
GitHub: CMA - Contiguous Memory Allocator
Email: BuddyZhang1 buddy.zhang@aliyun.com
目录

CMA 分配器原理

CMA 分配器简介
CMA(Contiguous Memory Allocator)是连续内存分配技术,是 Linux Kernel 内存 管理系统的扩展,目的在于解决视频播放 (特别对于 4K 视频) 需要预留大量连续内 存导致运行内存紧张的问题。连续内存分配器(CMA - Contiguous Memory Allocator) 是一个框架,允许建立一个平台无关的配置,用于连续内存的管理。然后,设备所需 内存都根据该配置进行分配。CMA 框架的主要作用不是分配内存,而是解析和管理内 存配置,以及作为在设备驱动程序和可插拔的分配器之间的中间组件。因此,它是与 任何内存分配方法和分配策略没有依赖关系的。
从设备驱动角度看,任何事情都不应该被影响。因为 CMA 是被集成到 DMA 子系统, 所以以前调用 DMA API(例如dma_alloc_coherent())的地方应该照常工作。事实 上,设备驱动永远不需要直接调用 CMA API,因为它是在页和页帧编号(PFNs)上 操作而无关总线地址和内核映射,并且也不提供维护缓存一致性的机制。获取更多 信息,可以参考这两份有用的文档。这两篇文档描述了DMA 提供的方法接口及使用 用例。
CMA 分配器需求
在嵌入式设备中,很多设备都没有支持 scatter-getter 和 IO map,都需要连续 内存块的操作。如设备: 摄像机,硬件视频解码器,编码器等。这些设备往往需要 较大的内存缓冲区(如: 一个200万像素的高清帧摄像机,需要超过 6M 的内存), kmalloc 内存分配机制对于这么大的内存是没有效果的。一些嵌入式设备对缓冲区 有一些额外的要求,比如: 在含有多个内存 bank 的设备中,要求只能在特定的 bank 中分配内存; 而还有一些要定内存边界对齐的缓存区。近来,嵌入式设备有 了较大的发展(特别是 V4L 领域),并且这些驱动都有自己的内存分配代码。它们 众多的大多数都是采用 bootmem 分配方法。CMA 框架企图采用统一的连续内存分 配机制,并为这些设备驱动提供简单的 API,而且是可以定制化和模块化的。
CMA 分配器设计
CMA 主要设计目标是提供一个可定制的模块化框架,并且是可以配置的,以适应个 别系统的需要。配置指定的内存区域,然后将这些内存分配给制定的设备。这些内 存区域可以共享给多个设备驱动,也可以专门分配一个。这是通过以下方式实现的:
1. CMA 的核心不是处理内存分配和空闲空间管理。专用分配器是用来处理内存分配和
空闲内存管理的。因此,如果现有的解决方案不符合给定的系统,那么可以开发一
种新的算法,这种算法可以很容易地插入到 CMA 框架中。所提出的解决方案中包括
一个最适算法(best-fit)的一个实现。
2. CMA 允许运行时配置即将分配的内存区域。内存区域都是经由命令行给出的,所以
可以很容易地改变它,而不需要重新编译内核。每个地区都有自己的大小,对齐标
准,起始地址(物理地址)和对应该内存区域的内存分配算法。这意味着同一时刻
可以有多种机制在运行,如果在一个平台上同时运行多个不同的设备,这些设备具
有不同的存储器使用特性,那么局可以匹配最好的算法。
3. 当设备请求内存时,设备必须“自我介绍”,即附带自己的信息以告知 CMA。这样 CMA
可以知道谁分配内存。这允许系统架构师来指定哪个移动设备应该使用哪些存储区。
设备也可以指定一个“类”内存区域,这使得系统更容易配置,进而一个单一的设备
可能使用来自不同内存区域的内存。例如,一个视频解码器驱动程序可能要分配一
些共享的缓冲区,那么从第一个 bank 中分配一些,再从第二个 bank 中分配一些,
可以获得尽可能高的内存吞吐量
4. 通过这套机制,我们可以做到不预留内存,这些内存平时是可用的,只有当需要的
时候才被分配给 Camera,HDMI 等设备。CMA 核心技术
如何保证内存被复用
CMA 通过在启动阶段预先保留内存。这些内存叫做 CMA 区域或 CMA 上下文,稍后返 回给伙伴系统从而可以被用作正常申请。如果要保留内存,则需要恰好在底层 MEMBLOCK 分配器初始化之后,及大量内存被占用之前调用,并在伙伴系统建立 之前调用:
void dma_contiguous_reserve(phys_addr_t limit)CMA 与页迁移。
当从伙伴系统申请内存的时候,需要提供一个 gfp_mask 参数。不管其他事情,这个 参数指定了要申请内存的迁移类型。迁移类型是 MIGRATE_MOVABLE,它背后的意思是 在可移动页面上的数据可以被迁移(或者移动,因此而命名),这对于磁盘缓存或者 进程页面来说很有效。为了使相同迁移类型的页面在一起,伙伴系统把页面组成 “页面块 (pageblock)”,每组都有一个指定的迁移类型。分配器根据请求的类型在 不同的页面块上分配页。如果尝试失败,分配器会在其它页面块上分配并甚至修改 页面块的迁移类型。这意味着一个不可移动的页可能分配自一个 MIGRATE_MOVABLE 页面块,并导致该页面块的迁移类型改变。这不是 CMA 想要的,所以它引入了一个 MIGRATE_CMA 类型,该类型又一个重要的属性: 只有可移动页可以从 MIGRATE_CMA 页面块种分配。那么,在启动期间,当 dma_congiguous_reserve() 和 dma_declare_contiguous() 方法被调用的时候,CMA 在 memblock 中预留一部分 RAM,并在随后将其返还给伙伴系统,仅将其页面块的迁移类型置为 MIGRATE_CMA. 最终的结果是所有预留的页都在伙伴系统里,所以它们都可以用于可移动页的分配。
在CMA分配的时候,dma_alloc_from_contiguous() 选择一个页范围并调用:
int alloc_contig_range(unsigned long start, unsigned long end,unsigned migratetype);start 和 end 参数指定了目标内存的页框个数(或 PFN 范围)。最后一个参数 migratetype 指定了潜在的迁移类型; 在 CMA 的情况下,这个参数就是 MIGRATE_CMA。 这个函数所做的第一件事是将包含 (start, end) 范围内的页面块标记为 MIGRATE_ISOLATE。伙伴系统不会去触动这种类型的页面块。改变迁移类型不会魔 法般地释放页面,因此接下来需要调用 __alloc_conting_migrate_range()。它扫 描PFN范围并寻找可以迁移的页面。迁移是将页面复制到系统其它内存部分并更新相 关引用的过程。迁移部份很直接,后面的部分需要内存管理子系统来完成。当数据迁 移完成,旧的页面被释放并回归伙伴系统。这就是为什么之前那些需要包含的页面块 一定要标记为 MIGRATE_ISOLATE 的原因。如果指定了其它的迁移类型,伙伴系统会 毫不犹豫地将它们用于其它类型的申请。
现在所有 alloc_contig_range 关心的页都是空闲的了。该方法将从伙伴系统中取 出它们,并将这些页面块的类型改为 MIGRATE_CMA。然后将这些页返回给调用者。 释放内存就更简单了。dma_release_from_contiguous() 将其工作转交给:
void free_contig_range(unsigned long pfn, unsigned nr_pages);这个函数迭代所有的页面并将其返还给伙伴系统。

CMA 源码分析

CMA 分配器启动流程
CMA 分配器的启动流程按顺序分为基础的三个部分:
CMA 分配器初始化
CMA 分配器最先初始化部分是 CMA 分配器构建参数获得并初始化新的 CMA 区域, 其与内核策略有关,可以分配 DTS-CMA 初始化、CMDLINE-CMA 初始化和 Kbuild-CMA 初始化。三者之间存在互斥关系,也就是根据内核配置,只 有其中一个其作用,开发者可以分别参考下面三个的初始化过程对该阶段 的初始化进行了解:

DTS-CMA 构建 CMA 初始化
DTS-CMA 方式指的是通过 DTS 传入 CMA 构造的信息,其优先级最高,系统 优先采用 DTS 中的参数构造 CMA 内存分配器,其流程大概如下:
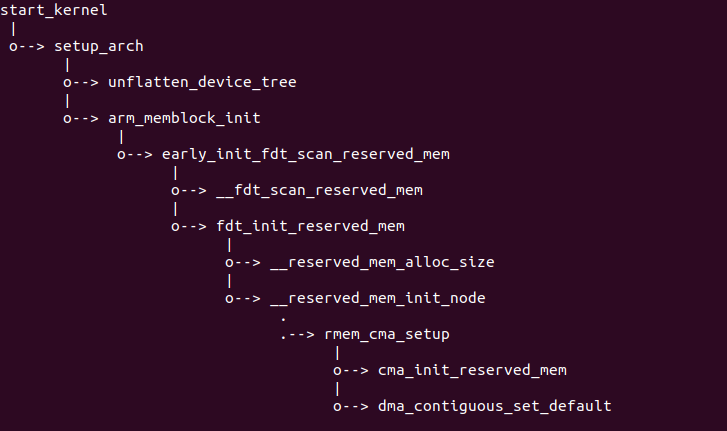
内核初始化过程中进入 start_kernel() 函数之后,根据不同的体系结构调用 各自的 setup_arch 函数。在 setup_arch() 函数中,函数首先调用 unflatten_device_tree() 函数从 DTB 中解析出所有节点,其中也包括了 “/reserved-memory” 节点,这时对 CMA 分配器并没有任何初始化。 setup_arch() 函数接着调用了 arm_memblock_init() 函数,此时系统 的物理内存已经被 MEMBLOCK 接管,MEMBLOCK 将物理内存分作三种区域: 可用物理内存、预留内存以及完全隐蔽的物理内存。在 arm_memblock_init() 函数中函数调用了 early_init_fdt_scan_reserved_mem() 函数,该函数 从 DTB 中将所有预留区的信息读取出来,然后从 MEMBLOCK 分配器中 申请指定长度的物理内存,并将这些预留区加入到系统预留区数组 reserved-mem[] 进行管理,以供后期内核初始化使用。此时涉及的函数 是 __fdt_scan_reserved_mem() 从 DTB 中读取 CMA 预留区的信息, 然后调用 fdt_init_reserved_mem() 函数将从 MEMBLOCK 分配中分配 了物理内存,在该函数中,函数通过调用 __reserved_mem_alloc_size() 函数实现连续物理内存的最初分配,并完成将该区域加入到系统的预留区 数组 reserved-mem[] 中。最后在函数中调用 __reserved_mem_init_node() 函数遍历 __reservedmem_of_table section, 该 section 内包含了 对预留区的初始化函数, __reserved_mem_init_node() 遍历所有预留区 的方式比较隐蔽,一般代码工具无法跟踪到。但遍历 __reservedmem_of_table section 内的预留区时,函数都会调用 rmem_cma_setup() 函数,该函数 用于将全局 reserved-mem[] 数组的区域加入到 CMA 分配器中,即添加 一块新的 CMA 区域。在该函数内,涉及从 MEMBLOCK 分配物理内存和加入 新的 CMA 区域,也包含了设置 CMA 分配器使用的默认分配区。至此 DTS-CMA 方式构造 CMA 已经完毕。具体函数实现可以参看下面链接:
CMDLINE-CMA 构建 CMA 初始化
CMDLINE-CMA 方式指的是通过 CMDLINE 方式传入 CMA 的配置信息,该信息 可以包括 CMA 的长度,起始物理地址和终止地址。其初始化流程如下:
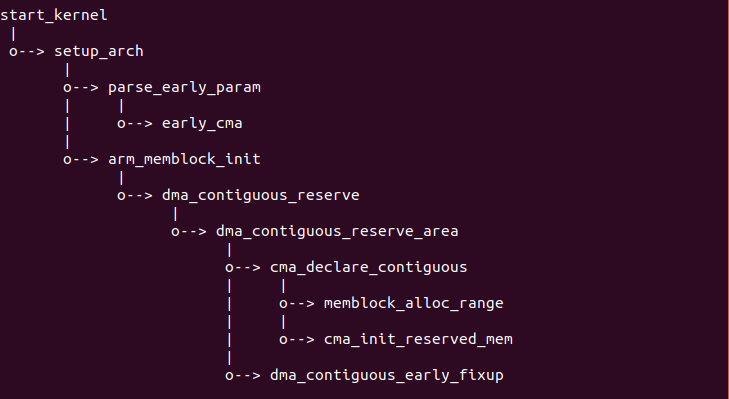
内核初始化过程中进入 start_kernel() 函数之后,根据不同的体系结构调用 各自的 setup_arch 函数。在 setup_arch() 函数中,函数首先调用 parse_early_param() 函数解析 CMDLINE 参数,其中会调用 early_cma() 函数 进行 CMA 长度,起始物理地址以及终止物理地址的解析。内核继续初始化, 当执行到 arm_memblock_init() 函数,内核调用 dma_contiguous_reserve() 函数检测到内核已经从 CMDLIEN 中解析出 CMA 的配置参数,那么函数处理 之后,直接调用 dma_contiguous_reserve_area() 函数,该函数涉及到物理 内存的分配和 CMA 的构建。在该函数中,函数通过调用 cma_declare_contiguous() 函数,函数转而首先调用 cma_declare_contiguous() 函数,函数里面 继续调用 memblock_alloc_range() 函数从 MEMBLOCK 内存分配器中分配 所需的连续物理内存,然后调用 cma_init_reserved_mem() 函数为 CMA 分配器构建一块新的 CMA 区域。函数最后调用 dma_contiguous_early_fixup() 函数将 CMA 区域加入到 dma_mmu_remap[] 数组。至此 CMDLINE-CMA 方式 已经为 CMA 分配器构建一个新的 CMA 区域。以上具体函数实现可以参看下 面链接:

Kbuild-CMA 构建 CMA 初始化
Kbuild-CMA 方式指的是通过内核配置方式传入 CMA 的配置信息,该信息 可以包括 CMA 的长度信息。其初始化流程如下:
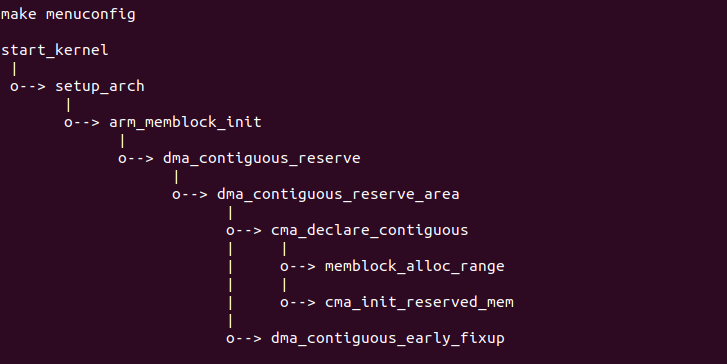
内核在内核配置阶段,对 CMA 的长度进行配置。内核初始化过程中 进入 start_kernel() 函数之后,根据不同的体系结构调用 各自的 setup_arch 函数。在 setup_arch() 函数中,函数首先调用 arm_memblock_init() 函数,由于 Kbuild-CMA 与 CMALINE-CMA 是互排斥 的,因此在该函数中,内核根据不同的宏配置设置 CMA 区域的长度。 接着函数调用 dma_contiguous_reserve_area() 函数,该函数涉及到物理 内存的分配和 CMA 的构建。在该函数中,函数通过调用 cma_declare_contiguous() 函数,函数转而首先调用 cma_declare_contiguous() 函数,函数里面 继续调用 memblock_alloc_range() 函数从 MEMBLOCK 内存分配器中分配 所需的连续物理内存,然后调用 cma_init_reserved_mem() 函数为 CMA 分配器构建一块新的 CMA 区域。函数最后调用 dma_contiguous_early_fixup() 函数将 CMA 区域加入到 dma_mmu_remap[] 数组。至此 CMDLINE-CMA 方式 已经为 CMA 分配器构建一个新的 CMA 区域。以上具体函数实现可以参看下 面链接:

CMA 页表与物理页初始化
构建完 CMA 区域之后,CMA 需要将每个 CMA 区域的页表进行映射,以及将 CMA 区域内的物理页进行初始化。该阶段初始化完毕之后还不能使用 CMA 分配器。

内核初始化过程中 进入 start_kernel() 函数之后,根据不同的体系结构调用 各自的 setup_arch 函数。在 setup_arch() 函数中,函数初始化完 CMA 分配器 之后,调用 paging_init() 函数,该函数用于建立页表,其中继续调用 dma_contiguous_remap() 函数为 CMA 对应的区域建立页表。由于之 CMA 初始化 阶段可知,CMA 区域在初始化阶段将 CMA 区域加入到了 dma_mmu_remap[] 数组, dma_contiguous_remap() 函数就是为数组里的每个区域建立页表,这也包括 了 CMA 所有区域的对应的页表。

CMA 分配器激活
内核初始化到一定阶段,已经构建基础的操作系统,此时内核会再次间接对 CMA 进行激活初始化,激活之后 CMA 就可用供其他模块、设备和子系统使用。
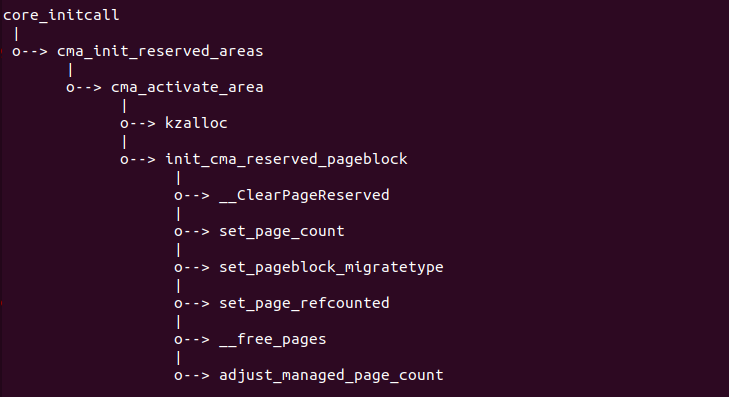
内核初始化过程中,通过 core_initcall() 函数将该 section 内的初始化 函数遍历执行,其中包括 CMA 的激活入口 cma_init_reserved_areas() 函数, 该函数遍历 CMA 分配的所有 CMA 分区并激活每一个 CMA 分区。在该函数中, 函数首先调用 kzalloc() 函数为 CMA 分区的 bitmap 所需的内存,然后调用 init_cma_reserved_pageblock() 函数,在该函数中,内核将 CMA 区块内的 所有物理页都清除 RESERVED 标志,引用计数设置为 0,接着按 pageblock 的 方式设置区域内的页组迁移类型都是 MIGRATE_CMA。函数继续调用 set_page_refcounted() 函数将引用计数设置为 1 以及调用 __free_pages() 函数将所有的页从 CMA 分配器中释放并归还给 buddy 管理器。最后调用 adjust_managed_page_count() 更新系统可用物理页总数。至此系统的其他 部分可以开始使用 CMA 分配器分配的连续物理内存。以上具体函数实现可以参看下 面链接:

CMA 分配器使用
CMA 激活之后,内核可以使用 CMA API 就可以使用连续物理内存,内核如果 要分配 CMA 里面的连续物理内存,可以使用:
当使用完 CMA 连续物理内存之后,可以将物理内存归还给 CMA 内存管理器, 使用如下:
如果需要将设备使用特定的 CMA 区域,可以设置 struct device 的 cma_area 指向所需的 cma 区域.

CMA 核心数据结构
struct cma

struct cma 结构用于维护一块 CMA 区域. CMA 分配器维护着所有可用的 CMA 区域,每个 CMA 区域都是一段连续的物理内存。base_pfn 成员表示该 CMA 区域 起始物理地址对应的物理页帧好; count 成员用于描述 CMA 区域总共维护的 page 数量 (page 的大小默认为 4K,也与当前的内核配置有关); bitmap 成员 用于使用 bitmap 机制将该 CMA 区域的所有物理页维护在该 bitmap 中,bitmap 中每个 bit 代表一定数量的物理页,至于代表多少物理页与 order_per_bit 有关; order_per_bit 成员用于指明该 CMA 区域的 bitmap 中,每个 bit 代表 的 page 数量; lock 成员是一个互斥锁,用于 CMA 分配器分配时独占 CMA 区域时候使用; name 成员用于描述 CMA 区域的名字。
cma_areas

cma_areas 是一个 struct cma 数组,由于维护 CMA 分配器中可用的 CMA 区域。 每个 CMA 区域包含了一段可用的物理内存。cma_areas[] 数组的最大值有内核 配置 CONFIG_CMA_AREAS 有关。
cma_area_count

cma_area_count 变量用于指向当前最大可用的 CMA 区域数量。
reserved_mem

reserved_mem[] 数组用于维护系统早期的预留内存区。系统初始化节点会将 CMA 区域和 DMA 区域加入到该数组。reserved_mem[] 数组总共包含 MAX_RESERVED_REGIONS 个区域,reserved_mem_count 指定了最大可用的预留区数。
struct reserved_mem
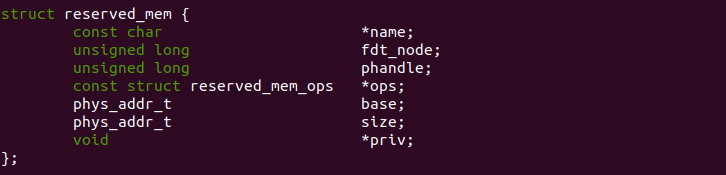
struct reserved_mem 数据结构基于 DTS 维护一块预留内存。该预留内存的 信息从 DTS 中获得。name 成员用于指向对应节点的名字; fdt_node 成员 用于指向节点在 DTS 中的偏移; phandle 成员用于指向节点的 phandle; ops 成员用于指向处理该预留区的函数接口,接口包括了预留区的初始化和 释放动作; base 成员指向预留区的起始物理地址; size 成员指向预留区的 长度; priv 成员用于存储私有数据。
reserved_mem_count
reserved_mem_count 用于指明当前最大可用的预留区数.

CMA 分配器函数列表
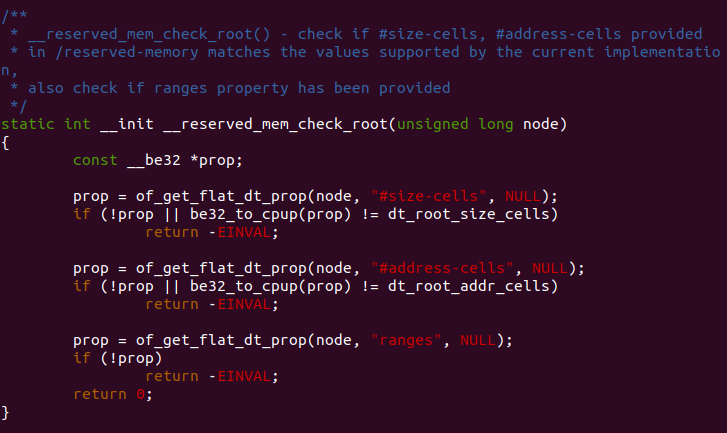
__reserved_mem_check_root
__reserved_mem_check_root() 函数用于检查 DTS 中,根节点的子节点 “reserved-memory” 其属性是否符合要求。在 DTS 中的根节点中定义了 一个名为 “reserved-memory” 的节点,该节点用于描述物理内存中用于 预留的区域,例如:
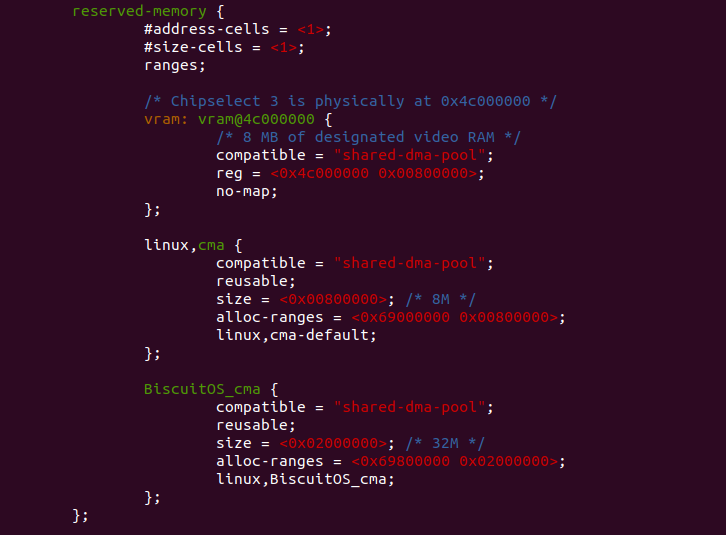
参数 node 用于指向 DTS 中的 “/reserved-memory” 节点,如上图所示, 节点包含了 “#address-cells”、”#size-cells” 和 “ranges” 属性,以及 一些子节点,子节点就是代表一些预留区域。函数调用 of_get_flat_dt_prop() 函数读取 “#size-cell” 和 “#address-cells” 属性,首先判断属性是否 存在,通过调用 be32_to_cpup() 函数读取属性的值,然后判断其值是否 和根节点定义的是否一致,dt_root_size_cells 存储 DTS reg 属性的 “#size-cells” 长度,dt_root_addr_cells 存储 DTS reg 属性的 “#address-cells” 长度。函数最后判断 “/reserved-memory” 是否包含 “range” 属性,因此一个合格的 “/reserved-memory” 节点应该包含 “#address-cells”、”#size-cells” 和 “ranges” 属性,并且 “#address-cells” 与 “#size-cells” 必须与根节点一致。如果以上 只要一点不符合要求,就返回错误码 EINVAL.
__reserved_mem_reserve_reg
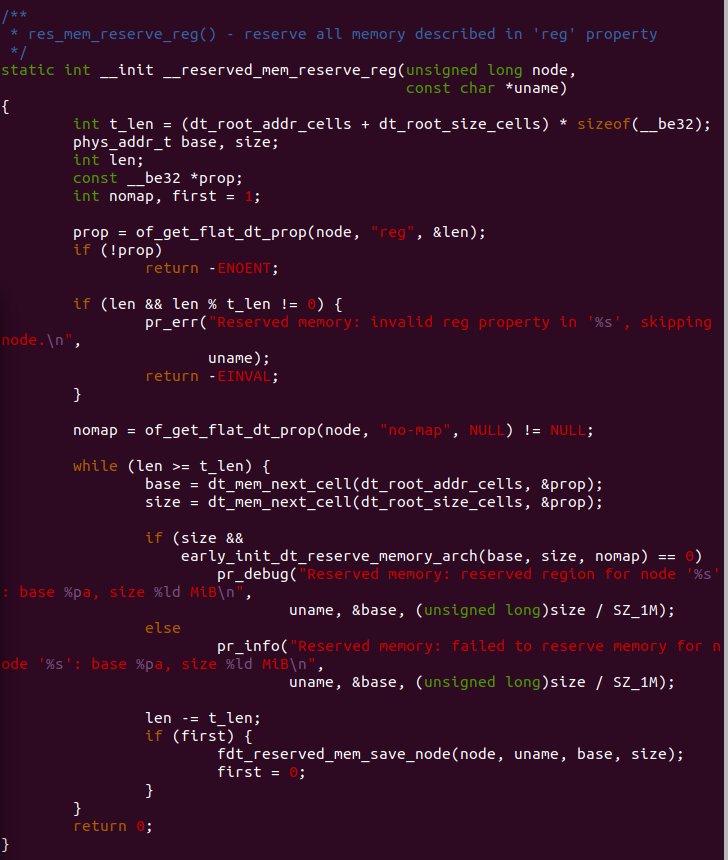
__reserved_mem_reserve_reg() 函数用于处理 “/reserved-memory” 节点 中包含 “reg” 的子节点,通过解析 reg 的属性值,将属性值对应的区域加入 到预留区内。参数 node 指向节点,参数 uname 指向节点名字。函数定义了 多个局部变量,t_len 用于指明系统支持 reg 属性长度,局部变量 base, size 用于 存储从 reg 属性中获得预留区的基地址和长度。
函数首先调用 of_get_flat_dt_prop() 函数获得节点的 reg 属性,如果 节点不包含 reg 属性,那么直接返回 ENOENT. 如果包含 reg 属性,但 reg 属性的长度和系统 reg 属性长度不等,系统直接报错并返回错误值。 函数接着检查节点是否包含 “no-map” 属性,如果节点包含 “no-map” 属性, 那么该区域不会建立页表,虚拟地址使用不到这段物理地址的。函数 使用一个 while() 循环,在循环中,函数按 dt_root_X_cells 的长度 读取预留区的基地址和长度并存储在 base 和 size 中,如果 size 不为零,那么函数调用 early_init_dt_reserve_memory_arch() 函数 将区域加入到 MEMBLOCK 的预留区内,如果 nomap 参数不为 0,那么 函数将这块区域从 MEMBLOCK 区域移除,移除之后这块区域将无法建立 页表,那么虚拟地址是无法映射到这块区域。如何此时添加失败,函数 答应错误信息。函数将 len 减去 t_len 的长度以便读取下一个区域的 值,如果此时 first 为 1,即第一次循环,那么函数调用 fdt_reserved_mem_save_node() 函数将该区域加入到系统的预留区数组 reserved_mem[] 里面,以供系统初始化预留区使用。
fdt_reserved_mem_save_node

fdt_reserved_mem_save_node() 函数用于将预留区域加入到 reserved_mem[] 数组中。参数 node 指向预留的节点,参数 uname 指向节点的名字,base 指向预留区的起始物理地址,size 指向预留区的长度。函数首先定义了 一个局部变量 rmem, 该变量配合 reserved_mem_count 指向预留数组 “reserved_mem[]” 中可用位置。函数接着判断 reserved_mem_count 是否已经超过 reserved_mem[] 数组支持的最大值,如果超过直接返回。 反之,函数将 struct reserved_mem 的 fdt_node 指向 node,以此将 该区域与一个节点挂钩,name 成员设置为 uname 参数,base 和 size 均设置 struct reserved_mem 对应的成员,至此一个新的预留区已经添加 到系统维护的预留区内。最后增加 reserved_mem_count 的值,让其指向 下一个可用的预留区数据。
__fdt_scan_reserved_mem

__fdt_scan_reserved_mem() 函数用于从 DTS 中将 “/reserved-memory” 自己诶单对应的区域加入到系统预留区数组 reserved_mem[] 内,以供 系统初始化预留区。node 参数对应一个 DTS 中的节点,uname 参数对应 节点的名字,depth 对应节点的深度,以此确认节点是根节点的子节点还是 非根节点的子节点,参数 data 用于存储私有数据。函数定义了一个局部 静态变量 found,因此 found 初始值为 0,然后系统每次调用到该函数的 时候,函数只会第一次 found 变量。
系统通过遍历的方式将所有的 DTS 节点都传入该函数,函数就使用第一个 条件对传入节点进行过滤。首先 found 为 0,接着 depth 为 1 表示该 节点是根节点的子节点,而不是其他节点的子节点,最后检查节点的名字 是不是 “reserved-memory”, 如果上面三个条件都满足了,那么函数就会 调用 __reserved_mem_check_root() 函数检查该节点是否包含了 “/reserved-memory” 所需的三个属性,分别是 “#address-cells”、 “#size-cells” 和 “ranges” 属性。如果此时满足条件,那么函数 就认为找到了根节点下的 “reserved-memory” 节点,那么将 found 置为 1 之后就返回。函数继续接受 DTS 遍历到的节点,由于遍历函数 的逻辑可以知道,遍历完节点之后,接着遍历节点的子节点。那么函数 接下来就通过 depth 进一步判断该节点是不是 “/reserved-memory” 的 子节点,如果是,那么函数接下来将调用 of_fdt_device_is_available() 函数检查节点是否可用,如果节点的 status 属性不存在,或者 status 属性值为 “ok” 和 “okay”, 那么节点是可用的,否则其他情况视为不可用。
err = __reserved_mem_reserve_reg(node, uname);
if (err == -ENOENT && of_get_flat_dt_prop(node, "size", NULL))
fdt_reserved_mem_save_node(node, uname, 0, 0);当节点设置为可用之后,函数首先调用 __reserved_mem_reserved_reg() 函数 将包含 reg 属性的节点对应的区域加入全局预留区数组 reserved_mem[]。 如果 err 等于 -ENOENT,那么表示节点不包含 reg 属性,那么函数就会 调用 of_get_flat_dt_prop() 函数是否包含 size 属性,如果包含,那么 函数就调用 fdt_reserved_mem_save_node() 函数将节点对应的区域加入到 系统 reserved_mem[] 数组。值得注意的是包含 reg 属性的节点调用 __reserved_mem_reserve_reg() 函数时内部也调用了 fdt_reserved_mem_save_node() 函数,包含 “size” 属性的节点也 同样调用 fdt_reserved_mem_save_node() 函数,但不同点就是包含 “reg” 属性的节点将区域的基地址和长度都传递给 fdt_reserved_mem_save_node() 函数,而包含 “size” 属性的节点则将基地址和长度设为 0 传入 fdt_reserved_mem_save_node() 函数。最终经过函数的处理, 函数将 “/reserved-memory” 对应子节点的区域都加入到系统预留区 数组 reserved_mem[].
__reserved_mem_alloc_size
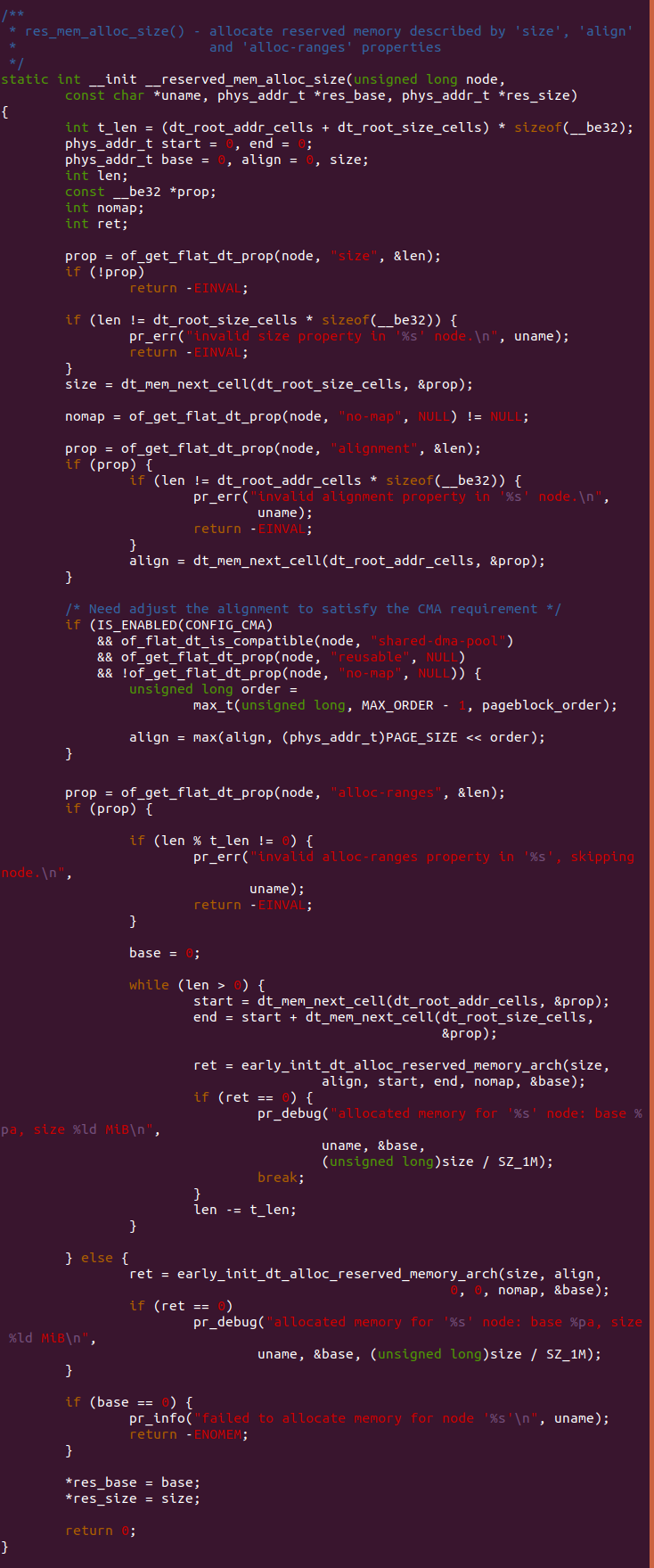
__reserved_mem_alloc_size() 函数用于将系统预留数组 reserved_mem[] 中 size 成员为 0 的成员分配对应长度的物理内存作为预留区。参数 node 指向 DTS 的某个节点,参数 uname 指向节点名字,参数 res_base 用于 指向预留区的基地址,参数 res_size 用于指向预留区的长度。函数首先 定义局部变量 t_len 用于表示一组地址和长度占用的字节数。
函数首先调用 of_get_flat_dt_prop() 函数确认节点是否包含 size 属性, 如果不包含,那么函数直接返回 -EINVAL. 函数接着调用 dt_mem_next_cell() 函数获得 size 属性的属性值,接着调用 of_get_flat_dt_prop() 函数读取判断节点是否包含 “no-map” 属性, 其结果存储再 nomap 中。函数解析调用 of_get_flat_dt_prop() 函数 判断节点是否包含 “aligment” 属性,如果包含,那么函数读取 “alignment” 属性值存储在 align 里面。函数接下来同时判断多个 条件,只有同时满足: CONFIG_CMA 宏启用,节点包含 “shared-dma-pool” 属性, 节点包含 “reusable” 属性,节点不包含 “no-map” 属性,那么同时 满足上面多个条件,那么函数计算最大对齐,并存储在局部变量 align. 函数继续调用 of_get_flat_dt_prop() 函数判断属性是否包含 “alloc-ranges” 属性,如果包含,那么函数将 alloc-ranges 属性里面 的多对区域读取出来,然后调用 early_init_dt_alloc_reserved_memory_arch() 函数分配符合要求的物理空间作为预留; 如果节点不包含 “alloc-ranges” 属性,那么函数调用 early_init_dt_alloc_reserved_memory_arch() 函数在可用物理内存中找到长度为 size 的区域作为预留。如果成功 运行上面的代码,那么函数将最新的基地址和长度存储到 res_base 和 res_size 里面,最后返回。
_OF_DECLARE
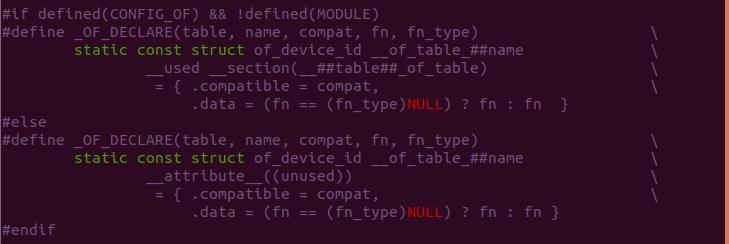
OF_DECLARE 宏用于创建一个 of_device_id 结构体,并将这个结构体加入 到 “##table##of_table” 里面,并填充 compatible 和 data 两个成员。 参数 table 用于指明 of_device_id 结构体要加入的 section 名字,其 通过宏构造之后为 “##table##of_table”; name 参数用于指明 struct of_device_id 的名字,由宏构造为 “__of_table##name”; compat 参数用于提供节点的 compatible 属性值,fn 用于设置 data 成员, 用于挂钩一个回调函数,fn_type 参数用于指明 fn 函数的返回值。 从图片可以知道 _OF_DECLARE 宏提供了两种定义方法,由 CONFIG_OF 宏 和 MODULE 宏控制。
RESERVEDMEM_OF_DECLARE

RESERVEDMEM_OF_DECLARE 宏由于在系统中创建一个 struct of_device_id 结构,并将该结构加入到 “_reservedmem_of_table” section 内。 参数 name 用于指明 struct of_device_of 结构的名字为 “__of_table##name”, 参数 compat 用于填充 struct of_device_id 的 compatible 成员; init 参数用于指向 struct of_device_of 结构的 data 成员。
内核中有两个地方调用该宏,如下:
RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup);
RESERVEDMEM_OF_DECLARE(dma, "shared-dma-pool", rmem_dma_setup);cma_init_reserved_mem
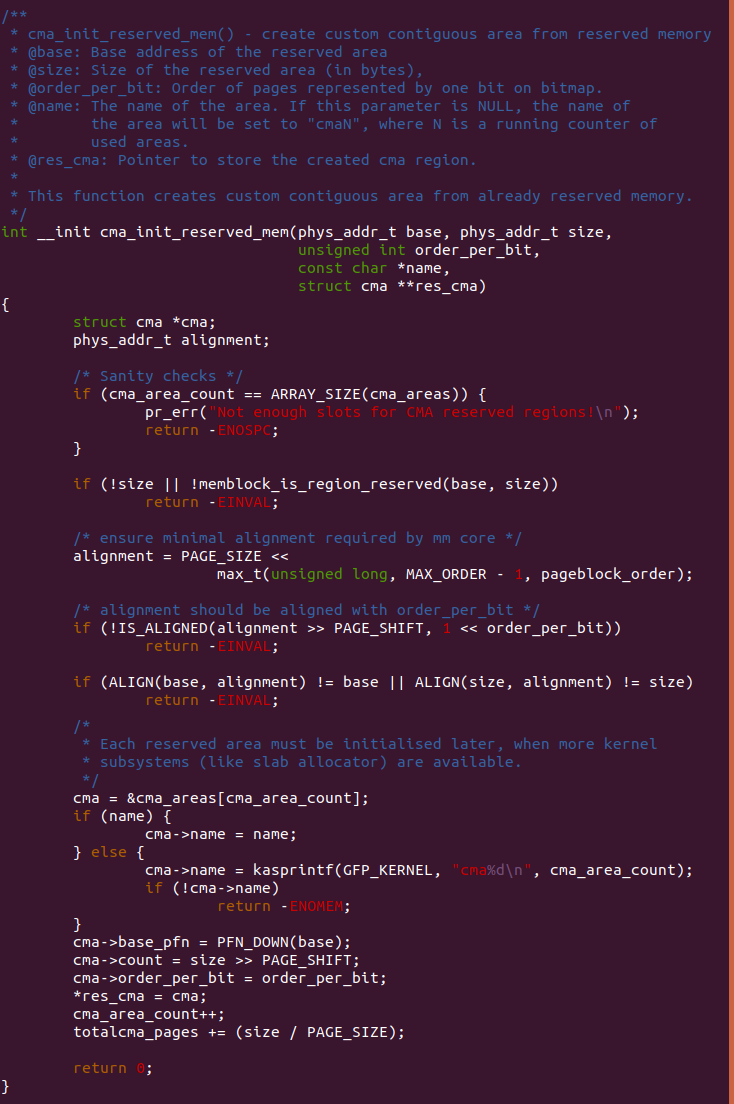
cma_init_reserved_mem() 函数的作用是将一块系统预留区加入到 CMA 区域 内。参数 base 指向预留区的起始地址; 参数 size 指向预留区的长度; 参数 order_per_bit 参数用于指明 CMA 中一个 bitmap 代表 page 的数量。name 用于 指明新加入 CMA 区域的名字; 参数 cma 由于指向一个 CMA 区域。
函数首先检查当前 CMA 区域数量是否超过系统支持最大 CMA 区域数,如果 超过那么系统报错并返回 -ENOSPC. 接着判断新将区域是否已经在 MEMBLOCK 分配器中已经是一块预留区了,如果此时 size 为 0,或者该区域已经是 MEMBLOCK 预留区的一部分,那么系统不能将这块区域加入到 CMA 区域中。 上面的检测通过之后,函数根据 pageblock_order 和 “MAX_ODRDER - 1” 算出最大对齐占用的 page 数量,如果这个对齐值没有按参数 order_per_bit 方式对齐,那么函数直接返回 -EINVAL, 而且如果基地址或长度没有按 最新的方式对齐,那么函数直接返回 -EINVAL.
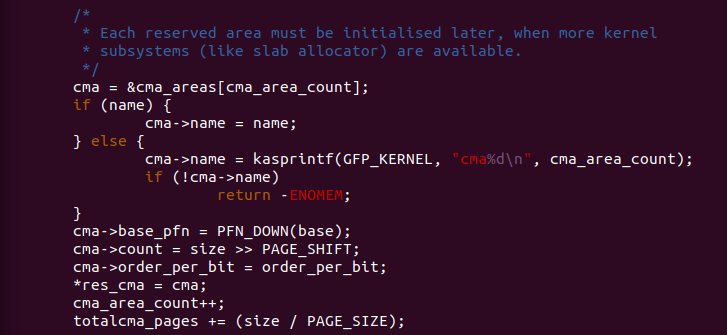
函数接下来从系统 CMA 数组 cma_area[] 中取出当前可用的 struct cma, 如果此时参数 name 不为空,那么将 struct cma 的 name 成员指向参数 name; 如果 name 参数为空,那么函数调用 kasprintf() 函数为 struct cma 的 name 成员分配一定的空间存储新的名字,名字的定义为 “cma%d”, 具体的 名字与当前 cma_area_count 的值有关,例如此时 cma_area_count 为 2, 那么 struct cma 的 name 为 “cma2”。
函数使用 PFN_DOWN() 函数将基地址对应的页帧号存储在 struct cma 的 base_pfn 成员里,以此表示该 CMA 区域的其实物理页帧号。 函数将 CMA 长度右移 PAGE_SHIFT 的值存储在 struct cma 的 count 成员, 以此表示该 CMA 总共包含 page 的数量。函数将参数 oreder_per_bit 存储在 struct cma 的 order_per_bit 里,以此表示该 CMA bitmap 的一个 bit 包含的 page 数量. 函数继续将 res_cma 指向新获得的 cma,然后 将 cma_area_count 加一指向下一个可用的 CMA 区域的索引。最后函数 将 “size/PAGE_SIZE” 的值加入到 totalcma_pages 以此系统维护最新 系统 CMA 总 page 数。
dma_contiguous_early_fixup

dma_contiguous_early_fixup() 函数用于将一个区域加入到系统 DMA 映射 数组 dma_mmu_remap[] 中。参数 base 指向区域的起始地址,参数 size 指向 区域的长度。函数将 base 和 size 加入到当前可用的 dma_mmu_remap[] 数组,并增加 dma_mmu_remap_num 的值,以供系统初始化 DMA 映射时使用。
dma_contiguous_set_default

dma_contiguous_set_default() 函数的作用是将一个 CMA 区域作为系统 CMA 分配默认使用的 CMA 区域。dma_contiguous_default_area 用于指向 系统默认的 CMA 区域.
rmem_cma_device_init

rmem_cma_device_init() 函数用于设置设备使用的 CMA 区域。由于 CMA 子系统 可以支持多个 CMA 区域,因此设备也可以设置使用特定的 CMA 区域,因此 函数用于设置设备使用的 CMA 区域。rmem 参数用于指向一个预留区,参数 dev 用于指向一个设备。函数最终调用 dev_set_cma_area() 函数完成设置。
dev_set_cma_area

dev_set_cma_area() 函数用于设置设备使用的 CMA 区域。参数 dev 指向一个 设备,参数 cma 指向一个 cma 区域。内核中,每个设备对应的结构 struct device 包含了 cma_area 成员用于指定该设备使用的 CMA 区域。 函数首先判断 dev 是否有效,如果有效直接设置 dev 的 cma_area 为参数 cma。
rmem_cma_device_release

rmem_cma_device_release() 用于将设备预留区信息设置为 NULL.
rmem_cma_setup

rmem_cma_setup() 函数用于将预留区添加到 CMA 子系统。参数 rmem 指向一个 预留区。
函数首先调用 of_get_flat_dt_prop() 函数检查预留区对应的节点是否包含 “no-map” 或者不包含 “reusable” 属性,那么函数就直接返回 -EINVAL, 因为 在节点中符合上面的情况表示预留区不建立映射关系。接着函数对预留区的 基地址和长度进行对齐检测,如果没有对齐,那么系统报错并返回 -EINVAL. 通过上面的检测之后,函数调用 cma_init_reserved_mem() 函数将预留区 加入到一块可用的 CMA 区域内,并初始化这块 CMA 区域的管理数据。如果 函数正常执行,那么函数接着调用 dma_contiguous_early_fixup() 函数将 预留区加入到 dma_mmu_remap[] 数组,以供系统初始化 DMA 映射时使用。 如果节点中包含了 “linux,cma-default” 属性,那么函数调用 dma_contiguous_set_default() 函数将当前 CMA 区域作为系统设备默认 使用的 CMA 区域。函数最后将该预留区的 ops 指向 rmem_cma_ops, rmem_cma_ops 包含了两个实现 “rmem_cma_device_init” 和 “rmem_cma_device_release”,这两个函数在设备初始化时使用。函数 最后打印一些预留区信息。
__reserved_mem_init_node
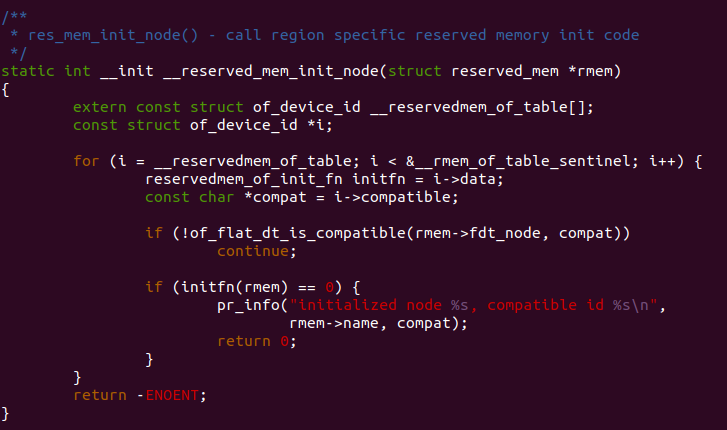
__reserved_mem_init_node() 函数用于将系统 __reservedmem_of_table section 内的所有预留区加入到系统的 CMA 区域或 DMA 区域。参数 rmem 指向一个 预留区。函数通过 extern 引用了 __reservedmem_of_table section。该 section 的其实地址是 __reservedmem_of_table,终止地址是 __rmem_of_table_sentinel,函数使用 for 循环遍历了 __reservedmem_of_table section 内的所有 struct of_device_id 结构,每遍历到一个 struct of_device_id 结构,函数首先调用 of_flat_dt_is_compatible() 函数检查参数对应节点的 compatible 是否和遍历到 struct of_device_id 的 compatible 一致,如果一致,那么函数就调用 struct of_device_id 的 回调函数,以此处理该预留区。在内核中通过使用 RESERVEDMEM_OF_DECLARE 宏可以向 __reservedmem_of_table 中添加一个新的 struct of_device_id。
fdt_init_reserved_mem

fdt_init_reserved_mem() 函数用于将 reserved_mem[] 数组的预留区 加入到 CMA 或 DMA 区域中。函数使用 for 循环遍历 reserved_mem[] 区域里的所有预留区,预留区的个数通过 reserved_mem_count 指定, 函数调用 of_get_flat_dt_prop() 首先判断没有预留区是否包含 “phandle” 或 “linux,phandle” 属性,在 DTS 规范中,每个节点都会 包含了 “phandle” 或兼容 “linux,phandle”, 函数就将预留区 struct reserved_mem 的 phandle 设置为该属性值。函数接着判断 预留区的长度是否为 0,如果为 0,那么调用 __reserved_mem_alloc_size() 函数将预留区对应的区域在 MEMBLOCK 分配器内进行分配。这里 值得注意的是什么样的预留区长度为 0,在 __fdt_scan_reserved_mem() 函数中,如果 DTS 节点中包含了 size 属性的化,那么会将长度 和基地址为 0 的区域加入到系统预留区 reserved_mem[] 数组。 如果 __reserved_mem_alloc_size() 函数返回 0,那么函数继续 调用 __reserved_mem_init_node() 函数将预留区的内存加入到 CMA 区域。
early_init_fdt_scan_reserved_mem

early_init_fdt_scan_reserved_mem() 函数由于为 DTS 中的预留区分配内存。 DTS 中预留区分做两类,一类是 DTB 本身需要预留的区域,另一类是 “/reserved-memory” 节点中描述的预留区。在后者中,预留区分配需要 的内存之后,还会将这些预留区加入到 CMA 或 DMA 中。
函数首先检查 initial_boot_params 的有效性,initial_boot_params 指向 DTB 所在的位置。函数接着调用 for 循环,从 DTB 中读取预留区的信息, 将这些信息对应的区域在 MEMBLOCK 做预留。
函数接着调用 of_scan_flat_dt() 函数遍历 DTB 中的所有节点,每个 节点都传入 __fdt_scan_reserved_mem() 函数,__fdt_scan_reserved_mem,() 函数将 DTS 中 “reserved-memory” 中的预留区解析出来存储在全局 reserved_mem[] 数组里,然后调用 fdt_init_reserved_mem() 函数将 预留区中的区域在 MEMBLOCK 分配之后加入到 CMA 和 DMA 区域中。
early_cma
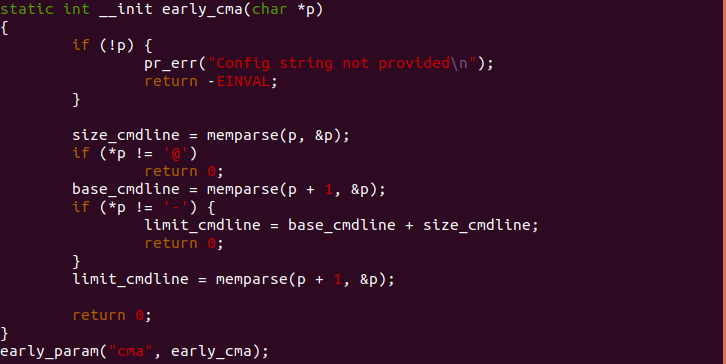
early_cma() 函数用于从 CMDLINE 中解析出 cma 信息,函数首先调用 memparse() 解析 cma 的长度信息,存储再全局变量 size_cmdline 中, 函数继续解析 cma 配置,如果 cma 信息中包含了 “@” 信息,那么系统 会设置 CMA 区域的其实地址,如果 cma 信息中还有包含 “-“ 表示 CMA 区域的结束地址,起始地址存储在 base_cmdline, 结束地址存储在 limit_cmdline. 通过该函数,内核已经获得 CMA 的信息。CMDLINE 支持的 cma 配置 方式如下:
cmdline=".... cma=32M"
cmdline=".... cma=32M@0x68000000"
cmdline=".... cma=32M@0x68000000-0x6a000000"cma_early_percent_memory
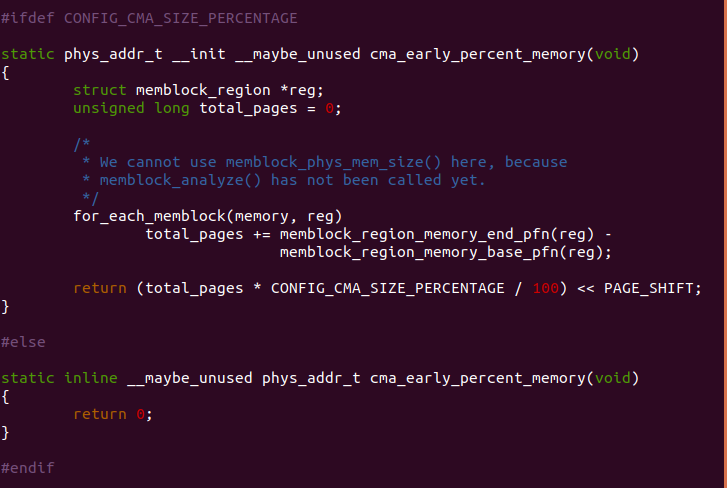
cma_early_percent_memory() 函数用于按内核配置获得一定百分比的物理 内存数。函数使用 for_each_memblock() 遍历 MEMBLOCK 内存分配器中所有 可用的物理内存,统计总共可用物理内存数,然后使用该值与 CONFIG_CMA_SIZE_PERCENTAGE 相乘获得分配给 CMA 的物理内存数。
cma_declare_contiguous

cma_declare_contiguous() 函数用于将一块物理区块从 MEMBLOCK 内存分配器分配并将该区域加入到 CMA 区域内。参数 base 指向内存区块 的起始地址,size 指向内存区块的长度,limit 指向内存区块的结束地址, aligment 参数指向对齐方式,order_per_bit 参数指向 CMA bitmap 中每个 bit 所代表的 pages 数量,fixed 参数表示是否将该区域加入到 MEMBLOCK 内存分配器的预留区内。name 参数用于指明 CMA 区域的名字,res_cma 参数指向分配的 CMA 区块。函数定义了两个局部变量,memblock_end 局部变量指向 MEMBLOCK 内存区块最大可用物理地址。

函数首先获得高端内存的其实地址,存储在 highmem_start 局部变量,函数 接着检查当前可用 CMA 区域索引的值是否超过 cma_areas[] 数组支持的最大 索引值,如果超过,那么函数报错并返回 -ENOSPC. 如果此时 size 为 0, 那么函数直接返回 -EINVAL. 函数如果检测到 alignment 参数不是 2 的幂, 那么函数直接返回 -EINVAL.
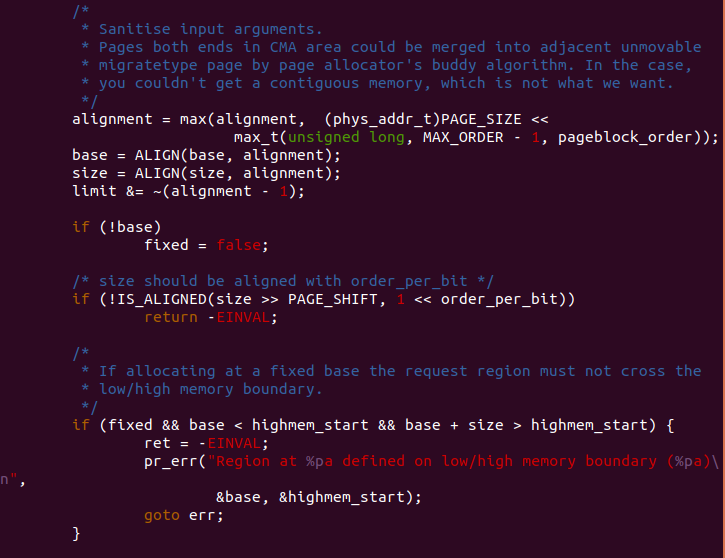
函数通过 “MAX_ORDER” 和 “pageblock_order” 变量计算出最大的对齐值, 基于该对齐方式,计算合理的基地址和长度,以及结束地址。如果此时 base 为 0,那么将 fixed 设置为 false。
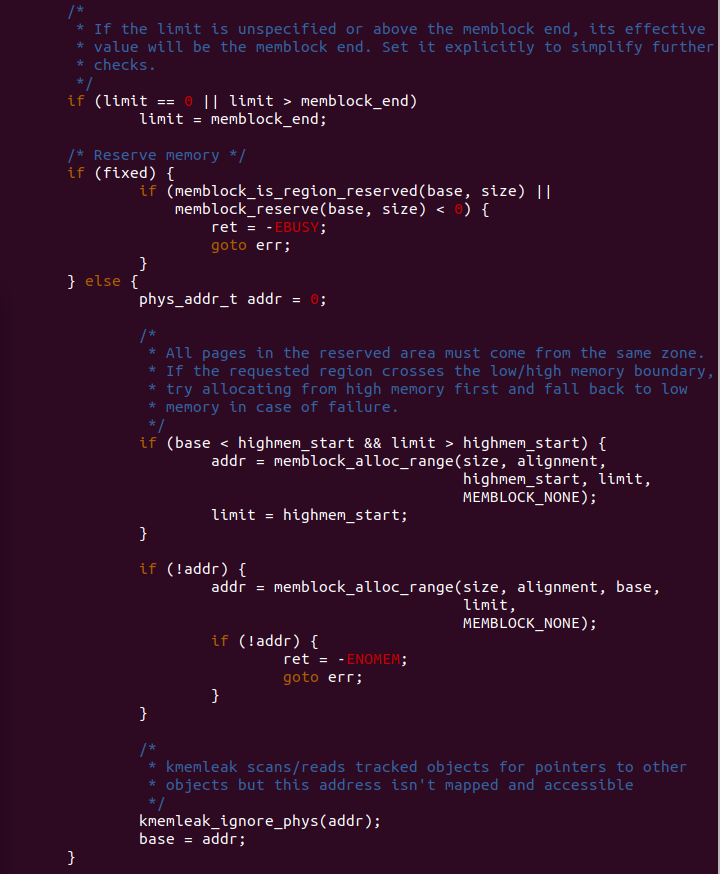
如果此时 limit 为 0,或者 limit 大于 MEMBLOCK 内存分配至支持最大可用 物理内存,那么函数将 limit 设置为 memblock_end. 如果此时 fixed 为真, 那么函数判断该区域是否已经在 MEMBLOCK 内存分配器的保留区内,如果 不在,那么将该区域加入到 MEMBLOCK 内存分配器的预留区内; 如果 fixed 为假,那么通过调用 memblock_alloc_range() 函数将区域加入到 MEMBLOCK 分配器的预留区内。
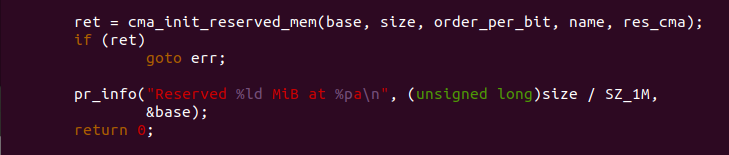
函数最后调用 cma_init_reserved_mem() 函数将预留区加入到 CMA 区域内。
dma_contiguous_reserve_area
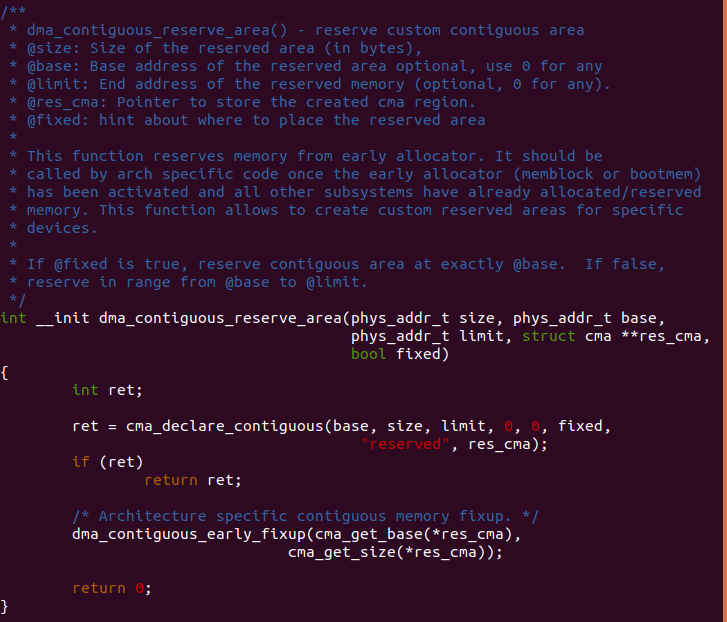
dma_contiguous_reserve_area() 函数用于预留用户使用的连续物理内存。 参数 size 指明预留区的长度,参数 base 用于指明预留区的基地址, limit 参数用于指明预留区最大地址,res_cma 参数用于指向 CMA 区域, fixed 用于放置预留的位置。
函数首先调用 cma_declare_contiguous() 函数从 MEMBLOCK 内存分配器 中分配符合要求的物理区块, 并将物理区块加入到 CMA 区域内。如果加入 成功,函数继续调用 dma_contiguous_early_fixup() 将 CMA 区域加入到 全局的 dma_mmu_remap[] 数组内部,此处函数调用 cma_get_base() 获得 CMA 区域的起始物理地址,调用 cma_get_size() 函数获得 CMA 区域的 长度。
cma_get_base

cma_get_base() 函数用于获得 CMA 区域的起始物理地址。cma 参数指向 CMA 区域。函数调用 PFN_PHYS() 函数将 struct cma 的 base_pfn 成员 对应的其实物理页帧转换成物理地址。
cma_get_size

cma_get_size() 函数用于获得 CMA 区域的长度。cma 参数指向 CMA 区域。 struct cma 的 count 成员包含了 CMA 区域的 pages 数量,函数通过向左 偏移 PAGE_SHIFT,以此获得 CMA 区域的总长度。
cma_get_size

dma_contiguous_reserve() 将一块物理内存区块预留做连续物理内存使用。 参数 limit 指向最大可用物理地址。函数首先检查 size_cmdline 是否为 -1, 如果不为 -1 代表 CMA 构建信息通过 CMDLINE 获得,如果此时 size_cmdline 不为 -1, 那么函数从 size_cmdline 可以得到需要构建 CMA 的长度信息, base_cmdline 提供了需要构建 CMA 的基地址信息,limit_cmdline 获得 CMA 最大物理地址信息。如果此时起始地址和长度的和大于 CMA 最大物理 地址,那么将 fixed 设置为 true; 如果此时 size_cmdline 为 -1 表示, 那么 CMA 构建信息将从 Kbuild 的配置中获得,也就是内核配置获得。 如果此时 CONFIG_CMA_SIZE_SEL_MBYTES 宏定义,那么函数将 size_bytes 作为 CMA 的长; 如果此时 CONFIG_CMA_SIZE_SEL_PERCENTAGE 宏定义,那么 函数调用 cma_early_percent_memory() 将一定比例的可用物理内存 作为 CMA 区域的长度; 如果 CONFIG_CMA_SIZE_SEL_MIN 宏定义,那么函数 将 size_bytes 和 cma_early_percent_memory() 中最小的一个值 做为 CMA 长度; 如果 CONFIG_CMA_SIZE_SEL_MAX 宏定义,那么函数将 size_bytes 和 cma_early_percent_memory() 中最大的一个值作为 CMA 长度。
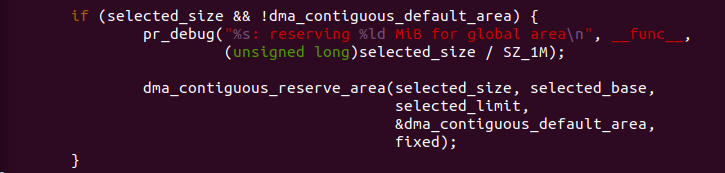
如果此时 dma_contiguous_default_area 没有定义,并且 selected_size 不为 0,那么函数调用 dma_contiguous_reserve_area() 函数将从 MEMBLOCK 分配器管理的可用物理内存中找到一块指定长度的空间进行 预留,然后将其加入到 CMA 区域。该函数也是 CMDLINE 方式和 Kbuild 方式配置一个可用的 CMA 区域。
init_cma_reserved_pageblock
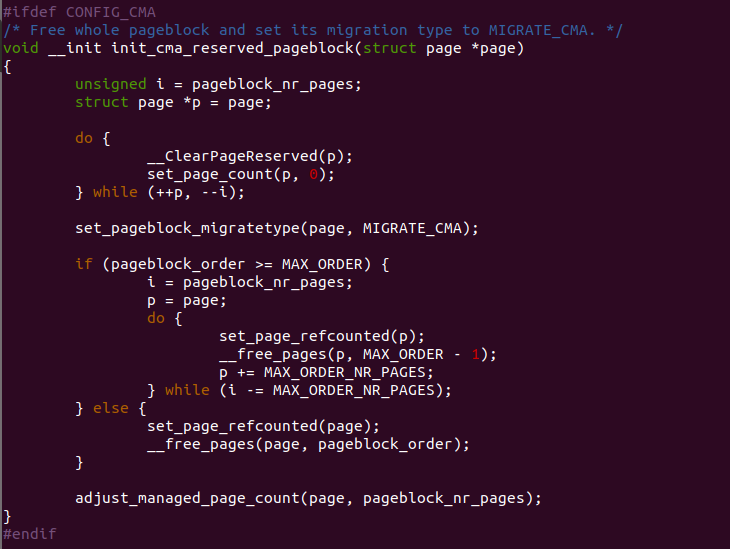
init_cma_reserved_pageblocK() 函数用于将 CMA 区域对应的多个 pageblock 的迁移类型设置为 MIGRATE_CMA, 并将占用的页释放给 Buddy 管理器,以及 增加系统的可用物理页数量。参数 page 指向 pageblock 的第一个页。 函数首先定义了局部变量 i 用于存储 pageblock 包含的 page 数,接着 定义局部变量 p 用于指向 pageblock 的起始页。
函数首先使用 do-while 循环,将 pageblock 内的所有 page 清楚了 Reserved 标志,并将所有 page 的引用设置为 0。函数接着调用 set_pageblock_migratetype() 函数将 pageblock 的迁移类型设置为 MIGRATE_CMA, 如果此时 pageblock_order 大于 MAX_ORDER,那么表示 pageblock 最大的 page 数量大于 Buddy 管理器最大 page 数,那么函数 将 pageblock 分作多个大小为 MAX_ORDER_NR_PAGES 的区域块,然后将 p 指向每个块的起始页帧,接着调用 do-while 循环,将每个区块的组 page 引用计数设置为 1,并调用 __free_pages() 将对应的页释放给 Buddy 管理器; 如果 pageblock_order 小于 MAX_ORDER, 那么将组 page 引用 计数设置为 1,并将对应的页释放给 Buddy 分配器。最后函数调用 adjust_managed_page_count() 函数将释放的 page 数量全部加到系统 可用物理页帧数里进行维护。
cma_activate_area
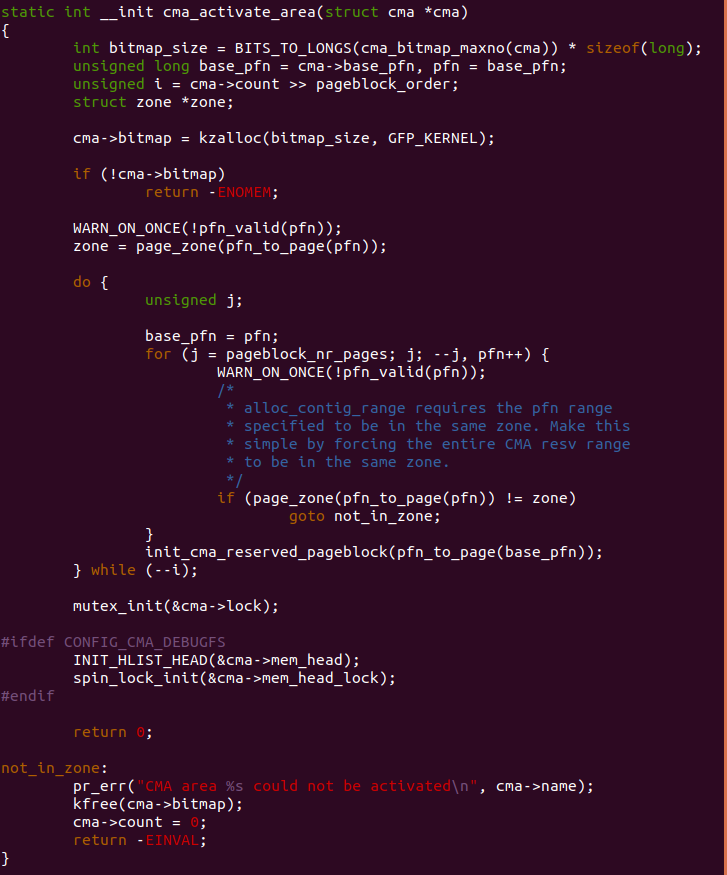
cma_activate_area() 函数用于将 CMA 区域内的预留页全部释放添加到 Buddy 管理器内,然后激活 CMA 区域供系统使用。参数 cma 指向一个可用的 CMA 区域。函数定义了多个局部变量,bitmap_size 变量用户存储 CMA 的 bitmap 需要使用的字节数,base_pfn 变量用于存储 CMA 区域的起始物理页帧, pfn 也指向 CMA 区域的起始物理页帧。局部变量 i 表示 CMA 区域占用 pageblock 的数量。
函数首先调用 kzalloc() 函数分配一定长度的内存用于存储 CMA 区域的 bitmap。如果分配失败,那么函数直接报错。函数继续检查 CMA 区域起始 页帧的合法性,并通过起始页帧获得对应的 struct zone 信息,即 ZONE 分区信息。函数接着调用 do-while() 循环,首先检查 CMA 区域的每个 pageblock 内所有页是否有效,并且所有页与起始页是在同一个 ZONE 分区 内。检查通过之后,函数调用 init_cma_reserved_pageblock() 函数将 pageblock 内所有的物理页的 RESERVED 标志清除,让后将这些页都返回 给 Buddy 系统使用。函数最后调用 mutex_init() 函数初始化了 CMA 区域 使用的互斥锁。
cma_init_reserved_areas
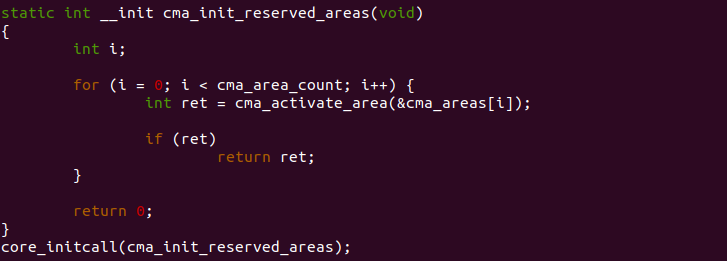
cma_init_reserved_areas() 函数用于激活系统的所有 CMA 区域,以供 其他子系统使用 CMA。
函数使用 for 循环遍历 cma_areas[] 数组内的所有 CMA 区域,当前系统 总共包含 cma_area_count 个 CMA 区域。循环每遍历到一个 CMA 区域, 函数就调用 cma_activate_area() 函数激活该 CMA 区域。函数通过 core_initcall() 进行调用。
cma_get_name

cma_get_name() 函数用于获得 CMA 区域的名字。CMA 区域的名字存储在 struct cma 的 name 成员里。如果 name 成员不为空,那么直接返回 name; 反之如果不存在,那么函数返回 “(undefined)”.
cma_bitmap_aligned_mask

cma_bitmap_aligned_mask() 函数用于获得指定页块的掩码。参数 cma 指向 一个 CMA 区域,参数 align_order 按 2 幂进行掩码。函数首先判断参数 align_order 如果小于或等于该 CMA 区域内 order_per_bit,那么函数直接 返回 0; 反之将 align_order 与 order_per_bit 之间的差值偏移求掩码,以此 获得更大块的掩码。
cma_bitmap_aligned_offset
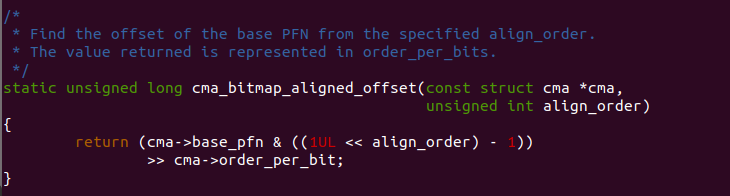
cma_bitmap_aligned_offset() 函数用于获得该 CMA 区域的起始页帧按 一定的对齐方式在 bitmap 中的位置。函数通过将该 CMA 区域的起始 物理页帧与掩码进行运算,运算之后的结果右移 order_per_bit.
cma_bitmap_pages_to_bits

cma_bitmap_pages_to_bits() 函数用于获得一定 page 数占用 bit 数量。
cma_clear_bitmap
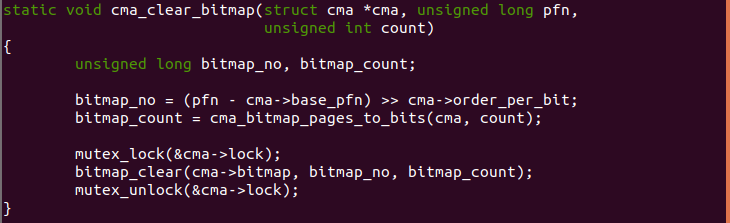
cma_clear_bitmap() 函数用于清除 CMA 区域 bitmap 中一定长度的 bit。 参数 cma 指向 CMA 区域,参数 pfn 指向即将清除 bit 的起始页帧,count 参数表示要清除页帧数量。函数首先计算 pfn 相关 CMA 起始页帧的偏移, 接着调用 cma_bitmap_pages_to_bits() 函数计算要删除 page 数量占用 的 bit 数。最后调用 bitmap_clear() 函数将 CMA bitmap 指定的 bit 清零, 并在调用情况加锁和解锁一个互斥锁。
cma_alloc
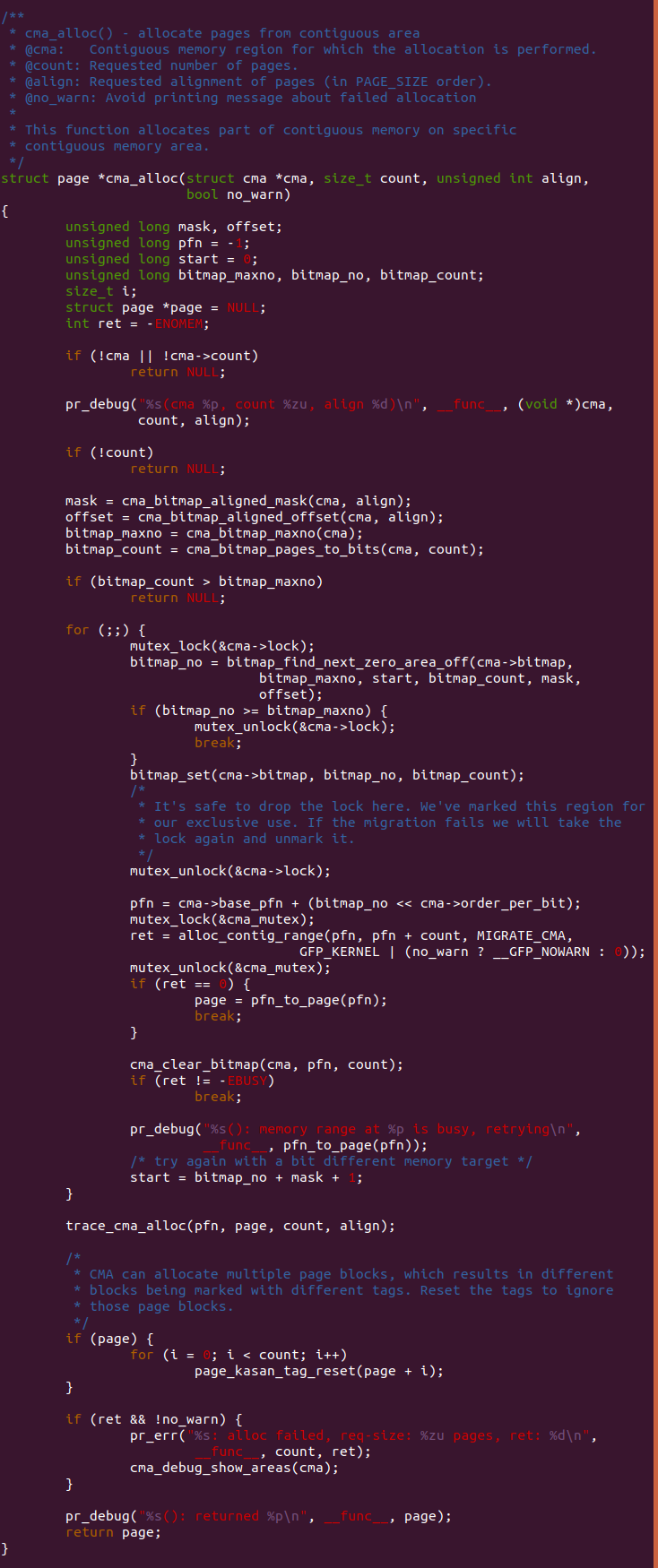
cma_alloc() 函数的作用是从 CMA 区域内分配指定长度的连续物理内存。参数 cma 指向一个 CMA 区域,参数 count 指向分配连续物理内存的数量,参数 align 表示分配时使用的对齐方式,no_warn 参数用于控制 warn 信息的打印。
函数首先检查 cma 和 cma->count 的有效性,如果其中一个无效,那么函数 直接返回 NULL. 如果参数 count 为 0,那也是无效,直接返回 NULL.
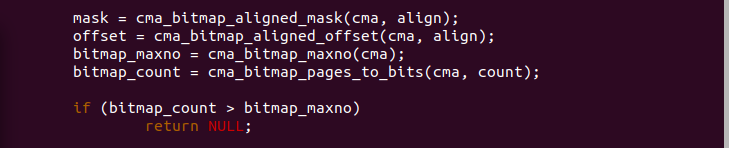
函数调用 cma_bitmap_aligned_mask() 函数与 align 参数配合计算一个 用于分配的掩码,函数调用 cma_bitmap_aligned_offset() 函数获得符合 对齐要求的 CMA 起始页帧。函数调用 cma_bitmap_maxno() 函数获得该 CMA 区域 bitmap 包含 bit 总数,函数同时调用 cma_bitmap_pages_to_bits() 函数获得参数 count 在 CMA bitmap 中对应 bit 数量。如果此需要分配 的 bit 总数大于 CMA 区域 bitmap 支持的最大 bit 数,那么函数直接 返回 NULL. 函数继续调用 for 循环,在每次循环过程中:
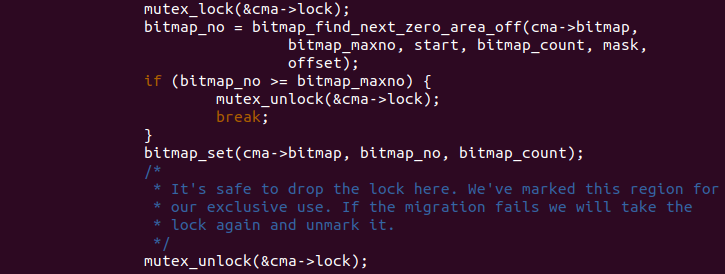
函数首先调用 mutex_lock() 上互斥锁,以让分配是独占的。接着函数 调用 bitmap_find_next_zero_area_off() 函数从 start 开始到 bitmap_maxno 区间中,在 CMA 的 bitmap 中找到第一块长度为 bitmap_count 的连续 物理内存区块。查找的结果存储在 bitmap_no 中,如果此时 bitmap_no 大于 bitmap_maxno, 那么表示没有找到,解锁之后退出循环。如果找到, 那么函数调用 bitmap_set() 函数将 bitmap 中对应的 bit 全部置位。 函数最后调用 mutex_unlock() 解锁。

函数继续通过获得的 bitmap_no 计算出对应的起始页帧号,然后调用 mutex_lock() 上互斥锁,调用 alloc_contig_range() 从 buddy 系统 中分配从 pfn 到 “pfn+count” 的所有物理页,迁移类型为 MIGRATE_CMA, 最终调用 mutex_unlock() 解锁,这个过程就是 cma 核心分配过程, 之后 CMA 就真正用户这部分连续物理内存。如果上面的代码成功,那么 函数通过 pfn_to_page() 函数获得获得连续物理内存起始页帧对应的 物理页,并跳出循环; 如果失败,那么函数调用 cma_clear_bitmap() 函数清除之前置位的 bit,并将 start 指向 bitmap_no 之后,最后 重新循环执行查找和分配过程,直到找到符合要求的区域或遍历完所有 的 bitmap,否则循环不会停止。最后函数进行一些额外处理之后就 返回申请区域的起始物理页。
cma_bitmap_maxno

cma_bitmap_maxno() 函数用于获得该 CMA 区域 bitmap 总共含有的 bit 数。 在 struct cma 中,count 成员用于存储 CMA 区域包含的 page 数量, order_per_bit 成语用于表示 bitmap 中一个 bit 包含的 page 数量。 函数通过将 CMA 区域 page 总数右移 order_per_bit 之后可以获得 CMA 区域 bitmap 的总 bit 数量。
cma_release

cma_release() 函数用于释放一块连续物理内存区块。参数 cma 指向一块 CMA 区域,参数 page 指向要释放物理内存区块的起始物理页,参数 count 指明 要释放物理页的数量。
函数首先检查 cma 和 pages 参数的有效性,如果无效,直接返回 false。 函数调用 page_to_pfn() 函数将 pages 参数转换成页帧号,如果页帧号小于 该 CMA 区域的起始页帧号获得大于该 CMA 区域的最大页帧号,那么函数 直接返回 false。如果释放的区域大于 CMA 区域,那么系统报错。如果 检查通过之后,函数首先调用 free_contig_range() 函数将所有页帧返回 给 Buddy 系统,然后调用 cma_clear_bitmap() 函数将 CMA 区域对应的 bitmap 清除。最后返回 true。
cma_for_each_area
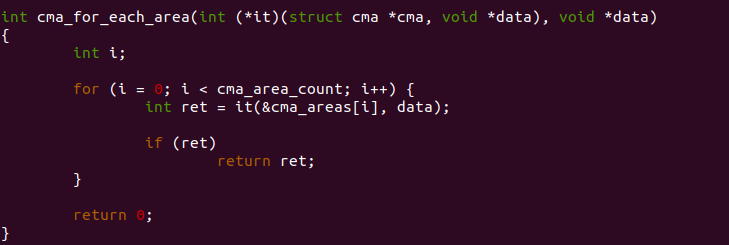
cma_for_each_area() 函数用于遍历所有的 CMA 区域,并在每个区域内 处理指定的任务。参数 it 是一个回调函数,data 参数是传入的参数。 函数使用 for 循环从 0 到 cma_area_count 遍历所有的 CMA 区域,每次 遍历到一个 CMA 区域都调用 it 对应的函数。
dma_alloc_from_contiguous
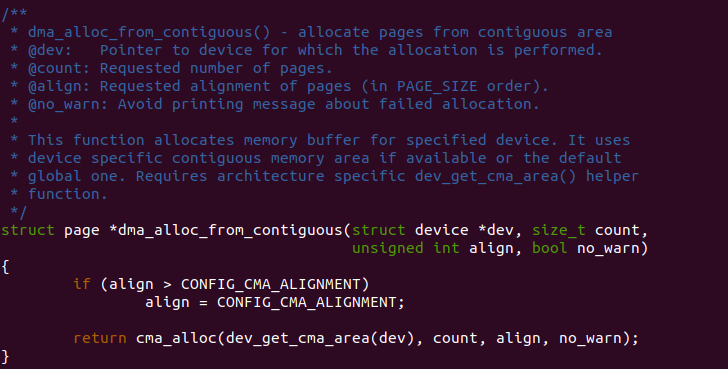
dma_alloc_from_contiguous() 函数用于从系统中分配指定长度的连续物理 内存。参数 dev 指向一个设备,参数 count 指明分配的长度,align 参数 指明对齐的方式,no_warn 控制警告消息的打印。
函数首先判断 align 参数是否大于 CONFIG_CMA_ALIGNMENT, 内核 CONFIG_CMA_ALIGNMENT 宏默认值为 8. 如果大于。那么将 align 设置 为 CONFIG_CMA_ALIGNMENT。函数接着调用 dev_get_cma_area() 函数获得 设备所使用的 CMA 区域,将其传入到 cma_alloc() 函数进行分配, 至此函数将从 CMA 中分配一块连续的物理内存。
dev_get_cma_area

dev_get_cma_area() 函数用于获得设备对应的 CMA 信息。如果设备配置了 CMA 信息,那么 struct device 的 cma_area 成员中可以获得 CMA 信息。 如果没有定义,那么使用默认的 CMA 区域 dma_contiguous_default_area。
dma_release_from_contiguous
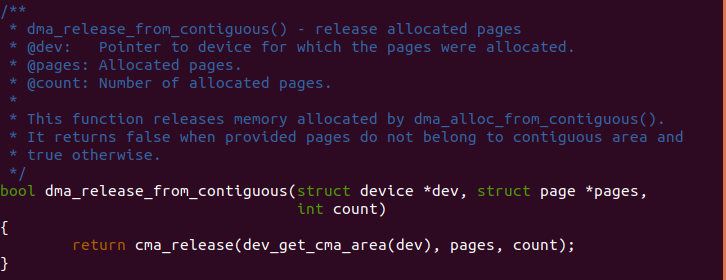
dma_release_from_contiguous() 函数的作用是释放一段连续物理内存 到 CMA。参数 dev 指向一个设备,pages 指向连续物理内存的起始页, 参数 count 表示释放连续物理内存的长度。函数首先调用 dev_get_cma_area() 函数获得设备对应的 CMA 区域,然后调用 cma_release() 释放这块连续 的物理内存区块。
CMA 器实践部署
CMA BiscuitOS 实践部署
BiscuitOS 目前已经完整的支持 CMA 实践,包括了驱动和应用程序的部署, 开发者按着下列详细步骤进行实践:
实践准备
本例基于 BiscuitOS linux 5.0 进行实践,BiscuitOS linux 5.0 开发环境 部署请参考下文:
实践配置
准备好开发环境之后,紧接着就是通过配置选择 CMA 实践相关的项目, 开发者可以参考如下命令:
cd BiscuitOS
make linux-5.0-arm32_defconfig
make menuconfig
进入 Kbuild 的配置界面之后,选择并进入 “Package —>”,
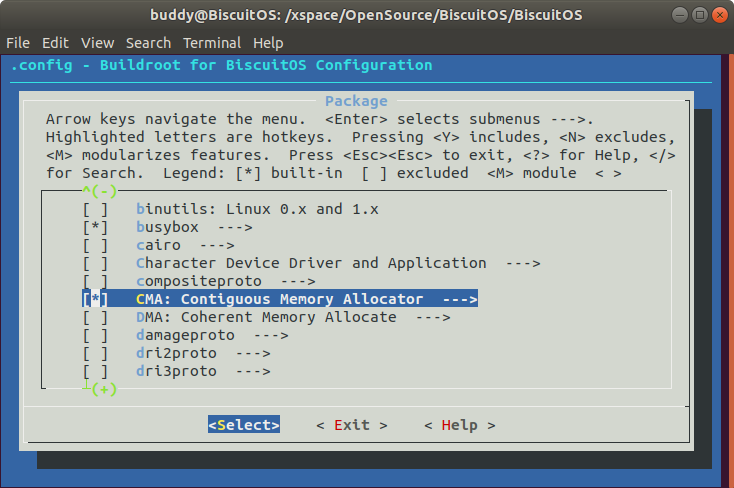
接着选择并进入 “CMA: Contiguous Memory Allocator —>”
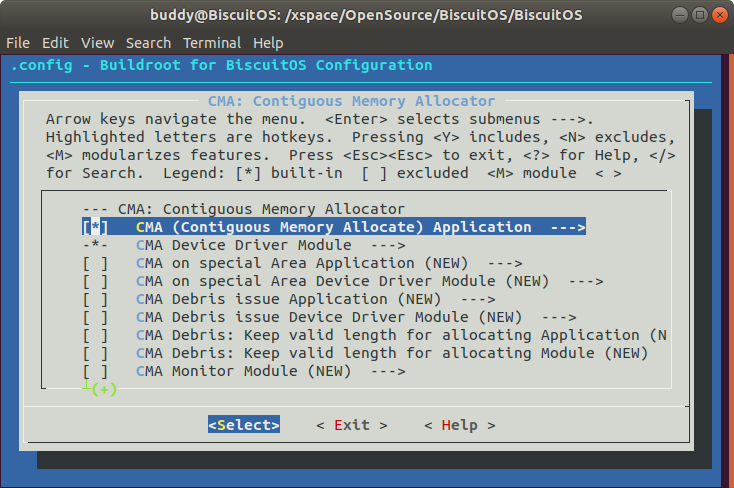
测试选择 “CMA (Contiguous Memory Allocate) Application” 选项和 “CMA Device Driver Module” 选项,此时已经选择完毕,保存并退出。 配置完毕之后,使用接下来的命令进行项目安装:
cd BiscuitOS
make
通过上图可以看到实践所需的项目已经安装到指定位置,从图中可以看出 源码位于 “BiscuitOS/output/linux-5.0-arm32/package” 目录下,如下:
Application:
BiscuitOS/output/linux-5.0-arm32/package/CMA_app-0.0.1
Module:
BiscuitOS/output/linux-5.0-arm32/package/CMA_module-0.0.1CMA 区域配置
在使用项目之前,还需要配置 CMA 的大小,通过之前的分析可以知道, 内核支持多种方案进行 CMA 的配置,具体配置方法可以参考下列文章:
本节采用 CMDLINE 方案进行配置 CMA 区域,CMDLINE 通过 uboot 传递,在 BiscuitOS 项目中,可以简单的配置实现通过 uboot 的 CMDLINE 传递 cma 配置参数。开发者可以修改 RunBiscuitOS.sh 实现,请参考如下命令:
cd BiscuitOS/output/linux-5.0-arm32/
vi RunBiscuitOS.sh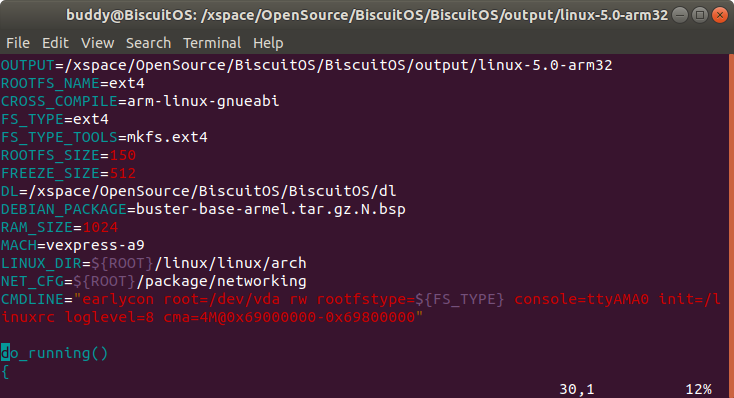
在 RunBiscuitOS.sh 文件中,找到 CMDLINE 变量,向其添加参数 “cma=4M@0x69000000-0x69800000”, 这将模拟 uboot 传递 CMDLINE 给内核, 其参数函数是需要创建一个长度为 4M,起始地址为 0x690000000, 最大可用 物理地址是 0x69800000 的区域内分配连续的物理内存作为 一块新的 cma 区域。 为了使配置生效,请确保内核没有采用 DTS 方案配置 CMA.
CMA 内核宏配置
为了在内核中使用 CMA,在内核配置中请确保相关的宏已经启用, 如下:
请参考如下命令进行配置的配置:
cd BiscuitOS/output/linux-5.0-arm32/linux/linux
make menuconfig ARCH=arm
实践编译
准备好前几个步骤之后,本节用于编译 CMA 的驱动程序和应用程序。开发者可以 参考如下步骤进行实践:
CMA 驱动编译
BiscuitOS 已经支持完整的驱动编译机制,开发者只需要使用简单的命令 便可快速实践驱动。同理,CMA 驱动的实践步骤如下:
cd BiscuitOS/output/linux-5.0-arm32/package/CMA_module-0.0.1
make prepare
make download
make
make install
make pack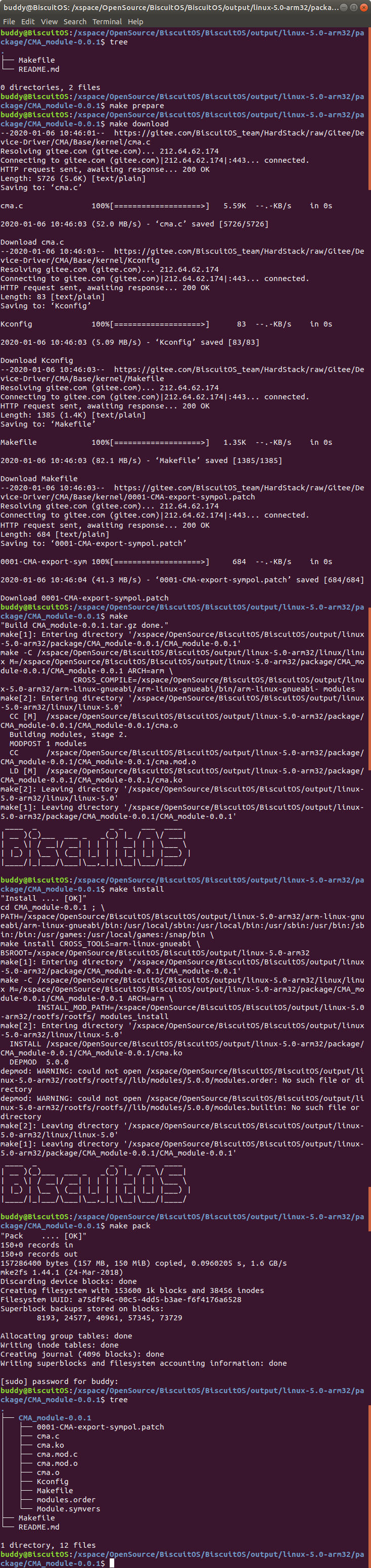
BiscuitOS 快速驱动编译体系,减少了很多不必要的部署准备。首先执行 “make prepare” 命令,那么 BiscuitOS 就会去部署驱动依赖的环境; “make download” 命令用于下载 CMA 驱动相关的源码; “make” 用于编译驱动 程序; “make install” 命令用于将编译好的驱动 ko 文件安装到 rootfs 所在的目录; “make pack” 命令用于将 rootfs 打包更新到 BiscuitOS 系统里, 下一次运行 BiscuitOS 就可以在 “/lib/module/5.0.0/extra” 目录下找到对应 的驱动.
接着需要对内核添加相应的补丁,补丁位于:
BiscuitOS/output/linux-5.0-arm32/package/CMA_module-0.0.1/CMA_module-0.0.1/0001-CMA-export-sympol.patch为内核打上上面的补丁并重新编译内核,使用如下命令:
cd BiscuitOS/output/linux-5.0-arm32/linux/linux
make ARCH=arm CROSS_COMPILE=BiscuitOS/output/linux-5.0-arm32/arm-linux-gnueabi/arm-linux-gnueabi/bin/arm-linux-gnueabi- -j4至此 CMA 驱动程序安装完毕.
CMA 应用程序编译
BiscuitOS 已经支持完整的应用程序编译机制,开发者只需使用简单的命令 便可以快速实践应用程序。同理,CMA 应用程序实践如下:
cd BiscuitOS/output/linux-5.0-arm32/package/CMA_app-0.0.1
make prepare
make download
make
make install
make pack
BiscuitOS 快速应用程序编译体系,减少了很多不必要的部署准备。首先执行 “make prepare” 命令,那么 BiscuitOS 就会去部署驱动依赖的环境; “make download” 命令用于下载 CMA 应用相关的源码; “make” 用于编译应用 程序; “make install” 命令用于将编译好的可执行应用文件安装到 rootfs 所在的目录; “make pack” 命令用于将 rootfs 打包更新到 BiscuitOS 系统里, 下一次运行 BiscuitOS 的时候,直接运行 CMA_app-0.0.1. 至此 CMA 应用程 序安装完毕.
实践运行
准备好前面几个内容之后,现在可以在 BiscuitOS 中使用 CMA,具体命令 如下:
cd BiscuitOS/output/linux-5.0-arm32/
./RunBiscuitOS.sh
系统启动过程中,内核输出 CMA 区域创建的信息:

可以看出通过 CMDLINE 配置 CMA 区域的从 0x69400000 起始分配了 4M 物理 内存空间。系统运行之后,查看系统内存布局情况:

从上面的信息可以知道系统 CMA 总共 4096KB,即 4M。当前可用的 CMA 连续物理 内存为 2304KB. 接着安装实践所使用的 CMA 驱动和应用程序,运行情况如下:
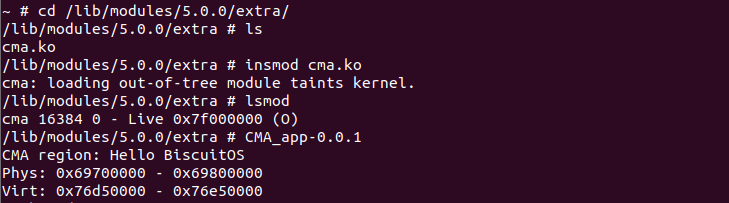
从上图可以看到 CMA 应用程序分配了一块长度为 1M 的连续物理内存,其 范围是 “0x69700000” 到 “0x69800000”, 应用程序将物理内存映射到虚拟 地址空间,映射后的方位是 “0x76d50000” 到 “0x76e50000”
实践源码
本次实践的源码如下:
驱动相关的源码
驱动相关的源码位于:
BiscuitOS/output/linux-5.0-arm32/package/CMA_module-0.0.1/CMA_module-0.0.1
驱动实践文件包含了上面几个文件,每个文件的描述如下:

0001-CMA-export-sympol.patch 文件是为了让驱动运行起来内核必须打的补丁, 其核心内容就是将 “dma_alloc_from_contiguous” 和 “dma_release_from_contiguous” 两个函数到处供给其他外部驱动使用。

Kconfig 文件适用于驱动在 Kbuild 中的描述和宏开关,当将驱动编译进内核, 可以使用该文件定义的宏控制驱动的开关.
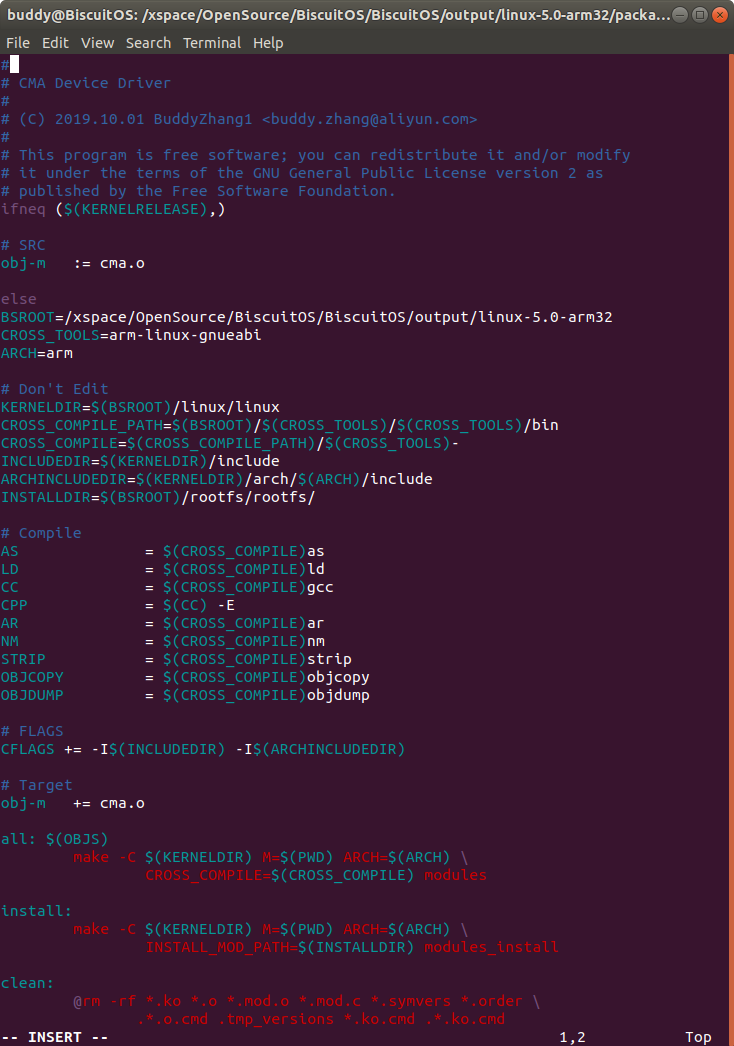
Makefile 文件提供了驱动外部编译的编译逻辑,使用这个编译逻辑可以独立于 内核源码树进行外部编译。

该驱动注册了一个字符设备,向 “/dev” 目录下创建了一个名为 “CMA_demo” 的 节点,并未字符设备提供了 ioctl、mmap 接口以供用户空间使用。ioctl 提供了两个命令 “CMA_MEM_ALLOCATE” 和 “CMA_MEM_RELEASE”,用户空间通过 这两个命令实现 CMA 的申请和释放,驱动程序维护着已经申请的 CMA 内存。
应用程序相关的源码
应用程序相关的源码位于:
BiscuitOS/output/linux-5.0-arm32/package/CMA_app-0.0.1/CMA_app-0.0.1
应用程序实践文件包含了上面几个文件,每个文件的描述如下:
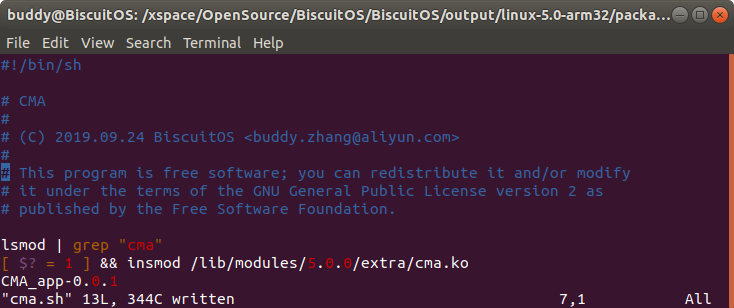
cma.sh 脚本文件包含了 CMA 应用程序的基本使用方法,由于应用程序 依赖驱动,因此应用程序运行之前确保驱动已经安装.
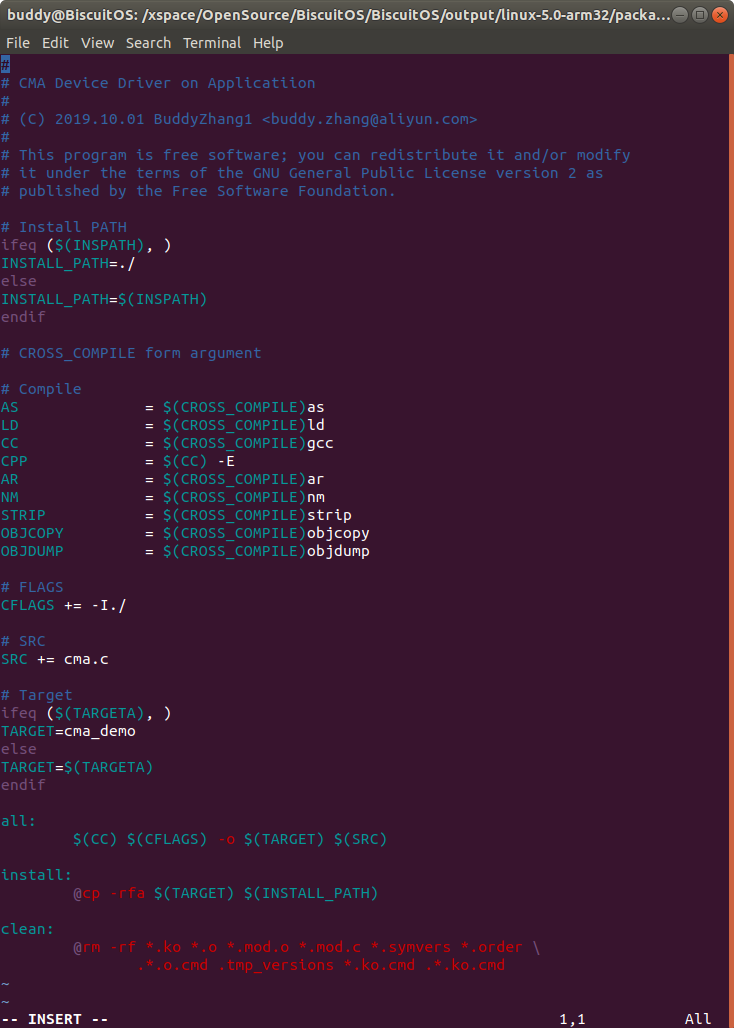
Makefile 包含了 CMA 应用程序的编译逻辑,可以使用该逻辑交叉编译所使用 的 CMA 应用。
cma.c 是 CMA 应用程序的核心实现,应用程序打开 “/dev/CMA_demo” 节点 之后,通过 ioctl 命令传递 “CMA_MEM_ALLOCATE” 向 CMA 驱动申请连续 物理内存,然后将申请后的连续物理内存重映射到虚拟地址空间。使用完毕 之后再将虚拟地址解除映射,然后通过 ioctl 命令 CMA_MEM_RELEASE 将 连续物理内存归还 CMA 驱动.
CMA 工程实践部署
开发者同样可以将 CMA 运用到各自的工程项目中,开发者可以参考本节内容 进行实践部署。
源码部署
开发者首先获取实践相关的源码:
获取源码之后开发者将驱动加入到源码数进行编译。开发者编译之前给内核打上 对应的补丁 “0001-CMA-export-sympol.patch”. 编译完驱动之后,开发者将 应用程序交叉编译并安装到目标板子的 rootfs 上。
CMA 部署
源码移植完毕之后,接下来是配置 CMA 区域,内核提供了多种方案配置, 开发者可以参考下面章节进行移植:
附录
赞赏一下吧 🙂
