, 从上面可以看出 _start 位于 .text section 的首地址,所以这里链接脚本告诉开发者,vmlinux 运行的第一行代码就是 vmlinux .text section 的第一行代码。继续查看链接脚本, .text section 的布局是所有目标文件的 .start section 位于 vmlinux .text section 的最前部,所以开发者只需找到目标文件 中函数 .start section 的文件即可。更多链接脚本的学习可以查看下列文档:
查找 arch/arm/boot/compressed/ 目录下,含有 .start section 的源码位于
arch/arm/boot/compressed$ grep "\.start" * -nR
big-endian.S:9: .section ".start", #alloc, #execinstr
Binary file head.o matches
head.S:146: .section ".start", #alloc, #execinstr
head-sa1100.S:14: .section ".start", "ax"
head-sharpsl.S:23: .section ".start", "ax"
head-xscale.S:11: .section ".start", "ax"所以该目录下一共有 4 个文件含有 .start section. 接下来就要根据 arch/arm/boot/compressed/Makefile 来确定 .start section 链接先后顺序了。
HEAD = head.o
ifeq ($(CONFIG_ARCH_SA1100),y)
OBJS += head-sa1100.o
endif
ifeq ($(CONFIG_CPU_XSCALE),y)
OBJS += head-xscale.o
endif
ifeq ($(CONFIG_PXA_SHARPSL_DETECT_MACH_ID),y)
OBJS += head-sharpsl.o
endif
ifeq ($(CONFIG_CPU_ENDIAN_BE32),y)
ifeq ($(CONFIG_CPU_CP15),y)
OBJS += big-endian.o
else
$(obj)/vmlinux: $(obj)/vmlinux.lds $(obj)/$(HEAD) $(obj)/piggy.o \
$(addprefix $(obj)/, $(OBJS)) $(lib1funcs) $(ashldi3) \
$(bswapsdi2) $(efi-obj-y) FORCE
@$(check_for_multiple_zreladdr)
$(call if_changed,ld)
@$(check_for_bad_syms)从 Makefile 编译位置上可以知道,生成 vmlinux 的时候,head.S 最先被链接到 vmlinux 里面,接着是 head-sa1100.o,head-xscale.o, head-sharpsl.o, big-endian.o。 所以 vmlinux .text section 第一个 section 从 head.S 的 .start section 开始。 因此可以推断 zImage 的第一行代码位于 arch/arm/boot/compressed/head.S 里面。接下来 分析 head.S 文件
head.S
在 head.S 文件中,可以找到 .start section, 源码如下(代码较长,分段解析):
.section ".start", #alloc, #execinstr
/*
* sort out different calling conventions
*/
.align
/*
* Always enter in ARM state for CPUs that support the ARM ISA.
* As of today (2014) that's exactly the members of the A and R
* classes.
*/
AR_CLASS( .arm )
start:
.type start,#function
.rept 7
__nop
.endr首先使用 .section 伪指令定义了一个名为 .start 的 section,并定义了 section 的属性是可分配和可执行的,使用 objdump 工具查看其 ELF 信息:
$objdump -sShxd head.o
head.o: file format elf32-little
head.o
architecture: UNKNOWN!, flags 0x00000011:
HAS_RELOC, HAS_SYMS
start address 0x00000000
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000890 00000000 00000000 00000040 2**5
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000000 00000000 00000000 000008d0 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 00000000 00000000 000008d0 2**0
ALLOC
3 .start 00000098 00000000 00000000 000008d0 2**2
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
4 .stack 00001000 00000000 00000000 00000968 2**0
ALLOC
5 .debug_line 00000277 00000000 00000000 00000968 2**0
CONTENTS, RELOC, READONLY, DEBUGGING
6 .debug_info 00000092 00000000 00000000 00000bdf 2**0
CONTENTS, RELOC, READONLY, DEBUGGING
7 .debug_abbrev 00000012 00000000 00000000 00000c71 2**0
CONTENTS, READONLY, DEBUGGING
8 .debug_aranges 00000028 00000000 00000000 00000c88 2**3
CONTENTS, RELOC, READONLY, DEBUGGING
9 .debug_ranges 00000020 00000000 00000000 00000cb0 2**3
CONTENTS, RELOC, READONLY, DEBUGGING
10 .ARM.attributes 0000001f 00000000 00000000 00000cd0 2**0
CONTENTS, READONLY从上面的运行结果可以看出,.start section 的属性为 CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE,这些属性正好符合定义时的属性,这正好是一个代码段该有的属性。
接着使用了 .align 伪指令和 .arm 伪指令告诉汇编器,这是一个使用 arm32 指令集并 要求对齐的 section。创建第一个标号 start,开发者可以使用 GDB 工具在 start 处 打断点进行调试。紧接着调用 .type 伪指令告诉汇编器,start 这个标号的类型是一个 #function,也就是 start 标号是一个函数类型。.rept 伪指令和 .endr 伪指令配合 使用,告诉汇编器,这里需要循环 7 次,每次都执行 .rept 伪指令和 .endr 伪指令 之间的代码,这里对应的代码就是 __nop 宏,实现了 7 次等待动作。__nop 宏定义如下:
.macro __nop
#ifdef CONFIG_EFI_STUB
@ This is almost but not quite a NOP, since it does clobber the
@ condition flags. But it is the best we can do for EFI, since
@ PE/COFF expects the magic string "MZ" at offset 0, while the
@ ARM/Linux boot protocol expects an executable instruction
@ there.
.inst MZ_MAGIC | (0x1310 << 16) @ tstne r0, #0x4d000
#else
AR_CLASS( mov r0, r0 )
M_CLASS( nop.w )
#endif
.endm由于本实践过程没有考虑 CONFIG_ELF_STUB 对应的内容,所以调用 .marco 伪指令和 .endm 伪指令定义了 __nop 宏的过程是 “mov r0, r0”, 也就是无意义的操作,起到延时 的作用。接着继续分析 head.S 里面的代码,内容如下:
#ifndef CONFIG_THUMB2_KERNEL
mov r0, r0
#else
AR_CLASS( sub pc, pc, #3 ) @ A/R: switch to Thumb2 mode
M_CLASS( nop.w ) @ M: already in Thumb2 mode
.thumb
#endif
W(b) 1f
.word _magic_sig @ Magic numbers to help the loader
.word _magic_start @ absolute load/run zImage address
.word _magic_end @ zImage end address
.word 0x04030201 @ endianness flag
.word 0x45454545 @ another magic number to indicate
.word _magic_table @ additional data table
__EFI_HEADER
1:这段代码首先判断有没有定义 CONFIG_THUMB2_KERNEL 宏,以此确定内核此时是否支持 Thumb 指令集,由于本实践未打开这个宏,所以不执行对应的功能。代码中,没有打开 CONFIG_THUBM2_KERNEL 宏之后,只调用 “mov r0, r0”,一个空操作,等效于 nop, 接着代码条用 b 指令直接跳转到 1f 标签处继续执行。在 1 标签之前,代码为数据分配 了一些存储空间,这些数据也位于 .start section 内部,由于这个段的属性可知, 这些数据是只读而不可写的。下面来分析这些数据的含义:
_magic_sig 用于存储 Magic 号,加载时候有用
_magic_start 用于指定 zImage 的加载和运行的绝对地址
_magic_end 用于指定 zImage 的结束地址
0x04030201 表示字节序标志
0x45454545 表示另一个 Magic 号
_magic_table 指向附加的数据表
__EFI_HEADER 指向 EFI 头
以上的数据用于 zImage 加载和运行时候使用,其具体的数字是 vmlinux 加载的时候 就决定了,可以通过查看 vmlinux.lds.S 链接脚本查看,部分内容如下:
.table : ALIGN(4) {
_table_start = .;
LONG(ZIMAGE_MAGIC(2))
LONG(ZIMAGE_MAGIC(0x5a534c4b))
LONG(ZIMAGE_MAGIC(__piggy_size_addr - _start))
LONG(ZIMAGE_MAGIC(_kernel_bss_size))
LONG(0)
_table_end = .;
}
_magic_sig = ZIMAGE_MAGIC(0x016f2818);
_magic_start = ZIMAGE_MAGIC(_start);
_magic_end = ZIMAGE_MAGIC(_edata);
_magic_table = ZIMAGE_MAGIC(_table_start - _start);链接过程中,创建了一个名为 .table section,这个 section 按四个字节对齐, 首先定义了 _table_start 指向 section 的起始地址,然后定义了一个 LONG 变量 存储 ZIMAGE_MAGIC(2) 的值,接着定义了一个 LONG 变量存储 ZIMAGE_MAGIC(0x5a534c4b) 的值;定义一个 LONG 变量用于存储 ZIMAGE_MAGIC(__piggy_size_addr - _start) 的值,也就是 __piggy_size_addr 到 _start 之间的长度;第一个 LONG 变量存储 ZIMAGE_MAGIC(_kernel_bss_size) 的值,也就是内核 .bss section 的值;最后定义了 一个为 0 的 LONG 值,以及定义 _table_end 指向 .table section 的结束地址。 接着在 vmlinux.lds.S 链接脚本中,给 _magic_sig 赋值为 ZIMAGE_MAGIC(0x016f2818); 给 _magic_start 赋值为 ZIMAGE_MAGIC(_start);给 _magic_end 赋值为 ZIMAGE_MAGIC(_edata);_magic_table 赋值给了 ZIMAGE_MAGIC(_table_start - _start), 接着开发者可以使用 GDB 工具实践看看运行时布局,如下:
(gdb) b BS_debug
Breakpoint 1 at 0x3c: file arch/arm/boot/compressed/head.S, line 181.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:181
181 bl BS_func
(gdb) list
176 .word _magic_table @ additional data table
177
178 __EFI_HEADER
179 1:
180 ENTRY(BS_debug)
181 bl BS_func
182 ARM_BE8( setend be ) @ go BE8 if compiled for BE8
183 AR_CLASS( mrs r9, cpsr )
184 #ifdef CONFIG_ARM_VIRT_EXT
185 bl __hyp_stub_install @ get into SVC mode, reversibly
(gdb) print &_magic_sig
$1 = (<variable (not text or data), no debug info> *) 0x16f2818
(gdb) print &_magic_start
$2 = (<text variable, no debug info> *) 0x0 <_text>
(gdb) print &_magic_end
$3 = (<variable (not text or data), no debug info> *) 0x42ba08 <free_mem_end_ptr>
(gdb) print &_magic_table
$4 = (<variable (not text or data), no debug info> *) 0x3af8
(gdb)在使用 objdump 工具查看 vmlinux 的 .text section, 内容如下:
$ objdump -sShdx vmlinux
Contents of section .text:
0000 0000a0e1 0000a0e1 0000a0e1 0000a0e1 ................
0010 0000a0e1 0000a0e1 0000a0e1 0000a0e1 ................
0020 050000ea 18286f01 00000000 08ba4200 .....(o.......B.
0030 01020304 45454545 f83a0000 d00d00eb ....EEEE.:......
0040 00900fe1 8d0d00eb 0170a0e1 0280a0e1 .........p......
0050 00200fe1 030012e3 0100001a 1700a0e3 . ..............
0060 563412ef 00000fe1 1a0020e2 1f0010e3 V4........ .....
0070 1f00c0e3 d30080e3 0400001a 010c80e3 ................从上面的运行分析之后,可以知道,在 .text section 的头部定义了一个 zImage 的 Magic 头,这个 zImage Magic 头的布局如下:
+-------------------------------------+ low_addr
| Magic Number |
+-------------------------------------+
| Magic Start Address |
+-------------------------------------+
| Magic End Address |
+-------------------------------------+
| 0x01020304 |
+-------------------------------------+
| 0x45454545 |
+-------------------------------------+
| Magic Table Base Address |
+-------------------------------------+
| __EFI_HEADER |
+-------------------------------------+ high_addr__EFI_HEADER 定义在 elf-header.S 文件中,由于本实践不支持 CONFIG_EFI_STUB 功能, 所以这里不讨论这个部分。接着继续讨论 head.S 文件中内容。
ARM_BE8( setend be ) @ go BE8 if compiled for BE8
AR_CLASS( mrs r9, cpsr )
#ifdef CONFIG_ARM_VIRT_EXT
bl __hyp_stub_install @ get into SVC mode, reversibly
#endif由于不支持 ARM_BE8, 所以 “setend be” 指令不被执行,继续执行 “mrs r9, cpsr” 指令,这个指令的作用就是将 CPSR 寄存器的值存储到 R9 寄存器中。接下来检查是否支持 CONFIG_ARM_VIRT_EXT 拓展,本实践平台上支持这个功能,所以接上来调用 “bl __hyp_stub_install” 指令。__hyp_stub_install 函数定义在 hyp-stub.S 文件中,如下:
/*
* Hypervisor stub installation functions.
*
* These must be called with the MMU and D-cache off.
* They are not ABI compliant and are only intended to be called from the kernel
* entry points in head.S.
*/
@ Call this from the primary CPU
ENTRY(__hyp_stub_install)
store_primary_cpu_mode r4, r5, r6
ENDPROC(__hyp_stub_install)
@ fall through...
@ Secondary CPUs should call here
ENTRY(__hyp_stub_install_secondary)
.macro store_primary_cpu_mode reg1:req, reg2:req, reg3:req
.endm从函数的注释可以看出,函数的作用是安装管理程序, __hyp_stub_install 函数内部调用 了 store_primary_cpu_mode 宏,并传入 r4, r5, 和 r6 三个参数,由于 store_primary_cpu_mode 宏的定义里不做任何实际操作,那么 __hyp_stub_install 函数就继续执行 __hyp_stub_install_secondary 函数,函数的源码如下:
/*
* The zImage loader only runs on one CPU, so we don't bother with mult-CPU
* consistency checking:
*/
.macro compare_cpu_mode_with_primary mode, reg1, reg2, reg3
cmp \mode, \mode
.endm
@ Secondary CPUs should call here
ENTRY(__hyp_stub_install_secondary)
mrs r4, cpsr
and r4, r4, #MODE_MASK
/*
* If the secondary has booted with a different mode, give up
* immediately.
*/
compare_cpu_mode_with_primary r4, r5, r6, r7
retne lr
/*
* Once we have given up on one CPU, we do not try to install the
* stub hypervisor on the remaining ones: because the saved boot mode
* is modified, it can't compare equal to the CPSR mode field any
* more.
*
* Otherwise...
*/
cmp r4, #HYP_MODE
retne lr @ give up if the CPU is not in HYP mode函数首先调用 mrs 指令将 CPSR 寄存器的值存储到 R4 寄存器里,然后调用 and 指令 将 r4 中的值与 MODE_MASK 相与,结果存放在 r4 中,总所周知,CPSR 的低 5 位描述当前 CPU 的模式,如下图:
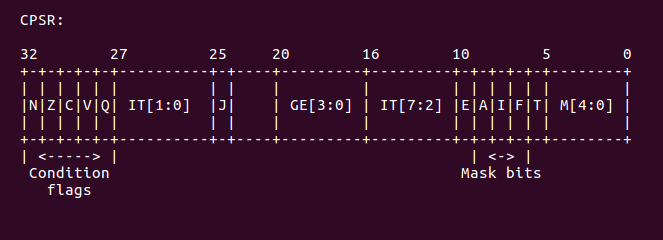
ARM 所支持的模式定义如下:
#if defined(__KERNEL__) && defined(CONFIG_CPU_V7M)
/*
* Use 0 here to get code right that creates a userspace
* or kernel space thread.
*/
#define USR_MODE 0x00000000
#define SVC_MODE 0x00000000
#else
#define USR_MODE 0x00000010
#define SVC_MODE 0x00000013
#endif
#define FIQ_MODE 0x00000011
#define IRQ_MODE 0x00000012
#define MON_MODE 0x00000016
#define ABT_MODE 0x00000017
#define HYP_MODE 0x0000001a
#define UND_MODE 0x0000001b
#define SYSTEM_MODE 0x0000001f
#define MODE32_BIT 0x00000010
#define MODE_MASK 0x0000001f代码中调用 compare_cpu_mode_with_primary 宏对 r4 寄存器进行带优先级的比较 操作,如果比较的结果不等于零那么就直接退出函数;如果等于零,那么就继续执行函数, 从 compare_cpu_mode_with_primary 宏的定义可知,它将 r4 与 r4 寄存器进行对比, 对比的值一定等于 0, 所以函数继续执行,接下来函数调用 cmp 指令,将 r4 的值 与 HYP_MODE 模式进行对比,确定当前模式是否是 HYP_MODE,如果是,那么就继续执行 函数;如果不是,则直接返回。使用 GDB 实际测试结果如下:
(gdb) b BS_X
Note: breakpoint 1 also set at pc 0x3680.
Breakpoint 2 at 0x3680: file arch/arm/boot/compressed/hyp-stub.S, line 97.
(gdb) c
Continuing.
Breakpoint 1, __hyp_stub_install_secondary ()
at arch/arm/boot/compressed/hyp-stub.S:97
97 mrs r4, cpsr
(gdb) n
98 and r4, r4, #MODE_MASK
(gdb) n
104 compare_cpu_mode_with_primary r4, r5, r6, r7
(gdb) n
105 retne lr
(gdb) n
116 cmp r4, #HYP_MODE
(gdb) info reg
r0 0x0 0
r1 0x0 0
r2 0x0 0
r3 0x0 0
r4 0x13 19
r5 0x0 0
r6 0x0 0
r7 0x0 0
r8 0x0 0从上面可知,r4 所存储的当前模式不是 HYP 模式,所以放弃进入 HYP 模式。接下来函数 直接返回。接着函数返回之后,函数继续在 head.S 中继续执行如下代码:
mov r7, r1 @ save architecture ID
mov r8, r2 @ save atags pointer
#ifndef CONFIG_CPU_V7M
/*
* Booting from Angel - need to enter SVC mode and disable
* FIQs/IRQs (numeric definitions from angel arm.h source).
* We only do this if we were in user mode on entry.
*/
mrs r2, cpsr @ get current mode
tst r2, #3 @ not user?
bne not_angel
mov r0, #0x17 @ angel_SWIreason_EnterSVC
ARM( swi 0x123456 ) @ angel_SWI_ARM
THUMB( svc 0xab ) @ angel_SWI_THUMB
not_angel:
safe_svcmode_maskall r0
msr spsr_cxsf, r9 @ Save the CPU boot mode in
@ SPSR
#endif由于 uboot 结束后,会将 architecture ID 存放在 r7 寄存器,将 uboot 的 ATAG 参数的指针存放在 r8 寄存器里。于是代码中调用 mov 指令将 r7 的值存储到 r1 寄存器里, 将 r8 寄存器的值存储到 r2 寄存器里。由于本实践过程中,CONFIG_CPU_V7M 宏没有打开, 那么继续执行下一条指令是 “mrs r2, cpsr”, 这条指令将 CPSR 寄存器的值存储到 r2 寄存器 内,然后调用 tst 指令将 r2 寄存器的值与立即数 3 相与,如果相与的结果不等于 0, 那么 表示当前 CPU 所处的模式不是 User 模式,那么跳转到 not_angel 标签处继续执行; 如果相与的结果等于零,那么 CPU 处于 User 模式,那么调用 swi 指令直接进入 SVC 模式。 这段代码的主要任务就是如果当前模式是 User 模式,那么从 Angel 启动,在启动之前, 需要进入 SVC 模式,并关闭所有的 FIQs/IRQs 中断。接着调用 safe_svcmode_maskall 宏,接下来分析 safe_svcmode_maskall 宏,代码如下:
/*
* Helper macro to enter SVC mode cleanly and mask interrupts. reg is
* a scratch register for the macro to overwrite.
*
* This macro is intended for forcing the CPU into SVC mode at boot time.
* you cannot return to the original mode.
*/
.macro safe_svcmode_maskall reg:req
#if __LINUX_ARM_ARCH__ >= 6 && !defined(CONFIG_CPU_V7M)
mrs \reg , cpsr
eor \reg, \reg, #HYP_MODE
tst \reg, #MODE_MASK
bic \reg , \reg , #MODE_MASK
orr \reg , \reg , #PSR_I_BIT | PSR_F_BIT | SVC_MODE
THUMB( orr \reg , \reg , #PSR_T_BIT )
bne 1f
orr \reg, \reg, #PSR_A_BIT
badr lr, 2f
msr spsr_cxsf, \reg
__MSR_ELR_HYP(14)
__ERET
1: msr cpsr_c, \reg
2:
#else
/*
* workaround for possibly broken pre-v6 hardware
* (akita, Sharp Zaurus C-1000, PXA270-based)
*/
setmode PSR_F_BIT | PSR_I_BIT | SVC_MODE, \reg
#endif
.endm由于本实践内容符合 LINUX_ARM_ARCH 大于 6,而且 CONFIG_CPU_V7M 宏没有 定义,所以宏执行的代码为上部。宏首先执行 “mrs \reg, cpsr” 指令,根据调用宏处可知, 宏将 CPSR 的值存储到 r0 寄存器中,然后将 r0 寄存器的值与 HYP_MODE 宏进行异或 操作,结果存储到 r0 寄存器内,然后调用 tst 指令将 r0 寄存器的值与 MODE_MASK 进行与操作, 最后调用 bic 指令清除掉 MODE_MASK 对应的位,这样 r0 中模式位就全部 清零。接着调用 orr 指令将 (PSR_I_BIT | PSR_F_BIT | SVC_MODE) 的值与 r0 寄存器 的值相与之后存储到 r0 寄存器中。根据 CPSR 寄存器的布局可知:
PSR_I_BIT 对应的是 CPSR 的 I 位,这个位用于 IRQ 的掩码位;PSR_F_BIT 对应的是 CPSR 的 F 位,该位用于 FIQ 的掩码。这两位只要置位,那么对应的中断就断就会被屏蔽。 或上 SVC_MODE 就是将模式设置为 SVC 模式。orr 指令执行的结果不等于零,那么跳转 到 1 标签处,1 标签处调用 “msr cpsr_c, \reg” ,这里 cpsr_c 代表 CPSR 的低 8 位,也就是 CPSR 的控制位。这样 CPU 就进入屏蔽了 IRQ,FRQ 的 SVC 模式。 调用完 safe_svcmode_maskall 之后,head.S 调用 “msr spsr_cxsf, r9” 将 r9 寄存器的值存储到 spsr_cxsf,这里 spsr_cxsf 代表 SPSR 寄存器的 C 域, X 域, S 域, 和 F 域。由于在设置进入 SVC 模式之前,就将 CPSR 寄存器的值存储到 r9 寄存器,所以 r9 寄存器保存了 CPU 最开始的模式。最后将原始的 CPU 模式存储到了 SPSR 寄存器中。
接下来,head.S 将找到物理地址的起始地址,这个时候 MMU 是没有打开的,这个时候是 忽略任何地址对齐和偏移。head.S 选择最开始的 128MB 处作为对齐地址,然后将 zImage 放在这物理地址起始处,这 128MB 就是用来专门存放 zImage 镜像的。具体 代码如下:
#ifdef CONFIG_AUTO_ZRELADDR
/*
* Find the start of physical memory. As we are executing
* without the MMU on, we are in the physical address space.
* We just need to get rid of any offset by aligning the
* address.
*
* This alignment is a balance between the requirements of
* different platforms - we have chosen 128MB to allow
* platforms which align the start of their physical memory
* to 128MB to use this feature, while allowing the zImage
* to be placed within the first 128MB of memory on other
* platforms. Increasing the alignment means we place
* stricter alignment requirements on the start of physical
* memory, but relaxing it means that we break people who
* are already placing their zImage in (eg) the top 64MB
* of this range.
*/
ENTRY(BS_debug)
mov r4, pc
and r4, r4, #0xf8000000
/* Determine final kernel image address. */
add r4, r4, #TEXT_OFFSET
#else
ldr r4, =zreladdr
#endif这段代码主要用于计算内核的解压地址,并将解压地址存储到 r4 寄存器中。 首先调用代码 “mov, r4, pc”,将当前 CPU 执行的地址存储到 r4 ,然后在将 0xf8000000 的值与 r4 相与达到对齐的作用,确保之后的内核解压地址按 128M 对齐,然后将 r4 寄存器的 值加上 TEXT_OFFSET,TEXT_OFFSET 代表内核的解压地址,这样 r4 寄存器就存储了内核的解压 地址。TEXT_OFFSET 定义在 arch/arm/Makefile 中,如下:
# Text offset. This list is sorted numerically by address in order to
# provide a means to avoid/resolve conflicts in multi-arch kernels.
textofs-y := 0x00008000
# The byte offset of the kernel image in RAM from the start of RAM.
TEXT_OFFSET := $(textofs-y)运行到这里插一个 gdb 的内容,由于本实践运行在 qemu 上,并且 gdb 进行调试的时候,使用 了如下默认命令:
# Debug zImage before reload zImage
#
# (C) 2019.04.11 BuddyZhang1 <buddy.zhang@aliyun.com>
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License version 2 as
# published by the Free Software Foundation.
# Remote to gdb
#
target remote :1234
# Reload vmlinux for zImage
#
add-symbol-file BiscuitOS/output/linux-5.0-arm32/linux/linux/arch/arm/boot/compressed/vmlinux 0x60010000上面的命令就会让 zImage 运行的起始地址是 0x60010000, 所以此时使用 GDB 调试的情况 如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60010094: file arch/arm/boot/compressed/head.S, line 96.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:96
96 mov r4, pc
(gdb) info reg
r0 0x1d3 467
r1 0x8e0 2272
pc 0x60010094 0x60010094 <BS_debug>
(gdb) n
97 and r4, r4, #0xf8000000
(gdb) n
99 add r4, r4, #TEXT_OFFSET
(gdb) n
108 mov r0, pc
(gdb) info reg
r0 0x1d3 467
r1 0x8e0 2272
r2 0x800001d3 -2147483181
r3 0x0 0
r4 0x60008000 1610645504
r5 0x0 0
pc 0x600100a0 0x600100a0 <BS_debug+12>
cpsr 0x1d3 467从上面的运行可知,通过计算,内核解压地址是 0x60008000. 接着执行如下代码:
/*
* Set up a page table only if it won't overwrite ourself.
* That means r4 < pc || r4 - 16k page directory > &_end.
* Given that r4 > &_end is most unfrequent, we add a rough
* additional 1MB of room for a possible appended DTB.
*/
ENTRY(BS_debug)
mov r0, pc
cmp r0, r4
ldrcc r0, LC0+32
addcc r0, r0, pc
cmpcc r4, r0
orrcc r4, r4, #1 @ remember we skipped cache_on
blcs cache_on这段代码的主要任务就是确认 zImage 自己建立的页表会不会被 zImage 镜像的重定位 给覆盖掉。从原理可以知道,zImage 被加载到内存运行之后,会将自己重定位到新的物理地址 运行,这就会出现要创建的页表可能被 zImage 重定位之后覆盖。zImage 镜像如果不被自己给 覆盖,需要满足两个条件中的任意一个:
r4 < PC
这种情况下,内核的解压地址小于当前 PC 运行物理地址。
r4 - 16k page directory > &_end
这种情况下,内核的解压地址大于 zImage 结束地址之后的 16KB。一般情况下解压内核 的地址大于 zImage 的结束地址是不太寻常的。这种情况下需要添加 1MB 的空间与链接在 zImage 中的 DTB 隔开。
运行到这里,首先获得 PC 寄存器的值,然后调用 “cmp r0, r4”, 从之前的代码可知, r4 寄存器存储着解压内核的地址,这里执行这条命令的含义是,如果 r0 > r4,那么代表当前 PC 执行地址大于内核解压地址,这种情况符合之前的讨论,所以那么就执行 cache_on 宏; 如果 r0 < r4, 那么 zImage 的运行范围包含了要解压内核的地址,因此需要继续进行检测。 这里执行命令 “ldrcc r0, LC0+32”, 通过这个命令,将 LC0 偏移 32 个字节地址对应的内容 拷贝到 r0 寄存器。从后面的讨论可以知道,”LC0+32” 处对应的内容是 zImage 需要重定位 的长度再加上 “16K + 1M” 的长度。这里再加上 PC 的值,确保当前运行的代码也不会被覆盖。 接着执行命令 “cmpcc r4, r0”, 重新确定解压内核的物理地址与 zImage 重定位的物理地址 是否存在重叠。如果存在,那么将 r4 寄存器的值加 1,以此标记 cache_on 被跳过;否则 执行 “blcs cache_on” 打开缓存。开发者们可以通过实际 GDB 调试代码可验证。
(gdb) b BS_debug
Breakpoint 1 at 0x600100a0: file arch/arm/boot/compressed/head.S, line 108.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:108
108 mov r0, pc
(gdb) n
109 cmp r0, r4
(gdb) info reg
r0 0x600101d3 467
r1 0x8e0 2272
r2 0x800001d3 -2147483181
r3 0x0 0
r4 0x60008000 1610645504
Quit
(gdb) n
110 ldrcc r0, LC0+32
(gdb) n
111 addcc r0, r0, pc
(gdb) n
112 cmpcc r4, r0
(gdb) n
113 orrcc r4, r4, #1 @ remember we skipped cache_on
(gdb) n
114 blcs cache_on
(gdb) n
cache_on () at arch/arm/boot/compressed/head.S:148
148 mov r3, #8 @ cache_on function
(gdb)从上面的运行结果可以看出,进行第一次 cmp 的时候,r0 中的地址是大于 r4 寄存器中 地址,那么接下来带 cc 条件的指令都不执行,那么代码就直接跳转到 cache_on 代码继续 执行。接下来的代码如下:
/*
* Turn on the cache. We need to setup some page table so that we
* can have both the I and D cache on.
*
* We place the page tables 16k down from the kernel execution address,
* and we hope that nothing else is using it. If we're using it, we
* will go pop!
*
* On entry,
* r4 = kernel execution address
* r7 = architecture number
* r8 = atags pointer
* On exit,
* r0, r1, r2, r3, r9, r10, r12 corrupted
* This routine must preserve:
* r4, r7, r8
*/
.align 5
cache_on:
mov r3, #8 @ cache_on function
b call_cache_fncache_on 用于打开 ARM 的 cache 功能,cache 包括 I-Cache (指令 cache) 和 D-cache (数据 cache)。为了正常使用 cache,需要建立一个页表供 MMU 使用。zImage 会将这个页表 放在真正内核开始执行地址之前的 16K 位置,希望这个地址不要被非法使用。在执行 cache_on 之前, r4 寄存器里存储值内核解压地址,这个地址也被成为正真内核开始执行的地址。r7 寄存器存储这体系 相关的数据;r8 寄存器存储着 uboot 传递给内核 ATAG 参数的地址。cache_on 使用伪指令 .align 指定了对齐方式为 5 字节对齐。由于 ARM 将所有家族芯片关于 cache 的操作都放在一个表里维护, 因此 armv7 的 cache 操作也在这个表内,并且 cache_on 操作在表中的偏移是 8,因此代码 将立即数 8 存储到 r3 寄存器,并跳转到 call_cache_fn 出执行,代码如下:
#define PROC_ENTRY_SIZE (4*5)
/*
* Here follow the relocatable cache support functions for the
* various processors. This is a generic hook for locating an
* entry and jumping to an instruction at the specified offset
* from the start of the block. Please not this is all position
* independent code.
*
* r1 = corrupted
* r2 = corrupted
* r3 = block offset
* r9 = corrupted
* r12 = corrupted
*/
call_cache_fn: adr r12, proc_types
#ifdef CONFIG_CPU_CP15
mrc p15, 0, r9, c0, c0 @ get processor ID
#endif
1: ldr r1, [r12, #0] @ get value
ldr r2, [r12, #4] @ get mask
eor r1, r1, r9 @ (real ^ mask)
tst r1, r2 @ & mask
ARM( addeq pc, r12, r3 ) @ call cache function
add r12, r12, #PROC_ENTRY_SIZE
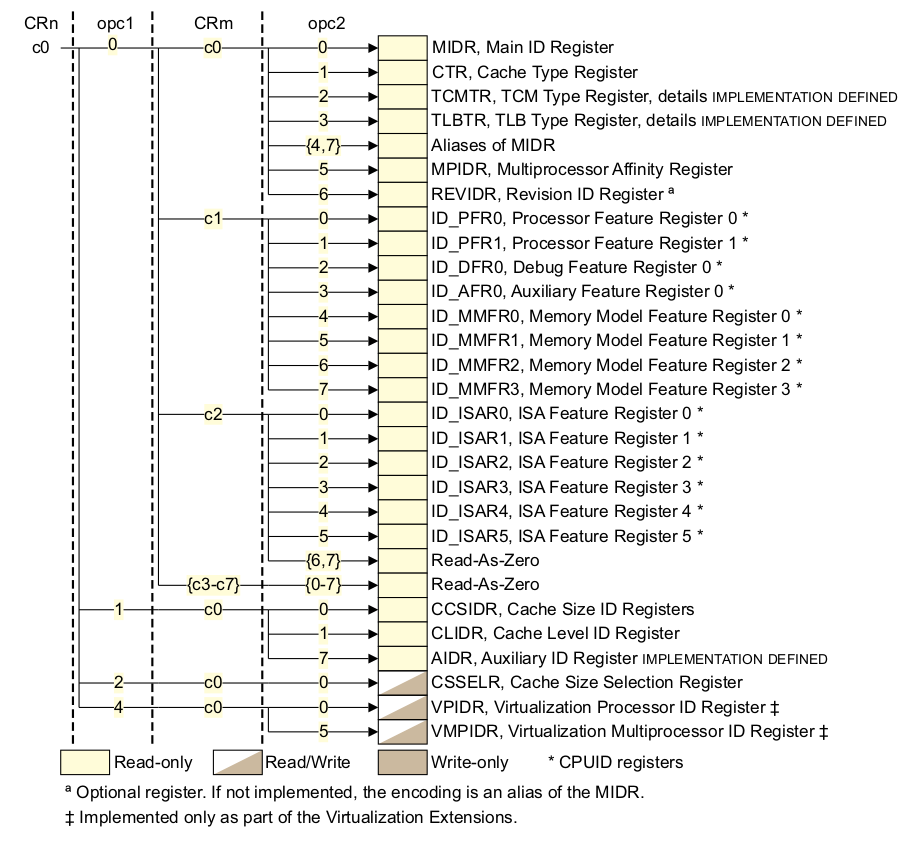
b 1b本段代码的主要任务就是 cache_on 表中找到 armv7 对应的 cache_on 操作。代码首先使用 adr 伪指令获得 proc_types 的地址,然后在 CONFIG_CPU_CPU15 宏启用的情况下,armv7 这个宏启用, 使用 mrc 指令,读取了 CPU ID 寄存器,寄存器布局如下:
将 ID 相关的信息存储在 r9 寄存器里,然后使用 ldr 指令,从 proc_types 表里按顺序取出每个 成员的第一个值和第二个值,分别存储在 r1, r2 寄存器中。接着代码将 r1 寄存器的值与 r9 寄存器 的值做异或运算,然后将结果存储到 r1 寄存器,接着再调用 tst 命令,将 r1 寄存器与 r2 寄存器 按位与操作。如果结果为零,那么就执行 addeq 指令,将 pc 指向表中的位置;如果结果不为零, 那么调用 add 指令,将 r12 指向下一个表成员,调用 b 指令继续循环。开发者可以在此段代码中 加入适当的断点进行 GDB 调试,调试情况下:
(gdb) b BS_debug
Breakpoint 1 at 0x600100d8: file arch/arm/boot/compressed/head.S, line 166.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:166
166 eor r1, r1, r9 @ (real ^ mask)
(gdb) info reg r1
r1 0xf0000 983040
(gdb) info reg r2
r2 0xf0000 983040
(gdb) info reg r9
r9 0x410fc090 1091551376
(gdb) n
167 tst r1, r2 @ & mask
(gdb) info reg r1
r1 0x4100c090 1090568336
(gdb) n
168 ARM( addeq pc, r12, r3 ) @ call cache function
(gdb) info reg r1
r1 0x4100c090 1090568336
(gdb) info reg cpsr
cpsr 0x600001d3 1610613203
(gdb) info reg pc
pc 0x600100e0 0x600100e0 <BS_debug+8>
(gdb) n
proc_types () at arch/arm/boot/compressed/head.S:191
191 W(b) __armv7_mmu_cache_on
(gdb)从调试结果可以看出,从 ID 寄存器读出的值是 0x410fc090, 经过 r1 0xf000 异或运算之后, 其值是 4100c090, 然后再通过与 r2 f0000 进行按位与运算之后,结果为 0, 那么找到了需要 的 cache_on 入口,这是将入口地址存入 pc 寄存器中,代码跳转到对应的地址,这里可以看一下 表成员的内容如下:
/*
* Table for cache operations. This is basically:
* - CPU ID match
* - CPU ID mask
* - 'cache on' method instruction
* - 'cache off' method instruction
* - 'cache flush' method instruction
*
* We match an entry using: ((real_id ^ match) & mask) == 0
*
* Writethrough caches generally only need 'on' and 'off'
* methods. Writeback caches _must_ have the flush method
* defined.
*/
.align 2
.type proc_types,#object
proc_types:
.word 0x000f0000 @ new CPU Id
.word 0x000f0000
W(b) __armv7_mmu_cache_on
W(b) __armv7_mmu_cache_off
W(b) __armv7_mmu_cache_flush
.word 0 @ unrecognised type
.word 0
mov pc, lr
mov pc, lr
mov pc, lr
.size proc_types, . - proc_types
/*
* If you get a "non-constant expression in ".if" statement"
* error from the assembler on this line, check that you have
* not accidentally written a "b" instruction where you should
* have written W(b).
*/
.if (. - proc_types) % PROC_ENTRY_SIZE != 0
.error "This size of one or more proc_types entries is wrong."
.endif表 proc_types 定义为一个 object 对象,其中包含了 armv7 对应的成员,cache_on 对应的入口 函数就是: __armv7_mmu_cache_on, 接下来继续分析 __armv7_mmu_cache_on 函数:
__armv7_mmu_cache_on:
mov r12, lr
#ifdef CONFIG_MMU
mrc p15, 0, r11, c0, c1, 4 @ read ID_MMFR0
tst r11, #0xf @ VMSA
movne r6, #CB_BITS | 0x2 @ !XN
blne __setup_mmu
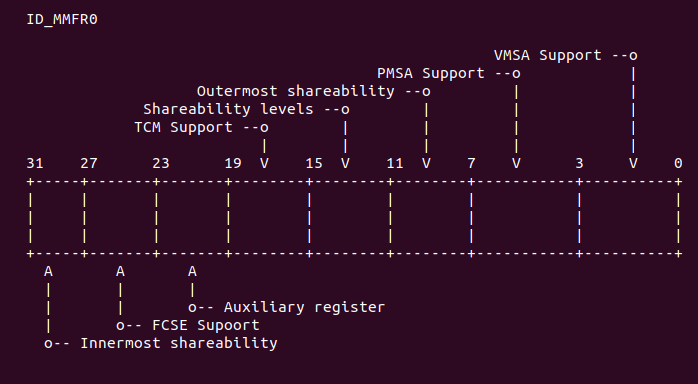
#endif__armv7_mmu_cache_on 函数首先将 lr 寄存器的值存储到 r12 寄存器,然后判断 CONFIG_MMU 宏是否启用。在 armv7 里,这个宏是启用的,所以执行宏限定的代码。首先也是通过 mrc 指令读取 ID_MMFR0 寄存器的值到 r11 寄存器中,ID_MMFR0 寄存器如下:
其中, ID_MMFR0 的最低位用于指示当前 CPU 是支持 VMSA 还是 PMSA。VMSA 指的是 Virtual Memory System Architecture。PMSA 指的是 Protected Memory System Architecture。 两种模式具有不同的内存管理策略,具体介绍开发者可以参考 ARMv7 Reference Manual。接着使用 tst 指令查看 r11 寄存器的最低 4 位的值,以此判断目前 CPU 是 VMSA 模式还是 PMSA 模式。 如果 r11 寄存器的最低 4 bit 不为零,即 CPU 支持 VMSA 模式,那么代码继续执行带 ne 条件 的指令,这里可以加上适当的断点,然后使用 GDB 进行调试,调试结果如下:
(gdb) b BS_debug
Breakpoint 1 at 0x600100c4: file arch/arm/boot/compressed/head.S, line 130.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:130
130 mrc p15, 0, r11, c0, c1, 4 @ read ID_MMFR0
(gdb) n
131 tst r11, #0xf @ VMSA
(gdb) n
132 movne r6, #CB_BITS | 0x2 @ !XN
(gdb) info reg r11
r11 0x100103 1048835
(gdb) info reg cpsr
cpsr 0x200001d3 536871379
(gdb)从上面的实践结果可以看出,目前 CPU 支持 VMSA,所以将 CB_BITS 或上 0x2 的值存储到 r6 寄存器,并将跳转到 __setup_mmu 继续执行,代码如下:
__setup_mmu: sub r3, r4, #16384 @ Page directory size
bic r3, r3, #0xff @ Align the pointer
bic r3, r3, #0x3f00__setup_mmu 的主要功能是建立一个临时页表,并打开 MMU,以此供解压程序使用虚拟地址。正如 上面的代码所示,此时 r4 寄存器指向真正内核运行的起始地址,那么就在这个地址前 16K 处开始 建立页表,将页表的起始地址存储到 r3 寄存器,并使用 bic 指令对 r3 的地址做对齐。开发者 可以在上面适当的位置加上断点,使用 GDB 进行调试,调试情况如下:
(gdb) b BS_debug
Breakpoint 1 at 0x600100c0: file arch/arm/boot/compressed/head.S, line 125.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:125
125 bic r3, r3, #0xff @ Align the pointer
(gdb) n
126 bic r3, r3, #0x3f00
(gdb) info reg r3
r3 0x60004000 1610629120
(gdb) n
132 mov r0, r3
(gdb) info reg r3
r3 0x60004000 1610629120
(gdb) info reg r4
r4 0x60008000 1610645504
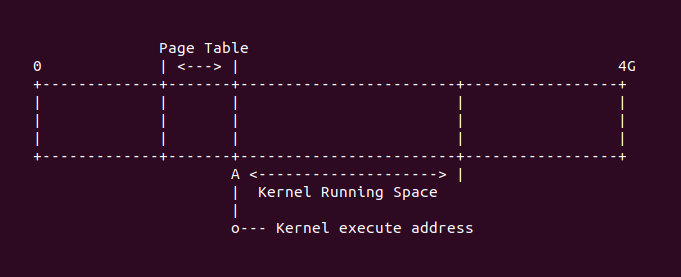
(gdb)从上面的调试情况可以知道,内核运行的地址是 0x60008000, 页表的地址就是 0x60004000,此时 内存的布局如下:
继续执行下面代码:
/*
* Initialise the page tables, turning on the cacheable and bufferable
* bits for the RAM area only.
*/
mov r0, r3
mov r9, r0, lsr #18
mov r9, r9, lsl #18 @ start of RAM
add r10, r9, #0x10000000 @ a reasonable RAM size
mov r1, #0x12 @ XN|U + section mapping
orr r1, r1, #3 << 10 @ AP=11
add r2, r3, #16384代码首先将 r3 寄存器的值存储到 r0 寄存器,并通过对 r0 寄存器按 (1«18) 对齐,获得 RAM 的起始地址,然后假设 RAM 的长度大概是 256M,并将 RAM 结束地址存放在 r10 寄存器中。这里 这样做的目的是:该阶段,内核采用一个临时页表,页表按 1:1 映射物理地址与虚拟地址,通过计算 获得 RAM 的长度,以此对能真实映射 RAM 的页表项设置一种标志集;同理对不能映射物理地址的页表 项设置另外一种标志集。接着将 0x12 的值和 (3 « 10) 值存储到 r1 寄存器中。将 r3 寄存器 的值加上 16K 存放到 r2 寄存器,主要是为了防止写页表时越界。上面的左移 18 bit, 再右移 18 bit, 主要是按 1M 页表进行对齐。在适当的位置加上断点,使用 GDB 调试,情况如下:
(gdb) b BS_debug
Breakpoint 1 at 0x600100c8: file arch/arm/boot/compressed/head.S, line 132.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:132
132 mov r0, r3
(gdb) n
133 mov r9, r0, lsr #18
(gdb) n
134 mov r9, r9, lsl #18 @ start of RAM
(gdb) info reg r9
r9 0x1800 6144
(gdb) n
135 add r10, r9, #0x10000000 @ a reasonable RAM size
(gdb) info reg r9
r9 0x60000000 1610612736
(gdb) info reg r0
r0 0x60004000 1610629120
(gdb) n
136 mov r1, #0x12 @ XN|U + section mapping
(gdb) info reg r10
r10 0x70000000 1879048192
(gdb) n
137 orr r1, r1, #3 << 10 @ AP=11
(gdb) info reg r1
r1 0x12 18
(gdb) n
138 add r2, r3, #16384
(gdb) info reg r1
r1 0xc12 3090
(gdb) n
139 1: cmp r1, r9 @ if virt > start of RAM
(gdb) info reg r2
r2 0x60008000 1610645504
(gdb) info reg r3
r3 0x60004000 1610629120
(gdb)从上面的调试结果可以看出 RAM 的起始地址是 0x60000000, RAM 的结束地址是 0x70000000。 页表的起始地址是 0x60004000, 页表的结束地址是 0x60008000。继续执行下面代码:
1: cmp r1, r9 @ if virt > start of RAM
cmphs r10, r1 @ && end of RAM > virt
bic r1, r1, #0x1c @ clear XN|U + C + B
orrlo r1, r1, #0x10 @ Set XN|U for non-RAM
orrhs r1, r1, r6 @ set RAM section settings
str r1, [r0], #4 @ 1:1 mapping
add r1, r1, #1048576
teq r0, r2
bne 1b这段代码的主要任务就是设置各个页表项。有前面的代码可以知道,r1 存储着虚拟地址,并且从虚拟 地址 0 开始。r9 寄存器值存储着物理起始地址。上面代码的逻辑基本可以归纳为当虚拟地址不在 RAM 对于的物理地址上,那么执行 bic 指令将 r1 寄存器的 0x1c 对应的位清理,然后将 r1 与 0x10 做或运算,以此标记这类页表;如果虚拟地址在 RAM 对于的物理地址上,那么执行 bic 指令将 r1 寄存器的 0x1c 对应的位清理,然后将 r6 对应的标志与 r1 相与。经过上面的处理之后调用 str 指令将 r1 的值写入 r0 寄存器对应的内存里,然后将 r0 寄存器的值加上 4. 然后将 r1 寄存器 的值加上 1M,如果 r0 的值小于 r2, 那么跳转到 1 处继续循环写页表。通过上面分析,可以获得 两种页表的表示分别是: 1) 0xc12 (不映射 RAM) 2)0xc0e (映射 RAM)。可以在上面代码适当 位置加入断点,然后使用 GDB 进行调试,这里在最后面加上断点,调试情况如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60010108: file arch/arm/boot/compressed/head.S, line 155.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:155
155 orr r1, r6, #0x04
(gdb) x/16x 0x60004000
0x60004000: 0x00000c12 0x00100c12 0x00200c12 0x00300c12
0x60004010: 0x00400c12 0x00500c12 0x00600c12 0x00700c12
0x60004020: 0x00800c12 0x00900c12 0x00a00c12 0x00b00c12
0x60004030: 0x00c00c12 0x00d00c12 0x00e00c12 0x00f00c12
(gdb) x/16x 0x600057f0
0x600057f0: 0x5fc00c12 0x5fd00c12 0x5fe00c12 0x5ff00c12
0x60005800: 0x60000c0e 0x60100c0e 0x60200c0e 0x60300c0e
0x60005810: 0x60400c0e 0x60500c0e 0x60600c0e 0x60700c0e
0x60005820: 0x60800c0e 0x60900c0e 0x60a00c0e 0x60b00c0e
(gdb) x/16x 0x60005bf0
0x60005bf0: 0x6fc00c0e 0x6fd00c0e 0x6fe00c0e 0x6ff00c0e
0x60005c00: 0x70000c12 0x70100c12 0x70200c12 0x70300c12
0x60005c10: 0x70400c12 0x70500c12 0x70600c12 0x70700c12
0x60005c20: 0x70800c12 0x70900c12 0x70a00c12 0x70b00c12
(gdb) x/16x 0x60007ff0
0x60007ff0: 0xffc00c12 0xffd00c12 0xffe00c12 0xfff00c12
0x60008000: 0x00000000 0x00000000 0x00000000 0x00000000
0x60008010: 0x00000000 0x00000000 0x00000000 0x00000000
0x60008020: 0x00000000 0x00000000 0x00000000 0x00000000
(gdb)RAM 对于的页表范围从 0x60005800 到 0x60005c00, 从上面的运行结果符合上面代码分析。接下 继续执行如下代码:
/*
* If ever we are running from Flash, then we surely want the cache
* to be enabled also for our execution instance... We map 2MB of it
* so there is no map overlap problem for up to 1 MB compressed kernel.
* If the execution is in RAM then we would only be duplicating the above.
*/
orr r1, r6, #0x04 @ ensure B is set for this
orr r1, r1, #3 << 10
mov r2, pc
mov r2, r2, lsr #20
orr r1, r1, r2, lsl #20
add r0, r3, r2, lsl #2
str r1, [r0], #4
add r1, r1, #1048576
str r1, [r0]
mov pc, lr
ENDPROC(__setup_mmu)接下来这段代码主要的目的就是为了区分系统是从 Flash 启动,如果是,那么就将 RAM 对应的页表 的前 2M 设置特殊的页表标志。此时经过映射之后,r1 指向了虚拟地址 0,然后调用 orr 指令将 r1 寄存器存储特定的标志。通过将 PC 的值传入 r2 寄存器,并计算出 r2 对应的页表中的偏移, 然后写入 r1 中的值到页表中,然后在将 r1 的值指向下 1M 地址空间,最后将 lr 的值传递给 pc 寄存器,那么函数至此返回。开发者可以在适当的位置加入断点,然后使用 GDB 进行调试,调试情况 如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60010108: file arch/arm/boot/compressed/head.S, line 155.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:155
155 orr r1, r6, #0x04
(gdb) info reg r1
r1 0xc12 3090
(gdb) info reg r6
r6 0xe 14
(gdb) n
156 orr r1, r1, #3 << 10
(gdb) n
157 mov r2, pc
(gdb) n
158 mov r2, r2, lsr #20
(gdb) info reg r2
r2 0x60010118 1610678552
(gdb) n
159 orr r1, r1, r2, lsl #20
(gdb) info reg r2
r2 0x600 1536
(gdb) n
160 add r0, r3, r2, lsl #2
(gdb) info reg r1
r1 0x60000c0e 1610615822
(gdb) info reg r3
r3 0x60004000 1610629120
(gdb) info reg r2
r2 0x600 1536
(gdb) n
161 str r1, [r0], #4
(gdb) info reg r2
r2 0x600 1536
(gdb) info reg r3
r3 0x60004000 1610629120
(gdb) info reg r0
r0 0x60005800 1610635264
(gdb) n
162 add r1, r1, #1048576
(gdb) n
163 str r1, [r0]
(gdb) n
164 mov pc, lr
(gdb) x/4x 0x60005800
0x60005800: 0x60000c0e 0x60100c0e 0x60200c0e 0x60300c0e
(gdb)上面的调试情况可以看出,内核不是从 Flash 启动,所以页表项的值没有改变。接着返回 __setup_mmu 的调用点。执行如下代码:
__armv7_mmu_cache_on:
mov r12, lr
#ifdef CONFIG_MMU
mrc p15, 0, r11, c0, c1, 4 @ read ID_MMFR0
tst r11, #0xf @ VMSA
movne r6, #CB_BITS | 0x2 @ !XN
blne __setup_mmu
mov r0, #0
mcr p15, 0, r0, c7, c10, 4 @ drain write buffer
tst r11, #0xf @ VMSA
mcrne p15, 0, r0, c8, c7, 0 @ flush I,D TLBs
#endif从 __setup_mmu 返回之后,代码首先将 r0 寄存器设置为 0,然后调用 mcr 指令实现以此 DMB, 也就是内存屏障,保证这条指令之前所有内存访问都必须完成。继续使用 tst 指令确定当前模式是 VMSA 模式。如果是 VMSA 模式,那么就是调用 mcrne 指令,此时 CP15 调用情况如下图:

因此此时选择的是 TLBIALL 寄存器,向该寄存器写入任何值都会影响刷 I-TLB 和 D-TLB. 这在 MMU 启用之前是必要的。接下来执行的代码是:
mrc p15, 0, r0, c1, c0, 0 @ read control reg
bic r0, r0, #1 << 28 @ clear SCTLR.TRE
orr r0, r0, #0x5000 @ I-cache enable, RR cache repla
orr r0, r0, #0x003c @ write buffer
bic r0, r0, #2 @ A (no unaligned access fault)
orr r0, r0, #1 << 22 @ U (v6 unaligned access model)
@ (needed for ARM1176)首先通过 mrc 指令读取 CP15 寄存器,该寄存器的布局如下:

选择 SCTLR 寄存器,其位布局图如下:
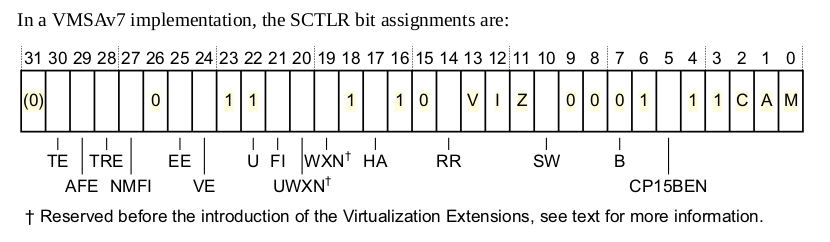
接着就是对 SCTLR 寄存器特定位的操作,首先清楚掉 TRE 位,然后选中 I-cache enable, RR cache 替代算法,写缓存,设置对齐方式,具体细节可以查看 ARMv7 Reference Manual。设置 完使用的 cache 策略之后,开发者可以在上面的适当位置加上断点,然后使用 GDB 进行调试,调试 结果如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60010154: file arch/arm/boot/compressed/head.S, line 179.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:179
179 mrc p15, 0, r0, c1, c0, 0 @ read control reg
(gdb) n
180 bic r0, r0, #1 << 28 @ clear SCTLR.TRE
(gdb) info reg r0
r0 0xc50078 12910712
(gdb) n
181 orr r0, r0, #0x5000 @ I-cache enable, RR cache replacement
(gdb) info reg r0
r0 0xc50078 12910712
(gdb) n
182 orr r0, r0, #0x003c @ write buffer
(gdb) info reg r0
r0 0xc55078 12931192
(gdb) n
183 bic r0, r0, #2 @ A (no unaligned access fault)
(gdb) info reg r0
r0 0xc5507c 12931196
(gdb) n
184 orr r0, r0, #1 << 22 @ U (v6 unaligned access model)
(gdb) info reg r0
r0 0xc5507c 12931196开发者可以参考 ARMv7 手册对比上面的各个位的含义。接下来执行的代码如下:
#ifdef CONFIG_MMU
mrcne p15, 0, r6, c2, c0, 2 @ read ttb control reg
orrne r0, r0, #1 @ MMU enable
movne r1, #0xfffffffd @ domain 0 = client
bic r6, r6, #1 << 31 @ 32-bit translation system
bic r6, r6, #(7 << 0) | (1 << 4) @ use only ttbr0
mcrne p15, 0, r3, c2, c0, 0 @ load page table pointer
mcrne p15, 0, r1, c3, c0, 0 @ load domain access control
mcrne p15, 0, r6, c2, c0, 2 @ load ttb control
#endif接下来的代码是设置 MMU 最重要的代码,这段代码主要任务就是设置页表的基地址寄存器,并将该寄存器 的值指向了页表的基地址。首先调用 mrcne 指令,代表了在 VMSA 模式下,读取 TTB 控制器,对应 的 CP15 c2 寄存器如下:
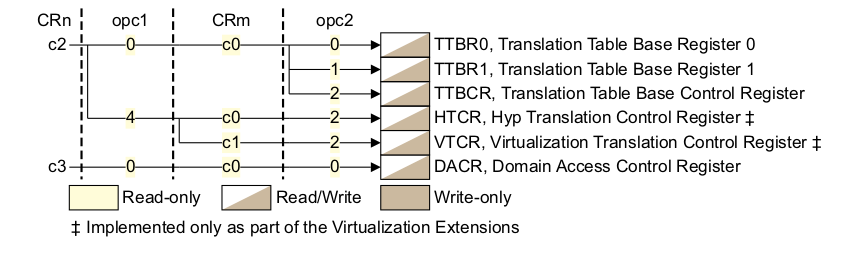
选择了 TTBCR 寄存器,对应的位图如下:
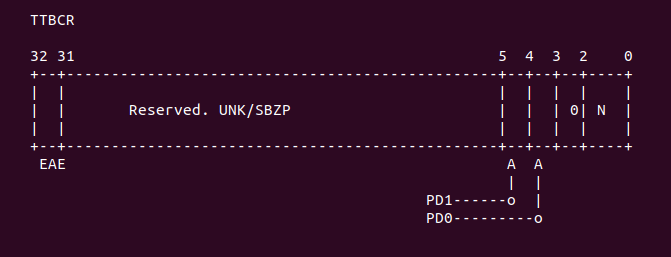
继续上面 r0 寄存器,设置了 r0 最地位,这里对应这 MMU enable 位,置位之后一旦写入 SCTR 寄存器,那么 MMU 就可以使用了。domain 的访问设置为 client. 对于 TTBCR 寄存器,将 31 bit 清理,以此支持 32 位的地址转换,然后对 TTBCR 寄存器,清楚低 3 位和第 4 位,以此告诉页表 只是用 TTBR0 作为页表的基地址。接下来是将值写到 CP15 对应的寄存器上,第一条指令是 “mcrne p15, 0, r3, c2, c0, 0”, 这条命令的作用是将页表的基地址存储到 TTBR0 寄存器, 从上面的代码可以知道,r3 寄存器一直存储着页表的基地址。第二条指令是 “mcrne p15, 0, r1, c3, c0, 0”, 设置了 domain 的访问域。第三条指令是 “mcrne p15, 0, r6, c2, c0, 2”, 告诉页表控制器, 目前使用的页表是 32 位装换方式,并且只使用 TTBR0 寄存器作为页表的基地址。更多页表知识请查看:
开发者可以在上面的适当位置打上断点,然后使用 GDB 进行调试,调试结果如下:
(gdb) b BS_debug
Breakpoint 1 at 0x6001016c: file arch/arm/boot/compressed/head.S, line 188.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:188
188 mrcne p15, 0, r6, c2, c0, 2 @ read ttb control reg
(gdb) info reg r3
r3 0x60004000 1610629120
(gdb) n
189 orrne r0, r0, #1 @ MMU enable
(gdb) info reg r6
r6 0x0 0
(gdb) n
190 movne r1, #0xfffffffd @ domain 0 = client
(gdb) n
191 bic r6, r6, #1 << 31 @ 32-bit translation system
(gdb) n
192 bic r6, r6, #(7 << 0) | (1 << 4) @ use only ttbr0
(gdb) info reg r6
r6 0x0 0
(gdb) n
193 mcrne p15, 0, r3, c2, c0, 0 @ load page table pointer
(gdb) info reg r6
r6 0x0 0
(gdb) n
194 mcrne p15, 0, r1, c3, c0, 0 @ load domain access control
(gdb) info reg r3
r3 0x60004000 1610629120
(gdb) info reg r1
r1 0xfffffffd -3
(gdb) n
195 mcrne p15, 0, r6, c2, c0, 2 @ load ttb control
(gdb) info reg r6
r6 0x0 0通过上面实践,可以看出目前页表支持的模式是 32 位地址转换以及只使用 TTBR0 页基址寄存器。 接下来执行的代码是:
mcr p15, 0, r0, c7, c5, 4 @ ISB
mcr p15, 0, r0, c1, c0, 0 @ load control register
mrc p15, 0, r0, c1, c0, 0 @ and read it back
mov r0, #0
mcr p15, 0, r0, c7, c5, 4 @ ISB
mov pc, r12运行到最后阶段,将这前设置好的值写入到对应的寄存器中。首先执行以此 ISB 指令,将流水线,内存 访问操作全部 flush 一次。接着执行命令 “mcr p15, 0, r0, c1, c0, 0”, 将之前关于 MMU enable/I-cache/D-cache 等在 SCTR 控制器的配置全部写入到 SCTR 寄存器中,写入之后, 系统立即生效。至此 MMU 和 I-cache 和 D-cache 都能使用。这里再次调用 ISB 指令,将流水线 上的指令等同步到最新的配置。最后将 r12 的返回地址赋值给 pc,实现函数返回。
在启用 MMU 之后,此时物理地址和虚拟地址按 1:1 映射。回到之前执行代码的位置继续执行如下 代码:
restart: adr r0, LC0
ldmia r0, {r1, r2, r3, r6, r10, r11, r12}
ldr sp, [r0, #28]这段代码很简单,就是 zImage 阶段创建了一个简单的表 LC0,然后将 LC0 表的内容分别赋值给指定 的寄存器。LC0 表用于存储 zImage 链接阶段各个重要段的偏移值,这里首先查看一下 LC0 表的内容:
.align 2
.type LC0, #object
LC0: .word LC0 @ r1
.word __bss_start @ r2
.word _end @ r3
.word _edata @ r6
.word input_data_end - 4 @ r10 (inflated size location)
.word _got_start @ r11
.word _got_end @ ip
.word .L_user_stack_end @ sp
.word _end - restart + 16384 + 1024*1024
.size LC0, . - LC0从上面的定义可以知道:
1) LC0 + 0: LC0 在 zImage 中的偏移地址
2) LC0 + 4: BSS 段起始地址在 zImage 镜像中的偏移地址
3) LC0 + 8: BSS 段结束地址在 zImage 镜像中的偏移地址
4) LC0 + 12: 压缩内核的长度在 zImage 镜像中的偏移地址
5) LC0 + 16: zImage GOT 表起始地址在 zImage 镜像中的偏移地址
6) LC0 + 20: zImage GOT 表结束的地址 zImage 镜像中的偏移地址
7) LC0 + 24: zImage 堆栈的位置
8) LC0 + 28: zImage 重定位的长度
9) LC0 + 32: LC0 表长因此执行命令 “ldmia r0, {r1, r2, r3, r6, r10, r11, r12}” 之后,这些值就被存储到 指定寄存器里,并且调用命令 “ldr sp, [r0, #28]” 获得堆栈的偏移地址。开发者可以在适当 的位置加入断点进行 GDB 调试,调试情况如下:
(gdb) b BS_debug
Breakpoint 1 at 0x600100bc: file arch/arm/boot/compressed/head.S, line 116.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:116
116 restart: adr r0, LC0
(gdb) n
117 ldmia r0, {r1, r2, r3, r6, r10, r11, r12}
(gdb) n
118 ldr sp, [r0, #28]
(gdb) n
(gdb) info reg
r0 0x60010214 1610678804
r1 0x214 532
r2 0x438410 4424720
r3 0x438410 4424720
r4 0x60008000 1610645504
r5 0x0 0
r6 0x438410 4424720
r7 0x8e0 2272
r8 0x69cf8000 1775206400
r9 0x60000000 1610612736
r10 0x438408 4424712
r11 0x43840c 4424716
r12 0x43840c 4424716
sp 0x439410 0x439410经过上面的实践之后,各个寄存器已经载入指定的值,接下来执行的代码是:
/*
* We might be running at a different address. We need
* to fix up various pointers.
*/
sub r0, r0, r1 @ caclculate the delta offset
add r6, r6, r0 @ _edata
add r10, r10, r0 @ inflated kernel size location由于 LC0 表内的值有的是链接时相对于 zImage 镜像的偏移值,此时开发者需要通过这些值 加载到内存之后对应的值,因此上面的代码就是用于矫正 LC0 内的新值。从之前的代码可以知道, r0 寄存器存储的值是 LC0 表在内存中的地址,此时由于 MMU 已经启用,因此 r0 的值代表 LC0 表的虚拟地址,r1 寄存器存储着 LC0 相对于 zImage 镜像的偏移值。因此命令 “sub r0, r0, r1” 可以计算 LC0 表的基础偏移,然后表内各项的偏移都可以通过这个值 进行计算。开发者在适当的位置加入断点,使用 GDB 进行调试,情况如下:
(gdb) b BS_debug
Breakpoint 1 at 0x600100c8: file arch/arm/boot/compressed/head.S, line 124.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:124
124 sub r0, r0, r1 @ caclculate the delta offset
(gdb) info reg r0
r0 0x60010214 1610678804
(gdb) info reg r1
r1 0x214 532
(gdb) n
125 add r6, r6, r0 @ _edata
(gdb) info reg r6
r6 0x438410 4424720
(gdb) info reg r0
r0 0x60010000 1610678272
(gdb) n
126 add r10, r10, r0 @ inflated kernel size location
(gdb) info reg r6
r6 0x60448410 1615102992
(gdb)从上面的实践结果可以看出,zImage 的起始地址为 0x60010000,这和之前的设定是一直的,符合 要求。r10 寄存器经过矫正之后对应这内核原始大小,那么原始内核大小是如何被存放到 LC0 表里 呢?回答这个问题首先应该明确几点:解压后的内核就是之前所说的 Image, Image 有完整的 vmlinux 经过 OBJCOPY 命令生成的二进制文件,这个 Image 是可以直接在内存上运行的, 所以知道 Image 长度是一个至关重要的问题。那么下面介绍一下编译系统 Kbuild 是如何 计算 Image 长度呢?
首先 Image 经过压缩之后获得压缩内核 piggy_data,其使用的压缩命令如下:
$(obj)/piggy_data: $(obj)/../Image FORCE
$(call if_changed,$(compress-y))这段代码位于 arch/arm/boot/compressed/Makefile, 这段代码就是 Image 压缩生成 piggy_data 压缩内核的过程,具体使用哪种压缩方法,通过 compress-y 决定,其定义 也在同一个文件中,如下:
compress-$(CONFIG_KERNEL_GZIP) = gzip
compress-$(CONFIG_KERNEL_LZO) = lzo
compress-$(CONFIG_KERNEL_LZMA) = lzma
compress-$(CONFIG_KERNEL_XZ) = xzkern
compress-$(CONFIG_KERNEL_LZ4) = lz4从上面的定义可知,内核支持多种压缩方式,其中以 gzip 为例,piggy_data 的压缩命令是:
$(obj)/piggy_data: $(obj)/../Image FORCE
$(call if_changed,gzip)于是开发者可以去 Kbuild 的命令库里查看这个命令的具体过程,Kbuild 的命令库位于源码 scripts/Makefile.lib, gzip 命令如下:
quiet_cmd_gzip = GZIP $@
cmd_gzip = cat $(filter-out FORCE,$^) | gzip -n -f -9 > $@所以可以看到 gizp 的执行过程,这里有个很重要的概念:压缩工具无论进行何种压缩算法, 会在压缩文件的最后四个字节存储原始文件的大小,并按大端的模式存储。例如使用工具分别 查看 Image 的大小以及 piggy_data 的最后四个字节,如下:
$ ll arch/arm/boot/Image
-rwxrwxr-x 1 buddy buddy 11931944 4月 1 07:06 Image*
$ bless arch/arm/boot/compressed/piggy_data
EB 11 97 AB C6 BC B8 40 5D 87 38 5B 35 E6 05 45 6A EC 99 66 4F 5F
49 A3 3F 96 EB A4 1D 2B E9 1A BB 1B D7 B7 78 F5 80 26 4E 4E FF 0F
A1 10 18 DA 28 11 B6 00通过上面的数据分析可到,piggy_data 的最后四个字节是 28 11 B6 00, 按小端调整之后的 值是 0x00B61128, 对应十进制值是 11931944, 数值正好对应 Image 的长度,因此上面的 推论是正确的。这是 piggy_data 的最后四字节存储着 Image 的长度,根据原理可以知道 Kbuild 编译系统将 piggy.S 汇编文件将 piggy_data 二进制文件封装成一个汇编文件,并 链接成一个 ELF 文件,并在 piggy.S 中定义了两个全局符号: “input_data” 和 “input_data_end”, 这两个符号标记了 piggy.o 里 piggy_data 的起始偏移地址和 终止偏移地址。并在该目录下的 vmlinux.lds.S 脚本里定义了 .piggydata section, section 内部也定义了一个变量 __piggy_size_addr, 这个变量正好指向了 piggy_data 最后 4 个字节。因此在 LC0+32 处定义为 “input_data_end - 4”, 因此以上数据都可以 知道压缩内核解压之后的长度。其他压缩方法同理。接着执行如下命令:
/*
* The kernel build system appends the size of the
* decompressed kernel at the end of the compressed data
* in little-endian form.
*/
ldrb r9, [r10, #0]
ldrb lr, [r10, #1]
orr r9, r9, lr, lsl #8
ldrb lr, [r10, #2]
ldrb r10, [r10, #3]
orr r9, r9, lr, lsl #16
orr r9, r9, r10, lsl #24通过上面的分析可以知道,r10 寄存里存储 piggy_data 的最后面四个字节地址,这个地址 存储着压缩内核解压之后的长度,也就是 Image 的长度,但是其长度在这四个字节里按大端 格式存储,因此需要上面的代码将大端数据读出转换为小端格式。代码逻辑很简单,就是使用 ldrb 指令从 r10 对应的地址上读一个字节,然后调整字节序,最后压缩内核解压之后的长度 存储到 r9 寄存器里。使用 GDB 调试结果如下:
(gdb) b BS_debug
Breakpoint 1 at 0x600100d4: file arch/arm/boot/compressed/head.S, line 133.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:133
133 ldrb r9, [r10, #0]
(gdb) n
134 ldrb lr, [r10, #1]
(gdb) n
135 orr r9, r9, lr, lsl #8
(gdb) n
136 ldrb lr, [r10, #2]
(gdb) n
137 ldrb r10, [r10, #3]
(gdb) n
138 orr r9, r9, lr, lsl #16
(gdb) n
139 orr r9, r9, r10, lsl #24
(gdb) n
__setup_mmu () at arch/arm/boot/compressed/head.S:149
149 __setup_mmu: sub r3, r4, #16384 @ Page directory size
(gdb) info reg r9
r9 0xb61128 11931944
(gdb)从上面的实践可以看出,获得了 Image 长度的正确值。接着继续执行代码:
#ifndef CONFIG_ZBOOT_ROM
/* malloc space is above the relocated stack (64k max) */
add sp, sp, r0
add r10, sp, #0x10000
#endif
mov r5, #0 @ init dtb size to 0这里主要作用是分配 64K 的空间。首先矫正了堆栈的虚拟地址,并且将堆栈之后增加了 64K 空间 用于 malloc,将 malloc + stack + zImage 的长度存储到 r10 寄存器中。然后将 r5 设置 为 0 供 DTB 使用,但是由于本实践不支持 DTB APPEND 模式,因此接下来执行代码如下:
/*
* Check to see if we will overwrite ourselves.
* r4 = final kernel address (possibly with LSB set)
* r9 = size of decompressed image
* r10 = end of this image, including bss/stack/malloc space if non XIP
* We basically want:
* r4 - 16k page directory >= r10 -> OK
* r4 + image length <= address of wont_overwrite -> OK
* Note: the possible LSB in r4 is harmless here.
*/
add r10, r10, #16384
cmp r4, r10
bhs wont_overwrite
add r10, r4, r9
adr r9, wont_overwrite
cmp r10, r9
bls wont_overwrite这段代码的主要任务是确定当前 zImage 运行的范围会不会与内核解压之后的地址范围重合,如果 重合,那么 zImage 要做相应的调整,这里涉及到 zImage 重定位到一个新的地址继续运行,这样 zImage 和解压内核相互影响。在执行代码之前,r4 指向解压内核的起始地址,r9 代表解压 之后内核的长度,r10 寄存器代表当前 zImage 的长度(该长度也包含了 bss/stack/malloc) 的长度,因此需要做对比操作。那么在什么情况下不用重定位或重合呢,如下面几种情况:
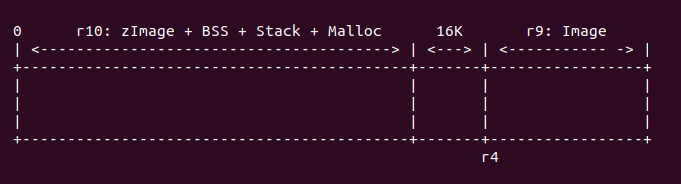
r4 - 16K >= r10
对于这种情况,内存分布如下:
在这种情况下,zImage 运行的地址域与内核解压之后的地址域是不重合的,所以 zImage 不需要重定位,直接在原始地址上直接运行。
r4 + image < wont_overwrite
对于这种情况,内存布局如下:
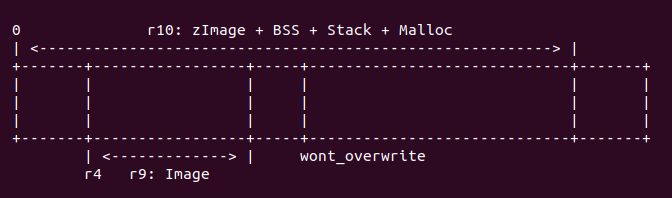
首先调用命令 “add r10, r10, #16384”, 将 r10 的长度再增加 16K,此时 r10 代表 zImage 长度加上 BSS/Stack/Malloc,再加上 16K 的长度,此时 r10 也可以表示 zImage 运行时完整的长度。接着调用 “cmp r4, r10” 命令,查看此时 zImage 的长度域与解压内核 长度域之间的关系是否满足 “r4 - 16K >= r10” 条件, 如果满足,则执行 “bhs wont_overwrite”, 这样 zImage 就不需要重定位;如果不满足,那么继续确认是否 满足第二个条件,执行命令 “add r10, r4, r9”, 使 r10 寄存器存储解压内核的终止 物理地址,再调用命令 “adr r9, wont_overwrite” 获得 zImage 中 wont_overwrite 的地址,最后执行命令 “cmp r10, r9”, 如果 r10 小于 r9, 那么满足第二个条件,则执行 “bls wont_overwrite”, zImage 不需要重定位;反之 zImage 需要重定位。 这里开发者们可以使用 GDB 调试这段代码,运行结果如下:
(gdb) b BS_debug
Breakpoint 1 at 0x600100fc: file arch/arm/boot/compressed/head.S, line 158.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:158
158 add r10, r10, #16384
(gdb) n
159 cmp r4, r10
(gdb) n
160 bhs wont_overwrite
(gdb) n
161 add r10, r4, r9
(gdb) n
162 adr r9, wont_overwrite
(gdb) n
163 cmp r10, r9
(gdb) info reg r10
r10 0x60b69128 1622577448
(gdb) info reg r9
r9 0x6001011c 1610678556
(gdb) n
164 bls wont_overwrite因此从实践结果看出,zImage 与解压之后的内核存在重叠,zImage 需要重定位,它们 之间的关系如下:

经过上面代码执行,r9 寄存器存储着 wont_overwrite 的地址, r10 寄存器存储着解压之后 内核的终止地址。接下来运行代码:
/*
* Relocate ourselves past the end of the decompressed kernel.
* r6 = _edata
* r10 = end of the decompressed kernel
* Because we always copy ahead, we need to do it from the end and go
* backward in case the source and destination overlap.
*/
/*
* Bump to the next 256-byte boundary with the size of
* the relocation code added. This avoids overwriting
* ourself when the offset is small.
*/
add r10, r10, #((reloc_code_end - restart + 256) & ~255)
bic r10, r10, #255
/* Get start of code we want to copy and align it down. */
adr r5, restart
bic r5, r5, #31此时 r10 寄存器存储着解压之后内核的终止地址。”((reloc_code_end - restart + 256) & ~255)” 表示了 head.S 中 reloc_code_end 的长度,并按 256 字节对齐,运行命令之后,r10 寄存器 存储了解压之后内核的终止地址再加上 head.s 重定位代码的长度。并将 head.S 中 restart 的地址存储在 r5 寄存器中,并按 32 字节对齐。接下来执行代码:
sub r9, r6, r5 @ size to copy
add r9, r9, #31 @ rounded up to a multiple
bic r9, r9, #31 @ ... of 32 bytes
add r6, r9, r5
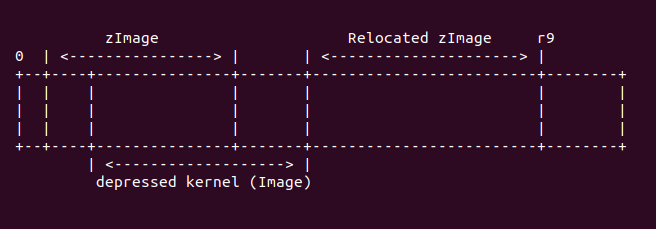
add r9, r9, r10此处,r6 寄存器表示 zImage 不带 BSS 段的长度,即原始 zImage 的长度。这里调用命令 “sub r9, r6, r5”,将 zImage 的长度减去需要 head.S 中需要重定位的长度之后的值, 存储到 r9 寄存器中,并将 r9 寄存器按 32 字节对齐。接着将 r9 寄存器的值存储到 r6 寄存器中,这样 r6 寄存器存储着 zImage 减去 head.S 中重定位长度之后的终止地址。接着执行命令 “add r9, r9, r10”, 通过这个命令,r9 存储了 zImage 重定位之后的结束物理地址, 他们之间关系如下图:
接下来执行代码:
1: ldmdb r6!, {r0 - r3, r10 - r12, lr}
cmp r6, r5
stmdb r9!, {r0 - r3, r10 - r12, lr}
bhi 1b
/* Preserve offset to relocated code. */
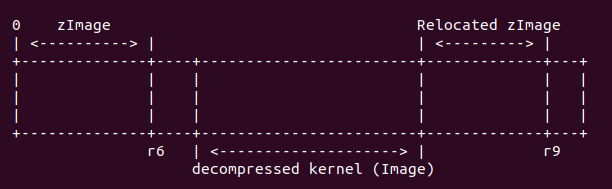
sub r6, r9, r6这段代码的主要任务就是搬运 zImage 到重定位的位置,搬运的内容不包括 zImage 的 BSS/ Stack/Malloc 区域。此时 r6 寄存器存储着 zImage 的减去 head.S 重定位段之后的结束地址。 r9 寄存器存储着解压之后的内核终止地址加上 zImage 重定位的地址。此时内存布局如下:
这里使用 ldmdb 从 r6 对应的 zImage 的末尾往重定位 zImage 的末尾拷贝数据,这里 也就是搬运 zImage 到新的地址。ldmdb 一直循环知道 r6 的地址与 r5 对应的地址重合, 方才停止循环。可以在适当的位置加入断点,然后使用 GDB 进行调试,调试情况如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60010164: file arch/arm/boot/compressed/head.S, line 209.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:209
209 sub r6, r9, r6
(gdb) info reg r6
r6 0x600100a0 1610678432
(gdb) info reg r9
r9 0x60b69400 1622578176
(gdb) x/16x 0x60b69400
0x60b69400: 0xe1a0000f 0xe1500004 0x359f0224 0x3080000f
0x60b69410: 0x31540000 0x33844001 0x2b000068 0xe28f0e1f
0x60b69420: 0xe8901c4e 0xe590d01c 0xe0400001 0xe0866000
0x60b69430: 0xe08aa000 0xe5da9000 0xe5dae001 0xe189940e
(gdb) x/16x 0x600100a0
0x600100a0 <not_angel+64>: 0xe1a0000f 0xe1500004 0x359f0224 0x3080000f
0x600100b0 <not_angel+80>: 0x31540000 0x33844001 0x2b000068 0xe28f0e1f
0x600100c0 <restart+4>: 0xe8901c4e 0xe590d01c 0xe0400001 0xe0866000
(gdb) n
(gdb) info reg r6
r6 0xb59360 11899744
(gdb)从上面的运行情况可以看出,上面的代码已经将 zImage 拷贝到指定位置,最后将 r9 寄存器的值减去 r6 寄存器的值,然后存储到 r6 寄存器中,以此计算重定位安全距离。接下来执行的代码如下:
#ifndef CONFIG_ZBOOT_ROM
/* cache_clean_flush may use the satck, so relocated it */
add sp, sp, r6
#endif本实践中并为定义 CONFIG_ZBOOT_ROM 宏,由于接下来要执行 cache_clean_flush 需要使用 堆栈,所以将堆栈指向一个合适的位置,这里将堆栈加上 r6 寄存器的值。接下来调用 cache_clean_flush. 具体代码如下:
/*
* Clean and flush the cache to maintain consistency
*
* On exit,
* r1, r2, r3, r9, r10, r11, r12 corrupted
* This routine must preserve:
* r4, r6, r7, r8
*/
.align 5
cache_clean_flush:
mov r3, #16
b call_cache_fncache_clean_flush 的定义很简单,与 cache_on 一样的机制,都是在 CACHE 表中找到 __armv7_mmu_cache_flush 的入口,具体查找过程,查看前面关于 call_cache_fn 源码解析, 通过 call_cache_fn 之后,会定位到 __armv7_mmu_cache_flush 处,代码如下:
__armv7_mmu_cache_flush:
tst r4, #1
bne iflush
mrc p15, 0, r10, c0, c1, 5 @ read ID_MMFR1
tst r10, #0xf << 16 @ hierarchical cache (ARMv7)
mov r10, #0
beq hierarchical
mcr p15, 0, r10, c7, c14, 0 @ clean+invalidate D
b iflush首先检查 r4 寄存器的最低位是否置位,从前面的代码可以知道,MMU 打开的情况下,r4 最低位清零; 如果 MMU 未启用,那么 r4 最低位置位。由之前的分析可知,此处 MMU 已经启用,所以 tst 的结果 未零,那么 “bne iflush” 命令将不被执行。接下来执行的代码是: “mrc p15, 0, r10, c0, c1, 5”, 此时 CP15 C0 寄存器的布局如下:
通过上面的代码选中了 ID_MMFR1 寄存器,该寄存器用于指定当前 CACHE 的类型,其位图如下:

接着调用 tst 命令查看 ID_MMFR1 寄存器的 [19:16] 域,该域表示:

有上面的定义可知,该域用于指示 L1 cache 的维护操作。但在 armv7 中,这是不需要的,因此 tst 的结果等于 0,那么代码接下来跳转到 hierarchical 处继续执行。开发者可以在适当的位置加入断点, 然后使用 GDB 进行调试,调试情况如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60010268: file arch/arm/boot/compressed/head.S, line 323.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:323
323 tst r4, #1
(gdb) n
324 bne iflush
(gdb) n
325 mrc p15, 0, r10, c0, c1, 5 @ read ID_MMFR1
(gdb) info reg r4
r4 0x60008000 1610645504
(gdb) n
326 tst r10, #0xf << 16 @ hierarchical cache (ARMv7)
(gdb) info reg r10
r10 0x20000000 536870912
(gdb) n
327 mov r10, #0
(gdb) n
328 beq hierarchical
(gdb) n
hierarchical () at arch/arm/boot/compressed/head.S:333
333 mcr p15, 0, r10, c7, c10, 5 @ DMB
(gdb)从上面的调试结果可知,与分析的一致,跳转到 hierarchical 处继续执行,由于 armv7 的 L1 cache 按分层管理,要给 cache 进行 flush 操作,首先要了解一下 cache 的基础知识, 这里只介绍必要的知识,更多 cache 知识请查看:
L1 cache
在 ARMv7 中,cache 分为了指令 cache (I-Cache) 和数据 cache (D-cache), cache 是 用来加速内存访问,其逻辑结构如下图:
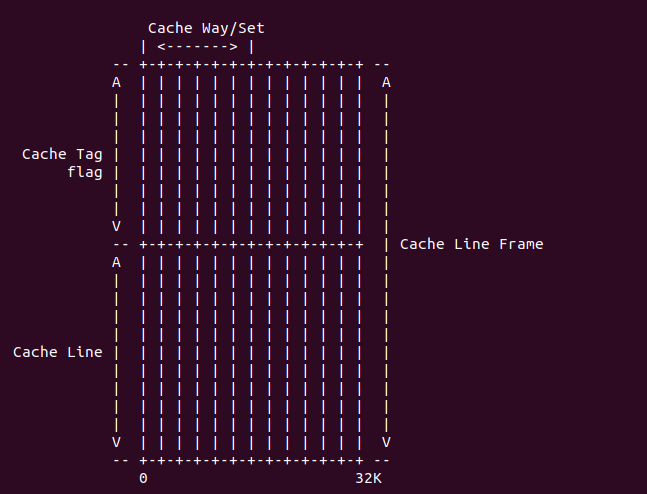
cache 的最小数据单位是 cache line, cache line 的长度成为 cache size;为了标记每个 cache line,使用的标记叫 cache tag, cache tag、cache line 与一些标志信息组成一个 cache line frame; 多个 cache line frame 组成一个 cache set;cache 被分成多个 cache set,每个 cache set 含有的 cache line 数成为 cache way.
在 armv7 中要 flush D-cache 按如下逻辑:

在 armv7 中,首先从 CLIDR 寄存器中读取 LoC 域对应的 Ctype,从中找到 D-cache, 然后 在 CSSELR 寄存器写入 D-cache 的 level 信息之后,CCSIDR 寄存器就指向了所要查找 cache 的信息,这些信息存储在 CCSIDR 寄存器中,从这个寄存器中可以获得当前 CACHE 的 cache line 数值,cache Set/Way 的值,通过这些值可以计算出需要 flush 的长度,最后将要清楚的值写入 到 DCCISW 寄存器中,这样该 level 的 cache 就被 flush 完了,接着遍历 flush 下一级 cache。 因此 CACHE 的 flush 逻辑就是这样。接下来通过代码分析具体过程:
hierarchical:
mcr p15, 0, r10, c7, c10, 5 @ DMB
stmfd sp!, {r0-r7, r9-r11}
mrc p15, 1, r0, c0, c0, 1 @ read clidr
ands r3, r0, #0x7000000 @ extract loc from clidr
mov r3, r3, lsr #23 @ left align loc bit field
beq finished @ if loc is 0, then no need to c
mov r10, #0 @ start clean at cache level 0首先做一次 DMB 内存屏蔽操作,将之前的内存访问都同步。然后使用 stmfd 指令保存指定的寄存器, 接着调用 mrc 寄存器读取 CP15 C0 寄存器,选择如下:
通过上面选中了 CLIDR 寄存器,该寄存器的布局如下图:
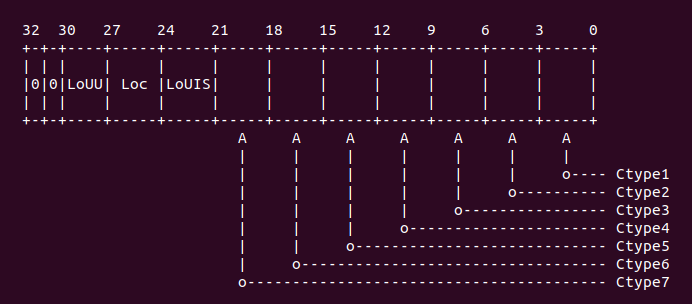
然后执行代码 “ands r3, r0, #0x7000000”, 以此读取 CLIDR [26:24] 域,这个域用于 LoC (Level of Coherence for the cache hierarchy). 这个域用于指定一致性数据 cache 所在的 cache Level,然后通过 “mov r3, r3, lsr #23” 获得 cache level 的具体 数值。如果该值为 0,那么代表没有对应的 cache,直接跳转到 finished 处;如果该值为 0, 那么代码存在对应需要 flush 的 cache,那么继续执行下面的代码不跳转。 开发者可以在上面适当位置加入断点,然后使用 GDB 进行调试,调试情况如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60010288: file arch/arm/boot/compressed/head.S, line 333.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:333
333 mcr p15, 0, r10, c7, c10, 5 @ DMB
(gdb) n
334 stmfd sp!, {r0-r7, r9-r11}
(gdb) info reg r10
r10 0x0 0
(gdb) n
335 mrc p15, 1, r0, c0, c0, 1 @ read clidr
(gdb) n
336 ands r3, r0, #0x7000000 @ extract loc from clidr
(gdb) n
337 mov r3, r3, lsr #23 @ left align loc bit field
(gdb) info reg r3
r3 0x1000000 16777216
(gdb) info reg r0
r0 0x9000003 150994947
(gdb) n
338 beq finished @ if loc is 0, then no need to clean
(gdb) n
339 mov r10, #0 @ start clean at cache level 0
(gdb)从上面的调试结果可以看出,LoC 使用了 cache,并且对应的 cache 是 ctype1, 然后接下来执行的代码逻辑是:
loop1:
add r2, r10, r10, lsr #1 @ work out 3x current cache leve
mov r1, r0, lsr r2 @ extract cache type bits from c
and r1, r1, #7 @ mask of the bits for current c
cmp r1, #2 @ see what cache we have at this
blt skip @ skip if no cache, or just i-ca
mcr p15, 2, r10, c0, c0, 0 @ select current cache level in
mcr p15, 0, r10, c7, c5, 4 @ isb to sych the new cssr&csidr
mcr p15, 1, r1, c0, c0, 0 @ read the new csidr由于在 armv7 中 LoC cache 采用分级模式,所以在 flush cache 的时候,需要从 ctype0 开始 flush,每个 cache ctype 之间相差 3,所以这里使用 “add r2, r10, r10, lsr #1” 达到遍历下一个 cache 的作用。接着就是对 ctypes 对应的值进行对比,这个值从手册中可以 知道:1) 当该值为 0, 代表没有 cache. 2) 该值为 1 代表指令 cache。 3) 该值为 2 代表数据 cache。4) 该值为 3 代表指令和数据分离的 cache。 5) 该值为 4 代表 Unified cache。 6) 其他值为 Reserved。如果此时 “cmp r1, #2” 的值小于 2,那么就代表这个 cache 是一个指令 cache 或者没有 cache。如果 r1 寄存器的值小于 2 那么直接跳转到 skip 处继续执行,如果大于等于 2,那么继续往下执行。接着如果是数据 cache,那么调用命令 “mcr p15, 2, r10, c0, c0, 0”, 此时 CP15 C0 的布局如下:
选中的寄存器是 CSSELR 寄存器,其内存布局如下:
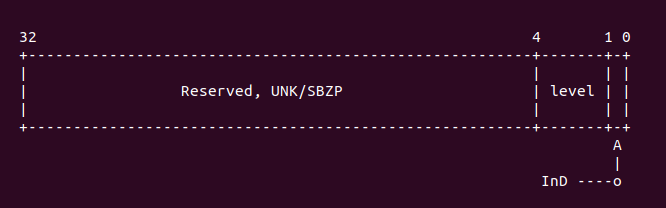
这里用于选择 Cache 的级数,在 armv7 中,只要在 CSSELR 寄存器的 Level 域中选中了 cache Level,那么 CSIDR 寄存器就反应被选中 cache 相关信息。为了是 CSSELR 写入有效, 这里调用了内存屏蔽指令 ISB,执行完 ISB 之后,CSIDR 寄存器的值就是反应 CSSELR 选中 的结果,CSSELR 的内存布局如下:
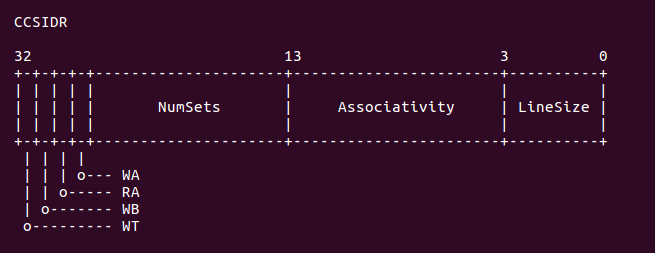
正如上图所示,CSIDR 寄存器包含了当前 cache 的 Set 域,Way 域,以及 line size 域。 开发者可以在上面代码中加入适当的断点,然后使用 GDB 进行调试,调试情况如下:
(gdb) b BS_debug
Breakpoint 1 at 0x600102a4: file arch/arm/boot/compressed/head.S, line 341.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:341
341 add r2, r10, r10, lsr #1 @ work out 3x current cache level
(gdb) n
342 mov r1, r0, lsr r2 @ extract cache type bits from clidr
(gdb) info reg r10
r10 0x0 0
(gdb) info reg r2
r2 0x0 0
(gdb) n
343 and r1, r1, #7 @ mask of the bits for current cache only
(gdb) info reg r1
r1 0x9000003 150994947
(gdb) n
344 cmp r1, #2 @ see what cache we have at this level
(gdb) info reg r1
r1 0x3 3
(gdb) n
345 blt skip @ skip if no cache, or just i-cache
(gdb) n
346 mcr p15, 2, r10, c0, c0, 0 @ select current cache level in cssr
(gdb) n
347 mcr p15, 0, r10, c7, c5, 4 @ isb to sych the new cssr&csidr
(gdb) info reg r10
r10 0x0 0
(gdb) n
348 mrc p15, 1, r1, c0, c0, 0 @ read the new csidr
(gdb) n
349 and r2, r1, #7 @ extract the length of the cache lines
(gdb) info reg r1
r1 0xe00fe019 -535830503
(gdb)从上面的实践可以看出,LoC 所使用的 cache 是一个数据 cache,对应的 Ctype1,并且 Ctype0 的 cache 为 0x3, 将该值写入到 CSIDR 寄存器,就获得 Ctype1 对应的 cache 长度信息。从 r1 读入的值为 0xe00fe019, 从这个数值中可以知道 Cache 的 set 数为 (0x3F + 1), 也就是该 cache 包含了 128 个 set。每个 set 包含的 cache line 数 (0x3 + 1), 那么该 cache 是 4 way。cache line size 是 8 字节。接下来执行的 代码是:
and r2, r1, #7 @ extract the length of the cache lines
add r2, r2, #4 @ add 4 (line length offset)
ldr r4, =0x3ff
ands r4, r4, r1, lsr #3 @ find maximum number on the way size
clz r5, r4 @ find bit position of way size increment
ldr r7, =0x7fff
ands r7, r7, r1, lsr #13 @ extract max number of the index size从之前的分析可以知道,r1 寄存器里面存储着当前 cache 长度相关的信息,首先使用 “and r2, r1, #7” 获得 cache line 的长度。然后调用 “add r2, r2, #4”,这条命令的 作用是为了后面 cache flush 特定寄存器写信息的特殊格式要求,可以参看后面 flush 操作。 接着将常量 0x3ff 赋值给 r4, 然后执行命令 “ands r4, r4, r1, lsr #3”,通过这条 命令读出 cache way 的信息,接着调用 “clz r5, r4” 也是为了拼凑一个格式化数据。同理, 将常量 0x7fff 赋值给 r7,然后获得 cache 的 set 信息。接下来执行的代码如下:
loop2:
mov r9, r4 @ create working copy of max way size
loop3:
ARM( orr r11, r10, r9, lsl r5 ) @ factor way and cache number into r11
ARM( orr r11, r11, r7, lsl r2 ) @ factor index number into r11
mcr p15, 0, r11, c7, c14, 2 @ clean & invalidate by set/way
subs r9, r9, #1 @ decrement the way
bge loop3
subs r7, r7, #1 @ decrement the index
bge loop2
skip:
add r10, r10, #2 @ increment cache number
cmp r3, r10
bgt loop1这段代码就是按 set/way 方式 flush cache,这讲解代码之前,先了解 cache flush 的 方法,armv7 中采用 set/way 方式管理 cache。通过之前 cache 基本原理可以知道,每个 cache set 包含了 way 个 cache line,而 cache 被均分成多个 cache set。因此可以将 cache set 理解为行,cache way 理解为列,所以刷新的时候按行-列的模式刷,因此这里 的代码就是用于实现将所有 set 和 way 都 flush。另外,armv7 中,往特定寄存器写入 set/way 信息就可以刷新指定的 set/way cache, 这个寄存器就是 DCCISW 寄存器,这个 寄存器的位图如下:
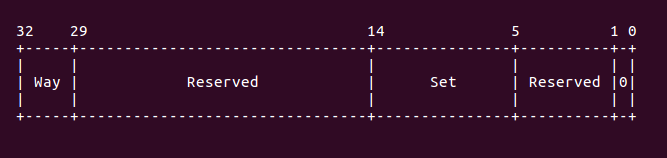
从上图可以知道,要刷新特定的 cache line,那么需要往 DCCISW 寄存器内写入 Way 和 Set 的信息。因此在分析之前的代码,为什么 line size 的值要加上 4,以及 way 的值要这么 处理也就知道了,就是为了制作出一个符合 DCCISW 格式的数据。因此上面的代码分析如下: 首先调用 “mov r9, r4”,为了进行 set 的遍历,接着 “orr r11, r10, r9, lsl r5” 和 “orr r11, r11, r7, lsl r2” 命令也是为了构建 DCCISW 格式化数据,准备好数据之后, 就将数据写入到 DCCISW 寄存器里面,使用的命令是 “mcr p15, 0, r11, c7, c14, 2”. 接下来的代码就是遍历所有的 set 以及 set 里面的所有 way,通过上面的操作,当前 cache 的所有 set/way 就被 flush 完毕。最后到达 skip 处,如果当前 cache flush 完毕, 那么跳转到 loop1 采用同样的方式遍历下一个 cache。开发者可以在适当的位置加入断点, 然后使用 GDB 进行调试,调试的结果如下:
(gdb) b BS_debug
Breakpoint 1 at 0x600102a4: file arch/arm/boot/compressed/head.S, line 341.
(gdb) c
Continuing.
loop3 () at arch/arm/boot/compressed/head.S:359
359 ARM( orr r11, r10, r9, lsl r5 ) @ factor way and cache number into r11
(gdb) n
360 ARM( orr r11, r11, r7, lsl r2 ) @ factor index number into r11
(gdb) n
361 mcr p15, 0, r11, c7, c14, 2 @ clean & invalidate by set/way
(gdb) info reg r11
r11 0xc0000fe0 -1073737760
(gdb) n
362 subs r9, r9, #1 @ decrement the way
(gdb) info reg r9
r9 0x3 3
(gdb) n
363 bge loop3
(gdb) n
359 ARM( orr r11, r10, r9, lsl r5 ) @ factor way and cache number into r11
(gdb) n
360 ARM( orr r11, r11, r7, lsl r2 ) @ factor index number into r11
(gdb)从上面的实践中,可以看出每一次 flush 时 DDCISW 寄存器的变化情况,以及遍历情况。 接下来执行的代码是:
finished:
ldmfd sp!, {r0-r7, r9-r11}
mov r10, #0 @ switch back to cache level 0
mcr p15, 2, r10, c0, c0, 0 @ select current cache level in cssr
iflush:
mcr p15, 0, r10, c7, c10, 4 @ DSB
mcr p15, 0, r10, c7, c5, 0 @ invalidate I+BTB
mcr p15, 0, r10, c7, c10, 4 @ DSB
mcr p15, 0, r10, c7, c5, 4 @ ISB
mov pc, lrcache flush 完毕之后,就做最后的收尾工作,将期间使用过的寄存器都恢复原值,然后 将当前 cache 设置为 0。然后刷新 I-cache。首先调用 DSB 内存屏障,将之访问全部落盘, 然后调用 “mcr p15, 0, r10, c7, c5, 0”, 此时 CP15 C7 的布局如下:

通过上面的命令选中了寄存器:ICIALLU, 向该寄存器写入任意值就会让 I-cache 无效。 接着调用两条内存屏障指令 DSB 和 ISB,让所有改变都生效。最后将 lr 赋值给 pc,实现 调用返回。支持 armv7 的 flush 操作已经全部完成。
代码继续执行如下:
badr r0, restart
add r0, r0, r6
mov pc, r0首先获得 restart 的地址,存储到 r0 寄存器内,然后将 r0 寄存器的值加上 r6 偏移值, 以此计算出 restart 重定位之后的地址,最后将该值赋值给 pc,然后 CPU 就跳转到 restart 重定位处继续执行。
zImage 重定位之后实践
zImage 加载到内存执行之后,进行简单初始化,计算 zImage 的运行空间是否与内核解压之后 的运行空间存在重叠现象,如果重叠,那么在解压内核之前需要将 zImage 重定位到一个安全 的地址,然后再完成解压内核的任务。通过上面的实践可以知道,zImage 加载到内存运行之后, 确实需要一次重定位,那么本节就介绍重定位之后的实践。本阶段实践 GDB 与 zImage 重定位 之前 GDB 调试不同,具体调试方法请看文档:
zImage 重定位之后,ARM 将 pc 指针指向了重定位 zImage restart 处继续执行,执行 代码如下:
restart: adr r0, LC0
ldmia r0, {r1, r2, r3, r6, r10, r11, r12}
ldr sp, [r0, #28]
/*
* We might be running at a different address. We need
* to fix up various pointers.
*/
sub r0, r0, r1 @ caclculate the delta offset
add r6, r6, r0 @ _edata
add r10, r10, r0 @ inflated kernel size location
/*
* The kernel build system appends the size of the
* decompressed kernel at the end of the compressed data
* in little-endian form.
*/
ldrb r9, [r10, #0]
ldrb lr, [r10, #1]
orr r9, r9, lr, lsl #8
ldrb lr, [r10, #2]
ldrb r10, [r10, #3]
orr r9, r9, lr, lsl #16
orr r9, r9, r10, lsl #24
#ifndef CONFIG_ZBOOT_ROM
/* malloc space is above the relocated stack (64k max) */
add sp, sp, r0
add r10, sp, #0x10000
#endif
mov r5, #0 @ init dtb size to 0代码基本逻辑与 zImage 一直,细节请参看上面内容,重定位之后,会重新执行一遍 restart 之后的代码。这段代码的主要任务就是通过 zImage 的 LC0 表计算出目前各个必要信息的地址, 并调整这些地址到一个正确的重定位地址。通过上面的代码,可以获得重定位之后 zImage 的结束地址,以及 Image 的长度。这里不做过多讲解,接下来的代码是:
/*
* Check to see if we will overwrite ourselves.
* r4 = final kernel address (possibly with LSB set)
* r9 = size of decompressed image
* r10 = end of this image, including bss/stack/malloc space if non XIP
* We basically want:
* r4 - 16k page directory >= r10 -> OK
* r4 + image lenght <= address of wont_overwrite -> OK
* Note: the possible LSB in r4 is harmless here.
*/
add r10, r10, #16384
cmp r4, r10
bhs wont_overwrite
add r10, r4, r9
adr r9, wont_overwrite
cmp r10, r9
bls wont_overwrite从上面的运行可知,此处 r10 寄存器存储了堆栈再加 64K 的地址,也就是堆栈加 malloc 之后的地址。然后跟 r4 寄存器对比,r4 寄存器是真正内核运行的起始地址。因为重定位 的原因,r4 的值决定比 r10 小,因此第一次 r4 与 r10 比较的结果不会导致 “bhs wont_overwrite” 执行。接着将 r4 寄存器和 r9 寄存器之和存储到 r10 寄存器, 这里 r10 寄存器代表真正内核运行的结束地址,又将 wont_overwrite 重定位之后的地址 赋值给 r9,通过对比 r10 和 r9 之间的大小,此时由于 zImage 已经重定位,r10 的值一定小于 r9, 那么执行 “bls wont_overwrite” 跳转到 wont_overwrite 处 继续执行。开发者可以在适当位置加入断点进行 GDB 调试,GDB 调试的实际情况如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60b6955c: file arch/arm/boot/compressed/head.S, line 158.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:158
158 add r10, r10, #16384
(gdb) info reg r9
r9 0xb611d8 11932120
(gdb) n
159 cmp r4, r10
(gdb) info reg r10
r10 0x60fa5c08 1627020296
(gdb) n
160 bhs wont_overwrite
(gdb) n
161 add r10, r4, r9
(gdb) info reg r4
r4 0x60008000 1610645504
(gdb) info reg r9
r9 0xb611d8 11932120
(gdb) n
162 adr r9, wont_overwrite
(gdb) n
163 cmp r10, r9
(gdb) info reg r9
r9 0x60b695dc 1622578652
(gdb) info reg r10
r10 0x60b691d8 1622577624
(gdb) n
164 bls wont_overwrite
(gdb)从上面的实践来看,符合之前的分析,之后,代码就会跳转到 wont_overwrite 处继续执行。 接下来的代码如下:
wont_overwrite:
/*
* If delta is zero, we are running at the address we were linked at.
* r0 = delta
* r2 = BSS start
* r3 = BSS end
* r4 = kernel execution address (possibly with LSB set)
* r5 = appended dtb size (0 if not present)
* r7 = architecture ID
* r8 = atags pointer
* r11 = GOT start
* r12 = GOT end
* sp = stack pointer
*/
orrs r1, r0, r5
beq not_relocated
add r11, r11, r0
add r12, r12, r0这段代码的任务就是确定自己是否重定位了,已经校正重定位之后的地址。在运行这段代码之前, 再次确定了此时每个寄存器的含义,r0 指向 LC0 表,也是 LC0 表内各项的偏移基地址; r2 寄存器指向 zImage 的 BSS 段的起始地址;r3 寄存器指向了 zImage 的 BSS 段的终止地址, r4 指向了内核运行的起始地址;r5 指向了 DTB 的大小;r7 存储体系相关的 ID 信息;r8 指向了 uboot 传递给内核的 atags 参数;r11 指向了 zImage 的 GOT 表的起始地址;r12 指向了 GOT 表的终止地址。sp 指向了重定位之后堆栈地址。
代码首先调用 orrs 指令将 r0 的值与 r5 相或,结果存储到 r1 寄存器中,如果结果为零, 那么跳转到 not_relocated 处继续执行;如果结果不为零,那么继续执行下面代码。接着调整 r11 和 r12 寄存器重定位之后的值。开发者可以在适当的位置加上断点,使用 GDB 进行调试, 调试的情况如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60b695dc: file arch/arm/boot/compressed/head.S, line 234.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:234
234 orrs r1, r0, r5
(gdb) info reg r0
r0 0x60b69460 1622578272
(gdb) info reg r2
r2 0x4277a8 4356008
(gdb) info reg r3
r3 0x4277a8 4356008
(gdb) info reg r4
r4 0x60008000 1610645504
(gdb) info reg r5
r5 0x0 0
(gdb) info reg r7
r7 0x8e0 2272
(gdb) info reg r8
r8 0x69cfe000 1775230976
(gdb) info reg r11
r11 0x4277a4 4356004
(gdb) info reg r12
r12 0x4277a4 4356004
(gdb) info reg sp
sp 0x60f91c08 0x60f91c08
(gdb) n
235 beq not_relocated
(gdb) n
237 add r11, r11, r0
(gdb) n
238 add r12, r12, r0
(gdb) info reg r11
r11 0x60f90c04 1626934276
(gdb)根据调试结果,代码继续执行下面代码:
#ifndef CONFIG_ZBOOT_ROM
/*
* If we're running fully PIC == CONFIG_ZBOOT_ROM = n,
* we need to fix up pointers into the BSS region.
* Note that the stack pointer has already been fixed up.
*/
add r2, r2, r0
add r3, r3, r0
/*
* Relocate all entries in the GOT table.
* Bump bss entries to _edata + dtb size
*/
1: ldr r1, [r11, #0] @ relocate entries in the GOT
add r1, r1, r0 @ This fixes up C references
cmp r1, r2 @ if entry >= bss_start &&
cmphs r3, r1 @ bss_end > entry
addhi r1, r1, r5 @ entry += dtb size
str r1, [r11], #4 @ next entry
cmp r11, r12
blo 1b
/* bump our bss pointers too */
add r2, r2, r5
add r3, r3, r5
#endif这段代码的主要任务是校正 GOT 表的入口项,由于代码完全支持 PIC 的,所有重定位之后, 需要校正所有的 GOT 表入口项,但 BSS 段除外。代码首先通过命令 “ldr r1, [r11, #0]” 获得 GOT 表入口项的地址,然后将该地址校正为重定位之后的地址。连续使用两个 cmp 指令 确定该入口地址是否位于 BSS 段内,如果不在 BSS 段内,那么将 r1 入口项的地址加上 DTB 的值;如果不在,那么不做特殊处理;接着调用 str 将校正后的入口地址重写到 GOT 表内, 然后将 r11 指向下一个 GOT 表的入口。如果当前 GOT 表入口小于 GOT 表的结束地址,那么 跳转到 1b 处继续校正下一个 GOT 表入口。最后,也校正了 BSS 段的起始地址和终止地址, 更多 GOT 表原理实践可以查看:
开发者可以在适当的位置加上断点,然后使用 GDB 调试,调试情况如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60b695ec: file arch/arm/boot/compressed/head.S, line 246.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:246
246 add r2, r2, r0
(gdb) n
247 add r3, r3, r0
(gdb) n
253 1: ldr r1, [r11, #0] @ relocate entries in the GOT
(gdb) info reg r11
r11 0x60f90c44 1626934340
(gdb) info reg r2
r2 0x60f90c48 1626934344
(gdb) info reg r3
r3 0x60f90c48 1626934344
(gdb) n
254 add r1, r1, r0 @ This fixes up C references
(gdb) n
255 cmp r1, r2 @ if entry >= bss_start &&
(gdb) info reg r1
r1 0x60b69460 1622578272
(gdb) info reg r2
r2 0x60f90c48 1626934344
(gdb) n
256 cmphs r3, r1 @ bss_end > entry
(gdb) info reg r3
r3 0x60f90c48 1626934344
(gdb) n
257 addhi r1, r1, r5 @ entry += dtb size
(gdb) info reg r5
r5 0x0 0
(gdb) n
258 str r1, [r11], #4 @ next entry
(gdb) info reg r1
r1 0x60b69460 1622578272
(gdb) n
259 cmp r11, r12
(gdb) info reg r11
r11 0x60f90c48 1626934344
(gdb) info reg r12
r12 0x60f90c44 1626934340
(gdb) n
260 blo 1b
(gdb) n
263 add r2, r2, r5
(gdb) n
264 add r3, r3, r5
(gdb) info reg r2
r2 0x60f90c48 1626934344
(gdb) info reg r3
r3 0x60f90c48 1626934344
(gdb)从上面的实践中可以看出校正 GOT 表入口项的整个过程。接下来运行的代码如下:
not_relocated: mov r0, #0
1: str r0, [r2], #4
str r0, [r2], #4
str r0, [r2], #4
str r0, [r2], #4
cmp r2, r3
blo 1b这段代码的主要任务就是清除 BSS 段的内容。调用 str 指令,将 r2 对应的地址写入 0, 然后 r2 地址增加 4,重复操作 4 次之后对比当前 r2 地址是否小于 r3,如果小于,那么 继续重复 1。开发者可以在适当位置加入断点进行 GDB 调试,调试结果如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60b6961c: file arch/arm/boot/compressed/head.S, line 267.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:267
267 not_relocated: mov r0, #0
(gdb) n
268 str r0, [r2], #4
(gdb)
269 str r0, [r2], #4
(gdb)
270 str r0, [r2], #4
(gdb)
271 str r0, [r2], #4
(gdb)
272 cmp r2, r3
(gdb)
273 blo 1b
(gdb) info reg r2
r2 0x60f90c58 1626934360
(gdb) info reg r3
r3 0x60f90c48 1626934344
(gdb)接着执行代码如下:
/*
* Did we skip the cache setup earlier?
* That is indicated by the LSB in r4
* Do it now if so.
*/
tst r4, #1
bic r4, r4, #1
blne cache_on这段代码的主要任务就是判断 cache 是否已经启动,如果没有就开启 cache。从之前的代码 可以知道,如果 cache 没有被开启,r4 寄存器的最低位会被置位。代码通过 tst 指令 查看 r4 寄存器的最低位情况,并使用 bic 指令清除最低位,因为这里一定要确保 cache 打开, 如果 cache 没有启用,那么会调用命令 “blne cache_on” 启用 cache。开发者可以在适当 位置添加断点进行 GDB 调试,调试的情况如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60b69638: file arch/arm/boot/compressed/head.S, line 280.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:280
280 tst r4, #1
(gdb) info reg r4
r4 0x60008000 1610645504
(gdb) n
281 bic r4, r4, #1
(gdb) n
282 blne cache_on
(gdb) n
__setup_mmu () at arch/arm/boot/compressed/head.S:291
291 __setup_mmu: sub r3, r4, #16384 @ Page directory size
(gdb)从实践结果可以看出,此时 cache 已经启用,所以不会跳转到 cache_on 处执行。 接下来执行的代码是:
/*
* The C runtime environment should now be setup sufficiently.
* Set up some pointers, and start decompressing.
* r4 = kernel execution address
* r7 = architecture ID
* r8 = atags pointer
*/
mov r0, r4
mov r1, sp @ malloc space above stack
add r2, sp, #0x10000 @ 64k max
mov r3, r7
bl decompress_kernel这段代码是为运行 C 函数 decompress_kernel 做准备。首先在执行代码之前,r4 寄存器指向了 内核执行的起始地址,r7 存储体系相关的 ID;r8 指向了 atags 参数。汇编调用 C 函数其中一种规则 就是 C 函数从左到右的第一个参数通过 r0 寄存器传递,C 函数的第二个参数通过 r1 寄存器传递, 依次类推。decompress_kernel 需要四个参数。代码首先将 r0 设置为内核执行的起始地址, 然后将堆栈的地址赋值给 r1 寄存器,再将 64 K 的空间赋值给 r2 寄存器,最后将 r7 的值 赋值给 r3 寄存器,通过上面的设置之后,最后调用 bl 指令跳转到 decompress_kernel 处 继续执行。记下来执行的代码位于 arch/arm/boot/compressed/misc.c 中,如下:
void decompress_kernel(unsigned long output_start,
unsigned long free_mem_ptr_p,
unsigned long free_mem_ptr_end_p, int arch_id)
{
int ret;
output_data = (unsigned char *)output_start;
free_mem_ptr = free_mem_ptr_p;
free_mem_end_ptr = free_mem_ptr_end_p;
__machine_arch_type = arch_id;
arch_decomp_setup();
putstr("Uncompressing Linux...");
ret = do_decompress(input_data, input_data_end - input_data,
output_data, error);
if (ret)
error("decompressor returned an error");
else
putstr(" done, booting the kernel.\n");
}decompress_kernel 函数的功能很简单,就是把 Image 从 zImage 中解压出来。通过 传入的参数,可以知道内核被解压到 output_start 位置,并将这个参数传递给全局变量 output_data。定义了两个全局变量 free_mem_ptr 和 free_mem_end_ptr 供解压程序使 用的内存空间。arch_id 将值传递给全局变量 __machine_arch_type。接下来就是调用 arch_decomp_setup() 函数做平台相关的解压设置。最后调 do_decompress() 函数进行 解压工作。开发者可以将 decompress_kernel 作为断点进行 GDB 调试,调试之前,使用 bless 二进制查看工具查看内核的数据内容,使用命令:
bless arch/arm/boot/Image查看 Image 起始处的数据如下图:
查看 Image 结尾处的数据如下图:
接着调用 GDB 查看实际运行效果,根据上图,特别查看 do_decompress() 函数运行前后, 内存 0x60008000 和 0x60b6911a 处内存内容的变化情况,实际调试如下图:
(gdb) b decompress_kernel
Breakpoint 1 at 0x60b698f4: file arch/arm/boot/compressed/misc.c, line 82.
(gdb) c
Continuing.
Breakpoint 1, decompress_kernel (output_start=1610645504,
free_mem_ptr_p=1627022200, free_mem_ptr_end_p=1627087736, arch_id=2272)
at arch/arm/boot/compressed/misc.c:82
warning: Source file is more recent than executable.
82 {
(gdb) n
85 output_data = (unsigned char *)output_start;
(gdb)
86 free_mem_ptr = free_mem_ptr_p;
(gdb)
87 free_mem_end_ptr = free_mem_ptr_end_p;
(gdb)
88 __machine_arch_type = arch_id;
(gdb) x/16x 0x60008000
0x60008000: 0x00000000 0x00000000 0x00000000 0x00000000
0x60008010: 0x00000000 0x00000000 0x00000000 0x00000000
0x60008020: 0x00000000 0x00000000 0x00000000 0x00000000
0x60008030: 0x00000000 0x00000000 0x00000000 0x00000000
(gdb) x/16x 0x60b6911a
0x60b6911a: 0x00000000 0x00000000 0x00000000 0x00000000
0x60b6912a: 0x00000000 0x00000000 0x00000000 0x00000000
0x60b6913a: 0x00000000 0x00000000 0x00000000 0x00000000
0x60b6914a: 0x00000000 0x00000000 0x00000000 0x00000000
(gdb) n
92 putstr("Uncompressing Linux...");
(gdb) n
94 ret = do_decompress(input_data, input_data_end - input_data,
(gdb) n
96 if (ret)
(gdb) x/16x 0x60008000
0x60008000: 0xeb043156 0xe10f9000 0xe229901a 0xe319001f
0x60008010: 0xe3c9901f 0xe38990d3 0x1a000004 0xe3899c01
0x60008020: 0xe28fe00c 0xe16ff009 0xe12ef30e 0xe160006e
0x60008030: 0xe121f009 0xee109f10 0xeb03e973 0xe1b0a005
(gdb) x/16x 0x60b6911a
0x60b6911a: 0xa3680000 0xb9b08071 0x012f8094 0x00000000
0x60b6912a: 0x00000000 0x00000000 0x00000000 0x00000000
0x60b6913a: 0x00000000 0x00000000 0x00000000 0x00000000
0x60b6914a: 0x00000000 0x00000000 0x00000000 0x00000000
(gdb)从上面实践结果可以看出,当执行 do_decompress() 函数之前,0x60008000 和 0x60b6911a 的内存都是 0。但当执行完 do_decompress() 函数之后,0x60008000 和 0x60b6911a 的内容与上图中 Image 的开始和结束处的内容一致,因此内核解压正确。接着继续 分析一下 do_decompress() 函数,函数定义在 arch/arm/boot/decompress.c
// SPDX-License-Identifier: GPL-2.0
#define _LINUX_STRING_H_
#include <linux/compiler.h> /* for inline */
#include <linux/types.h> /* for size_t */
#include <linux/stddef.h> /* for NULL */
#include <linux/linkage.h>
#include <asm/string.h>
#include "misc.h"
#define STATIC static
#define STATIC_RW_DATA /* non-static please */
#define Assert(cond,msg)
#define Trace(x)
#define Tracev(x)
#define Tracevv(x)
#define Tracec(x)
#define Tracecv(c,v)
/* Not needed, but used in some headers pulled in by decompressors */
extern char *strstr(const char *s1, const char *s2);
extern size_t strlen(const char *s);
extern int memcmp(const void *cs, const void *ct, size_t count);
#ifdef CONFIG_KERNEL_GZIP
#include "../../../../lib/decompress_inflate.c"
#endif
int do_decompress(u8 *input, int len, u8 *output, void (*error)(char *x))
{
return __decompress(input, len, NULL, NULL, output, 0, NULL, error);
}整个文件很简单,就是将 gzip 对应的库函数直接在预处理阶段包含到这个文件里,然后通过 调用库函数 __decompress() 进行解压,如果开发者感兴趣 gzip 解压的过程,可以查看 文件 lib/decompress_inflate.c,这里不做解释。
至此,内核已经正确的解压到指定位置,zImage 再做一些收尾工作之后就将 CPU 的执行权移交 给真正内核。接下来要执行的代码是:
bl cache_clean_flush
bl cache_off在将 CPU 执行权交给真正内核之前,需要将 MMU 关闭,并刷新 cache。cache_clean_flush 之前就讨论过,源码分析请看 cache_clean_flush。至于 cache_off, 其实现过程和 cache_on 类似,也是从 armv7 的 CACHE 表中读取对应的 off 操作,最终会调用: __armv7_mmu_cache_off, 在讲解 __armv7_mmu_cache_off 之前, 开发者可以在适当的位置添加断点,以此跟踪 cache_off 的调用过程,GDB 调试过程如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60b69658: file arch/arm/boot/compressed/head.S, line 296.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:296
296 bl cache_clean_flush
(gdb) n
297 bl cache_off
(gdb) s
cache_off () at arch/arm/boot/compressed/head.S:494
494 cache_off: mov r3, #12 @ cache_off function
(gdb)
495 b call_cache_fn
(gdb)
call_cache_fn () at arch/arm/boot/compressed/head.S:511
511 call_cache_fn: adr r12, proc_types
(gdb)
513 mrc p15, 0, r9, c0, c0 @ get processor ID
(gdb)
515 1: ldr r1, [r12, #0] @ get value
(gdb)
516 ldr r2, [r12, #4] @ get mask
(gdb)
517 eor r1, r1, r9 @ (real ^ mask)
(gdb)
518 tst r1, r2 @ & mask
(gdb)
519 ARM( addeq pc, r12, r3 ) @ call cache function
(gdb)
proc_types () at arch/arm/boot/compressed/head.S:543
543 W(b) __armv7_mmu_cache_off
(gdb)
__armv7_mmu_cache_off () at arch/arm/boot/compressed/head.S:387接下来继续分析 __armv7_mmu_cache_off 的源码,如下:
__armv7_mmu_cache_off:
mrc p15, 0, r0, c1, c0
#ifdef CONFIG_MMU
bic r0, r0, #0x000d
#else
bic r0, r0, #0x000c
#endif
mcr p15, 0, r0, c1, c0 @ turn MMU and cache off
mov r12, lr
bl __armv7_mmu_cache_flush
mov r0, #0代码原理很简单,就是将 SCTR 控制器中,关于 CACHE 和 MMU 的位设置成指定状态, SCTR 寄存器的位图如下:
首先调用 mcr 指令获得 SCTR 寄存器的值,存储到 r0 寄存器中,然后执行 bic 指令,将 bit0, bit2 和 bit3 清零,并写入到 SCTR 寄存器中,这样就关闭了 MMU 和 cache, 接着将返回地址存储到 r12 寄存器中。调用 __armv7_mmu_cache_flush,刷新 LoC 数据缓存 的数据,接下来执行的代码是:
#ifdef CONFIG_MMU
mcr p15, 0, r0, c8, c7, 0 @ invalidate whole TLB
#endif
mcr p15, 0, r0, c7, c5, 6 @ invalidate BTC
mcr p15, 0, r0, c7, c10, 4 @ DSB
mcr p15, 0, r0, c7, c5, 4 @ ISB
mov pc, r12函数继续调用 mcr 执行向 CP15 C8 寄存器写值,此时布局如下:

选中了 TLBIALL 寄存器,当往寄存器执行写操作时会将所有的 TLB 无效。接着调用 mcr 执行 操作 CP15 c7 寄存器,此时寄存器布局如下:
选中了 BPILL 寄存器,当向寄存器写入值之后会使分支预取无效。最后执行两次内存屏障 DSB 和 ISB 将所有指令和设置同步到最新。最后将 r12 寄存器的传给 pc 实现返回到调用点。
至此,zImage 的收尾工作已经完成,接下来 zImage 将执行权转交给真正的内核。zImage 最后 的任务就是将执行权移交给真正的 kernel,执行代码如下:
#ifdef CONFIG_ARM_VIRT_EXT
mrs r0, spsr @ Get saved CPU boot mode
and r0, r0, #MODE_MASK
cmp r0, #HYP_MODE @ if not booted in HYP mode...
bne __entry_kernel
#endif
__entry_kernel:
mov r0, #0 @ must be 0
mov r1, r7 @ restore architecture number
mov r2, r8 @ restore atags pointer
ARM( mov pc, r4 ) @ call kernelzImage 首先判断当前模式是否是 HYP 模式,如果不是就直接跳转到 __entry_kernel 处执行。__entry_kernel 没有做其他特别的处理,就是设置 r0 寄存器为 0, r1 寄存器 为与体系相关的 ID,r2 设置为 atags 的参数,就直接将内核执行的起始地址 r4 寄存器内 的值直接传递给 PC,那么 PC 直接跳转到 0x60008000 处开始执行,至此 zImage 将 CPU 执行权全部移交给内核。开发者可以在适当位置添加断点标记,使用 GDB 进行调试,调试结果 如下:
(gdb) b BS_debug
Breakpoint 1 at 0x60b69a18: file arch/arm/boot/compressed/head.S, line 599.
(gdb) c
Continuing.
Breakpoint 1, BS_debug () at arch/arm/boot/compressed/head.S:599
599 mov r0, #0 @ must be 0
(gdb) n
600 mov r1, r7 @ restore architecture number
(gdb) n
601 mov r2, r8 @ restore atags pointer
(gdb) n
602 ARM( mov pc, r4 ) @ call kernel
(gdb) c通过上面的实践,内核最终运行起来了。