

目录


进程地址空间原理
在 Linux 中,进程是计算机的程序关于某些数据集合上的一次运行活动,是系统运行资源分配和调度的基本单位。用户层进程的虚拟地址空间简是 Linux 的一个重要抽象,它向每个运行的进程提供了同样的系统视图,这使得多个进程可同时运行,而不会干扰到其他进程内存中的内容。此外,它容许使用各种高级的程序设计技术,如内核映射等。对于一个进程其运行的空间称为用户空间,其只能看到虚拟空间上看到自己和内核,其他进程的用户空间看不到。

进程的地址空间起始与虚拟地址 0,延伸到 “TASK_SIZE - 1”, 其上是内核地址空间。在 IA32 架构上地址空间的范围高达 4G,总的地址空间通常按 3:1 比例进程划分。每个进程只能看到自己的地址空间,进程将地址空间划分成不同的区域,每个区域用于不同的目的:

进程的地址空间可以分作以上几部分:
- Code Segment 用于存放进程的代码.
- Data Segment 用于存储进程的数据.
- BSS 段用于存储进程 .bss 数据.
- BRK 是进程的堆区域.
- MMAP 是进程的内存映射区域。用于映射共享库等
- Stack 是进程的堆栈区域.
进程将其地址空间划分为几个不同的段之后,每个段都在进程的生命周期中负责不同的任务和功能。那么进程是如何创建这些区域的? 在 Linxu 中创建一个新的进程可以使用 SYS_execve、SYS_fork 和 SYS_clone 系统调用进程创建,这些系统调用有的是从父进程复制或共享这些段,有的则是创建进程的过程中独立创建这些段。无论采用何种方式,一个进程都要具有以上这些段,那么本文以 SYS_execve 系统调用的角度来分析一个进程是如何创建和布局这些段的.
Text Segment (ELF)
进程的地址空间是指进程所管理的虚拟地址空间,其由不同的虚拟区域构成
那么我们来分析一下进程是如何构建自己的进程地址空间呢。采用同样推理方法,边实践边分析,首先通过一个实践例子进行讲解,其在 BiscuitOS 上的部署如下:
cd BiscuitOS
make menuconfig
[*] Package --->
[*] Address Space Layout --->
[*] Process address space --->
BiscuitOS/output/linux-XXXX/package/BiscuitOS-address-space-process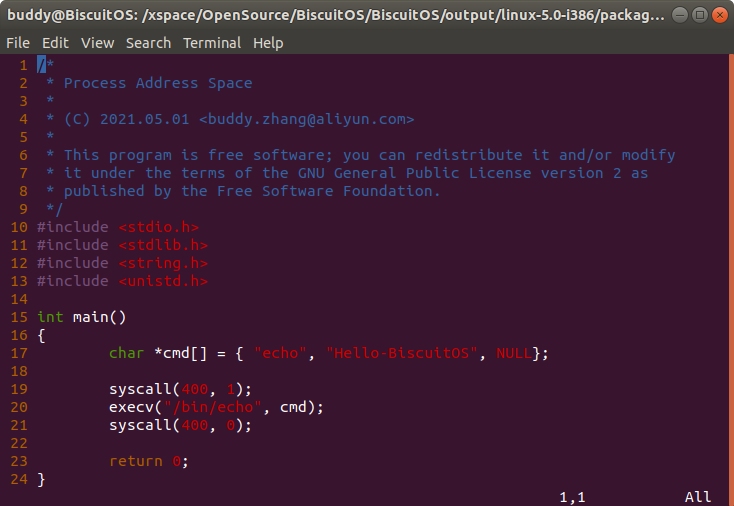
在实践例子的 19 和 21 行添加 BiscuitOS 提供的系统调用调试工具,本次实践与 i386 架构为例进行讲解,其他架构类似。程序的功能很简单,就是通过调用 execv() 函数启动一个新进程,新进程的作用是执行 “echo Hello-BiscuitOS” 命令打印一段字符串。execv() 函数最终会调用到 SYS_execve 系统调用,该系统调用就是进程创建的入口,因此从这里开始使用 BiscuitOS 工具进行研究, 接下来深入到内核 SYS_execve 函数进行分析:
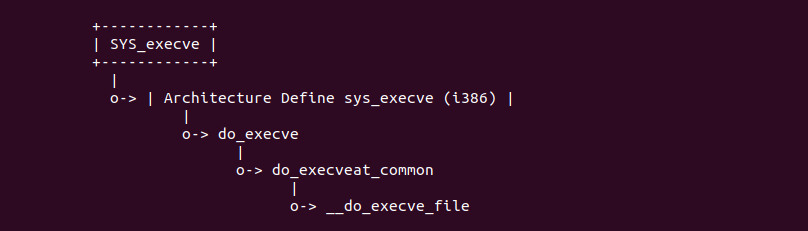

SYS_execve 系统调用最终调用到函数 __do_execve_file(), 如上图,函数在 1791 行调用 bprm_mm_init() 函数对进程的地址空间进行第一次初始化.
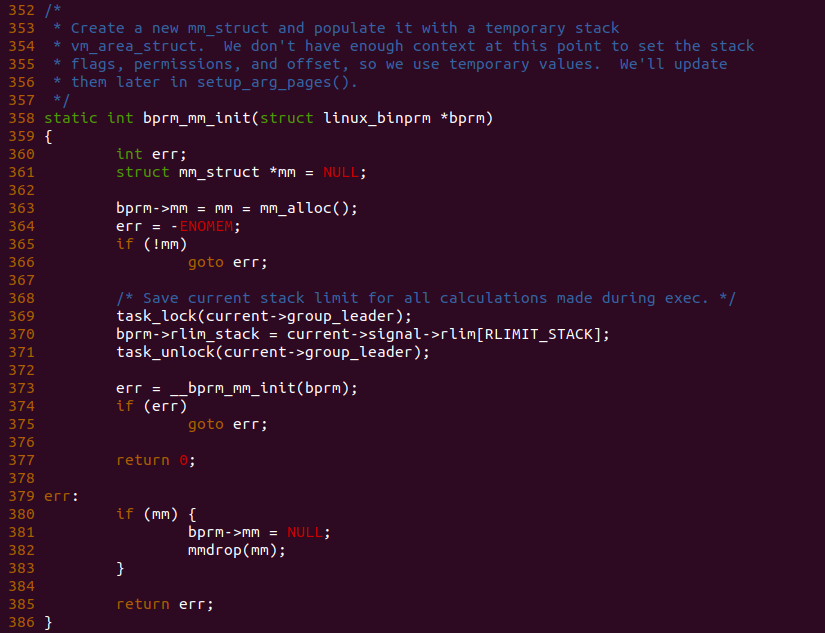
bprm_mm_init() 函数首先在 363 行调用 mm_alloc() 函数为新进程分配一个 struct mm_struct 数据结构,该数据结构用于维护进程的地址空间。函数在 370 行从 current->signal-rlim 中获得堆栈的限制信息。每个进程都有一组资源相关的限制,由于指定进程获得和使用某个资源的上限,以避免进程过度使用资源。内核使用 struct rlimit 数据结构描述一类限制的资源:

在 struct rlimit 数据结构中,rlim_curr 表示限制资源的当前限制值,而 rlim_max 表示限制资源的最大限制值。rlim_curr 是软限制,用户可以自行修改,只要不超过 rlim_max 就行; rlim_max 则是硬限制,只能管理员才用权限对 rlim_max 进行修改。目前限制资源包含如下:
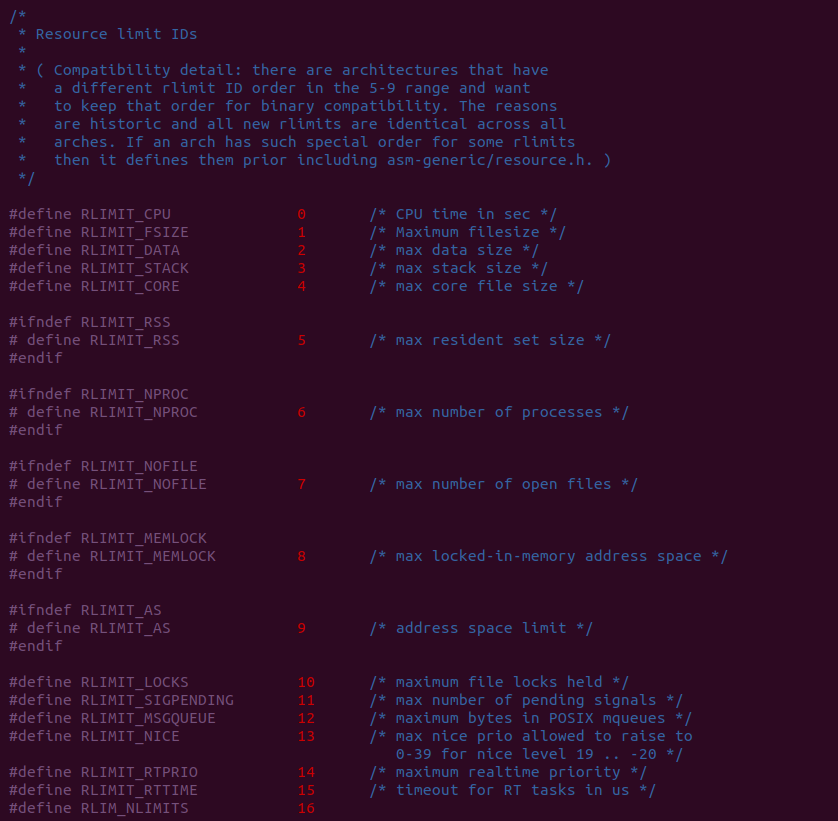
以上便是系统支持的限制资源,其中包含了堆栈的限制 RLIMIT_STACK。每个进程的资源限制数组存放在 current->signal->rlim 字段中,并且资源限制信息会被子进程自动集成。那么接下来在代码中添加调试信息:

在 371 行添加调试信息,以此查看当前进程的堆栈限制信息,此时在 BiscuitOS 上运行查看当前进程堆栈限制信息,并使用 ulimit 工具修改堆栈限制信息:
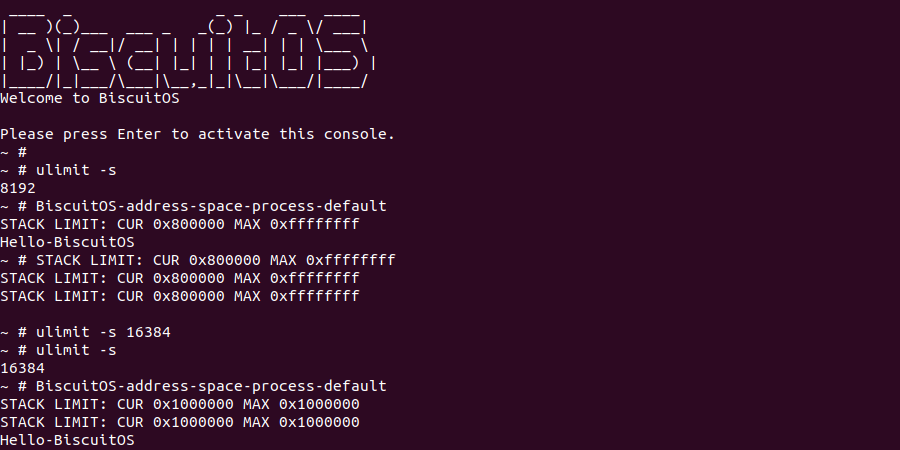
从运行情况可以看出堆栈的默认限制是 8192, 此时使用 ulimit 工具将堆栈的最大限制设置为 16 MiB, 此时运行测试程序可以看到进程堆栈的 rlimit 已经变成了 0x1000000。
在回到 bprm_mm_init() 函数,函数在 373 行调用 __bprm_mm_init() 函数进一步初始化进程的地址空间,函数执行完毕之后在 377 行进行返回。那么接下来看看 __bprm_mm_init() 函数的实现逻辑.
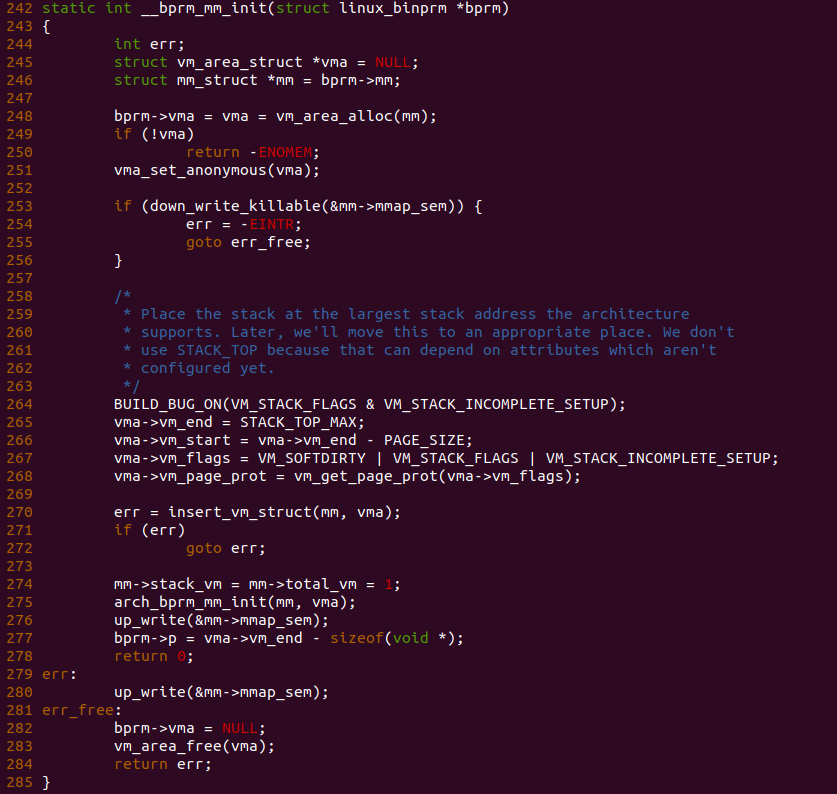
__bprm_mm_init() 函数的主要作用是为堆栈分配一个匿名的 VMA,并将该 VMA 插入到新进程的地址空间。函数在 246 行将局部变量 mm 指向新建进程的地址空间,并在 248 行调用 vm_area_alloc() 函数从新建进程的地址空间新申请一个 VMA,然后将 vma 变量指向新申请的 VMA。函数接着在 251 行调用 vma_set_anonymous() 函数将该 VMA 设置为一个匿名的 VMA。函数接着在 264 行检测堆栈虚拟区域的标志,系统默认使用 VM_STACK_FLAGS 表示堆栈虚拟区域的标志集合, 其定义如下:
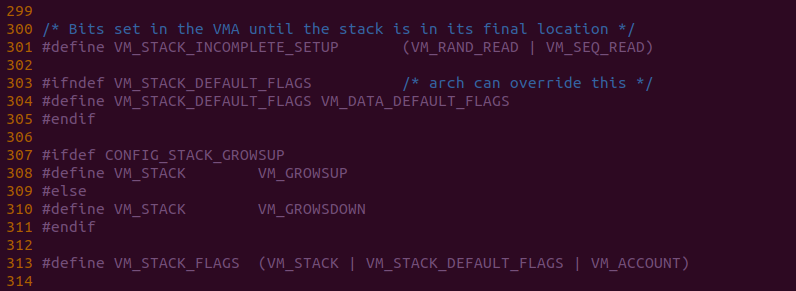
VM_STACK_INCOMPLETE_SETUP 宏包含了两个宏 VM_RAND_READ 和 VM_SEQ_READ, VM_RAND_READ 表示 VMA 需要扇区读,而 VM_SEQ_READ 则表示按照串行读。VM_STACK_FLAGS 包含了三个宏,VM_STACK 表示该 VMA 是一个 Stack,而 VM_ACCOUNT 表示 VMA 带统计功能,而 VM_STACK_DEFAULT_FLAGS 的定义与 VM_DATA_DEFAULT_FLAGS 有关,继续深入查看其定义:

VM_DATA_DEFAULT_FLAGS 宏定义如上,首先其判断 “current->personality & READ_IMPLIES_EXEC” 是否为真,这里的函数是判断堆栈是否为可执行栈,如果堆栈是可执行栈,那么 current->personality 中的 READ_IMPLIES_EXEC 标志置位,那么宏就必须包含 VM_EXEC 标志,以此表示该 VMA 可以执行; VM_READ 标志表示 VMA 可读; VM_WRITE 标志表示 VMA 可写。回到 __bprm_mm_init() 函数,函数此时将 VM_STACK_FLAGS 与 VM_STACK_INCOMPLETE_SETUP 宏进行相与操作,确保堆栈对应的 VMA 标志集合中不包括 VM_SEQ_READ 和 VM_RAND_READ, 如果检测处包含,那么系统将报错。
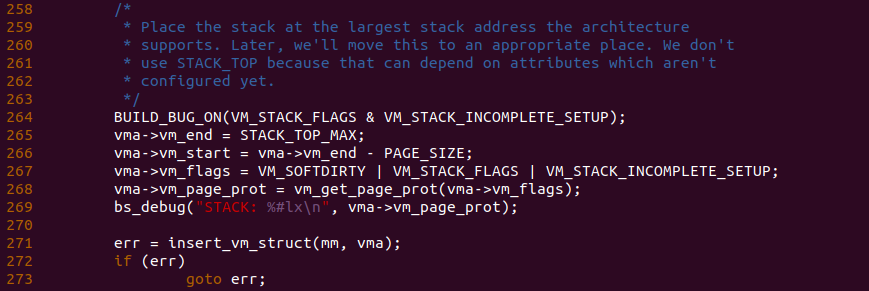
函数将堆栈的地址信息填充到新建的 VMA 中,由于堆栈是向下生长的,因此 VMA 的结束地址是 STACK_TOP_MAX, 而将堆栈栈底低 PAGE_SIZE 的地方作为栈顶的位置,该位置也是 VMA 的起始地址。函数在 267 行将 VM_SOFTDIRTY、VM_STACK_FLAGS 和 VM_STACK_INCOMPLETE_SETUP 标志集合作为堆栈 VMA 的标志。函数接着在 268 行将 VMA 的标志通过 vm_get_page_prot() 函数将其转化为页表的标志,此时可以在 269 行添加调试代码查看堆栈的页表信息, 并在 BiscuitOS 上运行:


通过运行情况以及 i386 32bit PTE 页表可以知道,堆栈区域的页表 0x25 包含了:
- R/W 标志置位,虚拟区域可读可写
- U/S 标志置位,虚拟区域来自用户空间
- A 标志置位,表示虚拟区域被访问过

__bprm_mm_init() 函数接着在 271 行调用 insert_vm_struct() 函数将 VMA 插入到新建进程地址空间维护的红黑树和双链表中。添加成功之后,函数在 275 行将进程地址空间 的 stack_vm 和 total_vm 成员设置为 1,以此更新新建进程可用堆栈的数量。函数最后将 bprm->p 指向了栈底的位置,最后函数返回.
回到 __do_execve_file() 函数,当为新进程创建好堆栈的 VMA 之后,函数接着在 1795 行调用 prepare_arg_pages() 函数。

在 prepare_arg_pages() 函数首先在 455 行调用 count 计算出新建进程参数的数量,接着在 459 行计算处新建进程环境变量的数量。函数在 471 行计算出默认堆栈大小的 3/4,并存储在 limit 变量里,函数接着调用 min() 函数从 limit 和新建进程堆栈最大限制的 1/4 中找出最小值,函数这么做的目的是要么使用 “_STK_LIM” 的 75% 或者新建进程堆栈最大限制的 25% 中的最小体积来存储新建进程的 “参数和环境变量”,这样就能确保固留二进制代码运行时不会超过堆栈空间,另外程序也需要一个合理的堆栈剩余保持程序的正常工作。函数继续在 477 行调用 max_t() 函数从 limit 和 ARG_MAX 中找到最大值,由于历史原因,程序支持高达 32 个页用于存储进程的参数和环境变量。函数接着在 485 行计算出指向环境变量和程序参数的指针数量,存储在 ptr_size 变量里。函数在 488 行将指针占用的内存从 limit 中减出之后,将栈底的位置更新为去除环境变量和进程参数的新地址,并将该地址存储在 bprm->argmin. 此时堆栈的布局如下:
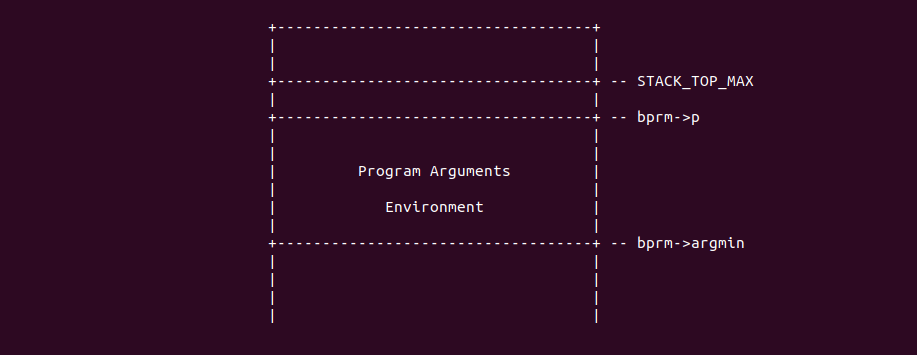
回到 __do_execve_file() 函数, 函数在 1799 行调用 prepare_binprm() 函数将新进程的 ELF 文件头从磁盘读入到 bprm 数据结构中。函数接着在 1807 行将 bprm->exec 指向了 bprm->p, 也就是 STACK_TOP_MAX。函数接着在 1808 和 1812 行调用 copy_strings() 函数将新进行的参数和环境变量加载到堆栈为其预留的虚拟区域内,接下来分析一下 copy_strings() 函数的实现过程,以新进程的参数为例:
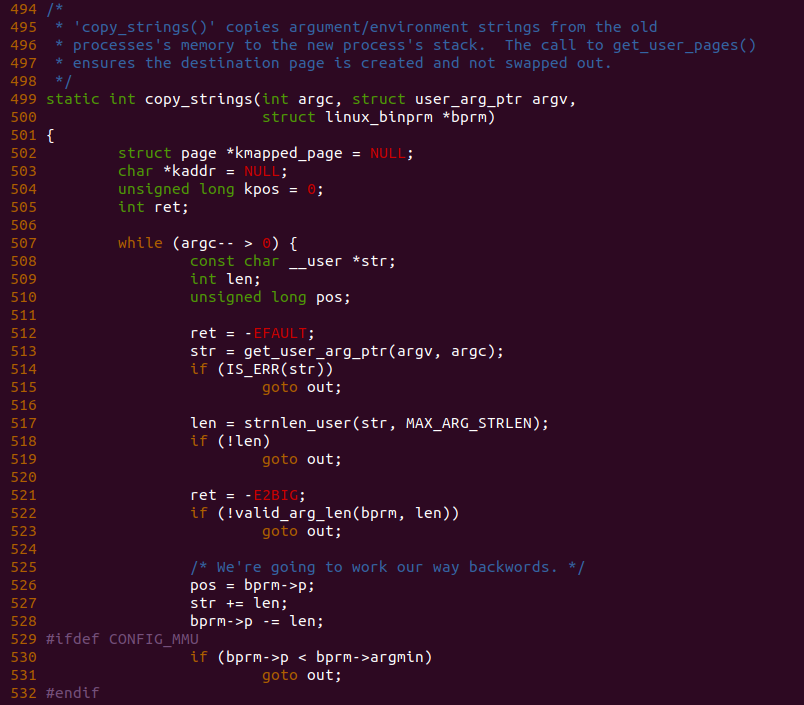
在 copy_strings() 函数中,参数 argc 指向程序参数的个数或者环境变量的个数,参数 argv 则存储着用户空间的程序参数或者环境变量,参数 bprm 则指向程序对应的 ELF 文件相关的描述数据结构。函数在 507 行使用 while 循环遍历所有的程序参数或者环境变量。函数在 513 行调用 get_user_arg_ptr() 函数取出一个用户空间的参数,并存储在 str 变量里,接着函数在 517 行调用 strnlen_user() 函数计算出参数的长度,并且在 522 行调用 valid_arg_len() 函数检测参数长度的有效性,系统规定参数的长度不能超过 MAX_ARG_STRLEN。处理完参数长度之后,函数在 526 行将 pos 指向了堆栈的栈底,然后将 str 指向参数的结尾,然后将 bprm->p 的值减去参数的参数,以此存储下一个参数,函数继续在 530 行判断 bprm->p 是否已经小于 bprm->argmin, bprm->argmin 用于指明存储进程参数和环境变量在堆栈中最小地址。经过上面处理,堆栈变化为:
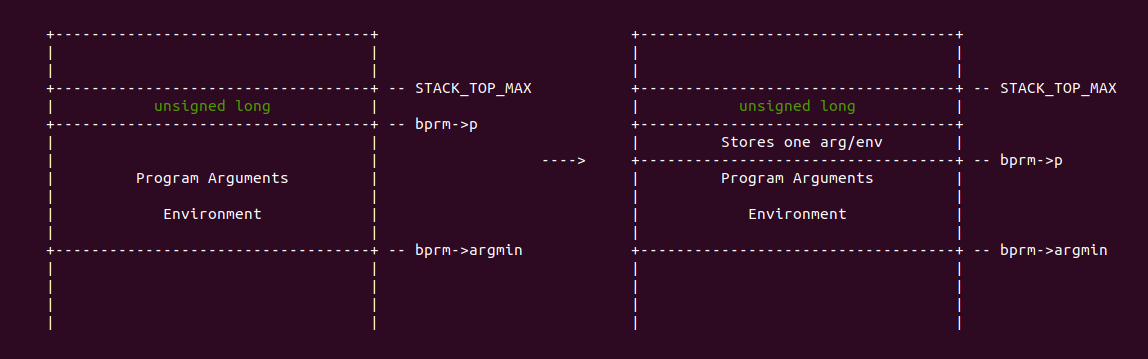

在 copy_strings() 函数中,函数获得第一个参数之后,接着函数在 543 行获得 pos 的页内偏移,由之前的代码逻辑可以知道,pos 指向了存储参数或者环境变量的虚拟内存地址。如果此时 pos 为 0,那么将 pos 设置为 PAGE_SIZE. 函数在 547 行将 offset 的值存储在 bytes_to_copy 变量里,如果此时 bytes_to_copy 的值大于参数或环境变量本身的长度,那么函数将 bytes_to_copy 的值修改为 len。函数在 551 行到 554 行的操作用是更新参数或环境变量在一个页末尾开发存储的位置,这样函数可以将参数或者环境变量从页的末尾开始存储,因此进程的参数和环境变量都是从栈底向栈顶堆积,这样做的好处可以保证最大限度的利用堆栈中参数或环境变量的存储空间。函数接着在 556 行检测 kmapped_page 变量是否为空,kmapped_page 变量指向堆栈某段虚拟内存页映射的物理页,这里可以理解为为了将进程参数或者环境变量写入进程的堆栈空间,那么被写入的虚拟地址必须与物理内存建立映射,这样才能正真存储参数和环境变量。那么问题来了,在用户空间进程只分配虚拟内存,当对该虚拟内存进行访问,那么会触发缺页中断,缺页中断为其建立页表后进程才能真正使用这些虚拟内存,同理,由于此时位于内核空间,不能像用户空间一样通过惰性的方式为堆栈的虚拟空间建立页表,那么接下来分析如果为堆栈的虚拟内存建立页表的,这里通过调用 get_arg_page() 函数:

从 get_arg_page() 函数调用链可以看出,该函数会为堆栈的虚拟区域分配物理内存,并将堆栈的虚拟内存映射到物理内存上。如上图的调用链,当调用到 follow_page_mask() 函数,如果函数检测到堆栈的虚拟地址没有映射物理内存,此时函数滴啊用 faultin_page() 函数,该函数会进入缺页中断处理函数,此时内核并未在缺页中断中,由于堆栈虚拟地址对应的 PTE 页表为空,那么函数会调用 handle_pte_fault() 函数,在该函数中,函数检测到堆栈的虚拟区域为匿名映射区域,那么函数最终调用 do_anonymous_page() 函数分配物理内存,并建立对应的页表。函数调用链在返回过程中,在 get_arg_page() 函数中存在如下逻辑:

函数当为虚拟内存分配物理页之后,函数就在 222 行调用 acct_arg_size() 函数统计内存使用情况:
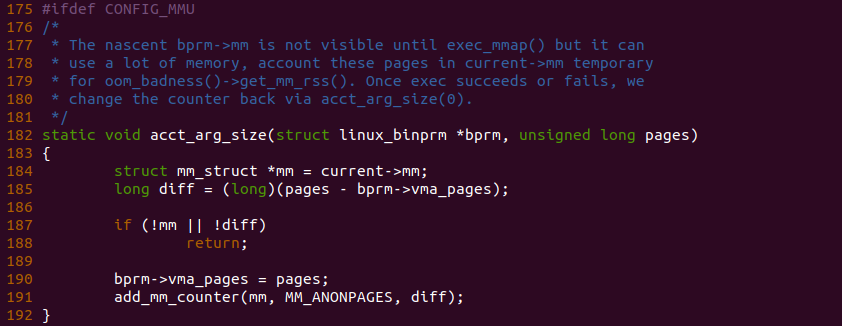
参数 pages 此时代表了已经建立页表的虚拟内存页数量,函数在 185 行计算 bprm 维护的页数据是否与真实的页数据存在差异,此时 brpm->vma_pages 为空,那么当检测到存在差异,且进程的地址空间存在,那么函数在 190 行将 bprm->vma_pages 设置为 pages,再次添加进程维护匿名页的数量,此时进程是老进程,而不是新的进程。
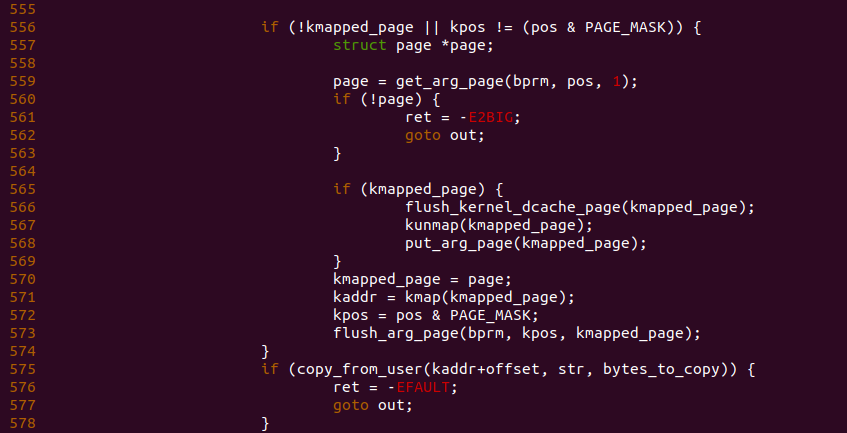
在回到 copy_strings() 函数,函数在 559 行调用完 get_arg_page() 函数之后,参数或者环境变量在堆栈中的虚拟内存已经与物理内存建立页表,此时 kmapped_page 为空,那么函数在 570 行将 kmapped_page 指向新分配的物理页,函数接着在 571 行将新分配的物理页通过 kmap() 函数临时映射到内核地址空间,接着函数在 575 行调用 copy_from_user() 函数将参数或者环境参数拷贝到新分配的物理内存里。至此一次完成的进程参数或环境变量拷贝完成。
copy_strings() 函数将进程的参数或者环境变量拷贝完成之后,由于之前将堆栈虚拟内存对应的物理内存临时映射到内核空间,因此函数在 585 行调用 kunmap() 函数接触临时映射,最后调用 put_arg_page() 函数介绍对物理页的引用计数。

回到 __do_execve_file() 函数,函数在 1818 行调用 exec_binprm() 函数,该函数就是启动新进程的核心实现,其通过调用 search_binary_handler() 函数查找对应的加载器.

search_binary_handler() 函数中,其通过调用 list_for_each_entry() 函数遍历 formats,该链表维护了内核所有的加载器,其根据执行文件的类型选择对应的加载器,由于函数在 1657 行通过回调函数方式调用,无法直接获得所使用的函数,此时可以在 1656 行添加打印函数,并在 BiscuitOS 行进行实践验证:
通过在 BiscuitOS 上运行的结果,可以看出进程最终采用 load_elf_binary() 函数进行进程的加载。在进行 load_elf_binary() 函数分析之前,这里对 ELF 文件进行分析讲解:
ELF 文件
ELF 文件布局可以分作三部分,分别是:
- ELF Header
- Section Header Table
- Program Header Table
ELF Header
其中 ELF Header 是 ELF 文件的头,包含了固定长度信息; Section Header Table 则包含了链接说需要的信息; Program Header Table 中包含了运行时加载程序所需的信息。ELF 文件头的定义如下:
# Define on elf/elf.h
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf32_Half e_type; /* Object file type */
Elf32_Half e_machine; /* Architecture */
Elf32_Word e_version; /* Object file version */
Elf32_Addr e_entry; /* Entry point virtual address */
Elf32_Off e_phoff; /* Program header table file offset */
Elf32_Off e_shoff; /* Section header table file offset */
Elf32_Word e_flags; /* Processor-specific flags */
Elf32_Half e_ehsize; /* ELF header size in bytes */
Elf32_Half e_phentsize; /* Program header table entry size */
Elf32_Half e_phnum; /* Program header table entry count */
Elf32_Half e_shentsize; /* Section header table entry size */
Elf32_Half e_shnum; /* Section header table entry count */
Elf32_Half e_shstrndx; /* Section header string table index */
} Elf32_Ehdr;在 ELF32_Ehdr 中存储的数据,里面涉及不同长度的数据类型,不同的数据类型占用的字节数有所不同,请长度如下:

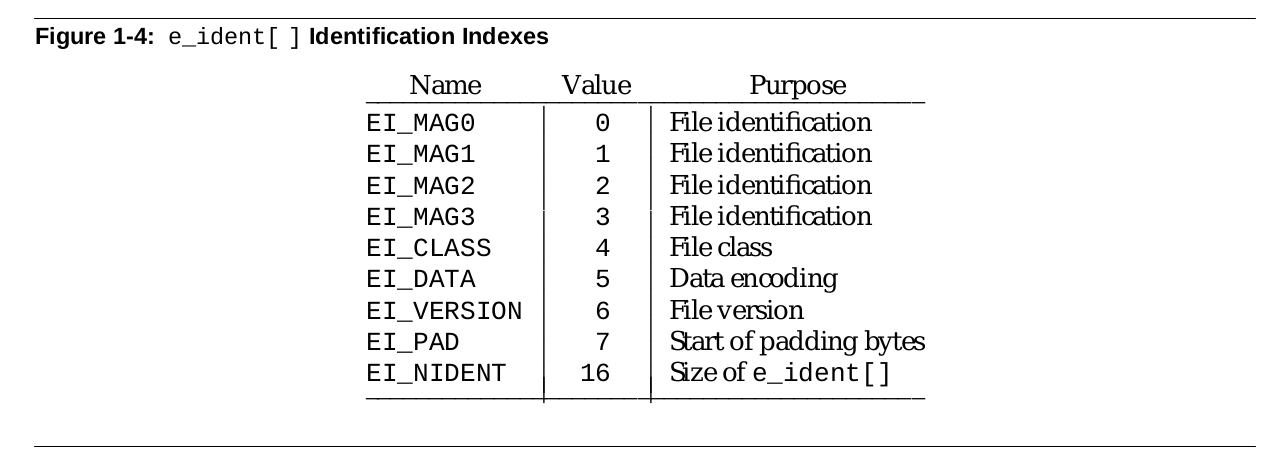
e_ident
e_ident[] 数组用于固定存储 ELF 的 Magic 和一些其他信息,其布局如下,其中前四个字节用于存储固定的 Magic 数据:

e_type
e_type 字段用于表示 ELF 文件的类型,目前支持的类型有:

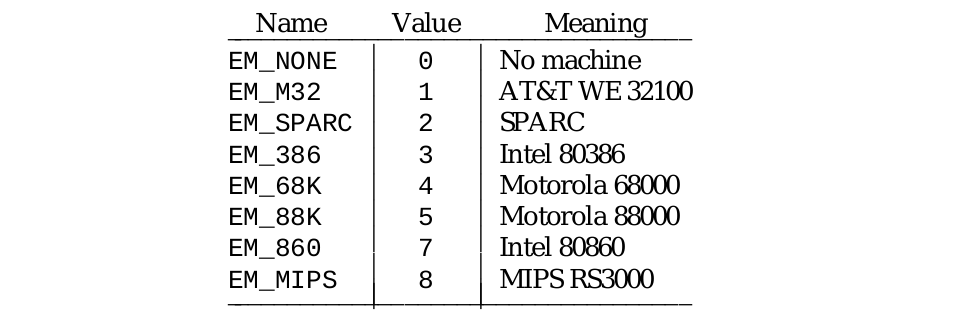
e_machine
e_machine 字段用于描述文件可以在哪些硬件平台上才能运行:
* e_version 用于表示 ELF 文件的版本信息。
* e_entry 用于指明操作系统运行该程序时,程序的入口虚拟地址,也就是操作
系统运行程序时将控制权移交到的虚拟地址,也就是程序开始执行的地方。该
地址不是 main() 函数的位置,而是 ".text" 段的首地址 "\_start". 当然
也要求程序本身非 PIE (-no-pie) 编译且 ASLR 关闭的情况下,对于非 ET_EXEC
类型通常并不是实际的虚拟地址值。
* e_phoff 用于指明程序头 (Program header table) 在文件的字节偏移值,如
果没有程序头,那么该值为 0.
* e_shoff 用来指明 Section Header Table 在文件的字节偏移值。若没有
Section Header Table,那么该值为 0.
* e_flags 用来指明与处理器相关的标志。
* e_ehsize 用于指明 ELF Header 的大小。
* e_phentsize 用来指明 Program Header Table 中每个 Entry 的字节大小, 即
每个用来描述段信息的数据结构的字节大小,该结构通过 struct Elf32_Phdr 表示.
* e_phnum 用来指明 Program Header Table 中 Entry 的数量,实际上是段的个数.
* e_shentsize 用来指明 Section Header Table 中每个 Entry 的字节大小,即
每个用来描述 Section 数据结构的字节大小。
* e_shnum 用来指明 Section Header Table 中 Entry 的数量.
* e_shstrndx 用来指明 string name table 在 Section Header Table 中的索引.Program Header
# Define on elf/elf.h
typedef struct
{
Elf32_Word p_type; /* Segment type */
Elf32_Off p_offset; /* Segment file offset */
Elf32_Addr p_vaddr; /* Segment virtual address */
Elf32_Addr p_paddr; /* Segment physical address */
Elf32_Word p_filesz; /* Segment size in file */
Elf32_Word p_memsz; /* Segment size in memory */
Elf32_Word p_flags; /* Segment flags */
Elf32_Word p_align; /* Segment alignment */
} Elf32_Phdr;Program Header Table 用来保存程序加载到内存中所需的信息,使用段 “Segment” 来表示,与 Section Header Table 类似。Program Header Table 在 ELF 文件中的偏移通过 ELF Header 的 e_phoff 进行指定; Program Header Table 中每个 Segment Table 的大小通过 ELF Header 的 e_phentsize 进行指定; Program Header Table 包含 Segment 的数量通过 ELF Header 的 e_phnum 进行指定. Program Header 的作用是提供用于初始化程序进程的段信息,那么 Program Header 各字段的描述如下:
- p_type: 描述 Segment 的类型。
- p_offset: 描述 Segment 的数据在文件中的偏移.
- p_vaddr: Segment 数据加载到进程的虚拟地址.
- p_paddr: Segment 数据加载到进程的物理地址. (nommu)
- p_filez: Segment 在 ELF 文件中的大小.
- p_flags: Segment 在进程中的权限 (R/W/X).
- p_align: Segment 数据对齐,2 的整数次幂. (p_offset % p_align = p_vaddr)
- p_memsz: Segment 数据在进程内存中的大小. 需要满足 p_memsz >= p_filez, 多处的部分初始化为 0,通常作为 .bss 段内容。
Section Header
# Define on elf/elf.h
typedef struct
{
Elf32_Word sh_name; /* Section name (string tbl index) */
Elf32_Word sh_type; /* Section type */
Elf32_Word sh_flags; /* Section flags */
Elf32_Addr sh_addr; /* Section virtual addr at execution */
Elf32_Off sh_offset; /* Section file offset */
Elf32_Word sh_size; /* Section size in bytes */
Elf32_Word sh_link; /* Link to another section */
Elf32_Word sh_info; /* Additional section information */
Elf32_Word sh_addralign; /* Section alignment */
Elf32_Word sh_entsize; /* Entry size if section holds table */
} Elf32_Shdr;Section Header Table 是一个数据结构,该数组在 ELF 文件中的位置通过 ELF Header 的 e_shoff 进行指定,该数组一共包含 Section 的数量通过 ELF Header 的 e_shnum 进行指定,每个 Section 的大小通过 ELF Header 的 e_shentsize 进行指定。系统使用 Elf32_Shdr 描述一个 Section. 其各成员描述如下:
- sh_offset: Section 内容的起始地址相对于文件开头偏移.
- sh_size: Section 内容的大小.
- sh_entsize: Section 是数组时表示数组元素大小.
- sh_addr: Section 需要运行时加载到虚拟内存的地址.
- sh_addralign: Section 内存对齐方式,需满足 sh_addr % sh_addralin = 0.
- sh_flags: Section 映射到虚拟内存的权限。
- sh_type: Section 类型.
- sh_name: Section 的名字.
Section 的名字通过 sh_name 字段进行描述,该字段不是一个直接的字符串,而是用一个 word 来表示该 Section name 在字符串表中的偏移,ELF 文件的字符串表通过 “.shstrtab” 进行维护,ELF Header 的 e_shstrndx 指明了字符串表中元素数量。ELF 文件通过 sh_name 的偏移在 ELF 字符串表中找到对应的名字字符串.Section 的类型通过 sh_type 字段进行描述,该字段描述的类型包括:
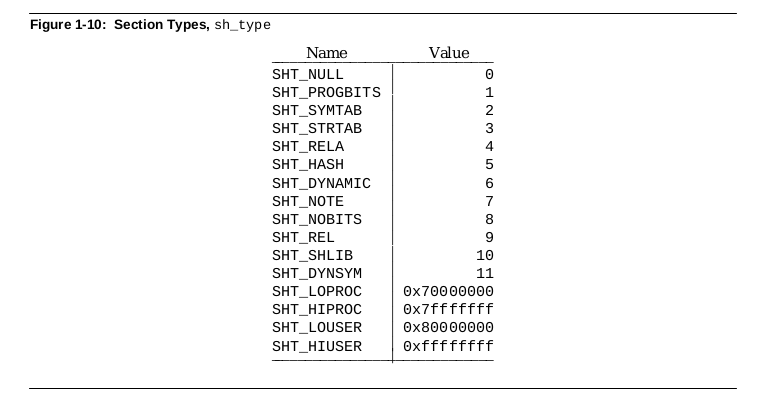
目前 ELF 支持的 Section 有:
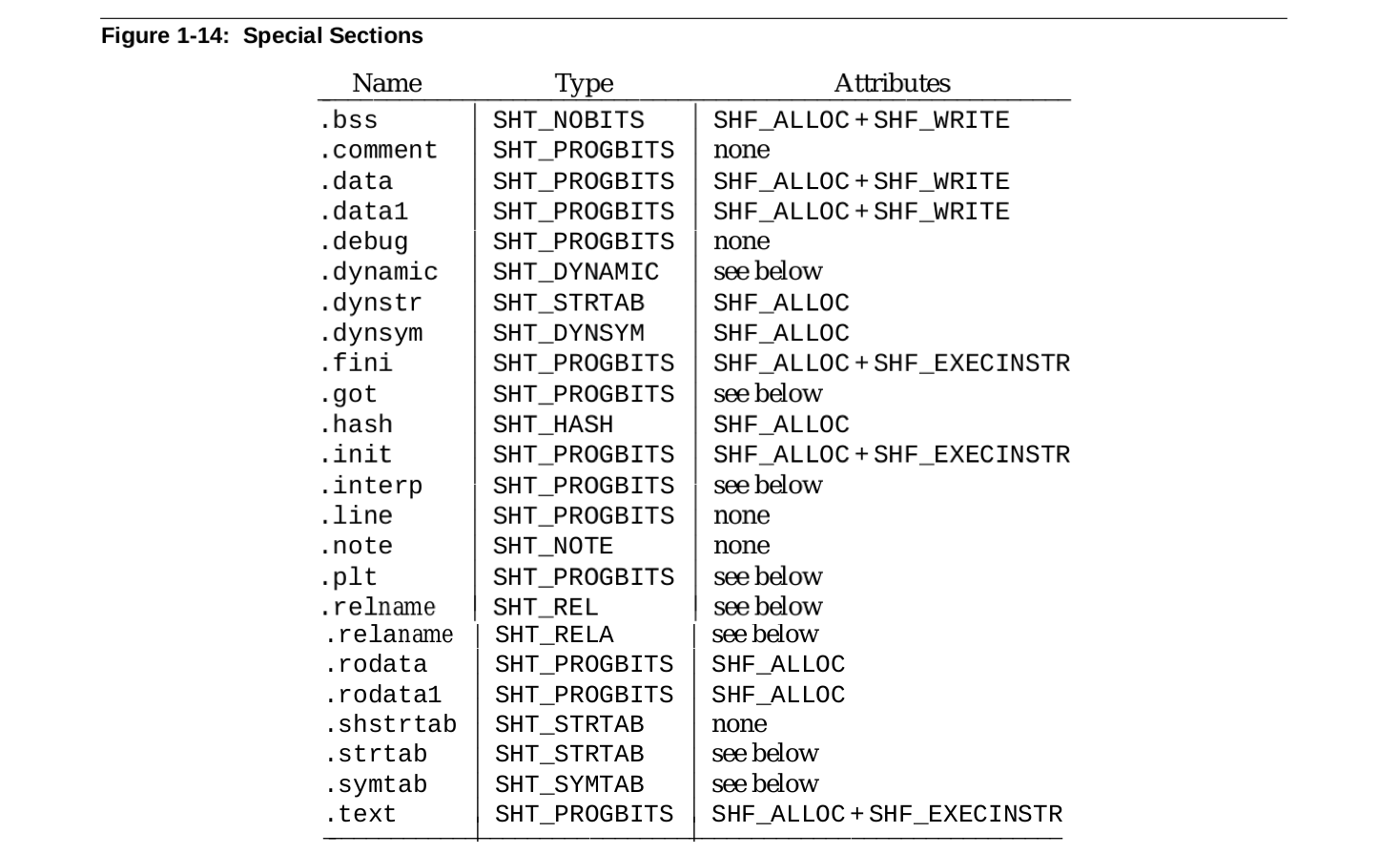
内核加载 ELF 文件

分析完 ELF 文件的结构之后再回到 load_elf_binary() 函数,函数在 707 行定义了一个局部变量 loc, 该变量包含了两个 ELF Header。函数在 714 行为 loc 分配了内存,接着在 721 行将 loc 的 elf_ex 指向了进程的 ELF Header.
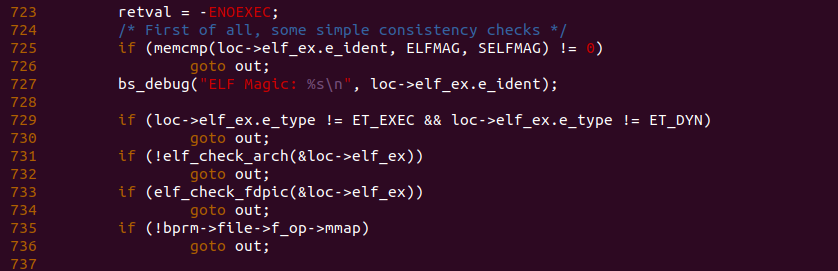
函数接下来在 725 行对进程 ELF Header 的 Magic 进行检测,以此确认文件是一个 ELF 文件。函数接着在 729 行检测 ELF 文件的类型,如果 ELF 文件同时不包含 ET_EXEC 和 ET_DYN, 那么函数认为 ELF 文件的类型不符合加载的要求,直接跳转到 out 分支. 函数接下来对 ELF 文件的运行平台和 PIC 进行检测,如果检测不通过都跳转到 out 分支。函数最后在 735 行确保 ELF 文件所在的文件系统提供 mmap 接口,如果没有提供则跳转到 out分支。此时开发者可以在 727 行添加调试信息查看进程 ELF Magic 信息:

在 BiscuitOS 运行的结果可以看出进程 ELF Magic 是 “ELF” 字符串.
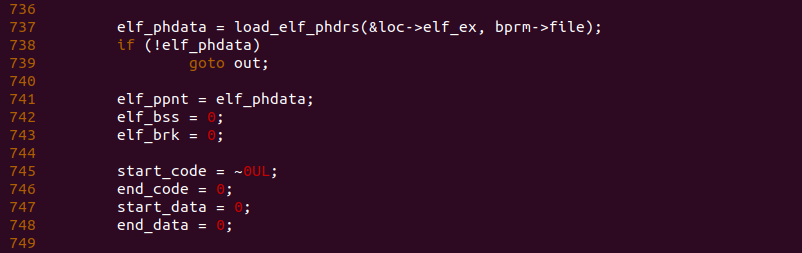
函数在 737 行调用 load_elf_phdrs() 函数将进程的 Program Header Table 加载到内存里,并使用 elf_phdata 变量指向该内存上. 函数接下来做一些初始化将 start_code 等变量初始化为 0.
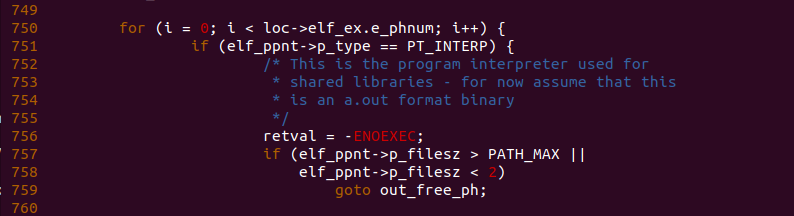
load_elf_binary() 函数接下来在 750 行遍历进程 ELF 文件的所有 Program Header,并在 751 行中找出 “Program Interpreter”, 其用于 a.out 格式二进制的共享库,但是由于此时没有使用该段,因此函数不会执行 752 行的代码分支.

函数在次在 808 行遍历进程 ELF 文件的所有 Program Header, 在每次遍历过程中,函数在 809 行对每次遍历到的 Segment 进行分流处理,如果遍历到的 Segment 是堆栈,那么函数进入 811 分支进行处理,函数在 811 行判断堆栈 Segment 是否包含执行权限,如果包含那么将 executable_stack 设置为 EXSTACK_ENABLE_X, 反之设置为 EXSTACK_DISABLE_X. 这里可以拓展进行说明,如果进程的栈是可执行栈,那么进程的所有可读的 Segment 都有执行权限,具体细节请查看:
如果函数遍历到的 Segment 类型是 PT_LOPROC 或者 PT_HIPROC, 那么这些 Segment 是预留给特定处理器的,那么其会在 818 行调用 arch_elf_pt_proc() 函数进行特殊处理。

函数继续在 869 行调用 flush_old_exec() 函数将原进程的地址空间进行清除,其代码逻辑如下:

函数 flush_old_exec() 首先在 1264 行调用 de_thread() 函数确认新建进程已经包含了私有的信号表。接着函数在 1273 行调用 set_mm_exe_file() 行将当前进程的 ELF 文件重新指向了新建进程的 ELF 文件。函数此时再次调用 acct_arg_size() 函数添加匿名映射页的数量,并将 bprm->vma_pages 设置为 0, 为新进程的内存统计初始化。函数在 1275 行调用 exec_mmap() 函数将当前进程的地址空间切换成新进程的地址空间,其代码逻辑如下:
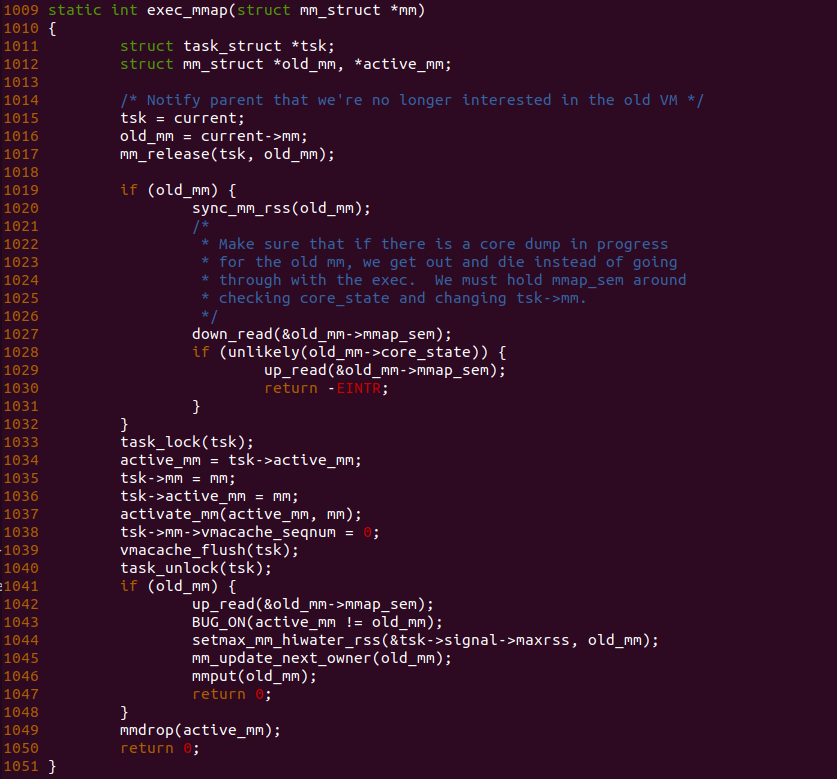
函数首先在 1016 行将 old_mm 指向当前进程地址空间,然后调用 mm_relase() 函数将当前进程的地址空间进行释放,函数接着在 1034 行将 active_mm 指向了当前进程的 active_mm, 然后将当前进程的地址空间指向了新进程的地址空间,同时也将当前进程 active_mm 指向了新建进程的地址空间,并调用 active_mm() 是新进程的地址空间激活。函数在 1038 行将当前进程地址空间的 vmacache_seqnum 设置为 0,以及调用 vmacache_flush() 函数将当前进程的 VMA CACHE 都初始化。函数最后调用 mmdrop() 函数将原进程的 active_mm 进程释放. 至此新进程的地址空间已经有效可以正常工作了.
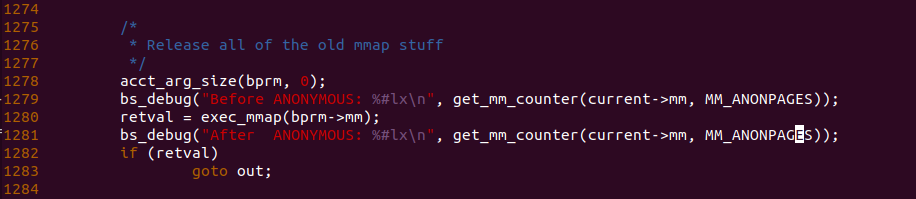
回到 flush_old_exec() 函数,通过调用 exec_mmap() 函数已经将进程的地址空间切换成新建进程的地址空间,此时可以像上图的 1279 行和 1281 行加上相应的调试 log,并在 BiscuitOS 上进行验证:
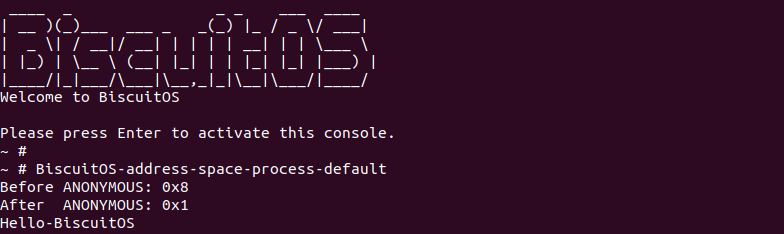
通过之前的分析可以知道,新建进程的堆栈使用了一个匿名页,因此 exec_mmap() 函数之后,当前进程的地址空间已经切换成新建进程的地址空间。
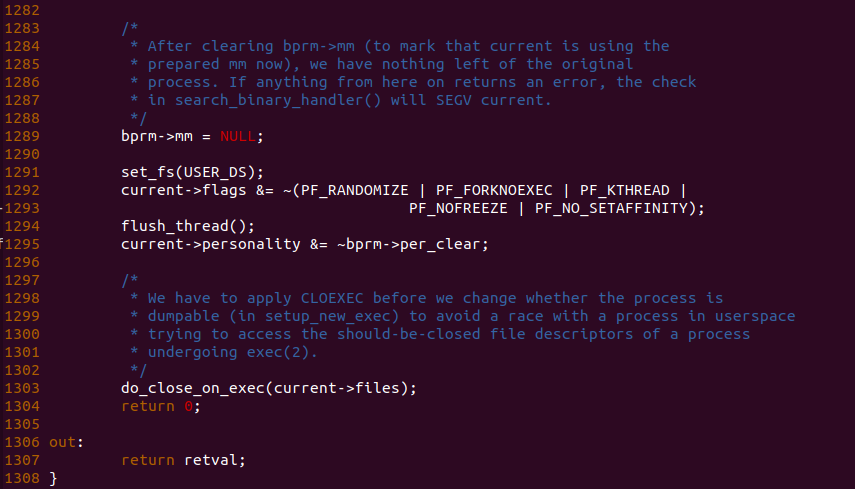
回到 flush_old_exec() 函数, 当前进程已经使用了新进程的地址空间,那么函数在 1289 行将 bprm->mm 设置为 NULL,以此作为新进程地址空间开始使用的标记。函数在 1292 行将进程的 PF_RANDOMIZE、PF_FORKNOEXEC、PF_NOFREEZE 和 PF_NO_SETAFFINITY 标志从当前进程的标志集合中移除, 几个标志的含义:
- PF_RANDOMIZE 支持虚拟地址随机化
- PF_FORKNOEXEC 进程刚刚创建,没有执行
- PF_KTHREAD 进程是内核进程
- PF_NOFREEZE 进程不应该被冻结
- PF_NO_SETAFFINITY 进程没有设置亲和性
函数继续调用调用 flush_thread() 函数将新更新的标志在当前进程中生效,通过上面的标志更新,那么当前进程被标榜为不是内核进程,且不是刚刚创建的进程,可以对进程设置亲和性,以及进程分配虚拟空间是不会添加随机的偏移,最后进程可能会被冻结。函数的最后是在 1303 行调用 do_close_on_exec() 函数,该函数用于关闭原始进程打开的文件。
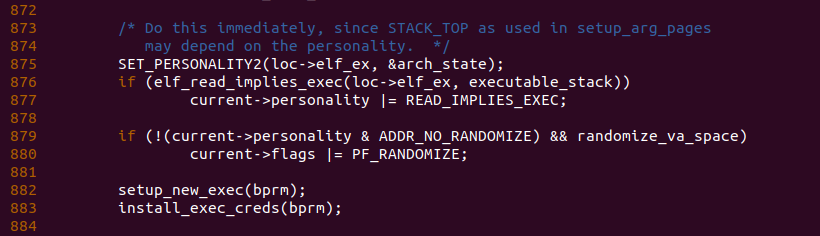
回到 load_elf_binary() 函数,函数此时在 875 行调用 SET_PERSONALITY2() 函数设置当前进程的 personality 标志集合. 当函数在 876 行探测到 executable_stack 的值不为 EXSTACK_DISABLE_X 是,也就是进程的堆栈是可执行栈,那么函数在 877 行将当前进程的 personality READ_IMPILES_EXEC 标志置位,这样在可执行栈的进程中,所有的可读 segment 都具有可执行权限。函数接着在 879 行判断当前进程的 personlity 中是否包含 ADDR_NO_RANDOMIZE 标志,如果包含且 randomize_va_space 为 true,那么会向当前进程添加 PF_RANDOMIZE 标志,这样进程在分配虚拟内存时候会在虚拟空间上移动随机长度的位置。函数继续在 882 行调用 setup_new_exec() 函数设置新进程的空间,其具体函数逻辑如下:
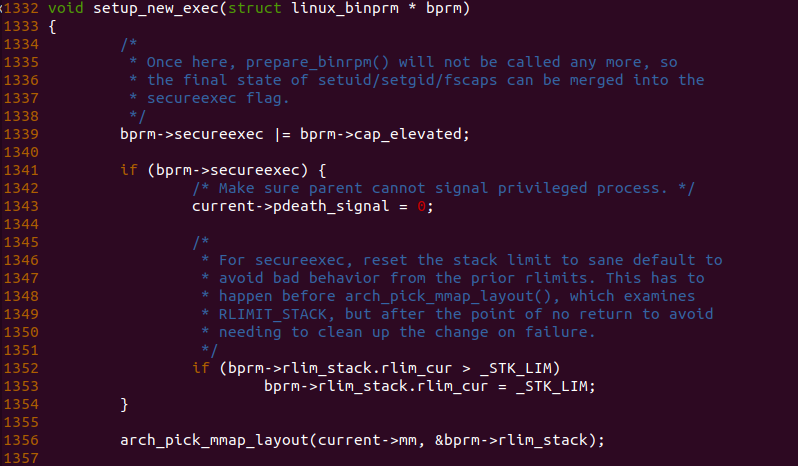
在 setup_new_exec() 函数中,函数首先将新进程的 uid/gid/fscap 的信息合并到 bprm 的 secureexec, 如果此时 bprm->secureexec 为真,那么函数将在 1343 行将进程的 pdeath_signal 设置为 0,以此确认父进程将优先级传递到新进程。函数此时检测堆栈当前限制是否大于 _STK_LIM, 如果大于那么将新进程的堆栈限制设置为 _STK_LIM, 为进程的 MMAP 区域布局做准备。函数接着在 1356 行调用 arch_pick_map_layout() 函数基于架构设置新进程的 MMAP 区域。由于该函数与架构有关,这里以 i386 架构为例进行讲解.
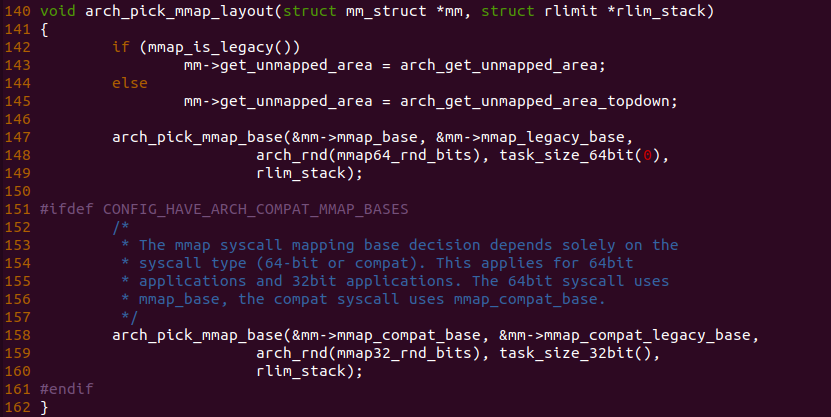
函数首先在 142 行调用 mmap_is_legacy() 函数判断当前系统支持的 MMAP 是否为 legacy 还是新版本的映射方式

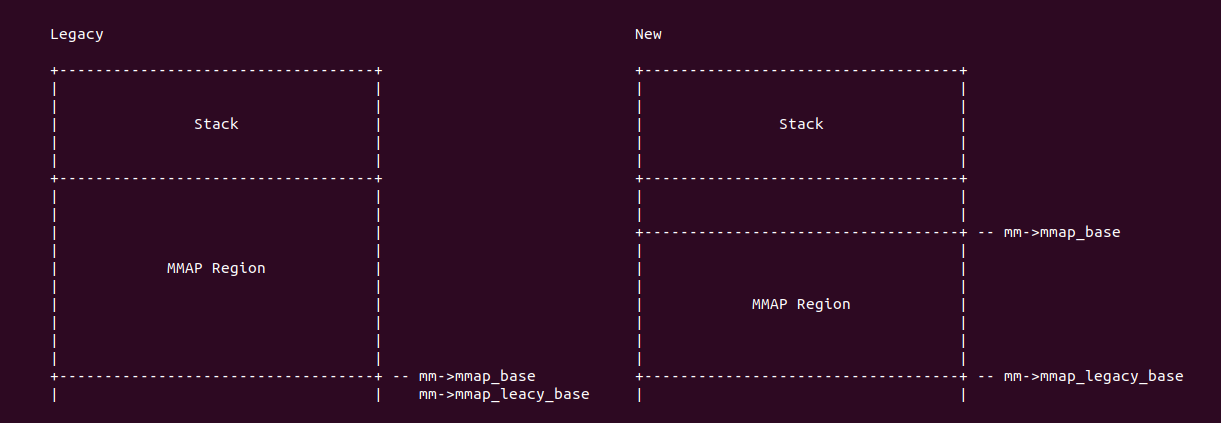
内核判断当前进程使用的 MMAP 是 legacy 还是新版本方式,有两个判断标准,第一个是进程的 personlity 的 ADDR_COMPAT_LAYOUT 是否置位,如果置位,那么采用 Legacy 方式; 反之函数通过判断 sysctl_legacy_va_layout 变量的值来判断,因此进程支持 MMAP 的方式是可变的,可根据实际情况进行调整。进程 Legacy MMAP 方式是进程地址空间的地址地址向高地址分配 MAMP 虚拟内存,而新版本的则是从进程的高地址向地址查找空闲区域进行分配。回到 arch_pick_mmap_layout() 函数,函数如果识别到当前进程采用的是 Legacy 方式,那么函数将进程地址空间的 get_unmapped_area 指向 arch_get_unmapped_area; 反之进程采用新版本的方式分配 MMAP 区域的虚拟内存,那么函数将进程地址空间的 get_unmapped_area 指向 arch_get_unmapped_area_topdown. 函数接着调用 arch_pick_mmap_base() 函数设置进程 MMAP 区域的基地址:

当前调用 arch_pick_mmap_base() 函数,参数 base 指向进程地址空间的 mmap_base, 参数 legacy_base 指向了进程地址空间的 mmap_compat_legacy_base, 参数 random_factor 则通过 arch_rnd(mmap64_rnd_bits) 函数获得,参数 task_size 通过 task_size_64bit(0) 函数获得进程用户空间最大值,参数 rlim_stack 则指向新进程堆栈的限制信息。函数首先在 133 行通过调用 mmap_legacy_base() 函数获得 Legacy 模式下 MMAP 区域最小值。
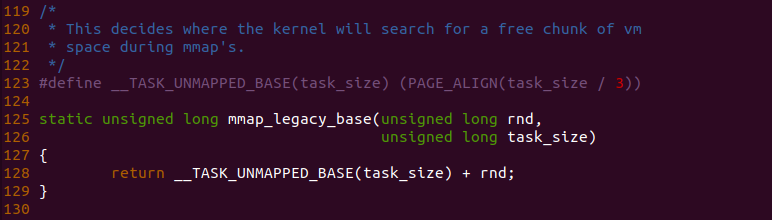
从 mmap_legacy_base() 的代码逻辑可以看出 Legacy 模式下,MMAP 区域的基地址是进程用户空间的 1/3 处。arch_pick_mmap_base() 函数在计算完 Legacy 模式下 MMAP 区域的基地址之后,函数在 134 行再次调用 mmap_is_legacy() 函数判断当前进程的 MMAP 区域的模式,如果是 Legacy,那么函数将进程地址空间的 mmap_base 设置为 legacy_base, 也就是进程用户空间的 1/3 处; 反之进程采用新模式的 MMAP,那么函数在 137 行调用 mmap_base() 计算新模式下的 MMAP 区域的基地址。

在计算进程 MMAP 区域新模式下的基地址,函数首先在 96 行获得堆栈的当前限制,接着在 97 行先调用 stack_maxrandom_size() 获得一个基于用户空间长度的随机值,然后加上 stack_guard_gap 的值存储在 pad 变量,这里 stack_guard_gap 用于 MMAP 区域与堆栈之间安全的间隔空隙。函数在 101 行进行判断,如果 gap 加上 pad 的值大于 gap,那么 pad 的值越界不符合要求。函数在 108 到 109 行计算处 MMAP 区域顶部的最大和最小范围,其最大值为用户空间的 5/6 的地方,最小值为用户空间 0x8000000. 如果此时堆栈当前限制小于 MMAP 区域顶部的最小值,那么将 gap 设置为 gap_min; 反之 gap 大于 MMAP 区域顶部的最大值,那么将 gap 设置为 gap_max, 最后函数基于上面处理好的数据,将用户空间最大值减去堆栈占用的范围,最后在减去一个随机值并将结果按页对齐,最后就可以获得 MMAP 区域顶部的位置。经过上面的处理之后,进程已经获得 MMAP 区域的范围,如下图:
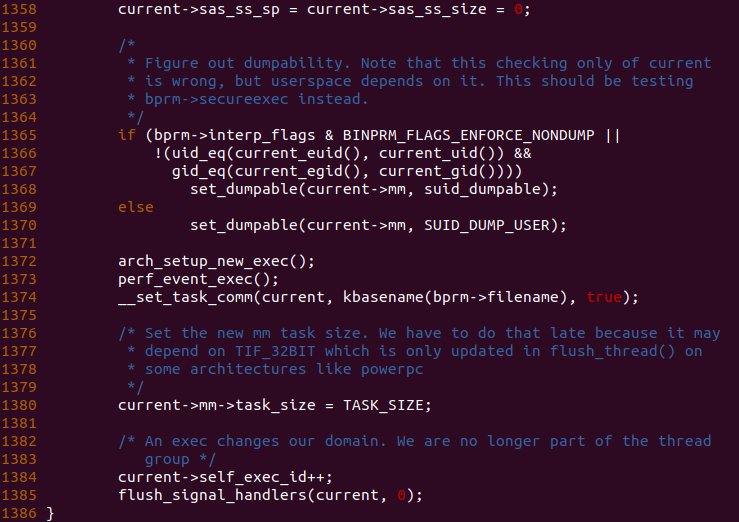
回到 setup_new_exec() 函数,函数在 1358 行将当前进程的 sas_ss_sp 和 sas_ss_size 设置为 0,并在 1380 行将当前进程地址空间的内核空间起始地址设置为 TASK_SIZE.
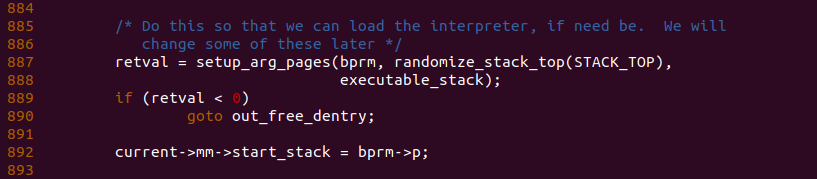
回到 load_elf_binary() 函数,函数在 887 行调用 setup_arg_pages() 函数将进程的堆栈由临时堆栈移动到最终位置,并拓展堆栈的范围。当前进程最红将堆栈的栈底指向了新堆栈的起始地址,即 bprm->p 指向的地址.

在系统调用到 setup_arg_pages() 函数,参数 stack_top 指向 STACK_TOP 加上了随机值,参数 bprm 指向了新进程的二进制文件,参数 executable_stack 用于指明堆栈是否具有执行权限。函数在 697 行定义了局部变量 vma,其指向了堆栈对应的 VMA。由于本文研究的堆栈是向下生长的堆栈,那么接下来就向下生长的堆栈进一步分析:
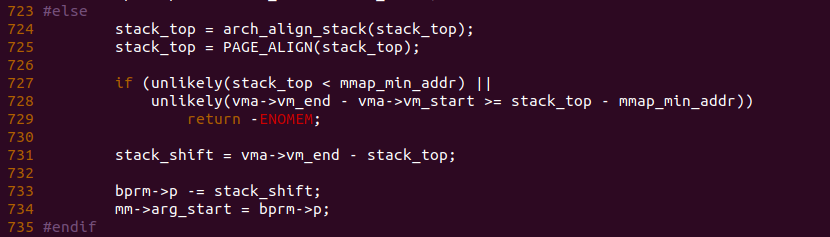
函数在 724 行和 725 行计算出了堆栈栈底的地址,函数接着在 727 行进行判断,如果堆栈栈底的地址小于进程规定的最小映射地址,或者堆栈的 VMA 区域大于堆栈栈底到最小映射地址的长度,那么系统判定这个堆栈是一个非法堆栈,直接返回 ENOMEM; 反之检测通过之后,函数出堆栈 VMA 的结束地址和加了偏移的栈底之间的偏移,并将该偏移存储在 stack_shift 里,由之前的代码分析可知,此时的堆栈布局如下:
此时 bprm->p 指向了堆栈中存储进程参数或环境变量的地址,函数在 733 行将 bprm->p 的值减去偏移值,并将进程地址空间的 arg_start 指向 bprm->p.
函数继续在 744 行将 vm_flags 设置为 VM_STACK_FLAGS, 函数接着在 751 行判断 executable_stack 的值是否为 EXSTACK_ENABLE_X, 如果堆栈是可执行栈,那么函数将 VM_EXEC 标志添加到 vm_flags 标志集合里; 反之将标志集合中 VM_EXEC 标志清除。函数接下来将新进程的 def_flags 和 VM_STACK_INCOMPLETE_SETUP 添加到 vm_flags 标志集合里。函数接着调用 mprotect_fixup() 修改堆栈 VMA 的映射标志,同时也修改了页表的标志。

由于之前进程创建的是一个临时堆栈,现在需要将临时堆栈移动到最终的位置,当函数在 765 行检测到 stack_shift 不为 0,那么就说明进程当前使用的堆栈就是临时堆栈,需要将其移动到最终的位置,那么函数调用 shift_arg_pages() 函数进行移动,其代码逻辑如下:

函数首先定义了一些局部变量,使用 old_start 和 old_end 描述临时堆栈的虚拟区域,使用 new_start 和 new_end 描述最终堆栈的虚拟区域。函数首先在 635 行检测 new_start 和 new_end 是否越界,起始函数在 641 行调用 find_vma() 函数查找包含 new_start 的 VMA,该 VMA 就是临时堆栈对应的 VMA。函数接着在 647 行调用 vma_adjust() 函数调增 VMA,将 VMA 的的起始地址修改为 new_start, 结束地址修改为 old_end, 此时可以通过打印查看调增前后 VMA 的变化:

开发者可以像上图一样在 647 行和 650 行添加调试信息,在 BiscuitOS 上运行如下图:
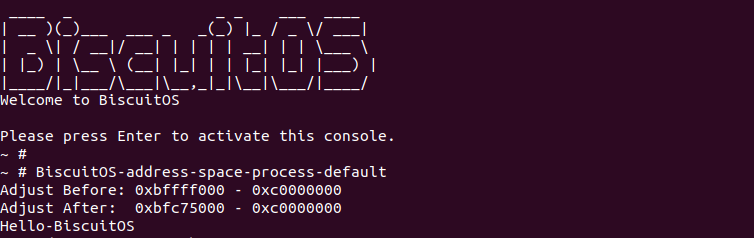
从 BiscuitOS 上运行的情况可以看出,VMA 的范围被修改为 new_start 到 old_end. 回到 shift_arg_pages() 函数,函数在 654 行调用 move_page_tables() 函数将旧的页表移动到新的堆栈虚拟地址对应的位置,并调用 tlb_gather_mmu() 函数准备刷新堆栈虚拟区域的页表和 TLB。
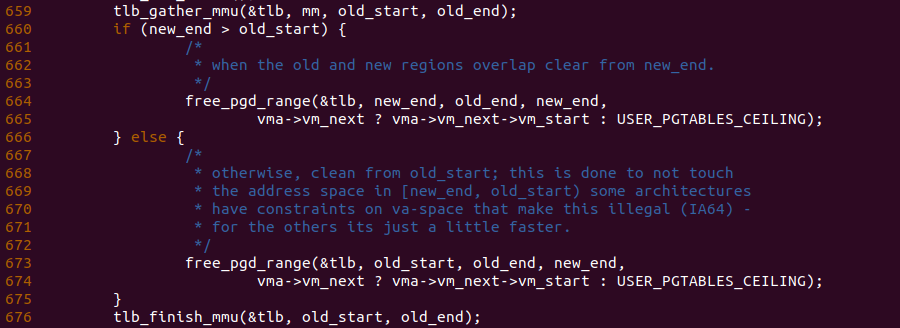
如果 new_end 大于 old_start, 那么新的区域和旧的区域之间存在重叠的部分,那么函数调用 free_pgd_range() 将旧区域不重叠部署对应的页表和 TLB 进行刷新,并将其对应的物理内存进行释放; 反之如果 new_end 小于 old_start, 那么表示新旧区域不重叠,那么函数直接调用 free_pgd_range() 函数就旧区域的页表 TLB 都刷新,并释放其对应的物理内存。函数最后再次调用 vma_adjust() 函数将 VMA 从 new_start 到 old_end 缩容成 new_start 到 new_end. 至此新建堆栈对应的 VMA 已经准备完毕.
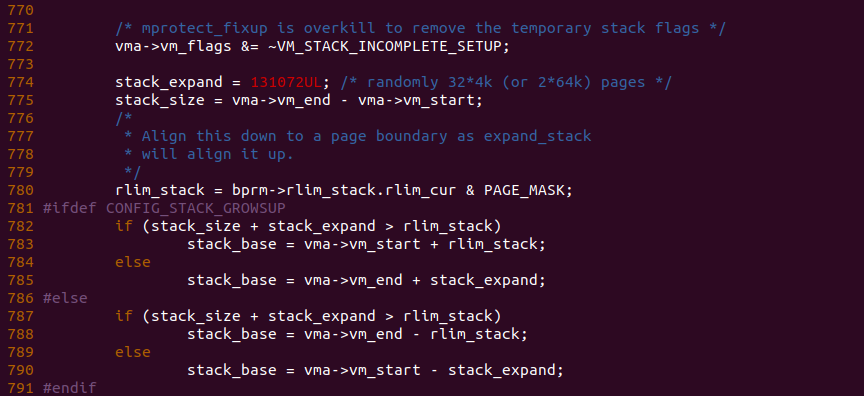
调整完堆栈的 VMA 之后,回到 setup_arg_pages() 函数,函数在 772 行将 VM_STACK_INCOMPLETE_SETUP 标志从堆栈 VMA 标志集合中剔除。函数接下来需要拓宽可用的堆栈,也就是拓宽建立页表映射的堆栈,函数首先在 774 行设置拓宽堆栈的长度为 32 个页大小,接着将新堆栈的大小存储在 stack_size 里。接着函数在 780 行获得新进程堆栈当前限制值,并存储在 rlim_stack 变量里,对于向下生长的堆栈,函数在 787 行判断堆栈的大小加上堆栈拓宽的长度是否超过当前进程的堆栈限制,如果超过,那么函数将 stack_base 设置为堆栈栈底减去 rlim_stack; 反之将 stack_base 设置为堆栈栈顶的值减去 stack_expand 的值。通过上面的代码逻辑,可以获得堆栈拓宽的合理长度。

函数接着将当前进程地址空间的 start_stack 设置为 bprm->p, 那么进程堆栈栈底重新更新为 bprm->p,此时 bprm->p 指向堆栈存储参数或环境变量的起始地址,此时堆栈布局如下图:

函数最后调用 expand_stack() 函数进行堆栈拓展,expand_stack() 函数最终调用到 expand_downwards() 函数,其实现如下:
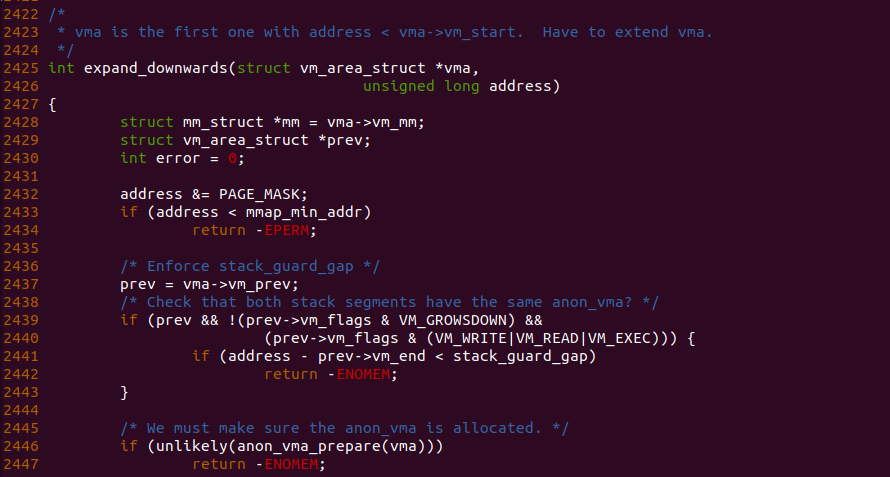
在 expand_downwards() 函数中,参数 vma 指向堆栈对应的 VMA,参数 address 则指向堆栈要拓展到的地址,由于堆栈向下生长,那么 address 是堆栈拓展的最低地址。函数首先在 2433 行检测堆栈拓展的基地址是否小于进程最小映射地址,如果小于,那么函数认为这是非法的,直接返回 EPERM. 由于此时系统只有堆栈的 VMA,因此 2439 行代码逻辑不成立。由于堆栈是匿名映射,函数在 2446 行调用 anon_vma_prepare() 函数为 vma 准备 anon_vma。
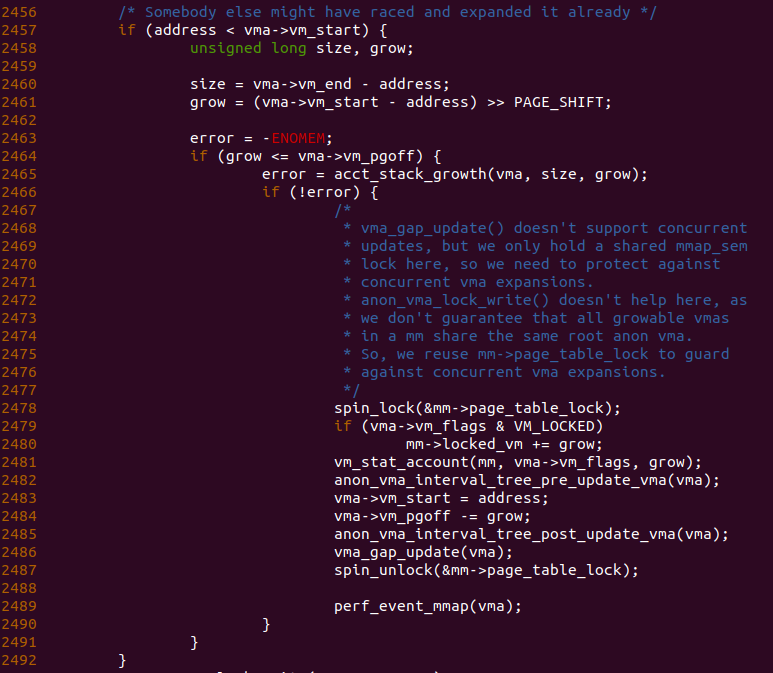
函数在2457 行再次检测拓展之后的基地址是否小于堆栈 VMA 的起始地址,如果不小于,那么表示堆栈 VMA 的范围已经涵盖了堆栈拓展的部分。从上面的分析可知,此时 address 绝对小于堆栈 VMA 的起始地址,因此函数进入 2458 行分支进行执行。函数在 2460 行计算处拓展的基地址到堆栈 VMA 结束地址之间的长度,并存储在 size 变量里,函数接着在 2461 行计算出堆栈起始地址到堆栈拓展基地址之间包含页的数量,并存储在 grow 变量里。如果 grow 小于或等于堆栈 VMA 的页偏移,那么函数进入到 2465 分支继续执行。函数在 2465 行调用 acct_stack_growth() 函数检测堆栈拓展的长度是否合理,其代码逻辑如下图:
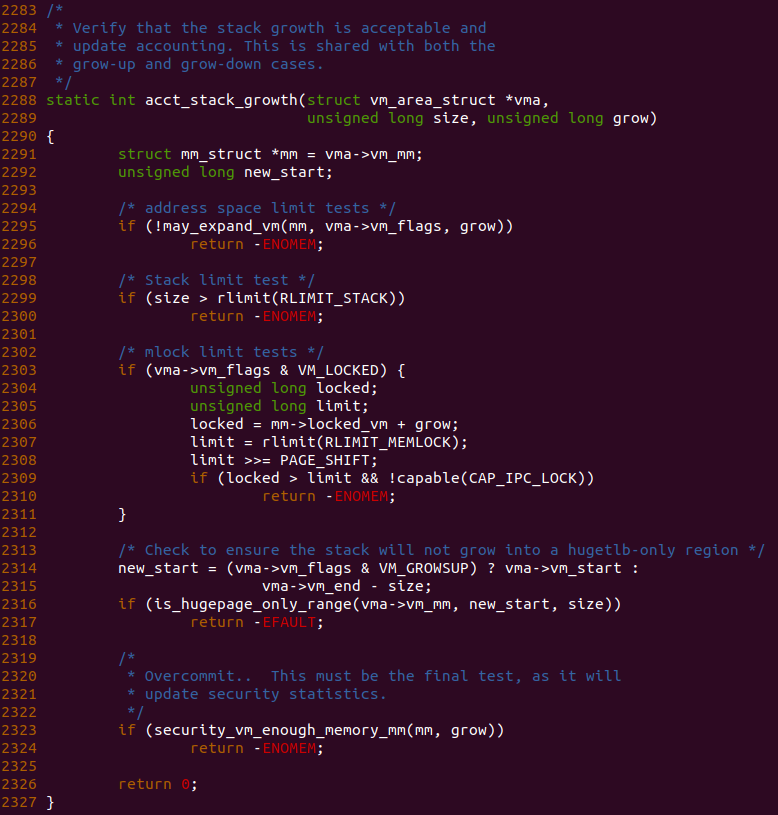
函数首先在 2295 行调用 may_expand_vm() 函数判断当前进程是否支持堆栈对应的 VMA 进行拓展操作,接着函数在 2299 行检查拓展的长度是否超过了堆栈的限制,如果有条件不符合,那么函数直接返回 ENOMEM. 剩下的两个检测可以忽略.
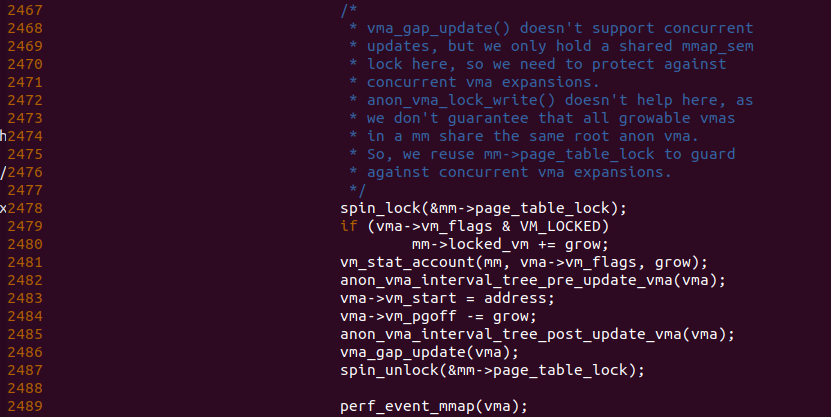
函数拓展检测通过之后,函数开始实际的拓展工作,函数在 2481 行调用 vm_stat_account() 函数统计进程不同 segment 的数量,这里用于对进程地址空间 mm->stack_vm 的数量加一操作。函数接着在 2482 行和 2485 行调用了匿名映射的方向映射树,该树用于通过 VMA 的 vm_pgoff 映射到对应的虚拟地址,因此函数在 2483 行到 2484 行修改了 VMA 的起始地址和 vm_pgoff, 那么需要将要更新对应的 interval 树的映射关系。最后函数在 2486 行调用 vma_gap_update() 函数更新了 VMA 的 gap 信息.

堆栈拓展完毕之后,函数进行一些收尾工作,该拓展只拓展了虚拟内存,而没有实际的物理内存分配,这也是合理的,等遇到向堆栈上存内容的时候,直接通过缺页为对应的虚拟内存绑定物理内存即可。最后可以在上图中添加打印信息来查看拓展之后的堆栈范围:

从 BiscuitOS 上运行情况可以看出,堆栈已经的拓展一个新的地址,堆栈由原先一个页拓展到多个页。回到 load_elf_bianry() 函数之前,由于接下来的代码将加载 ELF 各个 Segment,因此首先使用 readelf 工具将新进程的各个 Program Header 信息打印出来,请参考如下命令:
cd BiscuitOS
cd BiscuitOS/output/linux-XXXX/
readelf -lS BiscuitOS/output/linux-XXXX/rootfs/rootfs/bin/echo

从上图可以看出,在 Program Header Table 中,一个存在 6 个表项,每个表项中所含的 Section 从图中页可以看出,例如 Program Header Table 的第一个表项中包含了 “.text”、”.rodata”、”.init” 等多个 Section,其 Program Segment 的类型是 PT_LOAD, 也就是在加载进程的时候,需要将该 Segment 的内容映射到进程指定的虚拟内存上。在例如第二个 Segment 包含了 “.data”、”.bss” 等字段,可以理解为这是进程的数据段。
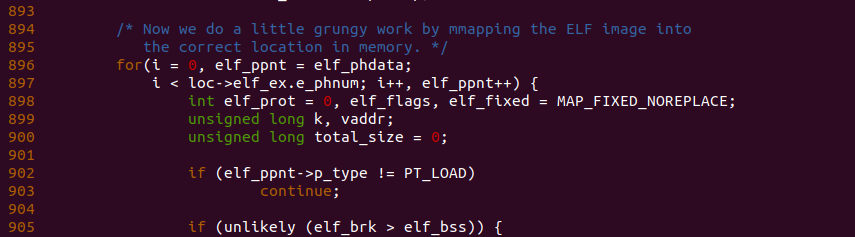
回到 load_elf_binary() 函数,函数在 896 行还是遍历新进程的 Program Header,由新进程通过 readelf 工具可以知道,新进程中包含了 6 个 Program Header,其中只有前两个 Program Header 的类型是 PT_LOAD, 而且新进程的第一个 Program Header 是一个只读的,因此第一个 Program Header 就是代码段。因此 902 行第一次处理的是代码段,那么此时 elf_brk 和 elf_bss 均为 0,那么代码段不会进入 906 的分支。

函数接下来判断代码段的属性,由于之前 readelf 的结果可以知道代码段具有只读权限和可执行权限,因此 elf_prot 会添加 PROT_READ 标志和 PROT_EXEC 标志。函数接着在 947 行将 MAP_PRIVATE、MAP_DENYWRITE 以及 MAP_EXECUTABLE 标志存储在 elf_flags 里,并在 948 行获得代码段加载到内存的虚拟地址,此时可以在 949 行打印一下代码段的虚拟地址:
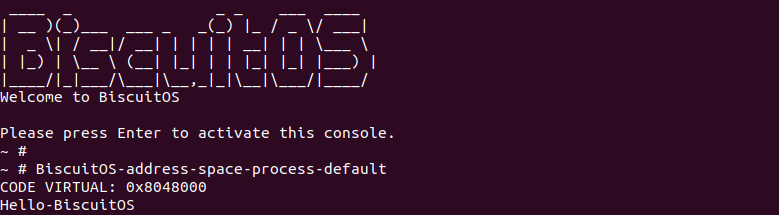
从 BiscuitOS 上运行情况可以看出代码段加载到虚拟地址 0x8048000, 符合预期.

函数接着在 953 行检测新进程的 ELF 文件的 ELF Header 的类型,也就是再次检测 ELF 的文件类型,由之前的分析可知,新进程的 ELF 文件是一个可执行文件,因此新进程文件的类型是 ET_EXEC, 那么函数进入 954 行执行,此时将 elf_fixed 包含的标志存储到 elf_flags 中,此时 elf_fixed 包含了 MAP_FIXED_NOREPLACE 标志,该标志用于映射到进程的固定地址,如果该虚拟地址已经有其他虚拟区域占用,那么则不进行任何操作直接返回错误。因此函数此时不会进入 956 行分支执行。

函数接着在 1011 行调用 elf_map() 函数将代码段映射到新进程地址空间的指定位置,此时只分配虚拟地址,并没有将代码段的实际内容加载到进程的代码段内。
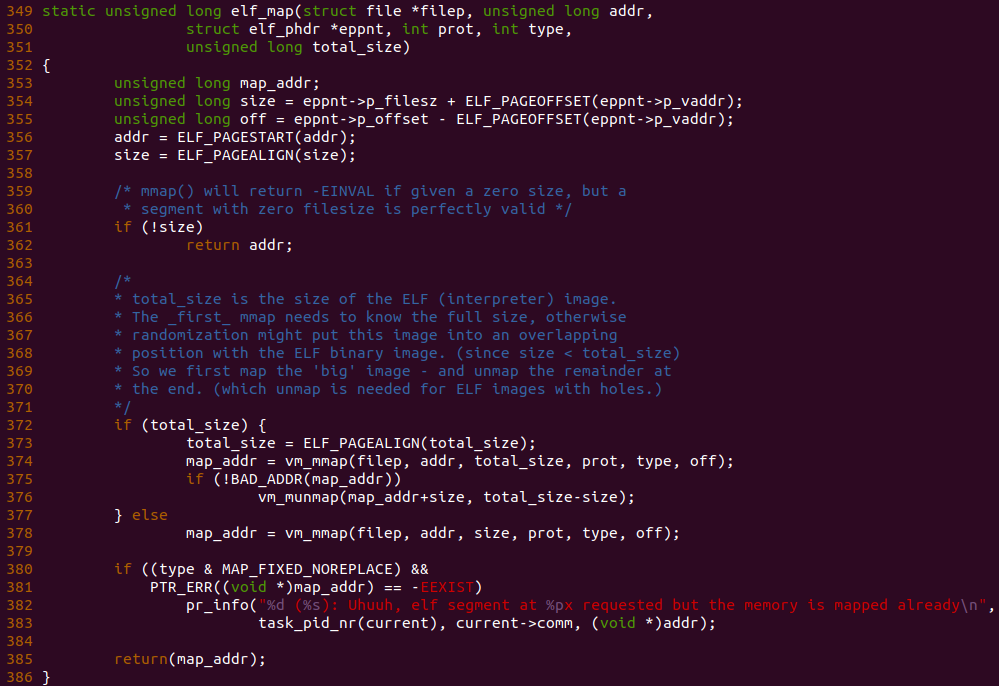
在 elf_map() 函数中,参数 filep 指向了新进程对应的 ELF 文件,参数 addr 指向了映射到进程的虚拟地址,参数 eppnt 则指向 Program Header,参数 prot 包含了映射权限,参数 type 则包含了映射的标志,参数 total_size 则表示 ELF interpreter image 的长度。函数首先在 354 行通过 eppnt->p_files 获得该段在 ELF 文件的大小,eppnt->p_vaddr 则表示段应该加载到进程的虚拟地址,”ELF_PAGEOFFSET(eppnt->p_vaddr)” 则表示加载地址在页内的偏移,因此函数在 354 行获得了该段的大小。eppnt->p_offset 则表示段相对于文件头的偏移,因此 off 变量用于存储段在文件中的偏移。函数在 356 行和 357 行将 addr 和 size 的值进行处理对齐之后获得一个可用的段范围。函数在 361 行检测 size 有效之后,继续在 372 行检测 total_size 是否不为 0,total_size 与 ELF interpreter image 有关系,由于本例子中 ELF 不包含 interprete,因此 total_size 一直保持为 0,那么函数只会调用 379 行的 vm_mmap() 函数进行映射,vm_mmap() 函数的作用就是将 ELF 文件的 off 处的内容映射到进程虚拟地址 addr 到 “addr+size” 的区域,此时函数只会为该段建立虚拟区域,并基于 off 建立 off 到虚拟区域的关系,但不会分配实际的物理内存,只有当进程真实的访问这段虚拟内存,发生缺页中断之后才会将虚拟内存绑定到物理内存上。当映射完毕之后函数返回映射成功的虚拟区域的起始地址. 在上面的映射中值得注意的是,映射采用 MAP_FIXED_NOREPLACE 标志,这可能会导致映射失败。

回到 load_elf_binary() 函数,函数在 1019 行检测 load_addr_set 变量是否为空,由于在加载代码段是第一次加载,那么 load_addr_set 此时为空,那么函数进入 1020 分支执行,函数将 load_addr_set 设置为 1,然后在 1021 行计算出代码段的加载地址,由于此时 ELF 文件是可执行文件,因此函数不会进入 1023 行代码分支进行执行。函数接着在 1029 行获得当前段段加载到进程的虚拟地址,由于此时 start_code 的值为 0xffffffff,start_data 的值为 0 ,因此此时函数会将 start_data 和 start_data 的值设置为代码段的加载地址。
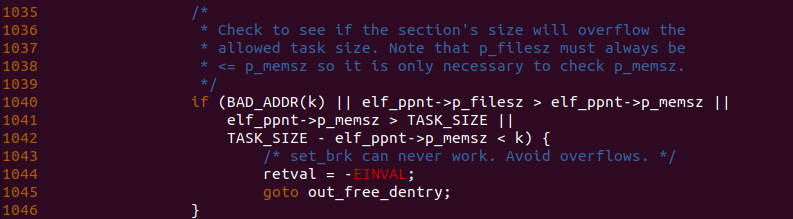
函数接着检测段加载的虚拟地址是否超过进程最大地址,其按下面三个条件进行检测:
- 函数调用 BAD_ADDR() 函数直接判断虚拟地址是否超过用户空间最大地址
- 函数检测段在文件中的长度 p_filesize 是否大于在内存中的大小 p_memsz.
- 段在内存中长度大于 TASK_SIZE
- 段的范围超过了进程用户空间的最大值
正常情况下 p_filesize 等于 p_memsz, 如果 p_memsz 大于 p_filesz, 那么该段是 .bss.以上只要有一个条件满足,那么这个段是非法不符合要求的,函数直接跳转到 out_free_entry 分支.
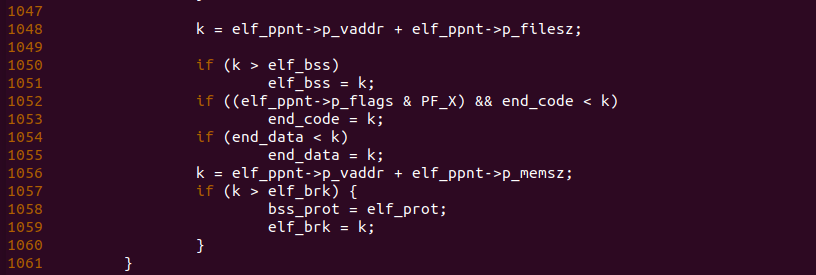
当加载代码段时,函数在 1048 行通过代码段在 ELF 文件中的长度和加载到进程地址空间的地址计算处了代码段的结束地址。此时 elf_bss 为 0,那么函数执行 1051 行将 elf_bss 设置为代码段结束的位置,此时 end_code 为 0,且代码段有执行权限,那么 1053 行条件成立,那么函数将 end_code 设置为 k,即代码段的结束地址。由之前的代码可知,end_data 此时也为 0,因此函数在 1055 行将 end_data 设置为 k。由于代码段的 p_memsz 等于 p_filesz, 此时 elf_brk 为 0,那么函数会进入 1058 分支进行执行,此时将 elf_brk 设置为代码段的结束虚拟地址,并将 elf_prot 的权限存储到 bss_prot 中。通过上面的处理,加载完代码段之后,start_code 和 end_code 都正确指向了代码段在进程地址空间的位置,而 start_code 和 end_code 以及 elf_bss 都还没有正确的位置,那么接下来再次循环遍历,查看数据段的加载过程:
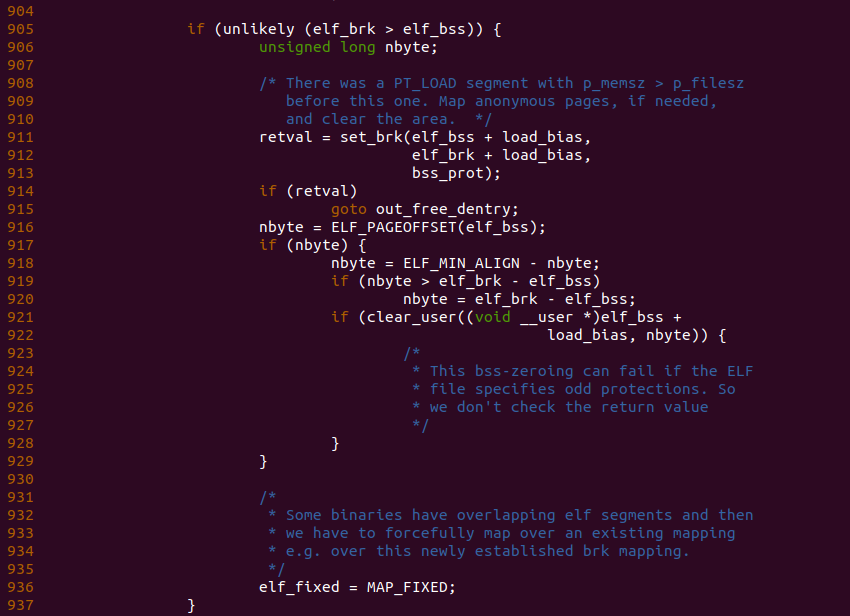
回到 load_elf_binary() 函数,函数在 896 行还是遍历新进程的 Program Header,由新进程通过 readelf 工具可以知道,新进程中包含了 6 个 Program Header,其中只有前两个 Program Header 的类型是 PT_LOAD, 而且新进程的第二个 Program Header 是一个可读可写的,因此第二个 Program Header 就是数据段。因此 902 行第二次处理的是数据段,由之前的分析可以知道此时 elf_brk 等于 elf_bss, 那么 906 行分支不会被执行。,那么代码段不会进入 906 的分支。
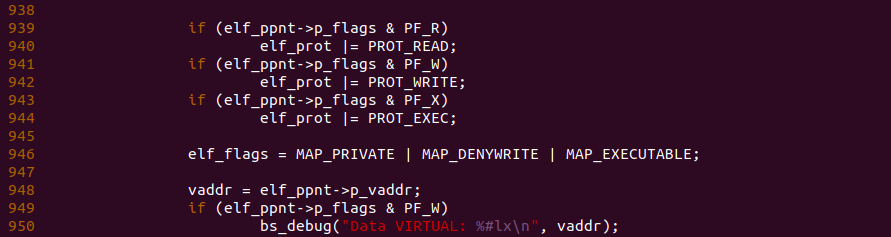
函数接下来判断代码段的属性,由于之前 readelf 的结果可以知道代码段具有可读可写权限,因此 elf_prot 会添加 PROT_READ 标志和 PROT_WRITE 标志。函数接着在 947 行将 MAP_PRIVATE、MAP_DENYWRITE 以及 MAP_EXECUTABLE 标志存储在 elf_flags 里,并在 949 行获得数据段加载到内存的虚拟地址,此时可以在 950 行打印一下代码段的虚拟地址:
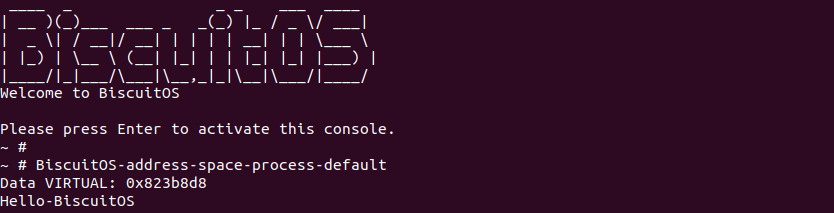
从 BiscuitOS 上运行情况可以看出数据段加载到虚拟地址 0x823b8d8, 与通过 readelf 工具获得的数据段的加载地址一致,符合预期.
函数接着在 953 行检测新进程的 ELF 文件的 ELF Header 的类型,也就是再次检测 ELF 的文件类型,由之前的分析可知,新进程的 ELF 文件是一个可执行文件,因此新进程文件的类型是 ET_EXEC, 并且此时 load_addr_set 为真,那么函数进入 954 行执行,此时将 elf_fixed 包含的标志存储到 elf_flags 中,此时 elf_fixed 包含了 MAP_FIXED_NOREPLACE 标志,该标志用于映射到进程的固定地址,如果该虚拟地址已经有其他虚拟区域占用,那么则不进行任何操作直接返回错误。因此函数此时不会进入 956 行分支执行。
函数接着在 1011 行调用 elf_map() 函数将数据段映射到新进程地址空间的指定位置,此时只分配虚拟地址,并没有将代码段的实际内容加载到进程的代码段内。
在 elf_map() 函数中,参数 filep 指向了新进程对应的 ELF 文件,参数 addr 指向了映射到进程的虚拟地址,参数 eppnt 则指向 Program Header,参数 prot 包含了映射权限,参数 type 则包含了映射的标志,参数 total_size 则表示 ELF interpreter image 的长度。函数首先在 354 行通过 eppnt->p_files 获得该段在 ELF 文件的大小,eppnt->p_vaddr 则表示段应该加载到进程的虚拟地址,”ELF_PAGEOFFSET(eppnt->p_vaddr)” 则表示加载地址在页内的偏移,因此函数在 354 行获得了该段的大小。eppnt->p_offset 则表示段相对于文件头的偏移,因此 off 变量用于存储段在文件中的偏移。函数在 356 行和 357 行将 addr 和 size 的值进行处理对齐之后获得一个可用的段范围。函数在 361 行检测 size 有效之后,继续在 372 行检测 total_size 是否不为 0,total_size 与 ELF interpreter image 有关系,由于本例子中 ELF 不包含 interprete,因此 total_size 一直保持为 0,那么函数只会调用 379 行的 vm_mmap() 函数进行映射,vm_mmap() 函数的作用就是将 ELF 文件的 off 处的内容映射到进程虚拟地址 addr 到 “addr+size” 的区域,此时函数只会为该段建立虚拟区域,并基于 off 建立 off 到虚拟区域的关系,但不会分配实际的物理内存,只有当进程真实的访问这段虚拟内存,发生缺页中断之后才会将虚拟内存绑定到物理内存上。当映射完毕之后函数返回映射成功的虚拟区域的起始地址. 在上面的映射中值得注意的是,映射采用 MAP_FIXED_NOREPLACE 标志,这可能会导致映射失败。
回到 load_elf_binary() 函数,函数在 1019 行再次检测 load_addr_set 变量是否为真,由之前的分析可知,此时 load_addr_set 为真,那么 1020 行分支不会被执行。函数此时将数据段的的虚拟地址存储在 k 变量里,并将 k 与 start_code 进行对比,此时 k 明显大于 start_code, 因此 1031 行分支不会被执行。函数继续判断 start_data 是否小于 k,此时 start_data 确实小于数据段的起始地址,那么函数将 start_code 指向了数据段的起始虚拟地址。
函数接着检测段加载的虚拟地址是否超过进程最大地址,其按下面三个条件进行检测:
- 函数调用 BAD_ADDR() 函数直接判断虚拟地址是否超过用户空间最大地址
- 函数检测段在文件中的长度 p_filesize 是否大于在内存中的大小 p_memsz.
- 段在内存中长度大于 TASK_SIZE
- 段的范围超过了进程用户空间的最大值
正常情况下 p_filesize 等于 p_memsz, 如果 p_memsz 大于 p_filesz, 那么该段是 .bss.以上只要有一个条件满足,那么这个段是非法不符合要求的,函数直接跳转到 out_free_entry 分支.
当加载完数据段,函数在 1048 行通过数据段在 ELF 文件中的长度和加载到进程地址空间的地址计算出了数据段的结束地址。此时 elf_bss 为代码段的结束地址,那么函数执行 1051 行将 elf_bss 设置为数据段结束的位置,此时数据段没有有执行权限,那么 1053 行条件不成立,那么 1053 行分支不会被执行。由之前的代码可知,end_data 此时也为代码段的结束地址,因此函数在 1055 行将 end_data 设置为 k。由于数据段中包含了 “.bss” section,那么数据段的 p_memsz 会大于 p_filesz, 并且此时 elf_brk 等于代码段的结束地址,因此 1057 行条件成立,那么函数更新了 elf_brk 的值为数据段最大结束地址,并将 elf_prot 存储到了 bss_prot. 经过上面的处理,程序的基础段布局已经形成,如下:

此时进程存在堆栈、堆、MMAP 映射区、BSS 段、DATA 段以及代码段。

如果新进程的 ELF 文件是动态加载,那么需要将各个段中添加 load_bias 偏移。

函数在 1076 行调用 set_brk() 函数为 BSS 段分配虚拟内存并设置进程堆的起始地址。此时由于 elf_bss 的值小于 elf_brk, 那么函数在 set_brk() 函数中的处理逻辑如下:
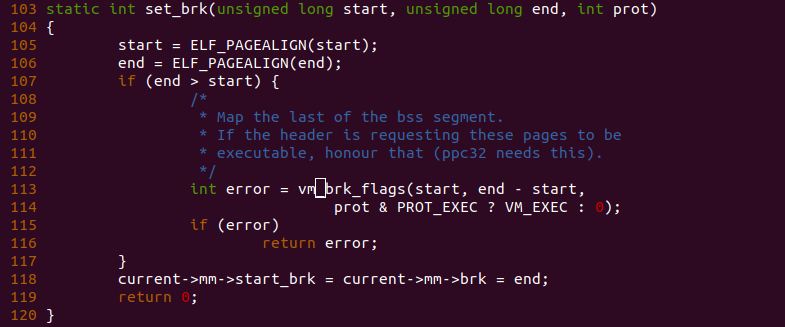
函数在 105 行和 106 行将 start 和 end 参数进行对齐,由上面分析可以知道 start 到 end 的区域正好是 BSS 区域,那么函数在 107 行判定 BSS 的长度不为零的情况下,在 113 行通过 vm_brk_flags() 函数为 BSS 在进程的地址空间中分配内存,映射完毕之后,函数将当前进程地址空间的 start_brk 和 brk 都设置为堆的起始地址,即 BSS 的结束地址。
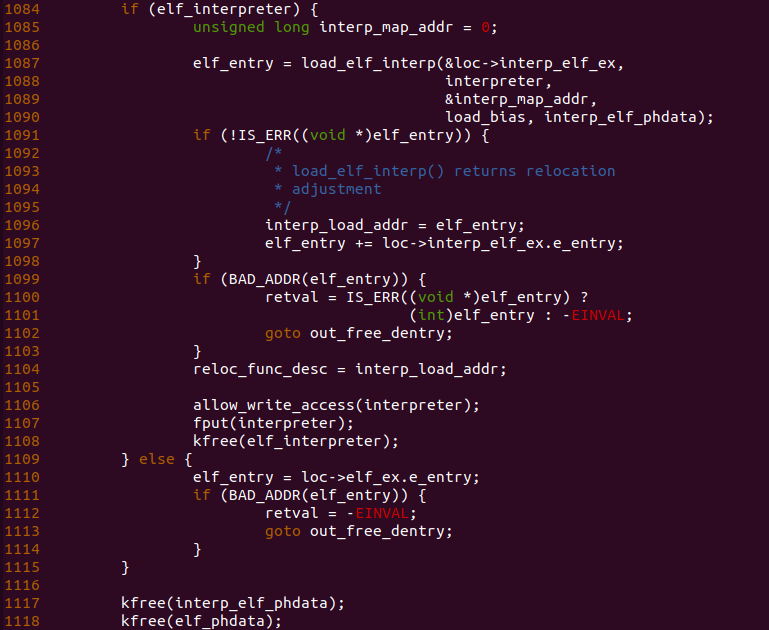
回到 load_elf_binary() 函数,由于之前分析可知道,elf_interprete 不存在,那么函数直接进入 1110 分支进行执行. 函数在 1110 行检测了 ELF 文件入口地址是否有效,如果无效则跳转到 out_free_dentry 分支。函数最后在 1117 行调用 kfree() 函数将 inerp_elf_phdata 和 elf_phdata 变量分配的内存进行释放。

函数接着在 1128 行调用 create_elf_table() 函数在新进程的堆栈里创建 ELF Table。
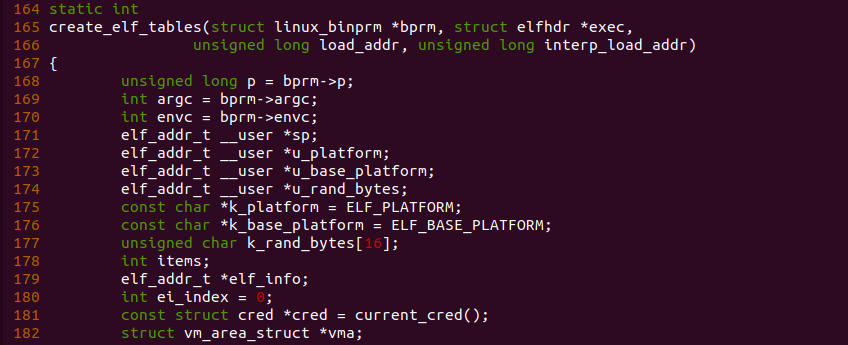
在 create_elf_tables() 函数中,此时参数 bprm 指向新进程的 ELF 文件信息,参数 exec 执行新进程的 ELF Header,参数 load_addr 指向了代码段的虚拟地址减去代码段在 ELF 文件中的偏移,inter_load_addr 参数则指向 interpret 的加载地址。函数定义了局部变量 k_platform,其指向了 ELF_PLATFORM, ELF_PLATFORM 指明的架构信息。函数还定义了 k_base_paltform 变量,其指向 ELF_BASE_PLATFORM, 不过该变量在 i386 架构上为空。

函数接下来在 190 行将堆栈的栈顶通过 arch_align_stack() 进行对齐,接着函数在 198 到 205 行在 k_platform 存储的情况下,在 202 行调用 STACK_ALLOC() 函数从新进程的堆栈中分配指定长度的空间,然后在 203 行调用 __copy_to_user() 函数将架构信息写入到堆栈。同理,如果 k_base_platform 信息存在,那么函数也会将该信息从内核写入到新进程的堆栈里。
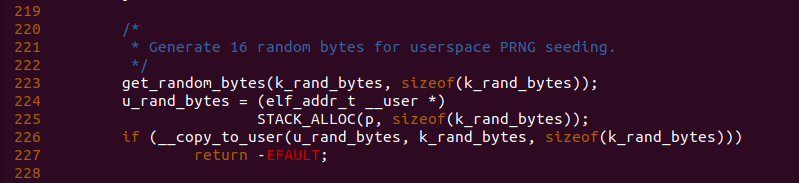
函数接着在 223 行调用 get_random_bytes() 函数获得一个随机数,并将其存储在 k_rand_bytes 数组里,接着函数在 224 行从新进程的堆栈中分配数组长度的空间,最后调用 __copy_to_user() 函数将 k_rand_bytes 的数据拷贝到新进程的堆栈里。
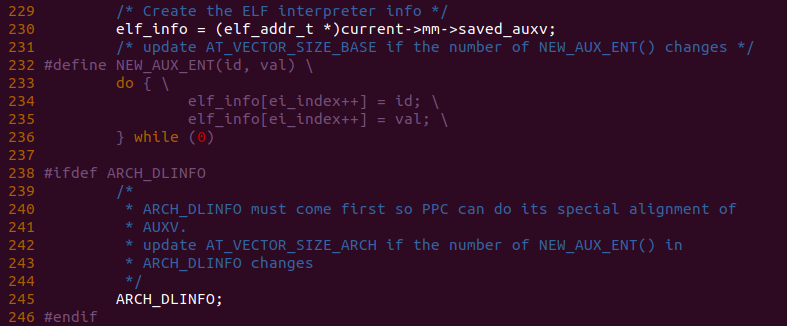
函数接着在 230 行将 elf_info 指向了当前进程的 saved_auxv 成员,并在 232 行定义了一个快捷宏,该宏用于向 elf_info[] 数组中填入指定的 ID 和 VAL 信息,该 ID 包含如下成员:


函数接着从 247 行到 277 行用于填充 elf_info[] 数组的信息。

函数接着在 279 行调用 memset() 函数将 elf_info[] 数组中空的位置清零。函数接着在 283 行将 ei_index 的数量加 2. 函数接着在 285 行调用 STACK_ADD() 函数从堆栈中分配 ei_index 长度的空间,并将 sp 指向新分配的空间。函数此时在 287 行通过 argc 和 envc 计算处新进程包含启动参数和环境变量的个数,接着行在 288 行调用 STACK_ROUND() 函数计算 sp 的地址加上 items 之后堆栈栈顶新地址,因此从这里可以知道函数其实从堆栈分配了一段空间用来存储指针,这些指针指向 ELF Table 和进程的参数/环境变量. 由于此处堆栈是向下生长的,那么函数在 295 行将 sp 的值再次指向了堆栈的栈顶.
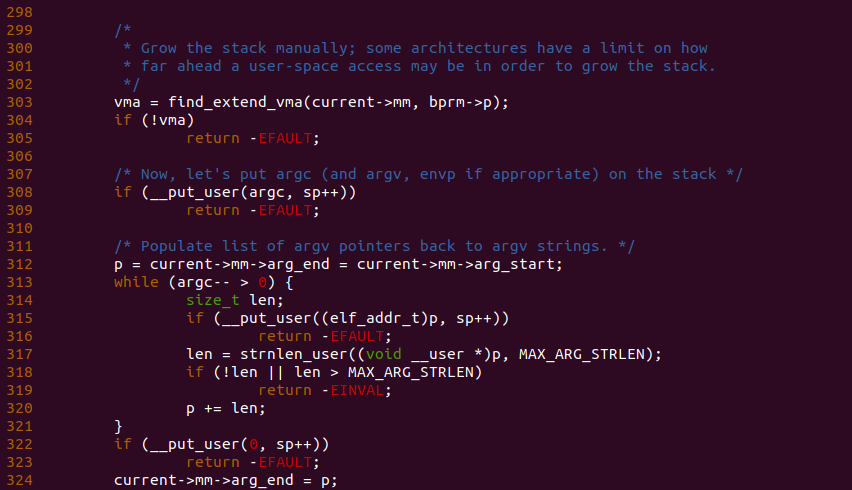
函数继续在 303 行调用 find_extend_vma() 函数在当前进程中找到堆栈对应的 VMA,此时如果 VMA 不存在的话,那么函数返回 EFAULT。函数在 308 行调用 __put_user() 函数将新进程启动参数的个数写入到堆栈的栈顶,接着函数在 312 行将新建进程地址空间的 arg_end 和 arg_start 都启动参数说在的位置,在之前的分析中可以知道,当新进程将临时堆栈移动到最终位置的过程中,将进程地址空间的 arg_start 指向了堆栈中存储参数的位置,可以参考 setup_arg_pages() 函数,此时根据新建进程启动参数的个数在 313 行使用 while 循环遍历每个启动参数,在每次遍历过程中,函数在 315 行将堆栈中存储参数的地址存储在堆栈指定的位置,接着在 317 行计算出参数的长度,以便在 320 行计算出下一个参数的位置,通过上面的处理,堆栈会在指定区域维护一个参数表,表中的每个项指向新进程的启动参数。当设置完所有新进程的启动参数的引用之后,函数在栈顶写入 0,以此作为参数的隔离目的,函数最后在 324 行将当前进程地址空间的 arg_end 指向了启动参数结束的位置,至此进程已经可以维护启动参数的内存。
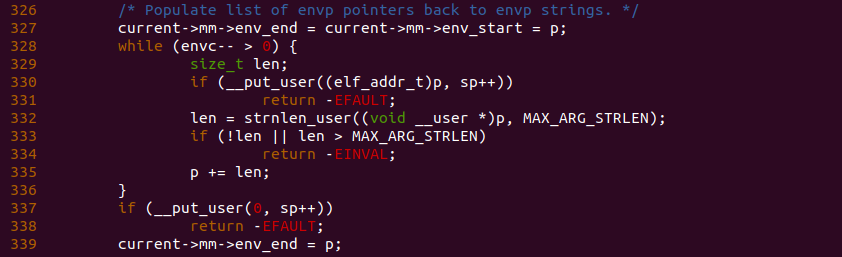
由之前的分析可知,新进程的环境变量存储在启动参数之后,因此函数在 327 行将当前进程地址空间的 env_end 和 env_start 都指向了新进程启动参数的末尾。同上函数在 328 行使用 while 循环遍历所有的环境变量,其在 330 行将环境变量在堆栈的地址通过 __put_user() 函数写入到存储参数指针列表出,当写完一个之后,函数在 332 行调用 strnlen_user() 函数计算出当前参数的长度,以便在 335 行计算出下一个参数的地址。函数同理在 337 行将 0 写到环境变量指针列表的最后一个位置。函数最终在 339 行将进程地址空间的 env_end 指向了最后一个环境变量.

函数最后将新建 ELF Table 通过 copy_to_user() 函数写入到堆栈的指定位置。通过该函数的处理,此时堆栈的布局如下:

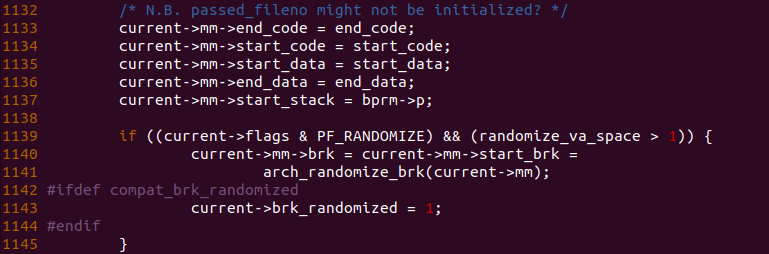
回到 load_elf_binary() 函数,函数在 1133 到 1137 行将之前布局好的代码段、数据段以及堆栈的布局信息同步到了当前进程地址空间。函数在 1139 行判断进程是否包含 PF_RANDOMIZE 以及 randomize_va_space 是否大于 1,根据之前的分析可以知道该条件成立,那么函数调用 arch_randomize_brk() 函数更新了当前进程的堆的位置,在更新之前堆的位置在 BSS 段之后,经过更新之后,堆与 BSS 段之间存在一段随机的空隙。

函数在 1147 行如果检测到进程的 personality 中包含了 MMAP_PAGE_ZERO 标志,那么函数会在 1152 行调用 vm_mmap() 函数为进程分配虚拟地址从 0 到 PAGE_SIZ 的虚拟区域。

load_elf_binary() 函数执行到最后阶段,函数在 1167 行调用 ELF_PALT_INIT() 函数将特定的寄存器初始化为 0,不同的架构初始化的寄存器集合不同。函数接着在 1170 行调用 finalize_exec() 函数设置了当前进程的堆栈限制,将其更新为新进程的堆栈限制,最后函数调用 start_thread() 启动一个新进程,其传入了寄存器集合,新进程执行的入口,以及堆栈的栈顶位置。
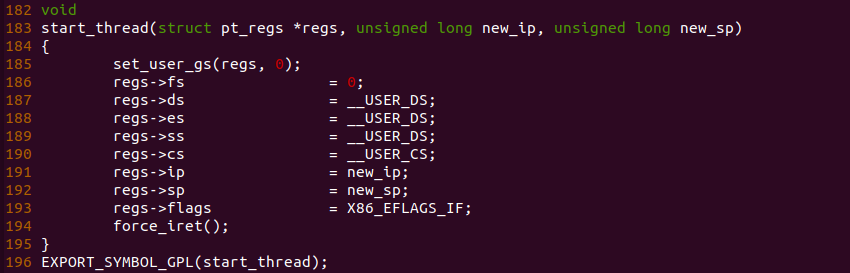
在 start_thread() 函数中,可以看出函数设置了寄存器的值,其中将 sp 指向了新进程堆栈的栈顶,将 ip 寄存器指向了新进程的入口地址,最后调用 force_irt() 函数启动新进程。此时的新进程的用户空间布局如下:
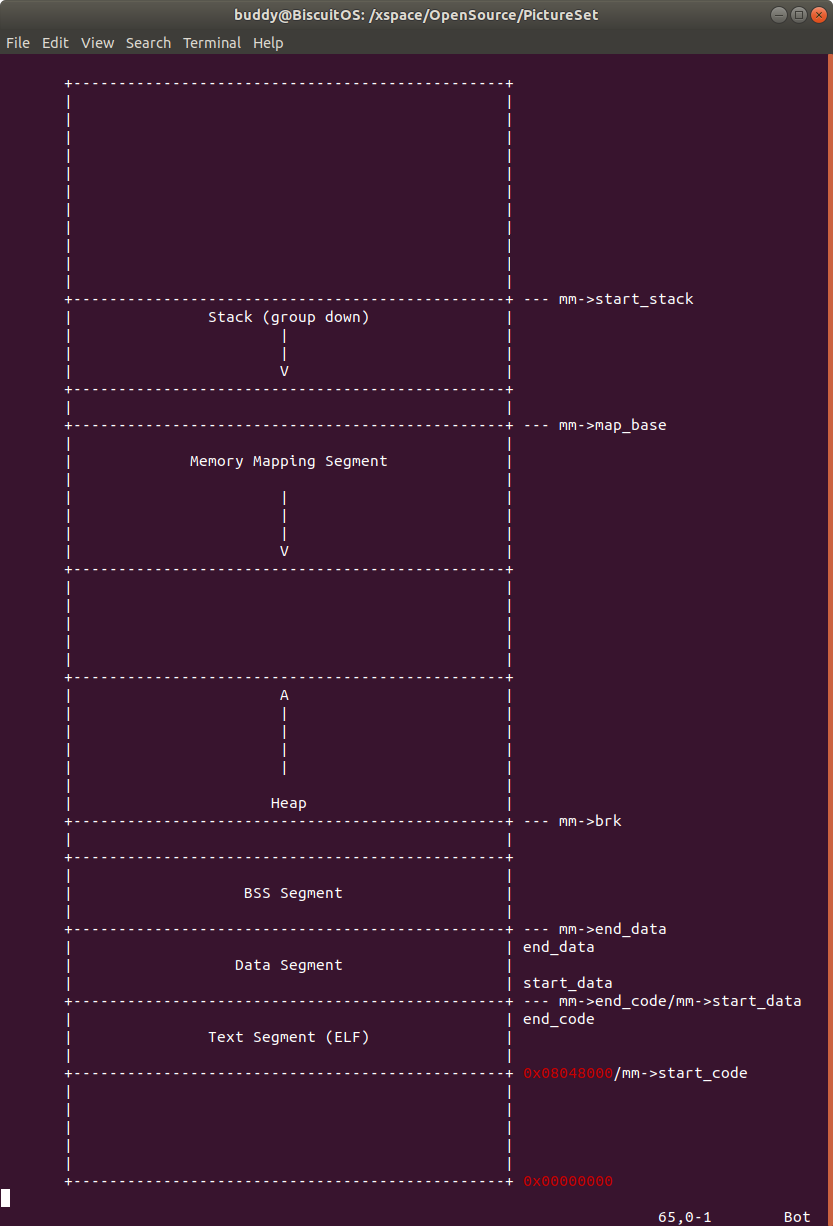
SYS_execve 系统调用到此基本将新进程的区域都部署完成,接下来用户空间的加载器会将新进程使用的动态库等资源加载到进程的地址空间,最终新进程执行,此时可以通过 strace 查看加载器在 execve 执行完毕之后的操作:
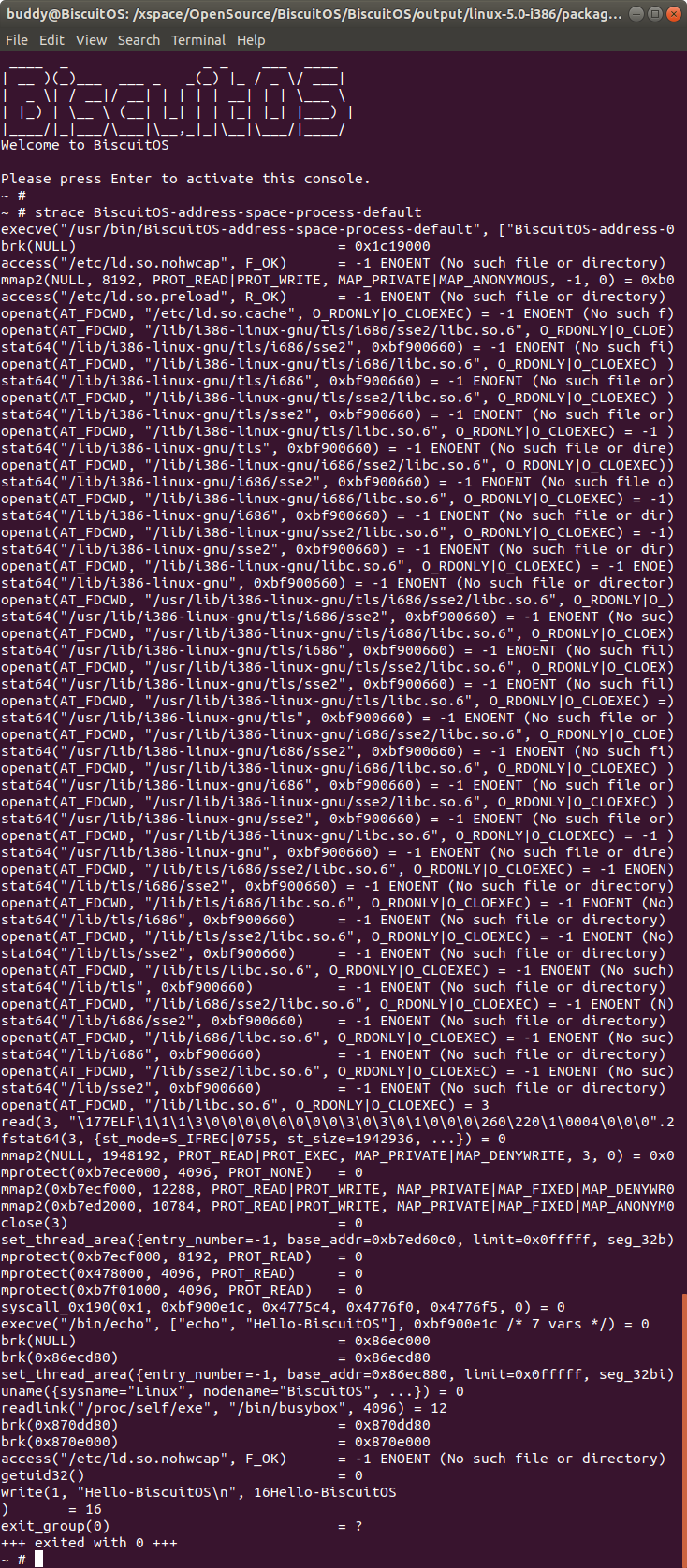
从上图可以看出,当新进程开始使用之后,也就是 execve() 执行完毕之后,可以看到用户空间加载器所做的动作。至此一个进程从创建到运行的内存构建逻辑已经分析完毕。
实践部署及调试建议
本文支持在 BiscuitOS 上进行实践及调试,设计的工具和技巧请参考本节,本文以 i386 架构为例子进行讲解,开发者可以基于 BiscuitOS 在 X64、ARM、RISCV 架构上进行调试。首先开发者基于 BiscuitOS 搭建一个 i386 架构的开发环境,请查考下文:
在部署完毕开发环境之后,开发者接下来部署实践所需的源码,具体部署方法参考如下:
cd BiscuitOS
make linux-5.0-i386_defconfig
make menuconfig
[*] Package --->
[*] Address Space Layout --->
[*] Process address space --->
make
BiscuitOS/output/linux-XXXX/package/BiscuitOS-address-space-process源码配置完毕之后,执行 make 进行实际的源码部署,部署完毕之后使用如下命令切到源码路径:
cd BiscuitOS/output/linux-5.0-i386/package/在该目录下生成目录 “BiscuitOS-address-space-process”, 接下来开发者使用如下命令进行编译安装:
cd BiscuitOS-address-space-process
make download
make
make install
make pack
tree
执行完上面的命令之后,用户空间的代码已经编译打包到 BiscuitOS 里,通过 tree 命令可以看到源码结构,其中 main.c 函数就是用户空间部分核心实现. 接下来就是运行实例:
cd BiscuitOS/output/linux-5.0-i386/
./RunBiscuitOS.sh
从上图可以看出程序已经创建了一个新的进程,新进程打印处 “Hello-BiscuitOS” 字符串。最后如果在实践过程中,如果修改了内核源码,请记得重新编译内核之后再运行系统.
调试建议
在实践过程中需要从用户空间到内核空间进行调试,为了方便开发者调试,BiscuitOS 提供了一个便捷的调试方式,开发者可以参考:
附录
捐赠一下吧 🙂
