
Email: BuddyZhang1 buddy.zhang@aliyun.com
Architecture: ARMv7 Cortex A9-MP
目录

atomic 原子操作
原子操作,顾名思义,就是说像原子一样不可再细分不可被中途打断。一个操作是原子操作, 意思就是说这个操作是以原子的方式被执行,要一口气执行完,执行过程不能够被操作系统 的其他行为打断,是一个整体的过程,在其执行过程中,操作系统的其它行为是插不进来的。 在 Linux中提供了两种形式的原子操作:
一种是对整数进行的操作
一种是对单独的位进行操作
在 Linux 中有一个专门的 atomic_t 类型(一个 24 位原子访问计数器)和一些对 atomic 类型变量进行相应操作的的函数,其 atomic_t 原型如下:
typedef struct {
volatile int counter;
} atomic_t;它是一个只含有一个 volatile 类型的成员变量的结构体;因此编译器不对相应的值进行访 问优化(因为是 volatile 类型的)。原子整数操作的使用:
常见的用途是计数器,因为计数器是一个很简单的操作,所以无需复杂的锁机制
能使用原子操作的地方,尽量不使用复杂的锁机制;
编译器优化
由于内存访问速度远不及CPU处理速度,为提高机器整体性能,在硬件上引入硬件高速缓存 Cache,加速对内存的访问。另外在现代 CPU 中指令的执行并不一定严格按照顺序执行,没 有相关性的指令可以乱序执行,以充分利用 CPU 的指令流水线,提高执行速度。以上是硬件 级别的优化。再看软件一级的优化:一种是在编写代码时由程序员优化,另一种是由编译器进 行优化。编译器优化常用的方法有:将内存变量缓存到寄存器;调整指令顺序充分利用CPU指 令流水线,常见的是重新排序读写指令。对常规内存进行优化的时候,这些优化是透明的,而 且效率很好。由编译器优化或者硬件重新排序引起的问题的解决办法是在从硬件(或者其他处 理器)的角度看必须以特定顺序执行的操作之间设置内存屏障(memory barrier),linux 提供了一个宏解决编译器的执行顺序问题。
void barrier(void);
__asm__ volatile ("isb");
__asm__ volatile ("dsb");
__asm__ volatile ("dmb");这个函数通知编译器插入一个内存屏障,但对硬件无效,编译后的代码会把当前 CPU 寄存器 中的所有修改过的数值存入内存,需要这些数据的时候再重新从内存中读出。volatile 总是 与优化有关,编译器有一种技术叫做数据流分析,分析程序中的变量在哪里赋值、在哪里使用、 在哪里失效,分析结果可以用于常量合并,常量传播等优化,进一步可以消除一些代码。但有 时这些优化不是程序所需要的,这时可以用volatile关键字禁止做这些优化。
volatile
volatile 的本意是 “易变的” 因为访问寄存器要比访问内存单元快的多, 所以编译器一般都 会作减少存取内存的优化,但有可能会读脏数据。当要求使用 volatile 声明变量值的时候, 系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。精确地说 就是,遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提 供对特殊地址的稳定访问;如果不使用 volatile,则编译器将对所声明的语句进行优化。 (简洁的说就是:volatile 关键词影响编译器编译的结果,用 volatile 声明的变量表示该 变量随时可能发生变化,与该变量有关的运算,不要进行编译优化,以免出错)。下面以一个 例子作为讲解:
不使用 volatile 的变量
#include <linux/kernel.h>
#include <linux/init.h>
static unsigned long R1;
/* atomic_* */
static __init int atomic_demo_init(void)
{
R1 = 0x100000;
R1 = 0x200000;
printk("R1: %#lx\n", R1);
return 0;
}
device_initcall(atomic_demo_init);在上面的驱动中,定义了一个全局变量 R1, 并在函数中对 R1 进行两次赋值。如果不是 用 volatile 限定变量的话,编译器就会将 “R1 = 0x100000” 优化去掉,而只保留 “R1 = 0x200000”。接着使用编译器编译这段代码,以此获得汇编代码,如下:
atomic_demo_init:
.fnstart
.LFB284:
.loc 1 44 0
movw r0, #:lower16:.LC0 @,
push {r4, lr} @
.save {r4, lr}
.LCFI0:
mov r1, #2097152 @,
movt r0, #:upper16:.LC0 @,
bl printk @从上面的实践结果可以看出,编译器将 C 代码进行优化,生成汇编代码的时候,只保留了 “R1 = 0x200000”, 对应汇编代码就是 “mov r1, #2097152”。因此在上面的 C 代码中, “R1 = 0x100000” 已经被优化掉。
使用 volatile 的变量
#include <linux/kernel.h>
#include <linux/init.h>
static volatile unsigned long R1;
/* atomic_* */
static __init int atomic_demo_init(void)
{
R1 = 0x100000;
R1 = 0x200000;
printk("R1: %#lx\n", R1);
return 0;
}
device_initcall(atomic_demo_init);在上面的定义中,使用 volatile 限定了 R1,这将让 “R1 = 0x100000” 和 “R1 = 0x200000” 两条代码都执行。接着使用编译器编译这段 C 代码,以此获得汇编代码,如下:
atomic_demo_init:
.fnstart
.LFB284:
.file 1 "drivers/BiscuitOS/atomic.c"
movw r3, #:lower16:.LANCHOR0 @ tmp112,
mov r2, #2097152 @ tmp115,
movt r3, #:upper16:.LANCHOR0 @ tmp112,
mov r1, #1048576 @ tmp113,
movw r0, #:lower16:.LC0 @,
push {r4, lr} @
.save {r4, lr}从上面的实践结果可以看出,”R1 = 0x100000” 和 “R1 = 0x200000” 两条代码都执行。 因此 volatile 限定的变量可以使编译器不被优化。确保了每次对 R1 的访问都是从内存 访问。
volatile 运用场景
中断服务程序中修改的供其它程序检测的变量需要加 volatile.
多任务环境下各任务间共享的标志应该加 volatile.
存储器映射的硬件寄存器通常也要加 voliate,因为每次对它的读写都可能有不同意义.
volatile 的本质
编译器的优化
在本次线程内, 当读取一个变量时,为提高存取速度,编译器优化时有时会先把变量读取到 一个寄存器中;以后,再取变量值时,就直接从寄存器中取值;当变量值在本线程里改变时, 会同时把变量的新值 copy 到该寄存器中,以便保持一致。当变量在因别的线程等而改变了值, 该寄存器的值不会相应改变,从而造成应用程序读取的值和实际的变量值不一致。
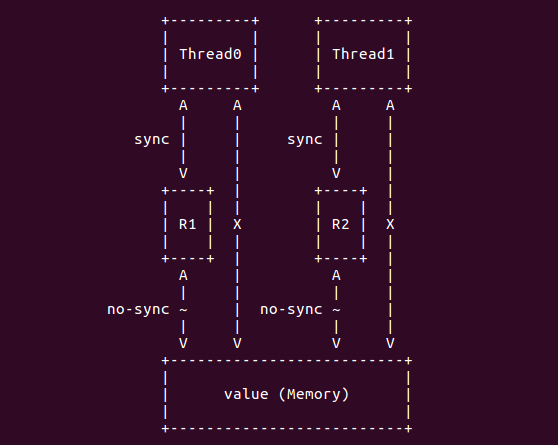
如上图,每个线程建立之初,都会从内存中将变量读到寄存器中 (每个线程存储这个变量的寄 存器是不同的),然后当线程修改了变量的值之后,就会将值更新到寄存器中,但不会更新到 内存中。因此这就存在如果这个变量是两个线程共享的,那么当线程 0 修改了变量的值之后, 线程 1 使用变量的值还是自己寄存器里的值,因此,两个线程看到变量的值就存在差异。
volatile 含义
volatile 应该解释为 “直接存取原始内存地址” 比较合适,“易变的”这种解释简直有点误导人。 正如上面提到的问题,如果两个线程共同使用的变量通过 volatile 限定之后,任意线程对 变量值修改之后,都会同步到内存,以此其他线程可以看到一样的值。如下图:
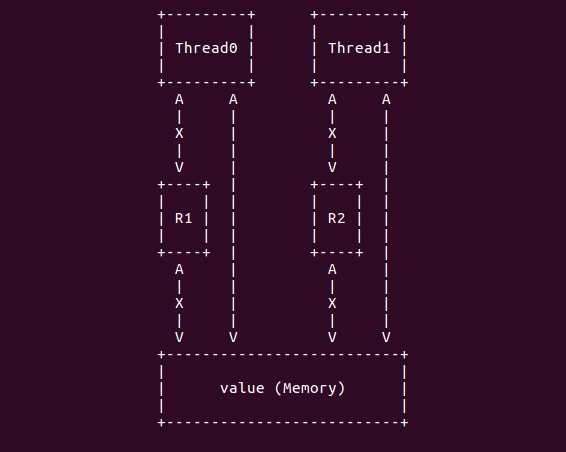
简单来说,volatile 就是不与 cache 发生关系,只与内存发生关系。
LDREX 和 STREX 原理
为了实现线程间同步,一般都要在执行关键代码段之前加互斥(Mutex)锁,且在执行完关键 代码段之后解锁。为了实现所谓的互斥锁的概念,一般都需要所在平台提供支持。ARM 平台上 特有的独占访问指令 LDREX 和 STREX。而它们也是 ARM 平台上,实现互斥锁等线程同步工 具的基础。先来看看 LDREX 和 STREX 两条指令的语义。其实 LDREX 和 STREX 指令,是将 单纯的更新内存的原子操作分成了两个独立的步骤。
LDREX
LDREX 用来读取内存的时候,并标记对该段内存的独占访问。
LDREX Rx, [Ry]上面的指令意味着,读取寄存器 Ry 指向的 4 字节内存值,将其保存到 Rx 寄存器中,同时 标记对 Ry 指向内存区域的独占访问。如果执行 LDREX 指令的时候发现已经被标记为独占访 问了,并不会对指令的执行产生影响。
如果物理地址有共享 TLB 属性,则 LDREX 会将该物理地址标记为由当前处理器独占访问, 并且会清除该处理器对其他任何物理地址的任何独占访问标记。否则,会标记:执行处理器 已经标记了一个物理地址,但访问尚未完毕。
STREX
STREX 在更新内存数值时,会检查该段内存是否已经被标记为独占访问,并以此来决定是否更 新内存中的值。
STREX Rx, Ry, [Rz]如果执行这条指令的时候发现已经被标记为独占访问了,则将寄存器 Ry 中的值更新到寄存器 Rz 指向的内存,并将寄存器 Rx 设置成 0。指令执行成功后,会将独占访问标记位清除。而如 果执行这条指令的时候发现没有设置独占标记,则不会更新内存,且将寄存器 Rx 的值设置成 1。 一旦某条 STREX 指令执行成功后,以后再对同一段内存尝试使用 STREX 指令更新的时候,会 发现独占标记已经被清空了,就不能再更新了,从而实现独占访问的机制。大致的流程如上,但 是 ARM 内部为了实现这个功能,还有不少复杂的情况要处理。
如果物理地址没有共享 TLB 属性,且执行处理器有一个已标记但尚未访问完毕的物理地址,那 么将会进行存储,清除该标记,并在 Rd 中返回值 0。如果物理地址没有共享 TLB 属性,且 执行处理器也没有已标记但尚未访问完毕的物理地址,那么将不会进行存储,而会在 Rd 中返 回值 1。如果物理地址有共享 TLB 属性,且已被标记为由执行处理器独占访问,那么将进行 存储,清除该标记,并在 Rd 中返回值 0。如果物理地址有共享 TLB 属性,但没有标记为由执 行处理器独占访问,那么不会进行存储,且会在 Rd 中返回值 1。
LDREX 和 STREX 使用例子
#include <linux/kernel.h>
#include <linux/init.h>
static volatile unsigned long R0 = 0;
/* atomic_* */
static __init int atomic_demo_init(void)
{
unsigned long tmp;
int result;
__asm__ volatile ("nop\n\t"
"ldrex %0, [%3]\n\t"
"add %0, %0, #9\n\t"
"strex %1, %0, [%3]"
: "=&r" (result), "=&r" (tmp), "+Qo" (R0)
: "r" (&R0)
: "cc");
printk("R0: %#lx - result: %d - tmp: %#lx\n", R0, result, tmp);
return 0;
}
device_initcall(atomic_demo_init);在上面的内嵌汇编中,首先使用 ldrex 指令从 R0 对应的内存地址中读取数据到 result 中, 此时,ldrex 会将这段区域设置为独占。接着调用 add 指令将 result 的值增加 9. 接着 调用 strex 指令,如果此时独占标志已经置位,那么将 result 的值更新到 R0 对应的内存 里,最后将 tmp 的值设置为 0;如果调用 strex 指令是,发现独占标志没有置位,也就是 有其他线程在写这块物理内存,内存被锁上了,因此 strex 指令不会将 result 的值写入 R0 对应的内存地址上,并将 tmp 的值设置为 1.
上面的代码运行后的结果如下:
usbcore: registered new interface driver usbhid
usbhid: USB HID core driver
R0: 0x9 - result: 9 - tmp: 0x0
aaci-pl041 10004000.aaci: FIFO 512 entries
oprofile: using arm/armv7-ca9从上面的执行结果可以看出,ldrex 指令和 strex 指令执行的时候,都独占了 R0 对应的内存。
独占监视器:Exclusive Monitor
在 ARM 系统中,内存有两种不同且对立的属性,即共享 (Shareable) 和非共享 (Non-shareable)。共享意味着该段内存可以被系统中不同处理器访问到,这些处理器可以是同 构的也可以是异构的。而非共享,则相反,意味着该段内存只能被系统中的一个处理器所访问到, 对别的处理器来说不可见。为了实现独占访问,ARM 系统中还特别提供了所谓独占监视器 (Exclusive Monitor) 的东西,其结构大致如下:
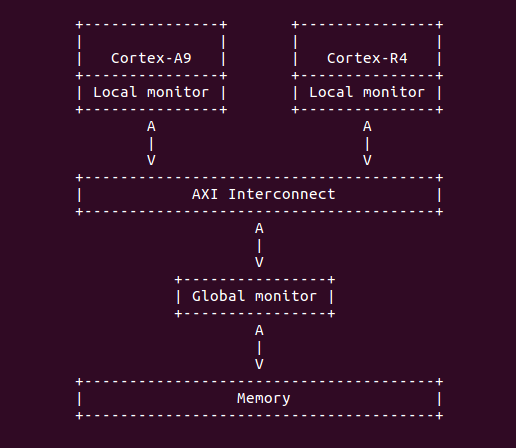
可以看出来,一共有两种类型的独占监视器。每一个处理器内部都有一个本地监视器 (Local Monitor),且在整个系统范围内还有一个全局监视器 (Global Monitor)。如果要 对非共享内存区中的值进行独占访问,只需要涉及本处理器内部的本地监视器就可以了;而如 果要对共享内存区中的内存进行独占访问,除了要涉及到本处理器内部的本地监视器外,由于 该内存区域可以被系统中所有处理器访问到,因此还必须要由全局监视器来协调。对于本地监 视器来说,它只标记了本处理器对某段内存的独占访问,在调用 LDREX 指令时设置独占访问 标志,在调用 STREX 指令时清除独占访问标志。而对于全局监视器来说,它可以标记每个处 理器对某段内存的独占访问。也就是说,当一个处理器调用 LDREX 访问某段共享内存时,全局 监视器只会设置针对该处理器的独占访问标记,不会影响到其它的处理器。当在以下两种情况下, 会清除某个处理器的独占访问标记:
1) 当该处理器调用 LDREX 指令,申请独占访问另一段内存时
2)当别的处理器成功更新了该段独占访问内存值时
对于第二种情况,也就是说,当独占内存访问内存的值在任何情况下,被任何一个处理器更改过 之后,所有申请独占该段内存的处理器的独占标记都会被清空。另外,更新内存的操作不一定非 要是 STREX 指令,任何其它存储指令都可以。但如果不是 STREX 的话,则没法保证独占访问 性。现在的处理器基本上都是多核的,一个芯片上集成了多个处理器。而且对于一般的操作系统, 系统内存基本上都被设置上了共享属性,也就是说对系统中所有处理器可见。因此,我们这里主 要分析多核系统中对共享内存的独占访问的情况。为了更加清楚的说明,我们可以举一个例子。 假设系统中有两个处理器内核,而一个程序由三个线程组成,其中两个线程被分配到了第一个 处理器上,另外一个线程被分配到了第二个处理器上。如下图,大致经历的步骤如下:
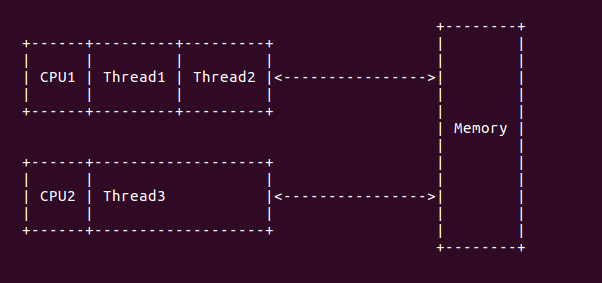
1) CPU2 上的线程 3 最早执行 LDREX,锁定某段共享内存区域。它会相应更新本地监视
器和全局监视器。
2) 然后,CPU1 上的线程 1 执行 LDREX,它也会更新本地监视器和全局监视器。这时在全
局监视器上,CPU1 和 CPU2 都对该段内存做了独占标记。
3) 接着,CPU1 上的线程 2 执行 LDREX 指令,它会发现本处理器的本地监视器对该段内存
有了独占标记,同时全局监视器上 CPU1 也对该段内存做了独占标记,但这并不会影响这
条指令的操作。
4) 再下来,CPU1 上的线程 1 最先执行了 STREX 指令,尝试更新该段内存的值。它会发现
本地监视器对该段内存是有独占标记的,而全局监视器上 CPU1 也有该段内存的独占标记,
则更新内存值成功。同时,清除本地监视器对该段内存的独占标记,还有全局监视器所有
处理器对该段内存的独占标记。
5) 下面,CPU2 上的线程 3 执行 STREX 指令,也想更新该段内存值。它会发现本地监视器拥
有对该段内存的独占标记,但是在全局监视器上 CPU1 没有了该段内存的独占标记(前面一
步清空了),则更新不成功。
6)最后,CPU1 上的线程 2 执行 STREX 指令,试着更新该段内存值。它会发现本地监视器已
经没有了对该段内存的独占标记(第4步清除了),则直接更新失败,不需要再查全局监视器了。所以,可以看出来,这套机制的精髓就是,无论有多少个处理器,有多少个地方会申请对同 一个内存段进行操作,保证只有最早的更新可以成功,这之后的更新都会失败。失败了就证 明对该段内存有访问冲突了。实际的使用中,可以重新用 LDREX 读取该段内存中保存的最新 值,再处理一次,再尝试保存,直到成功为止。
还有一点需要说明,LDREX 和 STREX 是对内存中的一个字(Word,32 bit)进行独占访问 的指令。如果想独占访问的内存区域不是一个字,还有其它的指令:
1)LDREXB 和 STREXB:对内存中的一个字节(Byte,8 bit)进行独占访问;
2)LDREXH和STREXH:中的一个半字(Half Word,16 bit)进行独占访问;
3)LDREXD和STREXD:中的一个双字(Double Word,64 bit)进行独占访问。它们必须配对使用,不能混用。

atomic 原子操作最小实践
本节提供了一个 atomic 原子操作的最小实践,开发者可以根据本节内容快速实践 atomic 原子操作。由于本文基于 Linux 5.x 进行讲解,如果还没有搭建 Linux 5.x 开发环境的 开发者,请参考下面文档进行搭建:
为了快速实践 atomic 原子操作,将代码通过一个驱动进行讲解,如下:
驱动源码
/*
* atomic
*
* (C) 2019.05.05 <buddy.zhang@aliyun.com>
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License version 2 as
* published by the Free Software Foundation.
*/
/* Memory access
*
*
* +----------+
* | |
* | Register | +--------+
* | | | |
* +----------+ | |
* A | |
* | | |
* +-----+ | +----------+ +----------+ | |
* | |<---o | | | | | |
* | CPU |<--------->| L1 Cache |<------>| L2 Cache |<------>| Memory |
* | |<---o | | | | | |
* +-----+ | +----------+ +----------+ | |
* | | |
* o--------------------------------------------->| |
* volatile/atomic | |
* | |
* +--------+
*/
/*
* atomic_add (ARMv7 Cotex-A9MP)
*
* static inline void atomic_add(int i, atomic_t *v)
* {
* unsigned long tmp;
* int result;
*
* prefetchw(&v->counter);
* __asm__ volatile ("\n\t"
* "@ atomic_add\n\t"
* "1: ldrex %0, [%3]\n\t" @ result, tmp115
* " add %0, %0, %4\n\t" @ result,
* " strex %1, %0, [%3]\n\t" @ tmp, result, tmp115
* " teq %1, #0\n\t" @ tmp
* " bne 1b"
* : "=&r" (result), "=&r" (tmp), "+Qo" (v->counter)
* : "r" (&v->counter), "Ir" (i)
* : "cc");
* }
*/
#include <linux/kernel.h>
#include <linux/init.h>
static atomic_t BiscuitOS_counter = ATOMIC_INIT(8);
/* atomic_* */
static __init int atomic_demo_init(void)
{
/* Atomic add */
atomic_add(1, &BiscuitOS_counter);
printk("Atomic: %d\n", atomic_read(&BiscuitOS_counter));
return 0;
}
device_initcall(atomic_demo_init);驱动安装
驱动的安装很简单,首先将驱动放到 drivers/BiscuitOS/ 目录下,命名为 atomic.c, 然后修改 Kconfig 文件,添加内容参考如下:
diff --git a/drivers/BiscuitOS/Kconfig b/drivers/BiscuitOS/Kconfig
index 4edc5a5..1a9abee 100644
--- a/drivers/BiscuitOS/Kconfig
+++ b/drivers/BiscuitOS/Kconfig
@@ -6,4 +6,14 @@ if BISCUITOS_DRV
config BISCUITOS_MISC
bool "BiscuitOS misc driver"
+config BISCUITOS_ATOMIC
+ bool "atomic"
+
+if BISCUITOS_ATOMIC
+
+config DEBUG_BISCUITOS_ATOMIC
+ bool "ATOMIC"
+
+endif # BISCUITOS_ATOMIC
+
endif # BISCUITOS_DRV接着修改 Makefile,请参考如下修改:
diff --git a/drivers/BiscuitOS/Makefile b/drivers/BiscuitOS/Makefile
index 82004c9..9909149 100644
--- a/drivers/BiscuitOS/Makefile
+++ b/drivers/BiscuitOS/Makefile
@@ -1 +1,2 @@
obj-$(CONFIG_BISCUITOS_MISC) += BiscuitOS_drv.o
+obj-$(CONFIG_BISCUITOS_ATOMIC) += atomic.o
--驱动配置
驱动配置请参考下面文章中关于驱动配置一节。在配置中,勾选如下选项,如下:
Device Driver--->
[*]BiscuitOS Driver--->
[*]atomic
[*]ATOMIC()具体过程请参考:
驱动编译
驱动编译也请参考下面文章关于驱动编译一节:
驱动运行
驱动的运行,请参考下面文章中关于驱动运行一节:
启动内核,并打印如下信息:
usbcore: registered new interface driver usbhid
usbhid: USB HID core driver
Atomic: 9
aaci-pl041 10004000.aaci: ARM AC'97 Interface PL041 rev0 at 0x10004000, irq 24
aaci-pl041 10004000.aaci: FIFO 512 entries
oprofile: using arm/armv7-ca9

Linux 内核为 atomic 原子操作提供了一套完整的接口,可以按一下几类进行分类:
atomic 原子操作加法操作
Linux 为 atomic 原子操作提供了无条件加法运算和有条件加法运行,分别如下:
atomic_add_negative: atomic 加法操作并判断结果是否为负数
atomic_add_return: atomic 加法操作并返回结果
atomic_add_return_relaxed: atomic 加法操作并返回结果
atomic_add_unless: atomic 不同值加法
atomic_add_unless_negative: atomic 非负数加法
atomic_fetch_add: 读取 atomic 原始值再进行加法操作
atomic 原子操作减法操作
Linux 为 atomic 原子操作提供了无条件加法运算和有条件减法运行,分别如下:
atomic_sub_and_test: atomic 减法操作并判断结果是否为 0
atomic_sub_return: atomic 减法操作并返回结果
atomic_sub_return_relaxed: atomic 减法操作并返回结果
atomic 原子操作加一操作
Linux 为 atomic 原子操作提供了无条件加法运算和有条件加一运行,分别如下:
atomic_inc_and_test: atomic 加一操作并判断结果是否为 0
atomic_inc_not_zero: atomic 非零的加一操作
atomic 原子操作减一操作
Linux 为 atomic 原子操作提供了无条件加法运算和有条件减一运行,分别如下:
atomic_dec_and_test: atomic 减一操作并判断结果是否为 0
atomic_dec_if_positive: atomic 正数减一操作
atomic_dec_return: atomic 减一操作并返回结果
atomic 原子操作 AND 运算
Linux 为 atomic 原子操作提供了按位 AND 操作,分别如下:
atomic 原子操作 OR 运算
Linux 为 atomic 原子操作提供了按位 OR 操作,分别如下:
atomic 原子操作 XOR 运算
Linux 为 atomic 原子操作提供了按位 XOR 操作,分别如下:
atomic 原子操作按位清除运算
Linux 为 atomic 原子操作提供了清除特定位操作,分别如下:
atomic 原子操作读取/设置值
Linux 为 atomic 原子操作提供了直接读值和设置值的操作,分别如下:
atomic 原子操作交换运算
Linux 为 atomic 原子操作提供了值交换操作,分别如下:
atomic 原子操作相关操作
__read_once_size: 按 size 从内存读值

atomic 原子操作进阶研究
atomic API 列表
附录
赞赏一下吧 🙂
