

Package-to-Package Bus
Die-to-Die Bus
Core-to-Core Bus

System Bus Underpinning

片上总线 也称作片上网络(Network on Chip, NoC),在 CPU 核心日益增多的今天,变得更加重要. CPU 由单核变成多核,由单 Socket 变成多 Socket,因此一个可靠高效的总线在多核 CPU 的今天越来越重要. 本文从 Intel 总线的发展为例子,为各位开发者讲述总线的发展史, 以此更全面认识系统总线. 在介绍总线之前先做一些技术铺垫.

CPU(Central processing unit) 中央处理器,作为计算机系统运算和控制的核心,是信息处理、程序运行的最后执行单元. 指令在这里处理,信号从这里发出去. CPU 的范围比较大,里面包含了 Core、内存控制器、PCIe 控制器、片外总线等。一个 CPU 中可能包含多个 Core,通常所说的物理核心指的是 Core,每个物理核心都包含各自的电路。
物理核与逻辑核(超线程)
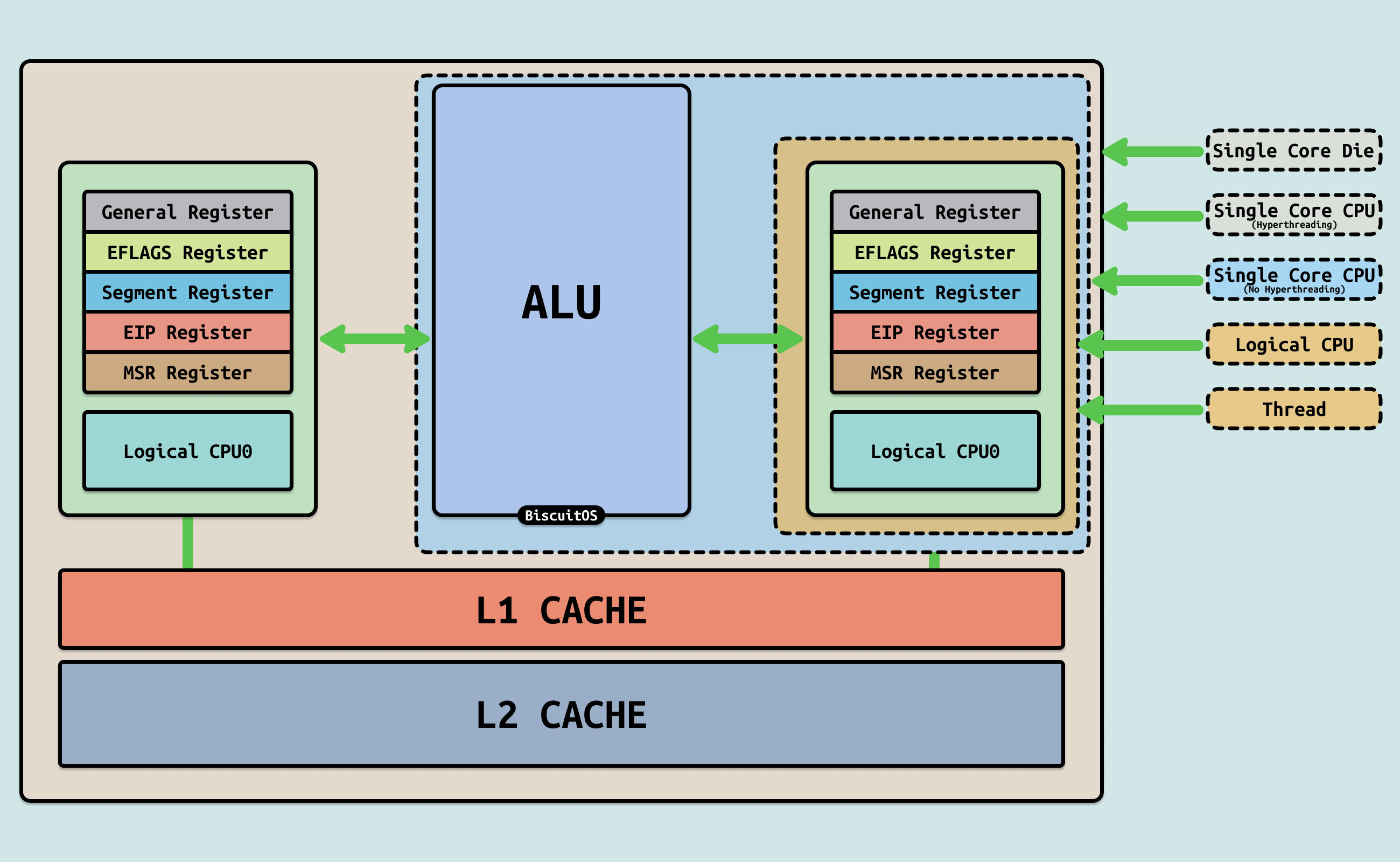
物理核(Physical Core) 是一个独立的执行单元,它可以其他物理核并行运行一个程序线程。现代 CPU 具有多个物理核,例如上图绿色虚线框内就是一个独立的物理核. 每个物理核上可以用于 2 个逻辑核(Logical Core), 逻辑核与在同一个物理核上运行的其他逻辑核心共享资源,例如上图红色框就是一个逻辑核, 两个逻辑核拥有属于各自的寄存器组,但共用一组 ALU 计算单元,如果每个逻辑 CPU 上运行一个进程,那么两个进程之间的通信完成在物理 CPU 核内部,无需系统总线,但从唯一的 ALU 来看无法真正意义上同时执行两个进程。可以将橙色款的部分看做一个没有逻辑核(超线程)的单核物理核. 在 Intel 超线程技术下,逻辑核也称为超线程, 那么在上图中,每个物理核拥有两个逻辑核。vCPU(虚拟 CPU) 等价于逻辑核(超线程),但存在差异: 虚拟 CPU 更多的是限定在虚拟化语境内. 一个宿主机上的逻辑核可以映射为虚拟机内部的一个虚拟CPU(vCPU), 因此在虚拟化语境中基本是同一个术语.
CPU Socket

多核架构指的是在一颗芯片上放多个处理器(CPU), 正如上图所示。一颗芯片插在主板的一个插槽(Socket) 上,一颗芯片上放了多个物理核. 在有的主板上也有多个插槽,那么就可以插多颗芯片,因此会看到 “2 颗 4 核”, 其含义的就是主板上有 2 个芯片插槽,每颗芯片上存在 4 个物理 CPU,那么总共 8 个物理 CPU,如果每个物理核存在 2 个超线程,那么总共 16 个超线程或逻辑核.

通常市面上看到的 CPU 一般会标识 X 核 Y 线程,意思就是该 CPU 包含了 X 个物理核,每个物理核上包含 (Y/X) 个逻辑核或超线程. 例如 Intel 酷睿 i7 11700 CPU 就是八核心十六线程 指的就是其包含 8 个物理核心且每个物理核包含 2 个超线程(逻辑核); 又如 AMD Ryzen 7000 CPU 就是96核心192线程, 指的就是包含了 96 个物理核心,每个物理核上包含了 2 个超线程(逻辑核).
CPU Die

Die 或者 CPU Die 指的是处理器在生产过程中,从晶圆(Silicon Wafer) 上切割下来的一个个小方块,在切割之前需要经过各种加工将电路逻辑刻在 Die 上面. Die 是一块半导体材料(通常是硅),一个 Die 可以包含任意数量的 Core,Die 是构成 CPU 的晶体管实际所在.

对于主流的 CPU 厂商 Intel 和 AMD,他们会将 1 个或者多个 CPU Die 封装起来形成一个 CPU Package, 有时也叫做 CPU socket(CPU 插槽). CPU Die 之间通过片内总线(Infinity Fabric) 互联,并且不同 CPU Die 上的 CPU 内核不能共享 CPU 缓存。在 Intel 的 Xeon 处理器里,同一个 CPU Die 上的物理核共享 L3 Cache.

例如 AMD EYPC CPU 而言,它的每个 CPU Socket 由 4 个 CPU Die 组成,每个 CPU Die 中含有 4 个 CPU 物理核,图中四个横的黑色长方体区域就是 CPU Die,每个 Die 中有 4 个物理核.
CPU Package

CPU Package 指的是包含一个或者多个 CPU Die 的塑料/陶瓷外壳和镀金的触电,也就是当你购买单个处理器时所得到的东西. 主板上每个 CPU 插槽(CPU Socket) 只能安装一个 Package, Package 也指是插在插座上的单元. 例如上图看到一个明亮外壳是 Package 的正面,背面全是金属触电,正好与主板的触电贴合在一起.

双核处理器是一个包含两个物理核(Core) 的 Package,可以是一个 CPU Die 也可以是两个 CPU Die。第一代多核处理器通常是在一个 Package 上使用多个 CPU Die,而现代设计将多个 Core 放到同一个 CPU Die 上,带来了一些优势,比如能够共享 On-Die 缓存。上图是一个双核心(Core) 的 CPU,使用了两片 CPU Die,每片上有一个物理核(Core).
CPU 系统信息
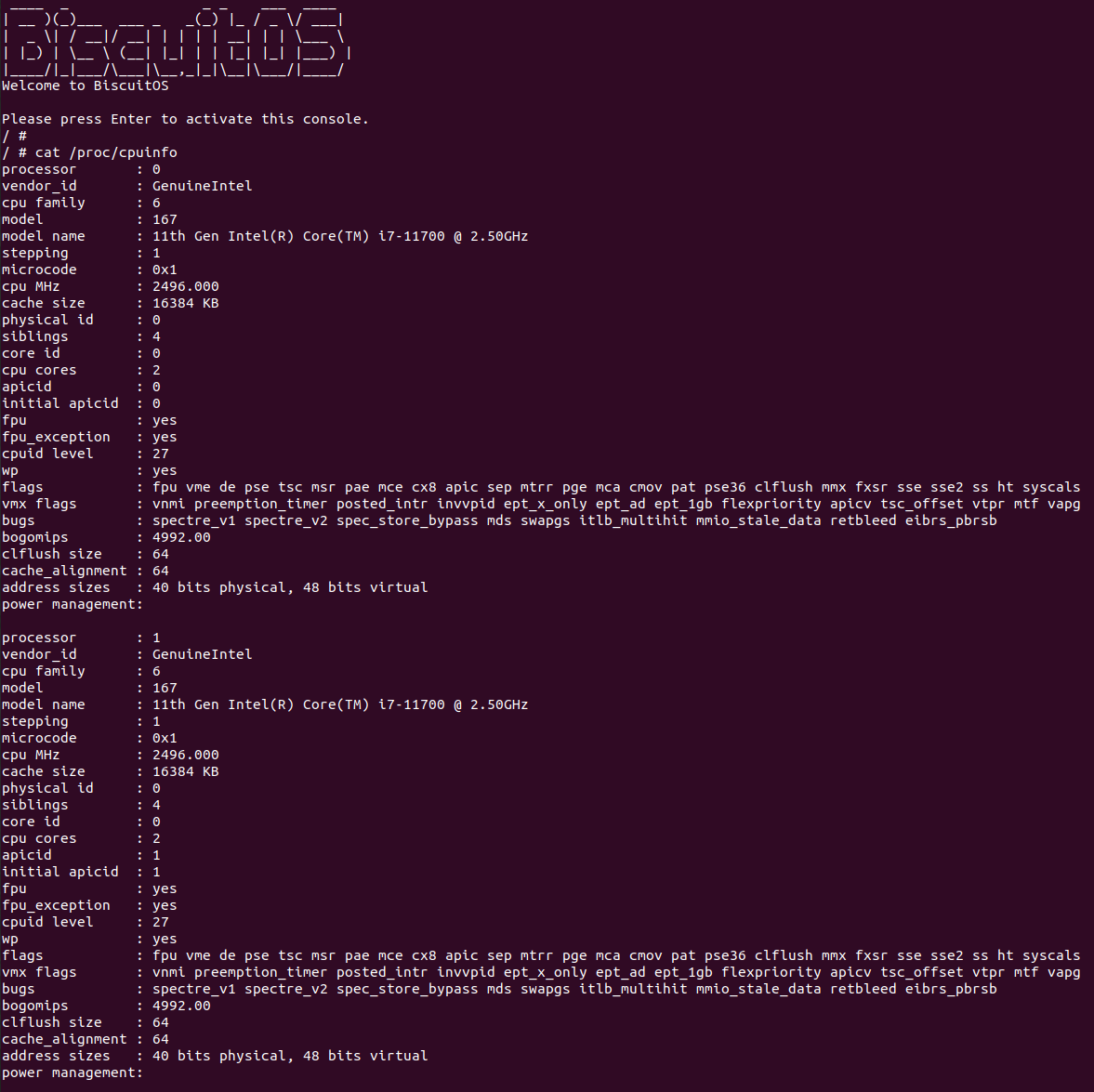
在一台拥有 2 个 Socket 的机器上安装上 2 个 CPU Package,每个 Package 拥有 2 个物理核(Core), 每个物理核上拥有两个超线程(逻辑核)。当系统运行之后,通过 “/proc/cpuinfo” 查看 CPU 相关的信息,其各字段含义:
- processor: 指超线程 ID 或者逻辑核 ID.
- apicid: 指逻辑核对应 LAPIC ID.
- core id: 指逻辑核或超线程所属的 Core ID(物理核 ID).
- physical id: 指超线程(逻辑核)对应的物理核插在 CPU Socket ID.
- cpu cores: 指系统包含物理核(Core) 的总数.
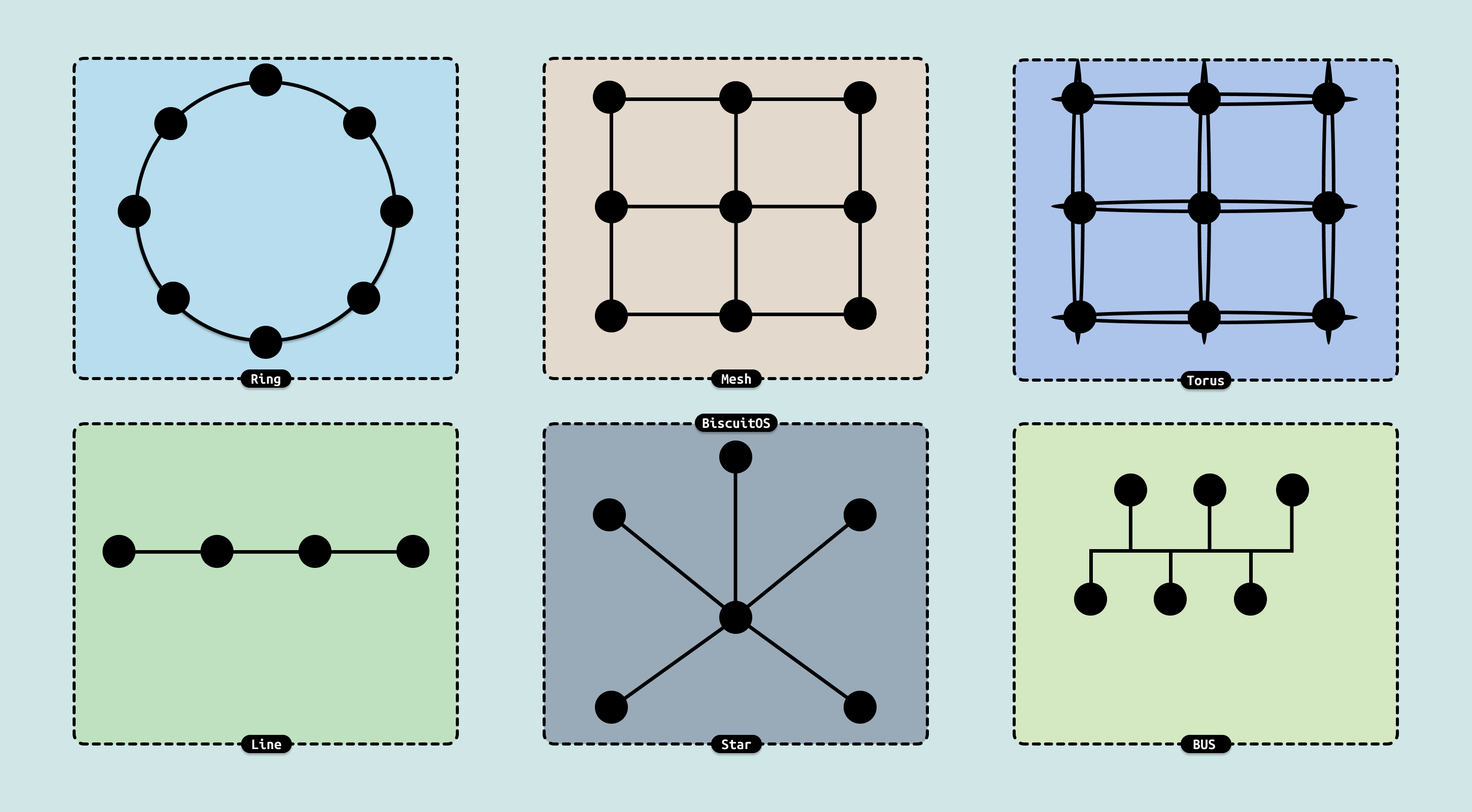
早期 CPU 内部模块数目较少和结构单一, 多采用星型、全连接或者交换开关(Crossbar)拓扑结构. 随着多核处理器逐渐取代了单核处理器,CPU 芯片中的 IP 逐渐增多,如何处理好它们之间的通讯成为了解决 CPU 性能的关键. 新型 CPU 片上总线主要基本结构有几种:
- Star(星型): 早期 CPU 内部模块数目较少,结构单一,星型连结是一个简单高效的办法. Core 被放在中心的位置,各个模块都和它连接. 而彼此并不直接交互,必须要 Core 中转, 这种设计简单高效,被使用了相当长的时间.
- Ring(环形): 已经广泛应用在消费品市场和服务器市场 CPU 中的环形总线(Ring Bus), 其主要用于多核内部互联总线,并不用于 Package 之间的互联.
- Mesh(网格): 主要应用在服务器 CPU 中的 Mesh Bus,可以接更多的 Core,延时并没有因为 Core 的增加而增加,每个 Core 之间由南北向和东西向的半环组成.
- Torus Bus: 在 Mesh 的基础上进行变形,将每个行列的节点收尾相连,组成了一个个环,可以看做 RingBus 和 Mesh 的复合体.
在总线里,每个节点连接数量称为维度(Degree), 如在环形总线(RingBus)上, 节点的维度为 2. 而在 Mesh 总线上,每个节点的维度是 2、3 或者 4. 维度是描述一个网格节点的开销重要数据,可以看出 RingBus 的开销最小. 一个节点到相邻节点称为一跳(Hop), 两个节点之间 Hop 的个数称为跳数(Hop Count, HC). 每一跳都需要消耗时间,两个节点之间的跳数(HC) 越少,延迟越少. 这里引申出两个重要指标: 最大跳数和平均跳数.
- 最大跳数: 指的节点之间 HC 最大是多少,它是延迟的最大值.
- 平均跳数: 值所有节点跳数的平均值,它很好反应平均延时.
在场景的几种总线结构里,RingBus 的最大跳数是 4,平均跳数是 2.22. Mesh 总线的最大跳数是 4,平均跳数是 1.77. Torus 总线的最大跳数是 2,平均跳数是 1.33. 因此从延时来看,Torus 的延迟最小,Mesh 次之,RingBus 垫底.
Package-to-Package 总线演变
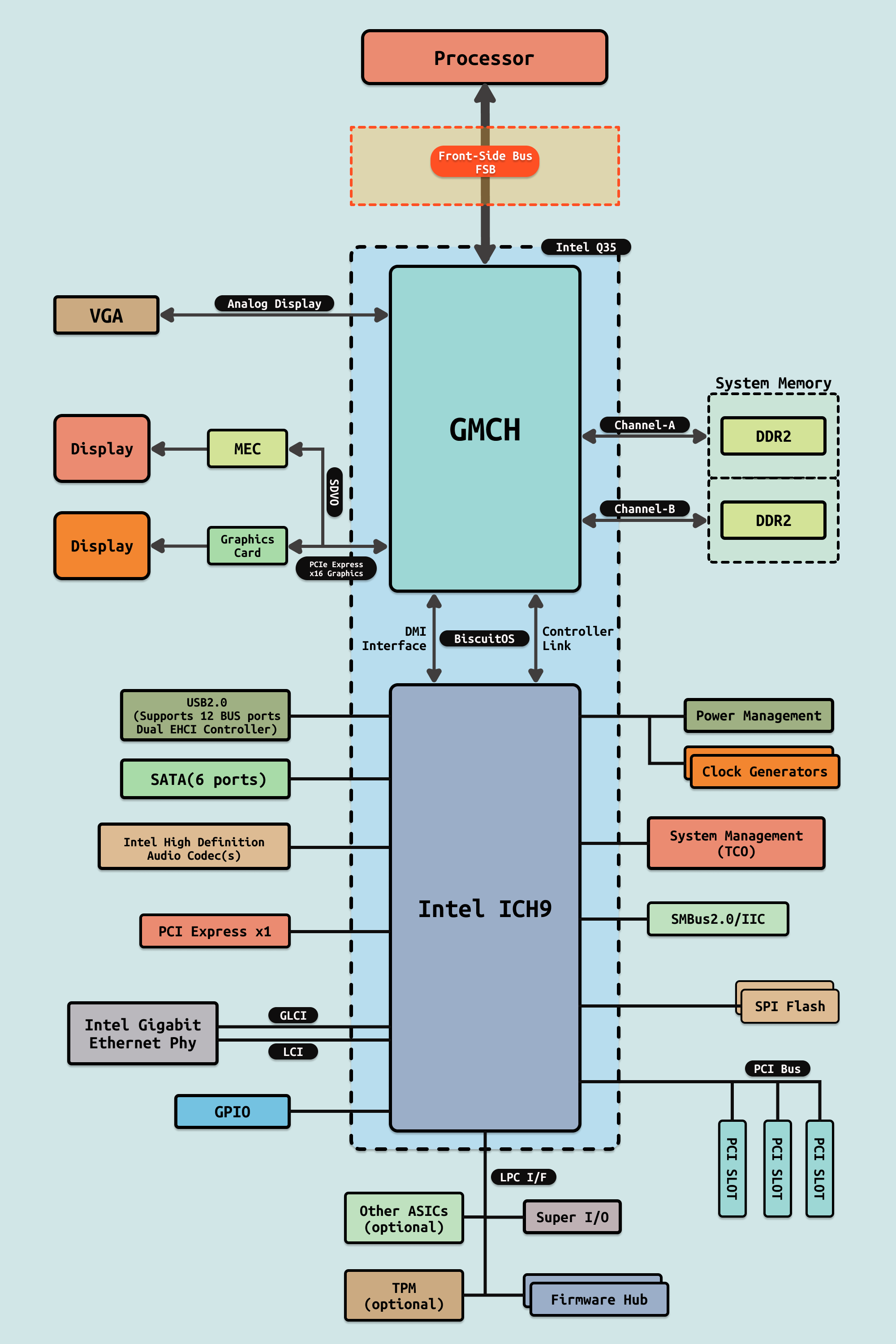
前端总线在最初设计时具有高灵活性和低成本的优势. 简单的对称多处理器将多个 CPU 放置在共享的 FSB 上,尽管由于带宽瓶颈,性能无法线性扩展. 前端总线一直被所有 Intel Atom、Celeron、Pentium、Core 2 和 Xeon 处理器型号使用,直到大约 2008 年. 最初这个总线是 CPU 和所有系统设备的中心连接点. 如果 CPU 不能像执行它们那样快速地获取指令和数据,那么更快的 CPU 潜力就被浪费了。CPU 在等待在主内存中读取或写入数据时可能会花费大量空闲时间,因此高性能处理器需要高带宽和低延迟访问内存。AMD 批评前端总线是一种旧的且缓慢的技术,限制了系统性能.
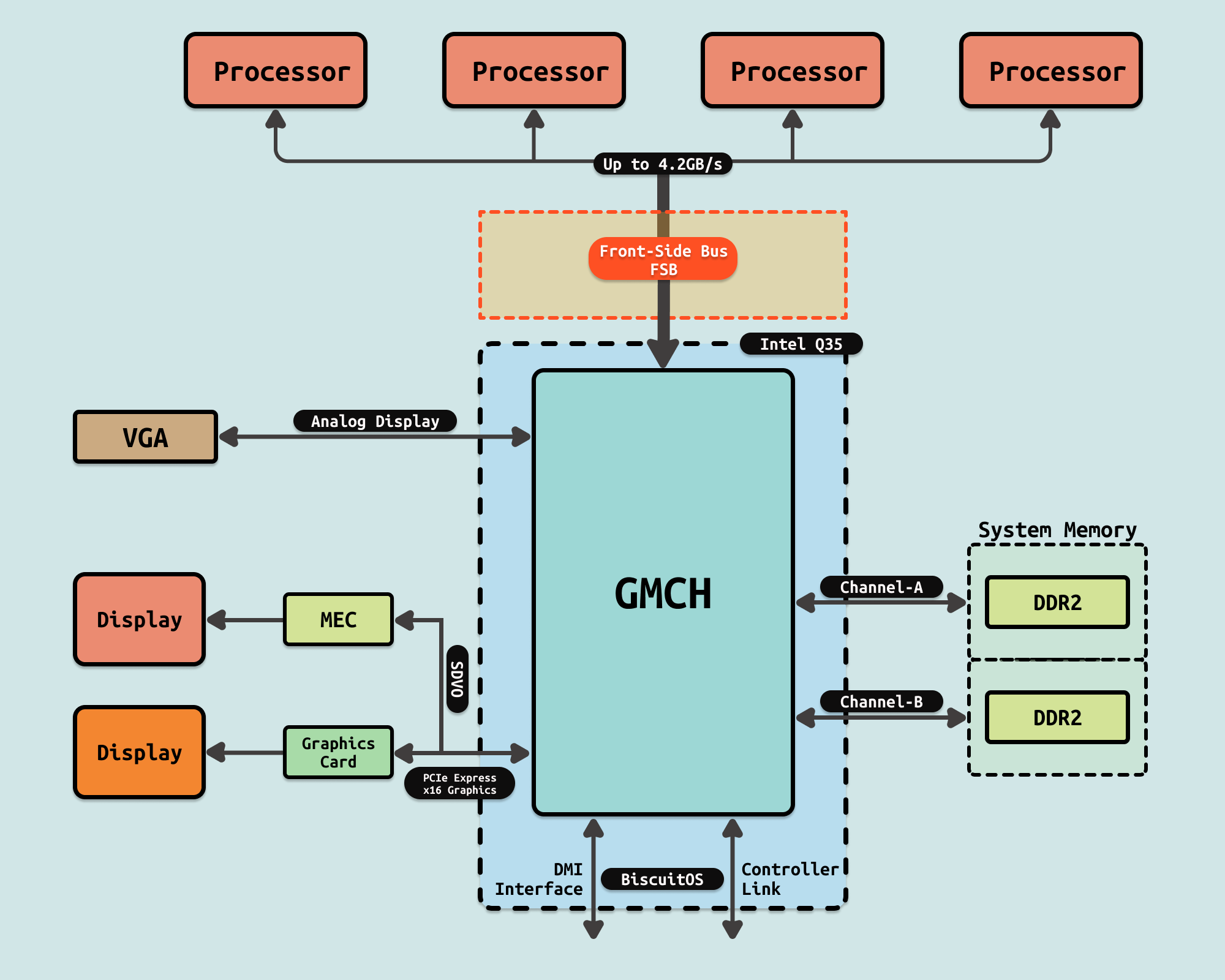
在较旧的共享 FSB 总线(Shared Front-Side Bus)系统中,所有流量都通过单个共享双向 FSB 总线发送. FSB 宽总线(Intel® Xeon® 处理器为 64 位, Intel® Itanium® 处理器为 128 位) 一次可接收多个数据字节. 这种方法的挑战是随着宽源同步总线频率的增加而遇到的电气限制.为了解决这个问题,英特尔通过一系列技术改进改进了总线. 最初在 20 世纪 90 年代末,数据以 2 倍总线时钟输入,也称为 double-pumped. 如今的 Intel® Xeon® 处理器 FSB 是 quad-pumped,以 4 倍总线时钟输入数据。如今 FSB 上的最高理论数据速率为 1.6 GT/s.
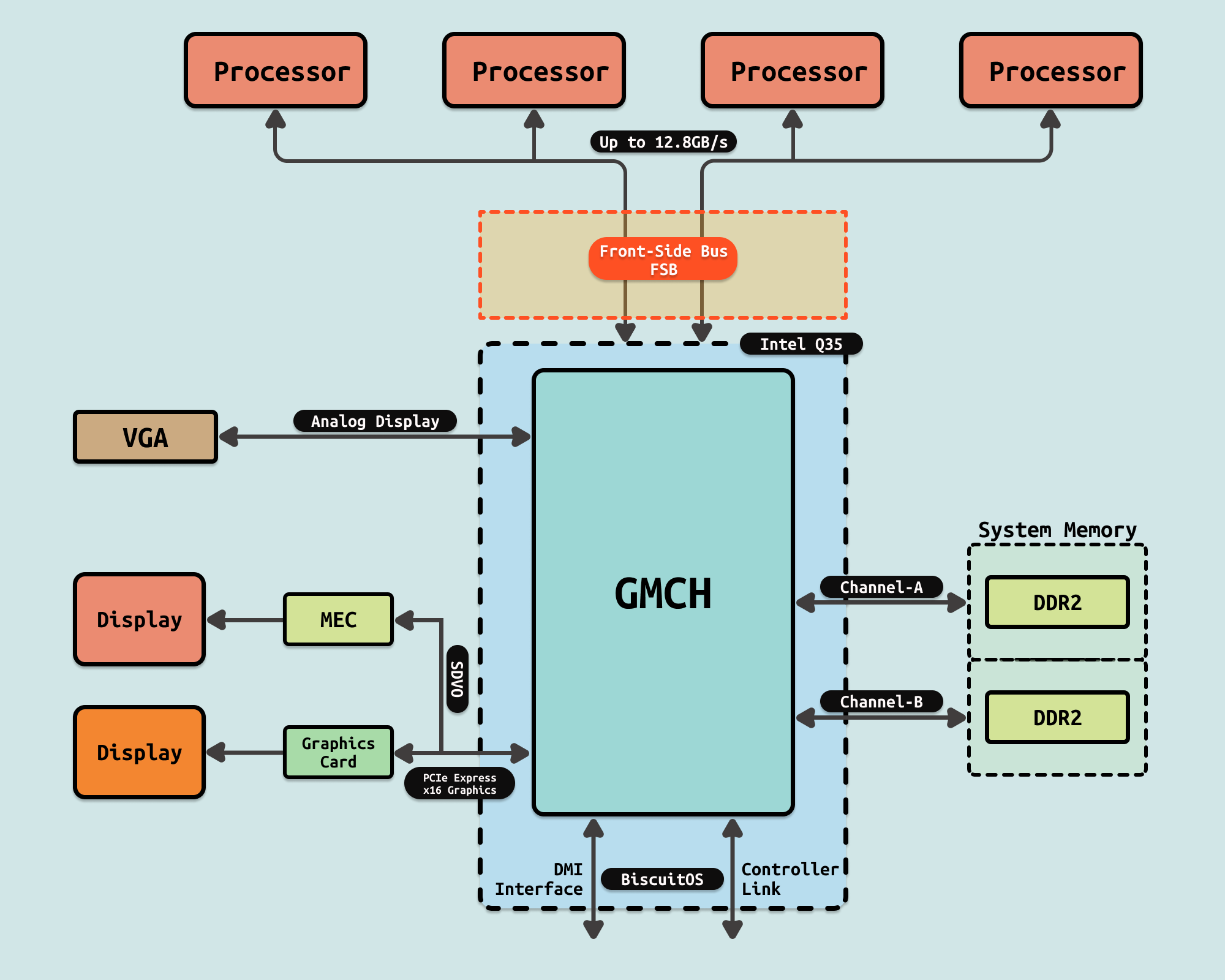
为了进一步增加基于 FSB 总线的平台的带宽,单共享总线方法演变为双独立总线(Dual Independent Buses: DIB). DIB 设计实质上使可用带宽翻倍。但是,所有监听流量都必须在两条总线上广播,如果不加以控制,将减少有效带宽。为了最大限度地减少此问题,在芯片组中采用了监听过滤器来缓存监听信息,从而大大减少了带宽负载.
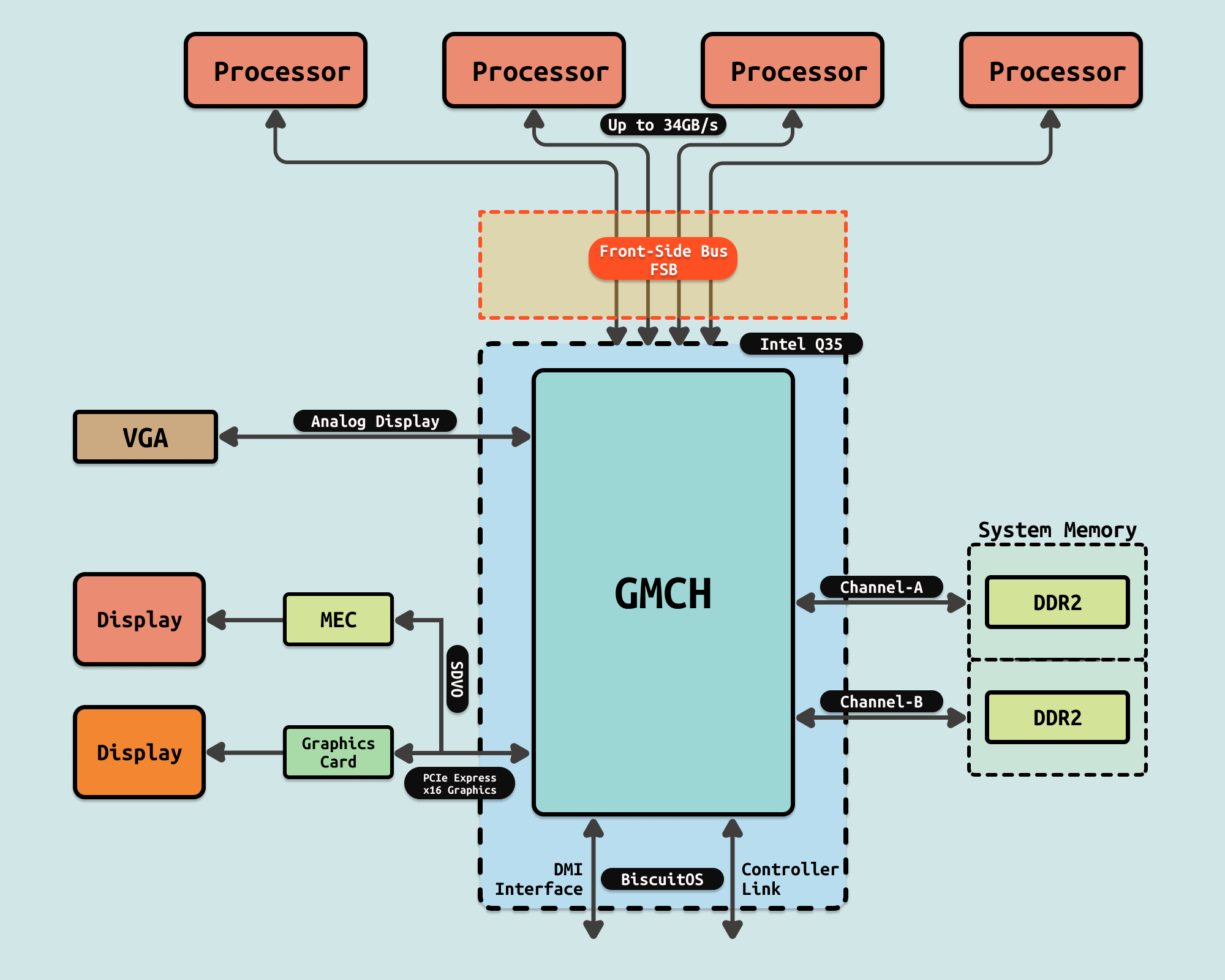
随着专用高速互连(Dedicated High-Speed Interconnects:DHSI) 的引入,DIB 方法得到了进一步的扩展. 基于 DHSI 的平台使用四个 FSB,平台中的每个处理器各一个. 同样还采用了监听过滤器来实现带宽扩展
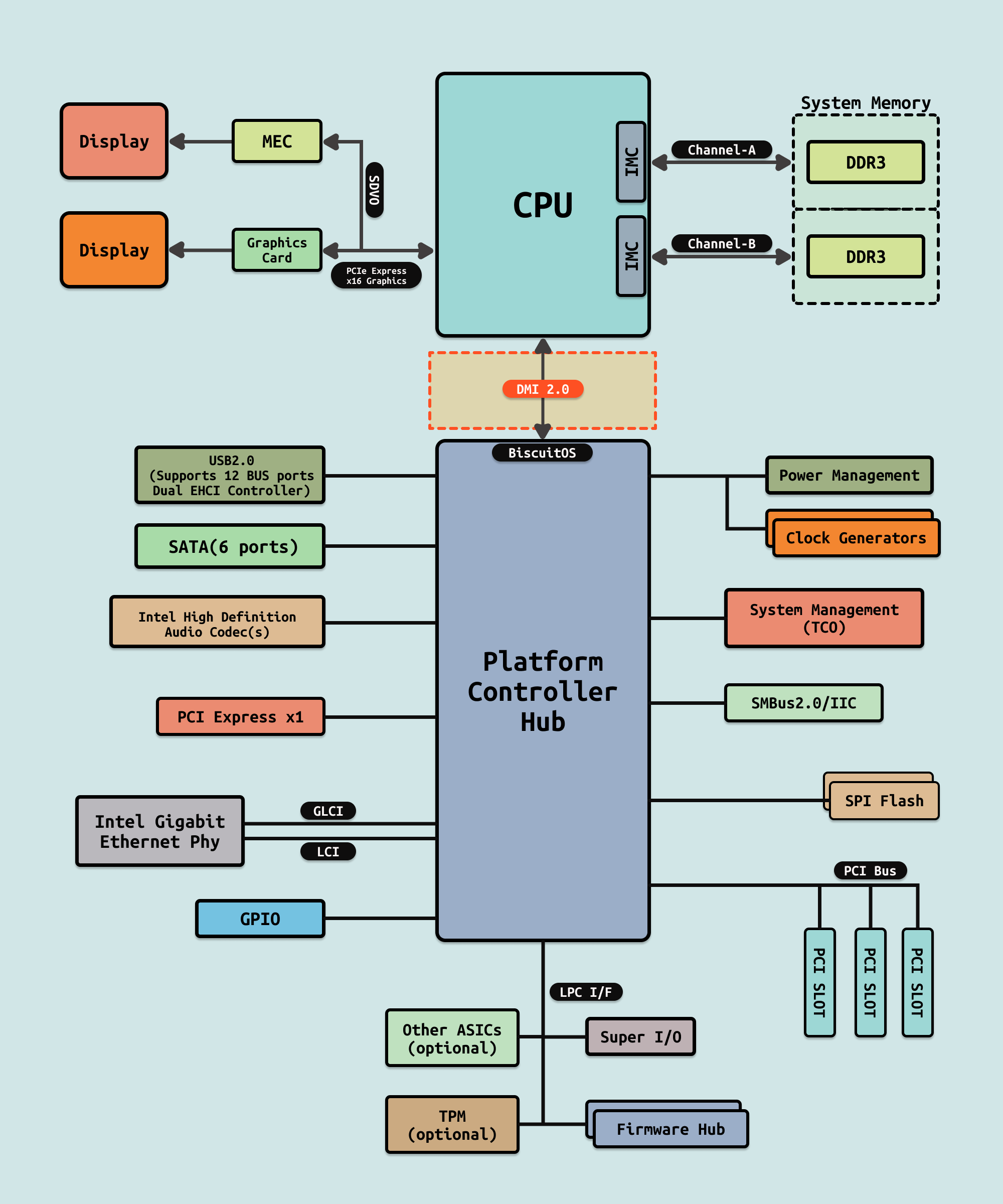
更现代的设计使用点对点和串行连接,如 AMD 的 HyperTransport 和 Intel 的 DMI 2.0 或 QuickPath Interconnect(QPI). 这些实现取消了传统的北桥,支持 CPU 直接链接到平台控制中心、南桥或 I/O 控制器. 在传统架构中,前端总线作为 CPU 与系统中所有其他设备(包括主内存)之间的直接数据链接.
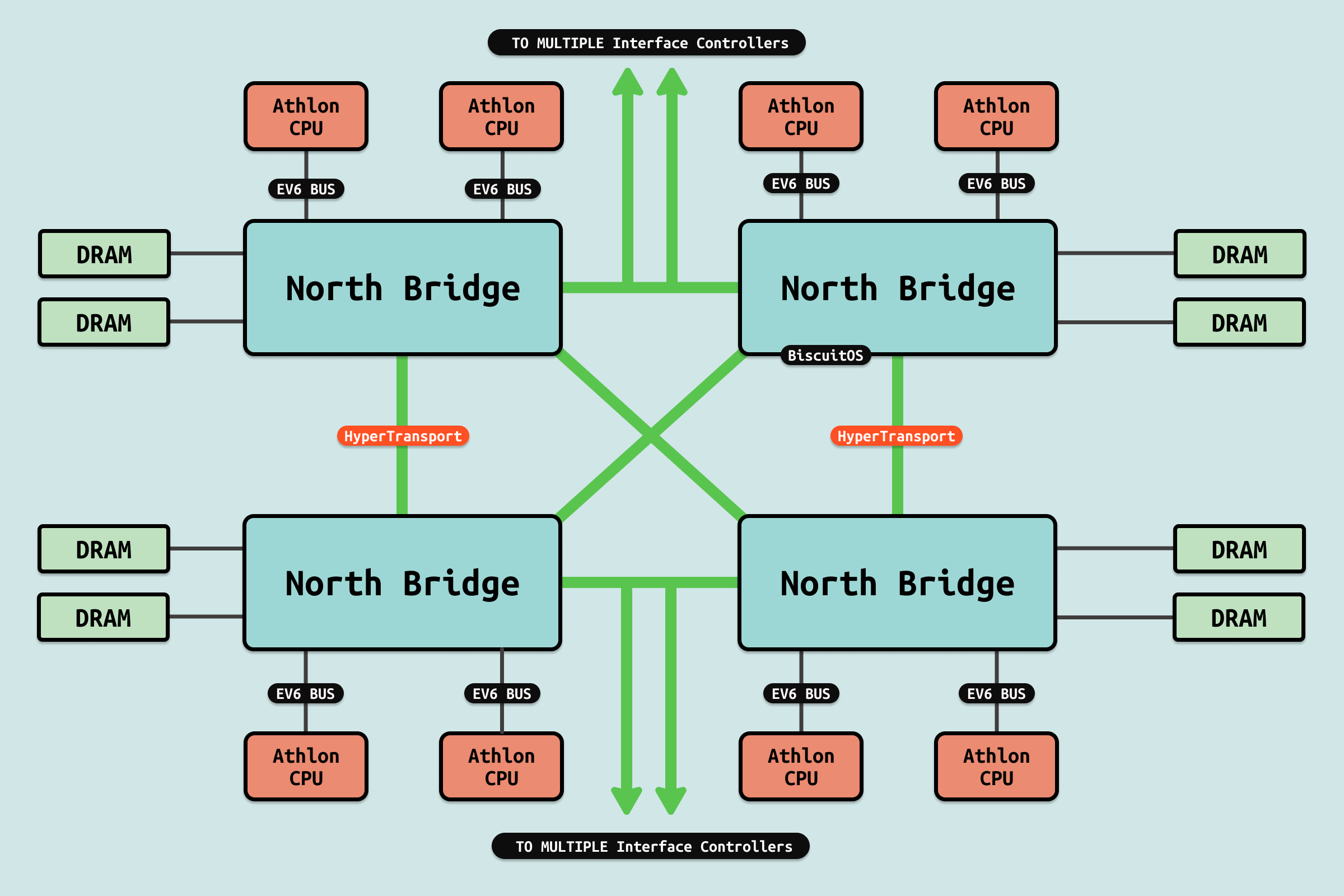
在基于 HyperTransport 和 QPI 的系统中,系统内存通过集成在 CPU 中的内存控制器独立访问,HyperTransport 或 QPI 链路的带宽用于其他用途. 这增加了 CPU 设计的复杂性,但提供了更大的吞吐量以及在多处理器系统中更好的扩展性.
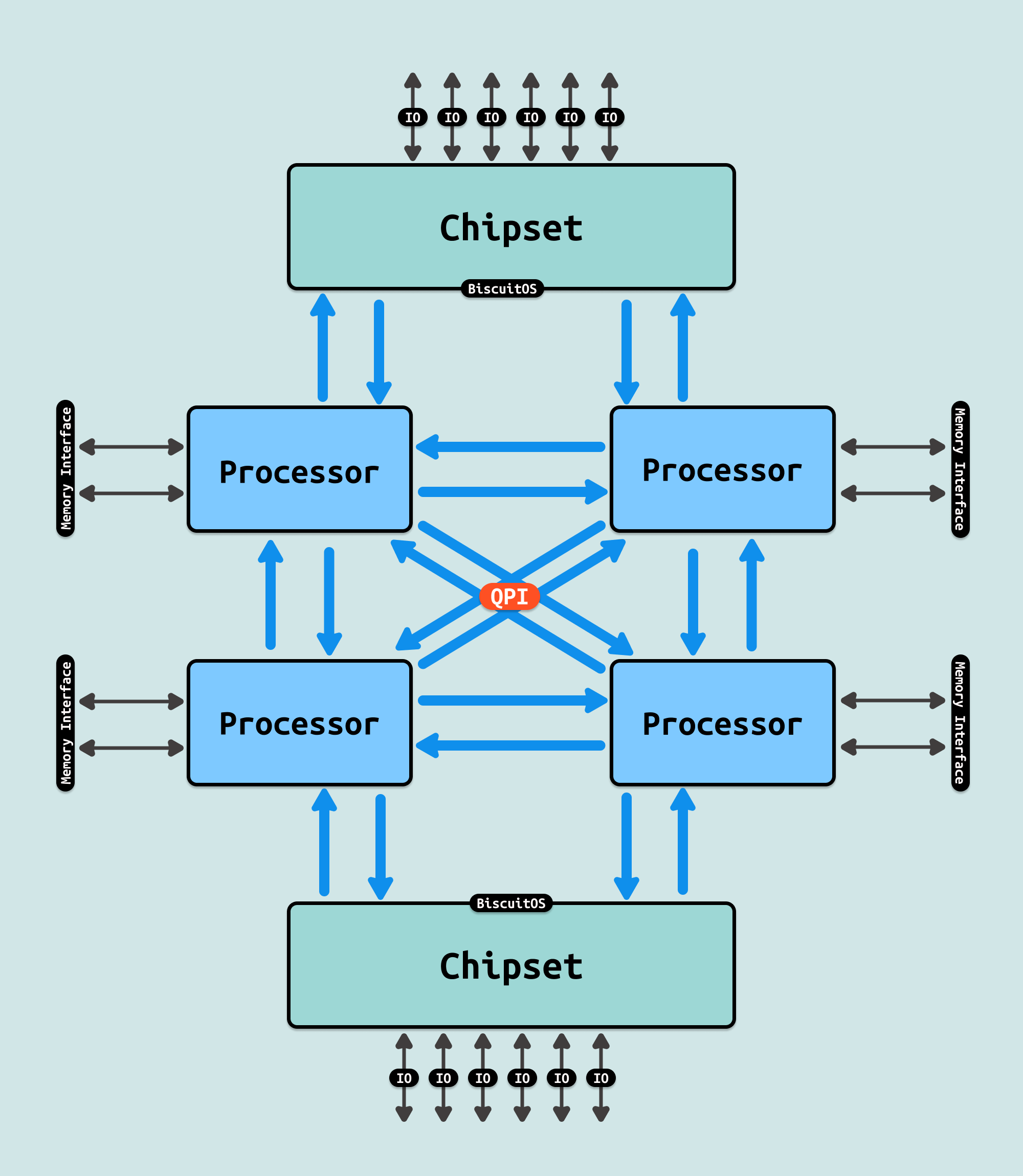
与 FSB 不同,QPI 提供了点对点的连接,允许直接连接处理器和内存控制器或其他处理器. 这种设计减少了数据传输路径,降低了延迟,提高了数据传输效率。每个处理器或核心可以直接访问连接到其上的内存,而不必通过一个共享总线,这在多处理器配置中特别有效. QPI 支持非一致性内存访问(NUMA),这使得在多处理器系统中,每个处理器都可以访问自己最近的内存,从而提高内存访问速度和总体性能。这对于数据中心和高性能计算应用尤其重要.
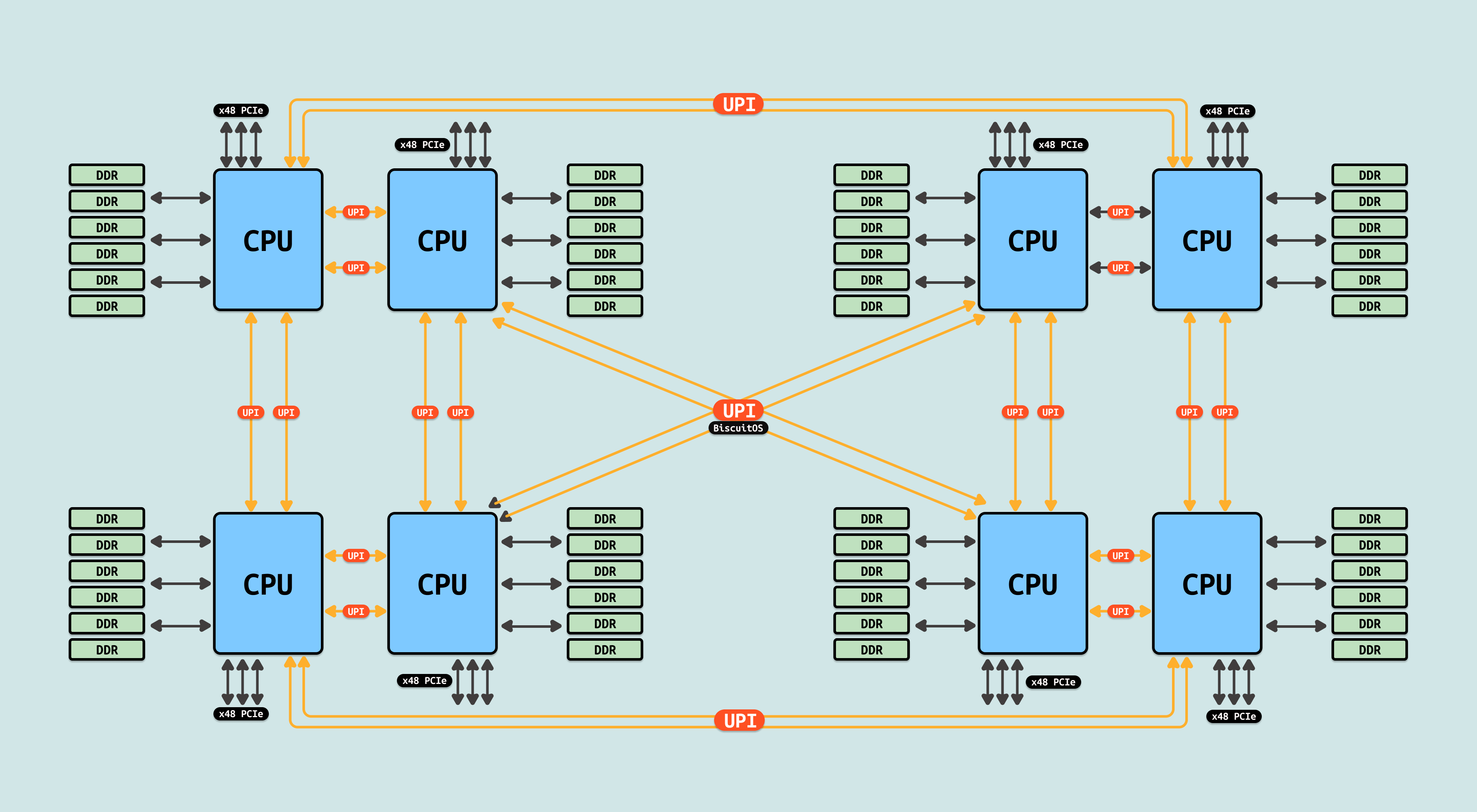
英特尔 Ultra Path Interconnect(UPI) 是英特尔开发的点对点处理器互连技术(Package 之间互联,并非物理 CPU 核之间的互联),自 2017 年起在 Xeon Skylake-SP 平台上替代了英特尔 QuickPath Interconnect(QPI).
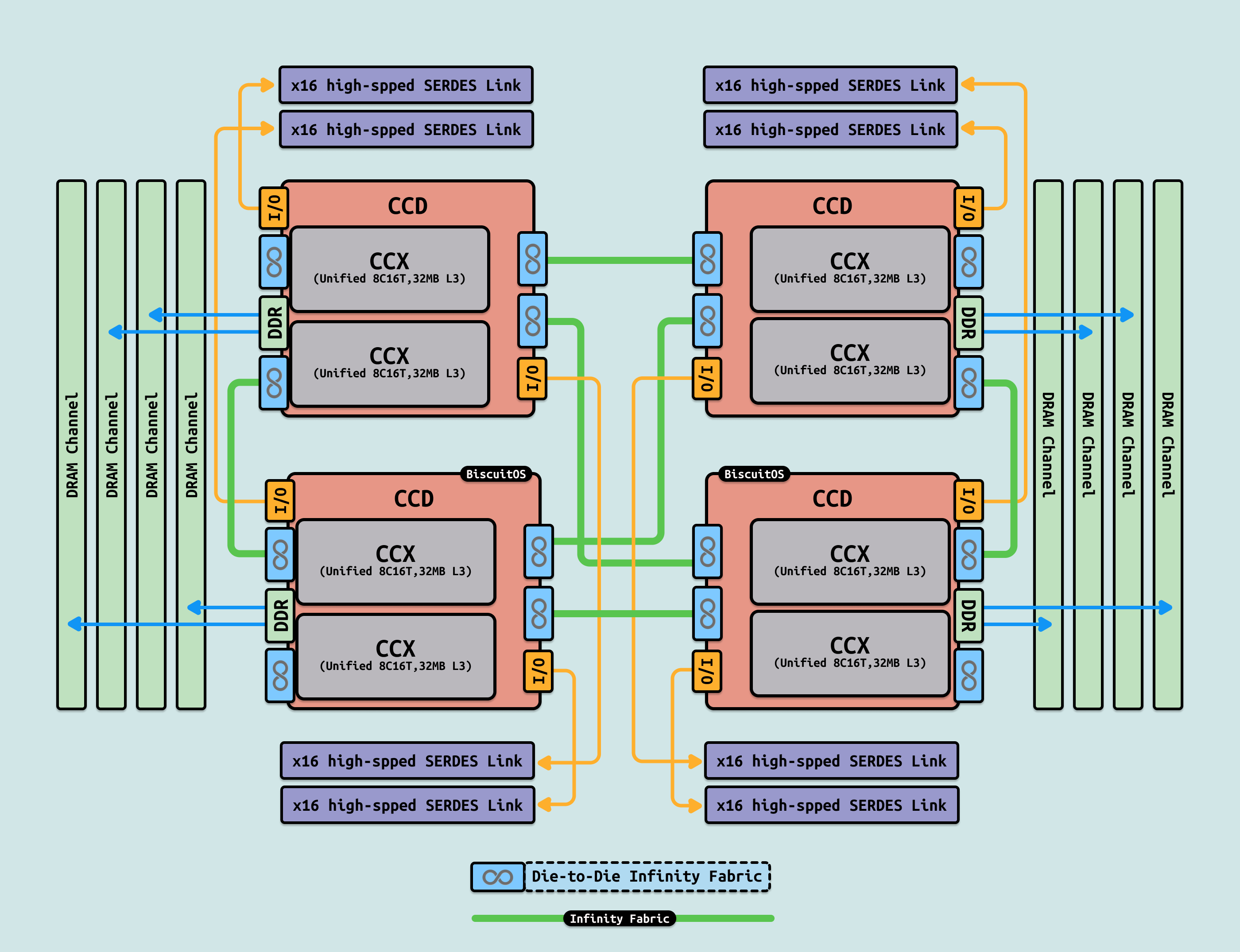
AMD Infinity Fabric 是一种高带宽、低延迟的互连架构,用于在单个芯片和芯片之间、以及芯片内部不同组件之间传输数据. 它由两部分组成: Infinity Scalable Data Fabric(SDF) 和 Infinity Scalable Control Fabric(SCF). SDF 是系统中数据在各端点(例如 NUMA 节点、PHYs)之间流动的主要方式. SDF 可能有数十个连接点将 PCIe PHYs、内存控制器、USB 集线器以及各种计算和执行单元连接在一起. SDF 是先前 HyperTransport 的超集. SCF 是一个补充平面,负责传输许多杂项系统控制信号——这包括诸如热管理和电源管理、测试、安全以及第三方 IP 等内容. 通过这两个平面,AMD 能够有效地扩展许多基本的计算模块.
Core-to-Core 总线演变
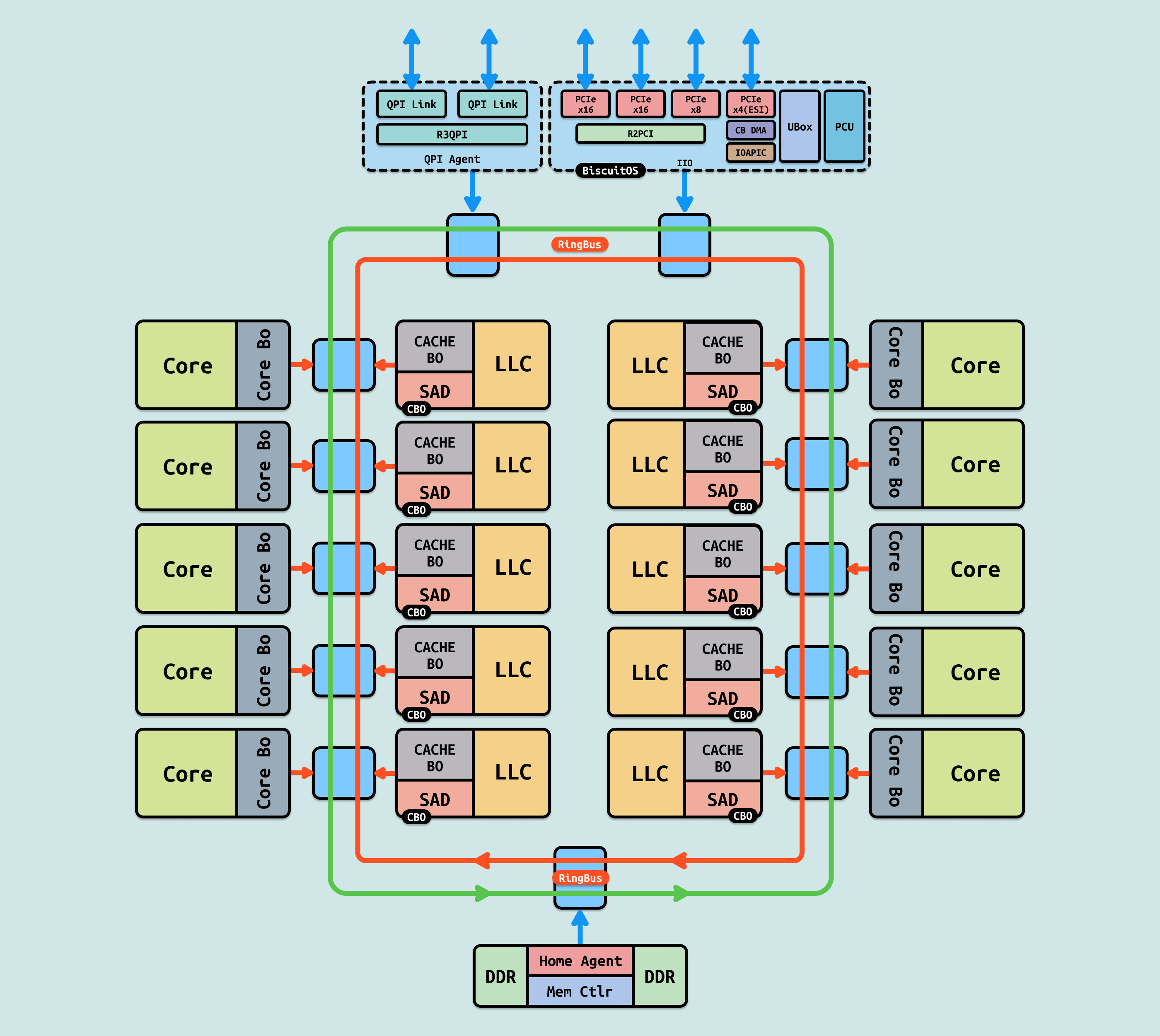
Intel 的 RingBus 架构是一种先进的处理器内部通信技术,用于在处理器的核心、缓存、输入/输出控制器等组件之间传输数据. 这种架构采用环形的数据路径,能够高效地管理多核处理器内部的数据流动. 从上图可以看到,Ring Bus 实际上是两个环,一个顺时针环和一个逆时针环. 各个模块一视同仁的通过 Ring Stop 挂接在 Ring Bus 上. 但由于 Core 的数量不断的增加,RingBus 的缺点很快暴露出来, 因此产生了很多变种:
- LCC(Low Core Count): 该配置配置从四核到八核,与较低核心数的 Ivy Bridge EP 非常相似. 它有一个双环,两列核心,只有一个内存控制器. 这种芯片的最后一级缓存(LLC)较小,延迟也较低

- MCC(Middle Core Count): 该配置支持 10 到 12 核心,该芯片有两个内存控制器. 蓝点表示数据可以跳上环形总线的位置。需要注意的是,其左边一个单 RingBus,而右边则是半个 RingBus, 也就是 1.5 RingBus.

- HCC(High Core Count): 该配置支持 14 到 18 核心,该芯片有两个内存控制器. 蓝点表示数据可以跳上环形总线的位置。需要注意的是,芯片的布局也是不对称的. 例如一个 18 核的 CPU 在一侧有 8 核(4-4)和 20MB 的 LLC,另一侧则有 25MB 的 LLC 和 10 个核心. 该配置在右侧的环上减少了六到八个核心,同时也减少了相应数量的 LLC. 两个 RingBus 直接用两个双向 Pipe Line 连接,保证通讯顺畅. 由于此时 Ring0(左边的 RingBus) 访问 Ring1(右边的 RingBus) 模块的延迟明显高于本 Ring,亲和度不同,所以两个 Ring 分属于不同的 NUMA.

Intel 随后推出了 Mesh 总线,Mesh 总线是一种高级的处理器互联技术,用于改善多核心处理器内部的数据传输效率. 这种技术首次出现在 Intel 的 Xeon Scalable 处理器(代号为 Skylake-SP)上,并继续用于后续的一些处理器系列. Mesh 总线替代了之前的环形总线(Ring Bus)架构,旨在提供更高的可扩展性和更低的延迟,特别是在拥有大量核心的处理器上.